Noticia
Quedan pocos días para que acabe el verano y, como en cada cambio de estación, es el momento de repasar lo que han dado de sí estos tres meses en el ecosistema de datos abiertos español.
En julio conocimos la última edición del informe DESI (Digital Economy and Society Index) de la Comisión Europea, que coloca a España por delante de la media de la UE en materia digital. Nuestro país se sitúa en la séptima posición, mejorando dos puestos con respecto a 2021. Una de las áreas donde se obtiene un mejor rendimiento es en los datos abiertos, donde ocupa el tercer lugar. Estos buenos datos son fruto de que cada vez más organismos apuestan por la apertura de la información que atesoran y más reutilizadores aprovechan esos datos para crear productos y servicios de valor, como veremos a continuación.
Avances en estrategia y acuerdos para impulsar el open data
Los datos abiertos ganan terreno en las estrategias políticas tanto a nivel nacional, como regional o local.
En este sentido, el Consejo de Ministros aprobó en julio el proyecto de Ley de Eficiencia Digital del Servicio Público de Justicia, una iniciativa que busca construir una Administración de Justicia más accesible, impulsando la orientación al dato de sus sistemas. Entre otras cuestiones, con esta ley se incorpora el concepto de “dato abierto” en la Administración de Justicia.
Otro ejemplo, este a nivel autonómico, proviene de la Generalitat de Valencia, que lanzó a comienzos de verano una nueva Estrategia de datos abiertos con el fin de ofrecer una información pública de calidad, por diseño y por defecto.
También hemos asistido al cierre de convenios de colaboración para impulsar el ecosistema open data, como por ejemplo:
- El Ajuntament de L'Hospitalet y la Universitat Politècnica de Catalunya han firmado un acuerdo para ofrecer formación a los estudiantes de grado o master sobre Big Data e inteligencia Artificial, partiendo del trabajo de datos abiertos.
- La Universidad de Castilla la Mancha ha acordado junto al Gobierno regional poner en marcha la cátedra ‘Gobierno Abierto’ con el fin de impulsar la formación superior y la investigación en materias como la transparencia, los datos abiertos o el acceso a la información pública.
- El Centro Nacional de Información Geográfica (CNIG) y Asedie han firmado un nuevo protocolo para mejorar el acceso a la información geográfica, con el fin de promover la apertura, el acceso y la reutilización de la información del Sector Público.
Ejemplos de reutilización de datos
El verano de 2022 lo recordaremos por las olas de calor y los incendios que han asolado los distintos rincones del país. Un contexto donde los datos abiertos han puesto de manifiesto su poder para dar a conocer el estado de la situación y ayudar en la extinción de fuegos. Los datos de Copernicus o de la Agencia Estatal de Meteorología (AEMET) han sido utilizados para monitorizar la situación y tomar decisiones. Estas fuentes de datos, junto a otras, también están sirviendo para conocer las consecuencias que la escasez de lluvias y las elevadas temperaturas están dejando en los embalses europeos. Además, estos datos han sido utilizados por medios de comunicación para contar a la ciudadanía la última hora de la evolución de los incendios.
La lucha contra el fuego basada en datos abiertos también se ha desarrollado a nivel autonómico. Por ejemplo, el Gobierno de Navarra ha lanzado Agronic, una herramienta que trabaja con Infraestructuras de Datos Espaciales de Navarra para prevenir los incendios producidos por máquinas cosechadoras. Por su parte, el portal de datos abiertos de la Diputación de Barcelona ha publicado conjuntos de datos con "información esencial" para la prevención de incendios forestales. Entre ellos se encuentran la red de puntos de agua, las franjas de baja combustibilidad y las actuaciones de gestión forestal, utilizados por los organismos públicos para la elaboración de planes para hacer frente al fuego.
Otros ejemplos de uso de datos abiertos que hemos conocido en este periodo son:
- La Red de Vigilancia Radiológica Ambiental de la Generalitat de Catalunya ha desarrollado, a partir de datos abiertos, un sistema para monitorizar la radiación presente en el ambiente de las centrales nucleares (Vandellòs y Ascó) y del resto del territorio catalán.
- Gracias a los datos abiertos compartidos por Aragón Open Data se ha redactado un nuevo artículo científico sobre la Covid-19 cuya finalidad es conocer e identificar patrones espaciotemporales en relación a la incidencia del virus y la organización de recursos sanitarios.
- La iniciativa Barcelona Open Data ha lanzado #DataBretxaWomen un proyecto que busca sensibilizar a la ciudadanía sobre la desigualdad existente entre hombres y mujeres en distintos sectores.
- Maldito dato ha utilizado los datos abiertos de la estadística desarrollada por Instituto Nacional de Estadística (INE) a partir de los datos de posicionamiento móvil, para mostrar cómo cambia la densidad de población de los distintos municipios españoles durante julio y agosto.
- Dentro de su Programa de Analítica de Datos para la Investigación y la Innovación en Salud, Cataluña ha priorizado 8 propuestas para hacer investigación basada en análisis de datos. Entre ellos encontramos estudios sobre migrañas, psicosis o cardiopatías.
Novedades en las plataformas de datos abiertos
El verano también ha sido la época elegida por distintos organismos para lanzar o actualizar sus plataformas open data. Algunos ejemplos son:
- El Instituto de Estadística de Navarra lanzó un nuevo portal web, con visualizaciones más dinámicas y atractivas. En el proceso de creación han logrado automatizar la producción estadística e integrar todos los datos en un único entorno.
- El Ayuntamiento de Zaragoza también acaba de publicar un nuevo portal de datos abiertos que ofrece toda la información municipal de una manera más clara y concisa. Este nuevo portal ha sido consensuado con otros ayuntamientos dentro del proyecto ‘Ciudades abiertas’.
- Otra ciudad que ya cuenta con portal de datos abiertos es Cádiz. Su Ayuntamiento ha puesto en marcha una plataforma que permitirá a los gaditanos conocer, acceder, reutilizar y redistribuir los datos abiertos presentes en la ciudad.
- El Instituto Valenciano de Competitividad Empresarial (IVACE) presentó un portal de datos abiertos con todos los registros de certificación energética de edificios de la Comunidad Valenciana desde 2011. Esto permitirá, entre otras acciones, realizar análisis del consumo y establecer estrategias de rehabilitación.
- Aragón Open Data ha incluido una nueva funcionalidad en su API que permite a los usuarios obtener datos geográficos en formato GeoJSON.
- El Instituto Geográfico Nacional comunicó una nueva versión de la app de terremotos, con novedades, contenido didáctico e información.
- El Ministerio para la Transición Ecológica y el Reto Demográfico presentó SIDAMUN, una plataforma que facilita el acceso a información estadística territorial a partir de datos municipales.
- El portal de datos abiertos del Gobierno de Canarias lanzó un nuevo buscador que permite localizar las páginas del portal utilizando metadatos, y que permite exportar en CVS, ODS o PDF.
Algunos organismos han aprovechado el verano para anunciar novedades que verán la luz en los próximos meses como la Xunta de Galicia, que avanza en el desarrollo de un Observatorio de Salud Pública mediante una plataforma de datos abiertos, el Ayuntamiento de Burgos, que estrenará portal de datos abiertos, o la Diputación de Pontevedra que lanzará próximamente un visor presupuestario en tiempo real.
Acciones para promover los datos abiertos
En junio conocimos a los finalistas del IV Desafío Aporta: “El valor del dato para la salud y el bienestar de los ciudadanos”, cuya final se celebrará en octubre. Además, en estos meses se han lanzado algunas competiciones para promover la reutilización de datos abiertos cuyo plazo de inscripción todavía está abierto, como el concurso de Castilla y León o el primer Datathon de UniversiData. También se puso en marcha el concurso de datos abiertos de Euskadi, que actualmente se encuentra en fase de evaluación.
Con respecto a los eventos, el verano comenzó con la celebración de la Semana de la Administración abierta, que reunió diversas actividades, algunas de ellas enfocadas en los datos. Si te lo perdiste, algunas organizaciones han puesto a disposición de los ciudadanos diversos materiales. Por ejemplo, puedes ver en vídeo el coloquio “Los datos abiertos con perspectiva de género: sí o sí” impulsado por el Gobierno de Canarias o acceder a las presentaciones del webinar para conocer a la Oficina del Dato y la Iniciativa Aporta.
Otros eventos que se han celebrado, con la participación de la Oficina del Dato, y cuyos vídeos son públicos son: el Congreso Nacional de Archivo y Documento Electrónico y los Espacios de Datos como ecosistemas para que las entidades puedan llegar más lejos.
Por último, en el campo de la formación, algunos ejemplos de cursos que se han lanzado estos meses son:
- El Instituto Geográfico Nacional ha lanzado un Plan de Formación Interadministrativo, con el fin de generar una cultura común entre todos los expertos en Información Geográfica de los organismos públicos.
- Andalucía Vuela ha lanzado una serie de formaciones gratuitas y dirigidas a la ciudadanía interesada en datos o inteligencia artificial.
Novedades a nivel internacional
El verano también ha dado lugar a muchas novedades en el ámbito internacional. Algunos ejemplos son:
- A comienzos del verano meteorológico se publicaron los resultados de la primera edición del Global Data Barometer, que mide el estado de los datos con respecto a cuestiones sociales como la Covid19 o el clima.
- También se dieron a conocer los 12 finalistas del Eu Datathon 2022.
- Se publico una edición interactiva del anuario regional 2021 de Eurostat.
- Inglaterra ha elaborado una estrategia para aprovechar el potencial de los datos en la sanidad y la atención sanitaria de forma segura, fiable y transparente.
Esta es solo una selección de noticias entre todas las novedades del ecosistema de datos abiertos de los últimos tres meses. Si quieres hacer alguna contribución, puedes dejarnos un mensaje en los comentarios o escribir a dinamizacion@datos.gob.es.
Evento
Un año más desde el 2016, la Junta de Castilla y León abre el plazo para recibir las propuestas más innovadoras en materia de datos abiertos. La sexta edición del concurso que lleva el mismo nombre tiene como finalidad “reconocer la realización de proyectos que suministren cualquier tipo de idea, estudio, servicio, sitio web o aplicaciones para dispositivos móviles, y que para ello utilicen conjuntos de datos del Portal de Datos Abiertos de la Junta de Castilla y León”.
Con este tipo de iniciativas, Castilla y León busca visibilizar el talento digital presente en la comunidad autónoma, a la vez que impulsa el uso de los datos abiertos y el papel de las empresas reutilizadoras castellanoleonesas.
El plazo para la presentación de las candidaturas está abierto desde el pasado 5 de agosto y concluirá el próximo 4 de octubre. A la hora de presentar los proyectos, los participantes podrán elegir entre la opción presencial o digital. Esta última se llevará a cabo a través de la Sede Electrónica de Castilla y León y podrán tramitarla tanto personas físicas como jurídicas.
4 categías distintas
Al igual que en ediciones anteriores, los proyectos y premios asociados a los mismos se dividen en cuatro categorías diferenciadas:
- Categoría “Ideas”: Aquí se incluyen aquellos proyectos que describan una idea que pueda utilizarse para crear estudios, servicios, sitios web o aplicaciones para dispositivos móviles. El requisito principal que deben cumplir es utilizar conjuntos de datos del portal de Datos Abiertos de la Junta de Castilla y León .
- Categoría “Productos y Servicios”: Engloba aquellos que proporcionen estudios, servicios, sitios web o aplicaciones para dispositivos móviles y que empleen conjuntos de datos del portal de Datos Abiertos de la Junta de Castilla y León, que estén accesibles para toda la ciudadanía vía web mediante una URL.
- Categoría “Recurso Didáctico”: En este apartado se recoge la creación de recursos didácticos abiertos (publicados con licencias Creative Commons) nuevos e innovadores que usen conjuntos de datos del portal de Datos Abiertos de la Junta de Castilla y León, y sirvan de apoyo a la enseñanza en el aula.
- Categoría “Periodismo de Datos”: Por último, esta categoría incluye piezas periodísticas publicadas o actualizadas (de forma relevante) en cualquier soporte (escrito o audiovisual) que utilice conjuntos de datos del portal de Datos Abiertos de la Junta de Castilla y León.
Respecto a los galardones de esta sexta edición, los premios ascienden a una dotación económica 12.000€ que se distribuye en función de la categoría premiada y el puesto alcanzado.
Categoría Ideas
- Primer premio 1.500€
- Segundo premio 500€
Categoría Productos y servicios
- Primer premio 2.500€
- Segundo premio 1.500€
- Tercer premio 500€
- Premio estudiantes: 1.500€
Categoría Recurso didáctico
- Primer premio 1.500€
Categoría Periodismo de datos
- Primer premio 1.500€
- Segundo premio 1.000€
Al igual que en ediciones anteriores, el veredicto final será emitido por un jurado formado por integrantes que cuentan con acreditada experiencia en el ámbito de los datos abiertos, el análisis de información o la economía digital. Igualmente, las decisiones del jurado se adoptarán por mayoría de votos y, en caso de empate, decidirá quién ostente la presidencia.
Por último y respecto a los ganadores, estos tendrán un plazo de 5 días hábiles para aceptar el galardón. De no producirse la aceptación del premio se entenderá que se renuncia al mismo. Si quieres consultar en detalle las condiciones y las bases legales del concurso puedes acceder a ellas a través de este enlace.
Ganadores de la edición 2021
La V edición del Concurso de Datos de Castilla y León contó con un total de 37 propuestas de las cuales tan solo ocho de ellas se alzaron con algún tipo de galardón. Así y de cara a participar en la edición vigente, puede resultar de interés conocer cuáles fueron los proyectos que se ganaron la atención del jurado en 2021.
Categoría Ideas
El primer premio, de 1.500€, fue para APP SOLAR-CYL, una herramienta web de dimensionamiento óptimo de instalaciones de autoconsumo solar fotovoltaico. Dirigida tanto a ciudadanos como a gestores energéticos de la Administración Pública, la solución busca ser un apoyo para el análisis de la viabilidad técnica y económica de este tipo de sistemas.
Categoría Productos y Servicios
Repuéblame es en una web destinada a redescubrir los mejores lugares en los que vivir o teletrabajar. De esta forma, la app cataloga los municipios castellanoleoneses en base a una serie de indicadores numéricos, de elaboración propia, relacionados con la calidad de vida. Al llevarse el primer premio de esta categoría, consiguió una dotación económica de 2.500 euros.
Categoría Periodismo de datos
La Asociación Maldita contra la desinformación obtuvo el primer premio de 1.500€ gracias al proyecto MAPA COVID-19: consulta cuántos casos de coronavirus hay y cómo está la ocupación de tu hospital.
Por último y después de que el jurado dictaminase que las candidaturas presentadas no cumplían con los criterios recogidos en las bases, la categoría “Recurso Didáctico” fue declarada desierta y, por ende, ninguno de los participantes fue premiado.
Si tienes alguna duda o consulta acerca del concurso, puedes escribir un correo a: datosabiertos@jcyl.es.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información en forma de conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre los embalses nacionales. A partir de estos datos realizaremos el análisis de su estado y de su evolución temporal en los últimos años.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio para la Transición Ecológica y el Reto Demográfico, que dentro del boletín hidrológico recoge series temporales de datos sobre él volumen de agua embalsada de los últimos años para todos los embalses nacionales con una capacidad superior a 5hm3. Datos históricos del volumen de agua embalsada disponibles en:
También se ha seleccionado un conjunto de datos geoespaciales. Durante su búsqueda, se han encontrado dos posibles archivos con datos de entrada, el que contiene las áreas geográficas correspondientes a los embalses de España y el que contiene las presas que incluye su geoposicionamiento como un punto geográfico. Aunque evidentemente no son lo mismo, embalses y presas guardan relación y para simplificar este ejercicio práctico optamos por utilizar el archivo que contiene la relación de presas de España. Inventario de presas disponible en: https://www.mapama.gob.es/ide/metadatos/index.html?srv=metadata.show&uuid=4f218701-1004-4b15-93b1-298551ae9446 , concretamente:
Este conjunto de datos contiene geolocalizadas (Latitud, Longitud) las presas de toda España con independencia de su titularidad. Se entiende por presa, aquellas estructuras artificiales que, limitando en todo o en parte el contorno de un recinto enclavado en el terreno, esté destinada al almacenamiento de agua dentro del mismo.
Para generar los puntos geográficos de interés se realiza un procesamiento mediante la herramienta QGIS, cuyos pasos son los siguientes: descargar el archivo ZIP, cargarlo en QGIS y guardarlo como CSV incluyendo la geometría de cada elemento como dos campos que especifican su posición como un punto geográfico (Latitud y Longitud).
También se he realizado un filtrado para quedarnos con los datos correspondientes a las presas de los embalses que tengan una capacidad mayor a 5hm3
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación Python desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada a cada una de las presas en el dataset con datos geoespaciales, se realiza un proceso de enriquecimiento de datos explicado a continuación.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador, en caso de que eso no ocurriese, se accedería a dicha aplicación tecleando en la barra de búsqueda del navegador \"localhost:3333\".
Pasos a seguir:
- Paso 1: Carga del CSV en el sistema (Figura 1).

Figura 1 - Carga de un archivo CSV en OpenRefine
- Paso 2: Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.

Figura 2 - Creación de un proyecto en OpenRefine
- Paso 3: Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones (pasos 3.1 a 3.3):
- Paso 3.1: Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, habitualmente se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, hemos encontrado la columna NOMBRE que contiene el nombre de cada embalse que puede servir como identificador único de cada ítem y puede ser un buen candidato para enlazar.
- Paso 3.2: Comienzo de la reconciliación. Comenzamos la reconciliación como se indica en la figura 3 y seleccionamos la única fuente que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.

Figura 3 – Inicio del proceso de reconciliación de la columna NOMBRE en OpenRefine
- Paso 3.3: Selección de la clase de Wikidata. En este paso obtendremos los valores de la reconciliación. En este caso como valor más probable, seleccionamos el valor de la propiedad “reservoir” cuya descripción se puede ver en https://www.wikidata.org/wiki/Q131681, que corresponde a la descripción de un “lago artificial para acumular agua”. Únicamente habrá que pulsar otra vez en Start Reconciling.
OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión. Para ello ajustamos la propiedad P4568 cuya descripción se corresponde con el identificador de un embalse en España, en el SNCZI-Inventario de Presas y Embalses, como se observa en la figura 4.

Figura 4 - Selección de la clase de Wikidata que mejor representa los valores de la columna NOMBRE
- Paso 4: Generar una nueva columna con los valores reconciliados o enlazados. Para ello debemos pulsar en la columna NOMBRE e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser WIKIDATA_EMBALSE). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura 6. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“ALMODOVAR”) = Q5369429.
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
El proceso lo repetimos para añadir otro tipo de información enriquecida como la referencia en Google u OpenStreetMap.

Figura 5 - Generación de las entidades de Wikidata gracias a la reconciliación a partir de una nueva columna
- Paso 5: Descargar el CSV enriquecido. Utilizamos la función Export → Custom tabular exporter situada en la parte superior derecha de la pantalla y seleccionamos las características como se indica en la Figura 6.

Figura 6 - Opciones de descarga del fichero CSV a través de OpenRefine
5. Preprocesamiento de datos
Durante el preprocesamiento es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creadas posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Modificación y ajuste de las variables
- Detención y tratamiento de datos ausentes (NAs)
- Generación de nuevas variables
- Creación de tabla para visualización \"Evolución histórica de la reserva hídrica entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Reserva hídrica (hm3) entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Reserva hídrica (%) entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Evolución mensual de la reserva hídrica (hm3) para distintas series temporales\"
- Guardado de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
6. Visualización de datos
Una vez hemos realizado un preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos las siguientes:
- ¿Cuál es la localización de los embalses dentro del territorio nacional?
-
¿Qué embalses son los de mayor y menor aporte de volumen de agua embalsada (reserva hídrica en hm3) al conjunto del país?
-
¿Qué embalses poseen el mayor y menor porcentaje de llenado (reserva hídrica en %)?
-
¿Cuál es la tendencia en la evolución de la reserva hídrica en los últimos años?
¡Vamos a buscar las respuestas viendo los datos!
6.1. Localización geográfica y principal información de cada embalse
Esta representación visual se ha realizado teniendo en cuenta las coordenadas geográficas de los embalses y distinta información asociada a cada uno de ellos. Para ello se ha generado durante el preprocesamiento de datos la tabla “geo.csv”
Mediante un mapa de puntos geográficos se visualiza la localización de los embalses en el territorio nacional.
Una vez obtenido el mapa, pinchando en cada uno de los embalses podemos acceder a información complementaria sobre dicho embalse en la tabla inferior. También, mediante las pestañas despegables, aparece la opción de filtrar el mapa por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.2. Reserva hídrica (hm3) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) por embalse entre los años los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “volumen.csv”
Mediante un gráfico de jerarquía rectangular se visualiza de forma intuitiva la importancia de cada embalse en cuanto a volumen embalsado dentro del conjunto nacional para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.3. Reserva hídrica (%) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (%) por embalse entre los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “porcentaje.csv”
Mediante un gráfico de barras se visualiza de forma intuitiva el porcentaje de llenado de cada embalse para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.4. Evolución histórica de la reserva hídrica entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta los datos históricos de la reserva hídrica (hm3 y %) para todas las mediciones semanales registradas entre los años 2012(inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas.csv”
Mediante gráficos de líneas y sus líneas de tendencia se visualiza la evolución temporal de la reserva hídrica (hm3 y %).
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos modificar la serie temporal, filtrar por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.5. Evolución mensual de la reserva hídrica (hm3) para distintas series temporales
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) de los distintos embalses desglosada por meses para distintas series temporales (cada uno de los años desde el 2012 hasta el 2022). Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas_mensual.csv”
Mediante un gráfico de líneas se visualízala la reserva hídrica mes a mes para cada una de las series temporales.
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos filtrar por demarcación hidrográfica y por embalse. También tenemos la opción de elegir la serie o series temporales (cada uno de los años desde el 2012 hasta el 2022) que queremos visualizar mediante el icono que aparece en la parte superior derecha del gráfico.
Ver la visualización en pantalla completa
7. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
Se observa una tendencia significativa en la disminución del volumen de agua embalsada por el conjunto de embalses nacionales entre los años 2012 y 2022.
-
El año 2017 es el que presenta valores más bajos de porcentaje de llenado total de los embalses, llegando a ser este inferior al 45% en ciertos momentos del año.
-
El año 2013 es el que presenta valores más altos de porcentaje de llenado total de los embalses, llegando a ser este superior al 80% en ciertos momentos del año.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por demarcación hidrográfica y por embalse. Te animamos a lo que lo hagas para sacar conclusiones más específicas de las demarcaciones hidrográficas y embalses que estés interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Noticia
El pasado mes de noviembre se lanzó la 4ª edición del Desafío Aporta, organizado por Red.es, en colaboración con la Secretaría de Estado de Digitalización e Inteligencia Artificial. Bajo el lema “El valor del dato para la salud y el bienestar de los ciudadanos”, la competición busca identificar nuevos servicios y soluciones, basadas en datos abiertos, que impulsen mejoras en dicho ámbito.
El reto se divide en dos fases: un concurso de ideas, seguido de una segunda fase donde los finalistas tienen que desarrollar y presentar un prototipo. Ahora nos encontramos en el ecuador de la competición. La fase I ha llegado a su fin y es el momento de conocer quiénes son los 10 finalistas que pasarán a la fase II.
Tras el análisis de las propuestas presentadas, muy diversas y de gran calidad, el jurado ha determinado una serie de finalistas, como ha quedado reflejado en la resolución publicada en la sede electrónica de Red.es.

Veamos cada candidatura en detalle:
Acercándonos al paciente
- Equipo:
SialSIG aporta, integrado por Laura García y María del Mar Gimeno.
- ¿En qué consiste?
Se construirá una plataforma que permitirá reducir el tiempo del rescate y optimizar la atención médica ante una emergencia. Se analizarán parámetros para categorizar las zonas definiendo el riesgo de mortalidad y se identificarán los lugares más óptimos para el aterrizaje de los medios aéreos de rescate. Esta información permitirá, además, conocer cuáles son las zonas más aisladas y vulnerables ante emergencias médicas, una información de gran valor para definir estrategias de actuación que conlleven una mejora de las gestiones y los medios a emplear.
- Datos
La plataforma busca integrar la información de todas las comunidades autónomas, incluyendo datos de población (censo, edad, sexo, etc.), datos de hospitales y helipuertos, datos de usos del suelo y cultivos, etc. En concreto, se obtendrán datos del padrón municipal del Instituto Nacional de Estadística (INE), los límites de provincias y municipios, la calificación de uso de los terrenos del Instituto Geográfico Nacional (IGN) y datos del SIGPAC (MAPA), entre otros.
Monitorización de la presión hospitalaria
- Equipo:
DSLAB, grupo de investigación en ciencia de datos de la Universidad Rey Juan Carlos, integrado por Isaac Martín, Alberto Fernández, Marina Cuesta y María del Carmen Lancho.
- ¿En qué consiste?
Con el objetivo de mejorar la gestión hospitalaria, el DSLAB propone un cuadro de mando interactivo y fácil de usar que permita:
- Monitorizar la presión hospitalaria
- Evaluar la carga y saturación real de los centros sanitarios
- Predecir la evolución de dicha presión
De esta forma se podrá ejecutar una mejor planificación de recursos, anticipar la toma de decisiones y evitar posibles colapsos.
- Datos
Para plasmar el potencial de la herramienta, el prototipo se realizará con datos abiertos relativos al COVID en la Comunidad Autónoma de Castilla y León, como la ocupación de camas o la situación epidemiológica por hospitales y provincias. No obstante, la solución es escalable y extrapolable a cualquier otro territorio con datos similares.
RIAN - Recomendador Inteligente de Actividades y Nutrición
- Equipo:
RIAN Open Data Team, integrado por Jesús Noguera y Raúl Micharet.
- ¿En qué consiste?
RIAN surge para fomentar hábitos saludables y combatir el sobrepeso, la obesidad, el sedentarismo y la mala nutrición entre niños y adolescentes. Se trata de una aplicación para dispositivos móviles que utiliza técnicas de gamificación, así como realidad aumentada y algoritmos de inteligencia artificial para realizar recomendaciones. Los usuarios tienen que resolver retos personalizados, de forma individual o colectiva, ligados con aspectos nutricionales y actividades físicas, como yincanas o juegos en espacios verdes públicos.
- Datos
El piloto utiliza datos relativos a zonas verdes, puntos de interés, vías verdes, actividades y eventos pertenecientes a las ciudades de Málaga, Madrid, Zaragoza y Barcelona. Estos datos se combinan con recomendaciones nutricionales (datos de alimentos y valores nutricionales y productos alimentarios con marca) y datos destinados al reconocimiento de alimentos por imágenes de Tensorflow o Kaggle, entre otros.
MentalReview - visualización del dato para la salud mental
- Equipo:
Kairos Digital Analytics and Big Data Solutions S.L.
- ¿En qué consiste?
MentalReview es una herramienta de monitorización de la salud mental para apoyar la gestión y planificación sociosanitaria, permitiendo a las instituciones mejorar los servicios de atención al ciudadano. La herramienta permitirá analizar la información extraída de bases de datos abiertas, calcular indicadores y, finalmente, visualizar la información a través de gráficas y un mapa interactivo. Esto permitirá conocer el estado actual de la salud mental en la población española, identificar tendencias o hacer un estudio de su evolución.
- Datos
Para su desarrollo se utilizarán datos del INE, el Centro de Investigaciones Sociológicas, los Servicios de Salud Mental de las distintas autonomías, la Agencia Española de Medicamentos y Productos Sanitarios o EUROSTAT, entre otros. Algunos ejemplos concretos de conjuntos de datos a utilizar son: los problemas de ansiedad en la juventud, la tasa de mortalidad por suicidio por comunidad autónoma, edad, sexo y periodo o el consumo de ansiolíticos.
HelpVoice!
- Equipo:
Data Express, integrado por Sandra García, Antonio Ríos y Alberto Berenguer.
- ¿En qué consiste?
HelpVoice! es un servicio que ayuda a nuestros mayores a través de técnicas de reconocimiento de voz basadas en aprendizaje automático. Ante una situación de emergencia, el usuario solo tendrá que hacer clic en un dispositivo que puede ser un botón de emergencia, un teléfono móvil o herramientas de domótica y comentar sus síntomas. El sistema enviará un informe con la transcripción realizada y predicciones al hospital más cercano, agilizando la respuesta de los sanitarios. En paralelo, HelpVoice! también recomendará al paciente qué hacer mientras espera a los servicios de emergencia.
- Datos
Entre otros datos abiertos, se utilizarán el mapa de hospitales de España. También se utilizarán datos de reconocimiento del habla y sentimientos en el texto.
Ciudades vivas y habitables: creando mapas de sombras de alta resolución para favorecer la adaptación de las ciudades al cambio climático
- Equipo:
Ciudades Vivas, integrado por Francisco Rodríguez-Sánchez y Jesús Sánchez-Dávila.
- ¿En qué consiste?
En el contexto actual de aumento de temperaturas, el equipo de Ciudades Vivas propone desarrollar un software abierto para promover la adaptación de las ciudades al cambio climático, facilitando la planificación del sombreado urbano. Utilizando técnicas de análisis espacial, teledetección y modelización, dicho software permitirá conocer el nivel de insolación (o sombreado) con alta resolución espaciotemporal (cada hora del día y sobre cada metro cuadrado de suelo) para cualquier municipio de España. El equipo analizará particularmente la situación del sombreado en la ciudad de Sevilla, ofreciendo sus resultados públicamente mediante una aplicación web que permitirá consultar los mapas de insolación y obtener rutas de sombra entre distintos puntos de la ciudad.
- Datos
Ciudades Vivas se basa en el uso de datos abiertos de teledetección (LiDAR) del Programa Nacional de Ortofotografía Aérea (PNOA), el arbolado de la ciudad de Sevilla y los datos espaciales de OpenStreetMap.
Impacto de la calidad del aire en la salud respiratoria en la ciudad de Madrid
- Equipo:
So Good Data, integrado por Ana Belén Laguna, Manuel López, Vicente Lorenzo, Javier Maestre e Iván Robles.
- ¿En qué consiste?
So Good Data propone un estudio para analizar el impacto de la contaminación atmosférica en el número de ingresos hospitalarios por causa de enfermedades respiratorias. También determinará cuáles son las partículas contaminantes que podrían resultar más perjudiciales. Con esta información, se podría predecir el número de ingresos a los que se va a enfrentar un hospital en función de la contaminación atmosférica en una fecha concreta, para tomar las medidas necesarias con antelación y reducir la mortalidad.
- Datos
Entre otros conjuntos de datos, se utilizarán para el estudio las hospitalizaciones por enfermedades respiratorias, la calidad del aire, las ventas de tabaco o el polen atmosférico en la Comunidad de Madrid.
PLES
- Equipo:
BOLT, integrado por Víctor José Montiel, Núria Foguet, Borja Macías, Alejandro Pelegero y José Luis Álvarez.
- ¿En qué consiste?
El equipo BOLT creará una aplicación web que permita al usuario obtener una estimación del tiempo medio de espera para consultas, pruebas o intervenciones en el sistema sanitario público de Cataluña. Los modelos de predicción de series temporales se desarrollarán mediante Python con técnicas estadísticas y de machine mearning. El usuario solo tendrá que indicar el hospital y el tipo de consulta, operación o prueba por la cual están esperando. Además de mejorar la transparencia con el paciente, la web también podrá ser utilizada por los profesionales sanitarios para gestionar mejor sus recursos.
- Datos
Se utilizarán los datos de las listas de espera públicas de Cataluña publicadas por CatSalut mensualmente. En concreto, se emplearán los datos mensuales de las listas de espera de intervenciones quirúrgicas, de consultas externas especializadas y de pruebas diagnósticas desde, por lo menos, 2019 a la actualidad. En el futuro la idea podría ser adaptada a otras Comunidades Autónomas.
La Encuesta de Morbilidad Hospitalaria: Propuesta de desarrollo de un entorno web MERN+Python para su análisis y la visualización gráfica
- Equipo:
Marc Coca Moreno
- ¿En qué consiste?
Se trata de un entorno web basado en las herramientas MERN, Python y Pentaho para el análisis y la visualización interactiva de los microdatos de la Encuesta de Morbilidad Hospitalaria. Todo el proyecto se desarrollará con herramientas open source y gratuitas. Tanto el código como el producto final serán accesibles de forma abierta.
En concreto, ofrece 3 grandes análisis con el fin de mejorar la planificación sanitaria:
o Descriptivos: recuento de las altas hospitalarias y serie temporal
o KPI: tasas e indicadores estandarizados para la comparación y el benchmarking de las provincias y comunidades.
o Flujos: recuento y análisis de las altas de una región hospitalaria y procedencia del paciente.
Todos los datos serán filtrables según las variables del juego de datos (edad, sexo, diagnósticos, circunstancia de ingreso y alta, etc.)
- Datos
Además de los microdatos de la Encuesta de Morbilidad Hospitalaria del INE, también integrará Estadísticas del Padrón Continuo (también del INE), datos de los catálogos de diagnósticos CIE10 del Ministerio de Sanidad y de los catálogos e indicadores de Agency for Healthcare Research and Quality (AHRQ) y de las Comunidades Autónomas, como Cataluña: catálogos y herramientas de estratificación.
TWINPLAN: Sistema de apoyo a la toma de decisión para rutas accesibles y saludables
- Equipo:
TWINPLAN, integrado por Ivan Araquistain, Josu Ansola e Iñaki Prieto.
- ¿En qué consiste?
Se trata de una web App para facilitar la accesibilidad de las personas con problemas de movilidad y promover el ejercicio saludable de toda la ciudadanía. La herramienta evalúa si su ruta está afectada por alguna incidencia en los ascensores públicos y, en caso afirmativo, propone una ruta accesible alternativa, indicando también el nivel de tráfico (ruido) en la zona, la calidad del aire y los puntos de cardioprotección. Así mismo, facilita el contacto de medios de transporte próximos.
Esta web App también podrá ser utilizada por las administraciones públicas para la monitorización del uso y planificación de nuevas infraestructuras accesibles.
- Datos
El prototipo se desarrollará utilizando datos del Gemelo Digital de los ascensores públicos de Ermua, aunque el modelo es escalable a otros territorios. Estos datos se complementan con otros datos públicos de Ermua como la red de sensores ambientales, tráfico y LurData, entre otras fuentes.
Ahora estas 10 propuestas cuentan con varios meses para desarrollar sus propuestas, que tendrán que presentar el 18 de octubre. Los tres prototipos mejor valorados por el jurado recibirán 5.000€, 4.000€ y 3.000€, respectivamente.
¡Mucha suerte a todos los finalistas!

(Puedes descargar la versión accesible en word aquí)
Blog
La vida digital ha llegado para incorporarse a nuestro día a día y con ella también nuevos hábitos de comunicación y consumo de información. Conceptos como realidad aumentada participan de forma activa en este proceso de cambio en el que cada vez más empresas y organismos están involucrados.
Diferencias entre realidad aumentada y virtual
A pesar de que la nomenclatura de estos conceptos guarda cierta similitud, en la práctica, hablamos de escenarios diferentes entre sí:
- Realidad virtual: Se trata de una experiencia digital que permite al usuario sumergirse en un mundo artificial donde puede experimentar matices sensoriales aislados de lo que sucede en su exterior.
- Realidad aumentada: Es una alternativa de visualización de datos que mejora la experiencia de usuario al incorporar elementos digitales a la realidad tangible. Es decir, permite añadir aspectos visuales sobre el entorno que nos rodea. Esto la hace especialmente interesante en el mundo de la visualización de datos, ya que permite superponer elementos gráficos a nuestra realidad. Para conseguirlo, lo más habitual es utilizar unas gafas especializadas. De forma paralela, la realidad aumentada también puede desarrollarse sin necesidad de recurrir a gadgets externos. Haciendo uso de la cámara de nuestro teléfono móvil, algunas aplicaciones son capaces de combinar la visualización de elementos reales presentes a nuestro alrededor con otros procesados digitalmente y que nos permiten interactuar con la realidad tangible.
En este artículo nos vamos a centrar en la realidad aumentada que se presenta como una fórmula eficaz para compartir, presentar y divulgar la información que contienen los conjuntos de datos.
Retos y oportunidades
El uso de herramientas de realidad aumentada es especialmente útil a la hora de distribuir y divulgar conocimiento de forma online. De esta forma, en lugar de compartir un conjunto de datos a través de texto y representaciones gráficas, la realidad aumentada permite explorar fórmulas divulgativas que facilitan la compresión desde el punto de vista de la experiencia de usuario.
Estas son algunas de las oportunidades asociadas a su empleo:
- A través de visualizaciones 3D, la realidad aumentada permite al usuario tener una experiencia inmersiva que facilita la toma de contacto y la interiorización de este tipo de información.
- Permite consultar información en tiempo real e interactuar con el entorno. La realidad aumentada permite que el usuario pueda interactuar con los datos en lugares remotos. Los datos pueden adaptarse, incluso en términos espaciales, a las necesidades y características del entorno. Esto es de especial utilidad en trabajos de campo, permitiendo que operarios que reparan averías o agricultores en medio de sus cultivos puedan acceder a la información actualizada que necesitan, de forma muy visual, combinada con el entorno.
- Es posible mostrar una mayor densidad de datos a la vez, algo que facilita el procesamiento cognitivo de la información. De este modo, la realidad aumentada ayuda a agilizar los procesos de comprensión y, por ende, nuestra capacidad para concebir nuevas realidades.

Ejemplo de visualización de datos de agricultura sobre el entorno
A pesar de estas ventajas, nos encontramos ante un mercado aun en desarrollo, que tiene que hacer frente a retos como los costes de implementación, la falta de estándares comunes o la preocupación de los usuarios por la seguridad.
Casos de Uso
Más allá de los retos, oportunidades y fortalezas, la realidad aumentada cobra aún más relevancia cuando las organizaciones la incorporan a su área de innovación para mejorar la experiencia de usuario o la eficiencia de procesos. Así, a través de los casos de uso, podemos comprender mejor el universo de utilidad que se esconde detrás de la realidad aumentada.
Un campo donde suponen una gran oportunidad es el turismo. Un ejemplo es Gijón en un clic, una aplicación móvil gratuita que pone al alcance de los visitantes 3 rutas. Durante los recorridos, se han instalado unas placas en el suelo desde donde los turistas pueden lanzar recreaciones de realidad aumentada con su propio teléfono móvil.
Desde el punto de vista de las empresas de hardware, podemos resaltar el ejemplo, entre un amplio listado, del prototipo de casco inteligente diseñado por la empresa Aegis Rider, que permite obtener información sin apartar la vista de la carretera. Este casco utiliza la realidad aumentada para proyectar a la altura de la mirada del motorista una serie de indicadores que le ayudarán a minimizar el riesgo de accidente.
Entre los datos proyectados destacan algunos que proceden de fuentes de datos abiertos como la información sobre el estado de las carreteras, el trazado de las mismas o la velocidad máxima de circulación. Además, utilizando un sistema basado en el reconocimiento de objetos y el deep learning, el casco de Aegis Rider también detecta objetos, animales, peatones u otros vehículos presentes en la calzada y que podrían suponer un riesgo de accidente al estar en la misma trayectoria.
Al margen de la seguridad vial, pero siguiendo con las posibilidades que ofrece la realidad aumentada, Accuvein utiliza la realidad aumentada para evitar que los pacientes crónicos, como los oncológicos, tengan que sufrir pinchazos fallidos a la hora de recibir su medicación. Para ello, Accuvein ha diseñado un escáner manual que proyecta la ubicación exacta de las distintas venas sobre la piel del paciente. Tal y como recogen sus propios desarrolladores, el nivel de acierto es 3,5 veces mayor respecto a un pinchazo tradicional.
Por otro lado, los ciudadanos de a pie pueden encontrarse también la realidad aumentada como material de apoyo informativo de noticias y reportajes. Medios de comunicación como The New York Times ofrecen, cada vez con más frecuencia, informaciones que utilizan la realidad aumentada para visualizar conjuntos de datos y facilitar su comprensión.
Herramientas para generar visualizaciones con realidad aumentada
Como hemos visto, la realidad aumentada también sirve para crear visualizaciones de datos que faciliten la comprensión de conjuntos de información que, a priori, pudiesen resultar abstractos. Para crear estas visualizaciones existen distintas herramientas, como por ejemplo Flow, cuya función es facilitar el trabajo de programadores y desarrolladores. Esta plataforma que muestra conjuntos de datos a través de la API del dispositivo WebXR permite a este tipo de profesionales cargar datos, crear visualizaciones y agregar pasos para la transición entre ellos. Otras herramientas son 3Data o Virtualitics. También compañías como IBM están entrando en el sector.
Por todo ello y al hilo de las evidencias que dejan casos como los anteriores, la realidad aumentada se posiciona como una de las tecnologías de visualización y transmisión de datos que han llegado para expandir aún más los límites de la sociedad del conocimiento en la que estamos inmersos.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
La primavera, además de la llegada del buen tiempo, nos ha traído gran cantidad de novedades relacionadas con el ecosistema open data y la compartición de datos. Durante los tres últimos meses han continuado los avances impulsados desde Europa, destacando dos iniciativas que actualmente se encuentran en fase de consulta pública:
- Avances en los espacios de datos. Se ha iniciado la tramitación de la primera iniciativa regulatoria de un espacio de datos. Esta primera propuesta se centra en los datos del sector salud y busca establecer un marco jurídico uniforme, facilitar el acceso electrónico de los pacientes a sus propios datos e impulsar su reutilización para otros fines secundarios. Actualmente se encuentra en fase de consulta pública hasta el 28 de julio.
- Impulso de los datos de alto valor. El concepto de datos de alto valor, recogido en la Directiva 2019/1024, hace referencia a aquellos datos cuya reutilización conlleva considerables beneficios para la sociedad, el medio ambiente y la economía. Aunque en dicha directiva se incluía una propuesta de categorías temáticas iniciales a considerar, actualmente se está trabajando en la creación de un listado más concreto. Este listado ya se ha hecho público y cualquier ciudadano que lo desee puede hacer comentarios sobre el mismo hasta el 24 de junio. En la misma línea, la Comisión Europea también ha sacado una serie de ayudas que buscan apoyar a las administraciones públicas a nivel local, regional y nacional con el fin de impulsar la disponibilidad, calidad y facilidad de uso de datos de alto valor.
Estas dos iniciativas ayudan a impulsar un ecosistema que en nuestro país no deja de crecer, como recogen estos ejemplos de noticias que hemos recopilado a lo largo de los últimos meses.
Ejemplos de reutilización de datos abiertos
En esta estación también hemos conocido distintos proyectos que ponen de manifiesto las ventajas del uso de los datos:
- Gracias al uso de Datos Abiertos Enlazados (Linked Open Data) un profesor de la Universidad de Valladolid ha creado la aplicación web LOD4Culture. Esta app permite explorar el patrimonio cultural mundial a partir de las bases de datos semánticas de dbpedia y wikidata.
- La Universidad de Zaragoza ha lanzado sensoriZAR para controlar la calidad del aire y reducir el consumo energético de sus espacios. Construida sobre IoT, datos abiertos y ciencia abierta, la solución está enfocada a la toma de decisiones basadas en datos.
- El Hospital de Villalba ha creado un mapa de riesgo cardiovascular en la Sierra de Madrid gracias al Big Data. El mapa recoge datos clínicos y demográficos de los pacientes para informar sobre la probabilidad de desarrollar una enfermedad de este tipo en el futuro.
- El Laboratorio de Gobierno Abierto de Aragón ha presentado recientemente "RADAR", una aplicación que ofrece información georeferenciada sobre las iniciativas en el ámbito rural.
Acuerdos para impulsar los datos abiertos
El compromiso de los organismos públicos con los datos abiertos queda patente en diversos acuerdos y planes que se han puesto en marcha en los últimos meses:
- El 13 de abril, los alcaldes de Madrid y Málaga sellaron dos acuerdos de colaboración para potenciar en conjunto la transformación digital y el crecimiento turístico en ambas ciudades. Gracias a ellos, se podrán adoptar políticas de seguridad y protección de datos, datos abiertos y Big Data, entre otros.
- El Govern de les Illes Balears y Asedie colaborarán para implementar medidas de datos abiertos, transparencia y reutilización de datos públicos. Así se recoge en un acuerdo que busca impulsar la colaboración público-privada y el desarrollo de soluciones comerciales, entre otros.
- La Generalitat Valenciana ha firmado un convenio con la Universitat Politècnica de València a través del cual destinará 70.000€ para la realización de actividades centradas en la apertura y reutilización de datos durante el ejercicio 2022.
- El Ayuntamiento de Madrid también ha iniciado el proceso para la elaboración del III Plan de acción de Gobierno Abierto de la ciudad, para lo cual puso en marcha una consulta pública.
Además, continúan enriqueciéndose las plataformas de datos abiertos con nuevos conjuntos de datos y herramientas dirigidas a facilitar el acceso y uso de la información. Algunos ejemplos son:
- Aragón Open Data ha presentado su asistente virtual para acercar los datos del portal a los usuarios de una forma sencilla y amena. La solución ha sido desarrollada por Itainnova junto al Gobierno de Aragón.
- Cartociudad, perteneciente al Ministerio de Transportes, Movilidad y Agenda Urbana, cuenta con un nuevo visualizador para localizar direcciones postales. Se ha desarrollado a partir de un buscador basado en servicios REST y que ha sido creado con API-CNIG.
- El Ayuntamiento de Madrid también ha puesto en marcha un nuevo visualizador de datos abiertos. En él se pueden consultar cuadros de mando interactivos con datos sobre energía, meteorología, aparcamientos, bibliotecas, etc.
- La Consejería de Transición Ecológica del Gobierno de Canarias ha estrenado un nuevo buscador de certificados energéticos mediante referencia catastral, que cuenta con información del portal de Datos Abiertos de Canarias.
- El Ayuntamiento de Segovia ha renovado su web para alojar todas las páginas de las áreas municipales, incluyendo el Portal de datos abiertos, bajo el paraguas del proyecto Smart Digital Segovia.
- La Universidad de Navarra ha publicado un nuevo juego de datos a través de GBIF, que muestra las observaciones de 10 años sobre la sucesión natural de plantas vasculares en cultivos abandonados.
- La Diputación de Castellón ha publicado en su portal de datos abiertos un conjunto de datos que recoge la relación de los 52 municipios en los que se ha impulsado la instalación de cajeros automáticos para luchar contra la despoblación.
Auge de eventos, formaciones e informes
La primavera es una de las épocas más proliferas en eventos y presentaciones. Algunas de las actividades que se han desarrollado durante esto meses son:
- Asedie presentó la 10ª edición de su Informe sobre el estado del sector infomediario, en esta ocasión centrado en la economía del dato. El informe destaca que este sector tiene un volumen de ventas superior a los 2.000 millones de euros al año y emplea a casi 23.000 profesionales. En la página web de Asedie puedes acceder al vídeo de la presentación del informe, que contó con la participación de la Oficina del Dato.
- Durante esta estación, también se presentaron los resultados del Gobal Data Barometer. Este informe refleja ejemplos del uso e impacto de los datos abiertos, pero también pone de manifiesto las numerosas barreras que impiden el acceso y uso efectivo de los mismos, limitando la innovación y la resolución de problemas.
- El 26 de mayo se celebraron las Jornadas del dato de la Seguridad Social, las cuales se grabaron en vídeo y puedes ver en este enlace. En ellas se mostraron las grandes líneas estratégicas de la Gerencia de Informática de la Seguridad Social (GISS) en esta materia.
- También está disponible la grabación de la jornada “Estrategias Públicas para el Desarrollo de los Espacios de Datos”, organizada por AIR4S (Digital Innovation Hub en IA y Robótica para los Objetivos de Desarrollo Sostenible) y el Ayuntamiento de Madrid. Durante la jornada se dieron a conocer políticas e iniciativas de carácter público basadas en el uso y explotación de datos.
- Otro vídeo disponible es el de la presentación de Oscar Corcho, Catedrático de la Universidad Politécnica de Madrid (UPM), codirector del Grupo de Ingeniería Ontológica (OEG) y cofundador de LocaliData, hablando del proyecto colaborativo Ciudades Abiertas en el webinar “Improving knowledge transfer across organisations by knowledge graphs”. Puedes verlo en este enlace a partir del minuto 15:55 (en inglés).
- En materia de formación, la Red de Entidades Locales por la Transparencia y Participación de la FEMP aprobó su Plan de Formación para este año. Incluye temas relativos a la evaluación de políticas públicas, datos abiertos, transparencia, innovación pública y ciberseguridad, entre otros.
- El Ayuntamiento de Alcobendas ha puesto en marcha una sección con podcast en su web, con el fin de divulgar entre la ciudadanía temas como el uso de datos abiertos en las administraciones públicas.
Otras noticias de interés en Europa
Acabamos el repaso recogiendo algunas de las novedades ligadas al ecosistema de datos europeo:
- Ya se han hecho públicos los 24 equipos preseleccionados para el EUDatathon 2022. Entre ellos se encuentra el equipo español Astur Data Team.
- El Consorcio Europeo de Infraestructuras Científicas Digitales e Interconectadas LifeWatch ERIC, con sede en Sevilla, ha asumido la responsabilidad de dar soporte tecnológico a la red mundial de datos abiertos sobre biodiversidad.
- La Comisión Europea ha puesto en marcha recientemente Kohesio. Se trata de una nueva plataforma online pública (en inglés) que ofrece datos sobre proyectos europeos de cohesión. A través de los datos, muestra la contribución de la política a la cohesión económica, territorial y social de las regiones de la Unión Europea, así como a las transiciones ecológica y digital.
- El Portal Europeo de Datos Abierto ha publicado un nuevo estudio sobre cómo hacer más reutilizables sus datos. Este es el primero de una serie de informes que se centran en la sostenibilidad de las infraestructuras de los portales de open data.
Esta es solo una selección de noticias entre todas las novedades del ecosistema de datos abiertos de los últimos tres meses. Si quieres hacer alguna contribución, puedes dejarnos un mensaje en los comentarios o escribir a dinamizacion@datos.gob.es.
Documentación
Este informe que publica el European Data Portal (EDP) tiene como objetivo ayudar a los usuarios de datos abiertos en el aprovechamiento del potencial de los datos generados por el programa Copernicus.
El proyecto Copernicus genera datos de alto valor obtenidos vía satélite, generando una gran cantidad de datos sobre la observación terrestre, en consonancia con el objetivo del portal Europeo de Datos de aumentar la accesibilidad y el valor de los datos abiertos.
El informe aborda las siguientes cuestiones, ¿Qué puedo hacer con los datos de Copernicus?, ¿Cómo puedo acceder a los datos? ,y ¿Qué herramientas necesito para utilizar los datos? utilizando la información que se encuentra en el Portal Europeo de Datos, catálogos especializados y examinando ejemplos prácticos de aplicaciones que usen datos de Copernicus.
Este informe se encuentra disponible en este enlace: "Copernicus data for the open data community"
Aplicación
El Visor Municipal de Sagunto es una herramienta web que permite consultar de una manera gráfica e interactiva los presupuestos del municipio. Gracias a esta aplicación, se facilita a la ciudadanía la visualización y comprensión de las cuentas del Ayuntamiento, así como el seguimiento trimestral de los gastos e ingresos del municipio.
A través de esta plataforma es posible consultar quién, en qué y para qué se destinan los gastos del Ayuntamiento o cuántos ingresos se perciben y cuál es el origen de estos.
Todos los datos del visor se actualizan de manera trimestral y se encuentran disponibles en formato abierto para su posible reutilización.
Noticia
¿Quién no ha utilizado alguna vez una aplicación para planificar una escapada romántica, un fin de semana con amigos o unas vacaciones en familia? Cada vez son más las plataformas digitales que surgen para ayudarnos a calcular la ruta más adecuada, encontrar la gasolinera con el precio más barato o hacernos recomendaciones sobre hoteles y restaurantes según nuestros gustos y necesidades. Muchas de ellas tienen un denominador común, y es que su funcionamiento está basado en el uso de datos procedentes, en su mayoría, de administraciones públicas.
Cada día resulta más sencillo encontrar datos relacionados con el turismo que han sido publicados en abierto por diversos organismos públicos. El turismo es uno de los sectores que más ingresos genera en España año tras año. Por ello, no es de extrañar que muchos organismos opten por abrir datos turísticos a cambio de atraer un mayor número de visitantes a las distintas zonas de nuestro país.
A continuación, realizamos un repaso de algunos conjuntos de datos sobre turismo que puedes encontrar el Catálogo Nacional de Datos Abiertos con el fin de reutilizarlos para desarrollar nuevas aplicaciones o servicios que ofrezcan mejoras en este campo.
Estos son los tipos de datos sobre turismo que puedes encontrar en datos.gob.es
En nuestro portal puedes acceder a un amplio catálogo de datos que se encuentra clasificado por diferentes sectores. La categoría de Turismo cuenta actualmente con 2.600 conjuntos de datos de diferente naturaleza, incluyendo estadísticas, ayudas económicas, puntos de interés, precios de alojamientos, etc.
De todos estos conjuntos de datos, recogemos a continuación algunos de los más destacados junto al formato en el que puedes consultarlos:
A nivel estatal
- Instituto Nacional de Estadística (Ministerio de Asuntos Económicos y Transformación Digital). Estancia media, por tipo de alojamiento por comunidades y ciudades autónomas. CSV, XLSX, XLS, HTML, JSON, PC-Axis.
- Agencia Estatal de Meteorología (AEMET). Predicción por municipios, 7 días. XML.
- Instituto Geológico y Minero de España (Ministerio de Ciencia e Innovación). Inventario español de lugares de Interés Geológico (IELIG). HTML, JSON, KMZ, XML.
- Instituto Nacional de Estadística (Ministerio de Asuntos Económicos y Transformación Digital). Índice de Precios en Alojamientos de Turismo Rural: índices y desglose por tarifas. CSV, HTML, JSON, PC-Axis, CSV.
- Instituto Nacional de Estadística (Ministerio de Asuntos Económicos y Transformación Digital). Índice de precios en apartamentos: índices y desglose por tarifas. CSV, HTML, JSON, PC-Axis, CSV.
- Instituto Nacional de Estadística (Ministerio de Asuntos Económicos y Transformación Digital). Índice de precios de campings: índices y desglose por tarifas. CSV, HTML, JSON, PC-Axis.
A nivel CC.AA.
- Junta de Andalucía. Encuesta de coyuntura turística de Andalucía. CSV, HTML.
- Comunidad Autónoma del País Vasco. Destinos turísticos de Euskadi: pueblos, comarcas, rutas, paseos y experiencias. RSS, API, XLSX, GeoJSON, XML, JSON, KML.
- Comunidad Foral de Navarra. Señalización Camino Santiago. CSV, HTML, JSON, ODS, TSV, XLSX, XML.
- Comunidad Autónoma de Canarias. Actividades de Turismo Activo inscritas en el Registro General Turístico. XLS, CSV.
- Comunidad Foral de Navarra. Turismo ornitológico. CSV, HTML, JSON, ODS, TSV, XLSX, XML.
- Comunidad de Aragón. Senderos de Aragón. XML, JSON, CSV, XLS.
- Instituto Cántabro de Estadística. Directorio de Alojamientos Turísticos Colectivos (ALOJATUR) de Canarias. JSON, XML, ZIP, CSV.
A nivel local
- Ayuntamiento de Valencia. Monumentos turísticos. CSV, GML, JSON, KML, KMZ, OCTET-STREAM, WFS, WMS.
- Ayuntamiento de Lorca. Itinerarios rutas turísticas casco urbano. KMZ.
- Ayuntamiento de Almendralejo. Restaurantes y bares de Almendralejo. XML, TSV, CSV, JSON, XLSX.
- Ayuntamiento de Madrid. Oficinas de turismo de Madrid. HTML, RDF-XML, RSS, XML, CSV, JSON.
- Ayuntamiento de Vigo. Turismo Urbano. CSV, JSON, KML, ZIP, XLS, CSV.
Algunos ejemplos de reutilización de datos relacionados con el turismo
Tal y como indicábamos al inicio de este artículo, la apertura de datos por parte de las administraciones públicas facilita la creación de aplicaciones y plataformas que, reutilizando esa información, ofrecen un servicio de calidad a la ciudadanía, mejorando la experiencia de los viajeros, por ejemplo, proporcionando información actualizada de interés. Es el caso de Playas de Mallorca, que informa a sus usuarios acerca del estado de las playas de la isla en tiempo real, o Castilla y León Gurú, un asistente turístico para Telegram, con información sobre restaurantes, monumentos, oficinas de turismo, etc. También encontramos aplicaciones que facilitan el ahorro (Geogasolineras) o que ayudan a las personas discapacitadas a moverse por el destino (Ruta Accesible · Cómo llegar en silla de ruedas).
También las Administraciones púbicas pueden aprovechar esta información para conocer mejor a los turistas. Por ejemplo, Madrid en Bici, gracias a los datos ofrecidos por el portal de la ciudad, consigue trazar una radiografía del uso real de la bicicleta en la capital. Esto permite tomar decisiones relacionadas con este servicio.
En nuestra sección de impacto, además de aplicaciones también puedes encontrar numerosas empresas relacionadas con el sector turístico que recurren a datos públicos para ofrecer y mejorar sus servicios. Es el caso de Smartvel o Bloowatch.
¿Conoces alguna empresa que utilice datos turísticos o aplicación que se base en ellos? Entonces no dudes en dejarnos un comentario con toda la información o enviarnos un correo a contacto@datos.gob.es. ¡Estaremos encantados de leerte!
Blog
La industria del turismo actual tiene un importante desafío en la gestión de la concentración de personas visitando tanto espacios abiertos como espacios cerrados. Esta cuestión ya era muy importante en 2019, año en el que según la Organización Mundial del Turismo se superó la cifra de 1.400 millones de viajeros en todo el mundo. Con ello se buscaba minimizar el impacto negativo del turismo masivo en el medio ambiente, las comunidades locales y las propias atracciones turísticas. Pero también garantizar la calidad de la experiencia de un visitante que preferirá programar sus visitas en situaciones en las que la ocupación total del espacio que pretende visitar sea menor.
Las restricciones asociadas a la pandemia redujeron drásticamente el número de visitantes, que en el año 2020 y 2021 sumaron menos de un tercio del número registrado en 2019, pero hicieron mucho más importante la gestión de los flujos de visitantes, aunque en este caso fuese por motivos de salud pública.
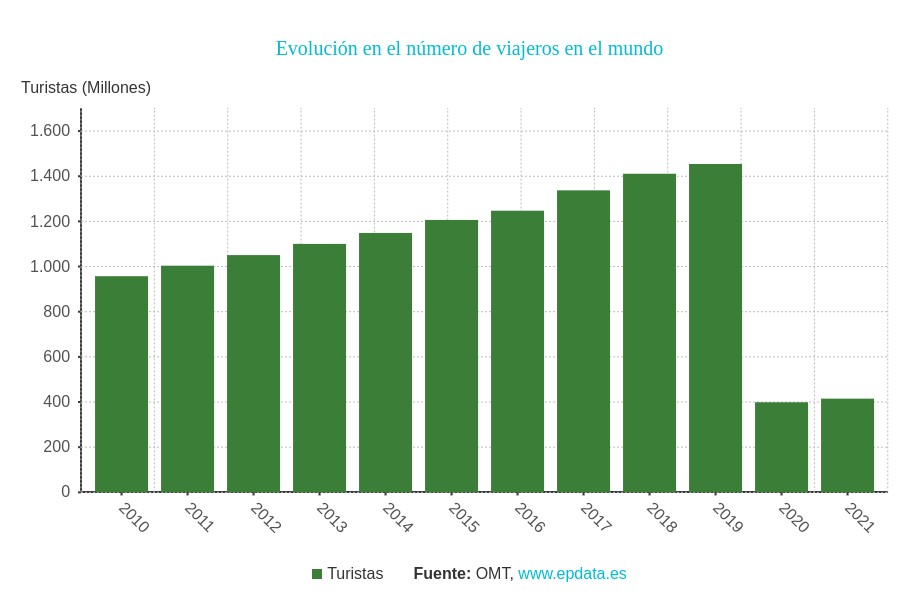
En este momento nos encontramos en una situación intermedia entre unas restricciones que parecen estar en su fase final y un crecimiento constante del número de visitantes por lo que las ciudades son más sensibles que nunca a recurrir a soluciones basadas en datos para fomentar el turismo y al mismo tiempo controlar los flujos de visitantes.
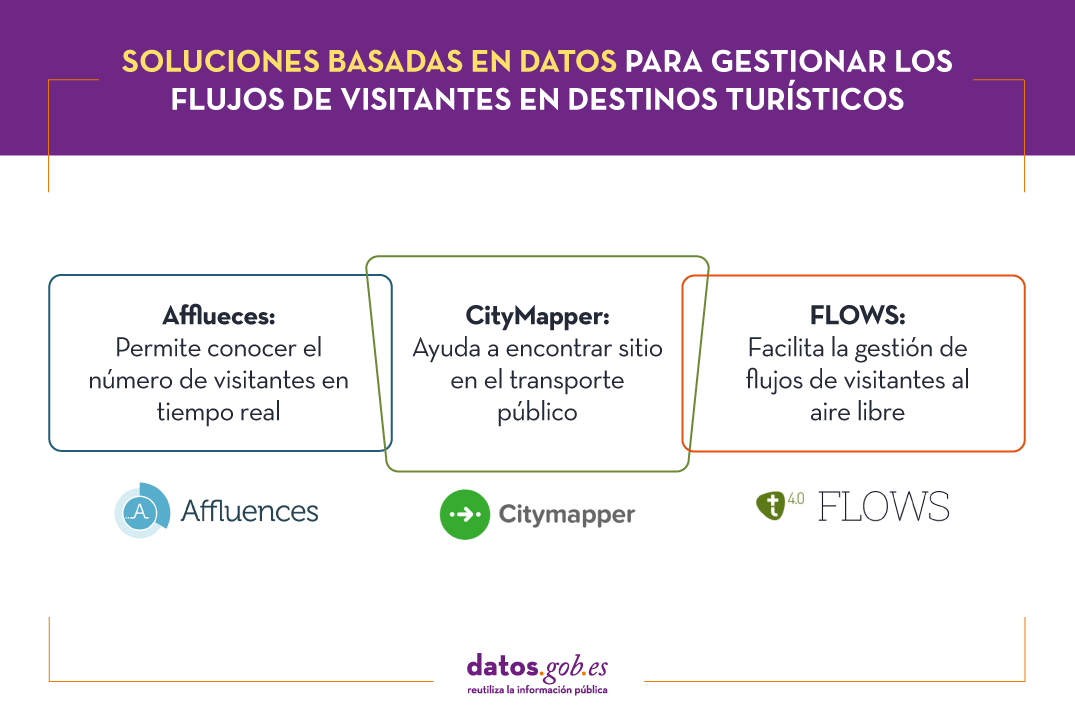
Conocer el número de visitantes en tiempo real con Afflueces
Entre las aplicaciones de gestión de la ocupación que ayudan a los turistas a evitar colas y aglomeraciones en interiores encontramos Affluences, una solución nacida en Francia que permite a los turistas monitorizar la ocupación de museos, bibliotecas, piscinas y tiendas en tiempo real.

La propuesta de esta solución consiste en medir la afluencia de visitantes en espacios cerrados utilizando sistemas de conteo de personas para después analizarla y comunicarla al usuario ofreciendo datos como el tiempo de espera y el índice de ocupación.
En algunos casos, Affluences instala sensores en las instituciones o utilizan los que ya tienen instalados para medir en tiempo real el número de personas presentes en la institución. En otros casos utiliza los datos de ocupación en tiempo real que las instalaciones proporcionan como datos abiertos, como en el caso de las piscinas de la ciudad de Estrasburgo.
Los datos medidos en tiempo real se enriquecen con otras fuentes de información como el historial de asistencia, el calendario de apertura, etc. y son procesados por algoritmos de análisis predictivo cada 5 minutos. Este enfoque permite ofrecer al usuario una información mucho más precisa que la que puede obtener, por ejemplo, a través de Google Maps, basada en el análisis de los datos de ubicación capturados a través de los teléfonos móviles.
Encontrar sitio en el transporte público con CityMapper
CityMapper es probablemente la más conocida aplicación de movilidad urbana en grandes ciudades europeas y una de las más populares en todo el mundo. Fue fundada en Londres, pero ya está presente en 71 ciudades europeas en 31 países y agrega 368 modos de transporte diferentes. Entre estas ciudades se encuentran por supuesto Madrid y Barcelona, pero también un buen número de ciudades grandes en España como Valencia, Sevilla, Zaragoza o Málaga.
CityMapper permite calcular rutas multimodales combinando gran cantidad de medios de transporte: metros y autobuses junto con bicicletas, patinetes e incluso ciclomotores allí donde están disponibles. Si elegimos, por ejemplo, la bicicleta como medio de transporte la aplicación ofrece al usuario datos tan granulares como cuántas bicicletas hay disponibles en el lugar de recogida y cuántos aparcamientos vacíos están disponibles en el destino.
Pero el factor diferencial de CityMapper y probablemente el que ha tenido mayor influencia en su gran éxito de adopción es la inteligente forma en la que utiliza una combinación de datos abiertos y privados y la inteligencia artificial para proporcionar a los usuarios unas estimaciones de los tiempos de espera, la duración de los viajes e incluso las interrupciones del tráfico de gran precisión.
Por ejemplo, CityMapper es capaz incluso de ofrecer información sobre la ocupación de algunos de los medios de transporte que nos sugiere en las rutas para que el usuario pueda por ejemplo elegir el vagón menos congestionado en el tren que está esperando. La aplicación incluso sugiere dónde debe situarse el usuario para optimizar el viaje especificando qué entradas y salidas debe utilizar.
Flujos de visitantes al aire libre con FLOWS
La gestión de los flujos de visitantes al aire libre introduce nuevos elementos de dificultad tanto a la hora de medir la ocupación como a la hora de establecer modelos predictivos estables que sean útiles para los visitantes y para los responsables de planificar medidas de seguridad. Por ello son necesarias nuevas fuentes de datos y prestar especial atención a la privacidad de los usuarios cuyos datos se analizan.
FLOWS es un proyecto que está trabajando para ayudar a las ciudades y a los establecimientos turísticos a prepararse para los períodos pico de turismo y redirigir a los visitantes hacia áreas menos congestionadas. Para alcanzar este ambicioso objetivo combina datos anonimizados de diversas fuentes como sensores de control de tráfico, datos de redes Wi-Fi abiertas, datos de operadores de telefonía móvil, datos de los registros de turistas o sistemas de gestión de itinerarios y reservas, datos de consumo de agua y energía, de recogida de residuos o de publicaciones en redes sociales.
A través de una sencilla interfaz de usuario permitirá análisis avanzados y previsiones de movimientos turísticos mostrando los flujos de tráfico, congestiones de tráfico, desviaciones estacionales, entradas/salidas al destino, movimiento dentro del destino, etc. Será posible mostrar los análisis en el intervalo de tiempo seleccionado y realizar predicciones basadas en datos históricos teniendo en cuenta factores estacionales.

Estos son solo algunos ejemplos de las múltiples iniciativas que están trabajando en la solución de un importante desafío del turismo durante la transición verde y digital, la gestión de los flujos de afluencia tanto en espacios cerrados como en espacios abiertos. Sin duda en los próximos años veremos grandes avances que cambiarán la forma en la que experimentamos el turismo y conseguirán que disfrutemos más de la experiencia minimizando a la vez el impacto que tenemos sobre el medio ambiente y las comunidades locales.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.