Blog
Los datos abiertos pueden transformar cómo interactuamos con nuestras ciudades, ofreciendo oportunidades para mejorar la calidad de vida. Cuando se ponen a disposición del público, permiten el desarrollo de aplicaciones innovadoras y herramientas que abordan desafíos urbanos, desde la accesibilidad hasta la seguridad vial y la participación.
La información en tiempo real puede tener impactos positivos en la ciudadanía. Por ejemplo, aplicaciones que utilizan datos abiertos pueden sugerir las rutas más eficientes, considerando factores como el tráfico y las obras en curso; la información sobre la accesibilidad de espacios públicos puede mejorar la movilidad de personas con discapacidades; los datos sobre rutas ciclistas o peatonales animan a optar por modos de transporte más ecológicos y sanos, y el acceso a datos urbanos puede empoderar a la ciudadanía para participar en la toma de decisiones sobre su ciudad. En otras palabras, el empleo ciudadano de datos abiertos no solo mejora la eficiencia de la ciudad y sus servicios, sino que también promueve una ciudad más inclusiva, sostenible y participativa.
Para ilustrar estas ideas, en este artículo se abordan mapas para “navegar” ciudades, realizados con datos abiertos. Es decir, se muestran iniciativas que mejoran la relación de la ciudadanía con su entorno urbano desde diferentes aspectos como la accesibilidad, la seguridad escolar o la participación ciudadana. El primer proyecto es Mapcesible, que permite a usuarios y usuarias mapear y evaluar la accesibilidad de diferentes lugares en España. El segundo, Eskola BideApp, una aplicación móvil diseñada para apoyar los caminos escolares seguros. Y finalmente, unos mapas que fomentan la transparencia y la participación ciudadana en la gestión urbana. El primero identifica la contaminación acústica, el segundo ubica los servicios disponibles en varias áreas que se encuentran a un máximo de 15 minutos y el tercero visualiza los bancos que hay en la ciudad. Estos mapas utilizan diversas fuentes de datos públicos para ofrecer una visión detallada de diferentes aspectos de la vida urbana.
La primera iniciativa es un proyecto de una gran fundación, la segunda, una propuesta colaborativa y local, y la tercera, un proyecto personal. Aunque parten de planteamientos muy diferentes, las tres tienen en común el uso de datos públicos y abiertos y la vocación de ayudar a entender y vivir la ciudad. La variedad de orígenes de estos proyectos indica que el uso de datos públicos y abiertos no está limitado a grandes organizaciones.
A continuación, realizamos un resumen de cada proyecto, seguido de una comparación y una reflexión sobre el empleo de datos públicos y abiertos en entornos urbanos.
Mapcesible, mapa para personas con movilidad reducida
Mapcesible se lanzó en 2019 para evaluar la accesibilidad de diversos espacios como comercios, aseos públicos, estacionamientos, alojamientos, restaurantes, espacios culturales y entornos naturales.

Figura 1. Mapcesible. Fuente: https://mapcesible.fundaciontelefonica.com/intro
Este proyecto cuenta con el apoyo de organizaciones como la ONG Confederación Española de Personas con Discapacidad Física y Orgánica (COCEMFE) y la empresa ILUNION. Actualmente cuenta con más de 40.000 espacios accesibles evaluados y miles de usuarios y usuarias.

Figura 2. Mapcesible. Fuente: https://mapcesible.fundaciontelefonica.com/filters
Mapcesible utiliza datos abiertos como parte de su funcionamiento. Específicamente, la aplicación incorpora catorce conjuntos de datos de organismos oficiales, incluyendo del Ministerio de Agricultura y Medioambiente, ayuntamientos de diferentes ciudades (incluidos Madrid y Barcelona) y de los gobiernos autonómicos. Estos datos abiertos se combinan con la información aportada por las personas usuarias de la aplicación, que pueden mapear y evaluar la accesibilidad de los lugares que visitan. Esta combinación de datos oficiales y colaboración ciudadana permite a Mapcesible proporcionar información actualizada y detallada sobre la accesibilidad de diversos espacios en toda España, beneficiando así a las personas con movilidad reducida.
Eskola BideAPP, aplicación para definir trayectos escolares seguros
Eskola BideAPP es una aplicación desarrollada por Montera34 –un equipo que se dedica a la visualización de datos y el desarrollo de proyectos colaborativos— en alianza con la Asociación Solasgune para apoyar los caminos escolares. Eskola BideAPP ha servido para garantizar que los niños y las niñas puedan acceder a sus escuelas de manera segura y eficiente. El proyecto usa sobre todo datos públicos del callejero de OpenStreetMap, por ejemplo, datos geográficos y cartográficos de calles, aceras, cruces, así como datos recabados durante el proceso de creación de rutas seguras para que los niños y las niñas vayan andando a sus colegios con el objetivo de promover su autonomía y la movilidad sostenible.
La aplicación ofrece un panel de control interactivo para visualizar los datos recopilados, la generación de mapas en papel para sesiones con el alumnado, y la creación de informes para técnicos municipales. Utiliza tecnologías como QGIS (un sistema de información geográfica de software libre y de código abierto) y un entorno de desarrollo para el lenguaje de programación R, dedicado a la computación estadística y gráficos.
El proyecto se divide en tres etapas principales:
- Recolección de datos mediante cuestionarios en las aulas.
- Análisis y discusión de resultados con los niños para co-diseñar rutas personalizadas.
- Prueba de las rutas diseñadas.

Figura 3. Eskola BideaAPP. Foto de Julián Maguna (Solasgune). Fuente: https://montera34.com/project/eskola-bideapp/
Pablo Rey, uno de los promotores de Montera34 junto con Alfonso Sánchez, informa para este artículo de que Eskola BideAPP, desde 2019, se ha usado en ocho municipios, incluidos Derio, Erandio, Galdakao, Gatika, Plentzia, Leioa, Sopela y Bilbao. Sin embargo, ahora mismo sólo está operativa en los dos últimos mencionados. “La idea es implementarla en Portugalete a principios de 2025”, añade.
Merece la pena recordar los mapas de Montera34 que mostraban el “efecto” AirBnB en San Sebastián y en otras ciudades, y los análisis de datos y mapas publicados durante la epidemia de COVID-19, que también visualizaban datos públicos. Además, Montera34 ha usado datos públicos para analizar la abstención, segregación escolar, contratos menores o poner los datos abiertos a disposición del público. Para este último proyecto, Montera34 ha comenzado por las ordenanzas del ayuntamiento de Bilbao y las actas de sus plenos, de manera que no solo estén disponibles en un documento PDF sino en forma de datos abiertos y accesibles.
Mapas de Madrid sobre contaminación acústica, servicios y ubicación de bancos
Abel Vázquez Montoro ha realizado diversos mapas con datos abiertos que resultan muy interesantes, por ejemplo, el elaborado con datos del Mapa Estratégico de Ruido (MER) ofrecido por el Ayuntamiento de Madrid y datos del catastro. El mapa muestra el ruido que afecta a cada edificio, fachada y planta en Madrid.

Figura 4. Mapas del ruido en Madrid. Fuente: https://madb.netlify.app/
Este mapa se organiza como un dashboard con tres secciones: datos generales de la zona visible en el mapa, mapa dinámico en 2D y 3D con opciones configurables e información detallada de edificios específicos. Se trata de una plataforma abierta, gratuita y de uso no comercial que usa software libre y de código abierto como GitLab — una plataforma web de gestión de repositorios Git— y QGIS. El mapa permite evaluar el cumplimiento de las normativas de ruido y el impacto en la calidad de vida, ya que también calcula el riesgo para la salud asociado a los niveles de ruido, utilizando la proporción de riesgo atribuible (RA%).
15-minCity es otro mapa interactivo que visualiza el concepto de la "ciudad de 15 minutos" aplicado a diferentes áreas urbanas; es decir, calcula cuán accesibles son diferentes servicios dentro de un radio de 15 minutos a pie o en bicicleta desde cualquier punto de la ciudad seleccionada.

Figura 5. 15-minCity. Fuente: https://whatif.sonycsl.it/15mincity/15min.php?idcity=9166
Por último, "Dónde sentarse en Madrid" es otro mapa interactivo que expone la ubicación de bancos y otros lugares para sentarse en espacios públicos de Madrid, destacando las diferencias entre barrios ricos (generalmente con más asientos públicos) y pobres (con menos). Este mapa utiliza la herramienta para creación de mapas, Felt, para visualizar y compartir información geoespacial de forma accesible. El mapa presenta diferentes tipos de asientos, incluyendo bancos tradicionales, asientos individuales, gradas y otros tipos de estructuras para sentarse.

Figura 6. Dónde sentarse en Madrid. Fuente: https://felt.com/map/Donde-sentarse-en-Madrid-TJx8NGCpRICRuiAR3R1WKC?loc=40.39689,-3.66392,13.97z
Sus mapas visualizan datos públicos de información demográfica (por ejemplo, datos poblacionales distribuidos por edades, género y nacionalidades), información urbanística sobre el uso del suelo, edificaciones y espacios públicos, datos socioeconómicos (por ejemplo, renta, empleo y otros indicadores económicos de los diferentes distritos y barrios), datos medioambientales, incluyendo calidad del aire, zonas verdes y otros aspectos relacionados, y datos sobre la movilidad.
¿Qué tienen en común?
| Nombre | Promotor/a | Tipo de datos usados | Afán de lucro | Usuarios/as | Características |
|---|---|---|---|---|---|
| Mapcesible | Fundación Telefónica. | Combina datos generados por usuarios/as y datos públicos (14 conjuntos de datos abiertos de organismos oficiales) | Sin ánimo de lucro. | Más de 5.000 | App colaborativa, disponible en iOS y Android, más de 40.000 puntos accesibles mapeados. |
| Eskola BideAPP | Montera34 y Asociación Solasgune. | Combina datos generados por usuarios/as y públicos (cuestionarios en aulas) y algunos datos abiertos. | Sin ánimo de lucro. | 4.185 | Enfocada en rutas escolares seguras, usa QGIS y R para procesamiento de datos |
| Mapa Estratégico de Ruido (MER) | Ayuntamiento de Madrid. | Datos geográficos y de zona visible en 2D y 3D | Sin ánimo de lucro. | No existen cifras públicas | Permite evaluar el cumplimiento de las normativas de ruido y el impacto en la calidad de vida, ya que también calcula el riesgo para la salud asociado |
| 15 min-City | Sony GSL | Servicios y datos geográficos. | Sin ánimo de lucro. | No existen cifras públicas | Mapa interactivo que visualiza el concepto de la "ciudad de 15 minutos" aplicado a diferentes áreas urbanas |
| MAdB "Dónde sentarse en Madrid" | Particular | Datos públicos (demográficos, electorales, urbanísticos, socioeconómicos, etc.) | Sin ánimo de lucro. | No existen cifras públicas | Mapas interactivos de Madrid |
Figura 7. Tabla comparativa de las soluciones
Estos proyectos comparten el enfoque de emplear datos abiertos para mejorar el acceso a los servicios urbanos, aunque difieren en sus objetivos específicos y en la forma de recopilar y presentar la información. Mapcesible, Eskola BideApp, MAdB y "Dónde sentarse en Madrid" tienen un gran valor.
Por un lado, Mapcesible ofrece información unificada y actualizada que permite a personas con discapacidad moverse por la ciudad y acceder a los servicios. Eskola BideApp involucra a la comunidad en el diseño y testeo de rutas seguras para ir caminando al colegio; esto no solo mejora la seguridad vial, sino que también empodera a los y las más jóvenes para que sean agentes activos en la planificación urbana. Entretanto, 15-min city, MER y los mapas desarrollados por Vázquez Montoro visualizan datos complejos sobre Madrid de manera que la ciudadanía pueden entender mejor cómo funciona su ciudad y cómo se toman las decisiones que les afectan.
En su conjunto, el valor de estos proyectos radica en su capacidad para crear una cultura de datos, enseñando a valorar, interpretar y utilizar la información para mejorar las comunidades.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Blog
El procesamiento del lenguaje natural (NLP, por sus siglas en inglés) es una rama de la inteligencia artificial que permite a las máquinas comprender y manipular el lenguaje humano. En el núcleo de muchas aplicaciones modernas, como asistentes virtuales, sistemas de traducción automática y chatbots, se encuentran los word embeddings. Pero, ¿qué son exactamente y por qué son tan importantes?
¿Qué son los word embeddings?
Los word embeddings son una técnica que permite a las máquinas representar el significado de las palabras de manera que se puedan capturar relaciones complejas entre ellas. Para entenderlo, pensemos en cómo las palabras se usan en un contexto determinado: una palabra adquiere significado en función de las palabras que la rodean. Por ejemplo, la palabra banco podría referirse a una institución financiera o a un asiento, dependiendo del contexto en el que se encuentre.
La idea detrás de los word embeddings es que se asigna a cada palabra un vector en un espacio de varias dimensiones. La posición de estos vectores en el espacio refleja la cercanía semántica entre las palabras. Si dos palabras tienen significados similares, sus vectores estarán cercanos. Si sus significados son opuestos o no tienen relación, estarán distantes en el espacio vectorial.
Para visualizarlo, imaginemos que palabras como lago, río y océano estarían cerca entre sí en este espacio, mientras que palabras como lago y edificio estarían mucho más separadas. Esta estructura permite que los algoritmos de procesamiento de lenguaje puedan realizar tareas complejas, como encontrar sinónimos, hacer traducciones precisas o incluso responder preguntas basadas en contexto.
¿Cómo se crean los word embeddings?
El objetivo principal de los word embeddings es capturar relaciones semánticas y la información contextual de las palabras, transformándolas en representaciones numéricas que puedan ser comprendidas por los algoritmos de machine learning (aprendizaje automático). En lugar de trabajar con texto sin procesar, las máquinas requieren que las palabras se conviertan en números para poder identificar patrones y relaciones de manera efectiva.
El proceso de creación de word embeddings consiste en entrenar un modelo en un gran corpus de texto, como artículos de Wikipedia, para aprender la estructura del lenguaje. El primer paso implica realizar una serie de preprocesamientos en el corpus, que incluye tokenizar las palabras, eliminar puntuación y términos irrelevantes, y, en algunos casos, convertir todo el texto a minúsculas para mantener la consistencia.
El uso del contexto para capturar el significado
Una vez preprocesado el texto, se utiliza una técnica conocida como "ventana de contexto deslizante" para extraer información. Esto significa que, para cada palabra objetivo, se toman en cuenta las palabras que la rodean dentro de un cierto rango. Por ejemplo, si la ventana de contexto es de 3 palabras, para la palabra avión en la frase “El avión despega a las seis”, las palabras de contexto serán El, despega, a.
El modelo se entrena para aprender a predecir una palabra objetivo usando las palabras de su contexto (o a la inversa, predecir el contexto a partir de la palabra objetivo). Para ello, el algoritmo ajusta sus parámetros de manera que los vectores asignados a cada palabra se acerquen más en el espacio vectorial si esas palabras aparecen frecuentemente en contextos similares.
Cómo los modelos aprenden la estructura del lenguaje
La creación de los word embeddings se basa en la capacidad de estos modelos para identificar patrones y relaciones semánticas. Durante el entrenamiento, el modelo ajusta los valores de los vectores de manera que las palabras que suelen compartir contextos tengan representaciones similares. Por ejemplo, si avión y helicóptero se usan frecuentemente en frases similares (por ejemplo, en el contexto de transporte aéreo), los vectores de avión y helicóptero estarán cerca en el espacio vectorial.
A medida que el modelo procesa más y más ejemplos de frases, va afinando las posiciones de los vectores en el espacio continuo. De este modo, los vectores no solo reflejan la proximidad semántica, sino también otras relaciones como sinónimos, categorías (por ejemplo, frutas, animales) y relaciones jerárquicas (por ejemplo, perro y animal).
Un par de ejemplos simplificado
Imaginemos un pequeño corpus de solo seis palabras: guitarra, bajo, batería, piano, coche y bicicleta. Supongamos que cada palabra se representa en un espacio vectorial de tres dimensiones de la siguiente manera:
guitarra [0.3, 0.8, -0.1]
bajo [0.4, 0.7, -0.2]
batería [0.2, 0.9, -0.1]
piano [0.1, 0.6, -0.3]
coche [0.8, -0.1, 0.6]
bicicleta [0.7, -0.2, 0.5]
En este ejemplo simplificado, las palabras guitarra, bajo, batería y piano representan instrumentos musicales y están ubicadas cerca unas de otras en el espacio vectorial, ya que se utilizan en contextos similares. En cambio, coche y bicicleta, que pertenecen a la categoría de medios de transporte, se encuentran alejadas de los instrumentos musicales pero cercanas entre ellas. Esta otra imagen muestra cómo se verían distintos términos relacionados con cielo, alas e ingeniería en un espacio vectorial.

Figura1. Ejemplos de representación de un corpus en un espacio vectorial. Fuente: Adaptación de “Word embeddings: the (very) basics”, de Guillaume Desagulier.
Estos ejemplos solo utilizan tres dimensiones para ilustrar la idea, pero en la práctica, los word embeddings suelen tener entre 100 y 300 dimensiones para capturar relaciones semánticas más complejas y matices lingüísticos.
El resultado final es un conjunto de vectores que representan de manera eficiente cada palabra, permitiendo a los modelos de procesamiento de lenguaje identificar patrones y relaciones semánticas de forma más precisa. Con estos vectores, las máquinas pueden realizar tareas avanzadas como búsqueda semántica, clasificación de texto y respuesta a preguntas, mejorando significativamente la comprensión del lenguaje natural.
Estrategias para generar word embeddings
A lo largo de los años, se han desarrollado múltiples enfoques y técnicas para generar word embeddings. Cada estrategia tiene su forma de capturar el significado y las relaciones semánticas de las palabras, lo que resulta en diferentes características y usos. A continuación, se presentan algunas de las principales estrategias:
1. Word2Vec: captura de contexto local
Desarrollado por Google, Word2Vec es uno de los enfoques más conocidos y se basa en la idea de que el significado de una palabra se define por su contexto. Usa dos enfoques principales:
- CBOW (Continuous Bag of Words): en este enfoque, el modelo predice la palabra objetivo usando las palabras de su entorno inmediato. Por ejemplo, dado un contexto como "El perro está ___ en el jardín", el modelo intenta predecir la palabra jugando, basándose en las palabras El, perro, está y jardín.
- Skip-gram: A la inversa, Skip-gram usa una palabra objetivo para predecir las palabras circundantes. Usando el mismo ejemplo, si la palabra objetivo es jugando, el modelo intentaría predecir que las palabras en su entorno son El, perro, está y jardín.
La idea clave es que Word2Vec entrena el modelo para capturar la proximidad semántica a través de muchas iteraciones en un gran corpus de texto. Las palabras que tienden a aparecer juntas tienen vectores más cercanos, mientras que las que no están relacionadas aparecen más distantes.
2. GloVe: enfoque basado en estadísticas globales
GloVe, desarrollado en la Universidad de Stanford, se diferencia de Word2Vec al utilizar estadísticas globales de co-ocurrencia de palabras en un corpus. En lugar de considerar solo el contexto inmediato, GloVe se basa en la frecuencia con la que dos palabras aparecen juntas en todo el corpus.
Por ejemplo, si pan y mantequilla aparecen juntas con frecuencia, pero pan y planeta rara vez se encuentran en el mismo contexto, el modelo ajusta los vectores de manera que pan y mantequilla estén cerca en el espacio vectorial.
Esto permite que GloVe capture relaciones globales más amplias entre palabras y que las representaciones sean más robustas a nivel semántico. Los modelos entrenados con GloVe tienden a funcionar bien en tareas de analogía y similitud de palabras.
3. FastText: captura de sub-palabras
FastText, desarrollado por Facebook, mejora a Word2Vec al introducir la idea de descomponer las palabras en sub-palabras. En lugar de tratar cada palabra como una unidad indivisible, FastText representa cada palabra como una suma de n-gramas. Por ejemplo, la palabra jugando se podría descomponer en ju, uga, ando, etc.
Esto permite que FastText capture similitudes incluso entre palabras que no aparecieron explícitamente en el corpus de entrenamiento, como variaciones morfológicas (jugando, jugar, jugador). Esto es particularmente útil para lenguajes con muchas variaciones gramaticales.
4. Embeddings contextuales: captura de sentido dinámico
Modelos como BERT y ELMo representan un avance significativo en word embeddings. A diferencia de las estrategias anteriores, que generan un único vector para cada palabra independientemente del contexto, los embeddings contextuales generan diferentes vectores para una misma palabra según su uso en la frase.
Por ejemplo, la palabra banco tendrá un vector diferente en la frase "me senté en el banco del parque" que en "el banco aprobó mi solicitud de crédito". Esta variabilidad se logra entrenando el modelo en grandes corpus de texto de manera bidireccional, es decir, considerando no solo las palabras que preceden a la palabra objetivo, sino también las que la siguen.
Aplicaciones prácticas de los word embeddings
Los word embeddings se utilizan en una variedad de aplicaciones de procesamiento de lenguaje natural, como:
- Reconocimiento de Entidades Nombradas (NER, por sus siglas en inglés): permiten identificar y clasificar nombres de personas, organizaciones y lugares en un texto. Por ejemplo, en la frase "Apple anunció su nueva sede en Cupertino", los word embeddings permiten al modelo entender que Apple es una organización y Cupertino es un lugar.
- Traducción automática: ayudan a representar palabras de una manera independiente del idioma. Al entrenar un modelo con textos en diferentes lenguas, se pueden generar representaciones que capturan el significado subyacente de las palabras, facilitando la traducción de frases completas con un mayor nivel de precisión semántica.
- Sistemas de recuperación de información: en motores de búsqueda y sistemas de recomendación, los word embeddings mejoran la coincidencia entre las consultas de los usuarios y los documentos relevantes. Al capturar similitudes semánticas, permiten que incluso consultas no exactas se correspondan con resultados útiles. Por ejemplo, si un usuario busca "medicamento para el dolor de cabeza", el sistema puede sugerir resultados relacionados con analgésicos gracias a las similitudes capturadas en los vectores.
- Sistemas de preguntas y respuestas: los word embeddings son esenciales en sistemas como los chatbots y asistentes virtuales, donde ayudan a entender la intención detrás de las preguntas y a encontrar respuestas relevantes. Por ejemplo, ante la pregunta “¿Cuál es la capital de Italia?”, los word embeddings permiten que el sistema entienda las relaciones entre capital e Italia y encuentre Roma como respuesta.
- Análisis de sentimiento: los word embeddings se utilizan en modelos que determinan si el sentimiento expresado en un texto es positivo, negativo o neutral. Al analizar las relaciones entre palabras en diferentes contextos, el modelo puede identificar patrones de uso que indican ciertos sentimientos, como alegría, tristeza o enfado.
- Agrupación semántica y detección de similaridades: los word embeddings también permiten medir la similitud semántica entre documentos, frases o palabras. Esto se utiliza para tareas como agrupar artículos relacionados, recomendar productos basados en descripciones de texto o incluso detectar duplicados y contenido similar en grandes bases de datos.
Conclusión
Los word embeddings han transformado el campo del procesamiento de lenguaje natural al ofrecer representaciones densas y significativas de las palabras, capaces de capturar sus relaciones semánticas y contextuales. Con la aparición de embeddings contextuales, el potencial de estas representaciones sigue creciendo, permitiendo que las máquinas comprendan incluso las sutilezas y ambigüedades del lenguaje humano. Desde aplicaciones en sistemas de traducción y búsqueda, hasta chatbots y análisis de sentimiento, los word embeddings seguirán siendo una herramienta fundamental para el desarrollo de tecnologías cada vez más avanzadas y humanizadas en el campo del lenguaje natural.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Los próximos días 11, 12 y 13 de noviembre se celebra en Granada una nueva edición de DATAfórum Justicia. La cita reunirá a más de 100 ponentes para debatir sobre temas relacionados con los sistemas digitales de justicia, la inteligencia artificial (IA) y el uso del dato en el ecosistema judicial.
El evento está organizado por el Ministerio de Presidencia, Justicia y Relaciones con las Cortes, con la colaboración de la Universidad de Granada, la Junta de Andalucía, el Ayuntamiento de Granada y la entidad Formación y Gestión de Granada.
A continuación, se resumen algunos de los aspectos más importantes de estas jornadas.
Una cita dirigida a un público amplio
Este foro anual está dirigido tanto a profesionales del sector público, como del privado, sin dejar de lado al público general, que quiera saber más sobre la transformación digital de la justicia en nuestro país.
El DATAfórum Justicia 2024 cuenta, además, con un itinerario específico dirigido a estudiantes, cuyo objetivo es proporcionar a los jóvenes herramientas y conocimientos de valor en el ámbito de la justicia y la tecnología. Para ello, contarán con ponencias específicas y se pondrá en marcha un DATAthon. Estas actividades están especialmente dirigidas a estudiantes de derecho, ciencias sociales en general, ingenierías informáticas o materias relacionadas con la transformación digital. Los asistentes podrán obtener hasta 2 créditos ECTS (European Credit Transfer and Accumulation System o, en español, Sistema Europeo de Transferencia y Acumulación de Créditos): uno por asistir a las jornadas y otro por participar en el DATAthon.
Los datos, protagonistas de la agenda
El Paraninfo de la Universidad de Granada acogerá a expertos provenientes de la administración, instituciones y empresas privadas, que contarán su experiencia haciendo hincapié en las nuevas tendencias del sector, los retos que hay por delante y las oportunidades de mejora.
Las jornadas comenzarán el lunes 11 de noviembre a las 9:00 horas, con la bienvenida a los alumnos y la presentación del DATAthon. La inauguración oficial, dirigida a todas las audiencias, será a las 11:35 horas y correrá a cargo de Manuel Olmedo Palacios, Secretario de Estado de Justicia, y Pedro Mercado Pacheco, Rector de la Universidad de Granada.
A partir de entonces se sucederán diversas charlas, debates, entrevistas, mesas redondas y conferencias, entre las que encontramos un gran número de temáticas relacionadas con los datos. Entre otras cuestiones, se profundizará en la gestión del dato, tanto en administraciones como en empresas. También se abordará el uso de los datos abiertos para prevenir desde bulos hasta suicidios o la violencia sexual.
Otro tema con gran protagonismo será las posibilidades de la inteligencia artificial para optimizar el sector, tocando aspectos como la automatización de la justicia, la realización de predicciones. Se incluirán ponencias de casos de uso concretos, como la utilización de IA para la identificación de personas fallecidas, sin dejar de lado cuestiones como la gobernanza de algoritmos.
El evento finalizará el miércoles 13 a las 17:00 horas con la clausura oficial. En esta ocasión, Félix Bolaños, Ministro de la Presidencia, Justicia y Relaciones con las Cortes, acompañará al Rector de la Universidad de Granada.
Puedes ver la agenda completa aquí.
Un Datathon para resolver los retos del sector a través de los datos
En paralelo a esta agenda, se celebrará un DATAthon en el que los participantes presentarán ideas y proyectos innovadores para mejorar la justicia en nuestra sociedad. Se trata de un concurso destinado a estudiantes, profesionales del ámbito legal e informático, grupos de investigación y startups.
Los participantes se dividirán en equipos multidisciplinares para proponer soluciones a una serie de retos, planteados por la organización, utilizando tecnologías orientadas a la ciencia de datos. Durante las dos primeras jornadas los participantes dispondrán de tiempo para investigar y desarrollar su solución original. En la tercera jornada, deberán presentar una propuesta a un jurado cualificado. Los premios se entregarán el último día, antes de la clausura y del vino español y concierto que darán final a la edición 2024 del DATAfórum Justicia.
En la edición de 2023 participaron 35 personas, divididas en 6 equipos que resolvieron dos casos prácticos con datos de carácter público y se otorgaron dos premios de 1.000 euros.
Cómo inscribirse
El plazo de inscripción al DATAfórum Justicia 2024 ya está abierto. Debe realizarse a través de la web del evento, indicando si se trata de público general, personal de la administración pública, profesionales del sector privado o medios de comunicación.
Para participar en el DATAthon es necesario registrarse también en el site dedicado al concurso.
La edición del año pasado, centrada en propuestas para aumentar la eficiencia y transparencia en los sistemas judiciales, fue un gran éxito, con más de 800 inscritos. Este año se espera también una gran afluencia de público, así que te animamos a reservar tu plaza lo antes posible. Se trata de una gran oportunidad para conocer de primera mano experiencias exitosas y poder intercambiar opiniones con expertos en el sector.
Blog
Un gemelo digital es una representación virtual e interactiva de un objeto, sistema o proceso del mundo real. Hablamos, por ejemplo, de una réplica digital de una fábrica, una ciudad o incluso un cuerpo humano. Estos modelos virtuales permiten simular, analizar y predecir el comportamiento del elemento original, lo que es clave para la optimización y el mantenimiento en tiempo real.
Debido a sus funcionalidades, los gemelos digitales se están utilizando en diversos sectores como la salud, el transporte o la agricultura. En este artículo, repasamos las ventajas que aporta su uso y mostramos dos ejemplos relacionados con los datos abiertos.
Ventajas de los gemelos digitales
Los gemelos digitales utilizan fuentes de datos reales del entorno, obtenidos a través de sensores y plataformas abiertas, entre otros. Gracias a ello, los gemelos digitales se actualizan en tiempo real para reflejar la realidad, lo que aporta una serie de ventajas:
- Aumento del rendimiento: una de las principales diferencias con las simulaciones tradicionales es que los gemelos digitales utilizan datos en tiempo real para su modelización, lo que permite tomar decisiones más acertadas para optimizar el rendimiento de equipos y sistemas según las necesidades de cada momento.
- Mejora de la planificación: utilizando tecnologías basadas en inteligencia artificial (IA) y aprendizaje automático, el gemelo digital puede analizar problemas de rendimiento o realizar simulaciones virtuales de «qué pasaría si». De esta forma, se pueden predecir fallos y problemas antes de que ocurran, lo que permite un mantenimiento proactivo.
- Reducción de costes: la mejora en la gestión de datos gracias a un gemelo digital genera beneficios equivalentes al 25% del gasto total en infraestructuras. Además, al evitar fallos costosos y optimizar procesos, se pueden reducir significativamente los costes operativos. También permiten monitorear y controlar sistemas en remoto, desde cualquier lugar, mejorando la eficiencia al centralizar las operaciones.
- Personalización y flexibilidad: al crear modelos virtuales detallados de productos o procesos, las organizaciones pueden adaptar rápidamente sus operaciones para satisfacer las demandas cambiantes del entorno y las preferencias individuales de los clientes / ciudadanos. Por ejemplo, en la fabricación, los gemelos digitales permiten la producción personalizada en masa, ajustando las líneas de producción en tiempo real para crear productos únicos según las especificaciones del cliente. Por otro lado, en el ámbito de la salud, los gemelos digitales pueden modelar el cuerpo humano para personalizar tratamientos médicos, mejorando así la eficacia y reduciendo los efectos secundarios.
- Impulso de la experimentación e innovación: los gemelos digitales proporcionan un entorno seguro y controlado para probar nuevas ideas y soluciones, sin los riesgos y costes asociados a los experimentos físicos. Entre otras cuestiones, permiten experimentar con grandes objetos o proyectos que, por su tamaño, no suelen prestarse a la experimentación en la vida real.
- Mejora de la sostenibilidad: al permitir la simulación y el análisis detallado de procesos y sistemas, las organizaciones pueden identificar áreas de ineficiencia y desperdicio, optimizando así el uso de recursos. Por ejemplo, los gemelos digitales pueden modelar el consumo y la producción de energía en tiempo real, permitiendo ajustes precisos que reducen el consumo y las emisiones de carbono.
Ejemplos de gemelos digitales en España
A continuación, se muestran tres ejemplos que ponen de manifiesto estas ventajas.
Proyecto GeDIA: inteligencia artificial para predecir los cambios en los territorios
GeDIA es una herramienta para la planificación estratégica de ciudades inteligentes, que permite realiza simulaciones de escenarios. Para ellos utiliza modelos de inteligencia artificial basados en fuentes de datos y herramientas ya existentes en el territorio.
El alcance de la herramienta es muy amplio, pero sus creadores destacan dos casos de uso:
- Necesidades de infraestructuras futuras: la plataforma realiza análisis detallados considerando las tendencias, gracias a los modelos de inteligencia artificial. De esta forma, se pueden realizar proyecciones de crecimiento y planificar las necesidades de infraestructuras y servicios, como energía y agua, en áreas específicas de un territorio, garantizando su disponibilidad.
- Crecimiento y turismo: GeDIA también se utiliza para estudiar y analizar el crecimiento urbano y turístico en zonas concretas. La herramienta identifica patrones de gentrificación y evalúa su impacto en la población local, utilizando datos censales. De esta forma se pueden comprender mejor los cambios demográficos y su impacto, como las necesidades de vivienda, y tomar decisiones que faciliten el crecimiento equitativo y sostenible.
Esta iniciativa cuenta con la participación de diversas empresas y la Universidad de Málaga (UMA), así como el respaldo económico de Red.es y la Unión Europea.
Gemelo digital del Mar menor: datos para cuidar el medio ambiente
El Mar Menor, la laguna salada de la Región de Murcia, ha sufrido graves problemas ecológicos en los últimos años, influenciados por la presión agrícola, el turismo y la urbanización.
Para conocer mejor las causas y valorar posibles soluciones, TRAGSATEC, una entidad de protección ambiental de propiedad estatal, desarrolló un gemelo digital. Para ello mapeó un área circundante de más de 1.600 kilómetros cuadrados, conocida como la Región del Campo de Cartagena. En total se obtuvieron 51.000 imágenes nadirales, 200.000 imágenes oblicuas y más de cuatro terabytes de datos LiDAR.
Gracias a este gemelo digital, TRAGSATEC ha podido simular diversos escenarios de inundaciones y el impacto que tendría instalar elementos de contención u obstáculos, como un muro, que redirigieran el flujo del agua. También han podido estudiar la distancia entre el terreno y el agua subterránea, para determinar el impacto de la filtración de fertilizantes, entre otras cuestiones.
Retos y camino hacia el futuro
Estos son solo dos ejemplos, pero ponen de manifiesto el potencial de una tecnología cada vez más popular. No obstante, para que su implementación sea aun mayor es necesario hacer frente a algunos retos, como los costes iniciales, tanto en tecnología como en capacitación, o la seguridad, al aumentar la superficie de ataque. Otro de los retos a destacar son los problemas de interoperabilidad que surgen cuando las distintas administraciones públicas establecen gemelos digitales y espacios de datos locales. Para profundizar en esta problemática, la Comisión Europea ha publicado una guía que ayuda a identificar los principales retos organizativos y culturales de interoperabilidad, ofreciendo buenas prácticas para solventarlos.
En resumen, los gemelos digitales ofrecen numerosas ventajas, como la mejora del rendimiento o la reducción de costes. Estos beneficios están impulsando su adopción en diversas industrias y es probable que, a medida que se superen los retos actuales, los gemelos digitales se conviertan en una herramienta esencial para optimizar procesos y mejorar la eficiencia operativa en un mundo cada vez más digitalizado.
Blog
Muchas personas utilizan aplicaciones para desplazarse en su día a día. Apps como Google Maps, Moovit o CityMapper facilitan la ruta más rápida y eficaz para llegar a un destino. Sin embargo, lo que muchos usuarios desconocen es que tras estas plataformas se encuentra una valiosa fuente de información: los datos abiertos. Gracias a la reutilización de conjuntos de datos públicos, como los relacionados con la calidad del aire, el tráfico o el transporte público, estas aplicaciones pueden ofrecer un mejor servicio.
En este post, exploraremos cómo la reutilización de datos abiertos por parte de estas plataformas potencia un ecosistema urbano más inteligente y sostenible.
Google Maps: agrega información de calidad del aire y datos de transporte en GTFS.
Más de mil millones de personas utilizan Google Maps mensualmente alrededor del mundo. El gigante tecnológico ofrece un mapa mundial actualizado y gratuito que obtiene sus datos de diferentes fuentes, algunas de ellas, abiertas.
Una de las funciones que brinda la app es la información sobre la calidad del aire en la ubicación en la que se encuentra el usuario. El Índice de Calidad del Aire (ICA) es un parámetro que viene determinado por cada país o región. La referencia europea se puede consultar en este mapa que muestra calidad del aire por zonas geolocalizadas en tiempo real.
Para mostrar la calidad de aire de la ubicación del usuario, Google Maps aplica un modelo basado en un enfoque multicapa conocido como “enfoque de fusión”. Este método combina datos de varias fuentes de entrada y pondera las capas con un procedimiento sofisticado. Las capas de entrada son:
- Estaciones de monitorización de referencia de los gobiernos
- Redes de sensores comerciales
- Modelos de dispersión mundiales y regionales
- Modelos de polvo y humo de incendios
- Información obtenida por satélite
- Datos del tráfico
- Información auxiliar como la superficie
- Meteorología
En el caso de España, esta información se obtiene de fuentes de datos abiertos como el Ministerio de Transición Ecológica y Reto Demográfico, el Instituto Geográfico Nacional (que le permite obtener la cartografía con nombres oficiales de carreteras, poblaciones, etc.) la Conselleria de Medio Ambiente, Territorio y Vivienda de la Xunta de Galicia o la Comunidad de Madrid. Puedes consultar aquí las fuentes de datos abiertos que se utilizan en otros países del mundo.
Otra funcionalidad que ofrece Google Maps para planificar las mejores rutas para llegar a un destino es la información sobre el transporte público. Estos datos son proporcionados de manera voluntaria por las empresas públicas que ofrecen el servicio de transporte en cada ciudad. Para que estos datos abiertos estén a disposición del usuario, primero se vuelcan en Google Transit y deben cumplir el estándar abierto de transporte público GTFS (General Transit Feed Specification). Además, Google Maps también integra datos de transporte en GTFS del Punto de Acceso Nacional.
Moovit: reutiliza datos abiertos para ofrecer información en tiempo real
Moovit es otra de las aplicaciones de movilidad urbana, que utiliza datos abiertos y colaborativos para facilitar a los usuarios la planificación de sus desplazamientos en transporte público.
Desde su lanzamiento en 2012, la app de descarga gratuita ofrece información en tiempo real de las distintas opciones de transporte, sugiere las mejores rutas para llegar al destino indicado, guía al usuario durante su recorrido (cuánto tiene que esperar, cuántas paradas faltan, cuándo tiene que bajar, etc.) y realiza actualizaciones constantes ante cualquier alteración en el servicio.
Como otras apps de movilidad, también está disponible en modalidad offline y permite guardar las rutas y líneas frecuentes en “Favoritos”. Además, se trata de una solución inclusiva ya que integra VoiceOver (iOs) o TalkBack (Android) para personas invidentes.
La plataforma no solo aprovecha datos abiertos proporcionados por gobiernos y autoridades locales, sino que también recopila información de sus usuarios, lo que le permite ofrecer un servicio dinámico y constantemente actualizado.
CityMapper: nace como reutilizador de datos abiertos de movilidad
El equipo de desarrollo de CityMapper reconoce que la aplicación nació con un ADN abierto que todavía se mantiene. Reutilizan conjuntos de datos abiertos de, por ejemplo, OpenStreetMap a nivel global o RENFE y Cercanías Bilbao a nivel nacional. A medida que la aplicación está disponible en más ciudades, mayor es la lista de fuentes de referencia de datos abiertos de las que obtiene información.
La plataforma ofrece información en tiempo real sobre rutas de transporte público, incluyendo autobuses, trenes, metro o bicicletas compartidas. También añade opciones para desplazarse a pie, en bici o en sistemas de transporte compartido. Está diseñada para proporcionar la ruta más eficiente y rápida para llegar a un destino, integrando datos de diferentes medios de transporte en una sola interfaz.
Tal y como publicamos en el informe monográfico “Innovación municipal a través de datos abiertos” CityMapper utiliza principalmente open data de las autoridades de transporte locales normalmente utilizando el estándar GTFS (General Transit Feed Specification). No obstante, cuando estos datos no son suficientes o no son suficientemente precisos, CityMapper los combina con conjuntos de datos generados por los propios usuarios de la aplicación que colaboran voluntariamente. También utiliza datos mejorados y gestionados por el trabajo de los propios empleados locales de la empresa. Todos estos datos se combinan con algoritmos de inteligencia artificial desarrollados para optimizar las rutas y ofrecer recomendaciones ajustadas a las necesidades de los usuarios.
En conclusión, el uso de datos abiertos en el transporte impulsa una transformación significativa en el sector de la movilidad en ciudades. Gracias al aporte que ofrecen a las aplicaciones, los usuarios pueden acceder a datos actualizados y precisos, planificar sus viajes de manera eficiente y tomar decisiones informadas. Los gobiernos, por su parte, han asumido el rol de facilitadores al hacer posible la difusión de datos mediante plataformas abiertas, optimizando recursos y fomentando la colaboración entre distintos sectores. Además, los datos abiertos han creado nuevas oportunidades para los desarrolladores y el sector privado, quienes han contribuido con soluciones tecnológicas, como pueden ser Google Maps, Moovit o CityMapper. En definitiva, el potencial de los datos abiertos para transformar el futuro de la movilidad urbana es algo innegable.
Blog
En la actualidad, las tecnologías digitales están revolucionando diversos sectores, incluido el de la construcción, impulsadas por la Estrategia Digital Europea, que no solo promueve la innovación y la adopción de tecnologías digitales, sino también el uso y la generación de posibles datos abiertos. La incorporación de tecnologías avanzadas ha fomentado una transformación significativa en la gestión de proyectos de construcción, permitiendo que la información sea más accesible y transparente para todos los actores involucrados.
Uno de los elementos clave en esta transformación son los Permisos de Construcción Digital (Digital Building Permit en inglés) y los Registros Digitales de Construcción (Digital Building Log en inglés), conceptos que están mejorando la eficiencia en los procesos administrativos y en la ejecución de proyectos de construcción, estas tecnologías podrán tener un impacto significativo en la generación y gestión de datos de los municipios que las adopten.
Los Digital Building Permits (DBP) y Digital Building Logs (DBL) no solo generan información clave sobre la planificación, ejecución y mantenimiento de infraestructuras, sino que también hacen que estos datos sean accesibles para el público y otras partes interesadas. La disponibilidad de estos datos abiertos permite el análisis avanzado, la investigación académica, y el desarrollo de soluciones innovadoras para la construcción de infraestructuras más sostenibles y seguras.
¿Qué es el Digital Building Permit?
El Digital Building Permit es la digitalización de los procesos tradicionales de obtención de permisos de construcción. Tradicionalmente, este proceso era manual, implicando un intercambio extenso de documentos físicos y la coordinación entre múltiples partes interesadas. Con la digitalización, este procedimiento se simplifica y se vuelve más eficiente, permitiendo una revisión más rápida, transparente y menos propensa a errores. Además, gracias a esta digitalización, se generan grandes cantidades de datos valiosos de manera proactiva que no solo optimizan el proceso, sino que también pueden ser utilizados para mejorar la transparencia y llevar a cabo investigaciones en el sector. Estos datos pueden ser aprovechados para análisis avanzados, contribuyendo al desarrollo de infraestructuras más inteligentes y sostenibles. Facilita, asimismo, la integración de tecnologías como el Building Information Modeling (BIM) y los gemelos digitales, que son fundamentales para el desarrollo de infraestructuras inteligentes.
- BIM permite crear representaciones digitales detalladas de las infraestructuras, incorporando información precisa sobre cada componente del edificio. Este modelo digital no solo facilita el diseño, sino también la gestión y el mantenimiento de la construcción a lo largo de su ciclo de vida. En España, la legislación relacionada con el uso de Building Information Modeling (BIM) está regida principalmente por la Ley 9/2017 de Contratos del Sector Público. Esta ley establece la posibilidad de exigir el uso de BIM en los proyectos de obras públicas. Esta normativa tiene como objetivo mejorar la eficiencia, transparencia y sostenibilidad en la contratación y ejecución de obras públicas y servicios en España.
- Los gemelos digitales son réplicas virtuales de las infraestructuras físicas que permiten simular y analizar el comportamiento de un edificio en tiempo real gracias a los datos generados. Estos datos no solo son cruciales para el funcionamiento del gemelo digital, sino que también pueden ser utilizados como datos abiertos para la investigación, la mejora de políticas públicas y la transparencia en el manejo de las infraestructuras. Estos gemelos digitales son fundamentales para prever problemas antes de que ocurran, optimizar la eficiencia energética y gestionar el mantenimiento de manera proactiva.
En conjunto, estas tecnologías no solo podrán optimizar el proceso de obtención de permisos, sino que también aseguran que las construcciones sean más seguras, sostenibles y alineadas con las normativas actuales, promoviendo el desarrollo de infraestructuras inteligentes en un entorno cada vez más digitalizado.
¿Qué es un Digital Building Log?
El Digital Building Log es una herramienta que permite llevar un registro detallado y digitalizado de todas las actividades, decisiones y modificaciones realizadas durante la vida de un proyecto de construcción. Este registro incluye datos con información sobre los permisos otorgados, inspecciones realizadas, cambios en los diseños, y cualquier otra intervención relevante. Funciona como una bitácora digital que ofrece una visión transparente y trazable de todo el proceso de construcción.
Este enfoque no solo mejora la transparencia y la trazabilidad, sino que también facilita la supervisión y el cumplimiento normativo, al mantener un registro actualizado y accesible para todas las partes interesadas.
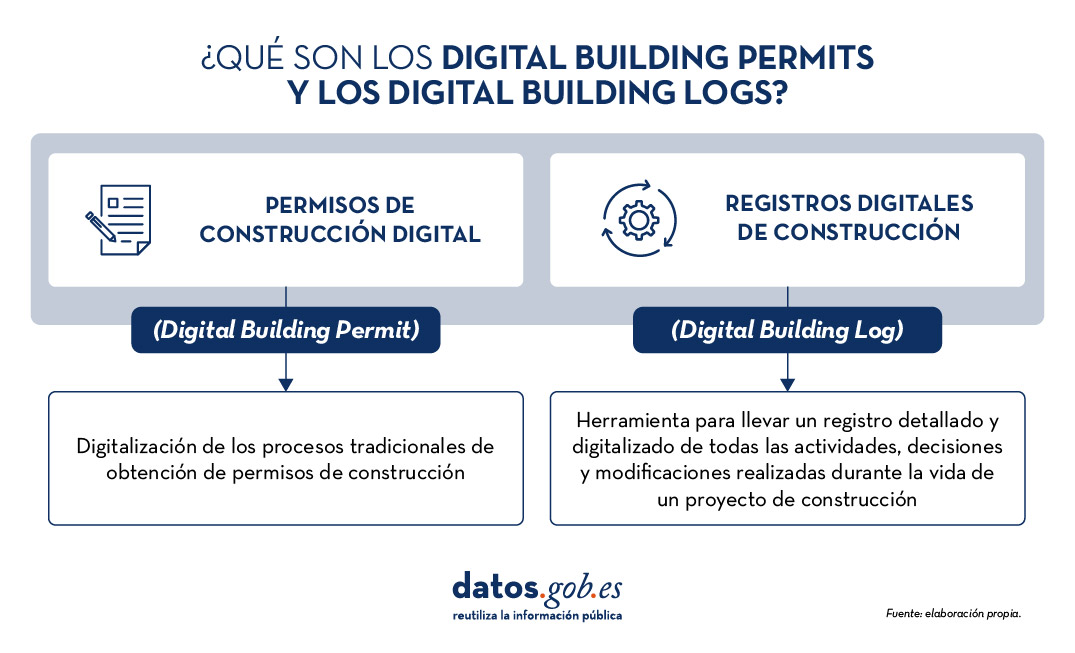
Figura 1. ¿Qué son los Digital Building Permits y los Digital Building Logs? Elaboración propia.
Proyectos Clave y Objetivos en el Sector
Diversos proyectos europeos están incorporando Digital Building Permits y Digital Building Logs como parte de su estrategia para modernizar el sector de la construcción. A continuación, se destacan algunos de los proyectos más innovadores en este ámbito:
ACCORD
El Proyecto ACCORD (2022-2025) es una iniciativa europea que busca transformar el proceso de obtención y gestión de permisos de construcción a través de la digitalización. ACCORD, que significa "Automated Compliance Checking and Orchestration of Building Projects", tiene como objetivo principal desarrollar un marco semántico para verificar automáticamente el cumplimiento normativo, mejorar la eficiencia, y garantizar la transparencia en el sector de la construcción. Además, ACCORD desarrollará:
- Una herramienta de formalización de reglas basada en tecnologías web semánticas.
- Una base de datos de reglas semánticas.
- Microservicios para la verificación de conformidad en la construcción.
- Un conjunto de API abiertas y estandarizadas para permitir el flujo de datos integrado entre permisos de construcción, cumplimiento y otros servicios de información.
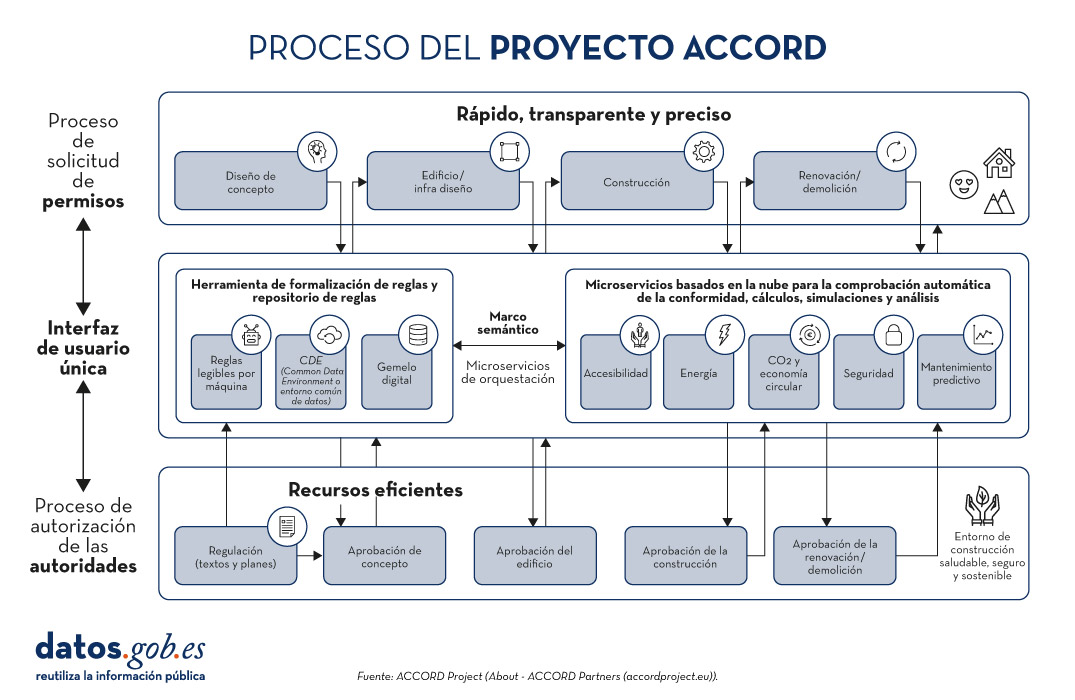
Figura 2. Proceso del proyecto ACCORD.Fuente: Proyecto ACCORD.
El Proyecto ACCORD se centra en diversas demostraciones en varios países europeos, cada una con un enfoque específico facilitado por el análisis y uso de los datos:
- En Estonia y Finlandia, ACCORD se enfoca en mejorar la accesibilidad y seguridad en espacios urbanos a través de la automatización de permisos de construcción. En Estonia, se trabaja en la verificación automática del cumplimiento de normativas de planificación y zonificación, mientras que, en Finlandia, el enfoque está en desarrollar espacios urbanos saludables y seguros mediante la digitalización del proceso de permisos y la integración de datos urbanos.
- En Alemania, ACCORD se centra en la verificación automatizada para permisos de uso del suelo y la certificación de edificios verdes. El proyecto busca automatizar la comprobación del cumplimiento normativo en estos ámbitos, integrando microservicios que permiten verificar automáticamente si los proyectos de construcción cumplen con las normativas de sostenibilidad y uso del suelo antes de que se otorguen los permisos.
- En el Reino Unido, ACCORD se enfoca en asegurar la integridad del diseño de componentes estructurales de las casas modulares de acero utilizando el modelado BIM y análisis por elementos finitos (FEA). Este enfoque permite verificar automáticamente si los componentes estructurales cumplen con las normas de seguridad y diseño antes de su implementación en la construcción. El proyecto facilita la detección temprana de posibles fallos estructurales, mejorando así la seguridad y eficiencia en el proceso de construcción.
- En España, ACCORD se centra en la automatización del cumplimiento de normativas urbanísticas en el ayuntamiento de Malgrat de Mar utilizando BIM y datos catastrales abiertos. El objetivo es mejorar la eficiencia en la fase de diseño y construcción, asegurando que los proyectos cumplan con las regulaciones locales antes de que se inicien. Esto incluye la verificación automática de las regulaciones urbanas para facilitar la obtención de permisos de construcción de manera más rápida y precisa.
CHEK
El Proyecto CHEK (2022-2025) que significa "Change Toolkit for Digital Building Permit" es una iniciativa europea que busca eliminar las barreras que enfrentan los municipios para adoptar la digitalización de procesos de gestión de permisos de construcción.
CHEK desarrollará soluciones escalables que incluyen estándares abiertos e interoperabilidad (geoespacial y BIM), herramientas educativas para cerrar brechas de conocimiento y nuevas tecnologías para la digitalización de permisos y verificación automática de conformidad. El objetivo es alinear tecnologías digitales con la tramitación administrativa de ámbito municipal, mejorar la precisión y eficiencia, y demostrar la escalabilidad en áreas urbanas europeas, alcanzando un nivel de madurez tecnológica TRL 7E.
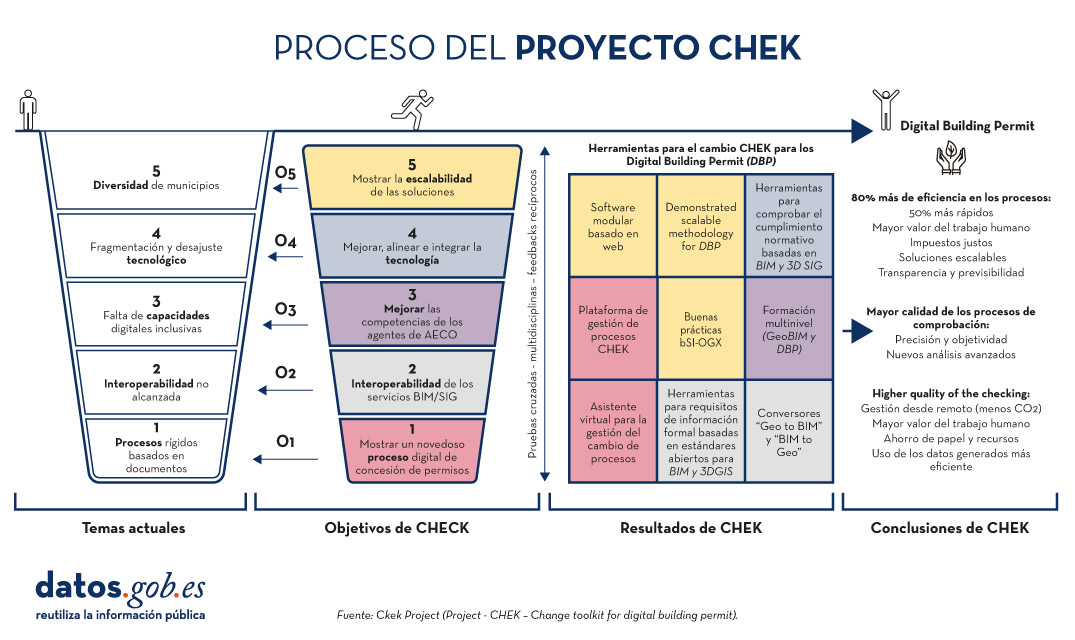
Figura 3. Proceso del Proyecto CHEK. Fuente: Proyecto CHEK.
Para ello es necesario:
- Adaptar las tecnologías digitales disponibles a los procesos municipales, posibilitando nuevos métodos y modelos empresariales.
- Desarrollar estándares abiertos de datos, incluidos los modelos de información de construcción (BIM), los modelos urbanos en 3D y la integración recíproca (GeoBIM).
- Mejorar la formación de empleados público y usuarios.
- Mejorar, adaptar e integrar la tecnología.
- Realizar y demostrar la escalabilidad.
CHEK proporcionará un conjunto de herramientas metodológicas y tecnológicas para digitalizar por completo los permisos de construcción y automatizar parcialmente las comprobaciones de conformidad de los diseños de los edificios, lo que supondrá una mejora de la eficiencia del 60% y la adopción del DBP por parte del 85% de los municipios europeos.
El futuro de la construccion y el aporte a los datos abiertos
La implementación de Digital Building Permits y Digital Building Logs está transformando el paisaje de la construcción. A medida que estas herramientas se integran en los procesos de construcción, los escenarios futuros que se vislumbran incluyen:
- Construcción digitalizada: En un futuro no muy lejano, los proyectos de construcción podrían gestionarse completamente de manera digital, desde la solicitud de permisos hasta el monitoreo continuo del proyecto. Esto eliminará la necesidad de documentos físicos y reducirá significativamente los errores y las demoras.
- Gemelos digitales en tiempo real: Los Digital Building Logs alimentarán gemelos digitales en tiempo real, permitiendo un monitoreo continuo y predictivo de los proyectos. Esto permitirá a los desarrolladores y reguladores anticipar problemas antes de que ocurran y tomar decisiones informadas rápidamente.
- Interoperabilidad global de datos: Con el avance los espacios de datos, se espera que los sistemas de construcción sean interoperables a nivel global. Esto facilitará la colaboración internacional y permitirá que los estándares y mejores prácticas se compartan y adopten ampliamente.
Los Digital Building Permits y los Digital Building Logs no son simplemente herramientas para la optimización de procesos en el sector de la construcción, sino también vehículos para la creación de datos abiertos que pueden ser aprovechados por un amplio abanico de actores. La implementación de estos sistemas no solo genera datos técnicos sobre el progreso de las obras, sino que también proporciona datos que pueden ser reutilizados por autoridades, desarrolladores y ciudadanos, lo que fomenta un entorno de colaboración abierta. Estos datos pueden ser usados para mejorar los análisis urbanos, ayudar en la planificación de infraestructuras públicas y optimizar la supervisión y transparencia en la ejecución de los proyectos.
El uso de datos abiertos a través de estas plataformas también facilita el desarrollo de aplicaciones innovadoras y servicios tecnológicos que mejoran la eficiencia, promueven la sostenibilidad y contribuyen a una gestión más eficiente de los recursos en las ciudades. Estos datos abiertos pueden, por ejemplo, permitir a los ciudadanos acceder a información sobre las condiciones de construcción en su área, mientras que a los gobiernos les da una visión más clara y en tiempo real de cómo se desarrollan los proyectos, permitiendo la toma de decisiones basadas en datos.
Proyectos como ACCORD y CHECK demuestran cómo estas tecnologías pueden integrar la digitalización, la automatización y los datos abiertos para transformar el sector de la construcción en Europa.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Es una web que recopila información pública sobre el estado de los diferentes embalses que hay en España. El usuario puede filtrar la información por cuencas hidrográficas y unidades administrativas como provincias o comunidades autónomas.
Los datos se actualizan diariamente y se muestran con porcentajes y gráficas. Además, también ofrece información sobre pluviómetros y la comparación entre el porcentaje de agua embasada actual y la que había hace un año y hace 10 años.
Embales.net comparte de manera clara y entendible datos abiertos que obtiene de AEMET y el Ministerio de Transición Ecológica y Reto Demográfico.
Blog
Casi la mitad de los adultos europeos carecen de competencias digitales básicas. De acuerdo con el último informe sobre el estado de la Década Digital, en 2023, solo el 55,6% de los ciudadanos declararon tener este tipo de capacidades. Este porcentaje crece al 66,2% en el caso de España, situado por delante de la media europea.
Tener capacidades digitales básicas es esencial en la sociedad actual, porque permite acceder a una mayor cantidad de información y servicios, así como comunicarse de manera efectiva en entornos online, facilitando una mayor participación en actividades cívicas y sociales. Y también supone una gran ventaja competitiva en el mundo laboral.
En Europa, más del 90% de las funciones profesionales requieren un nivel básico de conocimientos digitales. Hace mucho tiempo que el conocimiento tecnológico dejó de ser únicamente necesario para profesiones técnicas, sino que se está extendiendo a todos los sectores, desde las empresas hasta el transporte e incluso la agricultura. En este sentido, más del 70% de las empresas han afirmado que la falta de personal con las competencias digitales adecuadas es un obstáculo para la inversión.
Por ello, un objetivo clave de la Década Digital es garantizar que al menos el 80% de las personas de entre 16 y 74 años posean al menos competencias digitales básicas de aquí a 2030
Capacidades tecnológicas básicas que todos deberíamos tener
Cuando hablamos de capacidades tecnológicas básicas nos referimos, de acuerdo con el framework DigComp, a diversas áreas, entre las que se encuentran:
- Alfabetización informacional y de datos: incluye localizar, recuperar, gestionar y organizar datos, juzgando la pertinencia de la fuente y su contenido.
- Comunicación y colaboración: supone interactuar, comunicarse y colaborar a través de las tecnologías digitales teniendo en cuenta la diversidad cultural y generacional. También incluye la gestión de la propia presencia, identidad y reputación digitales.
- Creación de contenidos digitales: se definiría como la mejora e integración de información y contenidos para generar nuevos mensajes, respetando los derechos de autor y las licencias. También implica saber dar instrucciones comprensibles para un sistema informático.
- Seguridad: se circunscribe a la protección de dispositivos, contenidos, datos personales y la intimidad en los entornos digitales, para proteger la salud física y mental.
- Resolución de problemas: permite identificar y resolver necesidades y problemas en entornos digitales. También se enfoca en el uso de herramientas digitales para innovar procesos y productos, manteniéndose al día de la evolución digital.
¿Qué puestos de trabajo relacionados con datos son los más demandados?
Una vez que tenemos claro cuáles son las competencias básicas, cabe destacar que en un mundo donde cada vez cobra más importancia la digitalización no es de extrañar que también crezca la demanda de conocimientos tecnológicos avanzados y relacionados con los datos.
De acuerdo con los datos de la plataforma de empleo LinkedIn, entre las 25 profesiones que más crecen en España en 2024 encontramos analistas de seguridad (puesto 1), analistas de desarrollo de software (2), ingenieros de datos (11) e ingenieros de inteligencia artificial (25). Datos similares ofrece el Mapa del Empleo de Fundación Telefónica, que además destaca cuatro de los perfiles más demandados relacionados con los datos:
- Analista de datos: encargados de la gestión y aprovechamiento de la información, se dedican a la recopilación, análisis y explotación de los datos, para lo cual suelen recurrir a la creación de cuadros de mando e informes.
- Diseñador/a o administrador/a de bases de datos: enfocados en diseñar, implementar y gestionar bases de datos. Así como mantener su seguridad, ejecutando procedimientos de respaldo y recuperación de datos en caso de fallos.
- Ingeniero/a de datos: responsables del diseño e implementación de arquitecturas de datos e infraestructuras para captar, almacenar, procesar y acceder a los datos, optimizando su rendimiento y garantizando su seguridad.
- Científico/a de datos: centrado en el análisis de datos y modelado predictivo, la optimización de algoritmos y la comunicación de resultados.
Todos ellos son puestos con buenos salarios y expectativas de futuro, en los que sin embargo sigue existiendo una gran brecha entre hombres y mujeres. De acuerdo con datos europeos, sólo 1 de cada 6 especialistas en TIC y 1 de cada 3 licenciados en ciencias, tecnología, ingeniería y matemáticas (STEM) son mujeres.
Para desarrollar profesiones relacionadas con los datos, se necesitan, entre otros, conocimientos de lenguajes de programación populares como Python, R o SQL, y múltiples herramientas de procesado y visualización de datos, como las detalladas en estos artículos:
- Herramientas de depuración y conversión de datos
- Herramientas de análisis de datos
- Herramientas de visualización de datos
- Librerías y APIs de visualización de datos
- Herramientas de visualización geoespacial
- Herramientas de análisis de redes
Actualmente la oferta de formaciones sobre todas estas capacidades no deja de crecer.
Perspectivas de futuro
Casi una cuarta parte de todos los puestos de trabajo (23%) cambiarán en los próximos cinco años, de acuerdo con el Informe sobre el Futuro del Empleo 2023 del Foro Económico Mundial. Los avances tecnológicos crearán nuevos empleos, transformarán los existentes y destruirán aquellos que se queden anticuados. Los conocimientos técnicos, relacionados con áreas como la inteligencia artificial o el Big Data, y el desarrollo de habilidades cognitivas, como el pensamiento analítico, supondrán grandes ventajas competitivas en el mercado laboral del futuro. En este contexto, las iniciativas políticas para impulsar la recapacitación de la sociedad, como el Plan europeo de Acción de Educación Digital (2021-2027), ayudaran a generar marcos y certificados comunes en un mundo en constante evolución.
La revolución tecnológica ha venido para quedarse y continuará cambiando nuestro mundo. Por ello, quienes antes empiecen a adquirir nuevas capacidades, tendrán una posición más ventajosa en el panorama laboral futuro.
Blog
La ciencia ciudadana se está consolidando como una de las fuentes de referencia más relevantes en la investigación contemporánea. Así lo reconoce el Centro Superior de Investigaciones Científicas (CSIC) que define la ciencia ciudadana como una metodología y un medio para el fomento de la cultura científica en la que confluyen estrategias propias de la ciencia y de la participación ciudadana.
Ya hablamos hace un tiempo de la importancia que la ciencia ciudadana tenía en la sociedad. Hoy en día, los proyectos de ciencia ciudadana no solo han aumentado en número, diversidad y complejidad, sino que también han impulsado un significativo proceso de reflexión sobre cómo la ciudadanía puede contribuir activamente a la generación de datos y conocimiento.
Para llegar a este punto, programas como Horizonte 2020, que reconocía explícitamente la participación ciudadana en ciencia, han jugado un papel fundamental. Más en concreto, el capítulo "Ciencia con y para la sociedad” dio un importante empuje a este tipo de iniciativas en Europa y también en España. De hecho, a raíz de la participación española en dicho programa, así como en iniciativas paralelas, los proyectos españoles han ido aumentando su envergadura y las conexiones con iniciativas internacionales.
Este creciente interés por la ciencia ciudadana también se traduce en políticas concretas. Ejemplo de ello es la actual Estrategia Española de Ciencia, Tecnología e Innovación (EECTI), para el periodo 2021-2027 que incluye “la responsabilidad social y económica de la I+D+I a través de la incorporación de la ciencia ciudadana”.
En definitiva, comentamos hace un tiempo, las iniciativas de ciencia ciudadana buscan incentivar una ciencia más democrática, que responda a los intereses de toda la ciudadanía y que genere información que se pueda reutilizar en pro de la sociedad. A continuación, mostramos algunos ejemplos de proyectos de ciencia ciudadana que ayudan a recolectar datos cuya reutilización puede tener un impacto positivo en la sociedad:
Proyecto AtmOOs Academic: Educación y ciencia ciudadana sobre contaminación atmosférica y movilidad.
En este programa, Thigis desarrolló una prueba piloto de ciencia ciudadana sobre movilidad y medio ambiente con los alumnos de un colegio del distrito del Eixample de Barcelona. Este proyecto, que ya es replicable en otros centros educativos, consiste en recoger datos de patrones de movilidad del alumnado para analizar cuestiones relacionadas con la sostenibilidad.
En la web de AtmOOs Academic se pueden visualizar los resultados de todas las ediciones que llevan realizándose anualmente desde el curso 2017-2018 y muestran información sobre los vehículos que emplean los alumnos para ir a clase o las emisiones generadas según etapa escolar.
WildINTEL: Proyecto de investigación sobre el monitoreo de vida en Huelva
La Universidad de Huelva y la Agencia Estatal de Investigaciones Científicas (CSIC) colaboran para construir un sistema de monitoreo de vida silvestre para obtener las variables esenciales de biodiversidad. Para llevarlo a cabo, se utilizan cámaras de fototrampeo de captura remota de datos e inteligencia artificial.
El proyecto WildINTEL se centra en el desarrollo de un sistema de monitoreo que sea escalable y reproducible, facilitando así la recolección y gestión eficiente de datos sobre biodiversidad. Este sistema incorporará tecnologías innovadoras para proporcionar estimaciones demográficas precisas y objetivas de las poblaciones y comunidades.
A través de este proyecto, que empezó en diciembre de 2023 y seguirá ejecutándose hasta diciembre de 2026, se espera conseguir herramientas y productos para mejorar la gestión de la biodiversidad no solo en la provincia de Huelva sino en toda Europa.
IncluScience-Me: Ciencia ciudadana en el aula para impulsar la cultura científica y la conservación de la biodiversidad.
Este proyecto de ciencia ciudadana que combina educación y biodiversidad surge de la necesidad de abordar la investigación científica en las escuelas. Para ello, el alumnado toma el rol de persona investigadora para abordar un reto real: rastrear e identificar los mamíferos que habitan en sus entornos cercanos para ayudar a la actualización de un mapa de distribución y, por ende, a su conservación.
IncluScience-Me nace en la Universidad de Córdoba y, en concreto, en el Grupo de Investigación en Educación y Gestión de la Biodiversidad (Gesbio), y ha sido posible gracias a la participación de la Universidad de Castilla-La Mancha y el Instituto de Investigación en Recursos Cinegéticos de Ciudad Real (IREC), con la colaboración de la Fundación Española para la Ciencia y la Tecnología - Ministerio de Ciencia, Innovación y Universidades.
La Memoria del Rebaño: Corpus documental de la vida pastoril.
Este proyecto de ciencia ciudadana que lleva activo desde julio de 2023 tiene como objetivo recabar conocimientos y experiencias de pastores y pastoras, en activo y jubilados, sobre el manejo de rebaños y la actividad ganadera.
La entidad responsable del programa es el Institut Català de Paleoecología Humana i Evolució Social aunque también colaboran el Museu Etnogràfic de Ripoll, Institució Milà i Fontanals-CSIC, Universidad Autònoma de Barcelona y Universidad Rovira i Virgili.
A través del programa, se ayuda a interpretar el registro arqueológico y contribuye a conservar los conocimientos de la práctica pastoril. Además, pone en valor la experiencia y los conocimientos de las personas mayores, un trabajo que contribuye a acabar con la connotación negativa de la “vejez” en una sociedad que prima la “juventud”, es decir, que pasen de ser considerados sujetos pasivos a ser considerados sujetos sociales activos.
Plastic Pirates España: Estudio de la contaminación por plástico en ríos europeos.
Es un proyecto de ciencia ciudadana que se ha llevado a cabo durante el último año con jóvenes de entre 12 y 18 años de las comunidades de Castilla y León y Cataluña pretende contribuir a generar evidencias científicas y concienciación ambiental sobre los residuos plásticos en los ríos.
Para ello, grupos de jóvenes de diferentes centros educativos, asociaciones y agrupaciones juveniles, han participado en campañas de muestreo donde se recogen datos de la presencia de residuos y basuras, principalmente plásticos y microplásticos en las riberas y agua de los ríos.
En España este proyecto lo ha coordinado el Centro Tecnológico BETA de la Universidad de Vic - Universidad Central de Cataluña junto a la Universidad de Burgos y la Fundación Oxígeno. Puedes acceder a más información en su página web.
Estos son algunos ejemplos de proyectos de ciencia ciudadana. Puedes consultar más en el Observatorio de Ciencia Ciudadana en España, una iniciativa que recoge múltiples recursos didácticos, informes y más información de interés sobre la ciencia ciudadana y su impacto en España. ¿Conoces algún otro proyecto? Mándanoslo a dinamizacion@datos.gob.es y podemos darlo a conocer a través de nuestros canales de difusión.
Blog
En la era digital actual, la compartición de datos y los datos abiertos (open data) han emergido como pilares fundamentales para la innovación, la transparencia y el desarrollo económico. Diversas compañías y organizaciones alrededor del mundo están adoptando estos enfoques para fomentar el acceso abierto a la información y potenciar la toma de decisiones basada en datos. A continuación, exploramos algunos ejemplos internacionales y nacionales de cómo estas prácticas están siendo implementadas.
Casos de éxito globales
Uno de los referentes globales en la compartición de datos es LinkedIn con su programa Data for Impact. Este programa facilita a gobiernos y organizaciones el acceso a datos económicos agregados y anonimizados, basados en el Economic Graph de LinkedIn, el cual representa la actividad profesional global. Es importante aclarar que los datos solo pueden utilizarse con fines de investigación y desarrollo. El acceso debe solicitarse vía email, adjuntando una propuesta para su evaluación, y se priorizan propuestas de gobiernos y organizaciones multilaterales. Estos datos han sido utilizados por entidades como el Banco Mundial y el Banco Central Europeo para informar de políticas y decisiones económicas clave. El enfoque de LinkedIn en la privacidad y la calidad de los datos asegura que estas colaboraciones beneficien tanto a las organizaciones como a los ciudadanos, promoviendo un crecimiento económico inclusivo, verde y alineado con las tecnologías digitales.
Por otro lado, el Registry of Open Data on AWS (RODA) es un repositorio gestionado Amazon Web Services (AWS) que alberga conjuntos de datos públicos. Los datasets no son proporcionados directamente por AWS, sino que son mantenidos por organizaciones gubernamentales, investigadores, empresas y particulares. Podemos encontrar, en el momento de escribir este post, más de 550 conjuntos de datos publicados por diferentes organizaciones, incluyendo algunas como el Allen Institute for Artificial Intelligence (AI2) o la propia NASA. Esta plataforma facilita que los usuarios aprovechen los servicios de computación en la nube de AWS para su análisis.
En el ámbito del periodismo de datos, FiveThirtyEight, propiedad de ABC News, ha adoptado un enfoque de transparencia radical al compartir públicamente los datos y códigos detrás de sus artículos y visualizaciones. Estos se encuentran accesibles a través de GitHub en formatos fácilmente reutilizables como CSV. Esta práctica no solo permite la verificación independiente de su trabajo, sino que también impulsa la creación de nuevas historias y análisis por parte de otros investigadores y periodistas. FiveThirtyEight se ha convertido en un modelo a seguir en lo relativo a cómo los datos abiertos pueden mejorar la calidad y la credibilidad del periodismo.
Casos de éxito en España
España no se queda atrás en cuanto a iniciativas de compartición de datos y open data por parte de compañías privadas. Varias empresas españolas están liderando iniciativas que promueven la accesibilidad y transparencia de los datos en diferentes sectores. Veamos algunos ejemplos.
Idealista, uno de los portales inmobiliarios más importantes del país, ha publicado un conjunto de datos abiertos que incluye información detallada sobre más de 180,000 viviendas en Madrid, Barcelona y Valencia. Este conjunto de datos proporciona las coordenadas geográficas y los precios de venta de cada propiedad, junto con sus características internas y la información oficial del catastro español. Este conjunto de datos está disponible para su acceso a través de GitHub como un paquete en R y se ha convertido en una gran herramienta para el análisis del mercado inmobiliario, permitiendo a investigadores y profesionales del sector desarrollar modelos de valoración automática y realizar estudios detallados sobre la segmentación del mercado. Cabe destacar que Idealista también reutiliza datos públicos de organismos como el catastro o el INE para ofrecer servicios de datos que dan soporte a las decisiones en el mercado inmobiliario, como contratación de hipotecas, estudios de mercado, valoración de carteras, etc.Por su parte BBVA, a través de su Fundación, ofrece acceso a un extenso fondo estadístico con bases de datos que incluyen cuadros, tablas y gráficos dinámicos. Estas bases de datos, de descarga libre, cubren temas como la productividad, la competitividad, el capital humano o la desigualdad en España, entre otros. Además, proporcionan series históricas sobre la economía española, inversiones, actividades culturales y gasto público. Estas herramientas están diseñadas para complementar publicaciones impresas y ofrecer una visión profunda sobre la evolución económica y social del país.
Además, Esri España habilita su Portal de Datos Abiertos, que pone a disposición de los usuarios una amplia variedad de contenidos que pueden ser consultados, analizados y descargados. Este portal incluye datos gestionados por Esri España, junto con una recopilación de otros portales de datos abiertos desarrollados con tecnología Esri. Esto amplía significativamente las posibilidades para investigadores, desarrolladores y profesionales que buscan aprovechar los datos geoespaciales en sus proyectos. Podemos encontrar conjuntos de datos en las categorías de salud, ciencia y tecnología o economía, entre otros.
En el ámbito de las empresas públicas, España también cuenta con ejemplos destacados de compromiso con los datos abiertos. Renfe, la principal operadora ferroviaria, y Red Eléctrica Española (REE), la entidad responsable de la operación del sistema eléctrico, han desarrollado programas de open data que facilitan el acceso a información relevante para la ciudadanía y para el desarrollo de aplicaciones y servicios que mejoren la eficiencia y la sostenibilidad. Destaca, en el caso de REE, la posibilidad de consumo de los datos disponibles a través de APIs REST, que facilitan la integración de aplicaciones sobre conjuntos de datos que reciben continuas actualizaciones sobre el estado de los mercados eléctricos.
Conclusión
La compartición de datos y el open data representan una evolución crucial en la forma en que las organizaciones gestionan y aprovechan la información. Desde gigantes tecnológicos internacionales como LinkedIn y AWS hasta innovadores nacionales como Idealista y BBVA, están proporcionando acceso abierto a los datos con el fin de impulsar un cambio significativo en cómo se toman decisiones, el desarrollo de políticas y la creación de nuevas oportunidades económicas. En España, tanto las empresas privadas como las públicas están mostrando un fuerte compromiso con estas prácticas, posicionando al país como un líder en la adopción de modelos de datos abiertos y de compartición de datos que beneficien a toda la sociedad.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.