Aplicación
Edalitics es un servicio de analítica en la nube que permite conectar datos, modelarlos, crear informes y cuadros de mando sin desplegar infraestructura propia y sin conocimientos técnicos. Está basado en EDA (Enterprise Data Analytics), la plataforma open source de la empresa Jortilles y se ofrece como Saas (Software as a Service), lo que reduce la complejidad técnica: el usuario accede a través de un navegador, selecciona sus fuentes y construye visualizaciones simplemente arrastrando y soltando, o bien mediante SQL.
Edalitics funciona como una plataforma de datos corporativos y públicos: puede conectarse a bases de datos y servicios web, y también admite ficheros CSV que el usuario sube para enriquecer su modelo. A partir de ahí, se crean dashboards, KPIs y alertas por correo, y se publican informes privados o públicos para distintos perfiles de decisión, con control de acceso y trazabilidad. Permite tener usuarios ilimitados, lo que la hace interesante para grandes organizaciones con muchos usuarios.
Es importante aclarar que Edalitics no incorpora datasets por defecto, sino que se integra con APIs o portales abiertos. Organismos como el Consell Comarcal del Baix Empordà han utilizado Edalitics para desplegar sus catálogos de datos abiertos.
Edalitics ofrece dos modalidades de uso:
- Versión en la nube (Cloud). La plataforma puede utilizarse directamente en la nube, con un modelo de tarifas escalonado. Esta versión es gratuita para organizaciones con un uso limitado. Las organizaciones con mayores exigencias de uso o volumen de datos pueden acceder a una versión de pago mediante una cuota mensual.
- Instalación en servidores propios (On-Premise). Para aquellas organizaciones que prefieran alojar Edalitics en su propia infraestructura, Jortilles ofrece:
- Asistencia en la instalación y configuración, adaptándose al entorno del cliente.
- Posibilidad de contratar un mantenimiento anual que incluye: soporte técnico directo del equipo desarrollador y acceso a actualizaciones y mejoras de forma proactiva, asegurando el buen funcionamiento y evolución de la plataforma.
Blog
El almacenamiento de datos en la nube es actualmente uno de los segmentos de software empresarial que experimenta un crecimiento más rápido, lo que está facilitando la incorporación de un gran número de nuevos usuarios al campo de la analítica.
Como ya presentamos en un post anterior, un nuevo formato, Parquet, tiene entre sus objetivos potenciar y avanzar en la analítica para esta comunidad en rápido crecimiento y facilitar la interoperabilidad entre diversos almacenes de datos en la nube y motores informáticos.
Parquet es descrito por su propio creador, Apache, como: “Un formato de archivo de datos de código abierto diseñado para el almacenamiento y la recuperación eficiente de datos. Proporciona un rendimiento mejorado para manejar datos complejos de forma masiva".
Parquet se define como un formato de datos orientado a columnas que se plantea como una alternativa moderna a los archivos CSV. A diferencia de los formatos basados en filas, como el CSV, Parquet almacena los datos en función de columnas, lo que implica que los valores de cada columna de la tabla se almacenan contiguamente, en lugar de los valores de cada registro, como se muestra a continuación:
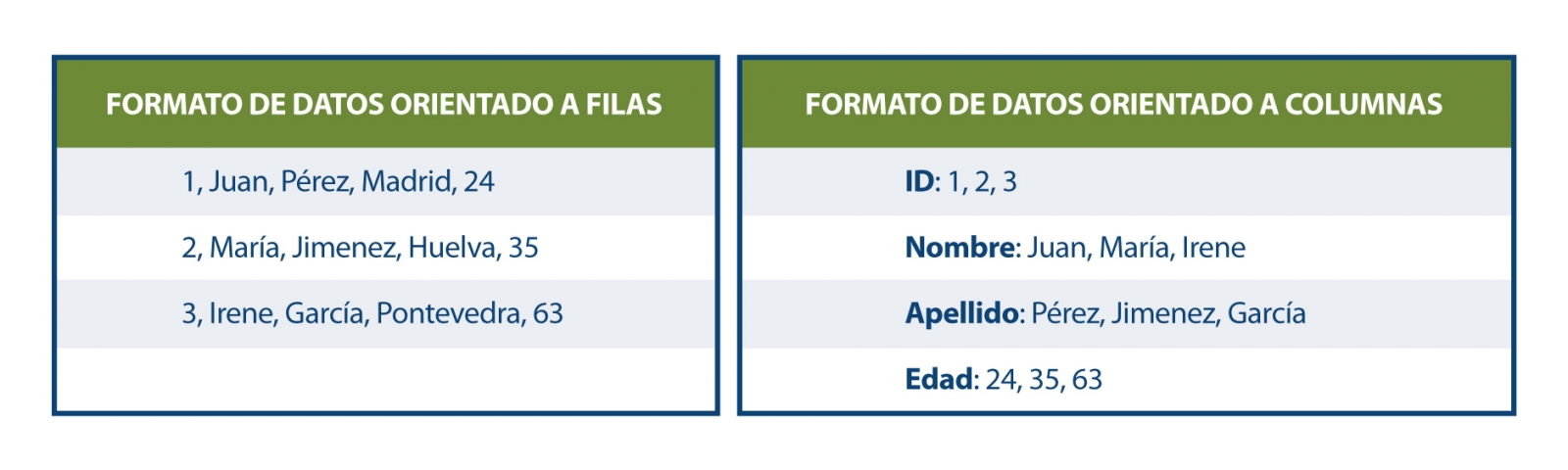
Este método de almacenamiento presenta ventajas en términos de almacenamiento compacto y consultas rápidas en comparación con los formatos clásicos. Parquet funciona eficazmente en los conjuntos de datos desnormalizados que contienen muchas columnas y permite consultar estos datos de manera más rápida y eficiente.
En agosto de 2023 se lanzó un nuevo formato para datos espaciales: el GeoParquet 1.0.0. Durante ese mismo mes, el Open Geospatial Consortium (OGC) informó sobre la formación de un nuevo Grupo de Trabajo de Estándares GeoParquet, cuyo objetivo es promover la adopción de este formato como un estándar de codificación OGC para datos vectoriales nativos en la nube.
GeoParquet 1.0.0 corrige algunas carencias de Parquet, que no ofrecía un buen soporte de datos espaciales. Igualmente la interoperabilidad en los entornos de la nube era compleja para los datos geoespaciales, porque al no existir un estándar o directrices sobre cómo almacenar los datos geográficos, estoseran interpretados de diferente manera por cada sistema. Esto conllevaba dos resultados significativos:
- No era posible exportar datos espaciales de un sistema e importarlos a otro sin un procesamiento significativo entre ellos.
· Los proveedores de datos no podían compartir sus datos en un formato unificado. Si deseaban habilitar a los usuarios en diferentes sistemas, debían admitir las diversas variaciones de soporte espacial en los diferentes motores.
Estas deficiencias han sido solventadas con GeoParquet que, además agrega tipos geoespaciales al formato Parquet, al mismo tiempo que establece una serie de estándares para varios aspectos claves en la representación de datos espaciales:
· Columnas que contienen datos espaciales: se permite tener múltiples columnas que contengan datos espaciales (Punto, Línea y Polígono), con la designación de una columna como "principal".
· Codificación de geometría/geografía: define cómo se codifica la información de geometría o geografía. Inicialmente se utiliza una codificación en binario conocida y Well-known text (WKT) , pero se está trabajando para implementar GeoArrow como una nueva forma de codificación.
· Sistema de referencia espacial: especifica en qué sistema de referencia espacial se encuentran los datos. La especificación es compatible con varios sistemas de referencia de coordenadas alternativos.
· Tipo de coordenadas: define si las coordenadas son planas o esféricas, proporcionando información sobre la geometría y naturaleza de las coordenadas utilizadas.
A esto, hay que añadir que GeoParquet incluye metadatos en dos niveles:
- Metadatos de archivo que indican atributos como la versión de esta especificación utilizada.
- Metadatos de columna con características adicionales para cada geometría como son: sistema de referencia espacial, tipo de geometría, resolución de la geometría, etc.
Otra característica que hace que GeoParquet se esté convirtiendo en un formato muy recomendable, es que es más rápido y ligero que otros más extendidos. La siguiente comparativa muestra el tamaño en distintos formatos (GeoParquet, shaperfile y geopackage) de un mismo archivo con edificios en CSV de un tamaño de 498 megabytes. Se transforma este fichero a estos formatos y se muestra gráficamente el resultado:
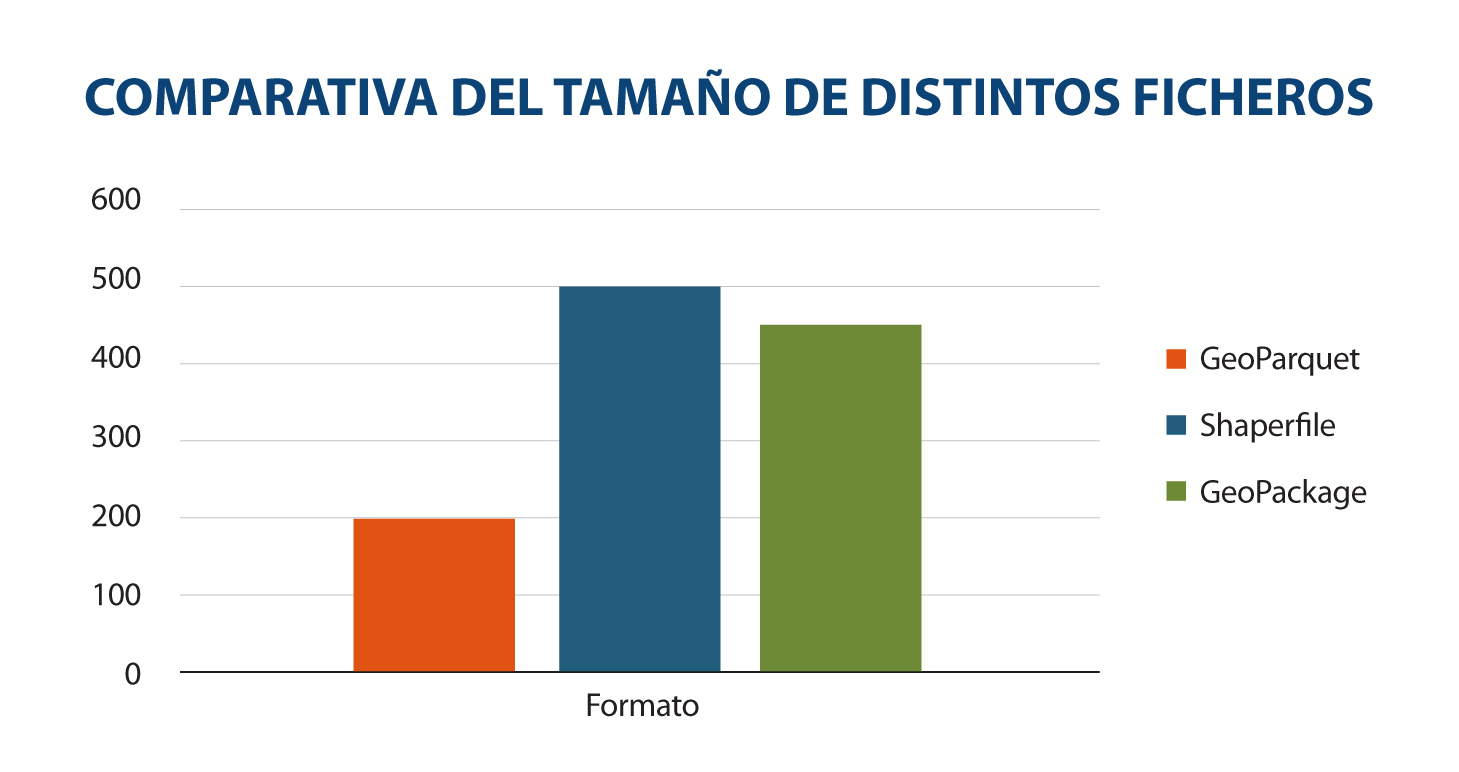
Fuente: Comparación de un mismo conjunto de datos en distintos formatos. Elaboración propia.
La reducción de tamaño para los datos en Geoparquet es notoria. La principal razón detrás de esto es que Parquet se comprime de forma predeterminada. Si bien otros formatos también pueden comprimirse, no se pueden utilizar directamente hasta que se descompriman. Además, se ha optimizado significativamente su rendimiento, contribuyendo así a su eficiencia en el procesamiento de datos espaciales.
Es aquí donde cobra vital importancia GeoParquet, al establecer una forma común de codificar y describir datos espaciales. Esto facilita la creación y compartición de datos espaciales en la nube, reduciendo la complejidad y los costos asociados. Asimismo, permite el intercambio de datos entre sistemas sin necesidad de transformaciones intermedias, convirtiendo a GeoParquet en un potencial formato de distribución geoespacial nativo de la nube y un recurso invaluable para cualquier tarea geoespacial cotidiana.
Estos estándares son fundamentales para garantizar la consistencia, interoperabilidad y comprensión uniforme de los datos espaciales, lo que facilita su manejo y uso en una variedad de aplicaciones y un conjunto variado de herramientas modernas de ciencia de datos, como BigQuery, DuckDB, R, Python, GeoPandas, GDAL, entre otras, que utilizan Parquet de manera efectiva y que están incorporando cada vez más capacidades de soporte geoespacial. Dentro del ecosistema GIS, tanto ArcGIS, FME y QGIS (a partir de la versión 3.28) ya cuentan con el soporte para este formato, permitiendo su carga así como la transformación de los datos a GeoParquet.
GeoParquet, ha sido ampliamente celebrado por las empresas dedicadas al análisis espacial: Carto, Google BigQuery, Planet, entre otras. Porque les permiten ampliar y mejorar su integración en el campo de la analítica espacial.
El lanzamiento en agosto de 2023 fue de la versión 1.0.0, pero en la hoja de ruta del proyecto se anuncian nuevas mejoras para la versión 2.0.0:
- Objetos 3D: GeoParquet tiene como objetivo incluir el soporte de coordenadas 3D.
- Particiones de datos espaciales: GeoParquet tiene como requisitos futuros el crear particiones geoespaciales para cargar datos de manera eficiente desde el datalake.
· Mejorar la especificación de datos espaciales: Incluyendo GeoArrow como codificación de los datos espaciales. Esto supondría un gran avance porque los datos espaciales en la actualidad pueden ser sólo de una tipología: o son puntos, o son líneas o son polígonos. GeoArrow permitiría almacenar varios tipos en una misma geometría.
· Índices: para obtener el mejor rendimiento posible, los índices espaciales son esenciales para encontrar más rápido aquello que buscamos y para agilizar las consultas a los datos.
GeoParquet es, en definitiva, un interesante formato ya que establece una forma común de codificar y describir datos espaciales, facilitando la creación y compartición en la nube, de una manera más eficiente que otros formatos. Permaneceremos atentos a las novedades de este formato de datos espaciales.
Referencias
- Especificación GeoParquet: https://geoparquet.org/releases/v1.0.0-beta.1/
- Especificación GeoParquet OGC: https://github.com/opengeospatial/geoparquet/
_________________________________________________________
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Vehículos autónomos, servicios de gestión de residuos inteligentes, zapatillas que controlan el ejercicio que hacemos… Vivimos en un entorno cada vez más digital y conectado, con mayores similitudes con el futuro que soñábamos de pequeños. Es el llamado Internet de las Cosas (IoT en sus siglas en inglés), una red de objetos físicos que utilizan sensores y APIs para conectarse entre sí e intercambiar datos a través de Internet. Su auge es imparable y para 2025 se espera que haya más de 30.000 millones de conexiones de IoT en el mundo, lo que supone una media de casi 4 dispositivos IoT por persona.
Este auge hace que el número de datos a tratar y gestionar sea cada vez mayor. Tradicionalmente, estos objetos conectados recolectan información y la envían a grandes centros de datos para su procesamiento. Pero enviar los datos para su procesamiento en el centro de datos requiere de un tiempo que en ocasiones no tenemos.El problema llega en determinados casos de uso donde se necesitan respuestas rápidas y cada milisegundo es crucial, como por ejemplo en la conducción autónoma. Es aquí donde entra el paradigma del edge computing, también llamado “computación de borde” o “cómputo de borde”, como una forma de mejorar la agilidad y eficiencia.
¿Qué es el edge computing?
El edge computing supone un nuevo enfoque para ejecutar ciertos servicios lo más cerca posible del origen de los datos. Es decir, los procesos computacionales se realizan en los propios dispositivos conectados o en servidores periféricos locales (nodos edge). Esto aporta una serie de ventajas:
- Menor tiempo de latencia y mayor velocidad. La latencia es el tiempo que tarda en transferirse un paquete de datos dentro de la red. Al ahorrarnos el paso de enviar toda la información para su procesamiento a la nube, se reduce el tiempo de respuesta, aportando inmediatez.
- Necesidad de un menor ancho de banda, ya que no es necesario enviar toda la información sin tratar a los servidores. El edge computing reduce las cargas de tráfico globales, evitando saturaciones del sistema.
- Reducción de riesgos de seguridad. Es cierto que el edge computing amplía la superficie de ataque potencial, pero disminuye el impacto en la organización en su conjunto. Cuando centralizamos todos los datos, análisis y procesamientos, un solo ataque de denegación de servicio puede interrumpir todas las operaciones. Al distribuir las cargas en los diversos nodos, también se distribuye el riesgo. Puede fallar un proceso, pero el resto podrían continuar operando.
- Facilita la escalabilidad. Dado el crecimiento exponencial de los datos y capacidades de análisis, es difícil prever las necesidades de infraestructura IT para hacer frente al futuro (por ejemplo, servidores con capacidad para el análisis de toda la información que vaya llegando). Gracias a la incorporación de servicios de edge computing, las organizaciones pueden ampliar el alcance de su red de forma rápida y rentable, incorporando un nuevo nodo edge.
- Reducción de costes. Los dispositivos de edge computing requieren más capacidades de software para un rendimiento óptimo que aquellos que solo se dedican a captar datos y enviarlos para su análisis en remoto. Sin embargo, también permiten clasificar los datos desde una perspectiva de gestión. Es decir, se pueden implementar dispositivos con capacidades personalizadas para los diversos análisis, sin necesidad de invertir más de la cuenta.
Los avances del edge computing van de la mano del 5G, que permite conectar entre sí una mayor cantidad de dispositivos que intercambian datos a mayor velocidad.
El edge computing se seguirá complementando, además, con entornos Cloud: las capacidades de edge computing serán más adecuadas cuando se necesite velocidad y baja latencia en la transferencia de datos, mientras que la nube seguirá siendo fundamental para tratar grandes volúmenes de datos que requieren una potencia de cálculo mayor.
El impacto del edge computing en las ciudades inteligentes
Vistas las ventajas anteriores, parece obvio que el edge computing supone un gran avance para la gestión de datos en diversos sectores, desde la sanidad y la telemedicina, hasta la industria 4.0. Por ejemplo, Navantia, empresa pública española de construcción naval, está implementando esta tecnología, con el apoyo de Red.es. Combinando el 5G, el edge computing y el uso de gafas de realidad aumentada, está innovando en los procesos de construcción y en la asistencia técnica remota.
Pero si hay un campo donde el edge computing tiene especial importancia es en las ciudades inteligentes. En esencia, las ciudades inteligentes se basan en dispositivos IoT para proporcionar conectividad y análisis de datos situacionales. Dispositivos como las cámaras de seguridad y los diversos sensores – que transmiten datos relacionados con los medios de transporte, la iluminación o los edificios inteligentes- funcionan dentro de una red que abarca toda la ciudad para ofrecer una mejor experiencia a la ciudadanía. El edge computing y el 5G facilitan las decisiones en tiempo real, que pueden ser tomadas de manera automática por los propios dispositivos en lugar de enviar los datos a otro ordenador central para su procesamiento, facilitando la gestión de la urbe. Esto también puede suponer un impacto en la publicación de datos abiertos, que podría hacerse de una manera más ágil y permitir su acceso a través de servicios dinámicos.
En la ciudad de Barcelona se están probando casos de uso de edge computing en diferentes aplicaciones, como el transporte urbano, la seguridad ciudadana o los servicios sanitarios, también con el apoyo de Red.es. Entre otras cuestionas, gracias a estas tecnologías están midiendo en tiempo real las mejores rutas para desplazarse o conseguir una actuación más rápida de la guarda urbana ante fenómenos atmosféricos.
El futuro del edge computing
La previsión es que el edge computing se vaya imponiendo poco a poco. Según datos de la UE - basados en un estido de IDC-, en 2018, el 80% del tratamiento de los datos se llevaba a cabo en instalaciones informáticas centralizadas y el 20% en los propios objetos inteligentes conectados. En 2025 la situación será a la inversa, como muestra la siguiente imagen:
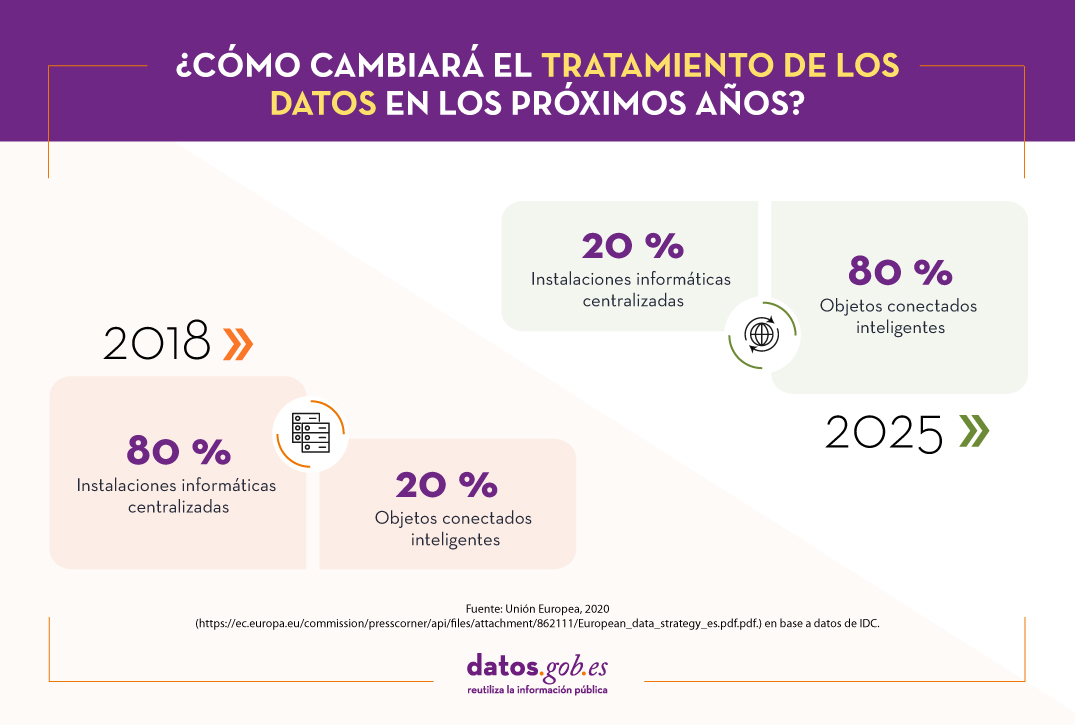
La Comisión Europea, entre sus actividades, también busca impulsar el despliegue de tecnologías ligadas al edge computing, debido a las numerosas oportunidades que supone. En este sentido, sus actividades sobre la nube se dividen en dos categorías:
- Invertir fondos en proyectos de vanguardia relacionados con cloud y edge computing
- Desarrollar políticas y normas que protejan a los usuarios, hagan más seguros los servicios en la nube, garanticen la competencia leal y creen las condiciones marco óptimas para una próspera industria europea.
En el caso de España, nos enfrentamos al reto de construir 1.000 nodos edge en nueve años.
En definitiva, nos encontramos ante un nuevo paradigma tecnológico necesario debido a la ingente cantidad de datos generados no solo por las ciudades inteligentes, si no por prácticamente todos los sectores que cada vez buscan estar más conectados. Ello genera unas necesidades de velocidad y capacidades de análisis inmediatos que el Edge computing puede ayudar a impulsar.
Contenido elaborado por el equipo de datos.gob.es.