Blog
La enorme aceleración de la innovación en torno a la inteligencia artificial (IA) en estos últimos años gira, en gran medida, en torno al desarrollo de los llamados “modelos fundacionales”. También conocidos como modelos grandes (Large [X] Models o LxM), Los modelos fundacionales, según la definición del Center for Research on Foundation Models (CRFM) del Institute for Human-Centered Artificial Intelligence's (HAI) de la Universidad de Stanford son modelos que han sido entrenados con conjuntos de datos de gran tamaño y gran diversidad y que pueden adaptarse a realizar una amplia gama de tareas mediante técnicas como el ajuste fino (fine-tuning).
Precisamente es esta versatilidad y capacidad de adaptación lo que ha convertido a los modelos fundacionales en la piedra angular de las numerosas aplicaciones de la inteligencia artificial que están desarrollándose, ya que una única arquitectura base puede utilizarse en multitud de casos de uso con un esfuerzo adicional limitado.
Tipos de modelos fundacionales
La "X" en LxM puede sustituirse por varias opciones según el tipo de datos o tareas para las que el modelo está especializado. Los más conocidos por el público son los LLM (Large Language Models), que están en la base de aplicaciones como ChatGPT o Gemini, y que se centran en la comprensión y generación de lenguaje natural. Por su parte, los LVM (Large Vision Models), como DINOv2 o CLIP, están diseñados para interpretar imágenes y vídeos, reconocer objetos o generar descripciones visuales. También existen modelos como como Operator o Rabbit R1 que se encuentran en la categoría de LAM (Large Action Models) y que están orientados a ejecutar acciones a partir de instrucciones complejas.
A medida que han ido surgiendo regulaciones en distintas partes del mundo, también han aparecido otras definiciones que buscan establecer criterios y responsabilidades sobre estos modelos para fomentar la confianza y la seguridad. La definición más relevante para nuestro contexto es la establecida en el Reglamento de IA de la Unión Europea (AI Act), el cual los denomina “modelos de IA de uso general” y los distingue por su “capacidad de realizar de manera competente una amplia variedad de tareas diferenciadas” y porque “suelen entrenarse usando grandes volúmenes de datos y a través de diversos métodos, como el aprendizaje autosupervisado, no supervisado o por refuerzo”.
Modelos fundacionales en español y otras lenguas cooficiales
Históricamente, el inglés ha sido el idioma dominante en el desarrollo de los grandes modelos de IA, hasta el punto de que en torno al 90% de los tokens de entrenamiento de los grandes modelos actuales se han extraído de textos en inglés. Por ello resulta lógico que los modelos más conocidos, por ejemplo la familia GPT de OpenAI, Gemini de Google o Llama de Meta, sean más competentes respondiendo en inglés y presenten menor desempeño al usarlos en otros idiomas como el español.
Por tanto, la creación de modelos fundacionales en español, como ALIA, no es un simple ejercicio técnico o de investigación, sino que se trata de un movimiento estratégico para garantizar que la inteligencia artificial no haga aún más profundas las asimetrías lingüísticas y culturales que ya existen en las tecnologías digitales en general. El desarrollo de ALIA, impulsado por la Estrategia de Inteligencia Artificial 2024 de España, “partiendo del amplio alcance de nuestras lenguas, habladas por 600 millones de personas, tiene como objetivo facilitar el desarrollo de servicios y productos avanzados en tecnologías del lenguaje, ofreciendo una infraestructura marcada por la máxima transparencia y apertura”.
Este tipo de iniciativas no son exclusivas de España. Otros proyectos similares incluyen BLOOM, un modelo multilingüe de 176 mil millones de parámetros desarrollado por más de 1.000 investigadores de todo el mundo y que soporta 46 lenguas naturales y 13 lenguajes de programación. En China, Baidu ha desarrollado ERNIE, un modelo con fuerte capacidad en mandarín, mientras que en Francia el modelo PAGNOL se ha centrado en mejorar las capacidades en francés. Estos esfuerzos paralelos muestran una tendencia global hacia la "democratización lingüística" de la IA.
Desde principios de 2025, están disponibles los primeros modelos de lenguaje en las cuatro lenguas cooficiales, dentro del proyecto ALIA. En la familia de modelos ALIA destaca ALIA-40B, un modelo con 40.000 millones de parámetros, que es por el momento el modelo fundacional multilingüe público más avanzado de Europa y que fue entrenado durante más de 8 meses en el supercomputador MareNostrum 5, procesando 6,9 billones de tokens que equivaldrían a unos 33 terabytes de texto (¡unos 17 millones de libros!). Aquí se incluyen todo tipo de documentos oficiales y repositorios científicos en español, desde los diarios de sesiones del Congreso hasta repositorios científicos o boletines oficiales para asegurar la riqueza y calidad de su conocimiento.
Aunque se trata de un modelo multilingüe, el español y lenguas cooficiales tienen un peso muy superior al habitual en estos modelos, en torno al 20%, ya que el entrenamiento del modelo se diseñó específicamente para estas lenguas, reduciendo la relevancia del inglés y adaptando los tokens a las necesidades del español, catalán, euskera y gallego. Gracias a ello, ALIA “entiende” mejor nuestras expresiones locales y matices culturales que un modelo genérico entrenado mayoritariamente en inglés.
Aplicaciones de los modelos fundacionales en español y lenguas cooficiales
Aún es muy pronto para juzgar el impacto en sectores y aplicaciones concretas que puedan tener ALIA y otros modelos que puedan desarrollarse a partir de esta experiencia. Sin embargo, se espera que sirvan de base para mejorar multitud de aplicaciones y soluciones de Inteligencia Artificial:
- Administración pública y gobierno: ALIA podría dar vida a asistentes virtuales que atiendan a la ciudadanía las 24 horas en trámites como pagar impuestos, renovar el DNI, solicitar becas, etc. ya que está entrenado específicamente con la normativa española. De hecho, ya se anunció un piloto para la Agencia Tributaria usando ALIA, que tendría como objetivo agilizar gestiones internas.
- Educación: un modelo como ALIA podría ser también la base de tutores virtuales personalizados que orienten a estudiantes en español y lenguas cooficiales. Por ejemplo, asistentes que expliquen conceptos de matemáticas o historia en lenguaje sencillo y respondan preguntas del alumnado, adaptándose a su nivel ya que, al conocer bien nuestra lengua, serían capaces de aportar matices importantes en las respuestas y entender las dudas típicas de hablantes nativos en estos idiomas. También podrían ayudar a profesores, generando ejercicios o resúmenes de lecturas o asistiéndoles en la corrección de los trabajos de los alumnos.
- Salud: ALIA podría servir para analizar textos médicos y ayudar a profesionales de la salud con informes clínicos, historiales, folletos informativos, etc. Por ejemplo, podría revisar expedientes de pacientes para extraer elementos clave, o asistir a los profesionales en el proceso de diagnóstico. De hecho, el Ministerio de Sanidad planea una aplicación piloto con ALIA para mejorar la detección temprana de insuficiencias cardíacas en atención primaria.
- Justicia: en el ámbito jurídico, ALIA entendería términos técnicos y contextos del derecho español mucho mejor que un modelo no especializado ya que ha sido entrenada con vocabulario legal de documentos oficiales. Un asistente legal virtual basado en ALIA podría ser capaz de contestar consultas básicas del ciudadano como, por ejemplo, cómo iniciar un determinado trámite legal, citando la normativa aplicable. La administración de justicia podría beneficiarse también con unas traducciones automáticas de documentos judiciales entre lenguas cooficiales mucho más precisas.
Líneas futuras
El desarrollo de modelos fundaciones en español, al igual que en otros idiomas, comienza a considerarse fuera de Estados Unidos como una cuestión estratégica que contribuye a garantizar la soberanía tecnológica de los países. Por supuesto, será necesario seguir entrenando versiones más avanzadas (se apunta a modelos de hasta 175 mil millones de parámetros, que serían equiparables a los más potentes del mundo), incorporando nuevos datos abiertos, y afinando las aplicaciones. Desde la Dirección del Dato y la SEDIA se pretende continuar apoyando el crecimiento de esta familia de modelos, para mantenerla en vanguardia y asegurar su adopción.
Por otra parte, estos primeros modelos fundacionales en español y lenguas cooficiales se han centrado inicialmente en el lenguaje escrito, así que la siguiente frontera natural podría estar en la multimodalidad. Integrar la capacidad de gestionar imágenes, audio o vídeo en español junto con el texto multiplicaría sus aplicaciones prácticas ya que en la interpretación de imágenes en español es uno de los ámbitos donde se detectan mayores deficiencias en los grandes modelos genéricos.
También habrá que vigilar los aspectos éticos para asegurarse que estos modelos no perpetúen sesgos y sean útiles para todos los colectivos, incluyendo aquellos que hablan en distintas lenguas o que tienen diferentes niveles educativos. En este aspecto la Inteligencia Artificial Explicable (XAI) no es algo opcional, sino un requisito fundamental para garantizar su adopción responsable. La Agencia Nacional de Supervisión de la IA, la comunidad investigadora y la propia sociedad civil tendrán aquí un rol importante.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Dirección General de Tráfico (DGT) es el organismo responsable de garantizar la seguridad y fluidez en las vías de circulación de España. Entre otras actividades, se encarga de la expedición de permisos, el control del tráfico y la gestión de infracciones.
Fruto de su actividad, se genera una gran cantidad de datos, muchos de los cuales se ponen a disposición de la ciudadanía como datos abiertos. Estos datasets no solo promueven la transparencia, sino que también son una herramienta para fomentar la innovación y mejorar la seguridad vial a través de su reutilización por parte de investigadores, empresas, administraciones públicas y ciudadanos interesados.
En este artículo vamos a repasar algunos de estos conjuntos de datos, incluyendo ejemplos de aplicación.
Cómo acceder a los datasets de la DGT
Los conjuntos de datos de la DGT ofrecen información detallada y estructurada sobre diversos aspectos de la seguridad vial y la movilidad en España, incluyendo desde estadísticas de accidentes hasta información sobre vehículos y conductores. La continuidad temporal de estos conjuntos de datos, disponibles desde principios de siglo hasta la actualidad, posibilita análisis longitudinales que reflejan la evolución de los patrones de movilidad y seguridad vial en España.
Los usuarios pueden acceder a los conjuntos de datos en diferentes espacios:
- DGT en cifras. Es una sección de la Dirección General de Tráfico que ofrece un acceso centralizado a estadísticas y datos clave relacionados con la seguridad vial, los vehículos y los conductores en España. Este portal incluye información detallada sobre siniestralidad, denuncias, parque vehicular y características técnicas de los vehículos, entre otros temas. Además, proporciona análisis históricos y comparativos que permiten evaluar tendencias y diseñar estrategias para mejorar la seguridad en las carreteras.
- Punto de Acceso Nacional de Tráfico y Movilidad (National Access Point o NAP). Gestionado por la DGT, es una plataforma diseñada para centralizar y facilitar el acceso a datos viarios y de tráfico, incluidas sus actualizaciones. Este portal ha sido creado bajo el marco de la Directiva Europea 2010/40/UE y reúne información proporcionada por diversas entidades de gestión del tráfico, autoridades viarias y operadores de infraestructuras. Entre los datos disponibles se incluyen incidencias de tráfico, puntos de recarga para vehículos eléctricos, zonas de bajas emisiones y ocupación de parkings, entre otros. Su objetivo es promover la interoperabilidad y el desarrollo de soluciones inteligentes que mejoren la seguridad vial y la eficiencia en el transporte.
Mientras el NAP está enfocado en datos en tiempo real y soluciones tecnológicas, DGT en cifras se centra en proporcionar estadísticas e información histórica para análisis y toma de decisiones. Además, el NAP reúne datos no solo de la DGT, sino también de otros organismos y empresas privadas.
La mayoría de estos datos están disponibles a través de datos.gob.es.
Ejemplos de conjuntos de datos de la DGT
Algunos ejemplos de dataset que se pueden encontrar en datos.gob.es son:
- Accidentes con víctimas: incluye información detallada sobre víctimas mortales, heridos hospitalizados y leves, así como las circunstancias por tipo de vía. Estos datos ayudan a entender por qué ocurren los accidentes y quiénes están involucrados, permiten identificar situaciones de riesgo y detectar comportamientos peligrosos en la carretera. Es útil para crear mejores campañas de prevención, detectar puntos negros en las carreteras y ayudar a las autoridades a tomar decisiones más informadas. También resultan de interés para profesionales de salud pública, urbanistas y compañías de seguros que trabajan para reducir los accidentes y sus consecuencias.
- Censo de conductores: ofrece una radiografía completa de quiénes tienen permiso para conducir en España. La información resulta especialmente útil para entender la evolución del parque de conductores, identificar tendencias demográficas y analizar la penetración de los diferentes tipos de permisos por territorio y género.
- Matriculaciones de turismos por marca y cilindrada: muestra qué coches nuevos compraron los españoles, organizados por marca y potencia del motor. La información permite identificar tendencias de consumo. Estos datos son valiosos para fabricantes, concesionarios y analistas del sector automovilístico, que pueden estudiar el comportamiento del mercado en un año concreto. También resultan útiles para investigadores en movilidad, medio ambiente y economía, permitiendo analizar la evolución del parque móvil español y su impacto en términos de emisiones, consumo energético y tendencias de mercado.
Casos de uso de los datasets de la DGT
La publicación de estos datos en formato abierto permite potenciar la innovación en áreas como la prevención de accidentes, el desarrollo de infraestructuras viales más seguras, la elaboración de políticas públicas basadas en evidencia, y la creación de aplicaciones tecnológicas relacionadas con la movilidad. A continuación, se recogen algunos ejemplos:
Uso de datos por la propia DGT
La propia DGT reutiliza sus datos para crear herramientas que faciliten la visualización de la información y la acerquen de forma sencilla a la ciudadanía. Es el caso del Mapa de estado del tráfico e incidencias, que se actualiza de forma constante y automática con la información introducida 24 horas al día por la Agrupación de Tráfico de la Guardia Civil y los responsables de los Centros de Gestión de Tráfico de la DGT, la Generalitat de Catalunya y el Gobierno Vasco. Incluye información sobre las carreteras afectadas por fenómenos meteorológicos (como hielo, inundaciones, etc.) y la previsión de evolución.
Además, la DGT también aprovecha sus datos para realizar estudios que proporcionen información sobre determinados aspectos relacionados con la movilidad y la seguridad vial, de gran utilidad para la toma de decisiones y elaboración de políticas. Un ejemplo, es este estudio que analizar el comportamiento y la actividad de determinados colectivos en accidentes de tráfico para plantear medidas de manera proactiva. Otro ejemplo: este proyecto para implementar un sistema informático que identifique, mediante geolocalización, los puntos críticos de mayor siniestralidad en carreteras para su tratamiento y traslado de conclusiones.
Uso de los datos por parte de terceros
Los conjuntos de datos ofrecidos por la DGT también son reutilizados por otras administraciones públicas, investigadores, emprendedores y empresas privadas, fomentando la innovación en este campo. Gracias a ellos, encontramos apps que permiten a los usuarios acceder a información detallada sobre vehículos en España (como características técnicas e historial de inspecciones) o que informan sobre los lugares más peligrosos para los ciclistas.
Además, su combinación con tecnologías avanzadas como la inteligencia artificial permite extraer aún más valor de los datos, facilitando la identificación de patrones y ayudando a ciudadanos y autoridades a tomar medidas preventivas. Un ejemplo es la aplicación Waze, que ha implementado una funcionalidad basada en inteligencia artificial para identificar y alertar a los conductores sobre tramos de alta siniestralidad en las carreteras, es decir, los conocidos como "puntos negros". Este sistema combina datos históricos de accidentes con análisis de características de las vías, como desniveles, densidad de tráfico e intersecciones, para ofrecer alertas precisas y de alta utilidad. La aplicación notifica a los usuarios con antelación cuando se aproximan a estas zonas peligrosas, con el objetivo de reducir riesgos y mejorar la seguridad vial. Esta innovación complementa los datos proporcionados por la Dirección General de Tráfico ayudando a salvar vidas al fomentar una conducción más precavida.
Para aquellos que quieran animarse y practicar con los datos de la DGT, desde datos.gob.es tenemos a disposición de los usuarios un ejercicio paso a paso de ciencia de datos. Los usuarios podrán analizar estos conjuntos de datos y utilizar modelos predictivos que permiten realizar estimaciones respecto a la evolución del vehículo eléctrico en España. Para ello se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En resumen, los conjuntos de datos que la DGT ofrecen grandes oportunidades de reutilización, más aún si se combinan con tecnologías disruptivas. Gracias a ello se impulsa la innovación, la sostenibilidad y un transporte más seguro y conectado, que está ayudando a transformar la movilidad urbana y rural.
Noticia
Un año más, la Comisión Europea organizó los EU Open Data Days, uno de los eventos de referencia sobre datos abiertos e innovación a nivel mundial. Los pasados días 19 y 20 de marzo, el Centro Europeo de Convenciones de Luxemburgo reunió a expertos, funcionarios públicos y representantes del ámbito académico para compartir conocimientos, experiencias y avances en materia de datos abiertos en Europa.
Durante estas dos intensas jornadas, que también pudieron seguirse online, se exploraron temas cruciales como la gobernanza, la calidad, la interoperabilidad y el impacto de la inteligencia artificial (IA) en los datos abiertos. Este evento se ha convertido en un foro esencial para impulsar el desarrollo de políticas y prácticas que fomenten la transparencia y la innovación basada en datos en toda la Unión Europea. En este post, repasamos cada una de las ponencias del evento.
Apertura e historia de los datos
Para empezar, la Directora General de la Oficina de Publicaciones de la Unión Europea, Hilde Hardeman, inauguró el evento dando la bienvenida a los asistentes y estableciendo el tono para las discusiones que seguirían. A continuación, Helena Korjonen y Emma Schymanski, dos expertas de la Universidad de Luxemburgo, presentaron una retrospectiva titulada "Un viaje de datos: de la oscuridad a la iluminación", donde exploraron la evolución del almacenamiento y compartición de datos a lo largo de 18.000 años. Desde las pinturas rupestres hasta los servidores modernos, este recorrido histórico destacó cómo muchos de los desafíos actuales en materia de datos abiertos, como la propiedad, la preservación y la accesibilidad, tienen raíces profundas en la historia de la humanidad.
A continuación, Slava Jankin, profesor del Centro de IA en Gobierno de la Universidad de Birmingham, presentó una ponencia sobre gemelos digitales impulsados por IA y datos abiertos para crear simulaciones dinámicas de sistemas de gobernanza, que permiten a los responsables políticos probar reformas y predecir resultados antes de implementarlos.
Casos de uso entre los datos abiertos y la IA
Por otro lado, también se presentaron varios casos de uso, como la experiencia práctica de Lituania en la catalogación exhaustiva de datos públicos. Milda Aksamitauskas de la Universidad de Wisconsin, abordó los desafíos de gobernanza y las estrategias de comunicación empleadas en el proyecto y presentó lecciones sobre cómo otros países podrían adaptar métodos similares para mejorar la transparencia y la toma de decisiones basadas en datos.
En relación, el coordinador científico Bastiaan van Loenen presentó las conclusiones del proyecto en el que trabaja, ODECO de Horizon 2020, centrado en la creación de ecosistemas sostenibles de datos abiertos. Tal y como explicó van Loenen, la investigación, que ha sido desarrollada durante cuatro años por 15 investigadores, ha explorado las necesidades de los usuarios y las estructuras de gobernanza para siete grupos distintos, destacando cómo los enfoques circulares, inclusivos y basados en habilidades pueden proporcionar valor económico y social a los ecosistemas de datos abiertos.
Además, la inteligencia artificial fue protagonista durante todo el evento. La profesora asistente Anastasija Nikiforova de la Universidad de Tartu ofreció una visión reveladora sobre cómo la inteligencia artificial puede transformar los ecosistemas de datos abiertos gubernamentales. En su presentación, "Datos para IA o IA para datos" exploró ocho roles distintos que la IA puede desempeñar. Por ejemplo, la IA puede servir de ‘limpiador’ de un portal de open data e incluso recuperar datos del ecosistema, proporcionando valiosas perspectivas para los responsables políticos y los investigadores sobre cómo aprovechar eficazmente la IA en las iniciativas de datos abiertos.
También utilizando herramientas impulsadas por IA, encontramos el EU Open Research Repository lanzado por Zenodo en 2024, una iniciativa de ciencia abierta que proporciona un repositorio de investigación adaptado para los beneficiarios de financiación de investigación de la UE. La presentación de Lars Holm Nielsen destacó cómo las herramientas impulsadas por IA y los conjuntos de datos abiertos de alta calidad reducen el coste y el esfuerzo de limpieza de datos, al tiempo que garantizan la adherencia a los principios FAIR.
La jornada continuó con la intervención de Maroš Šefčovič, Comisario Europeo de Comercio y Seguridad Económica, Relaciones Interinstitucionales y Transparencia, quien subrayó el compromiso de la Comisión Europea con los datos abiertos como pilar fundamental para la transparencia y la innovación en la Unión Europea.
Interoperabilidad y calidad de datos
Después de una pausa, Georges Lobo y Pavlina Fragkou coordinador de programa y de proyecto del SEMIC, respectivamente, explicaron cómo el Centro de Interoperabilidad Semántica de Europa (SEMIC) mejora el intercambio interoperable de datos en Europa a través del perfil de aplicación del vocabulario de catálogo de datos (DCAT-AP) y las secuencias de eventos de datos vinculados (LDES). Su presentación destacó cómo estos estándares facilitan la publicación y el consumo eficientes de datos, con casos prácticos como el Rijksmuseum y la Agencia Ferroviaria de la Unión Europea, demostrando su valor para fomentar ecosistemas de datos interoperables y sostenibles.
A continuación, Barbara Šlibar, de la Universidad de Zagreb, ofreció un análisis detallado de la calidad de los metadatos en los conjuntos de datos abiertos europeos, revelando disparidades significativas en cinco dimensiones clave. Su estudio, basado en muestras aleatorias de data.europa.eu, subrayó la importancia de mejorar las prácticas de metadatos y aumentar la concienciación entre las partes interesadas para mejorar la usabilidad y el valor de los datos abiertos en Europa.
Después, Bianca Sammer, de Bavarian Agency for Digital Affairs compartió su experiencia creando el portal de datos abiertos de Alemania en solo un año. Su presentación "Desbloqueando el potencial" destacó soluciones innovadoras para superar los desafíos en la gestión de datos abiertos. Por ejemplo, consiguieron una mejora automatizada de la calidad de los metadatos, una infraestructura de código abierto reutilizable y estrategias de participación para administraciones públicas y usuarios.
Actualidad y horizonte respecto a los datos abiertos
El segundo día comenzó con las intervenciones de Rafał Rosiński, Subsecretario de Estado del Ministerio de Asuntos Digitales de Polonia, quien presentó la perspectiva de la Presidencia polaca sobre datos abiertos y transformación digital, y Roberto Viola, Director General de la Dirección General de Redes de Comunicación, Contenido y Tecnología de la Comisión Europea, que habló sobre el camino europeo hacia la innovación digital.
Después de la presentación de la jornada, empezaron las ponencias sobre casos de uso y propuestas innovadoras en open data. En primer lugar, Stefaan Verhulst, cofundador del laboratorio de gobernanza neoyorquino GovLab, bautizó al momento histórico que estamos viviendo como la "cuarta ola de datos abiertos" caracterizada por la integración de la inteligencia artificial generativa con datos abiertos para abordar desafíos sociales. Su presentación planteó preguntas cruciales sobre cómo las interfaces conversacionales basadas en IA pueden mejorar la accesibilidad, qué significa que los datos abiertos estén "preparados para la IA" y cómo construir soluciones basadas en datos sostenibles que equilibren la apertura y la confianza.
A continuación, Christos Ellinides, Director General de Traducción de la Comisión Europea, destacó la importancia de los datos lingüísticos para la IA en el continente. Con 25 años de datos que abarcan múltiples idiomas y la experiencia para desarrollar servicios multilingües basados en inteligencia artificial, la Comisión está a la vanguardia en el ámbito de los espacios de datos lingüísticos y en el uso de infraestructuras europeas de computación de alto rendimiento para explotar datos e IA.
Casos de uso de reutilización de datos abiertos
La reutilización aporta múltiples beneficios. Kjersti Steien, de la agencia de digitalización noruega, presentó el portal nacional de datos de Noruega, data.norge.no, que emplea un motor de búsqueda impulsado por IA para mejorar la capacidad de descubrimiento de datos. Utilizando Google Vertex, el motor permite a los usuarios encontrar conjuntos de datos relevantes sin necesidad de conocer los términos exactos utilizados por los proveedores de datos, demostrando cómo la IA puede mejorar la reutilización de datos y adaptarse a los modelos de lenguaje emergentes.
Más allá de Noruega, también se pusieron en la mesa casos de uso de otras ciudades y países. Sam Hawkins, Director del programa de datos de Ember en el Reino Unido, subrayó la importancia de los datos energéticos abiertos para avanzar en la transición hacia energías limpias y garantizar la flexibilidad del sistema.
Otro caso fue el que presentó Marika Eik de la Universidad de Estonia, que aprovecha datos urbanos y la colaboración intersectorial para mejorar la sostenibilidad y el impacto comunitario. Su sesión examinó un enfoque a nivel de ciudad para las métricas de sostenibilidad y los cálculos de huella de CO2, basándose en datos de municipios, operadores inmobiliarios, instituciones de investigación y análisis de movilidad para ofrecer modelos replicables que mejoren la responsabilidad ambiental.
Por otro lado, Raphaël Kergueno, de Transparency International EU, explicó cómo Integrity Watch EU aprovecha los datos abiertos para mejorar la transparencia y la rendición de cuentas en la Unión. Esta iniciativa reutiliza conjuntos de datos como el Registro de Transparencia de la UE y los registros de reuniones de la Comisión Europea para aumentar la conciencia pública sobre las actividades de lobby y mejorar la supervisión legislativa, demostrando el potencial de los datos abiertos para fortalecer la gobernanza democrática.
También, Kate Larkin del Observatorio Marino Europeo, presentó la Red Europea de Observación y Datos Marinos, destacando cómo los servicios paneuropeos de datos marinos, que se adhieren a los principios FAIR contribuyen a iniciativas como el Pacto Verde Europeo, la planificación espacial marítima y la economía azul. Su presentación mostró casos de uso prácticos que demuestran la integración de datos marinos en ecosistemas de datos más amplios como el European Digital Twin Ocean.
Visualización y comunicación de datos
Además de casos de uso, los EU Open Data Days 2025 pusieron en valor la visualización de datos como mecanismo para acercar el open data a la gente. En este sentido, Antonio Moneo, CEO de Tangible Data, exploró cómo transformar conjuntos de datos complejos en esculturas físicas fomenta la alfabetización de datos y la participación comunitaria.
Por otro lado, Jan Willem Tulp, fundador de TULP interactive, examinó cómo el diseño visual influye en la percepción de los datos. Su sesión exploró cómo elementos de diseño como el color, la escala y el enfoque pueden dar forma a narrativas e introducir potencialmente sesgos, destacando las responsabilidades de los visualizadores de datos para mantener la transparencia mientras elaboran narrativas visuales convincentes.
Educación y alfabetización en datos
Davide Taibi, investigador del Consejo Nacional de Investigación de Italia, compartió experiencias sobre la integración de la alfabetización en datos e IA en los itinerarios educativos, basadas en proyectos financiados por la UE como DATALIT, DEDALUS y SMERALD. Estas iniciativas pilotaron módulos de aprendizaje digitalmente mejorados en educación superior, escuelas secundarias y formación profesional en varios Estados miembros de la UE, centrándose en enfoques orientados a competencias y sistemas de aprendizaje basados en TI.
Nadieh Bremer, fundadora de Visual Cinnamon, exploró cómo los enfoques creativos para la visualización de datos pueden revelar los intrincados vínculos entre personas, culturas y conceptos. Los ejemplos incluyeron un árbol genealógico de 3.000 personas de la realeza europea, las relaciones en el Patrimonio Cultural Inmaterial de la UNESCO y constelaciones interculturales en el cielo nocturno, demostrando cómo los procesos de diseño iterativo pueden descubrir patrones ocultos en redes complejas.
El artista digital Andreas Refsgaard cerró las presentaciones con una reflexión sobre la intersección de la IA generativa, el arte y la ciencia de datos. A través de ejemplos artísticos y atractivos, invitó a la audiencia a reflexionar sobre el vasto potencial y los dilemas éticos que surgen de la creciente influencia de las tecnologías digitales en nuestra vida cotidiana.
En resumen, los EU Open Data Days 2025 han demostrado, una vez más, la importancia de estos encuentros para impulsar la evolución del ecosistema de datos abiertos en Europa. Los debates, presentaciones y casos prácticos compartidos durante estas dos jornadas no solo han puesto de manifiesto los avances logrados, sino también los desafíos pendientes y las oportunidades emergentes. En un contexto donde la inteligencia artificial, la sostenibilidad y la participación ciudadana están transformando la manera en que utilizamos y valoramos los datos, eventos como este resultan fundamentales para fomentar la colaboración, compartir conocimientos y desarrollar estrategias que maximicen el valor social y económico de los datos abiertos. El compromiso continuo de las instituciones europeas, los gobiernos nacionales, la academia y la sociedad civil será esencial para construir un ecosistema de datos abiertos más robusto, accesible e impactante que responda a los desafíos del siglo XXI y contribuya al bienestar de todos los ciudadanos europeos.
Puedes volver las grabaciones de cada ponencia aquí.
Blog
Los datos geoespaciales han impulsado mejoras en diversos sectores y la energía no es la excepción. Estos datos nos permiten conocer mejor nuestro entorno para promover la sostenibilidad, la innovación y la toma de decisiones informadas.
Uno de los principales proveedores de datos abiertos geoespaciales es Copernicus, el programa de observación de la Tierra de la Unión Europea. A través de una red de satélites llamados Sentinel y datos de fuentes terrestres, marítimas y aéreas, Copernicus proporciona información geoespacial accesible de manera gratuita a través de diversas plataformas.
Aunque los datos de Copernicus son de gran utilidad en múltiples áreas, como la lucha contra el cambio climático, la planificación urbana o la agricultura, en este artículo nos vamos a centrar en su rol para impulsar la sostenibilidad y eficiencia energética. La disponibilidad de datos abiertos de alta calidad fomenta la innovación en este sector promoviendo el desarrollo de nuevas herramientas y aplicaciones que mejoran la gestión y el uso de la energía. A continuación mostramos algunos ejemplos.
Predicción climática para mejorar la producción
Los datos geoespaciales proporcionan información detallada sobre las condiciones meteorológicas, la calidad del aire y otros factores, fundamentales para comprender y predecir fenómenos ambientales, como tormentas o sequías, que afectan a la producción y distribución de energía.
Un ejemplo es este proyecto que ofrece previsiones de viento de alta resolución para dar respuesta a los sectores del petróleo y el gas, la aviación, el transporte marítimo y la defensa. Utiliza datos procedentes de observaciones por satélite como de modelos numéricos, incluyendo información sobre las corrientes oceánicas, las olas y la temperatura superficial del mar procedentes del “Servicio Marino de Copernicus”. Gracias a su granularidad puede ofrecer un sistema de previsión meteorológica preciso a una escala muy local, lo que permite conocer el comportamiento de fenómenos meteorológicos y climáticos extremos con un mayor nivel de exactitud.
Optimización de recursos
Los datos proporcionados por Copernicus también permiten identificar las mejores ubicaciones para la instalación de centros de generación energética, como parques solares y eólicos, al facilitar el análisis de factores como la radiación solar y la velocidad del viento. Además, ayudan a monitorear la eficiencia de estas instalaciones, asegurando que estén operando al máximo de su capacidad.
En este sentido,se ha desarrollado un proyecto para encontrar el mejor emplazamiento para un sistema flotante combinado de energía eólica y undimotriz (es decir, basada en el movimiento de las olas). Al obtener ambas energías con una sola plataforma, esta solución permite ahorrar espacio y reducir el impacto en el terreno, a la vez que supone una mejora de la eficiencia. El viento y las olas llegan en momentos diferentes a la plataforma, por lo que capturar ambos elementos ayuda a reducir la variabilidad y suaviza la producción total de electricidad. Gracias a los datos de Copernicus (obtenidos del servicio Atlántico -Vizcaya Ibérica Irlanda- Reanálisis de olas oceánicas), la empresa proveedora de esta situación pudo obtener componentes separados de olas de viento y oleaje, lo que permitió una comprensión más completa de la direccionalidad de ambos elementos. Este trabajo condujo a la selección de la Plataforma de Energía Marina de Vizcaya (BiMEP) para el despliegue del dispositivo.
Otro ejemplo es Mon Toit Solaire, un sistema integrado de ayuda a la decisión basado en Internet para el desarrollo de la generación de energía fotovoltaica en tejados. Esta herramienta simula y calcula el potencial energético de un proyecto fotovoltaico y proporciona a los usuarios información técnica y financiera fiable. Utiliza datos de radiación solar producidos por el “Servicio de vigilancia de la atmósfera de Copernicus”, junto con datos topográficos urbanos tridimensionales y simulaciones de incentivos fiscales, costes y precios de la energía, lo que permite calcular el rendimiento de la inversión.
Monitorización Ambiental y evaluación de impacto
La información geoespacial permite mejorar el monitoreo ambiental y realizar evaluaciones de impacto precisas en el sector energético. Estos datos permiten a las empresas energéticas identificar riesgos ambientales asociados a sus operaciones, diseñar estrategias para mitigar su impacto y optimizar sus procesos hacia una mayor sostenibilidad. Además, apoyan el cumplimiento de normativas ambientales al facilitar reportes basados en datos objetivos, fomentando un desarrollo energético más responsable y respetuoso con el medio ambiente.
Entre los retos que plantea la conservación de la biodiversidad de los océanos, el ruido submarino de origen humano se reconoce como una grave amenaza y está regulado a nivel europeo. Con el fin de evaluar el impacto en la vida marina de los parques eólicos a lo largo de la costa sur de Francia, este proyecto utiliza mapas de sonido estadísticos de alta resolución, que proporcionan una visión detallada de los procesos costeros, con una frecuencia temporal horaria y una alta resolución espacial de hasta 1,8 km. En concreto, utilizan información procedente de los servicios de “análisis y previsión de la física del mar Mediterráneo” y “Viento y tensión en la superficie del mar por hora en el océano mundial”.
Gestión de emergencias y desastres medioambientales
En situaciones de desastre o eventos climáticos extremos, los datos geoespaciales pueden ayudar a evaluar rápidamente los daños y coordinar las respuestas de emergencia de manera más eficiente.
También pueden prevenir cómo se van a comportar los vertidos. Esta es el objetivo del Instituto de Investigación Marina de la Universidad de Klaipeda, que ha desarrollado un sistema de vigilancia y previsión de episodios de contaminación química y microbiológica mediante un modelo hidrodinámico operativo 3D de alta resolución. Para ellos utilizan el “Análisis y previsiones físicas del Mar Báltico” de Copernicus. El modelo ofrece previsiones en tiempo real y a cinco días vista de las corrientes de agua, abordando los retos que plantean las aguas poco profundas y las zonas portuarias. Su objetivo es ayudar a gestionar incidentes de contaminación, sobre todo en regiones propensas a ella, como puertos y terminales petrolíferas.
Estos ejemplos ponen de manifiesto la utilidad de los datos geoespaciales, especialmente aquellos proporcionados por programas como Copernicus. El hecho de que empresas e instituciones puedan acceder libremente a estos datos está revolucionando el sector energético, contribuyendo a un sistema más eficiente, sostenible y resiliente.
Blog
La vivienda es una de las principales preocupaciones de los ciudadanos españoles, de acuerdo con el barómetro de enero de 2025 del Centro de Investigaciones Sociológicas (CIS). Para conocer la situación real del acceso a la vivienda, es necesario disponer de datos públicos, actualizados y de calidad, que permitan a todos los actores de este ecosistema realizar análisis y tomar decisiones informadas.
En este artículo vamos a repasar algunos ejemplos de datos abiertos disponibles, así como herramientas y soluciones que se han creado en base a ellos para acercar esta información a la ciudadanía.
Los datos abiertos pueden tener varios usos en este sector:
- Permitir a los organismos públicos conocer las necesidades de la ciudadanía y elaborar políticas acordes.
- Ayudar a particulares a encontrar viviendas para alquilar o comprar.
- Facilitar información a constructores y empresas para que desarrollen viviendas que den respuesta a esas necesidades.
Por ello, en este campo, los datos más utilizados incluyen aquellos que hacen referencia a las viviendas, pero también a aspectos demográficos y sociales, muchas veces con un alto componente geoespacial. Algunos de los datasets más populares en este sentido son el Índices de precios de consumo y vivienda del Instituto Nacional de Estadística (INE) o los datos del Catastro.
Diferentes organismos públicos han puesto a disposición de la ciudadanía espacios donde reúnen diversos datos relacionados con la vivienda. Es el caso del Ayuntamiento de Barcelona y su portal “Vivienda en datos”, un entorno que centraliza el acceso a información y datos de diversas fuentes, incluyendo datasets de su portal de datos abiertos.
Otro ejemplo es el portal de visualización de datos del Ayuntamiento de Madrid, donde se incluyen cuadros de mando con información sobre el número de inmuebles residenciales por distrito o barrio, así como su valor catastral, con acceso directo a la descarga de los datos utilizados.
Más ejemplos de organismos que también posibilitan el acceso a este tipo de información son la Junta de Castilla y León, el Gobierno Vasco o la Comunidad Valenciana. Además, aquellas personas que lo deseen pueden encontrar multitud de datos relacionados con la vivienda en el Catálogo Nacional de Datos Abiertos, albergado aquí, en datos.gob.es.
También cabe señalar que no solo los organismos públicos abren datos relacionados con esta materia. Hace unos meses, el portal inmobiliario idealista hizo público un conjunto de datos con información detallada de miles de viviendas en Madrid, Barcelona y Valencia. Está disponible como un paquete en R a través de Github.
Herramientas y soluciones para acercar esos datos a los ciudadanos
Datos como los anteriormente mencionados pueden ser reutilizados con múltiples fines, como mostramos en artículos anteriores y como podemos ver en esta nueva aproximación a los diversos casos de uso:
Periodismo de datos
Los medios de comunicación utilizan los datos abiertos sobre vivienda para ofrecer una visión más precisa de la situación del mercado inmobiliario, ayudando a los ciudadanos a comprender las dinámicas que afectan a los precios, la oferta y la demanda. Al acceder a datos sobre la evolución de los precios, la disponibilidad de viviendas o las políticas públicas relacionadas, los medios pueden generar reportajes e infografías que explican de manera accesible la situación y cómo estos factores impactan en la vida cotidiana de las personas. Estos artículos proporcionan información relevante a los ciudadanos, de forma sencilla, para tomar decisiones sobre su situación habitacional.
Un ejemplo es este artículo que permite visualizar, barrio a barrio, el precio del alquiler y el acceso a la vivienda según ingresos, para el cual se utilizaron datos abiertos del Ministerio de Vivienda y Agenda Urbana, el Catastro o el INE, entre otros. En la misma línea se mueve este artículo sobre el porcentaje de ingresos que se destina al alquiler.
Elaboración de informes y políticas
Los datos abiertos sobre vivienda son utilizados por organismos públicos como el Ministerio de Vivienda y Agenda Urbana en su Observatorio de Vivienda y Suelo, donde se generan boletines estadísticos electrónicos que integran datos disponibles en las principales fuentes estadísticas oficiales. El fin es realizar un seguimiento del sector desde diversas perspectivas y a lo largo de las distintas fases del proceso (mercado del suelo, productos edificados, accesibilidad y financiación, etc.). El Ministerio de Vivienda y Agenda Urbana también utiliza datos de diversas fuentes, como la Agencia Tributaria, el Catastro o el INE, para su Sistema Estatal de Referencia de Precios de Alquiler de Vivienda, que define rangos de valores de precios de alquiler de viviendas en zonas declaradas como tensionadas.
Oferta de servicios inmobiliarios
Los datos abiertos pueden ser valiosos para el sector de la construcción: la información abierta sobre el uso del suelo y los permisos se consultan antes de emprender trabajos de excavación y empezar a construir obras nuevas.
Además, algunas de las empresas que utilizan datos abiertos son sitios web inmobiliarios. Estos portales reutilizan conjuntos de datos abiertos para proporcionar a los usuarios precios comparables de las propiedades, estadísticas de delincuencia en los barrios o proximidad a instalaciones públicas educativas, sanitarias y recreativas. A ello ayudan, por ejemplo, herramientas como Location intelligence, que permite acceder a datos del padrón, precios de alquiler, características de la vivienda o planeamiento urbano. Los organismos públicos también pueden ayudar a este campo con sus propias soluciones, como Donde Vivo, del Gobierno de Aragón,que permite obtener un mapa interactivo y la información relacionada de los puntos de interés, centros educativos y sanitarios más cercanos así como información geoestadística del lugar donde vive.
También existen herramientas que ayudan a prever gastos futuros como, Urban3r, donde los usuarios pueden visualizar diferentes indicadores que les ayudan a conocer los datos de demanda energética de los edificios residenciales en su estado actual y tras someterlos a una rehabilitación energética, así como los costes estimados de estas intervenciones.Este es un campo donde las tecnologías disruptivas basadas en datos, como la inteligencia artificial, tendrán cada vez más protagonismo, al optimizar procesos y facilitar la toma de decisiones tanto para los compradores como para los proveedores de viviendas. A través del análisis de grandes volúmenes de datos, la IA puede predecir tendencias del mercado, identificar zonas con mayor demanda o proporcionar recomendaciones personalizadas según las necesidades de cada usuario. Algunas empresas ya han puesto en marcha chatbots, que responden a las preguntas de los usuarios, pero la IA puede ayudar incluso a crear proyectos para el desarrollo de viviendas económicas y sostenibles.
En resumen, nos encontramos en un campo donde las nuevas tecnologías van a hacer cada vez más fácil que los ciudadanos podamos conocer la oferta de viviendas, pero esta oferta debe estar alineada con las necesidades de los usuarios. Por ello es necesario continuar impulsando la apertura de datos de calidad, que ayuden a conocer la situación e impulsar políticas públicas y soluciones que facilitan el acceso a la vivienda.
Blog
El concepto de data commons o bienes comunes de datos surge como un enfoque transformador para la gestión y el intercambio de datos que sirvan a fines colectivos y como alternativa al creciente número de macrosilos de datos de uso privado. Al tratar los datos como un recurso compartido, los data commons facilitan la colaboración, la innovación y el acceso equitativo a los mismos, enfatizando el valor comunal de los datos por encima de cualquier otra consideración. A medida que navegamos por las complejidades de la era digital —marcada en la actualidad por los rápidos avances en inteligencia artificial (IA) y el continuo debate sobre los retos en la gobernanza de datos— el papel que pueden jugar los data commons es ahora probablemente más importante que nunca.
¿Qué son los data commons?
Los data commons se refieren a un marco cooperativo donde los datos son recopilados, gobernados y compartidos entre todos los participantes de la comunidad mediante protocolos que promueven la apertura, la equidad, el uso ético y la sostenibilidad. Los data commons se diferencian de los modelos tradicionales de intercambio de datos, principalmente, por la prioridad que se da a la colaboración y la inclusión sobre el control unitario.
Otro objetivo común de los data commons es la creación de conocimiento colectivo que pueda ser utilizado por cualquiera para el bien de la sociedad. Esto los hace particularmente útiles a la hora de afrontar los grandes desafíos actuales, como los retos del medio ambiente, la interacción multilingüe, la movilidad, las catástrofes humanitarias, la preservación del conocimiento o los nuevos desafíos de la salud y la sanidad.
Además, también es cada vez más frecuente que estas iniciativas para compartir datos incorporen todo tipo de herramientas que faciliten su análisis e interpretación consiguiendo así democratizar no sólo la propiedad y el acceso a los datos, sino también su uso.
Por todo lo anterior, los data commons podrían considerarse hoy en día como una infraestructura digital pública crítica a la hora de aprovechar los datos y promover el bienestar social.
Principios de los data commons
Los data commons se construyen sobre una serie de principios simples que serán clave para su correcta gobernanza:
- Apertura y accesibilidad: los datos deben ser accesibles para todos los autorizados.
- Gobernanza ética: equilibrio entre la inclusión y la privacidad.
- Sostenibilidad: establecer mecanismos de financiación y recursos para mantener los datos como bienes comunes a lo largo del tiempo.
- Colaboración: fomentar que los participantes contribuyan con nuevos datos e ideas que habiliten su uso para el beneficio mutuo.
- Confianza: relaciones basadas en la transparencia y la credibilidad entre partícipes.
Además, si queremos asegurarnos también de que los data commons cumplan su papel como infraestructura digital de dominio público, deberemos garantizar otros requisitos mínimos adicionales como: existencia de identificadores únicos permanentes, metadatos documentados, acceso fácil a través de interfaces de programación de aplicaciones (API), portabilidad de los datos, acuerdos de intercambio de datos entre pares y capacidad de realizar operaciones sobre los mismos.
El importante papel de los data commons en la era de la Inteligencia Artificial
La innovación impulsada por la IA ha incrementado exponencialmente la demanda de conjuntos de datos diversos y de alta calidad, un bien relativamente escaso a gran escala que puede dar lugar a cuellos de botella en el desarrollo futuro de la tecnología y que, al mismo tiempo, hace de los data commons un facilitador muy relevante a la hora de conseguir una IA más equitativa. Al proporcionar conjuntos de datos compartidos gobernados por principios éticos, los data commons contribuyen a mitigar riesgos frecuentes como los sesgos, los monopolios de datos y el acceso desigual a los beneficios de la IA.
Además, la actual concentración de los desarrollos en el ámbito de la IA representa también un desafío para el interés público. En este contexto, los data commons cuentan con la llave necesaria para habilitar un conjunto de sistemas y aplicaciones de IA alternativos, públicos y orientados al interés general, que puedan contribuir a rebalancear esta concentración de poder actual. El objetivo de estos modelos sería demostrar cómo se pueden diseñar sistemas más democráticos, orientados al interés público y con propósitos bien definidos, basados en los principios y modelos de gobernanza de la IA pública.
Sin embargo, la era de la IA generativa también presenta nuevos desafíos para los data commons como, por ejemplo y quizás el más destacado, el riesgo potencial de una explotación descontrolada de los conjuntos de datos compartidos que podría dar lugar a nuevos desafíos éticos por el uso indebido de los datos y la vulneración de la privacidad.
Por otro lado, la falta de transparencia en cuanto al uso de los data commons por parte de la IA podría también acabar desmotivando a las comunidades que los gestionan poniendo en riesgo su continuidad. Esto se debe a la preocupación de que al final su contribución pueda estar beneficiando principalmente a las grandes plataformas tecnológicas, sin que haya ninguna garantía de un reparto más justo del valor y el impacto generados tal como se pretendía inicialmente."
Por todo lo anterior, organizaciones como Open Future abogan desde hace ya varios años por una Inteligencia Artificial que funcione como un bien común, gestionada y desarrollada como una infraestructura pública digital en beneficio de todos, evitando la concentración de poder y promoviendo la equidad y la transparencia tanto en su desarrollo como en su aplicación.
Para ello proponen una serie de principios que guíen la gobernanza de los bienes comunes de datos en su aplicación para el entrenamiento de la IA de forma que se maximice el valor generado para la sociedad y se minimicen las posibilidades de potenciales abusos por intereses comerciales:
- Compartir tantos datos como sea posible, pero manteniendo las restricciones que puedan resultar necesarias para preservar los derechos individuales y colectivos.
- Ser completamente transparente y proporcionar toda la documentación existente sobre los datos, así como sobre su uso, permitiendo además distinguir claramente entre datos reales y sintéticos.
- Respetar las decisiones tomadas sobre el uso de los datos por parte de las personas que han contribuido previamente a la creación de los datos, ya sea mediante la cesión de sus propios datos o a través de la elaboración de nuevos contenidos, incluyendo también el respeto hacia cualquier marco legal existente.
- Proteger el beneficio común en el uso de los datos y un uso sostenible de los mismos para poder asegurar una gobernanza adecuada a lo largo del tiempo, reconociendo siempre su naturaleza relacional y colectiva.
- Garantizar la calidad de los datos, lo que resulta crítico a la hora de conservar su valor como bien de interés común, especialmente teniendo en cuenta los potenciales riesgos de contaminación asociados a su uso por parte de la IA.
- Establecer instituciones fiables que se encarguen de la gobernanza de los datos y faciliten la participación por parte de toda la comunidad creada en torno a los datos, yendo así un paso más allá de los modelos existentes en la actualidad para los intermediarios de datos.
Casos de uso y aplicaciones
Existen en la actualidad múltiples ejemplos reales que nos ayudan a ilustrar el potencial transformador de los data commons:
-
Data commons sanitarios: proyectos como la iniciativa del National Institutes of Health en los Estados Unidos - NIH Common Fund para analizar y compartir grandes conjuntos de datos biomédicos, o el Cancer Research Data Commons del National Cancer Institute, demuestran cómo los data commons pueden contribuir a la aceleración de la investigación y la innovación en salud.
- Entrenamiento de la IA y machine learning: la evaluación de los sistemas de IA depende de conjuntos de datos de prueba rigurosos y estandarizados. Iniciativas como OpenML o MLCommons construyen conjuntos de datos abiertos, a gran escala y diversos, ayudando a la comunidad en general a ofrecer sistemas de IA más precisos y seguros.
- Data commons urbanos y de movilidad: las ciudades que aprovechan plataformas compartidas de datos urbanos mejoran la toma de decisiones y los servicios públicos mediante el análisis colectivo de datos, como es el caso de Barcelona Dades, que además de un amplio repositorio de datos abiertos integra y difunde datos y análisis sobre la evolución demográfica, económica, social y política de la ciudad. Otras iniciativas como el propio OpenStreetMaps pueden también contribuir a proporcionar datos geográficos de libre acceso.
- Preservación de la cultura y el conocimiento: con iniciativas tan relevantes en este campo como el proyecto de Common Voice de Mozilla para preservar y revitalizar los idiomas del mundo, o Wikidata, cuyo objetivo consiste en proporcionar un acceso estructurado a todos los datos provenientes de los proyectos de Wikimedia, incluyendo la popular Wikipedia.
Desafíos en los data commons
A pesar de su promesa y potencial como herramienta transformadora para los nuevos desafíos en la era digital, los data commons afrontan también sus propios desafíos:
- Complejidad en la gobernanza: llegar a conseguir un equilibrio correcto entre la inclusión, el control y la privacidad puede resultar una tarea delicada.
- Sostenibilidad: muchos de los data commons existentes libran una batalla continua para intentar asegurarse la financiación y los recursos que necesitan para mantenerse y garantizar su supervivencia a largo plazo.
- Problemas legales y éticos: abordar los retos relativos a los derechos de propiedad intelectual, la titularidad de datos y el uso ético siguen siendo aspectos críticos que todavía no se han resulto por completo.
- Interoperabilidad: asegurar la compatibilidad entre conjuntos de datos y plataformas es un obstáculo técnico persistente en casi cualquier iniciativa de compartición de datos, y los data commons no iban a ser la excepción.
El camino a seguir
Para desbloquear su pleno potencial, los data commons requieren de una acción colectiva y una apuesta decidida por la innovación. Las acciones clave incluyen:
- Desarrollar modelos de gobernanza estandarizados que consigan el equilibrio entre las consideraciones éticas y los requisitos técnicos.
- Aplicar el principio de reciprocidad en el uso de los datos, exigiendo a aquellos que se benefician de ellos compartir sus resultados de vuelta con la comunidad.
- Protección de datos sensibles mediante la anonimización, evitando que los datos puedan ser utilizados para vigilancia masiva o discriminación.
- Fomentar la inversión en infraestructura para apoyar el intercambio de datos escalable y sostenible.
- Promover la concienciación sobre los beneficios sociales de los data commons para impulsar la participación y la colaboración.
Los responsables políticos, investigadores y organizaciones civiles deberían trabajar juntos para crear un ecosistema en el que los data commons puedan prosperar, fomentando un crecimiento más equitativo en la economía digital y garantizando que los bienes comunes de datos puedan beneficiar a todos.
Conclusión
Los data commons pueden suponer una poderosa herramienta a la hora de democratizar el acceso a los datos y fomentar la innovación. En esta era definida por la IA y la transformación digital, nos ofrecen un camino alternativo hacia el progreso equitativo, sostenible e inclusivo. Al abordar sus desafíos y adoptar un enfoque de gobernanza colaborativa mediante la cooperación entre comunidades, investigadores y reguladores se podrá garantizar un uso equitativo y responsable de los datos.
De este modo se conseguirá que los data commons se conviertan en un pilar fundamental del futuro digital, incluyendo las nuevas aplicaciones de la Inteligencia Artificial, pudiendo servir además como herramienta habilitadora fundamental para algunas de las acciones clave que forman parte de la recién anunciada brújula Europea de competitividad, como la estrategia de la nueva Unión de Datos y la iniciativa de las Gigafábricas de IA.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Los portales de datos abiertos son una fuente invaluable de información pública. Sin embargo, extraer insights significativos de estos datos puede resultar desafiante para usuarios sin conocimientos técnicos avanzados.
En este ejercicio práctico, exploraremos el desarrollo de una aplicación web que democratiza el acceso a estos datos mediante el uso de inteligencia artificial, permitiendo realizar consultas en lenguaje natural.
La aplicación, desarrollada utilizando el portal datos.gob.es como fuente de datos, integra tecnologías modernas como Streamlit para la interfaz de usuario y el modelo de lenguaje Gemini de Google para el procesamiento de lenguaje natural. La naturaleza modular permite que se pueda utilizar cualquier modelo de Inteligencia Artificial con mínimos cambios. El proyecto completo está disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en cuatro apartados principales e interconectados que trabajan para procesar las consultas de la persona usuaria:
- Generación del Contexto
- Analiza las características del dataset elegido.
- Genera una descripción detallada incluyendo dimensiones, tipos de datos y estadísticas.
- Crea una plantilla estructurada con guías específicas para la generación de código.
- Combinación de Contexto y Consulta
- Une el contexto generado con la pregunta de la persona usuaria creando el prompt que recibirá el modelo de inteligencia artificial.
- Generación de Respuesta
- Envía el prompt al modelo y obtiene el código Python que permite resolver la cuestión generada.
- Ejecución del Código
- Ejecuta de manera segura el código generado con un sistema de reintentos y correcciones automáticas.
- Captura y expone los resultados en el frontal de la aplicación.

Figura 1. Flujo de procesamiento de solicitudes
Proceso de desarrollo
El primer paso es establecer una forma de acceder a los datos públicos. El portal datos.gob.es ofrece vía API los datasets. Se han desarrollado funciones para navegar por el catálogo y descargar estos archivos de forma eficiente.
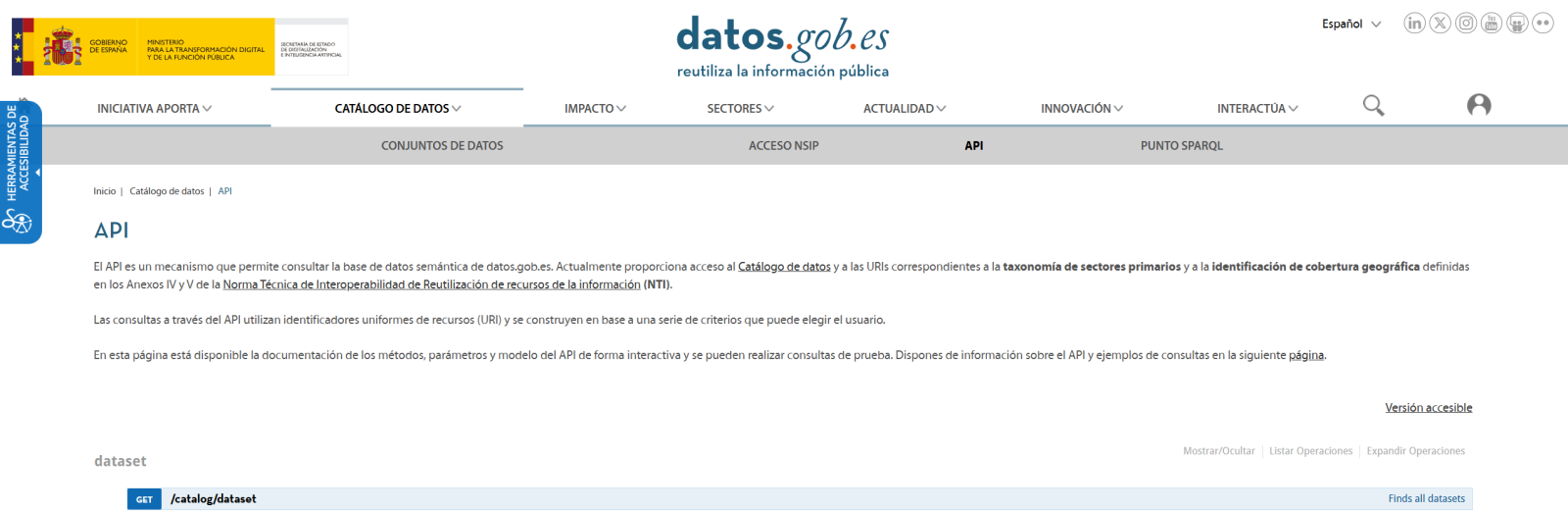
Figura 2. API de datos.gob
El segundo paso aborda la cuestión: ¿cómo convertir preguntas en lenguaje natural en análisis de datos útiles? Aquí es donde entra Gemini, el modelo de lenguaje de Google. Sin embargo, no basta con simplemente conectar el modelo; es necesario enseñarle a entender el contexto específico de cada dataset.
Se ha desarrollado un sistema en tres capas:
- Una función que analiza el dataset y genera una "ficha técnica" detallada.
- Otra que combina esta ficha con la pregunta del usuario.
- Y una tercera que traduce todo esto en código Python ejecutable.
Se puede ver en la imagen inferior como se desarrolla este proceso y, posteriormente, se muestran los resultados del código generado ya ejecutado.

Figura 3. Visualización del procesamiento de respuesta de la aplicación
Por último, con Streamlit, se ha construido una interfaz web que muestra el proceso y sus resultados al usuario. La interfaz es tan simple como elegir un dataset y hacer una pregunta, pero también lo suficientemente potente como para mostrar visualizaciones complejas y permitir la exploración de datos.
El resultado final es una aplicación que permite a cualquier persona, independientemente de sus conocimientos técnicos, realizar análisis de datos y aprender sobre el código ejecutado por el modelo. Por ejemplo, un funcionario municipal puede preguntar "¿Cuál es la edad media de la flota de vehículos?" y obtener una visualización clara de la distribución de edades.

Figura 4. Caso de uso completo. Visualizar la distribución de los años de matriculación de la flota automovilística del ayuntamiento de Almendralejo en 2018
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Integración de IA en Aplicaciones Web:
- Cómo comunicarse efectivamente con modelos de lenguaje como Gemini.
- Técnicas para estructurar prompts que generen código preciso.
- Estrategias para manejar y ejecutar código generado por IA de forma segura.
- Desarrollo Web con Streamlit:
- Creación de interfaces interactivas en Python.
- Manejo de estado y sesiones en aplicaciones web.
- Implementación de componentes visuales para datos.
- Trabajo con Datos Abiertos:
- Conexión y consumo de APIs de datos públicos.
- Procesamiento de archivos Excel y DataFrames.
- Técnicas de visualización de datos.
- Buenas Prácticas de Desarrollo:
- Estructuración modular de código Python.
- Manejo de errores y reintentos.
- Implementación de sistemas de feedback visual.
- Despliegue de aplicaciones web usando ngrok.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos públicos y los usuarios finales. A través del caso práctico desarrollado, hemos podido observar cómo la combinación de modelos de lenguaje avanzados con interfaces intuitivas permite democratizar el acceso al análisis de datos, transformando consultas en lenguaje natural en análisis significativos y visualizaciones informativas.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de modelos de lenguaje más avanzados que permitan análisis más sofisticados.
- Implementación de sistemas de aprendizaje que mejoren las respuestas basándose en el feedback del usuario.
- Integración con más fuentes de datos abiertos y formatos diversos.
- Desarrollo de capacidades de análisis predictivo y prescriptivo.
En resumen, este ejercicio no solo demuestra la viabilidad de democratizar el análisis de datos mediante la inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el acceso y análisis de datos públicos sea verdaderamente universal. La combinación de tecnologías modernas como Streamlit, modelos de lenguaje y técnicas de visualización abre un abanico de posibilidades para que organizaciones y ciudadanos aprovechen al máximo el valor de los datos abiertos.
Blog
Es posible que nuestra capacidad de sorpresa ante las nuevas herramientas de inteligencia artificial (IA) generativa esté empezando a mermar. El mejor ejemplo es GPT-o1, un nuevo modelo de lenguaje con la máxima habilidad de razonamiento lograda hasta ahora, capaz de verbalizar -algo similar a- sus propios procesos lógicos, pero que no despertó en su lanzamiento tanto entusiasmo como cabría esperar. A diferencia de los dos años anteriores, en los últimos meses hemos tenido menos sensación de disrupción y reaccionamos de manera menos masiva ante las novedades.
Una reflexión posible es que no necesitamos, por ahora, más inteligencia en los modelos, sino ver con nuestros propios ojos un aterrizaje en usos concretos que nos faciliten la vida: ¿cómo utilizo la potencia de un modelo de lenguaje para consumir contenido más rápido, para aprender algo nuevo o para trasladar información de un formato a otro? Más allá de las grandes aplicaciones de propósito general, como ChatGPT o Copilot, existen herramientas gratuitas y menos conocidas que nos ayudan a pensar mejor, y nos ofrecen capacidades basadas en IA para descubrir, entender y compartir conocimiento.
Generar pódcasts a partir de un fichero: NotebookLM
Los pódcasts automáticos de NotebookLM llegaron por primera vez a España en el verano de 2024 y sí levantaron un revuelo significativo, a pesar de no estar ni siquiera disponibles en español. Siguiendo el estilo de Google, el sistema es sencillo: basta con subir un fichero en PDF como fuente para obtener diferentes variaciones del contenido proporcionadas por Gemini 2.0 (el sistema de IA de Google), como un resumen del documento, una guía de estudio, una cronología o un listado de preguntas frecuentes. En este caso, hemos utilizado para el ejemplo un informe sobre inteligencia artificial y democracia publicado por la UNESCO en 2024.
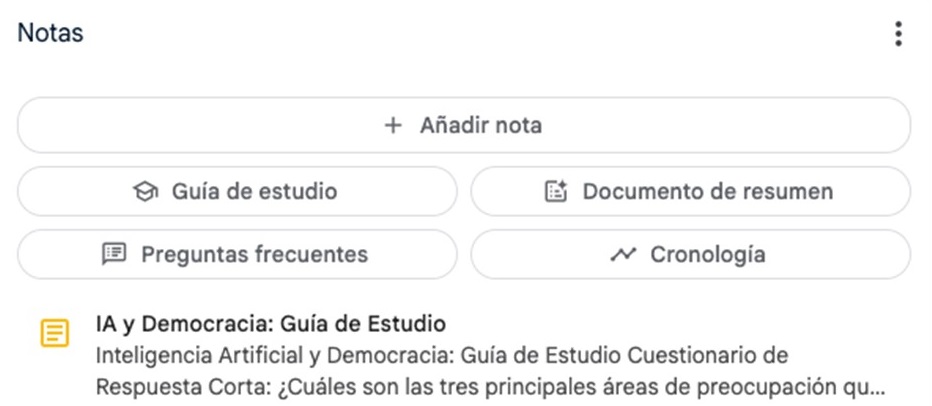
Figura 1. Diferentes opciones de resumen en NotebookLM.
Si bien la guía de estudio es una salida interesante, que ofrece un sistema de preguntas y respuestas para memorizar y un glosario de términos, la estrella de NotebookLM es el llamado “resumen de audio”: un pódcast conversacional completamente natural entre dos interlocutores sintéticos que comentan de manera amena el contenido del PDF.
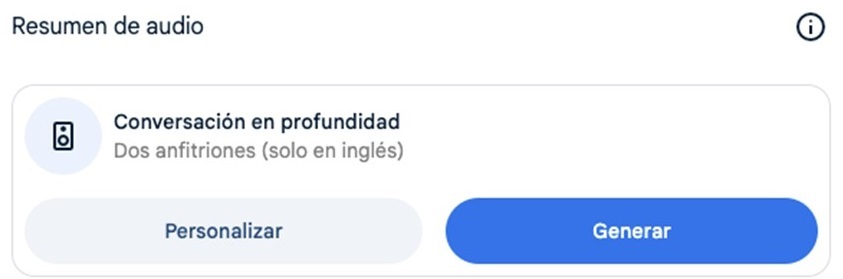
Figura 2. Resumen de audio en NotebookLM.
La calidad del contenido de este pódcast aún tiene margen de mejora, pero puede servirnos como un primer acercamiento al contenido del documento, o ayudarnos a interiorizarlo más fácilmente desde el audio mientras descansamos de las pantallas, hacemos ejercicio o nos desplazamos.
El truco: aparentemente, no se puede generar el pódcast en español, solo en inglés, pero puedes probar con este prompt: “Realiza un resumen de audio en español del documento”. Casi siempre funciona.
Crear visualizaciones a partir de un texto: Napkin AI
Napkin nos ofrece algo muy valioso: crear visualizaciones, infografías y mapas mentales a partir de un contenido en texto. En su versión gratuita, el sistema solo nos pide iniciar sesión con un correo electrónico. Una vez dentro, nos pregunta cómo queremos introducir el texto a partir del cual vamos a crear las visualizaciones. Podemos pegarlo o directamente generar con IA un texto automático sobre cualquier tema.
Figura 3. Puntos de partida en Napkin.ai.
En este caso, vamos a copiar y pegar un fragmento del informe de la UNESCO que recoge varias recomendaciones para la gobernanza democrática de la IA. A partir del texto que recibe, Napkin.ai nos ofrece ilustraciones y varios tipos de esquemas. Podemos encontrar desde propuestas más sencillas con texto organizado en llaves y cuadrantes hasta otras ilustradas con dibujos e iconos.
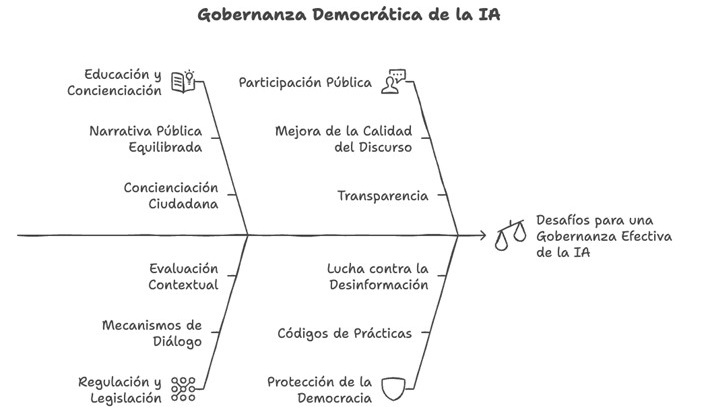
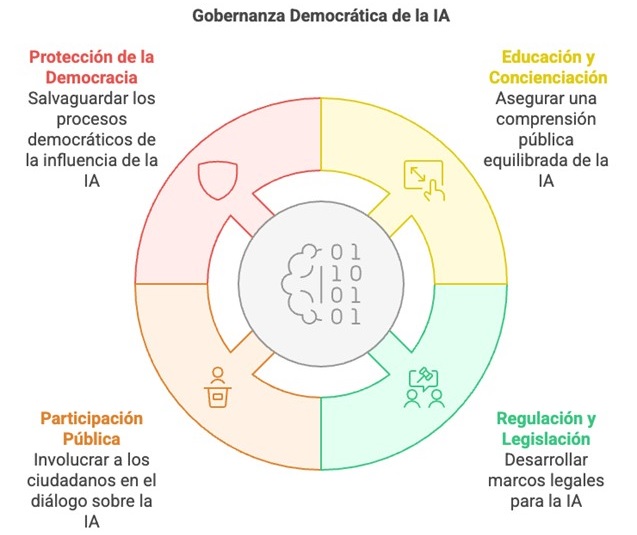
Figura 4. Propuesta de esquemas en Napkin.ai.
Aunque están muy lejos de la calidad de la infografía profesional, estas visualizaciones pueden servirnos a nivel personal y de aprendizaje, para ilustrar un post en redes, explicar conceptos internamente a nuestro equipo o enriquecer contenidos propios en el ámbito educativo.
El truco: si en cada propuesta de esquema haces clic en Styles, encontrarás más variaciones del esquema con colores y líneas diferentes. También puedes modificar los textos, simplemente haciendo clic en ellos una vez que seleccionas una visualización.
Presentaciones y diapositivas automáticas: Gamma
De todos los formatos de contenido que la IA es capaz de generar, las presentaciones con diapositivas es seguramente el menos logrado. En ocasiones los diseños no son demasiado elaborados, otras veces no conseguimos que la plantilla que queremos usar se respete, casi siempre los textos son demasiado simples. La particularidad de Gamma, y lo que la hace más práctica que otras opciones como Beautiful.ai, es que podemos crear una presentación directamente desde un contenido en texto que podemos pegar, generar con IA o subir en un archivo.

Figura 5. Puntos de partida para Gamma.
Si pegamos el mismo texto que en el ejemplo anterior, sobre las recomendaciones de la UNESCO para la gobernanza democrática de la IA, en el siguiente paso Gamma nos da a elegir entre “forma libre” o “tarjeta por tarjeta”. En la primera opción, la IA del sistema se encarga de organizar el contenido en diapositivas conservando el sentido completo de cada una. En la segunda, nos propone que dividamos el texto para indicar el contenido que queremos en cada diapositiva.
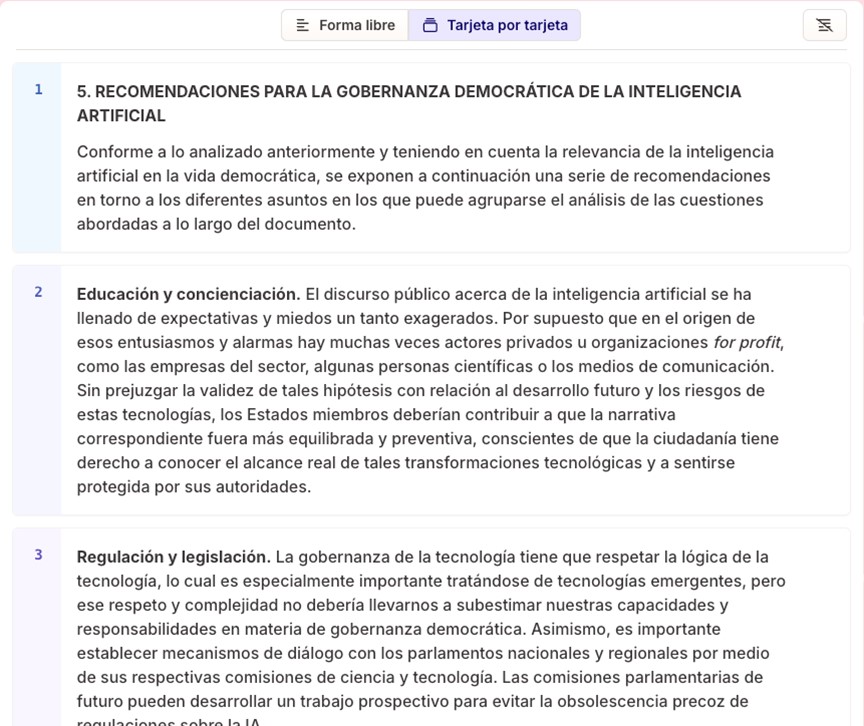
Figura 6. Texto dividido automáticamente en diapositivas por Gamma.
Seleccionamos la segunda opción, y el texto se divide automáticamente en diferentes bloques que serán nuestras diapositivas futuras. Pulsando en “Continuar”, nos pide que seleccionemos un tema de base. Por último, pulsando en “Generar”, se crea automáticamente la presentación completa.

Figura 7. Ejemplo de diapositiva creada con Gamma.
Gamma acompaña las diapositivas de imágenes creadas con IA que guardan cierta coherencia con el contenido, y nos da la opción de modificar los textos o de generar imágenes diferentes. Una vez lista, podemos exportarla directamente al formato Power Point.
Un truco: en el botón “editar con IA” de cada diapositiva podemos pedirle que la traduzca automáticamente a otro idioma, que corrija la ortografía o incluso que convierta el texto en una línea del tiempo.
Resumir desde cualquier formato: NoteGPT
El objetivo de NoteGPT es muy claro: resumir un contenido que podemos importar desde muchas fuentes diferentes. Podemos copiar y pegar un texto, subir un fichero o una imagen, o directamente extraer la información de un enlace, algo muy útil y no tan habitual en las herramientas de IA. Aunque esta última opción no siempre funciona bien, es una de las pocas herramientas que la ofrece.
Figura 8. Puntos de partida para NoteGPT.
En este caso, introducimos el enlace a un vídeo de YouTube que contiene una entrevista a Daniel Innerarity sobre la intersección entre la inteligencia artificial y los procesos democráticos. En la pantalla de resultados, lo primero que obtenemos a la izquierda es la transcripción completa de la entrevista, con buena calidad. Podemos localizar la transcripción de un fragmento concreto del vídeo, traducirla a distintos idiomas, copiarla o descargarla, incluso en un fichero SRT de subtítulos mapeados con los tiempos.
Figura 9. Ejemplo de transcripción con minutaje en NoteGPT.
Entre tanto, a la derecha encontramos el resumen del vídeo con los puntos más importantes, ordenados e ilustrados con emojis. También en el botón “AI Chat” podemos interactuar con un asistente conversacional y hacerle preguntas sobre el contenido.
Figura 10. Resumen de NoteGPT a partir de una entrevista en YouTube.
Y aunque esto ya es muy útil, lo mejor que podemos encontrar en NoteGPT son las flashcards, tarjetas de aprendizaje con preguntas y respuestas para interiorizar los conceptos del vídeo.


Figura 11. Tarjetas de aprendizaje de NoteGPT (pregunta y respuesta).
Un truco: si el resumen solo aparece en inglés, prueba a cambiar el idioma en los tres puntos de la derecha, junto a “Summarize” y haz clic de nuevo en “Summarize”. El resumen aparecerá en español más abajo. En el caso de las flashcards, para generarlas en español no lo intentes desde la página de inicio, hazlo desde “AI flashcards”. En “Create” podrás seleccionar el idioma.
Figura 12. Creación de flashcards en NoteGPT.
Crea vídeos sobre cualquier cosa: Lumen5
Lumen5 facilita la creación de vídeos con IA permitiendo crear el guion y las imágenes automáticamente a partir de contenido en texto o en voz. Lo más interesante de Lumen5 es el punto de partida, que puede ser un texto, un documento, simplemente una idea o también una grabación en audio o un vídeo ya existente.

Figura 13. Opciones de Lumen5.
El sistema nos permite, antes de crear el vídeo y también una vez creado, cambiar el formato de 16:9 (horizontal) a 1:1 (cuadrado) o a 9:16 (vertical), incluso con una opción en 9:16 especial para stories de Instagram.
Figura 14. Previsualización del vídeo y opciones de relación de aspecto.
En este caso, vamos a partir del mismo texto que en herramientas anteriores: las recomendaciones de la UNESCO para una gobernanza democrática de la IA. Seleccionando la opción de partida “Text on media”, lo pegamos directamente en el cajetín y hacemos clic en “Compose script”. El resultado es un guion muy sencillo y esquemático, dividido en bloques con los puntos básicos del texto, y una indicación muy interesante: una predicción sobre la duración del vídeo con ese guion, aproximadamente 1 minuto y 19 segundos.
Una nota importante: el guion no es una locución sonora, sino el texto que aparecerá escrito en las diferentes pantallas. Una vez terminado el vídeo, puedes traducirlo entero a cualquier otro idioma.

Figura 15. Propuesta de guion en Lumen5.
Si hacemos clic en “Continue” llegaremos a la última oportunidad para modificar el guion, donde podremos añadir bloques de texto nuevos o eliminar los existentes. Una vez listo, hacemos clic en “Convert to video” y encontraremos el story board listo para modificar imágenes, colores o el orden de las pantallas. El vídeo tendrá música de fondo, que también puedes cambiar, y en este punto podrás grabar tu voz por encima de la música para locutar el guion. Sin demasiado esfuerzo, este es el resultado final:
Figura 16. Resultado final de un vídeo creado con Lumen5.
Del amplio abanico de productos digitales basados en IA que ha florecido en los últimos años, quizá miles de ellos, hemos recorrido solo cinco ejemplos que nos demuestran que el conocimiento y el aprendizaje individual y colaborativo son más accesibles que nunca. La facilidad para convertir contenido de un formato a otro y la creación automática de guías y materiales de estudio debería promover una sociedad más informada y ágil, no solo a través del texto o la imagen sino también de la información condensada en ficheros o bases de datos.
Supondría un gran impulso para el progreso colectivo que entendiéramos que el valor de los sistemas basados en IA no es tan simple como escribir o crear contenido por nosotros, sino apoyar nuestros procesos de razonamiento, objetivar nuestra toma de decisiones y permitirnos manejar mucha más información de una manera eficiente y útil. Aprovechar las nuevas capacidades IA junto con iniciativas de datos abiertos puede ser clave en el siguiente paso de la evolución del pensamiento humano.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Los EU Open Data Days 2025 son un evento esencial para todos los interesados en el mundo de los datos abiertos y la innovación en Europa y el mundo. Este encuentro, que se celebrará los días 19 y 20 de marzo de 2025, reunirá a expertos, profesionales, desarrolladores, investigadores y responsables de políticas públicas para compartir conocimientos, explorar nuevas oportunidades y abordar los retos a los que se enfrenta la comunidad de datos abiertos.
El evento, organizado por la Comisión Europea a través de data.europa.eu, tiene como objetivo principal promover la reutilización de datos abiertos. Los participantes tendrán la oportunidad de aprender sobre las últimas tendencias en el uso de los datos abiertos, descubrir nuevas herramientas y debatir sobre las políticas y normativas que están modelando el panorama digital en Europa.
¿Dónde y cuándo se celebra?
El evento se celebrará en el Centro Europeo de Convenciones de Luxemburgo, aunque también se podrá seguir online, con el siguiente horario:
- Miércoles 19 de marzo de 2025, de 13:30 a 18:30.
- Jueves 20 de marzo de 2025, de 9:00 a 15:30.
¿Qué temáticas se abordarán?
Ya está disponible la agenda del evento, donde encontramos distintas temáticas, como, por ejemplo:
- Historias de éxito y buenas prácticas: el evento contará con la presencia de profesionales que desarrollan su trabajo en la primera línea de la política de datos europea, para que cuenten su experiencia. Entre otras cuestiones, estos expertos proporcionarán una guía práctica para inventariar y abrir los datos del sector público de un país, abordarán el trabajo que implica la compilación de conjuntos de datos de alto valor o analizarán las perspectivas sobre la reutilización de datos en los modelos de negocio. También se explicarán buenas prácticas para contar con metadatos de calidad o mejorar la gobernanza de datos y su interoperabilidad.
- Foco en el uso de inteligencia artificial (IA): los datos abiertos ofrecen una fuente invaluable para el desarrollo y avance de la IA. Además, la IA puede optimizar la localización, gestión y uso de estos datos, ofreciendo herramientas que ayuden a agilizar procesos y extraer un mayor conocimiento. En este sentido, en el evento se abordará el potencial de la IA para transformar los ecosistemas de datos gubernamentales abiertos, fomentando la innovación, mejorando la gobernanza y potenciando la participación ciudadana. Los responsables del portal nacional de datos de Noruega contará cómo emplean un motor de búsqueda basado en IA para mejorar la localización de datos. Además, se explicarán los avances en espacios de datos lingüísticos y su uso en modelos de lenguaje, y se analizará cómo combinar de forma creativa los datos abiertos para lograr un impacto social.
- Aprendizaje sobre visualización de datos: los asistentes al evento podrán explorar cómo la visualización de datos está transformando la comunicación, la elaboración de políticas y la participación ciudadana. A través de diversos casos (como el árbol genealógico de 3.000 personas de la realeza europea o las relaciones del Patrimonio Cultural Inmaterial de la UNESCO) se mostrará cómo los procesos iterativos de diseño pueden descubrir patrones ocultos en redes complejas, aportando ideas sobre la narración y la comunicación de datos. También se abordará cómo influyen los elementos de diseño, como el color, la escala y el enfoque, en la percepción de los datos.
- Ejemplos y casos de uso: se mostrarán múltiples ejemplos de proyectos concretos basados en la reutilización de datos, en campos como la energía, el desarrollo urbano o el medio ambiente. Entre las experiencias que se compartirán, encontramos una empresa española, Tangible Data, que contará cómo las esculturas físicas de datos convierten conjuntos de datos complejos en experiencias accesibles y atractivas.
Estos son solo algunos de los temas a tratar, pero también se hablará de ciencia abierta, el papel de los datos abiertos en la transparencia y la rendición de cuentas, etc.
¿Por qué son tan importantes los EU Open Data Days?
El acceso a datos abiertos ha demostrado ser una herramienta poderosa para mejorar la toma de decisiones, impulsar la innovación y la investigación, y mejorar la eficiencia de las organizaciones. En un momento en el que la digitalización está avanzando rápidamente, la importancia de compartir y reutilizar datos se hace cada vez más crucial para enfrentar desafíos globales como el cambio climático, la salud pública o la justicia social.
Los EU Open Data Days 2025 son una oportunidad para explorar cómo los datos abiertos pueden aprovecharse para construir una Europa más conectada, innovadora y participativa.
Además, para aquellos que decidan asistir de forma presencial, el evento será también una oportunidad para establecer contactos con otros profesionales y organizaciones del sector, creando nuevas colaboraciones que pueden dar lugar a proyectos innovadores.
¿Cómo puedo asistir?
Para asistir presencialmente, es necesario inscribirse a través de este enlace. Sin embargo, no es necesario el registro para atender el evento de manera online.
Para cualquier consulta, se ha habilitado una dirección de correo donde se atenderán todas las dudas relativas al evento: EU-Open-Data-Days@ec.europa.eu.
Más información en la página web del evento.
Noticia
Impulsar la cultura del dato es un objetivo clave a nivel nacional que también comparten las administraciones autonómicas. Uno de los caminos para llevar a cabo este propósito es premiar aquellas soluciones que han sido desarrolladas con conjuntos de datos abiertos, una iniciativa que potencia su reutilización e impacto en la sociedad.
En esta misión, la Junta de Castilla y León y el Gobierno Vasco llevan años organizando concursos de datos abiertos, temática de la que hablamos en nuestro primer episodio del pódcast de datos.gob.es que puedes escuchar aquí.
En este post, repasamos cuáles han sido los proyectos premiados en las últimas ediciones de los concursos de datos abiertos de Euskadi y Castilla y León.
Premiados en el VIII Concurso de Datos Abiertos de Castilla y León
En la octava edición de esta competición anual, que suele abrir su plazo a finales de verano, se presentaron 35 candidaturas, de las cuales se han escogido 8 ganadores divididos en diferentes categorías.
Categoría Ideas: los participantes tenían que describir una idea para crear estudios, servicios, sitios web o aplicaciones para dispositivos móviles. Se repartían un primer premio de 1.500€ y un segundo premio de 500€.
- Primer premio: Guardianes Verdes de Castilla y León presentado por Sergio José Ruiz Sainz. Se trata de una propuesta para desarrollar una aplicación móvil que oriente a los visitantes de los parques naturales de Castilla y León. Los usuarios pueden acceder a información (como mapas interactivos con puntos de interés) a la vez que pueden contribuir con datos útiles de su visita, que enriquecen la aplicación.
- Segundo premio: ParkNature: sistema inteligente de gestión de aparcamientos en espacios naturales presentado por Víctor Manuel Gutiérrez Martín. Consiste en una idea para la crear una aplicación que optimice la experiencia de los visitantes de los espacios naturales de Castilla y León, mediante la integración en tiempo real de datos sobre aparcamientos y la conexión con eventos culturales y turísticos cercanos.
Categoría Productos y Servicios: premiaba estudios, servicios, sitios web o aplicaciones para dispositivos móviles, los cuales deben estar accesibles para toda la ciudadanía vía web mediante una URL. En esta categoría se repartieron un primer, segundo y tercer premio de 2.500€, 1.500€ y 500€, respectivamente, además de un premio específico de 1.500€ para estudiantes.
- Primer premio: AquaCyL de Pablo Varela Vázquez. Es una aplicación que ofrece información sobre las zonas de baño en la comunidad autónoma.
- Segundo premio: ConquistaCyL presentado por Markel Juaristi Mendarozketa y Maite del Corte Sanz. Es un juego interactivo pensado para hacer turismo en Castilla y León y aprender a través de un proceso gamificado.
- Tercer premio: Todo el deporte de Castilla y León presentado por Laura Folgado Galache. Es una app que presenta toda la información de interés asociada a un deporte según la provincia.
- Premio estudiantes: Otto Wunderlich en Segovia por Jorge Martín Arévalo. Es un repositorio fotográfico ordenado según tipo de monumentos y localización de las fotografías de Otto Wunderlich.
Categoría Recurso Didáctico: consistía en la creación de recursos didácticos abiertos nuevos e innovadores, que sirvieran de apoyo a la enseñanza en el aula. Estos recursos debían ser publicados con licencias Creative Commons. En esta categoría se otorgaba un único primer premio de 1.500€.
- Primer premio: StartUp CyL: Creación de empresas a través de la Inteligencia Artificial y Datos Abiertos presentado por José María Pérez Ramos. Es un chatbot que utiliza la API de ChatGPT para asistir en la creación de una empresa utilizando datos abiertos.
Categoría Periodismo de Datos: premiaba piezas periodísticas publicadas o actualizadas (de forma relevante), tanto en soporte escrito como audiovisual, y ofrecía un premio de 1.500€.
- Primer premio: Codorniz, perdiz y paloma torcaz son las especies más cazadas en Burgos, presentado por Sara Sendino Cantera, que analiza datos sobre la caza en Burgos.
Premiados de la 5ª edición del Concurso de Datos Abiertos de Open Data Euskadi
Como ya venía sucediendo en ediciones anteriores, el portal de datos abiertos de Euskadi abrió dos modalidades de premios: un concurso de ideas y otro de aplicaciones, cada uno de los cuales estaba dividido en varias categorías. En esta ocasión, se presentaron 41 candidaturas en el concurso de ideas y 30 para el de aplicaciones
Concurso de ideas: en esta modalidad se han repartido dos premios por categoría, el primero de 3.000€ y el segundo de 1.500€.
Categoría Sanitaria y Social
- Primer premio: Desarrollo de un Modelo de Predicción de Volumen de Pacientes que acudirán al Servicio de urgencias de Osakidetza de Miren Bacete Martínez. Propone el desarrollo de un modelo predictivo usando series temporales capaz de anticipar tanto el volumen de personas que acudirán a urgencias, como el nivel de gravedad de los casos.
- Segundo premio: Euskoeduca de Sandra García Arias. Es una propuesta de solución digital diseñada para brindar orientación académica y profesional personalizada a estudiantes, padres y tutores.
Categoría Medio ambiente y Sostenibilidad
- Primer premio: Baratzapp de Leire Zubizarreta Barrenetxea. La idea consiste en el desarrollo de un software que facilita y asiste en la planificación de un huerto mediante algoritmos que buscan potenciar el conocimiento relacionado con la huerta de autoconsumo, a la vez que integra, entre otras, la información climatológica, medioambiental y parcelaria de una manera personalizada para el usuario.
- Segundo premio: Euskal Advice de Javier Carpintero Ordoñez. El objetivo de esta propuesta es definir un recomendador turístico basado en inteligencia artificial.
Categoría General
- Primer premio: Lanbila de Hodei Gonçalves Barkaiztegi. Es una propuesta de app que utiliza IA generativa y datos abiertos para emparejar curriculum vitae con ofertas de empleo de forma semántica. Proporciona recomendaciones personalizadas, alertas proactivas de empleo y formación, y permite decisiones informadas a través de indicadores laborales y territoriales.
- Segundo premio: Desarrollo de un LLM para la consulta interactiva de Datos Abiertos del Gobierno Vasco de Ibai Alberdi Martín. La propuesta consiste en el desarrollo de un Modelo de Lenguaje a Gran Escala (LLM) similar a ChatGPT, entrenado específicamente con datos abiertos, enfocado en proporcionar una interfaz conversacional y gráfica que permita a los usuarios obtener respuestas precisas y visualizaciones dinámicas.
Concurso de aplicaciones: esta modalidad ha seleccionado un proyecto en la categoría de servicios web, premiado con 8.000€, y dos más en la Categoría General que han recibido un primer premio de 8.000€ y 5.000€ como segundo premio.
Categoría Servicios web
- Primer premio: Bizidata: Plataforma de visualización del uso de bicicletas en Vitoria-Gasteiz de Igor Díaz de Guereñu de los Ríos. Es una plataforma que visualiza, analiza y permite descargar datos del uso de bicicletas en Vitoria-Gasteiz, y explorar cómo factores externos, como la climatología y el tráfico, influyen en el uso de la bicicleta.
Categoría General
- Primer premio: Garbiñe AI de Beatriz Arenal Redondo. Es un asistente inteligente que combina la inteligencia artificial (IA) con datos abiertos de Open Data Euskadi para promover la economía circular y mejorar los ratios de reciclaje en Euskadi.
- Segundo premio: Vitoria-Gasteiz Businessmap de Zaira Gil Ozaeta. Es una herramienta de visualización interactiva basada en datos abiertos, diseñada para mejorar las decisiones estratégicas en el ámbito del emprendimiento y la actividad económica en Vitoria-Gasteiz.
Todas estas soluciones premiadas reutilizan conjuntos de datos abiertos del portal autonómico de Castilla y León o Euskadi, según el caso. Te animamos a que eches un vistazo a las propuestas que pueden inspirarte de cara a participar en la próxima edición de estos concursos. ¡Síguenos en redes sociales para no perderte las convocatorias de este año!