Description
Data sharing has become a critical pillar for the advancement of analytics and knowledge exchange, both in the private and public sectors. Organizations of all sizes and industries—companies, public administrations, research institutions, developer communities, and individuals—find strong value in the ability to share information securely, reliably, and efficiently.
This exchange goes beyond raw data or structured datasets. It also includes more advanced data products such as trained machine learning models, analytical dashboards, scientific experiment results, and other complex artifacts that have significant impact through reuse. In this context, the governance of these resources becomes essential. It is not enough to simply move files from one location to another; it is necessary to guarantee key aspects such as access control (who can read or modify a given resource), traceability and auditing (who accessed it, when, and for what purpose), and compliance with regulations or standards, especially in enterprise and governmental environments.
To address these requirements, Unity Catalog emerges as a next-generation metastore, designed to centralize and simplify the governance of data and data-related resources. Originally part of the services offered by the Databricks platform, the project has now transitioned into the open source community, becoming a reference standard. This means that it can now be freely used, modified, and extended, enabling collaborative development. As a result, more organizations are expected to adopt its cataloging and sharing model, promoting data reuse and the creation of analytical workflows and technological innovation.

Figure 1. Image. Source: https://docs.unitycatalog.io/
Access the data lab repository on Github
Run the data preprocessing code on Google Colab
Objectives
In this exercise, we will learn how to configure Unity Catalog, a tool that helps us organize and share data securely in the cloud. Although we will use some code, each step will be explained clearly so that even those with limited programming experience can follow along through a hands-on lab.
We will work with a realistic scenario in which we manage public transportation data from different cities. We’ll create data catalogs, configure a database, and learn how to interact with the information using tools like Docker, Apache Spark, and MLflow.
Difficulty level: Intermediate.

Figure 2: Unity catalogue schematic
Required Resources
In this section, we’ll explain the prerequisites and resources needed to complete this lab. The lab is designed to be run on a standard personal computer (Windows, macOS, or Linux).
We will be using the following tools and environments:
- Docker Desktop: Docker allows us to run applications in isolated environments called containers. A container is like a "box" that includes everything needed for the application to run properly, regardless of the operating system.
- Visual Studio Code: Our main working environment will be a Python Notebook, which we will run and edit using the widely adopted code editor Visual Studio Code (VS Code).
- Unity Catalog: Unity Catalog is a data governance tool that allows us to organize and control access to resources such as tables, data volumes, functions, and machine learning models. In this lab, we will use its open source version, which can be deployed locally, to learn how to manage data catalogs with permission control, traceability, and hierarchical structure. Unity Catalog acts as a centralized metastore, making data collaboration and reuse more secure and efficient.
- Amazon Web Services (AWS): AWS will serve as our cloud provider to host some of the lab’s data—specifically, raw data files (such as JSON) that we will manage using data volumes. We’ll use the Amazon S3 service to store these files and configure the necessary credentials and permissions so that Unity Catalog can interact with them in a controlled manner
Key Learnings from the Lab
Throughout this hands-on exercise, participants will deploy the application, understand its architecture, and progressively build a data catalog while applying best practices in organization, access control, and data traceability.
Deployment and First Steps
- We clone the Unity Catalog repository and launch it using Docker.
- We explore its architecture: a backend accessible via API and CLI, and an intuitive graphical user interface.
- We navigate the core resources managed by Unity Catalog: catalogs, schemas, tables, volumes, functions, and models.
Figure 2. Screenshot
What Will We Learn Here?
How to launch theapplication, understand its core components, and start interacting with it through different interfaces: the web UI, API, and CLI.
Resource Organization
- We configure an external MySQL database as the metadata repository.
- We create catalogs to represent different cities and schemas for various public services.

Figure 3. Screenshot
What Will We Learn Here?
How to structure data governance at different levels (city, service, dataset) and manage metadata in a centralized and persistent way.
Data Construction and Real-World Usage
- We create structured tables to represent routes, buses, and bus stops.
- We load real data into these tables using PySpark.
- We set up an AWS S3 bucket as raw data storage (volumes).
- We upload JSON telemetry event files and govern them from Unity Catalog.
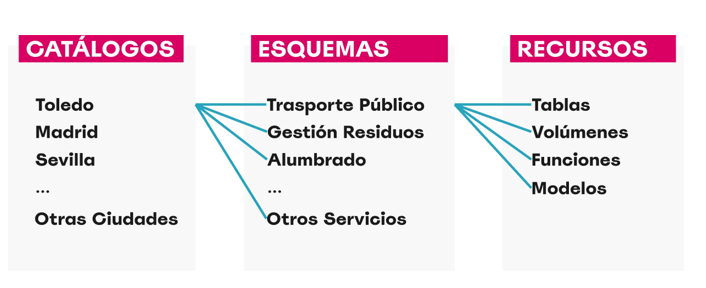
Figure 4. Diagram
What Will We Learn Here?
How to work with different types of data (structured and unstructured), and how to integrate them with external sources like AWS S3.
Reusable Functions and AI Models
- We register custom functions (e.g., distance calculation) directly in the catalog.
- We create and register machine learning models using MLflow.
- We run predictions from Unity Catalog just like any other governed resource.
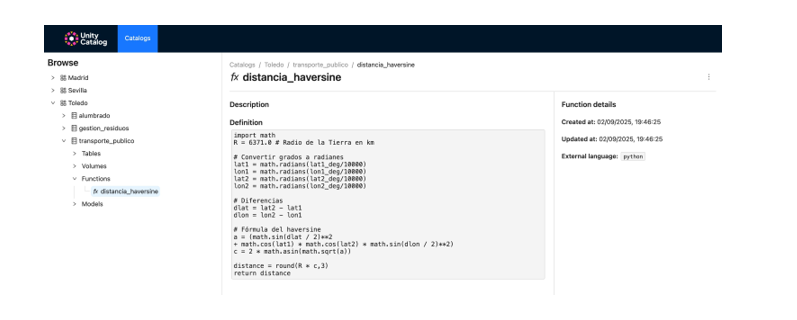
Figure 5. Screenshot
What Will We Learn Here?
How to extend data governance to functions and models, and how to enable their reuse and traceability in collaborative environments.
Results and Conclusions
As a result of this hands-on lab, we gained practical experience with Unity Catalog as an open platform for the governance of data and data-related resources, including machine learning models. We explored its capabilities, deployment model, and usage through a realistic use case and a tool ecosystem similar to what you might find in an actual organization.
Through this exercise, we configured and used Unity Catalog to organize public transportation data. Specifically, you will be able to:
- Learn how to install tools like Docker and Spark.
- Create catalogs, schemas, and tables in Unity Catalog.
- Load data and store it in an Amazon S3 bucket.
- Implement a machine learning model using MLflow.
In the coming years, we will see whether tools like Unity Catalog achieve the level of standardization needed to transform how data resources are managed and shared across industries.
We encourage you to keep exploring data science! Access the full repository here
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.



Comments