Publication date
31/08/2020
Update date
20/06/2024

Description
Machine learning is a branch within the field of Artificial Intelligence that provides systems with the ability to learn and improve automatically, based on experience. These systems transform data into information, and with this information, they can make decisions. A model needs to be fed with data to make predictions in a robust way. The more, the better. Fortunately, today's network is full of data sources. In many cases, data is collected by private companies for their own benefit, but there are also other initiatives, such as open data portals.
Once we have the data, we are ready to start the learning process. This process, carried out by an algorithm, tries to analyze and explore the data in search of hidden patterns. The result of this learning, sometimes, is nothing more than a function that operates on the data to calculate a certain prediction.
In this article we will see the types of machine learning that exist including some examples.
Types of machine learning
Depending on the data available and the task we want to tackle, we can choose between different types of learning. These are: supervised learning, unsupervised learning, semi-supervised learning and reinforcement learning.
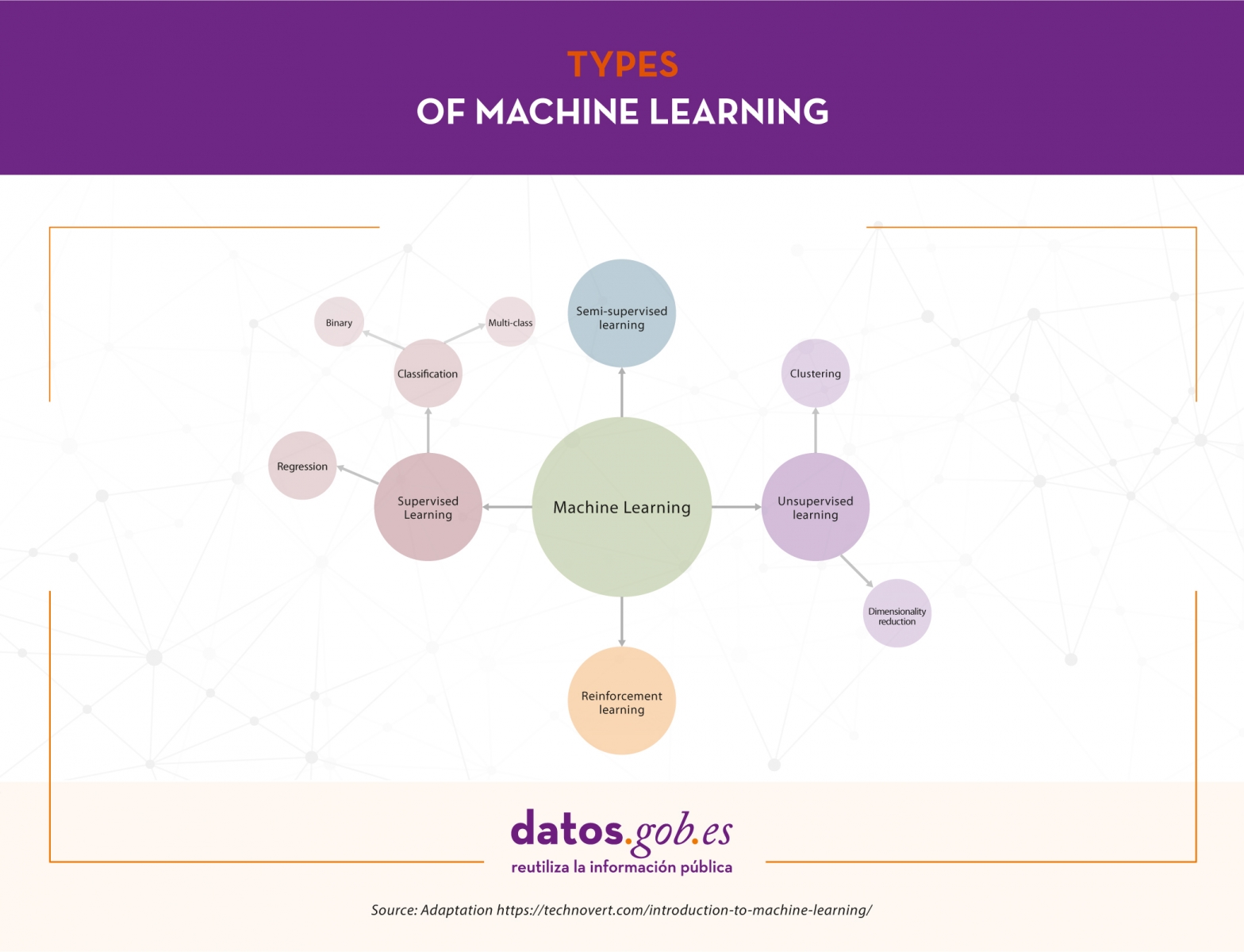
Supervised learning
Supervised learning needs labeled datasets, that is, we tell the model what we want it to learn. Suppose we have an ice cream shop and for the last few years we have been recording daily weather data, temperature, month, day of the week, etc., and we have also been doing the same with the number of ice creams sold each day. In this case, we would surely be interested in training a model that, based on the climatological data, temperature, etc. (characteristics of the model) of a specific day, tells us how many ice creams are going to be sold (the label to be predicted).
Depending on the type of label, within the supervised learning there are two types of models:
- Classification models, which produce as output a discrete label, that is, a label within a finite set of possible labels. In turn, classification models can be binary if we have to predict between two classes or labels (disease or not disease, classification of emails as "spam" or not "spam") or multiclass, when we have to classify more than two classes (classification of animal images, sentiment analysis, etc.).
- The regression models produce as output a real value, like the example we mentioned of the ice cream.
Unsupervised learning
Unsupervised learning, on the other hand, works with data that has not been labeled. We do not have a label to predict. These algorithms are mainly used in tasks where it is necessary to analyze the data to extract new knowledge or group entities by affinity.
This type of learning also has applications for reducing dimensionality or simplifying datasets. In the case of grouping data by affinity, the algorithm must define a similarity or distance metric that serves to compare the data with each other. As an example of unsupervised learning we have the clustering algorithms, which could be applied to find customers with similar characteristics to those who offer certain products or target a marketing campaign, discovery of topics or detection of anomalies, among others. On the other hand, sometimes some datasets such as those related to genomic information have large amounts of characteristics and for various reasons, such as reducing the training time of the algorithms, improving the performance of the model or facilitating the visual representation of the data, we need to reduce the dimensionality or number of columns in the dataset. Dimensionality reduction algorithms use mathematical and statistical techniques to convert the original dataset into a new one with fewer dimensions in exchange for losing some information. Examples of dimensionality reduction algorithms are PCA, t-SNE or ICA.
Semi-supervised learning
Sometimes it is very complicated to have a fully labeled dataset. Let's imagine that we are the owners of a dairy product manufacturing company and we want to study the brand image of our company through the comments that users have posted on social networks. The idea is to create a model that classifies each comment as positive, negative or neutral and then do the study. The first thing we do is dive into social networks and collect sixteen thousand messages where our company is mentioned. The problem now is that we don't have a label on the data, that is, we don't know what the feeling of each comment is. This is where semi-supervised learning comes into play. This type of learning has a little of the two previous ones. Using this approach, you start by manually tagging some of the comments. Once we have a small portion of tagged comments, we train one or more supervised learning algorithms on that small portion of tagged data and use the resulting training models to tag the remaining comments. Finally, we train a supervised learning algorithm using as labels those manually tagged plus those generated by the previous models.
Reinforcement learning
Finally, reinforcement learning is an automatic learning method based on rewarding desired behaviors and penalizing unwanted ones. Applying this method, an agent is able to perceive and to interpret the environment, to execute actions and to learn through test and error. It is a learning that sets long term objectives to obtain a maximum general reward and achieve an optimal solution. The game is one of the most used fields to test reinforcement learning. AlphaGo or Pacman are some games where this technique is applied. In these cases, the agent receives information about the rules of the game and learns to play by himself. At first, obviously, it behaves randomly, but with time it starts to learn more sophisticated movements. This type of learning is also applied in other areas as the robotics, the optimization of resources or systems of control.
Automatic learning is a very powerful tool that converts data into information and facilitates decision making. The key is to define in a clear and concise way the objective of the learning in order to, depending on the characteristics of the dataset we have, select the type of learning that best fits to give a solution that responds to the needs.
Content elaborated by Jose Antonio Sanchez, expert in Data Science and enthusiast of the Artificial Intelligence.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
con una buena base en programacion,estadistica y algebra lineal