Blog
Cuando se acaban de cumplir tres años desde que comenzó la aceleración del despliegue masivo de la Inteligencia Artificial con el lanzamiento de ChatGPT, un término nuevo emerge con fuerza: la IA agéntica (Agentic AI). En los últimos tres años hemos pasado de hablar de modelos de lenguaje (como por ejemplo, los LLM) y chatbots (o asistentes conversacionales) a diseñar los primeros sistemas capaces no solo de responder a nuestras preguntas, sino de actuar de forma autónoma para conseguir objetivos, combinando datos, herramientas y colaboraciones con otros agentes de IA o con personas humanas. Esto es, la conversación global sobre IA se está moviendo desde la capacidad para "conversar" hacia la capacidad para "actuar" de estos sistemas.
En el sector privado, informes recientes de grandes consultoras describen agentes de IA que resuelven de principio a fin incidencias de clientes, orquestan cadenas de suministro, optimizan inventarios en el sector retail o automatizan la elaboración de informes de negocio. En el sector público, esta conversación también comienza a tomar forma y cada vez más administraciones exploran cómo estos sistemas pueden ayudar a simplificar trámites o a mejorar la atención a la ciudadanía. Sin embargo, el despliegue parece que está siendo algo más lento porque lógicamente en la administración no solo debe tenerse en cuenta la excelencia técnica sino también el estricto cumplimiento del marco normativo, que en Europa lo marca el Reglamento de IA, para que los agentes autónomos sean, ante todo, aliados de la ciudadanía.
¿Qué es la IA agéntica (Agentic AI)?
Aunque se trate de un concepto reciente que aún está en evolución, varias administraciones y organismos empiezan a converger en una definición. Por ejemplo, el Gobierno del Reino Unido describe la IA agéntica como sistemas formados por agentes de IA que “pueden comportarse e interactuar de forma autónoma para lograr sus objetivos”. En este contexto un agente de IA sería una pieza especializada de software que puede tomar decisiones y operar de forma cooperativa o independiente para lograr los objetivos del sistema.
Podríamos pensar, por ejemplo, en un agente de IA en una administración local que recibe la solicitud de una persona para abrir un pequeño negocio. El agente, diseñado de acuerdo con el procedimiento administrativo correspondiente, comprobaría la normativa aplicable, consultaría datos urbanísticos y de actividad económica, verificaría requisitos, rellenaría borradores de documentos, propondría citas o trámites complementarios y prepararía un resumen para que el personal funcionario pudiera revisar y validar la solicitud. Esto es, no sustituiría la decisión humana, sino que automatizaría buena parte del trabajo que hay entre la solicitud realizada por el ciudadano y la resolución dictada por la administración.
Frente a un chatbot conversacional -que responde a una pregunta y, en general, termina ahí la interacción-, un agente de IA puede encadenar múltiples acciones, revisar resultados, corregir errores, colaborar con otros agentes de IA y seguir iterando hasta alcanzar la meta que se le ha definido. Esto no significa que los agentes autónomos decidan por su cuenta sin supervisión, sino que pueden hacerse cargo de buena parte de la tarea siempre siguiendo reglas y salvaguardas bien definidas.
Las características clave de un agente autónomo incluyen:
- Percepción y razonamiento: es la capacidad de un agente para comprender una solicitud compleja, interpretar el contexto y desglosar el problema en pasos lógicos que conduzcan a resolverlo.
- Planificación y acción: es la habilidad para ordenar esos pasos, decidir la secuencia en que se van a ejecutar y adaptar el plan cuando cambian los datos o aparecen nuevas restricciones.
- Uso de herramientas: un agente puede, por ejemplo, conectarse a diversas API, consultar bases de datos, catálogos de datos abiertos, abrir y leer documentos o enviar correos electrónicos según lo requieran las tareas que está intentando resolver.
- Memoria y contexto: es la capacidad del agente para mantener la memoria de las interacciones en procesos largos, recordando las acciones y respuestas pasadas y el estado actual de la solicitud que está resolviendo.
- Autonomía supervisada: un agente puede tomar decisiones dentro de unos límites previamente establecidos para avanzar hacia la meta sin necesidad de intervención humana en cada paso, pero permitiendo siempre la revisión y trazabilidad de las decisiones.
Podríamos resumir el cambio que supone con la siguiente analogía: si los LLM son el motor de razonamiento, los agentes de IA son sistemas que además de esa capacidad de “pensar” en las acciones que habría que hacer, tienen "manos" para interactuar con el mundo digital e incluso con el mundo físico y ejecutar esas mismas acciones.
El potencial de los agentes de IA en los servicios públicos
Los servicios públicos se organizan, en buena medida, alrededor de procesos de una cierta complejidad como son la tramitación de ayudas y subvenciones, la gestión de expedientes y licencias o la propia atención ciudadana a través de múltiples canales. Son procesos con muchos pasos, reglas y actores diferentes, donde abundan las tareas repetitivas y el trabajo manual de revisión de documentación.
Como puede verse en el eGovernment Benchmark de la Unión Europea, las iniciativas de administración electrónica de las últimas décadas han permitido avanzar hacia una mayor digitalización de los servicios públicos. Sin embargo, la nueva ola de tecnologías de IA, especialmente cuando se combinan modelos fundacionales con agentes, abre la puerta a un nuevo salto para automatizar y orquestar de forma inteligente buena parte de los procesos administrativos.
En este contexto, los agentes autónomos permitirían:
- Orquestar procesos de extremo a extremo como, por ejemplo, recopilar datos de distintas fuentes, proponer formularios ya cumplimentados, detectar incoherencias en la documentación aportada o generar borradores de resoluciones para su validación por el personal responsable.
- Actuar como “copilotos” de los empleados públicos, preparando borradores, resúmenes o propuestas de decisiones que luego se revisan y validan, asistiendo en la búsqueda de información relevante o señalando posibles riesgos o incidencias que requieren atención humana.
- Optimizar los procesos de atención ciudadana apoyando en tareas como la gestión de citas médicas, respondiendo consultas sobre el estado de expedientes, facilitando el pago de tributos o guiando a las personas en la elección del trámite más adecuado a su situación.
Diversos análisis sobre IA en el sector público apuntan a que este tipo de automatización inteligente, al igual que en el sector privado, puede reducir tiempos de espera, mejorar la calidad de las decisiones y liberar tiempo del personal para tareas de mayor valor añadido. Un informe reciente de PWC y Microsoft que explora el potencial de la IA agéntica para el sector público resume bien la idea, señalando que al incorporar la IA agéntica en los servicios públicos, los gobiernos pueden mejorar la capacidad de respuesta y aumentar la satisfacción ciudadana, siempre que existan las salvaguardas adecuadas.
Además, la implementación de agentes autónomos permite soñar con una transición desde una administración reactiva (que espera a que el ciudadano solicite un servicio) a una administración proactiva que se ofrece a hacer por nosotros parte de esas mismas acciones: desde avisarnos de que se ha abierto una ayuda para la que probablemente cumplamos los requisitos, hasta proponernos la renovación de una licencia antes de que caduque o recordarnos una cita médica.
Un ejemplo ilustrativo de esto último podría ser un agente de IA que, apoyado en datos sobre servicios disponibles y en la información que el propio ciudadano haya autorizado utilizar, detecte que se ha publicado una nueva ayuda para actuaciones de mejora de la eficiencia energética a través de la rehabilitación de viviendas y envíe un aviso personalizado a quienes podrían cumplir los requisitos. Incluso ofreciéndoles un borrador de solicitud ya pre-cumplimentado para su revisión y aceptación. La decisión final sigue siendo humana, pero el esfuerzo de buscar la información, entender las condiciones y preparar la documentación se podría reducir mucho.
El rol de los datos abiertos
Para que un agente de IA pueda actuar de forma útil y responsable necesita apalancarse sobre un entorno rico en datos de calidad y un sistema de gobernanza de datos sólido. Entre esos activos necesarios para desarrollar una buena estrategia de agentes autónomos, los datos abiertos tienen importancia al menos en tres dimensiones:
- Combustible para la toma de decisiones: los agentes de IA necesitan información sobre normativa vigente, catálogos de servicios, procedimientos administrativos, indicadores socioeconómicos y demográficos, datos de transporte, medio ambiente, planificación urbana, etc. Para ello, la calidad y estructura de los datos es de gran importancia ya que datos desactualizados, incompletos o mal documentados pueden llevar a los agentes a cometer errores costosos. En el sector público, esos errores pueden traducirse en decisiones injustas que en última instancia podrían llevar a la pérdida de confianza de la ciudadanía.
- Banco de pruebas para evaluar y auditar agentes: al igual que los datos abiertos son importantes para evaluar modelos de IA generativa, también pueden serlo para probar y auditar agentes autónomos. Por ejemplo, simulando expedientes ficticios con datos sintéticos basados en distribuciones reales para comprobar cómo actúa un agente en distintos escenarios. De este modo, universidades, organizaciones de la sociedad civil y la propia administración puedan examinar el comportamiento de los agentes y detectar problemas antes de escalar su uso.
- Transparencia y explicabilidad: los datos abiertos podrían ayudar a documentar de dónde proceden los datos que utiliza un agente, cómo se han transformado o qué versiones de los conjuntos de datos estaban vigentes cuando se tomó una decisión. Esta trazabilidad contribuye a la explicabilidad y la rendición de cuentas, especialmente cuando un agente de IA interviene en decisiones que afectan a los derechos de las personas o a su acceso a servicios públicos. Si la ciudadanía puede consultar, por ejemplo, los criterios y datos que se aplican para otorgar una ayuda, se refuerza la confianza en el sistema.
El panorama de la IA agéntica en España y en el resto del mundo
Aunque el concepto de IA agéntica es reciente, ya existen iniciativas en marcha en el sector público a nivel internacional y comienzan a abrirse paso también en el contexto europeo y español:
- La Government Technology Agency (GovTech) de Singapur ha publicado una guía Agentic AI Primer para orientar a desarrolladores y responsables públicos sobre cómo aplicar esta tecnología, destacando tanto sus ventajas como sus riesgos. Además, el gobierno está pilotando el uso de agentes en varios ámbitos para reducir la carga administrativa de los trabajadores sociales y apoyar a las empresas en procesos complejos de obtención de licencias. Todo ello en un entorno controlado (sandbox) para probar estas soluciones antes de escalarlas.
- El Gobierno de Reino Unido ha publicado una nota específica dentro de su documentación “AI Insights” para explicar qué es la IA agéntica y por qué es relevante para servicios gubernamentales. Además, ha anunciado una licitación para desarrollar un “GOV.UK Agentic AI Companion” que sirva de asistente inteligente para la ciudadanía desde el portal del gobierno.
- La Comisión Europea, en el marco de la estrategia Apply AI y de la iniciativa GenAI4EU, ha lanzado convocatorias para financiar proyectos piloto que introduzcan soluciones de IA generativa escalables y replicables en las administraciones públicas, plenamente integradas en sus flujos de trabajo. Estas convocatorias buscan precisamente acelerar el paso en la digitalización a través de IA (incluidos agentes especializados) para mejorar la toma de decisiones, simplificar procedimientos y hacer la administración más accesible.
En España, aunque la etiqueta “IA agéntica” todavía no se utiliza aún de forma amplia, ya se pueden identificar algunas experiencias que van en esa dirección. Por ejemplo, distintas administraciones están incorporando copilotos basados en IA generativa para apoyar a los empleados públicos en tareas de búsqueda de información, redacción y resumen de documentos, o gestión de expedientes, como muestran iniciativas de gobiernos autonómicos como el de Aragón y o entidades locales como el Ayuntamiento de Barcelona que empiezan a documentarse de forma pública.
El salto hacia agentes más autónomos en el sector público parece, por tanto, una evolución natural sobre la base de la administración electrónica existente. Pero esa evolución debe, al mismo tiempo, reforzar el compromiso con la transparencia, la equidad, la rendición de cuentas, la supervisión humana y el cumplimiento normativo que exige el Reglamento de IA y el resto del marco normativo y que deben guiar las actuaciones de la administración pública.
Mirando hacia el futuro: agentes de IA, datos abiertos y confianza ciudadana
La llegada de la IA agéntica ofrece de nuevo a la Administración pública nuevas herramientas para reducir la burocracia, personalizar la atención y optimizar sus siempre escasos recursos. Sin embargo, la tecnología es solo un medio, el fin último sigue siendo generar valor público reforzando la confianza de la ciudadanía.
En principio, España parte de una buena posición: dispone de una Estrategia de Inteligencia Artificial 2024 que apuesta por una IA transparente, ética y centrada en las personas, con líneas específicas para impulsar su uso en el sector público; cuenta con una infraestructura consolidada de datos abiertos; y ha creado la Agencia Española de Supervisión de la Inteligencia Artificial (AESIA) como organismo encargado de garantizar un uso ético y seguro de la IA, de acuerdo con el Reglamento Europeo de IA.
Estamos, por tanto, ante una nueva oportunidad de modernización que puede construir unos servicios públicos más eficientes, cercanos e incluso proactivos. Si somos capaces de adoptar la IA agéntica adecuadamente, los agentes que se desplieguen no serán una “caja negra” que actúa sin supervisión, sino “agentes públicos” digitales, transparentes y auditables, diseñados para trabajar con datos abiertos, explicar sus decisiones y dejar rastro de las acciones que realizan. Herramientas, en definitiva, inclusivas, centradas en las personas y alineadas con los valores del servicio público.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Rampa es un servicio de rutas para personas con movilidad reducida. Este proyecto, desarrollado en el marco de los Premios a la reutilización de datos abiertos del Ayuntamiento de Madrid 2025, combina datos abiertos y tecnología geoespacial para facilitar la búsqueda de rutas y servicios accesibles para personas con movilidad reducida.
La aplicación web proporciona los siguientes datos:
- Accesibilidad: ofrece rutas optimizadas para sillas de ruedas, andadores y personas con movilidad reducida.
- Datos demográficos: permite visualizar índices de envejecimiento, dependencia y densidad poblacional para entender mejor las necesidades de cada área.
- Panel de control: permite visualizar las áreas con mayor y menor accesibilidad en Madrid y detecta los barrios y distritos más accesibles.
Aplicación
Plataforma web para filtrar y organizar las proposiciones del Congreso de los diputados según los votos de los partidos, con la capacidad que mostrar lo que han votado en conjunto o de forma distintas uno o varios partidos.
Como las proposiciones pueden tener varias votaciones se saca con un modelo de IA de ChatGPT la votación principal de cada proposición. También con IA se saca la información de los distintos puntos que tiene un proposición se genera una descripción explicativa y entendible para cualquier persona sobre la proposición.
El objetivo tener una plataforma donde se vea de forma clara y sencilla la actividad del Congreso de los Diputados.
Noticia
La reutilización de los datos abiertos permite generar soluciones innovadoras que mejoran la vida de las personas, impulsan la participación ciudadana y refuerzan la transparencia pública. Prueba de ello son los concursos impulsados este año por la Junta de Castilla y León y el Ayuntamiento de Madrid.
Siendo la IX edición del Concurso de Castilla y León y la primera del de Madrid, ambas administraciones han hecho entrega de los premios a los proyectos seleccionados, reconociendo tanto a estudiantes y startups como a profesionales e investigadores que han sabido transformar datos públicos en herramientas y conocimientos útiles. En este post, repasamos los proyectos premiados en cada concurso y el contexto que los impulsa.
Castilla y León: novena edición de unos premios consolidados en una administración más abierta
En la entrega de los premios del IX Concurso de Datos Abiertos de la Junta de Castilla y León se puso en valor el refuerzo presupuestario (+65 %) en la Dirección General de Transparencia y Buen Gobierno, la ampliación de contenidos de publicidad activa y una mejora continua del derecho de acceso a la información pública, que ha reducido solicitudes y resoluciones desestimatorias. El Portal de Datos Abiertos de Castilla y León cuenta con 776 conjuntos de datos que permiten desarrollar servicios, aplicaciones y estudios cada año.
Los Premios Datos Abiertos reconocen iniciativas en cuatro categorías: Ideas, Productos y Servicios, Recursos Didácticos, Periodismo de Datos.
Ideas
-
Primer premio: CyL Rural Hub. Propuesta para desarrollar una plataforma integral del territorio rural que centralice servicios, infraestructuras, oportunidades laborales y oferta educativa. Su objetivo es facilitar a familias y profesionales información útil para planificar un proyecto de vida en los pueblos de la comunidad.
-
Segundo premio: App cultural de Castilla y León. Idea orientada a dinamizar la actividad cultural mediante una aplicación que centraliza eventos, actividades y localizaciones, ofreciendo además una experiencia intuitiva y cercana basada en datos abiertos.
Productos y Servicios
-
Primer premio: Puente CyL. Aplicación diseñada para apoyar la integración de personas migrantes mediante rutas personalizadas, un asistente de inteligencia artificial y un centro de recursos alimentado por datos públicos.
-
Segundo premio: MuniCyL. Herramienta que reúne información municipal dispersa y la presenta en una única plataforma clara, accesible y actualizada.
-
Tercer premio: Mapa interactivo de Espacios Naturales. Recurso que permite a los ciudadanos explorar los espacios protegidos del territorio de forma dinámica y en tiempo real.
-
Premios estudiantes: Info Salamanca. Plataforma que ofrece mapas interactivos, filtros temáticos y un asistente conversacional para acercar información provincial y facilitar la consulta de datos ciudadanos.
Recurso Didáctico
-
Primer premio: Uso de datos abiertos de la Junta de Castilla y León en desarrollo web. Un proyecto que introduce los datos abiertos en el aprendizaje del desarrollo web, con ejercicios prácticos y un buscador con IA para trabajar directamente con datos reales del portal.
Periodismo de Datos
-
Primer premio: Los infartos ya no son cosa de la edad, un reportaje sobre el aumento de infartos entre población joven.
-
Segundo premio: Burgos mantiene el liderazgo regional con 79 parques eólicos: un análisis del despliegue de energías renovables en la región.
Madrid: primera edición de unos premios que impulsan la reutilización en el ámbito urbano
Por otro lado, el Ayuntamiento de Madrid ha celebrado la primera edición de los Premios a la Reutilización de Datos Abiertos 2025. La ceremonia destacó la calidad y diversidad de las 65 candidaturas presentadas, muchas de ellas impulsadas por estudiantes universitarios y startups.
Los premios buscan impulsar el uso de los datos del Portal de Datos Abiertos del Ayuntamiento de Madrid, apoyar la creación de servicios y estudios que contribuyan al conocimiento de la ciudad y reforzar el papel del consistorio como administración referente en transparencia y rendición de cuentas.
En este caso, los galardones se estructuran en cuatro categorías: Servicios Web y Aplicaciones, Visualizaciones, Estudios e Ideas, y Mejora del Portal.
Servicios Web y Aplicaciones
-
Primer premio: Madriwa. Encuentra tu sitio en Madrid. Herramienta que facilita la búsqueda de vivienda mediante datos sobre barrios, servicios y precios, permitiendo una comparación informada y simplificada.
-
Segundo premio: Los guardianes del aire. Aplicación para consultar la calidad del aire de la ciudad, especialmente pensada para sensibilizar a población joven y centros educativos.
Visualizaciones
-
Primer premio: Rampa. Rutas para personas con movilidad reducida. Presenta itinerarios accesibles basados en datos geoespaciales y de orografía, ofreciendo rutas alternativas adaptadas a personas con movilidad reducida.
-
Segundo premio: AccesibiliMad. Muestra servicios públicos disponibles en cada entorno urbano, con especial atención a las necesidades específicas de distintos colectivos.
Estudios, Investigaciones e Ideas
-
Primer premio: Ciudades de quince minutos para la infancia. Análisis de la disponibilidad de servicios esenciales para menores en un radio máximo de 15 minutos, aportando una visión innovadora de planificación urbana.
-
Segundo premio: El impacto del turismo en las zonas urbanas. Estudio que profundiza en la relación entre viviendas turísticas, tejido comercial y dinámica laboral, utilizando datos urbanos y socioeconómicos.
Mejora de la Calidad del Portal
-
Primer premio: Your Open Data. Mejorando el harvesting en data.europa.eu. Propuesta que mejora la forma en que se facilitan los datos, elevando la calidad de los metadatos e impulsando la interoperabilidad europea.
-
Segundo premio: Descubrimiento, observabilidad y gobernanza inteligente de datos abiertos. Solución que introduce una capa automatizada de inteligencia y control sobre el catálogo municipal.
Tanto Castilla y León, con una trayectoria consolidada, como el Ayuntamiento de Madrid, que inaugura su propio reconocimiento, contribuyen de manera decisiva a fortalecer el ecosistema español de datos abiertos. Sus convocatorias son una muestra de cómo la colaboración entre administraciones, ciudadanía, ámbito académico y sector privado puede transformar los datos públicos en conocimiento, participación e innovación al servicio de toda la sociedad.
Documentación
En el ecosistema del sector público, las subvenciones representan uno de los mecanismos más importantes para impulsar proyectos, empresas y actividades de interés general. Sin embargo, entender cómo se distribuyen estos fondos, qué organismos convocan ayudas más voluminosas o cómo varía el presupuesto según la región o los beneficiarios no es trivial cuando se trabaja con cientos de miles de registros.
En esta línea, presentamos un nuevo ejercicio práctico de la serie “Ejercicios de datos paso a paso”, en el que aprenderemos a explorar y modelar datos abiertos utilizando Apache Spark, una de las plataformas más extendidas para el procesamiento distribuido y el machine learning a gran escala.
En este laboratorio trabajaremos con datos reales del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas (BDNS) y construiremos un modelo capaz de predecir el rango de presupuesto de nuevas convocatorias en función de sus características principales.
Todo el código utilizado está disponible en el correspondiente repositorio de GitHub para que puedas ejecutarlo, entenderlo y adaptarlo a tus propios proyectos.
Accede al repositorio del laboratorio de datos en GitHub
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
Contexto: ¿por qué analizar las subvenciones públicas?
La BDNS recoge información detallada sobre cientos de miles de convocatorias publicadas por distintas administraciones españolas: desde ministerios y consejerías autonómicas hasta diputaciones y ayuntamientos. Este conjunto de datos es una fuente extraordinariamente valiosa para:
-
analizar la evolución del gasto público,
-
entender qué organismos son más activos en ciertas áreas,
-
identificar patrones en los tipos de beneficiarios,
-
y estudiar la distribución presupuestaria según sector o territorio.
En nuestro caso, utilizaremos el dataset para abordar una pregunta muy concreta, pero de gran interés práctico:
¿Podemos predecir el rango de presupuesto de una convocatoria a partir de sus características administrativas?
Esta capacidad facilitaría tareas de clasificación inicial, apoyo a la toma de decisiones o análisis comparativos dentro de una administración pública.
Objetivo del ejercicio
El objetivo del laboratorio es doble:
- Aprender a manejar Spark de forma práctica:
- Cargar un dataset real de gran volumen
- Realizar transformaciones y limpieza
- Manipular columnas categóricas y numéricas
- Estructurar un pipeline de machine learning
2. Construir un modelo predictivo
Entrenaremos un clasificador capaz de estimar si una convocatoria pertenece a uno de estos rangos de presupuesto bajo (hasta 20 k€), medio (entre 20 y 150k€) o alto (superior a 150k€), basándonos para ello en variables como:
- Organismo concedente
- Comunidad Autónoma
- Tipo de beneficiario
- Año de publicación
- Descripciones administrativas
Recursos utilizados
Para completar este ejercicio empleamos:
Herramientas analíticas
- Python, lenguaje principal del proyecto
- Google Colab, para ejecutar Spark y crear Notebooks de forma sencilla
- PySpark, para el procesamiento de datos en las etapas de limpieza y modelado
- Pandas, para pequeñas operaciones auxiliares
- Plotly, para algunas visualizaciones interactivas
Datos
Dataset oficial del Sistema Nacional de Publicidad de Subvenciones (BDNS), descargado desde el portal de subvenciones del Ministerio de Hacienda.
Los datos utilizados en este ejercicio fueron descargados el 28 de agosto de 2025. La reutilización de los datos del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas está sujeta a las condiciones legales recogidas en https://www.infosubvenciones.es/bdnstrans/GE/es/avisolegal.
Desarrollo del ejercicio
El proyecto se divide en varias fases, siguiendo el flujo natural de un caso real de data science.
5.1. Volcado y transformación de datos
En este primer apartado vamos a descargar automáticamente el dataset de subvenciones desde la API del portal del Sistema Nacional de Publicidad de Subvenciones (BDNS). Posteriormente transformaremos los datos a un formato optimizado como Parquet (formato de datos columnar) para facilitar su exploración y análisis.
En este proceso utilizaremos algunos conceptos complejos, como:
-
Funciones asíncronas: permite procesar en paralelo dos o más operaciones independientes, lo que facilita hacer más eficiente el proceso.
-
Escritor rotativo: cuando se supera un límite de cantidad de información el fichero que se está procesando se cierra y se abre uno nuevo con un índice autoincremental (a continuación del anterior). Esto evita procesar ficheros demasiado grandes y mejora la eficiencia.
Figura 1. Captura de la API del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas
5.2. Análisis exploratorio
El objetivo de esta fase es obtener una primera idea de las características de los datos y de su calidad.
Analizaremos entre otros, aspectos como:
- Qué tipos de subvenciones tienen mayor número de convocatorias.
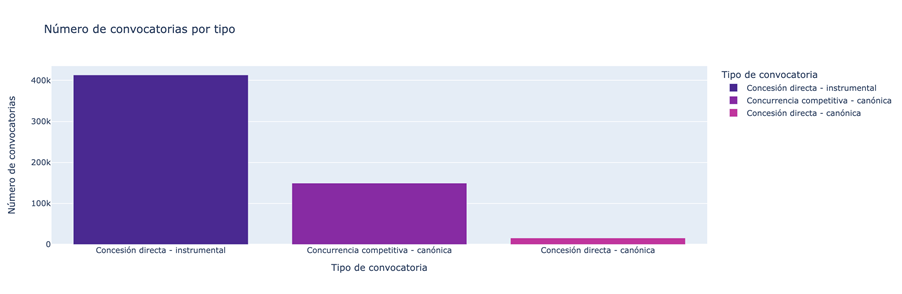
Figura 2. Tipos de subvenciones con mayor número de convocatorias.
- Cuál es la distribución de las subvenciones en función de su finalidad (i.e. Cultura, Educación, Fomento del empleo…).
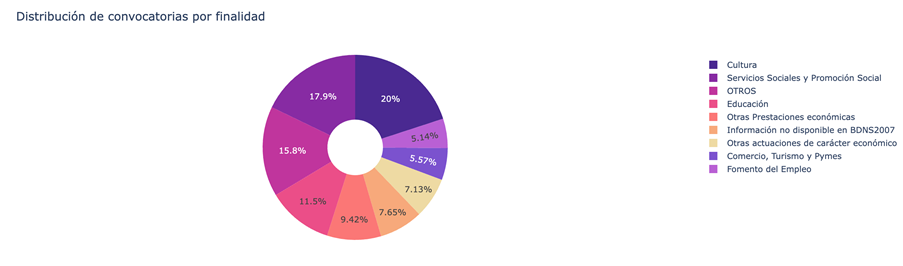
Figura 3. Distribución de las subvenciones en función de su finalidad.
- Qué finalidades agregan un mayor volumen presupuestario.
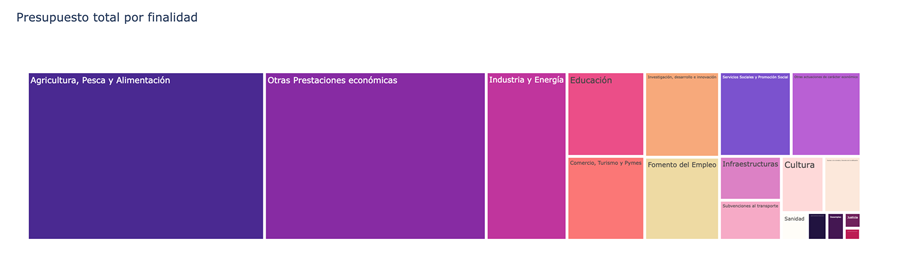
Figura 4. Finalidades con mayor volumen presupuestario.
5.3. Modelado: construcción del clasificador de presupuesto
Llegados a este punto, entramos en la parte más analítica del ejercicio: enseñar a una máquina a predecir si una nueva convocatoria tendrá un presupuesto bajo, medio o alto a partir de sus características administrativas. Para conseguirlo, diseñamos un pipeline completo de machine learning en Spark que nos permite transformar los datos, entrenar el modelo y evaluarlo de forma uniforme y reproducible.
Primero preparamos todas las variables —muchas de ellas categóricas, como el órgano convocante— para que el modelo pueda interpretarlas. Después combinamos toda esa información en un único vector que sirve como punto de partida para la fase de aprendizaje.
Con esa base construida, entrenamos un modelo de clasificación que aprende a distinguir patrones sutiles en los datos: qué organismos tienden a publicar convocatorias más voluminosas o cómo influyen elementos administrativos específicos en el tamaño de una ayuda.
Una vez entrenado, analizamos su rendimiento desde distintos ángulos. Evaluamos su capacidad para clasificar correctamente los tres rangos de presupuesto y analizamos su comportamiento mediante métricas como la accuracy o la matriz de confusión.
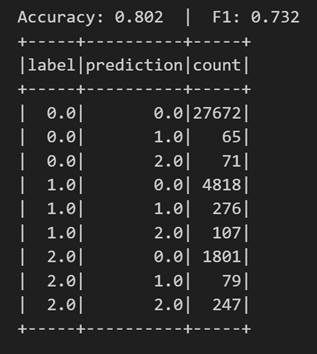
Figura 5. Métricas accuracy.
Pero no nos quedamos ahí: también estudiamos qué variables han tenido mayor peso en las decisiones del modelo, lo que nos permite entender qué factores parecen más determinantes a la hora de anticipar el presupuesto de una convocatoria.
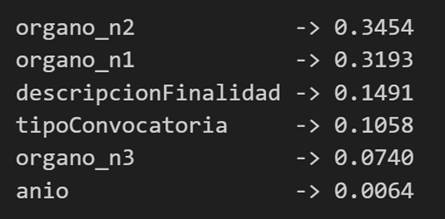
Figura 6. Variables que han tenido mayor peso en las decisiones del modelo.
Conclusiones del ejercicio
Este laboratorio nos permitirá comprobar cómo Spark simplifica el procesamiento y modelado de datos de gran volumen, especialmente útiles en entornos donde las administraciones generan miles de registros al año, y conocer mejor el sistema de subvenciones tras analizar algunos aspectos clave de la organización de estas convocatorias.
¿Quieres realizar el ejercicio?
Si te interesa profundizar en el uso de Spark y en el análisis avanzado de datos públicos, puedes acceder al repositorio y ejecutar el Notebook completo paso a paso.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Vivimos en una época en la que cada vez más fenómenos del mundo físico pueden observarse, medirse y analizarse en tiempo real. La temperatura de un cultivo, la calidad del aire de una ciudad, el estado de una presa, el flujo del tráfico o el consumo energético de un edificio ya no son datos que se revisan ocasionalmente: son flujos continuos de información que se generan segundo a segundo.
Esta revolución no sería posible sin los sistemas ciberfísicos (CPS), una tecnología que integra sensores, algoritmos y actuadores para conectar el mundo físico con el digital. Pero los CPS no sólo generan datos: también pueden alimentarse de datos abiertos, multiplicando su utilidad y permitiendo decisiones basadas en evidencia.
En este artículo exploraremos qué son los CPS, cómo generan datos masivos en tiempo real, qué retos plantea convertir esos datos en información pública útil, qué principios son esenciales para asegurar su calidad y trazabilidad, y qué ejemplos reales demuestran el potencial de su reutilización. Cerraremos con una reflexión sobre el impacto de esta combinación en la innovación, la ciencia ciudadana y el diseño de políticas públicas más inteligentes.
¿Qué son los sistemas ciberfísicos?
Un sistema ciberfísico es una integración estrecha entre componentes digitales —como software, algoritmos, comunicación y almacenamiento— y componentes físicos —sensores, actuadores, dispositivos IoT o máquinas industriales—. Su función principal es observar el entorno, procesar la información y actuar sobre él.
A diferencia de los sistemas tradicionales de monitorización, un CPS no se limita a medir: cierra un ciclo completo entre percepción, decisión y acción. Este ciclo se puede entender a través de tres elementos principales:
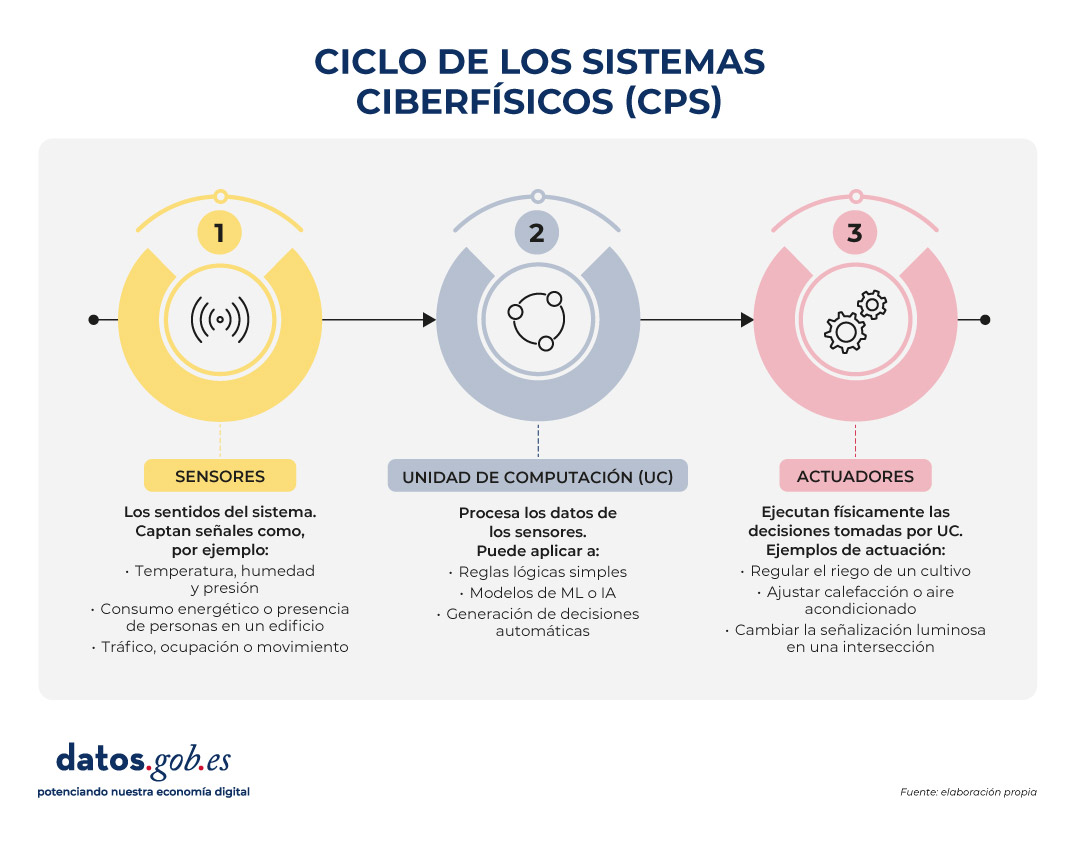
Figura 1. Ciclo de los sistemas ciberfísicos. Fuente: elaboración propia
Un ejemplo cotidiano que ilustra muy bien este ciclo completo de percepción, decisión y acción es el riego inteligente, cada vez más presente en la agricultura de precisión y en los sistemas domésticos de jardinería. En este caso, los sensores distribuidos por el terreno miden continuamente la humedad del suelo, la temperatura ambiente e incluso la radiación solar. Toda esa información fluye hacia la unidad de computación, que analiza los datos, los compara con umbrales previamente definidos o con modelos más complejos —por ejemplo, los que estiman la evaporación del agua o las necesidades hídricas de cada tipo de planta— y determina si realmente es necesario regar.
Cuando el sistema concluye que el suelo ha alcanzado un nivel de sequedad crítico, entra en juego el tercer elemento del CPS: los actuadores. Son ellos quienes abren las válvulas, activan la bomba de agua o regulan el caudal, y lo hacen durante el tiempo exacto necesario para devolver la humedad a niveles óptimos. Si las condiciones cambian —si empieza a llover, si la temperatura baja o si el suelo recupera humedad más rápido de lo esperado—, el propio sistema ajusta su comportamiento en consecuencia.
Todo este proceso ocurre sin intervención humana, de forma autónoma. El resultado es un uso más sostenible del agua, plantas mejor cuidadas y una capacidad de adaptación en tiempo real que solo es posible gracias a la integración de sensores, algoritmos y actuadores característica de los sistemas ciberfísicos.
Los CPS como fábricas de datos en tiempo real
Una de las características más relevantes de los sistemas ciberfísicos es su capacidad para generar datos de forma continua, masiva y con una resolución temporal muy alta. Esta producción constante puede apreciarse en múltiples situaciones del día a día:
- Una estación hidrológica puede registrar nivel y caudal cada minuto.
- Un sensor de movilidad urbana puede generar cientos de lecturas por segundo.
- Un contador inteligente registra el consumo eléctrico cada pocos minutos.
- Un sensor agrícola mide humedad, salinidad y radiación solar varias veces al día.
- Un dron cartográfico captura posiciones GPS decimétricas en tiempo real.
Más allá de estos ejemplos concretos, lo importante es comprender qué significa esta capacidad para el conjunto del sistema: los CPS se convierten en auténticas fábricas de datos, y en muchos casos llegan a funcionar como gemelos digitales del entorno físico que monitorizan. Esa equivalencia casi instantánea entre el estado real de un río, un cultivo, una carretera o una máquina industrial y su representación digital permite disponer de un retrato extremadamente preciso y actualizado del mundo físico, prácticamente al mismo tiempo que los fenómenos ocurren.
Esta riqueza de datos abre un enorme campo de oportunidades cuando se publica como información abierta. Los datos procedentes de CPS pueden impulsar servicios innovadores desarrollados por empresas, alimentar investigaciones científicas de alto impacto, potenciar iniciativas de ciencia ciudadana que complementen los datos institucionales, y reforzar la transparencia y la rendición de cuentas en la gestión de recursos públicos.
Sin embargo, para que todo ese valor llegue realmente a la ciudadanía y a la comunidad reutilizadora, es necesario superar una serie de retos técnicos, organizativos y de calidad que determinan la utilidad final del dato abierto. A continuación, analizamos cuáles son esos desafíos y por qué son tan importantes en un ecosistema cada vez más dependiente de información generada en tiempo real.
El reto: de datos en bruto a información pública útil
Que un CPS genere datos no significa que estos puedan publicarse directamente como datos abiertos. Antes de llegar a la ciudadanía y a las empresas reutilizadoras, la información necesita un trabajo previo de preparación, validación, filtrado y documentación. Las administraciones deben asegurarse de que esos datos son comprensibles, interoperables y fiables. Y en ese camino aparecen varios desafíos.
Uno de los primeros es la estandarización. Cada fabricante, cada sensor y cada sistema puede utilizar formatos distintos, diferentes frecuencias de muestreo o estructuras propias. Si no se armonizan esas diferencias, lo que obtenemos es un mosaico difícilmente integrable. Para que los datos sean interoperables se necesitan modelos comunes, unidades homogéneas, estructuras coherentes y estándares compartidos. Normativas como INSPIRE o los estándares de OGC (Open Geospatial Consortium) e IoT-TS son clave para que un dato generado en una ciudad pueda entenderse, sin transformación adicional, en otra administración o por cualquier reutilizador.
El siguiente gran reto es la calidad. Los sensores pueden fallar, quedarse congelados reportando siempre el mismo valor, generar lecturas físicamente imposibles, sufrir interferencias electromagnéticas o estar mal calibrados durante semanas sin que nadie lo note. Si esa información se publica tal cual, sin un proceso previo de revisión y limpieza, el dato abierto pierde valor e incluso puede inducir a errores. La validación —con controles automáticos y revisión periódica— es, por tanto, indispensable.
Otro punto crítico es la contextualización. Un dato aislado carece de significado. Un “12,5” no dice nada si no sabemos si son grados, litros o decibelios. Una medida de “125 ppm” no tiene utilidad si no conocemos qué sustancia se está midiendo. Incluso algo tan aparentemente objetivo como unas coordenadas necesita un sistema de referencia concreto. Y cualquier dato ambiental o físico solo puede interpretarse adecuadamente si se acompaña de la fecha, la hora, la ubicación exacta y las condiciones de captura. Todo esto forma parte de los metadatos, que son esenciales para que terceros puedan reutilizar la información sin ambigüedades.
También es fundamental abordar la privacidad y la seguridad. Algunos CPS pueden captar información que, directa o indirectamente, podría vincularse a personas, propiedades o infraestructuras sensibles. Antes de publicar los datos, es necesario aplicar procesos de anonimización, técnicas de agregación, controles de seguridad y evaluaciones de impacto que garanticen que el dato abierto no compromete derechos ni expone información crítica.
Por último, existen retos operativos como la frecuencia de actualización y la robustez del flujo de datos. Aunque los CPS generan información en tiempo real, no siempre es adecuado publicarla con la misma granularidad: en ocasiones es necesario agregarla, validar la coherencia temporal o corregir valores antes de compartirla. De igual modo, para que los datos sean útiles en análisis técnicos o en servicios públicos, deben llegar sin interrupciones prolongadas ni duplicados, lo que exige una infraestructura estable y mecanismos de supervisión.
Principios de calidad y trazabilidad necesarios para datos abiertos fiables
Superados estos retos, la publicación de datos procedentes de sistemas ciberfísicos debe apoyarse en una serie de principios de calidad y trazabilidad. Sin ellos, la información pierde valor y, sobre todo, pierde confianza.
El primero es la exactitud. El dato debe representar fielmente el fenómeno que mide. Esto requiere sensores correctamente calibrados, revisiones periódicas, eliminación de valores claramente erróneos y comprobación de que las lecturas se encuentran dentro de rangos físicamente posibles. Un sensor que marca 200 °C en una estación meteorológica o un contador que registra el mismo consumo durante 48 horas son señales de un problema que debe detectarse antes de la publicación.
El segundo principio es la completitud. Un conjunto de datos debe indicar cuándo hay valores perdidos, lagunas temporales o periodos en los que un sensor ha estado desconectado. Ocultar estos huecos puede llevar a conclusiones equivocadas, especialmente en análisis científicos o en modelos predictivos que dependen de la continuidad de la serie temporal.
El tercer elemento clave es la trazabilidad, es decir, la capacidad de reconstruir la historia del dato. Saber qué sensor lo generó, dónde está instalado, qué transformaciones ha sufrido, cuándo se capturó o si pasó por algún proceso de limpieza permite evaluar su calidad y fiabilidad. Sin trazabilidad, la confianza se erosiona y el dato pierde valor como evidencia.
La actualización adecuada es otro principio fundamental. La frecuencia con la que se publica la información debe adaptarse al fenómeno medido. Los niveles de contaminación atmosférica pueden necesitar actualizaciones cada pocos minutos; el tráfico urbano, cada segundo; la hidrología, cada minuto o cada hora según el tipo de estación; y los datos meteorológicos, con frecuencias variables. Publicar demasiado rápido puede generar ruido; demasiado lento, puede inutilizar el dato para ciertos usos.
El último principio es el de los metadatos enriquecidos. Los metadatos explican el dato: qué mide, cómo se mide, con qué unidad, qué precisión tiene el sensor, cuál es su rango operativo, dónde está ubicado, qué limitaciones tiene la medición y para qué se genera esa información. No son una nota al pie, sino la pieza que permite a cualquier reutilizador comprender el contexto y la fiabilidad del conjunto de datos. Con una buena documentación, la reutilización no solo es posible: se dispara.
Ejemplos: CPS que reutilizan datos públicos para ser más inteligentes
Además de generar datos, muchos sistemas ciberfísicos también consumen datos públicos para mejorar su desempeño. Esta retroalimentación convierte a los datos abiertos en un recurso central para el funcionamiento de los territorios inteligentes. Cuando un CPS integra información procedente de sensores propios con fuentes abiertas externas, su capacidad de anticipación, eficiencia y precisión aumenta de forma notable.
Agricultura de precisión: En el ámbito agrícola, los sensores instalados en el terreno permiten medir variables como la humedad del suelo, la temperatura o la radiación solar. Sin embargo, los sistemas de riego inteligente no dependen únicamente de esa información local: también incorporan predicciones meteorológicas de AEMET, mapas abiertos del IGN sobre pendiente o tipos de suelo y modelos climáticos publicados como datos públicos. Al combinar sus propias mediciones con estas fuentes externas, los CPS agrícolas pueden determinar con mucha mayor exactitud qué zonas del terreno necesitan agua, cuándo conviene sembrar y cuánta humedad debe mantenerse en cada cultivo. Esta gestión fina permite ahorros de agua y fertilizantes que, en algunos casos, superan el 30 %.
Gestión hídrica: Algo similar ocurre en la gestión del agua. Un sistema ciberfísico que controla una presa o un canal de riego necesita saber no solo qué está pasando en ese instante, sino qué puede ocurrir en las próximas horas o días. Por ello integra sus propios sensores de nivel con datos abiertos de aforos fluviales, predicciones de lluvia y nieve, e incluso información pública sobre caudales ecológicos. Con esta visión ampliada, el CPS puede anticipar inundaciones, optimizar el desembalse, responder mejor a fenómenos extremos o planificar el riego de forma sostenible. En la práctica, la combinación de datos propios y abiertos se traduce en una gestión más segura y eficiente del agua.
Impacto: innovación, ciencia ciudadana y decisiones basadas en datos
La unión entre sistemas ciberfísicos y datos abiertos genera un efecto multiplicador que se manifiesta en distintos ámbitos.
- Innovación empresarial: las empresas disponen de un terreno fértil para desarrollar soluciones basadas en información fiable y en tiempo real. A partir de datos abiertos y mediciones de CPS, pueden surgir aplicaciones de movilidad más inteligentes, plataformas de gestión hídrica, herramientas de análisis energético o sistemas predictivos para agricultura. El acceso a datos públicos reduce barreras de entrada y permite crear servicios sin necesidad de costosos datasets privados, acelerando la innovación y la aparición de nuevos modelos de negocio.
- Ciencia ciudadana: la combinación de CPS y datos abiertos también fortalece la participación social. Comunidades de vecinos, asociaciones o colectivos ambientales pueden desplegar sensores de bajo coste para complementar los datos públicos y entender mejor lo que ocurre en su entorno. Esto da lugar a iniciativas que miden el ruido en zonas escolares, monitorizan niveles de contaminación en barrios concretos, siguen la evolución de la biodiversidad o construyen mapas colaborativos que enriquecen la información oficial.
- Mejor toma de decisiones públicas: finalmente, los gestores públicos se benefician de este ecosistema de datos reforzado. La disponibilidad de mediciones fiables y actualizadas permite diseñar zonas de bajas emisiones, planificar de forma más efectiva el transporte urbano, optimizar redes de riego, gestionar situaciones de sequía o inundaciones o regular políticas energéticas basadas en indicadores reales. Sin datos abiertos que complementen y contextualicen la información generada por los CPS, estas decisiones serían menos transparentes y, sobre todo, menos defendibles ante la ciudadanía.
En resumen, los sistemas ciberfísicos se han convertido en una pieza esencial para entender y gestionar el mundo que nos rodea. Gracias a ellos podemos medir fenómenos en tiempo real, anticipar cambios y actuar de forma precisa y automatizada. Pero su verdadero potencial se despliega cuando sus datos se integran en un ecosistema de datos abiertos de calidad, capaz de aportar contexto, enriquecer decisiones y multiplicar usos.
La combinación de CPS y datos abiertos permite avanzar hacia territorios más inteligentes, servicios públicos más eficientes y una participación ciudadana más informada. Aporta valor económico, impulsa la innovación, facilita la investigación y mejora la toma de decisiones en ámbitos tan diversos como la movilidad, el agua, la energía o la agricultura.
Para que todo esto sea posible, es imprescindible garantizar la calidad, trazabilidad y estandarización de los datos publicados, así como proteger la privacidad y asegurar la robustez de los flujos de información. Cuando estas bases están bien asentadas, los CPS no solo miden el mundo: lo ayudan a mejorar, convirtiéndose en un puente sólido entre la realidad física y el conocimiento compartido.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Noticia
El portal europeo de datos abiertos ha publicado el tercer volumen de su Observatorio de Casos de Uso (Use Case Observatory, en inglés), un informe que recopila la evolución de proyectos de reutilización de datos en toda Europa. Esta iniciativa pone de relieve los avances logrados en cuatro áreas: impacto económico, gubernamental, social y medioambiental.
El cierre de una investigación de tres años
Entre 2022 y 2025, el portal europeo de datos abiertos ha llevado a cabo un seguimiento sistemático de la evolución de diversos proyectos europeos. La investigación comenzó con una selección inicial de 30 iniciativas representativas, que fueron analizadas en profundidad para identificar su potencial de impacto.
Tras dos años, 13 proyectos continuaron en el estudio, entre los que se encontraban tres españoles: Planttes, Tangible Data y UniversiDATA-Lab. Se estudió su desarrollo a lo largo del tiempo para comprender cómo la reutilización de datos abiertos puede generar beneficios reales y sostenibles.
La publicación del volumen III en octubre de 2025 marca el cierre de esta serie de informes, tras el volumen I (2022) y el volumen II (2024). Este último documento ofrece una visión longitudinal, mostrando cómo los proyectos han madurado en tres años de observación y qué impactos concretos han generado en sus respectivos contextos.
Conclusiones comunes
Este tercer y último informe recopila una serie de conclusiones clave:
Impacto económico
Los datos abiertos impulsan el crecimiento y la eficiencia en todos los sectores. Contribuyen a la creación de empleo, tanto de forma directa como indirecta, facilitan procesos de contratación más inteligentes y estimulan la innovación en ámbitos como la planificación urbana y los servicios digitales.
El informe muestra el ejemplo de:
- Naar Jobs (Bélgica): una aplicación para la búsqueda de empleo cerca del domicilio de los usuarios y focalizada en las opciones de transporte disponible.
Esta aplicación demuestra cómo los datos abiertos pueden convertirse en un motor para el empleo regional y el desarrollo empresarial.
Impacto gubernamental
La apertura de datos fortalece la transparencia, la rendición de cuentas y la participación ciudadana.
A este campo pertenecen dos casos de uso analizados:
- Waar is mijn stemlokaal? (Holanda): plataforma para la búsqueda de colegios electorales.
- Statsregnskapet.no (Noruega): web para visualizar los ingresos y gastos del gobierno.
Ambos ejemplos evidencian cómo el acceso a la información pública empodera a los ciudadanos, enriquece el trabajo de los medios de comunicación y respalda la elaboración de políticas basadas en evidencia. Todo ello ayuda a reforzar los procesos democráticos y la confianza en las instituciones.
Impacto social
Los datos abiertos promueven la inclusión, la colaboración y el bienestar.
A este campo pertenecen las siguientes iniciativas analizadas:
- UniversiDATA-Lab (España): repositorio de datos universitarios que facilita aplicaciones analíticas.
- VisImE-360 (Italia): herramienta para mapear la discapacidad visual y orientar recursos sanitarios.
- Tangible Data (España): empresa centrada en realizar esculturas físicas que convierten datos en experiencias accesibles.
- EU Twinnings (Países Bajos): plataforma que compara regiones europeas para encontrar “ciudades gemelas”
- Open Food Facts (Francia): base de datos colaborativa sobre productos alimenticios.
- Integreat (Alemania): aplicación que centraliza información pública para apoyar la integración de migrantes.
Todos ellos muestran cómo las soluciones basadas en datos pueden amplificar la voz de los colectivos vulnerables, mejorar los resultados en salud y abrir nuevas oportunidades educativas. Incluso los efectos más pequeños, como la mejora en la vida de una sola persona, pueden resultar significativos y duraderos.
Impacto medioambiental
Los datos abiertos actúan como un poderoso facilitador de la sostenibilidad.
Al igual que pasaba con el impacto ambiental, en esta área encontramos un gran número de casos de uso:
- Digital Forest Dryads (Estonia): proyecto que emplea datos para monitorizar los bosques y fomentar su conservación.
- Air Quality in Cyprus (Chipre): plataforma que informa sobre la calidad del aire y apoya políticas ambientales.
- Planttes (España): aplicación de ciencia ciudadana que ayuda a personas con alergias al polen mediante el seguimiento de la fenología de plantas.
- Environ-Mate (Irlanda): herramienta que promueve hábitos sostenibles y conciencia ecológica.
Estas iniciativas ponen de relieve cómo la reutilización de datos contribuye a sensibilizar, impulsar cambios de comportamiento y permitir intervenciones específicas para proteger los ecosistemas y fortalecer la resiliencia climática.
El volumen III también señala retos comunes: la necesidad de financiación sostenible, la importancia de combinar datos institucionales con datos generados por la ciudadanía y la conveniencia de involucrar a los usuarios finales en todo el ciclo de vida de los proyectos. Además, subraya la importancia de la colaboración europea y la interoperabilidad transnacional para escalar el impacto.
En conjunto, el informe refuerza la relevancia de seguir invirtiendo en ecosistemas de datos abiertos como herramienta clave para afrontar desafíos sociales y promover una transformación inclusiva.
El impacto de los proyectos españoles en la reutilización de datos abiertos
Como hemos mencionado, tres de los casos de uso analizados en el Use Case Observatory tienen sello español. Estas iniciativas destacan por su capacidad de combinar innovación tecnológica con impacto social y medioambiental, y ponen de manifiesto la relevancia de España dentro del ecosistema europeo de datos abiertos. Su trayectoria demuestra cómo nuestro país contribuye activamente a transformar los datos en soluciones que mejoran la vida de las personas y refuerzan la sostenibilidad y la inclusión. A continuación, hacemos un zoom en lo que el informe dice sobre ellas.
Esta iniciativa de ciencia ciudadana ayuda a personas con alergias al polen mediante información en tiempo real sobre plantas alergénicas en floración. Desde su aparición en el Volumen I del Use Case Observatory, ha evolucionado como plataforma participativa en la que los usuarios aportan fotos y datos fenológicos para crear un mapa de riesgo personalizado. Este modelo participativo ha permitido mantener un flujo constante de información validada por investigadores y ofrecer mapas cada vez más completos. Con más de 1.000 descargas iniciales y unos 65.000 visitantes anuales en su web, es una herramienta útil para personas con alergias, educadores e investigadores.
El proyecto ha reforzado su presencia digital, con una creciente visibilidad gracias al apoyo de instituciones como la Universidad Autónoma de Barcelona y la Universidad de Granada, además de la promoción realizada por la empresa Thigis.
Entre sus retos figuran ampliar la cobertura geográfica más allá de Cataluña y Granada y sostener la participación y validación de datos. Por ello, de cara al futuro, busca extender su alcance territorial, fortalecer la colaboración con escuelas y comunidades, integrar más datos en tiempo real y mejorar sus capacidades predictivas.
A lo largo de este tiempo, Planttes se ha consolidado como un ejemplo de cómo la ciencia impulsada por la ciudadanía puede mejorar la salud pública y la conciencia ambiental, demostrando el valor de la ciencia ciudadana en la educación ambiental, la gestión de alergias y el seguimiento del cambio climático.
El proyecto transforma conjuntos de datos en esculturas físicas que representan retos globales como el cambio climático o la pobreza, integrando códigos QR y NFC para contextualizar la información. Reconocido en los EU Open Data Days 2025, Tangible Data ha inaugurado su instalación Tangible climate en el Museo Nacional de Ciencias Naturales de Madrid.
Tangible Data ha evolucionado en tres años desde un proyecto prototipo basado en esculturas 3D para visualizar datos de sostenibilidad hasta convertirse en una plataforma educativa y cultural que conecta los datos abiertos con la sociedad. El Volumen III del Use Case Observatory refleja su expansión en escuelas y museos, la creación de un programa educativo para estudiantes de 15 años y el desarrollo de experiencias interactivas con inteligencia artificial, consolidando su compromiso con la accesibilidad y el impacto social.
Entre sus retos destacan la financiación y la ampliación del programa educativo, mientras que sus objetivos futuros incluyen escalar las actividades escolares, exhibir esculturas de gran formato en espacios públicos y reforzar la colaboración con artistas y museos. En conjunto, sigue fiel a su misión de hacer los datos tangibles, inclusivos y accionables.
UniversiDATA-Lab es un repositorio dinámico de aplicaciones analíticas basadas en datos abiertos de universidades españolas, creado en 2020 como colaboración público-privada y actualmente integrado por seis instituciones. Su infraestructura unificada facilita la publicación y reutilización de datos en formatos estandarizados, reduciendo barreras y permitiendo que estudiantes, investigadores, empresas y ciudadanos accedan a información útil para la educación, la investigación y la toma de decisiones.
En los últimos tres años, el proyecto ha pasado de ser un prototipo a una plataforma consolidada, con aplicaciones activas como el visor de presupuestos y de jubilaciones, y un visor de contratación en fase beta. Además, organiza un datathon periódico que impulsa la innovación y proyectos con impacto social.
Entre sus retos destacan la resistencia interna en algunas universidades y la compleja anonimización de datos sensibles, aunque ha respondido con protocolos sólidos y un enfoque en la transparencia. De cara al futuro, busca ampliar su catálogo, sumar nuevas universidades y lanzar aplicaciones sobre cuestiones emergentes como abandono escolar, diversidad del profesorado o sostenibilidad, aspirando a convertirse en referente europeo en reutilización de datos abiertos en educación superior.
Conclusión
Como conclusión, el tercer volumen del Use Case Observatory confirma que los datos abiertos se han consolidado como una herramienta clave para impulsar la innovación, la transparencia y la sostenibilidad en Europa. Los proyectos analizados —y en particular las iniciativas españolas Planttes, Tangible Data y UniversiDATA-Lab— demuestran que la reutilización de la información pública puede traducirse en beneficios concretos para la ciudadanía, la educación, la investigación y el medio ambiente.
Aplicación
embalses.info es una plataforma web que proporciona información actualizada sobre el estado de los embalses y pantanos de España. La aplicación ofrece datos hidrológicos en tiempo real con actualizaciones semanales, permitiendo a ciudadanos, investigadores y gestores públicos consultar niveles de agua, capacidades y evoluciones históricas de más de 400 embalses organizados en 16 cuencas hidrográficas.
La aplicación cuenta con un dashboard interactivo que muestra el estado general de los embalses españoles, un mapa interactivo (próximamente) de cuencas con niveles de llenado, y páginas detalladas para cada embalse con gráficos de evolución semanal, comparativas con años anteriores, e históricos desde los años 80. Incluye un potente buscador, análisis de datos con gráficos interactivos, y un formulario de contacto para sugerencias.
Desde el punto de vista técnico, la plataforma utiliza Next.js 14+ con TypeScript en el frontend, Prisma ORM para acceso a datos, y PostgreSQL/SQL Server como base de datos. Está optimizada para SEO con sitemap XML dinámico, meta tags optimizados, datos estructurados y URLs amigables. El sitio es completamente responsive, accesible y cuenta con tema claro/oscuro automático.
El valor público de la aplicación radica en proporcionar transparencia e información accesible sobre los recursos hídricos españoles, permitiendo a agricultores, administraciones, investigadores y medios de comunicación tomar decisiones informadas basadas en datos confiables y actualizados.
Blog
En todo entorno de gestión de datos (empresas, Administración pública, consorcios, proyectos de investigación), disponer de datos no basta: si no sabes qué datos tienes, dónde están, qué significan, quién los mantiene, con qué calidad, cuándo cambiaron o cómo se relacionan con otros datos, entonces el valor es muy limitado. Los metadatos —datos sobre los datos— son esenciales para:
-
Visibilidad y acceso: permitir que usuarios encuentren qué datos existen y puedan acceder.
-
Contextualización: saber qué significan los datos (definiciones, unidades, semántica).
-
Trazabilidad / linaje: entender de dónde vienen los datos y cómo han sido transformados.
-
Gobierno y control: conocer quién es responsable, qué políticas aplican, permisos, versiones, obsolescencia.
-
Calidad, integridad y consistencia: asegurar la fiabilidad de los datos mediante reglas, métricas y monitoreo.
-
Interoperabilidad: garantizar que diferentes sistemas o dominios puedan compartir datos, utilizando un vocabulario común, definiciones compartidas y relaciones explícitas.
En resumen, los metadatos son la palanca que convierte los datos “aislados” en un ecosistema de información gobernada. A medida que los datos crecen en volumen, diversidad y velocidad, su función va más allá de la simple descripción: los metadatos añaden contexto, permiten interpretar los datos y facilitan que puedan ser encontrados, accesibles, interoperables y reutilizables (FAIR).
En el nuevo contexto impulsado por la inteligencia artificial, esta capa de metadatos adquiere una relevancia aún mayor, ya que proporciona la información de procedencia (provenance) necesaria para garantizar la trazabilidad, la fiabilidad y la reproducibilidad de los resultados. Por ello, algunos marcos recientes amplían estos principios hacia FAIR-R, donde la “R” adicional resalta la importancia de que los datos estén listos para la IA (AI-ready), es decir, que cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial.
Así, hablamos de metadatos enriquecidos, capaces de conectar información técnica, semántica y contextual para potenciar el aprendizaje automático, la interoperabilidad entre dominios y la generación de conocimiento verificable.
De los metadatos tradicionales a los “metadatos enriquecidos”
Metadatos tradicionales
En el contexto de este artículo, cuando hablamos de metadatos con un uso tradicional, pensamos en catálogos, diccionarios, glosarios, modelos de datos de base de datos, y estructuras rígidas (tablas y columnas). Los tipos de metadatos más comunes son:
-
Metadatos técnicos: tipo de columna, longitud, formato, claves foráneas, índices, ubicaciones físicas.
-
Metadatos de negocio / semánticos: nombre de campo, descripción, dominio de valores, reglas de negocio, términos del glosario empresarial.
-
Metadatos operativos / de ejecución: frecuencia de actualización, última carga, tiempos de procesamiento, estadísticas de uso.
-
Metadatos de calidad: porcentaje de valores nulos, duplicados, validaciones.
-
Metadatos de seguridad / acceso: políticas de acceso, permisos, clasificación de sensibilidad.
-
Metadatos de linaje: rastreo de transformación en los pipelines de datos.
Estos metadatos se almacenan usualmente en repositorios o herramientas de catalogación, muchas veces con estructuras tabulares o en bases relacionales, con vínculos predefinidos.
¿Por qué metadatos enriquecidos?
Los metadatos enriquecidos son aquella capa que no solo describe atributos, sino que:
- Descubren e infieren relaciones implícitas, identificando vínculos que no están expresamente definidos en los esquemas de datos. Esto permite, por ejemplo, reconocer que dos variables con nombres diferentes en sistemas distintos representan en realidad el mismo concepto (“altitud” y “elevación”), o que ciertos atributos mantienen una relación jerárquica (“municipio” pertenece a “provincia”).
- Facilitan consultas semánticas y razonamiento automatizado, permitiendo que los usuarios y las máquinas exploren relaciones y patrones que no están explícitamente definidos en las bases de datos. En lugar de limitarse a buscar coincidencias exactas de nombres o estructuras, los metadatos enriquecidos permiten formular preguntas basadas en significado y contexto. Por ejemplo, identificar automáticamente todos los conjuntos de datos relacionados con “ciudades costeras” aunque el término no aparezca literalmente en los metadatos.
- Se adaptan y evolucionan de manera flexible, ya que pueden ampliarse con nuevos tipos de entidades, relaciones o dominios sin necesidad de rediseñar toda la estructura del catálogo. Esto permite incorporar fácilmente nuevas fuentes de datos, modelos o estándares, garantizando la sostenibilidad del sistema a largo plazo.
- Incorporan automatización en tareas que antes eran manuales o repetitivas, como la detección de duplicidades, el emparejamiento automático de conceptos equivalentes o el enriquecimiento semántico mediante aprendizaje automático. También pueden identificar incoherencias o anomalías, mejorando la calidad y la coherencia de los metadatos.
- Integran de forma explícita el contexto de negocio, enlazando cada activo de datos con su significado operativo y su rol dentro de los procesos organizativos. Para ello utilizan vocabularios controlados, ontologías o taxonomías que facilitan un entendimiento común entre equipos técnicos, analistas y responsables de negocio.
- Favorecen una interoperabilidad más profunda entre dominios heterogéneos, que va más allá del intercambio sintáctico facilitado por los metadatos tradicionales. Los metadatos enriquecidos añaden una capa semántica que permite comprender y relacionar los datos en función de su significado, no solo de su formato. Así, datos procedentes de diferentes fuentes o sectores —por ejemplo, Sistemas de información Geográfica (GIS en inglés), Building Information Modeling (BIM) o Internet de las Cosas (IoT)— pueden vincularse de manera coherente dentro de un marco conceptual compartido. Esta interoperabilidad semántica es la que posibilita integrar conocimiento y reutilizar información entre contextos técnicos y organizativos diversos.
Esto convierte los metadatos en un activo vivo, enriquecido y conectado con el conocimiento del dominio, no solo un “registro” pasivo.

La evolución de los metadatos: ontologías y grafos de conocimiento
La incorporación de ontologías y grafos de conocimiento representa una evolución conceptual en la manera de describir, relacionar y aprovechar los metadatos, de ahí que hablemos de metadatos enriquecidos. Estas herramientas no solo documentan los datos, sino que los conectan dentro de una red de significado, permitiendo que las relaciones entre entidades, conceptos y contextos sean explícitas y computables.
En el contexto actual, marcado por el auge de la inteligencia artificial, esta estructura semántica adquiere un papel fundamental: proporciona a los algoritmos el conocimiento contextual necesario para interpretar, aprender y razonar sobre los datos de forma más precisa y transparente. Ontologías y grafos permiten que los sistemas de IA no solo procesen información, sino que entiendan las relaciones entre los elementos y puedan generar inferencias fundamentadas, abriendo el camino hacia modelos más explicativos y confiables.
Este cambio de paradigma transforma los metadatos en una estructura dinámica, capaz de reflejar la complejidad del conocimiento y de facilitar la interoperabilidad semántica entre distintos dominios y fuentes de información. Para comprender esta evolución conviene definir y relacionar algunos conceptos:
Ontologías
En el mundo de los datos, una ontología es un mapa conceptual muy organizado que define claramente:
- Qué entidades existen (ej. ciudad, río, carretera).
- Qué propiedades tienen (ej. una ciudad tiene nombre, población, código postal).
- Cómo se relacionan entre sí (ej. un río atraviesa una ciudad, una carretera conecta dos municipios).
El objetivo es que personas y máquinas compartan un mismo vocabulario y entiendan los datos de la misma manera. Las ontologías permiten:
- Definir conceptos y relaciones: por ejemplo, “una parcela pertenece a un municipio”, “un edificio tiene coordenadas geográficas”.
- Poner reglas y restricciones: como “cada edificio debe estar exactamente en una parcela catastral”.
- Unificar vocabularios: si en un sistema se dice “parcela” y en otro “unidad catastral”, la ontología ayuda a reconocer que son análogos.
- Hacer inferencias: a partir de datos simples, descubrir nuevo conocimiento (si un edificio está en una parcela y la parcela en Sevilla, se puede inferir que el edificio está en Sevilla).
- Establecer un lenguaje común: funcionan como un diccionario compartido entre distintos sistemas o dominios (GIS, BIM, IoT, catastro, urbanismo).
En resumen: una ontología es el diccionario y las reglas del juego que permiten que diferentes sistemas geoespaciales (mapas, catastro, sensores, BIM, etc.) se entiendan entre sí y puedan trabajar de manera integrada.
Grafos de conocimiento (Knowledge Graphs)
Un grafo de conocimiento es una forma de organizar información como si fuera una red de conceptos conectados entre sí.
-
Los nodos representan cosas o entidades, como una ciudad, un río o un edificio.
-
Las aristas (líneas) muestran las relaciones entre ellas, por ejemplo: “está en”, “atraviesa” o “pertenece a”.
-
A diferencia de un simple dibujo de conexiones, un grafo de conocimiento también explica el significado de esas relaciones: añade semántica.
Un grafo de conocimiento combina tres elementos principales:
-
Datos: los casos concretos o instancias, como “Sevilla”, “Río Guadalquivir” o “Edificio Ayuntamiento de Sevilla”.
-
Semántica (u ontología): las reglas y vocabularios que definen qué tipos de cosas existen (ciudades, ríos, edificios) y cómo pueden relacionarse entre sí.
-
Razonamiento: la capacidad de descubrir nuevas conexiones a partir de las existentes (por ejemplo, si un río atraviesa una ciudad y esa ciudad está en España, el sistema puede deducir que el río está en España).
Además, los grafos de conocimiento permiten conectar información de distintos ámbitos (por ejemplo, datos sobre personas, lugares y empresas) bajo un mismo lenguaje común, facilitando el análisis y la interoperabilidad entre disciplinas.
En otras palabras, un knowledge graph es el resultado de aplicar una ontología (el modelo de datos) a varios conjuntos de datos individuales (elementos espaciales, otros datos del territorio, registros de pacientes o productos de catálogo, etc.). Los grafos de conocimiento son ideales para integrar datos heterogéneos, porque no requieren un esquema rígido previamente completo: se pueden ir creciendo de forma flexible. Además, permiten consultas semánticas y navegación con relaciones complejas. A continuación, se pone un ejemplo para datos espaciales con los que entender las diferencias:
|
Ontología de datos espaciales (modelo conceptual) |
Grafo de conocimiento (ejemplos concretos con instancias) |
|---|---|
|
|
|
|
Casos de uso
Para entender mejor el valor de los metadatos inteligentes y los catálogos semánticos, nada mejor que mirar ejemplos donde ya se están aplicando. Estos casos muestran cómo la combinación de ontologías y grafos de conocimiento permite conectar información dispersa, mejorar la interoperabilidad y generar conocimiento accionable en distintos contextos.
Desde la gestión de emergencias hasta la planificación urbana o la protección del medio ambiente, diferentes proyectos internacionales han demostrado que la semántica no es solo teoría, sino una herramienta práctica que transforma datos en decisiones.
Algunos ejemplos relevantes incluyen:
- LinkedGeoData que convirtió datos de OpenStreetMap en Linked Data, enlazándolos con otras fuentes abiertas.
- Virtual Singapore un gemelo digital 3D que integra datos geoespaciales, urbanos y en tiempo real para simulación y planificación.
- JedAI-spatial una herramienta para interconectar datos espaciales en 3D mediante relaciones semánticas.
- SOSA Ontology, estándar ampliamente usado en proyectos de sensores e IoT para observaciones ambientales con componente geoespacial.
- Proyectos europeos de permisos digitales de construcción (ej. ACCORD), que combinan catálogos semánticos, modelos BIM y datos GIS para validar automáticamente normativas de construcción.
Conclusiones
La evolución hacia metadatos enriquecidos, apoyados en ontologías, grafos de conocimiento y principios FAIR-R, representa un cambio sustancial en la manera de gestionar, conectar y comprender los datos. Este nuevo enfoque convierte los metadatos en un componente activo de la infraestructura digital, capaz de aportar contexto, trazabilidad y significado, y no solo de describir información.
Los metadatos enriquecidos permiten aprender de los datos, mejorar la interoperabilidad semántica entre dominios y facilitar consultas más expresivas, donde las relaciones y dependencias pueden descubrirse de forma automatizada. De este modo, favorecen la integración de información dispersa y apoyan tanto la toma de decisiones informadas como el desarrollo de modelos de inteligencia artificial más explicativos y confiables.
En el ámbito de los datos abiertos, estos avances impulsan la transición desde repositorios descriptivos hacia ecosistemas de conocimiento interconectado, donde los datos pueden combinarse y reutilizarse de manera flexible y verificable. La incorporación de contexto semántico y procedencia (provenance) refuerza la transparencia, la calidad y la reutilización responsable.
Esta transformación requiere, sin embargo, un enfoque progresivo y bien gobernado: es fundamental planificar la migración de sistemas, garantizar la calidad semántica, y promover la participación de comunidades multidisciplinares.
En definitiva, los metadatos enriquecidos son la base para pasar de datos aislados a conocimiento conectado y trazable, elemento clave para la interoperabilidad, la sostenibilidad y la confianza en la economía de los datos.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
Los datos abiertos tienen un gran potencial para transformar la forma en que interactuamos con nuestras ciudades. Al estar disponibles para toda la ciudadanía, permiten desarrollar aplicaciones y herramientas que dan respuesta a retos urbanos como la accesibilidad, la seguridad vial o la participación ciudadana. Facilitar el acceso a esta información no solo impulsa la innovación, sino que también contribuye a mejorar la calidad de vida en los entornos urbanos.
Este potencial cobra aún más relevancia si consideramos el contexto actual. El crecimiento urbano acelerado ha traído consigo nuevos desafíos, especialmente en materia de salud pública. Según datos de las Naciones Unidas, se estima que para 2050 más del 68% de la población mundial vivirá en ciudades. Por lo tanto, el diseño de entornos urbanos saludables es una prioridad en la que los datos abiertos se consolidan como una herramienta clave: permiten planificar ciudades más resilientes, inclusivas y sostenibles, poniendo el bienestar de las personas en el centro de las decisiones. En este post, te contamos qué son los entornos urbanos saludables y cómo pueden los datos abiertos ayudar a construirlos y mantenerlos.
¿Qué son los Entornos urbanos saludables? Usos y ejemplos
Los entornos urbanos saludables van más allá de la simple ausencia de contaminación o ruido. Según la Organización Mundial de la Salud (OMS), estos espacios deben promover activamente estilos de vida saludables, facilitar la actividad física, fomentar la interacción social y garantizar el acceso equitativo a servicios básicos. Como establece la "Guía para planificar ciudades saludables" del Ministerio de Sanidad, estos entornos se caracterizan por tres elementos clave:
-
Ciudades pensadas para caminar: deben ser espacios que prioricen la movilidad peatonal y ciclista, con calles seguras, accesibles y confortables que inviten al desplazamiento activo.
-
Incorporación de la naturaleza: integran zonas verdes, infraestructura azul y elementos naturales que mejoran la calidad del aire, regulan la temperatura urbana y ofrecen espacios de recreo y descanso.
-
Espacios de encuentro y convivencia: cuentan con áreas que facilitan la interacción social, reducen el aislamiento y fortalecen el tejido comunitario.
El papel de los datos abiertos en entornos urbanos saludables
En este escenario, los datos abiertos actúan como el sistema nervioso de las ciudades inteligentes, proporcionando información valiosa sobre patrones de uso, necesidades ciudadanas y efectividad de las políticas públicas. En concreto, en el ámbito de los espacios urbanos saludables son especialmente útiles los datos de:
-
Análisis de patrones de actividad física: los datos de movilidad, uso de instalaciones deportivas y frecuentación de espacios verdes revelan dónde y cuándo los ciudadanos son más activos, identificando oportunidades para optimizar la infraestructura existente.
-
Monitorización de la calidad ambiental: los sensores urbanos que miden la calidad del aire, los niveles de ruido y la temperatura proporcionan información en tiempo real sobre las condiciones de salubridad de diferentes áreas urbanas.
-
Evaluación de accesibilidad: el transporte público, la infraestructura peatonal y la distribución de servicios permiten identificar barreras al acceso y diseñar soluciones más inclusivas.
-
Participación ciudadana informada: las plataformas de datos abiertos facilitan procesos participativos donde los ciudadanos pueden contribuir con información local y colaborar en la toma de decisiones.
El ecosistema español de datos abiertos cuenta con sólidas plataformas que alimentan proyectos de espacios urbanos saludables. Por ejemplo, el Portal de Datos Abiertos del Ayuntamiento de Madrid ofrece información en tiempo real sobre la calidad del aire así como un inventario completo de zonas verdes. También Barcelona publica datos sobre calidad del aire, incluyendo las ubicaciones y características de las estaciones de medida.
Estos portales no solo almacenan información, sino que la estructuran de manera que desarrolladores, investigadores y ciudadanos puedan crear aplicaciones y servicios innovadores.
Casos de uso: aplicaciones que reutilizan datos abiertos
Varios proyectos demuestran cómo los datos abiertos se traducen en mejoras tangibles para la salud urbana. Por un lado, podemos destacar algunas aplicaciones o herramientas digitales como:
-
AQI Air Quality Index: utiliza datos gubernamentales para ofrecer información en tiempo real sobre la calidad del aire en diferentes ciudades españolas.
-
GV Aire: procesa datos oficiales de calidad atmosférica para generar alertas y recomendaciones ciudadanas.
-
Índice de Calidad del Aire Nacional: centraliza información de estaciones de medición de todo el país.
-
Valencia Verde: utiliza datos municipales para mostrar ubicación y características de parques y jardines de Valencia.
Por otro lado, existen iniciativas que combinan datos abiertos multisectoriales para ofrecer soluciones que mejoran la interacción entre urbe y ciudadanía. Por ejemplo:
-
Programa Supermanzanas: utiliza mapas que muestran los niveles de contaminación de calidad del aire y datos de tráfico disponibles en formatos abiertos como CSV y GeoPackage de Barcelona Open Data y el Ajuntament de Barcelona para identificar calles donde la reducción del tráfico rodado puede maximizar los beneficios para la salud, creando espacios seguros para peatones y ciclistas.
-
La plataforma DataActive: busca establecer una infraestructura internacional en la que participen investigadores, entidades deportivas públicas y privadas. Las temáticas que aborda incluyen la gestión del territorio, el urbanismo, la sostenibilidad, la movilidad, la calidad del aire y la justicia ambiental. Su objetivo es promover entornos urbanos más activos, saludables y accesibles mediante la implementación de estrategias basadas en el open data y la investigación.
La disponibilidad de datos se complementa con herramientas avanzadas de visualización. La Infraestructura de Datos Espaciales de Madrid (IDEM) ofrece visores geográficos especializados en calidad del aire y el Instituto Geográfico Nacional (IGN) ofrece el callejero nacional CartoCiudad con información de todas las ciudades de España.
Gobernanza efectiva y ecosistema de innovación
No obstante, la efectividad de estas iniciativas depende de nuevos modelos de gobernanza que integren múltiples actores. Para lograr una correcta coordinación entre administraciones públicas de diferentes niveles, empresas privadas, organizaciones del tercer sector y ciudadanía es esencial contar con datos abiertos de calidad.
Los datos abiertos no solo alimentan aplicaciones específicas, sino que crean un ecosistema completo de innovación. Desarrolladores independientes, startups, centros de investigación y organizaciones ciudadanas utilizan estos datos para:
-
Desarrollar estudios de impacto en salud urbana.
-
Crear herramientas de planificación participativa.
-
Generar alertas tempranas sobre riesgos ambientales.
-
Evaluar la efectividad de políticas públicas.
-
Diseñar servicios personalizados según las necesidades de diferentes grupos poblacionales.
Los proyectos de espacios urbanos saludables basados en datos abiertos generan múltiples beneficios tangibles:
-
Eficiencia en la gestión pública: los datos permiten optimizar la asignación de recursos, priorizar intervenciones y evaluar su impacto real sobre la salud ciudadana.
-
Innovación y desarrollo económico: el ecosistema de datos abiertos estimula la creación de startups y servicios innovadores que mejoran la calidad de vida urbana, como demuestran las múltiples aplicaciones disponibles en datos.gob.es.
-
Transparencia y participación: la disponibilidad de datos facilita el control ciudadano y fortalece los procesos democráticos de toma de decisiones.
-
Evidencia científica: los datos sobre salud urbana contribuyen al desarrollo de políticas públicas basadas en evidencia y al avance del conocimiento científico.
-
Replicabilidad: las soluciones exitosas pueden adaptarse y replicarse en otras ciudades, acelerando la transformación hacia entornos urbanos más saludables.
En definitiva, el futuro de nuestras ciudades depende de nuestra capacidad para integrar tecnología, participación ciudadana y políticas públicas innovadoras. Los ejemplos analizados demuestran que los datos abiertos no son solo información; son la base para construir entornos urbanos que promuevan activamente la salud, la equidad y la sostenibilidad.