Blog
El almacenamiento de datos en la nube es actualmente uno de los segmentos de software empresarial que experimenta un crecimiento más rápido, lo que está facilitando la incorporación de un gran número de nuevos usuarios al campo de la analítica.
Como ya presentamos en un post anterior, un nuevo formato, Parquet, tiene entre sus objetivos potenciar y avanzar en la analítica para esta comunidad en rápido crecimiento y facilitar la interoperabilidad entre diversos almacenes de datos en la nube y motores informáticos.
Parquet es descrito por su propio creador, Apache, como: “Un formato de archivo de datos de código abierto diseñado para el almacenamiento y la recuperación eficiente de datos. Proporciona un rendimiento mejorado para manejar datos complejos de forma masiva".
Parquet se define como un formato de datos orientado a columnas que se plantea como una alternativa moderna a los archivos CSV. A diferencia de los formatos basados en filas, como el CSV, Parquet almacena los datos en función de columnas, lo que implica que los valores de cada columna de la tabla se almacenan contiguamente, en lugar de los valores de cada registro, como se muestra a continuación:
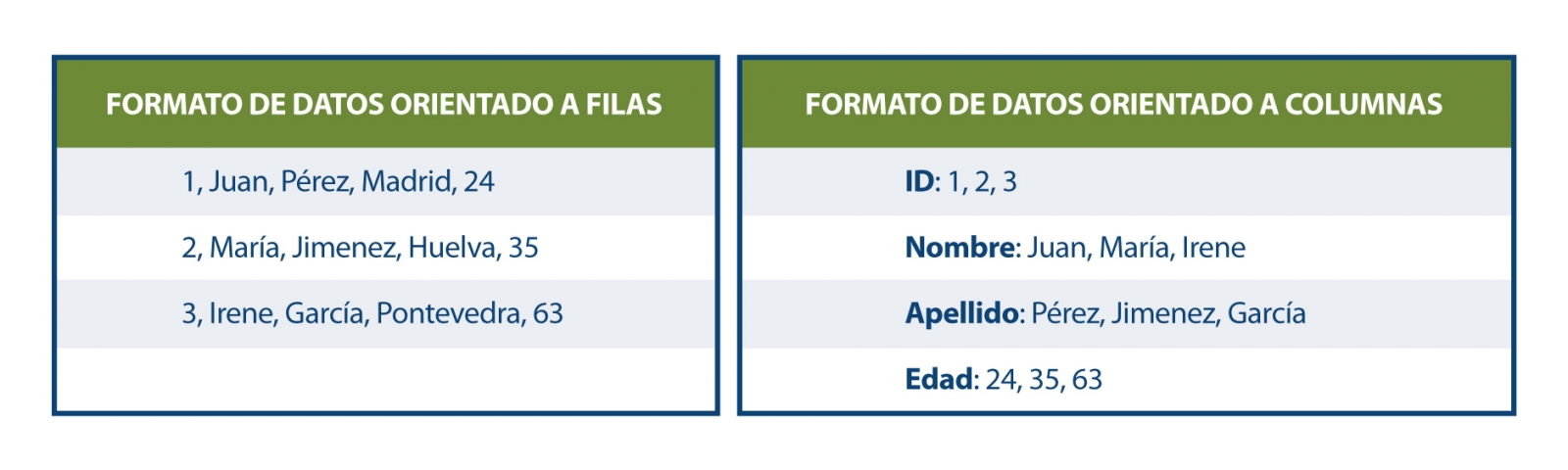
Este método de almacenamiento presenta ventajas en términos de almacenamiento compacto y consultas rápidas en comparación con los formatos clásicos. Parquet funciona eficazmente en los conjuntos de datos desnormalizados que contienen muchas columnas y permite consultar estos datos de manera más rápida y eficiente.
En agosto de 2023 se lanzó un nuevo formato para datos espaciales: el GeoParquet 1.0.0. Durante ese mismo mes, el Open Geospatial Consortium (OGC) informó sobre la formación de un nuevo Grupo de Trabajo de Estándares GeoParquet, cuyo objetivo es promover la adopción de este formato como un estándar de codificación OGC para datos vectoriales nativos en la nube.
GeoParquet 1.0.0 corrige algunas carencias de Parquet, que no ofrecía un buen soporte de datos espaciales. Igualmente la interoperabilidad en los entornos de la nube era compleja para los datos geoespaciales, porque al no existir un estándar o directrices sobre cómo almacenar los datos geográficos, estoseran interpretados de diferente manera por cada sistema. Esto conllevaba dos resultados significativos:
- No era posible exportar datos espaciales de un sistema e importarlos a otro sin un procesamiento significativo entre ellos.
· Los proveedores de datos no podían compartir sus datos en un formato unificado. Si deseaban habilitar a los usuarios en diferentes sistemas, debían admitir las diversas variaciones de soporte espacial en los diferentes motores.
Estas deficiencias han sido solventadas con GeoParquet que, además agrega tipos geoespaciales al formato Parquet, al mismo tiempo que establece una serie de estándares para varios aspectos claves en la representación de datos espaciales:
· Columnas que contienen datos espaciales: se permite tener múltiples columnas que contengan datos espaciales (Punto, Línea y Polígono), con la designación de una columna como "principal".
· Codificación de geometría/geografía: define cómo se codifica la información de geometría o geografía. Inicialmente se utiliza una codificación en binario conocida y Well-known text (WKT) , pero se está trabajando para implementar GeoArrow como una nueva forma de codificación.
· Sistema de referencia espacial: especifica en qué sistema de referencia espacial se encuentran los datos. La especificación es compatible con varios sistemas de referencia de coordenadas alternativos.
· Tipo de coordenadas: define si las coordenadas son planas o esféricas, proporcionando información sobre la geometría y naturaleza de las coordenadas utilizadas.
A esto, hay que añadir que GeoParquet incluye metadatos en dos niveles:
- Metadatos de archivo que indican atributos como la versión de esta especificación utilizada.
- Metadatos de columna con características adicionales para cada geometría como son: sistema de referencia espacial, tipo de geometría, resolución de la geometría, etc.
Otra característica que hace que GeoParquet se esté convirtiendo en un formato muy recomendable, es que es más rápido y ligero que otros más extendidos. La siguiente comparativa muestra el tamaño en distintos formatos (GeoParquet, shaperfile y geopackage) de un mismo archivo con edificios en CSV de un tamaño de 498 megabytes. Se transforma este fichero a estos formatos y se muestra gráficamente el resultado:
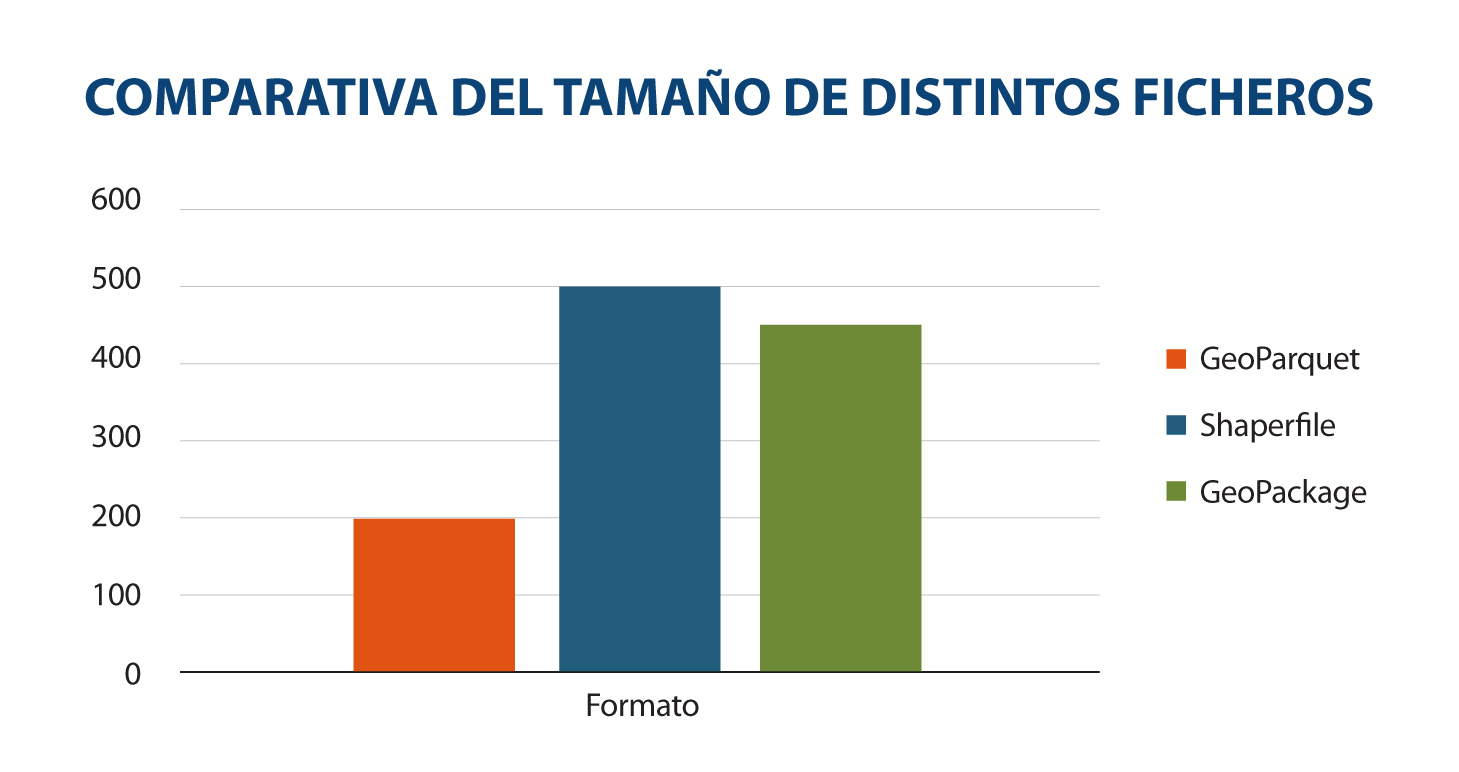
Fuente: Comparación de un mismo conjunto de datos en distintos formatos. Elaboración propia.
La reducción de tamaño para los datos en Geoparquet es notoria. La principal razón detrás de esto es que Parquet se comprime de forma predeterminada. Si bien otros formatos también pueden comprimirse, no se pueden utilizar directamente hasta que se descompriman. Además, se ha optimizado significativamente su rendimiento, contribuyendo así a su eficiencia en el procesamiento de datos espaciales.
Es aquí donde cobra vital importancia GeoParquet, al establecer una forma común de codificar y describir datos espaciales. Esto facilita la creación y compartición de datos espaciales en la nube, reduciendo la complejidad y los costos asociados. Asimismo, permite el intercambio de datos entre sistemas sin necesidad de transformaciones intermedias, convirtiendo a GeoParquet en un potencial formato de distribución geoespacial nativo de la nube y un recurso invaluable para cualquier tarea geoespacial cotidiana.
Estos estándares son fundamentales para garantizar la consistencia, interoperabilidad y comprensión uniforme de los datos espaciales, lo que facilita su manejo y uso en una variedad de aplicaciones y un conjunto variado de herramientas modernas de ciencia de datos, como BigQuery, DuckDB, R, Python, GeoPandas, GDAL, entre otras, que utilizan Parquet de manera efectiva y que están incorporando cada vez más capacidades de soporte geoespacial. Dentro del ecosistema GIS, tanto ArcGIS, FME y QGIS (a partir de la versión 3.28) ya cuentan con el soporte para este formato, permitiendo su carga así como la transformación de los datos a GeoParquet.
GeoParquet, ha sido ampliamente celebrado por las empresas dedicadas al análisis espacial: Carto, Google BigQuery, Planet, entre otras. Porque les permiten ampliar y mejorar su integración en el campo de la analítica espacial.
El lanzamiento en agosto de 2023 fue de la versión 1.0.0, pero en la hoja de ruta del proyecto se anuncian nuevas mejoras para la versión 2.0.0:
- Objetos 3D: GeoParquet tiene como objetivo incluir el soporte de coordenadas 3D.
- Particiones de datos espaciales: GeoParquet tiene como requisitos futuros el crear particiones geoespaciales para cargar datos de manera eficiente desde el datalake.
· Mejorar la especificación de datos espaciales: Incluyendo GeoArrow como codificación de los datos espaciales. Esto supondría un gran avance porque los datos espaciales en la actualidad pueden ser sólo de una tipología: o son puntos, o son líneas o son polígonos. GeoArrow permitiría almacenar varios tipos en una misma geometría.
· Índices: para obtener el mejor rendimiento posible, los índices espaciales son esenciales para encontrar más rápido aquello que buscamos y para agilizar las consultas a los datos.
GeoParquet es, en definitiva, un interesante formato ya que establece una forma común de codificar y describir datos espaciales, facilitando la creación y compartición en la nube, de una manera más eficiente que otros formatos. Permaneceremos atentos a las novedades de este formato de datos espaciales.
Referencias
- Especificación GeoParquet: https://geoparquet.org/releases/v1.0.0-beta.1/
- Especificación GeoParquet OGC: https://github.com/opengeospatial/geoparquet/
_________________________________________________________
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Ya ha pasado mucho tiempo desde la primera vez que oímos hablar del ecosistema Apache Hadoop para procesamiento de datos distribuidos. Las cosas han cambiado mucho desde entonces, y ahora usamos herramientas de más alto nivel para construir soluciones basadas en grandes cargas de datos. Sin embargo, es importante destacar algunas buenas prácticas relacionadas con los formatos de nuestros datos si queremos diseñar soluciones big data verdaderamente eficientes y escalables.
Introducción
Los que trabajamos en el sector de los datos sabemos de la importancia de la eficiencia en múltiples aspectos de las soluciones y arquitecturas de datos. Hablamos de eficiencia en tiempos de procesamiento, pero también, en términos de espacio ocupado y como no, de costes de almacenamiento. Una buena decisión en cuanto a tipos de formatos de datos puede ser vital con respecto a la escalabilidad futura de una solución basada en datos.
Para hablar de este tema, en este post os traemos una reflexión acerca del formato de datos Apache Parquet o simplemente Parquet. Las primeras versiones de Apache Parquet se lanzaron en el año 2013. Desde 2015, Apache Parquet es uno de los proyectos de cabecera patrocinados y mantenidos por Apache Software Foundation (ASF). ¡Arrancamos!
¿Qué es Apache Parquet?
Sabemos que es posible que nunca hayas oído hablar del formato de archivo Apache Parquet con anterioridad. El formato Parquet, es un tipo de fichero que contiene datos (de tipo tabla) en su interior, de forma similar a cuando hablamos del fichero tipo CSV. Aunque parezca obvio, los ficheros parquet tienen extensión .parquet y a diferencia de un CSV, no es un fichero en texto plano (se representa de forma binaria), lo que significa que no lo podemos abrir y examinar con un simple editor de texto. El formato parquet es un tipo de formato de los que clasificamos en orientados-a-columnas (column-oriented file format). Como habrás adivinado, existen otros formatos orientados-a-filas o row-oriented. Tal es el caso de los formatos tipo CSV, TSV o AVRO.
Pero, ¿qué significa que un formato de datos sea o esté orientado a filas o a columnas? En un fichero CSV (recordamos, orientado a filas) cada registro es una fila. En Parquet, sin embargo, es cada columna la que se almacena de forma independiente. La diferencia más extrema la notamos cuándo, en un fichero de tipo CSV, queremos leer solamente una columna. A pesar de que solo queremos acceder a la información de una columna, por el tipo de formato, tenemos irremediablemente que leer todas las filas de la tabla. Cuando usamos formato Parquet, cada columna es accesible de forma independiente al resto. Como los datos en cada columna se espera que sean homogéneos (del mismo tipo), el formato parquet abre un sin fin de posibilidades a la hora de codificar, comprimir y optimizar el almacenamiento de los datos. De lo contrario, si lo que queremos es almacenar datos con el objetivo de leer muchas filas completas muy a menudo, el formato parquet nos penalizará en esas lecturas y no seremos eficientes ya que estamos utilizando orientación a columnas para leer filas.
Otra característica de Parquet es que es un formato de datos autodescriptivo que integra el esquema o la estructura dentro de los datos en sí. Es decir, propiedades (o metadatos) de los datos como el tipo (si es un número entero, un real o una cadena de texto), el número de valores, el tipo de compresión (los datos se pueden comprimir para ahorrar espacio), etc. están incluidas en el propio fichero junto con los datos como tal. De esta forma, cualquier programa que se utilice para leer los datos, puede acceder a estos metadatos, para por ejemplo, determinar sin ambigüedades, qué tipo de datos se espera leer en una columna determinada. A quien no le ha pasado de importar un CSV en un programa y encontrarse con que los datos están mal interpretados (números como textos, fechas como números, etc.)
Como hemos comentado, una de las contrapartidas de parquet frente a CSV es que no lo podemos abrir con tan solo usar un editor de texto. No obstante, existen múltiples herramientas para manejar ficheros parquet. Para ilustrar un ejemplo sencillo podemos utilizar parquet-tools en Python. En este ejemplo se puede ver el mismo conjunto de datos representado en formato parquet y csv.
Anteriormente mencionamos que otra de las características diferenciadoras de parquet frente a CSV es que el primero incluye el esquema de los datos en su interior. Para demostrarlo vamos a ejecutar el comando parquet-tools inspect test1.parquet.
A continuación vemos como la herramienta nos muestra el esquema de los datos que contiene el fichero organizado por columnas. Vemos, primeramente, un resumen del número de columnas, filas y versión del formato y el tamaño en bytes. Seguidamente, vemos el nombre de las columnas y a continuación, para cada columna, los datos más importantes, entre los que destacan el tipo de dato. Vemos cómo en la columna “one” se almacenan datos de tipo DOUBLE (apropiado para números reales), mientras que en la columna “two” los datos son de tipo BYTE_ARRAY que sirven para almacenar cadenas de textos.
############ file meta data ############
created_by: parquet-cpp version 1.5.1-SNAPSHOT
num_columns: 3
num_rows: 3
num_row_groups: 1
format_version: 1.0
serialized_size: 2226
############ Columns ############
one
two
three
############ Column(one) ############
name: one
path: one
max_definition_level: 1
max_repetition_level: 0
physical_type: DOUBLE
logical_type: None
converted_type (legacy): NONE
############ Column(two) ############
name: two
path: two
max_definition_level: 1
max_repetition_level: 0
physical_type: BYTE_ARRAY
logical_type: String
converted_type (legacy): UTF8
############ Column(three) ############
name: three
path: three
max_definition_level: 1
max_repetition_level: 0
physical_type: BOOLEAN
logical_type: None
converted_type (legacy): NONE
Resumen de las características técnicas de los ficheros parquet
- Apache Parquet está orientado a columnas y diseñado para brindar un almacenamiento en columnas eficiente en comparación con los tipos de ficheros basados en filas, como CSV.
- Los archivos Parquet se diseñaron teniendo en cuenta estructuras de datos anidadas complejas.
- Apache Parquet está diseñado para admitir esquemas de compresión y codificación muy eficientes.
- Apache Parquet genera menores costes de almacenamiento para archivos de datos y maximiza la efectividad de las consultas de datos con tecnologías cloud actuales como Amazon Athena, Redshift Spectrum, BigQuery y Azure Data Lakes.
- Licenciado bajo la licencia Apache y disponible para cualquier proyecto.
¿Para qué se usa Parquet?
Ahora que ya conocemos un poco más este formato de datos, veamos en qué ocasiones está más recomendado su uso. Sin lugar a dudas el reino de los parquets son los Data Lakes. Los Data Lakes son espacios de almacenamiento de ficheros distribuidos muy usados hoy en día para crear grandes repositorios de datos corporativos heterogéneos en la nube. A diferencia de un Data Warehouse, un Data Lake no tiene un motor de base de datos subyacente ni existe un modelo relacional de los datos. Pero veamos un ejemplo práctico de las ventajas de usar Parquet frente a CSV en este tipo de almacenamiento.
Supongamos que tenemos un conjunto de datos en formato de tabla (4 columnas) que representa las ventas históricas de una empresa durante los últimos 10 años. Si almacenamos esta tabla en formato CSV en Amazon Web Services S3 veremos que el tamaño que ocupa son 4TB. Si comprimimos este fichero con GZIP veremos que su tamaño se reduce a la cuarta parte (1TB). Cuando esa misma tabla la almacenamos en el mismo servicio (S3) en formato Parquet, vemos que ocupa lo mismo que el CSV comprimido. Pero además, cuándo queramos acceder a una parte de los datos - pongamos 1 sola columna - en el caso del fichero CSV (como hemos comentado anteriormente) tenemos que leer toda la tabla, puesto que es un almacenamiento por filas. Sin embargo, como el formato Parquet es un almacenamiento orientado a columnas, podemos leer una sola columna de forma independiente, accediendo solo a un cuarto de la información de la tabla, con el ahorro en tiempo y en coste que esto supone.

Post original de Thomas Spicer en Medium.com
Una vez que hemos entendido la eficiencia de la lectura de datos usando Parquet debido al acceso columnar de los mismos, podemos entender ahora por qué la mayoría de los servicios de almacenamiento y procesamiento de datos actuales son favorables a Parquet frente a CSV. Estos servicios en nube para procesamiento de datos son altamente populares entre los profesionales de datos puesto que el analista o científico de datos tan solo se tiene que preocupar del análisis. Son los servicios los que garantizan la accesibilidad y la eficiencia en la lectura.
Podría parecer que solo los casos de uso más sofisticados y analíticos usan Parquet como formato de referencia, pero son ya muchos equipos en las compañías, que empiezan a usar Parquet desde el origen para sus aplicaciones de Inteligencia de Negocio o Business Intelligence con herramientas para usuarios de negocio (no técnicos) como Power BI o Tableau.
Como conclusión, en este post hemos resaltado las características positivas del formato de datos parquet para el almacenamiento y procesado de datos cuando se trata de casos de uso analíticos (machine learning, inteligencia artificial) o con una marcada orientación a columnas (como por ejemplo series temporales). Como todo en la vida, no hay una solución perfecta para todas las situaciones. Existen y seguirán existiendo casos de uso orientados a filas así como existen formatos específicos para almacenar imágenes o mapas. En cualquier caso, no hay duda de que si tu aplicación encaja con las características de parquet, experimentarás mejoras importantes de eficiencia si optas por este formato frente a otros más convencionales como CSV. ¡Nos vemos en el próximo post!
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.