Blog
2023 fue un año cargado de novedades en materia de inteligencia artificial, algoritmos y tecnologías relacionadas con los datos. Por ello, estas fiestas navideñas se configuran como un buen momento para aprovechar la llegada de los Reyes Magos y pedirles un libro para disfrutar de su lectura en los días de fiesta, el descanso merecido y la vuelta a la rutina tras el periodo vacacional.
Tanto si estás buscando una lectura que haga mejorar tu perfil profesional, conocer novedades y aplicaciones tecnológicas ligadas al mundo de los datos y la inteligencia artificial, como si quieres ofrecer a tus seres más queridos un regalo didáctico e interesante, desde datos.gob.es queremos proponerte algunos ejemplos. Para la elaboración de la lista hemos contado con la opinión de expertos en la materia.
¡Coge papel y lápiz porque todavía estás a tiempo de incluirlos en tu carta a los Reyes Magos!
1. Inteligencia Artificial: Ficción, Realidad y... sueños, Nuria Oliver, Real Academia de Ingeniería GTT (2023)
¿De qué trata?: El libro tiene su origen en el discurso de ingreso en la Real Academia de Ingeniería de la autora. En él, explora la historia de la IA, sus implicaciones y desarrollo, describe su impacto actual y plantea diversas perspectivas.
¿A quién va dirigido?: Está pensado para personas con interés en introducirse en el mundo de la Inteligencia Artificial, conocer su historia y aplicaciones prácticas. También se dirige a aquellas personas que quieren adentrarse en el mundo de la IA ética y aprender cómo utilizarla para un bien social.
2. A Data-Driven Company. 21 Claves para crear valor a través de los datos y de la Inteligencia Artificial, Richard Benjamins, Lid Editorial (2022)
¿De qué trata?: A Data-Driven Company analiza 21 decisiones clave a las que tienen que hacer frente las compañías para convertirse en una empresa orientada hacia los datos y la IA. En él se abordan las típicas decisiones organizativas, tecnológicas, empresariales, de personal y éticas que las organizaciones deben afrontar para empezar a tomar decisiones basadas en datos, incluyendo cómo financiar su estrategia de datos, organizar equipos, medir los resultados y escalar.
¿A quién va dirigido?: Sirve tanto para profesionales que empiezan a trabajar con datos, como para aquellos que ya tienen experiencia, pero necesitan adaptarse para trabajar con big data, analítica o inteligencia artificial.
3. Digital Empires: The Global Battle to Regulate Technology, Anu Bradford, OUP USA (2023)
¿De qué trata?: Ante los avances tecnológicos en todo el mundo y la llegada de gigantes empresariales repartidos en las potencias internacionales, Bradford examina tres enfoques regulatorios que compiten entre sí: el modelo estadounidense donde lo que prima es el mercado, el modelo chino condicionado por el Estado y el modelo regulatorio europeo, centrado en los derechos. A través de sus páginas, se analiza cómo los gobiernos y las empresas tecnológicas navegan por los inevitables conflictos que surgen cuando estos enfoques regulatorios chocan en el ámbito internacional.
¿A quién va dirigido?: Es un libro pensado para quienes desean conocer más sobre el enfoque regulador de las tecnologías alrededor del mundo y cómo afecta al ámbito empresarial. Está redactado de manera clara y comprensible, a pesar de la complejidad del tema. Sin embargo, el lector deberá saber inglés, porque aún no se ha traducido a nuestro idioma.
4. El mito del algoritmo, Richard Benjamins e Idoia Salazar, Anaya Multimedia (2020)
¿De qué trata?: La inteligencia artificial y su uso exponencial en múltiples disciplinas está provocando un cambio social sin precedentes. Con ello, empiezan a surgir pensamientos filosóficos tan profundos como la existencia del alma o debates relacionados con la posibilidad de que las máquinas tengan sentimientos. Se trata de un libro para conocer los desafíos, retos y oportunidades de esta tecnología.
¿A quién va dirigido?: Está dirigido a personas con interés en la filosofía de la tecnología y el desarrollo de avances tecnológicos. Al usar un lenguaje sencillo y esclarecedor, es un libro al alcance de un público generalista.
5. ¿Cómo sobrevivir a la incertidumbre?, de Anabel Forte Deltell, Next Door Publishers
¿De qué trata?: Explica de forma sencilla y con ejemplos cómo la estadística y la probabilidad están más presentes en la vida diaria. El libro parte de la actualidad, en la que datos, números, porcentajes y gráficos se han adueñado del día a día y se han convertido en indispensables para tomar decisiones o para comprender el mundo que nos rodea.
¿A quién va dirigido?: A un público general que quiere entender cómo el análisis de los datos, la estadística y la probabilidad van configurando buena parte de las decisiones políticas, sociales, económicas...
6. Análisis espacial con R: Usa R como un Sistema de Información Geográfica, Jean François Mas, European Scientific Institute
¿De qué trata?: Se trata de un libro más técnico, en el que se realiza una breve introducción de los principales conceptos para el manejo del lenguaje y entorno de programación R (tipos de objetos y operaciones básicas) para posteriormente acercar al lector al uso de la librería o paquete sf, para datos espaciales en formato vector a través de sus principales funciones para lectura, escritura y análisis. El libro aborda, desde una perspectiva práctica y aplicativa con un lenguaje de fácil entendimiento, los primeros pasos para iniciarse con el manejo de R en aplicaciones de análisis espacial; para ello, es necesario que los usuarios tengan conocimientos básicos de Sistemas de Información Geográfica.
¿A quién va dirigido?: A un público con algún conocimiento en R y conocimientos básicos de GIS que desean introducirse en el mundo de las aplicaciones de análisis espacial.
Esta es solo una pequeña muestra de la gran variedad de literatura existente relacionada con el mundo de los datos. Seguro que nos dejamos algún libro interesante sin incluir por lo que, si tienes alguna recomendación extra que quieres hacer, no dudes en dejarnos tu título favorito en comentarios. Quienes formamos el equipo de datos.gob.es estaremos encantados de leer vuestras recomendaciones.
Blog
En estos momentos nos encontramos en medio de una carrera sin precedentes por dominar las innovaciones en Inteligencia Artificial. Durante el último año, la estrella ha sido la Inteligencia Artificial Generativa (GenAI), es decir, aquella capaz de generar contenido original y creativo como imágenes, texto o música. Pero los avances no dejan de sucederse, y últimamente comienzan a llegar noticias en las que se sugiere que la utopía de la Inteligencia Artificial General (AGI) podría no estar tan lejos como pensábamos. Estamos hablando de máquinas capaces de comprender, aprender y realizar tareas intelectuales con resultados similares al cerebro humano.
Sea esto cierto o simplemente una predicción muy optimista, consecuencia de los asombrosos avances conseguido en un espacio muy corto de tiempo, lo cierto es que la Inteligencia Artificial parece ya capaz de revolucionar prácticamente todas las facetas de nuestra sociedad a partir de la cada vez mayor cantidad de datos que se utilizan para su entrenamiento.
Y es que si, como argumentaba Andrew Ng ya en 2017, la inteligencia artificial es la nueva electricidad, los datos abiertos serían el combustible que alimenta su motor, al menos en un buen número de aplicaciones cuya fuente principal y más valiosa es la información pública que se encuentra accesible para ser reutilizada. En este artículo vamos a repasar un campo en el que previsiblemente veremos grandes avances en los próximos años gracias a la combinación de inteligencia artificial y datos abiertos: la creación artística.
Creación Generativa basada en Datos Culturales Abiertos
La capacidad de la inteligencia artificial para generar nuevos contenidos podría llevarnos a una nueva revolución en la creación artística, impulsada por el acceso a datos culturales abiertos y a una nueva generación de artistas capaces de aprovechar estos avances para crear nuevas formas de pintura, música o literatura, trascendiendo barreras culturales y temporales.
Música
El mundo de la música, con su diversidad de estilos y tradiciones, representa un campo lleno de posibilidades para la aplicación de la inteligencia artificial generativa. Los conjuntos de datos abiertos en este ámbito incluyen grabaciones de música folclórica, clásica, moderna y experimental de todo el mundo y de todas las épocas, partituras digitalizadas, e incluso información sobre teorías musicales documentadas. Desde el archi-conocido MusicBrainz, la enciclopedia de la música abierta, hasta conjuntos de datos que abren los propios dominadores de la industria del streaming como Spotify o proyectos como Open Music Europe, son algunos ejemplos de recursos que están en la base del progreso en esta área. A partir del análisis de todos estos datos, los modelos de inteligencia artificial pueden identificar patrones y estilos únicos de diferentes culturas y épocas, fusionándolos para crear composiciones musicales inéditas con herramientas y modelos como MuseNet de OpenAI o Music LM de Google.
Literatura y pintura
En el ámbito de la literatura, la Inteligencia artificial también tiene potencial para hacer más productiva no solo la creación de contenidos en internet, sino para producir formas más elaboradas y complejas de contar historias. El acceso a bibliotecas digitales que albergan obras literarias desde la antigüedad hasta el momento actual hará posible explorar y experimentar con estilos literarios, temas y arquetipos de narración de diversas culturas a lo largo de la historia, con el fin de crear nuevas obras en colaboración con la propia creatividad humana. Incluso se podrá generar una literatura de carácter más personalizado a los gustos de grupos de lectores más minoritarios. La disponibilidad de datos abiertos como el Proyecto Guttemberg con más de 70.000 libros o los catálogos digitales abiertos de museos e instituciones que han publicado manuscritos, periódicos y otros recursos escritos producidos por la humanidad, son un recurso de gran valor para alimentar el aprendizaje de la inteligencia artificial.
Los recursos de la Digital Public Library of America (DPLA) en Estados Unidos o de Europeana en la Unión Europea son sólo algunos ejemplos. Estos catálogos no sólo incluyen texto escrito, sino que incluyen también vastas colecciones de obras de arte visuales, digitalizadas a partir de las colecciones de museos e instituciones, que en muchos casos ni tan siquiera pueden admirarse porque las organizaciones que las conservan no disponen de espacio suficiente para exponerlas al público. Los algoritmos de inteligencia artificial, al analizar estas obras, descubren patrones y aprenden sobre técnicas, estilos y temas artísticos de diferentes culturas y períodos históricos. Esto posibilita que herramientas como DALL-E2 o Midjourney puedan crear obras visuales a partir de unas sencillas instrucciones de texto con estética de pintura renacentista, impresionista o una mezcla de ambas.
Sin embargo, estas fascinantes posibilidades están acompañadas de una controversia aún no resuelta acerca de los derechos de autor que está siendo debatida en los ámbitos académicos, legales y jurídicos y que plantea nuevos desafíos en la definición de autoría y propiedad intelectual. Por una parte, está la cuestión sobre la propiedad de los derechos sobre las creaciones producidas por inteligencia artificial. Y por otra parte encontramos el uso de conjuntos de datos que contienen obras sujetas a derechos de propiedad intelectual y que se han utilizado en el entrenamiento de los modelos sin el consentimiento de los autores. En ambas cuestiones existen numerosas disputas judiciales en todo el mundo y solicitudes de retirada explícita de contenido de los principales conjuntos de datos de entrenamiento.
En definitiva, nos encontramos ante un campo donde el avance de la inteligencia artificial parece imparable, pero habrá que tener muy presente no solo las oportunidades, sino también los riesgos que supone.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El activismo de datos es una práctica ciudadana cada vez más significativa en la era de las plataformas por su creciente contribución a la democracia, la justicia social y los derechos. Se trata de un activismo que utiliza los datos y su análisis para generar evidencias y visualizaciones con el objetivo de revelar injusticias, mejorar la vida de las personas y fomentar el cambio social.
Frente al uso masivo de datos de vigilancia por parte de determinadas corporaciones, el activismo de datos es ejercido por la ciudadanía y organizaciones no gubernamentales. Por ejemplo, la organización Forensic Architecture (FA), un centro de Goldsmiths dependiente de la Universidad de Londres, investiga violaciones de derechos humanos, incluidas las violencias de Estado, usando datos públicos, ciudadanos y satelitales, y metodologías como la inteligencia de fuentes abiertas (conocida como OSINT). El análisis de datos y metadatos, la sincronización de vídeos tomados por testigos o periodistas, así como de grabaciones y documentos oficiales, permiten reconstruir los hechos y generar un relato alternativo acerca de eventos y crisis.
El activismo de datos ha suscitado el interés de centros de investigación y organizaciones no gubernamentales, generando una línea de trabajo dentro de la disciplina de los estudios críticos. Esto ha permitido reflexionar sobre el efecto de los datos, las plataformas y sus algoritmos en nuestras vidas, así como acerca del empoderamiento que se genera cuando la ciudadanía ejerce su derecho a los datos y los usa para el bien común.

Imagen 1: Ecocidio en Indonesia (2015)
Fuente: Forensic Architecture (https://forensic-architecture.org/investigation/ecocide-in-indonesia)
Centros de investigación como Datactive o Data + Feminism Lab han creado teoría y debates sobre la práctica del activismo de datos. Asimismo, organizaciones como Algorights –una red colaborativa que fomenta la participación de la sociedad civil en el campo de las tecnologías de IA- y AlgorithmWatch -organización de derechos humanos- generan conocimiento, redes y argumentos para luchar por un mundo donde los algoritmos y la Inteligencia Artificial (IA)contribuyan a la justicia, la democracia y la sostenibilidad, en vez de debilitarlas.
Este artículo revisa cómo surgió el activismo de datos, qué interés ha suscitado en la ciencia social y su relevancia en la era de las plataformas.
Historia de una práctica
La producción de mapas usando datos ciudadanos podría ser de las primeras manifestaciones del activismo de datos tal y como se conoce ahora. Un mapa fundamental en la historia del activismo de datos fue el generado por víctimas y activistas con datos sobre el terremoto de Haití en 2010, sobre la plataforma keniata Ushahidi (“testimonio”, en Suajili). Una comunidad de humanitaristas digitales creó el mapa desde otros países y convocó a las víctimas y a sus familiares y conocidos para que compartieran datos de lo que estaba ocurriendo en tiempo real. En cuestión de pocas horas, los datos se verificaron y se visualizaron en un mapa interactivo que continuó actualizándose con más datos, y que fue decisivo a la hora de asistir a las víctimas en el terreno. Hoy en día se generan mapas de este tipo cada vez que surge una crisis, y se enriquecen con datos ciudadanos, satelitales y generados por drones dotados de cámaras para esclarecer hechos y generar evidencias.
Emergiendo de movimientos conocidos como cypherpunk y el tecnopositivismo o tecnoptimismo (basado en la confianza en que la tecnología es la respuesta a los retos de la humanidad), el activismo de datos ha ido evolucionando como práctica para adoptar posturas más críticas frente a la tecnología y a las asimetrías de poder que surgen entre quienes originan y ceden sus datos, y quienes los captan y analizan.
Hoy día, por ejemplo, la plataforma de producción de mapas comunitarios Ushahidi se ha empleado para crear datos sobre la violencia machista en Egipto y en Siria, y sobre ginecólogos confiables en India, por ejemplo. Actualmente, la invisibilización y el silenciamiento de las mujeres es la razón por la cual algunas organizaciones luchan por el reconocimiento y una política de visibilidad, algo que se hizo evidente con el movimiento #MeToo (#Cuéntalo en español). Las prácticas de datos feministas buscan visibilidad e interpretaciones críticas de la datificación (o la transformación de toda acción humana y no humana en datos mesurables y transformables en valor). Por ejemplo, Datos Contra el Feminicidio o Feminicidio.net ofrecen mapas y análisis de datos sobre el feminicidio en varios lugares del mundo.
El potencial para el empoderamiento algorítmico que ofrecen estos proyectos elimina las barreras a la igualdad, mejorando las condiciones que permiten a las mujeres resolver problemas, determinar cómo se recaban y se usan los datos y ejercer el poder.
Nacimiento y evolución de un concepto
En 2015 se publicó Los medios ciudadanos se encuentran con los grandes datos: el surgimiento del activismo de datos, en el que, por primera vez, se acuñaba y definía el activismo de datos como un concepto basado en prácticas observadas en activistas que se involucran políticamente con la infraestructura de datos. La infraestructura de datos incluye los datos, el software, el hardware y los procesos necesarios para convertir los datos en valor. Más adelante, Data activism and social change (London, Palgrave) y Activismo de datos y cambio social. Alianzas, mapas, plataformas y acción para un mundo mejor (Madrid: Dykinson) desarrollan marcos analíticos basados en casos reales que ofrecen formas de analizar otros casos.
Acompañando las variadas prácticas que existen dentro de activismo de datos, su estudio está creando espacios para la investigación feminista y postcolonialista sobre las consecuencias de la datificación. Mientras que los cronistas de la historia (principalmente fuentes masculinas) definieron la tecnología en relación con el valor sus productos, los estudios de datos feministas consideran a las mujeres como usuarias y diseñadoras de sistemas algorítmicos y buscan utilizar los datos para la igualdad, y alejarse de la explotación capitalista y sus estructuras de dominación.
El activismo de datos es hoy un concepto establecido en la ciencia social. Por ejemplo, Google Scholar ofrece más de 2.000 resultados sobre “data activism”. Varios investigadores e investigadoras lo emplean como perspectiva para analizar diversos asuntos. Por ejemplo, Rajão y Jarke exploran el activismo ambiental en Brasil; Gezgin estudia la ciudadanía crítica y el uso que hace esta de la infraestructura de datos; Lehtiniemi y Haapoja explora la agencia de datos y la participación ciudadana; y Scott examina la necesidad de los usuarios y usuarias de plataformas de desarrollar una vigilancia digital y cuidar de sus datos personales.
En el centro de estas preocupaciones se encuentra el concepto de agencia de datos, que se refiere a que las personas no sólo son conscientes del valor de sus datos, sino que también ejercen control sobre ellos, determinando cómo se usan y comparten. Se podría definir como acciones y prácticas relacionadas con la infraestructura de datos basadas en la reflexión y el interés individual y colectivo. Es decir, mientras darle un like a un post no se consideraría una acción con un alto grado de agencia de datos, participar en un hackaton –un evento colectivo en el que se mejora un programa informático o se crea— sí lo sería. La agencia de datos se basa en la alfabetización en datos, o el grado de conocimientos, acceso a los datos y a sus herramientas, y a las oportunidades para ejercerla que tienen las personas. El activismo de datos no es posible sin agencia de datos.
En el panorama en rápida evolución de la economía de plataformas, la convergencia del activismo de datos, los derechos digitales y la agencia de datos se ha vuelto crucial. El activismo de datos, impulsado por una creciente conciencia del posible uso indebido de los datos personales, alienta a individuos y colectivos a utilizar la tecnología digital para el cambio social, así como a abogar por una mayor transparencia y responsabilidad por parte de las gigantes tecnológicas. Dado que cada vez más la generación de datos y el uso de algoritmos determinan nuestras vidas en áreas como la educación, el empleo, los servicios sociales y la salud, el activismo de datos emerge como una necesidad y un derecho, más que como una opción.
____________________________________________________________________________
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Documentación
En la era de los datos, nos enfrentamos al desafío de la escasez de datos de valor para la construcción de nuevos productos y servicios digitales. Aunque vivimos en una época en la que los datos están por todas partes, a menudo nos encontramos con dificultades para acceder a datos de calidad que nos permitan comprender procesos o sistemas desde una perspectiva basada en datos. La falta de disponibilidad, la fragmentación, la seguridad y la privacidad son solo algunas de las razones que dificultan el acceso a datos reales.
Sin embargo, los datos sintéticos han surgido como una solución prometedora a este problema. Los datos sintéticos son información fabricada artificialmente que imita las características y distribuciones de los datos reales, sin contener información personal o sensible. Estos datos se generan mediante algoritmos y técnicas que preservan la estructura y las propiedades estadísticas de los datos originales.
Los datos sintéticos son útiles en diversas situaciones donde la disponibilidad de datos reales es limitada o se requiere proteger la privacidad de las personas involucradas. Tienen aplicaciones en la investigación científica, pruebas de software y sistemas, y entrenamiento de modelos de inteligencia artificial. Permiten a los investigadores explorar nuevos enfoques sin acceder a datos sensibles, a los desarrolladores probar aplicaciones sin exponer datos reales y a los expertos en IA entrenar modelos sin la necesidad de recopilar todos los datos del mundo real que en ocasiones son, simplemente, imposibles de capturar en tiempos y costes asumibles.
Existen diferentes métodos para generar datos sintéticos, como el remuestreo, el modelado probabilístico y generativo, y los métodos de perturbación y enmascaramiento. Cada método tiene sus ventajas y desafíos, pero en general, los datos sintéticos ofrecen una alternativa segura y confiable para el análisis, la experimentación y el entrenamiento de modelos de inteligencia artificial.
Es importante destacar que el uso de datos sintéticos ofrece una solución viable para superar las limitaciones de acceso a datos reales y abordar preocupaciones de privacidad y seguridad. Los datos sintéticos permiten realizar pruebas, entrenar algoritmos y desarrollar aplicaciones sin exponer información confidencial. Sin embargo, es fundamental garantizar la calidad y la fidelidad de los datos sintéticos mediante evaluaciones rigurosas y comparaciones con los datos reales.
En este informe, abordamos de forma introductoria la disciplina de los datos sintéticos, ilustrando algunos casos de uso de valor para los diferentes tipos de datos sintéticos que se pueden generar. Los vehículos autónomos, la secuenciación de ADN o los controles de calidad en las cadenas de producción son solo algunos de los casos que detallamos en este informe. Además, hemos destacado el uso del software open-source SDV (Synthetic Data Vault), desarrollado en el entorno académico del MIT, que utiliza algoritmos de aprendizaje automático para crear datos sintéticos tabulares que imitan las propiedades y distribuciones de los datos reales. Desarrollamos un ejemplo práctico, en un entorno de Google Colab para generar datos sintéticos sobre clientes ficticios alojados en un hotel ficticio. Hemos seguido un flujo de trabajo que involucra la preparación de datos reales y metadatos, el entrenamiento del sintetizador y la generación de datos sintéticos basados en los patrones aprendidos. Además, hemos aplicado técnicas de anonimización para proteger los datos sensibles y hemos evaluado la calidad de los datos sintéticos generados.
En resumen, los datos sintéticos son una herramienta poderosa en la era de los datos, ya que nos permiten superar la escasez y la falta de disponibilidad de datos de valor. Con su capacidad para imitar los datos reales sin comprometer la privacidad, los datos sintéticos tienen el potencial de transformar la forma en que desarrollamos proyectos de inteligencia artificial y análisis. A medida que avanzamos en esta nueva era, es probable que los datos sintéticos desempeñen un papel cada vez más importante en la generación de nuevos productos y servicios digitales.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
En esta infografía se resume el concepto y sus principales aplicaciones:

Puedes descargarla en PDF aquí
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Blog
La tecnología digital y los algoritmos han revolucionado la forma en que vivimos, trabajamos y nos comunicamos. Si bien prometen eficiencia, precisión y conveniencia, estas tecnologías pueden exacerbar los prejuicios y las desigualdades sociales y crear nuevas formas de exclusión. Así, la invisibilización y la discriminación, que siempre han existido, cobran nuevas formas en la era de los algoritmos.
La falta de interés y de datos lleva a la invisibilización algorítmica, motivando que existan dos tipos de abandono algorítmico. El primero de ellos ocurre entre las personas desatendidas en el mundo, que incluye a los millones que no tienen un teléfono inteligente ni una cuenta bancaria y que, por ende, se encuentran al margen de la economía de plataformas y, para los algoritmos, no existen. El segundo tipo de abandono algorítimico incluye a individuos o grupos que son víctimas del fracaso del sistema algorítmico, como sucedió con SyRI (Systeem Risico Indicatie) en Países Bajos que señaló injustamente a unas 20.000 familias de origen socioeconómico bajo de cometer fraude fiscal, llevando a muchas a la ruina en 2021. El algoritmo, que fue declarado ilegal por un tribunal de La Haya meses más tarde, se aplicó en los barrios más pobres del país y bloqueó la posibilidad de muchas familias con más de una nacionalidad de percibir los beneficios sociales a los que tenían derecho por su condición socioeconómica.
Más allá del ejemplo en el sistema público neerlandés, la invisibilización y la discriminación también pueden originarse en el sector privado. Un ejemplo es el algoritmo de ofertas de trabajo de Amazon que mostró un sesgo contra las mujeres al aprender de datos históricos –es decir, datos incompletos al no incluir un universo amplio y representativo—, lo que llevó a Amazon a abandonar el proyecto. Otro ejemplo Apple Card, una tarjeta de crédito respaldada por Goldman Sachs, que también fue señalada cuando se descubrió que su algoritmo ofrecía límites de crédito más favorables a los hombres que a las mujeres.
En general, la invisibilidad y la discriminación algorítmica, en cualquier ámbito, puede derivar en un acceso desigual a los recursos y en una exacerbación de la exclusión social y económica.
Tomar decisiones basadas en algoritmos
Los datos y los algoritmos son componentes interconectados en el ámbito de la informática y el procesamiento de la información. Los datos sirven de base, pero pueden ser desestructurados, con excesiva variabilidad e incompletos. Los algoritmos son instrucciones o procedimientos diseñados para procesar y estructurar estos datos y extraer información, patrones o resultados significativos.
La calidad y relevancia de los datos impacta directamente en la efectividad de los algoritmos, ya que estos dependen de las entradas de datos para generar resultados. De ahí, el principio “basura entra basura sale”, que resume la idea de que, si entran datos de mala calidad, sesgados o inexactos en un sistema o proceso, el resultado también será de mala calidad o impreciso. Por su lado, los algoritmos bien diseñados pueden mejorar el valor de los datos al revelar relaciones ocultas o hacer predicciones.
Esta relación simbiótica subraya el papel fundamental que desempeñan tanto los datos como los algoritmos a la hora de impulsar los avances tecnológicos, permitir la toma de decisiones informadas y favorecer innovaciones.
La toma de decisiones algorítmica se refiere al proceso de utilizar conjuntos predefinidos de instrucciones o reglas para analizar datos y emitir predicciones que ayuden a decidir. Cada vez más, se aplica a decisiones que tienen que ver con el bienestar social y la oferta de servicios y productos comerciales a través de plataformas. Es ahí donde se puede encontrar la invisibilidad o la discriminación algorítmica.
Cada vez con más frecuencia, los sistemas de bienestar utilizan datos y algoritmos para ayudar en la toma de decisiones sobre asuntos como quién debe recibir asistencia y de qué tipo o quién presenta riesgos. Estos algoritmos consideran diferentes factores como ingresos, tamaño de la familia o de la vivienda, gastos, factores de riesgo, edad, sexo o género, que pueden incluir sesgos y omisiones.
Por eso el Relator Especial sobre la extrema pobreza y los derechos humanos, Philip Alston, advertía en un informe ante la Asamblea General de Naciones Unidas que la adopción sin cautelas de estos puede llevar a un bienestar social distópico. En dicho estado de bienestar distópico, los algoritmos se utilizan para reducir presupuestos, disminuir el número de personas beneficiarias, eliminar servicios, introducir formas exigentes e intrusivas de condicionalidad, modificar comportamientos, imponer sanciones y “revertir la noción de que el Estado debe rendir cuentas”.
Invisibilidad y discriminación algorítmicas: Dos conceptos opuestos
Aunque los datos y los algoritmos tienen mucho en común, la invisibilidad y la discriminación algorítmicas son dos conceptos opuestos. La invisibilidad algorítmica se refiere a lagunas en conjuntos de datos u omisiones en los algoritmos, que resultan en desatenciones en la aplicación de beneficios o servicios. Por el contrario, la discriminación algorítmica habla de puntos críticos que resaltan comunidades específicas o características sesgadas en conjuntos de datos, generando injusticia.
Es decir, la invisibilización algorítmica ocurre cuando individuos o grupos están ausentes en los conjuntos de datos, lo que hace imposible abordar sus necesidades. Por ejemplo, integrar en la toma de decisiones social datos sobre mujeres con discapacidad puede ser vital para la inclusión. A nivel mundial, las mujeres son más vulnerables a la invisibilización algorítmica que los hombres, ya que tienen menos acceso a la tecnología digital y dejan menos trazas digitales.
Los sistemas algorítmicos opacos que incorporan estereotipos pueden aumentar la invisibilización y la discriminación al ocultar, o bien apuntar, a personas o poblaciones vulnerables. Un sistema algorítmico opaco es aquel no permite el acceso a su funcionamiento.
Por otro lado, agregar o desagregar datos sin estudiar las consecuencias cuidadosamente puede resultar en omisiones u errores. Esto ilustra el doble filo de la contabilidad; es decir, la ambivalencia de la tecnología que cuantifica y cuenta, y que puede servir para mejorar la vida de las personas, pero también para perjudicarlas.
La discriminación puede surgir cuando las decisiones algorítmicas se basan en datos históricos, que normalmente incorporan asimetrías, estereotipos e injusticias, porque en el pasado existieron más desigualdades. El efecto de “basura entra basura sale” se produce si los datos están sesgados, como suele pasar con el contenido en línea. Asimismo, las bases de datos con sesgos o incompletas pueden ser incentivos de la discriminación algorítmica. Pueden aparecer sesgos de selección cuando los datos de reconocimiento facial, por ejemplo, se basan en rasgos de hombres blancos, mientras que las usuarias son mujeres de piel oscura, o en contenido en línea generado por una minoría de agentes, lo que dificulta la generalización.
Como se ve, abordar la invisibilidad y la discriminación algorítmica es un reto de primera magnitud que solo se podrá resolver con la concienciación y la colaboración de instituciones, organizaciones de campaña, empresas, e investigación.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Blog
La inteligencia artificial generativa se refiere a la capacidad de una máquina para generar contenido original y creativo, como imágenes, texto o música, a partir de un conjunto de datos de entrada. En lo que se refiere a la generación de texto, estos modelos son accesibles, en formato experimental, desde hace un tiempo, pero comenzaron a generar interés a mediados de 2020 cuando Open AI, una organización dedicada a la investigación en el campo de la inteligencia artificial general, publicó el acceso a su modelo de lenguaje GPT-3 a través de una API.
La arquitectura de GPT-3 está compuesta por 175 mil millones de parámetros, mientras que la de su antecesor GPT-2 era de 1.500 millones de parámetros, esto es, más de 100 veces más. GPT-3 representa por tanto un cambio de escala enorme ya que además fue entrenado con un corpus de datos mucho mayor y un tamaño de los tokens mucho más grande, lo que le permitió adquirir una comprensión más profunda y compleja del lenguaje humano.
A pesar de que fue de 2022 cuando OpenAI anunció la apertura de chatGPT, que permite dotar de una interfaz conversacional a un modelo de lenguaje basado en una versión mejorada de GPT-3, no ha sido hasta los últimos dos meses cuando la noticia ha llamado masivamente la atención del público, gracias a la amplia cobertura mediática que trata de dar respuesta al incipiente interés general.
Y es que, ChatGPT no sólo es capaz de generar texto a partir de un conjunto de caracteres (prompt) como GPT-3, sino que responde a preguntas en lenguaje natural en varios idiomas que incluyen inglés, español, francés, alemán, italiano o portugués. Es precisamente este cambio en la interfaz de acceso, pasando de ser una API a un chatbot, lo que lo ha convertido a la IA en accesible para cualquier tipo de usuario.
Tanto es así que más de un millón de personas se registraron para usarlo en tan solo cinco días, lo que ha motivado la multiplicación de ejemplos en los que chatGPT produce código de software, ensayos de nivel universitario, poemas e incluso chistes. Eso sin tener en cuenta que ha sido capaz de sacar adelante un examen de selectividad de Historia o de aprobar el examen final del MBA de la prestigiosa Wharton School.
Todo esto ha puesto a la IA generativa en el centro de una nueva ola de innovación tecnológica que promete revolucionar la forma en que nos relacionamos con internet y la web a través de búsquedas vitaminadas por IA o navegadores capaces de resumir el resultado de estas búsquedas.
Hace tan solo unos días, conocíamos la noticia de que Microsoft trabaja en la implementación de un sistema conversacional dentro de su propio buscador, el cual ha sido desarrollado a partir del conocido modelo de lenguaje de Open AI y cuya noticia ha puesto en jaque a Google.
Y es que, como consecuencia de esta nueva realidad en la que la IA ha llegado para quedarse, los gigantes tecnológicos han ido un paso más allá en la batalla por aprovechar al máximo los beneficios que esta reporta. En esta línea, Microsoft ha presentado una nueva estrategia dirigida a optimizar al máximo la manera en la que nos relacionamos con internet, introduciendo la IA para mejorar los resultados ofrecidos por los buscadores de navegadores, aplicaciones, redes sociales y, en definitiva, todo el ecosistema de la web.
Sin embargo, aunque el camino en el desarrollo de los nuevos y futuros servicios ofrecidos por la IA de Open AI aún están por ver, avances como los anteriores ofrecen una pequeña pista de la guerra de navegadores que se avecina y que, probablemente, cambie en el corto plazo la manera de crear y hallar contenido en la web.
Los datos abiertos
GPT-3, al igual que otros modelos que han sido generados con las técnicas descritas en la publicación científica original de GTP-3, es un modelo de lenguaje pre-entrenado, lo que significa que ha sido entrenado con un gran conjunto de datos, en total unos 45 terabytes de datos de texto. Según este paper, el conjunto de datos de entrenamiento estaba compuesto en un 60% por datos obtenidos directamente de internet en los que están contenidos millones de documentos de todo tipo, un 22% del corpus WebText2 construido a partir de Reddit, y el resto con una combinación de libros (16%) y Wikipedia (3%).
Sin embargo, no se sabe cuántos datos abiertos utiliza GPT-3 exactamente, ya que OpenAI no proporciona detalles más específicos sobre el conjunto de datos utilizado para entrenar el modelo. Lo que sí podemos hacer son algunas preguntas al propio chatGPT que nos ayuden a extraer interesantes conclusiones sobre el uso que hace de los datos abiertos.
Por ejemplo, si le preguntamos a chatGPT cuál era la población de España entre 2015 y 2020 (no podemos pedirle datos más recientes), obtenemos una respuesta de este tipo:

Tal como podemos ver en la imagen superior, aunque la pregunta sea la misma, la respuesta puede variar tanto en la redacción como en la información que contiene. Las variaciones pueden ser aún mayores si realizamos la pregunta en diferentes días o hilos de conversación:
Pequeñas variaciones en la redacción del texto, generar la pregunta en diferentes momentos del hilo de conversación (recordemos que guarda el contexto) o en hilos o días diferentes puede conducir a resultados ligeramente diferentes. Además, la respuesta no es completamente precisa, tal y como nos advierte la propia herramienta si las comparamos con las series de población residente en España del propio INE, donde nos recomienda consultar. Los datos que idealmente habríamos esperado en la respuesta podrían obtenerse en un conjunto de datos abiertos del INE:
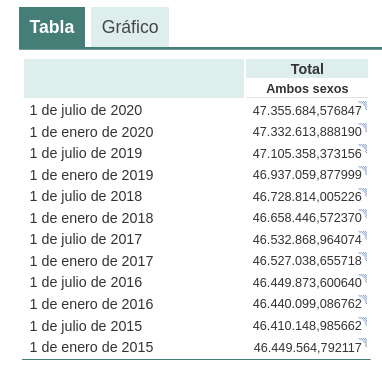
Este tipo de respuestas sugieren que los datos abiertos no se han empleado como una fuente autoritativa para responder preguntas de tipo factual, o al menos que aún no está completamente refinado el modelo en este sentido. Haciendo algunas pruebas básicas con preguntas sobre otros países hemos observado errores parecidos, por lo que no parece que se trate de un problema sólo con preguntas referentes a España.
Si hacemos preguntas algo más específicas como pedir la lista de los municipios de la provincia de Burgos que comienzan por la letra “G” obtenemos respuestas que no son completamente correctas, como es propio de una tecnología que todavía está en fase incipiente.
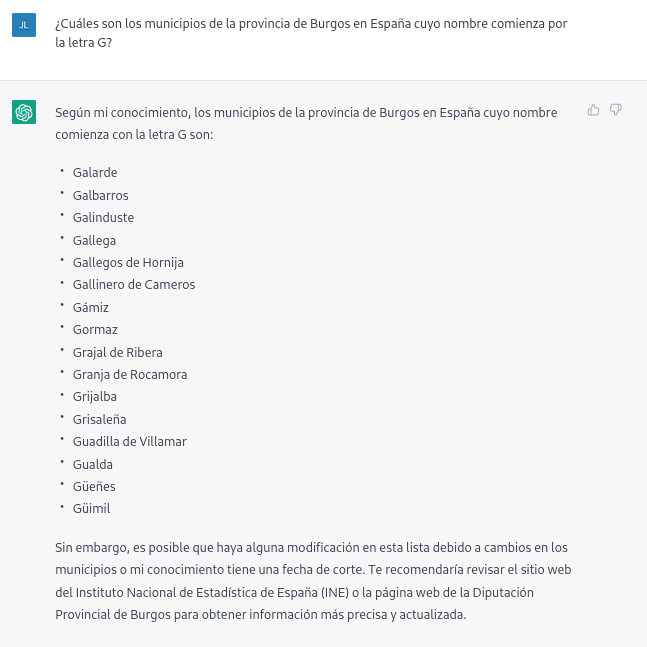
La respuesta correcta debería contener seis municipios: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán y Gumiel del Mercado. Sin embargo, la respuesta que hemos obtenido sólo contiene los cuatro primeros e incluye localidades de la provincia de Guadalajara (Gualda), municipios de la provincia de Valladolid (Gallegos de Hornija) o localidades de la provincia de Burgos que no son municipios (Galarde). En este caso, también podemos acudir a conjunto de datos abiertos para obtener la respuesta correcta.
A continuación, le preguntamos a ChatGPT por la lista de municipios que comienzan por la letra Z en la misma provincia. ChatGPT nos dice que nos hay ninguno, razonando la respuesta, cuando en realidad hay cuatro:
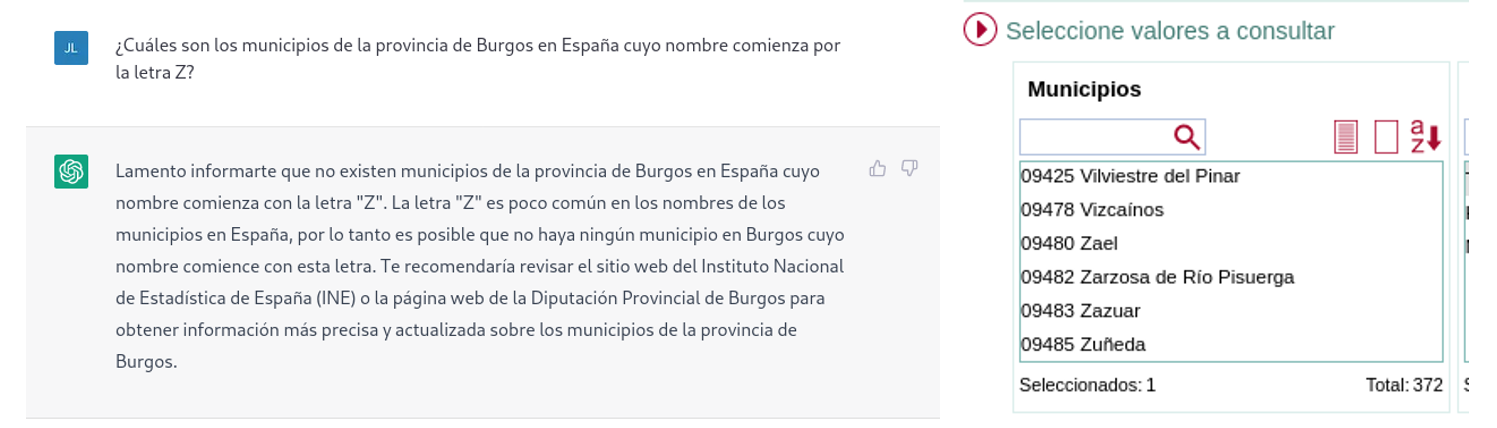
Como se deduce de los ejemplos anteriores, vemos cómo los datos abiertos sí pueden contribuir a la evolución tecnológica y, por ende, a mejorar el funcionamiento de la inteligencia artificial de Open AI. Sin embargo, dado el estado de madurez actual de la misma, aún es pronto para ver un empleo óptimo de estos, a la hora de dar respuesta a preguntas más complejas.
Por lo tanto, para que un modelo de inteligencia artificial generativa sea eficaz, es necesario que cuente con una gran cantidad de datos de alta calidad y diversidad, y los datos abiertos son una fuente de conocimiento valiosa para este fin.
Probablemente, en futuras versiones del modelo, podamos ver cómo los datos abiertos ya adquieren un peso mucho más importante en la composición del corpus de entrenamiento, logrando conseguir una mejora importante en la calidad de las respuestas de tipo factual.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Llevamos años anunciando que la Inteligencia Artificial está viviendo uno de sus periodos más prolíficos y excitantes. Un momento en el que comienzan a verse aplicaciones y casos de uso donde la inteligencia humana se funde con la artificial. Algunas profesiones están cambiando para siempre. Los periodistas y escritores disponen ahora de herramientas de software que pueden escribir por ellos. Los creadores de contenido - imágenes o video - pueden pedirle a la máquina que, mediante una frase, que cree por ellos. En este post profundizamos en este último ejemplo. Hemos podido probar Dall-e 2 y nos hemos quedado de piedra con los resultados.
Introducción
Estos días, en la comunidad tecnológica del mundo entero, hay un murmullo de fondo, una excitación colectiva de todos los amantes de las tecnologías digitales y en particular de la inteligencia artificial. En varias ocasiones hemos mencionado en este espacio de comunicación las innovaciones de la compañía OpenAI. Hemos escrito varios artículos donde hablamos del algoritmo GPT-3 y de lo que es capaz en el campo del procesamiento del lenguaje natural. Recientemente, OpenAI ha ido eliminando las listas de espera (en las que muchos llevábamos tiempo inscritos) para permitirnos probar de forma limitada las capacidades del algoritmo GPT-3 implementado en diferentes tipos de aplicación.
Ejemplo de las múltiples aplicaciones de GPT-3 en el ámbito del lenguaje natural.
Recomendamos a nuestros lectores experimentar con la herramienta para completar texto, en la que con tan solo proporcionar una corta frase, la IA nos completa el texto con varios párrafos indistinguibles de la redacción de un humano. Los últimos días, están siendo frenéticos con multitud de personas probando la herramienta de Chat GPT-3. El nivel de naturalidad de la IA para mantener una conversación es, sencillamente, alucinante. Los resultados están impactando en casos de uso muy variados, como por ejemplo, la asistencia para programadores de software. Chat GPT-3 está siendo capaz de programar sencillas rutinas de código o algoritmos con tan solo describir en lenguaje natural lo que se quiere programar. Pero, el resultado impresiona más aún si caemos en que la IA es capaz de corregir sus propios errores de programación.
DALL-E
Dejando a un lado, las capacidades de generar lenguaje natural indistinguible del escrito por un humano, vamos al tema central de este post. Una de las aplicaciones más sorprendentes de la IA de OpenAI es la solución conocida cómo DALL-E. Qué mejor manera de presentar DALL-E que preguntarle a Chat GPT-3 qué es DALL-E.
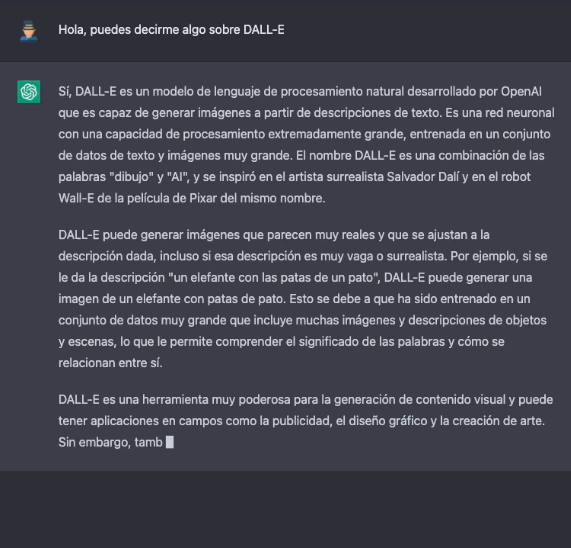
La descripción más formal de DALL-E, de acuerdo con su propia web es:
DALL·E es una versión de GPT-3 entrenado con 12 mil millones de parámetros para generar imágenes a partir de descripciones de texto. DALL-E tiene un conjunto diverso de capacidades, incluida la creación de versiones antropomórficas de animales y objetos, la combinación de conceptos no relacionados de manera plausible, la representación de texto y la aplicación de transformaciones a imágenes existentes.
Actualmente existe una segunda versión del algoritmo DALL-E 2 capaz de generar imágenes más realistas y precisas con una resolución 4 veces mayor. La herramienta para probar DALL-E está disponible aquí https://labs.openai.com/. Para usarla es necesario crear previamente una cuenta en OpenAI que nos permitirá jugar con todas las herramientas de la compañía. Cuándo accedemos a la web de prueba podemos escribir nuestro propio texto o pedirle a la herramienta que genere descripciones aleatorias de imágenes en lenguaje natural para crear imágenes. Por ejemplo, haciendo clic sobre el botón Surprise me:

La web nos genera esta descripción aleatoria: an astronaut lounging in a tropical resort in space, pixel art
Y este es el resultado:

Repetimos: an expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula

Podemos asegurar que el ejercicio resulta algo adictivo y damos fe de que algunos nos hemos pasado horas del fin de semana jugando con las descripciones y esperando, una y otra vez, el asombroso resultado.
Sobre el entrenamiento de DALL-E 2
DALL-E 2 (arXiv:2204.06125) es una versión refinada del sistema original DALL-E (arXiv:2102.12092). Para entrenar el modelo original de DALL-E, que contiene 12 mil millones de parámetros, se utilizó un conjunto de 250 millones de pares de texto-imagen (públicamente disponibles en Internet). Este conjunto de datos es una mezcla de varios datasets previos compuesto por: Conceptual Captions de Google; los pares de texto e imagen de Wikipedia y un subconjunto filtrado de YFCC100M.
Curiosidades de DALL-E 2
Algunas curiosidades más allá de las pruebas que podemos hacer para generar nuestras propias imágenes. OpenAI ha creado un repositorio específico de Github en el que describe los riesgos y limitaciones de DALL-E. En el sitio se informa, por ejemplo, de que, por el momento, el uso de DALL-E está limitado para propósitos no comerciales. Así que no es posible hacer ningún uso comercial de las imágenes generadas. Es decir, no pueden ser vendidas, ni licenciadas bajo ningún supuesto. En este sentido, todas las imágenes generadas por DALL-E incluyen una marca distintiva que permite saber que han sido generadas con la IA. En el sitio de Github podemos encontrar ingente cantidad de información sobre la generación de contenido explícito, los riesgos relacionados con el sesgo que la IA pueda introducir en la generación de imágenes y los usos inadecuados de DALL-E cómo por ejemplo, el acoso, el bullying o la explotación de individuos.

En clave nacional, MarIA
En clave nacional, tras meses de pruebas y ajustes, ha visto la luz MarIA: la primera inteligencia artificial supermasiva, entrenada con datos abiertos procedentes de los archivos web de la Biblioteca Nacional de España (BNE) y gracias a los recursos de computación del Centro Nacional de Supercomputación. En relación con este post, MarIA ha sido entrenada haciendo uso del algoritmo GPT-2, del que hemos hablado mucho meses atrás en este espacio. Para realizar el entrenamiento de MarIA, se han utilizado 135 mil millones de palabras precedentes del banco documental de la Biblioteca Nacional con un volumen total de 570 Gigabytes de información.
Conclusiones
A medida que transcurren los días y las semanas desde la apertura general de las APIs y las herramientas de OpenIA, se suceden torrencialmente las publicaciones en todo tipo de medios, redes sociales y blogs especializados sobre las capacidades y posibilidades de Chat GPT-3 y DALL-E. No creo que en estos momentos nadie sea capaz de avanzar las potenciales aplicaciones comerciales, científicas y sociales de esta tecnología. Lo que está claro, es que muchos pensamos que OpenAI ha enseñado solo una muestra de lo que es capaz y parece que podemos estar a las puertas de un hito histórico en el desarrollo de la IA tras muchos años de sobreexpectación y promesas a medio cumplir. Seguiremos informando sobre los avances de GTP-3, pero por el momento, no nos queda más que seguir disfrutando, jugando y aprendiendo con las sencillas herramientas que tenemos a disposición!
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Ya ha llovido bastante desde que en 2012 se publicara aquel famoso artículo titulado "Data Scientist: The Sexiest Job of the 21st Century". Desde entonces el campo de la ciencia de datos se ha profesionalizado mucho. Se han desarrollado multitud de técnicas, frameworks y herramientas que aceleran el proceso de convertir datos brutos en información de valor. Una de estas técnicas se conoce cómo Auto ML o Machine Learning automático. En este artículo revisaremos las ventajas y características de este método.
En un proceso de ciencia de datos (data science), cualquier científico de datos (data scientist) suele utilizar un método de trabajo sistemático, según el cual va destilando los datos crudos hasta conseguir extraer información de valor para el negocio del cual parten esos datos. Existen varias definiciones del proceso de análisis de datos, aunque suelen ser todas muy similares con pequeñas variantes. En la siguiente figura mostramos un ejemplo de proceso o workflow de análisis de datos.

Cómo vemos, podemos distinguir tres etapas:
-
Importación y limpieza.
-
Exploración y modelado.
-
Comunicación.
Dependiendo del tipo de datos de origen y del resultado que busquemos alcanzar con estos datos, el proceso de modelado puede variar. Sin embargo, independientemente del modelo, el científico de datos debe de ser capaz de obtener un conjunto de datos limpios y preparados para servir como entrada al modelo. En este post vamos a centrarnos en la segunda etapa: exploración y modelado.
Una vez obtenidos estos datos limpios y libres de errores (tras su importación y limpieza en la etapa 1), el científico de datos debe de decidir qué transformaciones aplica a dichos datos, con el objetivo de que algunos datos derivados de los originales (en conjunto con los originales), sean los mejores indicadores del modelo subyacente al conjunto de datos. A estas transformaciones las denominamos características (en inglés, features).
El siguiente paso es dividir nuestro conjunto de datos en dos partes: una parte, por ejemplo, un 60% del conjunto total, servirá cómo conjunto de datos de entrenamiento. El 40% restante lo reservaremos para aplicar nuestro modelo, una vez entrenado. A este segundo lo denominamos subset de prueba o test. Este proceso de división de los datos de origen se realiza con la intención de evaluar la fiabilidad del modelo antes de aplicarlo sobre nuevos datos desconocidos para el modelo. Ahora se desarrolla un proceso iterativo en el que el científico de datos prueba varios tipos de modelos que cree que pueden funcionar sobre este conjunto de datos. Cada vez que aplica un modelo, observa y mide los parámetros matemáticos (cómo precisión y reproducibilidad) que expresan cuánto de bien el modelo es capaz de reproducir los datos de prueba. Además de probar diferentes tipos de modelos, el científico de datos puede variar el conjunto de datos de entrenamiento con nuevas transformaciones, calculando nuevas y diferentes características, con el fin de dar con algunas características que hagan que el modelo en cuestión se ajuste mejor a los datos.
Podemos imaginar que este proceso, repetido decenas o centenas de veces, es un gran consumidor de recursos tanto humanos como de cómputo. El científico de datos intenta realizar diferentes combinaciones de algoritmos, modelos, características y porcentajes de datos, en base a su experiencia y habilidad con las herramientas. Sin embargo, ¿qué pasaría si fuera un sistema el que llevará a cabo todas estas combinaciones por nosotros y diera, finalmente, con la mejor combinación? Precisamente para responder a esta herramienta se han creado los sistemas Auto ML.
En mi opinión, un sistema o herramienta de Auto ML no tiene el objetivo de sustituir al científico de datos, pero sí de complementarlo, ayudando a éste a ahorrar mucho tiempo en el proceso iterativo de probar diferentes técnicas y datos para alcanzar el mejor modelo. De forma general, podríamos decir que un sistema de Auto ML tiene (o tendría que) aportar los siguientes beneficios al científico de datos:
-
Sugerir las mejores técnicas de Machine Learning y generar automáticamente modelos optimizados (ajustando automáticamente los parámetros), habiendo probado una gran cantidad de conjuntos de datos de entrenamiento y test respectivamente.
-
Informar al científico de datos de aquellas características (recordar que son transformaciones de los datos originales) que tienen el mayor impacto en el resultado final del modelo.
-
Generar visualizaciones que permitan al científico de datos entender el resultado del proceso llevado a cabo por el Auto ML. Es decir, enseñar al usuario del Auto ML los indicadores clave del resultado del proceso.
-
Generar un entorno interactivo de simulación que permita a los usuarios explorar rápidamente el modelo para ver cómo funciona.
Para terminar, mencionamos algunos de los sistemas y herramientas Auto ML más conocidos, como H2O.ai, Auto-Sklearn y TPOT. Hay que destacar que estos tres sistemas cubren la totalidad del proceso de Machine Learning que veíamos al principio. Sin embargo, existen más soluciones y herramientas que cubren parcialmente alguno de los pasos del proceso completo. También existen artículos en los que se compara la eficacia de estos sistemas ante determinados problemas de machine learning sobre conjuntos de datos abiertos y accesibles.
En conclusión, estas herramientas proporcionan soluciones valiosas a problemas comunes de ciencia de datos y tienen la capacidad de mejorar drásticamente la productividad de los equipos de ciencia de datos. Sin embargo, la ciencia de datos sigue teniendo un componente importante de arte y no todos los problemas se resuelven con herramientas de automatización. Animamos a todos los alquimistas de algoritmos y artesanos de datos a seguir dedicando tiempo y esfuerzo en el desarrollo de nuevas técnicas y algoritmos que nos permitan convertir datos en valor de forma rápida y efectiva.
El objetivo de este post es explicar al público general, de forma sencilla y asequible, cómo las técnicas de auto ML pueden simplificar el proceso de análisis avanzado de datos. En ocasiones puede recurrirse a simplificaciones excesivas con el fin de no complicar en exceso el contenido de este post.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hace unas semanas, os contamos los distintos tipos de aprendizaje automático a través de una serie de ejemplos, y analizamos cómo elegir uno u otro en base a nuestros objetivos y a los conjuntos de datos disponibles para entrenar el algoritmo.
Ahora supongamos que contamos con un conjunto de datos ya etiquetado y que necesitamos entrenar un modelo de aprendizaje supervisado para resolver la tarea que nos ocupa. En este punto, necesitamos algún mecanismo que nos diga si el modelo ha aprendido correctamente o no. Eso es lo que vamos a tratar en este post, las métricas más utilizadas para evaluar la calidad de nuestros modelos.
La evaluación de modelos es un paso muy importante en la metodología de desarrollo de sistemas de aprendizaje automático. Ayuda a medir el rendimiento del modelo, es decir, cuantificar la calidad de las predicciones que ofrece. Para realizar este cometido utilizamos las métricas de evaluación, que dependen de la tarea de aprendizaje que apliquemos. Como vimos en el post anterior, dentro del aprendizaje supervisado existen dos tipos de tareas que difieren, principalmente, en el tipo de salida que ofrecen:
- Las tareas de clasificación, que producen como salida una etiqueta discreta, es decir, cuando la salida es una dentro de un conjunto finito.
- Las tareas de regresión, que producen como salida un valor real y continuo.
A continuación, te explicamos algunas de las métricas más utilizadas para evaluar el rendimiento de ambos tipos de tareas:
Evaluación de modelos de clasificación
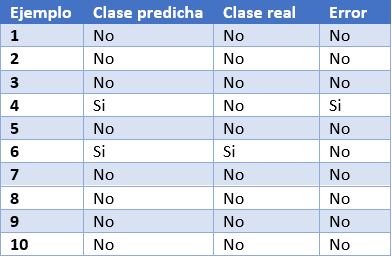
Para poder entender mejor estas métricas, vamos a poner como ejemplo las predicciones de un modelo de clasificación para detectar enfermos de COVID. En la siguiente tabla podemos ver en la primera columna el identificador de ejemplo, en la segunda la clase que ha predicho el modelo, en la tercera la clase real y la cuarta columna indica si el modelo ha fallado en su predicción o no. En este caso, la clase positiva es “Si” y la clase negativa es “No”.
Algunos ejemplos de métricas de evaluación de modelos de clasificación son los siguientes:
- Matriz de confusión: es una herramienta ampliamente utilizada que permite inspeccionar y evaluar visualmente las predicciones de nuestro modelo. En cada fila se representa el número de predicciones de cada clase y en las columnas las instancias de la clase real.

La descripción de cada elemento de la matriz es la siguiente:
Verdadero positivo (VP): número de ejemplos positivos que el modelo predice como positivos. En el ejemplo que presentamos anteriormente, VP es 1 (del ejemplo 6).
Falso positivo (FP): número de ejemplos negativos que el modelo predice como positivos. En nuestro ejemplo, FP es igual a 1 (del ejemplo 4).
Falso negativo (FN): número de ejemplos positivos que el modelo predice como negativos. FN en el ejemplo sería 0.
Verdadero negativo (VN): número de ejemplos negativos que el modelo predice como negativos. En el ejemplo, VN es 8.
- Exactitud o accuracy: la fracción de predicciones que el modelo realizó correctamente. Se representa como un porcentaje o un valor entre 0 y 1. Es una buena métrica cuando tenemos un conjunto de datos balanceado, esto es, cuando el número de etiquetas de cada clase es similar. La exactitud de nuestro modelo de ejemplo es de 0.9, ya que ha acertado 9 predicciones de 10. Si nuestro modelo hubiese predicho siempre la etiqueta “No”, la exactitud sería de igualmente de 0.9, pero no resuelve nuestro problema de identificar enfermos de COVID.
- Recall o sensibilidad: indica la proporción de ejemplos positivos que están identificados correctamente por el modelo entre todos los positivos reales. Es decir, VP / (VP + FN). En nuestro ejemplo, el valor de sensibilidad sería 1 / (1 + 0) = 1. Si evaluásemos con esta métrica un modelo que siempre prediga la etiqueta positiva (“Si”) tendría una sensibilidad de 1, pero no sería un modelo demasiado inteligente. Aunque lo ideal para nuestro modelo de detección de COVID es maximizar la sensibilidad, esta métrica por sí sola no nos asegura que tengamos un buen modelo.
- Precision: esta métrica está determinada por la fracción de elementos clasificados correctamente como positivo entre todos los que el modelo ha clasificado como positivos. La fórmula es VP / (VP + FP). El modelo de ejemplo tendría una precisión de 1 / (1 + 1) = 0.5. Volvamos ahora al modelo que siempre predice la etiqueta positiva. En ese caso, la precisión del modelo es 1 / (1 + 9) = 0.1. Vemos como este modelo tenía una sensibilidad máxima, pero tiene una precisión muy pobre. En este caso necesitamos de las dos métricas para evaluar la calidad real del modelo.
- F1 score: combina las métricas Precision y Recall para dar un único resultado. Esta métrica es la más apropiada cuando tenemos conjuntos de datos no balanceados. Se calcula como la media armónica de Precision y Recal. La fórmula es F1 = (2 * precision * recall) / (precision + recall). Quizá te preguntes por qué la media armónica y no la simple. Esto es porque la media armónica hace que si una de las dos medidas es pequeña (aunque la otra sea máxima), el valor de F1 score va a ser pequeño.
Evaluación de modelos de regresión
A diferencia de los modelos de clasificación, en los modelos de regresión es casi imposible predecir el valor exacto, sino que más bien se busca estar lo más cerca posible del valor real, por lo que la mayoría de las métricas, con sutiles diferencias entre ellas, van a centrarse en medir eso: lo cerca (o lejos) que están las predicciones de los valores reales.
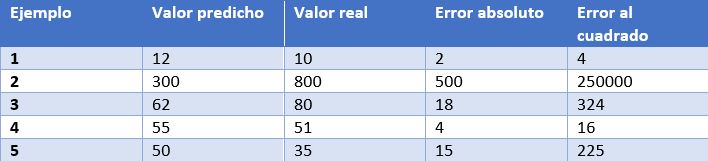
En este caso, tenemos como ejemplo las predicciones de un modelo que determina el precio de relojes dependiendo de sus características. En la tabla mostramos el precio predicho por el modelo, el precio real, el error absoluto y el error elevado al cuadrado.
Algunas de las métricas de evaluación más comunes para los modelos de regresión son:
- Error medio absoluto: Es la media de las diferencias absolutas entre el valor objetivo y el predicho. Al no elevar al cuadrado, no penaliza los errores grandes, lo que la hace no muy sensible a valores anómalos, por lo que no es una métrica recomendable en modelos en los que se deba prestar atención a éstos. Esta métrica también representa el error en la misma escala que los valores reales. Lo más deseable es que su valor sea cercano a cero. Para nuestro modelo de cálculo de precios de relojes, el error medio absoluto es 107.8.
- Media de los errores al cuadrado (error cuadrático medio): Una de las medidas más utilizadas en tareas de regresión. Es simplemente la media de las diferencias entre el valor objetivo y el predicho al cuadrado. Al elevar al cuadrado los errores, magnifica los errores grandes, por lo que hay que utilizarla con cuidado cuando tenemos valores anómalos en nuestro conjunto de datos. Puede tomar valores entre 0 e infinito. Cuanto más cerca de cero esté la métrica, mejor. El error cuadrático medio del modelo de ejemplo es 50113.8. Vemos como en el caso de nuestro ejemplo se magnifican los errores grandes.
- Raíz cuadrada de la media del error al cuadrado: Es igual a la raíz cuadrada de la métrica anterior. La ventaja de esta métrica es que presenta el error en las mismas unidades que la variable objetivo, lo que la hace más fácil de entender. Para nuestro modelo este error es igual a 223.86.
- R cuadrado: también llamado coeficiente de determinación. Esta métrica difiere de las anteriores, ya que compara nuestro modelo con un modelo básico que siempre devuelve como predicción la media de los valores objetivo de entrenamiento. La comparación entre estos dos modelos se realiza en base a la media de los errores al cuadrado de cada modelo. Los valores que puede tomar esta métrica van desde menos infinito a 1. Cuanto más cercano a 1 sea el valor de esta métrica, mejor será nuestro modelo. El valor de R cuadrado para el modelo será de 0.455.
- R cuadrado ajustado. Una mejora de R cuadrado. El problema de la métrica anterior es que cada vez que se añaden más variables independientes (o variables predictoras) al modelo, R cuadrado se queda igual o mejora, pero nunca empeora, lo que puede llegar a confundirnos, ya que, porque un modelo utilice más variables predictoras que otro, no quiere decir que sea mejor. R cuadrado ajustado compensa la adición de variables independientes. El valor de R cuadrado ajustado siempre va a ser menor o igual al de R cuadrado, pero esta métrica mostrará mejoría cuando el modelo sea realmente mejor. Para esta medida no podemos hacer el cálculo para nuestro modelo de ejemplo porque, como hemos visto antes, depende del número de ejemplos y el número de variables utilizadas para entrenar dicho modelo.
Conclusión
A la hora de trabajar con algoritmos de aprendizaje supervisado es muy importante la elección de una métrica de evaluación correcta para nuestro modelo. Para los modelos de clasificación es muy importante prestar atención al conjunto de datos y comprobar si es balanceado o no. En los modelos de regresión hay que considerar los valores anómalos y si queremos penalizar errores grandes o no.
No obstante, generalmente, el dominio de negocio será el que nos guíe en la correcta elección de la métrica. Para un modelo de detección de enfermedades, como el que hemos visto, nos interesa que tenga una alta sensibilidad, pero también nos interesa que tenga un buen valor de precisión, por lo que F1-score sería una opción inteligente. Por otro lado, en un modelo para predecir la demanda de un producto (y por lo tanto de producción), donde un exceso de stock puede incurrir en un sobrecoste por almacenamiento de mercancía, quizás sea una buena idea utilizar la media de los errores al cuadrado para penalizar los errores grandes.
Contenido elaborado por Jose Antonio Sanchez, experto en Ciencia de datos y entusiasta de la Inteligencia Artificial .
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
¿Te imaginas una IA capaz de escribir canciones, novelas, comunicados de prensa, entrevistas, ensayos, manuales técnicos, código de programación, prescribir medicamentos y mucho más que aún no sabemos? Viendo a GPT-3 en acción no parece que estemos muy lejos.
En nuestro último informe sobre procesamiento del lenguaje natural (NLP) mencionamos el algoritmo GPT-2 desarrollado por OpenAI (la compañía fundada por nombres tan reconocidos cómo Elon Musk) como un exponente en cuanto a sus capacidades para la generación de texto sintético con una calidad indistinguible de cualquier otro texto creado por un humano. Los sorprendentes resultados de GPT-2 llevaron a la compañía a no publicar el código fuente del algoritmo por sus potenciales efectos negativos en la generación de deepfakes o noticias falsas.
Recientemente (mayo de 2020) se ha liberado una nueva versión del algoritmo, ahora denominado GPT-3 que incluye novedades funcionales y mejoras de rendimiento y capacidad de analizar y generar textos en lenguaje natural.
En este post tratamos de resumir de forma sencilla y asequible las principales novedades de GPT-3. ¿Te atreves a descubrirlas?
Comenzamos de forma directa, yendo al grano. ¿Qué trae consigo GPT-3? (adaptación de el post original de Mayor Mundada).
- Es mucho más grande (complejo) que todo lo que teníamos antes. Los modelos de deep learning basados en redes neuronales se suelen clasificar por su número de parámetros. A mayor número de parámetros, mayor es la profundidad de la red y por lo tanto su complejidad. El entrenamiento de la versión completa de GPT-2 daba cómo resultado 1.500 millones de parámetros. GPT-3 da cómo resultado 175.000 millones de parámetros. GPT-3 ha sido entrenado sobre una base de 570 GB de texto comparados con los 40 GB de GPT-2.
- Por primera vez puede ser utilizado cómo un producto o servicio. Es decir, OpenAI, ha anunciado la puesta a disposición de los usuarios de un API público para poder experimentar con el algoritmo. En el momento de escribir este post, el acceso al API está restringido (es lo que denominamos un private preview) y hay que solicitar acceso.
- Lo más importante: sus resultados. A pesar de que la API se encuentra restringida por invitación, son numerosos los usuarios en Internet (con acceso a la API) que han publicado artículos sobre sus resultados en diferentes ámbitos.
¿Qué papel juegan los datos abiertos?
En pocas ocasiones se tiene la posibilidad de ver la potencia y los beneficios de los datos abiertos cómo en este tipo de proyectos. Cómo hemos comentado más arriba GPT-3 ha sido entrenado con 570 GB de datos en formato de texto. Pues bien, resulta que el 60% de los datos de entrenamiento del algoritmo vienen de la fuente https://commoncrawl.org. Common Crawl es un proyecto abierto y colaborativo que proporciona un corpus para la investigación, el análisis, la educación, etc. Cómo se especifica en la web de Common Crawl los datos proporcionados son abiertos y se hospedan bajo la iniciativa de datos abiertos de AWS. Buena parte del resto de datos de entrenamiento también son abiertos incluyendo fuentes cómo Wikipedia.
Casos de uso
A continuación mostramos algunos de los ejemplos y casos de uso impactantes.
Generación de texto sintético
En esta entrada (no spoilers ;) ) del blog de Manuel Araoz se muestra la potencia del algoritmo para generar un artículo 100% sintético sobre Inteligencia Artificial. Manuel realiza el siguiente experimento: proporciona a GPT-3 una mínima descripción de su biografía incluida en su blog y un pequeño fragmento de la última entrada en su blog. 117 palabras en total. Tras 10 ejecuciones de GPT-3 para generar texto artificial relacionado, Manuel es capaz de copiar y pegar el texto generado, colocar una imagen de portada y ya tiene listo un nuevo post para su blog. Honestamente, el texto del post sintético es indistinguible de un post original salvo por los posibles errores en nombres, fechas, etc. que pueda incluir el texto.
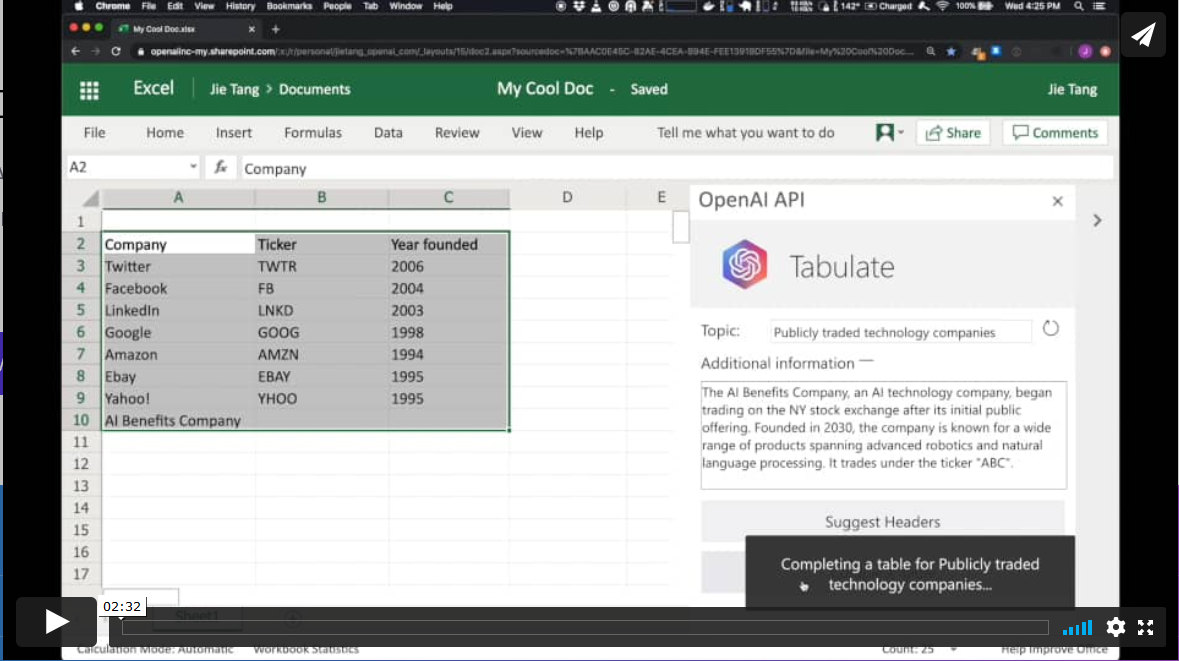
Productividad. Generación automática de tablas de datos.
En otro ámbito diferente, el algoritmo GPT-3 tiene aplicaciones en el ámbito de la productividad. En este ejemplo GPT-3 es capaz de crear una tabla de MS Excel sobre un determinado tema. Por ejemplo, si queremos obtener una tabla, a modo de lista, con las compañías tecnológicas más representativas y su año de fundación, simplemente proporcionamos a GPT-3 el patrón deseado y le pedimos que lo complete. El patrón de inicio puede ser algo similar a esta tabla de debajo (en un ejemplo real, los datos de entrada serán en inglés). GPT-3 completará la zona sombreada con datos reales. Sin embargo, si además del patrón de entrada, le proporcionamos al algoritmo una descripción verosímil de una compañía tecnológica ficticia y le volvemos a pedir que complete la tabla con la nueva información, el algoritmo incluirá los datos de esta nueva compañía ficticia.
Estos ejemplos son solo una muestra de lo que GPT-3 es capaz de hacer. Entre sus funcionalidades o aplicaciones se encuentran:
- la búsqueda semántica (diferente de la búsqueda por palabras clave)
- los chatbots
- la revolución de los servicios de atención al cliente (call-center)
- la generación de texto multipropósito (creación de poemas, novelas, música, noticias falsas, artículos de opinión, etc.)
- las herramientas de productividad. Hemos visto un ejemplo sobre cómo crear tablas de datos, pero se está hablando (y mucho), sobre la posibilidad de crear programas informáticos sencillos cómo páginas web y pequeñas aplicaciones sencillas sin necesidad de codificar, tan solo preguntándole a GPT-3 y sus hermanos que están por llegar.
- las herramientas de traducción on-line
- la comprensión y resúmenes de textos.
y tantas otras cosas que aún no hemos descubierto... Seguiremos informándoles sobre las próximas novedades en NLP y en particular de GPT-3, un game-changer que ha venido para revolucionar todo lo que conocemos por el momento.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.