Blog
Artificial intelligence (AI) assistants are already part of our daily lives: we ask them the time, how to get to a certain place or we ask them to play our favorite song. And although AI, in the future, may offer us infinite functionalities, we must not forget that linguistic diversity is still a pending issue.
In Spain, where Spanish coexists with co-official languages such as Basque, Catalan, Valencian and Galician, this issue is especially relevant. The survival and vitality of these languages in the digital age depends, to a large extent, on their ability to adapt and be present in emerging technologies. Currently, most virtual assistants, automatic translators or voice recognition systems do not understand all the co-official languages. However, did you know that there are collaborative projects to ensure linguistic diversity?
In this post we tell you about the approach and the greatest advances of some initiatives that are building the digital foundations necessary for the co-official languages in Spain to also thrive in the era of artificial intelligence.
ILENIA, the coordinator of multilingual resource initiatives in Spain
The models that we are going to see in this post share a focus because they are part of ILENIA, a state-level coordinator that connects the individual efforts of the autonomous communities. This initiative brings together the projects BSC-CNS (AINA), CENID (VIVES), HiTZ (NEL-GAITU) and the University of Santiago de Compostela (NÓS), with the aim of generating digital resources that allow the development of multilingual applications in the different languages of Spain.
The success of these initiatives depends fundamentally on citizen participation. Through platforms such as Mozilla's Common Voice, any speaker can contribute to the construction of these linguistic resources through different forms of collaboration:
- Spoken Read: Collecting different ways of speaking through voice donations of a specific text.
- Spontaneous speech: creates real and organic datasets as a result of conversations with prompts.
- Text in language: collaborate in the transcription of audios or in the contribution of textual content, suggesting new phrases or questions to enrich the corpora.
All resources are published under free licenses such as CC0, allowing them to be used free of charge by researchers, developers and companies.
The challenge of linguistic diversity in the digital age
Artificial intelligence systems learn from the data they receive during their training. To develop technologies that work correctly in a specific language, it is essential to have large volumes of data: audio recordings, text corpora and examples of real use of the language.
In other publications of datos.gob.es we have addressed the functioning of foundational models and initiatives in Spanish such as ALIA, trained with large corpus of text such as those of the Royal Spanish Academy.
Both posts explain why language data collection is not a cheap or easy task. Technology companies have invested massively in compiling these resources for languages with large numbers of speakers, but Spanish co-official languages face a structural disadvantage. This has led to many models not working properly or not being available in Valencian, Catalan, Basque or Galician.
However, there are collaborative and open data initiatives that allow the creation of quality language resources. These are the projects that several autonomous communities have launched, marking the way towards a multilingual digital future.
On the one hand, the Nós en Galicia Project creates oral and conversational resources in Galician with all the accents and dialectal variants to facilitate integration through tools such as GPS, voice assistants or ChatGPT. A similar purpose is that of Aina in Catalonia, which also offers an academic platform and a laboratory for developers or Vives in the Valencian Community. In the Basque Country there is also the Euskorpus project , which aims to constitute a quality text corpus in Basque. Let's look at each of them.
Proyecto Nós, a collaborative approach to digital Galician
The project has already developed three operational tools: a multilingual neural translator, a speech recognition system that converts speech into text, and a speech synthesis application. These resources are published under open licenses, guaranteeing their free and open access for researchers, developers and companies. These are its main features:
- Promoted by: the Xunta de Galicia and the University of Santiago de Compostela.
- Main objective: to create oral and conversational resources in Galician that capture the dialectal and accent diversity of the language.
- How to participate: The project accepts voluntary contributions both by reading texts and by answering spontaneous questions.
- Donate your voice in Galician: https://doagalego.nos.gal
Aina, towards an AI that understands and speaks Catalan
With a similar approach to the Nós project, Aina seeks to facilitate the integration of Catalan into artificial intelligence language models.
It is structured in two complementary aspects that maximize its impact:
- Aina Tech focuses on facilitating technology transfer to the business sector, providing the necessary tools to automatically translate websites, services and online businesses into Catalan.
- Aina Lab promotes the creation of a community of developers through initiatives such as Aina Challenge, promoting collaborative innovation in Catalan language technologies. Through this call , 22 proposals have already been selected with a total amount of 1 million to execute their projects.
The characteristics of the project are:
- Powered by: the Generalitat de Catalunya in collaboration with the Barcelona Supercomputing Center (BSC-CNS).
- Main objective: it goes beyond the creation of tools, it seeks to build an open, transparent and responsible AI infrastructure with Catalan.
- How to participate: You can add comments, improvements, and suggestions through the contact inbox: https://form.typeform.com/to/KcjhThot?typeform-source=langtech-bsc.gitbook.io.
Vives, the collaborative project for AI in Valencian
On the other hand, Vives collects voices speaking in Valencian to serve as training for AI models.
- Promoted by: the Alicante Digital Intelligence Centre (CENID).
- Objective: It seeks to create massive corpora of text and voice, encourage citizen participation in data collection, and develop specialized linguistic models in sectors such as tourism and audiovisual, guaranteeing data privacy.
- How to participate: You can donate your voice through this link: https://vives.gplsi.es/instruccions/.
Gaitu: strategic investment in the digitalisation of the Basque language
In Basque, we can highlight Gaitu, which seeks to collect voices speaking in Basque in order to train AI models. Its characteristics are:
- Promoted by: HiTZ, the Basque language technology centre.
- Objective: to develop a corpus in Basque to train AI models.
- How to participate: You can donate your voice in Basque here https://commonvoice.mozilla.org/eu/speak.
Benefits of Building and Preserving Multilingual Language Models
The digitization projects of the co-official languages transcend the purely technological field to become tools for digital equity and cultural preservation. Its impact is manifested in multiple dimensions:
- For citizens: these resources ensure that speakers of all ages and levels of digital competence can interact with technology in their mother tongue, removing barriers that could exclude certain groups from the digital ecosystem.
- For the business sector: the availability of open language resources makes it easier for companies and developers to create products and services in these languages without assuming the high costs traditionally associated with the development of language technologies.
- For the research fabric, these corpora constitute a fundamental basis for the advancement of research in natural language processing and speech technologies, especially relevant for languages with less presence in international digital resources.
The success of these initiatives shows that it is possible to build a digital future where linguistic diversity is not an obstacle but a strength, and where technological innovation is put at the service of the preservation and promotion of linguistic cultural heritage.
Blog
Data is a fundamental resource for improving our quality of life because it enables better decision-making processes to create personalised products and services, both in the public and private sectors. In contexts such as health, mobility, energy or education, the use of data facilitates more efficient solutions adapted to people's real needs. However, in working with data, privacy plays a key role. In this post, we will look at how data spaces, the federated computing paradigm and federated learning, one of its most powerful applications, provide a balanced solution for harnessing the potential of data without compromising privacy. In addition, we will highlight how federated learning can also be used with open data to enhance its reuse in a collaborative, incremental and efficient way.
Privacy, a key issue in data management
As mentioned above, the intensive use of data requires increasing attention to privacy. For example, in eHealth, secondary misuse of electronic health record data could violate patients' fundamental rights. One effective way to preserve privacy is through data ecosystems that prioritise data sovereignty, such as data spaces. A dataspace is a federated data management system that allows data to be exchanged reliably between providers and consumers. In addition, the data space ensures the interoperability of data to create products and services that create value. In a data space, each provider maintains its own governance rules, retaining control over its data (i.e. sovereignty over its data), while enabling its re-use by consumers. This implies that each provider should be able to decide what data it shares, with whom and under what conditions, ensuring compliance with its interests and legal obligations.
Federated computing and data spaces
Data spaces represent an evolution in data management, related to a paradigm called federated computing, where data is reused without the need for data flow from data providers to consumers. In federated computing, providers transform their data into privacy-preserving intermediate results so that they can be sent to data consumers. In addition, this enables other Data Privacy-Enhancing Technologies(Privacy-Enhancing Technologies)to be applied. Federated computing aligns perfectly with reference architectures such as Gaia-X and its Trust Framework, which sets out the principles and requirements to ensure secure, transparent and rule-compliant data exchange between data providers and data consumers.
Federated learning
One of the most powerful applications of federated computing is federated machine learning ( federated learning), an artificial intelligence technique that allows models to be trained without centralising data. That is, instead of sending the data to a central server for processing, what is sent are the models trained locally by each participant.
These models are then combined centrally to create a global model. As an example, imagine a consortium of hospitals that wants to develop a predictive model to detect a rare disease. Every hospital holds sensitive patient data, and open sharing of this data is not feasible due to privacy concerns (including other legal or ethical issues). With federated learning, each hospital trains the model locally with its own data, and only shares the model parameters (training results) centrally. Thus, the final model leverages the diversity of data from all hospitals without compromising the individual privacy and data governance rules of each hospital.
Training in federated learning usually follows an iterative cycle:
- A central server starts a base model and sends it to each of the participating distributed nodes.
- Each node trains the model locally with its data.
- Nodes return only the parameters of the updated model, not the data (i.e. data shuttling is avoided).
- The central server aggregates parameter updates, training results at each node and updates the global model.
- The cycle is repeated until a sufficiently accurate model is achieved.
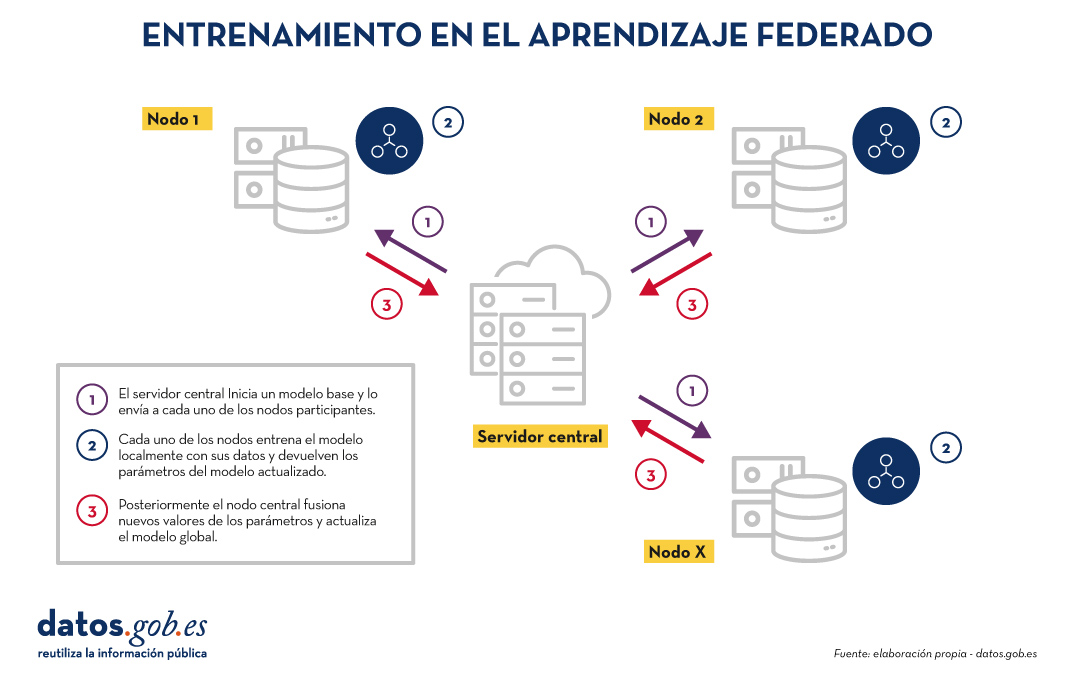
Figure 1. Visual representing the federated learning training process. Own elaboration
This approach is compatible with various machine learning algorithms, including deep neural networks, regression models, classifiers, etc.
Benefits and challenges of federated learning
Federated learning offers multiple benefits by avoiding data shuffling. Below are the most notable examples:
- Privacy and compliance: by remaining at source, data exposure risks are significantly reduced and compliance with regulations such as the General Data Protection Regulation (GDPR) is facilitated.
- Data sovereignty: Each entity retains full control over its data, which avoids competitive conflicts.
- Efficiency: avoids the cost and complexity of exchanging large volumes of data, speeding up processing and development times.
- Trust: facilitates frictionless collaboration between organisations.
There are several use cases in which federated learning is necessary, for example:
- Health: Hospitals and research centres can collaborate on predictive models without sharing patient data.
- Finance: banks and insurers can build fraud detection or risk-sharing analysis models, while respecting the confidentiality of their customers.
- Smart tourism: tourist destinations can analyse visitor flows or consumption patterns without the need to unify the databases of their stakeholders (both public and private).
- Industry: Companies in the same industry can train models for predictive maintenance or operational efficiency without revealing competitive data.
While its benefits are clear in a variety of use cases, federated learning also presents technical and organisational challenges:
- Data heterogeneity: Local data may have different formats or structures, making training difficult. In addition, the layout of this data may change over time, which presents an added difficulty.
- Unbalanced data: Some nodes may have more or higher quality data than others, which may skew the overall model.
- Local computational costs: Each node needs sufficient resources to train the model locally.
- Synchronisation: the training cycle requires good coordination between nodes to avoid latency or errors.
Beyond federated learning
Although the most prominent application of federated computing is federated learning, many additional applications in data management are emerging, such as federated data analytics (federated analytics). Federated data analysis allows statistical and descriptive analyses to be performed on distributed data without the need to move the data to the consumers; instead, each provider performs the required statistical calculations locally and only shares the aggregated results with the consumer according to their requirements and permissions. The following table shows the differences between federated learning and federated data analysis.
|
Criteria |
Federated learning |
Federated data analysis |
|
Target |
Prediction and training of machine learning models. | Descriptive analysis and calculation of statistics. |
| Task type | Predictive tasks (e.g. classification or regression). | Descriptive tasks (e.g. means or correlations). |
| Example | Train models of disease diagnosis using medical images from various hospitals. | Calculation of health indicators for a health area without moving data between hospitals. |
| Expected output | Modelo global entrenado. | Resultados estadísticos agregados. |
| Nature | Iterativa. | Directa. |
| Computational complexity | Alta. | Media. |
| Privacy and sovereignty | High | Average |
| Algorithms | Machine learning. | Statistical algorithms. |
Figure 1. Comparative table. Source: own elaboration
Federated learning and open data: a symbiosis to be explored
In principle, open data resolves privacy issues prior to publication, so one would think that federated learning techniques would not be necessary. Nothing could be further from the truth. The use of federated learning techniques can bring significant advantages in the management and exploitation of open data. In fact, the first aspect to highlight is that open data portals such as datos.gob.es or data.europa.eu are federated environments. Therefore, in these portals, the application of federated learning on large datasets would allow models to be trained directly at source, avoiding transfer and processing costs. On the other hand, federated learning would facilitate the combination of open data with other sensitive data without compromising the privacy of the latter. Finally, the nature of a wide variety of open data types is very dynamic (such as traffic data), so federated learning would enable incremental training, automatically considering new updates to open datasets as they are published, without the need to restart costly training processes.
Federated learning, the basis for privacy-friendly AI
Federated machine learning represents a necessary evolution in the way we develop artificial intelligence services, especially in contexts where data is sensitive or distributed across multiple providers. Its natural alignment with the concept of the data space makes it a key technology to drive innovation based on data sharing, taking into account privacy and maintaining data sovereignty.
As regulation (such as the European Health Data Space Regulation) and data space infrastructures evolve, federated learning, and other types of federated computing, will play an increasingly important role in data sharing, maximising the value of data, but without compromising privacy. Finally, it is worth noting that, far from being unnecessary, federated learning can become a strategic ally to improve the efficiency, governance and impact of open data ecosystems.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
The enormous acceleration of innovation in artificial intelligence (AI) in recent years has largely revolved around the development of so-called "foundational models". Also known as Large [X] Models (Large [X] Models or LxM), Foundation Models, as defined by the Center for Research on Foundation Models (CRFM) of the Institute for Human-Centered Artificial Intelligence's (HAI) Stanford University's models that have been trained on large and highly diverse datasets and can be adapted to perform a wide range of tasks using techniques such as fine-tuning (fine-tuning).
It is precisely this versatility and adaptability that has made foundational models the cornerstone of the numerous applications of artificial intelligence being developed, since a single base architecture can be used across a multitude of use cases with limited additional effort.
Types of foundational models
The "X" in LxM can be replaced by several options depending on the type of data or tasks for which the model is specialised. The best known by the public are the LLM (Large Language Models), which are at the basis of applications such as ChatGPT or Gemini, and which focus on natural language understanding and generation.. LVMs (Large Vision Models), such as DINOv2 or CLIP, are designed tointerpret images and videos, recognise objects or generate visual descriptions.. There are also models such as Operator or Rabbit R1 that fall into the LAM (Large Action Models) category and are aimed atexecuting actions from complex instructions..
As regulations have emerged in different parts of the world, so have other definitions that seek to establish criteria and responsibilities for these models to foster confidence and security. The most relevant definition for our context is that set out in the European Union AI Regulation (AI Act), which calls them "general-purpose AI models" and distinguishes them by their "ability to competently perform a wide variety of discrete tasks" and because they are "typically trained using large volumes of data and through a variety of methods, such as self-supervised, unsupervised or reinforcement learning".
Foundational models in Spanish and other co-official languages
Historically, English has been the dominant language in the development of large AI models, to the extent that around 90% of the training tokens of today's large models are drawn from English texts. It is therefore logical that the most popular models, for example OpenAI's GPT family, Google's Gemini or Meta's Llama, are more competent at responding in English and perform less well when used in other languages such as Spanish.
Therefore, the creation of foundational models in Spanish, such as ALIA, is not simply a technical or research exercise, but a strategic move to ensure that artificial intelligence does not further deepen the linguistic and cultural asymmetries that already exist in digital technologies in general. The development of ALIA, driven by the Spain's Artificial Intelligence Strategy 2024, "based on the broad scope of our languages, spoken by 600 million people, aims to facilitate the development of advanced services and products in language technologies, offering an infrastructure marked by maximum transparency and openness".
Such initiatives are not unique to Spain. Other similar projects include BLOOM, a 176-billion-parameter multilingual model developed by more than 1,000 researchers worldwide and supporting 46 natural languages and 13 programming languages. In China, Baidu has developed ERNIE, a model with strong Mandarin capabilities, while in France the PAGNOL model has focused on improving French capabilities. These parallel efforts show a global trend towards the "linguistic democratisation" of AI.
Since the beginning of 2025, the first language models in the four co-official languages, within the ALIA project, have been available. The ALIA family of models includes ALIA-40B, a model with 40.40 billion parameters, which is currently the most advanced public multilingual foundational model in Europeand which was trained for more than 8 months on the MareNostrum 5 supercomputer, processing 6.9 trillion tokens equivalent to about 33 terabytes of text (about 17 million books!). Here all kinds of official documents and scientific repositories in Spanish are included, from congressional journals to scientific repositories or official bulletins to ensure the richness and quality of your knowledge.
Although this is a multilingual model, Spanish and co-official languages have a much higher weight than usual in these models, around 20%, as the training of the model was designed specifically for these languages, reducing the relevance of English and adapting the tokens to the needs of Spanish, Catalan, Basque and Galician.. As a result, ALIA "understands" our local expressions and cultural nuances better than a generic model trained mostly in English.
Applications of the foundational models in Spanish and co-official languages
It is still too early to judge the impact on specific sectors and applications that ALIA and other models that may be developed from this experience may have. However, they are expected to serve as a basis for improving many Artificial Intelligence applications and solutions:.
- Public administration and government: ALIA could give life to virtual assistants that attend to citizens 24 hours a day for procedures such as paying taxes, renewing ID cards, applying for grants, etc., as it is specifically trained in Spanish regulations. In fact, a pilot for the Tax Agency using ALIA, which would aim to streamline internal procedures, has already been announced.
- Education: A model such as ALIA could also be the basis for personalised virtual tutors to guide students in Spanish and co-official languages. For example, assistants who explain concepts of mathematics or history in simple language and answer questions from the students, adapting to their level since, knowing our language well, they would be able to provide important nuances in the answers and understand the typical doubts of native speakers in these languages. They could also help teachers by generating exercises or summaries of readings or assisting them in correcting students' work.
- Health: ALIA could be used to analyse medical texts and assist healthcare professionals with clinical reports, medical records, information leaflets, etc. For example, it could review patient files to extract key elements, or assist professionals in the diagnostic process. In fact, the Ministry of Health is planning a pilot application with ALIA to improve early detection of heart failure in primary care.
- Justice: In the legal field, ALIA would understand technical terms and contexts of Spanish law much better than a non-specialised model as it has been trained with legal vocabulary from official documents. An ALIA-based virtual paralegal could be able to answer basic citizen queries, such as how to initiate a given legal procedure, citing the applicable law. The administration of justice could also benefit from much more accurate machine translations of court documents between co-official languages.
Future lines
The development of foundation models in Spanish, as in other languages, is beginning to be seen outside the United States as a strategic issue that contributes to guaranteeing the technological sovereignty of countries. Of course, it will be necessary to continue training more advanced versions (models with up to 175 billion parameters are targeted, which would be comparable to the most powerful in the world), incorporating new open data, and fine-tuning applications. From the Data Directorate and the SEDIA it is intended to continue to support the growth of this family of models, to keep it at the forefront and ensure its adoption.
On the other hand, these first foundational models in Spanish and co-official languages have initially focused on written language, so the next natural frontier could be multimodality. Integrating the capacity to manage images, audio or video in Spanish together with the text would multiply its practical applications, since the interpretation of images in Spanish is one of the areas where the greatest deficiencies are detected in the large generic models.
Ethical issues will also need to be monitored to ensure that these models do not perpetuate bias and are useful for all groups, including those who speak different languages or have different levels of education. In this respect, Explainable Artificial Intelligence (XAI) is not optional, but a fundamental requirement to ensure its responsible adoption.. The National AI Supervisory Agency, the research community and civil society itself will have an important role to play here.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.