Fecha publicación
24/01/2024
Fecha actualización
10/06/2026
Comparte este contenido

Descripción
Enseñar a los ordenadores a entender cómo hablan y escriben los humanos es un viejo desafío en el campo de la inteligencia artificial, conocido como procesamiento de lenguaje natural (PLN). Sin embargo, desde hace poco más de dos años, estamos asistiendo a la caída de este antiguo bastión con la llegada de los modelos grandes del lenguaje (LLM) y los interfaces conversacionales. En este post, vamos a tratar de explicar una de las técnicas clave que hace posible que estos sistemas nos respondan con relativa precisión a las preguntas que les hacemos.
Introducción
En 2020, Patrick Lewis, un joven doctor en el campo de los modelos del lenguaje que trabajaba en la antigua Facebook AI Research (ahora Meta AI Research) publica junto a Ethan Perez de la Universidad de Nueva York un artículo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog, varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del RAG. En este post vamos a tratar de explicarlo de la forma más sencilla posible.
Los modelos grandes del lenguaje o Large Language Models (hay cosas que es mejor no traducir…) son modelos de inteligencia artificial que se entrenan utilizando algoritmos de Deep Learning sobre conjuntos enormes de información generada por humanos. De esta manera, una vez entrenados, han aprendido la forma en la que los humanos utilizamos la palabra hablada y escrita, así que son capaces de ofrecernos respuestas generales y con un patrón muy humano a las preguntas que les hacemos. Sin embargo, si buscamos respuestas precisas en un contexto determinado, los LLM por sí solos no proporcionarán respuestas específicas o habrá una alta probabilidad de que alucinen y se inventen completamente la respuesta. Que los LLM alucinen significa que generan texto inexacto, sin sentido o desconectado. Este efecto plantea riesgos y desafíos potenciales para las organizaciones que utilizan estos modelos fuera del entorno doméstico o cotidiano del uso personal de los LLM. La prevalencia de la alucinación en los LLMs, estimada en un 15% o 20% para ChatGPT, puede tener implicaciones profundas para la reputación de las empresas y la fiabilidad de los sistemas de IA.
¿Qué es un RAG?
Precisamente, las técnicas RAG se han desarrollado para mejorar la calidad de las respuestas en contextos específicos, como por ejemplo, en una disciplina concreta o en base a repositorios de conocimiento privados como bases de datos de empresas.
RAG es una técnica extra dentro de los marcos de trabajo de la inteligencia artificial, cuyo objetivo es recuperar hechos de una base de conocimientos externa para garantizar que los modelos de lenguaje devuelven información precisa y actualizada. Un sistema RAG típico (ver imágen) incluye un LLM, una base de datos vectorial (para almacenar convenientemente los datos externos) y una serie de comandos o preguntas. Es decir, de forma simplificada, cuándo hacemos una pregunta en lenguaje natural a un asistente cómo ChatGPT, lo que ocurre entre la pregunta y la respuesta es algo como:
- El usuario realiza la consulta, también denominada técnicamente prompt.
- El RAG se encarga de enriquecer ese prompt o pregunta con datos y hechos que ha obtenido de una base de datos externa que contiene información relevante relativa a la pregunta que ha realizado el usuario. A esta etapa se le denomina retrieval.
- El RAG se encarga de enviar el prompt del usuario enriquecido o aumentado al LLM que se encarga de generar una respuesta en lenguaje natural aprovechando toda la potencia del lenguaje humano que ha aprendido con sus datos de entrenamiento genéricos, pero también con los datos específicos proporcionados en la etapa de retrieval.
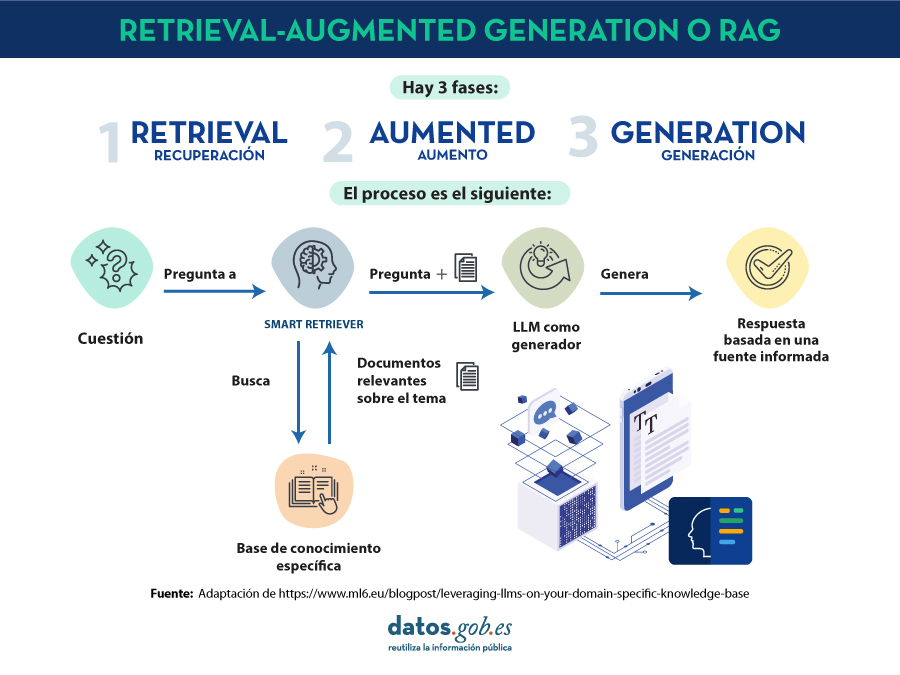
Entendiendo RAG con ejemplos
Pongamos un ejemplo concreto. Imagina que estás intentando responder una pregunta sobre dinosaurios. Un LLM generalista puede inventarse una respuesta perfectamente plausible, de forma que una persona no experta en la materia no la diferencia de una respuesta con base científica. Por el contrario, con el uso de RAG, el LLM buscaría en una base de datos de información sobre dinosaurios y recuperaría los hechos más relevantes para generar una respuesta completa.
Lo mismo ocurría si buscamos una información concreta en una base de datos privada. Por ejemplo, pensemos en un responsable de recursos humanos de una empresa. Éste desea recuperar información resumida y agregada sobre uno o varios empleados cuyos registros se encuentran en diferentes bases de datos de la empresa. Pensemos que podemos estar tratando de obtener información a partir de tablas salariales, encuestas de satisfacción, registros laborales, etc. Un LLM es de gran utilidad para generar una respuesta con un patrón humano. Sin embargo, es imposible que ofrezca datos coherentes y precisos puesto que nunca ha sido entrenado con esa información debido a su carácter privado. En este caso, RAG asiste al LLM para proporcionarle datos y contexto específico con el que poder devolver la respuesta adecuada.
De la misma forma, un LLM complementado con RAG sobre registros médicos podría ser un gran asistente en el ámbito clínico. También los analistas financieros se beneficiarían de un asistente vinculado a datos actualizados del mercado de valores. Prácticamente, cualquier caso de uso se beneficia de las técnicas RAG para enriquecer las capacidades de los LLM con datos de contexto específicos.
Recursos adicionales para entender mejor RAG
Cómo os podéis imaginar, tan pronto como nos asomamos por un momento a la parte más técnica de entender los LLM o RAG, las cosas se complican enormemente. En este post hemos tratado de explicar con palabras sencillas y ejemplos cotidianos cómo funciona la técnica de RAG para obtener respuestas más precisas y contextualizadas a las preguntas que le hacemos a un asistente conversacional como ChatGPT, Bard o cualquier otro. Sin embargo, para todos aquellos que tengáis ganas y fuerzas para profundizar en el tema, os dejamos una serie de recursos web disponibles para tratar de entender un poco más cómo se combinan los LLM con RAG y otras técnicas como la ingeniería de prompts para ofrecer las mejores apps de IA generativa posibles.
Videos introductorios:
Artículos de contenido de LLMs y RAG para principiantes:
- DEV - LLM for dummies
-
Digital Native - LLMs for Dummies
-
Hopsworks.ai - Retrieval Augmented Generation (RAG) for LLMs
-
Datalytyx - RAG For Dummies
¿Quieres pasar al siguiente nivel? Algunas herramientas para probar:
- LangChain. LangChain es un marco (framework) de desarrollo que facilita la construcción de aplicaciones usando LLMs, como GPT-3 y GPT-4. LangChain es para desarrolladores de software y permite integrar y gestionar varios LLMs, creando aplicaciones como chatbots y agentes virtuales. Su principal ventaja es simplificar la interacción y orquestación de LLMs para una amplia gama de aplicaciones, desde análisis de texto hasta asistencia virtual.
-
Hugging Face. Hugging Face es una plataforma con más de 350 mil modelos, 75 mil conjuntos de datos y 150 mil aplicaciones de demostración, todos ellos de código abierto y disponibles públicamente online donde la gente puede colaborar fácilmente y construir modelos de inteligencia artificial.
-
OpenAI. OpenAI es la plataforma más conocida en lo que a modelos de LLM e interfaces conversacionales se refiere. Los creadores de ChatGTP ponen a disposición de la comunidad de desarrolladores un conjunto de librerías para utilizar el API de OpenAI y poder crear sus propias aplicaciones utilizando los modelos GPT-3.5 y GPT- 4. Como ejemplo, os proponemos visitar la documentación de la librería de Python para entender cómo, con muy pocas líneas de código, podemos estar usando un LLM en nuestra propia aplicación. Aunque las interfaces conversacionales de OpenAI como ChatGPT, utilizan su propio sistema RAG, también podemos combinar los modelos GPT con nuestra propia RAG, como por ejemplo, lo que proponen en este artículo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Comentarios