Fecha publicación
30/06/2021
Comparte este contenido

Descripción
La iniciativa Hércules se inicia en noviembre de 2017, mediante un convenio entre la Universidad de Murcia y el Ministerio de Economía, Industria y Competitividad, con el objetivo de desarrollar un Sistema de Gestión de Investigación (SGI) basado en datos abiertos semánticos que ofrezca una visión global de los datos de investigación del Sistema Universitario Español (SUE), para mejorar la gestión, el análisis y las posibles sinergias entre universidades y el gran público.
Esta iniciativa es complementaria a UniversiDATA, donde varias universidades españolas colaboran para fomentar los datos abiertos en el sector de la educación superior mediante la publicación de conjuntos de datos a través de criterios estandarizados y comunes. En concreto se define un Núcleo Común con 42 especificaciones de datasets, de los cuales se han publicado 12 para la versión 1.0. Hércules, en cambio es una iniciativa específica del ámbito de investigación, estructurada en torno a tres pilares:
- Prototipo innovador de SGI
- Grafo unificado de conocimiento (ASIO) 1],
- Enriquecimiento de datos y análisis semántico (EDMA)
El objetivo final es la publicación de un grafo unificado de conocimiento donde queden integrados todos los datos de investigación que deseen hacer públicos las universidades participantes. Hércules prevé la integración de universidades a diferentes niveles, dependiendo de su disposición a reemplazar su SGI por el SGI de Hércules. En el caso de SGIs externos, el grado de accesibilidad que ofrezcan también tendrá implicación en el volumen de datos que puedan compartir a través del grafo unificado.
Organigrama general de la iniciativa Hércules
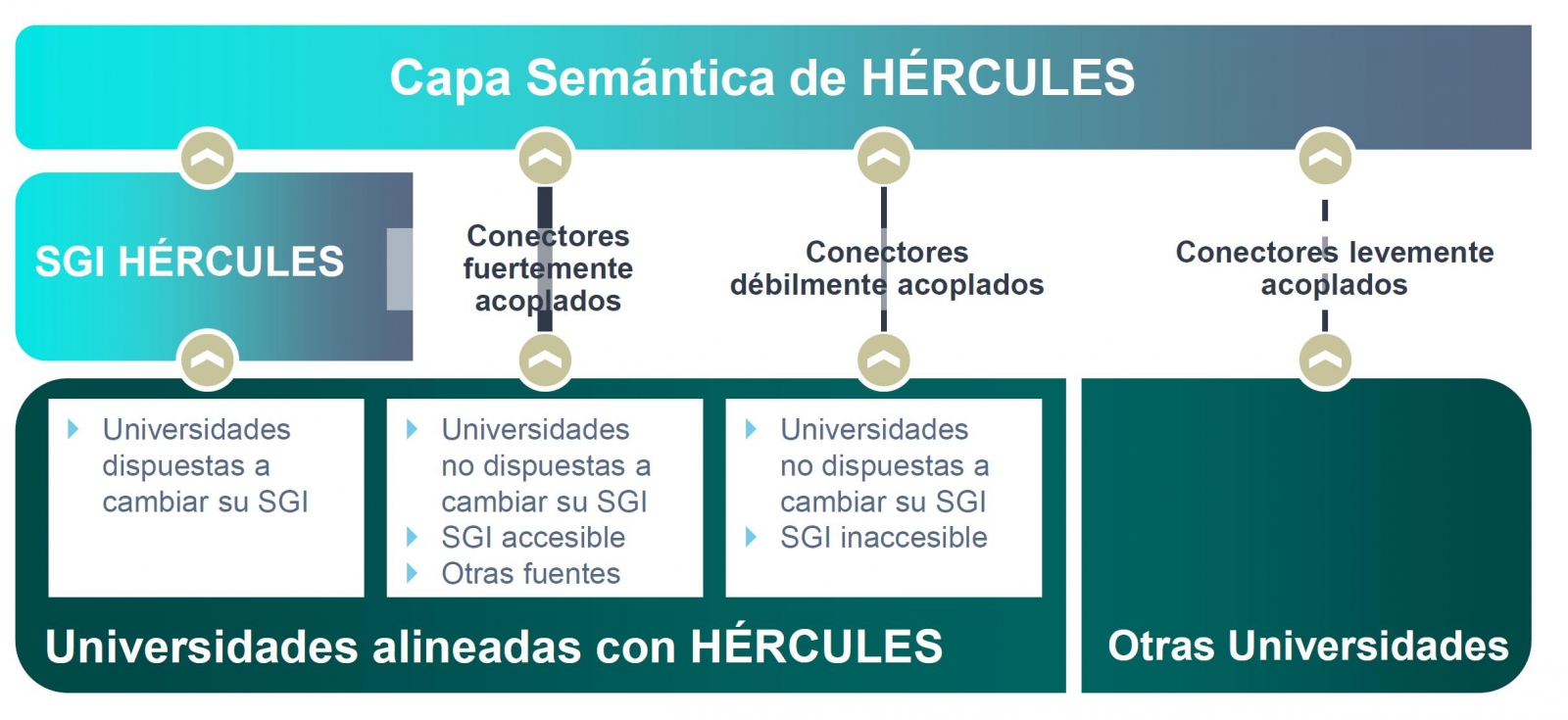
Dentro de la iniciativa Hércules, se integra el Proyecto ASIO (Arquitectura Semántica e Infraestructura Ontológica). El propósito de este sub-proyecto es definir una Red de Ontologías para la Gestión de la Investigación (Infraestructura Ontológica). Una ontología es una definición formal que describe con fidelidad y alta granularidad un dominio de discusión concreto. En este caso, el dominio de la investigación, que puede ser extrapolable a otras universidades españolas e internacionales (de momento el piloto se está desarrollando con la Universidad de Murcia). Es decir, se trata de crear un vocabulario de datos común.
Adicionalmente, a través del módulo de Arquitectura Semántica de Datos se ha desarrollado una plataforma eficiente para almacenar, gestionar y publicar datos de investigación del SUE, basándose en ontologías, con la capacidad de sincronizar instancias instaladas en diferentes universidades, así como la ejecución de consultas federadas distribuidas sobre aspectos clave de producción científica, líneas de investigación, búsqueda de sinergias, etc.
Como solución a este reto de innovación se han propuesto dos líneas complementarias, una centralizada (sincronización en escritura) y otra descentralizada (sincronización en consulta). En las próximas secciones se explica en detalle la arquitectura de la solución descentralizada.
Domain Driven Design
El modelo de datos sigue el enfoque Domain Driven Design, modelando entidades y vocabulario común, que pueda ser comprendido tanto por desarrolladores como expertos del dominio. Este modelo es independiente de la base de datos, del interfaz de usuario y del entorno de desarrollo, obteniendo una arquitectura de software limpia que permite adaptarse a los cambios del modelo.
Para ello se hace uso de Shape Expressions (ShEx), un lenguaje para validar y describir conjuntos de datos RDF, con sintaxis legible por humanos. A partir de estas expresiones se genera el modelo de dominio automáticamente y permite orquestar un proceso de integración continua (CI), tal y como se describe en la siguiente figura.
Proceso de integración continua mediante Domain Driven Design
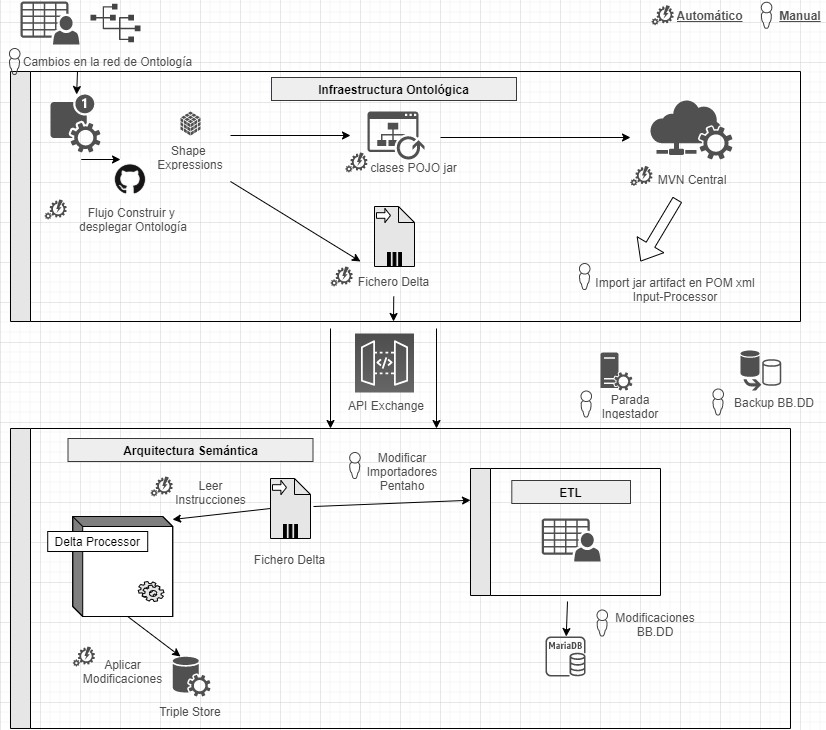
Mediante un sistema basado en de control de versiones como elemento central, se ofrece la posibilidad de que los expertos de dominio construyan y visualicen las ontologías multilingües. Estas a su vez se apoyan en ontologías tanto del ámbito de la investigación: VIVO, EuroCRIS/CERIF o Research Object, como ontologías de propósito general para la etiquetación de metadatos: Prov-O, DCAT, etc.
Linked Data Platform
El servidor de datos enlazados es el núcleo de la arquitectura, encargándose de renderizar la información sobre todas las entidades. Para ello recoge peticiones HTTP del exterior y las redirecciona a los servicios correspondientes, aplicando negociación de contenidos, la cual ofrece la mejor representación de un recurso basado en las preferencias del navegador para los distintos tipos de medios, idiomas, caracteres y codificación.
Todos los recursos se publican siguiendo un esquema de URIs persistentes diseñado a medida. Cada entidad representada mediante una URI (investigador, proyecto, universidad, etc) dispone de una serie de acciones para consultar y actualizar sus datos, siguiendo los patrones propuestos por Linked Data Platform (LDP) y el modelo de 5 estrellas.
Este sistema garantiza además el cumplimiento con los principios FAIR (Findable, Accesible, Interoperable, Reusable) y publica automáticamente los resultados de aplicar dichas métricas sobre el repositorio de datos.
Publicación de datos abiertos
El sistema de procesamiento de datos se encarga de la conversión, integración y validación de datos de terceras partes, así como la detección de duplicados, equivalencias y relaciones entre entidades. Los datos surgen de varias fuentes, principalmente el SGI unificado de Hércules, pero también de SGIs alternativos, o de otras fuentes que ofrecen datos en formato FECYT/CVN (Curriculum Vitae Normalizado), EuroCRIS/CERIF y otros posibles.
El sistema de importación convierte todas estas fuentes a formato RDF y los registra en un repositorio de propósito específico para datos enlazados, denominado Triple Store, por su capacidad para almacenar tripletas de tipo sujeto-predicado-objeto.
Una vez importados, se organizan formando un grafo de conocimiento, fácilmente accesible, permitiendo realizar inferencias y búsquedas avanzadas potenciadas por las relaciones entre conceptos.
Ejemplo de grafo de conocimiento describiendo el proyecto ASIO
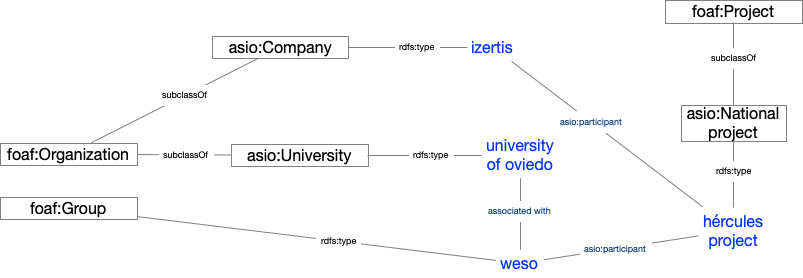
Resultados y conclusiones
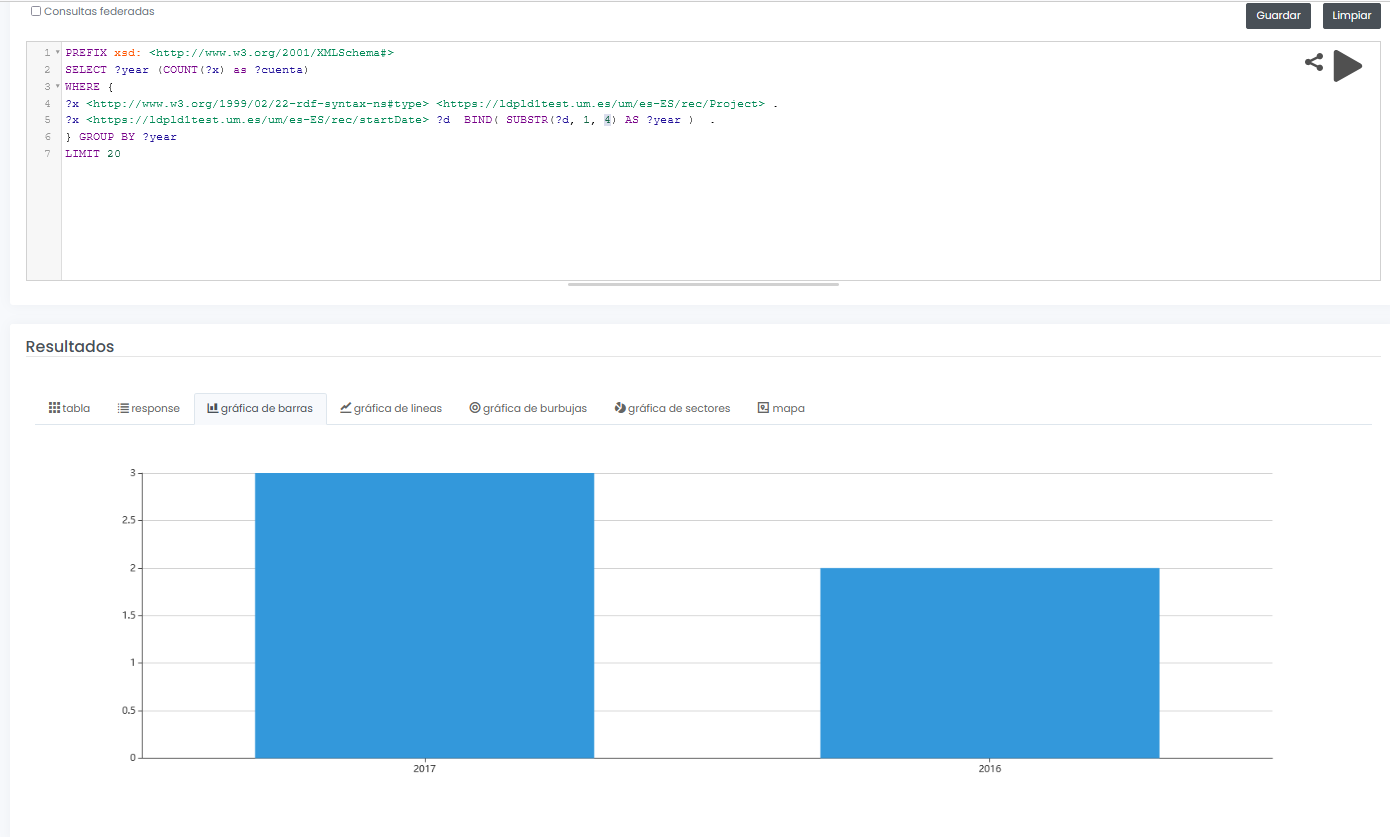
El sistema final no sólo permite ofrecer un interfaz gráfico para consulta interactiva y visual de datos de investigación, sino que además permite diseñar consultas SPARQL, como la que se muestra a continuación, incluso con la posibilidad de ejecutar la consulta de forma federada sobre todos los nodos de la red Hércules, y mostrar resultados de forma dinámica en diferentes tipos de gráficos y mapas.
En este ejemplo, se muestra una consulta (con datos limitados de prueba) de todos proyectos de investigación disponibles agrupados gráficamente por año:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
En definitiva, ASIO ofrece un marco común de publicación de datos abiertos enlazados, ofrecido como código libre y fácilmente adaptable a otros dominios. Para dicha adaptación, bastaría con diseñar un modelo de dominio específico, incluyendo la ontología y los procesos de importación y validación comentados en este artículo.
Actualmente el proyecto, en sus dos variantes (centralizada y descentralizada), se encuentra en proceso de puesta en pre-producción dentro de la infraestructura de la Universidad de Murcia, y en breve será accesible públicamente.
[1 Los grafos son una forma de representación del conocimiento que permiten relacionar conceptos a través de la integración de conjuntos de datos, utilizando técnicas de web semántica. De esta forma se puede conocer mejor el contexto de los datos, lo que facilita el descubrimiento de nuevo conocimiento.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Comentarios