Fecha publicación
08/01/2020
Comparte este contenido

Descripción
La música es una expresión sensorial de las matemáticas. Matemáticas y tecnología son nuestras principales herramientas para el análisis de datos así que: música para mis datos
(La imagen de la derecha pertenece a una partitura de John Andrew Buchanan (lyrics) y Henry Bernard Murtagh, (music) - Oregon Blue Book, Public Domain, https://commons.wikimedia.org/w/index.php?curid=8893618)
Podríamos decir que el tema de la música y los datos no es el más popular hoy en día. En el momento actual, donde parece que todo lo que suena a datos es importante e interesante, no es común tocar el tema de la relación entre música y datos. Sin embargo, este puede llegar a ser un asunto muy interesante de explorar desde muchos puntos de vista. Así, cuando realizamos una búsqueda sencilla por Internet sobre la relación entre música y datos, nos encontramos con algunas categorías interesantes. En este post vamos a destacar dos de esas categorías:
- Clasificaciones musicales.
- Sonificación de los datos.
Clasificaciones musicales
En Internet, abundan los artículos y posts en los que se analizan de forma muy visual los gustos y preferencias musicales en función de diferentes dimensiones como el género, la localización, la actividad que se esté desarrollando, etc. Veamos algunos ejemplos con algo más de detalle:
Para gustos, música
Por ejemplo, en la web towardsdatascience encontramos un interesante post donde se analizan (los datos de) las canciones de varias playlists. El objetivo es encontrar una explicación objetiva a por qué una persona opina (subjetivamente) que la lista de canciones de otra persona es un tanto aburrida. La mayoría de bases de datos musicales y repositorios de información musical proporcionan datos que ayudan a clasificar las canciones en géneros (Pop, Rock, Indi, etc.) y/o características como melódica, enérgica, bailable, instrumental, etc. Utilizando las APIs de los servicios o repositorios, algo de programación básica y nuestro ingenio podemos comparar las playlists de varias personas, analizando así el número de canciones de cada tipo. Además, en este post se atreven con una divertida fórmula matemática para definir cómo de aburrida es una canción. Y aquí es donde entran en juego de nuevo más datos. A parte del género y el tipo de música de una canción, existen otros parámetros importantes, como por ejemplo, la duración el tempo, el volumen, etc. En este post su definición de aburrimiento en lo que respecta a una canción se construye con:
|
aburrimiento_de_una_canción = volumen + tempo + (100*energía) + (100*bailabilidad) |
Con todos estos datos podemos calcular un índice de aburrimiento para cada canción. Si aplicamos esto a todas las canciones de todas las playlists de varios usuarios, podemos analizar el índice de aburrimiento musical por usuario, lo cual no deja de ser divertido.
¿Pero por qué parar aquí? ya que hemos creado un índice de aburrimiento musical por qué no intentamos construir un sistema que sea capaz de predecir a quién (a qué usuario) corresponde una canción en función de sus gustos musicales y también en función del índice de aburrimiento de la canción en cuestión. Para esto, necesitamos ya la ayuda de nuestras herramientas de machine learning. Utilizando un algoritmo muy sencillo y habitual conocido como Regresión Logística, el autor del post ha sido capaz de entrenar un modelo con el que clasificar una determinada canción y decidir a quién corresponde dicha canción.
Sonificación de los datos.
Si construir un índice de aburrimiento musical te parecía atrevido y divertido espera a ver lo que se puede hacer con algunos datos, un poco de imaginación y algunas herramientas open-source. Puede que no exista un objetivo claramente práctico para convertir conjuntos de datos en música, pero el experimento merece mucho la pena. Vamos a explicar ligeramente lo que vamos a hacer. Lo primero de todo es que vamos a utilizar un conjunto de datos abiertos muy habitual y bien organizado como es el de la Agencia Estatal de Meteorología (AEMET). En su portal de datos abiertos podemos encontrar diferentes catálogos de datos. En nuestro caso particular vamos descargar la climatología diaria desde el 1 de enero de 2019 hasta el 16 de noviembre de 2019 para dos provincias, muy distintas climatológicamente hablando, como son Asturias y Sevilla.
Un ejemplo del tipo de datos que obtenemos es el siguiente:
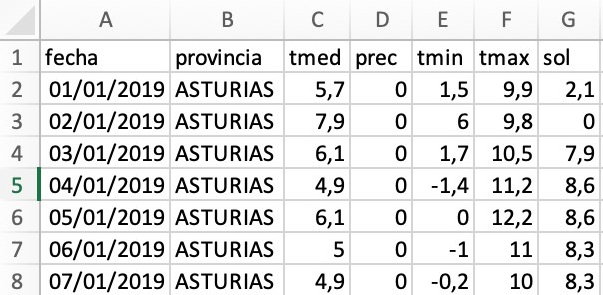
Lo que hacemos a continuación es utilizar la web de la aplicación https://app.twotone.io/ para construir la banda sonora de la cantidad de sol que reciben ambas provincias durante el año y compararlas entre sí. La documentación completa acerca de esta aplicación de código abierto se puede consultar en su repositorio de Github https://github.com/datavized/twotone/
El resultado cuando se construye la melodía tiene este aspecto:
Pudiendo elegir el instrumento con el que queremos tocar la banda sonora, el tempo, la clave, la escala, etc., la aplicación nos permite además exportar las melodías para su posterior comparación. El resultado es sorprendente y divertido:
| Horas de Sol en Asturias | Horas de Sol en Sevilla |
|---|---|
Finalmente, los datos son el resultado de la caracterización matemática que hacemos de nuestro entorno. Así, típicamente, describimos el tiempo atmosférico de una región en función de sus variables características. En este post, hemos ido un paso más allá. Hemos codificado esos datos en forma de notas musicales, como si de un mensaje se tratara. Los datos y la música tienen mucho ver y aquí hemos descrito una aplicación práctica de esta relación. Esperamos que disfrutéis de la banda sonora que acompaña a este post.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Comentarios