Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos la actual situación de la penetración de los vehículos eléctricos en España y las perspectivas de futuro de esta tecnología disruptiva en el transporte.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto: ¿Por qué es importante el vehículo eléctrico?
La transición hacia una movilidad más sostenible se ha convertido en una prioridad global, situando al vehículo eléctrico (VE) en el centro de numerosas discusiones sobre el futuro del transporte. En España, esta tendencia hacia la electrificación del parque automovilístico no solo responde a un creciente interés por parte de los consumidores en tecnologías más limpias y eficientes, sino también a un marco regulatorio y de incentivos diseñado para acelerar la adopción de estos vehículos. Con una creciente oferta de modelos eléctricos disponibles en el mercado, los vehículos eléctricos representan una pieza clave en la estrategia del país para reducir las emisiones de gases de efecto invernadero, mejorar la calidad del aire en las ciudades y fomentar la innovación tecnológica en el sector automotriz.
Sin embargo, la penetración de los vehículos eléctricos en el mercado español enfrenta una serie de desafíos, desde la infraestructura de carga hasta la percepción y el conocimiento del consumidor sobre estos vehículos. La expansión de la red de carga, junto con las políticas de apoyo y los incentivos fiscales, son fundamentales para superar las barreras existentes y estimular la demanda. A medida que España avanza hacia sus objetivos de sostenibilidad y transición energética, el análisis de la evolución del mercado de vehículos eléctricos se convierte en una herramienta esencial para entender el progreso realizado y los obstáculos que aún deben superarse.
3. Objetivo
Este ejercicio se centra en mostrar al lector técnicas para el tratamiento, visualización y análisis avanzado de datos abiertos mediante Python. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender la utilización de estas herramientas en el contexto de la resolución de un reto real y de actualidad como es el estudio de la penetración del VE en España. Este enfoque práctico no solo mejora la comprensión de las herramientas de ciencia de datos, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
Las preguntas a las que trataremos de dar respuesta a través de nuestro análisis son:
- ¿Qué marcas de vehículos lideraron el mercado en 2023?
- ¿Qué modelos de vehículos fueron los más vendidos en el 2023?
- ¿Qué cuota de mercado absorbieron los vehículos eléctricos en el 2023?
- ¿Qué modelos de vehículos eléctricos fueron los más vendidos en el 2023?
- ¿Cómo han evolucionado las matriculaciones de vehículos a lo largo del tiempo?
- ¿Observamos algún tipo de tendencia respecto a la matriculación de vehículos eléctricos?
- ¿Cómo esperamos que evolucionen las matriculaciones de vehículos eléctricos el próximo año?
- ¿Cuál es la reducción de emisiones de CO2 que podemos esperar gracias a las matriculaciones obtenidas durante el próximo año?
4. Recursos
Para completar el desarrollo de este ejercicio requeriremos el uso de dos categorías de recursos: Herramientas Analíticas y Conjuntos de Datos.
4.1. Conjunto de datos
Para completar este ejercicio utilizaremos un conjunto de datos provisto por la Dirección General de Tráfico (DGT) a través de su portal estadístico, también disponible desde el catálogo Nacional de Datos Abiertos (datos.gob.es). El portal estadístico de la DGT es una plataforma en línea destinada a ofrecer acceso público a una amplia gama de datos y estadísticas relacionadas con el tráfico y la seguridad vial. Este portal incluye información sobre accidentes de tráfico, infracciones, matriculaciones de vehículos, permisos de conducción y otros datos relevantes que pueden ser útiles para investigadores, profesionales del sector y el público en general.
En nuestro caso, utilizaremos su conjunto de datos de matriculaciones de vehículos en España disponibles vía:
- Catálogo de Datos Abiertos del Gobierno de España.
- Portal estadístico de la DGT.
Aunque durante el desarrollo del ejercicio mostraremos al lector los mecanismos necesarios para su descarga y procesamiento, incluimos en el repositorio de GitHub asociado los datos preprocesados*, de tal forma que el lector pueda proceder directamente al análisis de los mismos en el caso de que lo desee.
*Los datos utilizados en este ejercicio fueron descargados el 04 de marzo de 2024. La licencia aplicable a este conjunto de datos puede encontrarse en https://datos.gob.es/avisolegal.
4.2. Herramientas analíticas
- Lenguaje de programación: Python – es un lenguaje de programación ampliamente utilizado en análisis de datos debido a su versatilidad y a la amplia gama de bibliotecas disponibles. Estas herramientas permiten a los usuarios limpiar, analizar y visualizar grandes conjuntos de datos de manera eficiente, lo que hace de Python una elección popular entre los científicos de datos y analistas.
- Plataforma: Jupyter Notebooks – es una aplicación web que permite crear y compartir documentos que contienen código vivo, ecuaciones, visualizaciones y texto narrativo. Se utiliza ampliamente para la ciencia de datos, análisis de datos, aprendizaje automático y educación interactiva en programación.
- Principales librerías y módulos:
- Manipulación de datos: Pandas – es una librería de código abierto que proporciona estructuras de datos de alto rendimiento y fáciles de usar, así como herramientas de análisis de datos.
- Visualización de datos:
- Matplotlib: es una librería para crear visualizaciones estáticas, animadas e interactivas en Python.
- Seaborn: es una librería basada en Matplotlib. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.
- Estadística y algoritmia:
- Statsmodels: es una librería que proporciona clases y funciones para la estimación de muchos modelos estadísticos diferentes, así como para realizar pruebas y exploración de datos estadísticos.
- Pmdarima: es una librería especializada en la modelización automática de series temporales, facilitando la identificación, el ajuste y la validación de modelos para pronósticos complejos.
5. Desarrollo del ejercicio
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
El ejercicio propuesto se divide en cuatro fases principales.
5.1 Configuración inicial
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este breve primer apartado, configuraremos nuestro Jupyter Notebook y nuestro entorno de trabajo para poder trabajar con el conjunto de datos seleccionado. Importaremos las librerías Python necesarias y crearemos algunos directorios donde almacenaremos los datos descargados.
5.2 Preparación de datos
Este apartado podrás encontrarlo en el punto 2 del Notebook.
Todo análisis de datos requiere una fase de acceso y tratamiento de los mismos hasta obtener los datos adecuados en el formato deseado. En esta fase, descargaremos los datos del portal estadístico y los transformaremos al formato Apache Parquet antes de proceder a su análisis.
Aquellos usuarios que quieran profundizar en esta tarea, tienen a su disposición la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
5.3 Análisis de datos
Este apartado podrás encontrarlo en el punto 3 del Notebook.
5.3.1 Análisis descriptivo
En esta tercera fase, comenzaremos nuestro análisis de datos. Para ello, responderemos las primeras preguntas apoyándonos en herramientas de visualización de datos que además nos permitirán familiarizarnos con los mismos. Mostramos a continuación algunos ejemplos del análisis:
- Top 10 Vehículos matriculados en el 2023: En esta visualización representamos los diez modelos de vehículos con mayor número de matriculaciones durante el año 2023, indicando además el tipo de combustión de estos. Las principales conclusiones son:
- Los únicos vehículos de fabricación europea que aparecen en el Top 10 son el Arona y el Ibiza de la marca española SEAT. El resto son asiáticos.
- Nueve de los diez vehículos están propulsados por Gasolina.
- El único vehículo del Top 10 con un tipo de propulsión diferente es el DACIA Sandero GLP (Gas Licuado de Petróleo).
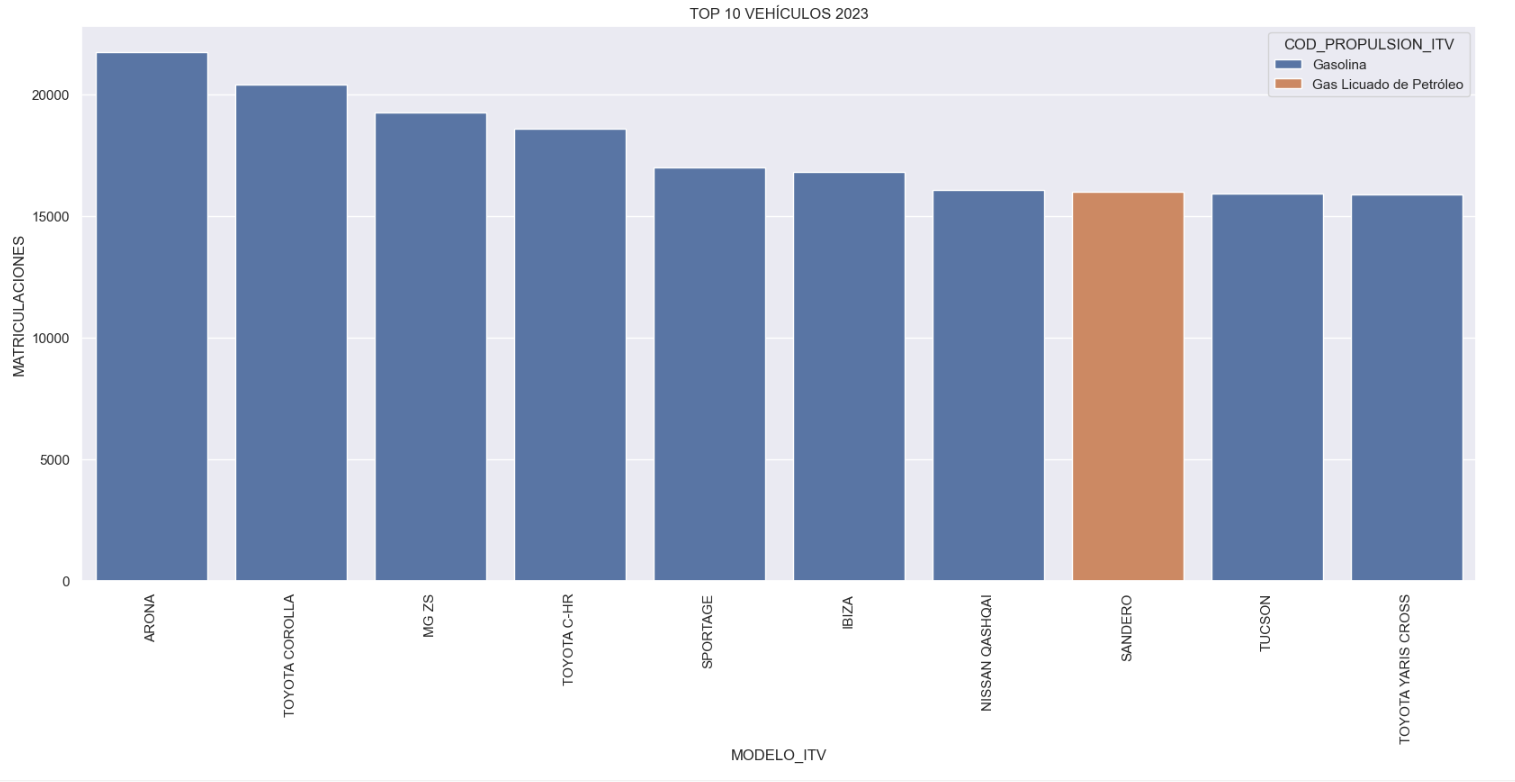
Figura 1. Gráfica "Top 10 Vehículos matriculados en el 2023"
- Cuota de mercado por tipo de propulsión: En esta visualización representamos el porcentaje de vehículos matriculado por cada tipo de propulsión (vehículos de gasolina, diésel, eléctricos u otros). Vemos cómo la inmensa mayoría del mercado (>70%) la absorbieron vehículos de gasolina, siendo los diésel la segunda opción, y como los vehículos eléctricos alcanzaron el 5.5%.
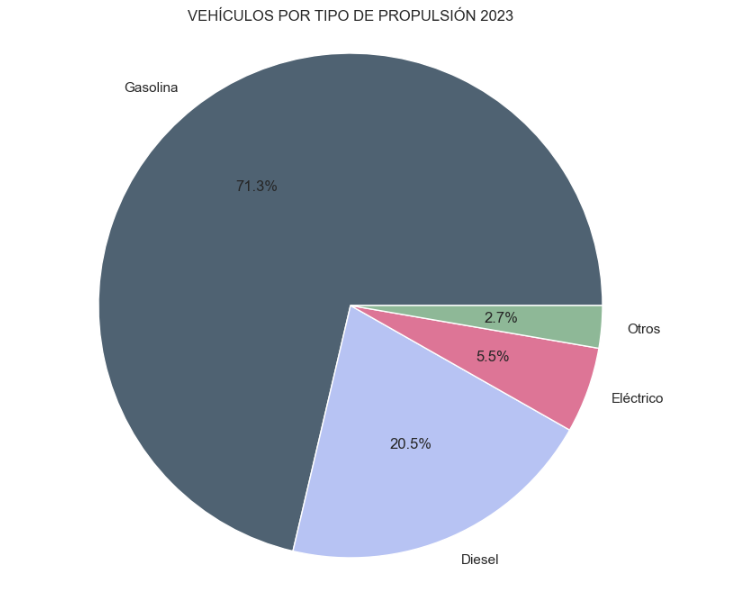
Figura 2. Gráfica "Cuota de mercado por tipo de propulsión".
- Evolución histórica de las matriculaciones: Esta visualización representa la evolución de las matriculaciones de vehículos en el tiempo. En ella se muestra el número de matriculaciones mensual entre enero de 2015 y diciembre de 2023 distinguiendo entre los tipos de propulsión de los vehículos matriculados.Podemos observar varios aspectos interesantes en este gráfico:
- Apreciamos un comportamiento estacional anual, es decir, observamos patrones o variaciones que se repiten a intervalos regulares de tiempo. Vemos cómo recurrentemente en junio/julio aparecen altos niveles de matriculación mientras que en agosto/septiembre decrecen drásticamente. Esto es muy relevante, pues el análisis de series temporales con factor estacional tiene ciertas particularidades.
- Es muy notable también la enorme caída de matriculaciones producida durante los primeros meses del COVID.
- Vemos también como los niveles de matriculación post-covid son inferiores a los previos.
- Por último, podemos observar cómo entre los años 2015 y 2023 la matriculación de vehículos eléctricos va creciendo paulatinamente.
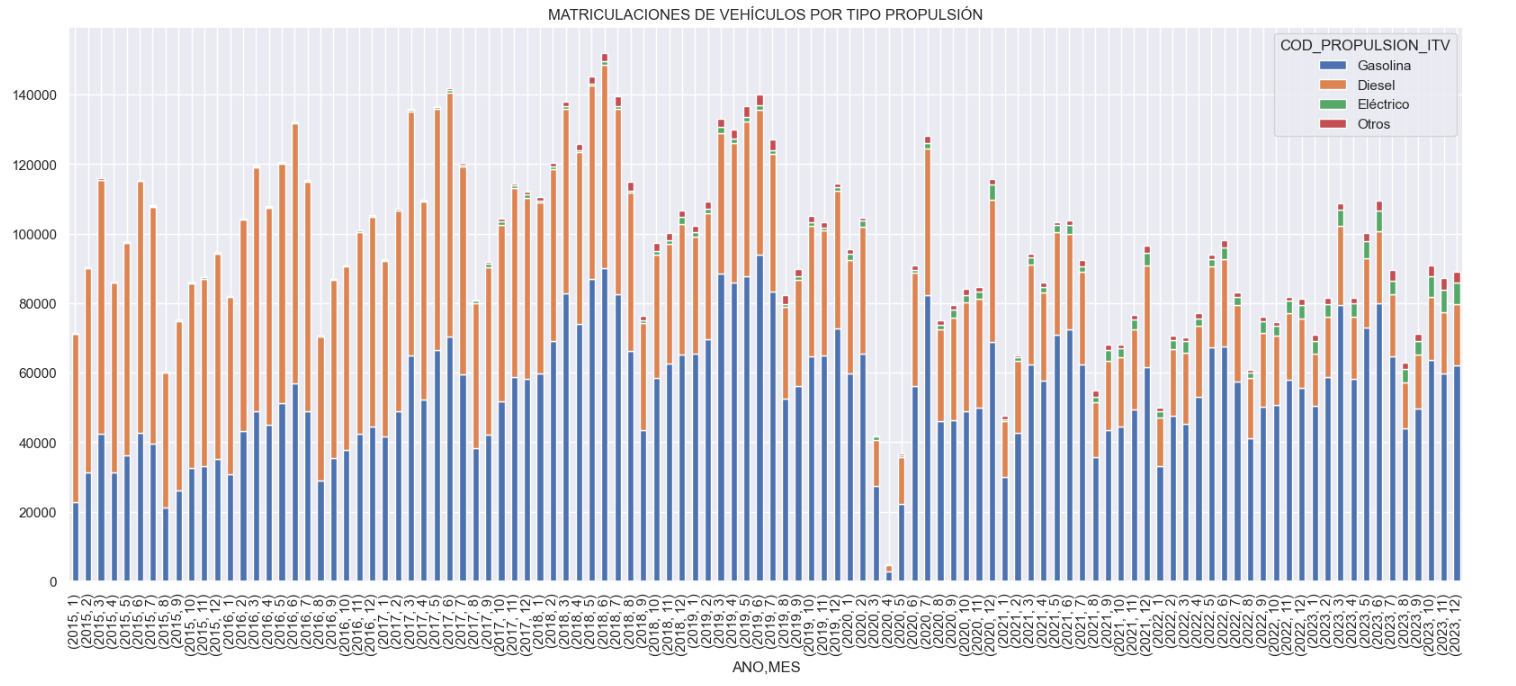
Figura 3. Gráfica "Matriculaciones de vehículos por tipo de propulsión".
- Tendencia en la matriculación de vehículos eléctricos: Analizamos ahora por separado la evolución de vehículos eléctricos y no eléctricos utilizando mapas de calor como herramienta visual. Podemos observar comportamientos muy diferenciados entre ambos gráficos. Observamos cómo el vehículo eléctrico presenta una tendencia de incremento de matriculaciones año a año y, a pesar de suponer el COVID un parón en la matriculación de vehículos, los años posteriores han mantenido la tendencia creciente.
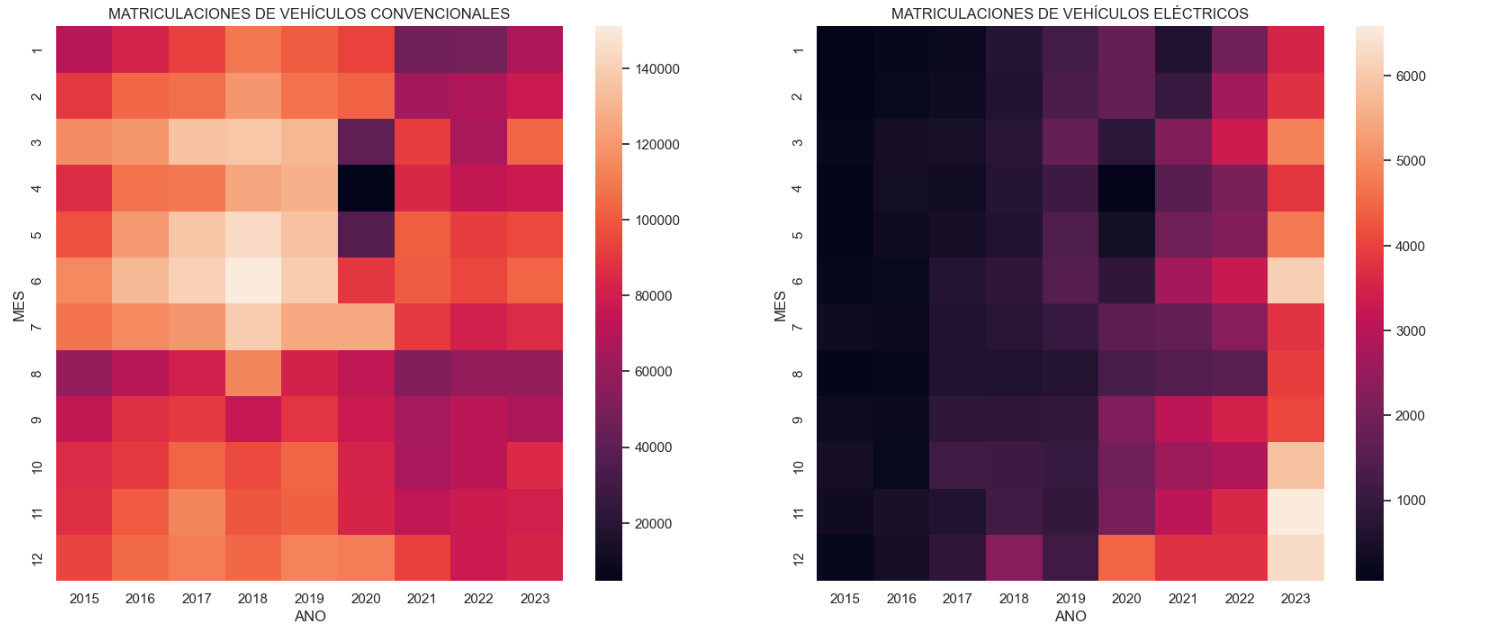
Figura 4. Gráfica "Tendencia en la matriculación de vehículos convencionales vs eléctricos".
5.3.2. Analítica predictiva
Para dar respuesta a la última de las preguntas de forma objetiva, utilizaremos modelos predictivos que nos permitan realizar estimaciones respecto a la evolución del vehículo eléctrico en España. Como podemos observar, el modelo construido nos propone una continuación del crecimiento en las matriculaciones esperadas a lo largo del año serán de 70.000, alcanzando valores cercanos a las 8.000 matriculaciones solo en el mes de diciembre del 2024.
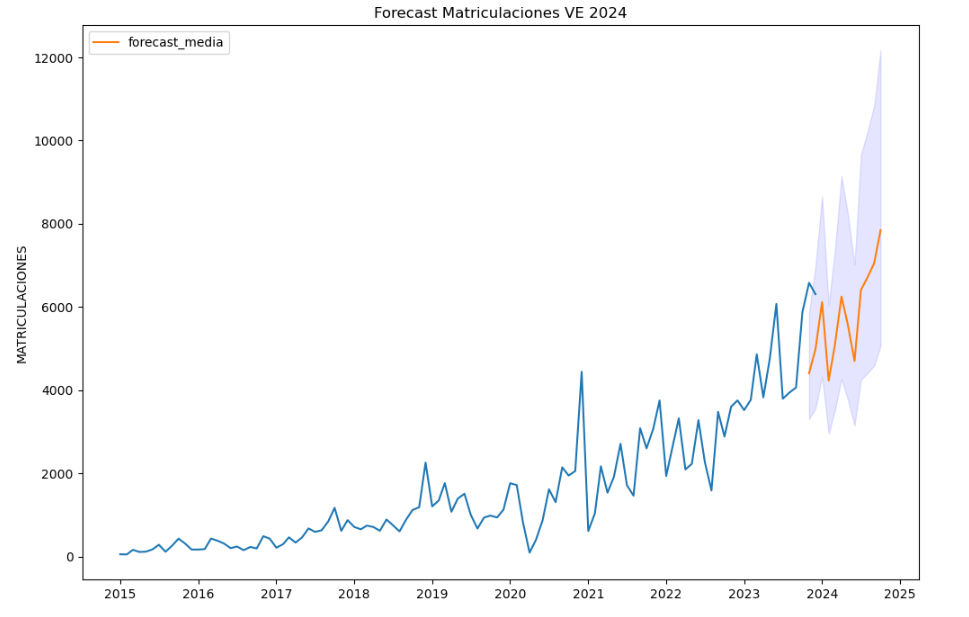
Figura 5. Gráfica "Predicción de matriculaciones de vehículos electricos".
5. Conclusiones del ejercicio
Como conclusión del ejercicio, podremos observar gracias a las técnicas de análisis empleadas como el vehículo eléctrico está penetrando cada vez a mayor velocidad en el parque móvil español aunque aún se encuentre a una distancia grande de otras alternativas como el Diésel o la Gasolina, por ahora liderado por el fabricante Tesla. Veremos en los próximos años si el ritmo crece al nivel necesario para alcanzar los objetivos de sostenibilidad fijados y si Tesla sigue siendo líder a pesar de la fuerte entrada de competidores asiáticos.
6. ¿Quieres realizar el ejercicio?
Si quieres conocer más sobre el Vehículo Eléctrico y poner a prueba tus capacidades analíticas, accede a este repositorio de código donde podrás desarrollar este ejercicio paso a paso.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato.Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la era digital, los datos se han convertido en una herramienta invaluable en casi todos los ámbitos de la sociedad, y el mundo del deporte no es una excepción. La disponibilidad de datos relacionados con este campo puede tener un impacto positivo en la promoción de la salud y el bienestar, así como en la mejora del rendimiento físico tanto de los deportistas como de los ciudadanos en general. Además, sus beneficios también quedan patentes en el ámbito económico, ya que estos datos pueden servir para dar a conocer la oferta deportiva o generar nuevos servicios, entre otras cuestiones.
A continuación, te mostramos tres ejemplos de su impacto.
Promoción de un estilo de vida activo y saludable
La disponibilidad de información pública puede inspirar a los ciudadanos a participar en actividades físicas y deportivas, ya que, por un lado, proporciona ejemplos de sus ventajas para la salud, y por otro, facilita el acceso a oportunidades que se adapten a sus preferencias y necesidades individuales.
Un ejemplo de las posibilidades de los datos abiertos en este campo lo encontramos en el proyecto OpenActive. Se trata de una iniciativa lanzada en 2016 por el Open Data Institute (ODI) junto a Sport England, organismo público dirigido a impulsar la actividad física de todos los habitantes de Inglaterra. OpenActive permite a los proveedores de actividades deportivas publicar datos abiertos normalizados, en base a un estándar desarrollado por el ODI para garantizar su calidad, interoperabilidad y fiabilidad. Estos datos han permitido desarrollar herramientas para facilitar la búsqueda y reserva de actividades, ayudando así a luchar contra la inactividad física de los ciudadanos. De acuerdo con una evaluación de impacto externa, este proyecto podría haber ayudado a evitar hasta 110 muertes prematuras, ahorrar hasta 3 millones de libras en costes sanitarios y generar un aumento de hasta 20 millones de libras en productividad al año. Además, ha supuesto un gran impacto económico para los operadores que participan compartiendo sus datos al incrementar sus clientes y con ello sus beneficios.
Optimización del trabajo físico
Los datos proporcionan a los equipos, entrenadores y deportistas acceso a una gran cantidad de información sobre las competiciones y su desempeño, permitiéndoles realizar un análisis detallado y encontrar formas de mejorar el rendimiento. Esto incluye datos sobre estadísticas de juego, salud, etc.
En este sentido, la Agencia Nacional Francesa del Deporte, junto con el Instituto Nacional del Deporte, la Experiencia y el Rendimiento (INSEP) y la Dirección General de Deportes, han desarrollado Sport Data Hub - FFS. El proyecto nació en 2020 con la idea de impulsar el rendimiento individual y colectivo del deporte francés de cara a los Juegos Olímpicos de País 2024. Consiste en la creación de una herramienta colaborativa para todos los implicados en el movimiento deportivo (federaciones, atletas, entrenadores, equipos técnicos, instituciones e investigadores) donde compartir datos que permita realizar análisis comparativos agregados a nivel nacional e internacional.
Investigaciones para conocer el impacto de los datos en areas como la salud o la economía
Los datos relacionados con la actividad física también pueden utilizarse en la investigación científica para analizar los efectos del ejercicio en la salud y ayudar a prevenir lesiones o enfermedades. Asimismo, nos pueden ayudar a conocer el impacto económico de las actividades deportivas.
Como ejemplo, la Comisión europea lanzó en 2021 el informe Mapping of sport statistics and data in the EU, con datos relativos al impacto económico y social del deporte, tanto a nivel de la Unión Europea como de los países miembros, entre 2012 y 2021. El estudio identifica fuentes de datos disponibles y recopila datos cuantitativos y cualitativos. Estos datos se utilizan para elaborar una serie de indicadores del impacto del deporte en la economía y la sociedad, incluyendo una sección entera centrada en la salud.
Este tipo de estudios puede servir a los organismos públicos para elaborar políticas de impulso de estas actividades y que doten a la ciudadanía de servicios y recursos relacionados con el deporte y adaptados sus necesidades concretas. Una medida que podría ayudar a prevenir enfermedades con el consiguiente ahorro en gastos sanitarios.
¿Dónde localizar datos abiertos relacionados con el deporte?
Para poder llevar a cabo estos proyectos, es necesario contar con fuentes de datos fiables. En datos.gob.es se pueden encontrar diversos conjuntos de datos sobre la materia. La mayoría de ellos han sido publicados por administraciones locales y hacen referencia a instalaciones y equipamientos deportivos, así como a eventos de esta naturaleza.
Dentro del Catálogo Nacional, también destaca DEPORTEData, una base de datos del Ministerio de Educación, Formación Profesional y Deportes para el almacenamiento y difusión de resultados estadísticos del ámbito deportivo. A través de su web ofrecen magnitudes estructuradas en dos grandes bloques:
- Estimaciones de carácter transversal sobre el empleo y empresas, el gasto realizado por los hogares y por la administración pública, la enseñanza, el comercio exterior y el turismo, todas ellas vinculadas al deporte.
- Información de carácter específico del sector, entre la que se incluyen indicadores relativos al deporte federado, la formación de entrenadores, el control del dopaje, los hábitos deportivos, las instalaciones y espacios, así como los campeonatos universitarios y en edad escolar.
A nivel de Europa, podemos visitar el Portal europeo de datos abiertos (data.europa.eu), con más de 40.000 conjuntos de datos sobre deporte, o Eurostat. Y si queremos profundizar en el comportamiento de la ciudadanía, podemos acudir al Eurobarometro sobre deporte y actividad física, cuyos datos también se encuentran en data.europa.eu. De manera similar, a nivel mundial, la Organización Mundial de la Salud ofrece conjuntos de datos sobre los efectos de la falta de actividad física.
En conclusión, es necesario promover la apertura de datos de calidad, actualizados y fiables sobre deporte. Una información con un gran impacto no solo para la sociedad, sino también para la economía, y que puede ayudarnos a mejorar la forma en que participamos, competimos y disfrutamos del deporte.
Noticia
Entre el 2 de abril y el 16 de mayo se podrán presentar solicitudes en la sede electrónica del Ministerio para la Transformación Digital y de la Función Pública, para concurrir a la convocatoria de ayudas para la transformación digital de sectores productivos estratégicos. La Orden TDF/1461/2023, del 29 de diciembre, modificada por la Orden TDF/294/2024, regula ayudas por un total de 150 millones de euros para la creación de demostradores y casos de uso, como parte de una iniciativa más general de espacios de datos sectoriales, promovida por la Secretaría de Estado de Digitalización e Inteligencia Artificial y enmarcada en el Plan de Recuperación, Transformación y Resiliencia (PRTR). El objetivo es financiar el desarrollo de espacios de datos y el fomento de la innovación disruptiva en sectores estratégicos de la economía, acorde con las líneas estratégicas recogidas en la Agenda España Digital 2026.
Líneas, sectores y beneficiarios
La convocatoria actual incluye líneas de financiación para proyectos de desarrollo experimental en dos áreas de actuación complementarias: la creación de centros demostradores (desarrollo de plataformas tecnológicas de espacios de datos); y el fomento de casos de uso concretos de dichos espacios. Esta convocatoria se dirige a todos los sectores salvo al de turismo ya que este cuenta con una convocatoria propia. Podrán obtener la condición de beneficiarios las entidades únicas con personalidad jurídica propia, domicilio fiscal en la Unión Europea, y establecimiento o sucursal ubicado en España. En el caso de la línea destinada a centros demostradores deberán además tener carácter asociativo o representativo de las cadenas de valor de los sectores productivos en ámbitos territoriales, o con dominios científicos o tecnológicos.
Infografías-resumen
Las siguientes infografías muestra la información clave sobre esta convocatoria de ayudas:


¿Quieres más información?
- Acceso al portal de ayudas de la convocatoria desde en el siguiente enlace. En el portal encontrarás las bases reguladoras y la convocatoria, un resumen de su contenido, documentación y material divulgativo con presentaciones y vídeos, así como una completa lista de preguntas y respuestas. En el buzón de correo espaciosdedatos@digital.gob.es obtendrás ayuda sobre la convocatoria y el procedimiento de tramitación. Desde este portal se accede a la sede electrónica para poder hacer la solicitud
- Guía rápida para la convocatoria de ayudas en pdf + Infografías descargables (sobre el Programa de Datos Sectoriales y la Información Técnica)
- Enlace a otros documentos de interés:
- Información adicional sobre el concepto de espacio de datos
Blog
Los datos abiertos ofrecen información de interés sobre el estado y evolución de diferentes sectores, entre ellos, el empleo. Los datos de empleo suelen incluir estadísticas sobre la población activa e información sobre los empleados, así como datos económicos, demográficos o relacionados con prestaciones, entrevistas, salarios, vacantes, etc.
Gracias a esta información podemos tener una visión clara de la salud económica de un país y del bienestar de sus ciudadanos, fomentando la toma de decisiones informadas. Además, también pueden servir de base para la creación de soluciones innovadoras que ayuden en diversas tareas.
En este artículo repasaremos algunas fuentes de las que obtener datos abiertos de calidad de empleo, así como ejemplos de uso para mostrar los potenciales beneficios de su reutilización.
¿Dónde localizar datos de empleo?
En datos.gob.es hay disponible una gran cantidad de conjuntos de datos sobre empleo, destacando como publicador a nivel nacional el Instituto Nacional de Estadística (INE). Gracias a los datos del INE podemos conocer los ocupados por sector de actividad, tipos de estudios o jornada, así como los motivos para tener jornada parcial. Los datos proporcionados por esta entidad también nos permiten conocer la situación laboral de las personas con discapacidad o por sexo.
Otras fuentes de datos donde localizar información de interés es el Servicio Público de Empleo Estatal (sepe.es), donde podemos encontrar datos estadísticos sobre demandantes de empleo, puestos de trabajo y colocaciones, desde mayo de 2005 hasta la actualidad. A ello hay que sumar los organismos autonómicos, muchos de los cuales han puesto en marcha su propio portal de datos abiertos de empleo. Es el caso de la Junta de Andalucía.
Si estamos interesados en realizar una comparación entre países, también podemos acudir a los datos de la OCDE, Eurostat o el Banco Mundial.
Todos estos datos pueden ser de gran interés para:
- Los responsables políticos, para comprender mejor la dinámica del mercado laboral y reaccionar ante ella.
- Los empleadores, para optimizar sus actividades de contratación.
- Los demandantes de empleo, para tomar mejores decisiones profesionales.
- Los centros de educación y formación, para adaptar los planes de estudios a las necesidades del mercado laboral.
Casos de uso de datos abiertos en el sector empleo
Tan relevante es contar con fuentes de datos abiertos de empleo como saber interpretar la información que ofrecen sobre el sector. Es aquí donde entran los reutilizadores que aprovechan esta materia prima para crear productos de datos que permitan dar respuesta a distintas necesidades. Veamos algunos ejemplos:
- Toma de decisiones e implantación de políticas activas. Las políticas activas de empleo son herramientas que los gobiernos utilizan para intervenir directamente en el mercado laboral, a través de capacitación, orientación, incentivos a la contratación, etc. Para ello, necesitan conocer las tendencias y necesidades del mercado. Esto ha llevado a numerosos organismos públicos a poner en marcha observatorios, como el del SEPE o el Principado de Asturias. También encontramos observatorios específicos por áreas como el de Igualdad y Empleo. A nivel europeo, destaca la propuesta de Eurostat: establecer requisitos para crear un sistema paneuropeo de elaboración de estadísticas oficiales y análisis políticos específicos usando para ello datos abiertos relativos a ofertas de empleo online. Este proyecto se ha llevado a cabo utilizando la plataforma BDTI. Pero este campo no está limitado al sector público, sino que otros actores también pueden presentar sus propuestas. Es el caso de Iseak, entidad sin ánimo de lucro que impulsa un centro de investigación y transferencia en economía. Entre otras cuestiones, en Iseak buscan dar respuesta a preguntas como ¿provoca la subida del salario mínimo una destrucción del empleo? o ¿por qué existe una brecha de género en el mercado?
- Rendición de cuentas. Toda esta información no es solo útil para los organismos públicos, sino también para la ciudadanía, a la hora de valorar si las políticas de empleo de sus gobernantes están funcionando. Por ello, muchos gobiernos ponen estos datos a disposición de los ciudadanos a través de visualizaciones sencillas de comprender, como Castilla y León. Asimismo, en este campo tiene un papel protagonista el periodismo de datos, con piezas que acercan la información al gran público como estos ejemplos, relativos a los salarios o el nivel de desempleo por zonas. Si quieres saber cómo realizar este tipo de visualizaciones, te los explicamos en este ejercicio paso a paso que caracteriza la demanda de empleo y contratación registrada en España.
- Impulso de oportunidades laborales. Para acercar los datos de interés a los ciudadanos que se encuentran en búsqueda activa o de nuevas oportunidades laborales, existen herramientas, como esta app de convocatorias de empleo público o de ayudas, basadas en datos abiertos. También hay ayuntamientos que crean soluciones para impulsar el empleo y la economía en su localidad como la APP Paterna Empléate. Estas apps suponen una forma de consumo de datos mucho más sencilla y amigable que los tradicionales portales de búsqueda de empleo. Un paso más allá ha ido la Diputación de Barcelona. Con su Buscador de Información y Documentación Oficial (CIDO).Esta herramienta utiliza IA aplicada a los datos abiertos para, entre otras finalidades, ofrecer servicios personalizados para individuos, empresas y sectores rurales, así como acceso a convocatorias de empleo. La información que ofrece procede tanto de tablones de anuncios, como del Perfil del contratante y diversas páginas webs municipales.
- Desarrollo de soluciones avanzadas. Los datos de empleo también se pueden utilizar para potenciar una amplia variedad de casos de uso de aprendizaje automático. Un ejemplo es esta plataforma estadunidense para el análisis financiero que proporciona datos e información a inversores y empresas. Para ello utiliza datos de tasas de desempleo de EE.UU, combinado con otros como códigos postales, datos demográficos o datos meteorológicos.
En definitiva, gracias a este tipo de datos nos solo podemos conocer más sobre la situación laboral de nuestro entorno, sino también alimentar soluciones que ayuden a impulsar la economía o que faciliten el acceso a oportunidades laborales. Se trata, por tanto, de una categoría de datos cuya publicación deben impulsar organismos públicos de todos los niveles.
Noticia
El año llega a su fin y es un buen momento para repasar algunas de las cuestiones que ha marcado el ecosistema de los datos abiertos y la compartición de datos en España, una comunidad que sigue creciendo y construyendo alianzas para el desarrollo de tecnologías innovadoras. Una sinergia que sienta las bases para afrontar un futuro interconectado, digital y lleno de posibilidades.
A pocos días del 2024, realizamos un balance de noticias, eventos y formaciones de interés que han marcado el año que dejamos atrás. En esta recopilación repasamos algunos avances regulatorios, nuevos portales y proyectos impulsados por el sector público, así como diversos recursos didácticos y documentación de referencia que nos ha dejado 2023.
Regulación jurídica para el desarrollo de entornos colaborativos
Durante este año, en datos.gob.es nos hemos hecho eco de noticias relevantes en el sector de los datos abiertos y la compartición de datos. Todas ellas han contribuido a consolidar el contexto adecuado para la interoperabilidad y el impulso del valor de los datos en nuestra sociedad. Realizamos a continuación un repaso de los anuncios más relevantes:
-
A principios de año la Comisión Europea publicó una primera lista de conjuntos de datos de alto valor que, por la información que atesoran, son de gran valor para la economía, el medio ambiente y la sociedad. Por este motivo, los estados miembros deberán ponerlos a disposición de la ciudadanía antes de verano de 2024. En esta primera lista de categorías se incluye: datos geoespaciales, de observación de la tierra y medioambiente, meteorológicos, estadísticos, de empresas y de movilidad. Por otro lado, a finales de 2023, el mismo organismo hizo una propuesta para ampliar la lista de categorías de conjuntos de datos a considerar de alto valor, añadiendo otras siete propuestas de categorías que se podrían incluir a futuro: pérdida climática, energía, financiero, administración pública y gobierno, salud, justicia y lenguaje.
-
En el primer trimestre del año, se modificó la Ley 37/2007 sobre reutilización de la información del sector público a la luz de la última Directiva europea de datos abiertos. Ahora, las administraciones públicas deberán cumplir, entre otros, dos requisitos esenciales: incidir en la publicación de datos de alto valor mediante APIs y designar una unidad responsable de información que vele por la correcta apertura de los datos. Estas medidas pretenden estar alineadas con las exigencias de competitividad e innovación que suscitan tecnologías como la IA y con el rol clave que juegan los datos a la hora de configurar espacios de datos.
-
La publicación de las especificaciones UNE sobre datos ha sido otro hito en materia de estandarización que ha marcado 2023. El volumen de datos no deja de crecer y son necesarios mecanismos que aseguren su adecuado uso y explotación. Para ello, existen:
-
Otro avance reseñable ha sido la aprobación de la redacción consolidada del Reglamento europeo de Datos (Data Act) que busca proporcionar normas armonizadas para un acceso justo a los datos y su utilización. La estructura jurídica que impulsará la economía del dato en la UE ya es una realidad. El Data Act y el Data Governance Act también aprobado en 2023 contribuirán al desarrollo de un Mercado Único Digital Europeo.
-
En octubre de 2023 la futura Ley de Europa Interoperable (Interoperable Europe Act) entró en la etapa legislativa final tras obtener el visto bueno de los estados miembros. El objetivo de Interoperable Europe Act es reforzar la interoperabilidad entre las administraciones del sector público en la UE y crear servicios públicos digitales centrados en los ciudadanos y las empresas.
Avances en el ecosistema de datos abiertos en España
En este último año han sido muchos los organismos públicos que han apostado por la apertura de sus datos en formatos adecuados para la reutilización, muchos de ellos centrados en temáticas concretas, como la meteorología. Algunos ejemplos son:
-
La Diputación de Segovia estrenó un portal de datos abiertos con información de ayuntamientos.
-
El Cabildo de Palma puso en marcha un nuevo portal de datos meteorológicos en abierto y en tiempo real que ofrece información sobre el tiempo actual e histórico como la calidad del aire.
-
El Ayuntamiento de Soria también creó un visor de información georreferenciada que permite consultar parámetros como la calidad del aire, el nivel de ruido, la meteorología o el tránsito de personas, entre otras variables.
-
El Ayuntamiento de Málaga se ha aliado recientemente con el CSIC para desarrollar un observatorio marino que recogerá y compartirá datos abiertos en tiempo real sobre la actividad litoral.
-
El avance en nuevos portales continuará durante 2024, ya que hay ayuntamientos que han manifestado su interés de desarrollar proyectos de este tipo. Un ejemplo es el Ayuntamiento de Las Torres de Cotillas: estrenó hace poco una web municipal y un portal de participación ciudadana en el que plantean habilitar próximamente un espacio de datos abiertos.
Por otro lado, muchas instituciones que ya publicaban datos abiertos han ido ampliando durante todo el año su catálogo de conjuntos de datos. Es el caso del Instituto Canario de Estadística (ISTAC) que ha implantado diferentes mejoras como la ampliación de su catálogo de datos abiertos semánticos para conseguir una mejor compartición de datos y metadatos.
En esta línea, también se han firmado más convenios para fomentar la apertura y compartición de datos, así como la adquisición de capacidades relacionadas. Por ejemplo, con universidades:
-
El portal de Datos Abiertos de Navarra incorporó información aportada por la Universidad Pública de Navarra (UPNA) sobre su estructura, actividad, datos económicos y plantilla.
-
La Universidad de Valladolid (UVa) ha presentado una Cátedra de Transparencia y Gobierno Abierto que abordará cuestiones como el gobierno del dato, entre otras.
-
La Universidad de Burgos ha implantado una política de ciencia abierta para fomentar la colaboración y el intercambio de conocimientos y brindar un acceso equitativo al trabajo científico y de investigación.
-
La Universidad Carlos III de Madrid (UC3M) se ha aliado con la Comunidad de Madrid para constituir la Cátedra sobre Dinamismo Territorial que promoverá la investigación y el desarrollo de actividades de análisis de datos abiertos, entre otros
Soluciones disruptivas que usan datos abiertos
La combinación ganadora entre datos abiertos y tecnología ha impulsado el desarrollo de múltiples iniciativas de interés fruto del esfuerzo de las administraciones públicas, como, por ejemplo:
-
La Comunidad de Madrid logró optimizar un 25% la fiabilidad de la predicción de los niveles de polen en el territorio gracias a la inteligencia artificial y los datos abiertos. A través del portal de datos abiertos de la CAM, la ciudadanía puede acceder a un mapa interactivo para conocer el nivel de polen en el aire de su zona.
-
La Cátedra de Gobernanza del Ayuntamiento de Valencia en la Universidad Politécnica (UPV) publicó un estudio que utiliza fuentes de datos abiertos para calcular la huella de carbono por barrios de la ciudad de Valencia.
-
La Xunta de Galicia presentó un proyecto de gemelo digital para la gestión del territorio que dispondrá de información almacenada en bases de datos públicas y privadas.
-
El Consejo Superior de Investigaciones Científicas (CSIC) inició el proyecto TeresIA de terminología en español que generará un metabuscador de acceso a terminologías de alcance panhispánico basado en IA y datos abiertos.
Durante 2023, las Administraciones Públicas no solo han puesto en marcha proyectos tecnológicos, sino que también han impulsado el emprendimiento alrededor de los datos abiertos con actividades como el concurso de Datos Abiertos de Castilla y León. Un evento en el que se premiaron proyectos desarrollados con datos abiertos como productos o servicios, ideas, trabajos de periodismo de datos y recursos didácticos.
Formaciones y eventos para estar al día de las tendencias
Los materiales didácticos sobre datos abiertos y tecnologías relacionadas no ha hecho más que crecer en este 2023. Destacamos algunos recursos gratuitos y virtuales que están disponibles:
-
El portal de datos abiertos europeo es una fuente de referencia en todos los aspectos, también a nivel formativo. Durante este último año, ha compartido recursos didácticos como este curso gratuito de visualización de datos, este sobre los aspectos legales del open data o este otro sobre cómo incorporar datos abiertos a una aplicación.
-
La Academia de Interoperabilidad Europea publicó en 2023 un curso breve, online y gratuito sobre licencias de código abierto para el que no es necesario tener conocimientos previos de la materia.
-
En 2023, hemos publicado más ejercicios prácticos de la serie de ‘Visualizaciones paso a paso’ como este tutorial para aprender a generar un mapa turístico personalizado con MyMaps o este análisis de datos meteorológicos utilizando la librería “ggplot2”.
Además, son muchas las actividades que se han llevado a cabo en 2023 para impulsar la cultura del dato. No obstante, si te perdiste alguna, puedes volver a ver las grabaciones online de las siguientes:
-
En marzo se retrasmitió la Conferencia Europea sobre Datos y Semántica, en la que se presentaron tendencias sobre datos multilingües.
-
En septiembre se llevó a cabo el II Encuentro Nacional de Datos Abiertos bajo el lema “Llamada urgente a la acción por el medio ambiente”. El evento continuó la tradición iniciada en 2022 en Barcelona, consolidándose como uno de los principales encuentros en España en el ámbito de la reutilización de datos del sector público y presentando materiales formativos de interés para la comunidad.
-
En octubre se organizó en Madrid la conferencia sobre interoperabilidad de referencia a nivel europeo: SEMIC 2023, Europa interoperable en la época de la IA.
Informes y otros documentos de referencia publicados en 2023
Una vez hemos repasado las noticias, iniciativas, formaciones y eventos, queremos destacar un compendio de conocimiento extenso como es el conjunto de informes en profundidad que se han publicado en 2023 sobre el sector de los datos abiertos y las tecnologías innovadoras. Algunos reseñables son:
-
La Asociación Multisectorial de la Información (ASEDIE) presentó en abril de 2023 su 11ª edición del Informe del Sector Infomediario en el que repasa la salud de las empresas que trabajan con datos, un sector con potencial de crecimiento. Aquí puedes leer las principales conclusiones.
-
A partir de octubre de 2023 España copresidió el Comité de Dirección de la Alianza para el Gobierno Abierto (OGP), una labor que ha implicado impulsar las iniciativas de la OGP y liderar las áreas temáticas de gobierno abierto. Esta organización presentó en 2023 su informe global de la Alianza para el Gobierno Abierto, un documento que pone en valor buenas prácticas como la publicación de grandes volúmenes de datos abiertos por parte de los países europeos. Además, también identifica distintas áreas de mejora como la publicación de más datos de alto valor (HDV) en formatos reutilizables e interoperables.
-
La Organización por la Economía Cooperativa y el Desarrollo (OECD) ha publicado en noviembre de 2023 un informe sobre principios de la administración pública en el que destacó, entre otros, la digitalización como herramienta para tomar decisiones basadas en datos y aplicar procesos eficaces y eficientes.
-
Durante este año, la Comisión Europea publicó un informe sobre la integración de los espacios de datos en la estrategia europea de datos. Firmado por expertos y expertas en la materia, este documento establece las bases para implementar los dataspaces europeos.
-
Por otro lado, el grupo de trabajo de datos abiertos de la Red de Entidades Locales por la Transparencia y la Participación Ciudadana y la Federación Española de Municipios y Provincias presentaron un listado de los 80 conjuntos de datos a publicar para seguir completando las guías publicadas en años anteriores. Lo puedes consultar aquí.
Estos son solo algunos ejemplos de lo que ha dado de sí el ecosistema de datos abiertos en el último año. Si quieres compartir con datos.gob.es alguna otra novedad, déjanos un comentario o mándanos un email a dinamizacion@datos.gob.es
Blog
En estos momentos nos encontramos en medio de una carrera sin precedentes por dominar las innovaciones en Inteligencia Artificial. Durante el último año, la estrella ha sido la Inteligencia Artificial Generativa (GenAI), es decir, aquella capaz de generar contenido original y creativo como imágenes, texto o música. Pero los avances no dejan de sucederse, y últimamente comienzan a llegar noticias en las que se sugiere que la utopía de la Inteligencia Artificial General (AGI) podría no estar tan lejos como pensábamos. Estamos hablando de máquinas capaces de comprender, aprender y realizar tareas intelectuales con resultados similares al cerebro humano.
Sea esto cierto o simplemente una predicción muy optimista, consecuencia de los asombrosos avances conseguido en un espacio muy corto de tiempo, lo cierto es que la Inteligencia Artificial parece ya capaz de revolucionar prácticamente todas las facetas de nuestra sociedad a partir de la cada vez mayor cantidad de datos que se utilizan para su entrenamiento.
Y es que si, como argumentaba Andrew Ng ya en 2017, la inteligencia artificial es la nueva electricidad, los datos abiertos serían el combustible que alimenta su motor, al menos en un buen número de aplicaciones cuya fuente principal y más valiosa es la información pública que se encuentra accesible para ser reutilizada. En este artículo vamos a repasar un campo en el que previsiblemente veremos grandes avances en los próximos años gracias a la combinación de inteligencia artificial y datos abiertos: la creación artística.
Creación Generativa basada en Datos Culturales Abiertos
La capacidad de la inteligencia artificial para generar nuevos contenidos podría llevarnos a una nueva revolución en la creación artística, impulsada por el acceso a datos culturales abiertos y a una nueva generación de artistas capaces de aprovechar estos avances para crear nuevas formas de pintura, música o literatura, trascendiendo barreras culturales y temporales.
Música
El mundo de la música, con su diversidad de estilos y tradiciones, representa un campo lleno de posibilidades para la aplicación de la inteligencia artificial generativa. Los conjuntos de datos abiertos en este ámbito incluyen grabaciones de música folclórica, clásica, moderna y experimental de todo el mundo y de todas las épocas, partituras digitalizadas, e incluso información sobre teorías musicales documentadas. Desde el archi-conocido MusicBrainz, la enciclopedia de la música abierta, hasta conjuntos de datos que abren los propios dominadores de la industria del streaming como Spotify o proyectos como Open Music Europe, son algunos ejemplos de recursos que están en la base del progreso en esta área. A partir del análisis de todos estos datos, los modelos de inteligencia artificial pueden identificar patrones y estilos únicos de diferentes culturas y épocas, fusionándolos para crear composiciones musicales inéditas con herramientas y modelos como MuseNet de OpenAI o Music LM de Google.
Literatura y pintura
En el ámbito de la literatura, la Inteligencia artificial también tiene potencial para hacer más productiva no solo la creación de contenidos en internet, sino para producir formas más elaboradas y complejas de contar historias. El acceso a bibliotecas digitales que albergan obras literarias desde la antigüedad hasta el momento actual hará posible explorar y experimentar con estilos literarios, temas y arquetipos de narración de diversas culturas a lo largo de la historia, con el fin de crear nuevas obras en colaboración con la propia creatividad humana. Incluso se podrá generar una literatura de carácter más personalizado a los gustos de grupos de lectores más minoritarios. La disponibilidad de datos abiertos como el Proyecto Guttemberg con más de 70.000 libros o los catálogos digitales abiertos de museos e instituciones que han publicado manuscritos, periódicos y otros recursos escritos producidos por la humanidad, son un recurso de gran valor para alimentar el aprendizaje de la inteligencia artificial.
Los recursos de la Digital Public Library of America (DPLA) en Estados Unidos o de Europeana en la Unión Europea son sólo algunos ejemplos. Estos catálogos no sólo incluyen texto escrito, sino que incluyen también vastas colecciones de obras de arte visuales, digitalizadas a partir de las colecciones de museos e instituciones, que en muchos casos ni tan siquiera pueden admirarse porque las organizaciones que las conservan no disponen de espacio suficiente para exponerlas al público. Los algoritmos de inteligencia artificial, al analizar estas obras, descubren patrones y aprenden sobre técnicas, estilos y temas artísticos de diferentes culturas y períodos históricos. Esto posibilita que herramientas como DALL-E2 o Midjourney puedan crear obras visuales a partir de unas sencillas instrucciones de texto con estética de pintura renacentista, impresionista o una mezcla de ambas.
Sin embargo, estas fascinantes posibilidades están acompañadas de una controversia aún no resuelta acerca de los derechos de autor que está siendo debatida en los ámbitos académicos, legales y jurídicos y que plantea nuevos desafíos en la definición de autoría y propiedad intelectual. Por una parte, está la cuestión sobre la propiedad de los derechos sobre las creaciones producidas por inteligencia artificial. Y por otra parte encontramos el uso de conjuntos de datos que contienen obras sujetas a derechos de propiedad intelectual y que se han utilizado en el entrenamiento de los modelos sin el consentimiento de los autores. En ambas cuestiones existen numerosas disputas judiciales en todo el mundo y solicitudes de retirada explícita de contenido de los principales conjuntos de datos de entrenamiento.
En definitiva, nos encontramos ante un campo donde el avance de la inteligencia artificial parece imparable, pero habrá que tener muy presente no solo las oportunidades, sino también los riesgos que supone.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
IATE, acrónimo en inglés de Interactive Terminology for Europe (Terminología Interactiva para Europa), es una base de datos dinámica diseñada para respaldar la redacción multilingüe de textos de la Unión Europea. Su objetivo es proporcionar datos relevantes, confiables y de fácil acceso con un valor añadido distintivo en comparación con otras fuentes de información léxica como pueden ser archivos electrónicos, memorias de traducción o internet.
Esta herramienta es de interés para las instituciones de la UE que la utilizan desde 2004 y para cualquier persona, como profesionales de la lengua o del mundo académico, administraciones públicas, empresas o público en general Este proyecto, puesto en marcha en 1999 por el Centro de Traducción, está disponible para cualquier organización o persona que necesite redactar, traducir o interpretar un texto sobre la UE.
Origen y usabilidad de la plataforma
IATE se creó en 2004 mediante la fusión de diferentes bases de datos terminológicas de la UE. Para su creación se importaron a IATE las bases de datos originales de Eurodicautom, TIS, Euterpe, Euroterms y CDCTERM. Este proceso originó una gran cantidad de entradas duplicadas, lo que tiene como consecuencia que muchos conceptos estén cubiertos por varias entradas en lugar de una sola. Para solucionar este problema, se constituyó un grupo de trabajo de limpieza que desde 2015 se encarga de organizar análisis e iniciativas de limpieza de datos para consolidar entradas duplicadas en una sola entrada. Esto explica por qué las estadísticas sobre el número de entradas y términos muestran una tendencia a la baja, ya que se eliminan y actualizan más contenidos de los que se crean.
Además de poder realizar consultas, existe la posibilidad de descargar sus ficheros de datos junto con la herramienta de extracción IATExtract que permite generar exportaciones filtradas.
Esta base terminológica interinstitucional fue inicialmente diseñada para gestionar y normalizar la terminología de las agencias de la UE. No obstante, posteriormente, también se empezó a utilizar como herramienta de apoyo en la redacción multilingüe de los textos de la UE, hasta llegar a convertirse en la actualidad en un sistema complejo y dinámico de gestión terminológica. Aunque su principal objetivo es facilitar la labor de los traductores que trabajan para la UE, también es de gran utilidadl para el público en general. .
IATE lleva a disposición del público desde 2007, y reúne los recursos terminológicos de todos los servicios de traducción de la UE. El Centro de Traducción gestiona los aspectos técnicos del proyecto en nombre de los socios que participan en él: el Parlamento Europeo (EP), el Consejo de la Unión Europea (Consilium), la Comisión Europea (COM), el Tribunal de Justicia (CJUE), el Banco Central Europeo (ECB), el Tribunal de Cuentas Europeo (ECA), el Comité Económico y Social Europeo (EESC/CoR), el Comité Europeo de las Regiones (EESC/CoR), el Banco Europeo de Inversiones (EIB) y el Centro de Traducción de los Órganos de la Unión Europea (CdT).
La estructura de datos de IATE se basa en un enfoque orientado a conceptos, lo que significa que cada entrada corresponde a un concepto (los términos se agrupan por su significado), y cada concepto idealmente debería estar cubierto por una sola entrada. Cada entrada de IATE se divide en tres niveles:
-
Nivel independiente del idioma (LIL)
-
Nivel de idioma (LL)
-
Nivel de término (TL) Para obtener más información, consulte la Sección 3 ('Visión general de la estructura') a continuación.
Fuente de referencia para profesionales y útil para el público en general
En IATE se reflejan las necesidades de los traductores de la Unión Europea, por lo que puede cubrirse cualquier ámbito que haya aparecido o pueda aparecer en los textos de las publicaciones del entorno de la UE, sus agencias y organismos. La crisis financiera, el medio ambiente, la pesca y la migración son ámbitos en los que se ha trabajado de forma intensa durante los últimos años. Para conseguir el mejor resultado, IATE utiliza el tesauro EuroVoc como sistema de clasificación de campos temáticos.
Como ya hemos señalado, esta base de datos puede ser utilizada por cualquier persona que esté buscando el término adecuado sobre la Unión Europea. IATE permite explorar en campos diferentes al del término consultado y filtrar los dominios en todos los ámbitos y descriptores de EuroVoc. Las tecnologías utilizadas hacen que los resultados obtenidos tengan una gran precisión, mostrándose como una lista enriquecida que incluye además una clara distinción entre las coincidencias exactas y difusas del término.
La versión pública de IATE incluye las lenguas oficiales de la Unión Europea, que se definen en el Reglamento n.º 1 de 1958. . Además, se efectúa una alimentación sistemática a través de proyectos anticipativos: si se sabe que va a tratarse en textos de la UE un tema determinado, se crean o mejoran las fichas que guardan relación con ese tema para que, cuando lleguen los textos, los traductores dispongan ya en IATE de la terminología precisada.
Cómo utilizar IATE
Para realizar una búsqueda en IATE simplemente se debe escribir una palabra clave o parte del nombre de una colección. Se pueden definir más filtros para su búsqueda, como institución, tipo o fecha de creación. Una vez que se ha realizado la búsqueda, se selecciona una colección y al menos una lengua de visualización.
Para descargar subconjuntos de datos de IATE es necesario estar registrado, una opción totalmente gratuita que permite además de la descarga, almacenar algunas preferencias de usuario. La descarga es también un proceso sencillo y se puede realizar en formato csv o tbx.
El archivo de descarga de IATE, a cuya información se puede también acceder de otras formas, contiene los siguientes campos:
-
Nivel independiente de la lengua:
-
Número de ficha: el identificador único de cada concepto.
-
Campo temático: los conceptos están vinculados a ámbitos de conocimiento en los que se utilizan. La estructura conceptual se organiza en torno a veintiún campos temáticos con diversos subcampos. Hay que señalar que los conceptos pueden estar vinculados a más de un campo temático.
-
Nivel de la lengua:
-
Código de la lengua: cada idioma tiene su propio código ISO.
-
Nivel del término
-
Término: concepto de la ficha.
-
Tipo de término. Pueden ser: términos, abreviatura, frase, fórmula o fórmula corta.
-
Código de fiabilidad. IATE utiliza cuatro códigos para indicar la fiabilidad de los términos: sin comprobar, mínima, fiable o muy fiable.
-
Evaluación. Cuando se almacenan varios términos en una lengua, se pueden asignar evaluaciones específicas del siguiente modo: preferible, admisible, desechado, obsoleto y propuesto.
Una base de datos terminológica en continua actualización
La base de datos IATE es un documento en permanente crecimiento, abierto a la participación ciudadana, de forma que cualquier persona puede contribuir a su crecimiento proponiendo nuevas terminologías para añadir a fichas existentes, o para crear fichas nuevas: puede enviar su propuesta a iate@cdt.europa.eu, o bien utilizar el enlace ‘Observaciones’ que aparece en la parte inferior derecha de la ficha del término buscado. Se puede facilitar cuanta información pertinente se desee para justificar la fiabilidad del término propuesto, o plantear un nuevo término a incluir. Un terminólogo de la lengua en cuestión estudiará cada propuesta ciudadana y valorará su incorporación al IATE.
En agosto de 2023, la IATE anunciaba la disponibilidad de la versión 2.30.0 de este sistema de datos, añadiendo nuevos campos en su plataforma y la mejora de funciones, como la exportación de archivos enriquecidos para optimizar el filtrado de datos. Como hemos visto, esta base de datos terminológica interinstitucional de la UE seguirá evolucionando de manera continua para satisfacer las necesidades de los traductores de la UE y los usuarios de IATE en general.
Otro aspecto importante es que esta base de datos sirve para el desarrollo de herramientas de traducción asistida por ordenador (TAO), lo que contribuye a garantizar la calidad de los trabajos de traducción de los servicios de traducción de la UE. Los resultados de la labor de terminología de los traductores se almacenan en IATE y éstos, a su vez, utilizan esta base de datos para realizar búsquedas interactivas y para alimentar bases de datos terminológicas específicas para un ámbito o documento que utilizan en sus herramientas TAO.
IATE, con más de 7 millones de términos en más de 700.000 entradas, es una referencia en el ámbito de la terminología y está considerada como la mayor base de datos terminológica multilingüe del mundo. Cada año se realizan en IATE más de 55 millones de consultas desde más de 200 países, lo que da buena cuenta de su utilidad.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada uno de estos ejercicios prácticos, se utilizan desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El principal objetivo de este ejercicio es mostrar cómo realizar, de una forma didáctica, un análisis predictivo de series temporales partiendo de datos abiertos sobre el consumo de electricidad en la ciudad de Barcelona. Para ello realizaremos un análisis exploratorio de los datos, definiremos y validaremos el modelo predictivo, para por último generar las predicciones junto a sus gráficas y visualizaciones correspondientes.
Los análisis predictivos de series temporales son técnicas estadísticas y de aprendizaje automático que se utilizan para prever valores futuros en conjuntos de datos que se recopilan a lo largo del tiempo. Estas predicciones se basan en patrones y tendencias históricas identificadas en la serie temporal, siendo su objetivo principal anticipar cambios y eventos en función de datos pasados.
El conjunto de datos abiertos inicial consta de registros desde el año 2019 hasta el año 2022 ambos inclusive, por otra parte, las predicciones las realizaremos para el año 2023, del cual no tenemos datos reales.
Una vez realizado el análisis, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la predicción futura de consumo eléctrico?
- ¿Cómo de preciso ha sido el modelo con la predicción de datos ya conocidos?
- ¿Qué días tendrán un consumo máximo y mínimo según las predicciones futuras?
- ¿Qué meses tendrán un consumo medio máximo y mínimo según las predicciones futuras?
Estas y otras muchas preguntas pueden ser resueltas mediante las visualizaciones obtenidas en el análisis que mostrarán la información de una forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre el consumo eléctrico en la ciudad de Barcelona en los últimos años. La información que aportan es el consumo en (MWh) desglosados por día, sector económico, código postal y tramo horario.
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Barcelona en el catálogo de datos.gob.es, mediante ficheros que recogen los registros de forma anual. Cabe destacar que el publicador actualiza estos conjuntos de datos con nuevos registros con frecuencia, por lo que hemos utilizado solamente los datos proporcionados desde el 2019 hasta el 2022 ambos inclusive.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización del análisis se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones interactivas se ha usado la herramienta Looker Studio.
"Looker Studio", antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar visualizaciones interactivas que pueden insertarse en sitios web o exportarse como archivos.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Análisis predictivo de series temporales
El análisis predictivo de series temporales es una técnica que utiliza datos históricos para predecir valores futuros de una variable que cambia con el tiempo. Las series temporales son datos que se recopilan en intervalos regulares, como días, semanas, meses o años. No es el objetivo de este ejercicio explicar en detalle las características de las series temporales, ya que nos centramos en explicar brevemente el modelo de predicción. No obstante, si quieres saber más al respecto, puedes consultar el siguiente manual.
Este tipo de análisis se basa en el supuesto de que los valores futuros de una variable estarán correlacionados con los valores históricos. Utilizando técnicas estadísticas y de aprendizaje automático, se pueden identificar patrones en los datos históricos y utilizarlos para predecir valores futuros.
El análisis predictivo realizado en el ejercicio ha sido dividido en cinco fases; preparación de los datos, análisis exploratorio de los datos, entrenamiento del modelo, validación del modelo y predicción de valores futuros), las cuales se explicarán en los próximos apartados.
Los procesos que te describimos a continuación los encontrarás desarrollados y comentados en el siguiente Notebook ejecutable desde Google Colab junto al código fuente que está disponible en nuestra cuenta de Github.
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
4.1 Preparación de los datos
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este apartado se importan los conjuntos de datos abiertos descritos en los puntos anteriores que utilizaremos en el ejercicio, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores que puedan condicionar los pasos futuros.
4.2 Análisis exploratorio de los datos (EDA)
Este apartado podrás encontrarlo en el punto 2 del Notebook.
En este apartado realizaremos un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de origen, detectar anomalías, datos ausentes, errores u outliers que pudieran afectar a la calidad de los procesos posteriores y resultados.
A continuación, en la siguiente visualización interactiva, podrás inspeccionar la tabla de datos con los valores de consumo históricos generada en el punto anterior pudiendo filtrar por periodo temporal concreto. De esta forma podemos comprender, de una forma visual, la principal información de la serie de datos.
Una vez inspeccionada la visualización interactiva de la serie temporal, habrás observado diversos valores que potencialmente podrían ser considerados como outliers, como se muestra en la siguiente figura. También podemos calcular de forma numérica estos outliers, como se muestra en el notebook.

Una vez evaluados los outliers, para este ejercicio se ha decidido modificar únicamente el registrado en la fecha "2022-12-05". Para ello se sustituirá el valor por la media del registrado el día anterior y el día siguiente.
La razón de no eliminar el resto de outliers es debido a que son valores registrados en días consecutivos, por lo que se presupone que son valores correctos afectados por variables externas que se escapan del alcance del ejercicio. Una vez solucionado el problema detectado con los outliers, esta será la serie temporal de datos que utilizaremos en los siguientes apartados.
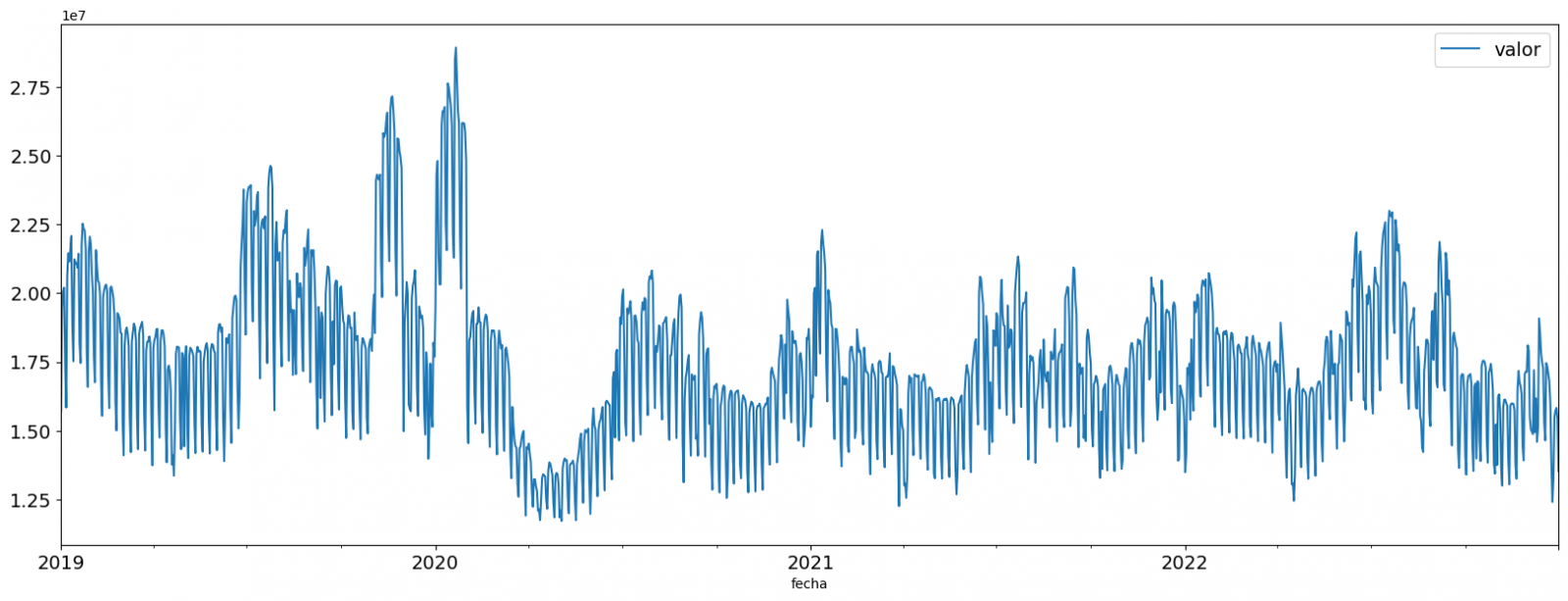
Figura 2. Serie temporal de datos históricos una vez tratados los outliers
Si quieres conocer más sobre estos procesos puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
4.3 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 3 del Notebook.
En primer lugar, creamos dentro de la tabla de datos los atributos temporales (año, mes, día de la semana y trimestre). Estos atributos son variables categóricas que ayudan a garantizar que el modelo sea capaz de capturar con precisión las características y patrones únicos de estas variables. Mediante las siguientes visualizaciones de diagramas de cajas, podemos ver su relevancia dentro de los valores de la serie temporal.
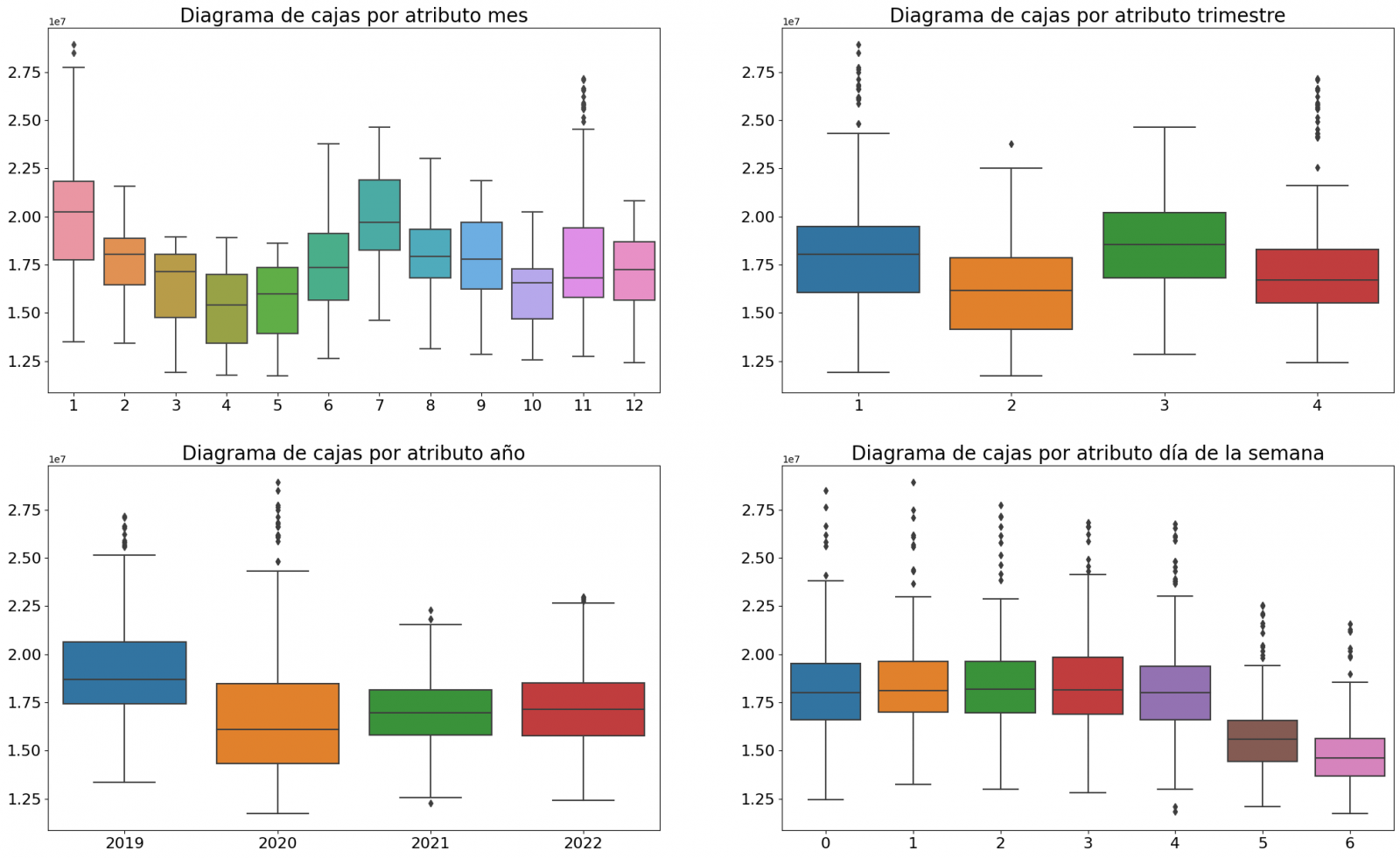
Figura 3. Diagramas de cajas de los atributos temporales generados
Podemos observar ciertos patrones en las gráficas anteriores como los siguientes:
- Los días laborales (lunes a viernes) presentan un mayor consumo que los fines de semana.
- El año que valores de consumo más bajos presenta es el 2020, esto entendemos que se debe a la reducción de actividad servicios e industrial durante la pandemia.
- El mes que mayor consumo presenta es julio, lo cual es entendible debido al uso de aparatos de aire acondicionado.
- El segundo trimestre es el que presenta valores más bajos de consumo, destacando abril como el mes con valores más bajos.
A continuación, dividimos la tabla de datos en set de entrenamiento y en set de validación. El set de entrenamiento se utiliza para entrenar el modelo, es decir, el modelo aprende a predecir el valor de la variable objetivo a partir de dicho set, mientras que el set de validación se utiliza para evaluar el rendimiento del modelo, es decir, el modelo se evalúa con los datos de dicho set para determinar su capacidad para predecir los nuevos valores.
Esta división de los datos es importante para evitar el sobreajuste siendo la proporción típica de los datos que se utilizan para el set de entrenamiento de un 70 % y el set de validación del 30% aproximadamente. Para este ejercicio hemos decidido generar el set de entrenamiento con los datos comprendidos entre el "01-01-2019" hasta el "01-10-2021", y el set de validación con los comprendidos entre el "01-10-2021" y el "31-12-2022" como podemos apreciar en la siguiente gráfica.
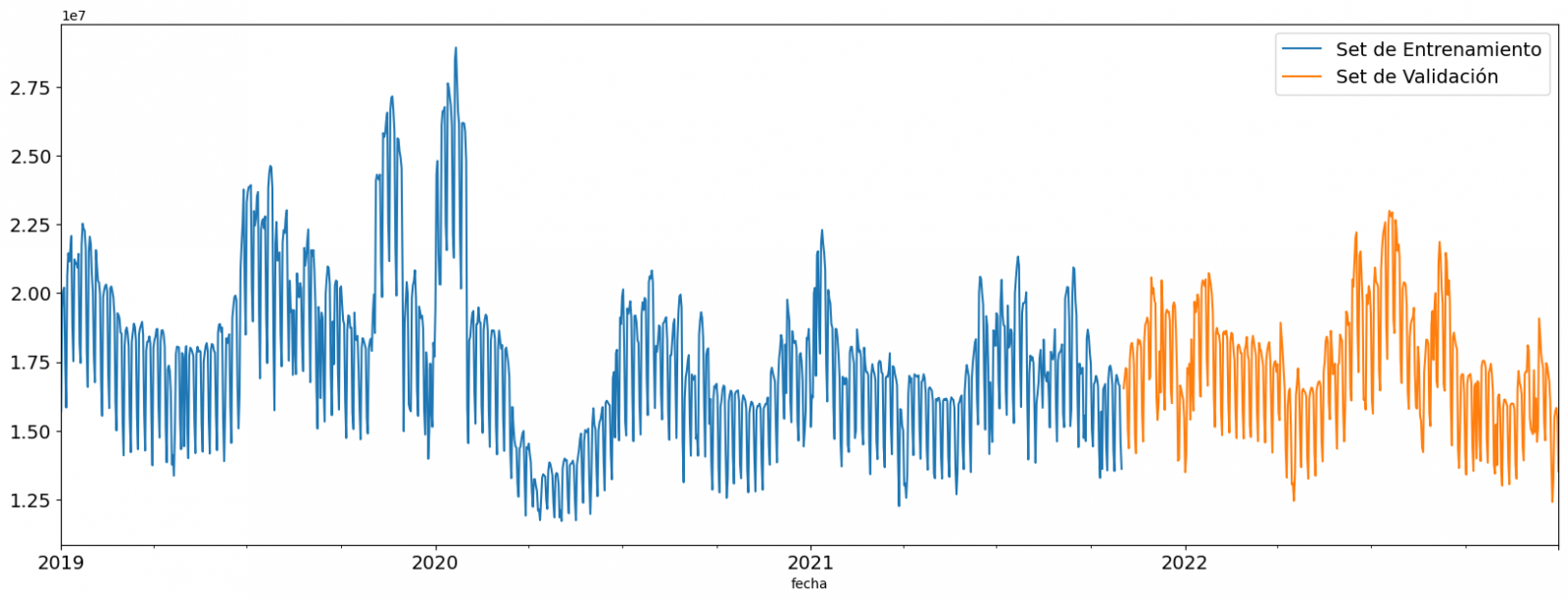
Figura 4. Serie temporal de datos históricos dividida en set de entrenamiento y set de validación
Para este tipo de ejercicio, tenemos que utilizar algún algoritmo de regresión. Existen diversos modelos y librerías que pueden utilizarse para predicción de series temporales. En este ejercicio utilizaremos el modelo “Gradient Boosting”, modelo de regresión supervisado que se trata de un algoritmo de aprendizaje automático utilizado para predecir un valor continúo basándose en el entrenamiento de un conjunto de datos que contienen valores conocidos para la variable objetivo (en nuestro ejemplo la variable “valor”) y los valores de las variables independientes (en nuestro ejercicio los atributos temporales).
Está basado en árboles de decisión y utiliza una técnica llamada "boosting" para mejorar la precisión del modelo siendo conocido por su eficiencia y capacidad para manejar una variedad de problemas de regresión y clasificación.
Sus principales ventajas son el alto grado de precisión, su robustez y flexibilidad, mientras que alguna de sus desventajas son la sensibilidad a valores atípicos y que requiere una optimización cuidadosa de los parámetros.
Utilizaremos el modelo de regresión supervisado ofrecido en la librería XGBBoost, el cuál puede ajustarse con los siguientes parámetros:
- n_estimators: parámetro que afecta al rendimiento del modelo indicando el número de árboles utilizados. Un mayor número de árboles generalmente resulta un modelo más preciso, pero también puede llevar más tiempo de entrenamiento.
- early_stopping_rounds: parámetro que controla el número de rondas de entrenamiento que se ejecutarán antes de que el modelo se detenga si el rendimiento en el conjunto de validación no mejora.
- learning_rate: controla la velocidad de aprendizaje del modelo. Un valor más alto hará que el modelo aprenda más rápido, pero puede provocar un sobreajuste.
- max_depth: controla la profundidad máxima de los árboles en el bosque. Un valor más alto puede proporcionar un modelo más preciso, pero también puede provocar un sobreajuste.
- min_child_weight: controla el peso mínimo de una hoja. Un valor más alto puede ayudar a prevenir el sobreajuste.
- gamma: controla la cantidad de reducción de la pérdida esperada que se necesita para dividir un nodo. Un valor más alto puede ayudar a prevenir el sobreajuste.
- colsample_bytree: controla la proporción de las características que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
- subsample: controla la proporción de los datos que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
Estos parámetros se pueden ajustar para mejorar el rendimiento del modelo en un conjunto de datos específico. Se recomienda experimentar con diferentes valores de estos parámetros para encontrar el valor que proporciona el mejor rendimiento en tu conjunto de datos.
Por último, mediante una gráfica de barras observaremos de forma visual la importancia de cada uno de los atributos durante el entrenamiento del modelo. Se puede utilizar para identificar los atributos más importantes en un conjunto de datos, lo que puede ser útil para la interpretación del modelo y la selección de características.
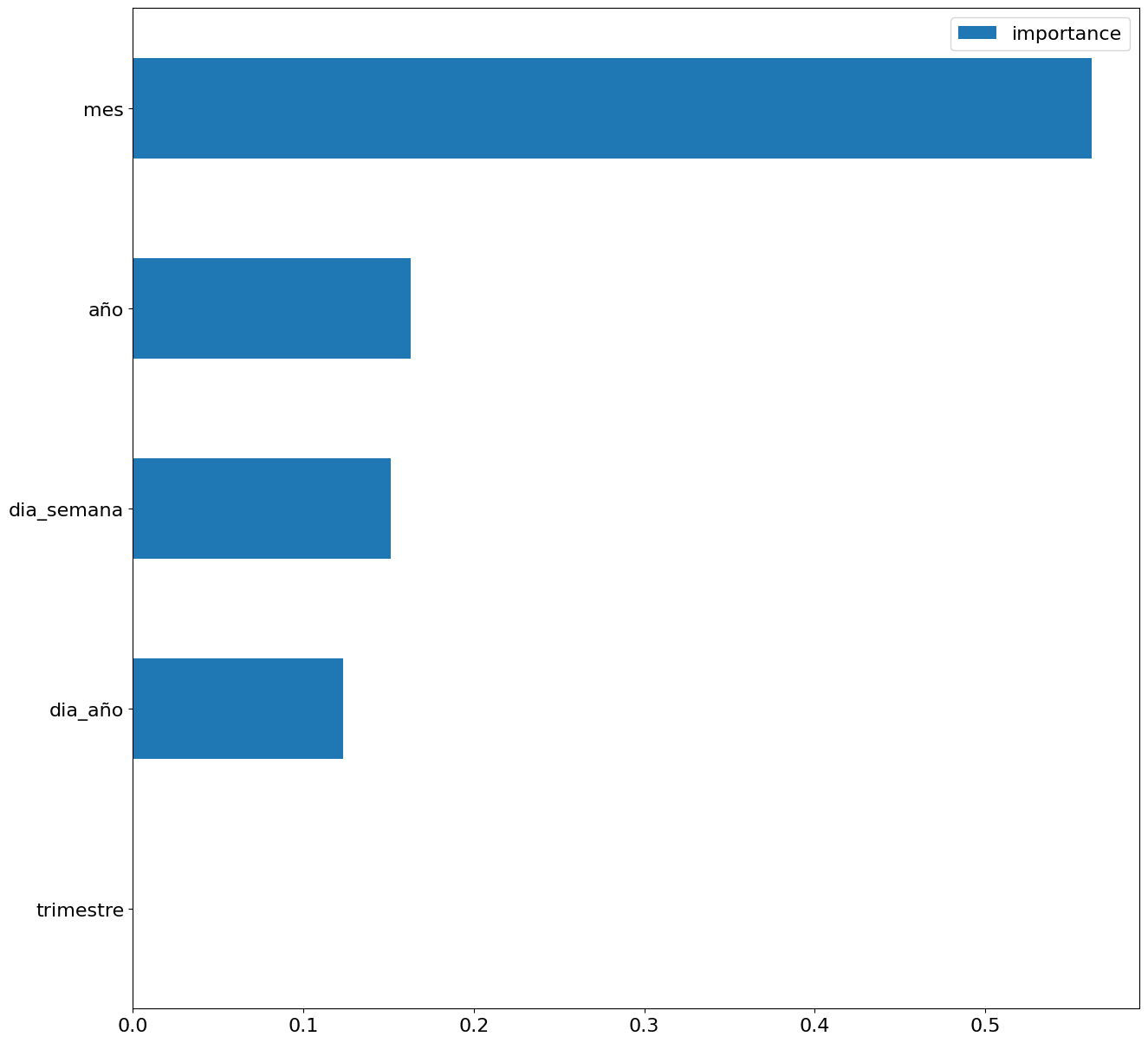
Figura 5. Gráfica de barras con importancia de los atributos temporales
4.4 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 4 del Notebook.
Una vez entrenado el modelo, evaluaremos cómo de preciso es para los valores conocidos del set de validación.
Podemos evaluar de forma visual el modelo ploteando la serie temporal con los valores conocidos junto a las predicciones realizadas para el set de validación como se muestra en la siguiente figura.
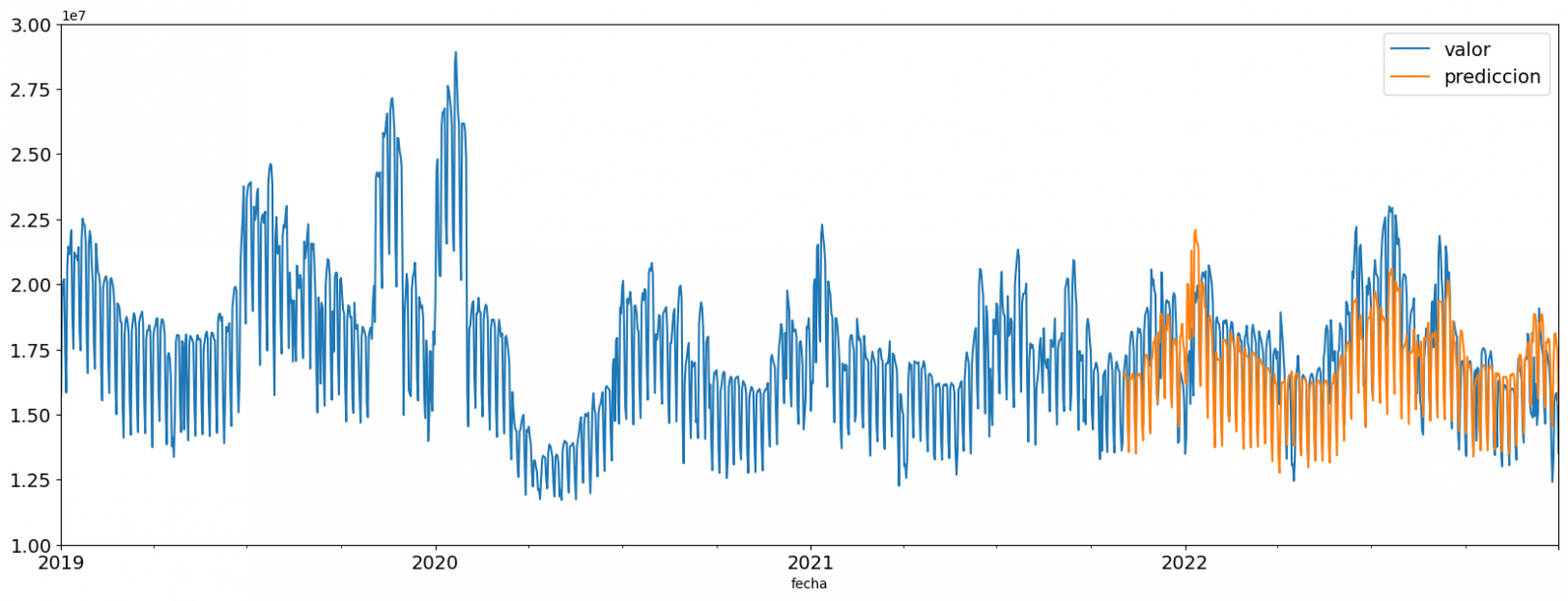
Figura 6. Serie temporal con los datos del set de validación junto a los de la predicción
También podemos evaluar de forma numérica la precisión del modelo mediante distintas métricas. En este ejercicio hemos optado por utilizar la métrica del error porcentual absoluto medio (MAPE), el cuál ha sido de un 6,58%. La precisión del modelo se considera alta o baja dependiendo del contexto y de las expectativas en dicho modelo, generalmente un MAPE se considera bajo cuando es inferior al 5%, mientras que se considera alto cuando es superior al 10%. En este ejercicio, el resultado de la validación del modelo puede ser considerado un valor aceptable.
Si quieres consultar otro tipo de métricas para evaluar la precisión de modelos aplicados a series temporales, puedes consultar el siguiente enlace.
4.5 Predicciones valores futuros
Este apartado podrás encontrarlo en el punto 5 del Notebook.
Una vez generado el modelo y evaluado su rendimiento MAPE = 6,58 %, pasamos a aplicar dicho modelo al total de datos conocidos, con la finalidad de predecir los valores de consumo eléctrico no conocidos del 2023.
En primer lugar, volvemos a entrenar el modelo con los valores conocidos hasta finales del 2022, sin dividir en set de entrenamiento y validación. Por último, calculamos los valores futuros para el año 2023.

Figura 7. Serie temporal con los datos históricos y la predicción para el 2023
En la siguiente visualización interactiva puedes observar los valores predichos para el año 2023 junto a sus principales métricas, pudiendo filtrar por periodo temporal.
Mejorar los resultados de los modelos predictivos de series temporales es un objetivo importante en la ciencia de datos y el análisis de datos. Varias estrategias que pueden ayudar a mejorar la precisión del modelo del ejercicio son el uso de variables exógenas, la utilización de más datos históricos o generación de datos sintéticos, optimización de los parámetros, …
Debido al carácter divulgativo de este ejercicio y para favorecer el entendimiento de los lectores menos especializados, nos hemos propuesto explicar de una forma lo más sencilla y didáctica posible el ejercicio. Posiblemente se te ocurrirán muchas formas de optimizar el modelo predictivo para lograr mejores resultados, ¡Te animamos a que lo hagas!
5. Conclusiones ejercicio
Una vez realizado el ejercicio, podemos apreciar distintas conclusiones como las siguientes:
- Los valores máximos para las predicciones de consumo en el 2023 se dan en la última quincena de julio superando valores de 22.500.000 MWh
- El mes con un mayor consumo según las predicciones del 2023 será julio, mientras que el mes con un menor consumo medio será noviembre, existiendo una diferencia porcentual entre ambos del 25,24%
- La predicción de consumo medio diario para el 2023 es de 17.259.844 MWh, un 1,46% inferior a la registrada entre los años 2019 y 2022.
Esperemos que este ejercicio te haya resultado útil para el aprendizaje de algunas técnicas habituales en el estudio y análisis de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar cómo realizar un análisis de redes o de grafos partiendo de datos abiertos sobre viajes en bicicleta de alquiler en la ciudad de Madrid. Para ello, realizaremos un preprocesamiento de los datos con la finalidad de obtener las tablas que utilizaremos a continuación en la herramienta generadora de la visualización, con la que crearemos las visualizaciones del grafo.
Los análisis de redes son métodos y herramientas para el estudio y la interpretación de las relaciones y conexiones entre entidades o nodos interconectados de una red, pudiendo ser estas entidades personas, sitios, productos, u organizaciones, entre otros. Los análisis de redes buscan descubrir patrones, identificar comunidades, analizar la influencia y determinar la importancia de los nodos dentro de la red. Esto se logra mediante el uso de algoritmos y técnicas específicas para extraer información significativa de los datos de red.
Una vez analizados los datos mediante esta visualización, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la estación de la red con mayor tráfico de entrada y de salida?
- ¿Cuáles son las rutas entre estaciones más frecuentes?
- ¿Cuál es el número medio de conexiones entre estaciones para cada una de ellas?
- ¿Cuáles son las estaciones más interconectadas dentro de la red?
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre los viajes en bicicleta de préstamo realizados en la ciudad de Madrid. La información que aportan se trata de la estación de origen y de destino, el tiempo del trayecto, la hora del trayecto, el identificador de la bicicleta, …
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Madrid, mediante ficheros que recogen los registros de forma mensual.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de la visualización interactiva se ha usado la herramienta Gephi
"Gephi" es una herramienta de visualización y análisis de redes. Permite representar y explorar relaciones entre elementos, como nodos y enlaces, con el fin de entender la estructura y patrones de la red. El programa precisa descarga y es gratuito.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Debido al alto volumen de viajes registrados en los conjuntos de datos, definimos los siguientes puntos de partida a la hora de analizarlos:
- Analizaremos la hora del día con mayor tráfico de viajes
- Analizaremos las estaciones con un mayor volumen de viajes
Antes de lanzarnos a analizar y construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, es necesario realizar un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de análisis de redes (Gephi) que de forma visual nos ayudará a comprender la información. Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en este Notebook de Google Colab, son los siguientes:
- Instalación de librerías y carga de los conjuntos de datos
- Análisis exploratorio de los datos (EDA)
- Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que, una vez cargado en el entorno de desarrollo, podrás ejecutar o modificar de manera sencilla.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente sino facilitar su comprensión, por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Análisis de la red
5.1. Definición de la red
La red analizada se encuentra formada por los viajes entre distintas estaciones de bicicletas en la ciudad de Madrid, teniendo como principal información de cada uno de los viajes registrados la estación de origen (denominada como “source”) y la estación de destino (denominada como “target”).
La red está formada por 253 nodos (estaciones) y 3012 aristas (interacciones entre las estaciones). Se trata de un grafo dirigido, debido a que las interacciones son bidireccionales y ponderado, debido a que cada arista entre los nodos tiene asociado un valor numérico denominado "peso" que en este caso corresponde al número de viajes realizados entre ambas estaciones.
5.2. Carga de la tabla preprocesada en Gephi
Mediante la opción “importar hoja de cálculo” de la pestaña archivo, importamos en formato CSV la tabla de datos previamente preprocesada. Gephi detectará que tipo de datos se están cargando, por lo que utilizaremos los parámetros predefinidos por defecto.


5.3. Opciones de visualización de la red
5.3.1 Ventana de distribución
En primer lugar, aplicamos en la ventana de distribución, el algoritmo Force Atlas 2. Este algoritmo utiliza la técnica de repulsión de nodos en función del grado de conexión de tal forma que los nodos escasamente conectados se separan respecto a los que tiene una mayor fuerza de atracción entre sí.
Para evitar que los componentes conexos queden fuera de la vista principal, fijamos el valor del parámetro "Gravedad en Puesta a punto" a un valor de 10 y para evitar que los nodos queden amontonados, marcamos la opción “Disuadir Hubs” y “Evitar el solapamiento”.

Dentro de la ventana de distribución, también aplicamos el algoritmo de Expansión con la finalidad de que los nodos no se encuentren tan juntos entre sí mismos.

Figura 3. Ventana distribución - algoritmo de Expansión
5.3.2 Ventana de apariencia
A continuación, en la ventana de apariencia, modificamos los nodos y sus etiquetas para que su tamaño no sea igualitario, sino que dependa del valor del grado de cada nodo (nodos con un mayor grado, mayor tamaño visual). También modificaremos el color de los nodos para que los de mayor tamaño sean de un color más llamativo que los de menor tamaño. En la misma ventana de apariencia modificamos las aristas, en este caso hemos optado por un color unitario para todas ellas, ya que por defecto el tamaño va acorde al peso de cada una de ellas.
Un mayor grado en uno de los nodos implica un mayor número de estaciones conectadas con dicho nodo, mientras que un mayor peso de las aristas implica un mayor número de viajes para cada conexión.

5.3.3 Ventana de grafo
Por último, en la zona inferior de la interfaz de la ventana de grafo, tenemos diversas opciones como activar/desactivar el botón para mostrar las etiquetas de los distintos nodos, adecuar el tamaño de las aristas con la finalizad de hacer más limpia la visualización, modificar el tipo de letra de las etiquetas, …

A continuación, podemos ver la visualización del grafo que representa la red una vez aplicadas las opciones de visualización mencionadas en los puntos anteriores.

Figura 6. Visualización del grafo
Activando la opción de visualizar etiquetas y colocando el cursor sobre uno de los nodos, se mostrarán los enlaces que corresponden al nodo y el resto de los nodos que están vinculados al elegido mediante dichos enlaces.
A continuación, podemos visualizar los nodos y enlaces relativos a la estación de bicicletas “Fernando el Católico". En la visualización se distinguen con facilidad los nodos que poseen un mayor número de conexiones, ya que aparecen con un mayor tamaño y colores más llamativos, como por ejemplo "Plaza de la Cebada" o "Quevedo".