Publication date
20/09/2018
Update date
20/06/2024

Description
On the internet we can find thousands of data repositories. Those interested in locating certain information have to navigate between multiple sources (national repositories, public organizations or private institutions platforms, digital libraries, specialized web, etc.) with the consequent consumption of time. A difficult search that don´t always produce the expected results.
Google wants to change this situation. On September 5, the famous internet search engine launched Google Dataset Search, a new search engine that facilitates universal access to data sets located on the Internet repositories. The service is aimed at journalists, researchers, students or any citizen interested in finding certain information.
The new search engine works similar to Google Scholar - the Google search engine focused on scientific and academic content-. This search engine locates the data sets, regardless their location or theme, depending on how they are described. That is, Google locates the datasets based on their metadata, instead of tracking the dataset content (distributions).
To improve search effectiveness, Google has provided a guide with tips for publishers. This guide explain how to share data sets in a way that Google can better locate their content.
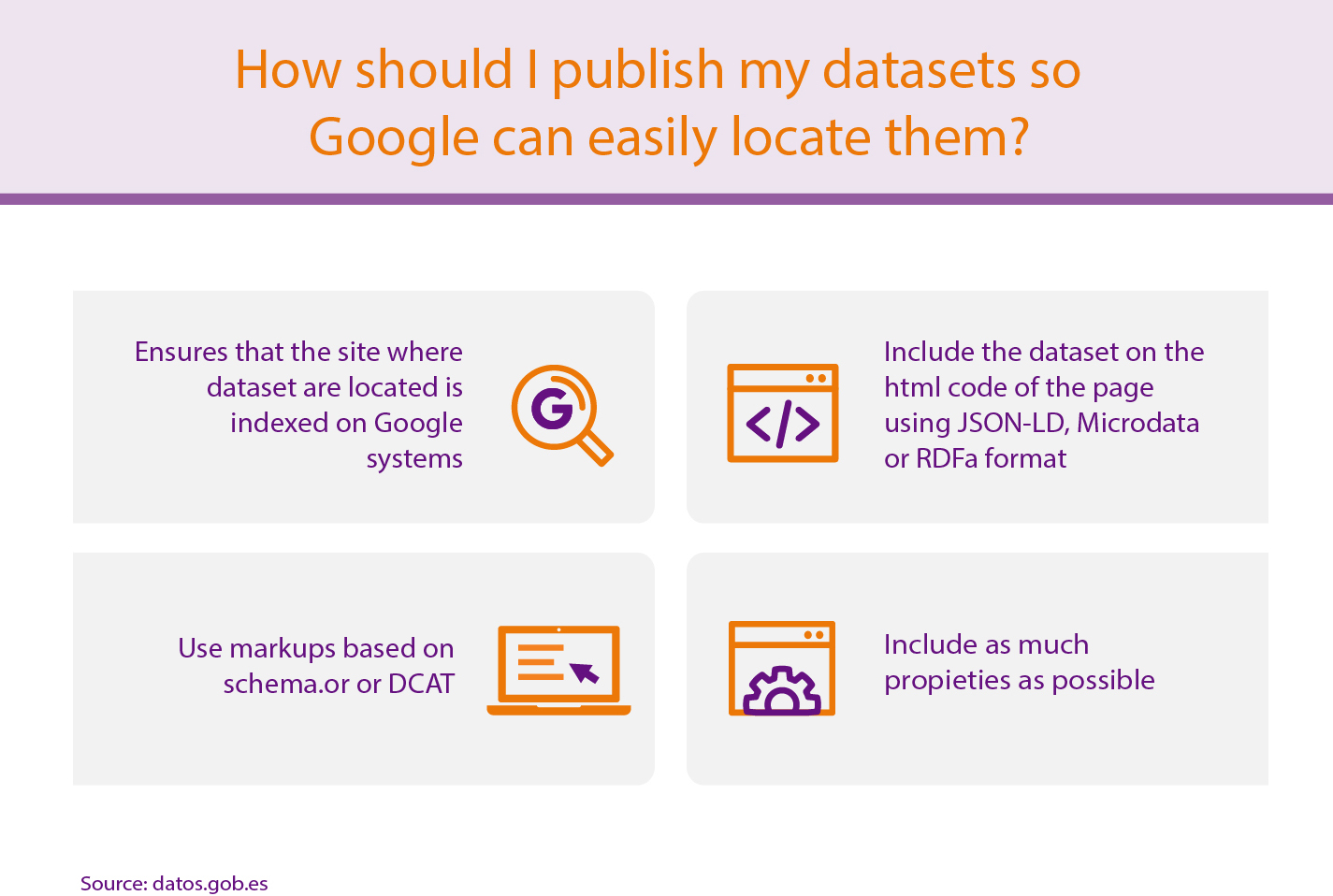
- The site where dataset are located must be indexed on Google systems. Then, Google begins to observe the HTML code and when it finds metadata related to Datasets (correctly tagged), Google Dataset Search indexes the content.
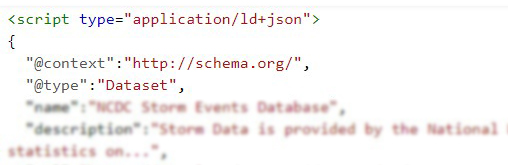
- The dataset must be included in the site code using JSON-LD, Microdata or RDFa format and correctly mark up using Schema.org (preferred) or equivalent structures represented in DCAT. Google is exploring the possibility of incorporating new formats, such as W3C CSVW.
- It is important to include as much information as possible about the datasets in the proprieties, based on the dataset definition by schema.org, such as: name, description, license, publisher, date created, date modified, data catalog, etc. The metadata here included will be showed by Google Data Search.
- In addition, Google recommends the use of proprieties such as 'sameAs' for data sets that are published in several repositories, to avoid duplicate results, or 'isBasedOn' for datasets coming from the modification or aggregation of other original datasets. Google provides a tool to check if the site proprieties are correct and the datasets are going to be correctly identified by the search engine.
In the case of Datos.gob.es, all datasets can be already consulted from Google Data Search, which provides greater visibility to our datasets.
Google Data Search is still in beta. Therefore, there are still challenges to be solved, such as defining more consistently what a dataset is, linking different datasets or expanding metadata between related datasets.
Even so, this is an important advance. Google believes that this project will boost the creation of a data exchange ecosystem and will encourage publishers to follow the best practices for storing and publishing data. Google also believes that Google Data Search will offer scientists a platform to show the impact of their work through citations of the data sets they have produced.
But it cannot be denied that it is a great step to promote open data, making easier for a greater number of users to locate the information they need in a fast and simple way.
Como acotación debería de ser privado el beneficio ya que así se producen controversias en información y pueden causar delitos indebidos a la sociedad.