Fecha publicación
26/11/2019
Fecha actualización
03/10/2024
Comparte este contenido

Descripción
La ciencia de datos es un campo interdisciplinar que busca extraer conocimiento actuable a partir de conjuntos de datos, estructurados en bases de datos o no estructurados como textos, audios o vídeos. Gracias a la aplicación de nuevas técnicas, la ciencia de datos nos está permitiendo responder preguntas que no son fáciles de resolver a través de otros métodos. El fin último es diseñar acciones de mejora o corrección a partir del nuevo conocimiento que obtenemos.
El concepto clave en ciencia de datos es CIENCIA, y no tanto datos, ya que incluso se ha comenzado a hablar de un cuarto paradigma de la ciencia, añadiendo el enfoque basado en datos a los tradicionales teórico, empírico y computacional.
La ciencia de datos combina métodos y tecnologías que provienen de las matemáticas, la estadística y la informática, y entre las que encontramos el análisis exploratorio, el aprendizaje automático (machine learning), el aprendizaje profundo (deep learning), el procesamiento del lenguaje natural, la visualización de datos y el diseño experimental.
Dentro de la Ciencia de Datos, las dos tecnologías de las que más se está hablando son el Aprendizaje Automático (Machine Learning) y el Aprendizaje profundo (Deep Learning), ambas englobadas en el campo de la inteligencia artificial. En los dos casos se busca la construcción de sistemas que sean capaces de aprender a resolver problemas sin la intervención de un humano y que van desde los sistemas de predicción ortográfica o traducción automática hasta los coches autónomos o los sistemas de visión artificial aplicados a casos de uso tan espectaculares como las tiendas de Amazon Go.
En los dos casos los sistemas aprenden a resolver los problemas a partir de los conjuntos de datos que les enseñamos para entrenarlos en la resolución del problema, bien de forma supervisada cuando los conjuntos de datos de entrenamiento están previamente etiquetados por humanos, o bien de forma no supervisada cuando estos conjuntos de datos no están etiquetados.
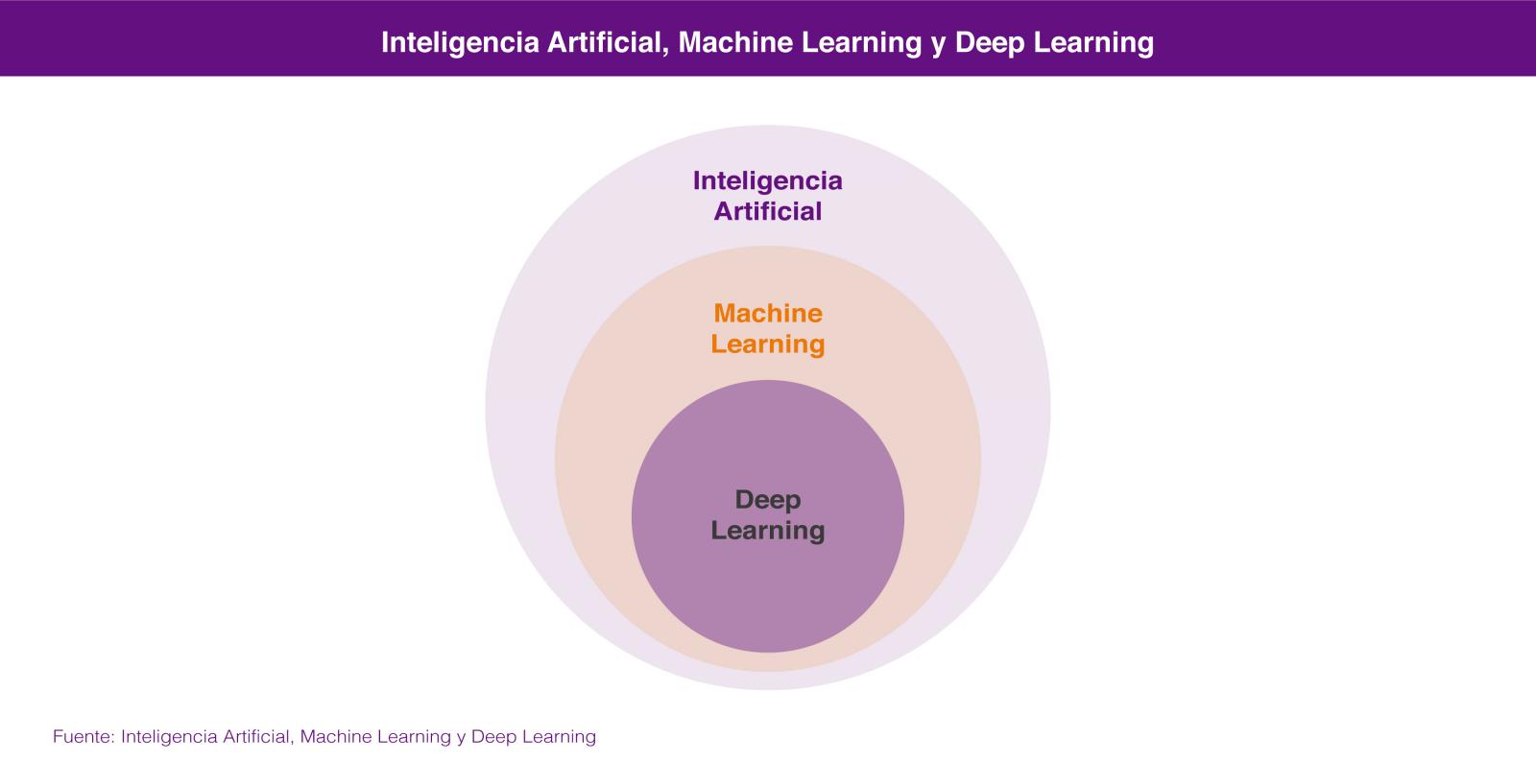
En realidad lo correcto es considerar el aprendizaje profundo como una parte del aprendizaje automático por lo que, si tenemos que buscar un atributo que nos permita diferenciarlas, éste sería su forma de aprender, que es completamente diferente. El aprendizaje automático se basa en algoritmos (redes bayesianas, máquinas de vectores de soporte, análisis de clusters, etc) que son capaces de descubrir patrones a partir de las observaciones incluidas en un conjunto de datos. En el caso del aprendizaje profundo se emplea un enfoque que está inspirado, salvando las distancias, en el funcionamiento de las conexiones de las neuronas del cerebro humano y existen también numerosas aproximaciones para diferentes problemas, como por ejemplo las redes neuronales convolucionales para reconocimiento de imágenes o las redes neuronales recurrentes para procesamiento del lenguaje natural.
La idoneidad de un enfoque u otro la marcará la cantidad de datos que tengamos disponibles para entrenar nuestro sistema de inteligencia artificial. En general podemos decir que para pequeñas cantidades de datos de entrenamiento, el enfoque basado en redes neuronales no ofrece un rendimiento superior al enfoque basado en algoritmos. El enfoque basado en algoritmos se suele estancar a partir de una cierta cantidad de datos, no siendo capaz de ofrecer una mayor precisión aunque le enseñemos más casos de entrenamiento. Sin embargo, a través del aprendizaje profundo podemos extraer un mejor rendimiento a partir de esa mayor disponibilidad de datos, ya que el sistema suele ser capaz de resolver el problema con una mayor precisión, cuanto más casos de entrenamiento tenga a su disposición.

Ninguna de estas tecnologías es nuevas en absoluto, ya que llevan décadas de desarrollo teórico. Sin embargo en los últimos años se han producido avances que han rebajado enormemente la barrera para trabajar con ellas: liberación de herramientas de programación que permiten trabajar a alto nivel con conceptos muy complejos, paquetes de software open source para administrar infraestructuras de gestión de datos, herramientas en la nube que permiten acceder a una potencia de computación casi sin límites y sin necesidad de administrar la infraestructura, e incluso formación gratuita impartida por algunos de los mejores especialistas del mundo.
Todo ello está contribuyendo a que capturemos datos a una escala sin precedentes y los almacenemos y procesemos a unos costes aceptables que permiten resolver problemas antiguos con enfoques novedosos. La inteligencia artificial está además al alcance de muchas más personas, cuya colaboración en un mundo cada vez más conectado están dando lugar a innovaciones que avanzan a un ritmo cada vez más veloz en todos los ámbitos: el transporte, la medicina, los servicios, la industria, etc.
Por algo el trabajo de científico de datos ha sido denominado el trabajo más sexy del siglo 21.
Contenido elaborado por Jose Luis Marín, Head of corporate Technology Strategy en MADISON MK y CEO de Euroalert.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
The field of Artificial Intelligence (AI System) and Machine Learning Algorithm covers Computer Science, Natural Language Processing, Python Code, Mathematics, Psychology, Neuroscience, Data Science, Machine Learning and many other subjects. AI is a good place to start an introductory course as it will give you an overview of the components to speed up AI research and development to date. You can get hands-on experience with AI programming of intelligent agents such as search agents, games and logic problems. Learn about examples of AI in use such as self-driving cars, facial recognition systems, military drones and natural language processors.
Fantastic blog extremely good well enjoyed with the incredible informative content which surely activates the learners to gain enough knowledge. This, in turn, makes the readers explore themselves and involve deeply in the subject. Wish you to dispatch similar content successively in the future as well.
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is wonderful, as well as
the content!
Hello gob.es administrator, Your posts are always a great source of knowledge.
To the gob.es admin, Your posts are always a great source of knowledge.
"No me he enteraó de ná"
Muchas gracias Antonio por tu comentario. Estamos trabajando en nuevos contenidos sobre esta temática que esperemos resuelvan tus dudas.
De momento, te podemos recomendar estos artículos: http://bit.ly/2qDAogF y http://bit.ly/2qGhbd8. Y si quieres profundizar en el tema, puedes leer este interesante informe de la Royal Sociaty: http://bit.ly/2qHxdUj
Un cordial saludo,
Datos.gob.es