Blog
La apuesta del gigante tecnológico Google con los datos abiertos ha quedado patente en distintas iniciativas llevadas a cabo en los últimos años. Por un lado, pusieron en marcha el buscador Google Dataset Search, que facilita la localización de datos abiertos publicados en cientos de repositorios de instituciones internacionales y gobiernos, entre los que se encuentra datos.gob.es. Por otro, lanzaron su propia iniciativa de apertura de datos, donde se ofrecen conjuntos de datos estandarizados y legibles por máquinas con el objetivo de ser utilizados por sistemas de machine learning. Esta última iniciativa se enmarca dentro de Google Research, el portfolio de proyectos de investigación e innovación de Google: desde la predicción de la propagación del COVID-19 hasta el diseño de algoritmos, pasando por el aprendizaje de la traducción automática de un mayor número de idiomas, entre otros. En estos y otros proyectos, Google no solo ha apostado por la publicación de datasets, si no que la propia compañía también actúa como reutilizador de datos públicos. En este post vamos a algunos ejemplos de soluciones y proyectos de Google que integran en su operativa datos abiertos.
Google Earth
A través de un globo terráqueo virtual basado en imágenes satelitales, Google Earth permite visualizar múltiples cartografías. Los usuarios pueden explorar territorios en 3D y añadir marcadores o dibujar líneas y áreas, entre otras herramientas.
Una de sus últimas actualizaciones ha sido la incorporación de la función Timelapse, la cual ha supuesto la integración de 24 millones de fotos satelitales captadas durante en los últimos 37 años (concretamente, entre 1984 y 2020). De esta forma se pueden observar los cambios en las distintas regiones del planeta. Entre otras informaciones, la solución muestra los cambios forestales, el crecimiento urbano o el calentamiento de nuestro planeta, lo que permite tomar consciencia de la crisis climática que vivimos para poder actuar en consecuencia. Se trata por tanto de una solución fundamental para la educación ambiental, con un gran potencial de uso en las clases.
Los datos integrados provienen del programa Landsat del Servicio Geológico de los Estados Unidos, y del programa Copernicus y los satélites Sentinel de la Unión Europea. En concreto, se contaba con 20 petabytes de imágenes satelitales que se han puesto a disposición de los usuarios en un único mosaico de vídeo de gran tamaño y resolución, para lo cual han sido necesarios más de 2 millones de horas de procesamiento. Cabe destacar que tanto los datos de Copernicus como de Landsat están abiertos a la reutilización de cualquier particular u empresa que desee poner en marcha sus propios servicios y productos.
Traductor de Google
Otra de las herramientas más conocidas del gigante tecnológico es su traductor, que se pudo en marcha en 2006. Diez años más tarde se actualizó con el sistema de traducción automática neural de Google (GNMT), que utiliza técnicas más modernas de machine learning para su entrenamiento.Google no hace públicos los datos exactos que utiliza para el entrenamiento del sistema, aunque en su informe Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation sí destacan que han realizado pruebas de referencia con dos corpus disponibles públicamente: WMT'14 English-to-French y WMT´14 English-German.
Aunque se ha avanzado mucho, el sistema todavía no se iguala al nivel de calidad que se obtiene con una traducción realizada por un ser humano experto en el campo, sobre todo en el caso de los idiomas más minoritarios, por lo que se siguen realizando ajustes y avances. Otra área donde se debe también seguir trabajando en los sesgos de los datos que utilizan para entrenar el sistema y que puede desencadenar en estereotipos. Por ejemplo, se ha detectado que el traductor introduce sesgos al utilizar el masculino y femenino en la traducción de frases de idiomas neutros, sin género, como el inglés o húngaro. En estos casos, se utiliza por defecto el femenino para tareas relacionadas con los cuidados y la belleza, y el masculino para opciones profesionales mejor valoradas. El gigante tecnológico ha indicado que ya está trabajando en la resolución de esta problemática.
Otros ejemplos de Google Research
Dentro del ya mencionado Google Research se llevan distintos proyectos, algunos de ellos muy ligados a la reutilización. Por ejemplo, en el contexto de pandemia actual, pusieron en marcha los informes de movilidad con información anónima sobre tendencias de desplazamiento –los cuales se pueden descargar en formato csv. Estos informes permiten comprender el impacto de las políticas de restricción de movimientos, así como realizar previsiones económicas. Los datos han sido aprovechados también por sus propios equipos de científicos de datos para realizar predicciones de la propagación del COVID-19 utilizando redes neuronales gráficas en lugar de modelos tradicionales basados en series temporales.
También han desarrollado proyectos en el campo de la predicción meteorológica, para desarrollar estimaciones en áreas cada vez más concretas (ya no se trata solo de saber si lloverá en mi ciudad, si no si habrá precipitaciones en mi área). Para ello se han utilizado recursos de NOAA (National Oceanic and Atmospheric Administration) y una nueva técnica llamada HydroNets, basada en una red de redes neuronales para modelar los sistemas fluviales reales del mundo.
Puedes ver más información sobre los últimos avances en Google Research en este artículo.

Todos estos ejemplos ponen de manifiesto que los datos abiertos no son solo fuente para la creación de soluciones innovadoras de emprendedores y pequeñas empresas, sino que también grandes compañías aprovechan su potencial para desarrollar servicios y productos que entran a formar parte del porfolio de la empresa.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
El gigante tecnológico Google ha vuelto a manifestar recientemente su interés por el open source y el open data. Bajo el dogma de que los datos abiertos “no son solo buenos para nosotros y nuestra industria, sino que también benefician al mundo en general”, aseguran apostar por compartir datos, servicios y software con la ciudadanía.
Esta política, ha llevado a Google a abrir conjuntos de datos y hacerlos accesibles a través de APIs o mediante herramientas que facilitan su uso por parte de personas y organizaciones.
Apertura de datos
Actualmente Google ha puesto a disposición de los usuarios más de 60 conjuntos de datos estandarizados y legibles por máquinas –pensados para poder ser utilizados por sistemas de machine learning-. Estos conjuntos de datos están acompañados de materiales de apoyo dirigidos a desarrolladores e investigadores que estén interesados en trabajar con colecciones de imágenes, corpus de vídeos anotados, datos con alta granularidad, etc. Un ejemplo: las herramientas Facets, que ayudan a analizar la composición de un conjunto de datos y evaluar cuáles son las mejores formas de usarlo.
Desde Google también están trabajando para mejorar la calidad y crear conjuntos de datos más representativos a través de interfaces como la aplicación Crowdsourcing, que se beneficia del trabajo de la comunidad de usuarios. Con esta aplicación las personas que lo deseen pueden verificar etiquetas, realizar y validar traducciones o ayudar a mejorar los sistemas de análisis de sentimientos.
Localización y análisis de datos abiertos
Pero abrir los datos no es suficiente, estos también tienen que ser fáciles de encontrar. En este sentido, Google ofrece Google Dataset Search, un buscador que facilita la localización de datos abiertos en cientos repositorios asociados a instituciones internacionales, como el Banco Mundial o el portal de datos europeo, así como en catálogos oficiales asociados a gobiernos en todo el mundo. Eso sí, es necesario que los datos estén descritos de tal manera que los motores de búsqueda pueden localizarlos.
Con el objetivo de ayudar a analizar y extraer valor de estos datos, los usuarios tienen a su disposición Data Commons, un grafo de conocimiento de las fuentes de datos que permite a investigadores y estudiantes tratar varios conjuntos de datos a la vez, independientemente de la fuente y el formato, como si todos estuvieran en una única base de datos local.
Como complementos añadidos y necesarios, Google también participa en la dinamización de comunidades de científicos de datos (Kaggle), ofrece cursos de formación en la materia, lanza retos dirigidos a dinamizar a la comunidad en el su uso de datos para la resolución de las cuestiones previamente planteadas, y ponen en marcha continuamente campañas dirigidas a que la disponibilidad de este nuevo recurso sea cada vez más abundante.
La apuesta de Google por la apertura de datos hace necesaria también una estrategia que tenga en cuenta aspectos clave como la confidencialidad y privacidad. Desde Google, afirman tener distintos mecanismos para garantizar estas cuestiones, como Federated Learning, una técnica para entrenar modelos globales de Machine Learning sin que los datos abandonen el dispositivo de una persona.
Noticia
En internet podemos encontrar miles de repositorios de datos. Aquellos interesados en localizar una determinada información tienen que navegar entre múltiples fuentes (repositorios nacionales, portales de organismos públicos o instituciones privadas, bibliotecas digitales, web especializadas, etc.) con el consiguiente consumo de tiempo. Una difícil búsqueda que no siempre da los resultados esperados.
Google quiere cambiar esta situación. El pasado 5 de septiembre, el famoso buscador de internet estrenó Google Dataset Search, un nuevo motor de búsqueda que facilita el acceso universal a los conjuntos de datos ubicados en los repositorios de internet. El servicio está dirigido a periodistas, investigadores, estudiantes o cualquier ciudadano interesado en encontrar cierto dato.
El nuevo buscador funciona de una manera similar a Google Scholar – el buscador de Google centrado en contenido científico y académico-. Su motor de búsqueda localiza los conjuntos de datos, independientemente de su ubicación o temática, en función de cómo sus propietarios los han etiquetado. Es decir, Google localiza los datasets en base a sus metadatos, en vez de leer o rastrear el contenido del dataset en sí (distribuciones).
Para que las búsquedas sean más efectivas, Google ha facilitado una guía con consejos para los publicadores. En ella se indica cómo se deben compartir los conjuntos de datos para que Google los localice.
-
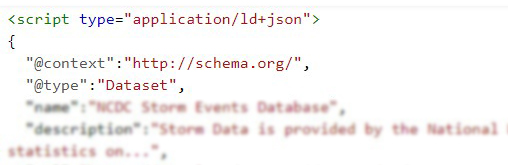
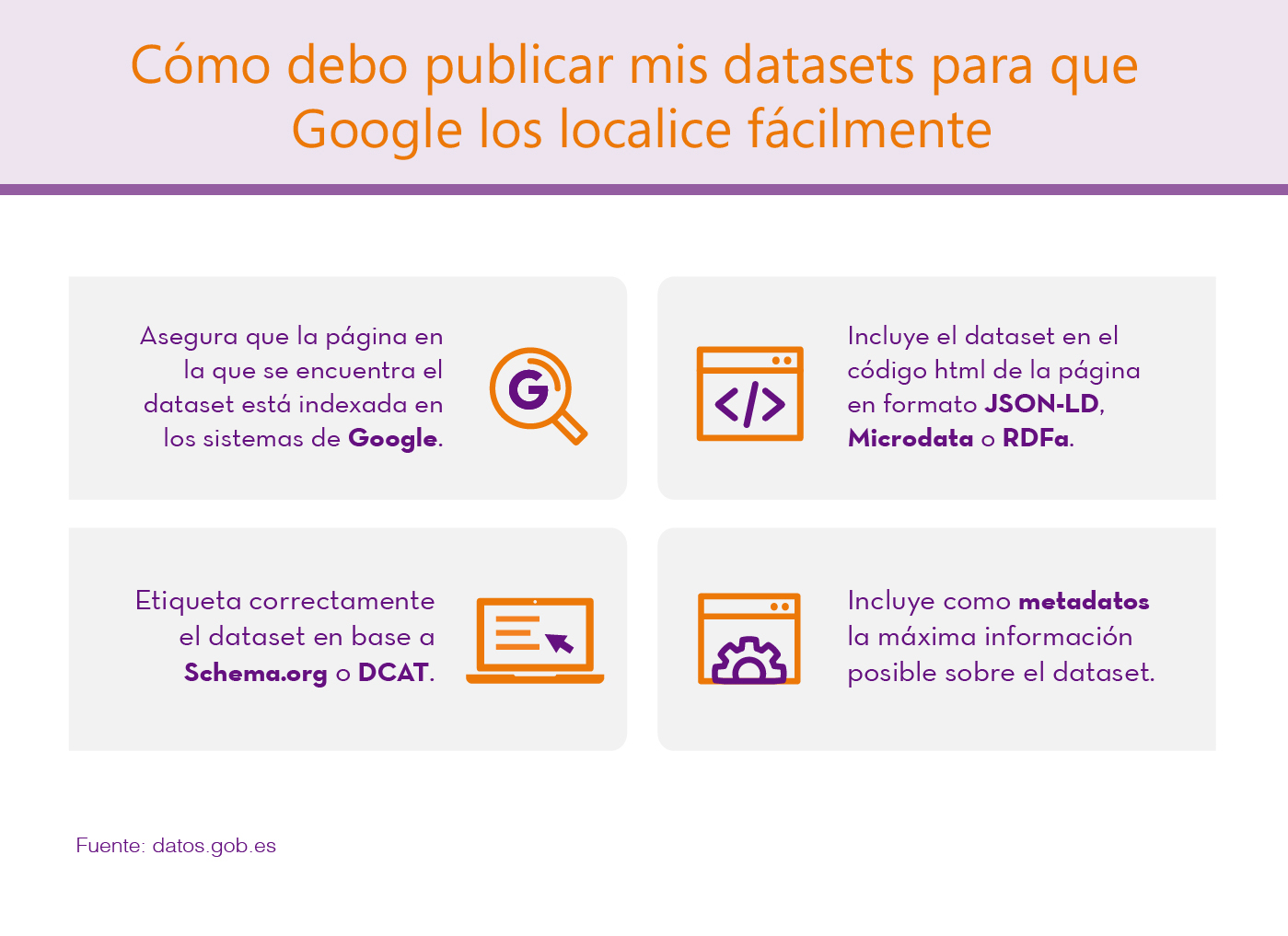
La página en la que se encuentran los dataset debe estar indexada en los sistemas de Google. Una vez indexada, Google comienza a observar el código HTML de la página web y cuando encuentra metadatos relacionados con Datasets (etiquetados correctamente), los indexa en Google Dataset Search.
-
El dataset debe estar incluido en el código de la página en formato JSON-LD, Microdata o RDFa y estar etiquetado correctamente en base a Schema.org (recomendado) o estructuras equivalentes representadas en DCAT. Google está explorando la posibilidad de ir incorporando nuevos formatos, como CSVW del W3C.
-
Es importante incluir la máxima información posible sobre el datasets en el etiquetado, en base a la definición de dataset en schema.org, como por ejemplo: el título, una descripción, el tipo de licencia, quién es el publicador, cuándo se creó el dato, cuándo se modificó, el catálogo de origen, etc. Los metadatos incluidos en este etiquetado serán los que muestre Google Data Search.
-
Además, Google recomienda el uso de etiquetas como 'sameAs' para conjuntos de datos que están publicados en varios repositorios, para evitar resultados duplicados en el buscador o 'isBasedOn' en el caso de que los datasets provengan de la modificación o agregación de otros datasets originales. Google proporciona una herramienta para comprobar si el etiquetado de la página es correcto y los datasets van a ser correctamente identificados por el motor de búsquedas.
En el caso de Datos.gob.es, todos los datasets pueden consultarse ya desde Google Data Search, lo cual proporciona una mayor visibilidad a nuestros conjuntos de datos.
Google Data Search se encuentra todavía en versión beta. Por ello, aún quedan retos por resolver, como por ejemplo definir de manera más consistente lo que constituye un conjunto de datos, relacionar los conjuntos de datos entre sí o expandir los metadatos entre conjuntos de datos relacionados.
Aun así, nos encontramos ante un avance importante. Google cree que este proyecto permitirá impulsar la creación de un ecosistema de intercambio de datos y que animará a los editores a seguir las prácticas recomendadas para almacenar y publicar datos. Además cree que ofrecerá a los científicos una plataforma para mostrar el impacto de su trabajo a través de las citas de los conjuntos de datos que hayan producido.
Lo que no se puede negar es que es un gran paso para fomentar los datos abiertos, facilitando que un mayor número de usuarios puedan localizar la información que necesitan de una manera rápida y sencilla.
Aplicación
Open Analytics Data ofrece algunas estadísticas de uso de los portales más importantes del Gobierno de Aragón. Este servicio ofrece de manera pública los datos más útiles en cuanto a la interacción de la ciudadanía con las páginas webs institucionales del Gobierno de Aragón y aporta de manera sencilla su uso, acceso e impacto, además también estos datos están disponibles mediante todo el potencial de los datos abiertos.
Noticia
Poco a poco las iniciativas de Gobierno Abierto (Open Govenment) mediante proyectos de Apertura de Datos (Open Data) empiezan a tener presencia en nuestras administraciones públicas.
El Ayuntamiento de Badalona ha puesto en marcha un mapa que ofrece información básica de ciertas actuaciones de la Guardia Urbana.