Blog
La combinación e integración de los datos abiertos con la inteligencia artificial (IA) es un área de trabajo que cuenta con el potencial de lograr avances significativos en múltiples campos y conseguir mejoras en varios aspectos de nuestras vidas. El área de sinergia que más frecuentemente se menciona suele ser la utilización de los datos abiertos como datos de entrada para el entrenamiento de los algoritmos utilizados por la IA, ya que estos sistemas necesitan devorar grandes cantidades de datos para alimentar su funcionamiento. Esto convierte a los datos abiertos en un elemento ya de por sí esencial para el desarrollo de la IA, pero su utilización como datos de entrada conlleva además otras múltiples ventajas como una mayor igualdad de acceso a la tecnología o una mejora de la transparencia sobre el funcionamiento de los algoritmos.
Así pues, hoy en día podemos encontrar datos abiertos alimentando algoritmos para la aplicación de la IA en áreas tan variadas como la prevención de crímenes, el desarrollo del transporte público, la igualdad de género, la protección del medioambiente, la mejora de la sanidad o la búsqueda de ciudades más amigables y habitables. Todos ellos son ya objetivos más fácilmente alcanzables gracias a la adecuada combinación de ambas tendencias tecnológicas.
Sin embargo, como veremos a continuación, puestos a imaginar el futuro conjunto de los datos abiertos y la IA, el uso combinado de ambos conceptos puede dar lugar también a muchas otras mejoras en la forma en que trabajamos actualmente con los datos abiertos y a lo largo de todo el ciclo de vida de los mismos. Repasamos, paso a paso, cómo la inteligencia artificial puede enriquecer un proyecto con datos abiertos.
Utilizar la IA para descubrir fuentes y preparar conjuntos de datos
La inteligencia artificial puede ayudar ya desde los primeros pasos de nuestros proyectos de datos mediante el apoyo en la fase de descubrimiento e integración de diversas fuentes de datos, facilitando a las organizaciones encontrar y usar datos abiertos de relevancia para sus aplicaciones. Además, las tendencias futuras pueden incluir el desarrollo de estándares comunes de datos, marcos de metadatos y APIs para facilitar la integración de los datos abiertos con tecnologías de IA, lo que ampliaría aún más las posibilidades de automatizar la combinación de datos de diversas fuentes.
Además de la automatización en la búsqueda guiada de fuentes de datos, los procesos automáticos de la inteligencia artificial pueden ser de utilidad, al menos en parte, en el proceso de limpieza y preparación de los datos. De esta forma se puede mejorar la calidad de los datos abiertos al identificar y corregir los errores, rellenar los vacíos existentes en los datos y mejorar así su completitud. Esto contribuiría a liberar a los científicos y analistas de datos de ciertas tareas básicas y repetitivas para que puedan centrarse en otras tareas más estratégicas, como desarrollar nuevas ideas y hacer predicciones.
Técnicas innovadoras para el análisis de datos con IA
Una de las características de los modelos de IA es su facilidad para detectar patrones y conocimiento en grandes cantidades de datos. Técnicas de IA como el aprendizaje automático, el procesamiento del lenguaje natural y la visión por computador se pueden usar fácilmente para extraer nuevas perspectivas, patrones y conocimiento de los datos abiertos. Por otro lado, a medida que el desarrollo tecnológico continúa avanzando, podremos ver el desarrollo de técnicas de IA aún más sofisticadas y especialmente adaptadas para el análisis de datos abiertos, permitiendo a las organizaciones extraer todavía más valor de los mismos.
Paralelamente, las tecnologías de IA pueden ayudarnos a ir un paso más allá en el análisis de los datos facilitando y asistiendo en el análisis de datos colaborativo. Mediante este proceso, las múltiples partes interesadas pueden trabajar juntas en problemas complejos y darles respuesta a través de los datos abiertos. Esto daría lugar también a una mayor colaboración entre investigadores, formuladores de políticas públicas y comunidades de la sociedad civil a la hora de sacar el mayor provecho de los datos abiertos para abordar los desafíos sociales. Además, este tipo de análisis colaborativo también contribuiría a mejorar la transparencia y la inclusividad en los procesos de toma de decisiones.
La sinergia de la IA y los datos abiertos
En definitiva, la IA también se puede utilizar para automatizar muchas de las tareas involucradas en la presentación de los datos, como por ejemplo crear visualizaciones interactivas proporcionando simplemente instrucciones en lenguaje natural o una descripción de la visualización deseada.
Por otro lado, los datos abiertos permiten desarrollar aplicaciones que, combinadas con la inteligencia artificial, pueden resultar soluciones innovadoras. El desarrollo de nuevas aplicaciones impulsadas por los datos abiertos y la inteligencia artificial puede contribuir en diversos sectores como la atención sanitaria, finanzas, transporte o educación entre otros. Por ejemplo, se están utilizando chatbots para proporcionar servicio al cliente, algoritmos para tomar decisiones de inversión o coches autónomos, todos ellos impulsados por la IA. Lo que conseguiríamos además si estos servicios utilizaran los datos abiertos como fuente principal de datos sería una mayor calidad y veracidad, gracias a un mejor entrenamiento de los modelos de IA. Además, cuanta mayor sea la disponibilidad de los datos abiertos, mayor será también el número de personas que tendrán estas aplicaciones a su alcance.
Finalmente, la IA se puede utilizar también para analizar grandes volúmenes de datos abiertos e identificar nuevos patrones y tendencias que serían difíciles de detectar únicamente a través de la intuición humana. Esta información puede utilizarse luego para tomar mejores decisiones, como por ejemplo qué políticas llevar a cabo en un área determinada para poder obtener los cambios deseados.
Estas son solo algunas de las posibles tendencias futuras en la intersección de los datos abiertos y la inteligencia artificial, un futuro lleno de oportunidades pero al mismo tiempo no exento de riesgos. A medida que la IA continúa desarrollándose, podemos esperar ver aplicaciones aún más innovadoras y transformadoras de esta tecnología. Para ello será también necesaria una colaboración más cercana entre investigadores de inteligencia artificial y la comunidad de los datos abiertos a la hora de abrir nuevos conjuntos de datos y desarrollar nuevas herramientas para explotarlos. Esta colaboración es esencial para poder darle forma al futuro conjunto de los datos abiertos y la IA y garantizar que los beneficios de la IA estén disponibles para todos de forma justa y equitativa.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos son una fuente de conocimiento muy valiosa para nuestra sociedad. Gracias a ellos, se pueden crear aplicaciones que contribuyen al desarrollo social y soluciones que ayudan a configurar el futuro digital de Europa y alcanzar los Objetivos de Desarrollo Sostenible (ODS).
El portal de datos abiertos europeo (data.europe.eu) organiza eventos en línea para poner en valor aquellos proyectos que se han llevado a cabo con fuentes de datos abiertos y han ayudado a hacer frente a alguno de los retos a los que nos enfrentamos como sociedad: desde la lucha contra el cambio climático, el impulso de la economía, la consolidación de la democracia europea o la transformación digital.
En lo que llevamos de año, en 2023 se han celebrado cuatro seminarios para analizar el impacto positivo que tienen los datos abiertos en cada una de las temáticas mencionadas. Todo el material que se presentó en los eventos está publicado en el portal europeo y las grabaciones están disponibles en su canal de Youtube, al alcance de cualquier usuario interesado.
En este post, realizamos un primer repaso de los casos de uso presentados en materia de impulso a la economía y a la democracia, así como los conjuntos de datos abiertos que se emplearon para su desarrollo.
Soluciones que impulsan la economía y el estilo de vida europeo
En un mundo en constante evolución, donde los desafíos económicos y las aspiraciones de un estilo de vida próspero convergen, la Unión Europea ha demostrado una capacidad inigualable para forjar soluciones innovadoras que no solo impulsan su propia economía, sino que también elevan el estándar de vida de sus ciudadanos. En este contexto, los datos abiertos han jugado un papel fundamental en el desarrollo de aplicaciones que han dado respuesta a desafíos actuales y han sentado las bases para un futuro próspero y prometedor. Dos de estos proyectos se presentaron en el segundo webinar de la serie “Stories of use cases”, un evento sobre “Datos abiertos para fomentar la economía y el estilo de vida europeo”: UNA WOMEN y YouthPOP.
El primero de ellos se centra en solucionar uno de los retos más relevantes que debemos superar para lograr una sociedad justa: la desigualdad de género. La eliminación de la brecha de género es un problema social y económico muy complejo. Según estimaciones del Foro Económico Mundial, se necesitarán 132 años para lograr la paridad de género total en Europa. La aplicación UNA Women nace con el propósito de reducir esa cifra, asesorando a las mujeres jóvenes para que puedan tomar mejores decisiones a la hora de elegir su futuro en cuanto a educación y primeros pasos en sus carreras profesionales. En este caso de uso, la empresa ITER IDEA ha utilizado más de 6 millones de líneas de datos procesados de distintas fuentes, como data.europa.eu, Eurostat, Censis, Istat (Instituto nacional de estadística de Italia) o NUMBEO.
El segundo caso de uso presentado también va dirigido a la población joven. Se trata de la aplicación YouthPOP (Youth Públic Open Procurement), una herramienta que anima a los jóvenes a participar en procesos de contratación pública. Para el desarrollo de esta app se han utilizado datos de data.europa.eu, Eurostat y ESCO, entre otros. Youth POP tiene entre sus objetivos mejorar el empleo juvenil y contribuir al correcto funcionamiento de la democracia en Europa.
Datos abiertos para impulsar y consolidar la democracia europea
En esta línea, el uso de los datos abiertos también contribuye a fortalecer y consolidar la democracia europea. Los datos abiertos desempeñan un papel fundamental en nuestras democracias a través de las siguientes vías:
- Proporcionando a los ciudadanos información confiable.
- Fomentando la transparencia en los gobiernos e instituciones públicas.
- Combatiendo la desinformación y las noticias falsas.
El tema del tercer webinar organizado por datos.europa.eu sobre casos de uso es “Datos abiertos y un nuevo impulso a la democracia europea”, evento en el que se presentaron dos soluciones innovadoras: EU Integrity Watch y EU Institute For Freedom of Information.
En primer lugar, EU Integrity Watch es una plataforma que proporciona herramientas en línea para que los ciudadanos, periodistas y la sociedad civil monitoricen la integridad de las decisiones tomadas por los políticos en la Unión Europea. Esta web ofrece visualizaciones para comprender la información y pone a disposición los datos recopilados y analizados. Los datos analizados se utilizan en divulgaciones científicas, investigaciones periodísticas y otros ámbitos, lo que contribuye a un gobierno más abierto y transparente. Esta herramienta procesa y ofrece datos de Transparency register.
La segunda iniciativa presentada en el webinar sobre democracia con datos abiertos es el EU Institute For Freedom of Information (IDFI), una organización no gubernamental georgiana que se centra en actividades de vigilancia y supervisión de las acciones del gobierno, revelando infracciones y manteniendo informada a la ciudadanía.
Las principales actividades del IDFI incluyen solicitar información pública a los organismos pertinentes, elaborar clasificaciones de organismos públicos, monitorizar los sitios web de dichos organismos y abogar por la mejora del acceso a la información pública, los estándares legislativos y las prácticas relacionadas. Este proyecto obtiene, analiza y presenta conjuntos de datos abiertos procedentes de instituciones públicas nacionales.
En definitiva, los datos abiertos hacen posible el desarrollo de aplicaciones para reducir la brecha laboral de género, impulsar el empleo juvenil o vigilar las acciones de gobierno. Estos son solo algunos ejemplos del valor que pueden ofrecer los datos abiertos a la sociedad.
Conoce más sobre estas aplicaciones en sus seminarios -> Grabaciones aquí
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar como generar un cuadro de mando interactivo que, partiendo de datos abiertos, nos muestre información relevante sobre el consumo en alimentación de los hogares españoles partiendo de datos abiertos. Para ello realizaremos un preprocesamiento de los datos abiertos con la finalidad de obtener las tablas que utilizaremos en la herramienta generadora de las visualizaciones para crear el cuadro de mando interactivo.
Los cuadros de mando son herramientas que permiten presentar información de manera visual y fácilmente comprensible. También conocidos por el témino en inglés "dashboards", son utilizados para monitorizar, analizar y comunicar datos e indicadores. Su contenido suele incluir gráficos, tablas, indicadores, mapas y otros elementos visuales que representan datos y métricas relevantes. Estas visualizaciones ayudan a los usuarios a comprender rápidamente una situación, identificar tendencias, detectar patrones y tomar decisiones informadas.
Una vez analizados los datos, mediante esta visualización podremos contestar a preguntas como las que se plantean a continuación:
-
¿Cuál es la tendencia de los últimos años en el gasto y del consumo per cápita en los distintos alimentos que componen la cesta básica?
-
¿Qué alimentos son los más y menos consumidos en los últimos años?
-
¿En qué Comunidades Autónomas se produce un mayor gasto y consumo en alimentación?
-
¿El aumento en el coste de ciertos alimentos en los últimos años ha significado una reducción de su consumo?
Éstas, y otras muchas preguntas pueden ser resueltas mediante el cuadro de mando que mostrará información de forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados en este ejercicio contienen distinta información sobre el consumo per cápita y el gasto per cápita de los principales grupos de alimentos desglosados por Comunidad Autónoma. Los conjuntos de datos abiertos utilizados, pertenecientes al Ministerio de Agricultura, Pesca y Alimentación (MAPA), se proporcionan en series anuales (utilizaremos las series anuales desde el 2010 hasta el 2021)
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación del cuadro de mando se ha utilizado la herramienta Looker Studio.
"Looker Studio" antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar cuadros de mandos interactivos que pueden insertarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el siguiente Notebook que podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, una vez cargados los conjuntos de datos iniciales, es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de visualización (Looker Studio). Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en el siguiente Notebook de Google Colab, son los siguientes:
-
Instalación de librerías y carga de los conjuntos de datos
-
Análisis exploratorio de los datos (EDA)
-
Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Visualización del cuadro de mandos interactivo
Una vez hemos realizado el preprocesamiento de los datos, vamos con la generación del cuadro de mandos. Un cuadro de mandos es una herramienta visual que proporciona una visión resumida de los datos y métricas clave. Es útil para el monitoreo, la toma de decisiones y la comunicación efectiva, al proporcionar una vista clara y concisa de la información relevante.
Para la realización de las visualizaciones interactivas que componen el cuadro de mando se ha usado la herramienta Looker Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí se necesita que la tabla de datos que le proporcionamos esté estructurada adecuadamente, razón por la que hemos realizado los pasos anteriores relativos al preprocesamiento de los datos. Si quieres saber más sobre cómo utilizar Looker Studio, en el siguiente enlace puedes acceder a formación sobre el uso de la herramienta.
El cuadro de mandos se puede abrir en una nueva pestalla en el siguiente link. En los próximos apartados desglosaremos cada uno de los componentes que lo integran.
5.1. Filtros
Los filtros en un cuadro de mando son opciones de selección que permiten visualizar y analizar datos específicos mediante la aplicación de varios criterios de filtrado a los conjuntos de datos presentados en el panel de control. Ayudan a enfocarse en información relevante y a obtener una visión más precisa de los datos.

Los filtros incluidos en el cuadro de mando generado permiten elegir el tipo de análisis a mostrar, el territorio o Comunidad Autónoma, la categoría de alimentos y los años de la muestra.
También incorpora diversos botones para facilitar el borrado de los filtros elegidos, descargar el cuadro de mandos como un informe en formato PDF y acceder a los datos brutos con los que se ha elaborado este cuadro de mando.
5.2. Visualizaciones interactivas
El cuadro de mandos está compuesto por diversos tipos de visualizaciones interactivas, que son representaciones gráficas de datos que permiten a los usuarios explorar y manipular la información de forma activa.
A diferencia de las visualizaciones estáticas, las visualizaciones interactivas brindan la capacidad de interactuar con los datos, permitiendo a los usuarios realizar diferentes e interesantes acciones como hacer clic en elementos, arrastrarlos, ampliar o reducir el enfoque, filtrar datos, cambiar parámetros y ver los resultados en tiempo real.
Esta interacción es especialmente útil cuando se trabaja con conjuntos de datos grandes y complejos, pues facilitan a los usuarios el examen de diferentes aspectos de los datos así como descubrir patrones, tendencias y relaciones de una manera más intuitiva.
De cara a la definición de cada tipo de visualización, nos hemos basado en la guía de visualización de datos para entidades locales presentada por la RED de Entidades Locales por la Transparencia y Participación Ciudadana de la FEMP.
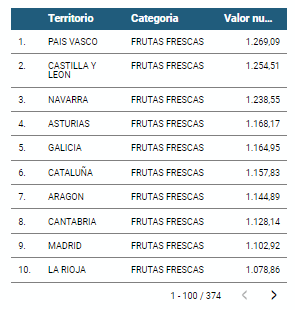
5.2.1 Tabla de datos
Las tablas de datos permiten la presentación de una gran cantidad de datos de forma organizada y clara, con un alto rendimiento de espacio/información.
Sin embargo, pueden dificultar la presentación de patrones o interpretaciones respecto a otros objetos visuales de carácter más gráfico.
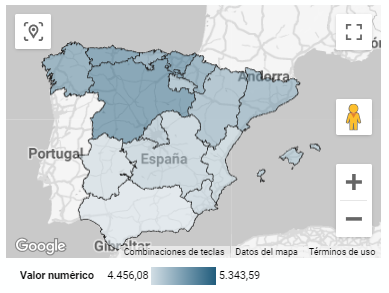
5.2.2 Mapa de cloropetas
Se trata de un mapa en el que se muestran datos numéricos por territorios marcando con intensidad de colores diferentes las distintas áreas. Para su elaboración se requiere de una medida o dato numérico, un dato categórico para el territorio y un dato geográfico para delimitar el área de cada territorio.
5.2.3 Gráfico de sectores
Se trata de un gráfico que muestra los datos a partir de unos ejes polares en los que el ángulo de cada sector marca la proporción de una categoría respecto al total. Su funcionalidad es mostrar las diferentes proporciones de cada categoría respecto a un total utilizando gráficos circulares.
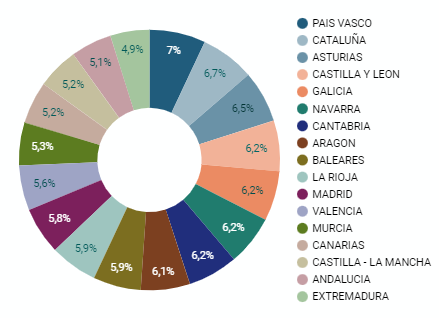
Figura 4. Gráfico de sectores del cuadro de mando
5.2.4 Gráfico de líneas
Se trata de un gráfico que muestra la relación entre dos o más medidas de una serie de valores en dos ejes cartesianos, reflejando en el eje X una dimensión temporal, y una medida numérica en el eje Y. Estos gráficos son idóneos para representar series de datos temporales con un elevado número de puntos de datos u observaciones.
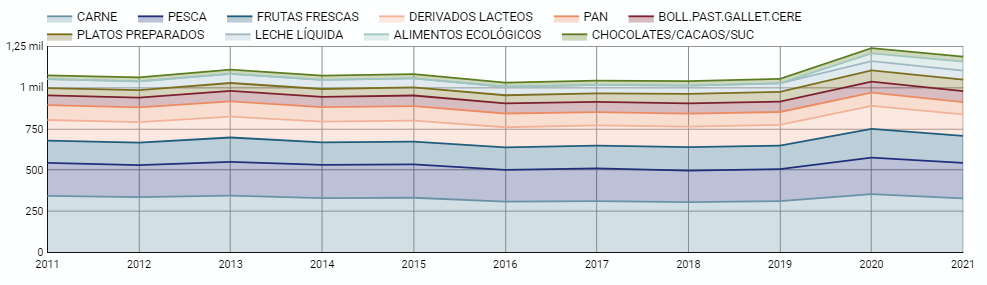
Figura 5. Gráfico de lineas del cuadro de mando
5.2.5 Gráfico de barras
Se trata de un gráfico de los más utilizados por la claridad y simplicidad de preparación. Facilita la lectura de valores a partir de la proporción de la longitud de las barras. El gráfico muestra los datos mediante un eje que representa los valores cuantitativos y otro que incluye los datos cualitativos de las categorías o de tiempo.
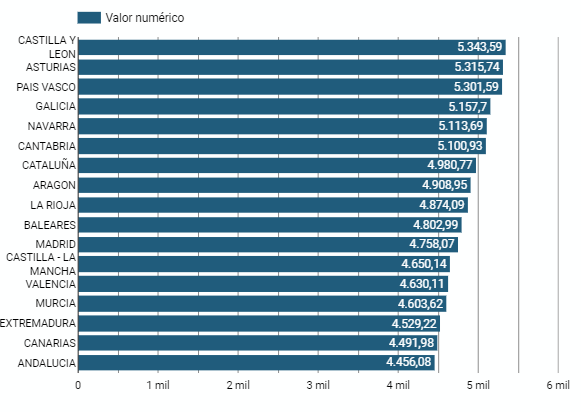
Figura 6. Gráfico de barras del cuadro de mando
5.2.6 Gráfico de jerarquías
Se trata de un gráfico formado por distintos rectángulos que representan categorías, y que permite agrupaciones jerárquicas de los sectores de cada categoría. La dimensión de cada rectángulo y su colocación varía en función del valor de la medida de cada una de las categorías que se muestran respecto del valor total de la muestra.
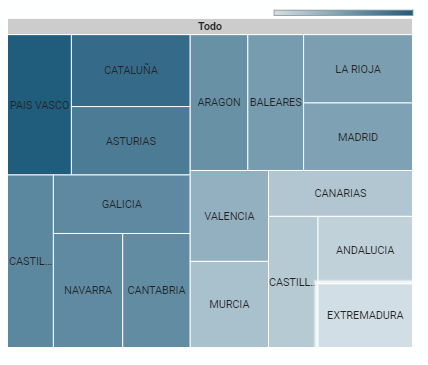
Figura 7. Gráfico de jerarquías del cuadro de mando
6. Conclusiones del ejercicio
Los cuadros de mando son uno de los mecanismos más potentes para explotar y analizar el significado de los datos. Cabe destacar la importancia que nos ofrecen a la hora de monitorear, analizar y comunicar datos e indicadores de una manera clara, sencilla y efectiva.
Como resultado, hemos podido responder a las preguntas originalmente planteadas:
-
La tendencia del consumo per cápita se encuentra en disminución desde el 2013, año en el que llegó a su máximo, con un pequeño repunte en los años 2020 y 2021.
-
La tendencia del gasto per cápita se ha mantenido estable desde el 2011 hasta que en 2020 ha sufrido una subida del 17,7% pasando de ser el gasto medio anual de 1052 euros a 1239 euros, produciéndose una leve disminución del 4,4% de los datos del 2020 a los del 2021.
-
Los tres alimentos más consumidos durante todos los años analizados son: frutas frescas, leche líquida y carne (valores en kgs)
-
Las Comunidades Autónomas donde el gasto per cápita es mayor son País Vasco, Cataluña y Asturias, mientras que Castilla la Mancha, Andalucía y Extremadura son las que menos gasto tienen.
-
Las Comunidad Autónomas donde un mayor consumo per cápita se produce son Castilla y León, Asturias y País Vasco, mientras que en las que menor son: Extremadura, Canarias y Andalucía.
También hemos podido observar ciertos patrones interesantes, como un aumento de un 17,33% en el consumo de alcohol (cervezas, vino y bebidas espirituosas) en los años 2019 y 2020 .
Puedes utilizar los distintos filtros para averiguar y buscar más tendencias o patrones en los datos según tus intereses e inquietudes.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
La Oficina del Dato elabora dos guías de ayuda para la concepción eficaz de espacios de datos
El concepto de espacio de datos, entendido como un ecosistema de compartición voluntaria de datos en un entorno de confianza, seguridad y soberanía, se va a desplegar con todo su potencial a lo largo de los próximos años, como apuesta clave de la Unión Europea para impulsar la economía del dato y preservar su soberanía digital. Dichos espacios se construyen alrededor de casos de uso concretos de compartición y explotación de datos donde satisfacer necesidades de negocio concretas, un proceso para el que no resulta sencillo descubrir dichas necesidades, ni su óptimo diseño, al estar presentes diversas consideraciones y áreas de conocimiento.
Para rebajar las barreras de entrada ligadas a su concepción, la Oficina del Dato, dependiente de la Secretaría de Estado de Digitalización e Inteligencia Artificial, ejerciendo su función de dinamizar el gobierno, gestión, compartición y el uso de datos, ha publicado sendas guías que facilitarán la puesta en marcha de casos de uso de compartición de datos: la Guía de evaluación de viabilidad de casos de uso y la Guía de diseño de casos de uso.
Ambos documentos tienen como objetivo ayudar a los potenciales creadores de espacios de datos a superar los desafíos propios de la puesta en marcha de un caso de uso de compartición de datos. En este sentido, las guías orientan paso a paso y en las sucesivas etapas del proceso, proporcionando plantillas con preguntas concretas a las diferentes situaciones que se irán presentando en su diseño. El uso de estas guías debe entenderse de forma iterativa, permitiendo un proceso de refinamiento; así, una vez establecida la viabilidad de un determinado escenario, se abordará su diseño detallado, en un proceso en el que la propia dinámica puede llevar a provocar un replanteamiento de la etapa original de viabilidad. De igual forma, las preguntas presentes en cada paso pueden provocar matizaciones en los pasos anteriores, permitiendo en todo momento una progresiva mejora.
Las guías tienen como origen el contenido de los trabajos realizados desde la iniciativa Data Sharing Coalition. Trabajos en los que, compartiendo experiencia y conocimiento, las organizaciones abordaron el desafío que supuso iniciar el camino de crear en la práctica casos de uso de compartición y explotación de datos. Tomando como base esta referencia, las guías que aquí presentamos han ido evolucionando y han sido particularizadas para el contexto español, siendo enriquecidas igualmente con las aportaciones de los participantes a los eventos de dinamización de espacios de datos organizados por la Oficina del Dato.
Guía de evaluación de viabilidad de casos de uso
La Guía de evaluación de viabilidad de casos de uso permite generar, describir y evaluar ideas de casos de uso escalables de compartición de datos. Con el objetivo final de tomar una decisión acerca de la viabilidad del escenario propuesto, la guía plantea una metodología estructurada a lo largo de cinco pasos: generación del caso de uso, definición de su alcance, evaluación del potencial, estudio de la complejidad de la interacción y toma de decisión final de viabilidad.

Guía de diseño de casos de uso
Una vez abordada la viabilidad del escenario planteado, y si ésta se estimase afirmativa, la Guía de diseño de casos de uso ofrece el soporte necesario para su puesta en marcha. En este punto, se incide tanto en su escalabilidad como en la reutilización de los datos más allá del ámbito inicial. A la hora de diseñar de forma óptima un caso de uso de intercambio y explotación de datos, creemos que las cuestiones de implementación técnica representan tan sólo uno de los factores a tomar en cuenta, resaltando también la criticidad de consideraciones tales como su gobernanza, el modelo de negocio, la experiencia de usuario y los diversos aspectos regulatorios sobre los que se articula y opera.
La Guía, a lo largo de diferentes etapas, aborda la definición detallada del caso de uso, fijando el objetivo y alcance, identificando las funcionalidades que permiten habilitar la compartición de datos, y detallando qué habilitadores permiten el desarrollo de dichas funcionalidades. Gracias al enfoque práctico de la guía, en ella se incluyen útiles plantillas de preguntas-clave que permiten descubrir fácilmente los diversos aspectos a considerar, abordando temas como los principios rectores del caso de uso, el modelo de iteración, los componentes funcionales, las reglas y regulaciones, los contratos, la privacidad, la gestión de la información y los riesgos, las herramientas de apoyo, o incluso los acuerdos de nivel de servicio o la planificación del proyecto.

Los documentos base de ambas guías, las plantillas de preguntas en formato de hoja de cálculo para facilitar su cumplimentación, así como un ejemplo relativo a la viabilidad del proyecto “Caminos de pasión” facilitado por la Fundación Santa María la Real, se encuentran disponibles a través de los siguientes enlaces.
Aplicación
Se trata de una aplicación colaborativa desarrollada para la captura y el envío de datos de cobertura de acceso a internet dentro de la Comunidad de Aragón. La ciudadanía puede participar y aportar información para ayudar a conocer la calidad de acceso a internet en sus municipios. Su principal objetivo es el de conocer la calidad en el acceso a internet en Aragón.
En definitiva, esta app obtiene y ofrece los datos de cobertura a internet de todos los municipios de Aragón a través de un trabajo de campo inicial unido a los datos aportados de forma anónima por los usuarios. Su finalidad es la de procesar los datos obtenidos y ofrecerlos abiertamente y de forma pública a través de un mapa. Para ello utiliza los sistemas y servicios cartográficos del Gobierno de Aragón los del Instituto Geográfico de Aragón.
Blog
Las soluciones abiertas, que comprenden los recursos educativos abiertos (REA), el Acceso abierto a la información científica (OA, por sus siglas en inglés), el software libre y de código abierto (FOSS) y los datos abiertos, fomentan la libre circulación de la información y el conocimiento, constituyéndose así en una base para responder a los desafíos mundiales, tal y como recuerda la UNESCO.
El organismo de las Naciones Unidas para la Educación, la Ciencia y la Cultura reconoce así el valor de los datos abiertos en el ámbito educativo y considera que su uso puede contribuir a medir el cumplimiento de los Objetivos de Desarrollo Sostenible, especialmente el objetivo número 4 de Educación de calidad. Otros organismos internacionales reconocen también el potencial de la apertura de datos en la educación. Por ejemplo, la Comisión Europea ha catalogado el sector educativo como un ámbito en el que los datos abiertos tienen un alto potencial.
Los datos abiertos se pueden utilizar como una herramienta para la educación y la formación de diferentes formas. Así, se pueden utilizar para desarrollar nuevos materiales didácticos y para recopilar y analizar información sobre el estado del sistema educativo que sirvan para impulsar mejoras.
La pandemia mundial marcó un hito en el ámbito educativo, cuando se hizo imprescindible el uso de las nuevas tecnologías en el proceso de enseñanza-aprendizaje que pasó a ser íntegramente virtual durante meses. Aunque desde hacía años se venía hablando de los beneficios de incorporar las TIC y las soluciones abiertas a la educación, una tendencia que se conoce como Edtech, el COVID-19 aceleró este proceso.
Los beneficios del uso de los datos abiertos en el aula
En la siguiente infografía resumimos los beneficios que supone la aplicación de los datos abiertos en el ámbito de la educación y la formación, tanto desde el punto de vista del alumno y del docente, como el de los gestores del sistema educativo.
Existen multitud de conjuntos de datos que pueden utilizarse para el desarrollo de soluciones educativas. En datos.gob.es hay más de 6.700 datasets disponibles, a los que se pueden sumar otros que se utilizan con fines educativos en diferentes áreas, como literatura, geografía, historia, etc.
Son mucha las soluciones desarrolladas con datos abiertos que se utilizan con estos objetivos. Recopilamos algunas de ellas en función de su finalidad: en primer lugar, las soluciones que ofrecen información sobre el sistema educativo de cara a conocer su situación y planificar nuevas medidas y, en segundo lugar, las que ofrecen material didáctico para utilizar en el aula.
En definitiva, los datos abiertos se constituyen como una herramienta fundamental para el fortalecimiento y progreso de la educación y no podemos olvidar que la educación es un derecho universal y una de las principales herramientas para el progreso de la humanidad.
Haz clic en la infografía para verla a tamaño real:

Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas, de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, puedes acceder al material que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es hacer un análisis de los datos meteorológicos recogidos en varias estaciones durante los últimos años. Para realizar este análisis utilizaremos distintas visualizaciones generadas mediante la librería “ggplot2” del lenguaje de programación “R”
De todas las estaciones meteorológicas españolas, hemos decidido analizar dos de ellas, una en la provincia más fría del país (Burgos) y otra en la provincia más cálida del país (Córdoba), según los datos de la AEMET. Se buscarán patrones y tendencias en los distintos registros entre los años 1990 y 2020 con el objetivo de entender la evolución meteorológica sufrida en este periodo de tiempo.
Una vez analizados los datos, podremos contestar a preguntas como las que se muestran a continuación:
-
¿Cuál es la tendencia en la evolución de las temperaturas en los últimos años?
-
¿Cuál es la tendencia en la evolución de las precipitaciones en los últimos años?
-
¿Qué estación meteorológica (Burgos o Córdoba) presenta una mayor variación de los datos climatológicos en estos últimos años?
-
¿Qué grado de correlación hay entre las distintas variables climatológicas registradas?
Estas, y muchas otras preguntas pueden ser resueltas mediante el uso de herramientas como ggplot2 que facilitan la interpretación de los datos mediante visualizaciones interactivas.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos contienen distinta información meteorológica de interés para las dos estaciones en cuestión desglosada por año. Dentro del centro de descargas de la AEMET, podremos descárgalos, previa solicitud de la clave API, en el apartado “climatologías mensuales/anuales”. De las estaciones meteorológicas existentes, hemos seleccionado dos de las que obtendremos los datos: Burgos aeropuerto (2331) y Córdoba aeropuerto (5402)
Cabe destacar, que, junto a los conjuntos de datos, también podremos descargar sus metadatos, los cuales son de especial importancia a la hora de identificar las distintas variables registradas en los conjuntos de datos.
Estos conjuntos de datos también se encuentran disponibles en el repositorio de Github
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación R escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones se ha usado la librería ggplot2.
"ggplot2" es un paquete de visualización de datos para el lenguaje de programación R. Se centra en la construcción de gráficos a partir de capas de elementos estéticos, geométricos y estadísticos. ggplot2 ofrece una amplia gama de gráficos estadísticos de alta calidad, incluyendo gráficos de barras, gráficos de líneas, diagramas de dispersión, gráficos de caja y bigotes, y muchos otros
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, una vez importadas las librerías necesarias y cargados los conjuntos de datos, es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso a dar es generar las tablas de datos preprocesadas que usaremos en las visualizaciones. Para ello, filtraremos los conjuntos de datos iniciales y calcularemos los valores que sean necesarios y de interés para el análisis realizado en este ejercicio.
Una vez terminado el preprocesamiento, obtendremos las tablas de datos “datos_graficas_C” y “datos_graficas_B” las cuales utilizaremos en el siguiente apartado del Notebook para generar las visualizaciones.
La estructura del Notebook en la que se realizan los pasos previamente descritos junto a comentarios explicativos de cada uno de ellos, es la siguiente:
- Instalación y carga de librerías
- Carga de los conjuntos de datos
- Análisis exploratorio de datos (EDA)
- Preparación de las tablas de datos
- Visualizaciones
- Guardado de gráficos
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y de cara a favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Visualizaciones
Diversos tipos de visualizaciones y gráficos se han realizado con la finalidad de extraer información sobre las tablas de datos preprocesadas y responder a las preguntas iniciales planteadas en este ejercicio. Como se ha mencionado previamente, se ha utilizado el paquete “ggplot2” de R para realizar las visualizaciones.
El paquete "ggplot2" es una biblioteca de visualización de datos en el lenguaje de programación R. Fue desarrollado por Hadley Wickham y es parte del conjunto de herramientas del paquete "tidyverse". El paquete "ggplot2" está construido en torno al concepto de "gramática de gráficos", que es un marco teórico para construir gráficos mediante la combinación de elementos básicos de la visualización de datos como capas, escalas, leyendas, anotaciones y temas. Esto permite crear visualizaciones de datos complejas y personalizadas, con un código más limpio y estructurado.
Si quieres tener una visión a modo resumen de las posibilidades de visualizaciones con ggplot2, consulta la siguiente “cheatsheet”. También puedes obtener información más en detalle en el siguiente "manual de uso".
5.1. Gráficos de líneas
Los gráficos de líneas son una representación gráfica de datos que utiliza puntos conectados por líneas para mostrar la evolución de una variable en una dimensión continua, como el tiempo. Los valores de la variable se representan en el eje vertical y la dimensión continua en el eje horizontal. Los gráficos de líneas son útiles para visualizar tendencias, comparar evoluciones y detectar patrones.
A continuación, podemos visualizar varios gráficos de líneas con la evolución temporal de los valores de temperaturas medias, mínimas y máximas de las dos estaciones meteorológicas analizadas (Córdoba y Burgos). Sobre estos gráficos, hemos introducido líneas de tendencia para poder observar de forma visual y sencilla su evolución.






Para poder comparar las evoluciones, no solamente de manera visual mediante las líneas de tendencia graficadas, sino también de manera numérica, obtenemos los coeficientes de pendiente de la recta de tendencia, es decir, el cambio en la variable respuesta (tm_ mes, tm_min, tm_max) por cada unidad de cambio en la variable predictora (año).
-
Coeficiente de pendiente temperatura media Córdoba: 0.036
-
Coeficiente de pendiente temperatura media Burgos: 0.025
-
Coeficiente de pendiente temperatura mínima Córdoba: 0.020
-
Coeficiente de pendiente temperatura mínima Burgos: 0.020
-
Coeficiente de pendiente temperatura máxima Córdoba: 0.051
-
Coeficiente de pendiente temperatura máxima Burgos: 0.030
Podemos interpretar que cuanto mayor es este valor, más abrupta es la subida de temperatura media en cada periodo observado.
Por últimos, hemos creado un gráfico de líneas para cada estación meteorológica, en el que visualizamos de forma conjunta la evolución de las temperaturas medias, mínimas y máximas a lo largo de los años.
