Blog
La visualización de datos no es una disciplina reciente. Desde hace siglos, las personas han utilizado gráficos, mapas y esquemas para representar información compleja. Ejemplos clásicos como los mapas estadísticos del siglo XIX o los gráficos utilizados en la prensa muestran que la necesidad de “ver” los datos para entenderlos ha existido siempre.
Durante mucho tiempo, la creación de visualizaciones requería conocimientos especializados y acceso a herramientas profesionales, lo que limitaba su producción a perfiles muy concretos. Sin embargo, la revolución digital y tecnológica ha transformado profundamente este panorama. En la actualidad, cualquier persona con acceso a un ordenador y a datos puede crear visualizaciones. Las herramientas se han democratizado, muchas de ellas son gratuitas o de código abierto, y el trabajo de visualización se ha extendido más allá del diseño para integrarse en ámbitos como la estadística, la ciencia de datos, la investigación académica, la administración pública o la educación.
Hoy en día, la visualización de datos es una competencia transversal que permite a la ciudadanía explorar información pública, a las instituciones comunicar mejor sus políticas y a los reutilizadores generar nuevos servicios y conocimientos a partir de los datos abiertos. En este post presentamos algunas de las opciones más accesibles y utilizadas en visualización de datos.
Un ecosistema amplio y diverso de herramientas
El ecosistema de herramientas de visualización de datos es amplio y diverso, tanto en funcionalidades como en niveles de complejidad. Existen opciones pensadas para una primera exploración de los datos, otras orientadas al análisis en profundidad y algunas diseñadas para crear visualizaciones interactivas o narrativas digitales complejas.
Esta variedad permite adaptar la visualización a distintos contextos y objetivos: desde comprender un conjunto de datos de forma preliminar hasta publicar gráficos interactivos, paneles de control o mapas en la web.
La encuesta anual de la Data Visualization Society refleja esta diversidad y muestra cómo el uso de determinadas herramientas evoluciona con el tiempo, consolidando algunas opciones ampliamente conocidas y dando paso a nuevas soluciones que responden a necesidades emergentes. Estas son algunas de las herramientas que se mencionan en la encuesta, ordenadas según perfiles de uso.
Para la elaboración de este listado se ha tenido en cuenta los siguientes criterios:
- Grado de uso y madurez de la herramienta.
- Acceso libre, gratuito o con versiones abiertas.
- Utilidad para proyectos relacionados con datos públicos.
- Prioridad a herramientas abiertas o con versiones gratuitas.
Herramientas sencillas para empezar
Estas herramientas se caracterizan por contar con interfaces visuales, una curva de aprendizaje baja y la posibilidad de crear gráficos básicos de forma rápida. Son especialmente útiles para comenzar a explorar conjuntos de datos abiertos o para actividades de divulgación.
- Excel: es una de las herramientas más extendidas y conocidas. Permite realizar gráficos básicos y primeras exploraciones de datos de forma sencilla. Aunque no está diseñada específicamente para la visualización avanzada, sigue siendo una puerta de entrada habitual al trabajo con datos y su representación gráfica.
- Google Sheets: funciona como una alternativa gratuita y colaborativa a Excel. Su principal ventaja es la posibilidad de trabajar de forma compartida y publicar gráficos sencillos en línea, lo que facilita la difusión de visualizaciones básicas.
- Datawrapper: muy utilizada en comunicación pública y periodismo de datos. Permite crear gráficos claros, mapas y tablas interactivas sin necesidad de conocimientos técnicos. Es especialmente adecuada para explicar datos de forma comprensible a un público amplio.
- RAWGraphs: herramienta de software libre orientada a la exploración visual. Permite experimentar con tipos de gráficos menos habituales y descubrir nuevas formas de representar datos. Resulta especialmente útil en fases exploratorias.
- Canva: aunque su enfoque es más divulgativo que analítico, puede ser útil para crear piezas visuales sencillas que integren gráficos básicos con elementos de diseño. Es adecuada para la comunicación visual de resultados, no tanto para el análisis de datos.
Herramientas de análisis y exploración de datos
Este grupo de herramientas está orientado a perfiles que desean ir más allá de los gráficos básicos y realizar análisis más estructurados. Muchas de ellas son abiertas y están ampliamente consolidadas en el ámbito del análisis de datos.
- R: lenguaje de programación libre muy utilizado en estadística y análisis de datos. Dispone de un amplio ecosistema de paquetes que permiten trabajar con datos públicos de forma reproducible y transparente.
- Ggplot2: librería de visualización del lenguaje R. Es una de las herramientas más potentes para crear gráficos rigurosos y bien estructurados, tanto para análisis como para comunicación de resultados.
- Python (Matplotlib y Plotly): Python es uno de los lenguajes más utilizados en análisis de datos. Matplotlib permite crear gráficos estáticos personalizables, mientras que Plotly facilita la creación de visualizaciones interactivas. Juntas ofrecen un buen equilibrio entre potencia y flexibilidad.
- Apache Superset: plataforma de código abierto para análisis de datos y creación de paneles de control. Tiene un enfoque más institucional y escalable, lo que la hace adecuada para organizaciones que trabajan con grandes volúmenes de datos públicos.
Este bloque resulta especialmente relevante para reutilizadores de datos abiertos y perfiles técnicos intermedios que buscan combinar análisis y visualización de forma sistemática.
Herramientas para visualización interactiva y web
Estas herramientas permiten crear visualizaciones avanzadas para su publicación en entornos web. Aunque requieren mayores conocimientos técnicos, ofrecen una gran flexibilidad y posibilidades expresivas.
- D3.js: es uno de los referentes en visualización web. Se basa en estándares abiertos y permite un control total sobre la representación visual de los datos. Su flexibilidad es muy alta, aunque también lo es su complejidad.
En este ejercicio práctico puedes ver cómo se utiliza esta librería
- Vega y Vega-Lite: lenguajes declarativos para visualización que simplifican el uso de D3. Permiten definir gráficos de forma estructurada y reproducible, ofreciendo un buen equilibrio entre potencia y simplicidad.
- Observable: entorno interactivo muy ligado a D3 y Vega. Es especialmente útil para crear ejemplos educativos, prototipos y visualizaciones exploratorias que combinan código, texto y gráficos.
- Three.js y WebGL: tecnologías orientadas a visualizaciones avanzadas y en tres dimensiones. Su uso es más experimental y suele estar vinculado a proyectos de divulgación o investigación visual.
En este apartado conviene destacar que, aunque las barreras técnicas son mayores, estas herramientas permiten crear experiencias interactivas ricas que pueden resultar muy eficaces para comunicar datos públicos complejos.
Herramientas de cartografía y datos geoespaciales
La visualización geográfica es especialmente relevante en el ámbito de los datos abiertos, ya que una gran parte de la información pública tiene una dimensión territorial. En este campo, el software libre tiene un peso destacado y está muy alineado con el uso en administraciones públicas.
- QGIS: referente en software libre para sistemas de información geográfica (GIS). Es ampliamente utilizado en administraciones públicas y permite analizar y visualizar datos espaciales con gran detalle.
- ArcGIS: muy extendido en el ámbito institucional. Aunque no es software libre, su uso está muy consolidado y forma parte del ecosistema habitual de muchas organizaciones públicas.
- Mapbox: plataforma orientada a la creación de mapas web interactivos. Es muy utilizada en proyectos de visualización online y permite integrar datos geográficos en aplicaciones web.
- Leaflet: librería de código abierto muy popular para crear mapas interactivos en la web. Es ligera, flexible y ampliamente utilizada en proyectos de reutilización de datos abiertos geográficos.
Este conjunto de herramientas facilita la representación territorial de los datos y su reutilización en contextos locales, regionales o nacionales.
En conclusión, la elección de una herramienta de visualización depende en gran medida del objetivo que se persiga. No es lo mismo aprender y experimentar que analizar datos en profundidad o comunicar resultados a un público amplio. Por ello, resulta útil reflexionar previamente sobre el tipo de datos disponibles, el público al que se dirige la visualización y el mensaje que se quiere transmitir.
Apostar por herramientas accesibles y abiertas permite que más personas puedan explorar, interpretar y comunicar datos públicos. En este sentido, visualizar datos es también una forma de acercar la información a la ciudadanía y fomentar su reutilización.
Blog
Las visualizaciones de datos actúan como puentes entre la información compleja y la comprensión humana. Un gráfico bien diseñado puede comunicar en segundos datos que llevaría minutos o incluso horas descifrar en formato tabular. Más aún, las visualizaciones interactivas permiten a cada usuario explorar los datos desde su propia perspectiva, filtrando, comparando y descubriendo insights personalizados.
Para alcanzar estos fines existen múltiples herramientas, algunas de las cuales hemos abordado en ocasiones anteriores. Hoy nos acercamos a un nuevo ejemplo: la librería gratuita D3.js. En este post te explicamos cómo permite generar visualizaciones de datos útiles y atractivas junto con la herramienta de código abierto Observable.
¿Qué es D3?
D3.js (Data-Driven Documents) es una biblioteca de JavaScript que permite crear visualizaciones de datos personalizadas en navegadores web. A diferencia de herramientas que ofrecen gráficos predefinidos, D3.js proporciona los elementos fundamentales para construir prácticamente cualquier tipo de visualización imaginable.
La biblioteca es completamente gratuita y de código abierto, publicada bajo licencia BSD, lo que significa que cualquier persona u organización puede utilizarla, modificarla y distribuirla sin restricciones. Esta característica ha contribuido a su adopción generalizada: medios de comunicación internacionales como The New York Times, The Guardian, Financial Times y locales como El País o el ABC utilizan D3.js para crear visualizaciones periodísticas que ayudan a contar historias con datos.
D3.js funciona manipulando el DOM (Document Object Model) del navegador. En términos prácticos, esto significa que toma información (por ejemplo, un archivo CSV con datos de población) y la transforma en elementos visuales (círculos, barras, líneas) que el navegador puede mostrar. La potencia de D3.js reside en su flexibilidad: no impone una forma específica de visualizar datos, sino que proporciona las herramientas para crear exactamente lo que se necesita.
¿Qué es Observable?
Observable es una plataforma web para crear y compartir código, especialmente diseñada para trabajar con datos y visualizaciones. Aunque ofrece un servicio freemium con algunas funcionalidades gratuitas y otras de pago, mantiene una filosofía de código abierto que resulta particularmente relevante para el trabajo con datos públicos.
La característica distintiva de Observable es su formato de "cuadernos computacionales" (notebooks). Similar a herramientas como Jupyter Notebooks en Python, un cuaderno de Observable combina código, visualizaciones y texto explicativo en un mismo documento interactivo. Cada celda del cuaderno puede contener código JavaScript que se ejecuta inmediatamente, mostrando resultados al instante. Esto crea un entorno de experimentación ideal para explorar datos.
Puedes verlo en la práctica en este ejercicio de ciencia de datos que hemos publicado en datos.gob.es
Observable se integra naturalmente con D3.js y otras bibliotecas de visualización. De hecho, el creador de D3.js, es también uno de los fundadores de Observable, por lo que ambas herramientas trabajan conjuntamente de manera fluida. Los cuadernos de Observable pueden compartirse públicamente, permitiendo que otros usuarios vean tanto el código como los resultados, los bifurquen (fork) para crear sus propias versiones, o los integren en sus propios proyectos.
Ventajas de la herramienta para trabajar con todo tipo de datos
Tanto D3.js como Observable presentan características que pueden resultar útiles para trabajar con datos, entre ellos, con datos abiertos:
- Transparencia y reproducibilidad: al publicar una visualización creada con estas herramientas es posible compartir tanto el resultado final como todo el proceso de transformación de datos. Cualquier persona puede inspeccionar el código, verificar los cálculos y reproducir los resultados. Esta transparencia resulta fundamental cuando se trabaja con información pública, donde la confianza y la verificabilidad son esenciales.
- Sin costes de licencia: tanto D3.js como la versión gratuita de Observable permiten crear y publicar visualizaciones sin necesidad de adquirir licencias de software. Esto elimina barreras económicas para organizaciones, periodistas, investigadores o ciudadanos que desean trabajar con datos abiertos.
- Formatos web estándar: las visualizaciones creadas funcionan directamente en navegadores web sin necesidad de plugins o software adicional. Esto facilita su integración en sitios web institucionales, artículos periodísticos o informes digitales, haciéndolas accesibles desde cualquier dispositivo.
- Comunidad y recursos: existe una amplia comunidad de usuarios que comparten ejemplos, tutoriales y soluciones a problemas comunes. Observable, en particular, alberga miles de cuadernos públicos que sirven como ejemplos y plantillas reutilizables.
- Flexibilidad técnica: a diferencia de herramientas con opciones predefinidas, estas bibliotecas permiten crear visualizaciones completamente personalizadas que se adapten exactamente a las necesidades específicas de cada conjunto de datos o historia que se quiera contar.
Es importante señalar que estas herramientas requieren conocimientos de programación, específicamente de JavaScript. Para personas sin experiencia en programación, existe una curva de aprendizaje que puede resultar pronunciada inicialmente. Otras herramientas como hojas de cálculo o software de visualización con interfaces gráficas pueden ser más apropiadas para usuarios que buscan resultados rápidos sin necesidad de escribir código.
Para quienes buscan alternativas open source con una curva de aprendizaje suave, existen herramientas basadas en interfaz visual que no requieren programar. Por ejemplo, RawGraphs permite crear visualizaciones complejas simplemente arrastrando y soltando archivos, mientras que Datawrapper es una opción excelente y muy intuitiva para generar gráficos y mapas listos para publicar.
Además, existen numerosas alternativas tanto de código abierto como comerciales para visualizar datos: Python con bibliotecas como Matplotlib o Plotly, R con ggplot2, Tableau Public, Power BI, entre muchas otras. En la sección didáctica de ejercicios de visualización y ciencia de datos de datos.gob.es puedes encontrar ejemplos prácticos de uso de algunas de ellas.
En resumen, la elección de herramientas debe basarse siempre en una evaluación de requisitos específicos, recursos disponibles y objetivos del proyecto. Lo importante es que los datos abiertos se transformen en conocimiento accesible, y existen múltiples caminos para lograr este objetivo. D3.js y Observable ofrecen uno de estos caminos, particularmente adecuado para quienes buscan combinar flexibilidad técnica con principios de apertura y transparencia. Si conoces alguna otra herramienta o te gustaría que profundizáramos en otra temática, háznosla llegar a través de nuestras redes sociales o en el formulario de contacto.
Blog
En 2010, tras el devastador terremoto de Haití, cientos de organizaciones humanitarias llegaron al país dispuestas a ayudar. Se encontraron con un obstáculo inesperado: no había mapas actualizados. Sin información geográfica fiable, coordinar recursos, localizar comunidades aisladas o planificar rutas seguras era casi imposible.
Ese vacío marcó un antes y un después: fue el momento en que la comunidad global de OpenStreetMap (OSM) demostró su enorme potencial humanitario. Más de 600 voluntarios de todo el mundo se organizaron y comenzaron a mapear Haití en tiempo récord. Este hecho impulsó el proyecto Humanitarian OpenStreetMap Team.
¿Qué es Humanitarian OpenStreetMap Team?
Humanitarian OpenStreetMap Team, conocida por el acrónimo HOT, es una organización internacional sin ánimo de lucro dedicada a mejorar la vida de las personas mediante datos geográficos precisos y accesibles. Su labor está inspirada en los principios de OSM, el proyecto colaborativo que busca crear un mapa digital abierto, gratuito y editable por cualquiera.
La diferencia con OSM es que HOT se orienta específicamente a contextos donde la falta de datos afecta de manera directa a la vida de las personas: se trata de aportar datos y herramientas que permitan tomar decisiones más informadas en situaciones críticas. Es decir, aplica los principios del software y datos abiertos al mapeo colaborativo con impacto social y humanitario.
En este sentido, el equipo de HOT no sólo produce mapas: también facilita las herramientas, las capacidades técnicas e impulsa nuevas formas de trabajo para distintos actores que necesitan datos espaciales precisos. Su labor va desde la respuesta inmediata cuando ocurre un desastre hasta programas estructurales que fortalecen la resiliencia local ante desafíos como el cambio climático o la expansión urbana.
Cuatro zonas geográficas prioritarias
Aunque HOT no se limita a un único país o región, sí ha establecido áreas prioritarias donde sus esfuerzos de mapeo tienen un mayor impacto debido a la existencia de brechas significativas en los datos o a necesidades humanitarias urgentes. Actualmente trabaja en más de 90 países y organiza sus actividades a través de cuatro Hubs de Mapeo Abierto (centros regionales) que coordinan iniciativas según las necesidades locales:
- Asia-Pacífico: los desafíos incluyen desde desastres naturales frecuentes (como tifones y terremotos) hasta el acceso a zonas rurales remotas con poca cobertura cartográfica.
- África Oriental y Meridional: esta región enfrenta múltiples crisis entrelazadas (sequías, movimientos migratorios, deficiencias en infraestructura básica) por lo que contar con mapas actualizados es clave para la planificación sanitaria, la gestión de recursos y la respuesta a emergencias.
- África Occidental y Norte de África: en esta zona, HOT impulsa actividades que combinan el fortalecimiento de capacidades locales con proyectos tecnológicos, promoviendo la participación activa de comunidades en la creación de mapas útiles para su entorno.
- América Latina y el Caribe: con frecuencia afectada por huracanes, terremotos y riesgos volcánicos, esta región ha visto una adopción creciente de mapeo colaborativo tanto en respuesta a emergencias como en iniciativas de desarrollo urbano y resiliencia climática.
La elección de estas zonas prioritarias no es arbitraria: responde a contextos en los que la falta de datos abiertos puede limitar respuestas rápidas y efectivas, así como la capacidad de gobiernos y comunidades para planificar su futuro con información fiable.
Herramientas de código abierto desarrolladas por HOT
Una parte esencial del impacto de HOT reside en las herramientas y plataformas de código abierto que facilitan el mapeo colaborativo y el uso de datos espaciales en escenarios reales. Para ello se desarrolló una Cadena de Valor de Mapeo E2E, la cual es la metodología central que permite a las comunidades pasar de la captura de imágenes y el mapeo al impacto. Esta cadena de valor respalda todos sus programas, garantizando que el mapeo sea un proceso transformador, basado en datos abiertos, educación y poder comunitario.
Estas herramientas no sólo apoyan el trabajo de HOT, sino que están disponibles para que cualquier persona o comunidad las utilice, adapte o amplíe. En concreto se han desarrollado herramientas para crear, acceder, gestionar, analizar y compartir datos de mapas abiertos. Puedes explorarlas en el Centro de Aprendizaje, un espacio de formación que ofrece desarrollo de capacidades, fortalecimiento de habilidades y un proceso de acreditación para personas y organizaciones interesadas. A continuación se describen estas herramientas:
Permite planificar vuelos de drones para obtener imágenes aéreas actualizadas de alta resolución, algo fundamental cuando las imágenes comerciales son demasiado costosas. De esta forma, cualquier persona con acceso a un dron -incluidos modelos de bajo coste y de uso común-, puede contribuir a un repositorio global de imágenes libres y abiertas, lo que democratiza el acceso a datos geoespaciales críticos para la respuesta ante desastres, la resiliencia comunitaria y la planificación local.
La plataforma coordina a múltiples operadores y genera planes de vuelo automatizados para cubrir áreas de interés, lo que facilita la captura de imágenes 2D y 3D con precisión y eficiencia. Además, incluye planes de formación y promueve la seguridad y el cumplimiento de regulaciones locales, apoyando la gestión de proyectos, la visualización de datos y el intercambio colaborativo entre pilotos y organizaciones.

Figura 1. Captura Drone Tasking Manager (DroneTM). Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Es una plataforma de código abierto que ofrece acceso a una biblioteca comunitaria de imágenes aéreas con licencia abierta, obtenidas desde satélites, drones u otras aeronaves. Cuenta con una interfaz sencilla donde se puede hacer zoom sobre un mapa para buscar imágenes disponibles. OAM permite tanto descargar como contribuir con nuevas imágenes, ampliando así un repositorio global de datos visuales que cualquiera puede usar y trazar en OpenStreetMap.
Todas las imágenes alojadas en OpenAerialMap están licenciadas bajo CC-BY 4.0, lo que significa que son de acceso público y pueden ser reutilizadas con atribución, facilitando su integración en aplicaciones de análisis geoespacial, proyectos de respuesta ante emergencias o iniciativas de planificación local. OAM se apoya en la Open Imagery Network (OIN) para estructurar y servir estas imágenes.
Facilita el mapeo colaborativo en OpenStreetMap. Su propósito principal es coordinar a miles de voluntarios de todo el mundo para añadir datos geográficos de forma organizada y eficiente. Para ello, divide un proyecto de mapeo grande en pequeñas “tareas” que pueden completarse rápidamente por personas que trabajan de forma remota.
El funcionamiento es sencillo: los proyectos se subdividen en cuadrículas, cada una asignable a un voluntario para que trace elementos como calles, edificios o puntos de interés en OSM. Cada tarea es validada por mappers experimentados para asegurar la calidad de los datos. La plataforma muestra claramente qué zonas aún necesitan mapeo o revisión, evitando duplicaciones y mejorando la eficiencia del trabajo colaborativo.

Figura 2. Captura Tasking Manager. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Utiliza inteligencia artificial para asistir el proceso de mapeo en OpenStreetMap con fines humanitarios. A través de modelos de computer vision, fAIr analiza imágenes satelitales o aéreas y sugiere la detección de elementos geográficos como edificios, caminos, cursos de agua o vegetación a partir de imágenes libres como las de OpenAerialMap. La idea es que los voluntarios puedan usar estas predicciones como asistencia para mapear más rápido y con mayor precisión, sin realizar importaciones masivas automatizadas, integrando siempre el juicio humano en la validación de cada elemento.
Una de las características más destacadas de fAIr es que la creación y entrenamiento de los modelos de IA está en manos de las propias comunidades mapeadoras: los usuarios pueden generar sus propios conjuntos de entrenamiento ajustados a su región o contexto, lo que ayuda a reducir sesgos de los modelos estándar y hace que las predicciones sean más relevantes para las necesidades locales.
Es una aplicación móvil y web que facilita la coordinación de campañas de mapeo directamente en el terreno. Field-TM se usa junto con OpenDataKit (ODK), una plataforma de recolección de datos en Android que permite introducir información sobre el terreno usando los propios dispositivos móviles. Gracias a ella, los voluntarios pueden introducir información geoespacial verificada por observación local, como la finalidad de cada edificio (si es una tienda, un hospital, etc.).
La aplicación proporciona una interfaz para asignar tareas, seguir el avance y asegurar la consistencia de los datos. Su propósito principal es mejorar la eficiencia, organización y calidad del trabajo de campo al enriquecerlo con información local, así como reducir duplicidades, evitar zonas no cubiertas y permitir un seguimiento claro del progreso de cada colaborador en una campaña de mapeo.
Transforma conversaciones de aplicaciones de mensajería instantánea (como WhatsApp) en mapas interactivos. En muchas comunidades, especialmente en zonas propensas a desastres o con poca alfabetización tecnológica, las personas ya utilizan apps de chat para comunicarse y compartir su ubicación. ChatMap aprovecha esos mensajes exportados, extrae datos de ubicación junto con textos, fotos y videos, y los representa automáticamente sobre un mapa, sin necesidad de instalaciones complejas o conocimientos técnicos avanzados.
Esta solución funciona incluso en condiciones de conectividad limitada o sin conexión, basándose en la señal GPS del teléfono para registrar ubicaciones y almacenarlas hasta que se pueda subir la información.

Figura 3. Captura de ChatMap. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Facilitar el acceso y descarga de datos geoespaciales actualizados de OpenStreetMap en formatos útiles para análisis y proyectos. A través de esta plataforma web se puede seleccionar un área de interés en el mapa, elegir qué datos se quieren (como carreteras, edificios o servicios) y descargar esos datos en múltiples formatos, como GeoJSON, Shapefile, GeoPackage, KML o CSV. Esto permite usar la información en un software SIG (Sistemas de Información Geográfica) o integrarla directamente en aplicaciones personalizadas. También se pueden exportar todos los datos de una zona o descargar datos asociados a un proyecto concreto del Tasking Manager.
La herramienta está diseñada para ser accesible tanto a analistas técnicos como a personas que no son expertas en SIG: en cuestión de minutos se pueden generar extractos personalizados de OSM sin necesidad de instalar software especializado. También ofrece una API y métricas de calidad de datos.
Es una plataforma de creación de mapas interactivos de código abierto que permite a cualquier persona visualizar, personalizar y compartir datos geoespaciales fácilmente. Sobre una base de mapas de OpenStreetMap, uMap deja añadir capas personalizadas, marcadores, líneas y polígonos, administrar colores e íconos, importar datos en formatos comunes (como GeoJSON, GPX o KML) y elegir licencias para los datos, sin necesidad de instalar software especializado. Los mapas creados pueden incrustarse en sitios web o compartirse mediante enlaces.
La herramienta ofrece plantillas y opciones de integración con otras herramientas de HOT, como ChatMap y OpenAerialMap, para enriquecer los datos en el mapa.
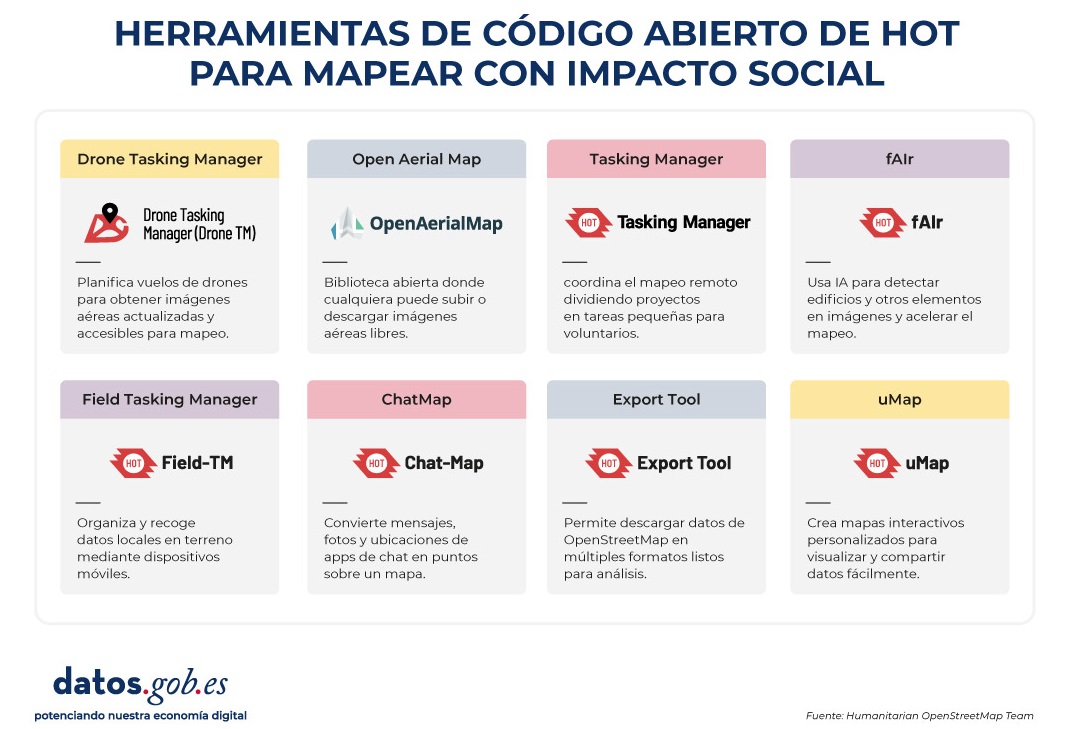
Figura 4. Herramientas de código abierto de HOT para mapear con impacto social. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Todas estas herramientas están a disposición de las comunidades locales de todo el mundo. Desde HOT también se ofrece formación para fomentar su uso y mejorar el impacto de los datos abiertos en las respuestas humanitarias.
¿Cómo puedes sumarte al impacto de HOT?
HOT se construye junto a una comunidad global que impulsa el uso de datos abiertos para fortalecer la toma de decisiones y salvar vidas. Si representas a una organización, universidad, colectivo, agencia pública o iniciativa comunitaria y tienes una idea de proyecto o interés en una alianza, el equipo de HOT está abierto a explorar colaboraciones. Puedes escribirles a partnerships@hotosm.org.
Cuando las comunidades tienen acceso a datos precisos, herramientas abiertas y el conocimiento para generar información geoespacial de forma continua, se convierten en agentes informados, listos para tomar decisiones en cualquier situación. Están mejor preparadas para identificar riesgos climáticos, responder ante emergencias, resolver problemas locales y movilizar apoyo. El mapeo abierto, por tanto, no solo representa territorios: empodera a las personas para transformar su realidad con datos que pueden salvan vidas.
Blog
La inteligencia artificial (IA) de código abierto es una oportunidad para democratizar la innovación y evitar la concentración de poder en la industria tecnológica. Sin embargo, su desarrollo depende en gran medida de la disponibilidad de conjuntos de datos de alta calidad y de la implementación de marcos sólidos de gobernanza de datos. Un informe reciente de Open Future y la Open Source Initiative (OSI) analiza los desafíos y oportunidades en esta intersección, proponiendo soluciones para una gobernanza de datos equitativa y responsable. Puedes leer aquí el informe completo.
En este post, analizaremos las ideas más relevantes del documento, así como los consejos que ofrece para garantizar una correcta y efectiva gobernanza de datos en la inteligencia artificial open source y aprovechar todas sus ventajas.
Los retos de la gobernanza de datos en la IA
A pesar de la gran cantidad de datos disponibles en la web, su acceso y uso para entrenar modelos de IA plantean importantes desafíos éticos, legales y técnicos. Por ejemplo:
- Equilibrio entre apertura y derechos: en línea con el Reglamento de Gobernanza de Datos (DGA), se debe garantizar un acceso amplio a los datos sin comprometer derechos de propiedad intelectual, privacidad y equidad.
- Falta de transparencia y estándares de apertura: es importante que los modelos etiquetados como “abiertos” cumplan con criterios claros de transparencia en el uso de datos.
- Sesgos estructurales: muchos conjuntos de datos reflejan sesgos lingüísticos, geográficos y socioeconómicos que pueden perpetuar desigualdades en los sistemas de IA.
- Sostenibilidad ambiental: el uso intensivo de recursos para entrenar modelos de IA plantea desafíos de sostenibilidad que deben abordarse con prácticas más eficientes.
- Involucrar a más actores: actualmente, los desarrolladores y las grandes corporaciones dominan la conversación sobre IA, dejando fuera a comunidades afectadas y organizaciones públicas.
Una vez identificados los retos, el informe propone una estrategia para alcanzar el objetivo principal: una gobernanza de datos adecuada en los modelos de IA de código abiertos. Este enfoque está basado en dos pilares fundamentales.
Hacia un nuevo paradigma de gobernanza de datos
En la actualidad, el acceso y la gestión de los datos para entrenar modelos de IA están marcados por una creciente desigualdad. Mientras algunas grandes corporaciones tienen acceso exclusivo a vastos repositorios de datos, muchas iniciativas de código abierto y comunidades marginadas carecen de los recursos para acceder a datos representativos y de calidad. Para abordar este desequilibrio es necesario un nuevo enfoque en la gestión y uso de los datos en la IA de código abierto. El informe destaca dos cambios fundamentales en la manera en que se concibe la gobernanza de datos:
Por un lado, adoptar un enfoque de data commons que no es más que un modelo de acceso que garantiza el equilibrio entre la apertura de datos y la protección de derechos. Para ello, sería importante utilizar licencias innovadoras que permitan compartir datos sin explotación indebida. También es relevante crear estructuras de gobernanza que regulen el acceso y uso de datos. Y, por último, implementar mecanismos de compensación para comunidades cuyos datos son utilizados en inteligencia artificial.
Por otro lado, es necesario trascender la visión centrada en desarrolladores de IA e incluir a más actores en la gobernanza de datos, como:
- Propietarios de los datos y comunidades que generan contenido.
- Instituciones públicas que pueden promover estándares de apertura.
- Organizaciones de la sociedad civil que velen por la equidad y el acceso responsable a los datos.
Al adoptar estos cambios, la comunidad de IA podrá establecer un sistema más inclusivo, en el que los beneficios del acceso a datos se distribuyan de manera equitativa y respetuosa con los derechos de todas las partes interesadas. Según el informe, la implementación de estos modelos no solo aumentará la cantidad de datos disponibles para la IA de código abierto, sino que también fomentará la creación de herramientas más justas y sostenibles para la sociedad en su conjunto.
Consejos y estrategia
Para hacer efectiva una gobernanza de datos robusta en la IA de código abierto, el informe propone seis áreas de acción prioritarias:
- Preparación y trazabilidad de datos: mejorar la calidad y documentación de los conjuntos de datos.
- Mecanismos de licenciamiento y consentimiento: permitir a los creadores de datos definir su uso de manera clara.
- Custodia de datos: fortalecer la figura de intermediarios que gestionen datos de forma ética.
- Sostenibilidad ambiental: reducir el impacto del entrenamiento de IA con prácticas eficientes.
- Compensación y reciprocidad: garantizar que los beneficios de la IA lleguen a quienes contribuyen con datos.
- Intervenciones de política pública: promover regulaciones que incentiven la transparencia y el acceso equitativo a datos.

La inteligencia artificial de código abierto puede impulsar la innovación y la equidad, pero para lograrlo es necesario un enfoque de gobernanza de datos más inclusivo y sostenible. Adoptar modelos de datos comunes y ampliar el ecosistema de actores permitirá construir sistemas de IA más justos, representativos y responsables con el bien común.
El informe que publican Open Future y Open Source Initiative hace una llamada a la acción a desarrolladores, legisladores y sociedad civil para establecer normas compartidas y soluciones que equilibren la apertura de datos con la protección de derechos. Con una gobernanza de datos sólida, la IA de código abierto podrá cumplir su promesa de servir al interés público.
Blog
La Infraestructura de Pruebas para el Análisis de Datos (BDTI, por sus siglas en inglés, Big Data Test Infrastructure) es una herramienta financiada por el Programa Digital Europeo, que permite a las administraciones públicas realizar análisis con datos abiertos y herramientas de código abierto con el fin de impulsar la innovación.
Esta herramienta, alojada en la nube y de uso gratuito, se creó en 2019 para acelerar la transformación digital y social. Con este planteamiento y siguiendo también la Directiva Europea de Datos Abiertos, la Comisión Europea llegó a la conclusión de que, para lograr un impulso digital y económico, debía aprovecharse el poder de los datos de las administraciones públicas; es decir, aumentar su disponibilidad, calidad y usabilidad. Es así como nace BDTI, con el propósito de fomentar la reutilización de esta información proporcionando un entorno de prueba de análisis gratuito que permite a las administraciones públicas crear prototipos de soluciones en la nube antes de implementarlas en el entorno de producción de sus propias instalaciones.
¿Qué herramientas ofrece BDTI?
Big Data Test Infrastructure ofrece a las administraciones públicas europeas un conjunto de herramientas estándar de código abierto para el almacenamiento, procesamiento y análisis de sus datos. La plataforma consta de máquinas virtuales, clústeres de análisis e instalaciones de almacenamiento y de red. Las herramientas que ofrece son:
- Bases de datos: para almacenar datos y realizar consultas sobre los datos almacenados. El BDTI incluye actualmente una base de datos relacional (PostgreSQL), una base de datos orientada a documentos (MongoDB) y una base de datos gráfica (Virtuoso).
- Lago de datos: para almacenar grandes cantidades de datos estructurados y sin estructurar (MinIO). Los datos en bruto no estructurados se pueden procesar con configuraciones desplegadas de otros bloques de construcción (componentes BDTI) y almacenarse en un formato más estructurado dentro de la solución de lago de datos.
- Entornos de desarrollo: proporcionan las capacidades informáticas y las herramientas necesarias para realizar actividades estándar de análisis de datos sobre datos que provienen de fuentes externas, como lagos de datos y bases de datos.
- JupyterLab, un entorno de desarrollo interactivo y online para crear cuadernos Jupyter, código y datos.
- Rstudio, un entorno de desarrollo integrado para R, un lenguaje de programación para computación estadística y gráficos.
- KNIME, una plataforma de análisis, informes e integración de datos de código abierto que cuenta con componentes para el aprendizaje automático y la minería de datos, que se puede utilizar para todo el ciclo de vida de la ciencia de datos.
- H2O.ai, una plataforma de aprendizaje automático (machine learning o ML) e inteligencia artificial (IA) de código abierto diseñada para simplificar y acelerar la creación, el funcionamiento y la innovación con ML e IA en cualquier entorno.
- Procesamiento avanzado: también se pueden crear clústeres y herramientas para procesar grandes volúmenes de datos y realizar operaciones de búsqueda en tiempo real (Apache Spark, Elasticsearch y Kibana
- Visualización: BDTI también ofrece aplicaciones para visualizar datos como Apache Superset, capaz de manejar datos a escala de petabytes o Metabase.
- Orquestación: para la automatización de los procesos basados en datos durante todo su ciclo de vida, desde la preparación de datos hasta la toma de decisiones basadas en ellos y la realización de acciones basadas en esas decisiones, se ofrece:
- Apache Airflow, una plataforma de gestión de flujos de trabajo de código abierto que permite programar y ejecutar fácilmente canalizaciones de datos complejas.
A través de estas herramientas que se encuentran en entorno nube, los trabajadores públicos de países de los países de la UE pueden crear sus propios proyectos piloto para demostrar el valor que los datos pueden aportar a la innovación. Una vez finalizado el proyecto, los usuarios tienen la posibilidad descargar el código fuente y los datos para continuar el trabajo por sí mismos, utilizando entornos de su elección. Además, la sociedad civil, la academia y el sector privado pueden participar en estos proyectos piloto, siempre y cuando haya una entidad pública involucrada en el caso de uso.
Casos de éxito
Estos recursos han posibilitado la creación de proyectos diversos en diferentes países de la UE. En la web de BDTI, se recogen algunos ejemplos de casos de uso. Por ejemplo, Eurostat llevó a cabo un proyecto piloto en el que se utilizaron datos abiertos de anuncios de empleo en internet para mapear la situación de los mercados laborales europeos. Otros casos de éxito fue la optimización de la contratación pública por parte de la Agencia Noruega de Digitalización, los esfuerzos de intercambio de datos por parte de la European Blood Alliance y el trabajo para facilitar la comprensión del impacto de COVID-19. sobre la ciudad de Florencia .
En España, BDTI hizo posible un proyecto de minería de datos en la Conselleria de Sanitat de la Comunidad Valenciana. Gracias a BDTI se pudieron extraer conocimientos de la enorme cantidad de artículos clínicos científicos; una tarea que apoyó a clínicos y gestores en sus prácticas clínicas y en su trabajo diario.

Cursos, boletín y otros recursos
Además de publicar casos de uso, la web Big Data Test Infrastructure ofrece un curso online y gratuito para aprender a sacar el máximo partido a BDTI. Este curso se centra en un caso de uso altamente práctico: analizar la financiación de proyectos verdes e iniciativas en regiones contaminadas de la UE, utilizando datos abiertos de data.europa.eu y otras fuentes abiertas.
Por otro lado, recientemente se ha lanzado una newsletter de envío mensual sobre las últimas noticias de BDTI, buenas prácticas y oportunidades de análisis de datos para el sector público.
En definitiva, la reutilización de los datos del sector público (RISP) es una prioridad para la Comisión Europea y BDTI (Big Data Test Infrastructure) una de las herramientas que contribuyen a su desarrollo. Si trabajas en la administración pública y te interesa utilizar BDTI regístrate aquí.
Evento
El próximo 1 de junio, la capital española albergará la cuarta edición de la Feria y Congreso sobre FLOSS (software y código libre) y Open Economy. El objetivo del Open Expo es reunir anualmente a las principales empresas e instituciones, desarrolladores, hackers, expertos, proveedores y usuarios para conocer soluciones tecnológicas y tendencias sobre código abierto, software libre, open data e innovación.
Desde su origen en 2012, cada una de las ferias organizadas ha buscado fomentar el uso y desarrollo del software libre y abierto para, así, impulsar la filosofía colaborativa y democratizar el acceso a las tecnologías de la información. Para esto, han tenido lugar varios eventos dedicados a temáticas específicas como el comercio electrónico, la inteligencia de negocio, los gestores de contenidos o el elearning, entre otras.
En esta ocasión, el Open Expo está enfocado a abordar los últimos desafíos relativos al código abierto y la transformación digital. Una oportunidad para descubrir cómo este tipo de tecnología permite modernizar el tejido empresarial y ayudar a las compañías en su camino hacia la innovación y la transformación digital de las operaciones corporativas.
A este respecto, la organización del evento ha abierto una convocatoria para encontrar ponentes que participen en el congreso compartiendo sus casos de éxito y experiencias en el ámbito de las tecnologías abiertas, mostrando cómo el open source y el software libre han ayudado a mejorar las actividades de sus empresas o bien presentando sus proyectos de código abierto.
Para participar es necesario enviar la candidatura antes del 2 de marzo a través de la página oficial del evento; un jurado analizará las ideas y seleccionará, antes del 20 del mismo mes, aquellas propuestas más relevantes en el campo a tratar.
De forma paralela, entre las actividades organizadas este año, a parte de la sala de expositores donde las principales compañías de la industria muestran sus servicios y productos, también se celebrará el foro de inversión, Open StartUp Connector, donde una decena de start-ups presentarán a posibles inversores sus proyectos TIC basados en código/datos abiertos, o bien desarrollados a través de herramientas y/o software libre.
A su vez, también están programadas actividades de networking con expertos para debatir acerca de soluciones relacionadas con la ciberseguridad, big data y el Internet de las Cosas y, a su vez, tendrá lugar los premio Open Awards España 2017 que galardonan a las mejores soluciones con tecnología open source a nivel nacional.