Blog
La inteligencia artificial está cada vez más presente en nuestras vidas. Sin embargo, su presencia es cada vez más sutil e inadvertida. A medida que una tecnología madura y permea más en la sociedad, ésta se vuelve cada vez más transparente, hasta que se naturaliza por completo. La inteligencia artificial está recorriendo este camino rápidamente, y hoy, os lo contamos con un nuevo ejemplo.
Introducción
En este espacio de comunicación y divulgación hemos hablado muchas veces de inteligencia artificial (IA) y sus aplicaciones prácticas. En otras ocasiones, hemos comunicado informes monográficos y artículos sobre aplicaciones concretas de la IA en la vida real. Es evidente que este es un tema de máxima actualidad y repercusión en el sector de la tecnología, y es por esto que continuamos incidiendo en nuestra labor divulgativa sobre este campo.
En esta ocasión, os hablamos sobre los últimos avances en inteligencia artificial aplicada al campo del procesamiento de lenguaje natural. A principios del año 2020 publicamos un informe en el que citamos los trabajos de Paul Daugherty y James Wilson - Human + Machine - para explicar los tres estados en los que la IA colabora con las capacidades humanas. Daugherty y Wilson explican estos tres estados de colaboración entre máquinas (IA) y humanos de la siguiente forma (ver figura 1). En el primer estado, la IA se entrena con características genuinamente humanas como el liderazgo, la creatividad y los juicios de valor. El estado opuesto, es aquel en el que se destacan características donde las máquinas demuestran un mejor desempeño que los humanos. Hablamos de actividades repetitivas, precisas y continuas. Sin embargo, el estado más interesante es el intermedio. En este estado, los autores identifican actividades o características en las que los humanos y las máquinas realizan actividades híbridas, en las que se complementan mutuamente. En este estado intermedio, se distinguen, a su vez, dos etapas de madurez.
- En la primera etapa -la más inmadura- los humanos complementan a las máquinas. Disponemos de numerosos ejemplos de esta etapa en la actualidad. Los humanos enseñamos a las máquinas a conducir (coches autónomos) o a entender nuestro lenguaje (procesado del lenguaje natural).
- La segunda etapa de madurez se produce cuando la IA potencia o amplifica nuestras capacidades humanas. En palabras de Daugherty y Wilson, la IA nos da superpoderes a los humanos.

Figura 1: Estados de colaboración entre humanos y máquinas. Fuente original
En este post, te mostramos un ejemplo de este superpoder que nos devuelve la IA. El superpoder de resumir libros de decenas de miles de palabras a tan solo unos cientos. Los resúmenes resultantes son similares a cómo los haría un humano con la diferencia de que la IA lo hace en unos pocos segundos. Hablamos, en concreto, de los últimos avances que ha publicado la compañía OpenAI dedicada a la investigación en sistemas de inteligencia artificial.
Resumiendo libros como un humano
OpenAI define de forma similar el razonamiento de Daugherty y Wilson sobre los modelos de colaboración de la IA con los humanos. Los autores del último trabajo de OpenAI explican que, para implementar modelos de inteligencia artificial tan potentes que resuelvan problemas globales y genuinamente humanos, debemos asegurarnos de que los modelos de IA actúen alineados con las intenciones humanas. De hecho, este reto se conoce como el problema de alineamiento.
Los autores explican que: "Para probar técnicas de alineación escalables, entrenamos un modelo para resumir libros completos [...] Nuestro modelo funciona primero resumiendo pequeñas secciones de un libro, luego resumiendo esos resúmenes en un resumen de nivel superior, y así sucesivamente".
Veamos un ejemplo
Los autores han refinado el algoritmo GPT-3 para resumir libros completos basándose en una aproximación conocida como: descomposición recursiva de tareas acompañada con un refuerzo a partir de comentarios humanos. La técnica se denomina descomposición recursiva porque se fundamenta en realizar múltiples resúmenes de la obra completa (por ejemplo, un resumen por cada capítulo o sección) y, en iteraciones posteriores, ir realizando, a su vez, resúmenes de los resúmenes previos, cada vez con menor número de palabras. En la siguiente figura se explica el proceso de forma más visual.

Fuente original: https://openai.com/blog/summarizing-books/
Resultado final:

Fuente original: https://openai.com/blog/summarizing-books/
Como hemos citado en anteriores ocasiones, el algoritmo GPT-3 ha sido entrenado gracias al conjunto de libros digitalizados bajo el amparo del proyecto Gutenberg. El vasto repositorio del proyecto Gutenberg incluye hasta 60.000 libros en formato digital que, actualmente, son de dominio público en Estados Unidos. De la misma forma que se ha usado el proyecto Gutenberg para entrenar GPT-3 en inglés, se podrían haber usado otros repositorios de datos abiertos para entrenar el algoritmo en otros idiomas. En nuestro país, la Biblioteca Nacional cuenta con un portal de datos abiertos para explotar el catálogo disponible de obras bajo dominio público en español.
Los autores del trabajo afirman que la descomposición recursiva plantea ciertas ventajas con respecto a las aproximaciones más integrales que tratan de resumir el libro de una sola vez.
- La evaluación de la calidad de los resúmenes por humanos es más sencilla cuándo se trata de evaluar resúmenes de partes concretas de un libro que si se trata de la obra entera.
- Un resumen, trata siempre de identificar las partes clave de un libro o un capítulo de un libro, manteniendo los datos fundamentales y descartando aquellos que no aporten a la hora de entender el contenido. Evaluar este proceso para entender si realmente se han capturado esos detalles fundamentales es mucho más sencillo con esta aproximación basada en la descomposición del texto en unidades más pequeñas.
- Esta aproximación descompositiva mitiga las limitaciones que pueden existir cuándo las obras a resumir son muy grandes.
Además del ejemplo principal que hemos expuesto en este post sobre la obra de Shakespeare, Romeo y Julieta, los lectores pueden experimentar por ellos mismos cómo funciona esta IA en el explorador de resúmenes de openAI. Esta web, pone a disposición dos repositorios de libros (obras clásicas) abiertos sobre los que se puede experimentar la capacidad de resumir de esta IA navegando desde el resumen final del libro hacia los resúmenes anteriores en el proceso de descomposición recursiva.
Concluyendo, el procesamiento del lenguaje natural es una capacidad humana clave que está siendo reforzada por el desarrollo de la IA de forma espectacular en los últimos años. No solo OpenAI realiza contribuciones de calado en este campo. Otros gigantes tecnológicos, como Microsoft y NVIDIA, también están realizando grandes avances como se constata con el último anuncio de estas dos compañías y su nuevo modelo Megatron-Turing NLG. Este nuevo modelo muestra grandes avances en tareas como por ejemplo: la generación de texto predictivo o el entendimiento del lenguaje humano para interpretación de comandos de voz en asistentes personales. Con todo ello, no cabe duda que veremos a las máquinas hacer cosas increíbles en los próximos años.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
¿Te imaginas una IA capaz de escribir canciones, novelas, comunicados de prensa, entrevistas, ensayos, manuales técnicos, código de programación, prescribir medicamentos y mucho más que aún no sabemos? Viendo a GPT-3 en acción no parece que estemos muy lejos.
En nuestro último informe sobre procesamiento del lenguaje natural (NLP) mencionamos el algoritmo GPT-2 desarrollado por OpenAI (la compañía fundada por nombres tan reconocidos cómo Elon Musk) como un exponente en cuanto a sus capacidades para la generación de texto sintético con una calidad indistinguible de cualquier otro texto creado por un humano. Los sorprendentes resultados de GPT-2 llevaron a la compañía a no publicar el código fuente del algoritmo por sus potenciales efectos negativos en la generación de deepfakes o noticias falsas.
Recientemente (mayo de 2020) se ha liberado una nueva versión del algoritmo, ahora denominado GPT-3 que incluye novedades funcionales y mejoras de rendimiento y capacidad de analizar y generar textos en lenguaje natural.
En este post tratamos de resumir de forma sencilla y asequible las principales novedades de GPT-3. ¿Te atreves a descubrirlas?
Comenzamos de forma directa, yendo al grano. ¿Qué trae consigo GPT-3? (adaptación de el post original de Mayor Mundada).
- Es mucho más grande (complejo) que todo lo que teníamos antes. Los modelos de deep learning basados en redes neuronales se suelen clasificar por su número de parámetros. A mayor número de parámetros, mayor es la profundidad de la red y por lo tanto su complejidad. El entrenamiento de la versión completa de GPT-2 daba cómo resultado 1.500 millones de parámetros. GPT-3 da cómo resultado 175.000 millones de parámetros. GPT-3 ha sido entrenado sobre una base de 570 GB de texto comparados con los 40 GB de GPT-2.
- Por primera vez puede ser utilizado cómo un producto o servicio. Es decir, OpenAI, ha anunciado la puesta a disposición de los usuarios de un API público para poder experimentar con el algoritmo. En el momento de escribir este post, el acceso al API está restringido (es lo que denominamos un private preview) y hay que solicitar acceso.
- Lo más importante: sus resultados. A pesar de que la API se encuentra restringida por invitación, son numerosos los usuarios en Internet (con acceso a la API) que han publicado artículos sobre sus resultados en diferentes ámbitos.
¿Qué papel juegan los datos abiertos?
En pocas ocasiones se tiene la posibilidad de ver la potencia y los beneficios de los datos abiertos cómo en este tipo de proyectos. Cómo hemos comentado más arriba GPT-3 ha sido entrenado con 570 GB de datos en formato de texto. Pues bien, resulta que el 60% de los datos de entrenamiento del algoritmo vienen de la fuente https://commoncrawl.org. Common Crawl es un proyecto abierto y colaborativo que proporciona un corpus para la investigación, el análisis, la educación, etc. Cómo se especifica en la web de Common Crawl los datos proporcionados son abiertos y se hospedan bajo la iniciativa de datos abiertos de AWS. Buena parte del resto de datos de entrenamiento también son abiertos incluyendo fuentes cómo Wikipedia.
Casos de uso
A continuación mostramos algunos de los ejemplos y casos de uso impactantes.
Generación de texto sintético
En esta entrada (no spoilers ;) ) del blog de Manuel Araoz se muestra la potencia del algoritmo para generar un artículo 100% sintético sobre Inteligencia Artificial. Manuel realiza el siguiente experimento: proporciona a GPT-3 una mínima descripción de su biografía incluida en su blog y un pequeño fragmento de la última entrada en su blog. 117 palabras en total. Tras 10 ejecuciones de GPT-3 para generar texto artificial relacionado, Manuel es capaz de copiar y pegar el texto generado, colocar una imagen de portada y ya tiene listo un nuevo post para su blog. Honestamente, el texto del post sintético es indistinguible de un post original salvo por los posibles errores en nombres, fechas, etc. que pueda incluir el texto.
Productividad. Generación automática de tablas de datos.
En otro ámbito diferente, el algoritmo GPT-3 tiene aplicaciones en el ámbito de la productividad. En este ejemplo GPT-3 es capaz de crear una tabla de MS Excel sobre un determinado tema. Por ejemplo, si queremos obtener una tabla, a modo de lista, con las compañías tecnológicas más representativas y su año de fundación, simplemente proporcionamos a GPT-3 el patrón deseado y le pedimos que lo complete. El patrón de inicio puede ser algo similar a esta tabla de debajo (en un ejemplo real, los datos de entrada serán en inglés). GPT-3 completará la zona sombreada con datos reales. Sin embargo, si además del patrón de entrada, le proporcionamos al algoritmo una descripción verosímil de una compañía tecnológica ficticia y le volvemos a pedir que complete la tabla con la nueva información, el algoritmo incluirá los datos de esta nueva compañía ficticia.
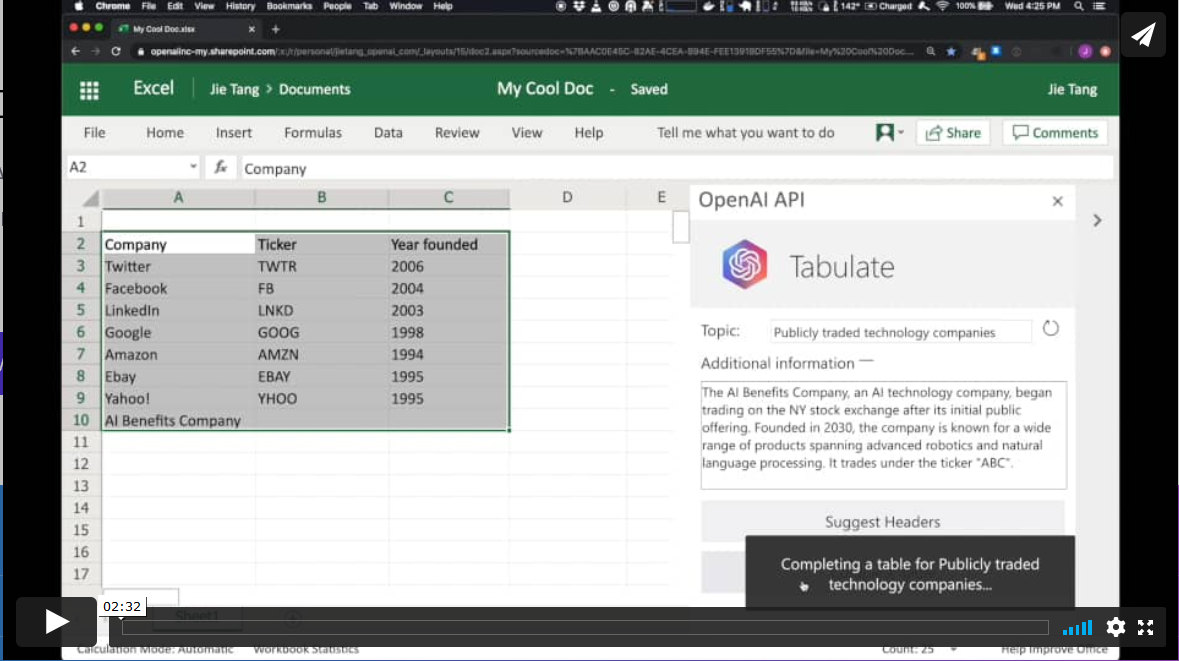
Estos ejemplos son solo una muestra de lo que GPT-3 es capaz de hacer. Entre sus funcionalidades o aplicaciones se encuentran:
- la búsqueda semántica (diferente de la búsqueda por palabras clave)
- los chatbots
- la revolución de los servicios de atención al cliente (call-center)
- la generación de texto multipropósito (creación de poemas, novelas, música, noticias falsas, artículos de opinión, etc.)
- las herramientas de productividad. Hemos visto un ejemplo sobre cómo crear tablas de datos, pero se está hablando (y mucho), sobre la posibilidad de crear programas informáticos sencillos cómo páginas web y pequeñas aplicaciones sencillas sin necesidad de codificar, tan solo preguntándole a GPT-3 y sus hermanos que están por llegar.
- las herramientas de traducción on-line
- la comprensión y resúmenes de textos.
y tantas otras cosas que aún no hemos descubierto... Seguiremos informándoles sobre las próximas novedades en NLP y en particular de GPT-3, un game-changer que ha venido para revolucionar todo lo que conocemos por el momento.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.