Evento
Solo unos meses después del éxito de su primera entrega, el Ayuntamiento de Madrid ha abierto la convocatoria de la segunda edición de los Premios a la Reutilización de Datos Abiertos. Se trata de una iniciativa que busca reconocer y promover proyectos innovadores que utilicen los conjuntos de datos publicados en el portal datos.madrid.es. Con una dotación total de 15.000 euros, estos premios consolidan el compromiso municipal con la cultura del dato, la transparencia y la creación de valor social y económico a partir de la información pública.
En este artículo te contamos algunas de las claves que debes tener en cuenta para participar.
Dos categorías de premios a considerar
La convocatoria establece dos categorías, cada una con varios premios:
1) Servicios web, aplicaciones y visualizaciones: premia proyectos que generen servicios, visualizaciones o aplicaciones web o para dispositivos móviles.
- Primer premio: 4.000 €
- Segundo premio: 3.000 €
- Tercer premio: 1.500 €
- Premio para estudiante: 1.500 €
2) Estudios, investigaciones e ideas: se centra en proyectos de investigación, análisis o descripción de ideas para crear servicios, estudios, visualizaciones, aplicaciones web o móviles. En esta categoría también pueden participar trabajos universitarios de fin de grado y de fin de máster (TFG-TFM).
- Primer premio: 2.500 €
- Segundo premio: 1.500 €
- Tercer premio: 1.000 €
En ambas categorías es necesario que se utilice al menos un conjunto de datos del portal municipal, pudiendo combinarse con fuentes públicas o privadas de cualquier ámbito territorial. Los proyectos pueden ser recientes o haber finalizado en los dos años previos al cierre de la convocatoria.
Los premios pueden declararse desiertos si no se alcanza la calidad mínima. En ese caso, los importes sobrantes se redistribuirán proporcionalmente entre el resto de premiados.
Requisitos para participar
La convocatoria está abierta a personas físicas y jurídicas autoras de los proyectos o iniciativas. El objetivo es que cualquier persona o entidad con interés en la reutilización de datos pueda presentar su propuesta, independientemente de su nivel técnico. Por ello, pueden participar tanto profesionales y empresas, personas investigadoras, periodistas y desarrolladores, como aficionados y amateurs interesados en el análisis y visualización de datos.
En el caso del premio para estudiante, solo podrán participar aquellas personas físicas matriculadas en cursos oficiales 2023/24, 2024/25 o 2025/26.
Por el contrario, quedan excluidos de todas las categorías:
- Proyectos ya premiados, subvencionados o contratados por el Ayuntamiento de Madrid.
- Proyectos que no utilicen ningún conjunto de datos del portal municipal.
Fases del proceso
En el portal municipal se detallan las fases de la convocatoria, que incluyen:
- Publicación de la convocatoria. El pasado 3 de marzo se publicaron las bases reguladoras en el Boletín Oficial del Ayuntamiento de Madrid.
- Presentación de candidaturas. El plazo para presentar las solicitudes abarca del 4 de marzo al 4 de mayo (ambos incluidos). Se pueden presentar online o presencialmente, como se explica más adelante.
-
Análisis y subsanación. Hasta el 3 de junio, se llevará a cabo la revisión de la documentación presentada. En caso necesario, se contactará con los solicitantes para la subsanación de errores.
-
Valoración y deliberación. Un jurado evaluará todos los proyectos admitidos, según los criterios establecidos en las bases de la convocatoria. Se tendrá en cuenta su utilidad, valor económico, valor social y contribución a la transparencia; su grado de innovación y creatividad; la variedad de conjuntos de datos utilizados del Portal de Datos Abiertos de Madrid; y su calidad técnica. Esta fase se extenderá hasta el 15 septiembre.
-
Resolución. En los meses de septiembre y octubre se llevará a cabo la propuesta de concesión y publicación oficial de la resolución.
-
Entrega de premios. Los galardones se entregarán en un acto público, estimado para el mes de noviembre.
La página oficial irá actualizando fechas y documentación a medida que avance el proceso.
Cómo se presentan las candidaturas
Como se mencionó anteriormente, las candidaturas se pueden presentar de manera telemática o presencial:
- En línea, a través de la sede electrónica del Ayuntamiento de Madrid. Para ello se requiere identificación y firma electrónica.
- Presencialmente, en las oficinas de asistencia en materia de registro del Ayuntamiento de Madrid, así como en los registros de otras administraciones públicas.
Las personas físicas podrán presentar la solicitud de ambas formas, mientras que las personas jurídicas solo podrán presentar la solicitud de forma telemática.
En ambos casos, las candidaturas deben incluir:
- Formulario oficial de solicitud, a descargar en la sede electrónica del Ayuntamiento de Madrid.
- Memoria del proyecto, en base a un modelo a descargar en la citada sede electrónica. Este documento incluirá el título, la autoría y una descripción detallada, así como la relación de conjuntos de datos utilizados, los objetivos, el público beneficiario, el impacto previsto, el grado de innovación y la tecnología empleada.
- Declaración responsable.
- Acuerdo de colaboración, en caso de presentarse como agrupación.
Inspírate con los proyectos ganadores de la primera edición
La segunda edición de los Premios a la Reutilización de Datos Abiertos llega precedida por el éxito de la convocatoria anterior. En 2025, el Ayuntamiento de Madrid celebró la primera edición de estos galardones, que reunió 65 candidaturas de gran calidad y diversidad. Entre ellas destacaron propuestas impulsadas por estudiantes universitarios, startups, equipos multidisciplinares y ciudadanía comprometida con el uso inteligente de los datos públicos.
Los proyectos premiados demostraron que los datos abiertos pueden convertirse en herramientas reales para mejorar la vida urbana, impulsar la transparencia y generar conocimiento útil para la ciudad. En este artículo te resumimos en qué consistían estos proyectos.
En resumen, los II Premios a la Reutilización de Datos Abiertos 2026 son una oportunidad para demostrar cómo los datos públicos pueden convertirse en innovación real. Una invitación a desarrollar proyectos que impulsen un Madrid más inteligente, transparente y participativo.
Noticia
El pasado miércoles 4 de marzo, la Cátedra Cajasiete Big Data, Open Data y Blockchain de la Universidad de La Laguna celebró un webinar para presentar las ideas ganadoras del l Concurso Datos Abiertos Cabildo de Tenerife: Ideas de Reutilización. Un evento para poner en valor el potencial que tiene la información pública cuando se pone al servicio de la ciudadanía. La grabación de la presentación está disponible aquí.
En este post repasaremos en qué consiste cada uno de los proyectos ganadores -que son todavía ideas pendientes de desarrollo en apps y a qué retos darían respuesta.
Cultiva+ Tenerife: agricultura de precisión para el campo tinerfeño
El proyecto ganador del primer premio nace de una necesidad muy concreta que conoce bien cualquier agricultor de la isla: tomar decisiones acertadas en el momento adecuado. ¿Qué cultivo es más rentable esta temporada? ¿Cuáles son las condiciones climáticas previstas para las próximas semanas? ¿Hay alguna feria o evento del sector que convenga no perderse?
Cultiva+ Tenerife es una aplicación diseñada específicamente para el sector agrícola que integra datos abiertos del Cabildo para responder a estas preguntas de forma sencilla e intuitiva.
En concreto, va dirigido tanto a trabajadores ya establecidos en el sector como a nuevos agricultores. En el primer caso, la app facilitaría el trabajo diario a través de recomendaciones de riego y otras cuestiones que mejoren la producción; mientras que para nuevos agricultores la aplicación ayudaría a seleccionar la mejor parcela para empezar una actividad agraria según tipo de suelo, condiciones climáticas, etc.
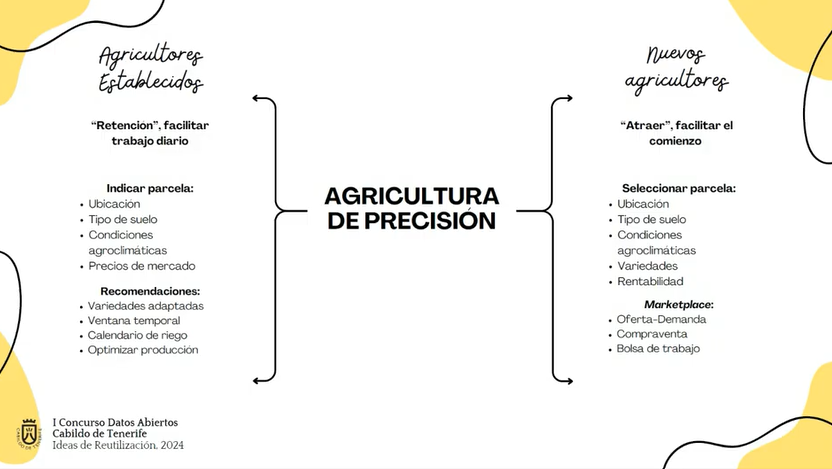
Figura 1. Posibles utilidades de la aplicación Cultiva+ Tenerife según el tipo de usuario. Fuente: presentación de Cultiva+Tenerife en el Webinar “De los datos a la innovación: Ideas de reutilización premiadas en el I Concurso de Datos Abiertos del Cabildo de Tenerife, Universidad de la Laguna”.
La aplicación recogería de forma intuitiva y clara información como:
- Información de precios: el agricultor puede consultar la evolución de los precios de mercado de distintos productos, lo que le permite planificar qué cultivar en función de la rentabilidad esperada.
- Condiciones climatológicas: la app cruza datos meteorológicos con las necesidades específicas de cada tipo de cultivo, ayudando a anticipar riegos, protecciones o cosechas.
-
Agenda de actividades de interés: ferias agrícolas, jornadas técnicas, convocatorias de ayudas... toda la información relevante para el sector, centralizada en un solo lugar.
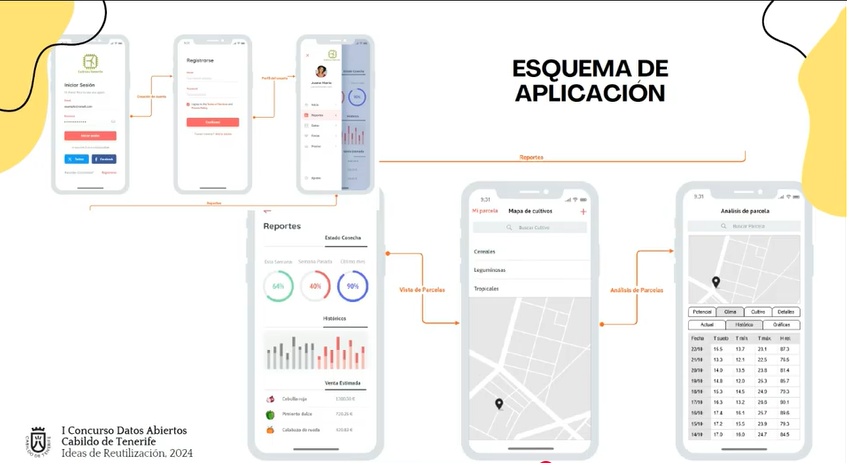
Figura 2. Estructura visual de la aplicación Cultiva+Tenerife. Fuente: presentación de Cultiva+Tenerife en el Webinar “De los datos a la innovación: Ideas de reutilización premiadas en el I Concurso de Datos Abiertos del Cabildo de Tenerife, Universidad de la Laguna”.
Algo que se destacó como valioso de este proyecto en el webinar es su enfoque en un colectivo que históricamente ha tenido menos acceso a herramientas digitales: los agricultores y agricultoras de Tenerife. La propuesta no busca complicar su día a día con tecnología innecesaria, sino simplificar decisiones que hoy se toman muchas veces a ojo o con información incompleta. La agricultura de precisión ya no es solo cosa de grandes explotaciones: con datos abiertos y una buena aplicación, puede estar al alcance de cualquier productor local.
Análisis de tendencias y modelos sobre el turismo en Tenerife: cuando los datos revelan una crisis
El segundo proyecto ganador aborda uno de los temas más complejos y urgentes de la realidad tinerfeña: la relación entre el turismo, la vivienda y el mercado laboral. Una ecuación con múltiples variables que afecta directamente a la calidad de vida de los residentes y que, hasta ahora, era difícil de analizar de forma rigurosa sin acceso a datos fiables.
El punto de partida del proyecto es revelador: en junio de 2024, el 35 % de los nuevos contratos laborales firmados en Tenerife correspondieron al sector de la hostelería. Un dato que ilustra a la perfección la dependencia estructural de la economía isleña respecto al turismo, pero que también abre preguntas incómodas: ¿hasta qué punto el crecimiento turístico está transformando el mercado de la vivienda? ¿Está desplazando a los residentes habituales de determinadas zonas? ¿Cómo evolucionará la llegada de turistas en los próximos años?
Este proyecto propone dar respuesta a estas preguntas a través de un modelo de análisis y predicción construido con herramientas de ciencia de datos. Su desarrolladora plantea utilizar datos como el número de turistas alojados en Tenerife según categoría y zona de establecimiento, disponible en datos.tenerife.es, para construir modelos con Python y NumPy que permitan identificar tendencias y proyectar escenarios futuros.
Los objetivos del proyecto son ambiciosos pero concretos:
- Analizar la relación entre demanda turística y oferta de alojamientos, identificando qué zonas de la isla sufren mayor presión y en qué momentos del año.
- Desarrollar un modelo predictivo capaz de estimar la llegada futura de turistas y su impacto en el sector de la vivienda turística.
- Contribuir a mitigar la crisis habitacional aportando datos y análisis que permitan entender cómo el turismo está afectando a la disponibilidad de vivienda para los residentes.
- Apoyar la planificación empresarial y urbanística, ofreciendo a empresas, inversores y administraciones una herramienta de análisis que facilite la toma de decisiones estratégicas.
Se trata, en definitiva, de poner la inteligencia de los datos al servicio de uno de los debates más actuales que tiene Tenerife sobre la mesa.
La universidad como puente entre los datos y la sociedad
La elección de la Cátedra Cajasiete Big Data, Open Data y Blockchain de la Universidad de La Laguna como espacio para dar visibilidad a los ganadores es en sí misma un mensaje: la Universidad tiene un papel clave en la construcción del ecosistema de datos abiertos en Tenerife.
Esta cátedra lleva años trabajando en la frontera entre la investigación académica y la aplicación práctica de tecnologías como el análisis de datos masivos, la cadena de bloques o la reutilización de información pública. Su implicación en este concurso y en la difusión de sus resultados refuerza la idea de que los datos abiertos son también un recurso de valor para la formación, la investigación y el desarrollo económico local.
El éxito de esta primera convocatoria ha confirmado que había demanda real de este tipo de iniciativas. Tanto es así que el Cabildo ya ha lanzado el II Concurso de Datos Abiertos: Desarrollo de APP, que da continuidad al proceso llevando las ideas al siguiente nivel: el desarrollo de aplicaciones funcionales.
Si en la primera edición se premiaron ideas y propuestas conceptuales, en esta segunda convocatoria el reto es construir soluciones reales, con código, interfaz de usuario y funcionalidades demostradas. La dotación económica es de 6.000 euros repartidos en tres premios.
Proyectos como Cultiva+ Tenerife o el Análisis del impacto turístico en la vivienda demuestran que hay ideas con potencial para convertirse en herramientas útiles y sostenibles. Esta segunda fase es la oportunidad de materializarlas.
Blog
“Voy a subirte un fichero CSV. Quiero que lo analices y me resumas las conclusiones más relevantes que puedas extraer de los datos”. Hace unos años, el análisis de datos era territorio de quien sabía escribir código y utilizar entornos técnicos complejos, y una petición así habría requerido programación o habilidades avanzadas de Excel. Hoy, poder analizar en poco tiempo ficheros de datos con herramientas de IA nos aporta una gran autonomía profesional. Formular preguntas, contrastar ideas preliminares y explorar de primera mano la información cambia nuestra relación con el conocimiento, sobre todo, porque dejamos de depender de intermediarios para obtener respuestas. Ganar la capacidad de analizar datos con IA de manera independiente acelera los procesos, pero también puede provocarnos un exceso de confianza en las conclusiones.
A partir del ejemplo de un fichero de datos en bruto, vamos a revisar posibilidades, precauciones y pautas básicas para explorar la información sin asumir conclusiones demasiado rápido.
El fichero:
Para mostrar un ejemplo de análisis de datos con IA utilizaremos un fichero del Instituto Nacional de Estadística (INE) que recoge información sobre flujos turísticos en Europa, en concreto sobre ocupación en alojamientos de turismo rural. El fichero de datos contiene información desde enero de 2001 hasta diciembre de 2025. Contiene desagregaciones por sexo, edad y comunidad o ciudad autónoma, lo que permite realizar análisis comparativos a lo largo del tiempo. En el momento de escribir este artículo, la última actualización de este conjunto de datos fue el 28 de enero de 2026.

Figura 1. Información del dataset. Fuente: Instituto Nacional de Estadística (INE).
1. Exploración inicial
Para esta primera exploración vamos a utilizar una versión gratuita de Claude, el chat multitarea basado en IA desarrollado por Anthropic. Es uno de los modelos de lenguaje más avanzados en benchmarks de razonamiento y análisis, lo que lo hace especialmente adecuado para este ejercicio, y es la opción más utilizada actualmente por la comunidad para realizar tareas que requieren código.
Pensemos que nos enfrentamos al fichero de datos por primera vez. Sabemos a grandes rasgos qué contiene, pero desconocemos la estructura de la información. Nuestro primer prompt, por tanto, debería centrarse en describirla:
PROMPT: Quiero trabajar con un fichero de datos sobre ocupación en alojamientos de turismo rural. Explícame qué estructura tiene el fichero: qué variables contiene, qué mide cada una y qué posibles relaciones existen entre ellas. Señala también posibles valores ausentes o elementos que requieran aclaración.

Figura 2. Exploración inicial del fichero de datos con Claude. Fuente: Claude.
Una vez que Claude nos ha dado la idea general y la explicación de las variables, es buena práctica abrir el fichero y hacer una comprobación rápida. El objetivo es evaluar que, como mínimo, el número de filas, el número de columnas, los nombres de las variables, el período temporal y el tipo de datos coinciden con lo que nos ha dicho el modelo.
Si detectamos algún error en este punto, el LLM puede no estar leyendo correctamente los datos. Si después de intentarlo en otra conversación el error persiste, es señal de que hay algo en el fichero que dificulta su lectura automática. En este caso, lo más recomendable es no proseguir con el análisis, ya que las conclusiones serán muy aparentes, pero estarán basadas en datos mal interpretados.
2. Gestión de anomalías
En segundo lugar, si hemos descubierto anomalías, lo habitual es documentarlas y decidir cómo manejarlas antes de seguir con el análisis. Podemos pedir al modelo que nos sugiera qué hacer, pero las decisiones finales serán nuestras. Por ejemplo:
- Valores faltantes: si hay celdas vacías, tenemos que decidir si rellenarlas con un valor “promedio” de la columna o simplemente eliminar esas filas.
- Duplicados: tenemos que eliminar filas repetidas o que no aportan información nueva.
- Errores de formato o inconsistencias: debemos corregirlos para que las variables sean coherentes y comparables. Por ejemplo, fechas representadas en distintos formatos.
- Outliers: si aparece un número que no tiene sentido o es exageradamente distinto del resto, tenemos que decidir si corregirlo, ignorarlo o tratarlo tal y como está.

Figura 3. Ejemplo de análisis de valores faltantes con Claude. Fuente: Claude.
En el caso de nuestro fichero, por ejemplo, hemos detectado que en Ceuta y Melilla los valores ausentes en la variable Total son estructurales, no hay turismo rural registrado en esas ciudades, por lo que podríamos excluirlas del análisis.
Antes de tomar la decisión, una buena práctica en este punto es pedir al LLM los pros y contras de la modificación en los datos. Su respuesta puede darnos alguna pista de cuál es la mejor opción, o indicarnos algún inconveniente que no habíamos tenido en cuenta.

Figura 4. Análisis de Claude sobre la posibilidad de eliminar o no valores. Fuente: Claude.
Si decidimos seguir adelante y excluir las ciudades de Ceuta y Melilla del análisis, Claude puede ayudarnos a efectuar esta modificación directamente sobre el fichero. El prompt sería el siguiente:
PROMPT: Elimina del fichero todas las filas correspondientes a Ceuta y Melilla, de manera que el resto de los datos se mantenga intacto. Explica también los pasos que estás siguiendo para que pueda revisarlos.
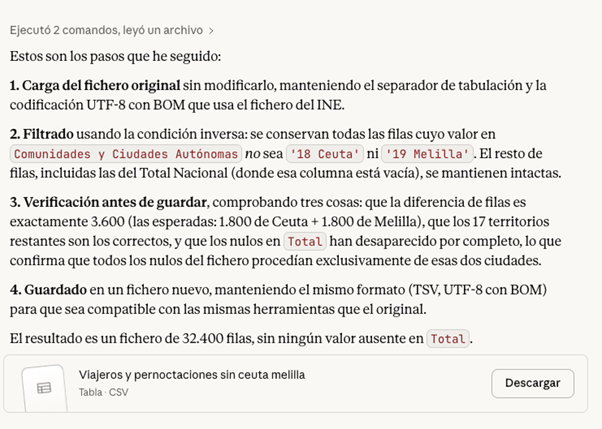
Figura 5. Paso a paso en la modificación de datos en Claude. Fuente: Claude.
En este punto, Claude nos ofrece descargar de nuevo el fichero modificado, así que una buena práctica de comprobación sería validar de forma manual que la operación se hizo bien. Por ejemplo, revisar el número de filas en un fichero y otro o cotejar algunas filas al azar con el primer fichero para asegurarnos de que los datos no se han corrompido.
3. Primeras preguntas y visualizaciones
Si el resultado hasta aquí es satisfactorio, ya podemos empezar a explorar los datos para hacernos preguntas iniciales y buscar patrones interesantes. Lo ideal al empezar la exploración es hacer preguntas grandes, claras y fáciles de responder con los datos, porque nos dan una primera visión.
PROMPT: Trabaja con el fichero sin Ceuta y Melilla a partir de ahora. ¿Cuáles han sido las cinco comunidades con más turismo rural en el período total?

Figura 6. Respuesta de Claude a las cinco comunidades con más turismo rural en el período. Fuente: Claude.
Por último, podemos pedirle a Claude que nos ayude a visualizar los datos. En lugar de hacer el esfuerzo de indicarle un tipo de gráfico concreto, le damos libertad para elegir el formato que mejor muestre la información.
PROMPT: ¿Puedes visualizar esta información en un gráfico? Elige el formato más adecuado para representar los datos.
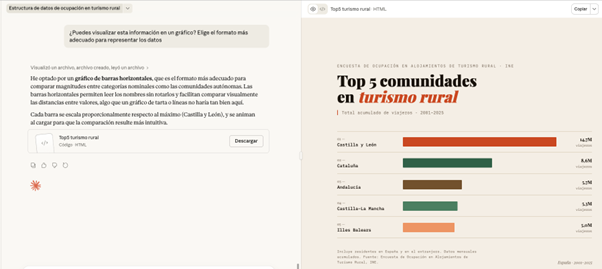
Figura 7. Gráfico elaborado por Cloude para representar la información. Fuente: Claude.
Aquí, la pantalla se desdobla: a la izquierda, podemos continuar con la conversación o descargar el fichero, mientras que a la derecha podemos visualizar el gráfico directamente. Claude ha generado una gráfica de barras horizontales muy visual y lista para usar. Los colores diferencian las comunidades y se indica correctamente el período y el tipo de datos.
¿Qué ocurre si le pedimos cambiar la paleta de color del gráfico por una inadecuada? En este caso, por ejemplo, vamos a pedirle una serie de tonos pastel que apenas se diferencian.
PROMPT: ¿Puedes cambiar la paleta de colores del gráfico por esta otra? #E8D1C5, #EDDCD2, #FFF1E6, #F0EFEB, #EEDDD3
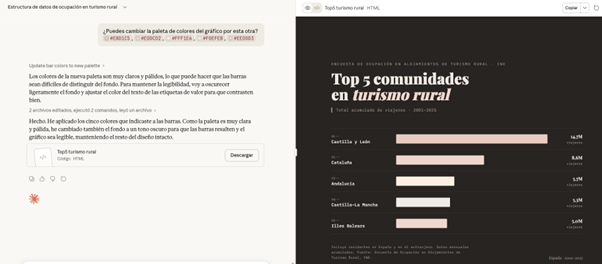
Figura 8. Ajustes realizados en el gráfico por Claude para representar la información. Fuente: Claude.
Ante el reto, Claude ajusta por sí mismo el gráfico de manera inteligente, oscurece el fondo y cambia el texto de las etiquetas para mantener legibilidad y contraste.
Todo el ejercicio anterior se ha realizado con Claude Sonnet 4.6, que no es el modelo de mayor calidad de Anthropic. Sus versiones superiores, como Claude Opus 4.6, tienen mayor capacidad de razonamiento, comprensión profunda y resultados más finos. Además, existen muchas otras herramientas para trabajar con datos y visualizaciones basadas en IA, como Julius o Quadratic. Aunque en ellas las posibilidades son casi infinitas, cuando trabajamos con datos sigue siendo fundamental mantener una metodología y un criterio propios.
Contextualizar en la vida real los datos que estamos analizando y conectarlos con otros conocimientos no es una tarea que se pueda delegar; necesitamos tener una mínima idea previa de qué queremos conseguir con el análisis para poder transmitirla al sistema. Esto nos permitirá hacer mejores preguntas, interpretar adecuadamente los resultados y por tanto hacer un prompting más eficaz.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Gasofinder es una aplicación web moderna y eficiente diseñada para ayudar a los usuarios a encontrar las gasolineras más económicas y cercanas a su ubicación en tiempo real. Utilizando datos oficiales y un mapa interactivo, la aplicación permite ahorrar dinero en cada repostaje. En concreto, ofrece
-
Mapa Interactivo:
- Visualización Clara: utiliza mapas de OpenStreetMap con un diseño limpio (Carto Voyager).
- Marcadores Inteligentes:
- 🟢 Verde: precios bajos.
- 🟡 Amarillo: precios medios.
- 🔴 Rojo: precios altos.
- Iconos Especiales: Identifica rápidamente la gasolinera más barata (⭐) y la más cara (⚠️) de la zona visible.
- Ahorro y Precios con datos en tiempo real: obtiene precios actualizados directamente del Ministerio para la Transición Ecológica. -
- Cálculo de Llenado: introduce la capacidad de tu depósito (por defecto 55L) para ver cuánto te costará llenarlo.
- Estimación de Ahorro: muestra cuánto ahorras en comparación con la opción más cara de la zona.
- Termómetro de Precios: una barra visual que indica si el precio de una estación es bueno, regular o malo en comparación con los mínimos y máximos locales.
- Personalización y Filtros
- Tipo de Combustible: filtra por Gasóleo A, Gasolina 95 E5, Gasolina 98 E5 o Gasóleo Premium.
- Tamaño del Depósito: ajustable para cálculos personalizados.
- Enlace a Puntos de Recarga: acceso directo al mapa oficial de puntos de recarga eléctrica.
- Navegación y Ubicación - Geolocalización: detecta tu ubicación automáticamente (primero aproxima y luego precisa).
- Rutas: calcula automáticamente la distancia y el tiempo de viaje a la gasolinera seleccionada.
- Integración con GPS: abre la ubicación directamente en Google Maps, Waze o Apple Maps con un solo clic.
- Modo Bloqueo: permite "fijar" una gasolinera seleccionada para que no cambie automáticamente mientras mueves el mapa.
Aclaración de Iconos
Ubicación(📍) Muestra tu posición actual.
Estrella (⭐) La opción más económica visible.
Alerta (⚠️) La opción más costosa visible.
Empresa reutilizadora
Centraldecomunicacion.es es una plataforma española especializada en bases de datos de empresas y listados de empresas listos para su uso en prospección comercial B2B, análisis de mercado, segmentación por sector/provincia y campañas de crecimiento. Trabajan con señales públicas y presencia digital verificable para construir registros empresariales que sean accionables: ubicación, actividad, reputación online y canales de contacto cuando están disponibles. Los datos se entregan en formatos compatibles (Excel/CSV) para integrarse en flujos de trabajo habituales (CRM, email marketing, BI/Excel, automatizaciones).
En las bases se incluyen campos como: nombre, categoría/sector, descripción, dirección completa, localidad/provincia, coordenadas, URL de Google Maps, además de teléfono, email corporativo, web y redes sociales cuando aparecen públicamente. También se incorporan señales de reputación como rating, número de reseñas y, en algunos casos, texto de reseñas, así como horarios.
Un diferenciador clave es el enfoque de calidad: se publican metodologías y herramientas de verificación (incluyendo verificación de emails) para reducir rebote y mejorar la utilidad real del dato. Además, se ofrecen recursos abiertos como el listado de códigos postales y utilidades relacionadas con categorización/segmentación.
Documentación
Introducción
Cada año se producen en España decenas de miles de accidentes, en los que miles de personas resultan heridas de diversa consideración, y que ocurren en circunstancias muy diversas, tanto de tipo de vía, como por el tipo de accidente.
Muchas de las estadísticas relacionadas con estos parámetros están recogidas en las bases de datos de la Dirección General de Tráfico (DGT) y algunas de ellas en el catálogo albergado en datos.gob.es.
En este ejercicio examinaremos el contenido de la base de datos de siniestralidad de la DGT para el año 2024 con el fin de realizar una serie de visualizaciones básicas que nos permitan ver de forma rápida e intuitiva cuáles son los hechos a destacar respecto a la incidencia de accidentes y sus consecuencias en ese año.
Para ello vamos a desarrollar código en Python que nos permita la lectura y cálculo de métricas básicas respecto al número total de víctimas, las particularidades de las infraestructuras así como las diferentes casuísticas de los accidentes. Y una vez tengamos disponibles esos datos, los visualizaremos utilizando la librería de Javascript D3.js, que nos permite tanto la representación de datos en su forma más tradicional como en diseños más contemporáneos, habituales en la prensa, favoreciendo así una narrativa fluída en estilo y coherente en contenido.
En el entorno de Python utilizaremos librerías de uso común y frecuente como son Numpy, para el cálculo básico - sumas, máximos y mínimos-, y Pandas, para estructurar los datos de forma intuitiva, facilitando tanto su organización como su transformación. Igualmente trabajaremos con Datetime, tanto para el formateo de los datos de entrada en tipos de fecha estándares dentro del mundo de la programación en Python, como para agregar los datos de forma fácil e intuitiva. De esta forma aprenderemos a abrir cualquier tipo de fichero de datos en formato .CSV, a estructurarlo de forma ordenada y a realizar transformaciones y operaciones básicas de forma sencilla.
En el entorno de Javascript desarrollaremos notebooks en D3.js gracias al uso de Observable, una iniciativa abierta y gratuita, para poder ejecutar código de Javascript directamente en un interfaz web, y sin tener que recurrir a servidores locales o complejas instalaciones. En diferentes notebooks crearemos visualizaciones clásicas -como las series temporales en ejes cartesianos o mapas- junto con otras propuestas tales como distribuciones de burbujas o elementos apilados por categorías.
En la Figura 1 se pueden ver las principales etapas de este ejercicio, desde la lectura de los datos dentro del fichero de la DGT, hasta las operaciones y las variables de salida en formato JSON, que nos servirán a su vez en un entorno Javascript para poder desarrollar las visualizaciones en D3.js.
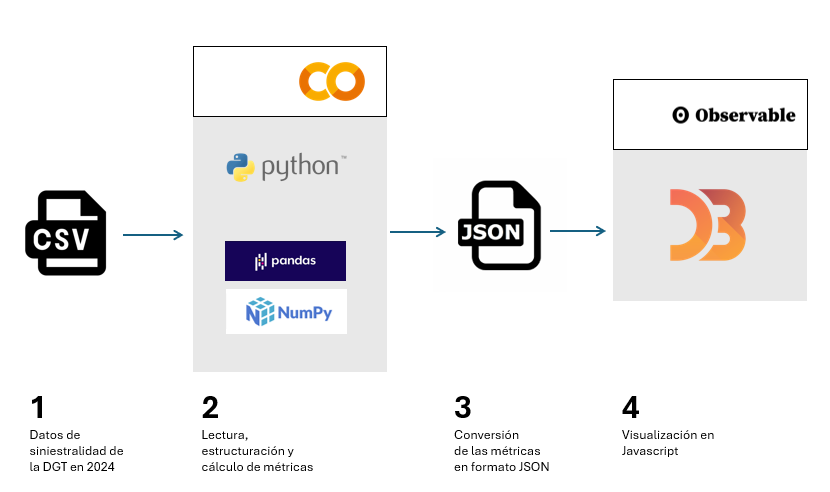
Figura 1. Pasos en los cuales se estructura este ejercicio, con punto de partida en la base de datos de la DGT, el procesado y manipulación de esos datos en Python, la creación de ficheros de salida en formato JSON y su uso en Javascript para visualizar los resultados.
El acceso al repositorio de Github, el notebook de Google Colab y los notebooks de Observable se pueden realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de GoogleColab
Accede a los notebooks de Observable
Proceso de Desarrollo
1. Lectura del fichero de datos
El primer paso será leer el fichero de la DGT que contiene todos los registros de accidentes del año 2024. Este paso nos permitirá identificar los campos de interés y sobre todo en qué formato se encuentran. Podremos identificar si se precisa de alguna transformación sobre todo en la información de la fecha, tal y como está estructurada en el fichero de origen.
Igualmente veremos cómo traducir los códigos de muchas de las categorías que nos ofrece la DGT, de modo que podamos hacer una interpretación real más allá de los números de categorías como tipo de accidente, tipo de vía o titularidad de la vía.
Una vez entendemos la estructura y contenido de los datos podemos empezar a operar con ellos.
2. Cálculo de métricas
La librería Pandas de Python nos permite operar con las diferentes columnas de datos y realizar cálculos básicos que serán suficientemente representativos para entender mínimamente la casuística de los accidentes en las carreteras españolas.
En este apartado se realizarán tres tipos de cálculos.
- El primero de ellos será el cálculo del número total de víctimas por hora del día para cada uno de los días de la semana. La base de datos de la DGT viene estructurada por día de la semana, de forma que utilizaremos también esa escala temporal para representar los datos en una serie. Cabe hacer notar que por víctima se considera toda aquella persona que ha fallecido o que sea diagnosticada como herida grave o leve.
- El segundo cálculo será la suma total de accidentes para diferentes categorías, tales como la titularidad de la vía, el tipo de accidente o el tipo de vía. Esto nos permitirá ver cuáles son las condiciones en las cuales los accidentes son más frecuentes.
- El tercer cálculo será el de número de accidentes por municipio. En este caso realizaremos el cálculo restringido a la provincia de Valencia como ejemplo, y que sería aplicable a cualquier provincia o municipio de nuestro interés. En este caso observaremos las diferencias entre los núcleos urbanos y no urbanos, así como aquellos municipios por los que pasan las principales vías de comunicación.
3. Diseño de las visualizaciones
Una vez hemos calculado las métricas de interés, desarrollaremos cinco ejercicios de visualización en D3.js. Para ello exportaremos en formato JSON el resultado de las métricas y crearemos notebooks en Observable. En concreto realizamos las siguientes visualizaciones:
- Serie temporal con el número total de víctimas en cada hora y día de la semana, con un menú desplegable interactivo para seleccionar el día de la semana de interés. A mayores de la curva que describe el número de víctimas dibujaremos sobre el fondo de la gráfica la incertidumbre de todos los días de la semana, de forma que la serie temporal diaria queda enmarcada en el contexto de toda la semana como referencia.
- Mapa de la provincia de Valencia con el número total de accidentes por municipio.
- Diagrama de burbujas, con las diferentes magnitudes de los diferentes tipos de accidentes con el número total de accidentes en cada caso escrita de forma detallada.
- Diagrama de puntos apilados, donde acumulamos círculos o cualquier otra forma geométrica para las diferentes titularidades de la vía y su número total de accidentes dentro del marco de cada titularidad.
- Diagrama de sierra, con la altura de cada montaña correspondiente al número de accidentes en cada tipo de vía en escala logarítmica.
Visualización de las métricas
El resultado de este ejercicio se podrá ver de forma gráfica y explícita en forma de visualizaciones realizadas para el formato web y accesibles desde una interfaz también web, tanto para su desarrollo como para su posterior publicación. Todo el conjunto de visualizaciones se encuentra en el repositorio de Datos.gob.es en Observable:
Accede a los notebooks de Observable
En la Figura 2 tenemos el resultado de la serie temporal del total de víctimas respecto a la hora del día para diferentes días de la semana. La serie temporal está enmarcada dentro de la incertidumbre del total de días de la semana, para dar una idea del margen de variabilidad que podemos tener dependiendo de la hora del día.
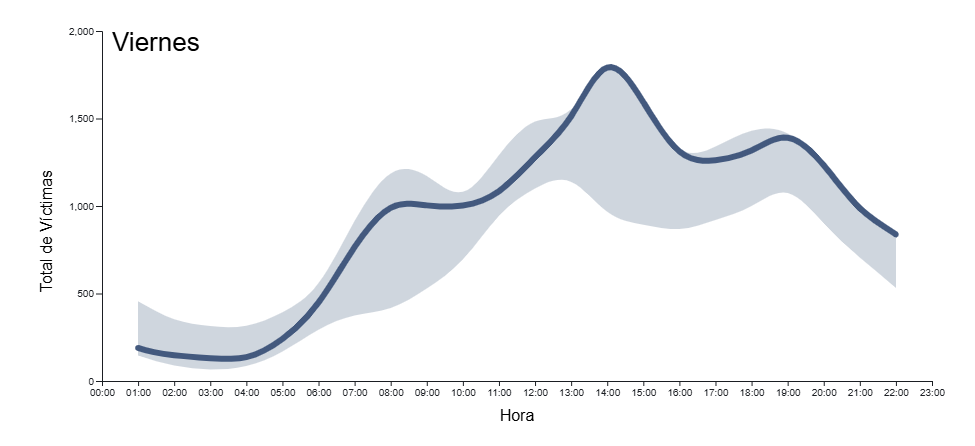
Figura 2. Serie temporal del total de víctimas en accidentes por hora del día para todos los días de la semana en 2024. En el fondo en color azul claro se indica la incertidumbre asociada a todos los días de la semana como contexto, con menú desplegable para seleccionar el día de la semana.
En la Figura 3 podemos observar el mapa de la provincia de Valencia con una intensidad de color proporcional al número de accidentes en cada municipio. Aquellos municipios en los cuales no se han registrado accidentes aparecen en color blanco. De forma intuitiva se puede adivinar el trazado de las principales carreteras que atraviesan la provincia, tanto la carretera hacia el este de la ciudad de Valencia en dirección Madrid como la carretera del interior hacia el sur de la ciudad en dirección a Alicante.
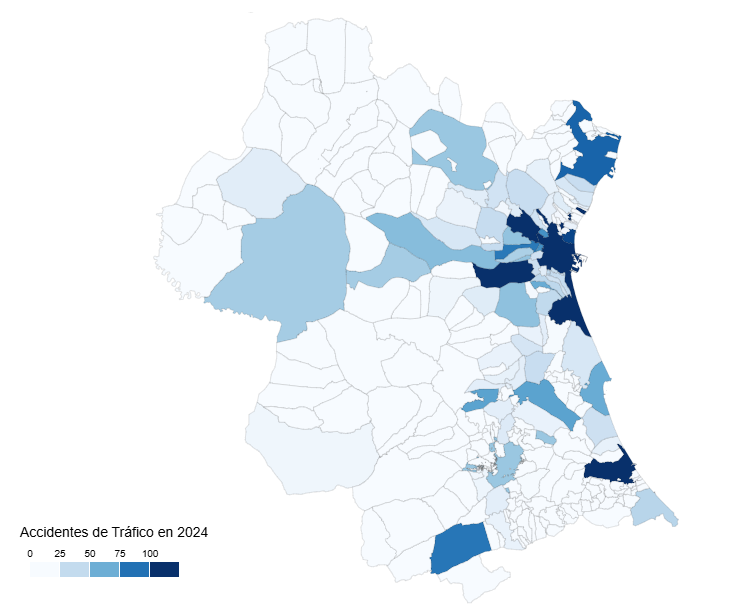
Figura 3. Mapa del número de accidentes por municipio en la provincia de Valencia en 2024.
En la Figura 4 vemos una forma geométrica, el círculo, asociada a los tipos de accidente, con el detalle del número de accidentes asociada a cada categoría. En este tipo de visualización emerge de forma natural aquellos accidentes más frecuentes en torno al centro del diagrama, mientras que aquellos minoritarios o residuales ocupan el perímetro del diagrama para dar igualmente una forma redonda al conjunto de formas.
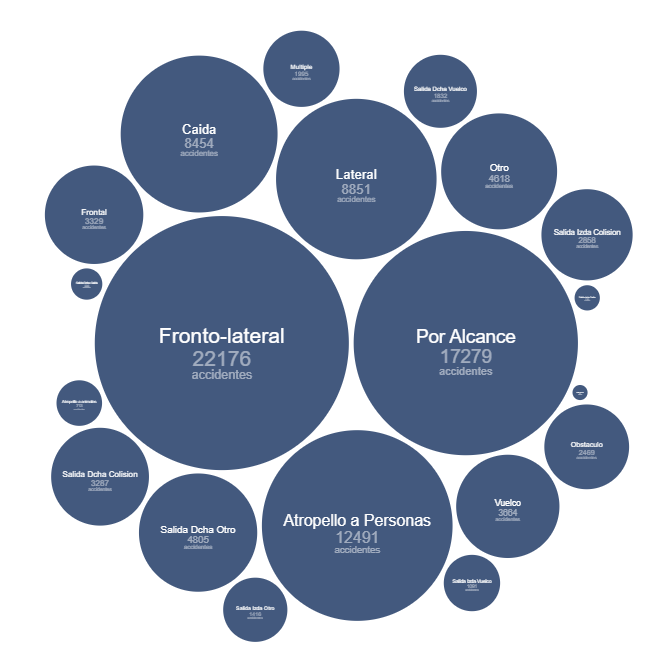
Figura 4. Diagrama de burbujas del número de accidentes por tipo de accidente en 2024.
En la Figura 5 se puede contemplar el tradicional diagrama de barras pero esta vez descompuesto en unidades más pequeñas, para afinar la cantidad de accidentes asociada a la titularidad de la vía donde han sucedido. Este tipo de diagramas permite discernir pequeñas diferencias entre magnitudes parecidas, preservando el mensaje general que obtenemos de un cálculo de estas características.
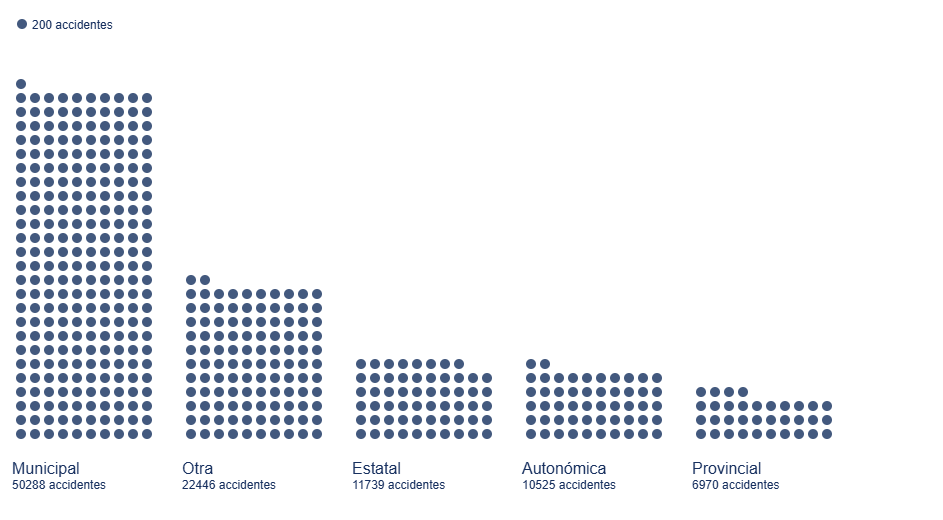
Figura 5. Diagrama de barras con discretización de puntos para el número de accidentes por titularidad de la vía en el 2024.
En la Figura 6 creamos una serie de formas geométricas que replican una cordillera o sierra donde los diferentes picos apuntan a la diferencia de número de accidentes por tipo de vía. Dada la diferencia en órdenes de magnitud establecemos una escala logarítmica, que permita comparar en el mismo diagrama diferentes casuísticas.
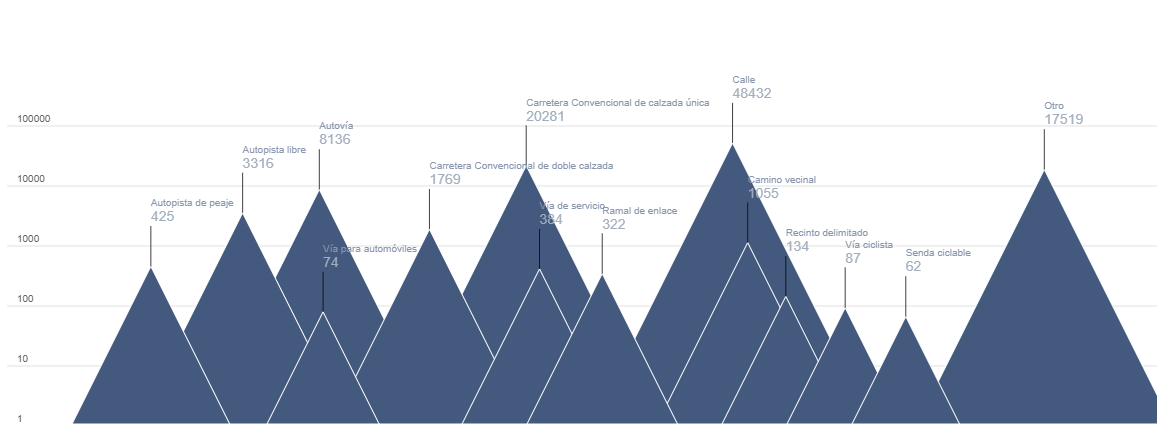
Figura 6. Diagrama en cordillera para los diferentes órdenes de magnitud del número de accidentes por tipo de vía en el 2024.
Lecciones aprendidas
A través de estos pasos aprenderemos toda una serie de habilidades transversales que nos permiten trabajar con aquellos conjunto de datos que se nos presentan en formato CSV en columnas, un formato muy popular para el cual podremos realizar tanto su análisis como su visualización. Estas lecciones son en concreto:
- Universalidad de lectura y estructuración de datos: el uso de herramientas como Python, con sus librerías Numpy y Pandas, permiten acceder a los datos en detalle y estructurarlos de forma ordenada e intuitiva con pocas líneas de código.
- Cálculos sencillos en Pandas: la propia librería de Python permite cálculos sencillos pero esenciales para la interpretación preliminar de resultados.
- Formato Datetime: a través de esta librería de Python podemos familiarizarnos con el estándar del formato de fecha, y así realizar todo tipo de transformaciones, filtros y selecciones que más nos interesen en cualquier intervalo temporal.
- Formato JSON: una vez que decidimos dar espacio a nuestras visualizaciones en la web, aprender la estructura y uso del formato JSON es de gran utilidad dado su amplio uso en todo tipo de aplicaciones y arquitecturas web.
- Espectro de posibilidades de D3.js: esta librería de Javascript nos permite explorar de lo más tradicional y conservador a lo más creativo gracias a sus principios basados en las formas más básicas, sin plantillas, templates o diagramas predefinidos.
Conclusiones y próximos pasos
Hemos aprendido a leer y a estructurar datos según los estándares de los formatos más utilizados en el mundo del análisis y visualización. Este ejercicio también sirve como módulo introductorio al mundo de D3.js, una herramienta muy versátil, vigente y popular dentro del mundo del storytelling y la visualización de datos a todos los niveles.
Para poder avanzar en este ejercicio se recomienda:
- Para los analistas y desarrolladores, se puede prescindir de la librería Pandas y estructurar los datos con objetos más elementales de Python como arrays y matrices, buscando qué funciones y qué operadores permiten realizar las mismas tareas que hace Pandas pero de una forma más fundamental, sobre todo si pensamos en entornos de producción para los cuales necesitamos el menor número de librerías posibles para aligerar la aplicación.
- Para los creadores de visualizaciones, la información sobre los municipios puede proyectarse igualmente sobre bases cartográficas ya existentes como OpenStreetMap y de esta forma vincular la incidencia de accidentes a características orográficas o infraestructuras ya reflejadas en esas bases cartográficas. Para las magnitudes de los números de accidentes se pueden explorar diagramas de tipo Treemap o diagramas de Voronoi y ver si transmiten el mismo mensaje que los que presentamos en este ejercicio.
Ámbitos de aplicación
Los pasos descritos en este ejercicio pueden pasar a formar parte de cualquier caja de herramientas de uso habitual para los siguientes perfiles:
- Analistas de datos: aquí se encuentran los pasos básicos para la descripción de un fichero de datos en formato CSV y los cálculos básicos a realizar tanto en el campo de la fecha como de operaciones entre variables de diferentes columnas. Estas herramientas pueden servir para introducirse en el mundo del análisis de datos y ayuda en esos primeros pasos a la hora de enfrentarse a un dataset.
- Científicos y personal investigador: la universalidad de las herramientas aquí descritas aplican a una gran variedad de origen de datos, como el que se experimenta en las ciencias experimentales y de observaciones o medidas de todo tipo. Estas herramientas permiten un análisis rápido a la vez que riguroso sin importar el campo de conocimiento en el que se trabaje.
- Desarrolladores web: la exportación de datos en formato JSON así como el código en Javascript que se ofrece en los notebooks de Observable son fácilmente integrables en todo tipo de entornos (Svelte, React, Angular, Vue) y permite la creación de visualizaciones en una web de forma sencilla e intuitiva.
- Periodistas: abarcar todo el proceso de vida de un fichero de datos, desde su lectura a su visualización, otorga al periodista o investigador independencia a la hora de evaluar e interpretar los datos por sí mismo sin depender de recursos técnicos ajenos. La creación del mapa por municipios abre la puerta a utilizar cualquier otro dato similar, como por ejemplo procesos electorales, con el mismo formato de salida para mostrar variabilidad geográfica respecto a cualquier tipo de magnitud.
- Diseñadores Gráficos: el manejo de herramientas de visualización con un amplio grado de libertad permite a los diseñadores cultivar toda su creatividad dentro del rigor y la exactitud que los datos necesitan.
Aplicación
Visor web que muestra en un único mapa los despliegues de fibra de todos los programas PEBA y UNICO, a partir de los datos disponibles en abierto. Cada área tiene el color de fondo del operador adjudicado, y el borde es de un color diferente para cada programa. Para el caso del plan PEBA 2013-2019, como los despliegues se asignan a entidades singulares de población, se muestra un marcador con la ubicación obtenida del CNIG. Además, cuando no se hace zoom sobre el mapa, se muestra un mapa de calor en el que se puede ver la distribución por zonas de los despliegues.
Esta visualización permite evitar tener que comparar en diferentes visores cartográficos si lo que nos interesa es ver qué operadores llegan a qué zonas o simplemente tener una visión global de qué despliegues quedan pendientes en mi zona, y además permite consultar aspectos como la fecha de finalización actualizada, que antes solamente estaban disponibles en los diferentes Excel de cada programa. También creo que podría ser útil de cara a análisis de cómo se reparten las zonas entre los diferentes programas (por ejemplo, si una zona cubierta en el UNICO 2021 luego tiene zonas cercanas en UNICO 2022 cubiertas por ejemplo por otro operador), o incluso posibles solapes (por ejemplo debido a zonas que quedaron sin ejecutar en anteriores programas)
Documentación
Los agentes de IA (como los de Google ADK, LangChain, etc.) son "cerebros". Pero un cerebro sin "manos" no puede actuar en el mundo real (consultar APIs, buscar en bases de datos, etc.). Esas "manos" son las herramientas.
El desafío es: ¿cómo conectas el cerebro con las manos de forma estándar, desacoplada y escalable? La respuesta es el Model Context Protocol (MCP).
Como ejercicio práctico, construiremos un sistema de agente conversacional que permite explorar el Catálogo Nacional de datos abiertos albergado en datos.gob.es mediante preguntas en lenguaje natural, facilitando así el acceso a datos públicos.
En este ejercicio práctico, el objetivo principal es ilustrar, paso a paso, cómo construir un servidor de herramientas independiente que hable el protocolo MCP.
Para hacer este ejercicio tangible y no solo teórico, usaremos, FastMCP para construir el servidor. Para probar que nuestro servidor funciona, crearemos un agente simple con Google ADK que lo consuma. El caso de uso (consultar la API de datos.gob.es) ilustra esta conexión entre herramientas y agentes. El verdadero aprendizaje es la arquitectura, que podrías reutilizar para cualquier API o base de datos.
A continuación se muestran las tecnologías que usaremos y un esquema de cómo están realizados entre sí los diferentes componentes
- FastMCP (mcp.server.fastmcp): implementación ligera del protocolo MCP que permite crear servidores de herramientas con muy poco código mediante decoradores Python. Es el 'protagonista' del ejercicio.
- Google ADK (Agent Development Kit): framework para definir el agente de IA, su prompt y conectarlo a las herramientas. Es el 'cliente' que prueba nuestro servidor.
- FastAPI: para servir el agente como una API REST con interfaz web interactiva.
- httpx: para realizar llamadas asíncronas a la API externa de datos.gob.es.
- Docker y Docker Compose: para paquetizar y orquestar los dos microservicios, permitiendo que se ejecuten y comuniquen de forma aislada.

Figura 1. Arquitectura desacoplada con comunicación MCP.
El diagrama ilustra una arquitectura desacoplada dividida en cuatro componentes principales que se comunican mediante el protocolo MCP. Cuando el usuario realiza una consulta en lenguaje natural, el Agente ADK (basado en Google Gemini) procesa la intención y se comunica con el servidor MCP a través del Protocolo MCP, que actúa como intermediario estandarizado. El servidor MCP expone cuatro herramientas especializadas (buscar datasets, listar temáticas, buscar por temática y obtener detalles) que encapsulan toda la lógica de negocio para interactuar con la API externa de datos.gob.es. Una vez que las herramientas ejecutan las consultas necesarias y reciben los datos del catálogo nacional, el resultado se propaga de vuelta al agente, que finalmente genera una respuesta comprensible para el usuario, completando así el ciclo de comunicación entre el "cerebro" (agente) y las "manos" (herramientas).
Accede al repositorio del laboratorio de datos en GitHub
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
La arquitectura: servidor MCP y agente consumidor
La clave de este ejercicio es entender la relación cliente-servidor:
- El Servidor (Backend): es el protagonista de este ejercicio. Su único trabajo es definir la lógica de negocio (las "herramientas") y exponerlas al mundo exterior usando el "contrato" estándar de MCP. Es el responsable de encapsular toda la lógica de comunicación con la API de datos.gob.es.
- El Agente (Frontend): es el "cliente" o "consumidor" de nuestro servidor. Su rol en este ejercicio es probar que nuestro servidor MCP funciona. Lo usamos para conectarnos, descubrir las herramientas que el servidor ofrece y llamarlas.
- El Protocolo MCP: es el "lenguaje" o "contrato" que permite que el agente y el servidor se entiendan sin necesidad de conocer los detalles internos del otro.
Proceso de desarrollo
El núcleo del ejercicio se divide en tres partes: crear el servidor, crear un cliente para probarlo y ejecutarlos.
1. El servidor de herramientas (el backend con MCP)
Aquí es donde reside la lógica de negocio y el foco de este tutorial. En el archivo principal (server.py), definimos funciones Python simples y usamos el decorador @mcp.tool de FastMCP para exponerlas como 'herramientas' consumibles.
La description que añadimos al decorador es crucial, ya que es la documentación que cualquier cliente MCP (incluyendo nuestro agente ADK) leerá para saber cuándo y cómo usar cada herramienta.
Las herramientas que definiremos en el ejercicio son:
- buscar_datasets(titulo: str): para buscar datasets por palabras clave en el título.
- listar_tematicas(): para descubrir qué categorías de datos existen.
- buscar_por_tematica(tematica_id: str): para encontrar datasets de un tema específico.
-
obtener_detalle_dataset(dataset_id: str): para obtener la información completa de un dataset.
2. El agente consumidor (el frontend con Google ADK)
Una vez construido nuestro servidor MCP, necesitamos una forma de probarlo. Aquí es donde entra Google ADK. Lo usamos para crear un "agente consumidor" simple.
La magia de la conexión ocurre en el argumento tools. En lugar de definir las herramientas localmente, simplemente le pasamos la URL de nuestro servidor MCP. El agente, al iniciarse, consultará esa URL, leerá el "contrato" MCP y sabrá automáticamente qué herramientas tiene disponibles y cómo usarlas.
# Ejemplo de configuración en agent.py
root_agent = LlmAgent(
...
instruction="Eres un asistente especializado en datos.gob.es...",
tools=[
MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url="http://mcp-server:8000/mcp",
),
)
]
)3. Orquestación con Docker Compose
Finalmente, para ejecutar nuestro Servidor MCP y el agente consumidor juntos, usamos docker-compose.yml. Docker Compose se encarga de construir las imágenes de cada servicio, crear una red privada para que se comuniquen (por eso el agente puede llamar a http://mcp-server:8000) y exponer los puertos necesarios.
Probando el servidor MCP en acción
Una vez que ejecutamos docker-compose up --build, podemos acceder a la interfaz web del agente (http://localhost:8080).
El objetivo de esta prueba no es solo ver si el bot responde bien, sino verificar que nuestro servidor MCP funciona correctamente y que el agente ADK (nuestro cliente de prueba) puede descubrir y usar las herramientas que este expone.
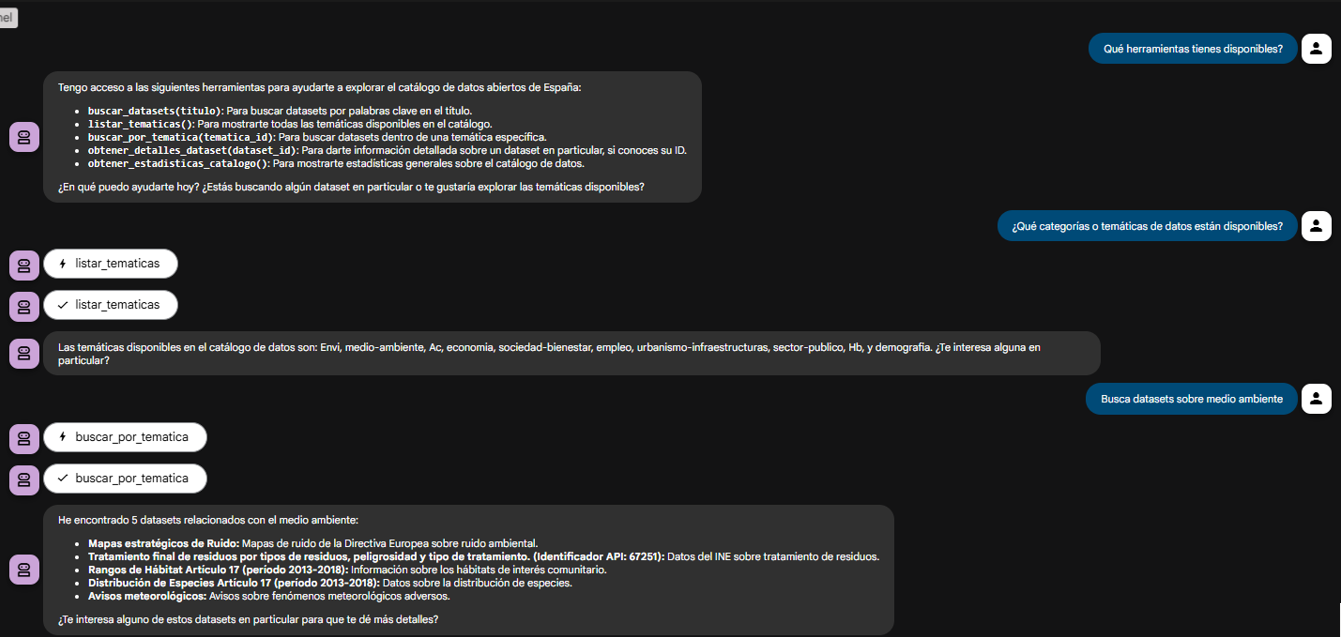
Figura 2. Pantalla del agente demostrando sus herramientas.
El verdadero poder del desacoplamiento se ve cuando el agente encadena lógicamente las herramientas que nuestro servidor le proveyó.
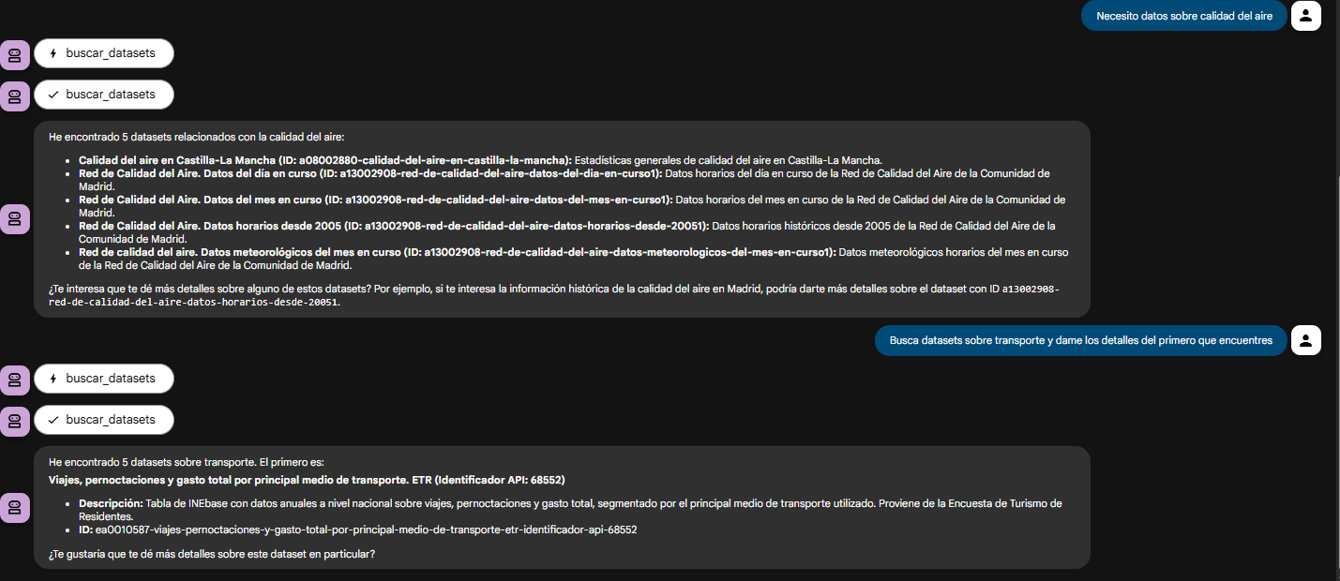
Figura 3. Pantalla del agente demostrando el uso conjunto de las herramientas.
¿Qué puedes aprender?
El objetivo de este ejercicio es aprender los fundamentos de una arquitectura de agentes moderna, centrándonos en el servidor de herramientas. En concreto:
- Cómo construir un servidor MCP: cómo crear un servidor de herramientas desde cero que hable MCP, usando decoradores como @mcp.tool.
- El patrón de una arquitectura desacoplada: el patrón fundamental de separar el 'cerebro' (LLM) de las 'herramientas' (lógica de negocio).
- Descubrimiento dinámico de herramientas: cómo un agente (en este caso, de ADK) puede conectarse dinámicamente a un servidor MCP para descubrir y consumir herramientas.
- Integración de API externas: el proceso de 'envolver' una API compleja (como la de datos.gob.es) en funciones simples dentro de un servidor de herramientas.
- Orquestación con Docker: cómo gestionar un proyecto de microservicios para desarrollo.
Conclusiones y futuro
Hemos construido un servidor de herramientas MCP robusto y funcional. El verdadero valor de este ejercicio es el cómo: una arquitectura escalable centrada en un servidor de herramientas que habla un protocolo estándar.
Esta arquitectura basada en MCP es increíblemente flexible. El caso de datos.gob.es es solo un ejemplo. Podríamos fácilmente:
- Cambiar el caso de uso: reemplazar el server.py por uno que conecte a una base de datos interna o a la API de Spotify, y cualquier agente que hable MCP (no solo ADK) podría consumirlo.
- Cambiar el "cerebro": cambiar el agente ADK por un agente de LangChain o cualquier otro cliente MCP, y nuestro servidor de herramientas seguiría funcionando sin cambios.
Para aquellos interesados en llevar este análisis al siguiente nivel, las posibilidades se centran en mejorar el servidor MCP:
- Implementar más herramientas: añadir filtros por formato, publicador o fecha al servidor MCP.
- Integrar caché: usar Redis en el servidor MCP para cachear las respuestas de la API y mejorar la velocidad.
- Añadir persistencia: guardar el historial de chat en una base de datos (esto sí sería en el lado del agente).
Más allá de estas mejoras técnicas, esta arquitectura abre la puerta a múltiples aplicaciones en contextos muy diversos.
- Periodistas y académicos pueden disponer de asistentes de investigación que les ayuden a descubrir conjuntos de datos relevantes en segundos.
- Organizaciones de transparencia pueden construir herramientas de monitorización que detecten automáticamente nuevas publicaciones de datos de contratación pública o presupuestos.
- Consultoras y equipos de inteligencia de negocio pueden desarrollar sistemas que crucen información de múltiples fuentes gubernamentales para elaborar informes sectoriales.
- Incluso en el ámbito educativo, esta arquitectura sirve como base didáctica para enseñar conceptos avanzados de programación asíncrona, integración de API y diseño de agentes de IA.
El patrón que hemos construido —un servidor de herramientas desacoplado que habla un protocolo estándar— es la base sobre la que puedes desarrollar soluciones adaptadas a tus necesidades específicas, independientemente del dominio o la fuente de datos con la que trabajes.
Evento
El Cabildo Insular de Tenerife ha convocado el II Concurso de Datos Abiertos: Desarrollo de APP, una iniciativa que premia la creación de aplicaciones web y móviles que aprovechen los conjuntos de datos disponibles en su portal datos.tenerife.es. Esta convocatoria representa una nueva oportunidad para desarrolladores, emprendedores y entidades innovadoras que quieran transformar información pública en soluciones digitales de valor para la sociedad. En este post, te contamos los detalles sobre la competición.
Un ecosistema en crecimiento: de las ideas a las aplicaciones
Esta iniciativa se enmarca en el proyecto de Datos Abiertos del Cabildo de Tenerife, que promueve la transparencia, la participación ciudadana y la generación de valor económico y social a través de la reutilización de información pública.
El Cabildo ha diseñado una estrategia en dos fases:
-
El I Concurso de Datos Abiertos: Ideas de Reutilización (ya celebrado) centrado en identificar propuestas creativas.
-
El II Concurso: Desarrollo de APP (convocatoria actual) que da continuidad al proceso y busca materializar ideas en aplicaciones funcionales.
Este enfoque progresivo permite construir un ecosistema de innovación que acompaña a los participantes desde la conceptualización hasta el desarrollo completo de soluciones digitales.
El objetivo es fomentar la creación de productos y servicios digitales que generen impacto social y económico, mientras se identifican nuevas oportunidades de innovación y emprendimiento en el ámbito de los datos abiertos.
Premios y dotación económica
Este concurso cuenta con una dotación total de 6.000 euros distribuidos en tres premios:
-
Primer premio: 3.000 euros
-
Segundo premio: 2.000 euros
-
Tercer premio: 1.000 euros
¿Quién puede participar?
La convocatoria está abierta a:
-
Personas físicas: desarrolladores individuales, diseñadores, estudiantes o cualquier persona interesada en la reutilización de datos abiertos.
-
Personas jurídicas: startups, empresas de tecnología, cooperativas, asociaciones u otras entidades.
Siempre y cuando presenten el desarrollo de una aplicación basada en datos abiertos del Cabildo de Tenerife. Una misma persona, física o jurídica, puede presentar tantas candidaturas como desee, tanto de forma individual como conjunta.
¿Qué tipo de aplicaciones se pueden presentar?
Las propuestas deben ser aplicaciones web o móviles que utilicen al menos un conjunto de datos del portal datos.tenerife.es. Algunas ideas que pueden servir de inspiración son:
-
Aplicaciones para optimizar el transporte y la movilidad en la isla.
-
Herramientas de visualización de datos turísticos o medioambientales.
-
Servicios de información ciudadana en tiempo real.
-
Soluciones para mejorar la accesibilidad y la participación social.
-
Plataformas de análisis de datos económicos o demográficos.
Criterios de evaluación: ¿qué valora el jurado?
El jurado evaluará las propuestas considerando los siguientes criterios:
-
Uso de datos abiertos: grado de aprovechamiento e integración de los conjuntos de datos disponibles en el portal.
-
Impacto y utilidad: valor que aporta la aplicación a la sociedad, capacidad para resolver problemas reales o mejorar servicios existentes.
-
Innovación y creatividad: originalidad de la propuesta y carácter innovador de la solución planteada.
-
Calidad técnica: solidez del código, buenas prácticas de programación, escalabilidad y mantenibilidad de la aplicación.
-
Diseño y usabilidad: experiencia de usuario (UX), diseño visual atractivo e intuitivo, garantía de accesibilidad digital en dispositivos Android e iOS.
¿Cómo participar?: plazos y forma de presentación:
Las solicitudes pueden presentarse hasta el 10 de marzo de 2026, tres meses desde la publicación de la convocatoria en el Boletín Oficial de la Provincia.
Sobre la documentación requerida, las propuestas deben presentarse en formato digital e incluir:
-
Descripción técnica detallada de la aplicación.
-
Memoria justificativa del uso de los datos abiertos.
-
Especificación de entornos tecnológicos utilizados.
-
Vídeo demostrativo del funcionamiento de la aplicación.
-
Código fuente completo.
-
Ficha técnica resumen.
Desde la institución organizadora recomiendan la presentación telemática a través de la Sede Electrónica del Cabildo de Tenerife, aunque también es posible la presentación presencial en los registros oficiales habilitados. Las bases completas y el modelo oficial de solicitud están disponibles en la Sede Electrónica del Cabildo.
Con esta segunda convocatoria, el Cabildo de Tenerife consolida su apuesta por la transparencia, la reutilización de información pública y la creación de un ecosistema de innovación digital. Iniciativas como esta demuestran cómo los datos abiertos pueden convertirse en catalizadores del emprendimiento, la participación ciudadana y el desarrollo económico local.
Noticia
En los últimos seis meses, el ecosistema de datos abiertos en España ha vivido una intensa actividad marcada por los avances normativos y estratégicos, la puesta en marcha de nuevas plataformas y funcionalidades en los portales de datos, o el lanzamiento de soluciones innovadoras basadas en la información pública.
En este artículo, repasamos algunos de esos avances, para que puedas estar al día. Te invitamos también a revisar el artículo sobre las novedades del primer semestre de 2025 para que puedas tener una visión general de lo que ha sucedido este año en el ecosistema de datos nacional.
Avances estratégicos, normativos y políticos de carácter transversal
La calidad, interoperabilidad y gobernanza de los datos se han situado en el centro de la agenda tanto nacional como europea, con iniciativas que buscan fomentar un marco sólido para aprovechar el valor de los datos como activo estratégico.
Una de las principales novedades ha sido el lanzamiento de un nuevo paquete digital por parte de la Comisión Europea con el fin de consolidar un ecosistema europeo de datos robusto, seguro y competitivo. Este paquete incluye un ómnibus digital para simplificar la aplicación del Reglamento de inteligencia artificial (IA). Además, se complementa con la nueva Estrategia Unión de Datos (Data Union Strategy) que se articula en torno a tres pilares:
- Ampliar el acceso a datos de calidad para impulsar la inteligencia artificial y la innovación.
- Simplificar el marco normativo existente para reducir barreras y burocracia.
- Proteger la soberanía digital europea frente a dependencias externas.
Su implementación se producirá de forma gradual durante los próximos meses. Será entonces cuando podamos ir apreciando sus efectos sobre nuestro país y el resto de territorios comunitarios.
La actividad en España también se ha visto -y se verá- marcada por el V Plan de Gobierno Abierto 2025-2029, aprobado el pasado octubre. Este plan cuenta con más de 200 iniciativas y aportaciones tanto de la sociedad civil como de administraciones, muchas de ellas relacionadas con la apertura y reutilización de datos. El compromiso de España con los datos abiertos también ha quedado patente en la adhesión a la Carta Internacional de Datos Abiertos, una iniciativa global que promueve la apertura y reutilización de datos públicos como herramientas para mejorar la transparencia, la participación ciudadana, la innovación y la rendición de cuentas.
Junto al impulso de la apertura de datos, también se ha trabajado en el desarrollo de espacios de compartición de datos. En este sentido, se presentó la normativa UNE 0087, que se suma a especificaciones UNE sobre datos y define por primera vez en España los principios y requisitos clave para crear y operar en espacios de datos, mejorando su interoperabilidad y gobernanza.
Más soluciones innovadoras basadas en datos
Los organismos españoles continúan aprovechando el potencial de los datos como motor de soluciones y políticas que optimizan la prestación de servicios a la ciudadanía. Algunos ejemplos son:
- El Ministerio de Sanidad y la iniciativa de ciencia ciudadana, Mosquito Alert, están utilizando inteligencia artificial y análisis de imágenes automatizado para mejorar la detección y seguimiento en tiempo real de mosquitos tigres y especies invasoras.
- La Fundación Valenciaport, junto a otras organizaciones europeas, ha lanzado una herramienta gratuita que permite evaluar los beneficios de instalar sistemas de energía eólica y fotovoltaica en los puertos.
- El Cabildo de la Palma apostó por una agricultura inteligente con la nueva web Smart Agro: los agricultores reciben recomendaciones de riego personalizadas según clima y ubicación. El Cabildo también ha puesto en marcha un visor para hacer seguimiento de la movilidad en la isla.
- El Ayuntamiento de Segovia ha implementado un gemelo digital que centraliza aplicaciones y datos geográficos de alto valor, permitiendo visualizar y analizar la ciudad en un entorno tridimensional interactivo. Mejora la gestión municipal y promueve la transparencia y la participación ciudadana.
- El Ayuntamiento de Vila-real ha lanzado una aplicación digital que integra transporte público, aparcamientos y puntos turísticos en tiempo real. El proyecto busca optimizar la movilidad urbana y fomentar la sostenibilidad mediante tecnología inteligente.
- El Ayuntamiento de Sant Boi ha lanzado un mapa interactivo elaborado con datos abiertos que centraliza información sobre transporte urbano, aparcamiento y opciones sostenibles en una única plataforma, con el fin de mejorar la movilidad urbana.
- Se ha inaugurado la Red Internacional de Investigación DataActive, una iniciativa financiada por el Consejo Superior de Deportes que busca impulsar el diseño de entornos urbanos activos mediante el uso de datos abiertos.
No solo los organismos públicos reutilizan los datos abiertos, desde las universidades también se trabaja en proyectos ligados a la innovación digital basados en información pública:
- Estudiantes de la Universitat de València han diseñado proyectos que utilizan IA y datos abiertos para prevenir desastres naturales.
- Investigadores de la Universidad de Castilla-La Mancha han demostrado que es viable reutilizar modelos de predicción de calidad del aire en distintas zonas de Madrid usando transfer learning.
Además de soluciones, los datos abiertos también sirven para dar forma a otros tipos de productos, incluso esculturas. Es el caso de “El esqueleto del cambio climático”, una figura que presentó el Museo Nacional de Ciencias Naturales, basada en datos sobre los cambios en la temperatura global desde 1880 hasta 2024.
Nuevos portales y funcionalidades para extraer valor de los datos
Las soluciones e innovaciones comentadas anteriormente son posibles gracias a la existencia de múltiples plataformas de apertura o compartición de datos que no dejan de incorporar nuevos conjuntos de datos y funcionalidades para extraerles valor. Algunas de las novedades que hemos visto a este respecto en los últimos meses son:
- El Observatorio Nacional de Tecnología y Sociedad (ONTSI) ha lanzado una nueva web. Una de sus novedades es Ontsi Data, una herramienta para elaborar informes con indicadores tanto de su portal como de terceros.
- El Consejo General del Notariado ha lanzado un Portal Estadístico de la Vivienda, una herramienta abierta con datos fiables y actualizados sobre el mercado inmobiliario en España.
- La Agencia Española de Seguridad Alimentaria y Nutrición (AESAN) ha inaugurado en su web un espacio de datos abiertos con microdatos sobre la composición de alimentos y bebidas comercializados en España.
- El Centro de Investigaciones Sociológicas (CIS) estrenó una web renovada, adaptada a cualquier dispositivo y con un buscador más potente para facilitar el acceso a sus estudios y datos.
- El Instituto Geográfico Nacional (IGN) ha presentado una nueva web del SIOSE, el Sistema de Información sobre Ocupación del Suelo de España, con un diseño más moderno, intuitivo y dinámico. Además, ha puesto a disposición de la ciudadanía una nueva versión de la Información Geográfica de Referencia de Redes de Transporte (IGR-RT), segmentada por provincias y modos de transporte, y disponible en Shapefile y GeoPackage.
- La Plataforma de Asesores AKIS, impulsada por el Ministerio de Agricultura, Pesca y Alimentación, ha puesto en marcha una nueva API de datos abiertos que permite a los usuarios registrados descargar y reutilizar contenidos relacionados con el sector agroalimentario en España.
- La Generalitat de Catalunya estrenó nueva web corporativa que centraliza aspectos clave sobre fondos europeos, contratación pública, transparencia y datos abiertos en un único punto. También ha lanzado una web donde recoge información sobre los sistemas de IA que utiliza.
- PortCastelló ha publicado sus Memorias 2024 en formato open data. Toda la gestión, tráficos, infraestructuras y datos económicos del puerto ahora son accesibles y reutilizables por cualquier ciudadano.
- Investigadores de la Universitat Oberta de Catalunya y del Instituto de Ciencias Fotónicas han creado una biblioteca abierta con datos de 140 biomoléculas. Un recurso pionero que impulsa la ciencia abierta y el uso de datos abiertos en biomedicina.
- También se presentó CitriData, un espacio federado de datos, modelos y servicios en la cadena de valor de los cítricos andaluces. Su objetivo es transformar el sector mediante el uso inteligente y colaborativo de los datos.
Otros organismos están inmersos en el desarrollo de sus novedades. Por ejemplo, próximamente veremos el nuevo Portal de Datos Abiertos de Aguas de Alicante, que permitirá un acceso público a información clave sobre la gestión del agua, fomentando el desarrollo de soluciones basadas en Big Data e IA.
Estos meses también se han presentado avances estratégicos ligados a mejorar la calidad y el uso de los datos, como el Modelo de Gobierno del Dato de la Generalitat Valenciana o la Hoja de Ruta para la Estrategia Provincial de inteligencia artificial de la diputación de Castellón.
Datos.gob.es también presentó una nueva plataforma dirigida a para optimizar tanto la publicación como el acceso a los datos. Si quieres conocer esta y otras novedades de la Iniciativa Aporta en el año 2025, te invitamos a leer este post.
Fomentando el uso de los datos a través de eventos, recursos y acciones ciudadanas
La segunda mitad del año 2025 fue la época elegida por gran cantidad de organismos públicos para lanzar concursos dirigidos a impulsar la reutilización de los datos que publican. Fue el caso de la Junta de Castilla y León, el Ayuntamiento Madrid, el Ayuntamiento de Valencia o la Diputación Foral de Bizkaia. También se ha participado desde nuestro país en eventos internacionales como el Desafío NASA Space Apps.
Entre los eventos donde se ha aprovecho para difundir el poder de los datos abiertos, destacan la Cumbre Global de Open Government Partnership (OGP), las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE), el Congreso Internacional de Transparencia y Gobierno Abierto o la 17ª Conferencia Internacional sobre Reutilización de la Información del Sector Público de ASEDIE, aunque hubo muchos más.
También se ha trabajado en informes que ponen de manifiesto el impacto de los datos en sectores concretos, como el Informe Cátedra DATAGRI 2025 de la Universidad de Córdoba, centrado en el sector agroalimentario. Otros documentos publicados buscan ayudar a mejorar la gestión de los datos, como “Fundamentos del Gobierno del Dato en el contexto de los espacios de datos", liderado por DAMA España, en colaboración con Gaia-X España.
La participación ciudadana también es fundamental para el éxito de la innovación basada en datos. En este sentido, hemos visto tanto actividades dirigidas a impulsar la publicación de datos como a mejorar los ya publicados o su reutilización:
- Desde la Iniciativa Barcelona Open Data se solicitó la ayuda ciudadana para elaborar un ranking de soluciones digitales basadas en datos abiertos para promover el envejecimiento saludable. También organizaron una actividad participativa para mejorar la app iCuida, dirigida a trabajadores del hogar y cuidados. Esta app permite buscar lavabos públicos, refugios climáticos y otros puntos de interés para el día a día de las cuidadoras.
- La Agencia Espacial Española lanzó una encuesta para conocer necesidades y usos de imágenes y datos de Observación de la Tierra en el marco de proyectos estratégicos como la Constelación Atlántica.
En conclusión, las actividades realizadas en el segundo semestre de 2025 ponen de manifiesto la consolidación del ecosistema de datos abiertos en España como un motor de innovación, transparencia y participación ciudadana. Los avances normativos y estratégicos, junto con la creación de nuevas plataformas y soluciones basadas en datos, muestran un compromiso firme por parte de las instituciones y la sociedad en aprovechar la información pública como recurso clave para el desarrollo sostenible, la mejora de servicios y la generación de conocimiento.
Como siempre, este artículo es solo una pequeña muestra de las actividades realizadas. Te invitamos a compartir otras actividades que conozcas a través de los comentarios.