Blog
Since the publication of Directive (EU) 2019/1024 on open data and re-use of public sector information, the European Commission is undertaking a number of actions to develop the concept of high-value data that this directive introduced as an important novelty in June 2019.
We recall that high-value datasets are defined in this directive as "documents whose re-use is associated with considerable benefits for society, the environment and the economy, in particular because of their suitability for the creation of value-added services, applications and new, decent and quality jobs". The Directive further proposes a first list of six thematic categories of high-value datasets: geospatial, earth observation and environment, meteorology, statistics, corporate and company ownership, and mobility.
In the last three years, numerous initiatives have been launched with the aim of deepening the liberation of this type of datasets and moving towards realising the economic and social benefits derived from their re-use. Studies have been launched such as the “Impact Assessment study on the list of High Value Datasets” by the Commission's DG CONNECT, which presents different options identified for policy-level interventions linked to high-value datasets in the six thematic areas. Or the report “High-value datasets: understanding the perspective of data providers” published by the official European data portal, which aims to understand the perspective of data providers and contains interesting conclusions such as that the perspective is not sufficient to understand where the "high value" actually lies.
A public consultation has also been launched in 2022 to gather public opinion on its draft High-Value Data Act. This draft act already contains a list of specific high-value datasets and provisions for their publication and re-use, which will represent a very significant advance on the objectives of the directive itself. At the end of June, the draft act was also presented to the Committee on Open Data and Re-use of Public Sector Information composed of representatives from EU countries and further progress is expected in September 2022.
For their part, Member States are also carrying out their own work in parallel, as in the case of Spain, which has already started by dedicating the 2019 Aporta Meeting to the promotion of high-value data.
However, the EU's focus on high-value data as a driver of the economy is not unique in the world and there are other initiatives with different degrees of progress and impact that have similar objectives.
Datasets of national interest in Australia
In the case of Australia, a pioneer in this regard, the first National Action Plan of the Australian Open Government Partnership 2016-2018 already contained among its objectives the implementation of actions to develop and publish a framework for high-value datasets and to design how best to facilitate the sharing and use of these datasets through the legislative consultation process.
The Productivity Commission in 2018 recommended recognising a new type of data asset, national interest datasets, defined as datasets that would generate significant benefits for society and would be a special subset of high-value data. At the time, the Australian government committed to appoint a National Data Commissioner, to implement, oversee and regulate a simpler and more efficient data sharing and publishing framework.
However, in 2019 the end-of-term self-assessment report for Australia's first national open government action plan 2016-18 already acknowledged the delay in the initiative. Work was resumed by the National Data Commissioner, who building on previous work continues to conceptualise a framework for identifying high-value data, although no documentation has been released to the general public at this stage.
Aligning open data in Canada
The Canadian Open Government Working Group (COGWG) already started in its 2016-2018 action plan to work on its commitment to align datasets across the country and specifically on the development of a list of priority high-value datasets for collaborative publication across jurisdictions. The plan recognised that publishing common types of data across Canadian jurisdictions would help foster innovation and provide significant socio-economic impact.
In 2018, Canada's Open Government Working Group released an initial list of 17 high-value datasets to be prioritised for publication by federal, provincial, territorial and municipal governments across Canada. This list is part of a report providing common criteria to help identify high-value datasets and is based on work done to unify criteria across levels of government, stakeholder surveys and international standards.
The National Open Government Action Plan 2018-2020 includes a commitment to carry out a pilot project to standardise across jurisdictions five high-value datasets from the list previously identified in the previous plan.
Although the results have not been openly published, the plan's evaluation system acknowledges the delay in meeting this objective as preliminary standards could only be completed for 4 of the 5 high-value datasets. These standards are available through an intranet system to all Canadian public servants (federal, provincial, territorial and municipal), academics and students, as well as to all Canadians by invitation. However, none of the work has been made public nor is it known what datasets they are working on.
India begins work on identifying datasets
More recently, in 2022, the Indian government has published a background note on data accessibility and usage policy in India announcing the development of new policies to improve data access, quality and usage, in line with the technological needs of the next decade.
As with other initiatives in other regions of the world, it recognises the lack of common criteria for consistently identifying and maintaining high-value datasets. It therefore envisages developing a data policy framework that makes data from multiple sources (public and private) accessible through G2G, G2B, B2G and B2B channels.
The objective is also similar to other initiatives, on the one hand, to make public services more efficient, and to enable a new generation of start-ups to drive digital innovation and growth in the Indian economy.
The approaches being followed in different regions of the world to identify and release high-value datasets are very similar and include public consultations, the formation of expert committees, pilot projects and the definition of assessment frameworks. However, we see that development is much slower than expected and that some initiatives, such as those started in Canada or Australia before the EU itself, have not yet been finalised and therefore their impact is not yet known.
For the time being, it seems that the work initiated by the EU is more advanced and, more importantly, more transparent, as the results are being published openly. Let us hope that the initiative does not lose momentum as seems to have happened in Australia or Canada and that we will soon be able to enjoy high-value datasets available for re-use and discuss the impact they have had on society and the European economy.
Content written by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
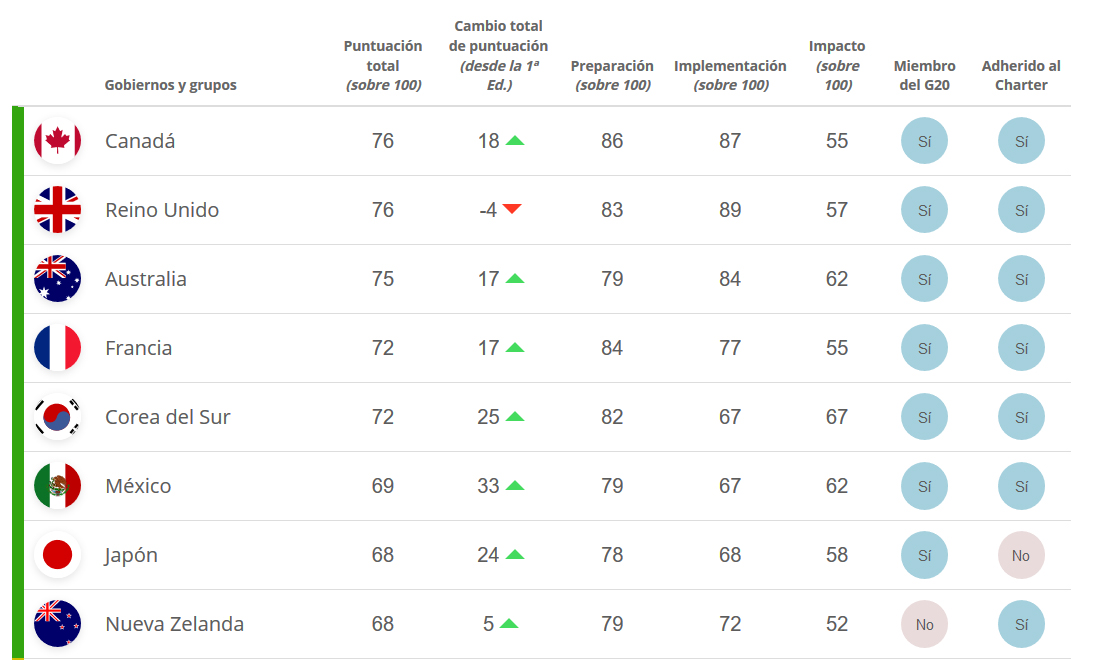
Last September, the last edition of Open Data Barometer was presented by the World Wide Web Foundation. The report measures how some governments, not including Spain, publish and use open data to facilitate accountability, boost innovation and generate social impact. It should be noted that this year's edition coincides with the tenth anniversary of 8 Open Data principles, a date considered the beginning of open data movement.
To carry out this barometer, 30 governments have been analyzed - those that have adopted the Open Data Charter or those that, as G20 members, have committed to G20 Anti-Corruption Open Data Principles -, based on a series of sub-indices that measure the level of preparation, implementation and impact of open data in the country. This year results show a generally slow progress. While some countries continue to see rapid improvement, the report shows that early leaders, such as the United Kingdom or the United States, are no longer in the top positions.
Canada, leader of open data movement
The first place on the podium went to Canada, which advances one position comparing to 2017 and overtakes the United Kingdom. The American country has continuously progressed in recent years, rising 18 positions since the first edition. This is due to the great political support of open data in the country.
The United Kingdom, on the other hand, drops one position. Although the British government has generally improved its data management practices, there is a lack of policies to boost open data and a reduction of engagement with civil society, something similar to United States, which falls to 9th position.
On the contrary, Mexico, South Korea, Colombia, Ukraine, Japan and Uruguay are the countries that most increased their scores in recent years.
Although the advances in recent years, the report shows that open data initiatives and projects carried out by government are still in an experimentation phase.
According to the report, only 19% of all datasets measured meet the requirements to be considered truly open, demonstrating that open data - in the strict sense- continue to be an exception. In addition, collaboration between government and civil society has stagnated, especially in countries such as Brazil, Italy, South Korea, New Zealand, Turkey and the United States.
Open data as a general rule
In order to continue advancing on the maturity scale, open data initiatives should stop being "isolated projects" and begin to be "the general rule". For this, it is necessary to develop specific promotion policies and invest in technical infrastructure and human ressources with the necessary skills.
Specifically, the report includes 3 key recommendations for those countries that want to lead the open data movement:
- Put “open by default” into action: The data should be directly published in open formats. This requires a solid strategies, resources and laws, as well as a cultural change.
- Build and consolidate open data infrastructure: Having the right management systems helps improve the quality of data and its interoperability, facilitating and standardizing the opening of public information.
- Publish data with purpose: Knowing the users’ needs is essential to ensure that we are providing the data that they need in the right conditions. This will facilitate their use and help boost the open data ecosystem. For this, it is advisable to work in close collaboration with civil society, through civic groups, data communities, etc.
After 10 years of open data initiatives, significant progress has been made, but there are still a number of challenges to overcome. With commitment, solid policies and strategies, and common work, government can take advantage of full open data potential, generating significant improvements for all citizens.
If you want to go deeper into the conclusions and recommendations of Open Data Barometer, the report is also available in Spanish.