Blog
Los asistentes de inteligencia artificial (IA) ya forman parte de nuestro día a día: les preguntamos la hora, cómo llegar a un determinado lugar o les pedimos que reproduzcan nuestra canción favorita. Y aunque la IA, en el futuro, pueda llegar a ofrecernos infinitas funcionalidades, no hay que olvidar que la diversidad lingüística es aún una asignatura pendiente.
En España, donde conviven el castellano junto con lenguas cooficiales como el euskera, catalán, valenciano y gallego, esta cuestión cobra especial relevancia. La supervivencia y vitalidad de estas lenguas en la era digital depende, en gran medida, de su capacidad para adaptarse y estar presentes en las tecnologías emergentes. Actualmente, la mayoría de asistentes virtuales, traductores automáticos o sistemas de reconocimiento de voz no entienden todos los idiomas cooficiales. Sin embargo, ¿sabías que existen proyectos colaborativos para garantizar la diversidad lingüística?
En este post te contamos el planteamiento y los mayores avances de algunas iniciativas que están construyendo los cimientos digitales necesarios para que las lenguas cooficiales en España también prosperen en la era de la inteligencia artificial.
ILENIA, el paraguas coordinador de iniciativas de recursos multilingües en España
Los modelos que vamos a ver en este post comparten enfoque porque forman parte de ILENIA, coordinador a nivel estatal que conecta los esfuerzos individuales de las comunidades autónomas. Esta iniciativa agrupa los proyectos BSC-CNS (AINA), CENID (VIVES), HiTZ (NEL-GAITU) y la Universidad de Santiago de Compostela (NÓS), con el objetivo de generar recursos digitales que permitan desarrollar aplicaciones multilingües en las diferentes lenguas de España.
El éxito de estas iniciativas depende fundamentalmente de la participación ciudadana. A través de plataformas como Common Voice de Mozilla, cualquier hablante puede contribuir a la construcción de estos recursos lingüísticos mediante diferentes modalidades de colaboración:
- Habla leída: recopilar diferentes maneras de hablar a través de las donaciones de voz de un texto específico.
- Habla espontánea: crea datasets reales y orgánicos fruto de conversaciones con los prompts.
- Texto en idioma: colaborar en la transcripción de audios o en la aportación de contenido textual, sugiriendo nuevas frases o preguntas para enriquecer los corpus.
Todos los recursos se publican bajo licencias libres como CC0, permitiendo su uso gratuito por parte de investigadores, desarrolladores y empresas.
El reto de la diversidad lingüística en la era digital
Los sistemas de inteligencia artificial aprenden de los datos que reciben durante su entrenamiento. Para desarrollar tecnologías que funcionen correctamente en una lengua específica, es imprescindible contar con grandes volúmenes de datos: grabaciones de audio, corpus de texto y ejemplos de uso real del idioma.
En otras publicaciones de datos.gob.es hemos abordado el funcionamiento de los modelos fundacionales y las iniciativas en castellano como ALIA, entrenadas con grandes corpus de texto como los de la Real Academia Española.
En ambos posts se explica por qué la recopilación de datos lingüísticos no es una tarea barata ni sencilla. Las empresas tecnológicas han invertido masivamente en recopilar estos recursos para lenguas con gran número de hablantes, pero las lenguas cooficiales españolas se enfrentan a una desventaja estructural. Esto ha llevado a que muchos modelos no funcionen correctamente o no estén disponibles en valenciano, catalán, euskera o gallego.
No obstante, existen iniciativas colaborativas y de datos abiertos que permiten crear recursos lingüísticos de calidad. Se trata de los proyectos que varias comunidades autónomas han puesto en marcha marcando el camino hacia un futuro digital multilingüe.
Por un lado, el Proyecto Nós en Galicia crea recursos orales y conversacionales en gallego con todos los acentos y variantes dialectales para facilitar la integración a través de herramientas como GPS, asistentes de voz o ChatGPT. Un propósito similar el de Aina en Catalunya que además ofrece una plataforma académica y un laboratorio para desarrolladores o Vives en la Comunidad Valenciana. En el País Vasco también existe el proyecto Euskorpus que tiene como objetivo la constitución de un corpus de texto de calidad en euskera. Veamos cada uno de ellos.
Proyecto Nós, un enfoque colaborativo para el gallego digital
El proyecto ha desarrollado ya tres herramientas operativas: un traductor neuronal multilingüe, un sistema de reconocimiento de voz que convierte habla en texto, y una aplicación de síntesis de voz. Estos recursos se publican bajo licencias abiertas, garantizando su acceso libre y gratuito para investigadores, desarrolladores y empresas. Estas son sus características principales:
- Impulsado por: la Xunta de Galicia y la Universidad de Santiago de Compostela.
- Objetivo principal: crear recursos orales y conversacionales en gallego que capturen la diversidad dialectal y de acentos de la lengua.
- Cómo participar: el proyecto acepta contribuciones voluntarias tanto leyendo textos como respondiendo a preguntas espontáneas.
- Dona tu voz en gallego: https://doagalego.nos.gal
Aina, hacia una IA que entienda y hable catalán
Con un planteamiento similar al proyecto Nós, Aina busca facilitar la integración del catalán en los modelos de lenguaje de inteligencia artificial.
Se estructura en dos vertientes complementarias que maximizan su impacto:
- Aina Tech se centra en facilitar la transferencia tecnológica al sector empresarial, proporcionando las herramientas necesarias para traducir automáticamente al catalán webs, servicios y negocios en línea.
- Aina Lab impulsa la creación de una comunidad de desarrolladores a través de iniciativas como Aina Challenge, fomentando la innovación colaborativa en tecnologías del lenguaje en catalán. A través de esta convocatoria se han premiado 22 propuestas ya seleccionadas con un importe total de 1 millón para que ejecuten sus proyectos.
Las características del proyecto son:
- Impulsado por: la Generalitat de Catalunya en colaboración con el Barcelona Supercomputing Center (BSC-CNS)
- Objetivo principal: va más allá de la creación de herramientas, busca construir una infraestructura de IA abierta, transparente y responsable con el catalán.
- Cómo participar: puedes añadir comentarios, mejoras y sugerencias a través del buzón de contacto: https://form.typeform.com/to/KcjhThot?typeform-source=langtech-bsc.gitbook.io.
Vives, el proyecto colaborativo para IA en valenciano
Por otro lado, Vives recopila voces hablando en valenciano para que sirvan de entrenamiento a los modelos de IA.
- Impulsado por: el Centro de Inteligencia Digital de Alicante (CENID).
- Objetivo: busca crear corpus masivos de texto y voz, fomentar la participación ciudadana en la recolección de datos, y desarrollar modelos lingüísticos especializados en sectores como el turismo y el audiovisual, garantizando la privacidad de los datos.
- Cómo participar: puedes donar tu voz a través de este enlace: https://vives.gplsi.es/instruccions/.
Gaitu: inversión estratégica en la digitalización del euskera
En Euskera, podemos destacar Gaitu que busca recopilar voces hablando en euskera para poder entrenar los modelos de IA. Sus características son:
- Impulsado por: HiTZ, el centro vasco de tecnología de la lengua.
- Objetivo: desarrollar un corpus en euskera para entrenar modelos de IA.
- Cómo participar: puedes donar tu voz en euskera aquí https://commonvoice.mozilla.org/eu/speak.
Ventajas de construir y preservar modelos de lenguaje multilingües
Los proyectos de digitalización de las lenguas cooficiales trascienden el ámbito puramente tecnológico para convertirse en herramientas de equidad digital y preservación cultural. Su impacto se manifiesta en múltiples dimensiones:
- Para la ciudadanía: estos recursos garantizan que hablantes de todas las edades y niveles de competencia digital puedan interactuar con la tecnología en su lengua materna, eliminando barreras que podrían excluir a determinados colectivos del ecosistema digital.
- Para el sector empresarial: la disponibilidad de recursos lingüísticos abiertos facilita que empresas y desarrolladores puedan crear productos y servicios en estas lenguas sin asumir los altos costes tradicionalmente asociados al desarrollo de tecnologías lingüísticas.
- Para el tejido investigador, estos corpus constituyen una base fundamental para el avance de la investigación en procesamiento de lenguaje natural y tecnologías del habla, especialmente relevante para lenguas con menor presencia en recursos digitales internacionales.
El éxito de estas iniciativas demuestra que es posible construir un futuro digital donde la diversidad lingüística no sea un obstáculo sino una fortaleza, y donde la innovación tecnológica se ponga al servicio de la preservación y promoción del patrimonio cultural lingüístico.
Blog
Los datos son un recurso fundamental para mejorar nuestra calidad de vida porque permiten mejorar los procesos de toma de decisiones para crear productos y servicios personalizados, tanto en el sector público como en el privado. En contextos como la salud, la movilidad, la energía o la educación, el uso de datos facilita soluciones más eficientes y adaptadas a las necesidades reales de las personas. No obstante, en el trabajo con datos, la privacidad juega un papel clave. En este post, analizaremos cómo los espacios de datos, el paradigma de computación federada y el aprendizaje federado, una de sus aplicaciones más potentes, plantean una solución equilibrada para aprovechar el potencial de los datos sin poner en riesgo la privacidad. Además, resaltaremos cómo el aprendizaje federado también puede usarse con datos abiertos para mejorar su reutilización de forma colaborativa, incremental y eficiente.
La privacidad, clave en la gestión de datos
Como se ha mencionado anteriormente, el uso intensivo de datos exige una creciente atención a la privacidad. Por ejemplo, en salud digital, un mal uso secundario de datos de historias clínicas electrónicas podría vulnerar derechos fundamentales de pacientes. Una forma eficaz de preservar la privacidad es mediante ecosistemas de datos que prioricen la soberanía de los datos, como es el caso de los espacios de datos. Un espacio de datos es un sistema de gestión federada de datos que permite su intercambio de manera confiable entre proveedores y consumidores. Además, el espacio de datos garantiza la interoperabilidad de los datos para crear productos y servicios que generen valor. En un espacio de datos, cada proveedor mantiene sus propias normas de gobernanza, conservando el control sobre sus datos (es decir, la soberanía sobre sus datos), a la vez que se posibilita su reutilización por consumidores. Esto implica que cada proveedor debe poder decidir qué datos comparte, con quién y bajo qué condiciones, garantizando el cumplimiento de sus intereses y obligaciones legales.
Computación federada y espacios de datos
Los espacios de datos representan una evolución en la gestión de datos, relacionada con un paradigma denominado computación federada (federated computing), donde los datos se reutilizan sin necesidad de que haya un trasiego de datos desde los proveedores de datos hacia los consumidores. En la computación federada, los proveedores transforman sus datos en resultados intermedios que preservan la privacidad con el fin de poder ser enviados a los consumidores de datos. Además, esto posibilita que puedan aplicarse otras técnicas de mejora de la privacidad de datos (Privacy-Enhancing Technologies). La computación federada se alinea perfectamente con arquitecturas de referencia como Gaia-X y su Trust Framework, que establece los principios y requisitos para garantizar un intercambio de datos seguro, transparente y conforme a reglas comunes entre proveedores y consumidores de datos.
Aprendizaje federado
Una de las aplicaciones más potentes de la computación federada es el aprendizaje automático federado (federated learning), una técnica de inteligencia artificial que permite entrenar modelos sin necesidad de centralizar los datos. Es decir, en lugar de enviar los datos a un servidor central para procesarlos, lo que se envía son los modelos entrenados localmente por cada participante.
Estos modelos se combinan posteriormente de manera centralizada para crear un modelo global. A modo de ejemplo, imaginemos un consorcio de hospitales que quiere desarrollar un modelo predictivo para detectar una enfermedad rara. Cada hospital posee datos sensibles de sus pacientes, y compartirlos abiertamente no es viable por cuestiones de privacidad (incluso otras cuestiones legales o éticas). Con el aprendizaje federado, cada hospital entrena localmente el modelo con sus propios datos, y solo comparte los parámetros del modelo (resultados del entrenamiento) de manera centralizada. Así, el modelo final aprovecha la diversidad de datos de todos los hospitales sin comprometer la privacidad individual y las reglas de gobernanza de datos de cada hospital.
El entrenamiento en el aprendizaje federado suele seguir un ciclo iterativo:
- Un servidor central inicia un modelo base y lo envía a cada uno de los nodos distribuidos participantes.
- Cada nodo entrena el modelo localmente con sus datos.
- Los nodos devuelven solo los parámetros del modelo actualizado, no los datos (es decir, se evita el trasiego de datos).
- El servidor central agrega las actualizaciones en los parámetros, resultados del entrenamiento en cada nodo y actualiza el modelo global.
- El ciclo se repite hasta alcanzar un modelo suficientemente preciso.
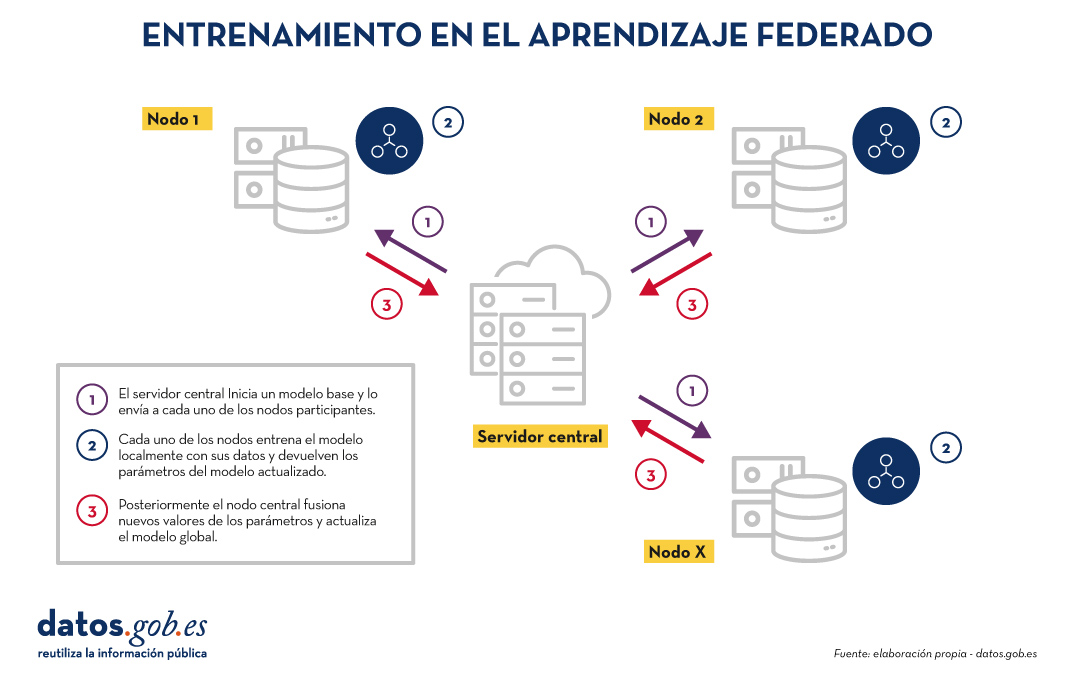
Figura 1. Visual que representa el proceso de entrenamiento del aprendizaje federados. Elaboración propia
Este enfoque es compatible con diversos algoritmos de aprendizaje automático, incluyendo redes neuronales profundas, modelos de regresión, clasificadores, etc.
Beneficios y desafíos del aprendizaje federado
El aprendizaje federado ofrece múltiples beneficios al evitar el trasiego de datos. Destacamos los siguientes:
- Privacidad y cumplimiento normativo: al permanecer en su origen, se reducen significativamente los riesgos de exposición de los datos y se facilita el cumplimiento de regulaciones como el Reglamento General de Protección de Datos (RGPD).
- Soberanía de los datos: cada entidad mantiene el control total sobre sus datos, lo que evita conflictos de competitividad.
- Eficiencia: evita los costes y la complejidad de intercambiar grandes volúmenes de datos, lo que acelera los tiempos de procesamiento y desarrollo.
- Confianza: facilita la colaboración entre organizaciones sin fricciones.
Existen diversos casos de uso en los cuales el aprendizaje federado es necesario, por ejemplo:
- Salud: hospitales y centros de investigación pueden colaborar en modelos predictivos sin compartir datos de pacientes.
- Finanzas: bancos y aseguradoras pueden construir modelos de detección de fraude o análisis de riesgo compartido, respetando la confidencialidad de sus clientes.
- Turismo inteligente: los destinos turísticos pueden analizar flujos de visitantes o patrones de consumo sin necesidad de unificar las bases de datos de sus actores (tanto públicos como privados).
- Industria: empresas del mismo sector pueden entrenar modelos para mantenimiento predictivo o eficiencia operativa sin revelar datos competitivos.
Aunque sus beneficios son claros en diversidad de casos de uso, el aprendizaje federado también presenta retos técnicos y organizativos:
- Heterogeneidad de datos: los datos locales pueden tener diferentes formatos o estructuras, lo que dificulta el entrenamiento. Además, el esquema de estos datos puede cambiar con el tiempo, lo que representa una dificultad añadida.
- Datos desbalanceados: algunos nodos pueden tener más datos o de mayor calidad que otros, lo que puede sesgar el modelo global.
- Costes computacionales locales: cada nodo necesita recursos suficientes para entrenar el modelo localmente.
- Sincronización: el ciclo de entrenamiento requiere buena coordinación entre nodos para evitar latencias o errores.
Más allá del aprendizaje federado
Aunque la aplicación más destacada de la computación federada es el aprendizaje federado, están surgiendo muchas otras aplicaciones adicionales en la gestión de datos como, por ejemplo, el análisis de datos federado (federated analytics). El análisis de datos federado permite realizar análisis estadísticos y descriptivos sobre datos distribuidos sin necesidad de moverlos a los consumidores, sino que cada proveedor realiza localmente los cálculos estadísticos requeridos y solo comparte con el consumidor los resultados agregados según sus requisitos y permisos. En la siguiente tabla se muestran las diferencias entre aprendizaje federado y análisis de datos federado.
|
Criterio |
Aprendizaje federado |
Análisis de datos federado |
|
Objetivo |
Predicción y entrenamiento de modelos de aprendizaje automático. | Análisis descriptivo y cálculo de estadísticas. |
| Tipo de tarea | Tareas predictivas (por ejemplo, clasificación o regresión). | Tareas descriptivas (por ejemplo, medias o correlaciones). |
| Ejemplo | Entrenar modelos de diagnóstico de enfermedades a través de imágenes médicas procedentes de diversos hospitales. | Cálculo de indicadores sanitarios de un área de salud sin mover los datos entre hospitales. |
| Salida esperada | Modelo global entrenado. | Resultados estadísticos agregados. |
| Naturaleza | Iterativa. | Directa. |
| Complejidad computacional | Alta. | Media. |
| Algoritmos | Aprendizaje automático. | Algoritmos estadísticos. |
Figura 1. Tabla comparativa. Fuente: elaboración propia
Aprendizaje federado y datos abiertos: una simbiosis por explorar
En principio, los datos abiertos resuelven los problemas de privacidad antes de su publicación, por lo que se podría pensar que no es preciso hacer uso de técnicas de aprendizaje federado. Nada más lejos de la realidad. El uso de técnicas de aprendizaje federado puede aportar ventajas significativas en la gestión y explotación de los datos abiertos. De hecho, el primer aspecto a resaltar es que los portales de datos abiertos como datos.gob.es o data.europa.eu son entornos federados. Por ello, en estos portales, la aplicación de aprendizaje federado sobre conjuntos de datos de gran tamaño permitiría entrenar modelos directamente en origen, evitando costes de transferencia y procesamiento. Por otro lado, el aprendizaje federado facilitaría la combinación de datos abiertos con otros datos sensibles sin comprometer la privacidad de estos últimos. Finalmente, la naturaleza de una gran variedad de tipos de datos abiertos es muy dinámica (como los datos de tráfico), por lo que el aprendizaje federado habilitaría un entrenamiento incremental, considerando automáticamente nuevas actualizaciones de conjuntos de datos abiertos a medida que se publican, sin necesidad de reiniciar costosos procesos de entrenamiento.
Aprendizaje federado, base para una IA respetuosa con la privacidad
El aprendizaje automático federado representa una evolución necesaria en la forma en que desarrollamos servicios de inteligencia artificial, especialmente en contextos donde los datos son sensibles o están distribuidos entre varios proveedores. Su alineación natural con el concepto de espacio de datos lo convierte en una tecnología clave para impulsar la innovación basada en la compartición de datos, teniendo en cuenta la privacidad y manteniendo la soberanía de los datos.
A medida que la regulación (como el Reglamento relativo al Espacio Europeo de Datos de Salud) y las infraestructuras de espacios de datos evolucionen, el aprendizaje federado, y otros tipos de computación federada, jugarán un papel cada vez más importante en la compartición de datos, maximizando el valor de los datos, pero sin comprometer la privacidad. Finalmente, cabe destacar que, lejos de ser innecesario, el aprendizaje federado puede convertirse en un aliado estratégico para mejorar la eficiencia, gobernanza e impacto de los ecosistemas de datos abiertos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La enorme aceleración de la innovación en torno a la inteligencia artificial (IA) en estos últimos años gira, en gran medida, en torno al desarrollo de los llamados “modelos fundacionales”. También conocidos como modelos grandes (Large [X] Models o LxM), Los modelos fundacionales, según la definición del Center for Research on Foundation Models (CRFM) del Institute for Human-Centered Artificial Intelligence's (HAI) de la Universidad de Stanford son modelos que han sido entrenados con conjuntos de datos de gran tamaño y gran diversidad y que pueden adaptarse a realizar una amplia gama de tareas mediante técnicas como el ajuste fino (fine-tuning).
Precisamente es esta versatilidad y capacidad de adaptación lo que ha convertido a los modelos fundacionales en la piedra angular de las numerosas aplicaciones de la inteligencia artificial que están desarrollándose, ya que una única arquitectura base puede utilizarse en multitud de casos de uso con un esfuerzo adicional limitado.
Tipos de modelos fundacionales
La "X" en LxM puede sustituirse por varias opciones según el tipo de datos o tareas para las que el modelo está especializado. Los más conocidos por el público son los LLM (Large Language Models), que están en la base de aplicaciones como ChatGPT o Gemini, y que se centran en la comprensión y generación de lenguaje natural. Por su parte, los LVM (Large Vision Models), como DINOv2 o CLIP, están diseñados para interpretar imágenes y vídeos, reconocer objetos o generar descripciones visuales. También existen modelos como como Operator o Rabbit R1 que se encuentran en la categoría de LAM (Large Action Models) y que están orientados a ejecutar acciones a partir de instrucciones complejas.
A medida que han ido surgiendo regulaciones en distintas partes del mundo, también han aparecido otras definiciones que buscan establecer criterios y responsabilidades sobre estos modelos para fomentar la confianza y la seguridad. La definición más relevante para nuestro contexto es la establecida en el Reglamento de IA de la Unión Europea (AI Act), el cual los denomina “modelos de IA de uso general” y los distingue por su “capacidad de realizar de manera competente una amplia variedad de tareas diferenciadas” y porque “suelen entrenarse usando grandes volúmenes de datos y a través de diversos métodos, como el aprendizaje autosupervisado, no supervisado o por refuerzo”.
Modelos fundacionales en español y otras lenguas cooficiales
Históricamente, el inglés ha sido el idioma dominante en el desarrollo de los grandes modelos de IA, hasta el punto de que en torno al 90% de los tokens de entrenamiento de los grandes modelos actuales se han extraído de textos en inglés. Por ello resulta lógico que los modelos más conocidos, por ejemplo la familia GPT de OpenAI, Gemini de Google o Llama de Meta, sean más competentes respondiendo en inglés y presenten menor desempeño al usarlos en otros idiomas como el español.
Por tanto, la creación de modelos fundacionales en español, como ALIA, no es un simple ejercicio técnico o de investigación, sino que se trata de un movimiento estratégico para garantizar que la inteligencia artificial no haga aún más profundas las asimetrías lingüísticas y culturales que ya existen en las tecnologías digitales en general. El desarrollo de ALIA, impulsado por la Estrategia de Inteligencia Artificial 2024 de España, “partiendo del amplio alcance de nuestras lenguas, habladas por 600 millones de personas, tiene como objetivo facilitar el desarrollo de servicios y productos avanzados en tecnologías del lenguaje, ofreciendo una infraestructura marcada por la máxima transparencia y apertura”.
Este tipo de iniciativas no son exclusivas de España. Otros proyectos similares incluyen BLOOM, un modelo multilingüe de 176 mil millones de parámetros desarrollado por más de 1.000 investigadores de todo el mundo y que soporta 46 lenguas naturales y 13 lenguajes de programación. En China, Baidu ha desarrollado ERNIE, un modelo con fuerte capacidad en mandarín, mientras que en Francia el modelo PAGNOL se ha centrado en mejorar las capacidades en francés. Estos esfuerzos paralelos muestran una tendencia global hacia la "democratización lingüística" de la IA.
Desde principios de 2025, están disponibles los primeros modelos de lenguaje en las cuatro lenguas cooficiales, dentro del proyecto ALIA. En la familia de modelos ALIA destaca ALIA-40B, un modelo con 40.000 millones de parámetros, que es por el momento el modelo fundacional multilingüe público más avanzado de Europa y que fue entrenado durante más de 8 meses en el supercomputador MareNostrum 5, procesando 6,9 billones de tokens que equivaldrían a unos 33 terabytes de texto (¡unos 17 millones de libros!). Aquí se incluyen todo tipo de documentos oficiales y repositorios científicos en español, desde los diarios de sesiones del Congreso hasta repositorios científicos o boletines oficiales para asegurar la riqueza y calidad de su conocimiento.
Aunque se trata de un modelo multilingüe, el español y lenguas cooficiales tienen un peso muy superior al habitual en estos modelos, en torno al 20%, ya que el entrenamiento del modelo se diseñó específicamente para estas lenguas, reduciendo la relevancia del inglés y adaptando los tokens a las necesidades del español, catalán, euskera y gallego. Gracias a ello, ALIA “entiende” mejor nuestras expresiones locales y matices culturales que un modelo genérico entrenado mayoritariamente en inglés.
Aplicaciones de los modelos fundacionales en español y lenguas cooficiales
Aún es muy pronto para juzgar el impacto en sectores y aplicaciones concretas que puedan tener ALIA y otros modelos que puedan desarrollarse a partir de esta experiencia. Sin embargo, se espera que sirvan de base para mejorar multitud de aplicaciones y soluciones de Inteligencia Artificial:
- Administración pública y gobierno: ALIA podría dar vida a asistentes virtuales que atiendan a la ciudadanía las 24 horas en trámites como pagar impuestos, renovar el DNI, solicitar becas, etc. ya que está entrenado específicamente con la normativa española. De hecho, ya se anunció un piloto para la Agencia Tributaria usando ALIA, que tendría como objetivo agilizar gestiones internas.
- Educación: un modelo como ALIA podría ser también la base de tutores virtuales personalizados que orienten a estudiantes en español y lenguas cooficiales. Por ejemplo, asistentes que expliquen conceptos de matemáticas o historia en lenguaje sencillo y respondan preguntas del alumnado, adaptándose a su nivel ya que, al conocer bien nuestra lengua, serían capaces de aportar matices importantes en las respuestas y entender las dudas típicas de hablantes nativos en estos idiomas. También podrían ayudar a profesores, generando ejercicios o resúmenes de lecturas o asistiéndoles en la corrección de los trabajos de los alumnos.
- Salud: ALIA podría servir para analizar textos médicos y ayudar a profesionales de la salud con informes clínicos, historiales, folletos informativos, etc. Por ejemplo, podría revisar expedientes de pacientes para extraer elementos clave, o asistir a los profesionales en el proceso de diagnóstico. De hecho, el Ministerio de Sanidad planea una aplicación piloto con ALIA para mejorar la detección temprana de insuficiencias cardíacas en atención primaria.
- Justicia: en el ámbito jurídico, ALIA entendería términos técnicos y contextos del derecho español mucho mejor que un modelo no especializado ya que ha sido entrenada con vocabulario legal de documentos oficiales. Un asistente legal virtual basado en ALIA podría ser capaz de contestar consultas básicas del ciudadano como, por ejemplo, cómo iniciar un determinado trámite legal, citando la normativa aplicable. La administración de justicia podría beneficiarse también con unas traducciones automáticas de documentos judiciales entre lenguas cooficiales mucho más precisas.
Líneas futuras
El desarrollo de modelos fundaciones en español, al igual que en otros idiomas, comienza a considerarse fuera de Estados Unidos como una cuestión estratégica que contribuye a garantizar la soberanía tecnológica de los países. Por supuesto, será necesario seguir entrenando versiones más avanzadas (se apunta a modelos de hasta 175 mil millones de parámetros, que serían equiparables a los más potentes del mundo), incorporando nuevos datos abiertos, y afinando las aplicaciones. Desde la Dirección del Dato y la SEDIA se pretende continuar apoyando el crecimiento de esta familia de modelos, para mantenerla en vanguardia y asegurar su adopción.
Por otra parte, estos primeros modelos fundacionales en español y lenguas cooficiales se han centrado inicialmente en el lenguaje escrito, así que la siguiente frontera natural podría estar en la multimodalidad. Integrar la capacidad de gestionar imágenes, audio o vídeo en español junto con el texto multiplicaría sus aplicaciones prácticas ya que en la interpretación de imágenes en español es uno de los ámbitos donde se detectan mayores deficiencias en los grandes modelos genéricos.
También habrá que vigilar los aspectos éticos para asegurarse que estos modelos no perpetúen sesgos y sean útiles para todos los colectivos, incluyendo aquellos que hablan en distintas lenguas o que tienen diferentes niveles educativos. En este aspecto la Inteligencia Artificial Explicable (XAI) no es algo opcional, sino un requisito fundamental para garantizar su adopción responsable. La Agencia Nacional de Supervisión de la IA, la comunidad investigadora y la propia sociedad civil tendrán aquí un rol importante.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.