Blog
The bet of the technological giant Google with open data it has been evident in various initiatives carried out in recent years. On the one hand, they launched the search engine Google Dataset Search, that facilitates the location of open data published in hundreds of repositories of international institutions and governments, among which is datos.gob.es. On the other, they launched their own data opening initiative, where they offer standardized and readable data sets by machines in order to be used by machine learning systems. This last initiative is part of Google research, the portfolio of research and innovation projects from Google: from the prediction of the spread of COVID-19 to the design of algorithms, through the learning of automatic translation of a greater number of languages, among others. In these and other projects, Google has not only opted for the publication of datasets, but the company itself also acts as a reuse of public data. In this post we are going to some examples of Google solutions and projects that integrate open data into their operations.
Google Earth
Through a virtual globe based on satellite images, Google Earth allows you to view multiple cartographies. Users can explore territories in 3D and add markers or draw lines and areas, among other tools.
One of his latest updates has been the incorporation of the Timelapse function, which has involved the integration of 24 million satellite photos captured during the last 37 years (specifically, between 1984 and 2020). In this way, changes can be observed in the different regions of the planet. Among other information, the solution shows the forest changes, the urban growth or the heating of our planet, which allows us to become aware of the climate crisis we are experiencing in order to act accordingly. It is therefore a fundamental solution for environmental education, with great potential for use in classes.
Integrated data comes from the program Landsat the United States Geological Survey, and the Copernicus program and the Sentinel satellites of the European Union. Specifically, there were 20 petabytes of satellite images that have been made available to users in a single large, high-resolution video mosaic, for which more than 2 million hours of processing have been required. It should be noted that both the Copernicus and Landsat data are open to reuse by any individual or company that wishes to launch its own services and products.
Google Translator
Another of the technology giant's best-known tools is its translator, which was launched in 2006. Ten years later it was updated with the Google Neural Machine Translation System (GNMT), which uses more modern machine learning techniques for its training.
Google does not make public the exact data it uses for training the system, although in its report Google's Neural Machine Translation System: Bridging the Gap
between Human and Machine Translation They do highlight that they have performed benchmark tests with two publicly available corpus: WMT'14 English-to-French and WMT´14 English-German.
Although much progress has been made, the system still does not match the level of quality that is obtained with a translation carried out by an expert human being in the field, especially in the case of the most minority languages, so they are followed making adjustments and advances. Another area where it is also necessary to continue working on the biases of the data that they use to train the system and that can lead to stereotypes. For example, it has been found that the translator introduces biases when using masculine and feminine in the translation of phrases from neutral languages, without gender, like English or Hungarian. In these cases, the feminine is used by default for tasks related to care and beauty, and the masculine for better valued professional options. The tech giant has indicated that is already working on the resolution of this problem.
Other examples from Google Research
Within the afore mentioned Google Research, different projects are carried out, some of them closely linked to reuse. For example, in the context of the current pandemic, the mobility reports with anonymous information on displacement trends–Which can be downloaded in csv format. These reports make it possible to understand the impact of movement restriction policies, as well as to make economic forecasts. The data has also been leveraged by their own teams of data scientists to perform predictions of the spread of COVID-19 using graphical neural networks instead of traditional time series-based models.
They have also developed projects in the field of meteorological prediction, to develop estimates in increasingly specific areas (it is no longer just a question of whether it will rain in my city, but whether there will be rainfall in my area). For this, resources from NOAA (National Oceanic and Atmospheric Administration) and a new technique called HydroNets, based on a network of neural networks to model the real river systems of the world.
You can see more information about the latest advances in Google Research at this article.

All these examples show that open data is not only a source for the creation of innovative solutions for entrepreneurs and small companies, but also that large companies take advantage of their potential to develop services and products that become part of the company's portfolio.
Content prepared by the datos.gob.es team.
Noticia
The tech giant Google has recently expressed its interest in open source and open data. Under the dogma that open data is "good not only for us and our industry, but also benefit the world at large", they say they are committed to sharing data, services and software with citizens.
This policy has led Google to open data sets and make them accessible through APIs or tools that facilitate their use by individuals and organizations.
Data opening
Currently, Google has made more than 60 sets of standardized and machine-readable data available to users - intended to be used by machine learning systems. These data sets are accompanied by supporting materials aimed at developers and researchers who are interested in working with image collections, corpus of annotated videos, high granularity data, etc. An example: Facets, which help analyze the composition of a data set and evaluate what are the best ways to use it.
From Google they are also working to improve quality and create more representative data sets through interfaces such as Crowdsourcing, an application that take advantage of the user communities´ work. With this application, users can check labels, perform and validate translations or help improve feelings analysis systems.
Location and analysis of open data
But opening the data is not enough, they also have to be easy to find. In this sense, Google offers Google Dataset Search, a search engine that facilitates the location of open data in hundreds of repositories associated with international institutions, such as the World Bank or the European data portal, as well as in official catalogues associated with governments worldwide. Of course, it is necessary that the data be described in such a way that search engines can locate them.
In order to help analyze and extract value from this data, users have at their disposal Data Commons, a graph of knowledge of data sources that allows researchers and students to process several data sets at once, regardless of the source and format, as if all were in just one local database.
As additional and necessary complements, Google also participates in the revitalization of communities of data scientists (Kaggle), offers training courses on the subject, launches challenges aimed at energizing the community in its use of data for the resolution of issues previously raised, and continuously launch campaigns aimed at making the availability of this new resource increasingly abundant.
Google's commitment to open data also requires a strategy that takes into account key aspects such as confidentiality and privacy. From Google, they claim to have different mechanisms to guarantee these issues, such as Federated Learning, a technique to train global Machine Learning models without the data leaving a person's device.
Noticia
On the internet we can find thousands of data repositories. Those interested in locating certain information have to navigate between multiple sources (national repositories, public organizations or private institutions platforms, digital libraries, specialized web, etc.) with the consequent consumption of time. A difficult search that don´t always produce the expected results.
Google wants to change this situation. On September 5, the famous internet search engine launched Google Dataset Search, a new search engine that facilitates universal access to data sets located on the Internet repositories. The service is aimed at journalists, researchers, students or any citizen interested in finding certain information.
The new search engine works similar to Google Scholar - the Google search engine focused on scientific and academic content-. This search engine locates the data sets, regardless their location or theme, depending on how they are described. That is, Google locates the datasets based on their metadata, instead of tracking the dataset content (distributions).
To improve search effectiveness, Google has provided a guide with tips for publishers. This guide explain how to share data sets in a way that Google can better locate their content.
- The site where dataset are located must be indexed on Google systems. Then, Google begins to observe the HTML code and when it finds metadata related to Datasets (correctly tagged), Google Dataset Search indexes the content.
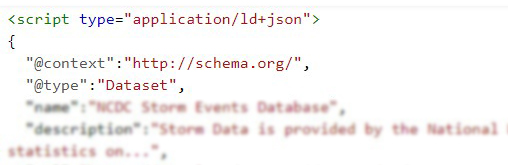
- The dataset must be included in the site code using JSON-LD, Microdata or RDFa format and correctly mark up using Schema.org (preferred) or equivalent structures represented in DCAT. Google is exploring the possibility of incorporating new formats, such as W3C CSVW.
- It is important to include as much information as possible about the datasets in the proprieties, based on the dataset definition by schema.org, such as: name, description, license, publisher, date created, date modified, data catalog, etc. The metadata here included will be showed by Google Data Search.
- In addition, Google recommends the use of proprieties such as 'sameAs' for data sets that are published in several repositories, to avoid duplicate results, or 'isBasedOn' for datasets coming from the modification or aggregation of other original datasets. Google provides a tool to check if the site proprieties are correct and the datasets are going to be correctly identified by the search engine.
In the case of Datos.gob.es, all datasets can be already consulted from Google Data Search, which provides greater visibility to our datasets.
Google Data Search is still in beta. Therefore, there are still challenges to be solved, such as defining more consistently what a dataset is, linking different datasets or expanding metadata between related datasets.
Even so, this is an important advance. Google believes that this project will boost the creation of a data exchange ecosystem and will encourage publishers to follow the best practices for storing and publishing data. Google also believes that Google Data Search will offer scientists a platform to show the impact of their work through citations of the data sets they have produced.
But it cannot be denied that it is a great step to promote open data, making easier for a greater number of users to locate the information they need in a fast and simple way.