Documentación
Se presenta a continuación una nueva guía de Análisis Exploratorio de Datos (AED) implementada en Python, que evoluciona y complementa la versión publicada en R en el año 2021. Esta actualización responde a las necesidades de una comunidad cada vez más diversa en el ámbito de la ciencia de datos.
El Análisis Exploratorio de Datos (AED o EDA, por sus siglas en inglés) representa un paso crítico previo a cualquier análisis estadístico, ya que permite:
- Comprender exhaustivamente los datos antes de analizarlos.
- Verificar el cumplimiento de los requisitos estadísticos que garantizarán la validez de los análisis posteriores.
Para ejemplificar su importancia, tomemos el caso de la detección y tratamiento de valores atípicos, una de las tareas a realizar en un AED. Esta fase tiene un impacto significativo en estadísticos fundamentales como la media, la desviación estándar o el coeficiente de variación.
Además de explicar las distintas fases de un AED, la guía las ilustra con un caso práctico. En este sentido, se mantiene como caso práctico el análisis de datos de calidad del aire de Castilla y León. A través de explicaciones que el usuario podrá replicar, se transforman los datos públicos en información valiosa mediante el uso de bibliotecas Python fundamentales como pandas, matplotlib y seaborn, junto con herramientas modernas de análisis automatizado como ydata-profiling.
¿Por qué una nueva guía en Python?
La elección de Python como lenguaje para esta nueva guía refleja su creciente relevancia en el ecosistema de la ciencia de datos. Su sintaxis intuitiva y su extenso catálogo de bibliotecas especializadas lo han convertido en una herramienta fundamental para el análisis de datos. Al mantener el mismo conjunto de datos y estructura analítica que la versión en R, se facilita la comprensión de las diferencias entre ambos lenguajes. Esto resulta especialmente valioso en entornos donde coexisten múltiples tecnologías. Este enfoque es particularmente relevante en el contexto actual, donde numerosas organizaciones están migrando sus análisis desde lenguajes/herramientas tradicionales como R, SAS o SPSS hacia Python. La guía busca facilitar estas transiciones y garantizar la continuidad en la calidad de los análisis durante el proceso de migración.
Novedades y mejoras
Se ha enriquecido el contenido con la introducción al AED automatizado y las herramientas de perfilado de datos, respondiendo así a una de las últimas tendencias en el campo. El documento profundiza en aspectos esenciales como la interpretación de datos medioambientales, ofrece un tratamiento más riguroso de los valores atípicos y presenta un análisis más detallado de las correlaciones entre variables. Además, incorpora buenas prácticas en la escritura de código.
La aplicación práctica de estos conceptos se ilustra a través del análisis de datos de calidad del aire, donde cada técnica cobra sentido en un contexto real. Por ejemplo, al analizar las correlaciones entre contaminantes, no solo se muestra cómo calcularlas, sino que se explica cómo estos patrones reflejan procesos atmosféricos reales y qué implicaciones tienen para la gestión de la calidad del aire.
Estructura y contenidos
La guía sigue un enfoque práctico y sistemático, cubriendo las cinco etapas fundamentales del AED:
- Análisis descriptivo para obtener una visión representativa de los datos
- Ajuste de los tipos de variables para garantizar la consistencia
- Detección y tratamiento de datos ausentes
- Identificación y gestión de datos atípicos
- Análisis de correlación entre variables
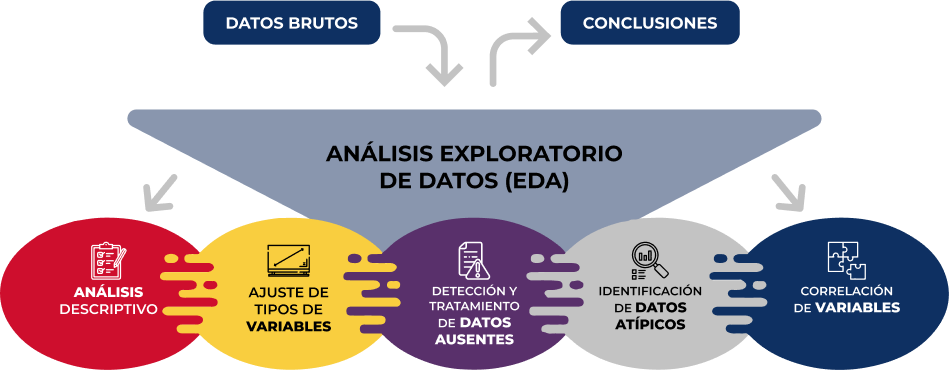
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
Como novedad en la estructura, se incluye una sección sobre análisis exploratorio automatizado, presentando herramientas modernas que facilitan la exploración sistemática de grandes conjuntos de datos.
¿A quién va dirigida?
Esta guía está diseñada para usuarios de datos abiertos que deseen realizar análisis exploratorios y reutilizar las valiosas fuentes de información pública que se encuentran en este y otros portales de datos a nivel mundial. Si bien es recomendable tener conocimientos básicos del lenguaje, la guía incluye recursos y referencias para mejorar las competencias en Python, así como ejemplos prácticos detallados que facilitan el aprendizaje autodidacta.
El material completo, que incluye tanto la documentación como el código fuente, se encuentra disponible en el repositorio de GitHub del portal. La implementación se ha realizado utilizando herramientas de código abierto como Jupyter Notebook en Google Colab, lo que permite reproducir los ejemplos y adaptar el código según las necesidades específicas de cada proyecto.
Se invita a la comunidad a explorar esta nueva guía, experimentar con los ejemplos proporcionados y aprovechar estos recursos para desarrollar sus propios análisis de datos abiertos.
Haz click para ver la infografía completa, en versión accesible

Figura 2. Captura de la infografía. Fuente: elaboración propia.
Documentación
Antes de realizar un análisis de datos, con fines estadístico o predictivos por ejemplo a través de técnicas de machine learning, es necesario comprender la materia prima con la que vamos a trabajar. Hay que entender y evaluar la calidad de los datos para así, entre otros aspectos, detectar y tratar los datos atípicos o incorrectos, evitando posibles errores que pudieran repercutir en los resultados del análisis.
Una forma de llevar a cabo este pre-procesamiento es mediante un análisis exploratorio de datos (AED) o exploratory data analysis (EDA).
¿Qué es el análisis exploratorio de los datos?
El AED consiste en aplicar un conjunto de técnicas estadísticas dirigidas a explorar, describir y resumir la naturaleza de los datos, de tal forma que podamos garantizar su objetividad e interoperabilidad.
Gracias a ello se pueden identificar posibles errores, revelar la presencia de valores atípicos, comprobar la relación entre variables (correlaciones) y su posible redundancia, así como realizar un análisis descriptivo de los datos mediante representaciones gráficas y resúmenes de los aspectos más significativos.
En muchas ocasiones, esta exploración de los datos se descuida y no se lleva a cabo de manera correcta. Por este motivo, desde datos.gob.es hemos elaborado una guía introductoria que recoge una serie de tareas mínimas para realizar un correcto análisis exploratorios de datos, paso previo y necesario antes de llevar a cabo cualquier tipo de análisis estadístico o predictivo ligado a las técnicas de machine learning.
¿Qué incluye la guía?
La guía explica de forma sencilla cuáles son los pasos a seguir para garantizar unos datos consistentes y veraces. Para su elaboración se ha tomado como referencia el análisis exploratorio de datos descrito en el libro R for Data Science de Wickman y Grolemund (2017) disponible de forma gratuita. Estos pasos son:
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
En la guía se explica cada uno de estos pasos y por qué son necesarios. Asimismo, se ilustran de manera práctica a través de un ejemplo. Para dicho caso práctico, se ha utilizado el dataset relativo al registro de la calidad del aire en la Comunidad Autónoma de Castilla y León incluido en nuestro catálogo de datos abiertos. El tratamiento se ha llevado a cabo con herramientas tecnológicas open source y gratuitas. En la guía se recoge el código para que los usuarios pueden replicarlo de forma autodidacta siguiendo los pasos indicados.
La guía finaliza con un apartado de recursos adicionales para aquellos que quieran seguir profundizando en la materia.
¿A quién va dirigida?
El público objetivo de la guía es el usuario reutilizador de datos abiertos. Es decir, desarrolladores, emprendedores o incluso periodistas de datos que quieran extraer todo el valor posible de la información con la que trabajan para obtener unos resultados fiables.
Es aconsejable que el usuario tenga nociones básicas del lenguaje de programación R, elegido para ilustrar los ejemplos. No obstante, en el apartado de bibliografía se incluyen recursos para adquirir mayores habilidades en este campo.
A continuación, en el apartado documentación, puedes descargarte la guía, así como una infografía-resumen que ilustra los principales pasos del análisis exploratorios de datos. También tienes disponible el código fuente del ejemplo práctico en nuestro Github.
Haz click para ver la infografía completa, en versión accesible
Figura 2. Captura de la infografía. Fuente: elaboración propia.
Infografía - Análisis de datos abiertos con herramientas open source PARTE I

Infografía - Visualización de datos abiertos con herramientas open source PARTE II

Ver infografía completa