Google lanza un nuevo buscador de datos abiertos


Fecha de la noticia: 20-09-2018

En internet podemos encontrar miles de repositorios de datos. Aquellos interesados en localizar una determinada información tienen que navegar entre múltiples fuentes (repositorios nacionales, portales de organismos públicos o instituciones privadas, bibliotecas digitales, web especializadas, etc.) con el consiguiente consumo de tiempo. Una difícil búsqueda que no siempre da los resultados esperados.
Google quiere cambiar esta situación. El pasado 5 de septiembre, el famoso buscador de internet estrenó Google Dataset Search, un nuevo motor de búsqueda que facilita el acceso universal a los conjuntos de datos ubicados en los repositorios de internet. El servicio está dirigido a periodistas, investigadores, estudiantes o cualquier ciudadano interesado en encontrar cierto dato.
El nuevo buscador funciona de una manera similar a Google Scholar – el buscador de Google centrado en contenido científico y académico-. Su motor de búsqueda localiza los conjuntos de datos, independientemente de su ubicación o temática, en función de cómo sus propietarios los han etiquetado. Es decir, Google localiza los datasets en base a sus metadatos, en vez de leer o rastrear el contenido del dataset en sí (distribuciones).
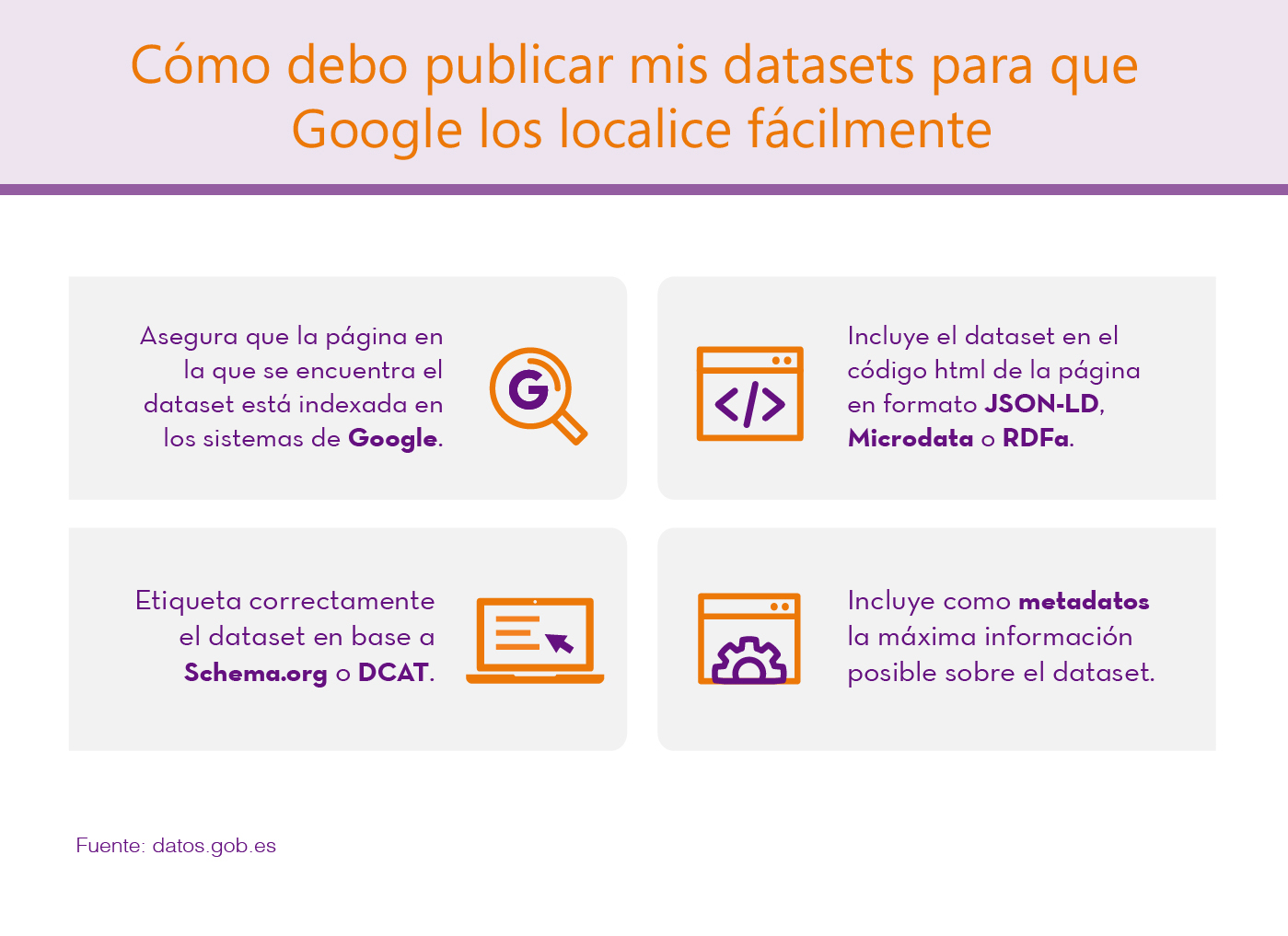
Para que las búsquedas sean más efectivas, Google ha facilitado una guía con consejos para los publicadores. En ella se indica cómo se deben compartir los conjuntos de datos para que Google los localice.
-
La página en la que se encuentran los dataset debe estar indexada en los sistemas de Google. Una vez indexada, Google comienza a observar el código HTML de la página web y cuando encuentra metadatos relacionados con Datasets (etiquetados correctamente), los indexa en Google Dataset Search.
-
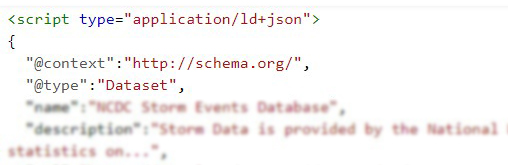
El dataset debe estar incluido en el código de la página en formato JSON-LD, Microdata o RDFa y estar etiquetado correctamente en base a Schema.org (recomendado) o estructuras equivalentes representadas en DCAT. Google está explorando la posibilidad de ir incorporando nuevos formatos, como CSVW del W3C.
-
Es importante incluir la máxima información posible sobre el datasets en el etiquetado, en base a la definición de dataset en schema.org, como por ejemplo: el título, una descripción, el tipo de licencia, quién es el publicador, cuándo se creó el dato, cuándo se modificó, el catálogo de origen, etc. Los metadatos incluidos en este etiquetado serán los que muestre Google Data Search.
-
Además, Google recomienda el uso de etiquetas como 'sameAs' para conjuntos de datos que están publicados en varios repositorios, para evitar resultados duplicados en el buscador o 'isBasedOn' en el caso de que los datasets provengan de la modificación o agregación de otros datasets originales. Google proporciona una herramienta para comprobar si el etiquetado de la página es correcto y los datasets van a ser correctamente identificados por el motor de búsquedas.
En el caso de Datos.gob.es, todos los datasets pueden consultarse ya desde Google Data Search, lo cual proporciona una mayor visibilidad a nuestros conjuntos de datos.
Google Data Search se encuentra todavía en versión beta. Por ello, aún quedan retos por resolver, como por ejemplo definir de manera más consistente lo que constituye un conjunto de datos, relacionar los conjuntos de datos entre sí o expandir los metadatos entre conjuntos de datos relacionados.
Aun así, nos encontramos ante un avance importante. Google cree que este proyecto permitirá impulsar la creación de un ecosistema de intercambio de datos y que animará a los editores a seguir las prácticas recomendadas para almacenar y publicar datos. Además cree que ofrecerá a los científicos una plataforma para mostrar el impacto de su trabajo a través de las citas de los conjuntos de datos que hayan producido.
Lo que no se puede negar es que es un gran paso para fomentar los datos abiertos, facilitando que un mayor número de usuarios puedan localizar la información que necesitan de una manera rápida y sencilla.