Noticia
España da un paso clave hacia la economía del dato con el lanzamiento del Kit Espacios de Datos, un programa de ayudas que subvencionará la integración de entidades públicas y privadas en espacios de datos sectoriales.
Los espacios de datos son ecosistemas seguros en los que organizaciones, tanto públicas como privadas, comparten información de forma interoperable, bajo reglas comunes y con garantías de privacidad. Éstos permiten desarrollar nuevos productos, mejorar la toma de decisiones y aumentar la eficiencia operativa, en sectores como la salud, la movilidad o la agroalimentación, entre otros.
Hoy, el Ministerio para la Transformación Digital y de la Función Pública, a través de la Secretaría de Estado de Digitalización e Inteligencia Artificial ha publicado en el BOE las bases que regulan la concesión de ayudas a entidades interesadas en incorporarse de forma efectiva a un espacio de datos.
Este programa, que recibe el nombre de “Kit Espacios de Datos”, estará gestionado por Red.es y subvencionará los costes en los que hayan incurrido las entidades beneficiarias para conseguir su incorporación a un espacio de datos elegible, es decir, que cumpla los requisitos fijados en las bases, a contar desde el día de la publicación de estas.
Destinatarios y financiación
Este plan de ayudas está dirigido a entidades tanto públicas como privadas, así como Administraciones Públicas. Dentro de los beneficiarios de estas ayudas se encuentran los participantes, que son aquellas entidades que buscan integrase en estos ecosistemas para compartir y aprovechar datos y servicios.
Para la ejecución de este plan, el Gobierno ha lanzado una ayuda de hasta 60 millones de euros que se repartirán, según el tipo de entidad o el nivel de integración de la siguiente manera:
- Entidades privadas y públicas con actividad económica tendrán una ayuda de hasta 15.000€ en régimen de incorporación efectiva o de hasta 30.000€ si se incorpora como proveedor.
- Por otro lado, las Administraciones Públicas tendrán financiación de hasta 25.000€ si se incorporan de manera efectiva, o de hasta 50.000€ si lo hacen como proveedor.
La incorporación de empresas de diferentes sectores en los espacios de datos generará beneficios tanto a nivel empresarial como para la economía nacional como el aumento de la capacidad de innovación de las empresas beneficiarias, la creación de nuevos productos y servicios basados en el análisis de los datos y la mejora de la eficiencia operativa y toma de decisiones.
Se prevé que la convocatoria se publique durante el cuarto trimestre de 2025. Las subvenciones se solicitarán en régimen de concurrencia no competitiva, por orden de llegada y hasta agotar los fondos disponibles.
Con la publicación en el BOE de estas bases reguladoras se pretende dinamizar el ecosistema de datos en España, fortalecer la competitividad de la economía en el ámbito global y consolidar la sostenibilidad financiera de modelos de negocio innovadores.
Más información:
Bases reguladoras en el BOE.
Página de LinkedIn del Centro de Referencia de Espacios de Datos.
Blog
Imagina una máquina que pueda saber si estás feliz, preocupado o a punto de tomar una decisión, incluso antes de que tú lo sepas con claridad. Aunque suena a ciencia ficción, ese futuro ya está empezando a tomar forma. Gracias a los avances en neurociencia y tecnología, hoy podemos registrar, analizar e incluso predecir ciertos patrones de actividad cerebral. A los datos que se generan a partir de estos registros se les conoce como neurodatos.
En este artículo vamos a explicar este concepto, así como potenciales casos de uso, tomando como base el informe “TechDispatch sobre Neurodatos”, de la Agencia Española de Protección de Datos (AEPD).
¿Qué son los neurodatos y cómo se recolectan?
El término neurodatos se refiere a los datos que se recopilan directamente del cerebro y el sistema nervioso, mediante tecnologías como la electroencefalografía (EEG), la resonancia magnética funcional (fMRI), los implantes neuronales o incluso interfaces cerebro-computadora. En este sentido, su captación se ve impulsada por las neurotecnologías.
De acuerdo con la OCDE, las neurotecnologías se identifican con “dispositivos y procedimientos que se utilizan para acceder, investigar, evaluar, manipular y emular la estructura y función de los sistemas neuronales”. Las neurotecnologías pueden ser invasivas (si requieren interfaces cerebro-ordenador que se implanten quirúrgicamente en el cerebro) o no invasivas, con interfaces que se colocan fuera del cuerpo (como gafas o diademas).
Asimismo, existen dos formas habituales de recopilar los datos:
- Recolección pasiva, donde los datos se captan de manera habitual sin que el sujeto tenga que realizar ninguna actividad específica.
- Recolección activa, donde se recogen datos mientras los usuarios realizan una actividad concreta. Por ejemplo, pensar explícitamente en algo, responder preguntas, realizar tareas físicas o recibir determinados estímulos.
Posibles casos de uso
Una vez se han recolectado los datos en bruto, se procede a su almacenamiento y tratamiento. El tratamiento variará según la finalidad y el uso que se quiera dar a los neurodatos.
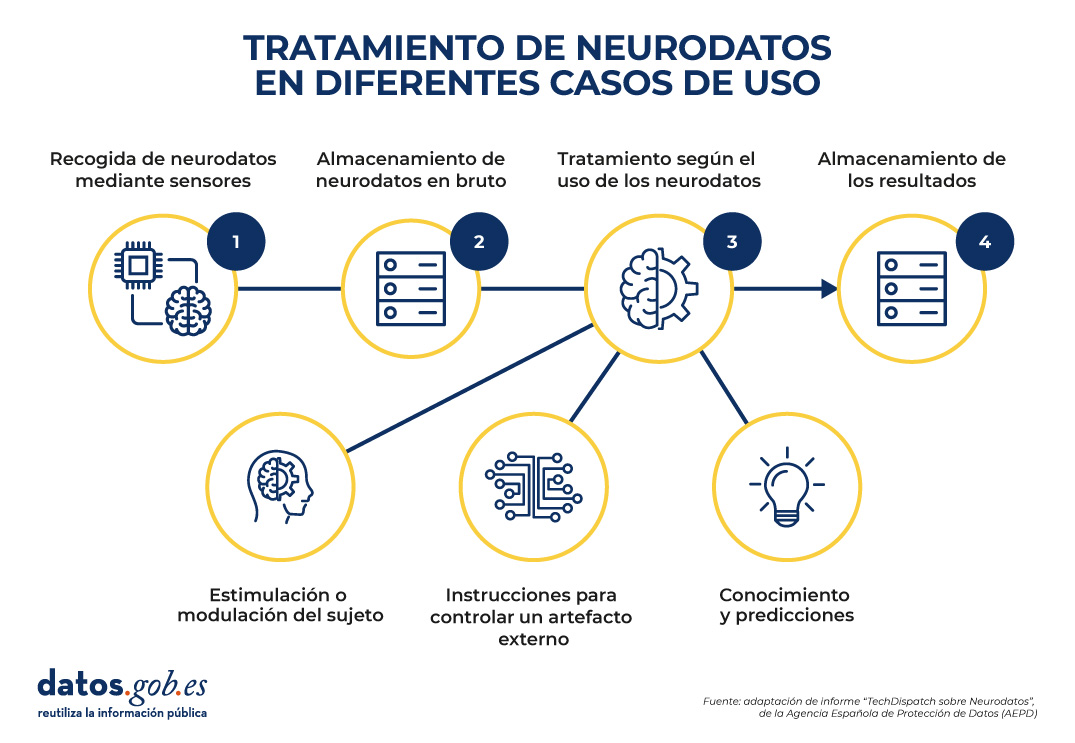
Figura 1. Estructura común para entender el tratamiento de neurodatos en diferentes casos de uso. Fuente: Informe “TechDispatch sobre Neurodatos”, de la Agencia Española de Protección de Datos (AEPD).
Como se puede ver en la imagen anterior, la Agencia Española de Protección de datos ha identificado 3 posibles finalidades:
-
Tratamiento de neurodatos para adquirir conocimiento directo y/o realizar predicciones.
Los neurodatos permiten descubrir patrones que decodifican la actividad cerebral en diversos sectores, como, por ejemplo:
- Salud: los neurodatos facilitan la investigación sobre el funcionamiento del cerebro y el sistema nervioso, lo que permite detectar signos de enfermedades neurológicas o mentales, realizar diagnósticos tempranos y predecir su comportamiento. Esto facilita el tratamiento personalizado desde etapas muy tempranas. Su impacto puede ser notable, por ejemplo, en la lucha contra el Alzheimer, la epilepsia o la depresión.
- Educación: a través de los estímulos cerebrales se puede analizar el rendimiento y los resultados del aprendizaje de los estudiantes. Por ejemplo, se puede medir la atención o el esfuerzo cognitivo del alumnado. Al cruzar estos datos con otros aspectos internos (como las preferencias del alumno) y externos (como las condiciones del aula o la metodología de enseñanza), se pueden tomar decisiones dirigidas a adaptar el ritmo de enseñanza.
- Marketing, economía y ocio: se puede analizar la respuesta cerebral ante ciertos estímulos para mejorar productos de ocio o campañas publicitarias. El objetivo es conocer las motivaciones y preferencias que impactan en la toma de decisiones. También se pueden utilizar en el ámbito laboral, para realizar un seguimiento de los empleados, conocer sus habilidades o determinar cómo funcionan ante la presión.
- Seguridad y vigilancia: los neurodatos se pueden usar para monitorizar factores que afectan a conductores o pilotos, como la somnolencia o la falta de atención, y así prevenir accidentes.
-
Tratamiento de neurodatos para controlar aplicaciones o dispositivos.
Al igual que en el estadio anterior, supone la recolección y análisis de información para la toma de decisiones, pero conlleva además una operación adicional: la generación de acciones a través de los impulsos mentales. Veamos varios ejemplos:
-
Ayudas ortopédicas o protésicas, implantes médicos o vida asistida por el entorno: gracias a tecnologías como las interfaces cerebro-computadora, es posible diseñar prótesis que respondan a la intención del usuario mediante la actividad cerebral. Además, los neurodatos pueden integrarse con sistemas inteligentes del hogar para anticipar necesidades, ajustar el entorno a los estados emocionales o cognitivos del usuario, e incluso emitir alertas ante signos tempranos de deterioro neurológico. Esto puede suponer una mejora de la autonomía de los pacientes y de su calidad de vida.
-
Robótica: se pueden interpretar las señales neuronales del usuario para controlar maquinaria, dispositivos de precisión o aplicaciones sin necesidad de utilizar las manos. Esto permite, por ejemplo, que una persona pueda manejar un brazo robótico o una herramienta quirúrgica simplemente con su pensamiento, lo cual es especialmente valioso en entornos donde se requiere precisión extrema o cuando el operador tiene movilidad reducida.
-
Videojuegos, realidad virtual y metaverso: dado que los neurodatos permiten controlar dispositivos de software, se pueden desarrollar interfaces cerebro-computadora que hagan posible manejar personajes o realizar acciones dentro de un juego, únicamente con la mente, sin necesidad de mandos físicos. Esto no solo incrementa la inmersión del jugador, sino que abre la puerta a experiencias más inclusivas y personalizadas.
- Defensa: los soldados pueden operar sistemas de armas, vehículos no tripulados, drones o robots de desactivación de explosivos en remoto, aumentando la seguridad personal y la eficiencia operativa en situaciones críticas.
-
Tratamiento de neurodatos para la estimulación o modulación del sujeto, logrando un neurofeedback.
En este caso, las señales del cerebro (salidas) se utilizan para generar nuevas señales que retroalimentan al cerebro (como entradas), lo que supone el control de las ondas cerebrales. Es el campo más complejo desde el punto de vista ético, ya que podrían generarse acciones de las que no es consciente el usuario. Algunos ejemplos son:
-
Psicología: los neurodatos tienen potencial para cambiar la forma en que el cerebro responde a ciertos estímulos. Se pueden utilizar, por tanto, como método de terapia para tratar el TDAH (Trastorno por Déficit de Atención e Hiperactividad), la ansiedad, la depresión, la epilepsia, el trastorno del espectro autista, el insomnio o la drogadicción, entre otros.
- Neuromejora: también se pueden utilizar para mejorar las capacidades cognitivas y afectivas en personas sanas. A través del análisis y estimulación personalizada de la actividad cerebral, es posible optimizar funciones como la memoria, la concentración, la toma de decisiones o la gestión emocional.
Retos éticos del uso de los neurodatos
Como hemos visto, aunque el potencial de los neurodatos es enorme, también plantea grandes retos éticos y legales. A diferencia de otros tipos de datos, los neurodatos pueden revelar aspectos profundamente íntimos de una persona, como sus deseos, emociones, miedos o intenciones. Esto abre la puerta a posibles usos indebidos, como la manipulación, la vigilancia encubierta o la discriminación basada en características neuronales. Además, se pueden recopilar en remoto y actuar sobre ellos sin que el sujeto sea consciente de la manipulación.
Esto ha generado un debate sobre la necesidad de nuevos derechos, como los neuroderechos, que buscan proteger la privacidad mental, la identidad personal y la libertad cognitiva. Desde diversas organizaciones internacionales, incluida la Unión Europea, se están tomando medidas para enfrentar estos desafíos y avanzar en la creación de marcos regulatorios y éticos que protejan los derechos fundamentales en el uso de tecnologías neurotecnológicas. Próximamente publicaremos un artículo que profundizará en estos aspectos.
En conclusión, los neurodatos suponen un avance muy prometedor, pero no exento de desafíos. Su capacidad para transformar sectores como la salud, la educación o la robótica es innegable, pero también lo son los desafíos éticos y legales que plantea su uso. A medida que avanzamos hacia un futuro donde mente y máquina están cada vez más conectadas, resulta crucial establecer marcos de regulación que garanticen la protección de los derechos humanos, en especial la privacidad mental y la autonomía individual. De esta forma podremos aprovechar todo el potencial de los neurodatos de manera justa, segura y responsable, en beneficio de toda la sociedad.
Documentación
La compartición de datos o data sharing se ha convertido en un pilar imprescindible para el avance de la analítica y el intercambio de conocimiento, tanto en el ámbito privado como en el público. Las organizaciones de cualquier tamaño y sector –empresas, administraciones públicas, instituciones de investigación, comunidades de desarrolladores o individuos– encuentran un fuerte valor en la capacidad de compartir información de forma segura, fiable y eficiente. Este intercambio no se limita a datos en crudo o datasets estructurados; también se extiende a productos de datos más avanzados, tales como modelos de machine learning entrenados, dashboards analíticos, resultados de experimentos científicos y otros artefactos complejos que generan un gran impacto a través de su reutilización.
En este contexto, la importancia de la gobernanza de estos recursos cobra un papel crítico. No es suficiente con disponer de un método para mover ficheros de un sitio a otro; es necesario garantizar aspectos clave como el control de acceso (quién puede leer o modificar cierto recurso), la trazabilidad y la auditoría (saber quién ha accedido, cuándo y con qué finalidad) o el cumplimiento de regulaciones o estándares, especialmente en entornos empresariales y gubernamentales.
Con el fin de unificar estos requisitos, Unity Catalog surge como un almacén de metadatos (metastore) de próxima generación, pensado para centralizar y simplificar la gobernanza de datos y recursos de datos. Originalmente, Unity Catalog formaba parte de los servicios ofrecidos por la plataforma Databricks, pero el proyecto ha dado un salto a la comunidad de código abierto para convertirse en un estándar de referencia. Esto implica que ahora es posible utilizarlo, modificarlo y, en definitiva, contribuir a su evolución desde un entorno libre y colaborativo. Con ello, se espera que más organizaciones adopten sus modelos de catálogo y compartición, impulsando la reutilización de datos y la creación de flujos analíticos e innovaciones tecnológicas.

Fuente: https://docs.unitycatalog.io/
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Objetivos
En este ejercicio, aprenderemos a configurar Unity Catalog, una herramienta que nos ayuda a organizar y compartir datos en la nube de manera segura. Aunque utilizaremos algo de código, explicaremos cada paso para que incluso personas con poca experiencia en programación puedan seguirlo a través de un laboratorio práctico.
Trabajaremos con un escenario realista donde gestionaremos datos sobre transporte público en diferentes ciudades. Crearemos catálogos de datos, configuraremos una base de datos y aprenderemos a interactuar con la información usando herramientas como Docker, Apache Spark y MLflow.
Nivel de dificultad: Intermedio.

Figura 1. Esquema Unity Catalog
Recursos Necesarios
En esta sección explicaremos los requisitos previos y recursos necesarios para poder desarrollar este laboratorio. El laboratorio está pensado para desarrollarse en un ordenador personal estándar (Windows, MacOS, Linux).
Adicionalmente utilizaremos las siguientes herramientas y entornos de trabajo:
- Docker Desktop: Docker es una herramienta que nos permite ejecutar aplicaciones en un entorno aislado llamado contenedor. Un contenedor es como una "caja" que contiene todo lo necesario para que una aplicación funcione correctamente, sin importar el sistema operativo que estés usando.
- Visual Studio Code: Nuestro entorno de trabajo será un Notebook Python que ejecutaremos y manipularemos a través del editor de código ampliamente utilizado Visual Studio Code (VS Code).
- Unity Catalog: Es una herramienta de gobernanza de datos que permite organizar y controlar el acceso a recursos como tablas, volúmenes de datos, funciones o modelos de machine learning. A lo largo del laboratorio, utilizaremos su versión open source, que puede desplegarse localmente, para aprender a gestionar catálogos de datos con control de permisos, trazabilidad y estructura jerárquica. Unity Catalog actúa como un metastore centralizado, facilitando la colaboración y la reutilización de datos de forma segura.
- Amazon Web Services: AWS será el proveedor cloud que utilizaremos para alojar ciertos datos del laboratorio, en concreto los datos en crudo (como archivos JSON) que gestionaremos mediante volúmenes de datos. Aprovecharemos su servicio Amazon S3 para almacenar estos archivos y configuraremos las credenciales y permisos necesarios para que Unity Catalog pueda interactuar con ellos de forma controlada.
Desarrollo del ejercicio
A lo largo del ejercicio, los participantes desplegarán la aplicación, comprenderán su arquitectura e irán construyendo un catálogo de datos paso a paso, aplicando buenas prácticas de organización, control de acceso y trazabilidad.
Despliegue y primeros pasos
- Clonamos el repositorio de Unity Catalog y lo levantamos con Docker.
- Exploramos su arquitectura: un backend accesible por API y CLI, y una interfaz gráfica intuitiva.
- Navegamos por los recursos que gestiona Unity Catalog: catálogos, esquemas, tablas, volúmenes, funciones y modelos.
Figura 2. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo levantar la aplicación, sus componentes principales, y cómo empezar a interactuar con ella desde distintos puntos: web, API y CLI.
Organización de recursos
- Configuramos una base de datos MySQL externa como repositorio de metadatos.
- Creamos catálogos para representar distintas ciudades y esquemas para distintos servicios públicos.

Figura 3. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo estructurar el gobierno de datos a distintos niveles (ciudad, servicio, dataset) y cómo gestionar los metadatos de forma centralizada y persistente.
Construcción de datos y uso real
- Creamos tablas estructuradas para representar rutas, autobuses o paradas.
- Cargamos datos reales en estas tablas usando PySpark.Habilitamos un bucket en AWS S3 como almacenamiento de datos en crudo (volúmenes).
- Subimos ficheros JSON con eventos de telemetría y los gobernamos desde Unity Catalog.
Figura 4. Esquema
¿Qué aprenderemos aquí?
Cómo convivir con distintos tipos de datos (estructurados y no estructurados), y cómo integrarlos con fuentes externas (como AWS S3).
Funciones reutilizables y modelos de IA
- Registramos funciones personalizadas (como el cálculo de distancias) reutilizables desde el catálogo.
- Creamos y registramos modelos de machine learning con MLflow.
- Ejecutamos predicciones desde Unity Catalog como si fueran cualquier otro recurso del ecosistema.
Figura 5. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo ampliar el gobierno de datos a funciones y modelos, y cómo facilitar su reutilización y trazabilidad en entornos colaborativos.
Resultados y conclusiones
Como resultado de este laboratorio práctico, vamos a poner conocer la herramienta Unity Catalog como plataforma abierta para la gobernanza de datos y recursos de datos como modelos de machine learning. Exploraremos, además, el contexto de un caso de uso concreto y con un ecosistema de herramientas similar al que podemos encontrar en una organización real, sus capacidades, su modo de despliegue y su uso.
Mediante este ejercicio configuraremos y utilizaremos Unity Catalog para organizar datos de transporte público. En concreto, podrás:
- Aprender a instalar herramientas como Docker o Spark.
- Crear catálogos, esquemas y tablas en Unity Catalog.
- Cargar datos y almacenarlos en un bucket de Amazon S3.
- Implementar un modelo de machine learning con MLflow.
Veremos, en los próximos años, si este tipo de herramientas alcanzan el nivel de estandarización necesario para transformar la forma en que se administran y comparten los recursos de datos en múltiples sectores.
¡Te animamos a realizar más ejercicios de ciencia de datos! Accede al repositorio aquí
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Las ciudades concentran más de dos tercios de la población europea y consumen alrededor del 80 % de la energía. En este contexto, el cambio climático está teniendo un impacto particularmente severo en los entornos urbanos, no solo por su densidad, sino por sus características constructivas, su metabolismo energético y la escasez de vegetación en muchas zonas consolidadas. Uno de los efectos más visibles y preocupantes es el fenómeno conocido como isla de calor urbana (UHI, por sus siglas en inglés).
Las islas de calor se producen cuando la temperatura en las zonas urbanas es significativamente más alta que en las zonas rurales o periurbanas cercanas, especialmente durante la noche. Este diferencial térmico puede superar fácilmente los cinco grados centígrados en determinadas condiciones. Las consecuencias de este fenómeno van más allá del malestar térmico: afecta directamente a la salud, la calidad del aire, el consumo energético, la biodiversidad urbana y la equidad social.
En los últimos años, la disponibilidad de datos abiertos —especialmente datos geoespaciales— ha permitido caracterizar, mapear y analizar las islas de calor urbanas con una precisión sin precedentes. Este artículo explora cómo estos datos pueden ser utilizados para diseñar soluciones urbanas adaptadas al cambio climático, tomando como eje la mitigación de las islas de calor.
Qué son las islas de calor urbanas y por qué se producen
Una isla de calor urbana es un fenómeno térmico que se genera cuando la infraestructura urbana absorbe y retiene más calor que las zonas no urbanizadas. Esta acumulación de calor se debe a varios factores que actúan de forma sinérgica:
- La presencia de materiales como asfalto, hormigón o ladrillo, que tienen una alta capacidad de absorción térmica.
- La escasez de vegetación, que limita el enfriamiento natural por evapotranspiración.
- La morfología urbana (altura y disposición de los edificios), que puede obstaculizar la ventilación natural.
- Las emisiones de calor derivadas de la actividad humana (vehículos, climatización o procesos industriales).
- La impermeabilización del suelo, que impide la infiltración de agua y reduce el efecto termorregulador del subsuelo húmedo.
El resultado es que muchas ciudades, especialmente en latitudes mediterráneas, se convierten en auténticos sumideros de calor durante los meses cálidos. Este fenómeno no afecta por igual a todos los barrios: los más vulnerables son, con frecuencia, los más densamente construidos, con menos arbolado y con una mayor proporción de población en situación de pobreza energética.

Figura 1. Elemento ilustrativo sobre las islas de calor.
El papel clave de los datos para entender y combatir las islas de calor
Para intervenir eficazmente en las islas de calor es necesario saber dónde, cuándo y cómo se producen. A diferencia de otros riesgos naturales, el efecto isla de calor no es visible a simple vista, y su intensidad varía según la hora del día, la época del año y las condiciones meteorológicas concretas. Por tanto, requiere una base de conocimiento sólida y dinámica, que solo se puede construir mediante la integración de datos diversos, actualizados y territorializados.
En este punto, los datos geoespaciales abiertos son una herramienta fundamental. A través de imágenes satelitales, mapas urbanos, datos meteorológicos, cartografía catastral y otros conjuntos accesibles al público, es posible construir modelos térmicos urbanos, identificar zonas críticas, estimar exposiciones diferenciales y evaluar el impacto de las medidas adoptadas.
A continuación, se detallan las principales categorías de datos que permiten abordar el fenómeno de las islas de calor desde una perspectiva territorial e interdisciplinar.
Tipologías de datos geoespaciales aplicables al estudio del fenómeno
1. Datos satelitales de observación de la Tierra
Los sensores térmicos embarcados en satélites como Landsat 8/9 (NASA/USGS) o Sentinel-3 (Copernicus) permiten generar mapas de temperatura superficial urbana con resoluciones que oscilan entre los 30 y los 1.000 metros. Aunque estas imágenes tienen limitaciones espaciales y temporales, son suficientes para detectar patrones y tendencias, sobre todo si se combinan con series temporales.
Estos datos, accesibles a través de plataformas como el Copernicus Open Access Hub o el USGS EarthExplorer, son fundamentales para realizar estudios comparativos entre ciudades o para observar la evolución temporal de una misma zona.
2. Datos meteorológicos urbanos
La red de estaciones de AEMET, junto con otras estaciones automáticas gestionadas por comunidades autónomas o ayuntamientos, permite analizar la evolución de las temperaturas del aire en diferentes puntos urbanos. En algunos casos, también se dispone de sensores ciudadanos o redes de sensores distribuidos en el espacio urbano que permiten generar mapas de calor en tiempo real con alta resolución.
3. Cartografía urbana y modelos digitales del terreno
Los modelos digitales de superficie (DSM), modelos digitales del terreno (DTM) y cartografías derivadas del LIDAR permiten estudiar la morfología urbana, la densidad edificatoria, la orientación de las calles, la pendiente del terreno y otros factores que afectan a la ventilación natural y la acumulación de calor. En España, estos datos son accesibles a través del Centro Nacional de Información Geográfica (CNIG).
4. Bases de datos de cobertura y uso de suelo
Las bases de datos como Corine Land Cover del Programa Copernicus, o los mapas de ocupación del suelo a nivel autonómico permiten distinguir entre zonas urbanizadas, zonas verdes, superficies impermeables y cuerpos de agua. Esta información es clave para calcular el grado de artificialización de una zona y su relación con el balance térmico.
5. Inventarios de arbolado y espacios verdes
Algunos ayuntamientos publican en sus portales de datos abiertos el inventario detallado del arbolado urbano, parques y jardines. Estos datos, georreferenciados, permiten analizar el efecto de la vegetación sobre el confort térmico, así como planificar nuevas plantaciones o corredores verdes.
6. Datos socioeconómicos y de vulnerabilidad
Los datos del Instituto Nacional de Estadística (INE), junto con los sistemas de información social de comunidades autónomas y ayuntamientos, permiten identificar los barrios más vulnerables desde el punto de vista social y económico. Su cruce con los datos térmicos permite incorporar una dimensión de justicia climática en la toma de decisiones.
Aplicaciones prácticas: cómo se utilizan los datos abiertos para actuar
Una vez reunidos e integrados los datos relevantes, se pueden aplicar múltiples estrategias de análisis que permiten fundamentar políticas públicas y proyectos urbanos con criterios de sostenibilidad y equidad. A continuación, se describen algunas de las principales aplicaciones.
- Cartografía de zonas de calor y mapas de vulnerabilidad: el uso conjunto de imágenes térmicas, datos meteorológicos y capas urbanas permite generar mapas de intensidad de isla de calor a nivel de barrio o manzana. Si estos mapas se combinan con indicadores sociales, demográficos y de salud pública, es posible construir mapas de vulnerabilidad térmica, que prioricen la intervención en zonas donde se cruzan altas temperaturas y altos niveles de riesgo social. Estos mapas permiten, por ejemplo:
- Identificar barrios prioritarios para reverdecimiento urbano.
- Planificar rutas de evacuación o zonas de sombra durante olas de calor.
- Determinar la localización óptima de refugios climáticos.
- Evaluación del impacto de soluciones basadas en la naturaleza: los datos abiertos también permiten monitorizar los efectos de determinadas actuaciones urbanas. Por ejemplo, mediante series temporales de imágenes satelitales o sensores de temperatura, se puede evaluar cómo la creación de un parque o la plantación de arbolado en una calle ha modificado la temperatura superficial. Este enfoque de evaluación ex post permite justificar inversiones públicas, ajustar diseños y escalar soluciones eficaces a otras zonas con condiciones similares.
- Modelización urbana y simulaciones climáticas: los modelos urbanos tridimensionales, construidos a partir de datos abiertos LIDAR o cartografía catastral, permiten simular el comportamiento térmico de un barrio o una ciudad bajo diferentes escenarios climáticos y urbanísticos. Estas simulaciones, combinadas con herramientas como ENVI-met o Urban Weather Generator, son fundamentales para apoyar la toma de decisiones en planeamiento urbano.
Estudios y análisis existentes sobre islas de calor urbanas: qué se ha hecho y qué podemos aprender
Durante la última década se han realizado múltiples estudios en España y Europa que muestran cómo los datos abiertos, especialmente los de carácter geoespacial, permiten caracterizar y analizar el fenómeno de las islas de calor urbanas. Estos trabajos son fundamentales no solo por sus resultados específicos, sino porque ilustran metodologías replicables y escalables. Seguidamente, se describen algunos de los más relevantes.
Estudio de la Universidad Politécnica de Madrid sobre temperatura superficial en Madrid
Un equipo del Departamento de Ingeniería Topográfica y Cartografía de la UPM analizó la evolución de la temperatura superficial en el municipio de Madrid utilizando imágenes térmicas del satélite Landsat 8 en el periodo estival. El estudio se centró en detectar los cambios espaciales de las zonas más cálidas y relacionarlos con el uso del suelo, la vegetación urbana y la densidad edificatoria.
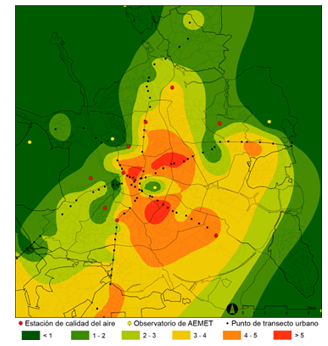
Figura 2. Imagen ilustrativa. Fuente: generada con IA
Metodología:
Se aplicaron técnicas de teledetección para extraer la temperatura superficial a partir del canal térmico TIRS del Landsat. Posteriormente, se realizó un análisis estadístico de correlación entre los valores térmicos y variables como el NDVI (índice de vegetación), el tipo de cobertura del suelo (datos CORINE) y la morfología urbana.
Resultados principales:
Las zonas con mayor densidad edificatoria, como los barrios del centro y del sur, mostraban temperaturas superficiales más altas. Por su parte, la presencia de parques urbanos reducía entre 3 y 5 °C la temperatura de su entorno inmediato. Se confirmó que el efecto isla de calor se intensifica en horarios nocturnos, especialmente durante olas de calor persistentes.
Este tipo de análisis es especialmente útil para diseñar estrategias de reverdecimiento urbano y para justificar intervenciones en barrios vulnerables.
Atlas de vulnerabilidad climática de Barcelona
El Ayuntamiento de Barcelona, en colaboración con expertos en salud pública y geografía urbana, desarrolló un Atlas de vulnerabilidad climática que incluye mapas detallados de exposición al calor, sensibilidad poblacional y capacidad adaptativa. El objetivo era orientar políticas municipales frente al cambio climático, especialmente en el ámbito de salud y servicios sociales.

Figura 3. Imagen que contiene cerca, exterior, edificios y pasto. Fuente: generada con IA
Metodología:
El atlas se elaboró combinando datos abiertos y administrativos a nivel de sección censal. Se analizaron tres dimensiones: exposición (datos de temperatura del aire y superficie), sensibilidad (edad avanzada, densidad, morbilidad) y capacidad adaptativa (acceso a zonas verdes, calidad de la vivienda, equipamientos). Los indicadores se normalizaron y combinaron mediante análisis espacial multicriterio para generar un índice de vulnerabilidad climática. El resultado permitió localizar los barrios con mayor riesgo frente al calor extremo y orientar medidas municipales.
Resultados principales:
A partir del atlas, se diseñó la red de “refugios climáticos”, que incluye bibliotecas, centros cívicos, escuelas y parques acondicionados, activados durante los episodios de calor extremo. La selección de estos espacios se basó directamente en los datos del atlas.
Análisis multitemporal del efecto isla de calor en Sevilla
Investigadores de la Universidad de Sevilla utilizaron datos satelitales de Sentinel-3 y Landsat 8 para estudiar la evolución del fenómeno de isla de calor en la ciudad entre 2015 y 2022. El objetivo fue evaluar la eficacia de ciertas actuaciones urbanas —como el plan “Reverdece tu barrio”— y anticipar los efectos del cambio climático en la ciudad.
Metodología:
Se emplearon imágenes térmicas y datos NDVI para calcular diferencias de temperatura entre áreas urbanas y zonas rurales circundantes. También se aplicaron técnicas de clasificación supervisada para identificar usos del suelo y su evolución. Se utilizaron datos abiertos de inventarios de arbolado y mapas de sombra urbana para interpretar los resultados.
Resultados principales:
Las actuaciones puntuales de renaturalización tienen un impacto local muy positivo, pero su efecto sobre el conjunto de la ciudad es limitado si no se integran en una estrategia de escala metropolitana. El estudio concluyó que una red continua de vegetación y cuerpos de agua es más eficaz que actuaciones aisladas.
Comparativa europea del proyecto Urban Heat Island Atlas (Copernicus)
Aunque no es un estudio español, el visor desarrollado por Copernicus para el programa europeo Urban Atlas ofrece un análisis comparativo entre ciudades europeas.
Metodología:
El visor integra imágenes térmicas de Sentinel-3, datos de ocupación del suelo y cartografía urbana para evaluar la severidad del efecto isla de calor.

Figura 4. Imagen ilustrativa
Ilustración: Infografía que muestra los principales factores que provocan el efecto isla de calor urbano (UHI). Las zonas urbanas retienen el calor debido a los edificios altos, las superficies impermeables y los materiales que retienen el calor, mientras que las zonas verdes son más frescas Fuente: Urban heat islands.
Resultados principales:
Este tipo de herramientas permite a ciudades de menor tamaño disponer de una primera aproximación del fenómeno sin necesidad de desarrollar modelos propios. Al estar basado en datos abiertos y gratuitos, el visor permite consultas directas por parte de técnicos y ciudadanía.
Limitaciones y desafíos actuales
A pesar del avance en la apertura de datos, todavía existen importantes retos:
- Desigualdad territorial: no todas las ciudades disponen de la misma calidad y cantidad de datos.
- Actualización irregular: algunos conjuntos se publican de forma puntual y no se actualizan regularmente.
- Escasa granularidad: los datos a menudo están agregados por distritos o secciones censales, lo que dificulta intervenciones a escala de calle.
- Falta de capacidades técnicas: muchas administraciones locales no cuentan con personal especializado en análisis geoespacial.
- Poca conexión con la ciudadanía: el conocimiento generado a partir de los datos no siempre se traduce en acciones visibles o comprensibles para la población.
Conclusión: construir resiliencia climática desde el dato geoespacial
Las islas de calor urbanas no son un fenómeno nuevo, pero en el contexto del cambio climático adquieren una dimensión crítica. Las ciudades que no planifiquen con base en datos se verán cada vez más expuestas a episodios de calor extremo, con impactos desiguales entre su población.
Los datos abiertos —y en particular los datos geoespaciales— ofrecen una oportunidad estratégica para transformar esta amenaza en una palanca de cambio. Con ellos podemos identificar, anticipar, intervenir y evaluar. Pero para que esto suceda, es imprescindible:
- Consolidar infraestructuras de datos accesibles, actualizadas y de calidad.
- Fomentar la colaboración entre niveles de gobierno, centros de investigación y ciudadanía.
- Capacitar a los técnicos municipales en el uso de herramientas geoespaciales.
- Promover una cultura de la toma de decisiones basada en evidencia y sensibilidad climática.
El dato no sustituye a la política, pero permite fundamentarla, mejorarla y hacerla más equitativa. En un escenario de calentamiento global, contar con datos geoespaciales abiertos es una herramienta clave para hacer que nuestras ciudades sean más habitables y mejor preparadas para el futuro.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El deporte siempre se ha caracterizado por generar muchos datos, estadísticas, gráficos… Pero acumular cifras no es suficiente. Es necesario analizar los datos, sacar conclusiones y tomar decisiones en base a ellos. Las ventajas de compartir datos en este sector van más allá de lo meramente deportivo, teniendo un impacto positivo en la salud y en el ámbito económico. van más allá de lo meramente deportivo, teniendo un impacto positivo en la salud y en el ámbito económico.
La inteligencia artificial (IA) ha llegado también al sector del deporte profesional y su capacidad para procesar enormes cantidades de datos ha abierto la puerta a aprovechar al máximo el potencial de toda esa información. El Manchester City, uno de los clubes de fútbol más conocidos de la Premier League británica, fue uno de los pioneros en utilizar la inteligencia artificial para mejorar su desempeño deportivo: utiliza algoritmos de IA para la selección de nuevos talentos y ha colaborado en el desarrollo de WaitTime, una plataforma de inteligencia artificial que gestiona la asistencia de multitudes en grandes recintos deportivos y de ocio. En España, el Real Madrid, por ejemplo, incorporó el uso de la inteligencia artificial hace unos años e impulsa foros sobre el impacto de la IA en el deporte.
Los sistemas de inteligencia artificial analizan volúmenes extensos de datos recopilados durante entrenamientos y competiciones, y son capaces de proporcionar evaluaciones detalladas sobre la efectividad de las estrategias y oportunidades de optimización. Además, es posible desarrollar alertas sobre riesgos de lesiones, permitiendo establecer medidas de prevención, o crear planes de entrenamiento personalizados que se adaptan automáticamente a cada deportista en función de sus necesidades individuales. Estas herramientas han modificado por completo la preparación deportiva contemporánea de alto nivel. Es este post vamos a repasar algunos de estos casos de uso.
De la simple observación a una gestión completa del dato para optimizar resultados
Los métodos tradicionales de evaluación deportiva han evolucionado hacia sistemas tecnológicos altamente especializados. Las herramientas de inteligencia artificial y aprendizaje automático procesan volúmenes masivos de información durante entrenamientos y competiciones, convirtiendo estadísticas, datos biométricos y contenido audiovisual en insights estratégicos para la gestión de la preparación y la salud de deportistas.
Los sistemas de análisis de rendimiento en tiempo real constituyen una de las implementaciones más consolidadas en el sector deportivo. Para recopilar estos datos, es habitual ver a los deportistas entrenar con bandas o chalecos que monitorizan en tiempo real diferentes parámetros. Tanto estos como otros dispositivos y sensores, registran movimientos, velocidades y datos biométricos. La frecuencia cardiaca, la velocidad o la aceleración son algunos de los datos más habituales. Los algoritmos de IA procesan esta información, generando resultados inmediatos que ayudan a optimizar programas de entrenamiento personalizados para cada deportista y adaptaciones tácticas, identificando patrones para localizar áreas de mejora.
En este sentido, las plataformas de inteligencia artificial deportiva evalúan tanto el desempeño individual como la dinámica colectiva en el caso de los deportes de equipos. Para evaluar el área táctica se analizan distintos tipos de datos según la modalidad deportiva. En disciplinas de resistencia se examina la velocidad, la distancia, el ritmo o la potencia, mientras que en los deportes de equipo cobran especial relevancia datos sobre la posición de los jugadores o la precisión en los pases o tiros.
Otro avance son las cámaras con IA, que permiten seguir la trayectoria de los jugadores en el campo y los movimientos de los distintos elementos, como el balón en los deportes de pelota. Estos sistemas generan multitud de datos sobre posiciones, desplazamientos y patrones de juego. El análisis de estos conjuntos de datos históricos permite identificar fortalezas y vulnerabilidades estratégicas tanto propias como de los oponentes. Esto ayuda a generar diferentes opciones tácticas y mejorar la toma de decisiones antes de una competición.
Salud y bienestar de las personas deportistas
Los sistemas de prevención de lesiones deportivas analizan datos históricos y métricas en tiempo real. Sus algoritmos identifican patrones de riesgo de lesiones, lo que permite tomar medidas preventivas personalizadas para cada atleta. En el caso del fútbol, equipos como el Manchester United, Liverpool, Valencia CF y Getafe CF implementan estas tecnologías desde hace varios años.
Además de los datos que hemos visto anteriormente, las plataformas de monitorización deportiva también registran variables fisiológicas de forma continua: frecuencia cardíaca, patrones de sueño, fatiga muscular y biomecánica del movimiento. Los dispositivos wearables con capacidades de inteligencia artificial detectan indicadores de fatiga, desequilibrios o estrés físico que preceden a lesiones. Con estos datos, los algoritmos predicen patrones que detectan riesgos y facilitan actuar de manera preventiva, ajustando entrenamientos o desarrollando programas específicos de recuperación antes de que se produzca una lesión. De esta forma se pueden calibrar cargas de entrenamiento, volumen de repeticiones, intensidad y períodos de recuperación según perfiles individuales. Este mantenimiento predictivo para deportistas es especialmente relevante para equipos y clubes en los que los atletas constituyen no solo activos deportivos, sino también económicos. Además, estos sistemas también optimizan procesos de rehabilitación deportiva, permitiendo reducir los tiempos de recuperación en lesiones musculares hasta un 30% y proporciona predicciones sobre riesgo de reincidencia.
Si bien no son infalibles, los datos indican que estas plataformas predicen aproximadamente 50% de lesiones durante temporadas deportivas, aunque no pueden pronosticar cuándo se van a producir. La aplicación de la IA al cuidado de la salud en el deporte contribuye así a la extensión de las carreras deportivas profesionales, facilitando un rendimiento óptimo y el bienestar atlético del deportista a largo plazo.
Mejora de la experiencia del público
La inteligencia artificial también está revolucionando la forma en que los aficionados disfrutan del deporte, tanto en estadios como desde casa. Gracias a sistemas de procesamiento de lenguaje natural (NLP), los espectadores pueden seguir comentarios y subtítulos en tiempo real, facilitando el acceso a personas con discapacidad auditiva o hablantes de otras lenguas. El Manchester City ha incorporado recientemente esta tecnología para la generación de subtítulos en tiempo real en las pantallas de su estadio. Estas aplicaciones han llegado también a otras disciplinas deportivas: IBM Watson ha desarrollado una funcionalidad que permite a los aficionados de Wimbledon ver los vídeos con comentarios destacados y subtítulos generados por IA.
Además, la IA optimiza la gestión de grandes aforos mediante sensores y algoritmos predictivos, agilizando el acceso, mejorando la seguridad y personalizando servicios como la ubicación de asientos. Incluso en las retransmisiones, herramientas impulsadas por IA ofrecen estadísticas instantáneas, highlights automatizados y cámaras inteligentes que siguen la acción sin intervención humana, haciendo la experiencia más inmersiva y dinámica. La NBA utiliza Second Spectrum, un sistema que combina cámaras con IA para analizar movimientos de jugadores y crear visualizaciones, como rutas de pases o probabilidades de tiro. Otros deportes, como el golf o la Fórmula 1, también utilizan herramientas similares que mejoran la experiencia de los aficionados.
La privacidad de los datos y otros desafíos
La aplicación de la IA en el deporte plantea también importantes desafíos éticos. La recopilación y análisis de información biométrica genera dudas sobre la seguridad y protección de datos personales de los deportistas, por lo que es necesario establecer protocolos que garanticen la gestión del consentimiento, así como la propiedad de dichos datos.
La equidad representa otra preocupación, ya que la aplicación de la inteligencia artificial otorga ventajas competitivas a los equipos y organizaciones con mayores recursos económicos, lo que puede contribuir a perpetuar desigualdades.
A pesar de estos desafíos, la inteligencia artificial ha transformado radicalmente el panorama deportivo profesional. El futuro del deporte parece estar unido a la evolución de esta tecnología. Su aplicación promete seguir elevando el rendimiento de los atletas y la experiencia del público, aunque es necesario superar algunos desafíos.
Blog
Imagina que quieres saber cuántas terrazas hay en tu barrio, cómo evolucionan los niveles de polen del aire que respiras cada día o si el reciclaje en tu ciudad está funcionando bien. Toda esa información existe en las bases de datos de tu ayuntamiento, pero se encuentra entre hojas de cálculo y documentos técnicos que solo los expertos sabían interpretar.
Aquí es donde entran en juego las iniciativas de visualización de datos abiertos: transforman esos números aparentemente fríos en historias que cualquier persona puede entender de un vistazo. Un gráfico colorido que muestra la evolución del tráfico en tu calle, un mapa interactivo con las zonas verdes de tu ciudad, o una infografía que explica en qué se gasta el presupuesto municipal. Estas herramientas convierten la información pública en algo cercano, útil y, además, comprensible para toda la ciudadanía.
Además, las ventajas de este tipo de soluciones no son solo para la ciudadanía, sino que también benefician a la Administración que realiza el ejercicio, porque permite:
- Detectar y corregir errores en los datos.
- Incorporar nuevos conjuntos al portal.
- Disminuir el número de preguntas del ciudadano.
- Generar más confianza por parte de la sociedad.
Por tanto, visualizar datos abiertos permite acercar la Administración a la ciudadanía, facilita la toma de decisiones informadas, ayuda a las Administraciones Públicas a mejorar su oferta de datos abiertos y permite crear una sociedad más participativa donde todos podemos entender mejor cómo funciona el sector público. En este post, te presentamos algunos ejemplos de iniciativas de visualización de open data en portales de datos abiertos autonómicos y municipales.
Visualiza Madrid: acercando los datos a la ciudadanía
El portal de datos abiertos del Ayuntamiento de Madrid ha desarrollado la iniciativa "Visualiza Madrid", un proyecto que nace con el objetivo específico de hacer que los datos abiertos y su potencial lleguen a la ciudadanía en general, trascendiendo los perfiles técnicos especializados. Tal y como explicó Ascensión Hidalgo Bellota, Subdirectora general de Transparencia del Ayuntamiento de Madrid, durante el IV Encuentro Nacional de Datos Abiertos, “esta iniciativa responde a la necesidad de democratizar el acceso a la información pública”.
Actualmente, Visualiza Madrid cuenta con 29 visualizaciones que abarcan diferentes temáticas de interés ciudadano, desde información sobre terrazas de hostelería hasta gestión de residuos y análisis del tráfico urbano. Esta diversidad temática demuestra la versatilidad de las visualizaciones como herramienta para comunicar información de sectores muy diversos de la administración pública.
Además, la iniciativa ha recibido este año un reconocimiento externo a través de los premios Audaz 2025, una iniciativa del capítulo español de la Red Académica de Gobierno Abierto (RAGA España).
Castilla y León: análisis integral de datos regionales
La Junta de Castilla y León también ha desarrollado un portal especializado en análisis y visualizaciones que destaca por su enfoque integral hacia la presentación de datos autonómicos. Su plataforma de visualizaciones ofrece una aproximación sistemática al análisis de información regional, permitiendo a los usuarios explorar diferentes dimensiones de la realidad de Castilla y León a través de herramientas interactivas y dinámicas.
Esta iniciativa permite presentar información compleja de manera estructurada y comprensible, facilitando tanto el análisis académico como el uso ciudadano de los datos. La plataforma integra diferentes fuentes de información autonómica, creando un ecosistema coherente de visualizaciones que permite obtener una visión panorámica de diversos aspectos de la gestión regional. Entre las temáticas que ofrece podemos mencionar datos de turismo, del mercado laboral o de la ejecución de los presupuestos. Todas las visualizaciones están realizadas con conjuntos de datos abiertos del portal autonómico de Castilla y León.
El enfoque de Castilla y León demuestra cómo las visualizaciones pueden servir como herramienta de análisis territorial, proporcionando insights valiosos sobre dinámicas económicas, sociales y demográficas que resultan fundamentales para la planificación y evaluación de políticas públicas regionales.
Canarias: integración tecnológica con widgets interactivos
Por otro lado, el Gobierno de Canarias ha apostado por una estrategia innovadora mediante la implementación de widgets que permiten la integración de visualizaciones de datos abiertos del Instituto Canario de Estadística (ISTAC) en diferentes plataformas y contextos. Esta aproximación tecnológica representa un salto cualitativo en la distribución y reutilización de visualizaciones de datos públicos.
Los widgets desarrollados por Canarias facilitan que terceros puedan incorporar visualizaciones oficiales en sus propias aplicaciones, sitios web o análisis, ampliando exponencialmente el alcance y la utilidad de los datos abiertos canarios. Esta estrategia no solo multiplica los puntos de acceso a la información pública, sino que también fomenta la creación de un ecosistema colaborativo donde diferentes actores pueden beneficiarse y contribuir al valor de los datos abiertos.
La iniciativa canaria ilustra cómo la tecnología puede ser utilizada para crear soluciones escalables y flexibles que maximicen el impacto de las inversiones en visualización de datos abiertos, estableciendo un modelo replicable para otras administraciones que busquen amplificar el alcance de sus iniciativas de transparencia.
Lecciones aprendidas y mejores prácticas
A modo de ejemplo, los casos analizados revelan patrones comunes que pueden servir como guía para futuras iniciativas. La orientación hacia la ciudadanía general, más allá de usuarios técnicos especializados, emerge como un factor de oportunidad para el éxito de estas plataformas. Para mantener el interés y la relevancia de las visualizaciones es importante ofrecer diversidad temática y actualizar los datos regularmente.
La integración tecnológica y la interoperabilidad, como demuestra el caso de Canarias, abren nuevas posibilidades para maximizar el impacto de las inversiones públicas en visualización de datos. Asimismo, el reconocimiento externo y la participación en redes profesionales, como evidencia el caso de Madrid, contribuyen a la mejora continua y al intercambio de mejores prácticas entre administraciones.
En términos generales, las iniciativas de visualización de datos abiertos representan una oportunidad muy valiosa en la estrategia de transparencia y gobierno abierto de las administraciones públicas españolas. Los casos de Madrid, Castilla y León, así como de Canarias, son ejemplo de que existe un potencial enorme para transformar datos públicos en herramientas de empoderamiento ciudadano y mejora de la gestión pública.
El éxito de estas iniciativas radica en su capacidad para conectar la información gubernamental con las necesidades reales de la ciudadanía, creando puentes de comprensión que fortalecen la relación entre administración y sociedad. A medida que estas experiencias maduren y se consoliden, será fundamental mantener el foco en la usabilidad, la accesibilidad y la relevancia de las visualizaciones, asegurando que los datos abiertos cumplan verdaderamente su promesa de contribuir a una sociedad más informada, participativa y democrática.
La visualización de datos abiertos no es solo una cuestión técnica, sino una oportunidad estratégica para redefinir la comunicación pública y fortalecer los cimientos de una Administración verdaderamente abierta y transparente.
Blog
En un mundo cada vez más interconectado y complejo, la inteligencia geoespacial (GEOINT) se ha convertido en una herramienta esencial para la toma de decisiones en el ámbito de la defensa y la seguridad. La capacidad de recopilar, analizar e interpretar datos geoespaciales permite a las Fuerzas Armadas y a las agencias de seguridad comprender mejor el entorno operativo, anticipar amenazas y planificar operaciones con mayor eficacia.
En este contexto, los datos satelitales, clasificados pero también los abiertos, han adquirido una relevancia significativa. Programas como Copernicus de la Unión Europea proporcionan acceso gratuito y abierto a una amplia gama de datos de observación de la Tierra, lo que democratiza el acceso a información crítica y fomenta la colaboración entre diferentes actores.
Este artículo explora el papel de los datos en la inteligencia geoespacial aplicada a la defensa, destacando su importancia, aplicaciones y el liderazgo de España en este ámbito.
¿Qué es la Inteligencia Geoespacial?
La inteligencia geoespacial (GEOINT) es una disciplina que combina la recopilación, análisis e interpretación de datos geoespaciales para apoyar la toma de decisiones en diversas áreas, incluyendo la defensa, la seguridad y la gestión de emergencias. Estos datos pueden incluir imágenes satelitales, información de sensores remotos, datos de sistemas de información geográfica (SIG) y otras fuentes que proporcionan información sobre la ubicación y las características del terreno.
En el ámbito de la defensa, la GEOINT permite a los analistas y planificadores militares obtener una comprensión detallada del entorno operativo, identificar amenazas potenciales y planificar operaciones con mayor precisión. Además, facilita la coordinación entre diferentes unidades y agencias, mejorando la eficacia de las operaciones conjuntas.
Aplicaciones en el ámbito de la defensa
La integración de datos satelitales abiertos en la inteligencia geoespacial ha ampliado significativamente las capacidades de defensa. A continuación, se presentan algunas de las aplicaciones más relevantes:

Figura 1. Aplicaciones GEOINT en defensa. Fuente: elaboración propia
La inteligencia geoespacial no solo apoya a las Fuerzas Armadas en la toma de decisiones tácticas, sino que también transforma la forma en que se planifican y ejecutan operaciones militares, de vigilancia y de respuesta a emergencias. Aquí presentamos casos de uso concretos donde la GEOINT, apoyado en datos satelitales abiertos, ha tenido un impacto decisivo.
Monitoreo de movimientos militares en conflictos
Caso: Guerra de Ucrania (2022–2024)
Organizaciones como el Centro de Satélites de la UE (SatCen) y ONGs como Conflict Intelligence Team han usado imágenes Sentinel-1 y Sentinel-2 (Copernicus) para:
- Detectar concentraciones de tropas y material militar ruso.
- Analizar cambios en aeródromos, bases o rutas logísticas.
- Apoyar la verificación independiente de eventos sobre el terreno.
Esto ha sido clave para la toma de decisiones de la UE y la OTAN, sin necesidad de recurrir a datos clasificados.
Vigilancia marítima y control de fronteras
Caso: Operaciones de FRONTEX en el Mediterráneo
GEOINT alimentado por Sentinel-1 (radar) y Sentinel-3 (óptico + altímetro) permite:
- Identificar embarcaciones no autorizadas, incluso bajo nubes o de noche.
- Integrar alertas con AIS (sistema de identificación automática de buques).
- Coordinar rescates y operaciones de intercepción.
Ventaja: el radar de apertura sintética (SAR) de Sentinel-1 puede ver a través de las nubes, lo que lo hace ideal para vigilancia continua.
Apoyo a misiones de paz y ayuda humanitaria
Caso: Terremoto en Siria/Turquía (2023)
Datos abiertos (Sentinel-2, Landsat-8, PlanetScope gratuito tras catástrofe) se emplearon para:
- Detectar zonas colapsadas y evaluar daños.
- Planificar rutas de acceso seguras.
Coordinar campamentos y recursos con el apoyo de militares.
El papel de España
España ha demostrado un compromiso significativo con el desarrollo y la aplicación de la inteligencia geoespacial en defensa.
|
Centro de Satélites de la Unión Europea (SatCen) |
Proyecto Zeus del Ejército Español |
Participación en Programas Europeos | Desarrollo de capacidades nacionales |
|
Ubicado en Torrejón de Ardoz, el SatCen es una agencia de la Unión Europea que proporciona productos y servicios de inteligencia geoespacial para apoyar la toma de decisiones en materia de seguridad y defensa. España, como país anfitrión, desempeña un papel central en las operaciones del SatCen. |
El Ejército de Tierra español ha lanzado el proyecto Zeus, una iniciativa tecnológica que integra inteligencia artificial, redes 5G y datos satelitales para mejorar las capacidades operativas. Este proyecto busca crear una nube táctica de combate que permita una mayor interoperabilidad y eficacia en las operaciones militares. |
España participa activamente en programas europeos relacionados con la observación de la Tierra y la inteligencia geoespacial, como Copernicus y MUSIS. Además, colabora en iniciativas bilaterales y multilaterales para el desarrollo de capacidades satelitales y la compartición de datos. |
A nivel nacional, España ha invertido en el desarrollo de capacidades propias en inteligencia geoespacial, incluyendo la formación de personal especializado y la adquisición de tecnologías avanzadas. Estas inversiones refuerzan la autonomía estratégica del país y su capacidad para contribuir a operaciones internacionales. |
Figura 2. Tabla comparativa de la participación de España en distintos proyectos satelitales. Fuente: elaboración propia
Desafíos y oportunidades
Aunque los datos satelitales abiertos ofrecen numerosas ventajas, también presentan ciertos desafíos que deben abordarse para maximizar su utilidad en el ámbito de la defensa.
-
Calidad y resolución de los datos: si bien los datos abiertos son valiosos, a menudo tienen limitaciones en términos de resolución espacial y temporal en comparación con datos comerciales o clasificados. Esto puede afectar su aplicabilidad en ciertas operaciones que requieren información de alta precisión.
-
Integración de datos: la integración de datos de múltiples fuentes, incluyendo datos abiertos, comerciales y clasificados, requiere sistemas y procesos que garanticen la interoperabilidad y la coherencia de la información. Esto implica desafíos técnicos y organizativos que deben ser superados.
-
Seguridad y confidencialidad: el uso de datos abiertos en contextos de defensa plantea cuestiones sobre la seguridad y la confidencialidad de la información. Es esencial establecer protocolos y medidas de seguridad que protejan la información sensible y eviten su uso indebido.
- Oportunidades de colaboración: a pesar de estos desafíos, los datos satelitales abiertos ofrecen oportunidades significativas para la colaboración entre diferentes actores, incluyendo gobiernos, organizaciones internacionales, el sector privado y la sociedad civil. Esta colaboración puede mejorar la eficacia de las operaciones de defensa y contribuir a una mayor seguridad global.
Recomendaciones para fortalecer el uso de datos abiertos en defensa
Con base en el análisis anterior, pueden extraerse algunas recomendaciones clave para aprovechar mejor el potencial de los datos abiertos:
-
Refuerzo de las infraestructuras de datos abiertos: consolidar plataformas nacionales que integren datos satelitales abiertos para su uso tanto civil como militar, con especial atención a la seguridad y a la interoperabilidad.
-
Promoción de estándares abiertos geoespaciales (OGC, INSPIRE): garantizar que los sistemas de defensa integren estándares internacionales que permitan el uso combinado de fuentes abiertas y clasificadas.
-
Formación especializada: fomentar el desarrollo de capacidades en análisis GEOINT con datos abiertos, tanto en el ámbito militar como en colaboración con universidades y centros tecnológicos.
-
Cooperación civil-militar: establecer protocolos que faciliten el intercambio de datos entre agencias civiles (AEMET, IGN, Protección Civil) y actores de defensa en situaciones de crisis o emergencias.
- Apoyo a la I+D+i: impulsar proyectos de investigación que exploren el uso avanzado de datos abiertos (por ejemplo, IA aplicada a Sentinel) con aplicaciones duales (civiles y de seguridad).
Conclusión
La inteligencia geoespacial y el uso de datos satelitales abiertos han transformado la forma en que las Fuerzas Armadas y las agencias de seguridad planifican y ejecutan sus operaciones. En un contexto de amenazas multidimensionales y escenarios en constante evolución, contar con información precisa, accesible y actualizada es más que una ventaja: es una necesidad estratégica.
Los datos abiertos se han consolidado como un activo fundamental no solo por su gratuidad, sino por su capacidad de democratizar el acceso a información crítica, fomentar la transparencia y habilitar nuevas formas de colaboración entre actores militares, civiles y científicos. En particular:
- Mejoran la resiliencia de los sistemas de defensa al permitir un análisis más amplio y transversal del entorno operativo.
- Aumentan la interoperabilidad, ya que los formatos y estándares abiertos facilitan el intercambio entre países y agencias.
- Impulsan la innovación, al ofrecer a startups, centros de investigación y universidades acceso a datos de calidad que de otro modo serían inaccesibles.
En este contexto, España ha demostrado una clara apuesta por esta visión estratégica, tanto desde sus instituciones nacionales como desde su papel activo en programas europeos como Copernicus, Galileo y las misiones de defensa común.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos son un recurso fundamental para mejorar nuestra calidad de vida porque permiten mejorar los procesos de toma de decisiones para crear productos y servicios personalizados, tanto en el sector público como en el privado. En contextos como la salud, la movilidad, la energía o la educación, el uso de datos facilita soluciones más eficientes y adaptadas a las necesidades reales de las personas. No obstante, en el trabajo con datos, la privacidad juega un papel clave. En este post, analizaremos cómo los espacios de datos, el paradigma de computación federada y el aprendizaje federado, una de sus aplicaciones más potentes, plantean una solución equilibrada para aprovechar el potencial de los datos sin poner en riesgo la privacidad. Además, resaltaremos cómo el aprendizaje federado también puede usarse con datos abiertos para mejorar su reutilización de forma colaborativa, incremental y eficiente.
La privacidad, clave en la gestión de datos
Como se ha mencionado anteriormente, el uso intensivo de datos exige una creciente atención a la privacidad. Por ejemplo, en salud digital, un mal uso secundario de datos de historias clínicas electrónicas podría vulnerar derechos fundamentales de pacientes. Una forma eficaz de preservar la privacidad es mediante ecosistemas de datos que prioricen la soberanía de los datos, como es el caso de los espacios de datos. Un espacio de datos es un sistema de gestión federada de datos que permite su intercambio de manera confiable entre proveedores y consumidores. Además, el espacio de datos garantiza la interoperabilidad de los datos para crear productos y servicios que generen valor. En un espacio de datos, cada proveedor mantiene sus propias normas de gobernanza, conservando el control sobre sus datos (es decir, la soberanía sobre sus datos), a la vez que se posibilita su reutilización por consumidores. Esto implica que cada proveedor debe poder decidir qué datos comparte, con quién y bajo qué condiciones, garantizando el cumplimiento de sus intereses y obligaciones legales.
Computación federada y espacios de datos
Los espacios de datos representan una evolución en la gestión de datos, relacionada con un paradigma denominado computación federada (federated computing), donde los datos se reutilizan sin necesidad de que haya un trasiego de datos desde los proveedores de datos hacia los consumidores. En la computación federada, los proveedores transforman sus datos en resultados intermedios que preservan la privacidad con el fin de poder ser enviados a los consumidores de datos. Además, esto posibilita que puedan aplicarse otras técnicas de mejora de la privacidad de datos (Privacy-Enhancing Technologies). La computación federada se alinea perfectamente con arquitecturas de referencia como Gaia-X y su Trust Framework, que establece los principios y requisitos para garantizar un intercambio de datos seguro, transparente y conforme a reglas comunes entre proveedores y consumidores de datos.
Aprendizaje federado
Una de las aplicaciones más potentes de la computación federada es el aprendizaje automático federado (federated learning), una técnica de inteligencia artificial que permite entrenar modelos sin necesidad de centralizar los datos. Es decir, en lugar de enviar los datos a un servidor central para procesarlos, lo que se envía son los modelos entrenados localmente por cada participante.
Estos modelos se combinan posteriormente de manera centralizada para crear un modelo global. A modo de ejemplo, imaginemos un consorcio de hospitales que quiere desarrollar un modelo predictivo para detectar una enfermedad rara. Cada hospital posee datos sensibles de sus pacientes, y compartirlos abiertamente no es viable por cuestiones de privacidad (incluso otras cuestiones legales o éticas). Con el aprendizaje federado, cada hospital entrena localmente el modelo con sus propios datos, y solo comparte los parámetros del modelo (resultados del entrenamiento) de manera centralizada. Así, el modelo final aprovecha la diversidad de datos de todos los hospitales sin comprometer la privacidad individual y las reglas de gobernanza de datos de cada hospital.
El entrenamiento en el aprendizaje federado suele seguir un ciclo iterativo:
- Un servidor central inicia un modelo base y lo envía a cada uno de los nodos distribuidos participantes.
- Cada nodo entrena el modelo localmente con sus datos.
- Los nodos devuelven solo los parámetros del modelo actualizado, no los datos (es decir, se evita el trasiego de datos).
- El servidor central agrega las actualizaciones en los parámetros, resultados del entrenamiento en cada nodo y actualiza el modelo global.
- El ciclo se repite hasta alcanzar un modelo suficientemente preciso.
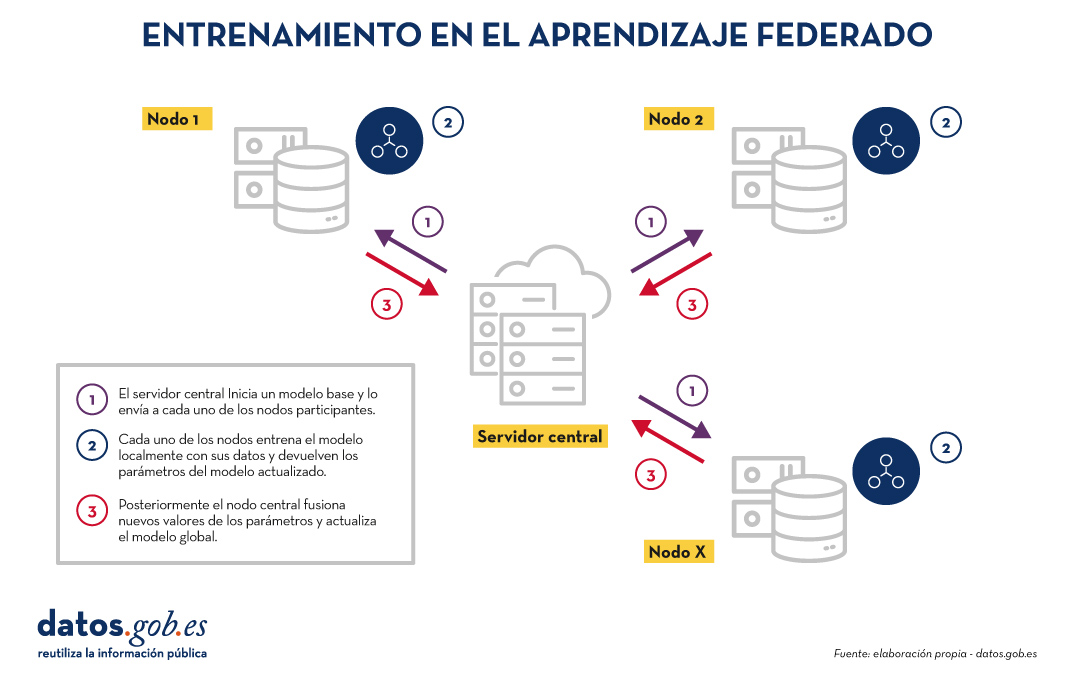
Figura 1. Visual que representa el proceso de entrenamiento del aprendizaje federados. Elaboración propia
Este enfoque es compatible con diversos algoritmos de aprendizaje automático, incluyendo redes neuronales profundas, modelos de regresión, clasificadores, etc.
Beneficios y desafíos del aprendizaje federado
El aprendizaje federado ofrece múltiples beneficios al evitar el trasiego de datos. Destacamos los siguientes:
- Privacidad y cumplimiento normativo: al permanecer en su origen, se reducen significativamente los riesgos de exposición de los datos y se facilita el cumplimiento de regulaciones como el Reglamento General de Protección de Datos (RGPD).
- Soberanía de los datos: cada entidad mantiene el control total sobre sus datos, lo que evita conflictos de competitividad.
- Eficiencia: evita los costes y la complejidad de intercambiar grandes volúmenes de datos, lo que acelera los tiempos de procesamiento y desarrollo.
- Confianza: facilita la colaboración entre organizaciones sin fricciones.
Existen diversos casos de uso en los cuales el aprendizaje federado es necesario, por ejemplo:
- Salud: hospitales y centros de investigación pueden colaborar en modelos predictivos sin compartir datos de pacientes.
- Finanzas: bancos y aseguradoras pueden construir modelos de detección de fraude o análisis de riesgo compartido, respetando la confidencialidad de sus clientes.
- Turismo inteligente: los destinos turísticos pueden analizar flujos de visitantes o patrones de consumo sin necesidad de unificar las bases de datos de sus actores (tanto públicos como privados).
- Industria: empresas del mismo sector pueden entrenar modelos para mantenimiento predictivo o eficiencia operativa sin revelar datos competitivos.
Aunque sus beneficios son claros en diversidad de casos de uso, el aprendizaje federado también presenta retos técnicos y organizativos:
- Heterogeneidad de datos: los datos locales pueden tener diferentes formatos o estructuras, lo que dificulta el entrenamiento. Además, el esquema de estos datos puede cambiar con el tiempo, lo que representa una dificultad añadida.
- Datos desbalanceados: algunos nodos pueden tener más datos o de mayor calidad que otros, lo que puede sesgar el modelo global.
- Costes computacionales locales: cada nodo necesita recursos suficientes para entrenar el modelo localmente.
- Sincronización: el ciclo de entrenamiento requiere buena coordinación entre nodos para evitar latencias o errores.
Más allá del aprendizaje federado
Aunque la aplicación más destacada de la computación federada es el aprendizaje federado, están surgiendo muchas otras aplicaciones adicionales en la gestión de datos como, por ejemplo, el análisis de datos federado (federated analytics). El análisis de datos federado permite realizar análisis estadísticos y descriptivos sobre datos distribuidos sin necesidad de moverlos a los consumidores, sino que cada proveedor realiza localmente los cálculos estadísticos requeridos y solo comparte con el consumidor los resultados agregados según sus requisitos y permisos. En la siguiente tabla se muestran las diferencias entre aprendizaje federado y análisis de datos federado.
|
Criterio |
Aprendizaje federado |
Análisis de datos federado |
|
Objetivo |
Predicción y entrenamiento de modelos de aprendizaje automático. | Análisis descriptivo y cálculo de estadísticas. |
| Tipo de tarea | Tareas predictivas (por ejemplo, clasificación o regresión). | Tareas descriptivas (por ejemplo, medias o correlaciones). |
| Ejemplo | Entrenar modelos de diagnóstico de enfermedades a través de imágenes médicas procedentes de diversos hospitales. | Cálculo de indicadores sanitarios de un área de salud sin mover los datos entre hospitales. |
| Salida esperada | Modelo global entrenado. | Resultados estadísticos agregados. |
| Naturaleza | Iterativa. | Directa. |
| Complejidad computacional | Alta. | Media. |
| Algoritmos | Aprendizaje automático. | Algoritmos estadísticos. |
Figura 1. Tabla comparativa. Fuente: elaboración propia
Aprendizaje federado y datos abiertos: una simbiosis por explorar
En principio, los datos abiertos resuelven los problemas de privacidad antes de su publicación, por lo que se podría pensar que no es preciso hacer uso de técnicas de aprendizaje federado. Nada más lejos de la realidad. El uso de técnicas de aprendizaje federado puede aportar ventajas significativas en la gestión y explotación de los datos abiertos. De hecho, el primer aspecto a resaltar es que los portales de datos abiertos como datos.gob.es o data.europa.eu son entornos federados. Por ello, en estos portales, la aplicación de aprendizaje federado sobre conjuntos de datos de gran tamaño permitiría entrenar modelos directamente en origen, evitando costes de transferencia y procesamiento. Por otro lado, el aprendizaje federado facilitaría la combinación de datos abiertos con otros datos sensibles sin comprometer la privacidad de estos últimos. Finalmente, la naturaleza de una gran variedad de tipos de datos abiertos es muy dinámica (como los datos de tráfico), por lo que el aprendizaje federado habilitaría un entrenamiento incremental, considerando automáticamente nuevas actualizaciones de conjuntos de datos abiertos a medida que se publican, sin necesidad de reiniciar costosos procesos de entrenamiento.
Aprendizaje federado, base para una IA respetuosa con la privacidad
El aprendizaje automático federado representa una evolución necesaria en la forma en que desarrollamos servicios de inteligencia artificial, especialmente en contextos donde los datos son sensibles o están distribuidos entre varios proveedores. Su alineación natural con el concepto de espacio de datos lo convierte en una tecnología clave para impulsar la innovación basada en la compartición de datos, teniendo en cuenta la privacidad y manteniendo la soberanía de los datos.
A medida que la regulación (como el Reglamento relativo al Espacio Europeo de Datos de Salud) y las infraestructuras de espacios de datos evolucionen, el aprendizaje federado, y otros tipos de computación federada, jugarán un papel cada vez más importante en la compartición de datos, maximizando el valor de los datos, pero sin comprometer la privacidad. Finalmente, cabe destacar que, lejos de ser innecesario, el aprendizaje federado puede convertirse en un aliado estratégico para mejorar la eficiencia, gobernanza e impacto de los ecosistemas de datos abiertos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
En el panorama actual del análisis de datos y la inteligencia artificial, la generación automática de informes completos y coherentes representa un desafío significativo. Mientras que las herramientas tradicionales permiten visualizar datos o generar estadísticas aisladas, existe la necesidad de sistemas que puedan investigar un tema a fondo, recopilar información de diversas fuentes, y sintetizar hallazgos en un informe estructurado y coherente.
En este ejercicio práctico, exploraremos el desarrollo de un agente de generación de reportes basado en LangGraph e inteligencia artificial. A diferencia de los enfoques tradicionales basados en plantillas o análisis estadísticos predefinidos, nuestra solución aprovecha los últimos avances en modelos de lenguaje para:
- Crear equipos virtuales de analistas especializados en diferentes aspectos de un tema.
- Realizar entrevistas simuladas para recopilar información detallada.
- Sintetizar los hallazgos en un informe coherente y bien estructurado.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Como se muestra en la Figura 1, el flujo completo del agente sigue una secuencia lógica que va desde la generación inicial de preguntas hasta la redacción final del informe.

Figura 1. Diagrama de flujo del agente.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en un diseño modular implementado como un grafo de estados interconectados, donde cada módulo representa una funcionalidad específica en el proceso de generación de reportes. Esta estructura permite un flujo de trabajo flexible, recursivo cuando es necesario, y con capacidad de intervención humana en puntos estratégicos.
Componentes principales
El sistema se compone de tres módulos fundamentales que trabajan en conjunto:
1. Generador de Analistas Virtuales
Este componente crea un equipo diverso de analistas virtuales especializados en diferentes aspectos del tema a investigar. El flujo incluye:
- Creación inicial de perfiles basados en el tema de investigación.
- Punto de retroalimentación humana que permite revisar y refinar los perfiles generados.
- Regeneración opcional de analistas incorporando sugerencias.
Este enfoque garantiza que el informe final incluya perspectivas diversas y complementarias, enriqueciendo el análisis.
2. Sistema de Entrevistas
Una vez generados los analistas, cada uno participa en un proceso de entrevista simulada que incluye:
- Generación de preguntas relevantes basadas en el perfil del analista.
- Búsqueda de información en fuentes vía Tavily Search y Wikipedia.
- Generación de respuestas informativas combinando la información obtenida.
- Decisión automática sobre continuar o finalizar la entrevista en función de la información recopilada.
- Almacenamiento de la transcripción para su procesamiento posterior.
El sistema de entrevistas representa el corazón del agente, donde se obtiene la información que nutrirá el informe final. Tal y como se muestra en la Figura 2, este proceso puede monitorizarse en tiempo real mediante LangSmith, una herramienta abierta de observabilidad que permite seguir cada paso del flujo.

Figura 2. Monitorización del sistema vía LangGraph. Ejemplo concreto de una interacción analista-entrevistador.
3. Generador de Informes
Finalmente, el sistema procesa las entrevistas para crear un informe coherente mediante:
- Redacción de secciones individuales basadas en cada entrevista.
- Creación de una introducción que presente el tema y la estructura del informe.
- Organización del contenido principal que integra todas las secciones.
- Generación de una conclusión que sintetiza los hallazgos principales.
- Consolidación de todas las fuentes utilizadas.
La Figura 3 muestra un ejemplo del informe resultante del proceso completo, demostrando la calidad y estructura del documento final generado automáticamente.

Figura 3. Vista del informe resultante del proceso de generación automática al prompt de “Datos abiertos en España”.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
Integración de IA avanzada en sistemas de procesamiento de información:
- Cómo comunicarse efectivamente con modelos de lenguaje.
- Técnicas para estructurar prompts que generen respuestas coherentes y útiles.
- Estrategias para simular equipos virtuales de expertos.
Desarrollo con LangGraph:
- Creación de grafos de estados para modelar flujos complejos.
- Implementación de puntos de decisión condicionales.
- Diseño de sistemas con intervención humana en puntos estratégicos.
Procesamiento paralelo con LLMs:
- Técnicas de paralelización de tareas con modelos de lenguaje.
- Coordinación de múltiples subprocesos independientes.
- Métodos de consolidación de información dispersa.
Buenas prácticas de diseño:
- Estructuración modular de sistemas complejos.
- Manejo de errores y reintentos.
- Seguimiento y depuración de flujos de trabajo mediante LangSmith.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos y los usuarios finales. A través del caso práctico desarrollado, podemos observar cómo la combinación de modelos de lenguaje avanzados con arquitecturas flexibles basadas en grafos abre nuevas posibilidades para la generación automática de informes.
La capacidad de simular equipos de expertos virtuales, realizar investigaciones paralelas y sintetizar hallazgos en documentos coherentes, representa un paso significativo hacia la democratización del análisis de información compleja.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de mecanismos de verificación automática de datos para garantizar la precisión.
- Implementación de capacidades multimodales que permitan incorporar imágenes y visualizaciones.
- Integración con más fuentes de información y bases de conocimiento.
- Desarrollo de interfaces de usuario más intuitivas para la intervención humana.
- Expansión a dominios especializados como medicina, derecho o ciencias.
En resumen, este ejercicio no solo demuestra la viabilidad de automatizar la generación de informes complejos mediante inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el análisis profundo de cualquier tema esté al alcance de todos, independientemente de su nivel de experiencia técnica. La combinación de modelos de lenguaje avanzados, arquitecturas de grafos y técnicas de paralelización abre un abanico de posibilidades para transformar la forma en que generamos y consumimos información.
Blog
La evolución de la IA generativa está siendo vertiginosa: desde los primeros grandes modelos del lenguaje que nos impresionaron con su capacidad para reproducir la lecto-escritura de los humanos, pasando por las avanzadas técnicas de RAG (Retrieval-Augmented Generation) que mejoraron cuantitativamente la calidad de las respuestas proporcionadas y la aparición de agentes inteligentes, hasta llegar a una innovación que redefine nuestra relación con la tecnología: Computer use.
A finales del mes de abril del año 2020, tan solo un mes después de que comenzara un periodo inédito de confinamiento domiciliario de alcance mundial debido a la pandemia mundial del SAR-Covid19, difundíamos desde datos.gob.es los grandes modelos del lenguaje GPT-2 y GPT-3. OpenAI, fundada en 2015, había presentado prácticamente un año antes (febrero del 2019) un nuevo modelo del lenguaje que era capaz de generar texto escrito prácticamente indistinguible del creado por un humano. GPT-2 se había entrenado con un corpus (conjunto de textos preparados para entrenar modelos del lenguaje) de unos 40 GB (Gigabytes) de tamaño (unos 8 millones de páginas web), mientras que la última familia de modelos basados en GPT-4 se estima que han sido entrenados con corpus del tamaño de TB (Terabytes); mil veces más.
En este contexto, es importante hablar de dos conceptos:
- LLM (Large Language Models): son modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas. Hoy, disponemos de incontables herramientas basadas en estos LLM que, por campos de especialidad, son capaces de generar código de programación, imágenes y videos ultra-realistas y resolver problemas matemáticos complejos. Todas las grandes empresas y organizaciones del sector tecnológico-digital se han lanzado a integrar estas herramientas en sus diferentes productos de software y hardware, desarrollando casos de uso que resuelven u optimizan tareas y actividades concretas que previamente tenían alta intervención humana.
- Agentes: la experiencia de uso con los modelos de inteligencia artificial cada vez es más completa, de forma que le podemos pedir a nuestra interfaz no sólo respuestas a nuestras preguntas, sino también que realice tareas complejas que requieren integración con otras herramientas informáticas. Por ejemplo, no solo le preguntamos a un chatbot información sobre los mejores restaurantes de la zona, sino que le pedimos que busque disponibilidad de mesa para unas fechas concretas y realice una reserva por nosotros. Esta experiencia de uso extendida es lo que nos proporcionan los agentes de inteligencia artificial. Basados en los grandes modelos del lenguaje, estos agentes son capaces de interaccionar con el mundo exterior (al modelo) y “hablar” con otros servicios mediante API e interfaces de programación preparadas para tal fin.
Computer use
Sin embargo, la capacidad de los agentes para realizar acciones de forma autónoma depende de dos elementos clave: por un lado, su programación concreta -la funcionalidad que se les haya programado o configurado-; por otro lado, la necesidad de que el resto de programas estén preparados para “hablar” con estos agentes. Es decir, sus interfaces de programación han de estar listas para recibir instrucciones de estos agentes. Por ejemplo, la aplicación de reservas del restaurante ha de estar preparada, no solo para recepcionar formularios rellenados por un humano, sino también, peticiones realizadas por un agente que previamente ha sido invocado por un humano mediante lenguaje natural. Este hecho impone una limitación sobre el conjunto de actividades y/o tareas que podemos automatizar desde un interfaz conversacional. Es decir, el interfaz conversacional puede proporcionarnos respuestas casi infinitas a las cuestiones que le planteemos, pero encuentra grandes limitaciones para interactuar con el mundo exterior debido a la falta de preparación del resto de aplicaciones informáticas.
Aquí es donde entra Computer use. Con la llegada del modelo Claude 3.5 Sonnet, la empresa Anthropic ha introducido Computer use, una capacidad en fase beta que permite a la IA interactuar directamente con interfaces gráficas de usuario.
¿Cómo funciona Computer use?
Claude puede mover el cursor de tu ordenador como si fueras tú, hacer clic en botones y escribir texto, emulando la forma en que los humanos operamos con un ordenador. La mejor forma de entender cómo funciona Computer use en la práctica es viéndolo en acción. Aquí os dejamos un link directo al canal de YouTube de la sección específica de Computer use.

Figura 1. Captura del canal de YouTube de Anthropic, sección específica de Computer use.
¿Te animas a probarlo?
Si has llegado hasta aquí, no te puedes quedar sin probarlo con tus propias manos.
A continuación, te proponemos una sencilla guía para poder probar Computer use en un entorno aislado. Es importante tener en cuenta las recomendaciones de seguridad que Antrophic propone en sus guías de Computer use. Esta característica del modelo Claude Sonet puede realizar acciones sobre un ordenador y esto puede ser potencialmente peligroso, por lo que se recomienda revisar cuidadosamente la advertencia de seguridad de Computer use.
Toda la documentación oficial para desarrolladores se encuentra en el repositorio oficial de Github de Antrophic. En este post, nosotros hemos optado por ejecutar Computer use en un entorno de un contenedor de Docker. Es la forma más sencilla y segura de probarlo. Si no lo tienes ya, puedes seguir las sencillas guías oficiales para pre-instalarlo en tu sistema.
Para reproducir esta prueba os proponemos seguir este guion paso a paso:
- Antropic API Key. Para interactuar con Claude Sonet necesitas una cuenta de Antropic que puedes crear gratuitamente aquí. Una vez dentro, puedes ir a la sección de API Keys y crear una nueva para tu prueba
- Una vez tengas tu API Key, deberás de ejecutar este comando en tu terminal, sustituyendo tu clave donde indica “%your_api_key%”:

3. Si todo ha ido bien, verás estos mensajes en tu terminal y ya solo te queda abrir tu navegador y escribir esta url en la barra de navegación: http://localhost:8080/
Verás que se abre tu interfaz:

Figura 2. Interfaz de Computer use.
Ya puedes emplazar a explorar cómo funciona Computer use. Te sugerimos el siguiente prompt para empezar:
Te proponemos que empieces poco a poco. Por ejemplo, pídele que abra un navegador y busque algo. También puedes pedirle que te de información sobre tu ordenador o sistema operativo. Poco a poco, puedes ir pidiendo tareas más complejas. Nosotros hemos probado este prompt y tras varias pruebas hemos conseguido que Computer use realice la tarea completa.
Abre un navegador, navega hasta el catálogo de datos.gob.es, usa el buscador para localizar un conjunto de datos sobre: Seguridad ciudadana. Siniestralidad Tráfico. 2014; Localiza el fichero en formato csv; descárgalo y ábrelo con libre Office.
Potenciales usos en plataformas de datos como datos.gob.es
A la vista de esta primera versión experimental de Computer use parece que el potencial de la herramienta es muy alto. Podemos imaginar cuantas más cosas podemos hacer gracias a esta herramienta. Aquí os dejamos algunas ideas:
- Podríamos pedirle al sistema que realice una búsqueda completa de datasets relacionados con una temática concreta y que hiciera un resumen en un documento de los principales resultados. De esta manera, si por ejemplo escribimos un artículo sobre datos del tráfico en España, podríamos obtener de forma desatendida un listado con los principales datasets abiertos de datos de tráfico en España en el catálogo de datos.gob.es.
- De la misma forma, podríamos solicitar un resumen igual, pero en este caso, no de dataset, sino de artículos de la plataforma.
- Un ejemplo un poco más sofisticado sería pedirle a Claude, mediante el interfaz conversacional de Computer use que nos haga una serie de llamadas a la API de datos.gob.es para obtener información de ciertos datasets de forma programática. Para ello, abrimos un navegador y nos logueamos en una aplicación como Postman (recordemos en este punto que Computer use está en modo experimental y no nos permite introducir datos sensibles como credenciales de usuario en páginas web). A continuación le podemos pedimos que busque información sobre la API de datos.gob.es y ejecute una llamada http aprovechando que dicha API no requiere autenticación.
A través de estos sencillos ejemplos, esperamos haberte presentado una nueva aplicación de la IA generativa y que hayas entendido el cambio de paradigma que supone esta nueva capacidad. Si la máquina es capaz de emular el uso de un ordenador como lo hacemos los humanos, se abren nuevas oportunidades inimaginables para los próximos meses.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su auto