Blog
Three years after the acceleration of the massive deployment of Artificial Intelligence began with the launch of ChatGPT, a new term emerges strongly: Agentic AI. In the last three years, we have gone from talking about language models (such as LLMs) and chatbots (or conversational assistants) to designing the first systems capable not only of answering our questions, but also of acting autonomously to achieve objectives, combining data, tools and collaborations with other AI agents or with humans. That is, the global conversation about AI is moving from the ability to "converse" to the ability to "act" of these systems.
In the private sector, recent reports from large consulting firms describe AI agents that resolve customer incidents from start to finish, orchestrate supply chains, optimize inventories in the retail sector or automate business reporting. In the public sector, this conversation is also beginning to take shape and more and more administrations are exploring how these systems can help simplify procedures or improve citizen service. However, the deployment seems to be somewhat slower because logically the administration must not only take into account technical excellence but also strict compliance with the regulatory framework, which in Europe is set by the AI Regulation, so that autonomous agents are, above all, allies of citizens.
What is Agentic AI?
Although it is a recent concept that is still evolving, several administrations and bodies are beginning to converge on a definition. For example, the UK government describes agent AI as systems made up of AI agents that "can autonomously behave and interact to achieve their goals." In this context, an AI agent would be a specialized piece of software that can make decisions and operate cooperatively or independently to achieve the system's goals.
We might think, for example, of an AI agent in a local government who receives a request from a person to open a small business. The agent, designed in accordance with the corresponding administrative procedure, would check the applicable regulations, consult urban planning and economic activity data, verify requirements, fill in draft documents, propose appointments or complementary procedures and prepare a summary so that the civil servants could review and validate the application. That is, it would not replace the human decision, but would automate a large part of the work between the request made by the citizen and the resolution issued by the administration.
Compared to a conversational chatbot – which answers a question and, in general, ends the interaction there – an AI agent can chain multiple actions, review results, correct errors, collaborate with other AI agents and continue to iterate until it reaches the goal that has been defined for it. This does not mean that autonomous agents decide on their own without supervision, but that they can take over a good part of the task always following well-defined rules and safeguards.
Key characteristics of a freelance agent include:
- Perception and reasoning: is the ability of an agent to understand a complex request, interpret the context, and break down the problem into logical steps that lead to solving it.
- Planning and action: it is the ability to order these steps, decide the sequence in which they are going to be executed, and adapt the plan when the data changes or new constraints appear.
- Use of tools: An agent can, for example, connect to various APIs, query databases, open data catalogs, open and read documents, or send emails as required by the tasks they are trying to solve.
- Memory and context: is the ability of the agent to maintain the memory of interactions in long processes, remembering past actions and responses and the current state of the request it is resolving.
- Supervised autonomy: an agent can make decisions within previously established limits to advance towards the goal without the need for human intervention at each step, but always allowing the review and traceability of decisions.
We could summarize the change it entails with the following analogy: if LLMs are the engine of reasoning, AI agents are systems that , in addition to the ability to "think" about the actions that should be done, have "hands" to interact with the digital world and even with the physical world and execute those same actions.
The potential of AI agents in public services
Public services are organized, to a large extent, around processes of a certain complexity such as the processing of aid and subsidies, the management of files and licenses or the citizen service itself through multiple channels. They are processes with many different steps, rules and actors, where repetitive tasks and manual work of reviewing documentation abound.
As can be seen in the European Union's eGovernment Benchmark, eGovernment initiatives in recent decades have made it possible to move towards greater digitalisation of public services. However, the new wave of AI technologies, especially when foundational models are combined with agents, opens the door to a new leap to intelligently automate and orchestrate a large part of administrative processes.
In this context, autonomous agents would allow:
- Orchestrate end-to-end processes such as collecting data from different sources, proposing forms already completed, detecting inconsistencies in the documentation provided, or generating draft resolutions for validation by the responsible personnel.
- Act as "co-pilots" of public employees, preparing drafts, summaries or proposals for decisions that are then reviewed and validated, assisting in the search for relevant information or pointing out possible risks or incidents that require human attention.
- Optimise citizen service processes by supporting tasks such as managing medical appointments, answering queries about the status of files, facilitating the payment of taxes or guiding people in choosing the most appropriate procedure for their situation.
Various analyses on AI in the public sector suggest that this type of intelligent automation, as in the private sector, can reduce waiting times, improve the quality of decisions and free up staff time for more value-added tasks. A recent report by PWC and Microsoft exploring the potential of Agent AI for the public sector sums up the idea well, noting that by incorporating Agent AI into public services, governments can improve responsiveness and increase citizen satisfaction, provided that the right safeguards are in place.
In addition, the implementation of autonomous agents allows us to dream of a transition from a reactive administration (which waits for the citizen to request a service) to a proactive administration that offers to do part of those same actions for us: from notifying us that a grant has been opened for which we probably meet the requirements, to proposing the renewal of a license before it expires or reminding us of a medical appointment.
An illustrative example of the latter could be an AI agent that, based on data on available services and the information that the citizen himself has authorised to use, detects that a new aid has been published for actions to improve energy efficiency through the renovation of homes and sends a personalised notice to those who could meet the requirements. Even offering them a pre-filled draft application for review and acceptance. The final decision is still human, but the effort of seeking information, understanding conditions, and preparing documentation could be greatly reduced.
The role of open data
For an AI agent to be able to act in a useful and responsible way, they need to leverage on an environment rich in quality data and a robust data governance system. Among those assets needed to develop a good autonomous agent strategy, open data is important in at least three dimensions:
- Fuel for decision-making: AI agents need information on current regulations, service catalogues, administrative procedures, socio-economic and demographic indicators, data on transport, environment, urban planning, etc. To this end, data quality and structure is of great importance as outdated, incomplete, or poorly documented data can lead agents to make costly mistakes. In the public sector, these mistakes can translate into unfair decisions that could ultimately lead to a loss of public trust.
- Testbed for evaluating and auditing agents: Just as open data is important for evaluating generative AI models, it can also be important for testing and auditing autonomous agents. For example, simulating fictitious files with synthetic data based on real distributions to check how an agent acts in different scenarios. In this way, universities, civil society organizations and the administration itself can examine the behavior of agents and detect problems before scaling their use.
- Transparency and explainability: Open data could help document where the data an agent uses came from, how it has been transformed, or which versions of the datasets were in place when a decision was made. This traceability contributes to explainability and accountability, especially when an AI agent intervenes in decisions that affect people's rights or their access to public services. If citizens can consult, for example, the criteria and data that are applied to grant aid, confidence in the system is reinforced.
The panorama of agent AI in Spain and the rest of the world
Although the concept of agent AI is recent, there are already initiatives underway in the public sector at an international level and they are also beginning to make their way in the European and Spanish context:
- The Government Technology Agency (GovTech) of Singapore has published an Agentic AI Primer guide to guide developers and public officials on how to apply this technology, highlighting both its advantages and risks. In addition, the government is piloting the use of agents in various settings to reduce the administrative burden on social workers and support companies in complex licensing processes. All this in a controlled environment (sandbox) to test these solutions before scaling them.
- The UK government has published a specific note within its "AI Insights" documentation to explain what agent AI is and why it is relevant to government services. In addition, it has announced a tender to develop a "GOV.UK Agentic AI Companion" that will serve as an intelligent assistant for citizens from the government portal.
- The European Commission, within the framework of the Apply AI strategy and the GenAI4EU initiative, has launched calls to finance pilot projects that introduce scalable and replicable generative AI solutions in public administrations, fully integrated into their workflows. These calls seek precisely to accelerate the pace of digitalization through AI (including specialized agents) to improve decision-making, simplify procedures and make administration more accessible.
In Spain, although the label "agéntica AI" is not yet widely used, some experiences that go in that direction can already be identified. For example, different administrations are incorporating co-pilots based on generative AI to support public employees in tasks of searching for information, writing and summarizing documents, or managing files, as shown by initiatives of regional governments such as that of Aragon and local entities such as Barcelona City Council that are beginning to document themselves publicly.
The leap towards more autonomous agents in the public sector therefore seems to be a natural evolution on the basis of the existing e-government. But this evolution must, at the same time, reinforce the commitment to transparency, fairness, accountability, human oversight and regulatory compliance required by the AI Regulation and the rest of the regulatory framework and which should guide the actions of the public administration.
Looking to the Future: AI Agents, Open Data, and Citizen Trust
The arrival of agent AI once again offers the public administration new tools to reduce bureaucracy, personalize care and optimize its always scarce resources. However, technology is only a means, the ultimate goal is still to generate public value by reinforcing the trust of citizens.
In principle, Spain is in a good position: it has an Artificial Intelligence Strategy 2024 that is committed to transparent, ethical and human-centred AI, with specific lines to promote its use in the public sector; it has aconsolidated open data infrastructure; and it has created the Spanish Agency for the Supervision of Artificial Intelligence (AESIA) as a body in charge of ensuring an ethical and safe use of AI, in accordance with the European AI Regulation.
We are, therefore, facing a new opportunity for modernisation that can build more efficient, closer and even proactive public services. If we are able to adopt the Agent AI properly, the agents that are deployed will not be a "black box" that acts without supervision, but digital, transparent and auditable "public agents", designed to work with open data, explain their decisions and leave a trace of the actions they take. Tools, in short, inclusive, people-centred and aligned with the values of public service.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The contents and views expressed in this publication are the sole responsibility of the author.
Documentación
Data sharing has become a critical pillar for the advancement of analytics and knowledge exchange, both in the private and public sectors. Organizations of all sizes and industries—companies, public administrations, research institutions, developer communities, and individuals—find strong value in the ability to share information securely, reliably, and efficiently.
This exchange goes beyond raw data or structured datasets. It also includes more advanced data products such as trained machine learning models, analytical dashboards, scientific experiment results, and other complex artifacts that have significant impact through reuse. In this context, the governance of these resources becomes essential. It is not enough to simply move files from one location to another; it is necessary to guarantee key aspects such as access control (who can read or modify a given resource), traceability and auditing (who accessed it, when, and for what purpose), and compliance with regulations or standards, especially in enterprise and governmental environments.
To address these requirements, Unity Catalog emerges as a next-generation metastore, designed to centralize and simplify the governance of data and data-related resources. Originally part of the services offered by the Databricks platform, the project has now transitioned into the open source community, becoming a reference standard. This means that it can now be freely used, modified, and extended, enabling collaborative development. As a result, more organizations are expected to adopt its cataloging and sharing model, promoting data reuse and the creation of analytical workflows and technological innovation.

Figure 1. Image. Source: https://docs.unitycatalog.io/
Access the data lab repository on Github
Run the data preprocessing code on Google Colab
Objectives
In this exercise, we will learn how to configure Unity Catalog, a tool that helps us organize and share data securely in the cloud. Although we will use some code, each step will be explained clearly so that even those with limited programming experience can follow along through a hands-on lab.
We will work with a realistic scenario in which we manage public transportation data from different cities. We’ll create data catalogs, configure a database, and learn how to interact with the information using tools like Docker, Apache Spark, and MLflow.
Difficulty level: Intermediate.

Figure 2: Unity catalogue schematic
Required Resources
In this section, we’ll explain the prerequisites and resources needed to complete this lab. The lab is designed to be run on a standard personal computer (Windows, macOS, or Linux).
We will be using the following tools and environments:
- Docker Desktop: Docker allows us to run applications in isolated environments called containers. A container is like a "box" that includes everything needed for the application to run properly, regardless of the operating system.
- Visual Studio Code: Our main working environment will be a Python Notebook, which we will run and edit using the widely adopted code editor Visual Studio Code (VS Code).
- Unity Catalog: Unity Catalog is a data governance tool that allows us to organize and control access to resources such as tables, data volumes, functions, and machine learning models. In this lab, we will use its open source version, which can be deployed locally, to learn how to manage data catalogs with permission control, traceability, and hierarchical structure. Unity Catalog acts as a centralized metastore, making data collaboration and reuse more secure and efficient.
- Amazon Web Services (AWS): AWS will serve as our cloud provider to host some of the lab’s data—specifically, raw data files (such as JSON) that we will manage using data volumes. We’ll use the Amazon S3 service to store these files and configure the necessary credentials and permissions so that Unity Catalog can interact with them in a controlled manner
Key Learnings from the Lab
Throughout this hands-on exercise, participants will deploy the application, understand its architecture, and progressively build a data catalog while applying best practices in organization, access control, and data traceability.
Deployment and First Steps
- We clone the Unity Catalog repository and launch it using Docker.
- We explore its architecture: a backend accessible via API and CLI, and an intuitive graphical user interface.
- We navigate the core resources managed by Unity Catalog: catalogs, schemas, tables, volumes, functions, and models.
Figure 2. Screenshot
What Will We Learn Here?
How to launch theapplication, understand its core components, and start interacting with it through different interfaces: the web UI, API, and CLI.
Resource Organization
- We configure an external MySQL database as the metadata repository.
- We create catalogs to represent different cities and schemas for various public services.

Figure 3. Screenshot
What Will We Learn Here?
How to structure data governance at different levels (city, service, dataset) and manage metadata in a centralized and persistent way.
Data Construction and Real-World Usage
- We create structured tables to represent routes, buses, and bus stops.
- We load real data into these tables using PySpark.
- We set up an AWS S3 bucket as raw data storage (volumes).
- We upload JSON telemetry event files and govern them from Unity Catalog.
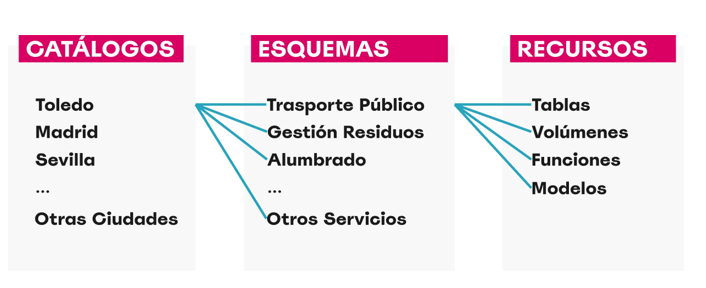
Figure 4. Diagram
What Will We Learn Here?
How to work with different types of data (structured and unstructured), and how to integrate them with external sources like AWS S3.
Reusable Functions and AI Models
- We register custom functions (e.g., distance calculation) directly in the catalog.
- We create and register machine learning models using MLflow.
- We run predictions from Unity Catalog just like any other governed resource.
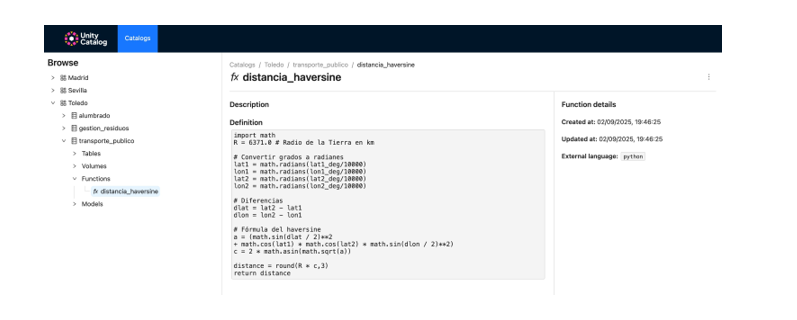
Figure 5. Screenshot
What Will We Learn Here?
How to extend data governance to functions and models, and how to enable their reuse and traceability in collaborative environments.
Results and Conclusions
As a result of this hands-on lab, we gained practical experience with Unity Catalog as an open platform for the governance of data and data-related resources, including machine learning models. We explored its capabilities, deployment model, and usage through a realistic use case and a tool ecosystem similar to what you might find in an actual organization.
Through this exercise, we configured and used Unity Catalog to organize public transportation data. Specifically, you will be able to:
- Learn how to install tools like Docker and Spark.
- Create catalogs, schemas, and tables in Unity Catalog.
- Load data and store it in an Amazon S3 bucket.
- Implement a machine learning model using MLflow.
In the coming years, we will see whether tools like Unity Catalog achieve the level of standardization needed to transform how data resources are managed and shared across industries.
We encourage you to keep exploring data science! Access the full repository here
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
In the current landscape of data analysis and artificial intelligence, the automatic generation of comprehensive and coherent reports represents a significant challenge. While traditional tools allow for data visualization or generating isolated statistics, there is a need for systems that can investigate a topic in depth, gather information from diverse sources, and synthesize findings into a structured and coherent report.
In this practical exercise, we will explore the development of a report generation agent based on LangGraph and artificial intelligence. Unlike traditional approaches based on templates or predefined statistical analysis, our solution leverages the latest advances in language models to:
- Create virtual teams of analysts specialized in different aspects of a topic.
- Conduct simulated interviews to gather detailed information.
- Synthesize the findings into a coherent and well-structured report.
Access the data laboratory repository on Github
Run the data preprocessing code on Google Colab
As shown in Figure 1, the complete agent flow follows a logical sequence that goes from the initial generation of questions to the final drafting of the report.

Figure 1. Agent flow diagram.
Application Architecture
The core of the application is based on a modular design implemented as an interconnected state graph, where each module represents a specific functionality in the report generation process. This structure allows for a flexible workflow, recursive when necessary, and with capacity for human intervention at strategic points.
Main Components
The system consists of three fundamental modules that work together:
1. Virtual Analysts Generator
This component creates a diverse team of virtual analysts specialized in different aspects of the topic to be investigated. The flow includes:
- Initial creation of profiles based on the research topic.
- Human feedback point that allows reviewing and refining the generated profiles.
- Optional regeneration of analysts incorporating suggestions.
This approach ensures that the final report includes diverse and complementary perspectives, enriching the analysis.
2. Interview System
Once the analysts are generated, each one participates in a simulated interview process that includes:
- Generation of relevant questions based on the analyst's profile.
- Information search in sources via Tavily Search and Wikipedia.
- Generation of informative responses combining the obtained information.
- Automatic decision on whether to continue or end the interview based on the information gathered.
- Storage of the transcript for subsequent processing.
The interview system represents the heart of the agent, where the information that will nourish the final report is obtained. As shown in Figure 2, this process can be monitored in real time through LangSmith, an open observability tool that allows tracking each step of the flow.

Figure 2. System monitoring via LangGraph. Concrete example of an analyst-interviewer interaction.
3. Report Generator
Finally, the system processes the interviews to create a coherent report through:
- Writing individual sections based on each interview.
- Creating an introduction that presents the topic and structure of the report.
- Organizing the main content that integrates all sections.
- Generating a conclusion that synthesizes the main findings.
- Consolidating all sources used.
The Figure 3 shows an example of the report resulting from the complete process, demonstrating the quality and structure of the final document generated automatically.

Figure 3. View of the report resulting from the automatic generation process to the prompt "Open data in Spain".
What can you learn?
This practical exercise allows you to learn:
Integration of advanced AI in information processing systems:
- How to communicate effectively with language models.
- Techniques to structure prompts that generate coherent and useful responses.
- Strategies to simulate virtual teams of experts.
Development with LangGraph:
- Creation of state graphs to model complex flows.
- Implementation of conditional decision points.
- Design of systems with human intervention at strategic points.
Parallel processing with LLMs:
- Parallelization techniques for tasks with language models.
- Coordination of multiple independent subprocesses.
- Methods for consolidating scattered information.
Good design practices:
- Modular structuring of complex systems.
- Error handling and retries.
- Tracking and debugging workflows through LangSmith.
Conclusions and future
This exercise demonstrates the extraordinary potential of artificial intelligence as a bridge between data and end users. Through the practical case developed, we can observe how the combination of advanced language models with flexible architectures based on graphs opens new possibilities for automatic report generation.
The ability to simulate virtual expert teams, perform parallel research and synthesize findings into coherent documents, represents a significant step towards the democratization of analysis of complex information.
For those interested in expanding the capabilities of the system, there are multiple promising directions for its evolution:
- Incorporation of automatic data verification mechanisms to ensure accuracy.
- Implementation of multimodal capabilities that allow incorporating images and visualizations.
- Integration with more sources of information and knowledge bases.
- Development of more intuitive user interfaces for human intervention.
- Expansion to specialized domains such as medicine, law or sciences.
In summary, this exercise not only demonstrates the feasibility of automating the generation of complex reports through artificial intelligence, but also points to a promising path towards a future where deep analysis of any topic is within everyone's reach, regardless of their level of technical experience. The combination of advanced language models, graph architectures and parallelization techniques opens a range of possibilities to transform the way we generate and consume information.