Blog
"Somos nuestro cerebro y por eso tenemos que hablar de derechos humanos, porque si tienes una tecnología que te permite medir la actividad del cerebro y cambiarla, esa misma tecnología te permitirá, antes o después, descifrar la actividad mental y alterarla."
Yuste, Rafael. (2025). Neuroderechos. Un viaje hacia la protección de lo que nos hace humanos. Paidós.
La neurotecnología incorpora un conjunto de métodos o dispositivos para registrar la actividad del cerebro o del sistema nervioso, pudiendo incluso llegar a alterarla. Por ello, a medida que aumentan las técnicas de análisis de la actividad cerebral y las posibilidades terapéuticas, crece la inquietud ética entre los profesionales.
Para integrar el análisis de este fenómeno con el marco jurídico europeo disponemos de una excelente guía: el trabajo del doctor Rafael Yuste y su libro “Neuroderechos” (2025). El método de imagen de calcio, en el que el Dr. Yuste fue pionero, revolucionó las posibilidades de la investigación neurocientífica. Se trata de una técnica óptica que usa colorantes o indicadores sensibles al calcio para inferir cuándo se activan las neuronas. Cuando una neurona se activa, aumenta su nivel de calcio, lo que produce una señal luminosa observable. Esta técnica ha evolucionado desde el uso de colorantes químicos hasta sensores genéticos que las propias neuronas producen, lo que permite estudiar tipos neuronales específicos y registrar su actividad durante periodos más prolongados.
Ejemplos de manipulación de conductas utilizando neurotecnología
El Dr. Yuste en su libro proporciona ejemplos muy gráficos que permiten entender las posibilidades que abre esta metodología:
- Se puede estimular una conducta en un ratón de laboratorio para que succione un líquido como respuesta al visionado de unas imágenes en video. Para ello, se mapean los conjuntos neuronales que se activan ante el estímulo visual aprendido. Después, con el estímulo apagado, se activan esas mismas neuronas con un láser y el ratón ejecuta la respuesta conductual esperada, sin ver nada en términos físicos.
- En humanos, se han desarrollado neuroprótesis del habla capaces de decodificar intentos de producción verbal en pacientes con parálisis y pérdida del habla. A partir del registro de la actividad cortical durante la lectura e intento de articulación de frases, estos sistemas pueden generar texto, voz sintética y la animación de un avatar facial.
- Asimismo, se experimenta con técnicas de neuroestimulación para mejorar la situación clínica de pacientes con enfermedad de Parkinson y para intervenir sobre determinados aspectos conductuales. También estamos asistiendo al desarrollo de nuevas técnicas neuroquirúrgicas basadas en interfaces cerebro-computador, tanto invasivas -por ejemplo, mediante implantes o chips inalámbricos- como no invasivas, que pueden operar mediante haces de energía o ultrasonidos.
- Finalmente, el neurofeedback se perfila como una tecnología cercana a la aplicación clínica y comercial, al permitir modular la actividad cerebral en casos como el trastorno por estrés postraumático, mediante videojuegos o entornos interactivos conectados a dispositivos de medición capaces de detectar ciertos estados emocionales y generar condiciones que favorezcan la mejoría del paciente.
Paradójicamente, la inteligencia artificial, que está acelerando los procesos de investigación en neurociencia, se ha desarrollado en buena medida a partir de modelos inspirados en las redes neuronales profundas. Ahora, el estudio de las redes neuronales biológicas podría, a su vez, transformar de manera decisiva la evolución futura de la propia IA. Descubrir los algoritmos matemáticos que subyacen al funcionamiento del cerebro podría favorecer el diseño de sistemas más eficientes, inspirados, tanto en su capacidad de procesamiento, como en su bajísimo coste energético.
La importancia de los neuroderechos
El Dr. Yuste y la Neurorights Foundation, han planteado que estos avances científicos requieren de un enfoque ético y jurídico específico: los neuroderechos. A tal respecto han propuesto cinco categorías:
-
Derecho a la privacidad mental.
La investigación en esta área de conocimiento revela inevitablemente información privada, incorporando nuevos riesgos a las técnicas de perfilado que con fundamento en la neurociencia despliegan las redes sociales.
-
Derecho a la identidad personal.
Nuestra identidad es altamente dependiente de la información y la experiencia que consolida nuestra memoria. Algunas terapias pueden afectar a nuestra identidad.
-
Derecho al libre albedrío: a poder decidir frente a las técnicas que generan alteraciones de la conducta.
Se ha constatado que el uso de neuroestimulación para tratar ciertos trastornos hace que el paciente se comporte de modo distinto. En esta afectación, ya no se trata solo de preservar la identidad, sino de garantizar que cualquier cambio esperable en la personalidad y conducta del paciente resulten de su libre elección.
-
Acceso justo a la neuroaumentación.
Un resultado esperable a futuro puede ser la aparición de tecnologías que potencien nuestras capacidades cognitivas. Existe el peligro que se genere un mercado de servicios que privilegie solo a aquellas clases sociales o econónicas con capacidad para contratarlos.
-
Protección contra sesgos y discriminaciones.
Del mismo modo que ya sucediera con la investigación genética, cuanta más información tengamos sobre el cerebro humano existirá un mayor riesgo de incurrir en sesgos y/o discriminaciones. Aquí el riesgo ya no es meramente pasivo, puede ser incrementado, por ejemplo, por el uso de la inteligencia artificial cuando el riesgo de sesgo en su funcionamiento no haya sido previsto o gobernado adecuadamente.
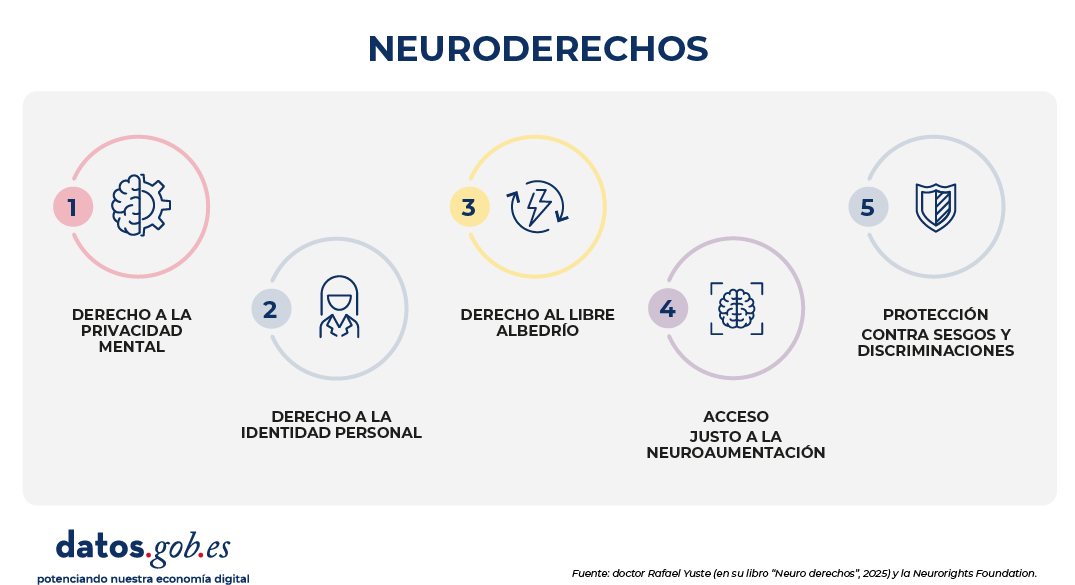
Figura 1. Neuroderechos - Fuente: doctor Rafael Yuste (en su libro "Neuro derechos", 2025) y la Neurorights Foundation.
Esta propuesta inspiró la consideración de los neuroderechos por la Carta de Derechos Digitales impulsada por el Gobierno de España y está generando un profundo debate en los planos académico y legislativo. La propuesta de regular la neurotecnología a través de los neuroderechos va más allá de la investigación científica y su origen, y se convierte en algo urgente debido al significativo interés de la industria.
Garantizar los neuroderechos desde el marco normativo existente: el derecho a la intimidad
Uno de los retos que debemos superar desde el mundo del derecho consiste en ser capaces de abordar los impactos de la tecnología desde las herramientas que nos proporciona el ordenamiento jurídico vigente. La ausencia de un derecho específico no implica que se pueda desarrollar y desplegar esta tecnología sin límites. La UE ha entendido la importancia de garantizar una concepción humanista de la tecnología centrada en la garantía de los derechos fundamentales, en asegurar la indemnidad de los pacientes frente a cualquier repercusión física o psicológica y en asegurar que la tecnología no pondrá en riesgo ni la democracia ni el estado de derecho.
El derecho a la privacidad mental se propone como la primera herramienta disponible para la garantía de los derechos de las personas en el ámbito de la neurotecnología. Y, aunque la tentación natural sea situar el foco en el ámbito del derecho fundamental a la protección de datos, lo cierto es que el derecho a la vida privada -que reconoce el artículo 18.4 de la Constitución española y los artículos 7 y 8 de la Carta europea de los Derechos Fundamentales- ofrece un conjunto de instrumentos prometedores para un enfoque temprano de los riesgos que puede plantear el uso de esta tecnología.
En primer lugar, desde el punto de vista de la dignidad humana, la intimidad se proyecta sobre nuestro cuerpo como un escenario de garantía de la libre autodeterminación del paciente. Esta capacidad de control y disposición se manifiesta claramente en Ley reguladora de la autonomía del paciente, y define el consentimiento informado como una primera barrera. En esto coincide con los principios vigentes en materia de investigación biomédica. Por ello, tanto quienes pretendan desarrollar sistemas basados en neurotecnología como implantarlos en un ámbito clínico encuentran en el deber de transparencia y en la fijación de garantías para obtener un consentimiento libre del paciente la primera barrera jurídica infranqueable. Las neurotecnologías son instrumentos particularmente complicados cuya comprensión puede escapar a las capacidades de la mayoría de la población, incluidos los propios expertos legales. En consecuencia, no bastará con la promesa de las ventajas que nos ofrece el tratamiento o el servicio que se nos pretenda prestar: será fundamental que la información se proporcione de forma clara, accesible y entendible en un proceso verificable y exento de cualquier tipo de coacción.
En segundo lugar, el artículo 18 de la Constitución incluye la garantía del derecho a la intimidad familiar, así como del honor y de la propia imagen. Desde un punto de vista material, cabe entender que el impacto en la conducta de un sujeto derivada de la utilización de neurotecnología podría incidir sobre estos derechos. Por una parte, si se provoca algún tipo de cambio en la personalidad del sujeto, se podría afectar a las relaciones interpersonales en el ámbito privado. Por otra parte, el honor garantiza la estima o consideración social ha tenido un sujeto. Por su propia naturaleza, implica una determinada autopercepción por parte del sujeto respecto de su personalidad, conducta y estima social, y podría verse afectado en el caso de que, como consecuencia del tratamiento, se produzca un cambio de personalidad con impacto reputacional. Más complicado resulta determinar la existencia de afectaciones al derecho a la propia imagen, salvo en lo relativo a la difusión de imagen médica o a la posibilidad de teorizar con la idea de que los cambios conductuales pueden repercutir sobre la imagen que proyecta un determinado sujeto cuando éste decide cambiarla.
Sin embargo, y aunque no haya sido objeto de un desarrollo legal específico, hay una propiedad emergente que vincula el derecho a la vida privada del artículo 18.1 de la Constitución con el problema que nos ocupa: el derecho a la identidad. Sin ánimo de teorizar en exceso, a lo largo de los dos últimos siglos se ha señalado de modo muy preciso que la garantía de la vida privada opera como una esfera de protección del individuo ante terceros, que le proporciona un espacio de libertad en el que desarrollar su personalidad. Esto es particularmente notorio en el caso de los niños, niñas y adolescentes para los que ampliar de modo gradual su esfera de intimidad frente a su entorno familiar resulta crucial para garantizar los procesos que permiten alcanzar la debida madurez y autonomía. La conclusión es evidente: la garantía del derecho a la vida privada debe aplicarse con rigor en el ámbito de las neurotecnologías como instrumento necesario para la preservación de la dignidad humana, la libre autodeterminación individual y el desarrollo de la personalidad.
Del derecho fundamental a la protección de datos al Reglamento de Inteligencia Artificial: la apuesta por la ingeniería de procesos
La garantía de nuestros derechos fundamentales respecto del desarrollo y uso de las neurotecnologías va a depender de modo esencial de los procesos que definen el Reglamento General de Protección de Datos (RGPD) y el Reglamento de Inteligencia Artificial (RIA).
El derecho a la protección de datos posee una naturaleza instrumental que los proyecta sobre el conjunto de los derechos fundamentales. No se concibe en abstracto, sino con referencia a un tratamiento concreto para una finalidad específica en un contexto determinado. Por ejemplo, cuando mediante algoritmos comportamentales se pretende perfilar a un sujeto en una red social y orientar su consumo de información, podemos estar afectando a la libertad ideológica o de creencias. El ejemplo paradigmático de esto lo podemos encontrar en el negacionismo científico. Los algoritmos de personalización, al apostar por monetizar con publicidad la experiencia de usuario, no hacen otra cosa que consolidar el sesgo de confirmación que alimenta creencias irracionales. Por ello, cuando aplicamos los procedimientos de la RGPD para el desarrollo de los sistemas que van a ser capaces de obtener información neuronal, de procesarla, de desarrollar tratamientos o de desplegar servicios, estamos garantizando que esta tecnología sea respetuosa con el conjunto de nuestros derechos fundamentales.
El RGPD y el RIA comparten un doble enfoque altamente productivo. El primero es el del diseño centrado en la garantía de los derechos del ser humano. Por ello, en ambos casos, antes de desarrollar cualquier invención en el ámbito de la neurotecnología, debemos preguntarnos si lo que pretendemos conseguir vulnera algún derecho fundamental, incurre en alguna práctica prohibida o encuentra alguna restricción jurídica en el derecho vigente. Con carácter complementario, podremos aplicar los estándares éticos propios de la investigación biomédica, así como los estándares emergentes tanto en el ámbito del desarrollo de la inteligencia artificial.
La segunda gran apuesta en ambas regulaciones, -y expresamente en el RIA-, es lo que podemos definir como orientación a producto. Es decir, en ambos casos las dos normas definen un conjunto de ingeniería de procesos claramente articulado que debe acompañar al proceso de desarrollo:
- En el ámbito del RGPD será necesario desplegar un análisis de riesgos o, en los casos más significativos, una evaluación de impacto relativa a la protección de datos. Este tipo de procesos nos proporcionará una clara identificación de todo tipo de riesgos. Los más importantes, los primarios son los que se refieren a los derechos de las personas. Ello sin perjuicio de que podamos identificar riesgos respecto de los principios de protección de datos. Aquí poseen particular importancia los relacionados con la calidad de la información y el principio de minimización, la seguridad de la información, así como cualquier tipo de riesgo inherente a la organización, incluidas las necesidades de formación del personal.
- En el diseño de sistemas de alto riesgo en el RIA se abordan prácticamente todas las variables. Al igual que ocurre en el RGPD es fundamental desarrollar una evaluación de impacto aquí en los derechos fundamentales. Por otra parte, como en el diseño de cualquier aplicación basada en IA, va a ser fundamental monitorizar y gestionar los riesgos, asegurar la gobernanza de datos, adoptar medidas específicas para garantizar la robustez y la resiliencia, desplegar estrategias de supervisión humana, garantizar la formación de los equipos que utilizarán la herramienta y asegurar que, gracias al cumplimiento de la transparencia en el despliegue, la tecnología se implante con total seguridad.
Ambas normas están sujetas a controles. En el RGPD, estos controles son propios de la organización y se basan en el establecimiento de controles periódicos, el desarrollo de auditorías regulares y la implantación de metodologías de gestión de las incidencias. En el ámbito de los sistemas de alto riesgo del RIA, además de implementarse procedimientos equivalentes a los del RGPD, es importante señalar que, al requerir la autorización de un organismo notificado, las exigencias de documentación son muy altas. Por otra parte, se trata de productos sujetos a vigilancia post comercial.
Por lo tanto, se puede afirmar que existe un marco de regulación que puede desplegar funciones esenciales a la hora de garantizar nuestros neuroderechos. Toda regulación adicional que precise las condiciones de desarrollo y despliegue de la neurotecnología será siempre bienvenida. Y no debemos olvidar un aspecto esencial: las dos normas que hemos citado son relevantes por cuanto ofrecen un conjunto de procesos que nos permite orientar nuestra estrategia de desarrollo e implantación de estas técnicas. Sin embargo, en los sistemas constitucionales de los Estados miembros de la Unión Europea y en la propia Unión, los derechos fundamentales que se garantizan para todas las personas ya son norma jurídica y aplican directamente: no hay excusas para su vulneración.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Vivimos en la era de la digitalización y de la datificación. Cada vez se generan más datos y observamos el mundo a través de ellos. Imágenes satelitales, datos de telefonía móvil, transacciones comerciales, sensores ambientales o redes sociales son algunos ejemplos de fuentes de información que sirven para responder a preguntas de interés público, en ámbitos como la salud, el medio ambiente, la planificación espacial o la producción alimentaria, entre otros.
El Open Data Policy Lab de la Universidad de Nueva York lleva años documentando este fenómeno como parte de lo que denomina la “Tercera ola de los datos abiertos”, un movimiento hacia un dato abierto orientado a propósitos concretos, que amplía su alcance al sector privado y que pone el foco en un uso responsable de la información. En su blog, el laboratorio recopila periódicamente ejemplos recientes de cómo investigadores, administraciones y organizaciones internacionales están aprovechando estos datos no tradicionales en diversos campos.
¿Qué son los datos no tradicionales?
Un artículo publicado en el Centre for Digital Development de la Universidad de Manchester define los datos no tradicionales (o non-traditional data, NTD) como aquellos capturados, mediados u observados mediante tecnologías digitales y que, en muchos casos, son generados por empresas privadas o plataformas tecnológicas. Este tipo de datos suelen surgir como subproductos de otra actividad cotidiana o proceden del funcionamiento de infraestructuras digitales: una llamada de teléfono, una compra en el supermercado, una publicación en una red social o el paso de un satélite sobre el territorio. Entre sus características destacan que ofrecen información de forma continua y con un elevado nivel de detalle geográfico.
Este término se suele usar en contraposición al de datos tradicionales, que son datos recopilados de forma deliberada mediante metodologías estandarizadas y procesos de medición consolidados, como los censos oficiales, las encuestas estadísticas o los registros administrativos. Estos datos suelen tener una periodicidad más baja, una estructura muy definida y una finalidad explícita: describir fenómenos sociales, económicos o demográficos con altos niveles de control y validación.
Ambos tipos de datos son de gran valor, pero su combinación hace que su potencial se multiplique. Gracias a su análisis conjunto se pueden capturar mejor cambios rápidos o patrones finos del comportamiento social.
A continuación, profundizamos en tres ejemplos recientes recogidos por el Open Data Policy Lab, que muestran cómo se están aplicando los datos no tradicionales en ámbitos muy distintos, con consecuencias tangibles para la sociedad.
Salud pública: tarjetas de fidelidad para detectar señales tempranas de cáncer
Uno de los ejemplos más singulares de uso de datos no tradicionales en el ámbito sanitario es la reutilización de los datos de tarjetas de fidelización comercial para investigar si los hábitos de compra pueden anticipar un diagnóstico de cáncer.
Un equipo de investigación del Imperial College London está utilizando datos de tarjetas de fidelización de dos cadenas británicas de supermercados, con el consentimiento de unos 3.000 participantes, para analizar si los patrones de compra, especialmente de medicamentos sin receta, cambian antes de que se produzca un diagnóstico de cáncer. Los investigadores compararon los hábitos de compra de personas con cáncer frente a personas sanas, lo que les permitió identificar cambios sutiles de comportamiento previos al diagnóstico.
Estudios anteriores ya habían mostrado que los patrones de compra podían anticipar un diagnóstico de cáncer de ovario hasta ocho meses antes de que se confirmara clínicamente. Extender este enfoque a otros tipos de cáncer podría facilitar una detección más temprana, animando a las personas a buscar atención médica antes. Se trata de un claro ejemplo de cómo datos generados con fines puramente comerciales pueden aportar señales de salud que los sistemas tradicionales no captan por sí solos.
Movilidad: respuesta a alertas de evacuación por SMS
Un estudio publicado en diciembre de 2025 utilizó datos anonimizados de redes de telefonía móvil para analizar cómo responde la población ante alertas de evacuación por incendios forestales enviadas por SMS. Los investigadores monitorizaron la actividad de unos 580.000 dispositivos a intervalos de 15 minutos durante los incendios forestales de febrero de 2024 en Valparaíso, Chile. Para ello, utilizaron los cambios de conexión a las antenas de telefonía como indicador del movimiento de la población, y compararon estos patrones antes y después del envío de las alertas. Esta información se combinó con los registros de las propias alertas y con datos socioeconómicos para entender si la respuesta variaba según el tipo de comunidad.
El análisis mostró que las primeras alertas provocaban un movimiento de población claro, mientras que las alertas repetidas generaban una respuesta cada vez más débil. También se observó que las zonas de mayor renta respondían con más rapidez y que se producían desplazamientos incluso en áreas que no habían recibido la alerta de forma directa. Este tipo de evidencia puede ayudar a diseñar protocolos de aviso más eficientes y a anticipar cómo se comportará realmente la población durante una emergencia.
Medio ambiente: evaluación de la resiliencia al calor de los edificios con drones e imágenes de calle
El calentamiento global es una de las mayores preocupaciones a nivel mundial. Un estudio realizado en la ciudad de Dar es Salaam, en el delta del río Msimbazi, en Tanzania, utilizó imágenes captadas por drones y fotografías a nivel de calle para analizar qué características de los edificios influyen en la exposición al calor en entornos urbanos. Los investigadores combinaron estas fuentes visuales con datos de temperatura de superficie obtenidos por satélite y mapas de edificaciones. Entrenaron un modelo de inteligencia artificial capaz de extraer automáticamente atributos como el material de los tejados y las fachadas, la presencia de vegetación, la densidad edificatoria o la reflectividad de las superficies, y relacionarlos con los patrones térmicos observados.
El análisis permite identificar qué características del entorno construido contribuyen a reducir la exposición al calor, ofreciendo pautas útiles para el diseño urbano y la rehabilitación de edificios. Esta información resulta especialmente relevante en ciudades expuestas a un riesgo creciente de olas de calor, ya que facilita intervenciones más específicas y orientadas a proteger a la población vulnerable, en lugar de medidas generales aplicadas a escala urbana.
El potencial de combinar datos
Estos tres casos ilustran cómo los datos no tradicionales son especialmente útiles donde la medición convencional suele resultar lenta o demasiado agregada, ya sea para detectar señales tempranas de enfermedad, entender cómo responde realmente la población ante una emergencia o identificar qué edificios están más expuestos al calor.
En estos ejemplos, así como en otros que ha venido recogiendo el Open Data Policy Lab en los últimos años, el mayor potencial aparece cuando estos datos se combinan con fuentes de referencia ya existentes, como datos socioeconómicos, registros de temperaturas o mapas, que permiten validar e interpretar correctamente las señales detectadas.
A medida que este tipo de fuentes se consolida, también aumenta su incorporación a procesos de toma de decisiones públicas y privadas. En este contexto, cobran cada vez más importancia las cuestiones de gobernanza, como quién tiene acceso a los datos o cómo garantizar un uso responsable que proteja la privacidad de las personas. Resolver estos desafíos será clave para que el potencial de estas fuentes pueda generar valor de forma segura y confiable.
Estos ejemplos muestran que es posible extraer información realmente útil de los datos no tradicionales. Ahora el reto es construir los marcos de protección necesarios para hacerlo sin erosionar la confianza de quienes generan esos datos cada día.
Noticia
El universo de los datos y la inteligencia artificial avanza a un ritmo frenético, consolidándose como el motor indiscutible de la innovación pública y empresarial. Para conocer mejor el estado de esta cuestión, en esta nueva edición de nuestras “Novedades del ecosistema de datos” recopilamos ejemplos de iniciativas, proyectos y actividades que han tenido lugar en los últimos seis meses y que están modelando el futuro digital, con el foco puesto en España.
Impulso estratégico de la economía del dato
Las administraciones públicas y los organismos reguladores continúan definiendo las reglas del juego y los planes de acción para impulsar un crecimiento tecnológico ordenado, competitivo y orientado al ciudadano. En Europa, se sigue avanzando en el Ómnibus Digital, que busca simplificar y unificar el marco legislativo digital europeo, afectando a la regulación sobre datos. Tras un periodo de consultas públicas y acuerdos políticos, el paquete de enmiendas ha sido aprobado por el Parlamento Europeo, aunque todavía es necesaria su aprobación por el Consejo Europeo. Un hito de este periodo es la reconfiguración del calendario regulatorio: las obligaciones de transparencia y etiquetado de contenidos generados por IA entrarán en vigor en agosto de 2026, mientras que las exigencias para los sistemas de IA de alto riesgo lo harán en diciembre de 2027 (en agosto de 2028 para los integrados en productos).
Otro avance legislativo europeo ha sido la adopción de la Estrategia de Código Abierto como parte del paquete de Soberanía Tecnológica. La iniciativa promueve ecosistemas digitales abiertos, interoperables y resilientes, con el fin de reducir la dependencia de proveedores mediante estándares abiertos.
A nivel nacional, el primer semestre de 2026 ha estado marcado por la aceleración en la creación de infraestructuras federadas a través del Plan de Impulso de Espacios de Datos, destacando la activación del Espacio Nacional de Datos de Salud. Resalta también el programa Impulsa DATA, que busca la compartición de datos bajo un modelo de gobernanza unificado que garantiza la calidad de la información para alimentar soluciones de inteligencia artificial. También se ha continuado trabajando en el impulso a los Territorios Inteligentes a través de ayudas destinadas a proyectos que utilicen IA, gemelos digitales o datos urbanos para dinamizar la economía y el sector productivo local. Todo ello está alineado con la hoja de ruta presentada en febrero para reforzar la soberanía digital en España.
El impulso de la economía del dato también tiene su reflejo en el ámbito regional y local. En este sentido, la Federación Española de Municipios y Provincias ha firmado un convenio con la Asociación Española para la Digitalización (DigitalES) para compartir conocimientos y coordinar proyectos de digitalización en el ámbito municipal. Además, a nivel estratégico, encontramos iniciativas como la de Castilla-La Mancha, que convierte el “Dato único” en el eje central del Plan Regional de Estadística 2026-2029. Este plan incluye más de 280 operaciones diseñadas para ofrecer datos actualizados, abiertos y útiles que sirvan de base para mejores políticas públicas.
Gracias a todas estas acciones, y muchas más, España sigue posicionada como país destacado en materia de datos. Si acabamos 2025 situándonos como uno de los referentes europeos en materia de datos abiertos de acuerdo con el portal europeo de datos, a inicios de 2026 conocimos el resultado de otros dos rankings que también ponen en valor el trabajo de nuestro país, esta vez publicados por la Organización para la Cooperación y el Desarrollo Económicos (OCDE). En estos nuevos rankings España se sitúa por encima de la media en digitalización, destacando una vez más en apertura y reutilización de datos públicos.
La reutilización de datos como base de innovación tecnológica
Los datos compartidos continúan enriqueciendo proyectos destinados a mejorar nuestras vidas. Algunas de las iniciativas con participación destacada de organismos públicos que hemos conocido estos meses son:
- El nuevo simulador de la Universitat Autònoma de Barcelona combina datos abiertos de satélites, meteorología y mapas de vegetación con sensores en tiempo real para predecir incendios casi al minuto y mejorar decisiones en emergencias forestales.
- XarMet es un proyecto educativo para impulsar el uso de datos reales en las aulas de las Illes Balears. A través de la instalación de 100 estaciones en centros educativos se genera información meteorológica en tiempo real, pública, accesible y reutilizable.
- El Vall d’Hebron Instituto de Oncología participa en Ligand-IA, un proyecto europeo que usa inteligencia artificial y datos abiertos para predecir nuevas moléculas con potencial terapéutico.
- La Universitat Politècnica de València impulsa OBEREK, una plataforma con sensores para vigilar en tiempo real la salud de la Albufera de València utilizando datos abiertos sobre salinidad, turbidez y oxígeno.
- LabIA es la nueva plataforma de retos de Inteligencia Artificial del Centro Criptológico Nacional. Permite entrenar la detección y mitigación de técnicas de manipulación de modelos de IA mediante desafíos prácticos e interactivos.
- El proyecto DigitAldeas busca impulsar el desarrollo sostenible de las zonas rurales mediante un modelo digital colaborativo basado en datos geoespaciales abiertos y participación ciudadana. La Diputación de Badajoz participa en esta iniciativa.
- Un estudio de la Universidad de Alicante ha utilizado uno de los mayores conjuntos de datos abiertos epidemiológicos sobre la COVID-19 para entrenar modelos de IA orientados a mejorar la gestión de las UCI en situaciones de emergencia sanitaria.
- El Observatori Marina Alta ha presentado una herramienta cartográfica para comparar los costes de repostaje en los diferentes municipios de la comarca.
Avances en plataformas para continuar proporcionando datos de calidad
Para poder poner en marcha proyectos como los anteriores, es necesario que las plataformas de datos abiertos ofrezcan datasets de calidad y funcionalidades que favorezcan su explotación. En este sentido, aquí se recogen algunas de las novedades presentadas en este periodo:
- El Ayuntamiento de Madrid ha presentado un nuevo portal de datos abiertos con un diseño más claro y mejoras en usabilidad que facilitan la navegación, filtros de fácil acceso a datasets y más opciones de descarga y conexión. Además, incluye gráficos y mapas integrados.
- El Instituto Nacional de Estadística también ha lanzado un nuevo portal de datos abiertos. Un espacio más accesible, transparente y fácil de usar para impulsar la reutilización de la información pública.
- La Agencia Estatal de Meteorología (AEMET) y el Consejo Superior de Investigaciones Científicas (CSIC) han presentado una nueva plataforma estatal destinada a la consulta y análisis de información climática. Esta herramienta permite acceder a escenarios de cambio climático regionalizados para España.
- La Infraestructura de Datos Espaciales de España (IDEE) ha facilitado el acceso a la información de la Vía de la Plata en el visualizador NCO (Naturaleza, Cultura y Ocio), dentro del apartado “Cultura” en “Rutas culturales de España”.
- MUFACE ha actualizado su espacio de datos abiertos con información relativa a recursos humanos, actividad administrativa, composición del colectivo y otros datos de interés.
- La Agencia Española de Protección de Datos ha lanzado una Red pública que reúne casi 100 grupos y proyectos de investigación en privacidad y tecnologías emergentes. Es una comunidad multidisciplinar para impulsar la colaboración, compartir el conocimiento y fortalecer la cultura de protección de datos en España.
- La Generalitat Valenciana impulsa “Colabora” en el Portal de Dades Obertes. Es un canal para proponer nuevos conjuntos de datos y compartir proyectos e investigaciones.
Para realizar un seguimiento continuo del volumen y calidad de los datasets publicados por las administraciones públicas españolas, puedes visitar este dashboard interactivo, lanzado por el equipo de Meloda.
Actividades para impulsar el uso de los datos
Los organismos públicos también hacen esfuerzos para dar a conocer el potencial de los datos que comparten. Este semestre ha concentrado una gran cantidad de eventos dirigidos al fomento de la publicación y reutilización de datos, destacando el V Encuentro Nacional de Datos Abiertos (ENDA), algunas actividades de la Semana de la Administración Abierta y el Open Data Day 2026. Cabe destacar que en el ENDA se presentó un recurso educativo para acercar el open data a estudiantes y docentes de Educación Secundaria Obligatoria (ESO), Bachillerato y Formación Profesional.
Cada vez se celebran más eventos sectoriales, lo que refleja la madurez de este campo y su valor transversal para diferentes áreas de actividad económica. Algunos ejemplos son “El congreso internacional sobre IA y datos aplicados al sector agroalimentario”, o la XI edición de la Jornada LEXDATUM esta vez centrada en los datos abiertos y la privacidad en el ámbito del derecho. Nuestro país también acogió las Jornadas de Estadística de las Comunidades Autónomas y Fira FAIR Data, centrado en la gestión y reutilización de datos según los principios FAIR (Encontrables, Accesibles, Interoperables y Reutilizables). Asociaciones como Iniciativa Open Data también ponen de manifiesto el poder de los datos con sesiones como Woman Data Lab para presentar herramientas de datos que sirven de soporte para la toma de decisiones Otro ejemplo: en la jornada Patrimonio Conectado, el Museo del Prado y Wikimedia destacaron cómo los datos abiertos y los grafos de conocimiento permiten conectar colecciones, enriquecer contenidos con IA y hacer el arte más accesible e interoperable a escala global.
También destacan las actividades dirigidas a conocer mejor a los usuarios de las plataformas, para adaptar contenidos y funcionalidades a sus necesidades. Es el caso de este grupo de discusión del Portal de Datos Abiertos del Ayuntamiento de Madrid, y esta sesión colaborativa para analizar datos abiertos útiles que ayuden a reforzar los servicios de atención a las personas mayores y el envejecimiento activo, celebrada en Mataró.
Los espacios de datos también fueron los protagonistas de múltiples citas, empezando por el II Encuentro Nacional de Economía del Dato, y siguiendo con actividades sectoriales o locales, como la sesión “Turismo conectado: el poder transformador de un espacio de datos único” organizada por SEGITTUR (Sociedad Mercantil Estatal para la Gestión de la Innovación y las Tecnologías Turísticas) o la jornada formativa sobre el Espacio de Datos de Zaragoza.
También cabe mencionar los concursos celebrados para impulsar la reutilización de los datos publicados por organismos públicos. En este periodo, por ejemplo, se dieron a conocer los ganadores del I Concurso de Datos Abiertos del Cabildo de Tenerife y se lanzó la 2ª edición de los Premios de Reutilización de Datos Abiertos del Ayuntamiento de Madrid o los Premios para proyectos de Datos Abiertos y periodismo de datos 2026 del Ayuntamiento de Valencia. También las universidades y asociaciones han presentado iniciativas como el hackathon “Data & Culture”, impulsado por la Cátedra ESPACIOS de la Universitat de València. Otro ejemplo es el concurso escolar “Andalucía en un mapa” dirigido a promover la utilización de la cartografía y la estadística de Andalucía. En la Fundación ONCE, celebraron una sesión colaborativa de análisis de datos para explorar, cruzar e interpretar información real sobre financiación pública y generar conocimiento útil.
A un nivel más empresarial, Asedie ha abierto la convocatoria para participar en la 12.ª edición de sus Premios, que reconocen proyectos e iniciativas que impulsan la economía del dato y la reutilización de la información. La Fundación Cotec, por su parte, lanzó la Convocatoria PIA 2026, que busca proyectos que impulsen la industria española en ámbitos como la I+D+I, el talento, la soberanía tecnológica, la sostenibilidad o la seguridad de las cadenas de valor.
Algunas lecturas de recomendadas
Si quieres saber más sobre la innovación basada en datos, recopilamos varios ejemplos de informes publicados en los últimos seis meses:
- La 14ª edición del Informe del Sector Infomediario de Asedie muestra cómo evoluciona el sector de la reutilización de la información del sector público en España.
- El capítulo “Open Data y ciudades inteligentes en la gestión de municipios saludables: una revisión sistemática”, de este libro de descarga gratuita, aborda el papel de los datos abiertos en la promoción de entornos más activos, saludables e innovadores a nivel municipal.
- La guía “Cómo usar la IA en tu empresa: aspectos jurídicos y gobierno de la IA” que publica la Fundación Cotec detalla cinco pasos clave en la implantación de la IA.
- El libro “Arquitectura jurídica de los espacios de datos” abarca desde aspectos tecnológicos hasta sus implicaciones jurídicas.
Otras lecturas interesantes, estas publicadas a nivel internacional, son el marco metodológico para evaluar cómo las instituciones pueden fortalecer la producción y uso de datos, publicado por OpenDataWatch, o el informe sobre innovación en gobernanza de datos de The Gov Lab.
¡Comparte más ejemplos!
En resumen, el dinamismo y la variedad de los casos que hemos visto son solo unos pocos ejemplos de un sector que se encuentra en un momento de expansión y que no para de crecer. La madurez de nuestro ecosistema de datos es una realidad y se consolida como un motor clave de innovación.
Las iniciativas y herramientas que hemos repasado a lo largo de este post son solo algunos ejemplos ilustrativos del enorme potencial de los datos. Dado que el sector avanza a pasos agigantados, estamos seguros de que nos hemos dejado grandes proyectos en el tintero. Te animamos a que utilices la sección de comentarios para compartir otros ejemplos de plataformas, eventos o informes que conozcas.
Blog
Cuando hablamos de datos abiertos, es fácil perderse en laberintos técnicos. A menudo el debate se centra en los formatos de archivo, la interoperabilidad semántica, las licencias de uso o la optimización de los metadatos. Sin embargo, detrás de cada conjunto de datos publicado por una administración pública, existe un potencial transformador que impacta de manera directa en la vida cotidiana de las personas.
En este post, explicamos tres proyectos concretos actualmente en marcha en España, que utilizan datos abiertos como materia prima, y que tienen consecuencias tangibles: en el control de la calidad del agua de un parque natural, en cómo la ciencia busca nuevos medicamentos contra el cáncer y en la mejora de la respuesta ante fenómenos meteorológicos extremos.
Medio ambiente: monitorizando en tiempo real la salud de la Albufera de València
La Albufera de València es uno de los humedales más importantes del Mediterráneo y, también, uno de los más presionados. Décadas de actividad agrícola, industrial y turística han dejado su huella en la calidad del agua y en la salud del ecosistema. Hasta ahora, la monitorización de este espacio se hacía con métodos discontinuos, costosos y con una capacidad de respuesta limitada ante eventos extremos. La DANA de octubre de 2024 puso en evidencia, una vez más, la necesidad de contar con información ambiental en tiempo real para poder actuar con rapidez.
En este contexto surge, a principios de 2026, OBEREK, un proyecto europeo en el que participa la Universitat Politècnica de València (UPV) y la Fundació Assut. El proyecto está desarrollando una plataforma de monitorización en tiempo real de la salud del ecosistema y la biodiversidad de la Albufera. La plataforma instalará nodos de transmisión y sensores en puntos críticos del lago como entradas de caudal o salidas de regadío para medir parámetros clave del agua y del entorno natural.
Lo que hace especialmente relevante esta iniciativa desde la perspectiva de los datos abiertos es su arquitectura de acceso: el sistema contará con un panel de control de acceso público para que ciudadanía, investigadores, agricultores y empresas puedan consultar y reutilizar los datos para la toma de decisiones. Además, el proyecto integrará diagramas de conocimiento que traducirán información técnica compleja en explicaciones comprensibles, pensados expresamente para facilitar su uso como herramienta de gobernanza participativa. En concreto, el proyecto es clave para:
- Prevención de crisis: permite detectar de forma precoz anomalías en la calidad del agua, evitando episodios de anoxia (falta de oxígeno) que pongan en peligro la fauna local.
- Gestión eficiente del agua: proporciona datos empíricos para regular las compuertas que conectan el humedal con el mar y los canales de riego, optimizando el recurso hídrico.
- Evidencia científica para políticas públicas: los gestores gubernamentales pueden diseñar normativas de protección basadas en un histórico de datos sólido y transparente.
El objetivo final, según los investigadores de la UPV, es que la solución sea replicable en al menos cinco nuevos humedales europeos en los próximos tres años.
Salud: inteligencia artificial para acelerar el descubrimiento de fármacos oncológicos
El segundo caso de uso se inscribe en el sector de la salud y la investigación biomédica, donde los datos abiertos están empezando a cambiar las reglas del juego en uno de los procesos más costosos y lentos de la ciencia moderna: el descubrimiento de nuevos medicamentos.
Desarrollar un fármaco desde cero puede llevar más de una década y costar miles de millones de euros. Una de las razones es la enorme dificultad para identificar qué moléculas tienen potencial terapéutico antes de iniciar los ensayos clínicos. Es aquí donde entra el proyecto europeo Ligand-IA, en el que participa el Vall d'Hebron Instituto de Oncología (VHIO), uno de los centros de investigación oncológica de referencia en España.
Este proyecto utiliza modelos computacionales avanzados y algoritmos de inteligencia artificial entrenados y alimentados de forma masiva mediante el uso de grandes bases de datos abiertos químicos, biológicos y clínicos de acceso público.
Las bases de datos abiertas aportan el volumen de información biológica y química necesario para entrenar algoritmos de inteligencia artificial. Mediante el análisis de estos datos, la IA es capaz de realizar una predicción masiva de interacciones moleculares en entornos virtuales, lo que optimiza el cribado de compuestos y reduce drásticamente los tiempos y costes en el descubrimiento acelerado de nuevos fármacos.
La inteligencia artificial requiere de un volumen masivo de datos previos para aprender y realizar predicciones precisas. Al reutilizar repositorios abiertos mundiales de estructuras moleculares y resultados de ensayos anteriores, el consorcio Ligand-IA puede simular virtualmente millones de interacciones entre proteínas tumorales y diferentes compuestos químicos. Así que Ligand-IA es especialmente útil para:
- Reducción drástica de plazos: lo que antes requería años de ensayo y error en el laboratorio de química, la IA lo puede cribar virtualmente en cuestión de semanas o meses.
- Optimización de recursos de investigación: permite a los científicos descartar de forma temprana aquellas moléculas que no serán efectivas, concentrando los esfuerzos económicos y humanos en los candidatos con mayores probabilidades de éxito.
- Democratización del conocimiento: al utilizar y enriquecer el ecosistema de datos abiertos, se fomenta un modelo de ciencia colaborativa global que beneficia a toda la comunidad médica.
Resiliencia climática: inteligencia de datos frente a fenómenos meteorológicos extremos
Predecir el tiempo a corto plazo mediante la observación meteorológica convencional es una práctica estandarizada. Sin embargo, anticipar con precisión matemática cómo, cuándo y dónde golpeará un evento climático extremo exige un nivel de computación muy superior. En el escenario actual de cambio climático, la clave para mitigar las pérdidas humanas y los millonarios costes económicos de estas catástrofes reside en transformar los flujos masivos de datos climáticos mundiales en conocimiento predictivo útil.
Con este propósito estratégico nace el proyecto europeo CLINT (Climate Intelligence), una iniciativa de vanguardia financiada por el programa marco de investigación, desarrollo e innovación (I+D+i) Horizonte Europa de la Unión Europea. En el consorcio internacional formado para el proyecto participa el Consejo Superior de Investigaciones Científicas (CSIC), contribuyendo en las líneas de investigación orientadas al desarrollo de algoritmos para la detección, causalidad y atribución de estos fenómenos meteorológicos extremos en escenarios futuros.
El núcleo operativo de CLINT consiste en el desarrollo de un marco avanzado de inteligencia artificial (IA) y machine learning que se nutre directamente de los grandes repositorios de datos abiertos y de acceso público globales. Entre ellos, destacan de manera muy especial los flujos de información paneuropeos procedentes del Servicio de Cambio Climático de Copernicus (C3S), así como, de análisis climáticos históricos y modelos de predicción estacional. Este proyecto es de ayuda para:
- Sistemas de alerta temprana de nueva generación: permite la creación de servicios climáticos operacionales basados en la web, ofreciendo a las confederaciones hidrográficas y a las autoridades de protección civil herramientas para anticipar sequías extremas o riadas con semanas de antelación en la Península Ibérica.
- Gestión eficiente del nexo agua-energía-alimentación: al refinar los modelos predictivos mediante datos abiertos, tanto las empresas del sector energético (hidroeléctrico) como las comunidades de regantes pueden tomar decisiones estratégicas fundamentadas sobre el almacenamiento de agua y la planificación de cultivos.
- Soporte científico a las políticas de adaptación locales: facilita a los planificadores y administraciones públicas datos rigurosos y proyecciones climáticas fiables a escala regional para diseñar planes de urbanismo y contingencia adaptados a los desafíos del calentamiento global.
En resumen, estos tres ejemplos ponen de manifiesto cómo al compartir información de manera accesible y estandarizada, el sector público actúa como un catalizador que multiplica exponencialmente las capacidades del tejido científico y empresarial. Al liberar conocimiento, permitimos que la ciencia avance más rápido, que nuestros recursos naturales se gestionen con responsabilidad y que la sociedad sea más resiliente ante los desafíos del mañana. Impulsar, mantener y defender la cultura del dato abierto es, por tanto, una inversión estratégica, inteligente y colaborativa en nuestro bienestar colectivo futuro.
Blog
Abrir los datos públicos es solo el primer paso de un camino mucho más ambicioso. El verdadero éxito de las políticas de datos abiertos no se mide en el número de datasets publicados ni en el volumen de gigabytes descargados, sino en el impacto real que esos datos generan en la sociedad, la economía y la innovación. Es decir, en su reutilización para generar servicios de valor añadido, apoyo a la toma de decisiones estratégicas, etc.
Sin embargo, debido al anonimato que generalmente prima en la descarga de datos, las iniciativas de datos abiertos a menudo desconocen quién está utilizando la información y para qué. Implementar una metodología activa de captación de casos de uso es fundamental para romper esta barrera y conocer el valor del dato.
A continuación, analizamos por qué es crucial realizar esta práctica, qué criterios seguir para seleccionar los casos a considerar y qué información clave debemos recopilar.
¿Por qué es importante captar y publicar ejemplos de reutilización?
La captación y análisis de casos de uso es uno de los mecanismos que los publicadores de datos abiertos tienen para medir el impacto de sus iniciativas open data. En este ámbito, entendemos por caso de uso cualquier modelo de negocio, aplicación, plataforma, servicio, análisis, etc. desarrollado por una entidad (ya sea una empresa, startup, ONG o la propia ciudadanía) que genere un valor tangible mediante la reutilización de datos públicos. Es decir, nos centramos en procesos que transforman datos abstractos en soluciones prácticas que resuelven un problema real, mejoran la toma de decisiones o crean una nueva oportunidad de negocio en el mercado. Las plataformas de datos abiertos suelen contar con una sección donde publican los casos de uso localizados, ya sea mediante catálogos o repositorios donde se recopilan empresas con modelos de negocio basados en datos abiertos, aplicaciones, servicios o historias de éxito a través de artículos o informes concretos. Se trata de un escaparate que beneficia a todos los actores del ecosistema de datos:
- Para las empresas reutilizadoras: funciona como un escaparate institucional gratuito de alta visibilidad. Aparecer en portales oficiales, ya sean internacionales, nacionales, autonómicos o locales, avala su reputación, su capacidad tecnológica y su modelo de negocio ante potenciales clientes e inversores.
- Para la sociedad: actúa como un elemento inspirador que puede desencadenar un "efecto llamada". Mostrar soluciones reales y tangibles fomenta la cultura del dato y estimula a emprendedores, investigadores y desarrolladores a crear nuevos servicios.
- Para la Administración pública: permite conocer qué conjuntos de datos son los más demandados y qué aspectos tienen en común (calidad, formatos, frecuencias de actualización, etc.), lo cual da pistas sobre qué cuestiones se deben impulsar o mejorar en el ejercicio de publicación. Además, el conocimiento sobre el uso de los datos es de gran utilidad para justificar la inversión de recursos en la apertura de datos y demostrar el retorno social de la inversión (SROI).

Figura 1. Beneficios de recopilar casos de uso de datos abiertos. Fuente: elaboración propia - datos.gob.es.
Tres vías para nutrir el repositorio de forma continua
Localizar empresas con modelos de negocio basados en datos abiertos y casos de uso concretos puede parecer una tarea complicada al principio, pero el secreto reside en combinar la automatización con la presencia en los foros adecuados. Para mantener el catálogo actualizado de forma constante, se recomienda activar tres vías complementarias:
- Escucha proactiva: consiste en monitorizar de manera constante las redes sociales, los medios de prensa tecnológica, los listados de empresas de asociaciones del sector (como ASEDIE), así como los ganadores de hackatones y premios de innovación.
- Canales reactivos: en paralelo a la búsqueda proactiva, es necesario mantener un canal de comunicación permanente y visible en el portal web. Lo habitual es contar con un formulario sencillo para que las propias empresas puedan postularse de forma autónoma. Difundir este canal de comunicación a través de los diversos medios de la iniciativa (como redes sociales, boletines periódicos, etc.) es fundamental para garantizar el crecimiento del catálogo de casos de uso.
- Alianzas del ecosistema: otra buena opción es colaborar estrechamente con asociaciones de empresas, universidades, incubadoras de startups y parques tecnológicos, que suelen ser los principales dinamizadores y focos de nacimiento de estas empresas reutilizadoras.
¿Cómo elegir las empresas y casos a categorizar?
Para que la colección de casos de uso sea una herramienta de referencia y mantenga un alto estándar de calidad, es necesario aplicar criterios de filtrado objetivos. Se recomienda priorizar los proyectos bajo las siguientes premisas:
- Uso significativo de datos públicos: el modelo de negocio o solución debe basarse total o parcialmente en la reutilización de conjuntos de datos de origen público (locales, autonómicos, nacionales o europeos), destacando positivamente la hibridación de distintas fuentes de datos (mashup de datos).
- Impacto y relevancia social o económica: se priorizarán aquellas empresas y soluciones que resuelvan problemas reales de la ciudadanía o de los sectores productivos (por ejemplo, optimización de la movilidad urbana, herramientas de diagnóstico de salud, eficiencia energética o transparencia financiera).
- Madurez y viabilidad: deben considerarse empresas que ofrezcan aplicaciones, plataformas o servicios que ya estén operativos en el mercado o, como mínimo, que cuenten con un Producto Mínimo Viable (MVP) testado y funcional. Es recomendable evitar ideas o proyectos en fase puramente conceptual. Estas soluciones iniciales pueden tener su escaparate en los concursos de datos que organizan diversos organismos, como la Junta de Castilla y León o el Cabildo de Tenerife, entre otros.
- Calidad y funcionalidad: las soluciones tecnológicas deben presentar un correcto diseño y funcionamiento técnico, con una experiencia de usuario óptima. El objetivo es garantizar que la reutilización del dato se traduce en un servicio verdaderamente eficiente y robusto para su público objetivo.
- Diversidad sectorial: es importante buscar un equilibrio temático para demostrar que el dato abierto es transversal. El repositorio o catálogo debe reflejar casos en sectores tan diversos como la agricultura, el turismo, la cultura o la educación.
¿Qué información se debe incluir sobre cada caso de uso?
Para que las fichas de los casos de uso sean homogéneas, comparables y útiles para los usuarios del portal, la recogida de información debe estructurarse de forma homogénea. Algunos de los pilares básicos a incluir son:
- Perfil del reutilizador: nombre de la empresa, organismo o persona que la ha puesto en marcha el modelo de negocio o desarrollado la solución. En el caso de las empresas se puede incluir su año de fundación, tamaño, sector de actividad, enlace a su web corporativa, etc.
- Descripción del modelo de negocio / solución: nombre de los productos o servicios, problemas que soluciona, descripción de su funcionalidad, público objetivo al que van dirigida, etc.
- Fuentes de datos abiertos utilizadas: detalle explícito de los datasets consumidos, incluyendo su fuente de procedencia (por ejemplo, "Datos meteorológicos de la Agencia Estatal de Meteorología - AEMET"). Esto ayuda de forma directa a conectar la oferta con la demanda de datos.
- Impacto obtenido: Indicadores cuantitativos o cualitativos del beneficio generado tanto para la empresa como para el reutilizador (ahorro de tiempo, reducción de emisiones, facturación, puestos de trabajo creados, etc.).
Ejemplos de catálogos de casos de uso
Para inspirar el diseño de un repositorio propio o entender cómo se plasman estas metodologías en el entorno real, es útil analizar cómo lo están implementando diferentes administraciones públicas.
En el caso de datos.gob.es, contamos con dos secciones diferenciadas, una para empresas y otra para aplicaciones. Ambos apartados permiten filtrar por sector de actividad o etiquetas, y además incluyen un buscador de texto libre, para que los usuarios puedan encontrar más fácilmente los casos de uso que se corresponden con sus necesidades.
A nivel autonómico y local también son muchos los organismos que han decidido incluir una sección específica en sus plataformas que muestre el potencial de uso de los conjuntos de datos publicados. Es el caso de la Junta de Andalucía, el Gobierno Vasco o el Ayuntamiento de Madrid.
Si miramos a Europa, nuestros vecinos también cuentan con esta funcionalidad en sus plataformas open data. Iniciativas nacionales como las de Francia o Lituania, que ocupan las primeras posiciones de madurez en datos abiertos de acuerdo con el Open Data Maturity 2025, cuentan también con este tipo de escaparates.
Conclusión: pasar del dato publicado al valor compartido
Medir el impacto de los datos abiertos es fundamental para garantizar la sostenibilidad a largo plazo de las iniciativas de datos abiertos. Sin una metodología clara para captar y estructurar las historias de éxito, los portales corren el riesgo de convertirse en meros almacenes de archivos digitales inertes.
Al poner a disposición de la ciudadanía ejemplos reales de la utilidad de los datos abiertos, la Administración no solo justifica la inversión pública en esta materia, sino que devuelve a la sociedad el conocimiento necesario para seguir innovando.
Documentación
Introducción
En 2018 la compañía Uber creó una herramienta para poder visualizar información geoespacial y poder representar gráficamente miles de puntos de localización, así como trayectorias en un amplio rango temporal. Esta herramienta pasó a ser de dominio público bajo el nombre de KeplerGL y, a día de hoy, está disponible como código abierto para la realización de mapas de forma sencilla.
KeplerGL permite representar información georreferenciada en un interfaz web sin necesidad de utilizar herramientas como ArcGIS o QGIS, o cualquier otro software que necesite de instalación en el ordenador o de complejas actualizaciones.
KeplerGL ofrece una amplia variedad de formas de representación, desde los convencionales puntos o rectángulos a formas de clustering tipo hexagonal binning o mapas de calor, hasta sistemas de mallas más sofisticados como H3.
Toda la gama de elementos gráficos viene con una serie muy completa de opciones de customización, tanto en el tamaño como en el color pasando por los rangos de valores. La propia cartografía de fondo que se utiliza para referenciar la información que queremos visualizar también dispone de todo un catálogo de opciones, entre los que se incluyen fondos claros, oscuros o imágenes satelitales del espectro visible.
En este ejercicio visualizaremos información georreferenciada relacionada con la actividad sísmica de la erupción del volcán de la Palma en torno a septiembre de 2021. Esta información se vio reflejada de formas diversas en varias infografías en medios de comunicación de ámbito estatal, donde se geolocalizaban los epicentros de los terremotos tomando como referencia la isla de La Palma. En la Figura 1 observamos el mismo tipo de mapa, en el cual se superponen círculos a una cartografía de fondo, y donde el radio de los círculos es proporcional a la actividad sísmica. En este ejercicio aprenderemos a hacer mapas similares en contenido y en estilo de forma rápida e intuitiva gracias a KeplerGL.
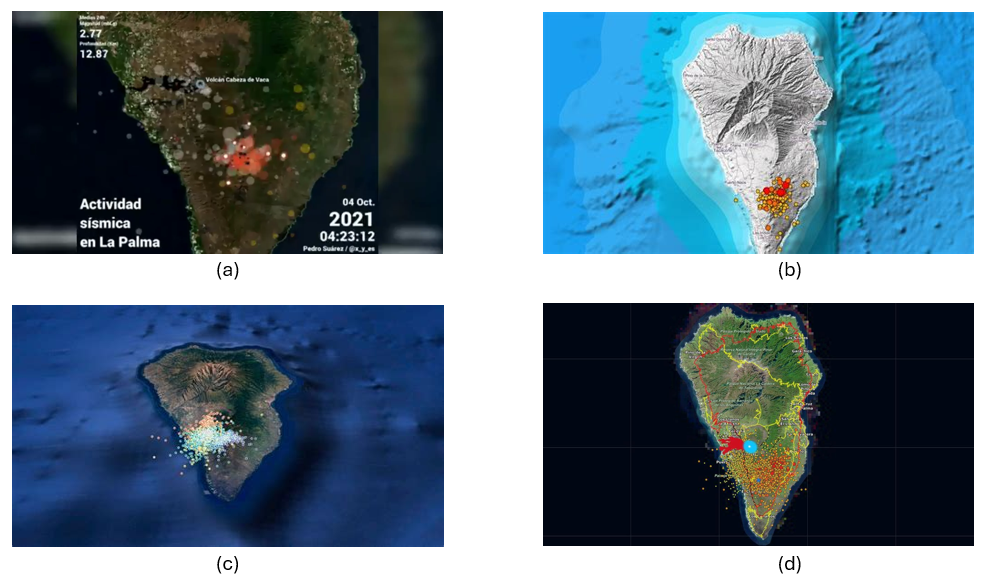
Figura 1: Mapa mostrado en diversos medios de comunicación con los epicentros de la actividad sísmica previa a la erupción del volcán de la Palma. (a) Antena3, (b) Telemadrid, (c) La Vanguardia y (d) ElDiario.es
Para crear el mapa de actividad sísmica tenemos dos alternativas dependiendo del nivel de detalle y de procesamiento que queramos realizar:
- La primera opción es utilizar los datos que nos bajaremos directamente del portal de datos tal y como están. En el apartado de Datos para el ejercicio se indica el enlace a través del cual podemos acceder a un fichero .CSV con todos los datos que necesitamos para crear el mapa y desarrollar todo el ejercicio sin necesidad de programar ni crear código.
- La segunda opción es procesar y filtrar los datos a través de Python por si queremos familiarizarnos con unas líneas sencillas de código y así seleccionar variables o intervalos temporales de nuestro interés. El acceso al repositorio de Github y el notebook de Google Colab para realizar la lectura, selección de variables y criterios de filtrado para obtener un subconjunto de datos se puede realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
Datos para el ejercicio
En este ejercicio vamos a utilizar datos abiertos del Cabildo Insular de La Palma recopilados durante la actividad sísmica anterior y posterior a la erupción volcánica en La Palma en 2021, y que están disponibles aquí:
https://datos.gob.es/es/catalogo/l03380010-terremotos
En este dataset encontramos el registro de cada uno de los puntos en los que se detectó actividad sísmica durante esos días, así como, entre otras, las siguientes métricas que caracterizan sus propiedades geológicas:
| Metrica | Descripción |
|---|---|
| ID | Identificador asociado a cada evento |
| Datetime | Fecha y hora de cada evento |
| ErrTime | Error asociado al tiempo de registro |
| RMS | Root Mean Square del tiempo de propagación |
| Latitude | Coordenada de latitud en grados |
| Longitude | Coordenada de longitud en grados |
| Az | Grado azimutal |
| Depth | Profundidad del evento en kilómetros |
| ErrDepth | Error asociado a la medida de la profundidad |
| Nsta | Número de estaciones empleadas en medir el evento |
| Gap | Mayor diferencia azimutal entre estaciones adyacentes |
| Author | Organismo responsable de la medición |
| Magnitud | Magnitud sísmica del evento |
| IntensMax | Intensidad máxima del evento |
| Localización | Localización |
| TipoMagnit | Tipo de magnitud |
| XUTM | Coordenada de longitud en el sistema UTM |
| YUTM | Coordenada de latitud en el sistema UTM |
| GlobalID | Identificador del evento |
Para la creación del mapa nos centraremos en la variable asociada a la actividad sísmica: magnitud, así como la longitud y latitud de cada punto y la fecha y la hora de cada evento.
Proceso de desarrollo
1. Acceso a la interfaz web
Como mencionábamos en la introducción, KeplerGL no necesita de instalación en el ordenador, sino que se accede a través de internet a su interfaz. Por lo tanto, lo primero que haremos será abrir un navegador y acceder a la web de KeplerGL a través del dominio:
Una vez en la página de inicio haremos click sobre Get Started para poder subir los datos y empezar a crear nuestro mapa.
Como vemos en la Figura 2, KeplerGL incluye otras opciones, como acceder a datos que estén almacenados en una base de datos o consultar directamente el código Github, especialmene útil para desarrolladores o para integrar KeplerGL dentro de otras aplicaciones. No obstante, en este caso nos centraremos en la opción más sencilla: la carga de nuestros datos directamente en la interfaz.
Figura 2: Pantalla principal de KeplerGL donde se nos ofrece un ejemplo de visualización, así como la opción de empezar el proceso de creación de nuestro mapa.
2. Carga de datos en la página
En la página de carga de datos tenemos el habitual cuadro de diálogo para poder subir nuestros datos. Como vemos en la Figura 3, KeplerGL acepta diferentes formatos:
- CSV: el tradicional formato con valores, generalmente separados por comas.
- JSON: alternativa al CSV con entradas estructuradas en formato de listas y objetos
- GeoJSON: formas geométricas estructuradas como un JSON.
- Arrow: datos estructurados en columnas para la aplicación Apache Arrow.
- Parquet: formato en columnas para grandes cantidades de datos.
En este punto subiremos los datos que hemos obtenido directamente del portal o aquellos filtrados que hemos realizado con el código de Python reflejado en el repositorio de Github y el notebook de GoogleColab. Ambas opciones son válidas para crear los mapas.
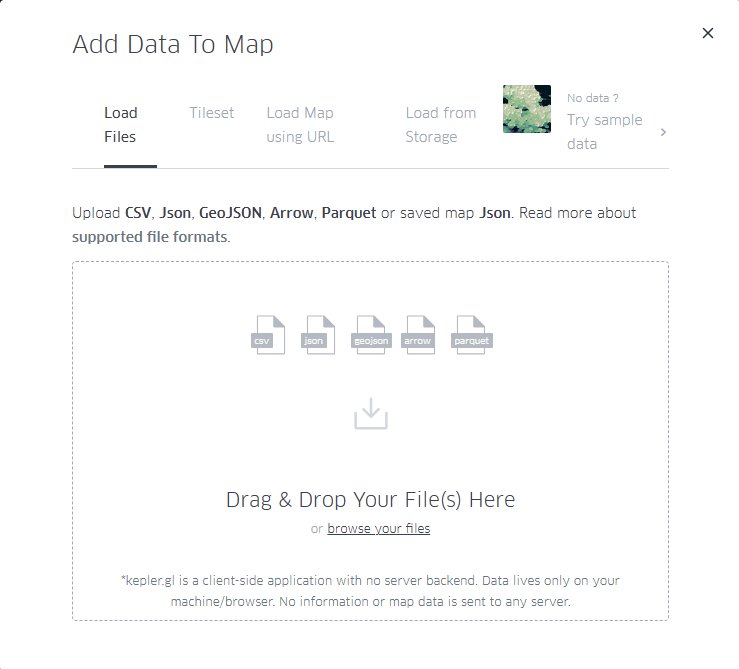
Figura 3: Cuadro de dialogo para la carga de archivos, ya sea mediante la selección desde el ordenador o arrastrándolos directamente al navegador.
3. Visualización
KeplerGL nos permite representar la informacion geografica a través de varios elementos, como puntos, rejillas (grids), distribuciones en hexágonos, mapas de calor, así como proyectar todas estas formas en tres dimensiones. En la Figura 4 se detallan los diferentes tipos de visualización posibles que ofrece la herramienta.
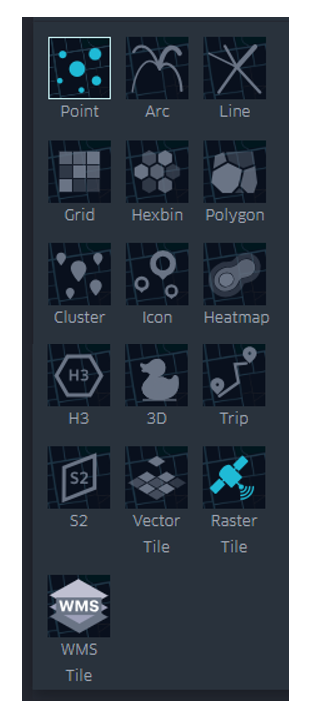
Figura 4: Opciones de visualización de la información georreferenciada, que incluye puntos, trayectorias, líneas, cuadros, hexágonos, polígonos, clusters, iconos, mapas de calor, celdas H3, tridimensional, viajes, celdas S2, vectorial y rasters.
A continuación vemos en detalle las características de las formas de visualización que podemos explorar con este conjunto de datos.
3.1 Puntos
Dentro de los puntos podremos parametrizar las siguientes variables: color del punto, borde del punto, magnitud adicional asociada al radio, dimensiones del radio, etiquetas, tooltip con información, interacción entre superposiciones o transparencia.
En la Figura 5 podemos observar la aplicación directa de la representación por puntos. KeplerGL identifica tanto la latitud como la longitud automáticamente para situar sobre el plano cada uno de los puntos. A partir de ahí dibuja un círculo con un radio determinado y asigna un color dependiendo de la intensidad de la magnitud.
En el panel de control de la izquierda se puede controlar tanto el radio de los círculos como la paleta de colores, y aplicar las opciones que más nos gusten para representar la intensidad. El hecho de poder jugar con ambos parámetros nos permitiría añadir otro eje de información a la visualización. En este caso, por simplicidad, dejamos esta representación tal y como está, explorando únicamente el color.
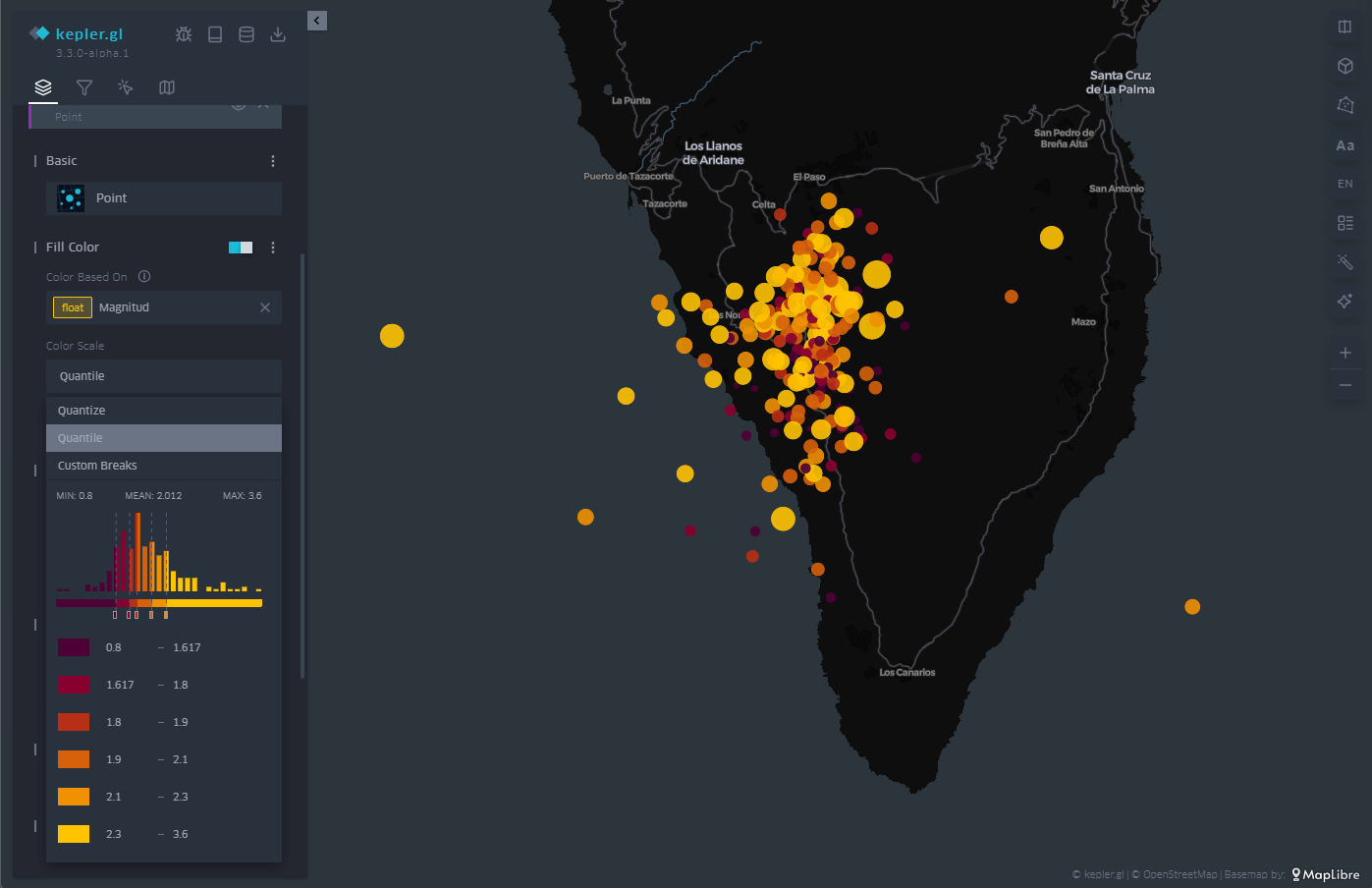
Figura 5: Mapa con los seísmos en la isla de La Palma representados por puntos. El color y el radio es proporcional a la magnitud del seísmo.
3.2 Malla de puntos
De la misma forma que KeplerGL identifica la latitud y la longitud para situar los círculos, también es capaz de promediar los valores de magnitud en celdas. Dichas celdas pueden englobar uno o varios puntos, y KeplerGL asigna en consecuencia un color que representa su valor en base al valor promedio, como vemos en la Figura 6.
Al igual que en el caso de los puntos, el cuadro de diálogo de la izquierda permite cambiar la paleta de colores, aumentar o disminuir el tamaño de las celdas para promediar sobre áreas más extensas o reducidas. Igualmente, la escala de valores sobre la cual se basa la asignación de cada uno de los colores de la escala también está sujeta a su personalización, dependiendo del rango de valores que queramos destacar en la visualización.
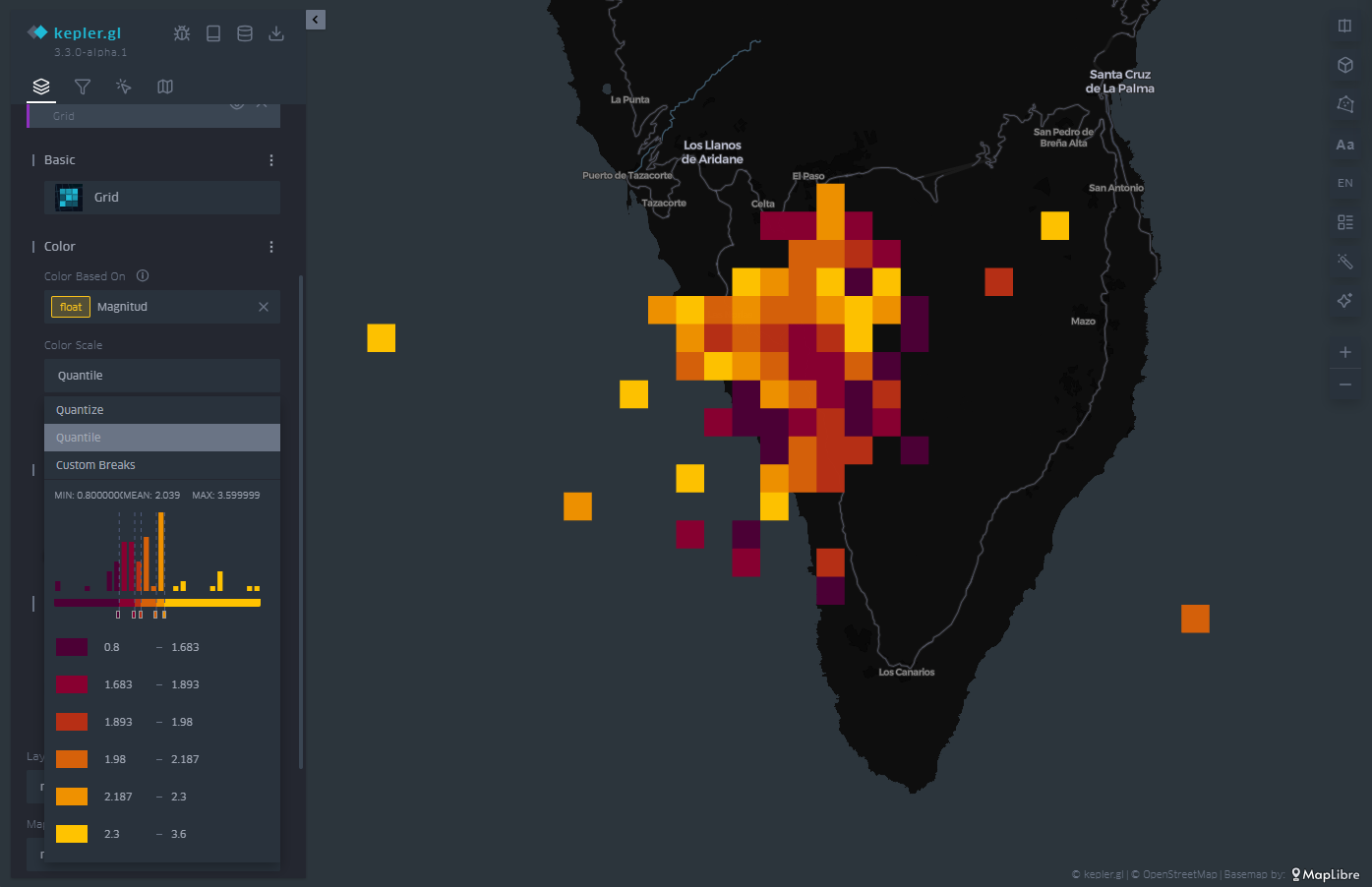
Figura 6: Mapa con los seísmos en la isla de La Palma representados por una malla. El color está asociado a la escala de magnitud del seísmo.
3.3 Hexbin
Similar a la malla de celdas, hexbin es un acrónimo de hexagonal binning, es decir, promediado de valores sobre celdas con forma de hexágono. A diferencia de las celdas rectangulares, el empaquetamiento de celdas con forma de hexágono responde a estructuras más compactas, similares a las que pueden observarse en la organización de partículas o átomos en la formación de estructuras de estado sólido.
El hexbin tiene las mismas propiedades que hemos visto en el caso de la malla de celdas, es decir, podemos cambiar el tamaño de la celda hexagonal para que ocupe una mayor superficie en su promedio, podemos cambiar igualmente la paleta de colores y también el rango de valores sobre el cual actúa cada intervalo de color. Un ejemplo del hexagonal binning se encuentra en la Figura 7.
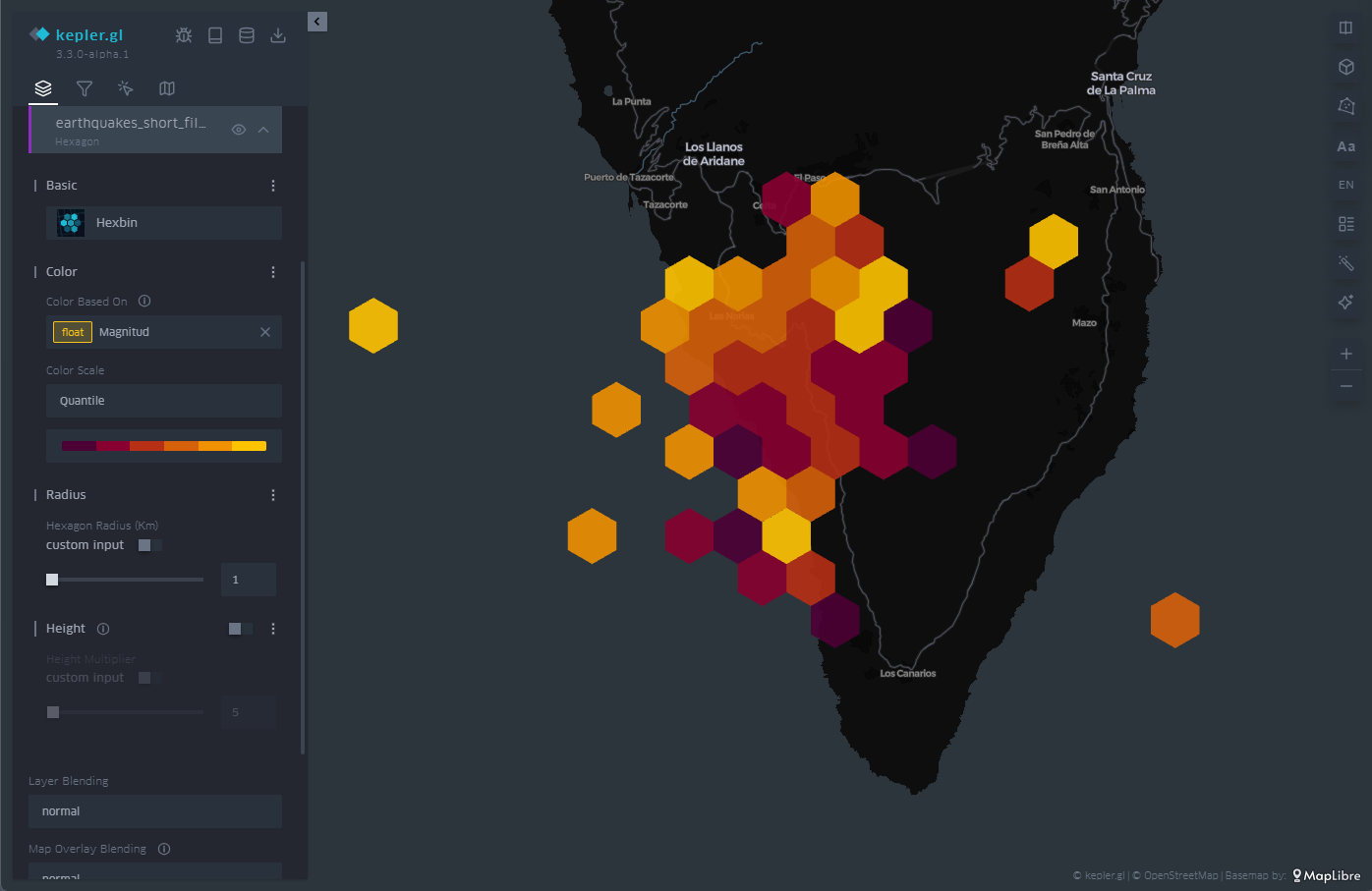
Figura 7: Mapa con los seísmos en la isla de La Palma representados por hexágonos. El color está asociado a la magnitud del seísmo y el hexágono agrega los puntos que cubre su extensión.
3.4 Heatmap
La última de las representaciones que veremos en el plano es el mapa de calor o heatmap, en su concepción en inglés. El heatmap no es más que un diagrama de contorno, donde cada curva de nivel corresponde a un intervalo determinado de valores. En el momento en el que el número de curvas de nivel es muy elevado obtenemos esa sensación de continuo que evoca al mapa de calor.
En este caso, tanto la paleta de color elegida con su número de niveles como el radio sobre el cual se promedian los valores son personalizables a través de las opciones del menú de la izquierda. En la Figura 8 tenemos un ejemplo, donde la densidad de eventos aflora de forma natural con este tipo de representación.
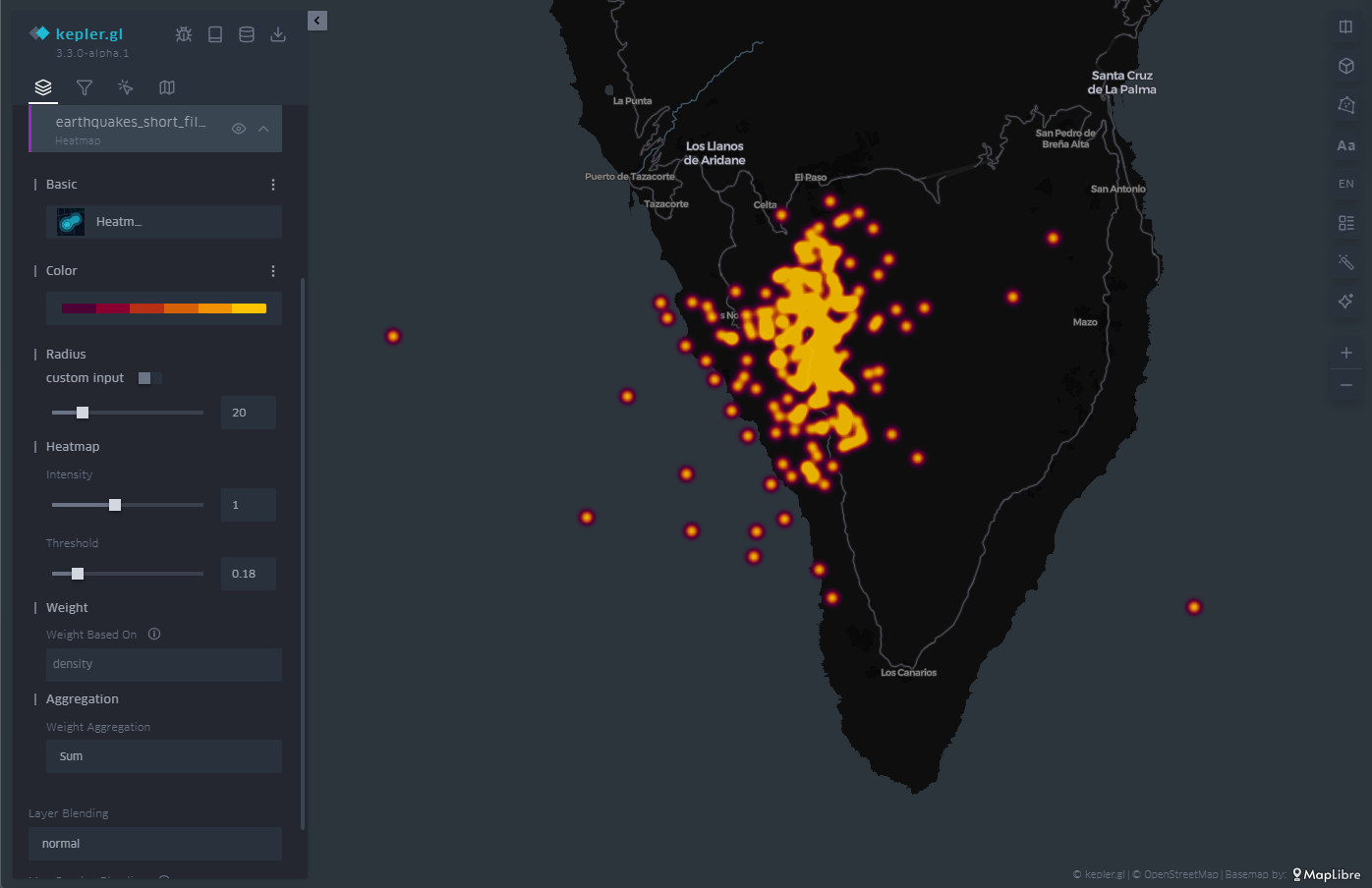
Figura 8: Mapa con los seísmos en la isla de La Palma representados por un mapa de calor. El color está asociado a la densidad de eventos sísmicos.
3.5 Tridimensionalidad
Por último, en la representación geográfica tenemos la posibilidad de utilizar el eje z, o eje vertical, para añadir o redundar información en esa dimensión. Para ello tenemos la opción denominada "Height" dentro del menú de la izquierda. La opción "Height" aplica tanto a círculos como a mallas de celdas, donde afecta al polígono que define cada una de las celdas.
De esta forma, proyectamos en la vertical otra magnitud a nuestra elección, que complementa aquella magnitud ya representada por el color de las celdas o círculos sobre el plano, tal y como ilustra la Figura 9.
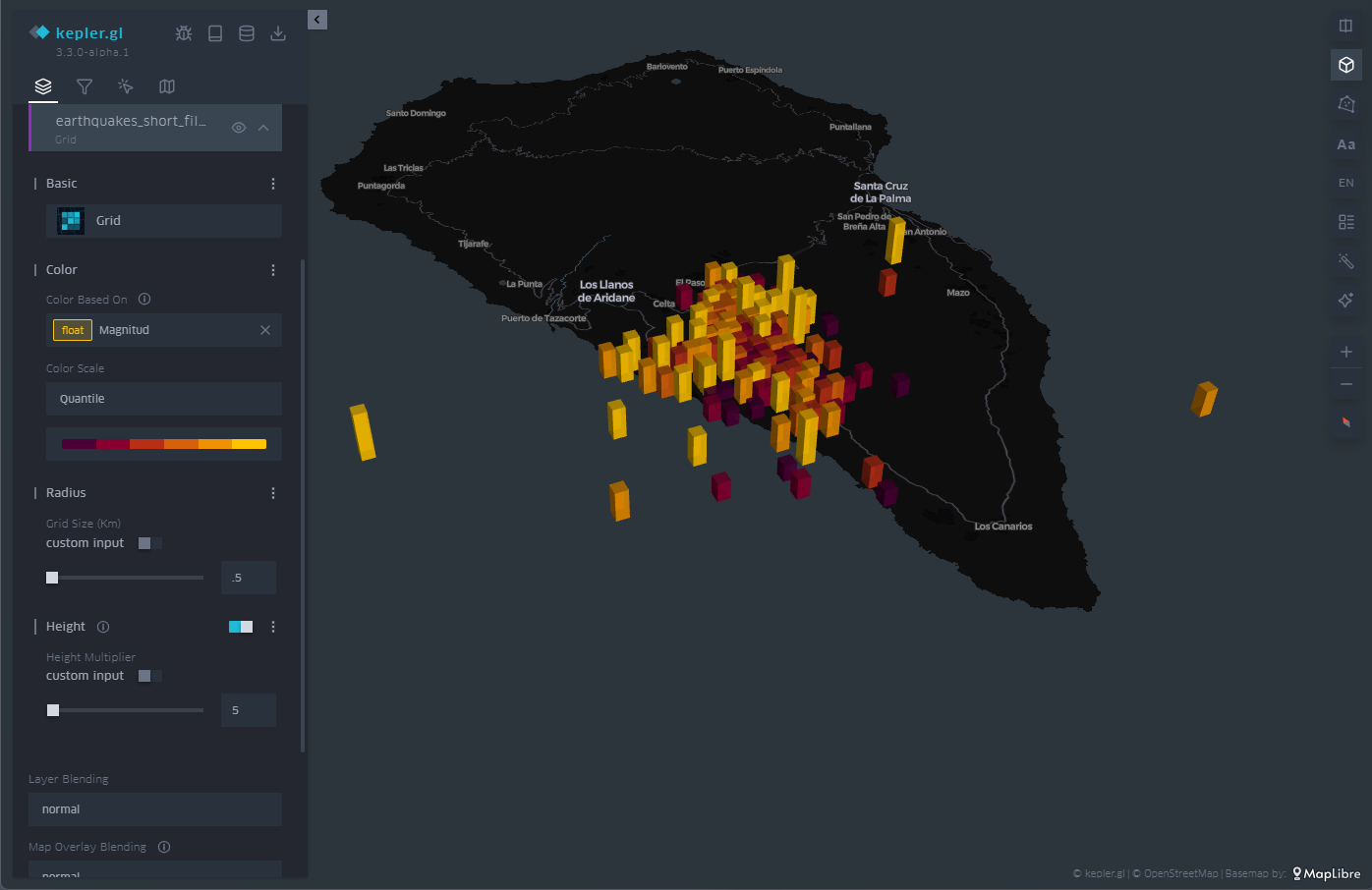
Figura 9: Mapa con los seísmos en la isla de La Palma representados por rectángulos. La altura y el color están asociados a la magnitud del seísmo.
3.6 Filtro Temporal
Como se puede ver en la Figura 10, en el menú superior de la izquierda encontramos una herramienta de gran utilidad como es el filtro de tiempo. Cuando, como en este caso, disponemos de información temporal de los eventos, a través del campo de fecha, podemos utilizar ese eje de información para filtrar la información que queremos representar y focalizar sobre aquellos días u horas de mayor interés para nuestro análisis y proyecto de visualización.
La herramienta de filtro permite elegir la magnitud sobre la cual vamos a realizar la selección filtrada. Una vez elegida, se despliega en la parte inferior un histograma en el cual podemos ver a simple vista la distribución del número de puntos que se corresponden con cada fecha. En la Figura 10 podemos ver el histograma en la parte inferior.
Esta herramienta permite no sólo seleccionar un día sino también un intervalo de tiempo. Deslizando ese intervalo de tiempo a lo largo del histograma nos permite, no sólo ver un determinado periodo de interés, sino también realizar una animación que desplace de forma automática ese intervalo de tiempo a lo largo de toda la serie temporal.
Esta característica hace de este filtro una opción muy atractiva para poder crear en segundos lo que se conoce como storytelling, esto es, una animación fácil y muy intuitiva.
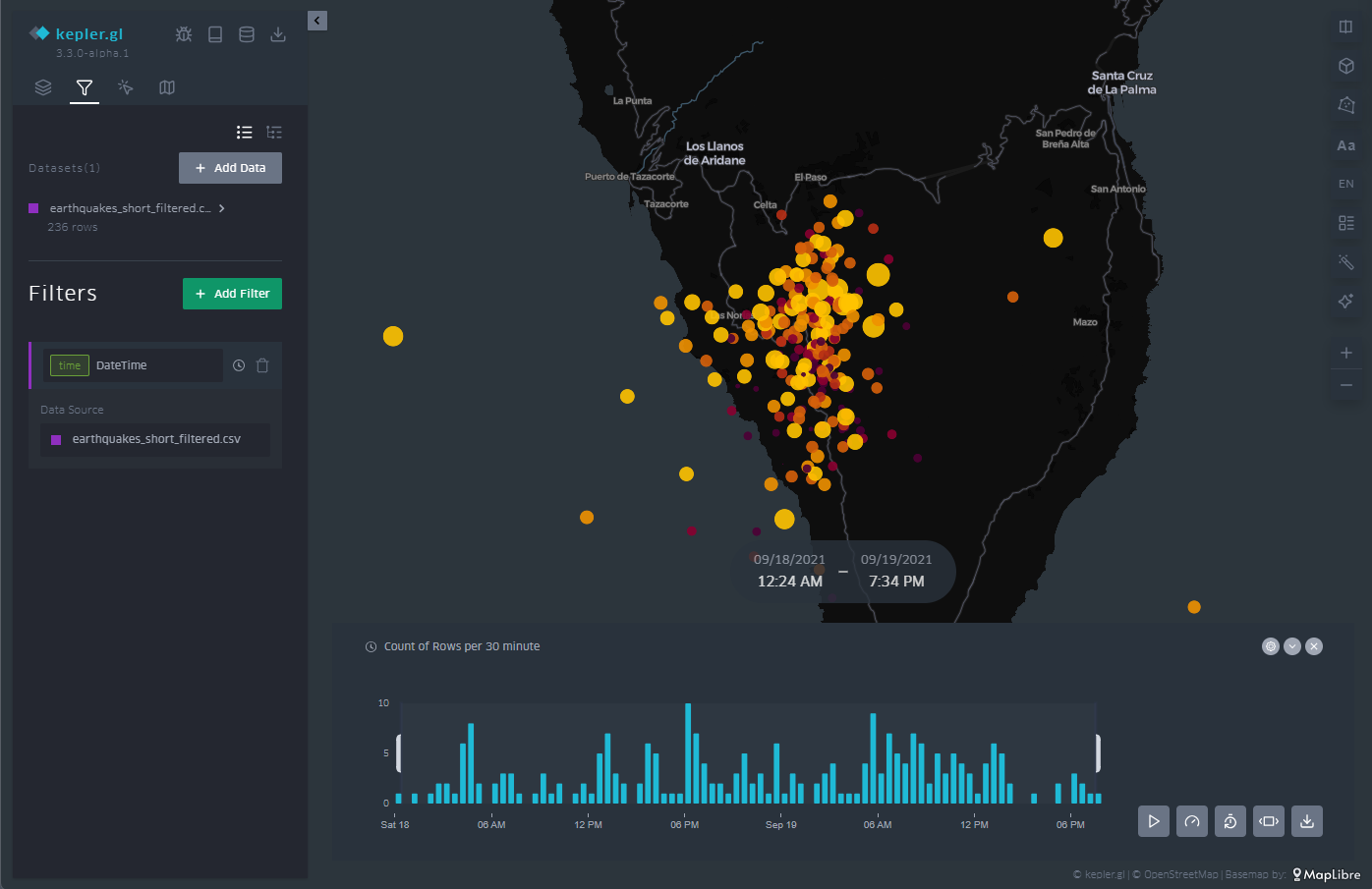
Figura 10: Mapas con los seísmos en la isla de la Palma a través de puntos con un filtro temporal aplicado a toda la secuencia de datos en la parte inferior. El intervalo a media altura en el histograma especifica la longitud temporal.
Como ejemplo de animación podemos ver en la Figura 11 un vídeo donde se muestra la herramienta del filtro y cómo la ventana que definimos va recorriendo el histograma. Esta animación se centra en los días anteriores y posteriores a la erupción del volcán el 19 de septiembre de 2021, así como toda la actividad sísmica que siguió a la erupción del volcán hasta entrado 2022.
El acceso al vídeo se puede realizar tanto a través de la miniatura de Youtube de la Figura 11 como a través de este enlace al canal de vídeos de datos.gob.es:
Accede al vídeo de la actividad sísmica en KeplerGL
Figura 11: Secuencia de la actividad sísmica detectada antes, durante y después de la erupción volcánica en la isla de La Palma alrededor de septiembre de 2021.
3.7 Leyenda
Como se ilustra en la Figura 12, en el menú de la derecha tenemos diferentes opciones, tales como disponer la proyección cartográfica en tres dimensiones o, en la esquina inferior derecha, activar la aparición de una leyenda.
La leyenda aparece asociada a la variable que hemos elegido para representar los puntos, en este caso, la magnitud. Los intervalos vienen predefinidos según los intervalos que hayamos definido cuando creamos los intervalos en la escala de color de los puntos.
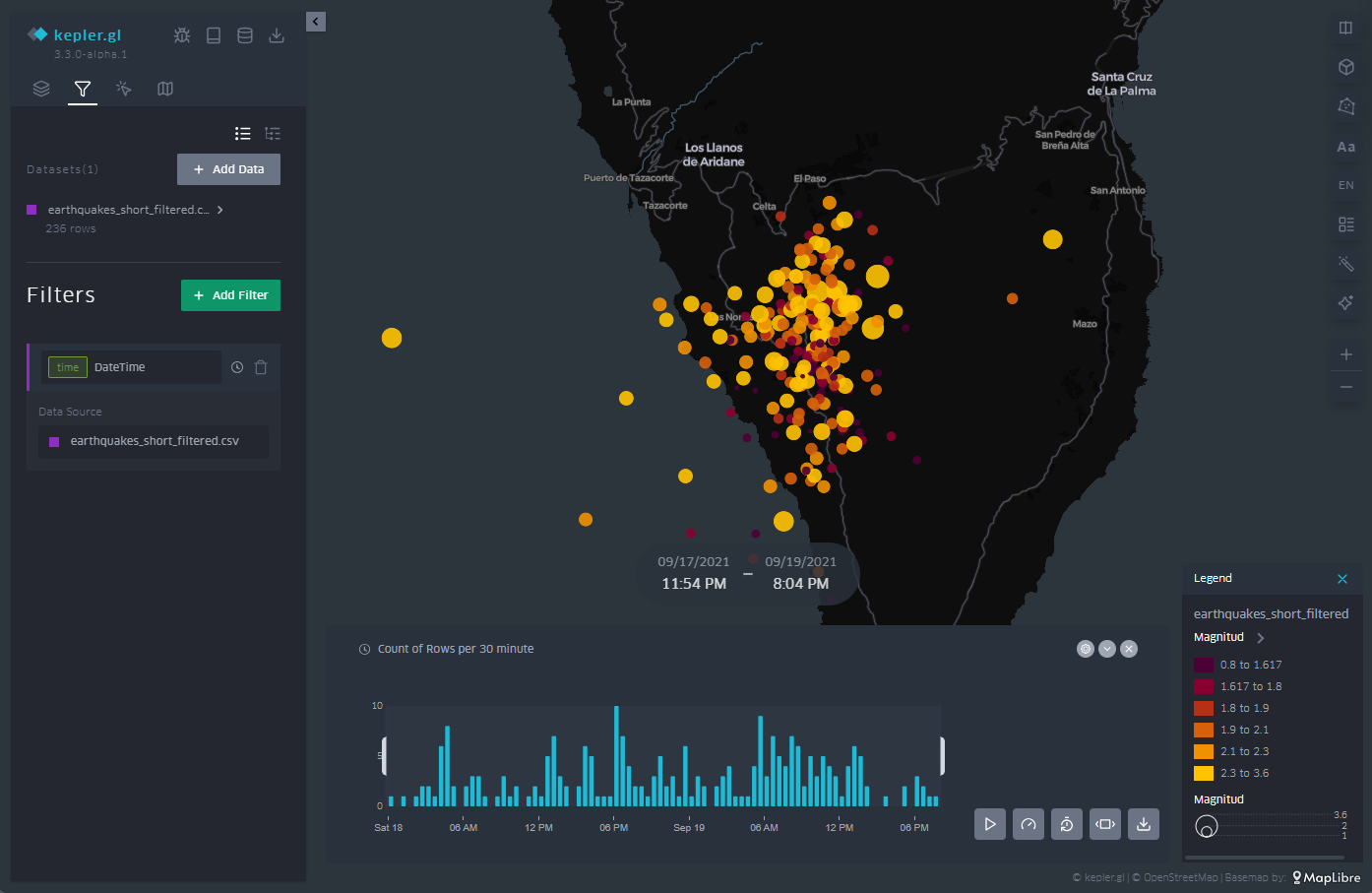
Figura 12: Leyenda del código de colores y valores utilizado para la representación por puntos, en sintonía con nuestras definiciones de intervalos en la configuración de la representación por puntos.
3.8 Cartografía de fondo
Dependiendo del evento que representemos en el mapa, es conveniente utilizar diferentes tipos de cartografías de fondo para una mejor comprensión del mensaje que se intenta transmitir a través de la visualización. Dependiendo de la audiencia y del contexto, la información que ofrece el mapa de fondo puede resultar más o menos útil. Si, como es en este caso, sólo queremos transmitir información geológica, su relevancia es menor. Si, por el contrario, queremos describir también infraestructuras civiles que se puedan ver afectadas por los terremotos, será necesario incorporar una cartografía base.
De esta forma, KeplerGL ofrece también toda una serie de cartografías de fondo, divididas mayormente en dos familias: las de fondo oscuro y las de fondo claro. Aquí conviene recordar que el ojo humano percibe mejor detalles pequeños sobre un fondo oscuro, e interpreta mejor formas grandes sobre fondo claro. En el caso de los terremotos y la escala a la cual los estamos representando, conviene utilizar un fondo oscuro, ya que seremos capaces de discernir con mejor precisión las distancias y los detalles.
Para seleccionar los diferentes mapas de fondo iremos al icono situado en la parte superior del panel de la izquierda, y en el menú desplegable podremos elegir aquel que más nos convenga. En la Figura 13 se muestran los diferentes tipos de mapas.
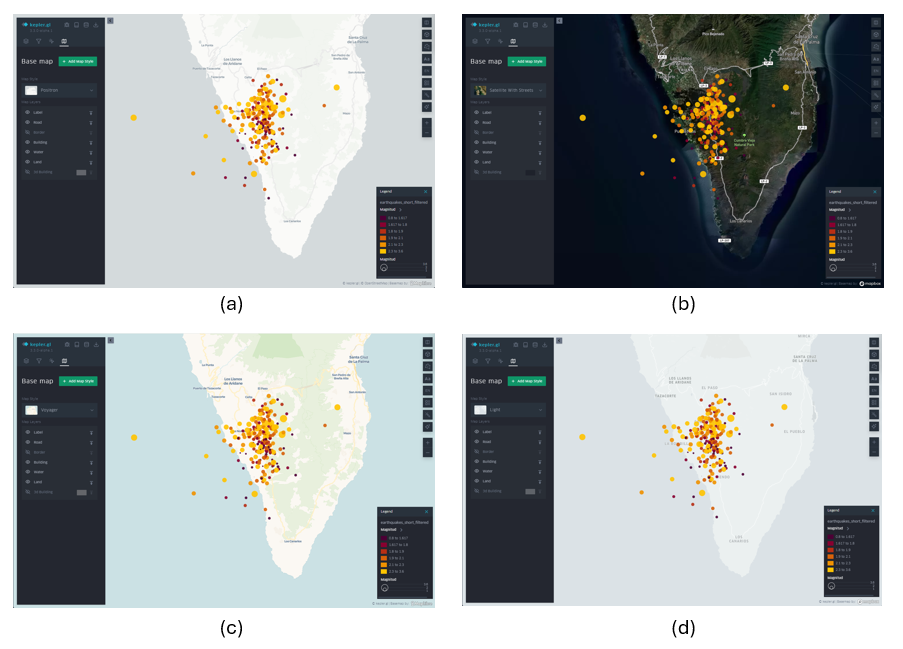
Figura 13: Diferentes cartografías de fondo en KeplerGL para la representación de la actividad sísmica en la isla de La Palma en septiembre de 2021: Positron (a), Satellite (b), Voyager (c) y Light (d).
4. Exporta el mapa
Por último, una vez realizado nuestro mapa, podemos exportar el resultado a través del icono de descarga situado en la parte superior del menú de la izquierda. Una vez seleccionado ese icono podemos guardar el mapa como imagen.
Las opciones que se nos ofrecen son: el tamaño mediante el ratio de la imagen respecto a sus dimensiones horizontales y verticales, la resolución ligada a ese ratio que hayamos seleccionado y la opción de incorporar una leyenda en la imagen de salida, tal y como muestra la Figura 14.
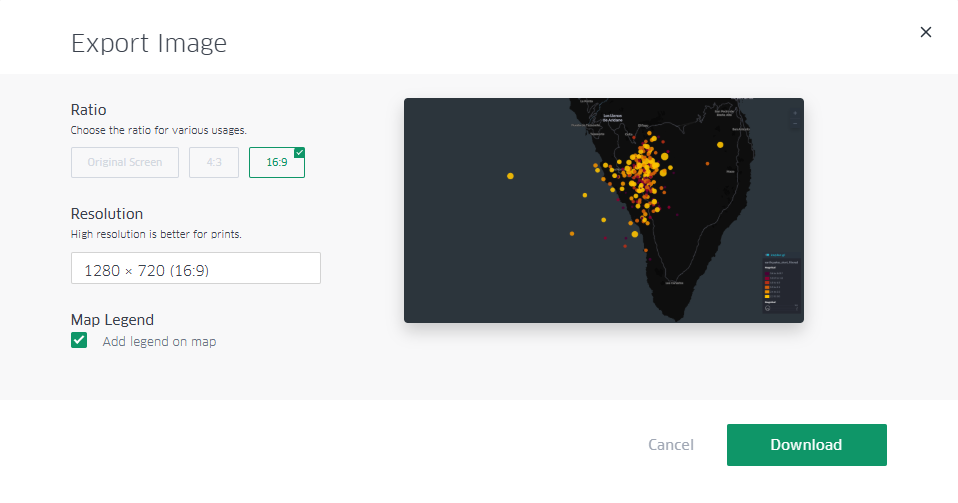
Figura 14: Cuadro de diálogo para exportar el mapa como una imagen. Nótese la selección de la casilla de mostrar la leyenda, así como la selección de un formato panorámico con espacio para incorporar más adelante elementos infográficos en otros contenidos
Adicionalmente existe la posibilidad de compartir el mapa con toda su interactividad a través del registro en Dropbox o en Carto, si la intención es la difusión del mapa a través de otros canales más allá de una imagen estática.
Lecciones aprendidas
En este ejercicio hemos aprendido a crear un mapa de forma sencilla e intuitiva con la ayuda de KeplerGL. En concreto hemos aprendido a:
- Subir un fichero a través del interfaz web de KeplerGL.
- Representar de diferentes maneras información georreferenciada.
- Aprender a utilizar un filtro temporal sobre la serie de datos y crear una animación para su difusión como vídeo.
- Añadir una leyenda y manejar los valores que refleja esa leyenda.
- Customizar cada una de las formas de visualización al detalle.
- Exportar el mapa resultante con un cierto grado de customización.
Conclusiones y próximos pasos
El mundo de la cartografía siempre ha necesitado de conocimientos previos sobre proyecciones, sistemas de referencia, formatos de datos georreferenciados y sobre todo la instalación de software específico para crear mapas. Gracias al desarrollo de productos web uno de estos proyectos nos permite crear mapas de forma muy sencilla y puede suponer una herramienta muy potente a la hora de crear mapas sin necesidad de muchos conocimientos previos y con un alto grado de customización.
A partir de este punto se pueden explorar herramientas más sofisticadas que requieren bien de conocimientos generales, bien de conocimientos de programación para poder realizar mapas con Leaflet o con D3.js, dependiendo de la audiencia y de la aplicación en la cual queremos encuadrar el mapa.
Ámbitos de Aplicación
La creación de mapas sencillos tiene muchos campos de aplicación, ya que la cartografía en general resulta ser una de las formas de visualización más claras y populares gracias a su uso desde el origen de la civilización. Los ámbitos propuestos incluyen:
- Redacciones de periodismo: reaccionar a eventos concretos tales como catástrofes naturales o grandes bases de datos de eventos georreferenciados puede ser más fácil gracias a herramientas como KeplerGL.
- Corporaciones y empresas: localización de volúmenes asociados a puntos concretos de la geografía se puede leer de forma intuitiva con la creación de mapas que pueden resumir grandes cantidades de datos.
- Aplicaciones: Integrar mapas dentro de las aplicaciones suele ayudar tanto en las capas tanto de información como en la de interactividad para explorar el rendimiento y resultado de un producto a diferentes escalas.
Aplicación
Embals.es muestra el estado del agua embalsada en España en tiempo casi real: porcentaje de llenado, capacidad y evolución de más de 380 embalses, agregados por provincia, comunidad autónoma y cuenca hidrográfica, sobre un mapa interactivo.
La aplicación reutiliza datos abiertos oficiales del Boletín Hidrológico Semanal del MITECO (serie histórica desde 1988) y los sistemas SAIH de las confederaciones hidrográficas (Duero, Ebro, Guadalquivir, Júcar, Segura y Cantábrico) para lecturas en tiempo real, el dataset de embalses de las cuencas internas de la Agència Catalana de l'Aigua y la previsión de precipitación de AEMET OpenData.
Incluye un comparador entre embalses, gráficas de evolución histórica frente a la media de los últimos 10 años, fichas individuales por embalse e imágenes resumen para compartir.
El acceso web es gratuito, sin registro.
Blog
¿Puede un algoritmo anticipar una inundación o ayudar a un agricultor a regar mejor sus cultivos? La respuesta es sí, y hay ocho equipos en América Latina que ya están demostrándolo.
El cambio climático no es un problema del futuro. Es una realidad que hoy desplaza familias, destruye cosechas, colapsa infraestructuras y pone en riesgo la biodiversidad. Ante este escenario, la tecnología y, en concreto, la combinación de datos abiertos e inteligencia artificial son una herramienta poderosa para construir soluciones más inteligentes, rápidas y eficaces.
En este post queremos presentar ocho proyectos seleccionados en el marco del Open Data and AI Innovation Challenge (Data2AIChallenge), una iniciativa impulsada por Open Data Charter (ODC) con el apoyo de la Fundación Patrick J. McGovern y los gobiernos de Colombia y Uruguay. Estos ocho equipos han sido elegidos entre todas las propuestas recibidas para recibir seis meses de mentoría especializada con la que llevar sus ideas a la realidad.
¿Qué es el Data2AIChallenge?
El Data2AIChallenge es una convocatoria regional centrada en la acción climática que busca apoyar el desarrollo de proyectos que reutilicen datos públicos abiertos y apliquen inteligencia artificial para dar respuesta a desafíos medioambientales concretos en Colombia y Uruguay.
Sus objetivos son:
- Fomentar la participación ciudadana.
- Promover usos éticos e innovadores de la IA y los datos abiertos.
- Visibilizar soluciones con impacto real.
La convocatoria admitió propuestas de estudiantes, desarrolladores, periodistas, activistas e investigadores. Un jurado multidisciplinar (integrado por especialistas en gobierno abierto, cambio climático y transformación digital de instituciones como el Banco de Desarrollo de América Latina, Agencia de Gobierno Electrónico y Sociedad de la Información y del Conocimiento de Uruguay y el Ministerio TIC de Colombia) evaluó las propuestas según criterios de innovación, relevancia y rigor metodológico.
De todos ellos, se seleccionaron ocho proyectos que demuestran que los datos abiertos pueden ser palanca de cambio en el sector medioambiental.
Los ocho proyectos seleccionados
1. Alerta Yí: alertas tempranas ante inundaciones con ciencia ciudadana
La cuenca del río Yí, en Uruguay, es una zona recurrentemente afectada por inundaciones. El equipo de Alerta Yí propone un sistema participativo de alerta temprana que integra datos abiertos, modelos de inteligencia artificial y ciencia ciudadana. El objetivo es tanto anticipar el riesgo como construir resiliencia comunitaria, es decir, que las propias comunidades sean parte activa del sistema de vigilancia y respuesta.
Este tipo de enfoque híbrido entre tecnología y participación ciudadana es especialmente valioso en contextos donde los recursos institucionales son limitados y el conocimiento local resulta imprescindible.
2. Minga Abierta: cartografía comunitaria para prevenir riesgos en Medellín
Las laderas de Medellín (Colombia) concentran barrios populares con alta exposición a deslizamientos e inundaciones. El Colectivo Pluriverso Narrativo, responsable del proyecto Minga Abierta, combina cartografía comunitaria, ciencia ciudadana y modelos predictivos para anticipar riesgos climáticos.
El nombre del proyecto no es casual: "minga" es una palabra de origen quechua que hace referencia al trabajo colectivo. La propuesta entiende que los datos sin comunidad no bastan, y que la prevención de riesgos es también un acto de organización social.
3. AgroClima Platform: prescripciones de riego inteligente para la agricultura familiar
El estrés hídrico amenaza directamente la seguridad alimentaria de pequeños productores en el Municipio del Magdalena (Colombia). AgroClima Platform utiliza inteligencia artificial y datos satelitales de acceso abierto para generar prescripciones de riego precisas y adaptadas a cada parcela.
Se trata de un ejemplo muy claro del potencial democratizador de los datos abiertos. Porque la información climática que antes solo estaba al alcance de grandes explotaciones agroindustriales puede ahora ponerse al servicio de los agricultores familiares que más necesitan adaptarse al cambio climático.
4. Amenaza Roboto: IA para abrir los expedientes ambientales
¿Cuántos procesos de evaluación de impacto ambiental quedan enterrados en documentos densos e inaccesibles? Amenaza Roboto aplica IA generativa para transformar esos expedientes en datos abiertos auditables, comprensibles y reutilizables por cualquier ciudadano.
Este proyecto defiende una premisa fundamental: la transparencia no es solo publicar datos, sino hacer que esos datos sean comprensibles y accionables. Cuando la ciudadanía puede entender lo que dicen los expedientes ambientales, la rendición de cuentas se vuelve real. Cabe destacar que Amenaza Roboto ya tiene una trayectoria previa: fue equipo ganador en un desafío anterior organizado por la propia ODC en Uruguay en 2022.
5. Luz Urbana: mapas de contaminación lumínica para proteger la biodiversidad
La contaminación lumínica es una de las formas de contaminación menos evidentes, pero con efectos documentados sobre la biodiversidad, los ciclos circadianos de animales y plantas, y también sobre la salud humana. Luz Urbana utiliza big data e inteligencia artificial para cruzar imágenes satelitales con datos urbanos y generar mapas de contaminación lumínica en Uruguay.
El proyecto representa un uso innovador de datos geoespaciales abiertos para abordar un problema ambiental que habitualmente queda fuera de las agendas políticas locales.
6. Observatorio de Reciclables: decisiones climáticas a partir de datos de residuos
¿Cómo comparar el impacto climático de distintas políticas de gestión de residuos? El proyecto del Observatorio de Reciclables, impulsado por CEMPRE Uruguay, responde a estas preguntas aplicando datos abiertos, metodología IPCC e inteligencia artificial para medir el impacto climático de las decisiones de reciclaje a escala territorial.
El valor de esta propuesta está en transformar datos dispersos sobre residuos en indicadores comparables y accionables que puedan orientar políticas públicas basadas en evidencia.
7. Guardianes de la Ladera: alertas climáticas accionables contra deslizamientos
Colombia es uno de los países del mundo con mayor incidencia de deslizamientos de tierra. Guardianes de la Ladera transforma datos geoespaciales abiertos en alertas climáticas locales, utilizando inteligencia artificial para anticipar deslizamientos con evidencia trazable y comunicarlos de forma que puedan orientar decisiones concretas a nivel comunitario.
La propuesta pone el foco en un problema clásico de los sistemas de alerta: la brecha entre los pronósticos generales y las decisiones locales.
8. BIO-IA: periodismo de datos para defender el Amazonas
El piedemonte amazónico en Caquetá (Colombia) alberga una riqueza de especies endémicas amenazada por la deforestación y la pérdida de hábitat. BIO-AI combina inteligencia artificial y periodismo de datos para construir experiencias audiovisuales orientadas a la conservación. La propuesta entiende que para que los datos científicos lleguen a la ciudadanía hay que convertirlos en relatos que la gente pueda comprender y que movilicen voluntades.
En un contexto donde la Amazonía sigue siendo objeto de disputas políticas y presiones económicas, proyectos como este demuestran que el conocimiento, cuando se comunica bien, puede ser una herramienta de defensa territorial.
¿Qué nos enseñan estos proyectos?
Más allá de sus particularidades, los ocho proyectos seleccionados comparten una serie de rasgos que merece la pena destacar:
- Los datos abiertos son infraestructura para la acción climática. Sin acceso libre a datos satelitales, climáticos, geoespaciales o de residuos, ninguno de estos proyectos sería posible. La apertura de datos públicos permite que la innovación ciudadana florezca.
- La IA es una herramienta, no una solución mágica. Todos estos equipos utilizan la inteligencia artificial al servicio de un problema concreto, con datos reales y objetivos claros. Pero la IA no es la idea en sí, sino una herramienta para obtener mejores resultados.
- La participación ciudadana amplifica el impacto. Varios de estos proyectos integran ciencia ciudadana y cartografía comunitaria. Esto no solo mejora la calidad de los datos; también genera apropiación local de las soluciones.
- Los datos abiertos reducen brechas. Agricultores familiares, comunidades de ladera, habitantes de zonas inundables: los proyectos seleccionados ponen las herramientas más sofisticadas al servicio de quienes más las necesitan.
Conclusión: cuando los datos abiertos se convierten en acción
Los ocho proyectos del Data2AIChallenge son una demostración práctica de que la apertura de datos públicos, combinada con inteligencia artificial y compromiso ciudadano, puede generar soluciones concretas a problemas climáticos reales. Desde las laderas de Medellín hasta el piedemonte amazónico, desde los campos del Magdalena hasta las noches iluminadas de Uruguay, estas iniciativas muestran que el cambio no siempre viene de grandes instituciones o presupuestos millonarios: a veces nace de equipos pequeños, con buenas preguntas, acceso a datos abiertos y voluntad de transformar su entorno.
El reto ahora es seguir ampliando la disponibilidad, calidad y usabilidad de los datos climáticos públicos, y acompañar a quienes quieren utilizarlos para construir un mundo más resiliente. Porque los datos abiertos son el punto de partida de todo lo que está por venir.
Documentación
Introducción
En los últimos años hemos visto cómo la inteligencia artificial generativa ha dejado de ser una curiosidad técnica para convertirse en una herramienta cotidiana en el flujo de trabajo de los profesionales del dato. Sin embargo, sigue existiendo una pregunta importante: ¿cómo se traduce esta tecnología en un proceso real de análisis de datos abiertos?, ¿Qué cambia en la práctica cuando un analista trabaja "junto a" un modelo de lenguaje en lugar de hacerlo en solitario?
Este post documenta un ejercicio práctico realizado con datos publicados en el portal datos.gob.es: el análisis de precios de las más de 11.000 estaciones de servicio en España. A diferencia de otros ejercicios publicados en este espacio, el análisis no se ha realizado de forma manual línea por línea, sino que se ha llevado a cabo en un entorno agéntico: una interfaz conversacional apoyada en un modelo grande de lenguaje (LLM) y un sistema de codificación asistido por inteligencia artificial. En la práctica, esto significa que en lugar de escribir el código de análisis nosotros mismos, le describimos al sistema en lenguaje natural qué queremos obtener, y este lo implementa.
El objetivo de este post es doble. Por un lado, explicar el análisis propiamente dicho: qué preguntas nos hacemos sobre los datos, qué problemas técnicos encontramos y qué conclusiones extraemos. Por otro, reflexionar sobre el método: cómo se estructura un proceso de análisis cuando trabajamos con un copiloto de IA, qué patrones de interacción funcionan mejor y dónde están los límites de la asistencia automatizada.
Nota metodológica: para la realización de este ejercicio hemos empleado una metodología Spec Driven Development (SDD), que guía a la IA a través de un proceso estructurado con el objetivo de evitar que la conversación pierda el foco del ejercicio. La explicación detallada de esta metodología queda fuera del alcance del presente post, pero el lector encontrará en el repositorio especificaciones, planes técnicos y checklists que la documentan.
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
En este vídeo, el autor te explica que vas a encontrar tanto en el GitHub como en Google Colab.
El proceso: un flujo clásico, asistido por IA
Antes de entrar en cada fase, conviene describir el esquema general del trabajo. El análisis sigue cinco etapas habituales en ciencia de datos —ingesta, limpieza, exploración, ingeniería de variables y análisis de impacto— pero introduciendo en cada una de ellas un patrón conversacional con la IA.
Ese patrón puede resumirse en cinco pasos:
- Describir el problema en lenguaje natural.
- Proponer una primera solución (lo hace la IA).
- Cuestionar los supuestos de esa propuesta (lo hace el analista humano).
- Refinar la solución hasta que sea robusta.
- Documentar el patrón para reutilizarlo en futuros proyectos.
A continuación, veremos, fase por fase, cómo se materializa este patrón en el análisis del precio de los combustibles. Cada apartado comienza explicando el reto conceptual, continúa describiendo cómo abordamos la resolución con la asistencia de la IA, y termina mostrando el código resultante y las lecciones aprendidas.
Fase 1: ingesta robusta de datos desde una API pública
El reto: API públicas que no siempre responden como se espera
Aviso para el lector: esta fase entra en cierto detalle técnico sobre integración de API, errores SSL y estrategias de respaldo. Si tu perfil es más analítico que de desarrollo, puedes hojear el bloque de código y centrarte en los apartados El enfoque y Reflexión, donde la idea de fondo —cómo diseñar una ingesta tolerante a fallos— se explica sin entrar en detalles de implementación.
La descarga de datos desde la API del Ministerio para la Transición Ecológica es conceptualmente sencilla: una petición HTTP GET a un endpoint conocido debería devolver un fichero JSON con aproximadamente 11.000 estaciones de servicio. En la práctica, sin embargo, las API públicas presentan dificultades habituales que cualquier analista termina encontrando antes o después:
- Certificados SSL caducados o mal configurados, que provocan errores del tipo SSLError.
- Bloqueo de IP procedentes de servidores en la nube (Google Colab, AWS, etc.), interpretadas como tráfico sospechoso.
- Servidores inestables, con tiempos de respuesta variables y timeouts esporádicos.
- Inconsistencias en la documentación, por ejemplo, cuando se describe una respuesta JSON pero el servidor devuelve XML.
La pregunta clave es: ¿cómo diseñamos un sistema de ingesta que tolere estos problemas en lugar de fallar al primer obstáculo?
El enfoque: una arquitectura de respaldos escalonados
En ingeniería de software, los sistemas críticos no dependen de un único componente. Cuando un canal falla, existe otro de respaldo (lo que en inglés se denomina fallback). Aplicar esta lógica a la ingesta de datos es especialmente útil cuando trabajamos con fuentes públicas sobre las que no tenemos control.
Para este ejercicio, diseñamos una estrategia de triple respaldo:
- Primer intento — requests con configuración permisiva: realizamos la petición HTTP con la librería estándar de Python, pero configurando un User-Agent que simula un navegador real y desactivando la verificación de SSL. Esto resuelve buena parte de los problemas de certificados.
- Segundo intento — curl desde la shell: si requests falla, invocamos curl como subproceso. La razón es que curl utiliza una pila TLS distinta a la de Python y no envía los mismos certificados, lo que permite sortear ciertos tipos de bloqueo.
- Tercer intento — datos de demostración: si todo lo anterior falla, generamos un conjunto sintético de 11.000 estaciones de servicio con distribuciones realistas. Esto garantiza que el notebook siempre sea ejecutable en un contexto educativo, aunque la API esté caída.
El razonamiento de fondo es sencillo: cada método sortea un tipo distinto de fallo de red, y su combinación proporciona robustez. A continuación, mostramos el código que implementa esta arquitectura.
El código resultante
El siguiente fragmento ilustra cómo se materializan los tres niveles de respaldo en una única función. Las cláusulas try/except permiten detectar el fallo de cada método y pasar automáticamente al siguiente:
def descargar_datos_api(url):
"""
Descarga datos con triple respaldo:
1. requests con verify=False (sortea problemas de SSL)
2. curl -k (pila TLS alternativa)
3. datos sintéticos (garantía de ejecución)
"""
# Intento 1: requests con cabeceras de navegador
try:
sesion = requests.Session()
sesion.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
})
response = sesion.get(url, timeout=45, verify=False)
return response.json()
except Exception as e_requests:
print(f"[Respaldo 1] requests ha fallado: {e_requests}")
# Intento 2: curl como subproceso
try:
resultado = subprocess.run(
["curl", "-s", "-k", url],
capture_output=True, timeout=45, text=True
)
return json.loads(resultado.stdout)
except Exception as e_curl:
print(f"[Respaldo 2] curl ha fallado: {e_curl}")
# Intento 3: datos sintéticos de demostración
print("[Respaldo 3] Utilizando datos de demostración")
return generar_datos_demo_gasolineras(11000)
Reflexión: dónde aporta valor la IA en esta fase
La iteración con la IA no produjo el código anterior de un solo intento. El proceso real fue más interesante: planteamos el problema ("la API a veces rechaza las peticiones, necesito respaldos"), la IA propuso una solución inicial, y el avance vino de cuestionar esa propuesta. La pregunta "¿por qué curl debería funcionar si requests ya ha fallado?" obligó al modelo a explicar las diferencias entre ambas pilas TLS, lo que a su vez nos permitió validar que la solución tenía fundamento técnico real, no era simplemente "probar lo mismo dos veces".
Una estimación razonable: resolver este problema mediante prueba y error puro habría llevado entre dos y tres horas de depuración. Con la iteración asistida, lo abordamos en aproximadamente treinta minutos.
Fase 2: limpieza con conocimiento de dominio
El reto: los datos reales nunca son perfectos
Una vez descargados los datos, comienza el trabajo menos visible pero más decisivo de cualquier análisis: la limpieza y preparación. La calidad del resultado final depende en gran medida del cuidado puesto en esta etapa. En el caso de los combustibles, las inconsistencias más habituales son:
- Variantes textuales no normalizadas: la marca "MOEVE" puede aparecer como "MOEVE", "Moeve" o "moeve" en distintos registros. Para una persona son obviamente la misma marca, pero en una agregación por groupby aparecen como tres categorías independientes.
- Coordenadas geográficas incorrectas: puntos situados fuera del territorio español (islas remotas, fragmentos de Marruecos, errores de captura).
- Separadores decimales inconsistentes: precios codificados como "1,349" con coma, que requieren conversión explícita antes de poder operar con ellos.
- Conversiones que introducen valores nulos: pd.to_numeric(..., errors='coerce') es muy útil, pero genera NaN silenciosos que pueden romper análisis posteriores.
La cuestión central de esta fase es: ¿cómo traducimos el conocimiento humano sobre el dominio en reglas de código?
El enfoque: validación organizada en capas
En lugar de limpiar "según va apareciendo", conviene organizar las reglas de validación en capas, cada una con una responsabilidad clara:
|
Capa |
Responsabilidad |
Ejemplo |
|---|---|---|
| Tipos | Conversión y coerción a tipos adecuados | Precio como float, fecha como datetime |
| Rangos | Valores dentro de límites razonables | Precio entre 0,5€ y 3,0€ por litro |
| Semántica | Coherencia con el dominio | Coordenadas dentro de España, marcas normalizadas |
Figura 1. Tabla de validación organizada en capas. Fuente: elaboración propia - datos.gob.es
La pregunta que cada capa debe responder es siempre la misma: ¿tiene sentido este valor en el contexto de las estaciones de servicio españolas? La novedad respecto a un flujo manual es que aquí describimos las reglas a la IA en lenguaje natural y dejamos que ella las traduzca a código pandas. Nosotros conservamos la responsabilidad de definir qué es válido y qué no.
El código resultante
El siguiente bloque implementa las tres capas de validación de forma secuencial. Conviene destacar que la lista de aliases de marcas (CEPSA → MOEVE) refleja conocimiento de negocio específico —el rebranding de CEPSA a MOEVE en 2023— que la IA no podría inferir por sí sola; es información que aporta el analista. Este es un ejemplo muy claro de aportación del conocimiento humano difícilmente alcanzable por la IA:
def validar_y_limpiar_carburantes(df):
# Capa 1: normalización de tipos
df['precio'] = (
df['precio'].astype(str)
.str.replace(',', '.')
.astype(float)
)
df['marca'] = df['marca'].str.upper().str.strip()
# Capa 2: validación de rangos
df = df[(df['precio'] >= 0.5) & (df['precio'] <= 3.0)]
df = df[
(df['latitud'] >= 27.5) & (df['latitud'] <= 43.8) &
(df['longitud'] >= -18.2) & (df['longitud'] <= 4.4)
]
# Capa 3: coherencia semántica (conocimiento de negocio)
aliases = {'CEPSA': 'MOEVE'} # Rebranding 2023
df['marca'] = df['marca'].map(lambda x: aliases.get(x, x))
# Auditoría de nulos
nulos = df[['precio', 'latitud', 'longitud', 'marca']].isnull().sum()
if nulos.sum() > 0:
print(f"Atención: se han detectado valores nulos:\n{nulos}")
return df.dropna(subset=['precio', 'latitud', 'longitud'])Reflexión: el reparto del trabajo entre la IA y el analista
Esta fase es especialmente reveladora del tipo de colaboración que la IA habilita. Las reglas más técnicas (conversión de tipos, detección de nulos, normalización de mayúsculas) son prácticamente automáticas: basta con describir el problema y el modelo propone una implementación correcta. En cambio, las reglas que dependen del dominio (que las islas Canarias tienen un sobrecoste logístico del 5%, que CEPSA y MOEVE son la misma marca tras la fusión, que un precio inferior a 0,5€ es probablemente un error de carga) deben ser especificadas por el analista humano.
La lección aprendida es importante: la calidad de la limpieza depende directamente del conocimiento de dominio que aporta el analista. La IA acelera la implementación, pero no inventa contexto. Por eso el patrón reutilizable es el mismo en cualquier proyecto: describe tu dominio con detalle, deja que la IA escriba las validaciones, y verifica tú mismo que los resultados son coherentes.
Fase 3: análisis exploratorio visual (EDA)
El reto: convertir números en intuiciones
Con 11.000 registros limpios ya en memoria, el siguiente paso es responder a las preguntas de negocio que motivaron el análisis. En este caso, formulamos cuatro preguntas concretas:
- ¿Qué provincias tienen los combustibles más caros?
- ¿Existe relación entre la ubicación geográfica (latitud y longitud) y el precio?
- ¿Hay diferencias significativas entre marcas?
- ¿Cómo se distribuyen los precios (media, mediana, valores atípicos)?
El reto técnico no es complejo —pandas y matplotlib resuelven cualquiera de estas preguntas— pero sí lo es el reto metodológico: elegir la visualización adecuada para cada pregunta. Una gráfica mal elegida puede ocultar tanto como una agregación incorrecta.
El enfoque: cada pregunta determina su gráfico
En análisis exploratorio existe una correspondencia natural entre el tipo de pregunta y la visualización más apropiada. Conviene tenerla presente antes de escribir una sola línea de código:
|
Pregunta |
Visualización adecuada |
Razón |
|---|---|---|
| ¿Ranking? | Gráfico de barras ordenado | Permite comparar valores ordenados |
| ¿Relación espacial? | Scatter con escala de color | Muestra correlación en dos dimensiones |
| ¿Distribución y atípicos? | Diagrama de caja (box plot) | Revela mediana, cuartiles y outliers |
| ¿Diferencias entre grupos? | Box plot o violin plot | Compara distribuciones simultáneamente |
Figura 2. Tabla de correspondencia natural entre el tipo de pregunta y la visualización más adecuada. Fuente: elaboración propia - datos.gob.es
El objetivo no es producir gráficos vistosos, sino gráficos que respondan a preguntas concretas. Esta es una idea aparentemente obvia, pero conviene recordarla: en la práctica, es frecuente que se generen visualizaciones por inercia, sin tener claro qué se quiere mostrar.
El código resultante
A continuación, mostramos uno de los gráficos como ejemplo, el ranking de precios por provincia. La estructura es siempre la misma: declaración del gráfico, configuración estética, y un breve comentario interpretando el resultado:
# Pregunta 1: ¿qué provincias son las más caras?
top_provincias = (
df.groupby('provincia')['precio']
.mean()
.sort_values(ascending=False)
.head(12)
)
fig, ax = plt.subplots(figsize=(12, 6))
top_provincias.plot(kind='bar', ax=ax, color='steelblue')
ax.set_title('Precio medio del combustible por provincia (Top 12)',
fontsize=14, fontweight='bold')
ax.set_ylabel('Precio (€/litro)')
ax.set_xlabel('Provincia')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# Hallazgo: las tres provincias más caras son insulares o costeras
# (Baleares, Canarias, Tarragona). Hipótesis: el coste logístico
# y la lejanía a los hubs de distribución elevan el precio.En el caso del scatter geográfico, aplicamos una segmentación adicional —península, Baleares y Canarias— para visualizar simultáneamente la ubicación y la insularidad. Esta segmentación reveló un patrón que ninguna agregación numérica había mostrado claramente: las estaciones insulares tienen precios sistemáticamente superiores, hallazgo probablemente atribuible a costes de transporte marítimo. El insight no emergió de un cálculo, sino de la visualización.
Reflexión: el punto ciego de la IA
Esta fase pone de manifiesto una limitación importante del modelo: la IA no ve el resultado gráfico. Puede sugerir el tipo de visualización adecuado, escribir el código correctamente y proponer una paleta de colores, pero no puede juzgar si la escala del eje es apropiada, si la densidad de puntos satura el gráfico o si los rótulos se solapan. Todas estas validaciones siguen siendo responsabilidad humana.
En la práctica, esto significa que la fase de EDA es la que requiere más iteración entre persona y máquina: la IA escribe, el analista observa, identifica un problema visual ("este eje no muestra bien la variación"), y describe la corrección ("ajusta el eje Y a [precio_min0.95, precio_max1.05]"). El patrón reutilizable es claro: una pregunta clara, un tipo de gráfico adecuado y una validación visual humana.
Fase 4: ingeniería de variables (feature engineering)
El reto: capturar variación con nuevas variables
El análisis exploratorio identifica patrones, pero rara vez los explica. Para entender qué factores influyen en el precio es necesario construir nuevas variables —features— que capturen hipótesis específicas sobre la dinámica del mercado. En este ejercicio formulamos tres hipótesis:
- Temporal: ¿Influye el día de la semana en el precio? ¿Es más caro repostar en fin de semana?
- Geográfica: ¿Influye la distancia a un hub económico (en este caso, Madrid)?
- Regional: ¿Existen diferencias estructurales entre el norte, el centro y el sur de España?
La ingeniería de variables consiste precisamente en traducir esas hipótesis en columnas calculadas que el resto del análisis pueda utilizar.
El enfoque: cada variable, una historia testable
Una buena variable debe contar una historia clara. No basta con calcular un número: hay que poder explicar qué pregunta intenta responder. En nuestro caso:
- es_fin_semana (0/1): ¿cambia el precio el sábado y el domingo?
- distancia_a_madrid (km): ¿se encarece el combustible al alejarse del hub logístico?
- region (norte/centro/sur): ¿hay brechas estructurales entre regiones?
Cada una de estas tres variables es, en realidad, una pregunta empírica disfrazada de columna. Si la variable no explica nada cuando la cruzamos con el precio, simplemente la descartamos.
El código resultante
Implementamos las tres variables en una única función. La más interesante técnicamente es la distancia a Madrid, que requiere la fórmula de Haversine para calcular distancias sobre la superficie terrestre teniendo en cuenta la curvatura del planeta:
from math import radians, cos, sin, asin, sqrt
def crear_features_carburantes(df):
# Variable temporal
df['es_fin_semana'] = (
df['fecha'].dt.dayofweek.isin([5, 6]).astype(int)
)
# Variable geográfica: distancia haversine a Madrid
madrid_lat, madrid_lon = 40.4168, -3.7038
def haversine(lat, lon):
lat, lon = radians(lat), radians(lon)
m_lat, m_lon = radians(madrid_lat), radians(madrid_lon)
dlat = lat - m_lat
dlon = lon - m_lon
a = sin(dlat/2)**2 + cos(m_lat) * cos(lat) * sin(dlon/2)**2
return 6371 * 2 * asin(sqrt(a)) # radio de la Tierra en km
df['distancia_a_madrid'] = df.apply(
lambda r: haversine(r['latitud'], r['longitud']), axis=1
)
# Variable regional
def region(lat):
if lat >= 42: return 'Norte'
if lat >= 39: return 'Centro'
return 'Sur'
df['region'] = df['latitud'].apply(region)
return dfReflexión: proponer variables con argumento, no solo con código
En esta fase la IA aporta un valor especialmente alto, pero no en lo que se podría pensar a primera vista. Lo verdaderamente útil no es que escriba la fórmula de Haversine —cualquier referencia técnica la contiene—, sino que proponga variables candidatas con argumentación detrás. Cuando le preguntamos "¿qué features podrían capturar la variación de precios?", la propuesta vino acompañada de razonamiento: Madrid se sugirió como hub porque es el mercado más eficiente y estable, y por tanto las desviaciones respecto a su precio funcionan como aproximación a la fricción logística.
Ese razonamiento es lo valioso: no la fórmula, sino la justificación. Trial-and-error puro habría llevado tres o cuatro horas explorando variables hasta encontrar las útiles; con la iteración asistida, llegamos a un conjunto razonado en aproximadamente cuarenta y cinco minutos.
Fase 5: análisis de impacto de las variables
El reto: cuantificar la contribución real
Construir variables es una cosa; demostrar que realmente explican algo es otra. En esta última fase del análisis evaluamos el impacto efectivo de cada una de las tres variables creadas, combinando dos enfoques: una medida numérica (correlación o diferencia de medias) y una representación visual que permita interpretar el resultado de un vistazo.
El enfoque: dos enfoques complementarios
Para cada variable, calculamos:
- Una medida numérica que cuantifica el efecto (correlación de Pearson para variables continuas; diferencia de medias para categóricas).
- Una representación visual que permite interpretar la magnitud del efecto y detectar relaciones no lineales.
El cruce de ambos enfoques es lo que da fiabilidad al resultado. Una correlación alta sin una visualización que la respalde puede ser engañosa (por ejemplo, si está dominada por outliers); una visualización sugestiva sin métrica puede llevar a sobreinterpretación.
El código resultante
Como ejemplo, mostramos el análisis de impacto de la distancia a Madrid. Primero calculamos la correlación, después segmentamos en cuartiles para hacer la relación visualmente interpretable:
# Medida numérica
correlacion = df['distancia_a_madrid'].corr(df['precio'])
print(f"Correlación (distancia a Madrid → precio): {correlacion:.3f}")
# Representación visual por cuartiles de distancia
df['cuartil_distancia'] = pd.qcut(
df['distancia_a_madrid'], q=4,
labels=['Q1 (cercano)', 'Q2', 'Q3', 'Q4 (lejano)']
)
precio_por_cuartil = df.groupby('cuartil_distancia')['precio'].mean()
fig, ax = plt.subplots(figsize=(10, 5))
precio_por_cuartil.plot(kind='bar', ax=ax, color='#2ecc71')
ax.set_title('Impacto geográfico: precio medio por cuartiles de distancia a Madrid')
ax.set_ylabel('Precio medio (€/litro)')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()El patrón emergente del análisis completo —comparando las tres variables— es que la distancia a Madrid es la más explicativa, seguida por la región, y por último por el efecto fin de semana, que en nuestro periodo de estudio resulta ser marginal. En conjunto, las tres variables explican aproximadamente el 60-70% de la variación de precios; el resto depende de factores como la marca específica, el tipo de estación (autopista, urbana, rural) y eventos puntuales del mercado.
Reflexión: no todas las variables impactan por igual
Una de las virtudes de este análisis estructurado es que revela cuáles de nuestras hipótesis iniciales se sostienen y cuáles no. En este caso, la hipótesis temporal (fin de semana) resultó ser mucho más débil de lo esperado, mientras que la hipótesis geográfica se confirmó con claridad. Sin este paso de cuantificación, habríamos podido seguir asumiendo que todas las variables aportan información valiosa.
Síntesis: las lecciones técnicas que nos llevamos
A lo largo de las cinco fases anteriores hemos ido acumulando soluciones a problemas concretos. La siguiente tabla resume las más reutilizables; cada una está documentada con mayor detalle en el directorio prompts del repositorio:
|
Fase |
Problema |
Solución |
Reutilizable en |
|---|---|---|---|
| Ingesta | Bloqueos SSL o de IP en APIs | Triple respaldo: request -> curl -> demo | Cualquier API pública |
| Ingesta | Documentación inconsistente | Validación de estructura + manejo de errores | APIs gubernamentales |
| Limpieza | Variantes textuales en marcas | .st.upper().str.trip() antes de agrupar | Cualquier agregación categórica |
| Limpieza | Coordenadas fuera de España | Bounding box [27.5-43.8, -18.2- 4.4] | Análisis geográficos en España |
| Limpieza | Rangos comprimidos en gráficos | ax.set_xlim(min*0.95, max*1.05) | Visualización con rangos estrechos |
| EDA | Elección de tipo de gráfico | Mapeo explícito pregunta -> gráfico | Cualquier EDA |
| Features | Variables sin justificación | Cada feature responde una hipótesis testable | Feature engineering en general |
| Análisis | Impacto no cuantificado | Métrica + visualización en paralelo | Cualquier análisis de impacto |
Figura 3. Tabla resumen de soluciones a problemas concretos. Fuente: elaboración propia - datos.gob.es
Reflexión final: qué hace que la IA sea un buen copiloto
Al cabo del ejercicio, podemos extraer algunas conclusiones generales sobre el uso de IA generativa como apoyo al análisis de datos. Las dividimos en dos planos: dónde aporta valor, y dónde no debe sustituir al criterio humano.
Donde la IA aporta valor de forma clara:
- Iteración rápida. El ciclo "describir problema – obtener solución – validar" se reduce de horas a minutos. Esto cambia cualitativamente la dinámica de trabajo: nos permite probar ideas que de otro modo descartaríamos por coste.
- Pensamiento lateral. La IA propone alternativas que un analista podría pasar por alto, como la idea de usar curl cuando requests falla. No siempre acierta, pero sí amplía el espacio de soluciones consideradas.
- Documentación articulada. La IA es especialmente buena explicando el porqué de una decisión técnica, no solo el qué. Esto facilita que el código resultante sea legible para personas no técnicas.
Donde el criterio humano sigue siendo imprescindible:
- Conocimiento de dominio. La IA no sabe que CEPSA y MOEVE son la misma marca, ni que Canarias tiene un sobrecoste logístico estructural. Esa información debe aportarla el analista.
- Validación estadística. La IA puede sugerir modelos, pero la validez estadística del análisis es responsabilidad humana.
- Lectura de gráficos. La IA no ve sus propias visualizaciones. El juicio sobre si una gráfica es legible, comunica lo que se pretende y respeta buenas prácticas visuales sigue siendo humano.
- Decisiones de negocio. Qué preguntar a los datos, qué considerar relevante, cómo comunicar los resultados a la organización: son decisiones que la IA puede apoyar, pero no sustituir.
En síntesis, la idea que resume mejor nuestra experiencia es la siguiente: la IA generativa funciona mejor cuando piensa con nosotros que cuando piensa por nosotros. El ejercicio que aquí presentamos no fue "pedir a Claude que hiciera el análisis", sino mantener una conversación estructurada en la que la IA proponía, el analista cuestionaba, la IA refinaba y el analista validaba. El resultado de esa conversación es un análisis más robusto, mejor documentado y más reutilizable que el que habríamos producido en solitario.
Cómo aprovechar este repositorio
El código completo, los prompts y la documentación están disponibles en el repositorio público del proyecto. Distintos perfiles pueden aprovecharlo de formas distintas:
- Si estudias análisis de datos: abre directamente el notebook en Google Colab y recorre cada celda en orden. Para cada visualización, consulta el prompt correspondiente en prompts/visualizacion/.
- Si trabajas como científico de datos: revisa specs/001-carburantes-ia/plan.md, donde están documentadas las decisiones arquitectónicas y las lecciones aprendidas. Los snippets de prompts/ son reutilizables tal cual en otros proyectos.
- Si te interesa la metodología de prompt engineering: el patrón "describe – cuestiona – refina – valida" está documentado caso por caso a lo largo de los prompts. Es replicable en cualquier dominio: finanzas, salud, marketing o cualquier análisis de datos abiertos.
Conclusión
El ejercicio que hemos presentado muestra que la IA generativa, utilizada con criterio, puede acelerar de manera notable el análisis de datos abiertos sin sacrificar rigor metodológico. Las cinco fases recorridas —ingesta, limpieza, exploración, ingeniería de variables y análisis de impacto— siguen siendo las mismas que en un flujo tradicional, pero la dinámica de trabajo cambia: pasamos de escribir código a describir intenciones y validar resultados.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Documentación
Uno de los mayores desafíos del ecosistema de datos abiertos es su difusión y el reconocimiento de su valor por parte de la sociedad. Conocer su existencia y comprender para qué sirven amplifica su impacto. En un entorno en el que los algoritmos están cada vez más presentes en la vida cotidiana, la alfabetización en datos se ha convertido en una habilidad cívica necesaria. Los derechos civiles se expresan cada vez más en clave digital y, en este contexto, los derechos digitales emergen como marco de referencia esencial para garantizar que la transformación tecnológica no deja a nadie atrás. A esto se suma el auge de la inteligencia artificial, que amplifica el valor de los datos, pero también de los riesgos derivados de su uso sesgado o poco transparente.
Incorporar la alfabetización en datos a los currículos educativos desde edades tempranas es clave para superar estos desafíos, ya que proporciona al alumnado conocimientos técnicos y herramientas para participar en la sociedad de manera informada. El V Encuentro Nacional de Datos Abiertos celebrado en Pamplona el 8 de mayo puso el foco precisamente en el papel de los datos en el sector educativo bajo el lema “Aprende y emprende”. El reto de esta edición ha sido EDUCA-DATA, un recurso que acerca los datos abiertos al aula de forma práctica y accesible, mostrando su valor para entender la realidad y generar oportunidades.
¿En qué consiste el reto anual del Encuentro Nacional de Datos Abiertos?
El Encuentro Nacional de Datos Abiertos plantea cada año un reto diferente, en el que expertos de diferentes ámbitos trabajan conjuntamente para encontrar soluciones. El reto es propuesto por la organización y voluntarios relacionados con el ámbito de los datos, ligados al mundo académico y a la Administración pública, colaboran a lo largo de todo el año para dar respuestas al desafío. Las conclusiones se presentan durante el evento anual y toda la documentación generada es pública.
¿Qué es EDUCA-DATA?
Los datos son una herramienta ciudadana para entender y transformar el mundo. EDUCA-DATA es un proyecto educativo que facilita el aprendizaje del uso y la reutilización de datos abiertos públicos. Busca fortalecer las competencias digitales, el pensamiento crítico y promover la cultura del conocimiento abierto.
EDUCA-DATA se dirige, principalmente, al alumnado y profesorado de Educación Secundaria Obligatoria, Bachillerato y Formación Profesional, pero también a la ciudadanía en general. El material educativo permite al alumnado trabajar en el aula los conceptos sobre datos abiertos, contiene recursos que el profesorado puede utilizar como apoyo en el aula y facilita que cualquier persona interesada pueda aprender de manera autónoma sobre este tema.
Durante el abordaje de este reto se han elaborado tres piezas documentales coordinadas y complementarias entre sí, sin que sea necesario consultar las tres para comprender el contenido completo. A continuación, se detalla el contenido de cada una. Todos los materiales están disponibles en el apartado 5 del reto EDUCA-DATA, al final de la página del encuentro.
Presentación de los datos abiertos, una recopilación de los datos esenciales
La pieza central de los materiales elaborados es una presentación en formato PowerPoint. Se trata de un documento de 65 diapositivas que permite que cualquier persona sin conocimiento previo pueda acercarse a los datos abiertos. Este documento incluye todo el contenido que el alumnado trabajará en el aula junto al profesorado y articula la secuencia didáctica completa, desde la introducción a los datos hasta los beneficios de su apertura.
Documento teórico: conceptos, ejemplos y recursos para profundizar
Todo el material elaborado se asienta sobre una sólida base teórica. El documento técnico desarrolla en mayor profundidad los conceptos, las definiciones y los ejemplos que aparecen en la presentación, y actúa como referencia cuando el alumnado o el profesorado necesite profundizar en algún punto concreto.
Con un enfoque didáctico, traza un recorrido que permite comprender cómo los datos abiertos, correctamente tratados y publicados, aportan un valor significativo en ámbitos tan diversos como el periodismo de investigación, la ciencia contra el cambio climático o la participación ciudadana. La inclusión de casos reales, explicados de una forma clara y accesible, facilita entender su impacto en nuestra vida diaria. El documento está concebido tanto para leerse de forma continua, con una lectura fluida y amena, como para consultarse de manera puntual cada vez que se quiera aclarar un concepto o ampliar un aspecto específico. Además, incluye enlaces a recursos externos para quienes deseen profundizar en los diferentes apartados.
Guía del profesorado, descubriendo el poder de los datos
Para que el profesorado pueda trabajar en el aula, se ha elaborado una exhaustiva guía docente, que les permite gestionar de forma autónoma el trabajo con el alumnado. Este documento contiene el marco curricular, las orientaciones didácticas y la información necesaria para la práctica en el aula. La guía se organiza en dos partes: la primera incluye el marco conceptual y el encaje curricular, y la segunda contiene los materiales de aula.
A nivel curricular, el material elaborado encaja principalmente en las siguientes materias: Digitalización, Economía, Geografía e Historia y Matemáticas.
El contenido se desarrolla en cinco unidades didácticas que permiten acercarse de manera gradual a los datos abiertos:
- Introducción. El mundo de los datos.
- Datos abiertos (Open Data). ¿Qué son y qué los define?
- Los formatos. El envase de la información.
- Las licencias. Las reglas del juego.
- Los beneficios. ¿Por qué importa todo esto?
Figura 1. Unidades didáctica de EDUCA-DATA: los datos abiertos en las aulas. Fuente: elaboración propia - datos.gob.es
En la guía didáctica el profesorado encontrará todo lo necesario para poder impartir las cinco unidades didácticas y sus actividades de forma autónoma, sin necesidad de formación previa específica en datos abiertos. Esto es:
- El contexto conceptual e histórico que enmarca los datos abiertos.
- Su encaje en el currículo LOMLOE de varias materias.
- Los objetivos y contenidos de cada unidad.
- Las ideas clave que conviene trasladar al aula.
- Los errores y confusiones más habituales del alumnado.
- Propuestas de evaluación rápida.
- Referencias para ampliar.
La guía recorre cuatro ámbitos:
- Un marco conceptual e histórico que proporciona al profesorado el contexto necesario sobre los datos abiertos. Es una información que no está pensada para trasladar al aula tal cual.
- Un marco curricular con la valoración del encaje en cuatro asignaturas (Digitalización, Economía, Geografía e Historia y Matemáticas), una recomendación didáctica argumentada, la progresión cognitiva según la taxonomía de Bloom y las tablas detalladas de alineación con LOMLOE.
- Las cinco unidades didácticas. Es el núcleo de este material y cada una sigue la misma estructura para facilitar la labor del profesorado.
- Dos piezas integradores que cierran el recorrido, en forma de ejercicios de aplicación práctica: un caso de estudio integrador planteado como un juego de rol periodístico y un ejercicio práctico avanzado para trabajar con datos.
Además, se incluyen como contenidos transversales un glosario básico y dos profundizaciones sobre los conceptos de distribución y licencia. La guía se presenta como una propuesta abierta que el profesorado puede tomar como referencia y adaptarla a su clase, su alumnado y su forma de enseñar.
Datos abiertos en el aula, una apuesta por la ciudadanía del futuro
Acercar los datos abiertos al alumnado de Educación Secundaria, Bachillerato y Formación Profesional contribuye a formar una ciudadanía capaz de comprender el ecosistema digital de la información, de contrastar lo que lee con datos públicos y de ejercer su derecho a la transparencia y a la participación. Por eso, estos recursos educativos tienen un gran valor que va más allá de la alfabetización digital y de datos, ya que, en su dimensión más cívica, contribuyen a formar personas más informadas, más críticas y mejor preparadas para entender y transformar el mundo en el que viven.