Noticia
El Ministerio para la Transformación Digital y de la Función Pública, el pasado 17 de diciembre, anunció la publicación de la convocatoria de productos y servicios para espacios de datos, una iniciativa que busca impulsar la innovación y el desarrollo en diversos sectores a través de ayudas económicas. Estas ayudas están diseñadas para apoyar a empresas y organizaciones en la implementación de soluciones tecnológicas avanzadas, promoviendo así la competitividad y la transformación digital en España.
Además, el 30 de diciembre, el Ministerio también lanzó la segunda convocatoria de demostradores y casos de uso. Esta convocatoria tiene como objetivo fomentar la creación y el desarrollo de espacios de datos sectoriales, promoviendo la colaboración y el intercambio de información entre los distintos actores del sector.
El Ministerio ha estado realizando promociones a través de jornadas online para informar y preparar a los interesados sobre las oportunidades y beneficios de los espacios de datos sectoriales. Se espera que estas jornadas continúen a lo largo de enero, brindando más oportunidades para que los sectores interesados se informen y participen.
A continuación, les facilitamos material de su interés:
Segunda convocatoria demostradores y casos de uso

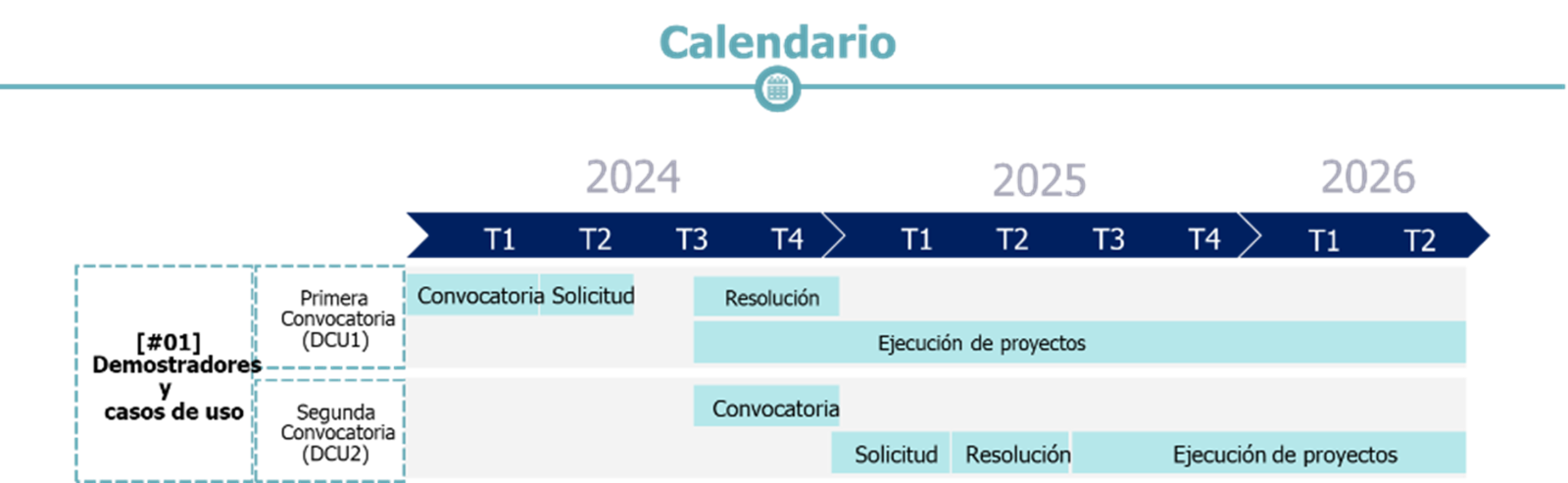
- Demostradores y casos de uso de espacios de datos (2ª convocatoria)
- Buzón de consultas: dcu2.espaciosdedatos@digital.gob.es
- Presentaciones y videos de ayuda:
Productos y servicios


- Convocatoria productos y servicios del Portal de Ayudas
- Buzón de consultas: ps.espaciosdedatos@digital.gob.es
- Presentaciones y videos de ayuda:
Noticia
Los últimos días del año siempre son un buen momento para echar la vista atrás y valorar los avances realizados. Si hace unas semanas hacíamos balance de lo sucedido en la iniciativa Aporta, ahora llega el momento de recopilar las novedades relacionadas con la compartición de datos, los datos abiertos y las tecnologías ligadas a ellos.
Hace seis meses, ya hicimos una primera recolección de hitos en el sector. En esta ocasión, vamos a resumir algunas de las innovaciones, mejoras y logros del último semestre del año.
Regulando e impulsando la inteligencia artificial
La inteligencia artificial (IA) continúa siendo uno de los campos donde cada día se aprecian nuevos avances. Se trata de un sector cuyo auge es relativamente nuevo y que necesita regulación. Por ello, la Unión Europea publicó el pasado julio el Reglamento de inteligencia artificial, una norma que marcará el entorno regulatorio europeo y global. Alineada con Europa, España ya presentó unos meses antes su nueva Estrategia de inteligencia artificial 2024, con el fin de establecer un marco para acelerar el desarrollo y expansión de la IA en España.
Por otro lado, en octubre, España asumió la copresidencia de Open Government Partnership (OGP). En su hoja de ruta está promover las ideas innovadoras, aprovechando las oportunidades que brindan los datos abiertos y la inteligencia artificial. Como parte del cargo, España organizará la próxima cumbre mundial de OGP en Vitoria.
Nuevas herramientas innovadoras basadas en datos
Los datos son el motor de una gran cantidad de herramientas tecnológicas disruptivas que pueden generar beneficios para toda la ciudadanía. Algunas de las puestas en marcha por organismos públicos durante estos últimos meses son:
- El Ministerio de Transportes y Movilidad Sostenible cumple un año más utilizando tecnología Big Data para analizar el tráfico de las carreteras y mejorar las inversiones y la seguridad vial. Este año han vuelto a compartir datos de movilidad diaria como ya hicieron durante la pandemia de COVID-19, también han desarrollado nuevas herramientas para facilitar la consulta y visualización de estos datos y se han abierto aplicaciones específicas para ayudar a la reutilización de los datos en el contexto de la gestión de la zona afectada por la DANA.
- El Principado de Asturias anuncia un plan para el uso de Inteligencia Artificial con el fin de acabar con los atascos durante el verano, a través de la elaboración de un gemelo digital.
- El Gobierno de Aragón presentó un nuevo sistema de inteligencia turística, que utiliza Big Data e IA para mejorar la toma de decisiones en el sector.
- La Región de Murcia ha lanzado "Murcia Business Insight" un aplicativo de business intelligence que permite realizar análisis dinámicos con datos sobre las empresas de la región: facturación, empleo, localización, sector de actividad, etc.
- El Ayuntamiento de Granada ha utilizado Inteligencia Artificial para mejorar el alcantarillado. El objetivo es conseguir una planificación y ejecución "más eficiente" del mantenimiento, con datos in situ.
- El Ayuntamiento de Segovia y Visa han firmado un acuerdo de colaboración para desarrollar una herramienta online con datos reales, agregados y anónimos de los patrones de gasto de los titulares extranjeros de tarjetas Visa en la capital. Esta iniciativa ofrecerá información de interés que permitirá adaptar las estrategias para fomentar el turismo internacional.
También los investigadores y estudiantes de diversos centros han comunicado avances fruto del trabajo con datos:
- Investigadores del Centro de Regulación Genómica (CRG) de Barcelona, la Universidad del País Vasco (UPV/EHU), el Donostia International Physics Center (DIPC) y la Fundación Biofísica Bizkaia han entrenado un algoritmo para detectar alteraciones de tejidos en los estadios iniciales y mejorar el diagnóstico de cáncer.
- Investigadores del Consejo Superior de Investigaciones Científicas (CSIC) y KIDO Dynamics, han puesto en marcha un proyecto para extraer metadatos de las antenas móviles para comprender el flujo de personas en parajes naturales. El objetivo es la identificación y control del impacto del turismo.
- Una estudiante de la Universidad de Valladolid (UVa) ha diseñado un proyecto para mejorar la gestión y el análisis de los ecosistemas forestales en España a nivel local. Para ello, convierte los límites municipales a un formato de datos abiertos enlazados. Los resultados están disponibles para su reutilización.
Avances en espacios de datos
Desde el Ministerio para la Transformación Digital y de la Función Pública y, en concreto, desde la Secretaría de Estado de Digitalización e Inteligencia Artificial se continúa avanzando en la implementación de espacios de datos, a través de diversas acciones:
- Se ha presentado un Plan de Impulso de los Espacios de Datos Sectoriales para impulsar la compartición segura de los datos.
- Se ha puesto en marcha el desarrollo de Espacios de Datos para las Infraestructuras Urbanas Inteligentes (EDINT). Este proyecto, que se llevará a cabo a través de la Federación Española de Municipios y Provincias (FEMP), contempla la creación de un espacio de datos multisectorial que reunirá toda la información recopilada por las entidades locales.
- Se han lanzado ayudas, en el ámbito de la digitalización, para la transformación digital de los sectores productivos estratégicos mediante el desarrollo de productos y servicios tecnológicos para espacios de datos.
Funcionalidades que acercan los datos a los reutilizadores
Las plataformas de datos abiertos de los diversos organismos también han presentado novedades, ya sean nuevos conjuntos de datos, funcionalidades, estrategias o informes:
- El Ministerio para la Transición Ecológica y el Reto Demográfico ha lanzado una nueva aplicación para la visualización del Índice Nacional de Calidad del Aire (ICA) en tiempo real. Incluye recomendaciones sanitarias para la población general y la población sensible.
- La Junta de Andalucía ha publicado una “Guía para el diseño de Estudios Piloto de Políticas Públicas”. En ella propone una metodología para diseñar estudios piloto y un sistema de recogida de evidencias para la toma de decisiones.
- La Generalitat de Catalunya ha iniciado los pasos para implantar un nuevo modelo de gobierno del dato que permita mejorar las relaciones con la ciudadanía y las empresas.
- El Ayuntamiento de Madrid está implantando una nueva cartografía 3D y un mapa térmico. En el Blog IDEE (Infraestructura de Datos Espaciales de España) nos contaron cómo se ha creado este modelo 3D de la capital utilizando diversas tecnologías de captura de dato.
- El Instituto Canario de Estadística (ISTAC) ha publicado 6.527 mapas temáticos con indicadores laborales sobre Canarias en su catálogo de datos abiertos.
- Iniciativa Open Data y la Unión Democrática de Pensionistas y Jubilados de España, con apoyo del Ministerio de Derechos Sociales, Consumo y Agenda 2030, presentaron la primera web de Datos del Observatorio de Datos x Mayores. Su objetivo es facilitar el análisis del envejecimiento saludable en España y la toma decisiones estratégicas. La Iniciativa de Barcelona también puso en marcha un reto para identificar 50 datasets relacionados con el envejecimiento saludable, un proyecto que cuenta con el soporte de la Diputación de Barcelona.
- El Centro para el Desarrollo Tecnológico y la Innovación (CDTI) ha presentado un dashboard en fase beta con datos abiertos en formato explotable.
Además, se continúa trabajando para favorecer la apertura de datos desde diversas instituciones:
- Asedie y la Universidad Rey Juan Carlos (Madrid) han puesto en marcha el Observatorio Open Data Reuse para promover la reutilización de los datos abiertos. Ya cuenta con el compromiso del Ayuntamiento de Madrid y están buscando más instituciones que se unan a su Manifiesto.
- El Cabildo de Tenerife y la Universidad de La Laguna han desarrollado una Estrategia de Movilidad Sostenible en la Reserva de la Biosfera Macizo de Anaga. Se busca obtener datos en tiempo real para tomar medidas adaptadas a la demanda.
Concursos de datos y eventos para animar a utilizar datos abiertos
El verano fue la época elegida por distintos organismos públicos para lanzar concursos donde se buscaban productos y/o servicios basados en datos abiertos. Es el caso de:
- La Comunidad de Madrid celebró DATAMAD 2024 en la Universidad Rey Juan Carlos de Madrid. El evento incluía un taller sobre cómo reutilizar datos abiertos y un datathon.
- Más de 200 estudiantes de inscribieron al I Malackathon, organizado por la Universidad de Málaga, un concurso que premiaba los proyectos que usaban datos abiertos para plantear soluciones en la gestión de recursos hídricos.
- La Junta de Castilla y León celebró el VIII Concurso de Datos Abiertos, cuyos ganadores se conocieron en el mes de noviembre.
- También se lanzó el II Datathon de UniversiData. Han sido seleccionados 16 finalistas. Los ganadores se conocerán el 13 de febrero de 2025.
- El Cabildo de Tenerife también organizó su I Concurso de Datos Abiertos: Ideas de reutilización. Actualmente se encuentran valorando las candidaturas recibidas. Más adelante lanzarán su II Concurso de Datos Abiertos: Desarrollo de APP.
- El Gobierno de Euskadi llevó a cabo su V Concurso de datos abiertos. Ya se conocen los finalistas tanto de la categoría de Aplicaciones como de Ideas.
También en estos meses se han celebrado múltiples eventos, que se pueden ver online, como:
- El III Congreso GeoEuskadi y XVI Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE).
- DATAfórum Justicia 2024.
Otros ejemplos de eventos que se celebraron pero no están disponibles online son el III Congreso & XIV Jornadas de Usuarios de R, el Congreso de Innovación Pública Novagob 2024, DATAGRI 2024 o la Jornada Gobierno del Dato para Entidades Locales, entre otros.
Estos son solo algunos ejemplos de la actividad realizada durante los últimos seis meses en el ecosistema de datos de España. Te animamos a compartir otras experiencias que conozcas en los comentarios o a través de nuestra dirección de correo electrónico dinamizacion@datos.gob.es
Blog
La capacidad de recopilar, analizar y compartir datos juega un papel crucial en el contexto de los desafíos globales a los que nos enfrentamos hoy en día como sociedad. Desde la contaminación y el cambio climático, pasando por la pobreza y las pandemias, hasta la movilidad sostenible y la falta de acceso a los servicios básicos. Los problemas globales exigen soluciones que puedan adaptarse a gran escala. Es ahí donde los datos abiertos pueden jugar un papel fundamental, ya que permiten que gobiernos, organizaciones y ciudadanos trabajen juntos de manera transparente, y facilitan el proceso hasta llegar a conseguir soluciones eficaces, innovadoras, adaptables y sostenibles.
El Banco Mundial como pionero en el uso integral de los datos abiertos
Uno de los ejemplos de buenas prácticas más relevantes que podemos encontrar a la hora de exprimir el potencial de los datos abiertos para afrontar los grandes desafíos globales es, sin duda, el caso del Banco Mundial, referente en el uso de los datos abiertos desde hace ya más de una década como herramienta fundamental para el desarrollo sostenible.
Desde el lanzamiento de su portal de datos abiertos en 2010, la institución ha llevado a cabo un completo proceso de transformación en cuanto al acceso y uso de los datos. Este portal, totalmente innovador en su día, se convirtió rápidamente en un modelo de referencia al ofrecer acceso libre y gratuito a una amplia gama de datos e indicadores que abarcan más de 250 economías. Además, su plataforma está en constante actualización y poco se parece en el presente a la versión inicial, ya que sigue mejorando continuamente y proporcionando nuevos conjuntos de datos y herramientas complementarias y especializadas con el objetivo de facilitar que los datos estén siempre accesibles y sean útiles para la toma de decisiones. Algunos ejemplos de esas herramientas serían:
- La Poverty and Inequality Platform (PIP): diseñada para monitorizar y analizar la pobreza y la desigualdad a nivel mundial. Con datos de más de 140 países, esta plataforma permite a los usuarios acceder a estadísticas actualizadas y comprender mejor las dinámicas del bienestar colectivo. También facilita la visualización de datos mediante gráficos interactivos y mapas, ayudando a los usuarios a obtener una comprensión clara y rápida de la situación en distintas regiones y a lo largo del tiempo.
- La Microdata Library: proporciona acceso a datos de encuestas y censos a nivel de hogar y empresa en diversos países. La biblioteca cuenta con más de 3.000 conjuntos de datos provenientes de estudios y encuestas realizadas tanto por el propio Banco, así como de otras organizaciones internacionales y agencias nacionales de estadística. Los datos están disponibles de forma gratuita y son totalmente accesibles para poder ser descargados y analizados.
- Los World Development Indicators (WDI): son una herramienta fundamental para poder seguir el progreso de la agenda de desarrollo global. Esta base de datos contiene una vasta colección de indicadores de desarrollo económico, social y ambiental, abarcando más de 200 países y territorios. Cuenta con datos que cubren áreas como pobreza, educación, salud, sostenibilidad ambiental, infraestructura y comercio. Los WDIs nos proporcionan un marco de referencia de confianza a la hora de analizar tendencias de desarrollo globales y regionales.


Figura 1. Capturas de los portales web Poverty and Inequality Platform (PIP), Microdata Library y World Development Indicators (WDI).
Un hito relevante que ha marcado la forma en la que el Banco Mundial hace uso de los datos ha sido la publicación del informe sobre el Desarrollo Mundial 2021, titulado "datos para mejorar nuestras vidas". Este informe se ha convertido en una publicación emblemática que explora el potencial transformador de los datos para abordar los grandes retos de la humanidad, mejorar los resultados de los esfuerzos invertidos en desarrollo y promover un crecimiento inclusivo y equitativo. A través del informe, la institución aboga por una nueva agenda social para los datos, incluyendo una gobernanza robusta, ética y responsable de los mismos, maximizando su valor para poder generar un beneficio económico y social significativo.
En el informe se examina cómo los datos pueden ser integrados en las políticas públicas y los programas de desarrollo para abordar los desafíos globales en áreas como educación, salud, infraestructuras o el cambio climático. Pero, además, supuso un antes y un después a la hora de reforzar el compromiso del Banco Mundial con los datos como motor de cambio a la hora de afrontar los grandes desafíos, adoptando desde entonces una nueva hoja de ruta con un enfoque del uso de los datos más innovador, transformador y orientado a la acción. Desde ese momento han venido pasando de la teoría a la práctica a través de sus propios proyectos, donde los datos se convierten en una herramienta fundamental durante todo el ciclo estratégico, como en los siguientes ejemplos:
- Datos abiertos y reducción del riesgo de desastres: en el informe "Bienes públicos digitales para la reducción del riesgo de desastres en un clima cambiante" se subraya cómo el acceso abierto a datos geoespaciales y meteorológicos facilita la toma de decisiones y una planificación estratégica más eficaz. También se hace referencia a herramientas como OpenStreetMap que permiten a las comunidades mapear en tiempo real áreas vulnerables. Esta democratización de los datos refuerza la respuesta ante emergencias y fomenta la resiliencia de las comunidades expuestas a los riesgos de inundaciones, sequías y huracanes.
- Datos abiertos ante los retos agroalimentarios: el informe "¿Qué se está cocinando?" muestra cómo los datos abiertos están revolucionando los sistemas agroalimentarios globales, haciéndolos más inclusivos, eficientes y sostenibles. En la agricultura, el acceso a datos abiertos sobre patrones climáticos, calidad del suelo y precios de mercado habilita a los pequeños agricultores para tomar decisiones informadas. Además, las plataformas que ofrecen datos geoespaciales abiertos sirven para fomentar la agricultura de precisión, permitiendo optimizar recursos clave como el agua y los fertilizantes, a la vez que se reducen costes y se minimiza el impacto ambiental.
- Optimización de los sistemas de transporte urbano: en Tanzania, el Banco Mundial ha respaldado un proyecto que utiliza los datos abiertos para mejorar el sistema de transporte público. La rápida urbanización de Dar es Salaam ha provocado una congestión de tráfico considerable en varias zonas, afectando tanto la movilidad urbana como la calidad del aire. Esta iniciativa aborda la congestión del tráfico mediante un sistema de información en tiempo real que mejora la movilidad y reduce el impacto ambiental. Este enfoque, basado en datos abiertos, no solo aumenta la eficiencia del transporte, sino que también contribuye a una mejor calidad de vida para los habitantes de la ciudad.
Predicando con el ejemplo
Por último, y dentro de esta misma visión integral, cabe destacar cómo este organismo internacional cierra el círculo de los datos abiertos a través de su utilización también como herramienta de transparencia y comunicación de sus propias actividades. Es por ello que entre las herramientas de datos destacadas de su catálogo podremos encontrar algunas como:
- Su portal de proyectos y operaciones: una herramienta que ofrece acceso detallado a los proyectos de desarrollo que la institución financia y ejecuta en todo el mundo. Este portal actúa como una ventana a todas sus iniciativas globales, proporcionando información sobre objetivos, financiación, resultados esperados y avances para los miles de proyectos del Banco.
- La plataforma Finances One: en la que centralizan todos sus datos financieros de interés público y los correspondientes a la cartera de proyectos de todas las entidades del grupo. Su objetivo es simplificar la presentación de información financiera, facilitando su análisis y compartición por parte de clientes y socios.
El impacto futuro de los datos abiertos en los grandes desafíos globales
Como hemos visto también anteriormente, la apertura de datos ofrece un potencial inmenso para avanzar en la agenda de desarrollo sostenible y poder así enfrentar los desafíos globales con mayor eficacia. El Banco Mundial ha venido demostrando cómo esta práctica puede evolucionar y adaptarse a los desafíos actuales. Su liderazgo en este ámbito ha servido como modelo para otras instituciones, mostrando el impacto positivo que los datos abiertos pueden tener en el desarrollo sostenible y a la hora de afrontar los grandes desafíos que afectan a la vida de millones de personas en todo el mundo.
No obstante, hay todavía un largo camino por recorrer, ya que es necesario seguir mejorando las políticas de transparencia y acceso a la información para que los datos puedan llegar a beneficiar al conjunto de la sociedad de forma más equitativa. Además, otro desafío clave es fortalecer las capacidades necesarias para maximizar el uso e impacto de estos datos, particularmente en los países en vías de desarrollo. Esto implica no solo ir más allá de facilitar el acceso, sino también trabajar en la alfabetización de datos y en el apoyo a la creación de las herramientas adecuadas que permitan que la información sea utilizada de manera efectiva.
El uso de datos abiertos está consiguiendo que cada vez más actores puedan participar en la creación de soluciones innovadoras y conseguir un cambio real. Todo ello da lugar a una nueva área de trabajo en expansión que, en las manos correctas y con el apoyo adecuado, puede desempeñar un papel crucial en la creación de un futuro más seguro, justo y sostenible para todos. Esperamos que sean muchas las organizaciones que sigan el ejemplo del Banco Mundial y adopten también un enfoque integral en el uso de los datos para afrontar los grandes retos de la humanidad.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El Ministerio para la Transformación Digital y de la Función Pública ha presentado un ambicioso Plan de Impulso de los Espacios de Datos Sectoriales. Su objetivo es fomentar la innovación y mejorar la competitividad y la generación de valor en todos los sectores económicos, impulsando la creación de espacios de datos donde realizar una compartición segura de los datos. Gracias a ellos, las empresas, y la economía en general, podrán beneficiarse de todo el potencial del mercado único de datos europeo.
El Plan movilizará 500 millones de euros de presupuesto del Plan de Recuperación, Transformación y Resiliencia, y se desarrollará en 6 ejes y 11 iniciativas con una duración prevista hasta el año 2026.
Espacios de datos
La compartición de datos en espacios de datos ofrece enormes beneficios a todas las empresas que participan en ellos, tanto individuales como colectivos. Entre estos beneficios encontramos la eficiencia en la gestión, la reducción de costes, una mayor competitividad, la innovación en modelos de negocio y una mejor adaptación a las regulaciones. Estos beneficios no pueden alcanzarse aisladamente por las empresas, sino que requieren de la compartición de datos entre todos los actores implicados.
Algunos ejemplos de estos beneficios serían:
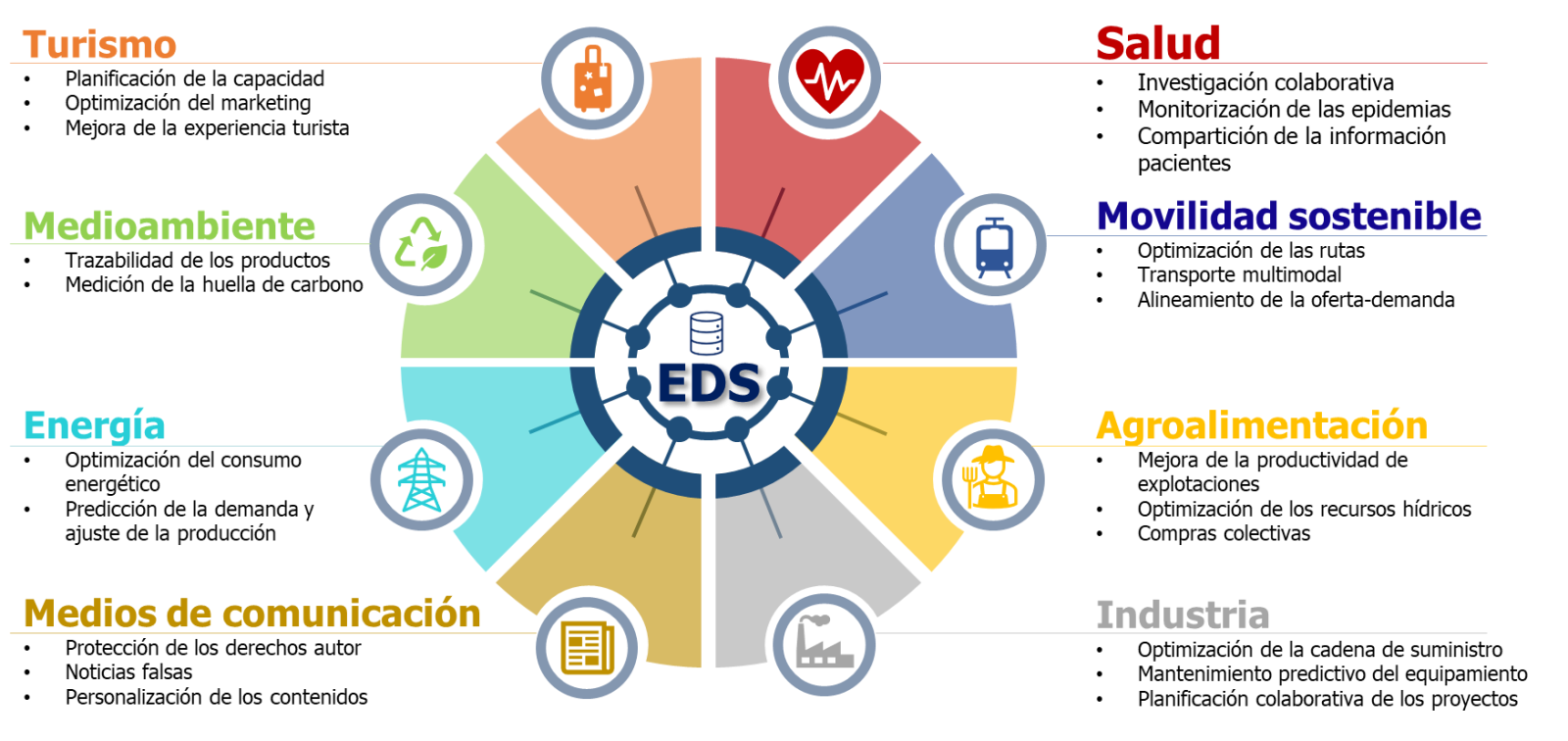
Figura 1. Impacto de los espacios de datos en diversos sectores.
Algunas iniciativas más concretas son:
-
El proyecto AgriDataSpace garantiza la calidad y seguridad alimentaria mediante la trazabilidad completa de los productos.
-
El Proyecto de Mobility Data Space mejora la planificación urbana y la eficiencia del transporte integrando datos de movilidad.
Beneficios del Plan de Impulso de los Espacios de Datos Sectoriales
El Plan ofrecerá más de 287 millones de euros en subvenciones para la creación y mantenimiento de espacios de datos, el desarrollo de casos de uso de alto interés y la reducción de los costes de las empresas participantes a la hora de consumir, compartir o proveer datos. También ofrecerá hasta 44 millones de euros en subvenciones al sector tecnológico industrial para que pueda adaptar sus productos y servicios digitales a las necesidades de los espacios de datos y de las entidades que participan en ellos compartiendo datos, y haciendo nuestra industria más competitiva en tecnologías para datos.
Finalmente, con un presupuesto de hasta 169 millones de euros, se desarrollarán varios proyectos singulares de interés público que actuarán de habilitadores para la transformación digital en torno a los datos y los espacios de datos en todos los sectores productivos. Estos habilitadores contribuirán a acelerar el proceso de despliegue de casos de uso y de espacios de datos, así como estimular a las empresas para que activamente compartan datos y puedan obtener los beneficios esperados. Para ello, se desarrollará una red de infraestructuras comunes y demostradores de espacios de datos, se pondrá en marcha un Centro de Referencia Nacional de espacios de datos, y se pondrá a disposición de los sectores económicos todo el enorme conjunto de datos públicos no abiertos, que están en poder de las administraciones públicas y que son de alto interés para las empresas.
Conoce más sobre el Plan y sus medidas


El conjunto de iniciativas que desarrollará el Plan se resume en la siguiente tabla:

Figura 2. Tabla resumen con las iniciativas incluidas en el Plan de Impulso de los Espacios de Datos Sectoriales.
Descubre las subvenciones que actualmente están activas y el calendario previsto para poder beneficiarte de ellas:

Más información sobre espacios de datos aquí.
Links de interés




Noticia
El turismo es uno de los motores económicos de España. En 2022, supuso el 11,6% del Producto Interior Bruto (PIB), superando los 155.000 millones de euros, de acuerdo con el Instituto Nacional de Estadística (INE). Una cifra que creció hasta los 188.000 millones y el 12,8% del PIB en 2023, según Exceltur, asociación de empresas del sector. Además, España es un destino muy popular entre los extranjeros, situándose en el segundo puesto mundial y creciendo: este 2024 se espera alcanzar récord de visitantes internacionales, llegando a los 95 millones.
En este contexto, la Secretaría de Estado de Turismo (SETUR), alineada con las políticas europeas, está desarrollando actuaciones que pretenden crear nuevas herramientas tecnológicas para la Red de Destinos Turísticos Inteligentes, a través de SEGITTUR (Sociedad Mercantil Estatal parala Gestión de la Innovación y las Tecnologías Turísticas), ente encargado de impulsar la innovación (I+D+i) en esta industria. Para ello trabaja tanto con el sector público como con el privado, impulsando:
- Modelos de gestión sostenible y más competitivos.
- La gestión y creación de destinos inteligentes.
- La exportación de tecnología española al resto del mundo.
Todas ellas son actividades donde los datos -y el conocimiento que se puede extraer de ellos- tienen un gran papel. En este post, vamos a repasar algunas de las acciones que SEGITTUR lleva a cabo para impulsar la compartición y apertura de datos, así como su reutilización. El objetivo es ayudar no solo a la toma de decisiones, sino también al desarrollo de productos y servicios innovadores que continúen posicionando a nuestro país en los primeros puestos del turismo mundial.
Dataestur, un portal de datos abiertos
Dataestur es un espacio web que recoge en un único entorno datos abiertos del turismo nacional. Los usuarios pueden encontrar cifras procedentes de distintas fuentes de información, públicas y privadas.
Los datos están estructurados en seis categorías:
- General: llegadas de turistas internacionales, gasto turístico, encuesta de turismo de residentes, barómetro del turismo mundial, datos de cobertura banda ancha, etc.
- Economía: ingresos por turismo, aportación al PIB, empleo turístico (demandantes de empleo, paro y contratos), etc.
- Transporte: pasajeros aéreos, capacidad aérea programada, tráfico de pasajeros por puertos, trenes y carreteras, etc.
- Alojamientos: ocupación hotelera, precio de alojamientos e indicadores de rentabilidad del sector hotelero, etc.
- Sostenibilidad: calidad del aire, protección de la naturaleza, valores climatológicos, calidad del agua en las zonas de baño, etc.
- Conocimiento: informes de escucha activa, comportamiento y percepción del visitante, revistas científicas de turismo, etc.
Los datos están disponibles para su descarga vía API.
Dataestur forma parte de un proyecto más ambicioso en el que el análisis de los datos constituye la base para mejorar el conocimiento del turista, a través de acciones con un amplio alcance, como las que veremos a continuación.
Desarrollo de una Plataforma Inteligente de Destinos (PID)
Dentro del cumplimiento de los hitos marcados por los fondos Next Generation, y correspondiente al desarrollo del Plan de Transformación Digital de Destinos Turísticos, la Secretaría de Estado de Turismo, a través de SEGITTUR, está desarrollando una Plataforma Inteligente de Destinos (PID). Se trata de una plataforma-nodo que recoge la oferta de servicios turísticos y facilita la interoperabilidad de operadores públicos y privados. Gracias a esta plataforma se podrá proveer de servicios para integrar y relacionar datos de ambas fuentes, públicas y privadas.
Algunos de los retos del ecosistema turístico español a los que da respuesta la PID son:
- Potenciar la integración y desarrollo del ecosistema turístico (academia, emprendedores, empresa, etc.) en torno a la inteligencia del dato y garantizar el alineamiento tecnológico, la interoperabilidad y el lenguaje común.
- Promover el uso de la economía del dato para mejorar la generación, agregación y compartición de conocimiento en el sector turístico español, impulsando su transformación digital.
- Contribuir a una correcta gestión de los flujos turísticos y de los puntos de afluencia turística del espacio ciudadano, mejorando la respuesta a los problemas de la ciudadanía y ofreciendo información en tiempo real para la gestión turística.
- Generar un impacto notable en el turista, residentes y empresa, además del resto de agentes, potenciando la marca “país turismo sostenible” durante todo el ciclo de viaje (antes, durante y después).
- Establecer un marco de referencia para consensuar objetivos y métricas que impulsen la sostenibilidad y la reducción de la huella de carbono en la industria turística, fomentando prácticas sostenibles y la integración de tecnologías limpias.

Figura 1. Objetivos de la Plataforma Inteligente de Destinos (PID).
Nuevos casos de uso y metodologías para implementarlos
Para avanzar en la armonización de la gestión de datos, se han definido hasta 25 casos de uso que permiten a los distintos verticales del sector trabajar de manera coordinada. Estos verticales incluyen áreas como enoturismo, turismo termal, gestión de playas, hoteles proveedores de datos, indicadores de impacto, cruceros, turismo deportivo, etc.
Para implementar estos casos de uso, se sigue una metodología de 5 pasos que busca alinear las prácticas del sector con un enfoque más estructurado en torno a los datos:
- Identificar los problemas públicos a resolver.
- Identificar qué datos son necesarios disponer para poder resolverlos.
- Modelizar esos datos para definir una nomenclatura, definición y relaciones comunes.
- Definir qué tecnología hay que desplegar para poder capturar o generar dichos datos.
- Analizar qué capacidades de intervención, tanto públicas como privadas, se necesitan para resolver el problema.
Impulso de la interoperabilidad a través de una ontología común y un espacio de datos
Como resultado de esa definición de los 25 casos de uso se ha creado una ontología del turismo que esperan sirva como referencia mundial. La ontología tiene la vocación de generar un impacto significativo en el sector turístico, ofreciendo una serie de beneficios:
- Interoperabilidad: la ontología es esencial para establecer una estructura de datos homogénea y permitir una interoperabilidad global, lo que facilita la integración de información y el intercambio de datos entre plataformas y países. Al proporcionar un lenguaje común, definiciones y una estructura conceptual unificada, los datos pueden ser comparables y utilizables en cualquier parte del mundo. Los destinos turísticos y el tejido empresarial pueden comunicarse de manera más efectiva y ágil, impulsando una colaboración más estrecha.
- Transformación digital: al fomentar el desarrollo de tecnologías avanzadas, como la inteligencia artificial, las empresas turísticas, el ecosistema innovador o académico pueden analizar grandes volúmenes de datos de manera más eficiente. Esto es debido principalmente a la calidad de la información disponible y a que los sistemas comprenden mejor el contexto en el que operan.
- Competitividad turística: alineado con la cuestión anterior, la implementación de esta ontología contribuye a eliminar desigualdades en el uso y aplicación de la tecnología dentro del sector. Al facilitar el acceso a herramientas digitales avanzadas, tanto las instituciones públicas como las empresas privadas pueden tomar decisiones más informadas y estratégicas. Esto no solo eleva la calidad de los servicios ofrecidos, sino que también impulsa la productividad y competitividad del sector turístico español en un mercado global cada vez más exigente.
- Experiencia turística: gracias a la ontología, es posible ofrecer recomendaciones adaptadas a las preferencias individuales de cada viajero. Esto se logra mediante un perfilado más preciso basado en características demográficas y comportamentales, así como en las motivaciones específicas relacionadas con diferentes tipos de turismo. Al personalizar las ofertas y servicios, se mejora la satisfacción del cliente antes, durante y tras el viaje, y se fomenta una mayor fidelidad hacia los destinos turísticos.
- Gobernanza: el modelo ontológico está diseñado para evolucionar y adaptarse a medida que surgen nuevos casos de uso ante las demandas cambiantes del mercado. SEGITTUR está trabajando activamente en establecer un modelo de gobernanza que promueva la colaboración efectiva entre instituciones públicas y privadas, así como con el sector tecnológico.
Además, para resolver problemas complejos que requieren compartición de datos de diferentes fuentes, se ha creado la Plataforma de Innovación Abierta (PIA), un espacio de datos que facilita la colaboración entre los diferentes actores del ecosistema turístico, tanto públicos como privados. Esta plataforma permite compartir datos de manera segura y eficiente, potenciando la toma de decisiones basadas en datos. El PIA promueve un entorno colaborativo donde se comparten datos abiertos y privados para crear soluciones conjuntas que aborden desafíos específicos del sector, como la sostenibilidad, la personalización de la experiencia turístico o la gestión del impacto ambiental.
Impulso del consenso
Desde SEGITTUR también se están llevando a cabo diversas iniciativas para lograr el consenso necesario en la recopilación, gestión y análisis de datos relacionados con el turismo, a través de la colaboración entre actores públicos y privados. Para ello, en 2021 se creó el Ente Promotor de la Plataforma Inteligente de Destinos, que juega un papel fundamental al aglutinar a diversos actores para coordinar esfuerzos y acordar grandes líneas y directrices en el ámbito de los datos turísticos.
En resumen, España está avanzando en la recopilación, gestión y análisis de datos turísticos mediante la coordinación entre los actores públicos y privados, utilizando metodologías y herramientas avanzadas como la creación de ontologías, casos de uso y plataformas colaborativas como la PIA que aseguran una gestión eficiente y consensuada del sector.
Todo ello no solo está modernizando el sector turístico español, sino que también está sentando las bases para un futuro más inteligente, conectado y eficiente. Con su enfoque en la interoperabilidad, la transformación digital y la personalización de experiencias, España se posiciona como líder en innovación turística, lista para afrontar los desafíos tecnológicos del mañana.
Documentación
Los portales de datos abiertos juegan un papel fundamental en el acceso y reutilización de la información pública. Un aspecto clave en estos entornos es el etiquetado de los conjuntos de datos, que facilita su organización y recuperación.
Los word embeddings representan una tecnología transformadora en el campo del procesamiento del lenguaje natural, permitiendo representar palabras como vectores en un espacio multidimensional donde las relaciones semánticas se preservan matemáticamente. En este ejercicio se explora su aplicación práctica en un sistema de recomendación de etiquetas, utilizando como caso de estudio el portal de datos abiertos datos.gob.es.
El ejercicio se desarrolla en un notebook que integra la configuración del entorno, la adquisición de datos y el procesamiento del sistema de recomendación, todo ello implementado en Python. El proyecto completo se encuentra disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Entendiendo los word embeddings
Los word embeddings son representaciones numéricas de palabras que revolucionan el procesamiento del lenguaje natural al transformar el texto en un formato matemáticamente procesable. Esta técnica codifica cada palabra como un vector numérico en un espacio multidimensional, donde la posición relativa entre vectores refleja relaciones semánticas y sintácticas entre palabras. La verdadera potencia de los embeddings radica en tres aspectos fundamentales:
- Captura de contexto: a diferencia de técnicas tradicionales como one-hot encoding, los embeddings aprenden del contexto en el que aparecen las palabras, permitiendo capturar matices de significado.
- Algebra semántica: los vectores resultantes permiten operaciones matemáticas que preservan relaciones semánticas. Por ejemplo, vector('Madrid') - vector('España') + vector('Francia') ≈ vector('París'), demostrando la captura de relaciones capital-país.
- Similitud cuantificable: la similitud entre palabras se puede medir mediante métricas, permitiendo identificar no solo sinónimos exactos sino también términos relacionados en diferentes grados y generalizar estas relaciones a nuevas combinaciones de palabras.
En este ejercicio se han utilizado embeddings pre-entrenados GloVe (Global Vectors for Word Representation), un modelo desarrollado por Stanford que destaca por su capacidad de capturar relaciones semánticas globales en el texto. En nuestro caso, empleamos vectores de 50 dimensiones, un equilibrio entre complejidad computacional y riqueza semántica. Para evaluar exhaustivamente su capacidad de representar el lenguaje castellano, se han realizado múltiples pruebas:
- Se ha analizado la similitud entre palabras mediante la similitud coseno, una métrica que evalúa el ángulo entre los vectores de dos palabras. Esta medida resulta en valores entre -1 y 1, donde valores cercanos a 1 indican alta similitud semántica, mientras que valores cercanos a 0 indican poca o ninguna relación. Se evaluaron términos como "amor", "trabajo" y "familia" para verificar que el modelo identificara correctamente palabras semánticamente relacionadas.
- Se ha probado la capacidad del modelo para resolver analogías lingüísticas, por ejemplo, "hombre es a mujer lo que rey es a reina", confirmando su habilidad para capturar relaciones semánticas complejas.
- Se han realizado operaciones vectoriales (como "rey - hombre + mujer") para comprobar si los resultados mantenían coherencia semántica.
- Finalmente, se han aplicado técnicas de reducción de dimensionalidad sobre una muestra representativa de 40 palabras en español, permitiendo visualizar las relaciones semánticas en un espacio bidimensional. Los resultados revelaron patrones de agrupación natural entre términos semánticamente relacionados, como se observa en la figura:
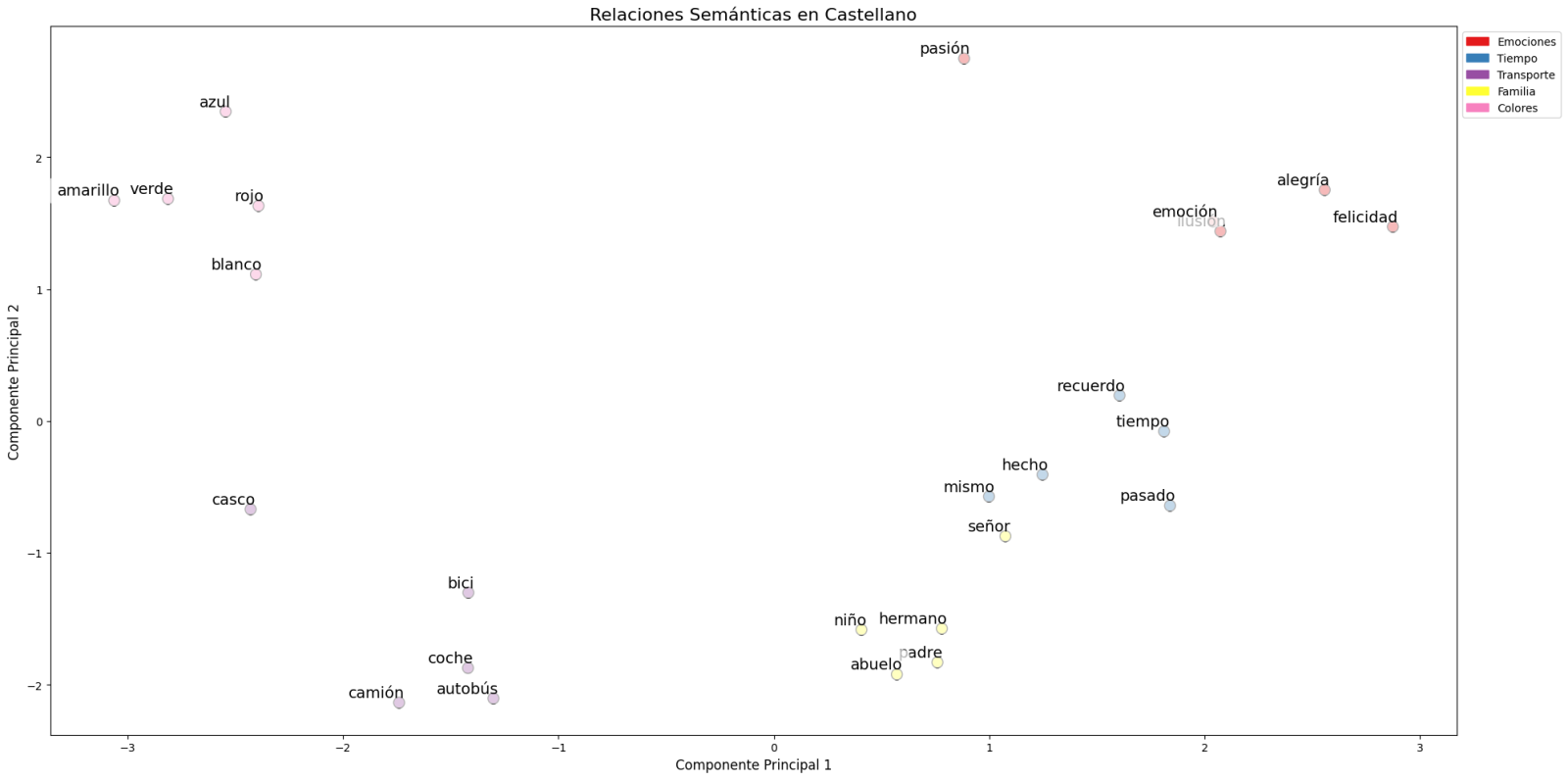
Figura 1. Análisis de Componentes principales sobre 50 dimensiones (embeddings) con un porcentaje de variabilidad explicada por los dos componentes de 0.46
- Los términos relacionados con familia (padre, hermano, abuelo) se concentran en la parte inferior.
- Los medios de transporte (coche, autobús, camión) forman un grupo distintivo.
- Los colores (azul, verde, rojo) aparecen próximos entre sí.
Para sistematizar este proceso de evaluación, se ha desarrollado una función unificada que encapsula todas las pruebas descritas anteriormente. Esta arquitectura modular permite evaluar de manera automática y reproducible diferentes modelos de embeddings pre-entrenados, facilitando así la comparación objetiva de su rendimiento en el procesamiento del lenguaje castellano. La estandarización de estas pruebas no solo optimiza el proceso de evaluación, sino que también establece un marco consistente para futuras comparaciones y validaciones de nuevos modelos por parte del público.
La buena capacidad para capturar relaciones semánticas en el lenguaje castellano es la que aprovechamos en nuestro sistema de recomendación de etiquetas.
Sistema de recomendación basado en embeddings
Aprovechando las propiedades de los embeddings, desarrollamos un sistema de recomendación de etiquetas que sigue un proceso de tres fases:
- Generación de embeddings: para cada conjunto de datos del portal, generamos una representación vectorial combinando el título y la descripción. Esto nos permite comparar datasets por su similitud semántica.
- Identificación de datasets similares: utilizando la similitud coseno entre los vectores, identificamos los conjuntos de datos más similares semánticamente.
- Extracción y estandarización de etiquetas: a partir de los conjuntos similares, extraemos sus etiquetas asociadas y las mapeamos con términos del tesauro Eurovoc. Este tesauro, desarrollado por la Unión Europea, es un vocabulario controlado multilingüe que proporciona una terminología estandarizada para la catalogación de documentos y datos en el ámbito de las políticas europeas. Aprovechando nuevamente la potencia de los embeddings, identificamos los términos de Eurovoc semánticamente más cercanos a nuestras etiquetas, garantizando así una estandarización coherente y una mejor interoperabilidad entre sistemas de información europeos.
Los resultados muestran que el sistema es capaz de generar recomendaciones de etiquetas coherentes y estandarizadas. Para ilustrar el funcionamiento del sistema, tomemos el caso del conjunto de datos “Agenda de Actividades Ciudad de Tarragona”:
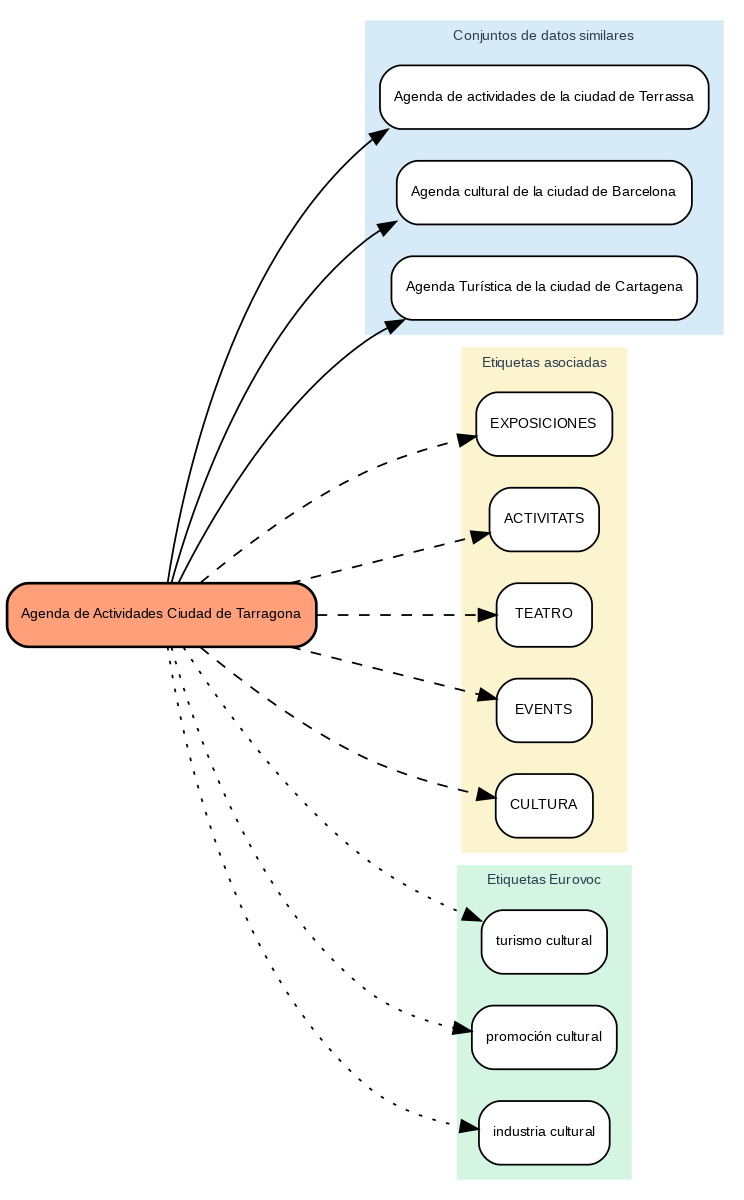
Figura 2. Agenda de Actividades Ciudad de Tarragona
El sistema:
- Encuentra conjuntos de datos similares como "Agenda de actividades de Terrassa" y "Agenda cultural de Barcelona".
- Identifica etiquetas comunes de estos conjuntos de datos, como "EXPOSICIONES", "TEATRO" y "CULTURA".
- Sugiere términos Eurovoc relacionados: "turismo cultural", "promoción cultural" e "industria cultural".
Ventajas del enfoque
Este enfoque ofrece ventajas significativas:
- Recomendaciones Contextuales: el sistema sugiere etiquetas basándose en el significado real del contenido, no solo en coincidencias textuales.
- Estandarización Automática: la integración con Eurovoc garantiza un vocabulario controlado y coherente.
- Mejora Continua: el sistema aprende y mejora sus recomendaciones a medida que se añaden nuevos datasets.
- Interoperabilidad: el uso de Eurovoc facilita la integración con otros sistemas europeos.
Conclusiones
Este ejercicio demuestra el gran potencial de los embeddings como herramienta para la asociación de textos en función de su naturaleza semántica. A través del caso práctico analizado, se ha podido observar cómo, mediante la identificación de títulos y descripciones similares entre datasets, es posible generar recomendaciones precisas de etiquetas o keywords. Estas etiquetas, a su vez, pueden vincularse con palabras clave de un tesauro estandarizado como Eurovoc, aplicando el mismo principio.
A pesar de los retos que pueden surgir, la implementación de este tipo de sistemas en entornos de producción presenta una valiosa oportunidad para mejorar la organización y recuperación de información. La precisión en la asignación de etiquetas puede verse influenciada por diversos factores interrelacionados del proceso:
- La especificidad de los títulos y descripciones de los datasets es fundamental, ya que de ella depende una correcta identificación de contenidos similares y, por tanto, una adecuada recomendación de etiquetas.
- La calidad y representatividad de las etiquetas existentes en los datasets similares determina directamente la relevancia de las recomendaciones generadas.
- La cobertura temática del tesauro Eurovoc, que, si bien es extensa, puede no abarcar términos específicos necesarios para describir ciertos datasets de manera precisa.
- La capacidad de los vectores para capturar fielmente las relaciones semánticas entre los contenidos, lo cual impacta directamente en la precisión de las etiquetas asignadas.
Para aquellos que deseen profundizar en el tema, existen otras aproximaciones interesantes al uso de embeddings que complementan lo visto en este ejercicio, tales como:
- Utilización de modelos de embeddings más complejos y computacionalmente costosos (como BERT, GPT, etc.).
- Entrenamiento de modelos en un corpus propio adaptado al dominio.
- Aplicación de técnicas más profundas de limpieza de datos.
En resumen, este ejercicio no solo demuestra la eficacia de los embeddings para la recomendación de etiquetas, sino que abre la puerta a que el lector explore todas las posibilidades que esta poderosa herramienta ofrece.
Blog
La crisis climática y los desafíos ambientales actuales demandan respuestas innovadoras y efectivas. En este contexto, la iniciativa Destination Earth (DestinE) de la Comisión Europea es un proyecto pionero que tiene como objetivo desarrollar un modelo digital y altamente preciso de nuestro planeta.
A través de este gemelo digital de la Tierra se podrá monitorear y prevenir posibles desastres naturales, adaptar las estrategias de sostenibilidad y coordinar esfuerzos humanitarios, entre otras funciones. En este post, analizamos en qué consiste el proyecto y en qué estado se encuentra su desarrollo.
Características y componentes de Destination Earth
Alineado con el Pacto Verde Europeo y la Estrategia de Europa Digital, Destination Earth integra el modelado digital y las ciencias climáticas para ofrecer una herramienta que sea de utilidad a la hora de abordar retos ambientales. Para ello, cuenta con un enfoque orientado hacia la precisión, el detalle local y la rapidez en el acceso a la información.
En general, la herramienta permite:
- Monitorear y simular los desarrollos del sistema terrestre, que incluyen la tierra, el mar, la atmósfera y la biosfera, así como las intervenciones humanas.
- Anticipar desastres ambientales y crisis socioeconómicas, permitiendo así la salvaguarda de vidas y la prevención de recesiones económicas significativas.
- Generar y probar escenarios que promuevan un desarrollo más sostenible en el futuro.
Para llevar esto a cabo, DestinE se subdivide en tres componentes principales que son:
- Lago de datos:
- ¿Qué es? Un repositorio centralizado que permite almacenar datos de diversas fuentes, como la Agencia Espacial Europea (ESA), EUMETSAT y Copernicus, así como de los nuevos gemelos digitales.
- ¿Qué ofrece? Esta infraestructura permite el descubrimiento y acceso a datos, así como el procesamiento de grandes volúmenes de información en la nube.
- ·La Plataforma de DestinE:
- ¿Qué es? Un ecosistema digital que integra servicios, herramientas de toma de decisiones basadas en datos y una infraestructura de computación abierta en la nube, flexible y segura.
- ¿Qué ofrece? Los usuarios tienen acceso a información temática, modelos, simulaciones, pronósticos y visualizaciones que facilitarán una comprensión más profunda del sistema terrestre.
- Gemelos digitales e ingeniería:
- ¿Qué son? Son varias réplicas digitales que cubren diferentes aspectos del sistema terrestre. Ya están desarrollados los dos primeros, uno relacionado con la adaptación al cambio climático y, el otro, sobre eventos climáticos extremos.
- ¿Qué ofrecen? Estos gemelos ofrecen simulaciones multidecadales (variación de la temperatura) y pronósticos de alta resolución.
Descubre los servicios y contribuye a mejorar DestinE
La plataforma de DestinE ofrece un recopilatorio de aplicaciones y casos de uso desarrollados en el marco de la iniciativa, como, por ejemplo:
- Gemelo digital del turismo (Beta): permite revisar y anticipar la viabilidad de las actividades turísticas en función de las condiciones medioambientales y meteorológicas de su territorio.
- VizLab: ofrece una interfaz gráfica de usuario intuitiva y tecnologías avanzadas de renderizado en 3D para proporcionar una experiencia narrativa haciendo que conjuntos de datos complejos sean accesibles y comprensibles para un público amplio.
- miniDEA: es una app de visualización web interactiva y fácil de usar, basado en DEA, para previsualizar datos de DestinE.
- GeoAI: es una plataforma de IA geoespacial para casos de uso de observación de la Tierra.
- Global Fish Tracking System (GFTS): es un proyecto para ayudar a obtener información precisa sobre las poblaciones de peces para elaborar políticas de conservación basadas en datos.
- Planificación urbana más resiliente: es una solución que proporciona un índice de estrés térmico que permite a los planificadores urbanos conocer cuáles son las mejores prácticas de adaptación contra las temperaturas extremas en entornos urbanos.
- Monitoreo de la reserva de agua del Delta del Danubio: es un análisis exhaustivo y preciso basado en el lago de datos DestinE para informar sobre los esfuerzos de conservación del Delta del Danubio, una de las regiones con mayor biodiversidad de Europa.
Desde octubre de este año la plataforma de DestinE acepta registros, una posibilidad que permite explorar todo el potencial de la herramienta y acceder a recursos exclusivos. Esta opción sirve para recabar feedback y mejorar el sistema del proyecto.
Para convertirte en usuario y poder generar servicios, debes seguir estos pasos.
Hoja de ruta del proyecto:
La Unión Europea plantea una serie de hitos ubicados en el tiempo que marcarán el desarrollo de la iniciativa:
- 2022 – Lanzamiento oficial del proyecto.
- 2023 – Inicio del desarrollo de los principales componentes.
- 2024 – Desarrollo de todos los componentes del sistema. Puesta en marcha de la plataforma de DestinE y el lago de datos. Demostración.
- 2026 - Mejora del sistema DestinE, integración de gemelos digitales adicionales y servicios relacionados.
- 2030 - Réplica digital completa de la Tierra.
Destination Earth no solo representa un avance tecnológico, sino que también es una herramienta poderosa para la sostenibilidad y la resiliencia frente a los desafíos climáticos. Al proporcionar datos precisos y accesibles, DestinE permite tomar decisiones basadas en datos y crear estrategias de adaptación y mitigación efectivas.
Noticia
Los premios 2024 Best Cases Award del observatorio Public Sector Tech Watch ya tienen finalistas. Estos premios buscan destacar soluciones que utilizan tecnologías emergentes, como inteligencia artificial o blockchain, en las administraciones públicas, a través de dos categorías:
- Soluciones para mejorar los servicios públicos que se ofrecen a los ciudadanos (Government-to-Citizen o G2C).
- Soluciones para mejorar los procesos internos de las propias administraciones (Government-to-Government o G2G).
Con estos premios se pretende generar un mecanismo para compartir las mejores experiencias sobre el uso de tecnologías emergentes en el sector público y así dar visibilidad a las administraciones más innovadoras de Europa.
Casi el 60% de las soluciones finalistas son españolas
En total, se han recibido 32 propuestas, 14 de las cuales han sido preseleccionadas en una evaluación previa. De ellas, más de la mitad son soluciones de organismos españoles. En concreto, se han preseleccionado nueve finalistas para la categoría G2G -cinco de ellas españolas- y cinco para G2C -tres de ellas ligadas a nuestro país-.
A continuación, se resumen en qué consisten estas soluciones españolas.
Soluciones para mejorar los procesos internos de las propias administraciones
- Innovación en el gobierno local: transformación digital y GeoAI para la gestión de datos (Diputación de Alicante).
Suma Gestión Tributaria, de la Diputación de Alicante, es el organismo encargado de gestionar y recaudar los tributos municipales de los ayuntamientos de su provincia. Para optimizar esta tarea, han desarrollado una solución que combina sistemas de información geográfica e inteligencia artificial (machine learning y deep learning) para mejorar la formación en detección de inmuebles que no tributan en los padrones. Esta solución recaba datos de múltiples administraciones y entidades con el objetivo de evitar retrasos en la recaudación de los ayuntamientos.
- Inspector autonómico de infraestructuras públicas: seguimiento de zonas de obras (Diputación Foral de Bizkaia e Interbiak).
El inspector autónomo de carreteras y el inspector autónomo urbano ayudan a las administraciones públicas a realizar un seguimiento automático de las carreteras. Estas soluciones, que se pueden instalar en cualquier vehículo, utilizan técnicas de visión artificial o por computadora junto a información procedente de sensores para comprobar de forma automática el estado de señales de tráfico, marcas viales, barreras de protección, etc. También realizan tareas de previsión temprana de la degradación del pavimento, monitorizan zonas de obras y generan alertas ante peligros, como posibles deslizamientos.
- Aplicación de drones para el transporte de muestras biológicas (Centro de Telecomunicaciones y Tecnologías de la Información -CTTI-, Generalitat de Catalunya).
Este proyecto piloto implementa y evalúa una ruta de transporte sanitario en la región sanitaria de Girona. Su objetivo es transportar muestras biológicas (sangre y orina) entre un centro de salud primaria y un hospital utilizando drones. Gracias a ello, el trayecto ha pasado de durar 20 minutos con el transporte terrestre a siete minutos con el uso de drones. Esto ha permitido mejorar la calidad de las muestras transportadas, aumentar la flexibilidad en la programación de los tiempos de transporte y reducir el impacto medioambiental.
- Automatización robótica de procesos en la administración de justicia (Ministerio de la Presidencia, Justicia y Relaciones con las Cortes).
Ministerio de la Presidencia, Justicia y Relaciones con las Cortes ha puesto en marcha una solución para la robotización de procesos administrativos con el fin de agilizar trabajos rutinarios, repetitivos y de bajo riesgo. Hasta la fecha, se han puesto en marcha más de 25 líneas de automatización de procesos, entre las que se encuentran la cancelación automática de antecedentes penales, las solicitudes de nacionalidad, la emisión automática de certificaciones de seguros de vida, etc. Gracias a ello se estima que se han ahorrado más de 500 mil horas de trabajo.
- Inteligencia artificial en el tratamiento de las publicaciones oficiales (Boletín Oficial de la Provincia de Barcelona y Servicio de Documentación y Publicaciones Oficiales, Diputación de Barcelona).
El CIDO (Buscador de Información y Documentación Oficial) ha implementado un sistema de IA que genera automáticamente resúmenes de publicaciones oficiales de las administraciones públicas de Barcelona. Utilizando técnicas de aprendizaje automático supervisado y redes neuronales, el sistema genera resúmenes de hasta 100 palabras para publicaciones en catalán o castellano. La herramienta permite el registro de modificaciones manuales para mejorar la precisión.
Soluciones para mejorar los servicios públicos que se ofrecen a los ciudadanos
- Escritorio Virtual de Inmediación Digital: acercar la Justicia a los ciudadanos a través de la digitalización (Ministerio de la Presidencia, Justicia y Relaciones con las Cortes).
El Escritorio Virtual de Inmediación Digital (EVID) permite realizar vistas a distancia con plenas garantías de seguridad jurídica utilizando tecnologías blockchain. La solución integra la convocatoria de la vista, la aportación de la documentación, la identificación de los participantes, la aceptación de consentimientos, la generación del documento justificativo de la actuación realizada, la firma de éste y la grabación de la sesión. De esta forma se pueden realizar actos jurídicos desde cualquier lugar, sin necesidad de desplazarse y de forma sencilla, haciendo que la justicia sea más inclusiva, accesible y ecológica. A finales de junio de 2024, se habían celebrado más de 370.000 sesiones virtuales a través de la EVID.
- Aplicación de la IA Generativa para facilitar a los ciudadanos la comprensión de los textos legales (Entitat Autònoma del Diari Oficial i Publicacions -EADOP-, Generalitat de Catalunya).
A menudo, el lenguaje jurídico es una barrera que impide a la ciudadanía entender fácilmente los textos legales. Para eliminar este obstáculo, el Govern pone a disposición de los usuarios del Portal Jurídico de Cataluña y de la población en general los resúmenes de normas de derecho catalán en lenguaje sencillo obtenidos a partir de la inteligencia artificial generativa. El objetivo es que, a finales de año, estén disponibles los resúmenes de las más de 14.000 disposiciones normativas vigentes adaptadas a la comunicación clara. Los resúmenes estarán editados en catalán y en castellano, con la perspectiva de ofrecer también en el futuro su versión en aranés.
- Emi - Empleo Inteligente (Consellería de Emprego, Comercio e Emigración de la Xunta de Galicia).
Emi, Empleo Inteligente es una herramienta de inteligencia artificial y big data que ayuda a las oficinas del Servicio Público de Empleo de Galicia a orientar a las personas desempleadas hacia las competencias que requiere el mercado laboral, en función de sus capacidades. Los modelos de IA realizan proyecciones a seis meses de los contratos de una ocupación concreta para una zona geográfica elegida. Además, permiten calcular la probabilidad de encontrar empleo de los individuos en los próximos meses.
Puedes ver todas las soluciones presentadas aquí. Los ganadores se anunciarán en el evento final que se celebrará el 28 de noviembre. La ceremonia se celebra en Bruselas, pero se podrá seguir también de manera online. Para ello es necesario registrarse aquí.
Public Sector Tech Watch: un observatorio para inspirar nuevos proyectos
Public Sector Tech Watch (PSTW), gestionado por la Comisión Europea, se posiciona como una “ventanilla única” para todos aquellos interesados -sector público, responsables políticos, empresas privadas, mundo académico, etc.- en los últimos avances tecnológicos para mejorar el funcionamiento del sector público y la prestación de servicios. Para ello cuenta con varias secciones donde se muestra la siguiente información de interés:
- Cases: contiene ejemplos de cómo utilizan tecnologías innovadores y sus datos asociados las organizaciones del sector público en Europa.
- Stories: presenta testimonios para mostrar los retos a los que se enfrentan las administraciones europeas en la aplicación de soluciones tecnológicas.
Si conoces algún caso de interés que actualmente no esté monitorizado por PSTW, puedes darlo de alta aquí. Los casos de éxito son revisados y evaluados antes de incluirse en la base de datos.
Documentación
Se presenta a continuación una nueva guía de Análisis Exploratorio de Datos (AED) implementada en Python, que evoluciona y complementa la versión publicada en R en el año 2021. Esta actualización responde a las necesidades de una comunidad cada vez más diversa en el ámbito de la ciencia de datos.
El Análisis Exploratorio de Datos (AED o EDA, por sus siglas en inglés) representa un paso crítico previo a cualquier análisis estadístico, ya que permite:
- Comprender exhaustivamente los datos antes de analizarlos.
- Verificar el cumplimiento de los requisitos estadísticos que garantizarán la validez de los análisis posteriores.
Para ejemplificar su importancia, tomemos el caso de la detección y tratamiento de valores atípicos, una de las tareas a realizar en un AED. Esta fase tiene un impacto significativo en estadísticos fundamentales como la media, la desviación estándar o el coeficiente de variación.
Además de explicar las distintas fases de un AED, la guía las ilustra con un caso práctico. En este sentido, se mantiene como caso práctico el análisis de datos de calidad del aire de Castilla y León. A través de explicaciones que el usuario podrá replicar, se transforman los datos públicos en información valiosa mediante el uso de bibliotecas Python fundamentales como pandas, matplotlib y seaborn, junto con herramientas modernas de análisis automatizado como ydata-profiling.
¿Por qué una nueva guía en Python?
La elección de Python como lenguaje para esta nueva guía refleja su creciente relevancia en el ecosistema de la ciencia de datos. Su sintaxis intuitiva y su extenso catálogo de bibliotecas especializadas lo han convertido en una herramienta fundamental para el análisis de datos. Al mantener el mismo conjunto de datos y estructura analítica que la versión en R, se facilita la comprensión de las diferencias entre ambos lenguajes. Esto resulta especialmente valioso en entornos donde coexisten múltiples tecnologías. Este enfoque es particularmente relevante en el contexto actual, donde numerosas organizaciones están migrando sus análisis desde lenguajes/herramientas tradicionales como R, SAS o SPSS hacia Python. La guía busca facilitar estas transiciones y garantizar la continuidad en la calidad de los análisis durante el proceso de migración.
Novedades y mejoras
Se ha enriquecido el contenido con la introducción al AED automatizado y las herramientas de perfilado de datos, respondiendo así a una de las últimas tendencias en el campo. El documento profundiza en aspectos esenciales como la interpretación de datos medioambientales, ofrece un tratamiento más riguroso de los valores atípicos y presenta un análisis más detallado de las correlaciones entre variables. Además, incorpora buenas prácticas en la escritura de código.
La aplicación práctica de estos conceptos se ilustra a través del análisis de datos de calidad del aire, donde cada técnica cobra sentido en un contexto real. Por ejemplo, al analizar las correlaciones entre contaminantes, no solo se muestra cómo calcularlas, sino que se explica cómo estos patrones reflejan procesos atmosféricos reales y qué implicaciones tienen para la gestión de la calidad del aire.
Estructura y contenidos
La guía sigue un enfoque práctico y sistemático, cubriendo las cinco etapas fundamentales del AED:
- Análisis descriptivo para obtener una visión representativa de los datos
- Ajuste de los tipos de variables para garantizar la consistencia
- Detección y tratamiento de datos ausentes
- Identificación y gestión de datos atípicos
- Análisis de correlación entre variables
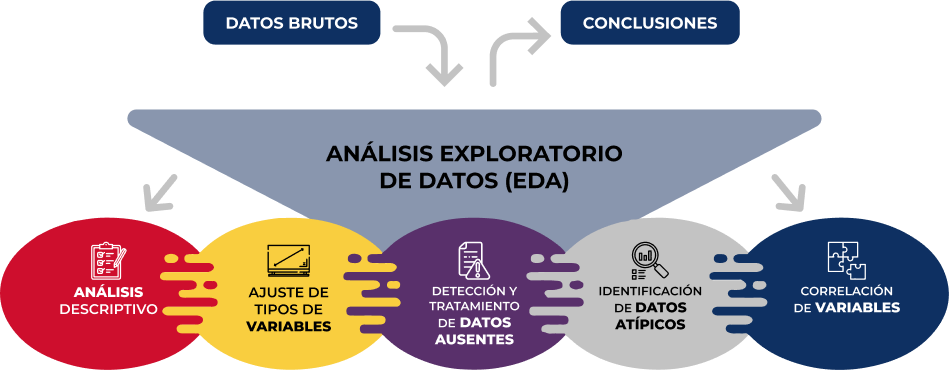
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
Como novedad en la estructura, se incluye una sección sobre análisis exploratorio automatizado, presentando herramientas modernas que facilitan la exploración sistemática de grandes conjuntos de datos.
¿A quién va dirigida?
Esta guía está diseñada para usuarios de datos abiertos que deseen realizar análisis exploratorios y reutilizar las valiosas fuentes de información pública que se encuentran en este y otros portales de datos a nivel mundial. Si bien es recomendable tener conocimientos básicos del lenguaje, la guía incluye recursos y referencias para mejorar las competencias en Python, así como ejemplos prácticos detallados que facilitan el aprendizaje autodidacta.
El material completo, que incluye tanto la documentación como el código fuente, se encuentra disponible en el repositorio de GitHub del portal. La implementación se ha realizado utilizando herramientas de código abierto como Jupyter Notebook en Google Colab, lo que permite reproducir los ejemplos y adaptar el código según las necesidades específicas de cada proyecto.
Se invita a la comunidad a explorar esta nueva guía, experimentar con los ejemplos proporcionados y aprovechar estos recursos para desarrollar sus propios análisis de datos abiertos.
Haz click para ver la infografía completa, en versión accesible

Figura 2. Captura de la infografía. Fuente: elaboración propia.
Evento
Los datos espaciales y geoespaciales son esenciales en la toma de decisiones, la planificación territorial y la gestión de recursos. La capacidad de visualizar y analizar datos en un contexto espacial ofrece herramientas valiosas para enfrentar desafíos complejos en diversas áreas, desde la defensa hasta la sostenibilidad. Participar en eventos que abordan estas temáticas no solo amplía nuestros conocimientos, sino que también fomenta la colaboración y la innovación en el sector.
En este post, presentamos dos eventos próximos que versan sobre datos geoespaciales y sus usos más innovadores. ¡No te los pierdas!
II Jornada de Inteligencia Geoespacial: Territorio y Defensa
El Instituto Geográfico de Aragón (IGEAR) en colaboración con la Academia General Militar, el Centro Universitario de la Defensa y Telespazio Ibérica, ha organizado la segunda edición de la Jornada de Inteligencia Geoespacial: Territorio y Defensa, un evento que reunirá a profesionales del sector para explorar cómo los datos geoespaciales pueden optimizar las estrategias en el ámbito de la seguridad y la gestión del territorio.
Durante el próximo 21 de noviembre, la sala de la corona del Edificio Pignatelli en Zaragoza reunirá ponentes y asistentes para debatir sobre el impacto de la inteligencia geoespacial en España. El evento acogerá a un máximo de 100 asistentes que podrán acudir por invitación.
La inteligencia geoespacial, o GEOINT por su abreviatura en inglés (Geospatial Intelligence), se enfoca en comprender las dinámicas que ocurren dentro de un determinado espacio geográfico. Para lograr esto, GEOINT se apoya en el análisis detallado de imágenes, bases de datos y otra información relevante, partiendo de la idea de que, aunque las circunstancias que rodean cada situación puedan variar, existe una característica común: toda acción tiene lugar en coordenadas geográficas específicas.
La GEOINT es un campo muy amplio que se puede aplicar tanto al ámbito militar, para ejecutar movimientos analizando el terreno, como en el científico, para estudiar entornos, o incluso en el ámbito empresarial, para ayudar a adaptar información censal, histórica, meteorológica, agrícola y geológica hacia usos comerciales.
En la II Jornada de Inteligencia Geoespacial se presentarán casos prácticos y avances tecnológicos y se promoverán debates sobre el futuro de la inteligencia geoespacial en contextos de defensa. Para más detalles, puedes visitar el sitio web del evento.
- ¿Cuándo? El próximo 21 de noviembre de 2024 a las 8:00h.
- ¿Dónde? Sala de la Corona del Edificio Pignatelli. Paseo María Agustín, 36. Zaragoza.
- ¿Cómo acceder? A través de este enlace
XV Edición de las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) y III geoEuskadi
Este año, el Consejo Directivo de la Infraestructura de Información Geográfica de España (CODIIGE) organiza de manera conjunta las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) y el III Congreso geoEuskadi Kongresua. Ambos eventos pretenden potenciar y promover las actividades vinculadas a la información geográfica en diversos sectores, abarcando tanto la publicación y accesibilidad normalizada de datos geográficos como su producción, procesamiento y explotación.
Por un lado, en las JIIDE colaboran la Direção-Geral do Território de Portugal, el Instituto Geográfico Nacional de España, a través del Centro Nacional de Información Geográfica, y el Govern d’Andorra.
Por su parte, el geoEuskadi Kongresua es organizado por la Dirección de Planificación Territorial y Agenda Urbana del Gobierno Vasco. Este año, todas estas entidades se unirán para llevar a cabo un único evento bajo el lema “El valor del dato geoespacial”.
Las jornadas se centrarán en las nuevas tendencias tecnológicas relacionadas con la accesibilidad y reutilización de datos, así como en las técnicas actuales de observación y representación de la Tierra.
Los datos geoespaciales digitales son un motor clave para el crecimiento económico, la competitividad, la innovación, la creación de empleo y el progreso social. Por ello, III geoEuskadi y la XV edición JIIDE 2024 enfatizarán la importancia de tecnologías, como el big data y la inteligencia artificial, para generar ideas que mejoren la toma de decisiones empresariales y la creación de sistemas que realicen tareas que tradicionalmente requieren intervención humana.
Además, se pondrá en valor la colaboración para la coproducción y armonización de datos entre diferentes administraciones y organizaciones, algo que sigue siendo esencial para generar datos geoespaciales de valor, que puedan convertirse en verdaderas referencias. Este es un momento de renovación, impulsado por la revisión de la Directiva INSPIRE, la actualización de las normativas sobre datos espaciales medioambientales y las nuevas regulaciones sobre datos abiertos y gobernanza de datos que propician una modernización en la publicación y reutilización de estos datos.
Durante el evento, también se presentarán ejemplos de reutilización de conjuntos de datos de alto valor, tanto a través de las OGC API como mediante servicios de descarga y formatos interoperables.
La combinación de estos eventos representará un espacio privilegiado para reflexionar sobre la información geográfica y será un escaparate de los proyectos más innovadores en la península ibérica. Además, se llevarán a cabo talleres técnicos para compartir conocimientos específicos y mesas redondas que promoverán el debate. Para conocer más sobre este evento, visita el portal de JIIDE.
- ¿Cuándo? Del 13 al 15 de noviembre.
- ¿Dónde? Palacio de Congresos Europa (Vitoria-Gasteiz).
- ¿Cómo me inscribo? A través de este enlace.
No pierdas la oportunidad de participar en estos eventos que promueven el avance en el uso de datos espaciales y geoespaciales. Te animamos a unirte a estas jornadas para aprender, colaborar y contribuir al desarrollo de este sector en constante evolución.