Blog
Cuando se acaban de cumplir tres años desde que comenzó la aceleración del despliegue masivo de la Inteligencia Artificial con el lanzamiento de ChatGPT, un término nuevo emerge con fuerza: la IA agéntica (Agentic AI). En los últimos tres años hemos pasado de hablar de modelos de lenguaje (como por ejemplo, los LLM) y chatbots (o asistentes conversacionales) a diseñar los primeros sistemas capaces no solo de responder a nuestras preguntas, sino de actuar de forma autónoma para conseguir objetivos, combinando datos, herramientas y colaboraciones con otros agentes de IA o con personas humanas. Esto es, la conversación global sobre IA se está moviendo desde la capacidad para "conversar" hacia la capacidad para "actuar" de estos sistemas.
En el sector privado, informes recientes de grandes consultoras describen agentes de IA que resuelven de principio a fin incidencias de clientes, orquestan cadenas de suministro, optimizan inventarios en el sector retail o automatizan la elaboración de informes de negocio. En el sector público, esta conversación también comienza a tomar forma y cada vez más administraciones exploran cómo estos sistemas pueden ayudar a simplificar trámites o a mejorar la atención a la ciudadanía. Sin embargo, el despliegue parece que está siendo algo más lento porque lógicamente en la administración no solo debe tenerse en cuenta la excelencia técnica sino también el estricto cumplimiento del marco normativo, que en Europa lo marca el Reglamento de IA, para que los agentes autónomos sean, ante todo, aliados de la ciudadanía.
¿Qué es la IA agéntica (Agentic AI)?
Aunque se trate de un concepto reciente que aún está en evolución, varias administraciones y organismos empiezan a converger en una definición. Por ejemplo, el Gobierno del Reino Unido describe la IA agéntica como sistemas formados por agentes de IA que “pueden comportarse e interactuar de forma autónoma para lograr sus objetivos”. En este contexto un agente de IA sería una pieza especializada de software que puede tomar decisiones y operar de forma cooperativa o independiente para lograr los objetivos del sistema.
Podríamos pensar, por ejemplo, en un agente de IA en una administración local que recibe la solicitud de una persona para abrir un pequeño negocio. El agente, diseñado de acuerdo con el procedimiento administrativo correspondiente, comprobaría la normativa aplicable, consultaría datos urbanísticos y de actividad económica, verificaría requisitos, rellenaría borradores de documentos, propondría citas o trámites complementarios y prepararía un resumen para que el personal funcionario pudiera revisar y validar la solicitud. Esto es, no sustituiría la decisión humana, sino que automatizaría buena parte del trabajo que hay entre la solicitud realizada por el ciudadano y la resolución dictada por la administración.
Frente a un chatbot conversacional -que responde a una pregunta y, en general, termina ahí la interacción-, un agente de IA puede encadenar múltiples acciones, revisar resultados, corregir errores, colaborar con otros agentes de IA y seguir iterando hasta alcanzar la meta que se le ha definido. Esto no significa que los agentes autónomos decidan por su cuenta sin supervisión, sino que pueden hacerse cargo de buena parte de la tarea siempre siguiendo reglas y salvaguardas bien definidas.
Las características clave de un agente autónomo incluyen:
- Percepción y razonamiento: es la capacidad de un agente para comprender una solicitud compleja, interpretar el contexto y desglosar el problema en pasos lógicos que conduzcan a resolverlo.
- Planificación y acción: es la habilidad para ordenar esos pasos, decidir la secuencia en que se van a ejecutar y adaptar el plan cuando cambian los datos o aparecen nuevas restricciones.
- Uso de herramientas: un agente puede, por ejemplo, conectarse a diversas API, consultar bases de datos, catálogos de datos abiertos, abrir y leer documentos o enviar correos electrónicos según lo requieran las tareas que está intentando resolver.
- Memoria y contexto: es la capacidad del agente para mantener la memoria de las interacciones en procesos largos, recordando las acciones y respuestas pasadas y el estado actual de la solicitud que está resolviendo.
- Autonomía supervisada: un agente puede tomar decisiones dentro de unos límites previamente establecidos para avanzar hacia la meta sin necesidad de intervención humana en cada paso, pero permitiendo siempre la revisión y trazabilidad de las decisiones.
Podríamos resumir el cambio que supone con la siguiente analogía: si los LLM son el motor de razonamiento, los agentes de IA son sistemas que además de esa capacidad de “pensar” en las acciones que habría que hacer, tienen "manos" para interactuar con el mundo digital e incluso con el mundo físico y ejecutar esas mismas acciones.
El potencial de los agentes de IA en los servicios públicos
Los servicios públicos se organizan, en buena medida, alrededor de procesos de una cierta complejidad como son la tramitación de ayudas y subvenciones, la gestión de expedientes y licencias o la propia atención ciudadana a través de múltiples canales. Son procesos con muchos pasos, reglas y actores diferentes, donde abundan las tareas repetitivas y el trabajo manual de revisión de documentación.
Como puede verse en el eGovernment Benchmark de la Unión Europea, las iniciativas de administración electrónica de las últimas décadas han permitido avanzar hacia una mayor digitalización de los servicios públicos. Sin embargo, la nueva ola de tecnologías de IA, especialmente cuando se combinan modelos fundacionales con agentes, abre la puerta a un nuevo salto para automatizar y orquestar de forma inteligente buena parte de los procesos administrativos.
En este contexto, los agentes autónomos permitirían:
- Orquestar procesos de extremo a extremo como, por ejemplo, recopilar datos de distintas fuentes, proponer formularios ya cumplimentados, detectar incoherencias en la documentación aportada o generar borradores de resoluciones para su validación por el personal responsable.
- Actuar como “copilotos” de los empleados públicos, preparando borradores, resúmenes o propuestas de decisiones que luego se revisan y validan, asistiendo en la búsqueda de información relevante o señalando posibles riesgos o incidencias que requieren atención humana.
- Optimizar los procesos de atención ciudadana apoyando en tareas como la gestión de citas médicas, respondiendo consultas sobre el estado de expedientes, facilitando el pago de tributos o guiando a las personas en la elección del trámite más adecuado a su situación.
Diversos análisis sobre IA en el sector público apuntan a que este tipo de automatización inteligente, al igual que en el sector privado, puede reducir tiempos de espera, mejorar la calidad de las decisiones y liberar tiempo del personal para tareas de mayor valor añadido. Un informe reciente de PWC y Microsoft que explora el potencial de la IA agéntica para el sector público resume bien la idea, señalando que al incorporar la IA agéntica en los servicios públicos, los gobiernos pueden mejorar la capacidad de respuesta y aumentar la satisfacción ciudadana, siempre que existan las salvaguardas adecuadas.
Además, la implementación de agentes autónomos permite soñar con una transición desde una administración reactiva (que espera a que el ciudadano solicite un servicio) a una administración proactiva que se ofrece a hacer por nosotros parte de esas mismas acciones: desde avisarnos de que se ha abierto una ayuda para la que probablemente cumplamos los requisitos, hasta proponernos la renovación de una licencia antes de que caduque o recordarnos una cita médica.
Un ejemplo ilustrativo de esto último podría ser un agente de IA que, apoyado en datos sobre servicios disponibles y en la información que el propio ciudadano haya autorizado utilizar, detecte que se ha publicado una nueva ayuda para actuaciones de mejora de la eficiencia energética a través de la rehabilitación de viviendas y envíe un aviso personalizado a quienes podrían cumplir los requisitos. Incluso ofreciéndoles un borrador de solicitud ya pre-cumplimentado para su revisión y aceptación. La decisión final sigue siendo humana, pero el esfuerzo de buscar la información, entender las condiciones y preparar la documentación se podría reducir mucho.
El rol de los datos abiertos
Para que un agente de IA pueda actuar de forma útil y responsable necesita apalancarse sobre un entorno rico en datos de calidad y un sistema de gobernanza de datos sólido. Entre esos activos necesarios para desarrollar una buena estrategia de agentes autónomos, los datos abiertos tienen importancia al menos en tres dimensiones:
- Combustible para la toma de decisiones: los agentes de IA necesitan información sobre normativa vigente, catálogos de servicios, procedimientos administrativos, indicadores socioeconómicos y demográficos, datos de transporte, medio ambiente, planificación urbana, etc. Para ello, la calidad y estructura de los datos es de gran importancia ya que datos desactualizados, incompletos o mal documentados pueden llevar a los agentes a cometer errores costosos. En el sector público, esos errores pueden traducirse en decisiones injustas que en última instancia podrían llevar a la pérdida de confianza de la ciudadanía.
- Banco de pruebas para evaluar y auditar agentes: al igual que los datos abiertos son importantes para evaluar modelos de IA generativa, también pueden serlo para probar y auditar agentes autónomos. Por ejemplo, simulando expedientes ficticios con datos sintéticos basados en distribuciones reales para comprobar cómo actúa un agente en distintos escenarios. De este modo, universidades, organizaciones de la sociedad civil y la propia administración puedan examinar el comportamiento de los agentes y detectar problemas antes de escalar su uso.
- Transparencia y explicabilidad: los datos abiertos podrían ayudar a documentar de dónde proceden los datos que utiliza un agente, cómo se han transformado o qué versiones de los conjuntos de datos estaban vigentes cuando se tomó una decisión. Esta trazabilidad contribuye a la explicabilidad y la rendición de cuentas, especialmente cuando un agente de IA interviene en decisiones que afectan a los derechos de las personas o a su acceso a servicios públicos. Si la ciudadanía puede consultar, por ejemplo, los criterios y datos que se aplican para otorgar una ayuda, se refuerza la confianza en el sistema.
El panorama de la IA agéntica en España y en el resto del mundo
Aunque el concepto de IA agéntica es reciente, ya existen iniciativas en marcha en el sector público a nivel internacional y comienzan a abrirse paso también en el contexto europeo y español:
- La Government Technology Agency (GovTech) de Singapur ha publicado una guía Agentic AI Primer para orientar a desarrolladores y responsables públicos sobre cómo aplicar esta tecnología, destacando tanto sus ventajas como sus riesgos. Además, el gobierno está pilotando el uso de agentes en varios ámbitos para reducir la carga administrativa de los trabajadores sociales y apoyar a las empresas en procesos complejos de obtención de licencias. Todo ello en un entorno controlado (sandbox) para probar estas soluciones antes de escalarlas.
- El Gobierno de Reino Unido ha publicado una nota específica dentro de su documentación “AI Insights” para explicar qué es la IA agéntica y por qué es relevante para servicios gubernamentales. Además, ha anunciado una licitación para desarrollar un “GOV.UK Agentic AI Companion” que sirva de asistente inteligente para la ciudadanía desde el portal del gobierno.
- La Comisión Europea, en el marco de la estrategia Apply AI y de la iniciativa GenAI4EU, ha lanzado convocatorias para financiar proyectos piloto que introduzcan soluciones de IA generativa escalables y replicables en las administraciones públicas, plenamente integradas en sus flujos de trabajo. Estas convocatorias buscan precisamente acelerar el paso en la digitalización a través de IA (incluidos agentes especializados) para mejorar la toma de decisiones, simplificar procedimientos y hacer la administración más accesible.
En España, aunque la etiqueta “IA agéntica” todavía no se utiliza aún de forma amplia, ya se pueden identificar algunas experiencias que van en esa dirección. Por ejemplo, distintas administraciones están incorporando copilotos basados en IA generativa para apoyar a los empleados públicos en tareas de búsqueda de información, redacción y resumen de documentos, o gestión de expedientes, como muestran iniciativas de gobiernos autonómicos como el de Aragón y o entidades locales como el Ayuntamiento de Barcelona que empiezan a documentarse de forma pública.
El salto hacia agentes más autónomos en el sector público parece, por tanto, una evolución natural sobre la base de la administración electrónica existente. Pero esa evolución debe, al mismo tiempo, reforzar el compromiso con la transparencia, la equidad, la rendición de cuentas, la supervisión humana y el cumplimiento normativo que exige el Reglamento de IA y el resto del marco normativo y que deben guiar las actuaciones de la administración pública.
Mirando hacia el futuro: agentes de IA, datos abiertos y confianza ciudadana
La llegada de la IA agéntica ofrece de nuevo a la Administración pública nuevas herramientas para reducir la burocracia, personalizar la atención y optimizar sus siempre escasos recursos. Sin embargo, la tecnología es solo un medio, el fin último sigue siendo generar valor público reforzando la confianza de la ciudadanía.
En principio, España parte de una buena posición: dispone de una Estrategia de Inteligencia Artificial 2024 que apuesta por una IA transparente, ética y centrada en las personas, con líneas específicas para impulsar su uso en el sector público; cuenta con una infraestructura consolidada de datos abiertos; y ha creado la Agencia Española de Supervisión de la Inteligencia Artificial (AESIA) como organismo encargado de garantizar un uso ético y seguro de la IA, de acuerdo con el Reglamento Europeo de IA.
Estamos, por tanto, ante una nueva oportunidad de modernización que puede construir unos servicios públicos más eficientes, cercanos e incluso proactivos. Si somos capaces de adoptar la IA agéntica adecuadamente, los agentes que se desplieguen no serán una “caja negra” que actúa sin supervisión, sino “agentes públicos” digitales, transparentes y auditables, diseñados para trabajar con datos abiertos, explicar sus decisiones y dejar rastro de las acciones que realizan. Herramientas, en definitiva, inclusivas, centradas en las personas y alineadas con los valores del servicio público.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La compartición de datos o data sharing se ha convertido en un pilar imprescindible para el avance de la analítica y el intercambio de conocimiento, tanto en el ámbito privado como en el público. Las organizaciones de cualquier tamaño y sector –empresas, administraciones públicas, instituciones de investigación, comunidades de desarrolladores o individuos– encuentran un fuerte valor en la capacidad de compartir información de forma segura, fiable y eficiente. Este intercambio no se limita a datos en crudo o datasets estructurados; también se extiende a productos de datos más avanzados, tales como modelos de machine learning entrenados, dashboards analíticos, resultados de experimentos científicos y otros artefactos complejos que generan un gran impacto a través de su reutilización.
En este contexto, la importancia de la gobernanza de estos recursos cobra un papel crítico. No es suficiente con disponer de un método para mover ficheros de un sitio a otro; es necesario garantizar aspectos clave como el control de acceso (quién puede leer o modificar cierto recurso), la trazabilidad y la auditoría (saber quién ha accedido, cuándo y con qué finalidad) o el cumplimiento de regulaciones o estándares, especialmente en entornos empresariales y gubernamentales.
Con el fin de unificar estos requisitos, Unity Catalog surge como un almacén de metadatos (metastore) de próxima generación, pensado para centralizar y simplificar la gobernanza de datos y recursos de datos. Originalmente, Unity Catalog formaba parte de los servicios ofrecidos por la plataforma Databricks, pero el proyecto ha dado un salto a la comunidad de código abierto para convertirse en un estándar de referencia. Esto implica que ahora es posible utilizarlo, modificarlo y, en definitiva, contribuir a su evolución desde un entorno libre y colaborativo. Con ello, se espera que más organizaciones adopten sus modelos de catálogo y compartición, impulsando la reutilización de datos y la creación de flujos analíticos e innovaciones tecnológicas.

Fuente: https://docs.unitycatalog.io/
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Objetivos
En este ejercicio, aprenderemos a configurar Unity Catalog, una herramienta que nos ayuda a organizar y compartir datos en la nube de manera segura. Aunque utilizaremos algo de código, explicaremos cada paso para que incluso personas con poca experiencia en programación puedan seguirlo a través de un laboratorio práctico.
Trabajaremos con un escenario realista donde gestionaremos datos sobre transporte público en diferentes ciudades. Crearemos catálogos de datos, configuraremos una base de datos y aprenderemos a interactuar con la información usando herramientas como Docker, Apache Spark y MLflow.
Nivel de dificultad: Intermedio.

Figura 1. Esquema Unity Catalog
Recursos Necesarios
En esta sección explicaremos los requisitos previos y recursos necesarios para poder desarrollar este laboratorio. El laboratorio está pensado para desarrollarse en un ordenador personal estándar (Windows, MacOS, Linux).
Adicionalmente utilizaremos las siguientes herramientas y entornos de trabajo:
- Docker Desktop: Docker es una herramienta que nos permite ejecutar aplicaciones en un entorno aislado llamado contenedor. Un contenedor es como una "caja" que contiene todo lo necesario para que una aplicación funcione correctamente, sin importar el sistema operativo que estés usando.
- Visual Studio Code: Nuestro entorno de trabajo será un Notebook Python que ejecutaremos y manipularemos a través del editor de código ampliamente utilizado Visual Studio Code (VS Code).
- Unity Catalog: Es una herramienta de gobernanza de datos que permite organizar y controlar el acceso a recursos como tablas, volúmenes de datos, funciones o modelos de machine learning. A lo largo del laboratorio, utilizaremos su versión open source, que puede desplegarse localmente, para aprender a gestionar catálogos de datos con control de permisos, trazabilidad y estructura jerárquica. Unity Catalog actúa como un metastore centralizado, facilitando la colaboración y la reutilización de datos de forma segura.
- Amazon Web Services: AWS será el proveedor cloud que utilizaremos para alojar ciertos datos del laboratorio, en concreto los datos en crudo (como archivos JSON) que gestionaremos mediante volúmenes de datos. Aprovecharemos su servicio Amazon S3 para almacenar estos archivos y configuraremos las credenciales y permisos necesarios para que Unity Catalog pueda interactuar con ellos de forma controlada.
Desarrollo del ejercicio
A lo largo del ejercicio, los participantes desplegarán la aplicación, comprenderán su arquitectura e irán construyendo un catálogo de datos paso a paso, aplicando buenas prácticas de organización, control de acceso y trazabilidad.
Despliegue y primeros pasos
- Clonamos el repositorio de Unity Catalog y lo levantamos con Docker.
- Exploramos su arquitectura: un backend accesible por API y CLI, y una interfaz gráfica intuitiva.
- Navegamos por los recursos que gestiona Unity Catalog: catálogos, esquemas, tablas, volúmenes, funciones y modelos.
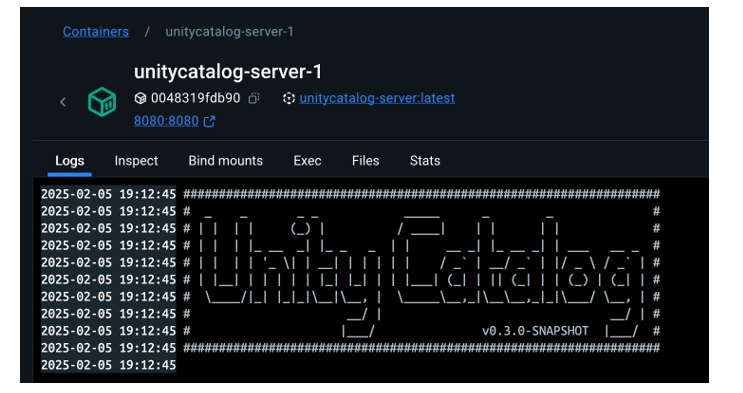
Figura 2. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo levantar la aplicación, sus componentes principales, y cómo empezar a interactuar con ella desde distintos puntos: web, API y CLI.
Organización de recursos
- Configuramos una base de datos MySQL externa como repositorio de metadatos.
- Creamos catálogos para representar distintas ciudades y esquemas para distintos servicios públicos.

Figura 3. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo estructurar el gobierno de datos a distintos niveles (ciudad, servicio, dataset) y cómo gestionar los metadatos de forma centralizada y persistente.
Construcción de datos y uso real
- Creamos tablas estructuradas para representar rutas, autobuses o paradas.
- Cargamos datos reales en estas tablas usando PySpark.Habilitamos un bucket en AWS S3 como almacenamiento de datos en crudo (volúmenes).
- Subimos ficheros JSON con eventos de telemetría y los gobernamos desde Unity Catalog.
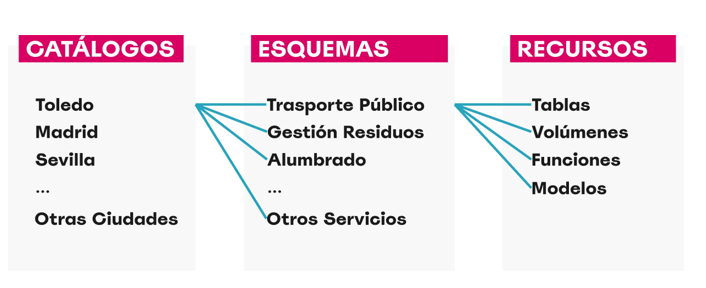
Figura 4. Esquema
¿Qué aprenderemos aquí?
Cómo convivir con distintos tipos de datos (estructurados y no estructurados), y cómo integrarlos con fuentes externas (como AWS S3).
Funciones reutilizables y modelos de IA
- Registramos funciones personalizadas (como el cálculo de distancias) reutilizables desde el catálogo.
- Creamos y registramos modelos de machine learning con MLflow.
- Ejecutamos predicciones desde Unity Catalog como si fueran cualquier otro recurso del ecosistema.
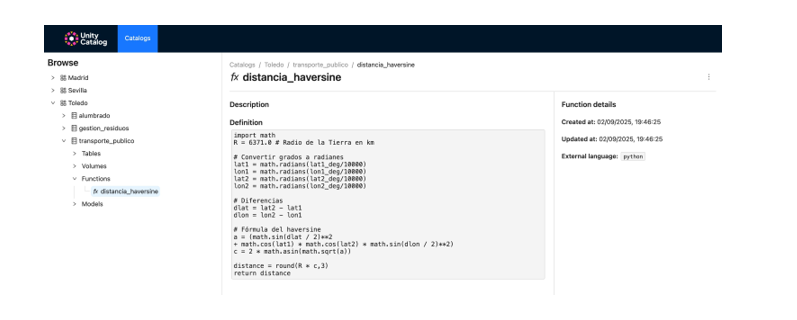
Figura 5. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo ampliar el gobierno de datos a funciones y modelos, y cómo facilitar su reutilización y trazabilidad en entornos colaborativos.
Resultados y conclusiones
Como resultado de este laboratorio práctico, vamos a poner conocer la herramienta Unity Catalog como plataforma abierta para la gobernanza de datos y recursos de datos como modelos de machine learning. Exploraremos, además, el contexto de un caso de uso concreto y con un ecosistema de herramientas similar al que podemos encontrar en una organización real, sus capacidades, su modo de despliegue y su uso.
Mediante este ejercicio configuraremos y utilizaremos Unity Catalog para organizar datos de transporte público. En concreto, podrás:
- Aprender a instalar herramientas como Docker o Spark.
- Crear catálogos, esquemas y tablas en Unity Catalog.
- Cargar datos y almacenarlos en un bucket de Amazon S3.
- Implementar un modelo de machine learning con MLflow.
Veremos, en los próximos años, si este tipo de herramientas alcanzan el nivel de estandarización necesario para transformar la forma en que se administran y comparten los recursos de datos en múltiples sectores.
¡Te animamos a realizar más ejercicios de ciencia de datos! Accede al repositorio aquí
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
En el panorama actual del análisis de datos y la inteligencia artificial, la generación automática de informes completos y coherentes representa un desafío significativo. Mientras que las herramientas tradicionales permiten visualizar datos o generar estadísticas aisladas, existe la necesidad de sistemas que puedan investigar un tema a fondo, recopilar información de diversas fuentes, y sintetizar hallazgos en un informe estructurado y coherente.
En este ejercicio práctico, exploraremos el desarrollo de un agente de generación de reportes basado en LangGraph e inteligencia artificial. A diferencia de los enfoques tradicionales basados en plantillas o análisis estadísticos predefinidos, nuestra solución aprovecha los últimos avances en modelos de lenguaje para:
- Crear equipos virtuales de analistas especializados en diferentes aspectos de un tema.
- Realizar entrevistas simuladas para recopilar información detallada.
- Sintetizar los hallazgos en un informe coherente y bien estructurado.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Como se muestra en la Figura 1, el flujo completo del agente sigue una secuencia lógica que va desde la generación inicial de preguntas hasta la redacción final del informe.

Figura 1. Diagrama de flujo del agente.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en un diseño modular implementado como un grafo de estados interconectados, donde cada módulo representa una funcionalidad específica en el proceso de generación de reportes. Esta estructura permite un flujo de trabajo flexible, recursivo cuando es necesario, y con capacidad de intervención humana en puntos estratégicos.
Componentes principales
El sistema se compone de tres módulos fundamentales que trabajan en conjunto:
1. Generador de Analistas Virtuales
Este componente crea un equipo diverso de analistas virtuales especializados en diferentes aspectos del tema a investigar. El flujo incluye:
- Creación inicial de perfiles basados en el tema de investigación.
- Punto de retroalimentación humana que permite revisar y refinar los perfiles generados.
- Regeneración opcional de analistas incorporando sugerencias.
Este enfoque garantiza que el informe final incluya perspectivas diversas y complementarias, enriqueciendo el análisis.
2. Sistema de Entrevistas
Una vez generados los analistas, cada uno participa en un proceso de entrevista simulada que incluye:
- Generación de preguntas relevantes basadas en el perfil del analista.
- Búsqueda de información en fuentes vía Tavily Search y Wikipedia.
- Generación de respuestas informativas combinando la información obtenida.
- Decisión automática sobre continuar o finalizar la entrevista en función de la información recopilada.
- Almacenamiento de la transcripción para su procesamiento posterior.
El sistema de entrevistas representa el corazón del agente, donde se obtiene la información que nutrirá el informe final. Tal y como se muestra en la Figura 2, este proceso puede monitorizarse en tiempo real mediante LangSmith, una herramienta abierta de observabilidad que permite seguir cada paso del flujo.

Figura 2. Monitorización del sistema vía LangGraph. Ejemplo concreto de una interacción analista-entrevistador.
3. Generador de Informes
Finalmente, el sistema procesa las entrevistas para crear un informe coherente mediante:
- Redacción de secciones individuales basadas en cada entrevista.
- Creación de una introducción que presente el tema y la estructura del informe.
- Organización del contenido principal que integra todas las secciones.
- Generación de una conclusión que sintetiza los hallazgos principales.
- Consolidación de todas las fuentes utilizadas.
La Figura 3 muestra un ejemplo del informe resultante del proceso completo, demostrando la calidad y estructura del documento final generado automáticamente.

Figura 3. Vista del informe resultante del proceso de generación automática al prompt de “Datos abiertos en España”.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
Integración de IA avanzada en sistemas de procesamiento de información:
- Cómo comunicarse efectivamente con modelos de lenguaje.
- Técnicas para estructurar prompts que generen respuestas coherentes y útiles.
- Estrategias para simular equipos virtuales de expertos.
Desarrollo con LangGraph:
- Creación de grafos de estados para modelar flujos complejos.
- Implementación de puntos de decisión condicionales.
- Diseño de sistemas con intervención humana en puntos estratégicos.
Procesamiento paralelo con LLMs:
- Técnicas de paralelización de tareas con modelos de lenguaje.
- Coordinación de múltiples subprocesos independientes.
- Métodos de consolidación de información dispersa.
Buenas prácticas de diseño:
- Estructuración modular de sistemas complejos.
- Manejo de errores y reintentos.
- Seguimiento y depuración de flujos de trabajo mediante LangSmith.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos y los usuarios finales. A través del caso práctico desarrollado, podemos observar cómo la combinación de modelos de lenguaje avanzados con arquitecturas flexibles basadas en grafos abre nuevas posibilidades para la generación automática de informes.
La capacidad de simular equipos de expertos virtuales, realizar investigaciones paralelas y sintetizar hallazgos en documentos coherentes, representa un paso significativo hacia la democratización del análisis de información compleja.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de mecanismos de verificación automática de datos para garantizar la precisión.
- Implementación de capacidades multimodales que permitan incorporar imágenes y visualizaciones.
- Integración con más fuentes de información y bases de conocimiento.
- Desarrollo de interfaces de usuario más intuitivas para la intervención humana.
- Expansión a dominios especializados como medicina, derecho o ciencias.
En resumen, este ejercicio no solo demuestra la viabilidad de automatizar la generación de informes complejos mediante inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el análisis profundo de cualquier tema esté al alcance de todos, independientemente de su nivel de experiencia técnica. La combinación de modelos de lenguaje avanzados, arquitecturas de grafos y técnicas de paralelización abre un abanico de posibilidades para transformar la forma en que generamos y consumimos información.
Aplicación
AirSPI es es un visualizador de marcas comerciales publicadas en el Boletín Oficial de la Propiedad Industrial (www.oepm.es):
- Visualización de los últimos 5 boletines.
- Búsqueda de parecidos fonéticos entre las Marcas Publicadas y denominaciones introducidas por el usuario.
- Búsqueda de Denominaciones en Boletín.
- Búsqueda de Agentes de Propiedad Industrial por situación geográfica.