Documentación
Introducción
Cada año se producen en España decenas de miles de accidentes, en los que miles de personas resultan heridas de diversa consideración, y que ocurren en circunstancias muy diversas, tanto de tipo de vía, como por el tipo de accidente.
Muchas de las estadísticas relacionadas con estos parámetros están recogidas en las bases de datos de la Dirección General de Tráfico (DGT) y algunas de ellas en el catálogo albergado en datos.gob.es.
En este ejercicio examinaremos el contenido de la base de datos de siniestralidad de la DGT para el año 2024 con el fin de realizar una serie de visualizaciones básicas que nos permitan ver de forma rápida e intuitiva cuáles son los hechos a destacar respecto a la incidencia de accidentes y sus consecuencias en ese año.
Para ello vamos a desarrollar código en Python que nos permita la lectura y cálculo de métricas básicas respecto al número total de víctimas, las particularidades de las infraestructuras así como las diferentes casuísticas de los accidentes. Y una vez tengamos disponibles esos datos, los visualizaremos utilizando la librería de Javascript D3.js, que nos permite tanto la representación de datos en su forma más tradicional como en diseños más contemporáneos, habituales en la prensa, favoreciendo así una narrativa fluída en estilo y coherente en contenido.
En el entorno de Python utilizaremos librerías de uso común y frecuente como son Numpy, para el cálculo básico - sumas, máximos y mínimos-, y Pandas, para estructurar los datos de forma intuitiva, facilitando tanto su organización como su transformación. Igualmente trabajaremos con Datetime, tanto para el formateo de los datos de entrada en tipos de fecha estándares dentro del mundo de la programación en Python, como para agregar los datos de forma fácil e intuitiva. De esta forma aprenderemos a abrir cualquier tipo de fichero de datos en formato .CSV, a estructurarlo de forma ordenada y a realizar transformaciones y operaciones básicas de forma sencilla.
En el entorno de Javascript desarrollaremos notebooks en D3.js gracias al uso de Observable, una iniciativa abierta y gratuita, para poder ejecutar código de Javascript directamente en un interfaz web, y sin tener que recurrir a servidores locales o complejas instalaciones. En diferentes notebooks crearemos visualizaciones clásicas -como las series temporales en ejes cartesianos o mapas- junto con otras propuestas tales como distribuciones de burbujas o elementos apilados por categorías.
En la Figura 1 se pueden ver las principales etapas de este ejercicio, desde la lectura de los datos dentro del fichero de la DGT, hasta las operaciones y las variables de salida en formato JSON, que nos servirán a su vez en un entorno Javascript para poder desarrollar las visualizaciones en D3.js.
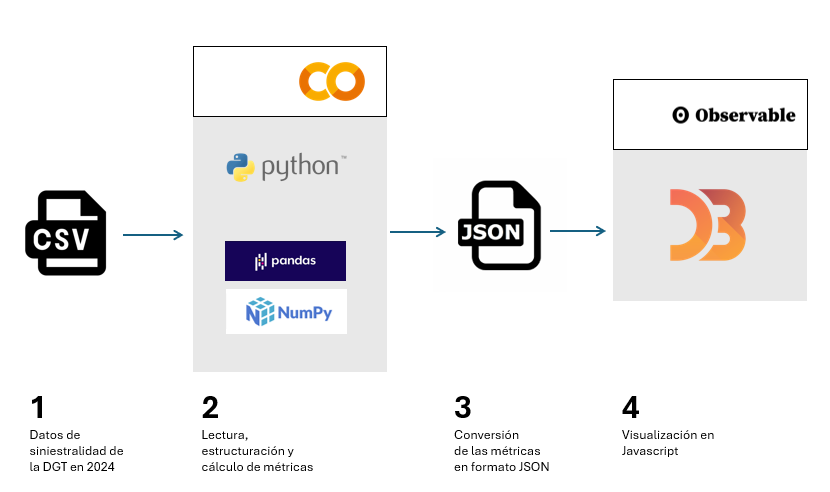
Figura 1. Pasos en los cuales se estructura este ejercicio, con punto de partida en la base de datos de la DGT, el procesado y manipulación de esos datos en Python, la creación de ficheros de salida en formato JSON y su uso en Javascript para visualizar los resultados.
El acceso al repositorio de Github, el notebook de Google Colab y los notebooks de Observable se pueden realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de GoogleColab
Accede a los notebooks de Observable
Proceso de Desarrollo
1. Lectura del fichero de datos
El primer paso será leer el fichero de la DGT que contiene todos los registros de accidentes del año 2024. Este paso nos permitirá identificar los campos de interés y sobre todo en qué formato se encuentran. Podremos identificar si se precisa de alguna transformación sobre todo en la información de la fecha, tal y como está estructurada en el fichero de origen.
Igualmente veremos cómo traducir los códigos de muchas de las categorías que nos ofrece la DGT, de modo que podamos hacer una interpretación real más allá de los números de categorías como tipo de accidente, tipo de vía o titularidad de la vía.
Una vez entendemos la estructura y contenido de los datos podemos empezar a operar con ellos.
2. Cálculo de métricas
La librería Pandas de Python nos permite operar con las diferentes columnas de datos y realizar cálculos básicos que serán suficientemente representativos para entender mínimamente la casuística de los accidentes en las carreteras españolas.
En este apartado se realizarán tres tipos de cálculos.
- El primero de ellos será el cálculo del número total de víctimas por hora del día para cada uno de los días de la semana. La base de datos de la DGT viene estructurada por día de la semana, de forma que utilizaremos también esa escala temporal para representar los datos en una serie. Cabe hacer notar que por víctima se considera toda aquella persona que ha fallecido o que sea diagnosticada como herida grave o leve.
- El segundo cálculo será la suma total de accidentes para diferentes categorías, tales como la titularidad de la vía, el tipo de accidente o el tipo de vía. Esto nos permitirá ver cuáles son las condiciones en las cuales los accidentes son más frecuentes.
- El tercer cálculo será el de número de accidentes por municipio. En este caso realizaremos el cálculo restringido a la provincia de Valencia como ejemplo, y que sería aplicable a cualquier provincia o municipio de nuestro interés. En este caso observaremos las diferencias entre los núcleos urbanos y no urbanos, así como aquellos municipios por los que pasan las principales vías de comunicación.
3. Diseño de las visualizaciones
Una vez hemos calculado las métricas de interés, desarrollaremos cinco ejercicios de visualización en D3.js. Para ello exportaremos en formato JSON el resultado de las métricas y crearemos notebooks en Observable. En concreto realizamos las siguientes visualizaciones:
- Serie temporal con el número total de víctimas en cada hora y día de la semana, con un menú desplegable interactivo para seleccionar el día de la semana de interés. A mayores de la curva que describe el número de víctimas dibujaremos sobre el fondo de la gráfica la incertidumbre de todos los días de la semana, de forma que la serie temporal diaria queda enmarcada en el contexto de toda la semana como referencia.
- Mapa de la provincia de Valencia con el número total de accidentes por municipio.
- Diagrama de burbujas, con las diferentes magnitudes de los diferentes tipos de accidentes con el número total de accidentes en cada caso escrita de forma detallada.
- Diagrama de puntos apilados, donde acumulamos círculos o cualquier otra forma geométrica para las diferentes titularidades de la vía y su número total de accidentes dentro del marco de cada titularidad.
- Diagrama de sierra, con la altura de cada montaña correspondiente al número de accidentes en cada tipo de vía en escala logarítmica.
Visualización de las métricas
El resultado de este ejercicio se podrá ver de forma gráfica y explícita en forma de visualizaciones realizadas para el formato web y accesibles desde una interfaz también web, tanto para su desarrollo como para su posterior publicación. Todo el conjunto de visualizaciones se encuentra en el repositorio de Datos.gob.es en Observable:
Accede a los notebooks de Observable
En la Figura 2 tenemos el resultado de la serie temporal del total de víctimas respecto a la hora del día para diferentes días de la semana. La serie temporal está enmarcada dentro de la incertidumbre del total de días de la semana, para dar una idea del margen de variabilidad que podemos tener dependiendo de la hora del día.
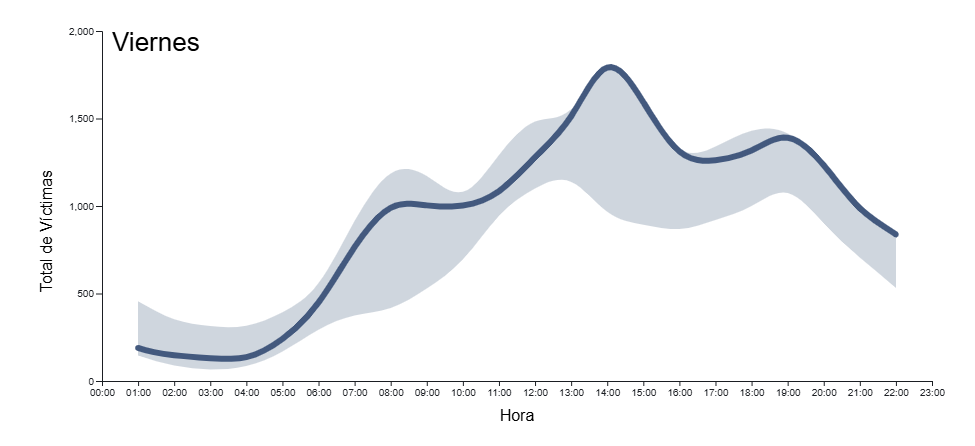
Figura 2. Serie temporal del total de víctimas en accidentes por hora del día para todos los días de la semana en 2024. En el fondo en color azul claro se indica la incertidumbre asociada a todos los días de la semana como contexto, con menú desplegable para seleccionar el día de la semana.
En la Figura 3 podemos observar el mapa de la provincia de Valencia con una intensidad de color proporcional al número de accidentes en cada municipio. Aquellos municipios en los cuales no se han registrado accidentes aparecen en color blanco. De forma intuitiva se puede adivinar el trazado de las principales carreteras que atraviesan la provincia, tanto la carretera hacia el este de la ciudad de Valencia en dirección Madrid como la carretera del interior hacia el sur de la ciudad en dirección a Alicante.
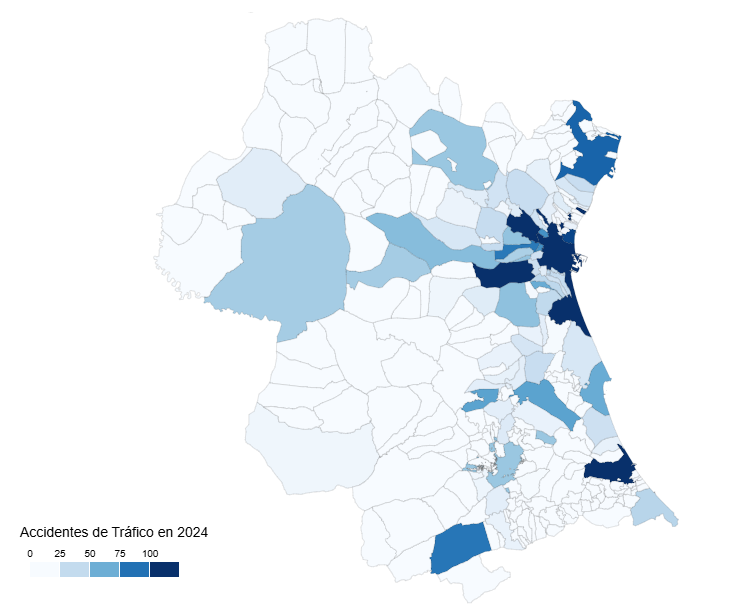
Figura 3. Mapa del número de accidentes por municipio en la provincia de Valencia en 2024.
En la Figura 4 vemos una forma geométrica, el círculo, asociada a los tipos de accidente, con el detalle del número de accidentes asociada a cada categoría. En este tipo de visualización emerge de forma natural aquellos accidentes más frecuentes en torno al centro del diagrama, mientras que aquellos minoritarios o residuales ocupan el perímetro del diagrama para dar igualmente una forma redonda al conjunto de formas.
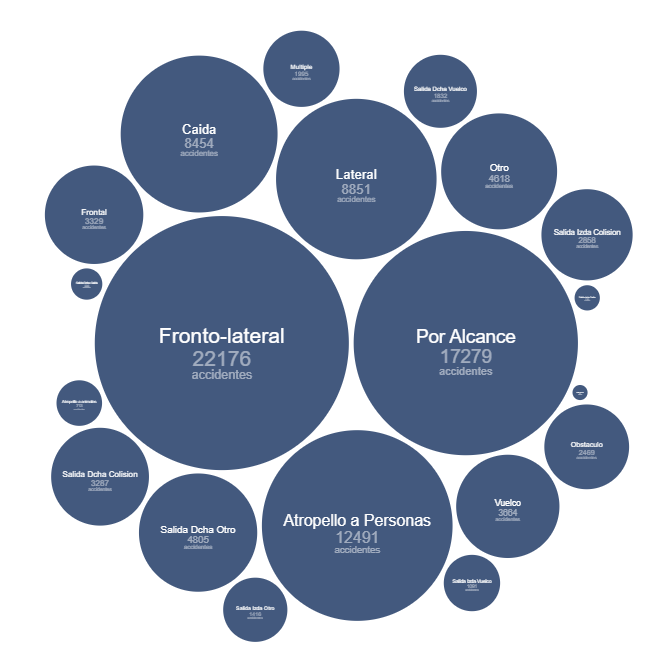
Figura 4. Diagrama de burbujas del número de accidentes por tipo de accidente en 2024.
En la Figura 5 se puede contemplar el tradicional diagrama de barras pero esta vez descompuesto en unidades más pequeñas, para afinar la cantidad de accidentes asociada a la titularidad de la vía donde han sucedido. Este tipo de diagramas permite discernir pequeñas diferencias entre magnitudes parecidas, preservando el mensaje general que obtenemos de un cálculo de estas características.
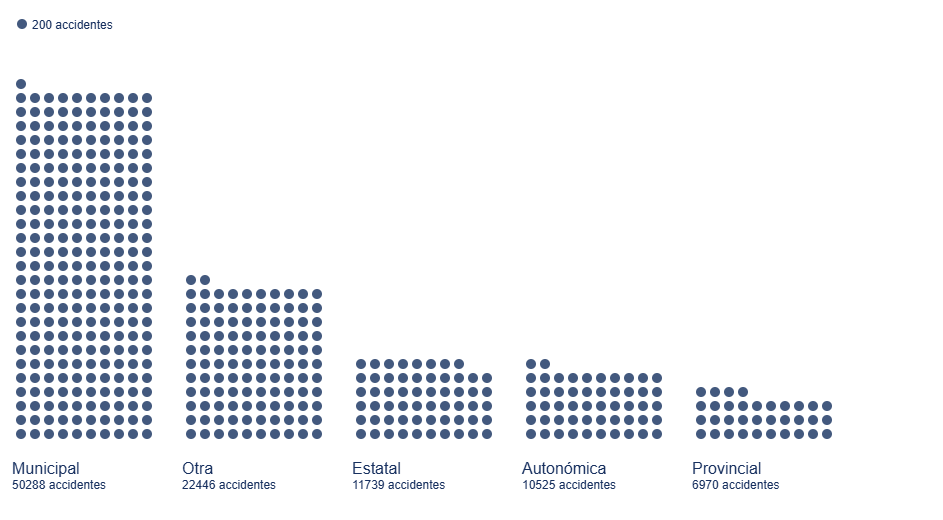
Figura 5. Diagrama de barras con discretización de puntos para el número de accidentes por titularidad de la vía en el 2024.
En la Figura 6 creamos una serie de formas geométricas que replican una cordillera o sierra donde los diferentes picos apuntan a la diferencia de número de accidentes por tipo de vía. Dada la diferencia en órdenes de magnitud establecemos una escala logarítmica, que permita comparar en el mismo diagrama diferentes casuísticas.
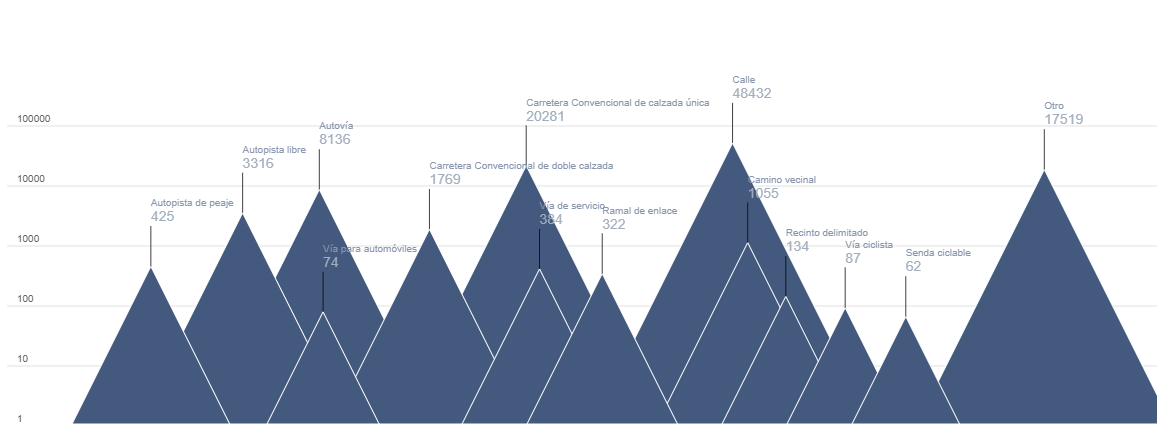
Figura 6. Diagrama en cordillera para los diferentes órdenes de magnitud del número de accidentes por tipo de vía en el 2024.
Lecciones aprendidas
A través de estos pasos aprenderemos toda una serie de habilidades transversales que nos permiten trabajar con aquellos conjunto de datos que se nos presentan en formato CSV en columnas, un formato muy popular para el cual podremos realizar tanto su análisis como su visualización. Estas lecciones son en concreto:
- Universalidad de lectura y estructuración de datos: el uso de herramientas como Python, con sus librerías Numpy y Pandas, permiten acceder a los datos en detalle y estructurarlos de forma ordenada e intuitiva con pocas líneas de código.
- Cálculos sencillos en Pandas: la propia librería de Python permite cálculos sencillos pero esenciales para la interpretación preliminar de resultados.
- Formato Datetime: a través de esta librería de Python podemos familiarizarnos con el estándar del formato de fecha, y así realizar todo tipo de transformaciones, filtros y selecciones que más nos interesen en cualquier intervalo temporal.
- Formato JSON: una vez que decidimos dar espacio a nuestras visualizaciones en la web, aprender la estructura y uso del formato JSON es de gran utilidad dado su amplio uso en todo tipo de aplicaciones y arquitecturas web.
- Espectro de posibilidades de D3.js: esta librería de Javascript nos permite explorar de lo más tradicional y conservador a lo más creativo gracias a sus principios basados en las formas más básicas, sin plantillas, templates o diagramas predefinidos.
Conclusiones y próximos pasos
Hemos aprendido a leer y a estructurar datos según los estándares de los formatos más utilizados en el mundo del análisis y visualización. Este ejercicio también sirve como módulo introductorio al mundo de D3.js, una herramienta muy versátil, vigente y popular dentro del mundo del storytelling y la visualización de datos a todos los niveles.
Para poder avanzar en este ejercicio se recomienda:
- Para los analistas y desarrolladores, se puede prescindir de la librería Pandas y estructurar los datos con objetos más elementales de Python como arrays y matrices, buscando qué funciones y qué operadores permiten realizar las mismas tareas que hace Pandas pero de una forma más fundamental, sobre todo si pensamos en entornos de producción para los cuales necesitamos el menor número de librerías posibles para aligerar la aplicación.
- Para los creadores de visualizaciones, la información sobre los municipios puede proyectarse igualmente sobre bases cartográficas ya existentes como OpenStreetMap y de esta forma vincular la incidencia de accidentes a características orográficas o infraestructuras ya reflejadas en esas bases cartográficas. Para las magnitudes de los números de accidentes se pueden explorar diagramas de tipo Treemap o diagramas de Voronoi y ver si transmiten el mismo mensaje que los que presentamos en este ejercicio.
Ámbitos de aplicación
Los pasos descritos en este ejercicio pueden pasar a formar parte de cualquier caja de herramientas de uso habitual para los siguientes perfiles:
- Analistas de datos: aquí se encuentran los pasos básicos para la descripción de un fichero de datos en formato CSV y los cálculos básicos a realizar tanto en el campo de la fecha como de operaciones entre variables de diferentes columnas. Estas herramientas pueden servir para introducirse en el mundo del análisis de datos y ayuda en esos primeros pasos a la hora de enfrentarse a un dataset.
- Científicos y personal investigador: la universalidad de las herramientas aquí descritas aplican a una gran variedad de origen de datos, como el que se experimenta en las ciencias experimentales y de observaciones o medidas de todo tipo. Estas herramientas permiten un análisis rápido a la vez que riguroso sin importar el campo de conocimiento en el que se trabaje.
- Desarrolladores web: la exportación de datos en formato JSON así como el código en Javascript que se ofrece en los notebooks de Observable son fácilmente integrables en todo tipo de entornos (Svelte, React, Angular, Vue) y permite la creación de visualizaciones en una web de forma sencilla e intuitiva.
- Periodistas: abarcar todo el proceso de vida de un fichero de datos, desde su lectura a su visualización, otorga al periodista o investigador independencia a la hora de evaluar e interpretar los datos por sí mismo sin depender de recursos técnicos ajenos. La creación del mapa por municipios abre la puerta a utilizar cualquier otro dato similar, como por ejemplo procesos electorales, con el mismo formato de salida para mostrar variabilidad geográfica respecto a cualquier tipo de magnitud.
- Diseñadores Gráficos: el manejo de herramientas de visualización con un amplio grado de libertad permite a los diseñadores cultivar toda su creatividad dentro del rigor y la exactitud que los datos necesitan.
Blog
Python, R, SQL, JavaScript, C++, HTML... Hoy en día podemos encontrar multitud de lenguajes de programación que nos permiten desarrollar programas de software, aplicaciones, páginas webs, etc. Cada uno tiene características únicas que lo diferencian del resto y que lo hacen más apropiado para determinadas tareas. Pero, ¿cómo sabemos cuándo y dónde utilizar cada lenguaje? En este artículo te damos algunas pistas.
Tipos de lenguajes de programación
Los lenguajes de programación son reglas sintácticas y semánticas que nos permiten ejecutar una serie de instrucciones. Según su nivel de complejidad, podemos hablar de distintos niveles:
- Lenguajes de bajo nivel: utilizan instrucciones básicas que la máquina interpreta directamente y que son difíciles de entender por las personas. Están diseñados a medida de cada hardware y no se pueden migrar, pero son muy eficaces, ya que aprovechan al máximo las características de cada máquina.
- Lenguajes de alto nivel: utilizan instrucciones claras usando un lenguaje natural, más entendible por los humanos. Estos lenguajes emulan nuestra forma de pensar y razonar, pero después deben ser traducidos a lenguaje máquina a través de traductores/intérpretes o compiladores. Se pueden migrar y no dependen del hardware.
En ocasiones también se habla de lenguajes de nivel medio para aquellos que, aunque funcionan como un lenguaje de bajo nivel, permiten cierto manejo abstracto independiente de la máquina.
Los lenguajes de programación más utilizados
En este artículo nos vamos a centrar en los lenguajes de alto nivel más utilizados en la ciencia de datos. Para ello nos vamos a fijar en esta encuesta, realizada por Anaconda en 2021, y en el artículo elaborado por KD Nuggets.
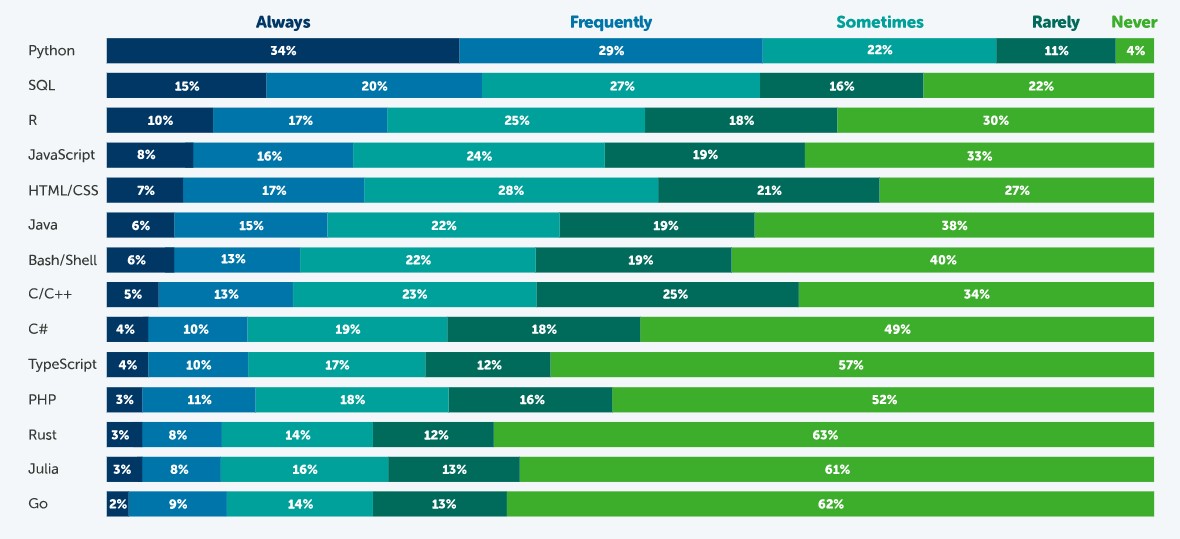
Fuente: Estado de la Ciencia de Datos en 2021, Anaconda.
Según esta encuesta, el lenguaje más popular es Python. El 63% de los encuestados – 3.104 científicos de datos, investigadores, estudiantes y profesionales del dato de todo el mundo- indicó que utiliza Python siempre o frecuentemente y solo un 4% indicó que nunca. Esto se debe a que es un lenguaje muy versátil, que se puede utilizar en las distintas tareas que existen a lo largo de un proyecto de ciencia de datos.
Un proyecto de ciencia de datos cuenta con distintas fases y tareas. Algunos lenguajes pueden ser utilizados para ejecutar distintas labores, pero con desigual rendimiento. La siguiente tabla, elaborada por KD Nuggets, muestra qué lenguaje es más recomendado para algunas de las tareas más populares:

Como vemos Python es el único lenguaje que resulta apropiado para todas las áreas analizadas por KD Nuggets, aunque existen otras opciones que también son muy interesantes, según la tarea a realizar, como veremos a continuación:
- Extracción y manipulación de datos. Estas tareas están dirigidas a obtener los datos y depurarlos con el fin de conseguir una estructura homogénea, sin datos incompletos, libre de errores y en el formato adecuado. Para ello se recomienda realizar un Análisis Exploratorio de Datos. SQL es el lenguaje de programación que más destaca con respecto a la extracción de datos, sobre todo cuando se trabaja con bases de datos relacionales. Es rápido en la recuperación de datos y cuenta con una sintaxis estandarizada, lo cual lo hace relativamente sencillo. Sin embargo, es más limitado a la hora de manipular datos. Una tarea en la que dan mejores resultados Python y R, dos programas que cuentan con una gran cantidad de librerías para estas tareas.
- Análisis estadístico y visualización de datos. Supone el tratamiento de los datos para encontrar patrones que luego se convierten en conocimiento. Existen distintos tipo de análisis según su propósito: conocer mejor nuestro entorno, realizar predicciones u obtener recomendaciones. El mejor lenguaje para ello es R, un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística. Python, Java y Julia son otras herramientas que dan un buen rendimiento en esta tarea, para la cual también se puede utilizar JavaScript. Los lenguajes anteriores permiten, además de realizar análisis, elaborar visualizaciones gráficas que facilitan la comprensión de la información.
- Modelización/aprendizaje automático (ML). Si queremos trabajar con machine learning y construir algoritmos, Python, Java, Java/JavaScript, Julia y TypeScript son las mejores opciones. Todas ellas simplifican la tarea de escribir código, aunque es necesario tener conocimientos amplios para poder trabajar con las diferentes técnicas de aprendizaje automático. Aquellos usuarios más expertos pueden trabajar con C/C++, un lenguaje de programación muy fácil de leer por máquinas, pero con mucho código, que puede ser difícil de aprender. Por el contrario, R puede ser una buena opción para aquellos menos expertos, aunque es más lento y poco apropiado para redes neuronales complejas.
- Despliegue de modelos. Una vez creado un modelo, es necesario su despliegue, teniendo en cuenta todos los requisitos necesarios para su entrada en producción en un entorno real. Para ello, los lenguajes más adecuados son Python, Java, JavaScript y C#, seguido de PHP, Rust, GoLang y, si trabajamos con aplicaciones básicas, HTML/CSS.
- Automatización. Aunque no todas las partes del trabajo de un científico de datos pueden automatizarse, hay algunas tareas tediosas y repetitivas cuya automatización agiliza el rendimiento. Python, por ejemplo, cuenta con una gran cantidad de librerías para la automatización de tareas de machine learning. Si trabajamos con aplicaciones móviles, entonces nuestra mejor opción será Java. Otras opciones son C# (especialmente útil para automatizar la construcción de modelos), Bash/Shell (para extracción y manipulación de datos) y R (para análisis estadísticos y visualizaciones).
En definitiva, el lenguaje de programación que utilicemos dependerá completamente de la tarea a realizar y de nuestras capacidades. No todos los profesionales de la ciencia de datos necesitan saber de todos los lenguajes, sino que deberán optar por profundizar en aquel más adecuado en base a su trabajo diario.
Algunos recursos adicionales para aprender más sobre estos lenguajes
En datos.gob.es hemos elaborado algunas guías y recursos que pueden ser de tu utilidad para aprender algunos de estos lenguajes:
- Informe sobre Herramientas de procesado y visualización de datos
- Cursos para aprender más sobre R
- Cursos para aprender más sobre Python
- Cursos online para aprender más sobre visualización de datos
- Comunidades de desarrolladores en R y Python
Contenido elaborado por el equipo de datos.gob.es.
Blog
El avance de la supercomputación y la analítica de datos en campos tan dispares como las redes sociales o la atención al cliente está fomentando que una parte de la inteligencia artificial (IA) se enfoque en desarrollar algoritmos capaces de procesar y generar un lenguaje natural.
Para poder llevar a cabo esta tarea en un contexto como el actual, tener acceso a un heterogéneo listado de bibliotecas de procesamiento de lenguaje natural es clave para diseñar soluciones IA eficaces y funcionales de forma ágil. Estos archivos de código fuente, que se utilizan para desarrollar software, facilitan la programación al proporcionar funcionalidades comunes, resueltas previamente por otros desarrolladores, evitando duplicidades y minimizando los errores.
Así y con el objetivo de fomentar la compartición y reutilización para diseñar aplicaciones y servicios que aporten valor económico y social, desglosamos cuatro conjuntos de bibliotecas de procesamiento de lenguaje natural, divididas en base al lenguaje de programación utilizado.
Librerías para Python
Idóneas para codificar utilizando el lenguaje de programación Python. Al igual que sucede con los ejemplos disponibles para otros lenguajes, estas librerías cuentan con gran variedad de implementaciones que permiten al desarrollador crear una nueva interfaz por su propia cuenta.
Algunos ejemplos son:
NLTK: Natural Language Toolkit
- Descripción: NLTK ofrece interfaces fáciles de usar para más de 50 corpus y recursos léxicos como WordNet, junto con un conjunto de bibliotecas de procesamiento de textos. Permite realizar tareas de preprocesado de texto, entre las que encontramos, la clasificación, tokenización, lematización o la exclusión de stop words, el análisis sintáctico y el razonamiento semántico.
- Materiales de apoyo: Una de las secciones más interesantes para consultar información y resolver dudas es el apartado dedicado a las preguntas frecuentes. Puedes encontrarlo en este enlace. También tiene disponible ejemplos de uso y una wiki.
Gensim
- Descripción: Gensim es una biblioteca Python de código abierto para representar documentos como vectores semánticos. La diferencia principal respecto al resto de librerías de lenguaje natural para Python reside en que Gensim es capaz de identificar automáticamente la temática del conjunto de documentos a tratar. También permite analizar la similitud entre ficheros, algo realmente útil cuando utilizamos la librería para realizar búsquedas.
- Materiales de apoyo: En la sección de Documentación de su página web, es posible encontrar materiales didácticos enfocados a tres áreas muy concretas. Por un lado, hay una serie de tutoriales dirigidos a aquellos programadores que nunca antes han utilizado este tipo de bibliotecas. Existen lecciones formativas orientadas a cuestiones específicas del lenguaje de programación, una serie de guías cuyo objetivo es resolver las dudas que surgen ante determinados problemas y también una sección dedicada únicamente a las preguntas frecuentes
Librerías para JavaScript
Las librerías de JavaScript sirven para diversificar el abanico de recursos que pueden utilizar los programadores y desarrolladores web que hacen uso de este lenguaje. Puedes elegir entre los siguientes ejemplos propuestos a continuación:
Apache OpenNLP
- Descripción: La biblioteca Apache OpenNLP es un conjunto de herramientas basadas en el aprendizaje automático para el procesamiento de textos en lenguaje natural. Es compatible con las tareas básicas de programación de lenguaje natural, tokenización, segmentación de frases, el etiquetado de las partes de un discurso, la extracción de entidades con nombre o la detección de idiomas, entre otras muchas.
- Materiales de apoyo: Dentro de la categoría General de su web, encontramos un subapartado denominado Books, Tutorials and Talks donde se proporcionan una serie de charlas, tutoriales y publicaciones destinadas a resolver las dudas de los programadores. Igualmente, en la categoría Documentation disponen de distintos manuales de uso.
NLP.js
- Descripción: NLP.js está dirigida a node.js, un entorno de ejecución de JavaScript de código abierto. Admite 41 idiomas de forma nativa e, incluso, puede ampliarse hasta 104 idiomas con el uso de Bert embeddings. Se trata de una librería utilizada principalmente para la construcción de bots, el análisis de sentimiento o la identificación automática del lenguaje, entre otras funciones. Precisamente por esta razón, es una librería a tener en cuenta para la construcción de chatbots.
- Materiales de apoyo: Dentro de su perfil alojado en el portal de código Github ofrecen un apartado de preguntas frecuentes y otro de ejemplos de uso que pueden resultar útiles a la hora de hacer uso de la librería para desarrollar una app o servicio.
Natural
- Descripción: Al igual que NLP.js, Natural también facilita el procesamiento del lenguaje natural para node.js. Ofrece una variada gama de funcionalidades como la tokenización, coincidencia fonética, frecuencia de términos (TF-IDF) y la integración con la base de datos WordNet, entre otras.
- Materiales de apoyo: Al igual que la anterior biblioteca, esta librería tampoco tiene web propia. En su perfil de Github, dispone de contenidos de apoyo como ejemplos de casos de uso desarrollados anteriormente por otros programadores.
Wink
- Descripción: Wink es una familia de paquetes de código abierto para el análisis estadístico, el procesamiento del lenguaje natural y el aprendizaje automático en NodeJS. Ha sido optimizada para lograr un equilibrio entre rendimiento y precisión, lo que hace que el paquete pueda manejar grandes cantidades de texto en bruto a una alta velocidad.
- Materiales de apoyo: Acceder a los tutoriales desde su página web resulta muy intuitivo ya que una de las categorías que tiene el mismo nombre recoge precisamente este tipo de contenido divulgativo. En ella es posible encontrar guías de aprendizaje divididas según el nivel de experiencia del programador o de la parte del proceso en el que esté inmerso.
Librerías para R
En este último apartado aglutinamos las bibliotecas específicas para construir una web, aplicación o servicio utilizando el lenguaje de codificación R. Algunas de ellas son:
koRpus
- Descripción: Se trata de un paquete de análisis de textos capaz de detectar el idioma de manera automática y diversos índices de diversidad léxica o legibilidad, entre otras funciones. Además, incluye el plugin RKWard que proporciona cuadros de diálogo gráficos para sus funciones básicas.
- Materiales de apoyo: koRpus ofrece una serie de directrices enfocadas a su instalación y aglutinadas en el documento Read me que puedes encontrar en este enlace. Igualmente, en el aparado News están disponibles las actualizaciones y cambios que se han ido realizando en las sucesivas versiones de la librería.
Quanteda
- Descripción: Esta biblioteca ha sido diseñada para que los programadores que utilizan R apliquen técnicas de procesamiento de lenguaje natural a sus textos desde la versión original hasta la obtención de los resultados finales. Por ello, su API ha sido desarrollada para permitir un análisis potente y eficiente con un mínimo de pasos, reduciendo así las barreras de aprendizaje, al procesamiento del lenguaje natural y el análisis cuantitativo de textos.
- Materiales de apoyo: Ofrece como material de apoyo principal esta guía de inicio rápido. A través de ella, es posible seguir las instrucciones principales para no cometer ningún error. Incluye también varios ejemplos que pueden servir para comparar resultados.
Isa - Natural Language Processing
- Descripción: Esta librería se basa en el análisis semántico latente que consiste en crear datos estructurados a partir de una colección de textos no estructurados.
- Materiales de apoyo: En el apartado dedicado a la documentación, podemos encontrar información útil para el desarrollo.
Librerías para Python y R
Hablamos de librerías para Python y R para referirnos a aquellas que son compatibles para codificar utilizando ambos lenguajes de programación.
spaCy
- Descripción: Es una herramienta muy útil para preparar textos que, posteriormente, serán empleados en otras tareas de aprendizaje automático. Además, permite aplicar modelos lingüísticos estadísticos para resolver diferentes problemas de procesamiento del lenguaje natural.
- Materiales de apoyo: spaCy ofrece una serie de cursos online divididos en distintos capítulos y que podrás encontrar aquí. A través de los contenidos compartidos en NLP Advanced podrás seguir paso a paso las utilidades de esta biblioteca, ya que cada capítulo se centra en una parte del procesamiento del texto. Si aún quieres aprender más sobre esta librería, te recomendamos leer este artículo de Alejandro Alija sobre su experiencia probando esta biblioteca.
En este artículo hemos compartido una muestra de algunas de las librerías más populares para el procesamiento del lenguaje natural. Aun así, conviene subrayar que se trata de una mera selección.
Por todo ello, si conoces de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Blog
Las librerías de programación hacen referencia a los conjuntos de archivos de código que han sido creados para desarrollar software de manera sencilla. Gracias a ellas, los desarrolladores pueden evitar la duplicidad de código y minimizar errores con mayor agilidad y menor coste. Existen multitud de librerías, enfocadas en distintas actividades. Hace unas semanas vimos algunos ejemplos de librerías para la creación de visualizaciones, y en esta ocasión nos vamos a centrar en librerías de utilidad para tareas de aprendizaje automático (Machine Learning).
Estas librerías son altamente prácticas a la hora de implementar flujos de Machine Learning. Esta disciplina, perteneciente al campo de la Inteligencia Artificial, utiliza algoritmos que ofrecen, por ejemplo, la capacidad de identificar patrones de datos masivos o la capacidad de ayudar a elaborar análisis predictivos.
A continuación, te mostramos algunas de las librerías de análisis de datos y Machine Learning más populares que existen en la actualidad para los principales lenguajes de programación, como Python o R:
Librerías para Python
NumPy
- Descripción:
Esta librería de Python está especializada en el cálculo matemático y en el análisis de grandes volúmenes de datos. Permite trabajar con arrays que permiten representar colecciones de datos de un mismo tipo en varias dimensiones, además de funciones muy eficientes para su manipulación.
- Materiales de apoyo:
Aquí encontramos la Guía para principiantes, con conceptos básicos y tutoriales, la Guía del usuario, con información sobre las características generales, o la Guía del colaborador, para contribuir al mantenimiento y desarrollo del código o en la redacción de documentación técnica. NumPy también cuenta con una Guía de referencia que detalla funciones, módulos y objetos incluidos en esta librería, así como una serie de tutoriales para aprender a utilizarla de forma sencilla.
Pandas
- Descripción:
Se trata de una de las librerías más utilizadas para el tratamiento de datos en Python. Esta herramienta de análisis y manipulación de datos se caracteriza, entre otros aspectos, por definir nuevas funcionalidades de datos basadas en los arrays de la librería NumPy. Permite leer y escribir fácilmente ficheros en formato CSV, Excel y especificar consultas a bases de datos SQL.
- Materiales de apoyo:
Su web cuenta con diferentes documentos como la Guía del usuario, con información básica detallada y explicaciones útiles, la Guía del desarrollador, que detalla los pasos a seguir ante la identificación de errores o sugerencia de mejoras en las funcionalidades, así como la Guía de referencia, con descripción detallada de su API. Además, ofrece una serie de tutoriales aportados por la comunidad y referencias sobre operaciones equivalentes en otros softwares y lenguajes como SAS, SQL o R.
Scikit-learn
- Descripción:
Scikit-Learn es una librería que implementa una gran cantidad de algoritmos de Machine Learning para tareas de clasificación, regresión, clustering y reducción de dimensionalidad. Además, es compatible con otras librerías de Python como NumPy, SciPy y Matplotlib (Matpotlib es una librería de visualización de datos y como tal está incluida en el artículo anterior).
- Materiales de apoyo:
Esta librería cuenta con diferentes documentos de ayuda como un Manual de instalación, una Guía del Usuario o un Glosario de términos comunes y elementos de su API. Además, ofrece una sección con diferentes ejemplos que ilustran las características de la librería, así como otras secciones de interés con tutoriales, preguntas frecuentes o acceso a su GitHub.
Scipy
- Descripción:
Esta librería presenta una colección de algoritmos matemáticos y funciones construidas sobre la extensión de NumPy. Incluye módulos de extensión para Python sobre estadística, optimización, integración, álgebra lineal o procesamiento de imágenes, entre otros.
- Materiales de apoyo:
Al igual que los ejemplos anteriores, esta librería también cuenta con materiales como Guías de instalación, Guías para usuarios, para desarrolladores o un documento con descripciones detalladas sobre su API. Además, ofrece información sobre act, una herramienta para ejecutar acciones de GitHub de forma local.
Librerías para R
mlr
- Descripción:
Esta librería ofrece componentes fundamentales para desarrollar tareas de aprendizaje automático, entre otros, preprocesamiento, pipelining, selección de características, visualización e implementación de técnicas supervisadas y no supervisadas utilizando un amplio abanico de algoritmos.
- Materiales de apoyo:
En su web cuenta con múltiples recursos para usuarios y desarrolladores, entre los que destaca un tutorial de referencia que presenta un extenso recorrido que abarca los aspectos básicos sobre tareas, predicciones o preprocesamiento de datos hasta la implementación de proyectos complejos utilizando funciones avanzadas.
Además, cuenta con un apartado que redirige a GitHub en el que ofrece charlas, vídeos y talleres de interés sobre el funcionamiento y los usos de esta librería.
Tidyverse
- Descripción:
Esta librería ofrece una colección de paquetes de R diseñados para la ciencia de datos que aporta funcionalidades muy útiles para importar, transformar, visualizar, modelar y comunicar información a partir de datos. Todos ellos comparten una misma filosofía de diseño, gramática y estructuras de datos subyacentes. Los principales paquetes que lo componen son: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr y purrr.
- Materiales de apoyo:
Tidyverse cuenta con un blog en el que podrás encontrar posts sobre programación, paquetes o trucos y técnicas para trabajar con esta librería. Además, cuenta con una sección que recomienda libros y workshops para aprender a utilizar esta librería de una manera más sencilla y amena.
Caret
- Descripción:
Esta popular librería contiene una interfaz que unifica bajo un único marco de trabajo cientos de funciones para entrenar clasificadores y regresores, facilitando en gran medida todas las etapas de preprocesado, entrenamiento, optimización y validación de modelos predictivos.
- Materiales de apoyo:
La web del proyecto contine exhaustiva información que facilita al usuario abordar tareas mencionadas. También se puede encontrar referencias en CRAN y el proyecto está alojado en GitHub. Algunos recursos de interés para el manejo de esta librería se pueden encontrar a través de libros como Applied Predictive Modeling, artículos, seminarios o tutoriales, entre otros.
Librerías para abordar tareas de Big Data
TensorFlow
- Descripción:
Además de Python y R, esta librería también es compatible con otros lenguajes como JavaScript, C++ o Julia. TensorFlow ofrece la posibilidad de compilar y entrenar modelos de ML utilizando APIs. La API más destacada es Keras, que permite construir y entrenar modelos de aprendizaje profundo (Deep Learning).
- Materiales de apoyo:
En su web se pueden encontrar recursos como modelos y conjuntos de datos previamente establecidos y desarrollados, herramientas, bibliotecas y extensiones, programas de certificación, conocimientos sobre aprendizaje automático o recursos y herramientas para integrar las prácticas de IA responsable. Puedes acceder a su página de GitHub aquí.
Dmlc XGBoost
- Descripción:
Librería de "Gradient Boosting" (GBM, GBRT, GBDT) escalable, portátil y distribuida es compatible con los lenguajes de programación C++, Python, R, Java, Scala, Perl y Julia. Esta librería permite resolver muchos problemas de ciencia de datos de una manera rápida y precisa y se puede integrar con Flink, Spark y otros sistemas de flujo de datos en la nube para abordar tareas Big Data.
- Materiales de apoyo:
En su web cuenta con un blog con temáticas relacionadas como actualizaciones de algoritmos o integraciones, además de una sección de documentación que cuenta con guías de instalación, tutoriales, preguntas frecuentes, foro de usuarios o paquetes para los distintos lenguajes de programación. Puedes acceder a su página de GitHub a través de este enlace.
H20
- Descripción:
Esta librería combina los principales algoritmos de Machine Learning y aprendizaje estadístico con Big Data, además de ser capaz de trabajar con millones de registros. H20 está escrita en Java, y sigue el paradigma Key/Value para almacenar datos y Map/Reduce para implementar algoritmos. Gracias a su API, se puede acceder desde R, Python o Scala.
- Materiales de apoyo:
Cuenta con una serie de vídeos en forma de tutorial para enseñar y facilitar su uso a los usuarios. En su página de GitHub podrás encontrar recursos adicionales como blogs, proyectos, recursos, trabajos de investigación, cursos o libros sobre H20.
En este artículo hemos ofrecido una muestra de algunas de las librerías más populares que ofrecen funcionalidades versátiles para abordar tareas típicas de ciencia de datos y aprendizaje automático, aunque hay muchas otras. Este tipo de librerías está en constante evolución gracias a la posibilidad que ofrece a sus usuarios de participar en su mejora a través de acciones como la contribución a la escritura de código, la generación de nueva documentación o el reporte de errores. Todo ello permite enriquecer y perfeccionar sus resultados continuamente.
Si sabes de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Blog
Las librerías de programación son conjuntos de archivos de código que se utilizan para desarrollar software. Su objetivo es facilitar la programación, al proporcionar funcionalidades comunes, que ya han sido resueltas previamente por otros programadores. Como curiosidad, el término proviene de una mala traducción de la palabra inglesa library, que en realidad significa biblioteca.
Las librerías (o bibliotecas) son un componente esencial para que los desarrolladores puedan programar de forma sencilla, evitando la duplicidad de código y minimizando errores. También permiten una mayor agilidad, al reducir el tiempo de desarrollo, así como los costes.
Estas ventajas se reflejan a la hora de usar librerías para realizar visualizaciones utilizando lenguajes tan populares como Python, R y JavaScript.
Librerías para Python
Python es uno de lenguajes de programación más utilizados. Se trata de un lenguaje interpretado (fácil de leer y escribir gracias a la semejanza que presenta con el lenguaje humano), multiplataforma, gratuito y de código abierto. En este artículo previo puedes encontrar cursos para aprender más sobre él.
Dada su popularidad, no es de extrañar que encontremos en la red múltiples librerías que nos facilitarán la creación de visualizaciones con este lenguaje, como por ejemplo:
Matplotlib
- Descripción:
Matplotlib es una biblioteca completa para la generación de visualizaciones estáticas, animadas e interactivas a partir de datos contenidos en listas o arrays en el lenguaje de programación Python y su extensión matemática NumPy.
- Materiales de apoyo:
En su web se recogen ejemplos de visualizaciones con el código fuente, para inspirar a nuevos usuarios, y diversas guías dirigidas tanto a usuarios principiantes como a aquellos más avanzados. En la web también hay disponible una sección de recursos externos que redirige a libros, artículos, vídeos y tutoriales elaborados por terceros.
Seaborn
- Descripción:
Seaborn es una biblioteca de visualización de datos en Python basada en matplotlib. Proporciona una interfaz de alto nivel que permite dibujar gráficos estadísticos atractivos e informativos.
- Materiales de apoyo:
En su web hay disponibles tutoriales, con información sobre la API y los distintos tipos de funciones, así como una galería de ejemplos. También es recomendable echar un vistazo a este paper elaborado por The Journal of Open Source Software.
Bokeh
- Descripción:
Bokeh es una librería para la visualización de datos de forma interactiva en un navegador web. Entre sus funciones está desde la creación de gráficos simples hasta la elaboración de cuadros de mando interactivos.
- Materiales de apoyo:
Los usuarios pueden encontrar en su guía descripciones detalladas y ejemplos que describen las tareas más comunes. La guía incluye la definición de conceptos básicos, el trabajo con datos geográficos o cómo generar interacciones, entre otros.
La web también cuenta con una galería con ejemplos, tutoriales y un apartado de comunidad, donde plantear y resolver dudas.
Geoplotlib
- Descripción:
Geoplotlib es una librería de código abierto en python para la visualización de datos geográficos. Se trata de una sencilla API que produce visualizaciones sobre mosaicos de OpenStreetMap. Permite la creación de mapas de puntos, estimadores de densidad de datos, gráficos espaciales y archivos ”shapes”, entre muchas otras visualizaciones espaciales.
- Materiales de apoyo:
En Github tienes disponible esta guía de usuarios, donde se explica cómo cargar datos, crear mapas de colores o añadir interactividad a las capas, entre otros. También hay disponibles ejemplos de código.
Librerías para R
R también es un lenguaje interpretado para la computación estadística y la creación de representaciones gráficas (puedes aprender más sobre ello siguiendo alguno de estos cursos). Cuenta con su propio entorno de programación, R-Studio, y con un conjunto de herramientas muy flexibles y versátiles que se pueden ampliar fácilmente mediante la instalación de librerías o paquetes –usando su propia terminología-, como las que se detallan a continuación:
ggplot 2
- Descripción:
Ggplot es una de las librerías más populares y utilizadas en R para la creación de visualizaciones interactivas de datos. Su funcionamiento se basa en el paradigma descrito en The Grammar of Graphics para la creación de visualizaciones con 3 capas de elementos: datos (data frame), la lista de relaciones entre las variables (aesthetics) y los elementos geométricos que se van a representar (geoms).
- Materiales de apoyo:
En su web puedes encontrar diversos materiales, como esta cheatsheet que recoge de manera resumida las principales funcionalidades de ggplot2. Por su parte, esta guía comienza explicando las características generales del sistema utilizando como ejemplo los diagramas de dispersión para detallar, a continuación, cómo representar algunos de los gráficos más conocidos. También se incluyen diversas FAQ que pueden ser de ayuda.
Lattice
- Descripción:
Lattice es un sistema de visualización de datos inspirado en los gráficos Trellis o de trama, prestando especial atención a los datos multivariantes. La interfaz de usuario de Lattice consiste en varias funciones genéricas de "alto nivel", cada una de ellas diseñada para crear un tipo particular de gráfico por defecto.
- Materiales de apoyo:
En este manual puedes encontrar información sobre las diversas funcionalidades, aunque si quieres profundizar en ellas, en esta sección de la web puedes encontrar diversos manuales como R Graphics de Paul Murrell o Lattice de Deepayan Sarkar.
Esquisse
- Descripción:
Esquise permite explorar interactivamente los datos y crear visualizaciones detalladas con el paquete ggplot2 a través de una interfaz de arrastrar y soltar. Incluye multitud de elementos: gráficos de dispersión, de líneas, de cajas, con ejes múltiples, sparklines, dendogramas, gráficos 3D, etc.
- Materiales de apoyo:
La documentación está disponible a través de este enlace, incluyendo información sobre la instalación y las diversas funciones. También tienes información en la web de R.
Leaflet
- Descripción:
Leaflet permite la creación de mapas altamente detallados, interactivos y personalizados. Está basado en la biblioteca de JavaScript del mismo nombre.
- Materiales de apoyo:
En esta web tienes documentación sobre las diversas funcionalidades: el funcionamiento del widget, marcadores, cómo trabajar con GeoJSON & TopoJSON, cómo integrarse con Shiny, etc.
Librerías para JavaScript
JavaScript también es un lenguaje de programación interpretado, responsable de dotar de mayor interactividad y dinamismo a las páginas web. Es un lenguaje orientado a objetos, basado en prototipos y dinámico.
Algunas de las principales librerías para JavaScript son:
D3.js
- Descripción:
D3.js está dirigida a la creación de visualizaciones de datos y animaciones utilizando estándares web, como SVG, Canvas y HTML. Es una librería muy potente y de cierta complejidad.
- Materiales de apoyo:
En Github puedes encontrar una galería con ejemplos de los diversos gráficos y visualizaciones que se pueden obtener con esta librería, así como diversos tutoriales e información sobre técnicas específicas.
Chart.js
- Descripción:
Chart.js es una librería de JavaScript que utiliza canvas de HTML5 para la creación de gráficos interactivos. En concreto, admite 9 tipos de gráficos: barra, línea, área, circular, burbuja, radar, polar, dispersión y mixtos.
- Materiales de apoyo:
En su propia web tienes información sobre la instalación y configuración, y ejemplos de los distintos tipos de gráficos. También hay un apartado para desarrolladores con diversa documentación.
Otras librerias
Plotly
- Descripción:
Plotly es una biblioteca de gráficos de alto nivel, que permite la creación de más de 40 tipos de gráficos, incluidos gráficos 3D, estadísticos y mapas SVG. Es una librería Open Source, pero tiene versiones de pago.
Plotly no está ligada a un único lenguaje de programación, si no que permite la integración con R, Python y JavaScript.
- Materiales de apoyo:
Cuenta con una completa página web donde los usuarios pueden encontrar guías, casos de uso por ámbitos de aplicación, ejemplos prácticos, webinars y una sección de comunidad donde compartir conocimiento.
Cualquier usuario que lo desee puede contribuir con cualquiera de estas librerías, escribiendo código, generando nueva documentación o reportando errores, entre otros. De esta forma se enriquecen y perfeccionan, mejorando sus resultados de manera continua.
¿Conoces alguna otra librería que quieras recomendar? Déjanos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.