Documentación
Medir el impacto de los datos abiertos es uno de los retos que tienen por delante las iniciativas de datos abiertos. En este contexto, el Portal de Datos Europeo ha puesto en marcha un observatorio de casos de uso que constará de diversos informes.
En el primer informe se presenta la metodología y 30 casos de reutilización seleccionados, incluyendo información sobre los servicios que ofrecen, los datos (abiertos) que utilizan y el impacto que tienen. Por último se presentan las conclusiones generales y las lecciones aprendidas en esta primera parte del proyecto. Para seleccionar los casos de uso, se realizó un inventario basado en tres fuentes: los ejemplos recogidos en los estudios de madurez que realiza cada año el portal europeo, las soluciones participantes en el EU Datathon y los ejemplos de reutilización disponibles en el repositorio de casos de uso de data.europa.eu.
Este informe se encuentra disponible en el siguiente enlace: "Observatorio de casos de uso: seguimiento de 3 años de 30 casos de reutilización para comprender el impacto económico, gubernamental, social y medioambiental de los datos abiertos (Volumen I) "
Noticia
Medir el impacto de los datos abiertos es uno de los retos que tienen por delante las iniciativas open data. Existen diversos métodos, la mayoría de los cuales combinan el análisis cuantitativo con el cualitativo, con el fin de conocer cuál es el valor de determinados conjuntos de datos.
En este contexto, data.europa.eu, el Portal Europeo de Datos Abiertos, ha puesto en marcha un Observatorio de casos de uso (Use Case Observatory). Se trata de un proyecto de investigación sobre el impacto económico, gubernamental, social y medioambiental de los datos abiertos.
¿En qué consiste el Observatorio de casos de uso?
Durante tres años, desde 2022 hasta 2025, el Portal Europeo de Datos realizará el seguimiento de 30 casos de reutilización de datos abiertos. Con ello se busca:
- Evaluar cómo se crea el impacto de los datos abiertos
- Compartir los retos y logros de los casos de reutilización analizados
- Contribuir al debate sobre la metodología a utilizar para medir dicho impacto
Los casos de uso analizados hacen referencia a cuatro áreas de impacto:
- Impacto económico: Incluye casos de reutilización relacionados con la creación de empresas y la (re)capacitación de los trabajadores, entre otros. Por ejemplo, se incluyen soluciones que ayudan a identificar licitaciones públicas o solicitar puestos de trabajo.
- Impacto gubernamental: Se refiere a casos de reutilización que impulsan el gobierno electrónico, la transparencia y la rendición de cuentas.
- Impacto social: Engloba casos de reutilización en los ámbitos de la asistencia sanitaria, el bienestar y la lucha contra la desigualdad.
- Impacto medioambiental: Se circunscribe a casos de reutilización que promueven la sostenibilidad y la reducción de energía, incluyendo soluciones relacionadas con el control de la calidad del aire o la preservación de los bosques.
Para seleccionar los casos de uso, se realizó un inventario basado en tres fuentes: los ejemplos recogidos en los estudios de madurez que realiza cada año el portal europeo, las soluciones participantes en el EU Datathon y los ejemplos de reutilización disponibles en el repositorio de casos de uso de data.europa.eu. Solo se tuvieron en cuenta aquellos proyectos desarrollados en Europa, intentando mantener un equilibrio entre los distintos países. Además, se destacaron aquellos proyectos que hubiesen obtenido algún premio o que estuviesen alineados con las prioridades de la Comisión Europea para 2019 a 2024. Para finalizar la selección, desde data.europa.eu se realizaron entrevistas con representantes de los casos de uso que cumplían los requisitos y que estaban interesados en participar en el proyecto.
Tres proyectos españoles entre los casos de uso analizados
Los casos de uso seleccionados se recogen en la siguiente imagen:

Entre ellos, encontramos tres españoles:
- En la categoría de Impacto social se sitúa UniversiDATA-Lab, un portal público para el análisis avanzado y automático de los conjuntos de datos publicados por las universidades. Este proyecto, que se hizo con el primer premio del III Desafío Aporta, fue concebido por el equipo creador de UniversiData, una iniciativa colaborativa orientada e impulsada por universidades públicas con el fin de fomentar los datos abiertos en el sector de la educación superior en España de una forma armonizada. Puedes conocer más sobre estos proyectos en esta entrevista.
- En la misma categoría también encontramos a Tangible data, un proyecto centrado en la creación de esculturas basadas en datos, para acercarlos a personas sin conocimientos técnicos. Entre otras fuentes de datos, utiliza datasets provenientes de la NASA o de Our World in Data.
- En la categoría de medio ambiente está Planttes. Se trata de un proyecto de ciencia ciudadana diseñado para informar sobre la presencia de plantas alergénicas en nuestro entorno y el nivel de riesgo de alergia en función de su estado. Este proyecto está promovido por el Punto de Información Aerobiológica (PIA) del Instituto de Ciencia y Tecnología Ambientales (ICTA-UAB) y el Departamento de Biología Animal, Biología Vegetal y Ecología (BABVE), en colaboración con el Centro de Visión por Computador (CVC) y el Library Living Lab, todos ellos de la Universidad Autónoma de Barcelona (UAB).
Primer informe ya disponible
Fruto del trabajo de análisis realizado se desarrollarán tres informes. El primero de ellos, que se acaba de publicar, presenta la metodología y los 30 casos de reutilización seleccionados. Incluye información sobre los servicios que ofrecen, los datos (abiertos) que utilizan y el impacto que tienen en el momento de la redacción. El informe finaliza con un resume de las conclusiones generales y las lecciones aprendidas de esta primera parte del proyecto de investigación, ofreciendo una visión general de los próximos pasos del observatorio.
El segundo y el tercer informe, que verán la luz en 2024 y 2025, evaluarán el progreso de los mismos casos de uso y permitirá ampliar las conclusiones de este primer volumen. Los informes se focalizarán en determinar los logros alcanzados y los retos presentes en un espacio de tres años, lo cual permitirá extrapolar ideas concretas para mejorar las metodologías de evaluación del impacto de los datos abiertos.
El proyecto fue presentado en un webinar el pasado 7 de octubre, cuya grabación está disponible, junto con la presentación utilizada. En el webinar se invitó a participar a representantes de 4 de los casos de uso: Openpolis, Integreat, ANP y OpenFoodFacts.
Noticia
La ciencia de los datos tiene un papel clave en la construcción de un mundo más equitativo, justo e inclusivo. Los datos abiertos relacionados con la justicia y la sociedad pueden servir de base para el desarrollo de soluciones tecnológicas que impulsen un sistema jurídico no solo más transparente, sino también más eficiente, ayudando a los juristas a realizar su trabajo de una manera más ágil y acertada. Es lo que se conoce como LegalTech, e incluye herramientas que permiten localizar información en grandes volúmenes de textos legales, realizar análisis predictivos o resolver disputas legales de forma sencilla, entre otros.
Además, este tipo de datos permite poner en marcha soluciones dirigidas a dar respuesta a los grandes desafíos sociales de la humanidad, ayudando a impulsar el bien común, como por ejemplo la inclusión de determinados colectivos, la ayuda a los refugiados y la población en zonas de conflicto o la lucha contra la violencia de género.
Cuando hablamos de datos abiertos relacionados con la justicia y la sociedad hacemos referencia tanto a datos jurídicos, como a otros que pueden tener repercusión a la hora de universalizar el acceso a servicios básicos, alcanzas la equidad, conseguir que todas las personas tengan las mismas oportunidades de desarrollo y promover la colaboración entre los diferentes agentes sociales.
¿Qué tipos de datos sobre justicia y sociedad puedo encontrar en datos.gob.es?
En nuestro portal puedes acceder a un amplio catálogo de datos que se encuentra clasificado por diferentes sectores. La categoría de Legislación y Justicia cuenta actualmente con más de 5.000 conjuntos de datos de diferente naturaleza, incluyendo información relacionadas con infracciones penales, recursos o víctimas de determinados delitos, entre otros. Por su parte, la categoría de sociedad y bienestar suma más de 8.000 datasets entre los que encontramos, por ejemplo, listados de ayudas, asociaciones o información sobre el desempleo.
De todos estos conjuntos de datos, recogemos a continuación algunos ejemplos de los más destacados junto al formato en el que puedes consultarlos:
A nivel estatal
- Instituto Nacional de Estadística (INE). Delitos según sexo por comunidades y ciudades autónomas. CSV, XLSX, XLS, JSON, PC-Axis, HTML (landing page de descarga de datos)
- Instituto Nacional de Estadística (INE). Agenda 2030 ODS - Población en riesgo de pobreza o exclusión social: indicador AROPE. CSV, XLS, XLSX, HTML (landing page de descarga de datos)
- Instituto Nacional de Estadística (INE). Uso de Internet por características demográficas y frecuencia de uso. CSV, XLSX, XLS, JSON, PC-Axis, HTML (landing page de descarga de datos)
- Instituto Nacional de Estadística (INE). Gasto según tamaño del municipio de residencia. CSV, XLSX, XLS, JSON, PC-Axis, HTML (landing page de descarga de datos)
- Instituto Nacional de Estadística (INE). Edad de jubilación en el acceso a la prestación. CSV, XLSX
- Ministerio de Justicia. Censo Judicial. XLSX, PDF, HTML (landing page de descarga de datos)
A nivel CC.AA.
- Instituto Cántabro de Estadística. Estadística de nulidades, separaciones y divorcios. RDF-XML, XLS, JSON, ZIP, PC-Axis, HTML (landing page de descarga de datos).
- Comunidad Autónoma del País Vasco. Normas y leyes en vigor aplicables en Euskadi. JSON, JSON-P, XML, XLSX.
- Comunidad Autónoma del País Vasco. Localización de las fosas comunes de la Guerra Civil y del Franquismo. CSV, XLS, XML.
- Generalitat de Cataluña. Estadísticas de los recursos del Departamento de Justicia. XLSX, HTML (landing page de descarga de datos).
- Generalitat de Cataluña. Estadísticas de la justicia juvenil en Cataluña. XLSX, HTML (landing page de descarga de datos).
- Comunidad Foral de Navarra. Estadística de transmisiones de derechos de la propiedad. XLSX, HTML (landing page de descarga de datos).
- Principado de Asturias. Indicadores de los Objetivos de Desarrollo Sostenible en Asturias. HTML, XLSX, ZIP.
- Principado de Asturias. Justicia en Asturias: plantillas de los órganos judiciales del Principado de Asturias según tipo. HTML (landing page de descarga de datos).
- Instituto Canario de Estadística. Jueces y magistrados en activo en Canarias. HTML, JSON, PC-Axis.
A nivel local
- Ayuntamiento de Santa Cruz de Tenerife. Aparcamientos para personas con movilidad reducida. SHP, KML, KMZ, RDF-XML, CSV, JSON, XLS
- Ayuntamiento de Madrid. Sedes de la Administración de Justicia en la ciudad de Madrid. CSV, XML, RSS, RDF-XML, JSON, HTML (landing page de descarga de datos)
- Ayuntamiento de Gijón. Cuerpos de seguridad. JSON, CSV, XLS, PDF, HTML, TSV, texto, XML, HTML (landing page de descarga de datos)
- Ayuntamiento de Madrid. Centros de atención para menores y familia. CSV, JSON, RDF-XML, XML, RSS, HTML (landing page de descarga de datos).
- Ayuntamiento de Zaragoza. Relación de comisarías de policía. CSV, JSON.
Algunos ejemplos de reutilización de datos relacionados con la justicia y el bien social
En la sección de empresas y aplicaciones de datos.gob.es puedes encontrar algunos ejemplos de soluciones elaboradas con datos abiertos relacionados con la justicia y el bien social. Un ejemplo es Papelea, una empresa que da respuesta a cuestiones legales y administrativas de los usuarios. Para ello se nutre de información pública como trámites administrativos de las principales administraciones, normas jurídicas, jurisprudencia, etc. Otro ejemplo es la Fundación ISEAK, especializada en la evaluación de políticas públicas en materia de empleo, desigualdad, inclusión o género, para lo cual utiliza fuentes de datos públicas como el Instituto Nacional de Estadística, la Seguridad Social o Eurostat u Opendata Euskadi.
A nivel internacional también encontramos ejemplos de iniciativas creadas para realizar el seguimiento de los casos procesales o mejorar la transparencia de los servicios policiales. En Europa está en auge la creación de empresas centradas en tecnología jurídica que buscan mejorar la vida cotidiana de la ciudadanía, así como de iniciativas que buscan usar los datos en pro de la equidad. Ejemplos concretos de soluciones en este ámbito son miHub, destinado a los solicitantes de asilo y a los refugiados, en Chipre, o Surviving in Brussels un sitio web para los sin techo y las personas que necesitan acceder a servicios como ayuda médica, alojamiento, ofertas de empleo, ayuda legal o asesoramiento financiero.
¿Conoces alguna empresa que utilice este tipo de datos o aplicación que se base en ellos para contribuir avance de la sociedad? Entonces no dudes en dejarnos un comentario con toda la información o enviarnos un correo a dinamizacion@datos.gob.es.
Blog
La demanda de profesionales con habilidades relacionadas con la analítica de datos no deja de crecer y ya se estima que la industria solo en España necesitaría más de 90.000 profesionales en datos e inteligencia artificial para impulsar la economía. Formar profesionales que puedan llenar este hueco es un gran reto que está haciendo incluso grandes compañías tecnológicas como Google, Amazon o Microsoft estén proponiendo programas de formación especializado que en paralelo a los que propone el sistema educativo reglado. Y en este contexto los datos abiertos tienen un papel muy relevante en la formación práctica de estos profesionales, ya que con frecuencia, los datos abiertos son la única posibilidad para realizar ejercicios reales y no solo simulados.
Además, aunque aún no existe un corpus de investigación sólido al respecto, algunos trabajos ya sugieren efectos positivos derivados del uso de datos abiertos como herramienta en el proceso de enseñanza-aprendizaje de cualquier materia y no solo de las relacionadas con la analítica de datos. Algunos países europeos han reconocido ya este potencial y han desarrollado proyectos piloto para determinar la mejor forma de introducir datos abiertos en el currículo escolar.
En este sentido, los datos abiertos se pueden utilizar como una herramienta para la educación y la formación de varias maneras. Por ejemplo, los datos abiertos se pueden utilizar para desarrollar nuevos materiales de enseñanza y aprendizaje, para crear proyectos basados en datos del mundo real para estudiantes o para apoyar la investigación sobre enfoques pedagógicos efectivos. Además, los datos abiertos se pueden utilizar para crear oportunidades de colaboración entre educadores, estudiantes e investigadores con el fin de compartir mejores prácticas y colaborar en soluciones a desafíos comunes.
Proyectos basados en datos del mundo real
Una aportación clave de los datos abiertos es su autenticidad, ya que son una representación de la enorme complejidad e incluso de los defectos del mundo real a diferencia de las construcciones artificiales o los ejemplos de libros de texto que se basan en supuestos muchos más simples.
Un ejemplo interesante en este sentido es el que documentó la Universidad Simon Fraser de Canadá en su Máster en Edición donde la mayor parte de sus alumnos proceden de programas universitarios no STEM y que por tanto tenían unas capacidades limitadas en el manejo de datos. El proyecto está disponible como recurso educativo abierto en la plataforma OER Commons y su objetivo es que los estudiantes comprendan que las métricas y la medición son herramientas estratégicas importantes para comprender el mundo que nos rodea.
Al trabajar con datos del mundo real, los estudiantes pueden desarrollar habilidades de construcción de relatos e investigación, y pueden aplicar habilidades analíticas y colaborativas en el uso de datos para resolver problemas del mundo real. El caso de estudio realizado con la primera edición en la que se utilizó este OER basado en datos abiertos está documentado en el libro “Open Data as Open Educational Resources - Case studies of emerging practice”. En él se muestra que la oportunidad de trabajar con datos pertenecientes a su campo de estudio resultó esencial para mantener a los estudiantes comprometidos con el proyecto. Sin embargo, lidiar con el desorden de los datos del "mundo real" fue lo que les permitió obtener un aprendizaje valioso y nuevas habilidades prácticas.
Desarrollo de nuevos materiales de aprendizaje
Los conjuntos de datos abiertos tienen un gran potencial para ser utilizados en el desarrollo de recursos educativos abiertos (REA) que son materiales de enseñanza, aprendizaje e investigación en soporte digital de carácter gratuito, pues son publicados con una licencia abierta (Creative Commons) que permite su uso, adaptación y redistribución para usos no comerciales de acuerdo con la definición de la UNESCO.
En este contexto, si bien los datos abiertos no siempre son REA, podemos decir que se convierten en REA cuando se usan en contextos pedagógicos. Los datos abiertos cuando se utilizan como recurso educativo facilitan que los estudiantes aprendan y experimenten trabajando con los mismos conjuntos de datos que utilizan investigadores, gobiernos y sociedad civil. Son un componente clave para que los estudiantes desarrollen habilidades de análisis, estadísticas, científicas y de pensamiento crítico.
Es difícil estimar la presencia actual de los datos abiertos como parte de los REA pero no resulta difícil encontrar ejemplos interesantes dentro de las principales plataformas de recursos educativos abiertos. En la plataforma Procomún podemos encontrar interesantes ejemplos como Aprender Geografía a través de la evolución de los paisajes agrarios de España que construye sobre la plataforma ArcGIS Online de la Universidad Complutense de Madrid un Webmap para el aprendizaje de los paisajes agrarios en España. El recurso educativo emplea ejemplos concretos de distintas comunidades autónomas empleando fotografías o imágenes fijas geolocalizadas y datos propios integrados con datos abiertos. De este modo los estudiantes trabajan los conceptos no a través de una mera descripción en texto sino con recursos interactivos que favorecen además la mejora de sus competencias digitales y espaciales
En la plataforma OER Commons encontramos por ejemplo el recurso “De los datos abiertos al compromiso cívico” que está dirigido a públicos a partir de enseñanza secundaria con el objetivo de enseñar a interpretar cómo se gasta el dinero público en un área regional, local, o barrio determinado. Para ello se apoya en los conocidos proyectos para analizar presupuestos públicos “¿Dónde van mis impuestos?”, disponibles en muchas zonas del mundo como fruto de las políticas de transparencia de los poderes públicos. Este recurso que podría ser portado a España con facilidad ya que contamos con numerosos proyectos ¿Donde van mis impuestos?, como el mantenido por Fundación Civio.
Habilidades relacionadas con datos
Cuando nos referimos a la formación y educación en habilidades relacionadas con los datos, en realidad nos estamos refiriendo a un área de gran amplitud que además es muy difícil dominar en todas sus facetas. De hecho, lo habitual es que los proyectos relacionados con datos se aborden en equipos donde cada miembro desempeña un rol especializado en alguna de estas áreas. Por ejemplo, es habitual diferenciar al menos la limpieza y preparación de datos, el modelado de datos y la visualización de datos como las principales actividades que se realizan en un proyecto de ciencia datos e inteligencia artificial.
En todos los casos el uso de datos abiertos está ampliamente adoptado como recurso central de los proyectos que se proponen para la adquisición de cualquiera de estas habilidades. La muy conocida comunidad de ciencia de datos Kaggle organiza competiciones basadas en conjuntos de datos abiertos aportados a la comunidad y que constituyen un recurso esencial para el aprendizaje basado en proyectos reales de quienes quieren adquirir habilidades relacionadas con los datos. Existen otras propuestas basadas en suscripciones como Dataquest o ProjectPro pero en todos los casos utilizan para los proyectos que proponen conjuntos de datos reales obtenidos de los múltiples repositorios de datos abiertos de carácter general o repositorios específicos de un área de conocimiento.
Los datos abiertos, al igual que en otras áreas, aún no han desarrollado todo su potencial como herramienta para la educación y la formación. Sin embargo como puede verse en el programa de la última edición de la OER Conference 2022, cada vez son más los ejemplos en los que los datos abiertos tienen un papel central en la enseñanza, las nuevas prácticas educativas y la creación de nuevos recursos educativos para todo tipo de materias, conceptos y habilidades.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El pasado 20 de octubre el concurso de datos abiertos organizado por la UE llegó a su fin tras varios meses de competición. La final de esta sexta edición del EU Datathon se celebró en Bruselas en el marco del Año Europeo de la Juventud y fue transmitido por streaming a nivel mundial.
Se trata de un certamen que brinda a los entusiastas de los datos abiertos y a los desarrolladores de aplicaciones de todo el mundo la oportunidad de demostrar el potencial de los datos abiertos, a la vez que sus ideas innovadoras obtienen visibilidad internacional y entran a competir por una parte del premio total, que asciende a 200.000 euros.
Los equipos finalistas fueron seleccionados previamente entre un total de 156 propuestas iniciales. Estas llegaron desde 38 países distintos, la mayor participación de la historia del concurso, para competir en cuatro categorías diferentes relacionadas con los retos a los que se enfrenta Europa hoy en día.
Antes de la final, los participantes seleccionados tuvieron la oportunidad de presentar en formato vídeo cada una de las propuestas que han ido desarrollando a partir de los datos abiertos procedentes de los catálogos europeos.
A continuación, desgranamos quiénes han sido los equipos ganadores de cada reto, en qué consiste la propuesta presentada y a cuánto asciende el premio.
Ganadores Reto "Pacto Verde Europeo"
El Pacto Verde Europeo (European Green Deal, en inglés) es el plan para impulsar una economía europea moderna, sostenible y competitiva. Los participantes que se decantaron por este reto tuvieron que desarrollar aplicaciones o servicios dirigidos a crear una Europa verde, capaz de impulsar el uso eficiente de los recursos.
1º premio: CROZ RenEUwable (Croacia)
La aplicación desarrollada por este equipo croata, "renEUwable", combina el análisis de datos medioambientales, sociales y económicos para ofrecer recomendaciones específicas y personales sobre el uso sostenible de la energía.
- Galardón: 25.000 €
2º premio: MyBioEUBuddy (Francia, Montenegro)
Este proyecto nace para ayudar a trabajadores del campo y gobiernos locales a encontrar regiones que cultiven productos orgánicos y puedan servir de ejemplo para construir una red de agricultura más sostenible.
- Galardón: 15.000 €
3º premio: Green Land Dashboard for Cities (Italia)
El bronce en esta categoría ha ido a parar a un proyecto italiano que pretende analizar y visualizar la evolución de las zonas verdes para ayudar a las ciudades, los gobiernos regionales y las organizaciones no gubernamentales a hacerlas más habitables y sostenibles.
- Galardón: 7.000 €
Ganadores Reto "Transparencia en la contratación pública"
La transparencia en la contratación pública ayuda a rastrear cómo se gasta el dinero, a combatir el fraude y a analizar las tendencias económicas y de mercado. Los participantes que eligieron este reto tuvieron que explorar la información disponible para desarrollar una aplicación que mejorase la transparencia.
1º premio: Free Software Foundation Europe e.V (Alemania)
Este equipo de desarrolladores tiene como objetivo poner al alcance de los usuarios los vínculos existentes entre el sector privado, las administraciones públicas, los usuarios y las licitaciones.
- Galardón: 25.000 €
2º premio: The AI-Team (Alemania)
Se trata de un proyecto que propone visualizar los datos del TED, el diario europeo de la contratación pública, en una base de datos gráfica y combinarlos con información sobre la propiedad y una lista de entidades sancionadas. Esto permitirá a los funcionarios públicos y a los competidores rastrear los importes y valores de los contratos adjudicados hasta llegar a los propietarios de las empresas.
- Galardón: 15.000 €
3º premio: EMMA (Francia)
Esta herramienta de prevención y detección temprana del fraude permite a las instituciones públicas, periodistas y a sociedad civil controlar automáticamente cómo se establece la relación entre empresas y administración a la hora de iniciarse un proceso de contratación pública.
- Galardón: 7.000 €
Ganadores Reto "Oportunidades de contratación pública en la UE para los jóvenes"
La contratación pública a menudo se percibe como un campo complejo, donde solo los especialistas se sienten cómodos para encontrar la información que necesitan. Así, los desarrolladores que participaron en este desafío tuvieron que diseñar, por ejemplo, aplicaciones destinadas a ayudar a los jóvenes a encontrar la información necesaria para aplicar a puestos de contratación pública.
1º premio: Hermix (Bélgica, Rumanía)
Se trata de una herramienta que desarrolla una metodología de marketing estratégico dirigido al sector B2G (bussines to goverment) para que, así, sea posible automatizar la creación y la monitorización de las estrategias de este sector.
- Galardón: 25.000 €
2º premio: YouthPOP (Grecia)
YouthPOP es una herramienta diseñada para democratizar las oportunidades de empleo y contratación pública para acercarlas a jóvenes trabajadores y empresarios. Para ello combinan datos históricos con tecnología de aprendizaje automático.
- Galardón: 15.000 €
3º premio: HasPopEU (Rumanía)
Esta propuesta aprovecha los datos abiertos de la contratación pública de la Unión Europea y las técnicas de machine learning para mejorar la comunicación de las competencias requeridas para acceder a este tipo de convocatorias laborales. La aplicación pone el foco en los jóvenes, los inmigrantes y las pymes.
- Galardón: 7.000 €
Ganadores Reto "Una Europa Adaptada a la Era Digital"
La UE aspira a una transformación digital que funcione para las personas y las empresas. Por ello, los participantes de este reto desarrollaron aplicaciones y servicios destinados a mejorar las competencias en materia de datos, conectividad o divulgación de los mismos, siempre tomando como base la Estrategia Europea de Datos.
1º premio: Lobium/Gavagai (Países Bajos, Suecia, Reino Unido)
Esta aplicación desarrollada a partir de técnicas de procesamiento del lenguaje natural nace con el objetivo de facilitar el trabajo de los periodistas de investigación, fomentando la transparencia y el rápido acceso a determinada información.
- Galardón: 25.000 €
2º premio: 100 Europeans (Grecia)
Se trata de una app interactiva que utiliza los datos abiertos para sensibilizar sobre los grandes retos de nuestro tiempo. De este modo y conscientes de lo difícil que es comunicar el impacto que estos retos tienen en la sociedad, ‘100 Europeans’ cambia la forma de trasladar el mensaje y personaliza los efectos del cambio climático, la contaminación o el sobrepeso en un total de cien personas. El objetivo de este proyecto es conseguir que la sociedad sea más consciente de estos retos al contarlos a través de historias de personas cercanas.
- Galardón: 15.000 €
3º premio: UNIOR NLP (Italia)
Aprovechando las técnicas de procesamiento del lenguaje natural y la recopilación de datos europeos, el grupo de investigación de lingüística computacional y procesamiento automático del lenguaje natural de la Universidad de Nápoles L'Orientale ha desarrollado un asistente personal llamado Maggie que guía a los usuarios para que exploren los contenidos culturales de toda Europa, respondiendo a sus preguntas y ofreciendo sugerencias personalizadas.
- Galardón: 7.000 €
Por último, el Premio del Público de esta edición de 2022 ha recaído también en CROZ RenEUwable, el mismo equipo que se llevó el primer premio del reto dedicado a fomentar el compromiso por el Pacto Verde europeo.

Al igual que sucedió con las ediciones anteriores, el EU Datathon es una competición organizada por la Oficina de Publicaciones de la Unión Europea en colaboración con la Estrategia de Datos Europea. Así, la edición recién clausurada de 2022 ha logrado activar el apoyo de una veintena de colaboradores y que representan a las partes interesadas en datos abiertos, dentro y fuera de las instituciones europeas.
Noticia
La IV edición del Desafío Aporta, cuyo lema ha girado en torno a ‘El valor del dato para la salud y el bienestar de los ciudadanos’, ya tiene a sus tres ganadores. La competición, impulsada por Red.es en colaboración con la Secretaría de Estado de Digitalización e Inteligencia Artificial, arrancó en noviembre de 2021 con un concurso de ideas y continuó a principios de este verano con una selección de diez propuestas finalistas.
Al igual que sucedió en las tres ediciones anteriores, los candidatos elegidos dispusieron de un plazo de tres meses para transformar sus ideas en un prototipo que, posteriormente, debían presentar de forma presencial en la gala final.
En un contexto postpandémico, donde la salud juega un papel cada vez más importante, la temática de la competición buscaba identificar, reconocer y premiar las ideas destinadas a mejorar la eficiencia de este sector con soluciones basadas en el uso de los datos abiertos.
El pasado 18 de octubre, los diez finalistas acudieron a la sede de Red.es para presentar sus propuestas frente a un jurado formado por representantes de las Administraciones Públicas, organismos ligados a la economía digital y el ámbito de la universidad y las comunidades de datos. En tan solo doce minutos, tuvieron que resumir la finalidad del proyecto o servicio propuesto, explicar cómo había sido el proceso de desarrollo, qué datos habían utilizado y detenerse en aspectos como la viabilidad económica o la trazabilidad del mismo.
Una decena de proyectos innovadores para mejorar el sector salud
Las diez propuestas presentadas frente al jurado hicieron gala de una alto nivel de innovación, creatividad, rigor y vocación pública. Así mismo, fueron capaces de evidenciar que es posible mejorar la calidad de vida de los ciudadanos creando iniciativas que monitoricen la calidad del aire, construyan soluciones frente al cambio climático o den una respuesta más ágil a un problema de salud repentino, entre otros ejemplos expuestos.
Por todo ello, no es de extrañar que el jurado lo haya tenido complicado a la hora de elegir a los tres vencedores de esta cuarta edición. Finalmente, ha sido la iniciativa HelpVoice la que se ha alzado con el primer premio de 5.000€, la Encuesta de Morbilidad Hospitalaria se ha llevado los 4.000€ vinculados a la segunda posición y RIAN, Recomendador Inteligente de Actividades y Nutrición, ha cerrado el ranking con el tercer puesto y 3.000 euros en calidad de galardón.

Primer premio: HelpVoice!
- Equipo: Data Express, integrado por Sandra García, Antonio Ríos y Alberto Berenguer.
HelpVoice! es un servicio cuyo objetivo es ayudar a las personas mayores utilizando técnicas de reconocimiento de voz basadas en aprendizaje automático. Así, ante una situación de emergencia, el usuario solo tendrá que hacer clic en un dispositivo que puede ser un botón de emergencia, un teléfono móvil o herramientas de domótica y comentar sus síntomas. El sistema enviará un informe con la transcripción realizada y predicciones al hospital más cercano, agilizando la respuesta de los sanitarios.
En paralelo, HelpVoice! también recomendará al paciente qué hacer mientras espera a los servicios de emergencia. Respecto al uso de los datos, el equipo Data Express ha utilizado información geográfica abierta como el mapa de hospitales de España y emplea datos de reconocimiento del habla y sentimientos en el texto.
Segundo premio: Encuesta de Morbilidad Hospitalaria
- Equipo: Marc Coca Moreno
Se trata de un entorno web basado en las herramientas MERN, Python y Pentaho para el análisis y la visualización interactiva de los microdatos de la Encuesta de Morbilidad Hospitalaria. Todo el proyecto se ha desarrollado con herramientas open source y gratuitas y, tanto el código como el producto final, serán accesibles de forma abierta.
Para ser exactos, ofrece 3 grandes análisis con el fin de mejorar la planificación sanitaria:
- Descriptivos: recuento de las altas hospitalarias y serie temporal.
- KPI: tasas e indicadores estandarizados para la comparación y el benchmarking de las provincias y comunidades.
- Flujos: recuento y análisis de las altas de una región hospitalaria y procedencia del paciente.
Todos los datos pueden filtrarse según las variables del juego de datos (edad, sexo, diagnósticos, circunstancia de ingreso y alta, etc.)
En este caso, además de los microdatos de la Encuesta de Morbilidad Hospitalaria del INE, también se han integrado estadísticas del Padrón Continuo (también del INE), datos de los catálogos de diagnósticos CIE10 del Ministerio de Sanidad y de los catálogos e indicadores de Agency for Healthcare Research and Quality (AHRQ) y de las Comunidades Autónomas, como Cataluña: catálogos y herramientas de estratificación.
Puedes ver el resultado de este trabajo aquí.
Tercer premio: RIAN, Recomendador Inteligente de Actividades y Nutrición
- Equipo: RIAN Open Data Team, integrado por Jesús Noguera y Raúl Micharet.
Este proyecto surge para fomentar los hábitos saludables y combatir el sobrepeso, la obesidad, el sedentarismo y la mala nutrición entre niños y adolescentes. Se trata de una aplicación diseñada para dispositivos móviles y que utiliza técnicas de gamificación, así como realidad aumentada y algoritmos de inteligencia artificial para realizar recomendaciones.
Los usuarios tienen que resolver retos personalizados, de forma individual o colectiva, ligados con aspectos nutricionales y actividades físicas, como yincanas o juegos en espacios verdes públicos.
En relación al uso de los datos abiertos, el piloto utiliza datos relativos a zonas verdes, puntos de interés, vías verdes, actividades y eventos pertenecientes a las ciudades de Málaga, Madrid, Zaragoza y Barcelona. Además, estos datos se combinan con recomendaciones nutricionales (datos de alimentos y valores nutricionales y productos alimentarios con marca) y datos destinados al reconocimiento de alimentos por imágenes de Tensorflow o Kaggle, entre otros.
Alberto Martínez Lacambra, Director General de Red.es entrega los galardones y anuncia la nueva edición
Los tres ganadores han sido anunciados por Alberto Martínez Lacambra, Director General de Red.es, en un acto que ha tenido lugar en la sede de Red.es. el 27 de octubre. El acto ha contado con la participación de varios miembros del jurado, que han podido conversar con los tres equipos ganadores.

Martínez Lacambra también ha anunciado que desde Red.es ya se está trabajando para dar forma al V Desafío Aporta, que girará en torno al valor del dato para la mejora del bien común, justicia, igualdad y equidad.
Un año más, desde la Iniciativa Aporta queremos dar la enhorabuena a los tres ganadores, así como agradecer el trabajo y el talento de todos los participantes que decidieron invertir su tiempo y conocimiento en pensar y desarrollar propuestas para la cuarta edición del Desafío Aporta.
Blog
El pasado 24 de febrero Europa se adentraba en un escenario que ni siquiera los datos hubiesen podido predecir: Rusia invadía Ucrania, desatando la primera guerra en suelo europeo de lo que llevamos de siglo XXI.
Casi cinco meses después, a fecha del 26 de septiembre, Naciones Unidas hacía públicas sus cifras oficiales: 4.889 fallecidos y 6.263 heridos. Según los datos oficiales de la ONU, mes tras mes, la realidad de los damnificados ucranianos que arrojaban los datos quedaba de la siguiente forma:
| Fecha | Fallecidos | Heridos |
|---|---|---|
| 24-28 febrero | 336 | 461 |
| Marzo | 3028 | 2384 |
| Abril | 660 | 1253 |
| Mayo | 453 | 1012 |
| Junio | 361 | 1029 |
| 1-3 julio | 51 | 124 |
Los datos extraídos por la misión que el Alto Comisionado de las Naciones Unidas para los Derechos Humanos realiza en Ucrania desde que en 2014 Rusia invadiese Crimea cifran en más de 7 millones de personas, el total de civiles desplazados como consecuencia del conflicto.
Sin embargo, al igual que sucede en otros ámbitos, los datos sirven no solo para elaborar soluciones, sino también para conocer en profundidad aspectos de la realidad que de otra forma no sería posible. En el caso de la guerra de Ucrania es precisamente la captación, monitorización y análisis de datos sobre el territorio lo que permite que organismos como Naciones Unidas puedan sacar sus propias conclusiones.
Con el objetivo de visibilizar cómo los datos pueden utilizarse para conseguir la paz, a continuación analizaremos cuál es el papel que estos desempeñan en relación con las siguientes labores:
Predicción
En este ámbito, los datos se utilizan para tratar de adelantarse a situaciones y planificar una respuesta adecuada al riesgo previsto. Así, si antes del estallido de la guerra se utilizaban los datos para evaluar el riesgo de un futuro conflicto, ahora se emplean para establecer un control y prever la escalada del mismo.
Por ejemplo, las imágenes satélite que arrojan aplicaciones tipo Google Maps han permitido monitorizar el avance de las tropas rusas. Igualmente, visualizadores como Subnational Surge Tracker identifican los picos de violencia registrados en distintos niveles administrativos: estados, provincias o municipios.
Información
Tan importante es conocer los datos para prevenir la violencia, como utilizar los mismos para limitar la desinformación y comunicar los hechos de forma objetiva, veraz y acorde a las cifras oficiales. Para conseguirlo, han comenzado a utilizarse aplicaciones de fact cheking, capaces de responder con datos oficiales a las noticias falsas.
Entre ellas destaca Newsguard, una entidad de verificación que ha elaborado un rastreador que reúne todos los sitios web que comparten desinformación sobre el conflicto, poniendo especial énfasis en las narrativas falsas más populares que circulan por la red. Incluso, cataloga este tipo de contenido en función del idioma en el que se promueve.
Daños materiales
Los datos también se pueden utilizar para localizar los daños materiales y rastrear la aparición de otros nuevos. A lo largo de estos meses, la ofensiva rusa ha dañado la red de infraestructura pública ucraniana, dejando inutilizadas carreteras, puentes, suministros de agua y electricidad e, incluso, hospitales.
Conocer a través de los datos esta realidad es muy útil de cara a organizar una respuesta dirigida a la reconstrucción de estas zonas y al envío de asistencia humanitaria para los civiles que se han quedado desprovistos de servicios.
En este sentido, destacamos los siguientes casos de uso:
- El algoritmo de aprendizaje automático del Programa de las Naciones Unidas para el Desarrollo (PNUD) ha sido desarrollado y mejorado para identificar y clasificar la infraestructura dañada por la guerra.
- De forma paralela, la organización HALO Trust utiliza minería de medios sociales capaz de captar información de las redes sociales, imágenes vía satélite e, incluso, datos geográficos que ayudan a identificar áreas con "restos explosivos". Gracias a este hallazgo las organizaciones desplegadas por el terreno ucraniano, pueden moverse con mayor seguridad para organizar una respuesta humanitaria coordinada.
- La información lumínica captada por los satélites de la NASA sirve también para construir una base de datos que ayude a identificar cuáles son las áreas de conflicto activo en Ucrania. Así, al igual que en los ejemplos anteriores, estos datos sirven para realizar un seguimiento y poder enviar ayuda a los puntos donde esta sea más necesaria.
Violación y abuso de derechos humanos
Lamentablemente, en este tipo de conflictos, la violación de los derechos humanos de la población civil está a la orden del día. De hecho, según la experiencia sobre el terreno y la información recopilada por el Alto Comisionado de las Naciones Unidas para los Derechos Humanos, se han documentado violaciones de este tipo durante todo el periodo de guerra en Ucrania.
Así y con el objetivo de comprender qué está sucediendo con los civiles ucranianos, los funcionarios de vigilancia y derechos humanos recopilan datos, información pública y relatos en primera persona de la guerra en Ucrania. Con todo ello, desarrollan un mapa-mosaico que facilita la toma de decisiones y la búsqueda de soluciones justas para la población.
Otro trabajo muy interesante y desarrollado con datos abiertos es el realizado por Conflict Observatory. Gracias a la colaboración de analistas y desarrolladores, y al empleo de información geoespacial e inteligencia artificial, han podido descubrirse y mapearse crímenes de guerra que de otro modo podrían quedar más invisibilizados.
Movimientos migratorios
Desde el estallido de la guerra el pasado mes de febrero, han escapado de la guerra y, por ende, de su propio país, más de 7 millones de ucranianos. Al igual que en los casos anteriores, los datos sobre los flujos migratorios se pueden utilizar para reforzar los esfuerzos humanitarios que demandan los refugiados y los desplazados internos.
Algunas de las iniciativas en las que los datos abiertos contribuyen son las siguientes:
La Matriz de Seguimiento de Desplazamiento es un proyecto desarrollado por la Organización Internacional para las Migraciones y cuya finalidad ha sido obtener datos sobre los flujos migratorios dentro de Ucrania. Gracias a la información facilitada por aproximadamente 2.000 encuestados a través de entrevistas telefónicas, se creó una base de datos que se ha ido utilizando para garantizar una distribución de las acciones humanitarias eficaz en función de las necesidades de cada zona del país.
Respuesta humanitaria
De forma similar al análisis realizado para controlar los movimientos migratorios, los datos recopilados sobre el conflicto también sirven para diseñar acciones de respuesta humanitaria y realizar un seguimiento de la ayuda proporcionada.
En esta línea, uno de los agentes más activos durante los últimos meses ha sido el Fondo de Población de las Naciones Unidas que creó un conjunto de datos que recoge proyecciones actualizadas por género, edad y región ucraniana. Es decir, gracias a este mapeo actualizado de la población ucraniana es mucho más sencillo pensar en cuáles son las necesidades que tiene cada zona en términos de suministros médicos, alimentos o, incluso, apoyo de salud mental.
Otras de las iniciativas que también está prestando apoyo en este ámbito es el Explorador de Datos de Ucrania, un proyecto desarrollado sobre código abierto en la plataforma Intercambio de Datos Humanitarios (HDX) que proporciona información obtenida de forma colaborativa sobre refugiados, víctimas y necesidades de financiación para los esfuerzos humanitarios.
Por último, los datos recopilados y, posteriormente analizados por Premise, visibilizan aquellas zonas que presentan déficit de alimentos y combustible. Monitorizar esta información es realmente útil de cara a localizar las zonas del país con menos recursos para las personas que han migrado internamente y, a su vez, para señalar a las organizaciones humanitarias cuáles son las áreas donde se está demandando más asistencia.
La innovación y el desarrollo de herramientas capaces de recopilar datos y extraer conclusiones sobre los mismos es, sin duda, un gran paso que ayuda a reducir el impacto de los conflictos armados. Gracias a este tipo de previsiones y análisis de datos es posible responder de forma rápida y coordinada a las necesidades de la sociedad civil que se encuentra en las zonas más afectadas, sin dejar de lado tampoco a los refugiados que se desplazan a miles de kilómetros de sus casas.
Estamos ante una crisis humanitaria que ha generado más de 12,6 millones de movimientos transfronterizos. En concreto, nuestro país ha atendido a más de 145.600 personas desde el inicio de la invasión y se han concedido más de 142.190 solicitudes de protección temporal, el 35% de ellas a menores. Tales cifras convierten a España en el quinto Estado Miembro con mayor número de resoluciones favorables de protección temporal. Asimismo, más de 63.500 personas desplazadas han sido dadas de alta en el Sistema Nacional de Salud y con el inicio del curso académico, hay 30. 919 estudiantes ucranianos desplazados escolarizados, de los que 28.060 son menores.
Contenido elaborado por el equipo de datos.gob.es.
Evento
¿Aceptas el reto de transformar Bizkaia a partir de sus datos abiertos? Así se presenta el “Datathon Open Data Bizkaia”, una competición de desarrollo colaborativo organizada por Lantik y la Diputación Foral de Bizkaia.
Los participantes tendrán que crear el mockup de una aplicación que ayude a resolver problemas que afecten la ciudadanía de Bizkaia. Para ello, deberán utilizar al menos un conjunto de datos entre todos aquellos disponibles en el portal Open Data Bizkaia. Estos datasets podrán ser combinados con datos procedentes de otras fuentes.
¿Cómo se desarrolla la competición?
La competición de desarrollará en dos fases:
- Primera fase. Los equipos participantes deberán entregar un documento con la propuesta en formato PDF. Entre otra información, dicha propuesta incluirá una breve descripción de la solución, sus funcionalidades y los conjuntos de datos utilizados.
- Segunda fase. Un jurado evaluará todas las solicitudes recibidas y que sean válidas en tiempo y forma. A continuación, se seleccionarán siete propuestas finalistas. Los equipos preseleccionados tendrán que realizar un mockup y un video promocional de máximo 2 minutos de duración, donde se presenten los integrantes del equipo y se describan las características más destacadas de la solución.
Estas fases se desarrollarán en base al siguiente calendario:
- Del 19 de septiembre al 19 de octubre. Abierto el plazo de inscripción para presentar las propuestas en pdf.
- 26 de octubre. Anuncio de los equipos preseleccionados.
- 14 de noviembre. Finaliza el plazo para entregar el mockup y el vídeo.
- 18 de noviembre. Celebración de la final en Bilbao, aunque también se podrá acudir, opcionalmente, de forma online. Se presentarán los videos y se seleccionarán los equipos ganadores.
¿Quiénes pueden participar?
La competición está dirigida a cualquier persona mayor de 16 años, independientemente de su nacionalidad, siempre y cuando disponga de DNI/NIF/NIE, pasaporte u otro documento público en vigor que acredite la identidad y edad del participante.
Se puede participar de manera individual o a través equipos de máximo seis personas.
¿En qué consisten los premios?
Entre los 7 finalistas se elegirán dos ganadores, que recibirán la siguiente cuantía económica:
- Primer premio: 2.500 euros.
- Segundo premio: 1.500 euros
Además, el resto de equipos finalistas recibirá 500 euros.
Para llevar a cabo la valoración, el jurado tomará como referencia una serie de criterios detallados en las bases de la competición: relevancia, reutilización de datos abiertos y aptitud para el propósito.
¿Cómo puedo participar?
Es necesario inscribirse a través del formulario que aparece en la web. Tras la inscripción, el equipo recibirá un correo electrónico con las indicaciones para presentar la propuesta.
Los participantes deberán subir su propuesta a un sharepoint habilitado para ello. En la web pueden encontrar un documento modelo que puede servir como referencia.
La propuesta deberá presentarse antes del 19 de octubre de 2022 a las 12h.
Descubre más sobre Open Data Bizkaia
Open Data Bizkaia facilita a la ciudadanía y los agentes reutilizadores el acceso a la información pública que gestiona la Diputación Foral de Bizkaia. Actualmente hay disponibles más de 900 conjuntos de datos.
En su web, además, ofrecen recursos para reutilizadores, una API, buenas prácticas y ejemplos de aplicaciones elaboradas con datasets del portal que pueden servir para inspirar a los participantes de esta competición.
Puedes conocer más sobre la estrategia Open Data de Bizkaia en este artículo.
Blog
Tras varios meses de pruebas y entrenamientos de distinto tipo, el primer sistema masivo de Inteligencia Artificial de la lengua española es capaz de generar sus propios textos y resumir otros ya existentes. MarIA es un proyecto que ha sido impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación, a partir de los archivos web de la Biblioteca Nacional de España (BNE).
Hablamos de un avance muy importante en este ámbito, ya que se trata del primer sistema de inteligencia artificial experto en comprender y escribir en lengua española. Enmarcada dentro del Plan de Tecnologías del Lenguaje, esta herramienta pretende contribuir al desarrollo de una economía digital en español, gracias al potencial que los desarrolladores pueden encontrar en ella.
El reto de crear los asistentes del lenguaje del futuro
Los modelos de lenguaje al estilo de MarIA son la piedra angular sobre la que se sustenta el desarrollo del procesamiento del lenguaje natural, la traducción automática o los sistemas conversacionales, tan necesarios para comprender y replicar de forma automática una lengua. MarIA es un sistema de inteligencia artificial formado por redes neuronales profundas que han sido entrenadas para adquirir una comprensión de la lengua, de su léxico y de sus mecanismos para expresar el significado y escribir a nivel experto.
Gracias a este trabajo previo, los desarrolladores pueden crear herramientas relacionadas con el lenguaje y capaces de clasificar documentos, realizar correcciones o elaborar herramientas de traducción.
La primera versión de MarIA fue elaborada con RoBERTa, una tecnología que crea modelos del lenguaje del tipo “codificadores”, capaces de generar una interpretación que puede servir para categorizar documentos, encontrar similitudes semánticas en diferentes textos o detectar los sentimientos que se expresan en ellos.
Así, la última versión de MarIA ha sido desarrollada con GPT-2, una tecnología más avanzada que crea modelos generativos decodificadores y añade prestaciones al sistema. Gracias a estos modelos decodificadores, la última versión de MarIA es capaz de generar textos nuevos a partir de un ejemplo previo, lo que resulta muy útil a la hora de elaborar resúmenes, simplificar grandes cantidades de información, generar preguntas y respuestas e, incluso, mantener un diálogo.
Avances como los anteriores convierten a MarIA en una herramienta que, con entrenamientos adaptados a tareas específicas, puede ser de gran utilidad para desarrolladores, empresas y administraciones públicas. En esta línea, modelos similares que se han desarrollado en inglés son utilizados para generar sugerencias de texto en aplicaciones de escritura, resumir contratos o buscar informaciones concretas dentro de grandes bases de datos de texto para relacionarlas posteriormente con otras informaciones relevantes.
En otras palabras, además de redactar textos a partir de titulares o palabras, MarIA puede comprender no solo conceptos abstractos, sino también el contexto de los mismos.
Más de 135 mil millones de palabras al servicio de la inteligencia artificial
Para ser exactos, MarIA se ha entrenado con 135.733.450.668 de palabras procedentes de millones de páginas web que recolecta la Biblioteca Nacional y que ocupan un total de 570 Gigabytes de información. Para estos mismos entrenamientos, se ha utilizado el superordenador MareNostrum del Centro Nacional de Supercomputación de Barcelona y ha sido necesaria una potencia de cálculo de 9,7 trillones de operaciones (969 exaflops).
Teniendo en cuenta que uno de los primeros pasos para diseñar un modelo del lenguaje pasa por construir un corpus de palabras y frases que sirva como base de datos para entrenar al propio sistema, en el caso de MarIA, fue necesario realizar un cribado para eliminar todos los fragmentos de texto que no fuesen “lenguaje bien formado” (elementos numéricos, gráficos, oraciones que no terminan, codificaciones erróneas, etc.) y así entrenar correctamente a la IA.
Debido al volumen de información que maneja, MarIA se sitúa ya como el tercer sistema de inteligencia artificial experto en comprender y escribir con mayor número de modelos masivos de acceso abierto. Por delante solo están los modelos del lenguaje elaborados para el inglés y el mandarín. Esto ha sido posible principalmente por dos razones. Por un lado, debido al elevado nivel de digitalización en el que se encuentra el patrimonio de la Biblioteca Nacional y, por el otro, gracias a la existencia de un Centro de Supercomputación Nacional que cuenta con superordenadores como el MareNostrum 4.
El papel de los conjuntos de datos de la BNE
Desde que en 2014 lanzase su propio portal de datos abiertos (datos.bne.es), la BNE ha apostado por acercar los datos que están a su disposición y bajo su custodia: datos de las obras que conserva, pero también de autores, vocabularios controlados de materias y términos geográficos, entre otros.
En los últimos años, se ha desarrollado también la plataforma educativa BNEscolar, que busca ofrecer contenidos digitales del fondo documental de la Biblioteca Digital Hispánica y que pueden resultar de interés para la comunidad educativa.
Así mismo y para cumplir con los estándares internacionales de descripción e interoperabilidad, los datos de la BNE están identificados mediante URIs y modelos conceptuales enlazados, a través de tecnologías semánticas y ofrecidos en formatos abiertos y reutilizables. Además, cuentan con un alto nivel de normalización.
Próximos pasos
Así y con el objetivo de perfeccionar y ampliar las posibilidades de uso de MarIA, se pretende que la versión actual dé lugar a otras especializadas en áreas de conocimiento más concretas. Teniendo en cuenta que se trata de un sistema de inteligencia artificial dedicado a comprender y generar texto, se torna fundamental que este sea capaz de desenvolverse con soltura ante léxicos y conjuntos de información especializada.
Para ello, el PlanTL continuará expandiendo MarIA para adaptarse a los nuevos desarrollos tecnológicos en procesamiento del lenguaje natural (modelos más complejos que el GPT-2 ahora implementado, entrenados con mayor cantidad de datos) y se buscará la forma de crear espacios de trabajo para facilitar el uso de MarIA por compañías y grupos de investigación.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Los portales de datos abiertos están experimentando un importante crecimiento en el número de conjuntos de datos que están siendo publicados en la categoría de transporte y movilidad. Sirva como ejemplo el portal de datos abiertos de la UE que ya cuenta con casi 48.000 conjuntos de datos en la categoría de transporte o el propio portal español datos.gob.es, que registra en torno a 2.000, si incluimos los que están dentro de la categoría de sector público. Una de las razones principales del crecimiento en la publicación de los datos relacionados con el transporte es la existencia de tres directivas que tienen entre sus objetivos maximizar la reutilización de conjuntos de datos en el área. La directiva PSI de reutilización de información del sector público en combinación con las directivas INSPIRE sobre infraestructura de información espacial e ITS sobre implantación de los sistemas de transporte inteligentes, junto con otros desarrollos legislativos, hacen que cada vez resulte más complicado justificar que los datos de transporte y movilidad permanezcan cerrados.
En este sentido, en España, la ley 37/2007 en su redacción de noviembre de 2021, añade la obligación de publicar datos abiertos a las sociedades mercantiles pertenecientes al sector público institucional que actúen como compañías aéreas. Con ello se consigue dar un paso más allá respecto a las más frecuentes obligaciones con los datos de los servicios públicos de transporte de viajeros por ferrocarril y carretera.
Además, los datos abiertos están en el corazón de las estrategias de movilidad inteligente, conectada y respetuosa con el medio ambiente, tanto en el caso de la estrategia española “es.movilidad”, como en el caso de la estrategia de movilidad sostenible propuesta por la comisión europea. En ambos casos los datos abiertos se han introducido como uno de los vectores de innovación clave en la transformación digital del sector para contribuir a la consecución de los objetivos de mejora en la calidad de vida de los ciudadanos y de protección al medio ambiente.
Sin embargo, se suele hablar mucho menos de la importancia y necesidad de los datos abiertos durante la fase de investigación, que después conduce a las innovaciones que todos disfrutamos. Y sin esta etapa en la que los investigadores trabajan para adquirir un mejor conocimiento del funcionamiento de las dinámicas de transporte y movilidad de las que todos somos parte, y en la que los datos abiertos tienen un papel fundamental, no sería posible obtener innovaciones relevantes o políticas públicas bien informadas. En este sentido vamos a revisar dos iniciativas muy relevantes en las que se están realizando esfuerzos coordinados plurinacionales en el ámbito de la investigación en movilidad y transporte.
El sistema de información y seguimiento de la investigación y la innovación en el transporte
A nivel europeo, la UE también apoya con firmeza la investigación e innovación en transporte, consciente de que necesita adaptarse a realidades globales como el cambio climático y la digitalización. La agenda estratégica de investigación e innovación en el transporte (STRIA) describe lo que está haciendo la UE para acelerar la investigación y la innovación necesarias para cambiar radicalmente el transporte apoyando prioridades como la electrificación, el transporte conectado y automatizado o la movilidad inteligente.
En este sentido, el sistema de información y seguimiento de la investigación y la innovación en el transporte (TRIMIS) es la herramienta que la Comisión Europea mantiene para proporcionar información de acceso abierto sobre la investigación y la innovación (I+i) en el transporte y que se lanzó con la misión de apoyar la formulación de las políticas públicas en el ámbito del transporte y la movilidad.
TRIMIS mantiene actualizado un cuadro de mando con el que visualizar los datos sobre investigación e innovación en transporte y ofrece una descripción general y datos detallados sobre la financiación y las organizaciones involucradas en estas investigaciones. La información puede filtrarse por las siete prioridades de STRIA y también incluye datos sobre la capacidad de innovación del sector del transporte.
Si nos fijamos en la distribución geográfica de los fondos de investigación que proporciona TRIMIS, vemos que España aparece en quinto lugar, muy lejos de Alemania y Francia. Los sistemas de transporte en los que se está haciendo un mayor esfuerzo son el transporte por carretera y aéreo, beneficiarios de más de la mitad del esfuerzo total.
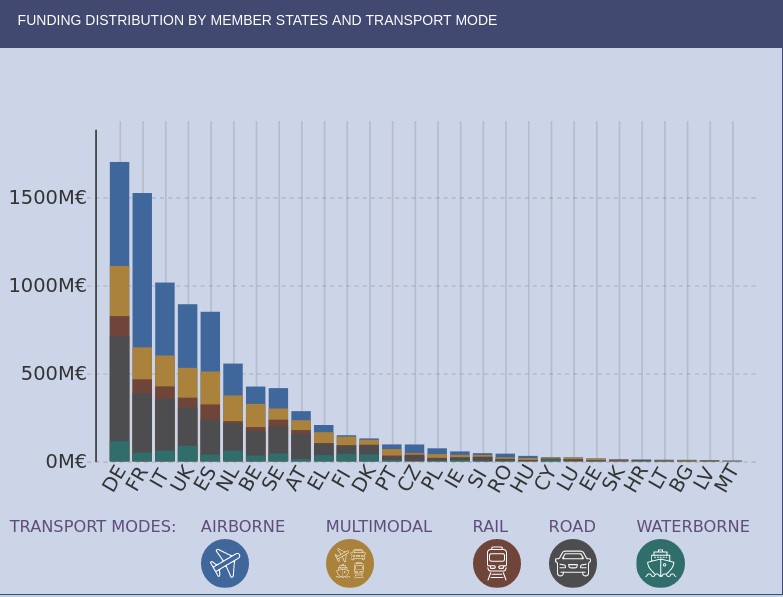
Sin embargo, encontramos que en el área estratégica de Servicios y movilidad inteligente (SMO), que se evalúan en términos de su contribución a la sostenibilidad general del sistema de energía y transporte, en España se está liderando el esfuerzo investigador al mismo nivel que Alemania. Cabe destacar además que el esfuerzo que se está realizando en España en lo que se refiere al transporte multimodal es superior al de otros países.
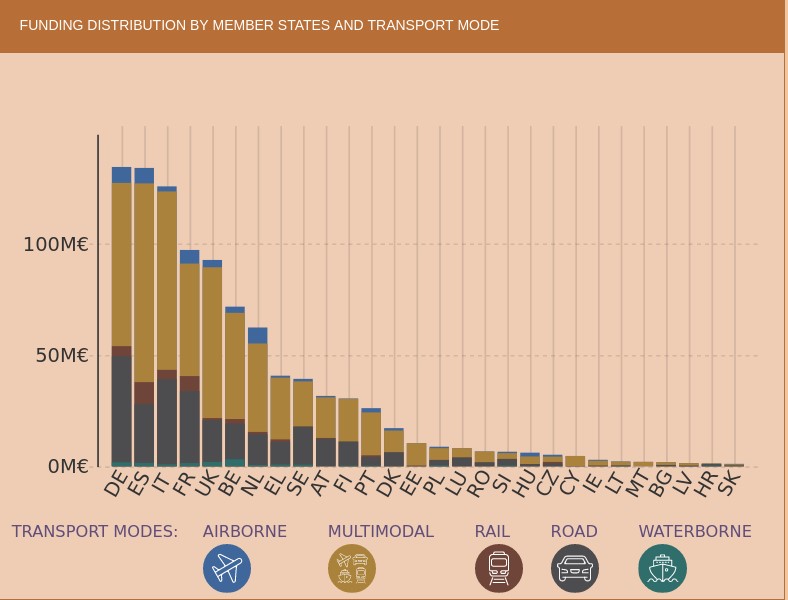
Como ejemplo del esfuerzo investigador que se está realizando en España tenemos el conjunto de datos piloto para implementar capacidades semánticas sobre la información de incidencias de tráfico relacionadas con la seguridad en la red estatal de carreteras españolas, excepto País Vasco y Cataluña, que publica la Dirección General de Tráfico y que utiliza una ontología para representar incidentes de tráfico que ha desarrollado a Universidad de Valencia.
El área de los sistemas y servicios de movilidad inteligente pretende contribuir a la descarbonización del sector del transporte europeo y entre sus principales prioridades están el desarrollo de sistemas que conecten los servicios de movilidad urbana y rural y promuevan el cambio modal, el uso sostenible del suelo, la suficiencia en la demanda de viajes y los modos de viaje activos y ligeros; el desarrollo de soluciones de gestión de datos de movilidad e infraestructura digital pública de acceso justo o la implantación de la intermodalidad, la interoperabilidad y el acoplamiento sectorial.
La iniciativa 100 preguntas en el ámbito de la movilidad
La Iniciativa de 100 Preguntas, lanzada por The Govlab en colaboración con Schmidt Futures, pretende identificar las 100 preguntas más importantes del mundo en una serie de dominios críticos para el futuro de la humanidad, como son el género, la migración o la calidad del aire.
Uno de estos dominios está dedicado precisamente al transporte y la movilidad urbana y tiene como objetivo identificar preguntas en las cuales los datos y la ciencia de datos tienen un gran potencial para obtener respuestas que contribuyan a impulsar importantes avances en conocimiento e innovación sobre los dilemas públicos más importantes y los problemas más graves que tienen que resolverse.
De acuerdo con la metodología utilizada, la iniciativa finalizó el 28 de julio la cuarta etapa en la que el público en general realizó la votación con la que se decidieron cuáles serían las 10 preguntas finales que deben ser abordadas. Las 48 preguntas iniciales fueron propuestas por un grupo de expertos en movilidad y científicos de datos por lo que están concebidas para que puedan ser respondidas con datos y pensadas para que, si se consiguen resolver, puedan tener un impacto transformador para las políticas de movilidad urbana.
En la próxima etapa, el grupo de trabajo de GovLab identificará cuáles son los conjuntos de datos que podrían proporcionar respuestas a las preguntas seleccionadas, algunas tan complejas como saber “¿dónde quieren ir los viajeros pero realmente no pueden y cuáles son las razones por las que no pueden alcanzar su destino con facilidad?” o “¿cómo podemos incentivar a las personas a realizar viajes en modos sostenibles, como caminar, andar en bicicleta y/o transporte público, en lugar de vehículos de motor personales?”
Otras preguntas están relacionadas con las dificultades encontradas por los reutilizadores y que han sido puestas de manifiesto con frecuencia en artículos de investigación como “Open Transport Data for maximising reuse in multimodal route”: “¿Cómo se pueden compartir los datos de transporte/movilidad recopilados con dispositivos como teléfonos inteligentes, y ponerlos a disposición de los investigadores, planificadores urbanos y legisladores?"
En algunos casos es previsible que los conjuntos de datos necesarios para responder las preguntas no estén disponibles o pertenezcan a compañías privadas por lo que también se intentará definir cuáles son los nuevos conjuntos de datos que deben generarse para ayudar a llenar los vacíos identificados. El objetivo final es proporcionar una definición clara de los requisitos de datos para responder a las preguntas y facilitar la formación de colaboraciones de datos que contribuyan a avanzar en la obtención de estas respuestas[2].
En definitiva, los cambios en el modo en que utilizamos el transporte y los estilos de vida, como el uso de teléfonos inteligentes, aplicaciones web móviles y redes sociales, junto con la tendencia a alquilar, en lugar de poseer un medio de transporte en particular, han abierto nuevos caminos hacia la movilidad sostenible y unas enormes posibilidades en el análisis e investigación de los datos capturados por estas aplicaciones.
Por ello las iniciativas globales para coordinar los esfuerzos de investigación son esenciales ya que las ciudades necesitan bases de conocimiento sólidas a las que recurrir para que las decisiones políticas sobre desarrollo urbano, transporte limpio, igualdad de acceso a oportunidades económicas y calidad de vida en los centros urbanos sean efectivas. No debemos olvidar que todo este conocimiento es además clave para que puedan establecerse adecuadamente prioridades y, de este modo, podamos aprovechar al máximo los escasos recursos públicos de los que habitualmente disponemos para afrontar los desafíos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.