Blog
Artificial Intelligence (AI) is becoming one of the main drivers of increased productivity and innovation in both the public and private sectors, becoming increasingly relevant in tasks ranging from the creation of content in any format (text, audio, video) to the optimization of complex processes through Artificial Intelligence agents.
However, advanced AI models, and in particular large language models, require massive amounts of data for training, optimization, and evaluation. This dependence generates a paradox: at the same time as AI demands more and higher quality data, the growing concern for privacy and confidentiality (General Data Protection Regulation or GDPR), new data access and use rules (Data Act), and quality and governance requirements for high-risk systems (AI Regulation), as well as the inherent scarcity of data in sensitive domains limit access to actual data.
In this context, synthetic data can be an enabling mechanism to achieve new advances, reconciling innovation and privacy protection. On the one hand, they allow AI to be nurtured without exposing sensitive information, and when combined with quality open data, they expand access to domains where real data is scarce or heavily regulated.
What is synthetic data and how is it generated?
Simply put, synthetic data can be defined as artificially fabricated information that mimics the characteristics and distributions of real data. The main function of this technology is to reproduce the statistical characteristics, structure and patterns of the underlying real data. In the domain of official statistics, there are cases such as the United States Census , which publishes partially or totally synthetic products such as OnTheMap (mobility of workers between place of residence and workplace) or SIPP Synthetic Beta (socioeconomic microdata linked to taxes and social security).
The generation of synthetic data is currently a field still in development that is supported by various methodologies. Approaches can range from rule-based methods or statistical modeling (simulations, Bayesian, causal networks), which mimic predefined distributions and relationships, to advanced deep learning techniques. Among the most outstanding architectures we find:
- Generative Adversarial Networks (GANs): a generative model, trained on real data, learns to mimic its characteristics, while a discriminator tries to distinguish between real and synthetic data. Through this iterative process, the generator improves its ability to produce artificial data that is statistically indistinguishable from the originals. Once trained, the algorithm can create new artificial records that are statistically similar to the original sample, but completely new and secure.
- Variational Selfencoders (VAE): These models are based on neural networks that learn a probabilistic distribution in a latent space of the input data. Once trained, the model uses this distribution to obtain new synthetic observations by sampling and decoding the latent vectors. VAEs are often considered a more stable and easier option to train compared to GANs for tabular data generation.
- Autoregressive/hierarchical models and domain simulators: used, for example, in electronic medical record data, which capture temporal and hierarchical dependencies. Hierarchical models structure the problem by levels, first sampling higher-level variables and then lower-level variables conditioned to the previous ones. Domain simulators code process rules and calibrate them with real data, providing control and interpretability and ensuring compliance with business rules.
You can learn more about synthetic data and how it's created in this infographic:
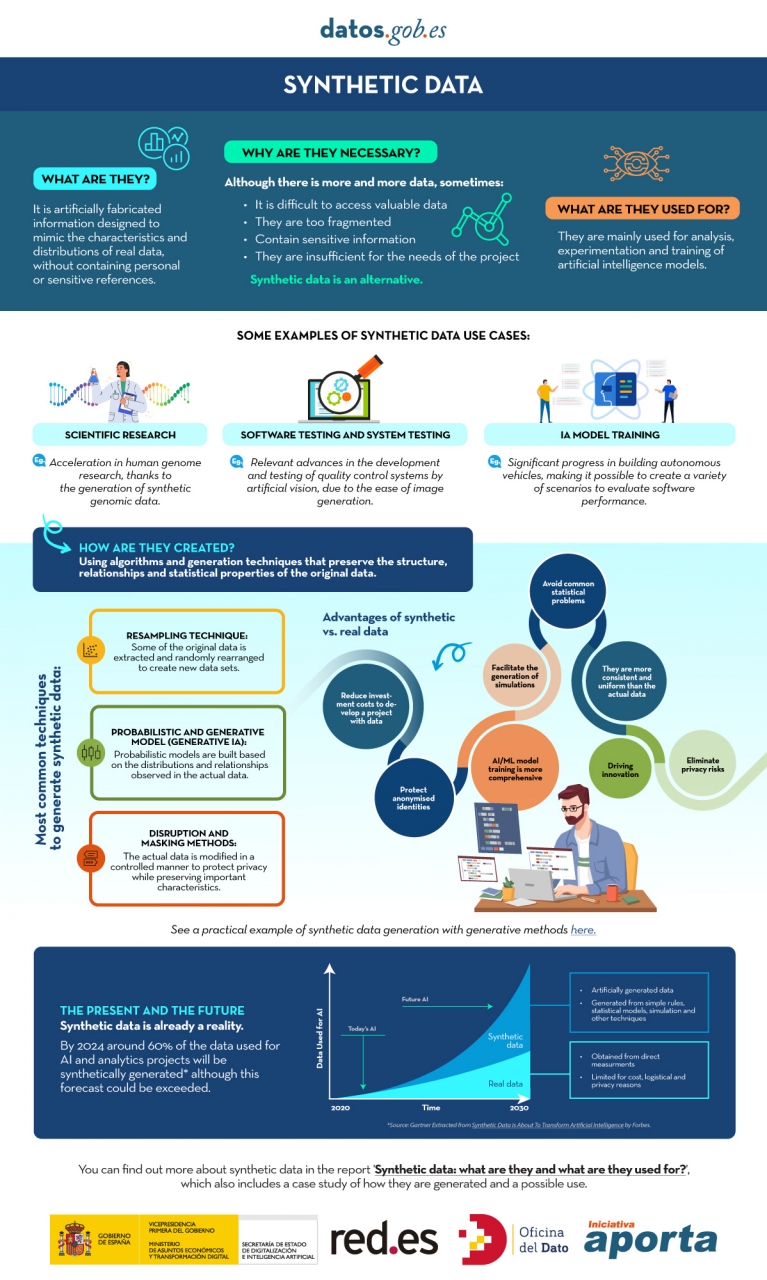
Figure 1. Infographic on synthetic data. Source: Authors' elaboration - datos.gob.es.
While synthetic generation inherently reduces the risk of personal data disclosure, it does not eliminate it entirely. Synthetic does not automatically mean anonymous because, if the generators are trained inappropriately, traces of the real set can leak out and be vulnerable to membership inference attacks. Hence, it is necessary to use Privacy Enhancing Technologies (PET) such as differential privacy and to carry out specific risk assessments. The European Data Protection Supervisor (EDPS) has also underlined the need to carry out a privacy assurance assessment before synthetic data can be shared, ensuring that the result does not allow re-identifiable personal data to be obtained.
Differential Privacy (PD) is one of the main technologies in this domain. Its mechanism is to add controlled noise to the training process or to the data itself, mathematically ensuring that the presence or absence of any individual in the original dataset does not significantly alter the final result of the generation. The use of secure methods, such as Stochastic Gradient Descent with Differential Privacy (DP-SGD), ensures that the samples generated do not compromise the privacy of users who contributed their data to the sensitive set.
What is the role of open data?
Obviously, synthetic data does not appear out of nowhere, it needs real high-quality data as a seed and, in addition, it requires good validation practices. For this reason, open data or data that cannot be opened for privacy-related reasons is, on the one hand, an excellent raw material for learning real-world patterns and, on the other, an independent reference to verify that the synthetic resembles reality without exposing people or companies.
As a seed of learning, quality open data, such as high-value datasets, with complete metadata, clear definitions and standardized schemas, provide coverage, granularity and timeliness. Where certain sets cannot be made public for privacy reasons, they can be used internally with appropriate safeguards to produce synthetic data that could be released. In health, for example, there are open generators such as Synthea, which produce fictitious medical records without the restrictions on the use of real data.
On the other hand, compared to a synthetic set, open data allows it to act as a verification standard, to contrast distributions, correlations and business rules, as well as to evaluate the usefulness in real tasks (prediction, classification) without resorting to sensitive information. In this sense, there are already works, such as that of the Welsh Government with health data, which have experimented with different indicators. These include total distance of change (TVD), propensity score and performance in machine learning tasks.
How is synthetic data evaluated?
The evaluation of synthetic datasets is articulated through three dimensions that, by their nature, imply a commitment:
- Fidelity: Measures how close the synthetic data is to replicating the statistical properties, correlations, and structure of the original data.
- Utility: Measures the performance of the synthetic dataset in subsequent machine learning tasks, such as prediction or classification.
- Privacy: measures how effectively synthetic data hides sensitive information and the risk that the subjects of the original data can be re-identified.
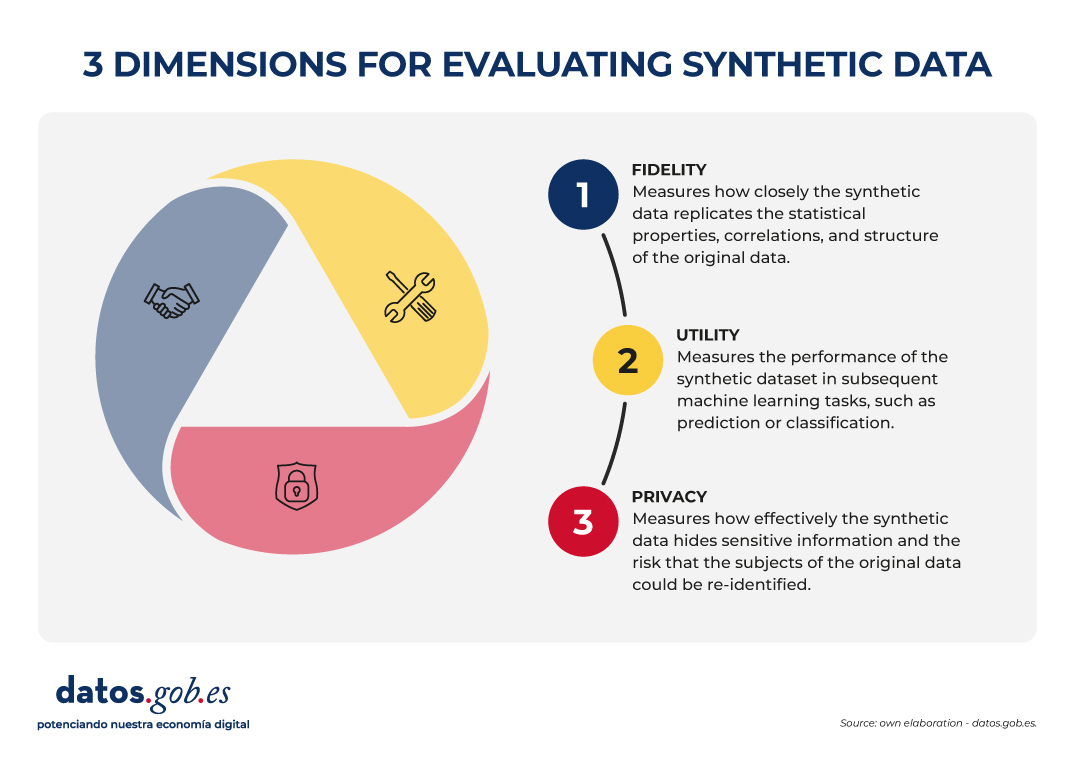
Figure 2. Three dimensions to evaluate synthetic data. Source: Authors' elaboration - datos.gob.es.
The governance challenge is that it is not possible to optimize all three dimensions simultaneously. For example, increasing the level of privacy (by injecting more noise through differential privacy) can inevitably reduce statistical fidelity and, consequently, usefulness for certain tasks. The choice of which dimension to prioritize (maximum utility for statistical research or maximum privacy) becomes a strategic decision that must be transparent and specific to each use case.
Synthetic open data?
The combination of open data and synthetic data can already be considered more than just an idea, as there are real cases that demonstrate its usefulness in accelerating innovation and, at the same time, protecting privacy. In addition to the aforementioned OnTheMap or SIPP Synthetic Beta in the United States, we also find examples in Europe and the rest of the world. For example, the European Commission's Joint Research Centre (JRC) has analysed the role of AI Generated Synthetic Data in Policy Applications, highlighting its ability to shorten the life cycle of public policies by reducing the burden of accessing sensitive data and enabling more agile exploration and testing phases. He has also documented applications of multipurpose synthetic populations for mobility, energy, or health analysis, reinforcing the idea that synthetic data act as a cross-sectional enabler.
In the UK, the Office for National Statistics (ONS) conducted a Synthetic Data Pilot to understand the demand for synthetic data. The pilot explored the production of high-quality synthetic microdata generation tools for specific user requirements.
Also in health , advances are observed that illustrate the value of synthetic open data for responsible innovation. The Department of Health of the Western Australian region has promoted a Synthetic Data Innovation Project and sectoral hackathons where realistic synthetic sets are released that allow internal and external teams to test algorithms and services without access to identifiable clinical information, fostering collaboration and accelerating the transition from prototypes to real use cases.
In short, synthetic data offers a promising, although not sufficiently explored, avenue for the development of artificial intelligence applications, as it contributes to the balance between fostering innovation and protecting privacy.
Synthetic data is not a substitute for open data, but rather enhances each other. In particular, they represent an opportunity for public administrations to expand their open data offering with synthetic versions of sensitive sets for education or research, and to make it easier for companies and independent developers to experiment with regulation and generate greater economic and social value.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Synthetic images are visual representations artificially generated by algorithms and computational techniques, rather than being captured directly from reality with cameras or sensors. They are produced from different methods, among which the antagonistic generative networks (Generative Adversarial NetworksGAN), the Dissemination models, and the 3D rendering techniques. All of them allow you to create images of realistic appearance that in many cases are indistinguishable from an authentic photograph.
When this concept is transferred to the field of Earth observation, we are talking about synthetic satellite images. These are not obtained from a space sensor that captures real electromagnetic radiation, but are generated digitally to simulate what a satellite would see from orbit. In other words, instead of directly reflecting the physical state of the terrain or atmosphere at a particular time, they are computational constructs capable of mimicking the appearance of a real satellite image.
The development of this type of image responds to practical needs. Artificial intelligence systems that process remote sensing data require very large and varied sets of images. Synthetic images allow, for example, to recreate areas of the Earth that are little observed, to simulate natural disasters – such as forest fires, floods or droughts – or to generate specific conditions that are difficult or expensive to capture in practice. In this way, they constitute a valuable resource for training detection and prediction algorithms in agriculture, emergency management, urban planning or environmental monitoring.
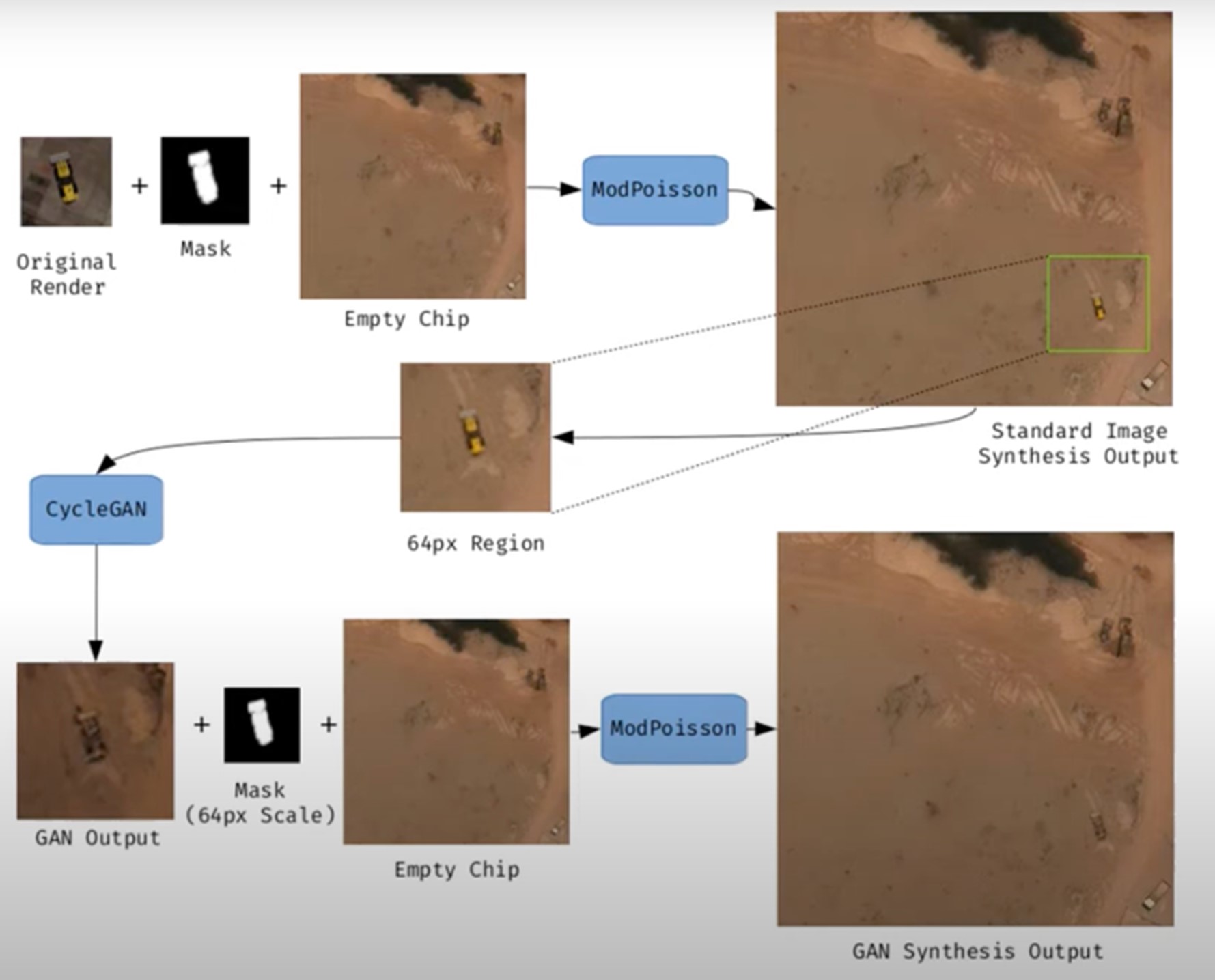
Figure 1. Example of synthetic satellite image generation.
Its value is not limited to model training. Where high-resolution images do not exist – due to technical limitations, access restrictions or economic reasons – synthesis makes it possible to fill information gaps and facilitate preliminary studies. For example, researchers can work with approximate synthetic images to design risk models or simulations before actual data are available.
However, synthetic satellite imagery also poses significant risks. The possibility of generating very realistic scenes opens the door to manipulation and misinformation. In a geopolitical context, an image showing non-existent troops or destroyed infrastructure could influence strategic decisions or international public opinion. In the environmental field, manipulated images could be disseminated to exaggerate or minimize the impacts of phenomena such as deforestation or melting ice, with direct effects on policies and markets.
Therefore, it is convenient to differentiate between two very different uses. The first is use as a support, when synthetic images complement real images to train models or perform simulations. The second is use as a fake, when they are deliberately presented as authentic images in order to deceive. While the former uses drive innovation, the latter threatens trust in satellite data and poses an urgent challenge of authenticity and governance.
Risks of satellite imagery applied to Earth observation
Synthetic satellite imagery poses significant risks when used in place of images captured by real sensors. Below are examples that demonstrate this.
A new front of disinformation: "deepfake geography"
The term deepfake geography has already been consolidated in the academic and popular literature to describe fictitious satellite images, manipulated with AI, that appear authentic, but do not reflect any existing reality. Research from the University of Washington, led by Bo Zhao, used algorithms such as CycleGAN to modify images of real cities—for example, altering the appearance of Seattle with non-existent buildings or transforming Beijing into green areas—highlighting the potential to generate convincing false landscapes.
One OnGeo Intelligence (OGC) platform article stresses that these images are not purely theoretical, but real threats affecting national security, journalism and humanitarian work. For its part, the OGC warns that fabricated satellite imagery, AI-generated urban models, and synthetic road networks have already been observed, and that they pose real challenges to public and operational trust.
Strategic and policy implications
Satellite images are considered "impartial eyes" on the planet, used by governments, media and organizations. When these images are faked, their consequences can be severe:
- National security and defense: if false infrastructures are presented or real ones are hidden, strategic analyses can be diverted or mistaken military decisions can be induced.
- Disinformation in conflicts or humanitarian crises: An altered image showing fake fires, floods, or troop movements can alter the international response, aid flows, or citizens' perceptions, especially if it is spread through social media or media without verification.
- Manipulation of realistic images of places: not only the general images are at stake. Nguyen et al. (2024) showed that it is possible to generate highly realistic synthetic satellite images of very specific facilities such as nuclear plants.
Crisis of trust and erosion of truth
For decades, satellite imagery has been perceived as one of the most objective and reliable sources of information about our planet. They were the graphic evidence that made it possible to confirm environmental phenomena, follow armed conflicts or evaluate the impact of natural disasters. In many cases, these images were used as "unbiased evidence," difficult to manipulate, and easy to validate. However, the emergence of synthetic images generated by artificial intelligence has begun to call into question that almost unshakable trust.
Today, when a satellite image can be falsified with great realism, a profound risk arises: the erosion of truth and the emergence of a crisis of confidence in spatial data.
The breakdown of public trust
When citizens can no longer distinguish between a real image and a fabricated one, trust in information sources is broken. The consequence is twofold:
- Distrust of institutions: if false images of a fire, a catastrophe or a military deployment circulate and then turn out to be synthetic, citizens may also begin to doubt the authentic images published by space agencies or the media. This "wolf is coming" effect generates skepticism even in the face of legitimate evidence.
- Effect on journalism: traditional media, which have historically used satellite imagery as an unquestionable visual source, risk losing credibility if they publish doctored images without verification. At the same time, the abundance of fake images on social media erodes the ability to distinguish what is real and what is not.
- Deliberate confusion: in contexts of disinformation, the mere suspicion that an image may be false can already be enough to generate doubt and sow confusion, even if the original image is completely authentic.
The following is a summary of the possible cases of manipulation and risk in satellite images:
|
Ambit |
Type of handling |
Main risk |
Documented example |
|---|---|---|---|
| Armed conflicts | Insertion or elimination of military infrastructures. | Strategic disinformation; erroneous military decisions; loss of credibility in international observation. | Alterations demonstrated in deepfake geography studies where dummy roads, bridges or buildings were added to satellite images. |
| Climate change and the environment | Alteration of glaciers, deforestation or emissions. | Manipulation of environmental policies; delay in measures against climate change; denialism. | Studies have shown the ability to generate modified landscapes (forests in urban areas, changes in ice) by means of GANs. |
| Gestión de emergencias | Creation of non-existent disasters (fires, floods). | Misuse of resources in emergencies; chaos in evacuations; loss of trust in agencies. | Research has shown the ease of inserting smoke, fire or water into satellite images. |
| Mercados y seguros | Falsification of damage to infrastructure or crops. | Financial impact; massive fraud; complex legal litigation. | Potential use of fake images to exaggerate damage after disasters and claim compensation or insurance. |
| Derechos humanos y justicia internacional | Alteration of visual evidence of war crimes. | Delegitimization of international tribunals; manipulation of public opinion. | Risk identified in intelligence reports: Doctored images could be used to accuse or exonerate actors in conflicts. |
| Geopolítica y diplomacia | Creation of fictitious cities or border changes. | Diplomatic tensions; treaty questioning; State propaganda | Examples of deepfake maps that transform geographical features of cities such as Seattle or Tacoma. |
Figure 2. Table showing possible cases of manipulation and risk in satellite images
Impact on decision-making and public policies
The consequences of relying on doctored images go far beyond the media arena:
- Urbanism and planning: decisions about where to build infrastructure or how to plan urban areas could be made on manipulated images, generating costly errors that are difficult to reverse.
- Emergency management: If a flood or fire is depicted in fake images, emergency teams can allocate resources to the wrong places, while neglecting areas that are actually affected.
- Climate change and the environment: Doctored images of glaciers, deforestation or polluting emissions could manipulate political debates and delay the implementation of urgent measures.
- Markets and insurance: Insurers and financial companies that rely on satellite imagery to assess damage could be misled, with significant economic consequences.
In all these cases, what is at stake is not only the quality of the information, but also the effectiveness and legitimacy of public policies based on that data.
The technological cat and mouse game
The dynamics of counterfeit generation and detection are already known in other areas, such as video or audio deepfakes: every time a more realistic generation method emerges, a more advanced detection algorithm is developed, and vice versa. In the field of satellite images, this technological career has particularities:
- Increasingly sophisticated generators: today's broadcast models can create highly realistic scenes, integrating ground textures, shadows, and urban geometries that fool even human experts.
- Detection limitations: Although algorithms are developed to identify fakes (analyzing pixel patterns, inconsistencies in shadows, or metadata), these methods are not always reliable when faced with state-of-the-art generators.
- Cost of verification: independently verifying a satellite image requires access to alternative sources or different sensors, something that is not always available to journalists, NGOs or citizens.
- Double-edged swords: The same techniques used to detect fakes can be exploited by those who generate them, further refining synthetic images and making them more difficult to differentiate.
From visual evidence to questioned evidence
The deeper impact is cultural and epistemological: what was previously assumed to be objective evidence now becomes an element subject to doubt. If satellite imagery is no longer perceived as reliable evidence, it weakens fundamental narratives around scientific truth, international justice, and political accountability.
- In armed conflicts, a satellite image showing possible war crimes can be dismissed under the accusation of being a deepfake.
- In international courts, evidence based on satellite observation could lose weight in the face of suspicion of manipulation.
- In public debate, the relativism of "everything can be false" can be used as a rhetorical weapon to delegitimize even the strongest evidence.
Strategies to ensure authenticity
The crisis of confidence in satellite imagery is not an isolated problem in the geospatial sector, but is part of a broader phenomenon: digital disinformation in the age of artificial intelligence. Just as video deepfakes have called into question the validity of audiovisual evidence, the proliferation of synthetic satellite imagery threatens to weaken the last frontier of perceived objective data: the unbiased view from space.
Ensuring the authenticity of these images requires a combination of technical solutions and governance mechanisms, capable of strengthening traceability, transparency and accountability across the spatial data value chain. The main strategies under development are described below.
Robust metadata: Record origin and chain of custody
Metadata is the first line of defense against manipulation. In satellite imagery, they should include detailed information about:
- The sensor used (type, resolution, orbit).
- The exact time of acquisition (date and time, with time precision).
- The precise geographical location (official reference systems).
- The applied processing chain (atmospheric corrections, calibrations, reprojections).
Recording this metadata in secure repositories allows the chain of custody to be reconstructed, i.e. the history of who, how and when an image has been manipulated. Without this traceability, it is impossible to distinguish between authentic and counterfeit images.
EXAMPLE: The European Union's Copernicus program already implements standardized and open metadata for all its Sentinel images, facilitating subsequent audits and confidence in the origin.
Digital signatures and blockchain: ensuring integrity
Digital signatures allow you to verify that an image has not been altered since it was captured. They function as a cryptographic seal that is applied at the time of acquisition and validated at each subsequent use.
Blockchain technology offers an additional level of assurance: storing acquisition and modification records on an immutable chain of blocks. In this way, any changes in the image or its metadata would be recorded and easily detectable.
EXAMPLE: The ESA – Trusted Data Framework project explores the use of blockchain to protect the integrity of Earth observation data and bolster trust in critical applications such as climate change and food security.
Invisible watermarks: hidden signs in the image
Digital watermarking involves embedding imperceptible signals in the satellite image itself, so that any subsequent alterations can be detected automatically.
- It can be done at the pixel level, slightly modifying color patterns or luminance.
- It is combined with cryptographic techniques to reinforce its validity.
- It allows you to validate images even if they have been cropped, compressed, or reprocessed.
EXAMPLE: In the audiovisual sector, watermarks have been used for years in the protection of digital content. Its adaptation to satellite images is in the experimental phase, but it could become a standard verification tool.
Open Standards (OGC, ISO): Trust through Interoperability
Standardization is key to ensuring that technical solutions are applied in a coordinated and global manner.
- OGC (Open Geospatial Consortium) works on standards for metadata management, geospatial data traceability, and interoperability between systems. Their work on geospatial APIs and FAIR (Findable, Accessible, Interoperable, Reusable) metadata is essential to establishing common trust practices.
- ISO develops standards on information management and authenticity of digital records that can also be applied to satellite imagery.
EXAMPLE: OGC Testbed-19 included specific experiments on geospatial data authenticity, testing approaches such as digital signatures and certificates of provenance.
Cross-check: combining multiple sources
A basic principle for detecting counterfeits is to contrast sources. In the case of satellite imagery, this involves:
- Compare images from different satellites (e.g. Sentinel-2 vs. Landsat-9).
- Use different types of sensors (optical, radar SAR, hyperspectral).
- Analyze time series to verify consistency over time.
EXAMPLE: Damage verification in Ukraine following the start of the Russian invasion in 2022 was done by comparing images from several vendors (Maxar, Planet, Sentinel), ensuring that the findings were not based on a single source.
AI vs. AI: Automatic Counterfeit Detection
The same artificial intelligence that allows synthetic images to be created can be used to detect them. Techniques include:
- Pixel Forensics: Identify patterns generated by GANs or broadcast models.
- Neural networks trained to distinguish between real and synthetic images based on textures or spectral distributions.
- Geometric inconsistencies models: detect impossible shadows, topographic inconsistencies, or repetitive patterns.
EXAMPLE: Researchers at the University of Washington and other groups have shown that specific algorithms can detect satellite fakes with greater than 90% accuracy under controlled conditions.
Current Experiences: Global Initiatives
Several international projects are already working on mechanisms to reinforce authenticity:
- Coalition for Content Provenance and Authenticity (C2PA): A partnership between Adobe, Microsoft, BBC, Intel, and other organizations to develop an open standard for provenance and authenticity of digital content, including images. Its model can be applied directly to the satellite sector.
- OGC work: the organization promotes the debate on trust in geospatial data and has highlighted the importance of ensuring the traceability of synthetic and real satellite images (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) in the US has publicly acknowledged the threat of synthetic imagery in defence and is driving collaborations with academia and industry to develop detection systems.
Towards an ecosystem of trust
The strategies described should not be understood as alternatives, but as complementary layers in a trusted ecosystem:
|
Id |
Layers |
Benefits |
|---|---|---|
| 1 | Robust metadata (source, sensor, chain of custody) |
Traceability guaranteed |
| 2 | Digital signatures and blockchain (data integrity) |
Ensuring integrity |
| 3 | Invisible watermarks (hidden signs) |
Add a hidden level of protection |
| 4 | Cross-check (multiple satellites and sensors) |
Validates independently |
| 5 | AI vs. AI (counterfeit detector) |
Respond to emerging threats |
| 6 | International governance (accountability, legal frameworks) |
Articulate clear rules of liability |
Figure 3. Layers to ensure confidence in synthetic satellite images
Success will depend on these mechanisms being integrated together, under open and collaborative frameworks, and with the active involvement of space agencies, governments, the private sector and the scientific community.
Conclusions
Synthetic images, far from being just a threat, represent a powerful tool that, when used well, can provide significant value in areas such as simulation, algorithm training or innovation in digital services. The problem arises when these images are presented as real without proper transparency, fueling misinformation or manipulating public perception.
The challenge, therefore, is twofold: to take advantage of the opportunities offered by the synthesis of visual data to advance science, technology and management, and to minimize the risks associated with the misuse of these capabilities, especially in the form of deepfakes or deliberate falsifications.
In the particular case of satellite imagery, trust takes on a strategic dimension. Critical decisions in national security, disaster response, environmental policy, and international justice depend on them. If the authenticity of these images is called into question, not only the reliability of the data is compromised, but also the legitimacy of decisions based on them.
The future of Earth observation will be shaped by our ability to ensure authenticity, transparency and traceability across the value chain: from data acquisition to dissemination and end use. Technical solutions (robust metadata, digital signatures, blockchain, watermarks, cross-verification, and AI for counterfeit detection), combined with governance frameworks and international cooperation, will be the key to building an ecosystem of trust.
In short, we must assume a simple but forceful guiding principle:
"If we can't trust what we see from space, we put our decisions on Earth at risk."
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
The Spanish Data Protection Agency has recently published the Spanish translation of the Guide on Synthetic Data Generation, originally produced by the Data Protection Authority of Singapore. This document provides technical and practical guidance for data protection officers, managers and data protection officers on how to implement this technology that allows simulating real data while maintaining their statistical characteristics without compromising personal information.
The guide highlights how synthetic data can drive the data economy, accelerate innovation and mitigate risks in security breaches. To this end, it presents case studies, recommendations and best practices aimed at reducing the risks of re-identification. In this post, we analyse the key aspects of the Guide highlighting main use cases and examples of practical application.
What are synthetic data? Concept and benefits
Synthetic data is artificial data generated using mathematical models specifically designed for artificial intelligence (AI) or machine learning (ML) systems. This data is created by training a model on a source dataset to imitate its characteristics and structure, but without exactly replicating the original records.
High-quality synthetic data retain the statistical properties and patterns of the original data. They therefore allow for analyses that produce results similar to those that would be obtained with real data. However, being artificial, they significantly reduce the risks associated with the exposure of sensitive or personal information.
For more information on this topic, you can read this Monographic report on synthetic data:. What are they and what are they used for? with detailed information on the theoretical foundations, methodologies and practical applications of this technology.
The implementation of synthetic data offers multiple advantages for organisations, for example:
- Privacy protection: allow data analysis while maintaining the confidentiality of personal or commercially sensitive information.
- Regulatory compliance: make it easier to follow data protection regulations while maximising the value of information assets.
- Risk reduction: minimise the chances of data breaches and their consequences.
- Driving innovation: accelerate the development of data-driven solutions without compromising privacy.
- Enhanced collaboration: Enable valuable information to be shared securely across organisations and departments.
Steps to generate synthetic data
To properly implement this technology, the Guide on Synthetic Data Generation recommends following a structured five-step approach:
- Know the data: cClearly understand the purpose of the synthetic data and the characteristics of the source data to be preserved, setting precise targets for the threshold of acceptable risk and expected utility.
- Prepare the data: iidentify key insights to be retained, select relevant attributes, remove or pseudonymise direct identifiers, and standardise formats and structures in a well-documented data dictionary .
- Generate synthetic data: sselect the most appropriate methods according to the use case, assess quality through completeness, fidelity and usability checks, and iteratively adjust the process to achieve the desired balance.
- Assess re-identification risks: aApply attack-based techniques to determine the possibility of inferring information about individuals or their membership of the original set, ensuring that risk levels are acceptable.
- Manage residual risks: iImplement technical, governance and contractual controls to mitigate identified risks, properly documenting the entire process.
Practical applications and success stories
To realise all these benefits, synthetic data can be applied in a variety of scenarios that respond to specific organisational needs. The Guide mentions, for example:
1 Generation of datasets for training AI/ML models: lSynthetic data solves the problem of the scarcity of labelled (i.e. usable) data for training AI models. Where real data are limited, synthetic data can be a cost-effective alternative. In addition, they allow to simulate extraordinary events or to increase the representation of minority groups in training sets. An interesting application to improve the performance and representativeness of all social groups in AI models.
2 Data analysis and collaboration: eThis type of data facilitates the exchange of information for analysis, especially in sectors such as health, where the original data is particularly sensitive. In this sector as in others, they provide stakeholders with a representative sample of actual data without exposing confidential information, allowing them to assess the quality and potential of the data before formal agreements are made.
3 Software testing: sis very useful for system development and software testing because it allows the use of realistic, but not real data in development environments, thus avoiding possible personal data breaches in case of compromise of the development environment..
The practical application of synthetic data is already showing positive results in various sectors:
I. Financial sector: fraud detection. J.P. Morgan has successfully used synthetic data to train fraud detection models, creating datasets with a higher percentage of fraudulent cases that significantly improved the models' ability to identify anomalous behaviour.
II. Technology sector: research on AI bias. Mastercard collaborated with researchers to develop methods to test for bias in AI using synthetic data that maintained the true relationships of the original data, but were private enough to be shared with outside researchers, enabling advances that would not have been possible without this technology.
III. Health sector: safeguarding patient data. Johnson & Johnson implemented AI-generated synthetic data as an alternative to traditional anonymisation techniques to process healthcare data, achieving a significant improvement in the quality of analysis by effectively representing the target population while protecting patients' privacy.
The balance between utility and protection
It is important to note that synthetic data are not inherently risk-free. The similarity to the original data could, in certain circumstances, allow information about individuals or sensitive data to be leaked. It is therefore crucial to strike a balance between data utility and data protection.
This balance can be achieved by implementing good practices during the process of generating synthetic data, incorporating protective measures such as:
- Adequate data preparation: removal of outliers, pseudonymisation of direct identifiers and generalisation of granular data.
- Re-identification risk assessment: analysis of the possibility that synthetic data can be linked to real individuals.
- Implementation of technical controls: adding noise to data, reducing granularity or applying differential privacy techniques.
Synthetic data represents a exceptional opportunity to drive data-driven innovation while respecting privacy and complying with data protection regulations. Their ability to generate statistically representative but artificial information makes them a versatile tool for multiple applications, from AI model training to inter-organisational collaboration and software development.
By properly implementing the best practices and controls described in Guide on synthetic data generation translated by the AEPD, organisations can reap the benefits of synthetic data while minimising the associated risks, positioning themselves at the forefront of responsible digital transformation. The adoption of privacy-enhancing technologies such as synthetic data is not only a defensive measure, but a proactive step towards an organisational culture that values both innovation and data protection, which are critical to success in the digital economy of the future.
Documentación
In the era of data, we face the challenge of a scarcity of valuable data for building new digital products and services. Although we live in a time when data is everywhere, we often struggle to access quality data that allows us to understand processes or systems from a data-driven perspective. The lack of availability, fragmentation, security, and privacy are just some of the reasons that hinder access to real data.
However, synthetic data has emerged as a promising solution to this problem. Synthetic data is artificially created information that mimics the characteristics and distributions of real data, without containing personal or sensitive information. This data is generated using algorithms and techniques that preserve the structure and statistical properties of the original data.
Synthetic data is useful in various situations where the availability of real data is limited or privacy needs to be protected. It has applications in scientific research, software and system testing, and training artificial intelligence models. It enables researchers to explore new approaches without accessing sensitive data, developers to test applications without exposing real data, and AI experts to train models without the need to collect all the real-world data, which is sometimes simply impossible to capture within reasonable time and cost.
There are different methods for generating synthetic data, such as resampling, probabilistic and generative modeling, and perturbation and masking methods. Each method has its advantages and challenges, but overall, synthetic data offers a secure and reliable alternative for analysis, experimentation, and AI model training.
It is important to highlight that the use of synthetic data provides a viable solution to overcome limitations in accessing real data and address privacy and security concerns. Synthetic data allows for testing, algorithm training, and application development without exposing confidential information. However, ensuring the quality and fidelity of synthetic data is crucial through rigorous evaluations and comparisons with real data.
In this report, we provide an introductory overview of the discipline of synthetic data, illustrating some valuable use cases for different types of synthetic data that can be generated. Autonomous vehicles, DNA sequencing, and quality controls in production chains are just a few of the cases detailed in this report. Furthermore, we highlight the use of the open-source software SDV (Synthetic Data Vault), developed in the academic environment of MIT, which utilizes machine learning algorithms to create tabular synthetic data that imitates the properties and distributions of real data. We present a practical example in a Google Colab environment to generate synthetic data about fictional customers hosted in a fictional hotel. We follow a workflow that involves preparing real data and metadata, training the synthesizer, and generating synthetic data based on the learned patterns. Additionally, we apply anonymization techniques to protect sensitive data and evaluate the quality of the generated synthetic data.
In summary, synthetic data is a powerful tool in the data era, as it allows us to overcome the scarcity and lack of availability of valuable data. With its ability to mimic real data without compromising privacy, synthetic data has the potential to transform the way we develop AI projects and conduct analysis. As we progress in this new era, synthetic data is likely to play an increasingly important role in generating new digital products and services.
If you want to know more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary and a presentation-summary.