Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información que finalmente se resume en unas conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre el alumnado de la universidad española a lo largo de los últimos años. A partir de estos datos observaremos las características que presenta el alumnado de la universidad española y cuáles son los estudios más demandados.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio de Universidades, que recoge series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presenta el alumnado de la universidad española. Estos datos se encuentran disponibles en el catálogo de datos.gob.es y en el propio catálogo de datos del Ministerio de Universidades. Concretamente los datasets que usaremos son:
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de doctorado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de máster por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de grado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculaciones por cada una de las titulaciones impartidas por las universidades españolas que se encuentra publicado en la sección de Estadísticas de la página oficial del Ministerio de Universidades. El contenido de esta dataset abarca desde el curso 2015-2016 al 2020-2021, aunque para este último curso los datos con provisionales.
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación R desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Datawrapper.
Datawrapper es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en línea o exportarse como PNG, PDF o SVG. Esta herramienta es muy sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Preprocesamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Creación de tablas de trabajo
- Ajuste del nombre de algunas variables
- Agrupación de varias variables en una única con diferentes factores
- Transformación de variables
- Detección y tratamiento de datos ausentes (NAs)
- Creación de nuevas variables calculadas
- Resumen de las tablas transformadas
- Preparación de datos para su representación visual
- Almacenamiento de archivos con las tablas de datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
5. Visualización de datos
Una vez realizado el preprocesamiento de los datos, vamos con la visualización. Para la realización de esta visualización interactiva usamos la herramienta Datawrapper en su versión gratuita. Se trata de una herramienta muy sencilla con especial aplicación en el periodismo de datos que te animamos a utilizar. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que la tabla de datos que le proporcionemos este estructurada adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos la siguientes:
- ¿Cómo se está distribuyendo el número de hombres y mujeres entre los alumnos matriculados de grado, máster y doctorado a lo largo de los últimos cursos?
Si nos centramos en el último curso 2020-2021:
- ¿Cuáles son las ramas de enseñanza más demandadas en las universidades españolas? ¿Y las titulaciones?
- ¿Cuáles son las universidades con mayor número de matriculaciones y dónde se ubican?
- ¿En qué rangos de edad se encuentra el alumnado universitario de grado?
- ¿Cuál es la nacionalidad de los estudiantes de grado de las universidades españolas?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Distribución de las matriculaciones en las universidades españolas desde el curso 2015-2016 hasta 2020-2021, desagregado por sexo y nivel académico
Esta representación visual la hemos realizado teniendo en cuenta las matriculaciones de grado, master y Doctorado. Una vez que hemos subido la tabla de datos a Datawrapper (conjunto de datos \"Matriculaciones_NivelAcademico\"), hemos seleccionado el tipo de gráfico a realizar, en este caso un diagrama de barras apiladas (stacked bars) para poder reflejar por cada curso y sexo, las personas matriculadas en cada nivel académico. De esta forma podemos ver, además, el global de estudiantes matriculados por curso. A continuación, hemos seleccionado el tipo de variable a representar (Matriculaciones) y las variables de desagregación (Sexo y Curso). Una vez obtenido el gráfico, podemos modificar de forma muy sencilla la apariencia, modificando los colores, la descripción y la información que muestra cada eje, entre otras características.
Para responder a las siguientes preguntas, nos centraremos en el alumnado de grado y en el curso 2020-2021, no obstante, las siguientes representaciones visuales pueden ser replicadas para el alumnado de máster y doctorado, y para los diferentes cursos.
5.2. Mapa de las universidades españolas georreferenciadas, donde se muestra el número de matriculados que presentan cada una de ellas
Para la realización del mapa hemos utilizado un listado de las universidades españolas georreferenciadas publicado por el Portal de Datos Abiertos de Esri España. Una vez descargados los datos de las distintas áreas geográficas en formato GeoJSON, los transformamos en Excel, para poder realizar una unión entre el datasets de las universidades georreferenciadas y el dataset que presenta el número de matriculados por cada universidad que previamente hemos preprocesado. Para ello hemos utilizado la función BUSCARV() de Excel que nos permitirá localizar determinados elementos en un rango de celdas de una tabla.
Antes de subir el conjunto de datos a Datawrapper, debemos seleccionar la capa que muestra el mapa de España dividido en provincias que nos proporciona la propia herramienta. Concretamente, hemos seleccionado la opción \"Spain>>Provinces(2018)\". Seguidamente procedemos a incorporar el conjunto de datos \"Universidades\", antes generado, (este conjunto de datos se adjunta en la carpeta de conjuntos de datos de GitHub para esta visualización paso a paso), indicando que columnas contienen los valores de las variables Latitud y Longitud.
A partir de este punto, Datawrapper ha generado un mapa en el que se muestran las ubicaciones de cada una de las universidades. Ahora podemos modificar el mapa según nuestras preferencias y ajustes. En este caso, haremos que el tamaño de los puntos y el color dependa del número de matriculaciones que presente cada universidad. Además, para que estos datos se muestren, en la pestaña “Annotate”, en la sección “Tooltips”, debemos indicarle las variables o el texto que deseemos que aparezca.
5.3. Ranking de matriculaciones por titulación
Para esta representación gráfica utilizamos el objeto visual de Datawrapper tabla (Table) y el conjunto de datos \"Titulaciones_totales\" para mostrar el número de matriculaciones que presenta cada una de las titulaciones impartidas durante el curso 2020-2021. Dado que el número de titulaciones es muy extenso, la herramienta nos ofrece la posibilidad de incluir un buscador que permite filtrar los resultados.
5.4. Distribución de matriculaciones por rama de enseñanza
Para esta representación visual, hemos utilizado el conjunto de datos \"Matriculaciones_Rama_Grado\" y seleccionado gráficos de sectores (Pie Chart), donde hemos representado el número de matriculaciones según sexo en cada una de las ramas de enseñanza en las cuales se dividen las titulaciones impartidas por las universidades (Ciencias Sociales y Jurídicas, Ciencias de la Salud, Artes y Humanidades, Ingeniería y Arquitectura y Ciencias). Al igual que en el resto de gráficos, podemos modificar el color del gráfico, en este caso en función de la rama de enseñanza.
5.5. Matriculaciones de Grado por edad y nacionalidad
Para la realización de estas dos representaciones de datos visuales utilizamos diagramas de barras (Bar Chart), donde mostramos la distribución de matriculaciones en el primero, desagregada por sexo y nacionalidad, utilizaremos el conjunto de datos \"Matriculaciones_Grado_nacionalidad\" y en el segundo, desagregada por sexo y edad, utilizando el conjunto de datos \"Matriculaciones_Grado_edad\". Al igual que los visuales anteriores, la herramienta facilita de forma sencilla la modificación de las características que presentan los gráficos.
6. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implamentar se puede observar lo siguiente:
- El número de matriculaciones aumenta a lo largo de los cursos académicos independientemente del nivel académico (grado, máster o doctorado).
- El número de mujeres matriculadas es mayor que el de hombres en grado y máster, sin embargo es menor en el caso de las matriculaciones de doctorado, excepto en el curso 2019-2020.
- La mayor concentración de universidades la encontramos en la Comunidad de Madrid, seguido de la comunidad autónoma de Cataluña.
- La universidad que concentra mayor número de matriculaciones durante el curso 2020-2021 es la UNED (Universidad Nacional de Educación a Distancia) con 146.208 matriculaciones, seguida de la Universidad Complutense de Madrid con 57.308 matriculaciones y la Universidad de Sevilla con 52.156.
- La titulación más demandada el curso 2020-2021 es el Grado en Derecho con 82.552 alumnos a nivel nacional, seguido del Grado de Psicología con 75.738 alumnos y sin apenas diferencia, el Grado en Administración y Dirección de Empresas con 74.284 alumnos.
- La rama de enseñanza con mayor concentración de alumnos es Ciencias Sociales y Jurídicas, mientras que la menos demandada es la rama de Ciencias.
- Las nacionalidades que más representación tienen en la universidad española son de la región de la unión europea, seguido de los países de América Latina y Caribe, a expensas de la española.
- El rango de edad entre los 18 y 21 años es el más representado en el alumnado de las universidades españolas.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
España fue el segundo país del mundo que más turistas recibió durante 2019, con 83,8 millones de visitantes. La actividad turística supuso ese año el 12,4% del PIB, empleando a más de 2,2 millones de personas (12,7% del total). Se trata por tanto de un sector fundamental para nuestra economía.
Estas cifras se han visto reducidas debido a la pandemia, pero se espera que el sector se vaya recuperando en los próximos meses. A ello pueden ayudar los datos abiertos. Contar con información actualizada puede generar beneficios a todos los actores implicados en esta industria:
- Turistas: El open data ayuda a los turistas a planificar sus viajes, dotándoles de la información necesaria para elegir donde alojarse o qué actividades realizar. La información actualizada que pueden proporcionar los datos abiertos cobra especial importancia en tiempos de COVID. Existen distintos portales que recogen información y visualizaciones de las restricciones de viaje, como Humanitarian Data Exchange, de las Naciones Unidas. Esta web alberga un mapa interactivo actualizado diariamente con las restricciones de viaje por país y compañía aérea.
- Empresas. Las empresas pueden generar distintas aplicaciones dirigidas a los viajeros, con información de utilidad. Además, analizando los datos, los establecimientos turísticos pueden detectar mercados y destinos sin explotar. También pueden personalizar sus ofertas e incluso crear sistemas de recomendaciones que ayuden a la promoción de diversas actividades, con un impacto positivo en la experiencia de los viajeros.
- Administraciones Públicas. Cada vez más gobiernos están implementando soluciones para captar y analizar datos de distintas fuentes en tiempo real, con el fin de conocer mejor el comportamiento de sus visitantes. Ejemplo de ello son Segovia, Mallorca y Gran Canaria. Gracias a estas herramientas podrán definir estrategias y tomar decisiones informadas, por ejemplo, dirigidas a evitar masificaciones. En este sentido, herramientas como Affluences permiten informar de la ocupación de museos, piscinas y tiendas en tiempo real, y obtener predicciones para las sucesivas franjas horarias.
Los beneficios de contar con datos de calidad relacionados con el turismo es tal que no es de extrañar que el Gobierno de España haya elegido este sector como prioritario a la hora de crear espacios de datos que permitan la compartición voluntaria de datos entre organizaciones. De esta forma se podrán cruzar datos de distintas fuentes, enriqueciendo los diversos casos de uso.
Los datos utilizados en este ámbito son muy diversos: datos sobre consumo, transporte, actividades culturales, tendencias económicas o incluso sobre la predicción meteorológica. Pero para poder aprovechar bien estos datos altamente dinámicos es necesarios que estén a disposición de los usuarios en formatos adecuados, actualizados y que el acceso se pueda automatizar a través de interfaces de programación de aplicaciones (APIs).
Ya son muchas las organizaciones que ofrecen datos a través de APIs. En esta infografía puedes ver varios ejemplos ligados a nuestro país a nivel nacional, autonómico y local. Pero además de portales de datos generalistas, también encontramos APIs en plataformas de datos abiertos ligadas exclusivamente al sector turismo. En la siguiente infografía puedes ver varios ejemplos:

Haz clic aquí para ver la infografía en tamaño completo y en su versión accesible
¿Conoces más ejemplos de APIs u otros recursos que faciliten el acceso a los datos abiertos relacionados con el turismo? ¡Déjanos un comentario o escribe a datos.gob.es!
Contenido elaborado por el equipo de datos.gob.es.
Noticia
Se acerca el fin del invierno y con el cambio de estación llega el momento de recopilar las principales novedades de los últimos tres meses.
El otoño acabó con la aprobación del Real Decreto-ley 24/2021, que incluye la transposición de la Directiva europea de datos abiertos y reutilización de la información del sector público, y ahora terminamos el invierno con otro avance normativo, esta vez a nivel europeo: la publicación del borrador de Reglamento relativo al establecimiento de normas armonizadas sobre el acceso y uso equitativo de los datos (Ley de Datos o Data Act), aplicable a todos los sectores económicos y que propone nuevas normas sobre quién puede utilizar y acceder a los datos generados en la UE y en qué condiciones.
A estas novedades en el terreno normativo se han unido otras muchas en el ámbito de la apertura y reutilización de datos. En este artículo te resaltamos algunos ejemplos.
El binomio datos públicos y tecnologías disruptivas
La relación entre datos abiertos y nuevas tecnologías queda cada vez más patente a través de diversos proyectos cuyo objetivo es generar mejoras en la sociedad. Las universidades son un actor destacado en este campo, con proyectos innovadores como:
- La Universitat Oberta de Catalunya (UOC) ha lanzado el proyecto “Bots para interactuar con datos abiertos – Interfaces conversacionales para facilitar el acceso a los datos públicos”. Su objetivo es ayudar a la ciudadanía a mejorar su toma de decisiones gracias al acceso a los datos, así como optimizar el retorno de la inversión de los proyectos de datos abiertos.
- La UOC también ha puesto en marcha, junto a la Universitat Politècnica de València (UPV) y la Universitat Politècnica de Catalunya (UPC), OptimalSharing@SmartCities, que optimiza el uso del coche compartido en las ciudades a través de algoritmos inteligentes capaces de procesar grandes cantidades de datos. De momento están trabajando con datos procedentes de la iniciativa Open Data BCN.
- Investigadores de la Universidad de Cantabria están participando en el proyecto SALTED, orientado a la reutilización de datos abiertos que provienen de dispositivos IoT, web y redes sociales. El objetivo es transformarlos en información "útil" en campos como la gestión urbana o la agricultura.
También los organismos públicos aprovechan cada vez más el potencial de los datos abiertos para poner en marcha soluciones que optimicen los recursos, impulsen la eficiencia y mejoren la experiencia de la ciudadanía. Muchos de estos proyectos están ligados con las ciudades inteligentes.
- El proyecto 'Enlaza, Córdoba Municipios Inteligentes' de la Diputación de Córdoba busca gestionar inteligentemente los suministros eléctricos municipales. Se ha desarrollado un software propio y se han sensorizado diferentes instalaciones municipales con el objetivo de obtener datos que faciliten la toma de decisiones. Entre otras cuestiones, se aprovecharán las infraestructuras de la provincia para incorporar una plataforma que favorezca el uso de datos abiertos.
- Los proyectos eCitySevilla y eCityMálaga han sumado la adhesión de 90 entidades públicas y privadas para impulsar un modelo de ciudad inteligente a la vanguardia de la innovación y la sostenibilidad. Entre otras cuestiones integrarán datos abiertos, energías renovables, transporte sostenible, edificaciones eficientes e infraestructuras digitales.
- Un campo donde las soluciones basadas en datos tienen un gran impacto es en el turismo. En este sentido, la Diputación de Segovia ha creado una plataforma digital para recoger datos turísticos y ajustar sus propuestas a las demandas de los visitantes. La visualización de datos actualizados se obtendrá en tiempo real y permitirá saber más sobre los comportamientos turísticos de los visitantes.
- Por su parte, el Consell de Mallorca ha puesto en marcha un Observatorio de Turismo Sostenible que permitirá contar con información permanentemente actualizada para definir estrategias y tomar decisiones a partir de datos reales.
Para impulsar el uso de la analítica de datos en organismos públicos, la Agencia Digital Andaluza ha anunciado el desarrollo de una unidad para impulsar el Big Data. Su objetivo es prestar servicios relacionados con el análisis de datos a diferentes organismos del Gobierno de Andalucía.
Otros ejemplos de reutilización de datos abiertos
Los datos abiertos también son cada vez más demandados por los periodistas para ejercer el llamado periodismo de datos. Esto es especialmente notable en periodos electorales, como las recientes elecciones a las Cortes de Castilla y León. Reutilizadores como Maldita o EPData han aprovechado los datos abiertos ofrecidos por la Junta para crear piezas informativas y mapas interactivos para acercar la información a la ciudadanía.
También los propios organismos públicos aprovechan las visualizaciones para acercar los datos a la ciudadanía de forma sencilla. Como ejemplo, el mapa de la biblioteca Nacional de España con los autores españoles fallecidos en 1941, cuyas obras pasan a dominio público en este 2022 y, por tanto, ya pueden ser editadas, reproducidas o difundidas públicamente.
Otro ejemplo de reutilización de datos abiertos nos lo encontramos en las Fallas de Valencia. Además de los clásicos ninot, esta festividad también cuenta con fallas inmateriales que unen tradición, tecnología y divulgación científica. Este año, una de ellas consiste en un juego interactivo que utiliza datos abiertos de la ciudad para plantear diversas preguntas.
Las plataformas de datos abiertos no dejan de actualizarse
Durante esta estación también hemos visto como muchos organismos públicos ponían en marcha nuevos portales y herramientas para facilitar el acceso a los datos, y con ello su reutilización. Asimismo, los catálogos no han dejado de actualizarse ampliando la información ofrecida. A continuación, se recogen algunos ejemplos:
- El Ayuntamiento de Sant Boi ha estrenado recientemente su plataforma digital Open Data. Se trata de un espacio que permite explorar y descargar datos abiertos del Ayuntamiento fácilmente, gratis y sin restricciones.
- Dentro de su proyecto Smart City, al Ayuntamiento de Alcoi ha habilitado una web con datos abiertos sobre tráfico e indicadores medioambientales. En ella se pueden consultar datos sobre la calidad del aire, la presión sonora, la temperatura o la humedad en diferentes partes de la ciudad.
- La Diputación de Castellón ha desarrollado una herramienta intuitiva y fácil de usar para facilitar y acompañar a la ciudadanía en las solicitudes de acceso a la información pública. También ha actualizado la información sobre infraestructuras y equipamiento de los municipios castellonenses en el portal de datos de la institución provincial en formatos geo-referenciados, lo que facilita su reutilización.
- El Instituto de Estadística y Cartografía de Andalucía (IECA) ha actualizado las tablas de datos que ofrecen a través de su banco de datos BADEA. Ahora los usuarios pueden ordenar y filtrar toda la información con un solo clic. Además, dentro de la web ha creado una nueva sección orientada a los reutilizadores de la información estadística. Su objetivo es que los datos sean más accesibles e interoperables.
- IDECanarias ha publicado una ortofoto de La Palma tras la erupción volcánica. Se puede ver a través del visor de GRAFCAN. Cabe destacar que los datos abiertos han sido de gran importancia a la hora de analizar los daños que ha ocasionado la lava en la isla.
- GRAFCAN también ha actualizado el Sistema de Información Territorial de Canarias (SITCAN) incorporando 25 nuevos puntos de interés. Esta actualización facilita la localización de 36.753 puntos de interés del Archipiélago a través del portal de Infraestructura de Datos Espaciales de Canarias (IDECanarias).
- La Diputación de Barcelona ofrece un nuevo servicio de descarga de datos abiertos geográficos, de acceso libre y gratuito, a través del geoportal IDEBarcelona. Este servicio se presentó a través de una sesión (en catalán), que fue grabada y está disponible en Youtube.
- El SIG municipal del Ayuntamiento de Cáceres ha puesto a disposición de la ciudadanía la descarga gratuita de la cartografía actualizada de la ciudad extremeña en diferentes formatos como DGN, DWG, SHP o KMZ.
Nuevos informes, guías, cursos y retos
En estos tres meses también hemos sido testigos de la publicación y lanzamiento de recursos y actividades encaminados a promover el open data:
- La Junta de Castilla y León ha publicado la guía "Gobernanza inteligente: el reto de la gestión de los servicios públicos en la administración local", donde incluye herramientas y casos de uso para impulsar la eficiencia y eficacia a través de la participación y datos abiertos.
- El Consejo Superior de Investigaciones Científicas (CSIC) ha actualizado el ranking de los portales y repositorios de acceso abierto de todo el mundo en apoyo de las iniciativas de Ciencia Abierta. Esta clasificación se ha construido a partir del número de trabajos indizados en la base de datos Google Scholar.
- El compromiso de los ayuntamientos con el open data también queda patente en la puesta en marcha de iniciativas de formación y de impulso interno de los datos abiertos. En este sentido, el Ayuntamiento de L'Hospitalet ha puesto en marcha dos nuevas herramientas internas para promover el uso y difusión de datos por parte de los empleados municipales: una guía de visualización de datos y otra de pautas gráficas y estilo de visualización de datos.
- En la misma línea, la Federación Española de Municipios y provincias (FEMP) ha lanzado el Curso de Tratamiento y gestión de los Datos Abiertos en las Entidades Locales, que se celebrará a finales de marzo (en concreto, los días 22, 24, 29 y 31 de marzo de 2022). El curso está dirigido a técnicos sin conocimientos básicos de entidades locales.
También se han lanzado múltiples competiciones, que buscan impulsar el uso de datos, especialmente en el ámbito universitario, como por ejemplo la Generalitat Valenciana con POLIS, un proyecto en el que alumnos de tres institutos aprenderán la importancia de entender y analizar las políticas públicas utilizando para ello los datos abiertos disponibles en organismos públicos.
Además, este invierno finalizó el plazo de inscripción del IV Desafío Aporta, centrado en el ámbito de la Salud y el Bienestar. Entre las propuestas recibidas encontramos modelos predictivos que nos permiten conocer la evolución de enfermedades o algoritmos que cruzan datos y determinar hábitos saludables.
Otras noticias de interés en Europa
Además de la publicación de la Data Act, en Europa también hemos visto otras novedades:
- JoinUp ha publicado el documento de la última versión de la especificación del perfil de aplicación de metadatos para portales de datos abiertos en Europa, DCAT-AP 2.1.
- En línea con la estrategia Europea de Datos, la Comisión Europea ha publicado un documento de trabajo con su visión general de los espacios de datos comunes europeos.
- La Oficina de Publicaciones de la Unión Europea ha lanzado la sexta edición del EU Datathon. En esta competición los participantes tienen que utilizar datos abiertos para abordar uno de los 4 retos propuestos.
- EU Science Hub ha publicado un informe (en inglés) donde presenta ejemplos de casos de uso ligados a la compartición de datos. En ellos se exploran tecnologías y herramientas emergentes para la innovación basada en datos.
Estos son solo algunos ejemplos de las últimas novedades del ecosistema de datos abiertos en nuestro país y Europa. Si quieres compartir algún proyecto o noticia con nosotros, déjanos un comentario o escribe a dinamizacion@datos.gob.es.
Noticia
El pasado 15 de febrero se cerró el plazo para recibir las solicitudes para participar en el IV Desafío Aporta. En total, se han recibido 38 propuestas válidas en tiempo y forma, todas de gran calidad, cuyo objetivo es impulsar mejoras en la salud y el bienestar de los ciudadanos a través de la reutilización de datos ofrecidos por las administraciones públicas para su reutilización.
Las tecnologías disruptivas, claves para extraer el máximo valor de los datos
De acuerdo con las bases del concurso, en esta primera fase los participantes tenían que presentar ideas que identificasen nuevas oportunidades de captar, analizar y utilizar la inteligencia de los datos en el desarrollo de soluciones de todo tipo: estudios, aplicaciones móviles, servicios o sitios webs.
Todas las ideas buscan hacer frente a diversos retos relacionados con la salud y el bienestar, muchos de las cuales impactan directamente sobre nuestro sistema sanitario, como la mejora de la eficiencia de los servicios, la optimización de los recursos o el impulso de la transparencia. Algunas de las áreas abordadas por los participantes son la presión sobre el sistema sanitario, el diagnóstico de enfermedades, la salud mental, los hábitos de vida saludables, la calidad del aire o el impacto del cambio climático.
Muchos de los participantes han elegido apostar por las tecnologías disruptivas para hacer frente a estos retos. Entre las propuestas, nos encontramos con soluciones que aprovechan el poder de los algoritmos para cruzar datos y determinar hábitos saludables o modelos predictivos que nos permiten conocer la evolución de enfermedades o la situación del sistema sanitario. Algunas, incluso, utilizan técnicas de gamificación. También hay gran cantidad de soluciones dirigidas a acercar información de utilidad a los ciudadanos, a través de mapas o visualizaciones.
Asimismo, son diversos los colectivos concretos a los que se dirigen las soluciones: encontramos herramientas dirigidas a mejorar la calidad de vida de personas con discapacidad, mayores, niños, individuos que viven solos o que necesitan asistencia domiciliaria, etc.
Propuestas de toda España y con mayor presencia de mujeres
Equipos y particulares de toda España se han animado a participar en el Desafío. Contamos con representantes de 13 comunidades Autónomas: Madrid, Cataluña, País Vasco, Andalucía, Valencia, Canarias, Galicia, Aragón, Extremadura, Castilla y León, Castilla – La Mancha, La Rioja y Asturias.
El 25% de las propuestas han sido presentadas por particulares y el 75% por equipos multidisciplinares integrados por diversos miembros. La misma distribución la encontramos entre personas físicas (75%) y personas jurídicas (25%). En esta última categoría encontramos equipos procedentes de universidades, organismos ligados a la Administración Pública y distintas empresas.
Cabe destacar que en esta edición ha aumentado el número de mujeres participantes, demostrando el avance de nuestra sociedad en el ámbito de la igualdad. Hace dos ediciones, el 38% de las propuestas estaban presentadas por mujeres o por equipos con mujeres entre sus miembros. Ahora ese número aumenta hasta el 47,5%. Si bien es una mejora significativa, aun queda trabajo por hacer a la hora de impulsar las materias STEM entre las mujeres y niñas de nuestro país.
Comienza la deliberación del jurado
Una vez aceptadas las propuestas, es el momento de la valoración del jurado, integrado por expertos del ámbito de la innovación, los datos y la salud. La valoración estará basada en una serie de criterios detallados en las bases, como la calidad y claridad global de la idea propuesta, las fuentes de datos utilizadas o el impacto esperado de la idea propuesta en la mejora de la salud y el bienestar de los ciudadanos.
Las 10 propuestas con la mejor valoración pasarán a la fase II, y contarán con un plazo mínimo de dos meses para desarrollar el prototipo fruto de su idea. Las propuestas se presentarán antes el mismo jurado, que puntuará cada proyecto de manera individual. Los tres prototipos con mayor puntuación serán los ganadores y recibirán una dotación económica de 5.000, 4.000 y 3.000 euros, respectivamente.
¡Mucha suerte a todos los participantes!
Blog
Hoy en día, nadie puede negar que los datos abiertos atesoran un gran poder económico. La propia Comisión Europea estima que la cifra de negocio de los datos abiertos en la EU27 podría alcanzar los 334.200 millones en 2025, impulsada por su uso en ámbitos ligados a tecnologías disruptivas como la inteligencia artificial, el machine learning o las tecnologías del lenguaje.
Pero junto a su impacto económico, los datos abiertos también tienen un importante valor para la sociedad: proporcionan información que permiten visibilizar la realidad social, impulsando la toma de soluciones informada en pro del beneficio común.
Son miles los campos donde la apertura de datos es fundamental, desde las crisis de refugiados hasta la inclusión de personas con discapacidad, pero en este artículo vamos a centrarnos en la lacra de la violencia de género.
¿Dónde puedo obtener datos sobre el tema?
A nivel mundial, organismos como la ONU, la Organización Mundial de la Salud o el Banco Mundial ofrecen recursos y estadísticas relacionados con la violencia contra la mujer.
En nuestro país, organismos locales, autonómicos y estatales publican conjuntos de datos relacionados. Para facilitar el acceso unificado a los mismos, la delegación del Gobierno contra la Violencia de Género cuenta con un portal estadístico que incluye en un único espacio datos que provienen de diversas fuentes como el Ministerio de Hacienda y Administraciones Públicas, el Consejo General del Poder Judicial o el Servicio Público de Empleo Estatal del Ministerio de Empleo y Seguridad Social. El usuario puede cruzar variables y crear tablas y gráficos que faciliten la visualización de la información, así como exportar los conjuntos de datos en formato CSV o Excel.
Proyectos para concienciar y visibilizar
Pero los datos por sí solos pueden ser complicados de entender. Necesitan de un contexto que los dote de significado y los transforme en información y conocimiento. Es aquí donde surgen distintos proyectos que buscan acercar los datos a la ciudadanía de forma sencilla.
Son muchas las asociaciones y organismos que aprovechan los datos publicados para crear visualizaciones e historias con datos que ayudan a concienciar sobre la violencia machista. Como ejemplo, la Iniciativa Barcelona Open Data desarrolla el proyecto “DatosXViolenciaXMujeres”. Se trata de un recorrido visual e interactivo sobre el impacto de la violencia de género en España y por Comunidades Autónomas durante el período 2008-2020, aunque se va actualizando periódicamente. Utilizando técnicas de data storytelling, se muestra la evolución de la violencia de género en el ámbito de la pareja, la respuesta judicial (órdenes dictadas y condenas firmes), los recursos públicos destinados, el impacto del COVID-19 en este ámbito y los delitos de violencia sexual. En cada gráfica se incluyen enlaces a la fuente original y a espacios dónde descargar los datos, para que puedan ser reutilizados en otros proyectos.
Otro ejemplo es “Datos contra el ruido”, desarrollado en el marco de GenderDataLab, plataforma de colaboración para el bien digital común que cuenta con el apoyo de distintas asociaciones, como Pyladies o Canodron, y el Ayuntamiento de Barcelona, entre otros. Esta asociación promueve la inclusión de la perspectiva de género en la recopilación de datos abiertos a través de distintos proyectos como el citado “Datos contra el ruido”, que visibiliza y hace comprensible la información que publica el sistema judicial y la policía sobre la violencia machistas. A través de datos y visualizaciones informa sobre las tipologías de delitos o su distribución geográfica a lo largo de nuestro país, entre otras cuestiones. Al igual que sucedía con “DatosXViolenciaXMujeres”, se incluye el enlace a la fuente original de los datos y a espacios de descarga.
Herramientas y soluciones para apoyar a las victimas
Pero además de visibilizar, los datos abiertos también nos pueden dar información sobre los recursos dedicados a ayudar a las víctimas, como veíamos en algunos de los proyectos anteriores. Poner esta información al alcance de las victimas de una forma rápida y sencilla es fundamental. Son de gran ayuda los mapas que muestran la situación de los centros de ayuda, como este del proyecto SOL.NET, con información sobre organizaciones que ofrecen servicios de apoyo y atención a víctimas de violencia de género en España. O este con los centros y servicios sociales de la Comunidad Valenciana dirigidos a colectivos desfavorecidos, entre los que se encuentras las víctimas de violencia de género, elaborado por la propia institución pública.
Esta información también se incorpora en aplicaciones dirigidas a víctimas, como Anticípate. Esta app no solo facilitar información y recursos a mujeres que se encuentre en situación vulnerable, sino que también cuenta con un botón de llamada de emergencia y posibilita el acceso a asesoramiento jurídico, psicológico o incluso sobre defensa personal, facilitando el apoyo de un criminólogo social.
En definitiva, nos encontramos ante un tema especialmente sensible, sobre el que es necesario seguir concienciando y luchando para poder ponerle fin. Una tarea en las que los datos abiertos pueden contribuir notablemente.
Si conoces algún otro ejemplo que muestre el poder de los datos abiertos en este campo, te animamos a compartirlo en la sección de comentarios o envíanos un email a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Hoy en día las aplicaciones de Inteligencia Artificial (IA) están presentes en múltiples ámbitos de la vida cotidiana, desde televisores y altavoces inteligentes que son capaces de entender lo que les solicitamos, hasta sistemas de recomendación que nos ofrecen servicios y productos adaptados a nuestras preferencias.
Estas IA “aprenden” gracias a las diversas técnicas que existen, entre las que destacan el aprendizaje supervisado, no supervisado y el aprendizaje por refuerzo. En este artículo nos centraremos en el aprendizaje por refuerzo, que se enfoca principalmente en el método de prueba y error, de forma similar a cómo aprendemos los humanos y los animales en general.
La clave de este tipo de sistemas está en fijar correctamente los objetivos a largo plazo para encontrar una solución global óptima, sin focalizarse en exceso en las recompensas inmediatas, que no permiten realizar una exploración adecuada del conjunto de soluciones posibles.
Entornos de simulación como complemento a los conjuntos de datos abiertos
Al contrario que en otros tipos de aprendizaje, donde normalmente se aprende a partir de conjuntos de datos históricos, este tipo de técnicas requieren de entornos de simulación que permitan entrenar a un agente virtual mediante su interacción con un entorno, donde recibe recompensas o penalizaciones en función del estado y las acciones que realiza. Este ciclo entre agente y entorno puede verse en el siguiente diagrama:
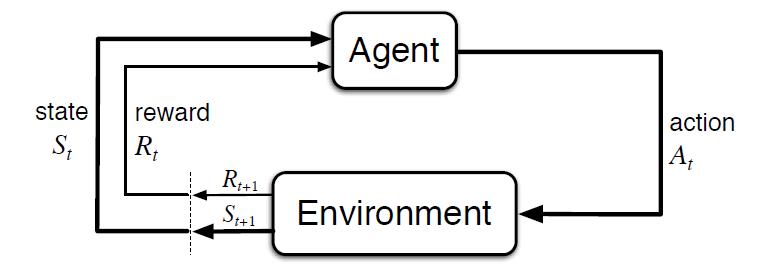
Figura 1 - Esquema de aprendizaje por refuerzo [Sutton & Barto, 2015]
Es decir, partiendo de un entorno simulado, con un estado inicial, el agente realiza una acción que genera un nuevo estado y una posible recompensa o penalización, que depende de los estados anteriores y la acción realizada. El agente aprende la mejor estrategia en este entorno simulado a partir de la experiencia, explorando el conjunto de estados, y siendo capaz de recomendar la mejor política de actuación si se configura de forma adecuada.
El ejemplo más conocido a nivel mundial fue el éxito conseguido por AlphaGo, al vencer al 18 veces campeón del mundo Lee Sedol en 2016. El Go es un juego ancestral, considerado una de las 4 artes básicas en la cultura China, junto con la música, la pintura y la caligrafía. Al contrario que con el ajedrez, el número de combinaciones de juego posibles es superior al número de átomos del Universo, siendo un problema imposible de resolver por algoritmos tradicionales.
Curiosamente, el avance tecnológico demostrado por AlphaGo al resolver un problema que se afirmaba fuera del alcance de una IA, quedó eclipsado un año después por su sucesor AlphaGo Zero. En esta versión sus creadores optaron por no emplear datos históricos, ni reglas heurísticas. AlphaGo Zero sólo emplea las posiciones del tablero y aprende por prueba y error jugando contra sí mismo.
Siguiendo esta innovadora estrategia de aprendizaje, en 3 días de ejecución consiguió superar a AlphaGo, y después de 40 días se convirtió en el mejor jugador de Go, acumulando miles de años de conocimiento en cuestión de días, y descubriendo incluso estrategias desconocidas hasta la fecha.
El impacto de este hito tecnológico abarca infinidad de ámbitos, pudiendo contar con soluciones de IA que aprendan a resolver problemas complejos desde la experiencia. Desde la gestión de recursos, la planificación de estrategias, o la calibración y optimización de sistemas dinámicos.
El desarrollo de soluciones en este ámbito está especialmente limitado por la necesidad de contar con entornos de simulación adecuados, siendo el componente más complejo de construir. Si bien existen múltiples repositorios donde se pueden obtener entornos de simulación abiertos que nos permitan probar este tipo de soluciones.
El referente más conocido es Open AI Gym, el cual incluye un extenso conjunto de librerías y entornos de simulación abiertos para el desarrollo y validación de algoritmos de aprendizaje por refuerzo. Entre otros incluye simuladores para el control básico de elementos mecánicos, aplicaciones de robótica y simuladores físicos, videojuegos ATARI en dos dimensiones, e incluso el aterrizaje de un módulo lunar. Además, permite integrar y publicar nuevos simuladores abiertos para el desarrollo de simuladores propios adaptados a nuestras necesidades que puedan ser compartidos con la comunidad:

Figura 2 - Ejemplos de entornos visuales de simulación ofrecidos por Open AI Gym
Otra referencia interesante es Unity ML Agents, donde también encontramos múltiples librerías y varios entornos de simulación, ofreciendo además la posibilidad de integrar nuestro propio simulador:

Figura 3 - Ejemplos de entornos visuales de simulación ofrecidos por Unity ML Agents
Posibles aplicaciones del aprendizaje por refuerzo en las administraciones públicas
Este tipo de aprendizaje se emplea especialmente en áreas como la robótica, la optimización de recursos o los sistemas de control, permitiendo definir políticas o estrategias óptimas de actuación en entornos concretos.
Uno de los ejemplos prácticos más conocidos, es el algoritmo de DeepMind empleado por Google para reducir un 40% el consumo de energía necesario para enfriar sus centros de datos en 2016, consiguiendo una reducción significativa en el consumo de energía durante su uso, como puede observarse en el siguiente gráfico (extraído del artículo anterior):
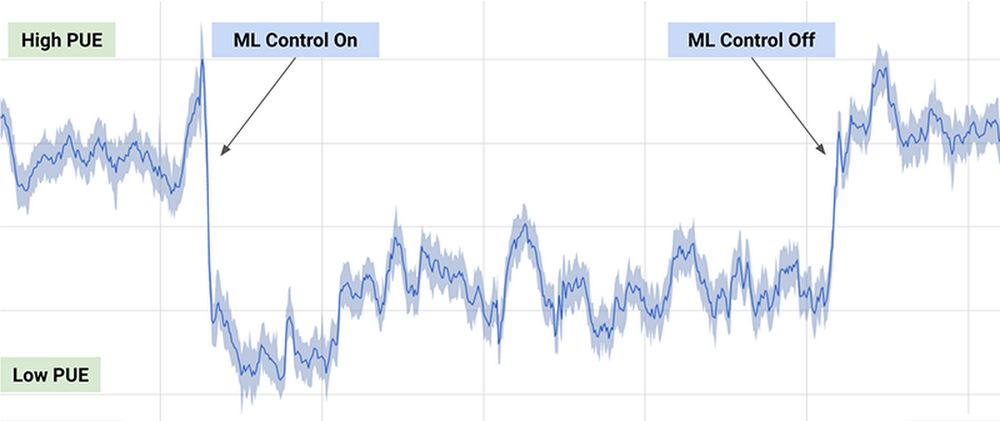
Figura 4 - Resultados del algoritmo de DeepMind sobre el consumo energético de los centros de datos de Google
El algoritmo empleado usa una combinación de técnicas de aprendizaje profundo y aprendizaje por refuerzo, junto con un simulador de propósito general para comprender sistemas dinámicos complejos que podría aplicarse en múltiples entornos como la transformación entre tipos de energía, el consumo de agua o la optimización de recursos en general.
Otras posibles aplicaciones en el ámbito público incluyen la búsqueda y recomendación de conjuntos de datos abiertos a través de chatbots, o la optimización de políticas públicas, como es el caso del proyecto europeo Policy Cloud, aplicado por ejemplo en el análisis de futuras estrategias de las diferentes denominaciones de origen de los vinos de Aragón.
En general, la aplicación de este tipo de técnicas podría optimizar el uso de recursos públicos mediante la planificación de políticas de actuación que reviertan en un consumo más sostenible, reduciendo la contaminación, los residuos y el gasto público.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Se acaba el otoño y, como cada vez que cambiamos de estación, en datos.gob.es queremos resumirte algunas de las principales noticias y novedades de los tres últimos meses.
Uno de los principales avances del open data en nuestro país se ha producido en el ámbito legislativo, con la aprobación de la transposición de la Directiva europea de datos abiertos y reutilización de la información del sector público. Se ha incluido en el Real Decreto-ley 24/2021, convalidado el pasado 2 de diciembre por el Congreso. Puedes leer las novedades que supone aquí.
Se espera que bajo el amparo de esta norma se continúe impulsando un ecosistema open data español que no deja de crecer, como demuestran las novedades vividas estos últimos meses. En el caso de datos.gob.es, hemos alcanzado los 160 administraciones públicas publicadoras de datos este otoño, superando los 50.000 conjuntos de datos accesibles desde el Catálogo nacional. Además, múltiples organismos y reutilizadores han puesto de en marcha nuevos proyectos ligados a los datos abiertos, como veremos a continuación.
El volcán de La Palma, un ejemplo del valor de los datos públicos
Si por algo será recordado este otoño en nuestro país, es por la erupción del Volcán de la isla de La Palma. Una situación que ha puesto de manifiesto la importancia de la publicación y utilización de datos abiertos para la gestión de emergencias naturales.
El portal de datos abiertos de La Palma ha ofrecido -y ofrece- información actualizada sobre la erupción en Cumbre Vieja. En su web se pueden consultar y descargar datos sobre perímetros, fotogrametrías, termografías o modelos del terreno. Además, el Cabildo Insular ha creado un punto unificado para recoger toda la información de interés en tiempo real de una manera sencilla. A ello hay que sumar los datos y herramientas puestas a disposición de la ciudadanía por el Instituto Geográfico Nacional y el Programa de Observación terrestre Copernicus, que ofrece datos y mapas de interés, así como apoyo en la gestión.
Todos estos datos han permitido elaborar visores 3D y herramientas para comparar la situación previa a la erupción con la actual, de gran utilidad para comprender la magnitud del evento y tomar decisiones en consecuencia. Los datos también han sido utilizados por los medios de comunicación y reutilizadores para crear visuales que ayuden a transmitir la información a la ciudadanía, como este recorrido visual de la lengua de fuego desde el registro de la actividad sísmica hasta su llegada al mar o esta animación que muestra en apenas 30 segundos, los 5.000 movimientos sísmicos registrados en La Palma hasta la fecha.
Crece el uso de datos abiertos y nuevas tecnologías
Además de para gestionar emergencias, los datos abiertos también son cada vez más utilizados por los organismos públicos para mejorar la eficiencia y eficacia de su actividad, muchas veces de la mano de tecnologías disruptivas como la inteligencia artificial. A continuación se muestran algunos ejemplos:
- El Ayuntamiento de Murcia ha anunciado que está desarrollando nuevos modelos de gestión sostenible de la movilidad utilizando datos del Programa de Observación Terreste Copernicus. La información obtenida permitirá ofrecer nuevos servicios de movilidad inteligente orientada a los ciudadanos, empresas y administraciones públicas del municipio.
- Las Palmas de Gran Canaria ha presentado un Sistema de Inteligencia del Turismo Sostenible. Se trata de una herramienta digital que permite contar con datos actualizados de múltiples fuentes para la toma de decisiones y mejora de la competitividad, tanto de las empresas como del propio destino turístico.
- El Ayuntamiento de Vigo planea realizar un modelo en 3D de toda la ciudad, combinando datos abiertos con datos geográficos. Esta acción servirá para desarrollar elementos como mapas de ruido, de contaminación o de tráfico, entre otros.
- La Junta de Castilla y León trabaja en el Proyecto Bision, un sistema de Business Intelligence para una mejor toma de decisiones en materia de salud. De forma automática, el nuevo sistema permitiría desarrollar instrumentos de evaluación de la calidad del sistema sanitario. Cabe mencionar que la Junta de Castilla y León ha recibido un premio por la calidad e innovación de su portal de transparencia durante la pandemia gracias a su plataforma de datos abiertos.
- El sistema masivo de Inteligencia Artificial de la lengua española MarIA, impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, avanza en su desarrollo. A partir de los archivos web de la Biblioteca Nacional Español, se ha creado una nueva versión que permite resumir textos existentes y crear nuevos a partir de titulares o palabras.
Novedades en plataformas de datos abiertos
Para que se puedan seguir desarrollando este tipo de proyectos, es fundamental continuar promoviendo el acceso a datos de calidad y herramientas que faciliten su explotación. En este sentido, algunas de las novedades son:
- El Ayuntamiento de Sagunto ha impulsado su primer portal de datos abiertos, a través de su concejalía de Transparencia. También ha implantado un Visor Presupuestario Municipal para consultar de una manera interactiva los gastos e ingresos del Ayuntamiento.
- El Gobierno de Navarra ha presentado un nuevo portal en una Jornada en la Universidad de Navarra, que ha contado con la participación de la iniciativa Aporta. Le seguirá en breve Córdoba, que también ha aprobado la implantación de un nuevo portal de datos abiertos y transparencia.
- El portal de datos abiertos de Aragón ha estrenado una nueva versión de su API, el servicio GA_OD_Core. Su objetivo es ofrecer a ciudadanos y desarrolladores la capacidad de obtener acceso a los datos ofrecidos en el portal y poder integrarlos en diferentes apps y servicios a través de la arquitectura REST. Además, Aragón también ha presentado un nuevo asistente virtual que facilita la localización y acceso a los datos. Se trata de un chatbot que frece respuestas basadas en los datos que contiene, con un nivel conversacional entendible por el receptor.
- El Ministerio Transportes, Movilidad y Agenda Urbana ha publicado un visor para consultar las infraestructuras de transporte pertenecientes a la Red Transeuropea de Transporte en España (TEN-T). El visor permite la descarga de datos abiertos de la red, así como de los proyectos cofinanciados con fondos CEF.
- El Ayuntamiento de Madrid ha presentado Cibeles+, un proyecto de inteligencia artificial para facilitar el acceso a la información urbanística. Mediante técnicas de procesamiento del lenguaje natural y el machine learning, el sistema responde a preguntas y cuestiones urbanísticas complejas a través de Alexa y Twitter.
- El geoportal del IDE Barcelona ha lanzado un nuevo servicio de descarga de datos abiertos geográficos de acceso libre y gratuito. Entre la información publicada en formato vectorial, destaca la cartografía topográfica (escala 1:1000), que incluye áreas urbanas y urbanizables y sectores de interés en suelo no urbanizable.
- El Ayuntamiento de Valencia ha desarrollado un inventario de datos para medir la eficiencia en la aplicación de políticas públicas. Esta herramienta permitirá, además, que la ciudadanía pueda acceder más rápido a la información pública.
Cabe destacar también que el Ayuntamiento de Pinto ha confirmado su adhesión a los principios de la Carta internacional de Datos Abiertos (ODC) con el compromiso de mejorar las políticas de datos abiertos y su gobernanza.
Impulso de la reutilización y las capacidades relacionadas con los datos
Los organismos públicos también han lanzado diversas iniciativas para promover el uso de los datos. Entre ellos, datos.gob.es que lanzó a finales de noviembre la cuarta edición del Desafío Aporta, centrado en el ámbito de la salud y el bienestar. Con ello se busca identificar y reconocer nuevas ideas y prototipos que impulsen mejoras en dicho campo, utilizando datos abiertos de organismos públicos.
Esta estación también hemos conocido a los ganadores del V Concurso de Datos Abiertos convocado por la Junta de Castilla y León. De las 37 candidaturas recibidas, un jurado de expertos en la materia ha elegido 8 proyectos que se han alzado como ganadores en las diversas categorías.
También son cada vez más populares los cursos y seminarios que se lanzan para aumentar la adquisición de conocimientos relacionos con los datos. Aquí se muestran dos ejemplos:
- El Ayuntamiento de L'Hospitalet de Llobregat ha puesto en marcha un programa de formación sobre el uso de datos para los trabajadores municipales. Este plan se estructura en 22 cursos diferentes que se impartirán hasta mayo del año próximo.
- El proyecto Ciudades Abiertas ha impartido un ciclo de talleres relacionados con datos abiertos en las Smart cities. El video completo está disponible en este enlace.
Otras noticias de interés en Europa
A nivel Europeo hemos terminado el otoño con dos grandes actuaciones: la publicación del índice de madurez de datos abiertos 2021, elaborado por el Portal Europeo de Datos, y la celebración de las Jornadas de Datos Abiertos de la Unión Europea (EU Open Data Days). Del primero, cabe destacar que España ocupa la tercera posición y vuelve a situarse entre los países líderes en datos abiertos de Europa. Por su parte, las Jornadas de Datos Abiertos de la Unión Europea estuvieron integradas por la conferencia EU DataViz 2021 y la final del EU Datathon 2021, donde la empresa española CleanSpot quedó en segunda posición en su categoría. Esta app impulsa la concienciación e incentivación del reciclaje y la reutilización de productos a través de la gamificación.
El portal europeo también ha lanzado la Open Data Academy, con todos los cursos disponibles estructurados en torno a cuatro temas: política, impacto, tecnología y calidad (los mismos que evalúa el anteriormente citado índice de madurez). El plan de estudios se actualiza constantemente con nuevos materiales.
Otras novedades son:
- Se ha actualizado el Perfil de Aplicación de DCAT para portales de datos en Europa (DCAT-AP). La versión preliminar del DCAT-AP versión 2.1.0 estuvo disponible para su revisión pública entre octubre y noviembre de 2021.
- Asedie ha sido seleccionada por la Global Data Barometer (GBD) y Access Info Europe, como “Country Researcher” para para la elaboración de la 1ª edición del Barómetro Global de Datos 20-21. Se trata de un proyecto de investigación que analiza cómo los datos se gestionan, se comparten y se utilizan para el bien común.
- Se ha actualizado el catálogo de mapas OpenCharts del Centro Europeo de Previsiones Meteorológicas a Plazo Medio, que ofrece cientos de gráficos en abierto. En este artículo de la revista RAM te cuentan las novedades.
- El gobierno del Reino Unido ha lanzado una de las primeras normas nacionales del mundo para la transparencia algorítmica. Esta medida responde a los compromisos asumidos en su Estrategia Nacional de Inteligencia Artificial y su Estrategia Nacional de Datos.
¿Conoces otros ejemplos de proyectos relacionados con datos abiertos? Déjanos un comentario o escribe a dinamizacion@datos.gob.es.
Documentación
1. Introducción
Las visualizaciones son una representación gráfica que nos permite comunicar de una manera sencilla la información ligada a los datos. Mediante elementos visuales, como gráficos, mapas o nubes de palabras, las visualizaciones, también nos ayudan a comprender tendencias, patrones o valores atípicos que pueden presentar los datos.
Las visualizaciones se pueden generar a partir de datos de diferente naturaleza, como pueden ser las palabras que conforman una noticia, un libro o una canción. Para realizar visualizaciones a partir de este tipo de datos, es necesario que las maquinas, mediante programas de software, sean capaces de entender, interpretar y reconocer las palabras que configuran el lenguaje humano (escrito o hablado) en múltiples idiomas. El campo de estudio enfocado en el tratamiento de estos datos se denomina Procesamiento del Lenguaje Natural (PLN). Es un campo interdisciplinar que combina el poder de la inteligencia artificial, la lingüística computacional y la informática. Los sistemas basados en PLN han permitido grandes innovaciones como el buscador de Google, el asistente de voz de Amazon, los traductores automáticos, el análisis de sentimientos de diferentes redes sociales o incluso detección de spam en una cuenta de correo electrónico.
En este ejercicio práctico, vamos a implementar una visualización gráfica de un resumen de palabras clave representativas de varios textos extraídas mediante la aplicación de técnicas de PLN. En concreto, vamos a crear una nube de palabras que resuma cuál son los términos que más se repiten en varios posts del portal.
Esta visualización se engloba dentro de la serie de ejercicios prácticos, en los cuales se utilizan datos abiertos disponibles en el portal datos.gob.es. En estos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar transformaciones y análisis que resulten pertinentes para la creación de la visualización, extrayendo la máxima información. En cada uno de los ejercicios prácticos se usan sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en GitHub.
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización que incluya imágenes, generadas a partir de conjuntos de palabras representativas de diversos textos, conocidas popularmente como “nubes de palabras”. Para este ejercicio práctico hemos escogido 6 post publicados en la sección de blog del portal de datos.gob.es. A partir de estos textos y utilizando técnicas de PLN generaremos una nube de palabras para cada texto que nos permitirá detectar de manera sencilla y visual la frecuencia e importancia de cada palabra, facilitando la identificación de las palabras clave y la temática principal de cada uno de los posts.

A partir de un texto construimos una nube de palabras aplicando técnicas de Procesamiento de Lenguaje Natural (PLN)
3. Recursos
3.1. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo), como la visualización propiamente dicha, se utiliza Python (versión 3.7) y Jupyter Notebook (versión 6.1), herramientas que encontraras integradas en, junto con muchas otras, en Anaconda, una de las plataformas más populares para instalar, actualizar y administrar software para trabajar en ciencia de datos. Para abordar las tareas relacionadas con el Procesamiento del Lenguaje Natural, utilizamos dos librerías, Scikit-Learn (sklearn) y wordcloud. Todas estas herramientas son Open Source y están disponibles de manera gratuita.
Scikit-Learn es una amplia librería muy popular, diseñada principalmente para llevar a cabo tareas de aprendizaje automático sobre datos en forma de texto. Entre otros, cuenta con algoritmos para realizar tareas de clasificación, regresión, clustering y reducción de dimensionalidades. Además, está diseñada para el aprendizaje profundo sobre datos textuales, siendo útil para el manejo de conjuntos de características textuales en forma de matrices, la realización de tareas como el cálculo de similitudes, la clasificación de texto y la agrupación de clústeres. En Python, para realizar este tipo de tareas, también es posible trabajar con otras librerías igualmente populares como NLTK o spacy, entre otras.
wordcloud es una librería especializada en la creación de nubes de palabras utilizando un algoritmo simple y que puede ser modificado fácilmente.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en Python que se incluye a continuación, al que puedes acceder haciendo click en el botón “Código” de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren formas alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de GitHub de datos.gob.es. La forma de proporcionar el código es a través de un Jupyter Notebook, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
3.2. Conjuntos de datos
Para este análisis se han seleccionado 6 posts publicados recientemente en el portal de datos abiertos datos.gob.es, en su sección de blog. Estos posts están relacionado con diferentes temáticas relativas a los datos abiertos:
- Lo último en el procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cientos de palabras.
- La importancia de la anonimización y la privacidad de datos.
- El valor de los datos en tiempo real a través de un ejemplo práctico.
- Nuevas iniciativas para abrir y aprovechar datos para investigación en salud.
- Kaggle y otras plataformas alternativas para aprender ciencia de datos.
- La infraestructura de Datos Espaciales de España (IDEE), un referente de la información geoespacial.
4. Tratamiento de datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos o preprocesamiento de los datos, prestando atención a la obtención de los mismos, asegurando que no contienen errores y se encuentran en un formato adecuado para su procesamiento. Un tratamiento previo de los datos es esencial para construir cualquier representación visual efectiva y consistente.
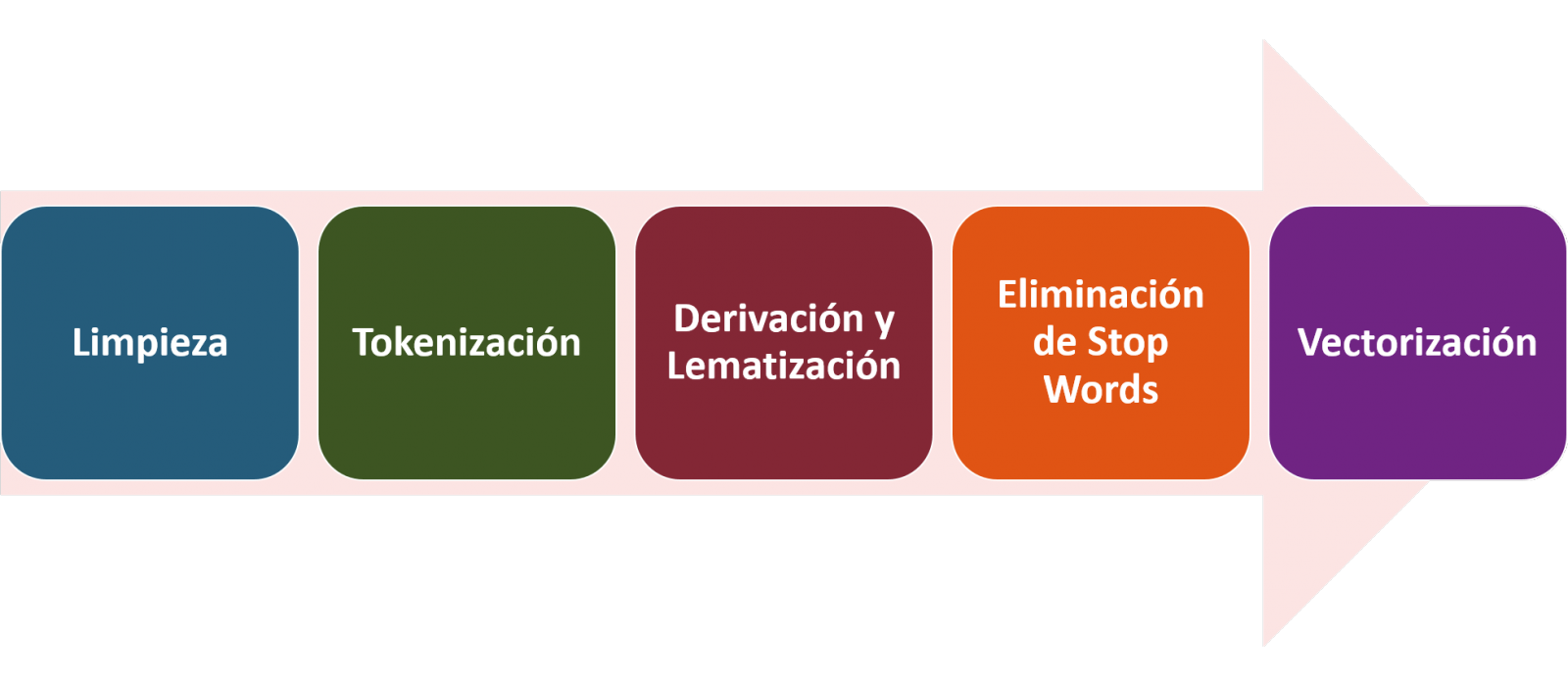
En PLN, el preprocesamiento de los datos consiste fundamentalmente en una serie de transformaciones que se realizan sobre los datos de entrada, en nuestro caso varios posts en formato TXT, con el objetivo de obtener datos uniformes y sin elementos que puedan afectar a la calidad de los resultados, con el fin de facilitar su posterior procesamiento para realizar tareas como, generar una nube de palabras, realizar minería de opiniones/sentimientos o generar resúmenes automatizados a partir de textos de entrada. De forma general, el flujograma que se sigue para realizar un preprocesamiento de texto incluye las siguientes etapas:
- Limpieza: eliminación de los caracteres y símbolos especiales que contribuyen a distorsionar los resultados, por ejemplo, los signos de puntuación.
- Tokenizar: la tokenización es el proceso de separar un texto en unidades más pequeñas, tokens. Los tokens pueden ser oraciones, palabras o incluso caracteres.
- Derivación y Lematización: este proceso consiste en transformar las palabras a su forma básica, es decir a su forma canónica o lema, eliminando plurales, tiempos verbales o géneros. Esta acción en ocasiones no es necesaria ya que no siempre se requiere para el procesamiento posterior saber la similitud semántica entre las diferentes palabras del texto.
- Eliminación de stop words: las stop words o palabras vacías son aquellas palabras de uso común pero que no contribuyen de una manera significativa en el texto. Estas palabras deben eliminarse antes del procesamiento del texto ya que no aportan ninguna información única que pueda ser usada para la clasificación o agrupación del texto, por ejemplo, los artículos determinantes como ‘los’, ‘las’, ‘una’ ‘unos’, etc.
- Vectorización: en este paso transformamos cada uno de los tokens obtenidos en el paso anterior a un vector de números reales que se genera en base a la frecuencia de la aparición de cada palabra en el texto. La vectorización permite que las maquinas sean capaces de procesar texto y aplicar, entre otras, técnicas de aprendizaje automático.
4.1. Instalación y carga de librerías
Antes de empezar con el preprocesamiento de datos, debemos importar las librerías con las cuales vamos a trabajar. Python dispone de una gran cantidad de librerías que permiten implementar funcionalidades para muchas tareas, como visualización de datos, Machine Learning, Deep Learning o Procesamiento del Lenguaje Natural, entre muchas otras. Las librerías que utilizaremos para este análisis y visualización son:
- os, que permite acceder a funcionalidades dependientes del sistema operativo, como manipular la estructura de directorios.
- re, proporciona funciones para procesar expresiones regulares.
- pandas, es una librería muy popular y esencial para procesar tablas de datos.
- string, proporciona una serie de funciones muy útiles para el manejo de cadenas de caracteres.
- matplotlib.pyplot, contiene una colección de funciones que nos permitirán generar las representaciones gráficas de las nubes de palabras.
- sklearn.feature_extraction.text (librería Scikit-Learn), convierte una colección de documentos de texto en una matriz de vectores. De esta librería usaremos algunos comandos que comentaremos más adelante.
- wordcloud, librería con la cual podremos generar la nube de palabras.
# Importaremos las librerías necesarias para realizar este análisis y la visualización. import os import re import pandas as pd import string import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from wordcloud import WordCloud4.2. Carga de datos
Una vez cargadas las librerías, preparamos los datos con los cuales vamos a trabajar. Antes de comenzar a cargar los datos, en el directorio de trabajo debemos tener: (a) una carpeta denominada “post” que contendrá todos los archivos en formato TXT con los cuales vamos a trabajar y que están disponibles en el repositorio de este proyecto del GitHub de datos.gob.es; (b) un archivo denominado “stop_words_spanish.txt” que contiene el listado de las stop words en español, que también está disponible en dicho repositorio y (c) una carpeta llamada “imagenes” donde guardaremos las imágenes de las nubes de palabras en formato PNG, que crearemos a continuación.
# Generamos la carpeta \"imagenes\".nueva_carpeta = \"imagenes/\" try: os.mkdir(nueva_carpeta)except OSError: print (\"Ya existe una carpeta llamada %s\" % nueva_carpeta)else: print (\"Se ha creado la carpeta: %s\" % nueva_carpeta)Seguidamente, procederemos a cargar los datos. Los datos de entrada, como ya hemos comentado anteriormente, se encuentran en ficheros TXT y cada fichero contiene un post. Como queremos realizar el análisis y la visualización de varios posts al mismo tiempo, cargaremos en nuestro entorno de desarrollo todos los textos que nos interesen, para posteriormente insertarlos en una única tabla o dataframe.
# Generamos una lista donde incluiremos todos los archivos que debe leer, indicándole la carpeta donde se encuentran.filePath = []for file in os.listdir(\"./post/\"): filePath.append(os.path.join(\"./post/\", file))# Generamos un dataframe en el cual incluiremos una fila por cada post.post_df = pd.DataFrame()for file in filePath: with open (file, \"rb\") as readFile: post_df = pd.DataFrame([readFile.read().decode(\"utf8\")], append(post_df)# Nombramos la columna que contiene los textos en el dataframe.post_df.columns = [\"texto\"]4.3. Preprocesamiento de datos
Para el objetivo que nos hemos planteado, generar nubes de palabras para cada post, vamos a realizar las siguientes tareas de preprocesamiento.
a) Limpieza de datos
Una vez generada la tabla que contiene los textos con los cuales vamos a trabajar, debemos eliminar el ruido ajeno al texto que nos interesa: caracteres especiales, signos de puntuación y retornos de carro.
En primer lugar, ponemos en minúscula todos los caracteres para evitar cualquier error en los procesos que distinguen entre mayúsculas y minúsculas, mediante el uso del comando lower().
Seguidamente eliminamos los signos de puntuación, como puntos, comas, exclamaciones, interrogaciones, entre muchos otros. Para la eliminación de estos recurriremos a la cadena preinicializada string.punctuacion de la librería string, que devuelve un conjunto de símbolos considerados signos de puntuación. Además, debemos eliminar las tabulaciones, saltos de carro y espacios extra, que no aportan información en este análisis, mediante el uso de expresiones regulares.
Es fundamental aplicar todos estos pasos en una única función para que se procesen de forma secuencial, debido a que todos los procesos están altamente relacionados.
# Eliminamos los signos de puntuación, los saltos de carro/tabulaciones y espacios en blanco extra.# Para ello generamos una función en la cual indicamos todos los cambios que queremos aplicar al texto.def limpiar_texto(texto): texto = texto.lower() texto = re.sub(\"\\[.*?¿\\]\\%\", \" \", texto) texto = re.sub(\"[%s]\" % re.escape(string.punctuation), \" \", texto) texto re.sub(\"\\w*\\d\\w*\", \" \", texto) return texto# Aplicamos los cambios al texto.limpiar_texto = lambda x: limpiar_texto(x)post_clean = pd.DataFrame(post_clean.texto.apply/limpiar_texto)b) Tokenizar
Una vez que hemos eliminado el ruido en los textos con los cuales vamos a trabajar, “tokenizaremos” en palabras cada uno de los textos. Para ello utilizaremos la funció split(), usando como separador entre palabras, el espacio. Esto permitirá separar las palabras de manera independiente (tokens) para análisis futuros.
# Tokenizar los textos. Se crea una nueva columna en la tabla con los tokens con el texto \"tokenizado\".def tokenizar(text): text = texto.split(sep = \" \") return(text)post_df[\"texto_tokenizado\"] = post_df[\"texto\"].apply(lambda x: tokenizar(x))c) Eliminación de \"stop words\"
Después de eliminar los signos de puntuación y otros elementos que pueden distorsionar la visualización objetivo, eliminaremos las “stop words” o palabras vacías. Para la realización de este paso usamos una lista de stop words del castellano dado que cada idioma posee su propia lista. Esta lista consta de un total de 608 palabras, en las que se incluyen artículos, preposiciones, verbos copulativos, adverbios, entre otros y está actualizada recientemente. Esta lista puede descargarse desde la cuenta de GitHub de datos.gob.es en formato TXT y debe estar ubicada en el directorio de trabajo.
# Leemos el archivo que contiene las palabras vacías en castellano.with open \"stop_words_spanish.txt\", encoding = \"UTF8\") as f: lines = f.read().splitlines()En esta lista de palabras, incluiremos nuevas palabras que no aportan información relevante a nuestros textos o aparecen recurrentemente debido al contexto de los mismos. En este caso, existe una serie de palabras, que nos conviene eliminar ya que están presentes en todos los posts de manera repetitiva dado que todos tratan sobre el tema de datos abiertos y existe una alta probabilidad de que éstas sean las palabras más significativas. Algunas de estas palabras son, “datos”, “dato”, “abiertos”, “caso”, entre otras. Esto permitirá obtener una representación gráfica más representativa del contenido de cada post.
Por otro lado, una inspección visual de los resultados obtenidos permite detectar palabras o caracteres derivados de errores incluidos en los textos, que evidentemente no tienen significado y que no han sido eliminados en los pasos anteriores. Estos, deben ser retirados del análisis para que no distorsionen los resultados posteriores. Se trata de palabras como, “nen”, “nun” o “nla”.
# Actualizamos nuestra lista de stop words.stop_words.extend((\"caso\", \"forma\",\"unido\", \"abiertos\", \"post\", \"espera\", \"datos\", \"dato\", \"servicio\", \"nun\", \"día\", \"nen\", \"data\", \"conjuntos\", \"importantes\", \"unido\", \"unión\", \"nla\", \"r\", \"n\"))# Eliminamos las stop words de nuestra tabla.post_clean = post_clean [~(post_clean[\"texto_tokenizado\"].isin(stop_words))]d) Vectorización
Las maquinas no son capaces de comprender palabras y oraciones, por lo que estas deben convertirse en alguna estructura numérica. El método consiste en generar vectores a partir de cada token. En este post utilizamos una técnica sencilla conocida como bolsa de palabras (BoW). Consiste en asignar un peso a cada token proporcional a la frecuencia de aparición de dicho token en el texto. Para ello, trabajamos sobre una matriz en la que cada fila representa un texto y cada columna un token. Para realizar la vectorización recurriremos a los comandos CountVectorizer() y TfidTransformer() de la lirería Scikit-Learn.
La función CountVectorizer() permite transformar un texto en un vector de frecuencias o recuentos de palabras. En este caso obtendremos 6 vectores con tantas dimensiones como tokens hay en cada texto, uno por cada post, que integraremos en una única matriz, donde las columnas serán los tokens o palabras y las filas serán los posts.
# Calculamos la matriz de frecuencia de palabras del texto.vectorizador = CountVectorizer()post_vec = vectorizador.fit_transform(post_clean.texto_tokenizado)Una vez generada la matriz de frecuencia de palabras, es necesario convertirla en una forma vectorial normalizada con el objetivo de reducir el impacto de los tokens que ocurren con mucha frecuencia en el texto. Para ello utilizaremos la función TfidfTransformer().
# Convertimos una matriz de frecuencia de palabras en una forma vectorial regularizada.transformer = TfidfTransformer()post_trans = transformer.fit_transform(post_vec).toarray()Si quieres saber más sobre la importancia de aplicar está técnica, encontrarás numerosos artículos en Internet que hablan sobre ello y lo relevante que es, entre otras cuestiones, para la optimización de SEO.
5. Creación de la nube de palabras
Una vez que hemos realizado un preprocesamiento del texto, como indicábamos al inicio del post, es posible realizar tareas propias de PLN. En este ejercicio crearemos una nube de palabras o “WordCloud” para cada uno de los textos analizados.
Una nube de palabras, es una representación visual de las palabras con mayor número de ocurrencias en el texto. Permite detectar de manera sencilla la frecuencia e importancia de cada una de las palabras, facilitando la identificación de las palabras clave y descubriendo con un solo golpe de vista la temática principal tratada en el texto.
Para ello vamos a utilizar la librería “wordcloud” que incorpora las funciones necesarias para construir cada representación. En primer lugar, debemos indicar las características que presentará cada nube de palabras, como es el color de fondo (función background_color), el mapa de colores que tomaran las palabras (función colormap), el tamaño máximo de letra (función max_font_size) o fijar una semilla para que la nube de palabras generada siempre sea igual (función random_state) en futuras ejecuciones. Podemos aplicar estas y muchas otras funciones para personalizar cada nube de palabras.
# Indicamos las características que presentará cada nube de palabras.wc = WordCloud(stopwords = stop_words, background_color = \"black\", colormap = \"hsv\", max_font_size = 150, random_state = 123)Una vez que hemos indicado las características que queremos que presente cada nube de palabras, procedemos a crearla y guardarla como imagen en formato PNG. Para generar la nube de palabras, usaremos un bucle en el cual le indicaremos diferentes funciones de la librería matplotlib (representada por el prefijo plt) necesarias para generar gráficamente la nube de palabras según la especificación definida en el paso anterior. Debemos indicarle que debe realizar una nube de palabras por cada fila de la tabla, es decir por cada texto, con la función plt.subplot(). Con el comando plt.imshow() indicamos que el resultado es una imagen en 2D. Si queremos que no se muestren los ejes debemos indicárselo con la función plt.axis(). Por último, con la función plt.savefig() guardaremos la visualización generada.
# Generamos las nubes de palabras para cada uno de los posts.for index, i in enumerate(post.columns): wc.generate(post.texto_tokenizado[i]) plt.subplot(3, 2, index+1 plt.imshow(wc, interpolation = \"bilinear\") plt.axis(\"off\") plt.savefig(\"imagenes/.png\")# Mostramos las nubes de palabras resultantes.plt.show()La visualización obtenida es:

Visualización de las nubes de palabras obtenidas a partir de los textos de diferentes posts de la sección de blog de datos.gob.es
5. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Las nubes de palabras son una herramienta que permite agilizar el análisis de datos textuales, puesto que a través de ellas podemos identificar e interpretar de manera rápida y sencilla las palabras con mayor relevancia en el texto analizado, lo que nos da una idea de la temática.
Si quieres aprender más sobre el Procesamiento del Lenguaje Natural, puedes consultar la guía \"Tecnologías emergentes y datos abiertos: Procesamiento del lenguaje natural\" y los posts \"Procesamiento del lenguaje natural\" y \"Lo último en procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cuentos de palabras\".
Esperemos que esta visualización paso a paso te haya enseñado algunas cosas sobre los entresijos del Procesamiento del Lenguaje Natural y la creación de nubes de palabras. Volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!
Evento
Red.es, en colaboración con la Secretaría de Estado de Digitalización e Inteligencia Artificial organiza la cuarta edición del Desafío Aporta. Como en otras ocasiones, se busca identificar y reconocer nuevas ideas y prototipos que impulsen mejoras en un sector concreto a través del uso de datos abiertos. Este año el foco estará puesto en la salud y el bienestar.
El objetivo es incentivar el talento, la competencia técnica y la creatividad de los participantes a la vez que se fomenta la reutilización directa de datos publicados por diversos organismos públicos.
¿Por qué es importante impulsar el uso de datos abiertos en el sector de la salud y el bienestar?
Si hay un sector donde se ha producido una demanda de datos durante el último año ha sido la sanidad, debido en parte a la pandemia mundial de COVID-19. No obstante, los datos abiertos relacionados con la salud y el bienestar no solo sirven para informar a la ciudadanía en un ejercicio de transparencia, sino que también son fundamentales como base de soluciones que impulsen mejoras en la atención sanitaria, la experiencia del paciente y su calidad de vida.
Consciente de ello, la Comisión europea tiene entre sus prioridades la creación de un espacio europeo de datos en el sector sanitario. Por su parte, el Gobierno español ha comenzado las acciones para constituir un data lake que pondrá una gran cantidad de datos a disposición de los investigadores para que puedan analizarlos, realizar predicciones o detectar tendencias.
Bajo el lema “El valor del dato para la salud y el bienestar de los ciudadanos” se llevará a cabo una competición que al igual que otros años constará de dos fases:
Fase I: Concurso de ideas. Del 22 de noviembre de 2021 al 15 de febrero de 2022.
Los participantes deberán presentar una idea que respondan al reto propuesto: se trata de identificar nuevas oportunidades de captar, analizar y utilizar la inteligencia de los datos para impulsar mejoras ligadas a la salud y el bienestar.
Las propuestas deberán estar basadas en el uso de al menos un conjunto de datos generado por las Administraciones Públicas, ya sean nacionales o internacionales. Estos datos se podrán combinar con otros de naturaleza pública o privada.
La idea presentada tiene que ser original y no haber sido premiada con anterioridad. No son válidas las soluciones que existieran previamente, si no que deben ser desarrolladas por parte del participante en el marco del Desafío.
Un jurado integrado por expertos en la materia valorará las ideas presentadas y elegirá 10, que pasan a la fase II. Los criterios que se tendrán en cuenta para la evaluación son:
- Relevancia
- Calidad y claridad global de la idea propuesta
- Impacto de la idea propuesta en la mejora de la salud y el bienestar de los ciudadanos
- Fuentes de datos utilizadas
- Fomento del acceso a los servicios de salud y bienestar de colectivos vulnerables
Fase II: Desarrollo de prototipos y exposición presencial. Abril-junio.
Los participantes cuyas ideas hayan sido seleccionadas en la fase anterior, desarrollarán el prototipo asociado y lo presentarán ante los miembros del Jurado. Para ello contarán con un plazo mínimo de 2 meses.
Los prototipos podrán ser una solución funcional, elemento gráfico dinámico o solución multimedia que simule el servicio o una ejemplificación funcional a partir de la extrapolación de una solución ya existente, por ejemplo, en otro sector, país, ámbito, etc.
En este caso, los criterios de evaluación serán:
- Facilidad de uso
- Calidad técnica del prototipo
- Viabilidad
- Calidad de la exposición
Las tres propuestas con mayor puntuación serán las ganadoras y recibirán la siguiente dotación económica:
- Primer clasificado: 5.000 €
- Segundo clasificado: 4.000 €
- Tercer clasificado: 3.000 €
Ejemplos de retos a solucionar
Algunos ejemplos de retos a los que pueden dar respuesta las soluciones presentadas son:
- Fomentar la adquisición y consolidación de hábitos saludables en la ciudadanía
- Conseguir una atención medica más eficaz y mejorar la experiencia del paciente
- Incrementar las capacidades de salud pública y vigilancia epidemiológica
- Obtener mejores resultados de salud y bienestar para las personas dependientes, enfermos crónicos o personas mayores
- Asegurar que todas las personas tengan las máximas oportunidades de preservar su salud y su bienestar
- Optimizar la formación y desarrollo de los profesionales del ámbito sanitario
- Impulsar la investigación que ayude a descubrir pautas saludables y nuevos tratamientos
- Favorecer la compartición de experiencias exitosas
- Aprovechar los datos para mejorar la seguridad del paciente y del usuario del servicio
¿Quién puede participar?
La inscripción está abierta a cualquier persona, equipo o empresa con domicilio en la Unión Europea, que quiera contribuir al desarrollo económico y social en el ámbito de la salud y el bienestar.
¿Cómo puedo inscribirme?
Puedes inscribirte a través de la sede electrónica de red.es. Para ello necesitarás tu clave o certificado electrónico. El plazo finaliza el 15 de febrero de 2022 a las 13.00 horas.
Debes incluir una descripción detallada de tu idea y su valor para la sociedad, así como un vídeo descriptivo de la idea en castellano, de entre 120 y 180 segundos de duración.
Tienes toda la información en la sede de red.es y las bases del Desafío.
¡Inspírate con los trabajos finalistas de las ediciones anteriores!
Si quieres buscar inspiración, mira los trabajos de años anteriores.
- III Desafío Aporta: “El valor del dato en la educación digital”
- II Desafío Aporta: “El valor del dato para el sector agroalimentario, forestal y rural”
- I Desafío Aporta: “El valor del dato para la Administración"
¡Anímate y pon a prueba tu talento!
Si quieres contribuir a hacer llegar esta información a otros, te ofrecemos materiales que te lo harán más fácil:
(Puedes descargar la versión accesible en word aquí)
Noticia
El pasado 2 de noviembre tuvo lugar la entrega de premios a los ganadores de la V edición del Concurso de Datos Abiertos de Castilla y León. Esta competición, organizada por la Consejería de Transparencia, Ordenación del Territorio y Acción Exterior de la Junta de Castilla y León, reconoce la realización de proyectos que suministran ideas, estudios, servicios, sitios web o aplicaciones móviles, utilizando para ello conjuntos de datos de su Portal de Datos Abiertos.
El acto ha contado con la participación de Francisco Igea, Vicepresidente de la Junta de Castilla y León, y Joaquín Meseguer, Director General de Transparencia y Buen Gobierno de la misma, encargados de otorgar los galardones a los premiados.

De las 37 candidaturas recibidas, un jurado de expertos en la materia ha elegido 8 proyectos que se han alzado como ganadores en las diversas categorías.
Categoría Ideas
En esta categoría se premian propuestas para desarrollar estudios, servicios, sitios web o aplicaciones para dispositivos móviles.
- El primer premio, de 1.500€, fue para APP SOLAR-CYL, una herramienta web de dimensionamiento óptimo de instalaciones de autoconsumo solar fotovoltaico. Dirigida tanto a ciudadanos como a gestores energéticos de la Administración Pública, la solución busca ser un apoyo para el análisis de la viabilidad técnica y económica de este tipo de sistemas. La idea fue presentada por profesores del Área de Ingeniería Eléctrica, integrantes del grupo de investigación ERESMA (Energy Resources’ Smart Management) de la Universidad de León: Miguel de Simón Martín, Ana María Díez Suárez, Alberto González Martínez, Álvaro de la Puente Gil y Jorge Blanes Peiró.
- El segundo premio, de 500€, recayó en Donde Te Esperan: Recomendador de municipios de España, de Mario Varona Bueno. Gracias a esta herramienta, los usuarios podrán buscar cuál es el mejor lugar para vivir en base a sus preferencias o incluso el azar.
Categoría Productos y Servicios
Esta categoría se diferencia de la anterior en que ya no se premian ideas, sino proyectos accesibles para toda la ciudadanía vía web mediante una URL.
- Repuéblame se alzó con el primer premio, que en esta ocasión consistía en 2.500€. Presentado por Guido García Bernardo y Javier García Bernardo, consiste en una web para redescubrir los mejores lugares en los que vivir o teletrabajar. La aplicación cataloga los municipios castellanoleoneses en base a una serie de indicadores numéricos, de elaboración propia, relacionados con la calidad de vida.
- El segundo premio, de 1.500€, fue para Plagrícola: Avisos de Plagas Agrícolas CyL, de José María Pérez Ramos. Se trata de una app móvil que informa a los agricultores de las alertas sobre plagas publicadas por el Instituto Tecnológico Agrario de Castilla y León (Itacyl), para que puedan llevar a cabo las medidas preventivas y curativas necesarias.
- Completa el pódium disCAPACIDAD.es [web], que se hizo con el tercer premio de 500 €. Su creador, Luis Hernández Fuentevilla, ha desarrollado una web que centraliza ofertas y ayudas relacionadas con el empleo para personas con discapacidad en Castilla y León.
- Esta categoría incluía también un premio dirigido a estudiantes de 1.500 €. El galardonado fue Ruta x Ruta x Castilla y León, presentado por Adrián Arroyo Calle. Esta aplicación web permite a los usuarios consultar rutas de todo tipo, así como los puntos de interés situados en sus proximidades, como monumentos, restaurantes o eventos. La solución también permite a los usuarios compartir sus tracks (grabaciones GPS).
Además, se ha otorgado una mención de honor a las candidaturas presentadas por estudiantes “APP BOCYL Boletín Oficial Castilla y León”, de Nicolás Silva Brenes y "COVID CyL" presentada por Silvia Pedrón Hermosa. Con ello se busca incentivar que los estudiantes trabajen con datos y presenten sus proyectos a convocatorias futuras.
Categoría Periodismo de Datos
Esta categoría está pensada para premiar piezas periodísticas relevantes publicadas o actualizadas en cualquier soporte, ya sea escrito o audiovisual.
- MAPA COVID-19: consulta cuántos casos de coronavirus hay y cómo está la ocupación de tu hospital de la Asociación Maldita contra la desinformación obtuvo el primer premio de 1.500€. Tras un trabajo de recopilación de todos los datos disponibles que los Gobiernos autonómicos publican sobre los hospitales, Maldita ha creado un mapa para consultar cuántos casos de coronavirus hay y cómo está la ocupación de los distintos hospitales. En algunos hospitales también se incluye información sobre la ocupación de las UCI.
- El segundo premio, de 1.000€, ha sido para De cero a 48.000 euros: quién cobra cuánto en las alcaldías de Castilla y León. Explorador de las retribuciones anuales. A través de diversas visualizaciones, su creadora, Laura Navarro Soler, da a conocer información disponible en el sistema de Información Salarial Puestos de la Administración (ISPA). Esta información se cruza con otro tipo de datos como el número de habitantes de cada región o el nivel de dedicación (exclusiva, parcial o sin dedicación).
La categoría “Recurso Didáctico” ha sido declarada desierta. El jurado ha considerado que las candidaturas presentadas no cumplían con los criterios recogidos en las bases.
En total, los 8 proyectos premiados han recibido 10.500 euros. También tendrán la opción de participar en una asesoría en materia de desarrollo empresarial.
¡Enhorabuena a todos los premiados!