Blog
Artificial intelligence is increasingly present in our lives. However, its presence is increasingly subtle and unnoticed. As a technology matures and permeates society, it becomes more and more transparent, until it becomes completely naturalized. Artificial intelligence is rapidly going down this path, and today, we tell you about it with a new example.
Introduction
In this communication and dissemination space we have often talked about artificial intelligence (AI) and its practical applications. On other occasions, we have communicated monographic reports and articles on specific applications of AI in real life. It is clear that this is a highly topical subject with great repercussions in the technology sector, and that is why we continue to focus on our informative work in this field.
On this occasion, we talk about the latest advances in artificial intelligence applied to the field of natural language processing. In early 2020 we published a report in which we cited the work of Paul Daugherty and James Wilson - Human + Machine - to explain the three states in which AI collaborates with human capabilities. Daugherty and Wilson explain these three states of collaboration between machines (AI) and humans as follows (see Figure 1). In the first state, AI is trained with genuinely human characteristics such as leadership, creativity and value judgments. In the opposite state, characteristics where machines demonstrate better performance than humans are highlighted. We are talking about repetitive, precise and continuous activities. However, the most interesting state is the intermediate one. In this state, the authors identify activities or characteristics in which humans and machines perform hybrid activities, in which they complement each other. In this intermediate state, in turn, two stages of maturity are distinguished.
- In the first stage - the most immature - humans complement machines. We have numerous examples of this stage today. Humans teach machines to drive (autonomous cars) or to understand our language (natural language processing).
- The second stage of maturity occurs when AI empowers or amplifies our human capabilities. In the words of Daugherty and Wilson, AI gives us humans superpowers.

Figure 1: States of human-machine collaboration. Original source.
In this post, we show you an example of this superpower returned by AI. The superpower of summarizing books from tens of thousands of words to just a few hundred. The resulting summaries are similar to how a human would do it with the difference that the AI does it in a few seconds. Specifically, we are talking about the latest advances published by the company OpenAI, dedicated to research in artificial intelligence systems.
Summarizing books as a human
OpenAI similarly defines Daugherty and Wilson's reasoning on models of AI collaboration with humans. The authors of the latest OpenAI paper explain that, in order to implement such powerful AI models that solve global and genuinely human problems, we must ensure that AI models act in alignment with human intentions. In fact, this challenge is known as the alignment problem.
The authors explain that: To test scalable alignment techniques, we train a model to summarize entire books [...] Our model works by first summarizing small sections of a book, then summarizing those summaries into a higher-level summary, and so on.
Let's look at an example.
The authors have refined the GPT-3 algorithm to summarize entire books based on an approach known as recursive task decomposition accompanied by reinforcement from human comments. The technique is called recursive decomposition because it is based on making multiple summaries of the complete work (for example, a summary for each chapter or section) and, in subsequent iterations, making, in turn, summaries of the previous summaries, each time with a smaller number of words. The following figure explains the process more visually.

Fuente original: https://openai.com/blog/summarizing-books/
Final result:

Original source: https://openai.com/blog/summarizing-books/
As we have mentioned before, the GPT-3 algorithm has been trained thanks to the set of books digitized under the umbrella of Project Gutenberg. The vast Project Gutenberg repository includes up to 60,000 books in digital format that are currently in the public domain in the United States. Just as Project Gutenberg has been used to train GPT-3 in English, other open data repositories could have been used to train the algorithm in other languages. In our country, the National Library has an open data portal to exploit the available catalog of works under public domain in Spanish.
The authors of the paper state that recursive decomposition has certain advantages over more comprehensive approaches that try to summarize the book in a single step.
- The evaluation of the quality of human summaries is easier when it comes to evaluating summaries of specific parts of a book than when it comes to the entire work.
- A summary always tries to identify the key parts of a book or a chapter of a book, keeping the fundamental data and discarding those that do not contribute to the understanding of the content. Evaluating this process to understand if those fundamental details have really been captured is much easier with this approach based on the decomposition of the text into smaller units.
- This decompositional approach mitigates the limitations that may exist when the works to be summarized are very large.
In addition to the main example we have exposed in this post on Shakespeare's Romeo and Juliet, readers can experience for themselves how this AI works in the openAI summary browser. This website makes available two open repositories of books (classic works) on which one can experience the summarization capabilities of this AI by navigating from the final summary of the book to the previous summaries in the recursive decomposition process.
In conclusion, natural language processing is a key human capability that is being dramatically enhanced by the development of AI in recent years. It is not only OpenAI that is making major contributions in this field. Other technology giants, such as Microsoft and NVIDIA, are also making great strides as evidenced by the latest announcement from these two companies and their new Megatron-Turing NLG model. This new model shows great advances in tasks such as: the generation of predictive text or the understanding of human language for the interpretation of voice commands in personal assistants. With all this, there is no doubt that we will see machines doing incredible things in the coming years.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Can you imagine an AI capable of writing songs, novels, press releases, interviews, essays, technical manuals, programming code, prescribing medication and much more that we don't know yet? Watching GPT-3 in action doesn't seem like we're very far away.
In our latest report on natural language processing (NLP) we mentioned the GPT-2 algorithm developed by OpenAI (the company founded by such well-known names as Elon Musk) as an exponent of its capabilities for generating synthetic text with a quality indistinguishable from any other human-created text. The surprising results of GPT-2 led the company not to publish the source code of the algorithm because of its potential negative effects on the generation of deepfakes or false news
Recently (May 2020) a new version of the algorithm has been released, now called GPT-3, which includes functional innovations and improvements in performance and capacity to analyse and generate natural language texts.
In this post we try to summarize in a simple and affordable way the main new features of GPT-3. Do you dare to discover them?
We start directly, getting to the point. What does GPT-3 bring with it? (adaptation of the original post by Mayor Mundada).
- It is much bigger (complex) than everything we had before. Deep learning models based on neural networks are usually classified by their number of parameters. The greater the number of parameters, the greater the depth of the network and therefore its complexity. The training of the full version of GPT-2 resulted in 1.5 billion parameters. GPT-3 results in 175 billion parameters. GPT-3 has been trained on a basis of 570 GB of text compared to 40 GB of GPT-2.
- For the first time, it can be used as a product or service. For the first time it can be used as a product or service. That is, OpenAI has announced the availability of a public API for users to experiment with the algorithm. At the time of writing this post, access to the API is restricted (this is what we call a private preview) and access must be requested.
- The most important thing: the results. Despite the fact that the API is restricted by invitation, many Internet users (with access to the API) have published articles on its results in different fields.
What role do open data play?
It is rarely possible to see the power and benefits of open data as in this type of project. As mentioned above GPT-3 has been trained with 570 GB of data in text format. Well, it turns out that 60% of the training data of the algorithm comes from the source https://commoncrawl.org. Common Crawl is an open and collaborative project that provides a corpus for research, analysis, education, etc. As specified on the Common Crawl website the data provided are open and hosted under the AWS open data initiative. Much of the rest of the training data is also open including sources such as Wikipedia.
Use cases
Below are some of the examples and use cases that have had an impact.
Generation of synthetic text
This entry (no spoilers ;) ) from Manuel Araoz's blog shows the power of the algorithm to generate a 100% synthetic article on Artificial Intelligence. Manuel performs the following experiment: he provides GPT-3 with a minimal description of his biography included in his blog and a small fragment of the last entry in his blog. 117 words in total. After 10 runs of GPT-3 to generate related artificial text, Manuel is able to copy and paste the generated text, place a cover image and has a new post ready for his blog. Honestly, the text of the synthetic post is indistinguishable from an original post except for possible errors in names, dates, etc. that the text may include.
Productivity. Automatic generation of data tables.
In a different field, the GPT-3 algorithm has applications in the field of productivity. In this example GPT-3 is able to create a MS Excel table on a certain topic. For example, if we want to obtain a table, as a list, with the most representative technology companies and their year of foundation, we simply provide GPT-3 with the desired pattern and ask it to complete it. The starting pattern can be something similar to this table below (in a real example, the input data will be in English). GPT-3 will complete the shaded area with actual data. However, if in addition to the input pattern, we provide the algorithm with a plausible description of a fictitious technology company and ask you again to complete the table with the new information, the algorithm will include the data from this new fictitious company.
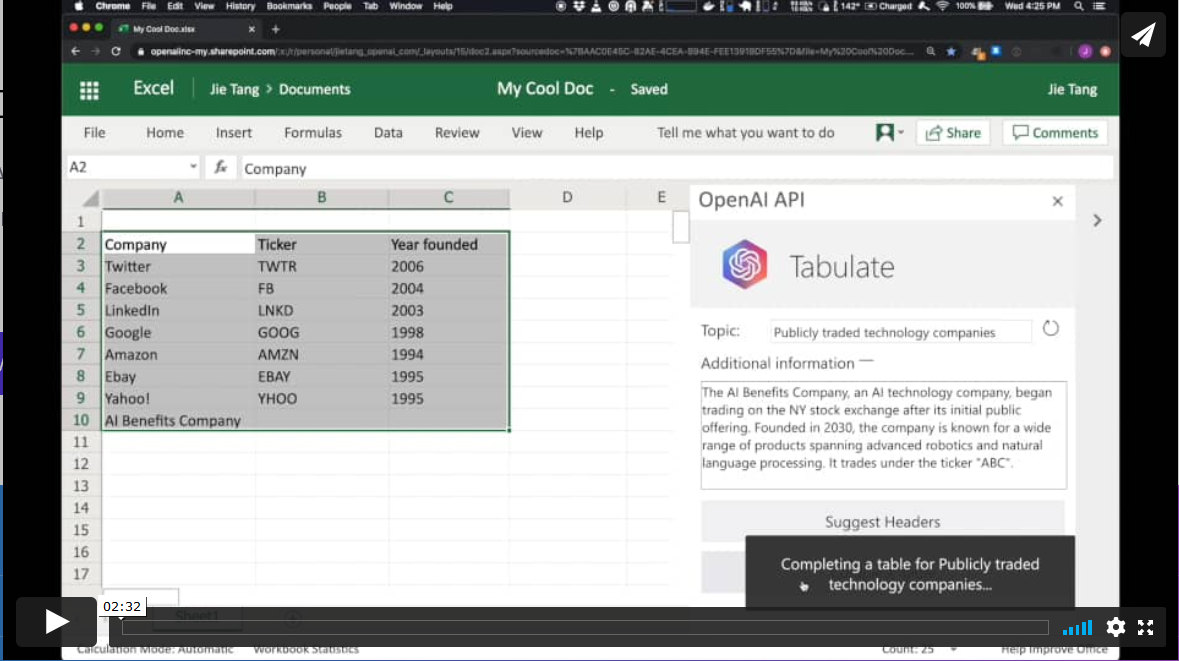
These examples are just a sample of what GPT-3 is capable of doing. Among its functionalities or applications are:
- semantic search (different from keyword search)
- the chatbots
- the revolution in customer services (call-center)
- the generation of multi-purpose text (creation of poems, novels, music, false news, opinion articles, etc.)
- productivity tools. We have seen an example on how to create data tables, but there is talk (and much) about the possibility of creating simple software such as web pages and small simple applications without the need for coding, just by asking GPT-3 and its brothers who are coming.
- online translation tools
- understanding and summarizing texts.
and so many other things we haven't discovered yet... We will continue to inform you about the next developments in NLP and in particular about GPT-3, a game-changer that has come to revolutionize everything we know at the moment.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.