Fecha publicación
04/01/2023
Comparte este contenido

Descripción
Llevamos años anunciando que la Inteligencia Artificial está viviendo uno de sus periodos más prolíficos y excitantes. Un momento en el que comienzan a verse aplicaciones y casos de uso donde la inteligencia humana se funde con la artificial. Algunas profesiones están cambiando para siempre. Los periodistas y escritores disponen ahora de herramientas de software que pueden escribir por ellos. Los creadores de contenido - imágenes o video - pueden pedirle a la máquina que, mediante una frase, que cree por ellos. En este post profundizamos en este último ejemplo. Hemos podido probar Dall-e 2 y nos hemos quedado de piedra con los resultados.
Introducción
Estos días, en la comunidad tecnológica del mundo entero, hay un murmullo de fondo, una excitación colectiva de todos los amantes de las tecnologías digitales y en particular de la inteligencia artificial. En varias ocasiones hemos mencionado en este espacio de comunicación las innovaciones de la compañía OpenAI. Hemos escrito varios artículos donde hablamos del algoritmo GPT-3 y de lo que es capaz en el campo del procesamiento del lenguaje natural. Recientemente, OpenAI ha ido eliminando las listas de espera (en las que muchos llevábamos tiempo inscritos) para permitirnos probar de forma limitada las capacidades del algoritmo GPT-3 implementado en diferentes tipos de aplicación.
Ejemplo de las múltiples aplicaciones de GPT-3 en el ámbito del lenguaje natural.
Recomendamos a nuestros lectores experimentar con la herramienta para completar texto, en la que con tan solo proporcionar una corta frase, la IA nos completa el texto con varios párrafos indistinguibles de la redacción de un humano. Los últimos días, están siendo frenéticos con multitud de personas probando la herramienta de Chat GPT-3. El nivel de naturalidad de la IA para mantener una conversación es, sencillamente, alucinante. Los resultados están impactando en casos de uso muy variados, como por ejemplo, la asistencia para programadores de software. Chat GPT-3 está siendo capaz de programar sencillas rutinas de código o algoritmos con tan solo describir en lenguaje natural lo que se quiere programar. Pero, el resultado impresiona más aún si caemos en que la IA es capaz de corregir sus propios errores de programación.
DALL-E
Dejando a un lado, las capacidades de generar lenguaje natural indistinguible del escrito por un humano, vamos al tema central de este post. Una de las aplicaciones más sorprendentes de la IA de OpenAI es la solución conocida cómo DALL-E. Qué mejor manera de presentar DALL-E que preguntarle a Chat GPT-3 qué es DALL-E.
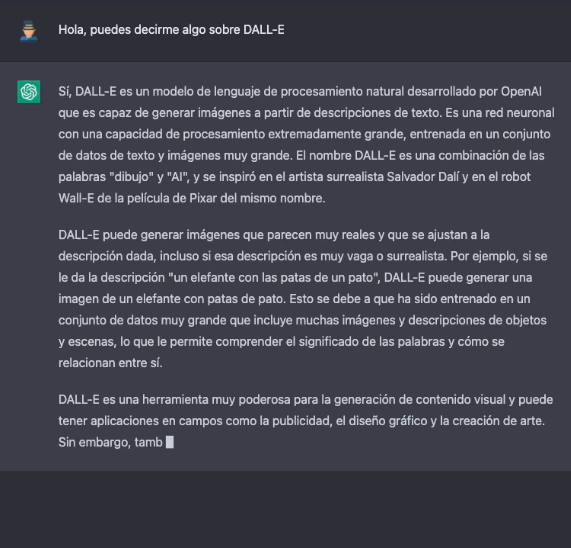
La descripción más formal de DALL-E, de acuerdo con su propia web es:
DALL·E es una versión de GPT-3 entrenado con 12 mil millones de parámetros para generar imágenes a partir de descripciones de texto. DALL-E tiene un conjunto diverso de capacidades, incluida la creación de versiones antropomórficas de animales y objetos, la combinación de conceptos no relacionados de manera plausible, la representación de texto y la aplicación de transformaciones a imágenes existentes.
Actualmente existe una segunda versión del algoritmo DALL-E 2 capaz de generar imágenes más realistas y precisas con una resolución 4 veces mayor. La herramienta para probar DALL-E está disponible aquí https://labs.openai.com/. Para usarla es necesario crear previamente una cuenta en OpenAI que nos permitirá jugar con todas las herramientas de la compañía. Cuándo accedemos a la web de prueba podemos escribir nuestro propio texto o pedirle a la herramienta que genere descripciones aleatorias de imágenes en lenguaje natural para crear imágenes. Por ejemplo, haciendo clic sobre el botón Surprise me:

La web nos genera esta descripción aleatoria: an astronaut lounging in a tropical resort in space, pixel art
Y este es el resultado:

Repetimos: an expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula

Podemos asegurar que el ejercicio resulta algo adictivo y damos fe de que algunos nos hemos pasado horas del fin de semana jugando con las descripciones y esperando, una y otra vez, el asombroso resultado.
Sobre el entrenamiento de DALL-E 2
DALL-E 2 (arXiv:2204.06125) es una versión refinada del sistema original DALL-E (arXiv:2102.12092). Para entrenar el modelo original de DALL-E, que contiene 12 mil millones de parámetros, se utilizó un conjunto de 250 millones de pares de texto-imagen (públicamente disponibles en Internet). Este conjunto de datos es una mezcla de varios datasets previos compuesto por: Conceptual Captions de Google; los pares de texto e imagen de Wikipedia y un subconjunto filtrado de YFCC100M.
Curiosidades de DALL-E 2
Algunas curiosidades más allá de las pruebas que podemos hacer para generar nuestras propias imágenes. OpenAI ha creado un repositorio específico de Github en el que describe los riesgos y limitaciones de DALL-E. En el sitio se informa, por ejemplo, de que, por el momento, el uso de DALL-E está limitado para propósitos no comerciales. Así que no es posible hacer ningún uso comercial de las imágenes generadas. Es decir, no pueden ser vendidas, ni licenciadas bajo ningún supuesto. En este sentido, todas las imágenes generadas por DALL-E incluyen una marca distintiva que permite saber que han sido generadas con la IA. En el sitio de Github podemos encontrar ingente cantidad de información sobre la generación de contenido explícito, los riesgos relacionados con el sesgo que la IA pueda introducir en la generación de imágenes y los usos inadecuados de DALL-E cómo por ejemplo, el acoso, el bullying o la explotación de individuos.

En clave nacional, MarIA
En clave nacional, tras meses de pruebas y ajustes, ha visto la luz MarIA: la primera inteligencia artificial supermasiva, entrenada con datos abiertos procedentes de los archivos web de la Biblioteca Nacional de España (BNE) y gracias a los recursos de computación del Centro Nacional de Supercomputación. En relación con este post, MarIA ha sido entrenada haciendo uso del algoritmo GPT-2, del que hemos hablado mucho meses atrás en este espacio. Para realizar el entrenamiento de MarIA, se han utilizado 135 mil millones de palabras precedentes del banco documental de la Biblioteca Nacional con un volumen total de 570 Gigabytes de información.
Conclusiones
A medida que transcurren los días y las semanas desde la apertura general de las APIs y las herramientas de OpenIA, se suceden torrencialmente las publicaciones en todo tipo de medios, redes sociales y blogs especializados sobre las capacidades y posibilidades de Chat GPT-3 y DALL-E. No creo que en estos momentos nadie sea capaz de avanzar las potenciales aplicaciones comerciales, científicas y sociales de esta tecnología. Lo que está claro, es que muchos pensamos que OpenAI ha enseñado solo una muestra de lo que es capaz y parece que podemos estar a las puertas de un hito histórico en el desarrollo de la IA tras muchos años de sobreexpectación y promesas a medio cumplir. Seguiremos informando sobre los avances de GTP-3, pero por el momento, no nos queda más que seguir disfrutando, jugando y aprendiendo con las sencillas herramientas que tenemos a disposición!
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Hola me parece que sobre IA deberiamos estar bien atentos a la informacion que es open data ya que esta claro que es el futuro de muchas cosas. gracias por dar a conocer a todos esta informacion.