
Description
As part of the European Cybersecurity Awareness Month, the European data portal, data.europa.eu, has organized a webinar focused on the protection of open data.This event comes at a critical time when organisations, especially in the public sector, face the challenge of balancing data transparency and accessibility with the need to protect against cyber threats.
The online seminar was attended by experts in the field of cybersecurity and data protection, both from the private and public sector.
The expert panel addressed the importance of open data for government transparency and innovation, as well as emerging risks related to data breaches, privacy issues and other cybersecurity threats. Data providers, particularly in the public sector, must manage this paradox of making data accessible while ensuring its protection against malicious use.
During the event, a number of malicious tactics used by some actors to compromise the security of open data were identified. These tactics can occur both before and after publication. Knowing about them is the first step in preventing and counteracting them.
Pre-publication threats
Before data is made publicly available, it may be subject to the following threats:
-
Supply chain attacks: attackers can sneak malicious code into open data projects, such as commonly used libraries (Pandas, Numpy or visualisation modules), by exploiting the trust placed in these resources. This technique allows attackers to compromise larger systems and collect sensitive information in a gradual and difficult to detect manner.
- Manipulation of information: data may be deliberately altered to present a false or misleading picture. This may include altering numerical values, distorting trends or creating false narratives. These actions undermine the credibility of open data sources and can have significant consequences, especially in contexts where data is used to make important decisions.
- Envenenamiento de datos (data poisoning): attackers can inject misleading or incorrect data into datasets, especially those used for training AI models. This can result in models that produce inaccurate or biased results, leading to operational failures or poor business decisions.
Post-publication threats
Once data has been published, it remains vulnerable to a variety of attacks:
-
Compromise data integrity: attackers can modify published data, altering files, databases or even data transmission. These actions can lead to erroneous conclusions and decisions based on false information.
- Re-identification and breach of privacy: data sets, even if anonymised, can be combined with other sources of information to reveal the identity of individuals. This practice, known as 're-identification', allows attackers to reconstruct detailed profiles of individuals from seemingly anonymous data. This represents a serious violation of privacy and may expose individuals to risks such as fraud or discrimination.
- Sensitive data leakage: open data initiatives may accidentally expose sensitive information such as medical records, personally identifiable information (emails, names, locations) or employment data. This information can be sold on illicit markets such as the dark web, or used to commit identity fraud or discrimination.
Following on from these threats, the webinar presented a case study on how cyber disinformation exploited open data during the energy and political crisis associated with the Ukraine war in 2022. Attackers manipulated data, generated false content with artificial intelligence and amplified misinformation on social media to create confusion and destabilise markets.
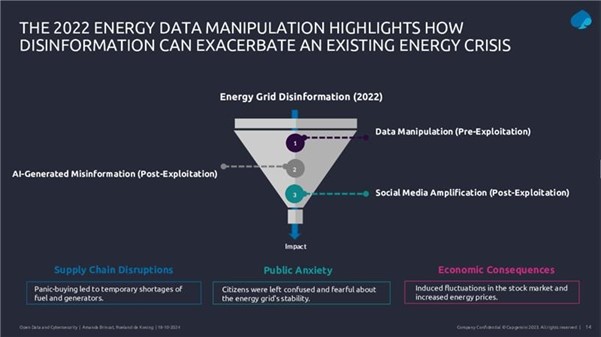
Figure 1. Slide from the webinar presentation "Safeguarding open data: cybersecurity essentials and skills for data providers".
Data protection and data governance strategies
In this context, the implementation of a robust governance structure emerges as a fundamental element for the protection of open data. This framework should incorporate rigorous quality management to ensure accuracy and consistency of data, together with effective updating and correction procedures. Security controls should be comprehensive, including:
- Technical protection measures.
- Integrity check procedures.
- Access and modification monitoring systems.
Risk assessment and risk management requires a systematic approach starting with a thorough identification of sensitive and critical data. This involves not only the cataloguing of critical information, but also a detailed assessment of its sensitivity and strategic value. A crucial aspect is the identification and exclusion of personal data that could allow the identification of individuals, implementing robust anonymisation techniques where necessary.
For effective protection, organisations must conduct comprehensive risk analyses to identify potential vulnerabilities in their data management systems and processes. These analyses should lead to the implementation of robust security controls tailored to the specific needs of each dataset. In this regard, the implementation of data sharing agreements establishes clear and specific terms for the exchange of information with other organisations, ensuring that all parties understand their data protection responsibilities.
Experts stressed that data governance must be structured through well-defined policies and procedures that ensure effective and secure information management. This includes the establishment of clear roles and responsibilities, transparent decision-making processes and monitoring and control mechanisms. Mitigation procedures must be equally robust, including well-defined response protocols, effective preventive measures and continuous updating of protection strategies.
In addition, it is essential to maintain a proactive approach to security management. A strategy that anticipates potential threats and adapts protection measures as the risk landscape evolves. Ongoing staff training and regular updating of policies and procedures are key elements in maintaining the effectiveness of these protection strategies. All this must be done while maintaining a balance between the need for protection and the fundamental purpose of open data: its accessibility and usefulness to the public.
Legal aspects and compliance
In addition, the webinar explained the legal and regulatory framework surrounding open data. A crucial point was the distinction between anonymization and pseudo-anonymization in the context of the GDPR (General Data Protection Regulation).
On the one hand, anonymised data are not considered personal data under the GDPR, because it is impossible to identify individuals. However, pseudo-anonymisation retains the possibility of re-identification if combined with additional information. This distinction is crucial for organisations handling open data, as it determines which data can be freely published and which require additional protections.
To illustrate the risks of inadequate anonymisation, the webinar presented the Netflix case in 2006, when the company published a supposedly anonymised dataset to improve its recommendation algorithm. However, researchers were able to "re-identify" specific users by combining this data with publicly available information on IMDb. This case demonstrates how the combination of different datasets can compromise privacy even when anonymisation measures have been taken.
In general terms, the role of the Data Governance Act in providing a horizontal governance framework for data spaces was highlighted, establishing the need to share information in a controlled manner and in accordance with applicable policies and laws. The Data Governance Regulation is particularly relevant to ensure that data protection, cybersecurity and intellectual property rights are respected in the context of open data.
The role of AI and cybersecurity in data security
The conclusions of the webinar focused on several key issues for the future of open data. A key element was the discussion on the role of artificial intelligence and its impact on data security. It highlighted how AI can act as a cyber threat multiplier, facilitating the creation of misinformation and the misuse of open data.
On the other hand, the importance of implementing Privacy Enhancing Technologies (PETs ) as fundamental tools to protect data was emphasized. These include anonymisation and pseudo-anonymisation techniques, data masking, privacy-preserving computing and various encryption mechanisms. However, it was stressed that it is not enough to implement these technologies in isolation, but that they require a comprehensive engineering approach that considers their correct implementation, configuration and maintenance.
The importance of training
The webinar also emphasised the critical importance of developing specific cybersecurity skills. ENISA's cyber skills framework, presented during the session, identifies twelve key professional profiles, including the Cybersecurity Policy and Legal Compliance Officer, the Cybersecurity Implementer and the Cybersecurity Risk Manager. These profiles are essential to address today's challenges in open data protection.
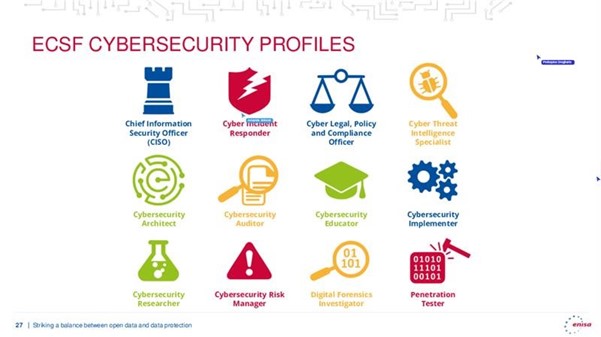
Figure 2. Slide presentation of the webinar " Safeguarding open data: cybersecurity essentials and skills for data providers".
In summary, a key recommendation that emerged from the webinar was the need for organisations to take a more proactive approach to open data management. This includes the implementation of regular impact assessments, the development of specific technical competencies and the continuous updating of security protocols. The importance of maintaining transparency and public confidence while implementing these security measures was also emphasised.


