Blog
La Inteligencia Artificial (IA) está convirtiéndose en uno de los principales motores del aumento de la productividad y la innovación tanto en el sector público como en el privado, siendo cada vez más relevante en tareas que van desde la creación de contenido en cualquier formato (texto, audio, video) hasta la optimización de procesos complejos a través de agentes de Inteligencia Artificial.
Sin embargo, los modelos avanzados de IA, y en particular los grandes modelos de lenguaje, exigen cantidades ingentes de datos para su entrenamiento, optimización y evaluación. Esta dependencia genera una paradoja: a la vez que la IA demanda más datos y de mayor calidad, la creciente preocupación por la privacidad y la confidencialidad (Reglamento General de Protección de Datos o RGPD), las nuevas reglas de acceso y uso de datos (Data Act), y los requisitos de calidad y gobernanza para sistemas de alto riesgo (Reglamento de IA), así como la inherente escasez de datos en dominios sensibles limitan el acceso a los datos reales.
En este contexto, los datos sintéticos pueden ser un mecanismo habilitador para conseguir nuevos avances, conciliando innovación y protección de la privacidad. Por una parte, permiten alimentar el progreso de la IA sin exponer información sensible, y cuando se combinan con datos abiertos de calidad amplían el acceso a dominios donde los datos reales son escasos o están fuertemente regulados.
¿Qué son los datos sintéticos y cómo se generan?
De forma sencilla, los datos sintéticos se pueden definir como información fabricada artificialmente que imita las características y distribuciones de los datos reales. La función principal de esta tecnología es reproducir las características estadísticas, la estructura y los patrones del dato real subyacente. En el dominio de las estadísticas oficiales existen casos como el del Censo de Estados Unidos que publica productos parcial o totalmente sintéticos como OnTheMap (movilidad de los trabajadores entre lugar de residencia y lugar trabajo) o el SIPP Synthetic Beta (microdatos socioeconómicos vinculados a impuestos y seguridad social).
La generación de datos sintéticos es actualmente un campo aún en desarrollo que se apoya en diversas metodologías. Los enfoques pueden ir desde métodos basados en reglas o modelado estadístico (simulaciones, bayesianos, redes causales), que imitan distribuciones y relaciones predefinidas, hasta técnicas avanzadas de aprendizaje profundo. Entre las arquitecturas más destacadas encontramos:
- Redes Generativas Adversarias (GAN): un modelo generativo, entrenado con datos reales, aprende a imitar sus características, mientras que un discriminador intenta distinguir entre datos reales y sintéticos. A través de este proceso iterativo, el generador mejora su capacidad para producir datos artificiales que son estadísticamente indistinguibles de los originales. Una vez entrenado, el algoritmo puede crear nuevos registros artificiales que son estadísticamente similares a la muestra original, pero completamente nuevos y seguros.
- Autoencoders Variacionales (VAE): Estos modelos se basan en redes neuronales que aprenden una distribución probabilística en un espacio latente de los datos de entrada. Una vez entrenado, el modelo utiliza esta distribución, para obtener nuevas observaciones sintéticas mediante el muestreo y decodificación de los vectores latentes. Los VAE son frecuentemente considerados una opción más estable y sencilla de entrenar en comparación con las GAN para la generación de datos tabulares.
- Modelos autorregresivos/jerárquicos y simuladores de dominio: utilizados, por ejemplo, en datos de historia clínica electrónica, que capturan dependencias temporales y jerárquicas. Los modelos jerárquicos estructuran el problema por niveles, primero muestrean variables de nivel superior y, después las de niveles inferiores condicionadas a las anteriores. Los simuladores de dominio codifican reglas del proceso y se calibran con datos reales, aportando control e interpretabilidad y garantizando el cumplimiento de reglas de negocio.
Puedes conocer más sobre los datos sintéticos y cómo se crean en esta infografía:
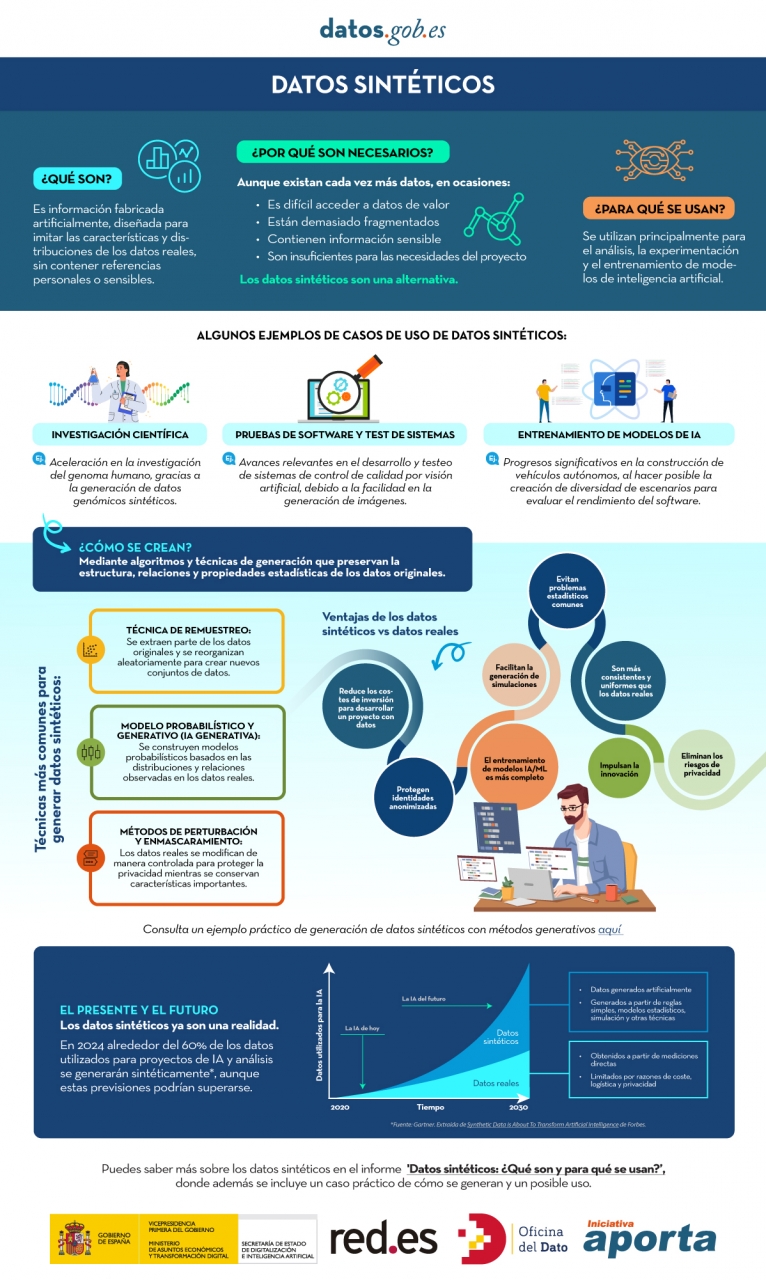
Figura 1. Infografía sobre datos sintéticos. Fuente: elaboración propia - datos.gob.es.
Si bien la generación sintética reduce inherentemente el riesgo de divulgación de datos personales, no lo elimina por completo. Sintético no significa automáticamente anónimo ya que, si los generadores se entrenan de forma inadecuada, pueden filtrarse trazas del conjunto real y ser vulnerables a ataques de inferencia de pertenencia (membership inference). De ahí que sea necesario utilizar Tecnologías de Mejora de la Privacidad (PET) como la privacidad diferencial y realizar evaluaciones de riesgo específicas. También el Supervisor Europeo de Protección de Datos (EDPS) ha subrayado la necesidad de realizar una evaluación de garantía de privacidad antes de que los datos sintéticos puedan ser compartidos, garantizando que el resultado no permita obtener datos personales reidentificables.
La Privacidad Diferencial (DP) es una de las tecnologías principales en este dominio. Su mecanismo consiste en añadir ruido controlado al proceso de entrenamiento o a los datos mismos, asegurando matemáticamente que la presencia o ausencia de cualquier individuo en el conjunto de datos original no altere significativamente el resultado final de la generación. El uso de métodos seguros, como el descenso de gradiente estocástico con privacidad diferencial (DP-SGD), garantiza que las muestras generadas no comprometan la privacidad de los usuarios que contribuyeron con sus datos al conjunto sensible.
¿Cuál es el papel de los datos abiertos?
Como es obvio, los datos sintéticos no aparecen de la nada, necesitan datos reales de alta calidad como semilla y, además, requieren buenas prácticas de validación. Por ello, los datos abiertos o los datos que no pueden abrirse por cuestiones relacionadas con la privacidad son, por una parte, una excelente materia prima para aprender patrones del mundo real y, por otra, una referencia independiente para verificar que lo sintético se parece a la realidad sin exponer a personas o empresas.
Como semilla de aprendizaje los datos abiertos de calidad, como los conjuntos de datos de alto valor, con metadatos completos, definiciones claras y esquemas estandarizados, aportan cobertura, granularidad y actualidad. Cuando ciertos conjuntos no pueden hacerse públicos por motivos de privacidad, pueden emplearse internamente con las adecuadas salvaguardas para producir datos sintéticos que sí podrían liberarse. En salud, por ejemplo, existen generadores abiertos como Synthea, que producen historias clínicas ficticias sin las restricciones de uso propias de los datos reales.
Por otra parte, frente a un conjunto sintético, los datos abiertos permiten actuar como patrón de verificación, para contrastar distribuciones, correlaciones y reglas de negocio, así como evaluar la utilidad en tareas reales (predicción, clasificación) sin recurrir a información sensible. En este sentido ya existen trabajos, como el del Gobierno de Gales con datos de salud, que han experimentado con distintos indicadores,. Entre ellos destacan la distancia de variación total (TVD), el índice de propensión (propensity score) y el desempeño en tareas de aprendizaje automático.
¿Cómo se evalúan los datos sintéticos?
La evaluación de los conjuntos de datos sintéticos se articula a través de tres dimensiones que, por su naturaleza, implican un compromiso:
- Fidelidad (Fidelity): mide lo cerca que está el dato sintético de replicar las propiedades estadísticas, correlaciones y la estructura de los datos originales.
- Utilidad (Utility): mide el rendimiento del conjunto de datos sintéticos en tareas posteriores de aprendizaje automático, como la predicción o la clasificación.
- Privacidad (Privacy): mide la efectividad con la que el dato sintético oculta la información sensible y el riesgo de que los sujetos de los datos originales puedan ser reidentificados.

Figura 2. Tres dimensiones para evaluar datos sintéticos. Fuente: elaboración propia - datos.gob.es.
El reto de gobernanza reside en que no es posible optimizar las tres dimensiones simultáneamente. Por ejemplo, aumentar el nivel de privacidad (inyectando más ruido mediante privacidad diferencial) inevitablemente puede reducir la fidelidad estadística y, en consecuencia, la utilidad para ciertas tareas. La elección de qué dimensión priorizar (máxima utilidad para investigación estadística o máxima privacidad) se convierte en una decisión estratégica que debe ser transparente y específica para cada caso de uso.
¿Datos abiertos sintéticos?
La combinación de datos abiertos y datos sintéticos ya puede considerarse algo más que una idea, ya que existen casos reales que demuestran su utilidad para acelerar la innovación y, al mismo tiempo, proteger la privacidad. Además de los ya citados OnTheMap o SIPP Synthetic Beta en Estados Unidos, también encontramos ejemplos en Europa y el resto del mundo. Por ejemplo, el Centro Común de Investigación (JRC) de la Comisión Europea ha analizado el papel de los datos sintéticos generados con IA en la formulación de políticas “AI Generated Synthetic Data in Policy Applications”, destacando su capacidad para acortar el ciclo de vida de las políticas públicas al reducir la carga de acceso a datos sensibles y habilitar fases de exploración y prueba más ágiles. También ha documentado aplicaciones de poblaciones sintéticas multipropósito para análisis de movilidad, energía o salud, reforzando la idea de que los datos sintéticos actúan como habilitador transversal.
En Reino Unido, el Office for National Statistics (ONS) llevó a cabo un Synthetic Data Pilot para entender la demanda de datos sintéticos. En el piloto se exploró la producción de herramientas de generación de microdatos sintéticos de alta calidad para requisitos específicos de los usuarios.
También en salud se observan avances que ilustran el valor de datos abiertos sintéticos para innovación responsable. El Departamento de Salud de la región de Australia Occidental ha impulsado un Synthetic Data Innovation Project y hackatones sectoriales donde se liberan conjuntos sintéticos realistas que permiten a equipos internos y externos probar algoritmos y servicios sin acceso a información clínica identificable, fomentando la colaboración y acelerando la transición de prototipos a casos de uso reales.
En definitiva, los datos sintéticos ofrecen una vía prometedora, aunque no suficientemente explorada, para el desarrollo de las aplicaciones de inteligencia artificial, ya que contribuyen al equilibrio entre el fomento de la innovación y la protección de la privacidad.
Los datos sintéticos no sustituyen a los datos abiertos, sino que se potencian mutuamente. En particular, representan una oportunidad para que las Administraciones públicas pueden ampliar su oferta de datos abiertos con versiones sintéticas de conjuntos sensibles para educación o investigación, y para facilitar que las empresas y desarrolladores independientes experimenten cumpliendo la regulación y puedan generar un mayor valor económico y social.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Las imágenes sintéticas son representaciones visuales generadas de forma artificial mediante algoritmos y técnicas computacionales, en lugar de capturarse directamente de la realidad con cámaras o sensores. Se producen a partir de distintos métodos, entre los que destacan las redes generativas antagónicas (Generative Adversarial Networks, GAN), los modelos de difusión, y las técnicas de renderizado 3D. Todas ellas permiten crear imágenes de apariencia realista que en muchos casos resultan indistinguibles de una fotografía auténtica.
Cuando se traslada este concepto al campo de la observación de la Tierra, hablamos de imágenes satelitales sintéticas. Estas no se obtienen a partir de un sensor espacial que capta radiación electromagnética real, sino que se generan digitalmente para simular lo que vería un satélite desde la órbita. En otras palabras, en vez de reflejar directamente el estado físico del terreno o la atmósfera en un momento concreto, son construcciones computacionales capaces de imitar el aspecto de una imagen satelital real.
El desarrollo de este tipo de imágenes responde a necesidades prácticas. Los sistemas de inteligencia artificial que procesan datos de teledetección requieren conjuntos muy amplios y variados de imágenes. Las imágenes sintéticas permiten, por ejemplo, recrear zonas de la Tierra poco observadas, simular desastres naturales -como incendios forestales, inundaciones o sequías- o generar condiciones específicas que son difíciles o costosas de capturar en la práctica. De este modo, constituyen un recurso valioso para entrenar algoritmos de detección y predicción en agricultura, gestión de emergencias, urbanismo o monitorización ambiental.
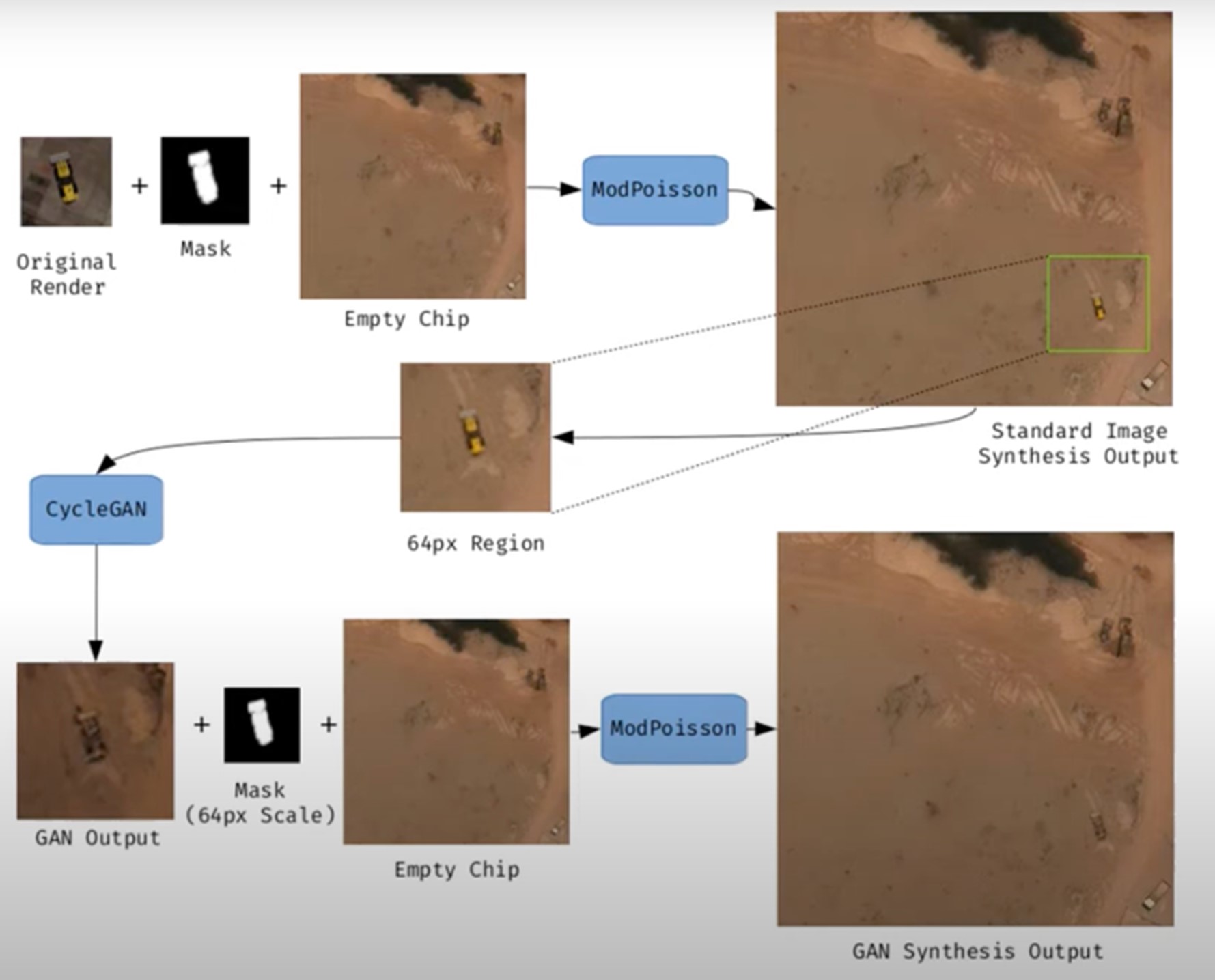
Figura 1. Ejemplo de generación de una imagen satelital sintética.
Su valor no se limita al entrenamiento de modelos. Allí donde no existen imágenes de alta resolución —por limitaciones técnicas, restricciones de acceso o motivos económicos—, la síntesis permite rellenar huecos de información y facilitar estudios preliminares. Por ejemplo, los investigadores pueden trabajar con imágenes sintéticas aproximadas para diseñar modelos de riesgo o simulaciones antes de disponer de datos reales.
Sin embargo, las imágenes satelitales sintéticas también plantean riesgos importantes. La posibilidad de generar escenas muy realistas abre la puerta a la manipulación y a la desinformación. En un contexto geopolítico, una imagen que muestre tropas inexistentes o infraestructuras destruidas podría influir en decisiones estratégicas o en la opinión pública internacional. En el terreno ambiental, se podrían difundir imágenes manipuladas para exagerar o minimizar impactos de fenómenos como la deforestación o el deshielo, con efectos directos en políticas y mercados.
Por ello, conviene diferenciar dos usos muy distintos. El primero es el uso como apoyo, cuando las imágenes sintéticas complementan a las reales para entrenar modelos o realizar simulaciones. El segundo es el uso como falsificación, cuando se presentan deliberadamente como imágenes auténticas con el fin de engañar. Mientras el primer uso impulsa la innovación, el segundo amenaza la confianza en los datos satelitales y plantea un reto urgente de autenticidad y gobernanza.
Riesgos de las imágenes satelitales aplicada a la observación de la Tierra
Las imágenes satelitales sintéticas plantean riesgos significativos cuando se utilizan en vez de imágenes captadas por sensores reales. A continuación, se detallan ejemplos que lo demuestran.
Un nuevo frente de desinformación: “deepfake geography”
El término deepfake geography ya se ha consolidado en la literatura académica y divulgativa para describir imágenes satelitales ficticias, manipuladas con IA, que parecen auténticas, pero no reflejan ninguna realidad existente. Una investigación de la Universidad de Washington, liderada por Bo Zhao, utilizó algoritmos como CycleGAN para modificar imágenes de ciudades reales -por ejemplo, alterando la apariencia de Seattle con edificios inexistentes o transformando Beijing en zonas verdes- lo que pone en evidencia el potencial para generar paisajes falsos convincentes.
Un artículo de la plataforma OnGeo Intelligence (OGC) subraya que estas imágenes no son puramente teóricas, sino amenazas reales que afectan a la seguridad nacional, el periodismo y el trabajo humanitario. Por su parte, el OGC advierte que ya se han observado imágenes satelitales fabricadas, modelos urbanos generados por IA y redes de carreteras sintéticas, y que representan desafíos reales a la confianza pública y operativa.
Implicaciones estratégicas y políticas
Las imágenes satelitales son consideradas "ojos imparciales" sobre el planeta, usadas por gobiernos, medios y organizaciones. Cuando estas imágenes se falsifican, sus consecuencias pueden ser graves:
- Seguridad nacional y defensa: si se presentan infraestructuras falsas o se ocultan otras reales, se pueden desviar análisis estratégicos o inducir decisiones militares equivocadas.
- Desinformación en conflictos o crisis humanitarias: una imagen alterada que muestre incendios, inundaciones o movimientos de tropas falsos puede alterar la respuesta internacional, los flujos de ayuda o la percepción de los ciudadanos, especialmente si se difunde por redes sociales o medios sin verificación.
- Manipulación de imágenes realistas de lugares: no solo las imágenes generales están en juego. Nguyen y colaboradores (2024) demostraron que es posible generar imágenes satelitales sintéticas altamente realistas de instalaciones muy específicas como plantas nucleares.
Crisis de confianza y erosión de la verdad
Durante décadas, las imágenes satelitales han sido percibidas como una de las fuentes más objetivas y fiables de información sobre nuestro planeta. Eran la prueba gráfica que permitía confirmar fenómenos ambientales, seguir conflictos armados o evaluar el impacto de desastres naturales. En muchos casos, estas imágenes se utilizaban como “evidencia imparcial”, difíciles de manipular y fáciles de validar. Sin embargo, la irrupción de las imágenes sintéticas generadas por inteligencia artificial ha empezado a poner en cuestión esa confianza casi inquebrantable.
Hoy en día, cuando una imagen satelital puede ser falsificada con gran realismo, surge un riesgo profundo: la erosión de la verdad y la aparición de una crisis de confianza en los datos espaciales.
La quiebra de la confianza pública
Cuando los ciudadanos ya no pueden distinguir entre una imagen real y una fabricada, se resquebraja la confianza en las fuentes de información. La consecuencia es doble:
- Desconfianza hacia las instituciones: si circulan imágenes falsas de un incendio, una catástrofe o un despliegue militar y luego resultan ser sintéticas, la ciudadanía puede empezar a dudar también de las imágenes auténticas publicadas por agencias espaciales o medios de comunicación. Este efecto “que viene el lobo” genera escepticismo incluso frente a pruebas legítimas.
- Efecto en el periodismo: los medios tradicionales, que han usado históricamente las imágenes satelitales como fuente visual incuestionable, corren el riesgo de perder credibilidad si publican imágenes adulteradas sin verificación. Al mismo tiempo, la abundancia de imágenes falsas en redes sociales erosiona la capacidad de distinguir qué es real y qué no.
- Confusión deliberada: en contextos de desinformación, la mera sospecha de que una imagen pueda ser falsa ya puede bastar para generar duda y sembrar confusión, aunque la imagen original sea completamente auténtica.
A continuación, se resumen los posibles casos de manipulación y riesgo en imágenes satelitales:
| Ámbito | Tipo de manipulación | Riesgo principal | Ejemplo documentado |
|---|---|---|---|
| Conflictos armados | Inserción o eliminación de infraestructuras militares. | Desinformación estratégica; decisiones militares erróneas; pérdida de credibilidad en observación internacional. | Alteraciones demostradas en estudios de deepfake geography donde se añadían carreteras, puentes o edificios ficticios en imágenes satelitales. |
| Cambio climático y medio ambiente | Alteración de glaciares, deforestación o emisiones. | Manipulación de políticas ambientales; retraso en medidas contra el cambio climático; negacionismo. | Estudios han mostrado la capacidad de generar paisajes modificados (bosques en zonas urbanas, cambios en el hielo) mediante GAN. |
| Gestión de emergencias | Creación de desastres inexistentes (incendios, inundaciones). | Mal uso de recursos en emergencias; caos en evacuaciones; pérdida de confianza en agencias. | Investigaciones han demostrado la facilidad de insertar humo, fuego o agua en imágenes satelitales. |
| Mercados y seguros | Falsificación de daños en infraestructuras o cultivos. | Impacto financiero; fraude masivo; litigios legales complejos. | Uso potencial de imágenes falsas para exagerar daños tras desastres y reclamar indemnizaciones o seguros. |
| Derechos humanos y justicia internacional | Alteración de pruebas visuales sobre crímenes de guerra. | Deslegitimación de tribunales internacionales; manipulación de la opinión pública. | Riesgo identificado en informes de inteligencia: imágenes adulteradas podrían usarse para acusar o exonerar a actores en conflictos. |
| Geopolítica y diplomacia | Creación de ciudades ficticias o cambios fronterizos. | Tensiones diplomáticas; cuestionamiento de tratados; propaganda estatal. | Ejemplos de deepfake maps que transforman rasgos geográficos de ciudades como Seattle o Tacoma. |
Figura 2. Tabla con los posibles casos de manipulación y riesgo en imágenes satelitales
Impacto en la toma de decisiones y políticas públicas
Las consecuencias de basarse en imágenes adulteradas van mucho más allá del terreno mediático:
- Urbanismo y planificación: decisiones sobre dónde construir infraestructuras o cómo planificar zonas urbanas podrían tomarse sobre imágenes manipuladas, generando errores costosos y de difícil reversión.
- Gestión de emergencias: si una inundación o un incendio se representan en imágenes falsas, los equipos de emergencia pueden destinar recursos a lugares equivocados, mientras descuidan zonas realmente afectadas.
- Cambio climático y medio ambiente: imágenes adulteradas de glaciares, deforestación o emisiones contaminantes podrían manipular debates políticos y retrasar la implementación de medidas urgentes.
- Mercados y seguros: aseguradoras y empresas financieras que confían en imágenes satelitales para evaluar daños podrían ser engañadas, con consecuencias económicas significativas.
En todos estos casos, lo que está en juego no es solo la calidad de la información, sino la eficacia y legitimidad de las políticas públicas basadas en esos datos.
El juego del gato y el ratón tecnológico
La dinámica de generación y detección de falsificaciones ya se conoce en otros ámbitos, como los deepfakes de vídeo o audio: cada vez que surge un método de generación más realista, se desarrolla un algoritmo de detección más avanzado, y viceversa. En el ámbito de las imágenes satelitales, esta carrera tecnológica tiene particularidades:
- Generadores cada vez más sofisticados: los modelos de difusión actuales pueden crear escenas de gran realismo, integrando texturas de suelo, sombras y geometrías urbanas que engañan incluso a expertos humanos.
- Limitaciones de la detección: aunque se desarrollan algoritmos para identificar falsificaciones (analizando patrones de píxeles, inconsistencias en sombras o metadatos), estos métodos no siempre son fiables cuando se enfrentan a generadores de última generación.
- Coste de la verificación: verificar de forma independiente una imagen satelital requiere acceso a fuentes alternativas o sensores distintos, algo que no siempre está al alcance de periodistas, ONG o ciudadanos.
- Armas de doble filo: las mismas técnicas usadas para detectar falsificaciones pueden ser aprovechadas por quienes las generan, perfeccionando aún más las imágenes sintéticas y haciendo más difícil diferenciarlas.
De la prueba visual a la prueba cuestionada
El impacto más profundo es cultural y epistemológico: lo que antes se asumía como una prueba objetiva ahora se convierte en un elemento sujeto a duda. Si las imágenes satelitales dejan de ser percibidas como evidencia fiable, se debilitan narrativas fundamentales en torno a la verdad científica, la justicia internacional y la rendición de cuentas política.
- En conflictos armados, una imagen de satélite que muestre posibles crímenes de guerra puede ser descartada bajo la acusación de ser un deepfake.
- En tribunales internacionales, pruebas basadas en observación satelital podrían perder peso frente a la sospecha de manipulación.
- En el debate público, el relativismo de “todo puede ser falso” puede usarse como arma retórica para deslegitimar incluso la evidencia más sólida.
Estrategias para garantizar autenticidad
La crisis de confianza en las imágenes satelitales no es un problema aislado del sector geoespacial, sino que forma parte de un fenómeno más amplio: la desinformación digital en la era de la inteligencia artificial. Así como los deepfakes de vídeo han puesto en cuestión la validez de pruebas audiovisuales, la proliferación de imágenes satelitales sintéticas amenaza con debilitar la última frontera de datos percibidos como objetivos: la mirada imparcial desde el espacio.
Garantizar la autenticidad de estas imágenes exige una combinación de soluciones técnicas y mecanismos de gobernanza, capaces de reforzar la trazabilidad, la transparencia y la responsabilidad en toda la cadena de valor de los datos espaciales. A continuación, se describen las principales estrategias en desarrollo.
Metadatos robustos: registrar el origen y la cadena de custodia
Los metadatos constituyen la primera línea de defensa frente a la manipulación. En imágenes satelitales, deben incluir información detallada sobre:
- El sensor utilizado (tipo, resolución, órbita).
- El momento exacto de la adquisición (fecha y hora, con precisión temporal).
- La localización geográfica precisa (sistemas de referencia oficiales).
- La cadena de procesado aplicada (correcciones atmosféricas, calibraciones, reproyecciones).
Registrar estos metadatos en repositorios seguros permite reconstruir la cadena de custodia, es decir, el historial de quién, cómo y cuándo ha manipulado una imagen. Sin esta trazabilidad, resulta imposible distinguir entre imágenes auténticas y falsificadas.
EJEMPLO: el programa Copernicus de la Unión Europea ya implementa metadatos estandarizados y abiertos para todas sus imágenes Sentinel, lo que facilita auditorías posteriores y confianza en el origen.
Firmas digitales y blockchain: garantizar la integridad
Las firmas digitales permiten verificar que una imagen no ha sido alterada desde su captura. Funcionan como un sello criptográfico que se aplica en el momento de adquisición y se valida en cada uso posterior.
La tecnología blockchain ofrece un nivel adicional de garantía: almacenar los registros de adquisición y modificación en una cadena inmutable de bloques. De esta manera, cualquier cambio en la imagen o en sus metadatos quedaría registrado y sería fácilmente detectable.
EJEMPLO: el proyecto ESA – Trusted Data Framework explora el uso de blockchain para proteger la integridad de datos de observación de la Tierra y reforzar la confianza en aplicaciones críticas como cambio climático y seguridad alimentaria.
Marcas de agua invisible: señales ocultas en la imagen
El marcado de agua digital consiste en incrustar señales imperceptibles en la propia imagen satelital, de modo que cualquier alteración posterior se pueda detectar automáticamente.
- Puede hacerse a nivel de píxel, modificando ligeramente patrones de color o luminancia.
- Se combina con técnicas criptográficas para reforzar su validez.
- Permite validar imágenes incluso si han sido recortadas, comprimidas o reprocesadas.
EJEMPLO: en el sector audiovisual, las marcas de agua se usa desde hace años en la protección de contenidos digitales. Su adaptación a imágenes satelitales está en fase experimental, pero podría convertirse en una herramienta estándar de verificación.
Estándares abiertos (OGC, ISO): confianza mediante interoperabilidad
La estandarización es clave para garantizar que las soluciones técnicas se apliquen de forma coordinada y global.
- OGC (Open Geospatial Consortium) trabaja en estándares para la gestión de metadatos, la trazabilidad de datos geoespaciales y la interoperabilidad entre sistemas. Su trabajo en API geoespaciales y metadatos FAIR (Findable, Accessible, Interoperable, Reusable) es esencial para establecer prácticas comunes de confianza.
- ISO desarrolla normas sobre gestión de la información y autenticidad de registros digitales que también pueden aplicarse a imágenes satelitales.
EJEMPLO: el OGC Testbed-19 incluyó experimentos específicos sobre autenticidad de datos geoespaciales, probando enfoques como firmas digitales y certificados de procedencia.
Verificación cruzada: combinar múltiples fuentes
Un principio básico para detectar falsificaciones es contrastar fuentes. En el caso de imágenes satelitales, esto implica:
- Comparar imágenes de diferentes satélites (ej. Sentinel-2 vs. Landsat-9).
- Usar distintos tipos de sensores (ópticos, radar SAR, hiperespectrales).
- Analizar series temporales para verificar la consistencia en el tiempo.
EJEMPLO: la verificación de daños en Ucrania tras el inicio de la invasión rusa en 2022 se realizó mediante la comparación de imágenes de varios proveedores (Maxar, Planet, Sentinel), asegurando que los hallazgos no se basaban en una sola fuente.
IA contra IA: detección automática de falsificaciones
La misma inteligencia artificial que permite crear imágenes sintéticas se puede utilizar para detectarlas. Las técnicas incluyen:
- Análisis forense de píxeles: identificar patrones generados por GAN o modelos de difusión.
- Redes neuronales entrenadas para distinguir entre imágenes reales y sintéticas en función de texturas o distribuciones espectrales.
- Modelos de inconsistencias geométricas: detectar sombras imposibles, incoherencias topográficas o patrones repetitivos.
EJEMPLO: investigadores de la Universidad de Washington y otros grupos han demostrado que algoritmos específicos pueden detectar falsificaciones satelitales con una precisión superior al 90% en condiciones controladas.
Experiencias actuales: iniciativas globales
Varios proyectos internacionales ya trabajan en mecanismos para reforzar la autenticidad:
- Coalition for Content Provenance and Authenticity (C2PA): una alianza entre Adobe, Microsoft, BBC, Intel y otras organizaciones para desarrollar un estándar abierto de procedencia y autenticidad de contenidos digitales, incluyendo imágenes. Su modelo se puede aplicar directamente al sector satelital.
- Trabajo del OGC: la organización impulsa el debate sobre confianza en datos geoespaciales y ha destacado la importancia de garantizar la trazabilidad de imágenes satelitales sintéticas y reales (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) en EE. UU. ha reconocido públicamente la amenaza de imágenes sintéticas en defensa y está impulsando colaboraciones con academia e industria para desarrollar sistemas de detección.
Hacia un ecosistema de confianza
Las estrategias descritas no deben entenderse como alternativas, sino como capas complementarias en un ecosistema de confianza:
|
Id |
Capas |
¿Qué aportan? |
|---|---|---|
| 1 | Metadatos robustos (origen, sensor, cadena de custodia) |
Garantizan trazabilidad |
| 2 | Firmas digitales y blockchain (integridad de datos) |
Aseguran integridad |
| 3 | Marcas de agua invisible (señales ocultas) |
Añade un nivel oculto de protección |
| 4 | Verificación cruzada (múltiples satélites y sensores) |
Valida con independencia |
| 5 | IA contra IA (detector de falsificaciones) |
Responde a amenazas emergentes |
| 6 | Gobernanza internacional (responsabilidad, marcos legales) |
Articula reglas claras de responsabilidad |
Figura 3. Capas para garantizar la confianza en las imágenes sintéticas satelitales
El éxito dependerá de que estos mecanismos se integren de manera conjunta, bajo marcos abiertos y colaborativos, y con la implicación activa de agencias espaciales, gobiernos, sector privado y comunidad científica.
Conclusiones
Las imágenes sintéticas, lejos de ser únicamente una amenaza, representan una herramienta poderosa que, bien utilizada, puede aportar un valor significativo en ámbitos como la simulación, el entrenamiento de algoritmos o la innovación en servicios digitales. El problema surge cuando estas imágenes se presentan como reales sin la debida transparencia, alimentando la desinformación o manipulando la percepción pública.
El reto, por tanto, es doble: aprovechar las oportunidades que ofrece la síntesis de datos visuales para avanzar en ciencia, tecnología y gestión, y minimizar los riesgos asociados al mal uso de estas capacidades, especialmente en forma de deepfakes o falsificaciones deliberadas.
En el caso particular de las imágenes satelitales, la confianza adquiere una dimensión estratégica. De ellas dependen decisiones críticas en seguridad nacional, respuesta a desastres, políticas ambientales y justicia internacional. Si la autenticidad de estas imágenes se pone en duda, se compromete no solo la fiabilidad de los datos, sino también la legitimidad de las decisiones basadas en ellos.
El futuro de la observación de la Tierra estará condicionado por nuestra capacidad de garantizar la autenticidad, transparencia y trazabilidad en toda la cadena de valor: desde la adquisición de los datos hasta su difusión y uso final. Las soluciones técnicas (metadatos robustos, firmas digitales, blockchain, marcas de agua, verificación cruzada e IA para detección de falsificaciones), combinadas con marcos de gobernanza y cooperación internacional, serán la clave para construir un ecosistema de confianza.
En definitiva, debemos asumir un principio rector sencillo pero contundente:
“Si no podemos confiar en lo que vemos desde el espacio, ponemos en riesgo nuestras decisiones en la Tierra.”
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La Agencia Española de Protección de Datos ha publicado recientemente la traducción al español de la Guía sobre generación de datos sintéticos, elaborada originalmente por la Autoridad de Protección de Datos de Singapur. Este documento ofrece orientación técnica y práctica para personas responsables, encargadas y delegadas de protección de datos sobre cómo implementar esta tecnología que permite simular datos reales manteniendo sus características estadísticas sin comprometer información personal.
La guía destaca cómo los datos sintéticos pueden impulsar la economía del dato, acelerar la innovación y mitigar riesgos en brechas de seguridad. Para ello, presenta casos prácticos, recomendaciones y buenas prácticas orientadas a reducir los riesgos de reidentificación. En este post, analizamos los aspectos clave de la Guía destacando casos de uso principales y ejemplos de aplicación práctica.
¿Qué son los datos sintéticos? Concepto y beneficios
Los datos sintéticos son datos artificiales generados mediante modelos matemáticos específicamente diseñados para sistemas de inteligencia artificial (IA) o aprendizaje automático (ML). Estos datos se crean entrenando un modelo con un conjunto de datos de origen para imitar sus características y estructura, pero sin replicar exactamente los registros originales.
Los datos sintéticos de alta calidad conservan las propiedades estadísticas y los patrones de los datos originales. Por lo tanto, permiten realizar análisis que produzcan resultados similares a los que se obtendrían con los datos reales. Sin embargo, al ser artificiales, reducen significativamente los riesgos asociados con la exposición de información sensible o personal.
Para profundizar en este tema, tienes disponible este Informe monográfico sobre datos sintéticos: ¿Qué son y para qué se usan? con información detallada sobre los fundamentos teóricos, metodologías y aplicaciones prácticas de esta tecnología.
La implementación de datos sintéticos ofrece múltiples ventajas para las organizaciones, por ejemplo:
- Protección de la privacidad: permiten realizar análisis de datos manteniendo la confidencialidad de la información personal o comercialmente sensible.
- Cumplimiento normativo: facilitan el seguimiento de regulaciones de protección de datos mientras se maximiza el valor de los activos de información.
- Reducción de riesgos: minimizan las posibilidades de brechas de datos y sus consecuencias.
- Impulso a la innovación: aceleran el desarrollo de soluciones basadas en datos sin comprometer la privacidad.
- Mejora en la colaboración: posibilitan compartir información valiosa entre organizaciones y departamentos de forma segura.
Pasos para generar datos sintéticos
Para implementar correctamente esta tecnología, la Guía sobre generación de datos sintéticos recomienda seguir un enfoque estructurado en cinco pasos:
- Conocer los datos: comprender claramente el propósito de los datos sintéticos y las características de los datos de origen que deben preservarse, estableciendo objetivos precisos respecto al umbral de riesgo aceptable y la utilidad esperada.
- Preparar los datos: identificar las ideas clave que deben conservarse, seleccionar los atributos relevantes, eliminar o seudonimizar identificadores directos, y estandarizar los formatos y estructuras en un diccionario de datos bien documentado.
- Generar datos sintéticos: seleccionar los métodos más adecuados según el caso de uso, evaluar la calidad mediante comprobaciones de integridad, fidelidad y utilidad, y ajustar iterativamente el proceso para lograr el equilibrio deseado.
- Evaluar riesgos de reidentificación: aplicar técnicas basadas en ataques para determinar la posibilidad de inferir información sobre individuos o su pertenencia al conjunto original, asegurando que los niveles de riesgo sean aceptables.
- Gestionar riesgos residuales: implementar controles técnicos, de gobernanza y contractuales para mitigar los riesgos identificados, documentando adecuadamente todo el proceso.
Aplicaciones prácticas y casos de éxito
Para obtener todas estas ventajas, los datos sintéticos pueden aplicarse en diversos escenarios que responden a necesidades específicas de las organizaciones. La Guía menciona, por ejemplo:
1. Generación de conjuntos de datos para entrenar modelos de IA/ML: los datos sintéticos resuelven el problema de la escasez de datos etiquetados (es decir, que se pueden utilizar) para entrenar modelos de IA. Cuando los datos reales son limitados, los datos sintéticos pueden ser una alternativa rentable. Además, permiten simular eventos extraordinarios o incrementar la representación de grupos minoritarios en los conjuntos de entrenamiento. Una aplicación interesante para mejorar el rendimiento y la representatividad de todos los grupos sociales en los modelos de IA.
2. Análisis de datos y colaboración: este tipo de datos facilitan el intercambio de información para análisis, especialmente en sectores como la salud, donde los datos originales son particularmente sensibles. Tanto en este sector como en otros, proporcionan a las partes interesadas una muestra representativa de los datos reales sin exponer información confidencial, permitiendo evaluar la calidad y potencial de los datos antes de establecer acuerdos formales.
3. Pruebas de software: son muy útiles para el desarrollo de sistemas y la realización de pruebas de software porque permiten utilizar datos realistas, pero no reales en entornos de desarrollo, evitando así posibles brechas de datos personales en caso de comprometerse el entorno de desarrollo.
La aplicación práctica de datos sintéticos ya está demostrando resultados positivos en diversos sectores:
I. Sector financiero: detección de fraudes. J.P. Morgan ha utilizado con éxito datos sintéticos para entrenar modelos de detección de fraude, creando conjuntos de datos con un mayor porcentaje de casos fraudulentos que permitieron mejorar significativamente la capacidad de los modelos para identificar comportamientos anómalos.
II. Sector tecnológico: investigación sobre sesgos en IA. Mastercard colaboró con investigadores para desarrollar métodos de prueba de sesgos en IA mediante datos sintéticos que mantenían las relaciones reales de los datos originales, pero eran lo suficientemente privados como para compartirse con investigadores externos, permitiendo avances que no habrían sido posibles sin esta tecnología.
III. Sector salud: salvaguarda de datos de pacientes. Johnson & Johnson implementó datos sintéticos generados por IA como alternativa a las técnicas tradicionales de anonimización para procesar datos sanitarios, logrando una mejora significativa en la calidad del análisis al representar eficazmente a la población objetivo mientras se protegía la privacidad de los pacientes.
El equilibrio entre utilidad y protección
Es importante destacar que los datos sintéticos no están inherentemente libres de riesgos. La semejanza con los datos originales podría, en determinadas circunstancias, permitir la filtración de información sobre individuos o datos confidenciales. Por ello, resulta crucial encontrar un equilibrio entre la utilidad de los datos y su protección.
Este equilibrio puede lograrse mediante la implementación de buenas prácticas durante el proceso de generación de datos sintéticos, incorporando medidas de protección como:
- Preparación adecuada de los datos: eliminación de valores atípicos, seudonimización de identificadores directos y generalización de datos granulares.
- Evaluación de riesgos de reidentificación: análisis de la posibilidad de que se puedan vincular los datos sintéticos con individuos reales.
- Implementación de controles técnicos: añadir ruido a los datos, reducir la granularidad o aplicar técnicas de privacidad diferencial.
Los datos sintéticos representan una oportunidad excepcional para impulsar la innovación basada en datos mientras se respeta la privacidad y se cumple con las normativas de protección de datos. Su capacidad para generar información estadísticamente representativa pero artificial los convierte en una herramienta versátil para múltiples aplicaciones, desde el entrenamiento de modelos de IA hasta la colaboración entre organizaciones y el desarrollo de software.
Al implementar adecuadamente las buenas prácticas y controles descritos en Guía sobre generación de datos sintéticos que ha traducido la AEPD, las organizaciones pueden aprovechar los beneficios de los datos sintéticos minimizando los riesgos asociados, posicionándose a la vanguardia de la transformación digital responsable. La adopción de tecnologías de mejora de la privacidad como los datos sintéticos no solo representa una medida defensiva, sino un paso proactivo hacia una cultura organizacional que valora tanto la innovación como la protección de datos, aspectos fundamentales para el éxito en la economía digital del futuro.
Documentación
En la era de los datos, nos enfrentamos al desafío de la escasez de datos de valor para la construcción de nuevos productos y servicios digitales. Aunque vivimos en una época en la que los datos están por todas partes, a menudo nos encontramos con dificultades para acceder a datos de calidad que nos permitan comprender procesos o sistemas desde una perspectiva basada en datos. La falta de disponibilidad, la fragmentación, la seguridad y la privacidad son solo algunas de las razones que dificultan el acceso a datos reales.
Sin embargo, los datos sintéticos han surgido como una solución prometedora a este problema. Los datos sintéticos son información fabricada artificialmente que imita las características y distribuciones de los datos reales, sin contener información personal o sensible. Estos datos se generan mediante algoritmos y técnicas que preservan la estructura y las propiedades estadísticas de los datos originales.
Los datos sintéticos son útiles en diversas situaciones donde la disponibilidad de datos reales es limitada o se requiere proteger la privacidad de las personas involucradas. Tienen aplicaciones en la investigación científica, pruebas de software y sistemas, y entrenamiento de modelos de inteligencia artificial. Permiten a los investigadores explorar nuevos enfoques sin acceder a datos sensibles, a los desarrolladores probar aplicaciones sin exponer datos reales y a los expertos en IA entrenar modelos sin la necesidad de recopilar todos los datos del mundo real que en ocasiones son, simplemente, imposibles de capturar en tiempos y costes asumibles.
Existen diferentes métodos para generar datos sintéticos, como el remuestreo, el modelado probabilístico y generativo, y los métodos de perturbación y enmascaramiento. Cada método tiene sus ventajas y desafíos, pero en general, los datos sintéticos ofrecen una alternativa segura y confiable para el análisis, la experimentación y el entrenamiento de modelos de inteligencia artificial.
Es importante destacar que el uso de datos sintéticos ofrece una solución viable para superar las limitaciones de acceso a datos reales y abordar preocupaciones de privacidad y seguridad. Los datos sintéticos permiten realizar pruebas, entrenar algoritmos y desarrollar aplicaciones sin exponer información confidencial. Sin embargo, es fundamental garantizar la calidad y la fidelidad de los datos sintéticos mediante evaluaciones rigurosas y comparaciones con los datos reales.
En este informe, abordamos de forma introductoria la disciplina de los datos sintéticos, ilustrando algunos casos de uso de valor para los diferentes tipos de datos sintéticos que se pueden generar. Los vehículos autónomos, la secuenciación de ADN o los controles de calidad en las cadenas de producción son solo algunos de los casos que detallamos en este informe. Además, hemos destacado el uso del software open-source SDV (Synthetic Data Vault), desarrollado en el entorno académico del MIT, que utiliza algoritmos de aprendizaje automático para crear datos sintéticos tabulares que imitan las propiedades y distribuciones de los datos reales. Desarrollamos un ejemplo práctico, en un entorno de Google Colab para generar datos sintéticos sobre clientes ficticios alojados en un hotel ficticio. Hemos seguido un flujo de trabajo que involucra la preparación de datos reales y metadatos, el entrenamiento del sintetizador y la generación de datos sintéticos basados en los patrones aprendidos. Además, hemos aplicado técnicas de anonimización para proteger los datos sensibles y hemos evaluado la calidad de los datos sintéticos generados.
En resumen, los datos sintéticos son una herramienta poderosa en la era de los datos, ya que nos permiten superar la escasez y la falta de disponibilidad de datos de valor. Con su capacidad para imitar los datos reales sin comprometer la privacidad, los datos sintéticos tienen el potencial de transformar la forma en que desarrollamos proyectos de inteligencia artificial y análisis. A medida que avanzamos en esta nueva era, es probable que los datos sintéticos desempeñen un papel cada vez más importante en la generación de nuevos productos y servicios digitales.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
En esta infografía se resume el concepto y sus principales aplicaciones:

Puedes descargarla en PDF aquí
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.