Publication date
17/01/2024
Update date
17/09/2024

Description
What challenges do data publishers face?
In today's digital age, information is a strategic asset that drives innovation, transparency and collaboration in all sectors of society. This is why data publishing initiatives have developed enormously as a key mechanism for unlocking the potential of this data, allowing governments, organisations and citizens to access, use and share it.
However, there are still many challenges for both data publishers and data consumers. Aspects such as the maintenance of APIs(Application Programming Interfaces) that allow us to access and consume published datasets or the correct replication and synchronisation of changing datasets remain very relevant challenges for these actors.
In this post, we will explore how Linked Data Event Streams (LDES), a new data publishing mechanism, can help us solve these challenges. what exactly is LDES? how does it differ from traditional data publication practices? And, most importantly, how can you help publishers and consumers of data to facilitate the use of available datasets?
Distilling the key aspects of LDES
When Ghent University started working on a new mechanism for the publication of open data, the question they wanted to answer was: How can we make open data available to the public? What is the best possible API we can design to expose open datasets?
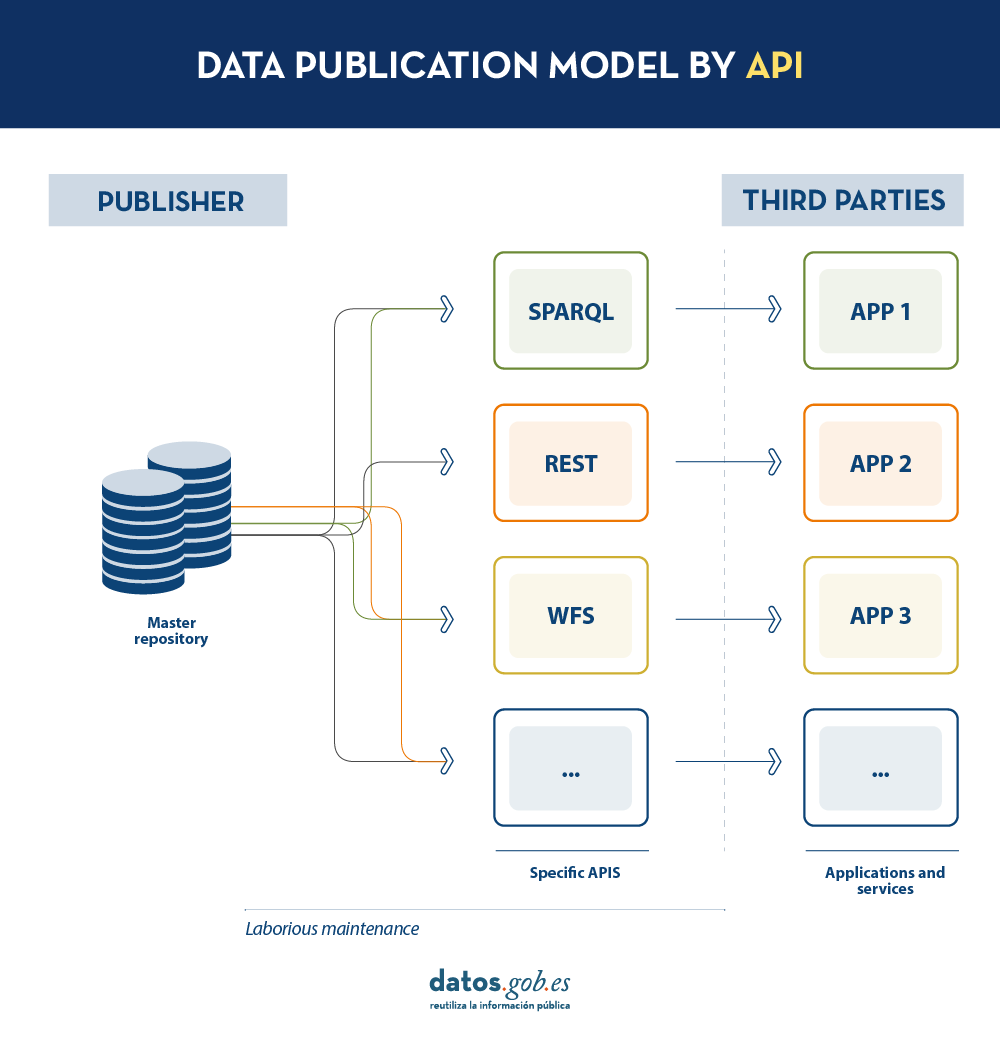
Today, data publishers use multiple mechanisms to publish their different datasets. On the one hand, it is easy to find APIs. These include SPARQL, a standard for querying linked data(Link Data), but also REST or WFS, for accessing datasets with a geospatial component. On the other hand, it is very common that we find the possibility to access data dumps in different formats (i.e. CSV, JSON, XLS, etc.) that we can download for use.
In the case of data dumps, it is very easy to encounter synchronisation problems. This occurs when, after a first dump, a change occurs that requires modification of the original dataset, such as changing the name of a street in a previously downloaded street map. Given this change, if the third party chooses to modify the street name on the initial dump instead of waiting for the publisher to update its data in the master repository to perform a new dump, the data handled by the third party will be out of sync with the data handled by the publisher. Similarly, if it is the publisher that updates its master repository but these changes are not downloaded by the third party, both will handle different versions of the dataset.
On the other hand, if the publisher provides access to data through query APIs, rather than through data dumps to third parties, synchronisation problems are solved, but building and maintaining a high and varied volume of query APIs is a major effort for data publishers.
LDES seeks to solve these different problems by applying the concept of Linked Data to an event stream . According to the definition in its own specification, a Linked Data Event Stream (LDES) is a collection of immutable objects where each object is described in RDF terns.
Firstly, the fact that the LDES are committed to Linked Data provides design principles that allow combining diverse data and/or data from different sources, as well as their consultation through semantic mechanisms that allow readability by both humans and machines. In short, it provides interoperability and consistency between datasets, thus facilitating search and discovery.
On the other hand, the event streams or data streams, allow consumers to replicate the history of datasets, as well as synchronise recent changes. Any new record added to a dataset, or any modification of existing records (in short, any change), is recorded as a new incremental event in the LDES that will not alter previous events. Therefore, data can be published and consumed as a sequence of events, which is useful for frequently changing data, such as real-time information or information that undergoes constant updates, as it allows synchronisation of the latest updates without the need for a complete re-download of the entire master repository after each modification.
In such a model, the publisher will only need to develop and maintain one API, the LDES, rather than multiple APIs such as WFS, REST or SPARQL. Different third parties wishing to use the published data will connect (each third party will implement its LDES client) and receive the events of the streams to which they have subscribed. Each third party will create from the information collected the specific APIs it deems appropriate based on the type of applications they want to develop or promote. In short, the publisher will not have to solve all the potential needs of each third party in the publication of data, but by providing an LDES interface (minimum base API), each third party will focus on its own problems.
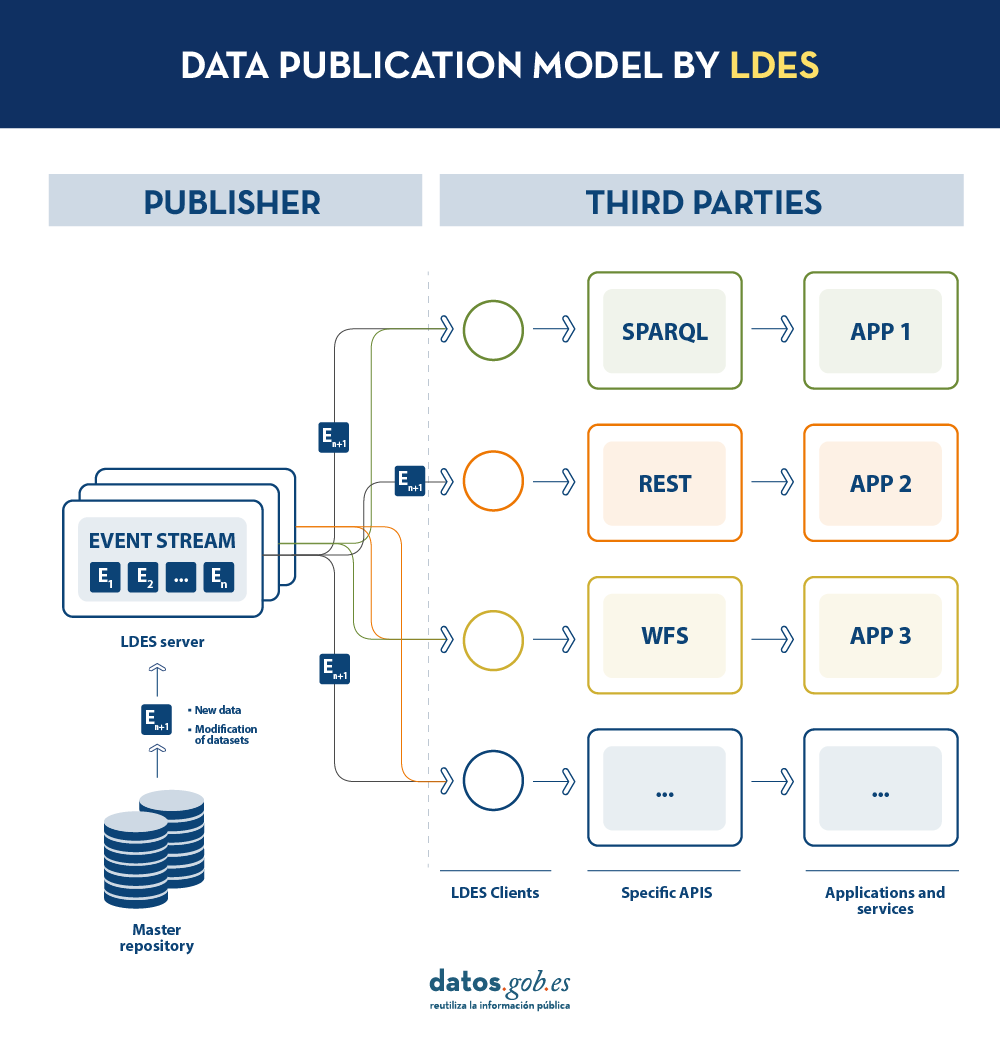
In addition, to facilitate access to large volumes of data or to data that may be distributed across different sources, such as an inventory of electric charging points in Europe, LDES provides the ability to fragment datasets. Through the TREE specification, LDES allows different types of relationships between data fragments to be established. This specification allows publishing collections of entities, called members, and provides the ability to generate one or more representations of these collections. These representations are organised as views, distributing the members through pages or nodes interconnected by relationships. Thus, if we want the data to be searchable through temporal indexes, it is possible to set a temporal fragmentation and access only the pages of a temporal interval. Similarly, alphabetical or geospatial indexes can be provided and a consumer can access only the data needed without the need to 'dump' the entire dataset.
What conclusions can we draw from LDES?
In this post we have looked at the potential of LDES as a mechanism for publishing data. Some of the most relevant learnings are:
- LDES aims to facilitate the publication of data through minimal base APIs that serve as a connection point for any third party wishing to query or build applications and services on top of datasets.
- The construction of an LDES server, however, has a certain level of technical complexity when it comes to establishing the necessary architecture for the handling of published data streams and their proper consultation by data consumers.
- The LDES design allows the management of both high rate of change data (i.e. data from sensors) and low rate of change data (i.e. data from a street map). Both scenarios can handle any modification of the dataset as a data stream.
- LDES efficiently solves the management of historical records, versions and fragments of datasets. This is based on the TREE specification, which allows different types of fragmentation to be established on the same dataset.
Would you like to know more?
Here are some references that have been used to write this post and may be useful to the reader who wishes to delve deeper into the world of LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Comments