Blog
Data visualization is not a recent discipline. For centuries, people have used graphs , maps, and diagrams to represent complex information. Classic examples such as the statistical maps of the nineteenth century or the graphs used in the press show that the need to "see" the data in order to understand it has always existed.
For a long time, creating visualizations required specialized knowledge and access to professional tools, which limited their production to very specific profiles. However, the digital and technological revolution has profoundly transformed this landscape. Today, anyone with access to a computer and data can create visualizations. Tools have been democratized, many of them are free or open source, and visualization work has extended beyond design to integrate into areas such as statistics, data science, academic research, public administration, or education.
Today, data visualization is a transversal competence that allows citizens to explore public information, institutions to better communicate their policies, and reusers to generate new services and knowledge from open data. In this post we present some of the most accessible and used options in data visualization.
A broad and diverse ecosystem of tools
The ecosystem of data visualization tools is broad and diverse, both in functionalities and levels of complexity. There are options designed for a first exploration of the data, others aimed at in-depth analysis and some designed to create interactive visualizations or complex digital narratives.
This variety allows you to tailor the visualization to different contexts and goals—from understanding a dataset in advance to publishing interactive charts, dashboards, or maps on the web.
The Data Visualization Society's annual survey reflects this diversity and shows how the use of certain tools evolves over time, consolidating some widely known options and giving way to new solutions that respond to emerging needs. These are some of the tools mentioned in the survey, ordered according to usage profiles.
The following criteria have been taken into account for the preparation of this list:
- Degree of use and maturity of the tool.
- Free access, free or with open versions.
- Useful for projects related to public data.
- Priority to open tools or with free versions.
Simple tools to get started
These tools are characterized by visual interfaces, a low learning curve, and the ability to create basic charts quickly. They are especially useful for getting started exploring open datasets or for outreach activities.
- Excel: it is one of the most widespread and well-known tools. It allows basic graphs and first data scans to be carried out in a simple way. While not specifically designed for advanced visualization, it is still a common gateway to working with data and its graphical representation.
- Google Sheets: works as a free and collaborative alternative to Excel. Its main advantage is the ability to work in a shared way and publish simple graphics online, which facilitates the dissemination of basic visualizations.
- Datawrapper: widely used in public communication and data journalism. It allows you to create clear graphs, maps, and interactive tables without the need for technical knowledge. It is particularly suitable for explaining data in a way that is understandable to a wide audience.
- RAWGraphs: free software tool aimed at visual exploration. It allows you to experiment with less common types of charts and discover new ways to represent data. It is especially useful in exploratory phases.
- Canva: While its approach is more informative than analytical, it can be useful for creating simple visual pieces that integrate basic graphics with design elements. It is suitable for visual communication of results, not so much for data analysis.
Data exploration and analysis tools
This group of tools is geared towards profiles that want to go beyond basic charts and perform more structured analysis. Many of them are open and widely consolidated in the field of data analysis.
- A: Free programming language widely used in statistics and data analysis. It has a wide ecosystem of packages that allow you to work with public data in a reproducible and transparent way.
- Ggplot2: R language display library. It is one of the most powerful tools for creating rigorous and well-structured graphs, both for analysis and for communicating results.
- Python (Matplotlib and Plotly): Python is one of the most widely used languages in data analysis. Matplotlib allows you to create customizable static charts, while Plotly makes it easy to create interactive visualizations. Together they offer a good balance between power and flexibility.
- Apache Superset: Open source platform for data analysis and dashboard creation. It has a more institutional and scalable approach, making it suitable for organizations that work with large volumes of public data.
This block is especially relevant for open data reusers and intermediate technical profiles who seek to combine analysis and visualization in a systematic way.
Tools for interactive and web visualization
These tools allow you to create advanced visualizations for publication in web environments. Although they require greater technical knowledge, they offer great flexibility and expressive possibilities.
- D3.js: it is one of the benchmarks in web visualization. It is based on open standards and allows full control over the visual representation of data. Its flexibility is very high, although so is its complexity.
In this practical exercise you can see how to use this library
- Vega and Vega-Lite: declarative languages for visualization that simplify the use of D3. They allow you to define graphics in a structured and reproducible way, offering a good balance between power and simplicity.
- Observable: interactive environment closely linked to D3 and Vega. It's especially useful for creating educational examples, prototypes, and exploratory visualizations that combine code, text, and graphics.
- Three.js and WebGL: technologies aimed at advanced and three-dimensional visualizations. Its use is more experimental and is usually linked to dissemination projects or visual research.
In this section, it should be noted that, although the technical barriers are greater, these tools allow for the creation of rich interactive experiences that can be very effective in communicating complex public data.
Geospatial data and mapping tools
Geographic visualization is especially relevant in the field of open data, since a large part of public information has a territorial dimension. In this field, free software has a prominent weight and is closely aligned with use in public administrations.
- QGIS: a benchmark in free software for geographic information systems (GIS). It is widely used in public administrations and allows spatial data to be analysed and visualised in great detail.
- ArcGIS: very widespread in the institutional field. Although it is not free software, its use is well established and is part of the regular ecosystem of many public organizations.
- Mapbox: platform aimed at creating interactive web maps. It is widely used in online visualization projects and allows geographic data to be integrated into web applications.
- Leaflet: A popular open-source library for creating interactive maps on the web. It is lightweight, flexible, and widely used in geographic open data reuse projects.
This toolkit facilitates the territorial representation of data and its reuse in local, regional or national contexts.
In conclusion, the choice of a visualization tool depends largely on the goal being pursued. Learning and experimenting is not the same as analyzing data in depth or communicating results to a wide audience. Therefore, it is useful to reflect beforehand on the type of data available, the audience to which the visualization is aimed and the message you want to convey.
Betting on accessible and open tools allows more people to explore, interpret and communicate public data. In this sense, visualising data is also a way of bringing information closer to citizens and encouraging its reuse.
Blog
Data visualizations act as bridges between complex information and human understanding. A well-designed graph can communicate in seconds data that would take minutes or even hours to decipher in tabular format. What's more, interactive visualizations allow each user to explore data from their own perspective, filtering, comparing, and uncovering personalized insights.
To achieve these ends there are multiple tools, some of which we have addressed on previous occasions. Today we are approaching a new example: the free bookstore D3.js. In this post, we explain how it allows you to generate useful and attractive data visualizations together with the open source tool Observable.
What is D3?
D3.js (Data-Driven Documents) is a JavaScript library that allows you to create custom data visualizations in web browsers. Unlike tools that offer predefined charts, D3.js provides the fundamental elements to build virtually any type of visualization imaginable.
The library is completely free and open source, published under a BSD license, which means that any person or organization can use, modify, and distribute it without restrictions. This feature has contributed to its widespread adoption: international media such as The New York Times, The Guardian, Financial Times, and local media such as El País or ABC use D3.js to create journalistic visualizations that help tell stories with data.
D3.js works by manipulating the browser's DOM (Document Object Model). In practical terms, this means that it takes information (e.g., a CSV file with population data) and transforms it into visual elements (circles, bars, lines) that the browser can display. The power of D3.js lies in its flexibility: it doesn't impose a specific way to visualize data, but rather provides the tools to create exactly what is needed.
What is Observable?
Observable is a web-based platform for creating and sharing code, specially designed to work with data and visualizations. Although it offers a freemium service with some free and some paid features, it maintains an open-source philosophy that is particularly relevant for working with public data.
The distinguishing feature of Observable is its "notebook" format. Similar to tools like Jupyter Notebooks in Python, an Observable notebook combines code, visualizations, and explanatory text into a single interactive document. Each cell in the notebook can contain JavaScript code that runs immediately, displaying results instantly. This creates an ideal experimentation environment for exploring data.
You can see it in practice in this data science exercise that we have published in datos.gob.es
Observable integrates naturally with D3.js and other display libraries. In fact, the creator of D3.js is also one of the founders of Observable, so both tools work together in a fluid way. Observable notebooks can be shared publicly, allowing other users to view both the code and the results, fork them to create their own versions, or integrate them into their own projects.
Advantages of the tool to work with all types of data
Both D3.js and Observable have features that can be useful for working with data, including open data:
- Transparency and reproducibility: by publishing a visualization created with these tools, it is possible to share both the final result and the entire data transformation process. Anyone can inspect the code, verify the calculations, and reproduce the results. This transparency is essential when working with public information, where trust and verifiability are essential.
- No licensing costs: Both D3.js and the free version of Observable allow you to create and publish visualizations without the need to purchase software licenses. This removes economic barriers for organizations, journalists, researchers, or citizens who want to work with open data.
- Standard web formats: The created visualizations work directly in web browsers without the need for plugins or additional software. This makes it easy to integrate them into institutional websites, newspaper articles or digital reports, making them accessible from any device.
- Community and resources: There is a large community of users who share examples, tutorials, and solutions to common problems. Observable, in particular, houses thousands of public notebooks that serve as examples and reusable templates.
- Technical flexibility: Unlike tools with predefined options, these libraries allow you to create completely customized visualizations that are exactly tailored to the specific needs of each dataset or story you want to tell.
It is important to note that these tools require programming knowledge, specifically JavaScript. For people with no programming experience, there is a learning curve that can be steep initially. Other tools such as spreadsheets or visualization software with graphical interfaces may be more appropriate for users looking for quick results without writing code.
For those looking for open source alternatives with a smooth learning curve, there are visual interface-based tools that don't require programming. For example, RawGraphs allows you to create complex visualizations by simply dragging and dropping files, while Datawrapper is an excellent and very intuitive option for generating ready-to-publish charts and maps.
In addition, there are numerous open source and commercial alternatives for visualizing data: Python with libraries such as Matplotlib or Plotly, R with ggplot2, Tableau Public, Power BI, among many others. In the didactic section of visualization and data science exercises of datos.gob.es you can find practical examples of how to use some of them.
In summary, the choice of tools should always be based on an assessment of specific requirements, available resources, and project objectives. The important thing is that open data is transformed into accessible knowledge, and there are multiple ways to achieve this goal. D3.js and Observable offer one of these paths, particularly suited to those looking to combine technical flexibility with principles of openness and transparency. If you know of any other tool or would like us to delve into another topic, please send it to us through our social networks or in the contact form.
Blog
In 2010, following the devastating earthquake in Haiti, hundreds of humanitarian organizations arrived in the country ready to help. They encountered an unexpected obstacle: there were no updated maps. Without reliable geographic information, coordinating resources, locating isolated communities, or planning safe routes was nearly impossible.
That gap marked a turning point: it was the moment when the global OpenStreetMap (OSM) community demonstrated its enormous humanitarian potential. More than 600 volunteers from all over the world organized themselves and began mapping Haiti in record time. This gave impetus to the Humanitarian OpenStreetMap Team project.
What is Humanitarian OpenStreetMap Team?
Humanitarian OpenStreetMap Team, known by the acronym HOT, is an international non-profit organization dedicated to improving people's lives through accurate and accessible geographic data. Their work is inspired by the principles of OSM, the collaborative project that seeks to create an open, free and editable digital map for anyone.
The difference with OSM is that HOT is specifically aimed at contexts where the lack of data directly affects people's lives: it is about providing data and tools that allow more informed decisions to be made in critical situations. That is, it applies the principles of open software and data to collaborative mapping with social and humanitarian impact.
In this sense, the HOT team not only produces maps, but also facilitates technical capacities and promotes new ways of working tools, the for different actors who need precise spatial data. Their work ranges from immediate response when a disaster strikes to structural programs that strengthen local resilience to challenges such as climate change or urban sprawl.
Four priority geographical areas
While HOT is not limited to a single country or region, it has established priority areas where its mapping efforts have the greatest impact due to significant data gaps or urgent humanitarian needs. It currently works in more than 90 countries and organizes its activities through four Open Mapping Hubs (regional centers) that coordinate initiatives according to local needs:
- Asia-Pacific: challenges range from frequent natural disasters (such as typhoons and earthquakes) to access to remote rural areas with poor map coverage.
- Eastern and Southern Africa: this region faces multiple intertwined crises (droughts, migratory movements, deficiencies in basic infrastructure) so having up-to-date maps is key for health planning, resource management and emergency response.
- West Africa and North Africa: in this area, HOT promotes activities that combine local capacity building with technological projects, promoting the active participation of communities in the creation of useful maps for their environment.
- Latin America and the Caribbean: frequently affected by hurricanes, earthquakes, and volcanic hazards, this region has seen a growing adoption of collaborative mapping in both emergency response and urban development and climate resilience initiatives.
The choice of these priority areas is not arbitrary: it responds to contexts in which the lack of open data can limit rapid and effective responses, as well as the ability of governments and communities to plan their future with reliable information.
Open source tools developed by HOT
An essential part of HOT's impact lies in the open-source tools and platforms that facilitate collaborative mapping and the use of spatial data in real-world scenarios. To this end, an E2E Value Chain Mapping was developed, which is the core methodology that enables communities to move from image capture and mapping to impact. This value chain supports all of its programs, ensuring that mapping is a transformative process based on open data, education, and community empowerment.
These tools not only support HOT's work, but are available for anyone or community to use, adapt, or expand. Specifically, tools have been developed to create, access, manage, analyse and share open map data. You can explore them in the Learning Center, a training space that offers capacity building, skills strengthening and an accreditation process for interested individuals and organisations. These tools are described below:
It allows drone flights to be planned for up-to-date, high-resolution aerial imagery, which is critical when commercial imagery is too expensive. In this way, anyone with access to a drone – including low-cost and commonly used models – can contribute to a global repository of free and open imagery, democratizing access to geospatial data critical to disaster response, community resilience, and local planning.
The platform coordinates multiple operators and generates automated flight plans to cover areas of interest, making it easy to capture 2D and 3D images accurately and efficiently. In addition, it includes training plans and promotes safety and compliance with local regulations, supporting project management, data visualization and collaborative exchange between pilots and organizations.

Figure 1. Drone Tasking Manager (DroneTM) screenshot. Source: Humanitarian OpenStreetMap Team (HOT).
It is an open-source platform that offers access to a community library of openly-licensed aerial imagery, obtained from satellites, drones, or other aircraft. It has a simple interface where you can zoom in on a map to search for available images. OAM allows you to both download and contribute new imagery, thus expanding a global repository of visual data that anyone can use and plot in OpenStreetMap.
All imagery hosted on OpenAerialMap is licensed under CC-BY 4.0, which means that they are publicly accessible and can be reused with attribution, facilitating their integration into geospatial analysis applications, emergency response projects, or local planning initiatives. OAM relies on the Open Imagery Network (OIN) to structure and serve these images.
It facilitates collaborative mapping in OpenStreetMap. Its main purpose is to coordinate thousands of volunteers from all over the world to aggregate geographic data in an organized and efficient way. To do this, it breaks down a large mapping project into small "tasks" that can be completed quickly by people working remotely.
The way it works is simple: projects are subdivided into grids, each assignable to a volunteer in order to map out elements such as streets, buildings, or points of interest in OSM. Each task is validated by experienced mappers to ensure data quality. The platform clearly shows which areas still need mapping or review, avoiding duplication and improving the efficiency of collaborative work.

Figure 2. Tasking Manager screenshot. Source: Humanitarian OpenStreetMap Team (HOT).
It uses artificial intelligence to assist the mapping process in OpenStreetMap for humanitarian purposes. Through computer vision models, fAIr analyzes satellite or aerial images and suggests the detection of geographical elements such as buildings, roads, watercourses or vegetation from free images such as those of OpenAerialMap. The idea is that volunteers can use these predictions as an aid to map faster and more accurately, without performing automated mass imports, always integrating human judgment into the validation of each element.
One of the most outstanding features of fAIr is that the creation and training of AI models is in the hands of the mapping communities themselves: users can generate their own training sets adjusted to their region or context, which helps reduce biases of standard models and makes predictions more relevant to local needs.
It is a mobile and web application that facilitates the coordination of mapping campaigns directly in the field. Field-TM is used in conjunction with OpenDataKit (ODK), a data collection platform on Android that allows information to be entered in the field using mobile devices themselves. Thanks to it, volunteers can enter geospatial information verified by local observation, such as the purpose of each building (whether it is a store, a hospital, etc.).
The app provides an interface to assign tasks, track progress, and ensure data consistency. Its main purpose is to improve the efficiency, organization and quality of fieldwork by enriching it with local information, as well as to reduce duplications, avoid uncovered areas and allow clear monitoring of the progress of each collaborator in a mapping campaign.
Transform conversations from instant messaging apps (like WhatsApp) into interactive maps. In many communities, especially in disaster-prone or low-tech literacy areas, people are already using chat apps to communicate and share their location. ChatMap leverages those exported messages, extracts location data along with texts, photos, and videos, and automatically renders them on a map, without the need for complex installations or advanced technical knowledge.
This solution works even in conditions of limited or offline connectivity, relying on the phone's GPS signal to record locations and store them until the information can be uploaded.

Figure 3. ChatMap screenshot. Source: OpenStreetMap Humanitarian Team (HOT).
Facilitate access to and download of up-to-date geospatial data from OpenStreetMap in useful formats for analysis and projects. Through this web platform, you can select an area of interest on the map, choose what data you want (such as roads, buildings, or services), and download that data in multiple formats, such as GeoJSON, Shapefile, GeoPackage, KML, or CSV. This allows the information to be used in GIS (Geographic Information Systems) software or integrated directly into custom applications. You can also export all the data for a zone or download data associated with a specific project from the Tasking Manager.
The tool is designed to be accessible to both technical analysts and non-GIS experts: in a matter of minutes, custom OSM extracts can be generated without the need to install specialized software. It also offers an API and data quality metrics.
It is an open-source interactive map creation platform that allows anyone to easily visualize, customize, and share geospatial data. Based on OpenStreetMap maps, uMap allows you to add custom layers, markers, lines and polygons, manage colors and icons, import data in common formats (such as GeoJSON, GPX or KML) and choose licenses for the data, without the need to install specialized software. The maps created can be embedded in websites or shared using links.
The tool offers templates and integration options with other HOT tools, such as ChatMap and OpenAerialMap, to enrich the data on the map.
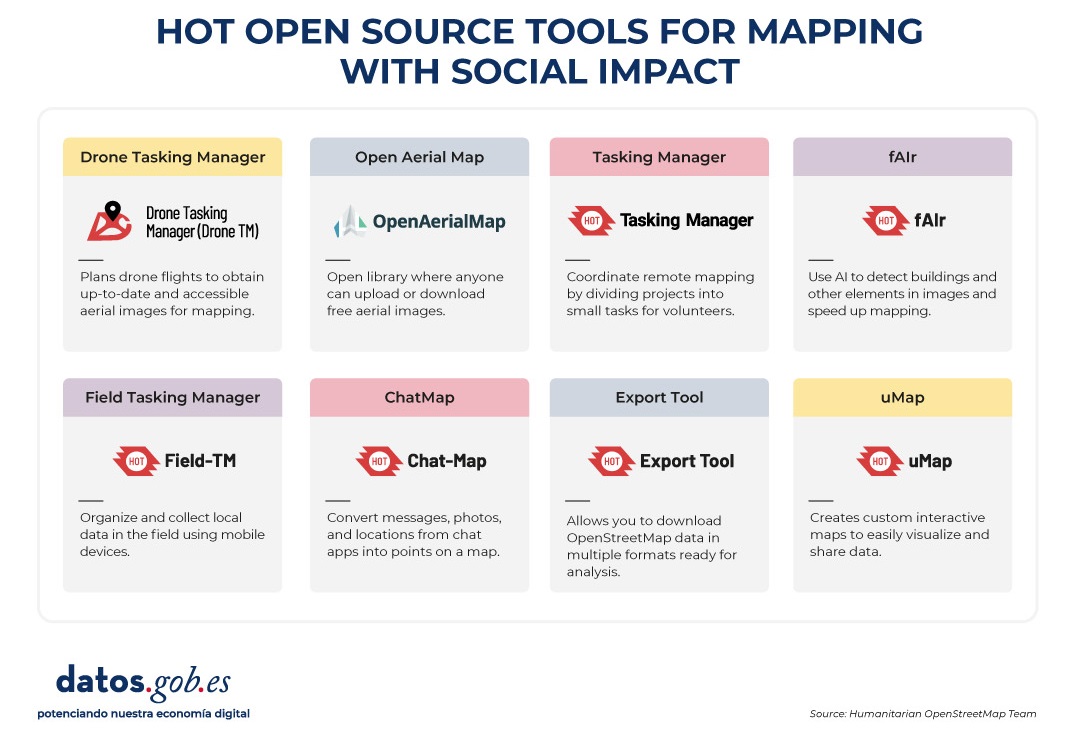
Figure 4. HOT open source tools for mapping with social impact. Source: Humanitarian OpenStreetMap Team (HOT).
All of these tools are available to local communities around the world. HOT also offers training to promote its use and improve the impact of open data in humanitarian responses.
How can you join HOT's impact?
HOT is built alongside a global community that drives the use of open data to strengthen decision-making and save lives. If you represent an organization, university, collective, public agency, or community initiative and have a project idea or interest in an alliance, the HOT team is open to exploring collaborations. You can write to partnerships@hotosm.org.
When communities have access to accurate data, open tools, and the knowledge to generate geospatial information on an ongoing basis, they become informed agents, ready to make decisions in any situation. They are better equipped to identify climate risks, respond to emergencies, solve local problems, and mobilize support. Open mapping, therefore, does not only represent territories: it empowers people to transform their reality with data that can save lives.
Blog
Open source artificial intelligence (AI) is an opportunity to democratise innovation and avoid the concentration of power in the technology industry. However, their development is highly dependent on the availability of high quality datasets and the implementation of robust data governance frameworks. A recent report by Open Future and the Open Source Initiative (OSI) analyses the challenges and opportunities at this intersection, proposing solutions for equitable and accountable data governance. You can read the full report here.
In this post, we will analyse the most relevant ideas of the document, as well as the advice it offers to ensure a correct and effective data governance in artificial intelligence open source and take advantage of all its benefits.
The challenges of data governance in AI
Despite the vast amount of data available on the web, accessing and using it to train AI models poses significant ethical, legal and technical challenges. For example:
- Balancing openness and rights: In line with the Data Governance Regulation (DGA), broad access to data should be guaranteed without compromising intellectual property rights, privacy and fairness.
- Lack of transparency and openness standards: It is important that models labelled as "open" meet clear criteria for transparency in the use of data.
- Structural biases: Many datasets reflect linguistic, geographic and socio-economic biases that can perpetuate inequalities in AI systems.
- Environmental sustainability: the intensive use of resources to train AI models poses sustainability challenges that must be addressed with more efficient practices.
- Engage more stakeholders: Currently, developers and large corporations dominate the conversation on AI, leaving out affected communities and public organisations.
Having identified the challenges, the report proposes a strategy for achieving the main goal: adequate data governance in open source AI models. This approach is based on two fundamental pillars.
Towards a new paradigm of data governance
Currently, access to and management of data for training AI models is marked by increasing inequality. While some large corporations have exclusive access to vast data repositories, many open source initiatives and marginalised communities lack the resources to access quality, representative data. To address this imbalance, a new approach to data management and use in open source AI is needed. The report highlights two fundamental changes in the way data governance is conceived:
On the one hand, adopting a data commons approach which is nothing more than an access model that ensures a balance between data openness and rights protection.. To this end, it would be important to use innovative licences that allow data sharing without undue exploitation. It is also relevant to create governance structures that regulate access to and use of data. And finally, implement compensation mechanisms for communities whose data is used in artificial intelligence.
On the other hand, it is necessary to transcend the vision focused on AI developers and include more actors in data governance, such as:
- Data owners and content-generating communities.
- Public institutions that can promote openness standards.
- Civil society organisations that ensure fairness and responsible access to data.
By adopting these changes, the AI community will be able to establish a more inclusive system, in which the benefits of data access are distributed in a manner that is equitable and respectful of the rights of all stakeholders. According to the report, the implementation of these models will not only increase the amount of data available for open source AI, but will also encourage the creation of fairer and more sustainable tools for society as a whole.
Advice and strategy
To make robust data governance effective in open source AI, the report proposes six priority areas for action:
- Data preparation and traceability: Improve the quality and documentation of data sets.
- Licensing and consent mechanisms: allow data creators to clearly define their use.
- Data stewardship: strengthen the role of intermediaries who manage data ethically.
- Environmental sustainability: Reduce the impact of AI training with efficient practices.
- Compensation and reciprocity: ensure that the benefits of AI reach those who contribute data.
- Public policy interventions: promote regulations that encourage transparency and equitable access to data.

Open source artificial intelligence can drive innovation and equity, but to achieve this requires a more inclusive and sustainable approach to data governance. Adopting common data models and broadening the ecosystem of actors will build AI systems that are fairer, more representative and accountable to the common good.
The report published by Open Future and Open Source Initiative calls for action from developers, policymakers and civil society to establish shared standards and solutions that balance open data with the protection of rights. With strong data governance, open source AI will be able to deliver on its promise to serve the public interest.
Blog
The Big Data Test Infrastructure (BDTI) is a tool funded by the European Digital Agenda, which enables public administrations to perform analysis with open data and open source tools in order to drive innovation.
This free-to-use, cloud-based tool was created in 2019 to accelerate digital and social transformation. With this approach and also following the European Open Data Directive, the European Commission concluded that in order to achieve a digital and economic boost, the power of public administrations' data should be harnessed, i.e. its availability, quality and usability should be increased. This is how BDTI was born, with the purpose of encouraging the reuse of this information by providing a free analysis test environment that allows public administrations to prototype solutions in the cloud before implementing them in the production environment of their own facilities.
What tools does BDTI offer?
Big Data Test Infrastructure offers European public administrations a set of standard open source tools for storing, processing and analysing their data. The platform consists of virtual machines, analysis clusters, storage and network facilities. The tools it offers are:
- Databases: to store data and perform queries on the stored data. The BDTI currently includes a relational database(PostgreSQL), a document-oriented database(MongoDB) and a graph database(Virtuoso).
- Data lake: for storing large amounts of structured and unstructured data (MinIO). Unstructured raw data can be processed with deployed configurations of other building blocks (BDTI components) and stored in a more structured format within the data lake solution.
- Development environments: provide the computing capabilities and tools necessary to perform standard data analysis activities on data from external sources, such as data lakes and databases.
- JupyterLab, an interactive, online development environment for creating Jupyter notebooks, code and data.
- Rstudio, an integrated development environment for R, a programming language for statistical computing and graphics.
- KNIME, an open source data integration, reporting and analytics platform with machine learning and data mining components, can be used for the entire data science lifecycle.
- H2O.ai, an open sourcemachine learning ( ML) and artificial intelligence (AI) platform designed to simplify and accelerate the creation, operation and innovation with ML and AI in any environment.
- Advanced processing: clusters and tools can also be created to process large volumes of data and perform real-time search operations(Apache Spark, Elasticsearch and Kibana)
- Display: BDTI also offers data visualisation applications such as Apache Superset, capable of handling petabyte-scale data, or Metabase.
- Orchestration: for the automation of data-driven processes throughout their lifecycle, from preparing data to making data-driven decisions and taking actions based on those decisions, is offered:
- Apache Airflow, an open source workflow management platform that allows complex data pipelines to be easily scheduled and executed.
Through these cloud-based tools, public workers in EU countries can create their own pilot projects to demonstrate the value that data can bring to innovation. Once the project is completed, users have the possibility to download the source code and data to continue the work themselves, using environments of their choice. In addition, civil society, academia and the private sector can participate in these pilot projects, as long as there is a public entity involved in the use case.
Success stories
These resources have enabled the creation of various projects in different EU countries. Some examples of use cases can be found on the BDTI website. For example, Eurostat carried out a pilot project using open data from internet job advertisements to map the situation of European labour markets. Other success stories included the optimisation of public procurement by the Norwegian Agency for Digitisation, data sharing efforts by the European Blood Alliance and work to facilitate understanding of the impact of COVID-19 on the city of Florence .
In Spain, BDTI enabled a data mining project atthe Conselleria de Sanitat de la Comunidad Valenciana. Thanks to BDTI, knowledge could be extracted from the enormous amount of scientific clinical articles, a task that supported clinicians and managers in their clinical practices and daily work.

Courses, newsletter and other resources
In addition to publishing use cases, theBig Data Test Infrastructure website offers an free online course to learn how to get the most out of BDTI. This course focuses on a highly practical use case: analysing the financing of green projects and initiatives in polluted regions of the EU, using open data from data.europa.eu and other open sources.
In addition, a monthly newsletter on the latest BDTI news, best practices and data analytics opportunities for the public sector has recently been launched .
In short, the re-use of public sector data (RISP) is a priority for the European Commission and BDTI(Big Data Test Infrastructure) is one of the tools contributing to its development. If you work in the public administration and you are interested in using BDTI register here.
Evento
On June 1, Madrid will host the fourth edition of Conference on FLOSS (software and free code) and Open Economy. The aim of the Open Expo is bringing together leading companies and institutions, developers, hackers, experts, suppliers and users to learn about technology solutions and trends on open source, open source, open data and innovation.
Since 2012, each of the events has sought to promote the use and development of free and open software to boost the collaborative philosophy and democratize the access to information technologies. For that purpose, there have been several events dedicated to specific topics such as e-commerce, business intelligence, content managers or elearning, among others.
On this occasion, the Open Expo is focused on addressing the latest challenges related to open source and digital transformation. An opportunity to discover how this technology can modernize businesses and help companies on their way to innovation and the digital transformation of their corporate operations.
In this regard, the organisers of the event has launched a call to find speakers who participate in the congress sharing their success stories and experiences in the field of open technologies, showing how open source and free software have helped improve their business activities or presenting their open source projects.
To participate, it is necessary to apply before March 2 through the official page of the event; a jury will analyze the proposals and select the most relevant ideas in the field to be discussed.
In addition, among the activities organized this year, apart from the showroom where the main companies of the industry show their services and products, there will be an investment forum, Open StartUp Connector, where a twelve start-ups will present to potential investors their ICT projects based onpen code/data, or developed through free tools or software.
At the same time, networking activities with experts are also planned to discuss on cybersecurity, big data and IoT solutions and, moreover, the Open Awards Spain 2017 will take place, which awardsthe best solutions developed with open source technology at the national level.