Comparte este contenido
Descripción
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en GitHub.
Captura del vídeo que muestra la interacción con el dashboard de la caracterización de la demanda de empleo y la contratación registrada en España disponible al final de este artículo
2. Objetivos
El objetivo principal de este post es realizar una visualización interactiva partiendo de datos abiertos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre la evolución de la demanda de empleo en España a lo largo de los últimos años. A partir de estos datos se determina el perfil que representa la demanda de empleo en nuestro país, estudiando específicamente cómo afecta la brecha de género al colectivo y la incidencia de variables como la edad, la prestación por desempleo o la región.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se han seleccionado conjuntos de datos publicados por el Servicio Público de Empleo Estatal (SEPE), coordinado por el Ministerio de Trabajo y Economía Social, que recogen series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presentan los demandantes de empleo. Estos datasets se encuentran disponibles en datos.gob.es con las siguientes características:
- Demandantes de empleo por municipio: contiene el número de demandantes de empleo desagregado por municipio, edad y sexo, desde 2006 hasta 2020.
- Gasto de prestaciones por desempleo por Provincia: serie temporal desde 2010 hasta 2020 sobre el gasto en prestaciones por desempleo, desagregado por provincia y el tipo de prestación.
- Contratos registrados por el Servicio Público de Empleo Estatal (SEPE) por municipio: estos conjuntos de datos contienen el número de contratos registrados tanto a demandantes como a no demandantes de empleo, desagregados por municipio, sexo y tipo de contrato, desde 2006 hasta 2020.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
RStudio es un entorno de desarrollo open source integrado para el lenguaje de programación R, dedicado al análisis estadístico y la creación de gráficos.
RMarkdown permite la realización de informes integrando texto, código y resultados dinámicos en un único documento.
Para la creación de los gráficos interactivos se ha utilizado la herramienta Kibana.
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstasg y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch. Las principales ventajas de esta herramienta son:
- Presenta la información de manera visual a través de dashboards interactivos y personalizables mediante intervalos temporales, filtros facetados por rango, cobertura geoespacial, entre otros.
- Dispone de un catálogo de herramientas de desarrollo (Dev Tools) para interactuar con los datos almacenados en Elasticsearch.
- Cuenta con una versión gratuita para utilizar en tu propio ordenador y una versión enterprise que se desarrolla en un cloud propio de Elastic u otras infraestructuras en cloud como Amazon Web Service (AWS).
En la propia web de Elastic encontramos manuales de usuario para la descarga e instalación de la herramienta, o cómo crear gráficos o dashboards, entre otros. Además ofrece vídeos cortos en su canal de youtube y organiza webinars donde explican diversos aspectos relacionados con Elastic Stack.
Si quieres saber más sobre estas herramientas u otras que pueden ayudarte en el procesado de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Para la realización una visualización, es necesario preparar los datos de la forma adecuada realizando una serie de tareas que incluyen el preprocesado y el análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer la realidad de los datos a los que nos enfrentamos. El objetivo es identificar características de los datos y detectar las posibles anomalías o errores que pudieran afectar a la calidad de los resultados. Un tratamiento previo de los datos es esencial para que los análisis o las visualizaciones que se realicen posteriormente sean consistentes y efectivas.
Para favorecer el entendimiento de los lectores no especialistas en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo clik en \"Código\", no está diseñado para su eficiencia sino para su fácil comprensión, por lo que es posible que lectores más avanzados en este lenguaje de programación consideren una forma de codificar algunas funcionalidades de forma alternativa. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en cuenta en GitHub de datos.gob.es. La forma de proporcionar el código es a través de un documento de RMarkdown. Una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
El paquete base de R, siempre disponible desde que abrimos la consola en RStudio, incorpora un amplio conjunto de funcionalidades para cargar datos de fuentes externas, llevar a cabo análisis estadísticos y obtener representaciones gráficas. No obstante, hay multitud de tareas para las que necesitamos recurrir a paquetes adicionales incorporando al entorno de trabajo las funciones y objetos definidos en ellas. Algunos de ellos ya están instalados en el sistema, pero otros será preciso descargarlos e instalarlos.
#Instalación de paquetes \r\n #El paquete dplyr presenta una colección de funciones para realizar de manera sencilla operaciones de manipulación de datos \r\n if (!requireNamespace(\"dplyr\", quietly = TRUE)) {install.packages(\"dplyr\")}\r\n #El paquete lubridate para el manejo de variables tipo fecha \r\n if (!requireNamespace(\"lubridate\", quietly = TRUE)) {install.packages(\"lubridate\")}\r\n#Carga de paquetes en el entorno de desarrollo \r\nlibrary (dplyr)\r\nlibrary (lubridate)\r\n4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros .CSV y .XLS. Debemos cargar en nuestro entorno de desarrollo todos los ficheros que nos interesan. El siguiente código muestra como ejemplo la carga de un único fichero .CSV en una tabla de datos para que la lectura de este post sea más comprensible.
Para agilizar el proceso de carga en el entorno de desarrollo, es necesario descargar en el directorio de trabajo los conjuntos de datos necesarios para esta visualización, que se encuentran disponibles en la cuenta de GitHub de datos.gob.es.
#Carga del datasets de demandantes de empleo por municipio de 2020. \r\n Demandantes_empleo_2020 <- \r\n read.csv(\"Conjuntos de datos/Demandantes de empleo por Municipio/Dtes_empleo_por_municipios_2020_csv.csv\",\r\n sep=\";\", skip = 1, header = T)\r\nUna vez que tenemos todos los conjuntos de datos cargados como tablas en el entorno de desarrollo, debemos unificarlos para así tener un único dataset que integre todos los años de la serie temporal, por cada una de las características relacionadas con los demandantes de empleo que se quiere analizar: número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados por el SEPE.
#Dataset de demandantes de empleo\r\nDatos_desempleo <- rbind(Demandantes_empleo_2006, Demandantes_empleo_2007, Demandantes_empleo_2008, Demandantes_empleo_2009, \r\n Demandantes_empleo_2010, Demandantes_empleo_2011,Demandantes_empleo_2012, Demandantes_empleo_2013,\r\n Demandantes_empleo_2014, Demandantes_empleo_2015, Demandantes_empleo_2016, Demandantes_empleo_2017, \r\n Demandantes_empleo_2018, Demandantes_empleo_2019, Demandantes_empleo_2020) \r\n#Dataset de gasto en prestaciones por desempleo\r\ngasto_desempleo <- rbind(gasto_2010, gasto_2011, gasto_2012, gasto_2013, gasto_2014, gasto_2015, gasto_2016, gasto_2017, gasto_2018, gasto_2019, gasto_2020)\r\n#Dataset de nuevos contratos a demandantes de empleo\r\nContratos <- rbind(Contratos_2006, Contratos_2007, Contratos_2008, Contratos_2009,Contratos_2010, Contratos_2011, Contratos_2012, Contratos_2013, \r\n Contratos_2014, Contratos_2015, Contratos_2016, Contratos_2017, Contratos_2018, Contratos_2019, Contratos_2020)b. Selección de variables
Una vez que tenemos las tablas con las tres series temporales (número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados), crearemos una nueva tabla que incluirá las variables que interesan de cada una de ellas.
En primer lugar, agregaremos por provincia las tablas de demandantes de empleo (“datos_desempleo”) y contratos nuevos contratos registrados (“contratos”) para facilitar la visualización y que coincidan con la desagregación por provincia de la tabla de gasto en prestaciones por desempleo (“gasto_desempleo”). En este paso, seleccionamos únicamente las variables que interesen de los tres conjuntos de datos.
#Realizamos un group by al dataset de \"datos_desempleo\", agruparemos las variables numéricas que nos interesen, en función de varias variables categóricas\r\nDtes_empleo_provincia <- Datos_desempleo %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(total.Dtes.Empleo = (sum(total.Dtes.Empleo)), Dtes.hombre.25 = (sum(Dtes.Empleo.hombre.edad...25)), \r\n Dtes.hombre.25.45 = (sum(Dtes.Empleo.hombre.edad.25..45)), Dtes.hombre.45 = (sum(Dtes.Empleo.hombre.edad...45)),\r\n Dtes.mujer.25 = (sum(Dtes.Empleo.mujer.edad...25)), Dtes.mujer.25.45 = (sum(Dtes.Empleo.mujer.edad.25..45)),\r\n Dtes.mujer.45 = (sum(Dtes.Empleo.mujer.edad...45)))\r\n#Realizamos un group by al dataset de \"contratos\", agruparemos las variables numericas que nos interesen en función de las varibles categóricas.\r\nContratos_provincia <- Contratos %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(Total.Contratos = (sum(Total.Contratos)),\r\n Contratos.iniciales.indefinidos.hombres = (sum(Contratos.iniciales.indefinidos.hombres)), \r\n Contratos.iniciales.temporales.hombres = (sum(Contratos.iniciales.temporales.hombres)), \r\n Contratos.iniciales.indefinidos.mujeres = (sum(Contratos.iniciales.indefinidos.mujeres)), \r\n Contratos.iniciales.temporales.mujeres = (sum(Contratos.iniciales.temporales.mujeres)))\r\n#Seleccionamos las variables que nos interesen del dataset de \"gasto_desempleo\"\r\ngasto_desempleo_nuevo <- gasto_desempleo %>% select(Código.mes, Comunidad.Autónoma, Provincia, Gasto.Total.Prestación, Gasto.Prestación.Contributiva)En segundo lugar, procedemos a unir las tres tablas en una que será con la que trabajemos a partir de este punto.
Caract_Dtes_empleo <- Reduce(merge, list(Dtes_empleo_provincia, gasto_desempleo_nuevo, Contratos_provincia))
c. Transformación de variables
Una vez tengamos la tabla con las variables de interés para el análisis y la visualización, debemos transformar algunas de ellas a otros tipos más adecuados para futuras agregaciones.
#Transformación de una variable fecha\r\nCaract_Dtes_empleo$Código.mes <- as.factor(Caract_Dtes_empleo$Código.mes)\r\nCaract_Dtes_empleo$Código.mes <- parse_date_time(Caract_Dtes_empleo$Código.mes(c(\"200601\", \"ym\")), truncated = 3)\r\n#Transformamos a variable numérica\r\nCaract_Dtes_empleo$Gasto.Total.Prestación <- as.numeric(Caract_Dtes_empleo$Gasto.Total.Prestación)\r\nCaract_Dtes_empleo$Gasto.Prestación.Contributiva <- as.numeric(Caract_Dtes_empleo$Gasto.Prestación.Contributiva)\r\n#Transformación a variable factor\r\nCaract_Dtes_empleo$Provincia <- as.factor(Caract_Dtes_empleo$Provincia)\r\nCaract_Dtes_empleo$Comunidad.Autónoma <- as.factor(Caract_Dtes_empleo$Comunidad.Autónoma)d. Análisis exploratorio
Veamos qué variables y estructura presenta el nuevo conjunto de datos.
str(Caract_Dtes_empleo)\r\nsummary(Caract_Dtes_empleo)La salida de esta porción de código se omite para facilitar la lectura. Las características principales que presenta el conjunto de datos son:
- El rango temporal abarca desde enero de 2010 hasta diciembre de 2020.
- El número de columnas (variables) es de 17.
- Presenta dos variables categóricas (“Provincia” y “Comunidad.Autónoma”), una variable tipo fecha (“Código.mes”) y el resto son variables numéricas.
e. Detección y tratamiento de datos perdidos
Seguidamente analizaremos si el dataset presenta valores perdidos (NAs). El tratamiento o la eliminación de los NAs es esencial, ya que si no es así no será posible procesar adecuadamente las variables numéricas.
any(is.na(Caract_Dtes_empleo)) \r\n#Como el resultado es \"TRUE\", eliminamos los datos perdidos del dataset, ya que no sabemos cual es la razón por la cual no se encuentran esos datos\r\nCaract_Dtes_empleo <- na.omit(Caract_Dtes_empleo)\r\nany(is.na(Caract_Dtes_empleo))4.3. Creación de nuevas variables
Para realizar la visualización, vamos a crear una nueva variable a partir de dos variables que se encuentran en la tabla de datos. Esta acción es muy común en el análisis de datos ya que en ocasiones interesa trabajar con datos calculados (por ejemplo, la suma o la media de diferentes variables) en lugar de los datos de origen. En este caso vamos a calcular el gasto medio en prestaciones por desempleo para cada demandante de empleo. Para ello utilizaremos las variables de gasto total por prestación (“Gasto.Total.Prestación”) y el total de demandantes de empleo (“total.Dtes.Empleo”).
Caract_Dtes_empleo$gasto_desempleado <-\r\n (1000 * (Caract_Dtes_empleo$Gasto.Total.Prestación/\r\n Caract_Dtes_empleo$total.Dtes.Empleo))4.4. Guardar el dataset
Una vez que tenemos la tabla con las variables que nos interesan para los análisis y las visualizaciones, la guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos. Es importante utilizar la codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta.
write.csv(Caract_Dtes_empleo,\r\n file=\"Caract_Dtes_empleo_UTF8.csv\",\r\n fileEncoding= \"UTF-8\")5. Creación de la visualización sobre la caracterización de la demanda de empleo en España usando Kibana
El desarrollo de esta visualización interactiva se ha realizado usando Kibana en nuestro entorno local. Tanto para la descarga del software, como para la instalación del mismo, hemos recurrido al tutorial realizado por la propia compañía, Elastic.
A continuación se adjunta un vídeo tutorial donde se muestra todo el proceso de realización de la visualización. En el vídeo podrás ver la creación de un cuadro de mando (dashboard) con diferentes indicadores interactivos mediante la generación de representaciones gráficas de diferentes tipos. Los pasos para obtener el dashboard son los siguientes:
- Cargamos los datos en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos en los archivos cargados, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
- Gráfico de líneas para representar la serie temporal sobre los demandantes de empleo en España desde 2006 hasta 2020.
- Gráfico de sectores de los demandantes de empleo desagregados por Provincia y Comunidad Autónoma.
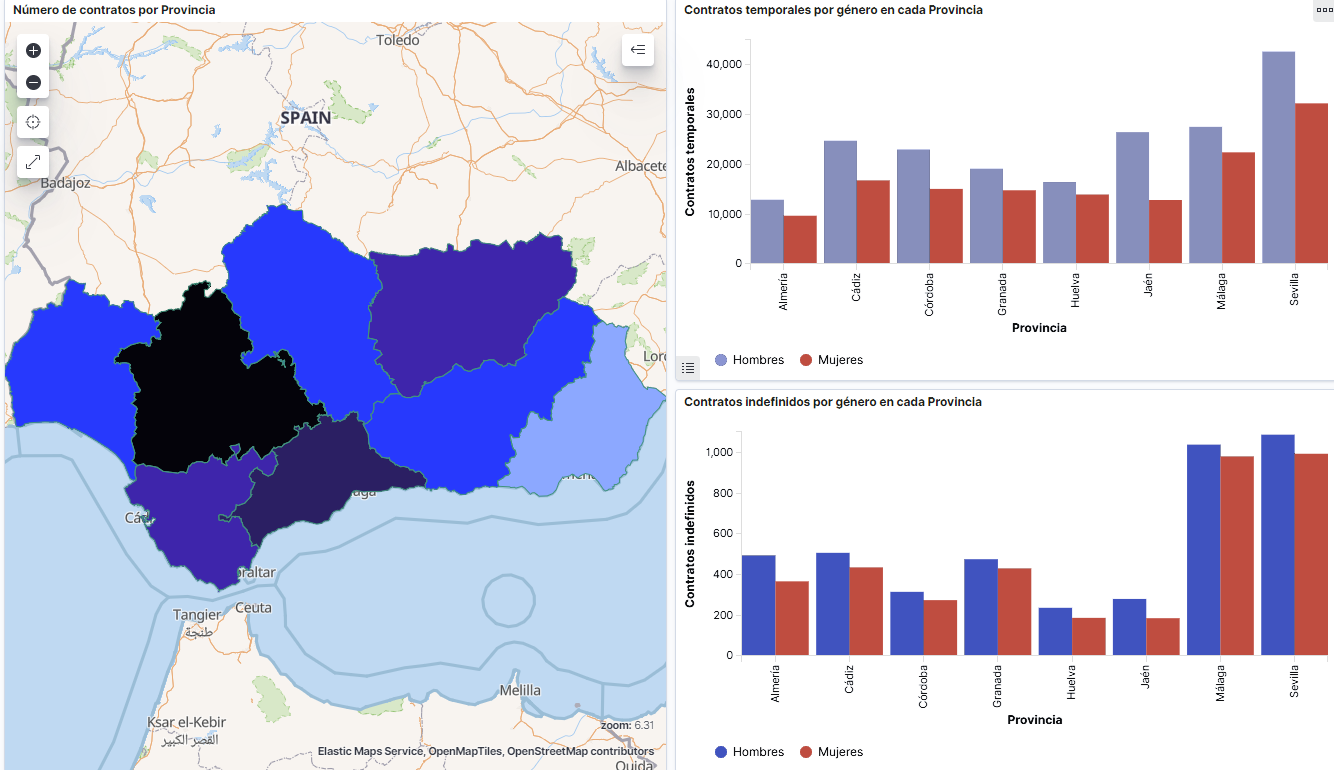
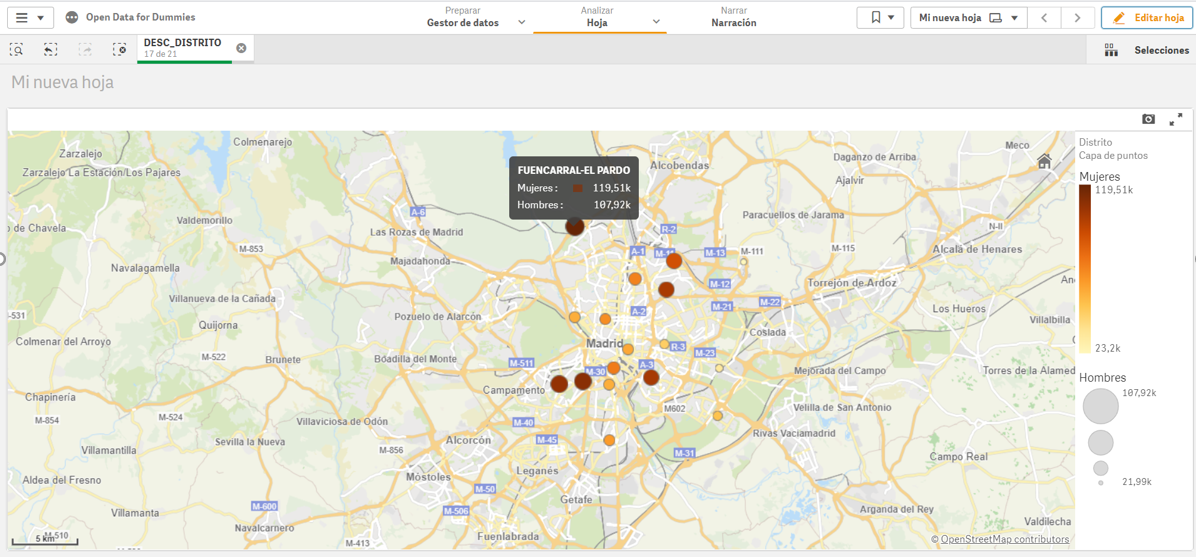
- Mapa temático, mostrando el número de contratos nuevos registrados en cada Provincia del territorio. Para la creación de este visual es necesaria la descarga de un dataset de la georeferenciación de las Provincias publicado en el portal de datos abiertos Open Data Soft.
- Construcción del dashboard.
Seguidamente mostraremos un vídeo tutorial interactuando con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre el perfil de los demandantes de empleo en España en el periodo 2010 hasta 2020, se pueden obtener, entre otras, las siguientes conclusiones:
- Existen dos incrementos significativos en el número de demandantes de empleo. El primero aproximadamente en 2010, que coincide con la crisis económica. El segundo, mucho más pronunciado en 2020, que coincide con la crisis derivada de la pandemia.
- Se observa que existe una brecha de género en el colectivo de demandantes de empleo: el número de mujeres demandantes de empleo es mayor a lo largo de toda la serie temporal, principalmente en los grupos de edad de mayores de 25.
- A nivel regional, Andalucía, seguida de Cataluña y Comunidad Valenciana, son las Comunidades Autónomas con mayor número de demandantes de empleo. En contraste, Andalucía, es la Comunidad Autónoma con menor gasto por desempleo, mientras que Cataluña, es la que presenta mayor gasto por desempleo.
- Los contratos de tipo temporal son los prioritarios y las provincias que generan mayor número de contratos son Madrid y Barcelona, que coinciden con las provincias con mayor número de habitantes, mientras que en el lado opuesto, las provincias que menos número de contratos realizan son Soria, Ávila, Teruel o Cuenca, que coincide con las zonas más despobladas de España.
Esta visualización nos ha ayudado a sintetizar gran cantidad de información y darle sentido pudiendo obtener unas conclusiones y si fuera necesario tomar decisiones en función de los resultados. Esperemos que os haya gustado este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!
Documentación
| Código fuente en R | 13.22KB | RMD |
|

Comentarios