Blog
Pensemos por un momento en cómo trabaja cualquier administración pública. Cada día se tramitan expedientes, se redactan informes técnicos, se levantan actas de reuniones y órganos colegiados, se intercambian miles de correos electrónicos, se publican contenidos en la sede electrónica, se digitalizan documentos en papel y se generan imágenes, grabaciones de audio y vídeos de todo tipo. Toda esa producción documental contiene información valiosa sobre cómo funciona la organización, qué decisiones toma y por qué las toma. Y, sin embargo, la mayor parte de esa información permanece fuera del radar de los sistemas de información tradicionales.
Cuando hablamos de los datos de una administración solemos pensar en bases de datos, hojas de cálculo, padrones, presupuestos o indicadores. Es lógico: durante décadas, la gestión del dato se ha centrado en este tipo de información estructurada. Sin embargo, esa visión solo muestra una pequeña parte de la realidad.
Gran parte del conocimiento que generan las administraciones no reside en sus bases de datos, sino en expedientes, informes, actas, resoluciones, correos electrónicos y contenidos multimedia que forman parte de su actividad diaria. Información que existe, que contiene un enorme valor y que, tradicionalmente, ha permanecido al margen de las estrategias de gobierno del dato.
La irrupción de la inteligencia artificial ha convertido ese patrimonio documental en una oportunidad sin precedentes, pero también ha puesto de manifiesto que la tecnología, por sí sola, no basta. En este artículo veremos por qué los datos no estructurados se han convertido en uno de los principales activos de las administraciones públicas, qué obstáculos impiden aprovechar todo su potencial y cómo una estrategia de gobierno del dato puede transformar ese enorme volumen de información en un recurso fiable, reutilizable y preparado para generar valor.
El dato que no vemos
La mejor forma de entender esta situación es imaginar un iceberg. La parte visible representa los datos estructurados sobre los que trabajan la mayoría de las aplicaciones corporativas, los cuadros de mando y las estadísticas oficiales. Bajo la línea de flotación, mucho más extensa, se encuentra el enorme volumen de información no estructurada que describe decisiones, procedimientos, conocimiento técnico y contexto administrativo.
Según estimaciones de firmas de análisis como IDG o Gartner, este tipo de contenido representa alrededor del 80 % de la información que maneja una organización, y todo apunta a que ese porcentaje seguirá creciendo.

Figura 1. Visual explicativo sobre el tipo de datos de una administración pública. Fuente: elaboración propia – datos.gob.es
La paradoja es evidente: la mayor parte del conocimiento de una administración no está en sus bases de datos, sino sumergida en sus documentos. Durante muchos años esa parte del iceberg apenas podía aprovecharse. Hoy, sin embargo, la situación ha cambiado radicalmente.
El valor latente que se está dejando pasar
Ignorar la parte sumergida del iceberg supone desperdiciar uno de los mayores activos de información del sector público. En esos contenidos se documentan la experiencia acumulada durante años, el conocimiento de los empleados públicos, las relaciones entre expedientes y buena parte del contexto que nunca llega a almacenarse en una base de datos. Su aprovechamiento tiene, por ello, un impacto directo y transversal en la gestión pública.
Cuando esa información puede localizarse, entenderse y relacionarse, un expediente deja de ser únicamente un conjunto de documentos para convertirse en una fuente de conocimiento reutilizable. El recorrido es siempre el mismo: los documentos contienen conocimiento institucional en forma de contexto, decisiones, criterios y evidencias, y es el gobierno del dato el que permite transformar ese conocimiento en valor público. Esto se traduce en mejores servicios para la ciudadanía, una mayor trazabilidad de la actividad administrativa, más transparencia, una mayor eficiencia interna y una mejor reutilización del conocimiento institucional.
Esta puesta en valor conecta, además, con una obligación legal muy concreta: el principio de "una sola vez", recogido en el artículo 28.2 de la Ley 39/2015, que reconoce el derecho de la ciudadanía a no aportar documentos que ya obren en poder de cualquier administración. Hacer efectivo ese derecho exige que la información que la administración ya posee, con frecuencia en forma de documentos, pueda localizarse, interpretarse e intercambiarse entre organismos: cada vez que se solicita a un ciudadano un dato que ya figura en un expediente, el problema no es normativo, sino de gestión e interoperabilidad de la información.
Pero hay un factor que ha convertido esta necesidad en una prioridad estratégica: la inteligencia artificial. Estos contenidos constituyen hoy la principal materia prima para las aplicaciones de IA, especialmente aquellas basadas en el procesamiento del lenguaje natural (PLN, por sus siglas en inglés) y los Grandes Modelos de Lenguaje (LLM, por sus siglas en inglés).
El aprovechamiento de la información no estructurada, sin embargo, no comenzó con la inteligencia artificial generativa. Desde hace años se utilizan técnicas como el reconocimiento óptico de caracteres, los procesos ETL (extraer, transformar, cargar, por sus siglas en inglés), el web scraping, las expresiones regulares, las taxonomías, los motores de reglas y las técnicas clásicas de procesamiento del lenguaje natural para extraer, clasificar, normalizar y trasladar información documental a estructuras explotables. Estas aproximaciones continúan siendo especialmente eficaces cuando las fuentes son relativamente homogéneas, los patrones son estables y las reglas de extracción pueden definirse de forma precisa. La inteligencia artificial no sustituye necesariamente estas técnicas, sino que amplía su alcance y permite abordar contenidos más variables, ambiguos o difíciles de procesar mediante reglas previamente definidas.
Hasta hace pocos años, gran parte de esta información podía explotarse mediante técnicas tradicionales, pero hacerlo exigía procesos muy específicos, dependientes del formato y difíciles de escalar o mantener cuando aumentaban la diversidad y la complejidad documental. Los documentos se generaban y almacenaban en sistemas y formatos muy diversos, su localización dependía a menudo de palabras clave o rutas de carpetas y la comprensión de los contenidos que no podían procesarse mediante reglas exigía una lectura manual lenta y costosa.La irrupción de la inteligencia artificial generativa ha cambiado completamente este escenario: hoy es posible resumir documentos, clasificar expedientes, extraer entidades relevantes, detectar relaciones entre documentos o responder preguntas sobre normativa de forma automática. La IA no ha creado el dato no estructurado; simplemente ha hecho posible aprovechar un patrimonio documental que llevaba décadas esperando su oportunidad.
El iceberg, por tanto, ya no es solo una metáfora sobre lo que no vemos: es una descripción bastante precisa de dónde está el valor que todavía no estamos capturando.
Sin embargo, existe un error frecuente: pensar que disponer de modelos de inteligencia artificial es suficiente para aprovechar todo ese conocimiento. Sin embargo, no lo es.
El obstáculo no es tecnológico, es de gobierno del dato
La tecnología ya está aquí: las herramientas capaces de procesar documentos y aplicar inteligencia artificial son cada vez más accesibles y evolucionan a un ritmo vertiginoso. Sin embargo, el verdadero reto no consiste en incorporar nuevos algoritmos, sino en gobernar adecuadamente la información sobre la que trabajan.
Un modelo de lenguaje puede resumir miles de expedientes en minutos, pero no puede determinar cuál es la versión válida de un documento, si su contenido sigue vigente o quién es responsable de mantenerlo actualizado. Únicamente puede trabajar con la información que recibe. Si esa información es incompleta, inconsistente o carece de contexto, sus respuestas heredarán esas mismas limitaciones.
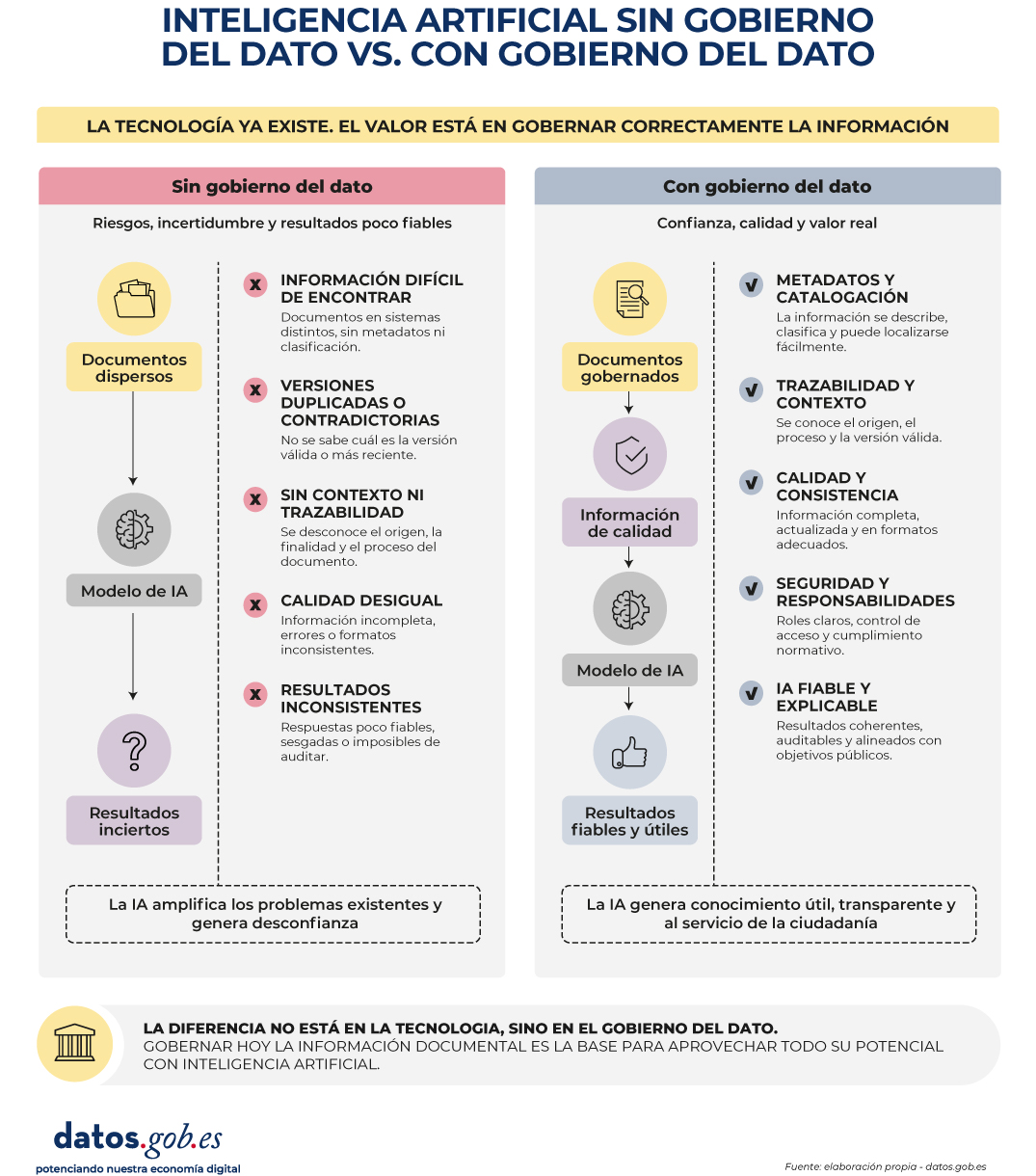
Figura 2. Visual explicativo sobre la inteligencia artificial sin gobierno del dato vs con gobierno del dato. Fuente: elaboración propia – datos.gob.es
Sin metadatos, catalogación, clasificación, criterios de calidad y responsabilidades claras, el dato no estructurado deja de ser un activo para convertirse en un pasivo organizativo: abundante, costoso de mantener y difícil de localizar, interpretar y reutilizar. Aplicar inteligencia artificial sobre documentación mal gobernada no genera conocimiento; genera respuestas aparentemente plausibles construidas sobre información poco fiable, probablemente el peor escenario posible para una administración pública.
Esta situación nos lleva directamente a un concepto que ya analizamos en el artículo De la ciénaga al lago: cómo evitar que tus datos se conviertan en un pantano. La acumulación de información sin gobierno acaba produciendo un data swamp, porque acumular información no equivale a generar conocimiento. Si esto ya es cierto para los datos estructurados, lo es aún más para los repositorios documentales, donde el volumen crece más rápido y el contexto se pierde antes. Sin gobierno del dato, la organización actúa como un simple trastero digital; con gobierno del dato, ese contenido se transforma en un activo útil, fiable y preparado para su explotación, tanto por las personas como por la inteligencia artificial.
La evolución natural del dato
El gobierno del dato cumple aquí otra función menos evidente y, sin embargo, fundamental: ayudar a identificar cuándo una información que nació como no estructurada debe dejar de serlo.
Muchas administraciones siguen almacenando determinados datos en documentos de texto, formularios PDF o campos de observaciones simplemente porque así se diseñó el proceso original. Con el paso del tiempo, esa información empieza a repetirse en miles de expedientes y deja de ser una excepción para convertirse en un patrón estable.
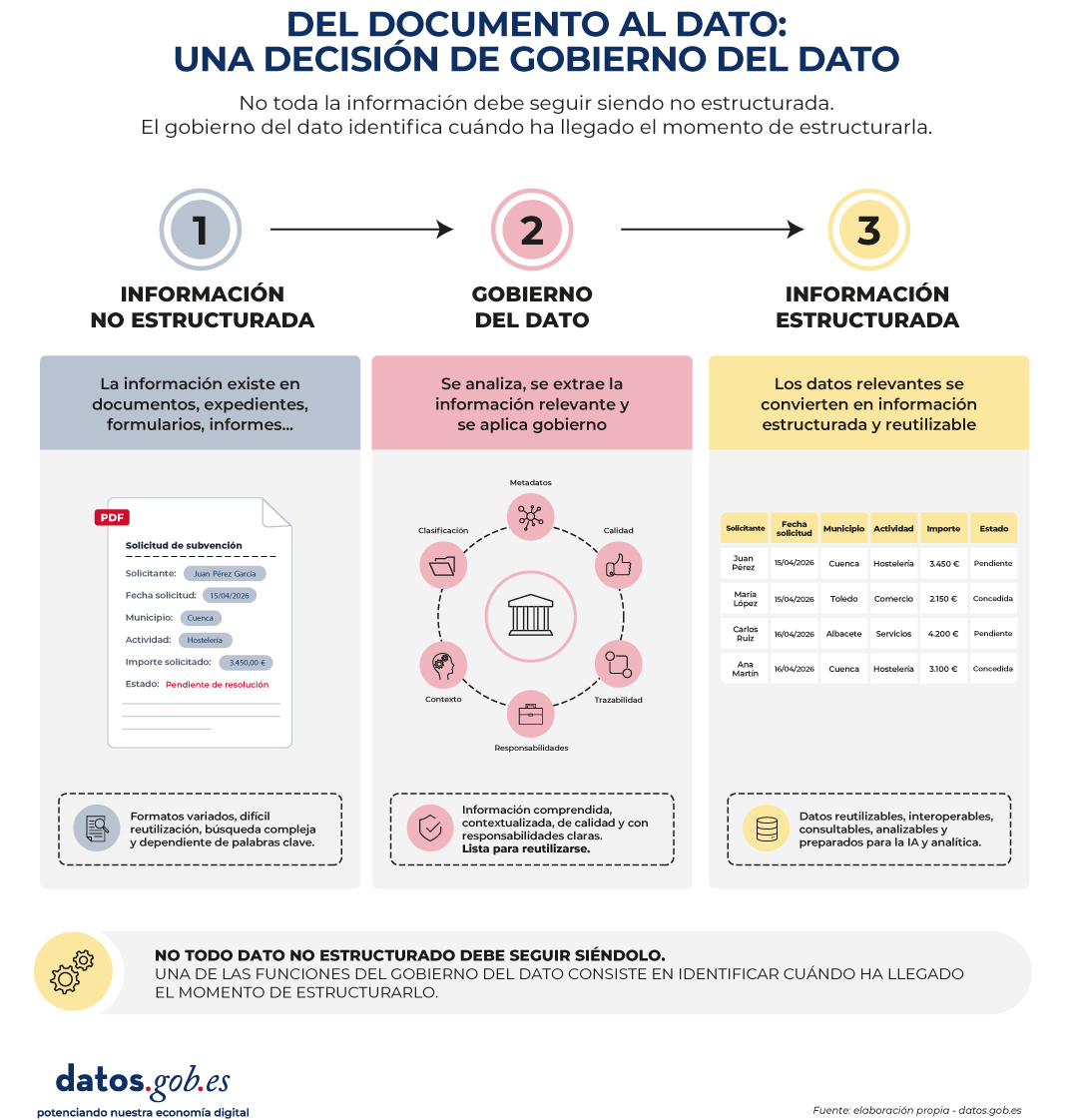
Figura 3. Visual explicativo sobre el paso del documento al dato. Fuente: elaboración propia – datos.gob.es
No todo dato no estructurado debe seguir siéndolo. Una de las funciones del gobierno del dato consiste precisamente en identificar cuándo ha llegado el momento de estructurarlo. Gobernar el dato significa decidir qué información debe conservar su riqueza documental y cuál conviene transformar en datos estructurados para facilitar su validación, interoperabilidad, explotación y reutilización. Es una decisión de diseño de la información, no una consecuencia inercial de cómo comenzaron a hacerse las cosas hace décadas.
Cómo activar ese valor: una hoja de ruta de gobernanza
Aprovechar este patrimonio documental no requiere comenzar implantando inteligencia artificial. Requiere construir primero unas bases sólidas de gobierno del dato. Los principios son los mismos que ya aplicamos al dato estructurado, extendidos ahora al conjunto de la información de la organización.
|
Pilar |
Objetivo |
| Políticas y responsabilidades | Definir quién es responsable de cada tipo de contenido y bajo qué reglas se crea, modifica, comparte y elimina. |
| Metadatos | Describir los documentos para que puedan localizarse, comprenderse y relacionarse automáticamente. |
| Clasificación | Organizar la información mediante taxonomías, tipologías documentales y niveles de sensibilidad. |
| Calidad | Garantizar que la información esté completa, actualizada, libre de duplicidades y preparada para su reutilización. |
| Interoperabilidad | Facilitar que documentos, expedientes y sistemas puedan intercambiar información mediante estándares comunes. |
| Ciclo de vida | Gestionar la información desde su creación hasta su archivo o eliminación, aplicando criterios homogéneos durante todo el proceso. |
Figura 4. Tabla sobre los pilares y objetivos de la hoja de ruta de gobernanza. Fuente: elaboración propia - datos.gob.es
Como referencia metodológica para recorrer este camino, España dispone del ecosistema de normas UNE sobre gobierno, gestión y calidad del dato (UNE 0077, UNE 0078, UNE 0079, UNE 0080 y UNE 0081). Este marco permite abordar de forma homogénea la gestión tanto del dato estructurado como del no estructurado, apoyándose en procesos, responsabilidades y mejora continua para convertir la información en un activo gobernado y medible.
Más allá del almacenamiento
Durante años, las administraciones públicas han realizado un enorme esfuerzo por digitalizar documentos y expedientes. Ese proceso ha permitido sustituir el papel por archivos electrónicos, pero digitalizar no siempre significa gestionar mejor la información.
El verdadero reto de los próximos años no consiste en almacenar más documentos, sino en convertir ese inmenso patrimonio documental en un activo gobernado, reutilizable y preparado para generar valor: mejorar los servicios públicos, reforzar la transparencia y proporcionar una base fiable para las aplicaciones de inteligencia artificial que ya están transformando la gestión pública.
Y conviene no perder de vista que el iceberg seguirá creciendo. La producción documental de las administraciones continuará aumentando, y con ella el volumen de conocimiento que permanece bajo la superficie. La diferencia entre las organizaciones que conviertan esa masa oculta en una ventaja y las que la sufran como un lastre no estará en la tecnología que utilicen, sino en cómo gobiernen su información.
Porque, como en todo iceberg, el mayor valor no está en la parte visible. Está bajo la superficie, esperando a que las administraciones desarrollen las capacidades necesarias para descubrirlo, comprenderlo y ponerlo al servicio de la ciudadanía.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Imagina un edificio sin mantenimiento. Al principio funciona perfectamente: las puertas abren, la fontanería fluye, todo está en orden. Pasa el tiempo y nadie se ocupa de las pequeñas cosas: una tubería que gotea, una ventana que no cierra bien, papeles que se acumulan en los pasillos. Cinco años después, el edificio sigue en pie, pero usarlo se ha convertido en una odisea. Nadie sabe dónde está nada, hay habitaciones a las que ya nadie entra, y cada vez que intentas arreglar algo aparecen tres problemas más.
Con los datos pasa lo mismo. Una organización puede empezar con las mejores intenciones: sistemas bien diseñados, datos ordenados, todo documentado. Pero sin mantenimiento activo, esos datos que, al principio, eran un activo valioso acaban convirtiéndose en una ciénaga: un espacio donde la información existe, pero es imposible encontrarla, entenderla o confiar en ella.
Del data lake al data swamp: una diferencia clave
El concepto de data lake se presentó como la solución definitiva: un repositorio centralizado donde almacenar datos en su formato nativo para que analistas y científicos pudieran explorarlos libremente. Muchos de estos lagos, sin embargo, han terminado convirtiéndose en lo que la industria llama data swamp, o pantano de datos: un repositorio de datos que, aunque contiene mucha información, se ha vuelto inútil en la práctica.
La diferencia entre un lago y una ciénaga no está en la tecnología. Dos organizaciones pueden usar arquitecturas similares y obtener resultados muy distintos. Lo que marca la diferencia es cómo se gestionan los datos: si se conocen sus responsables, si están descritos, si se puede evaluar su calidad, si se mantienen actualizados y si existen reglas claras para incorporarlos, transformarlos o retirarlos. Un data lake aporta valor cuando está gobernado; el pantano aparece cuando el almacenamiento crece más rápido que la capacidad de entender y reutilizar lo que se guarda.
¿Cómo se forma una ciénaga de datos?
El paso de un entorno saludable a uno degradado suele ser silencioso. Los pantanos, rara vez, son el resultado de un gran error puntual; son el efecto acumulado de pequeñas decisiones cotidianas: datos que se cargan sin documentar, sistemas que cambian sin avisar, responsables que se van y nadie sustituye. Con el tiempo, el repositorio pasa de ser un activo estratégico a un lastre operativo. Y, lo peor, es que este deterioro suele ser invisible hasta que alguien intenta hacer algo con los datos y descubre que no puede.
-
Ingesta sin propósito: se almacenan datos "por si acaso", sin un proceso de catalogación previo. Una organización empieza a capturar datos de nuevas fuentes (sensores, formularios, APIs externas) sin establecer quién los valida, cómo se documentan o dónde se almacenan de forma ordenada.
-
Falta de documentación desde el origen: los datos se ingresan sin explicar qué significan, de dónde vienen, con qué frecuencia se actualizan o bajo qué reglas se capturan. No se registra el linaje ni el propósito de cada conjunto de datos.
-
Acumulación sin criterio: se guarda "todo por si acaso", sin una política clara de qué datos son relevantes, cuánto tiempo deben conservarse o cuándo pueden archivarse o eliminarse.
-
Cambios organizativos sin seguimiento: personas que conocían los datos dejan la organización, se reorganizan departamentos, se migran sistemas… y nadie actualiza la documentación ni traspasa el conocimiento.
-
Proyectos piloto que se quedaron a medias: se cargan datos para un proyecto experimental, el proyecto termina (o nunca arranca), pero los datos se quedan ahí, sin contexto ni responsable.
-
Ausencia de controles de calidad: no se validan los datos antes de ingresar al sistema ni se monitorizan después, por lo que los errores y las inconsistencias se acumulan silenciosamente.
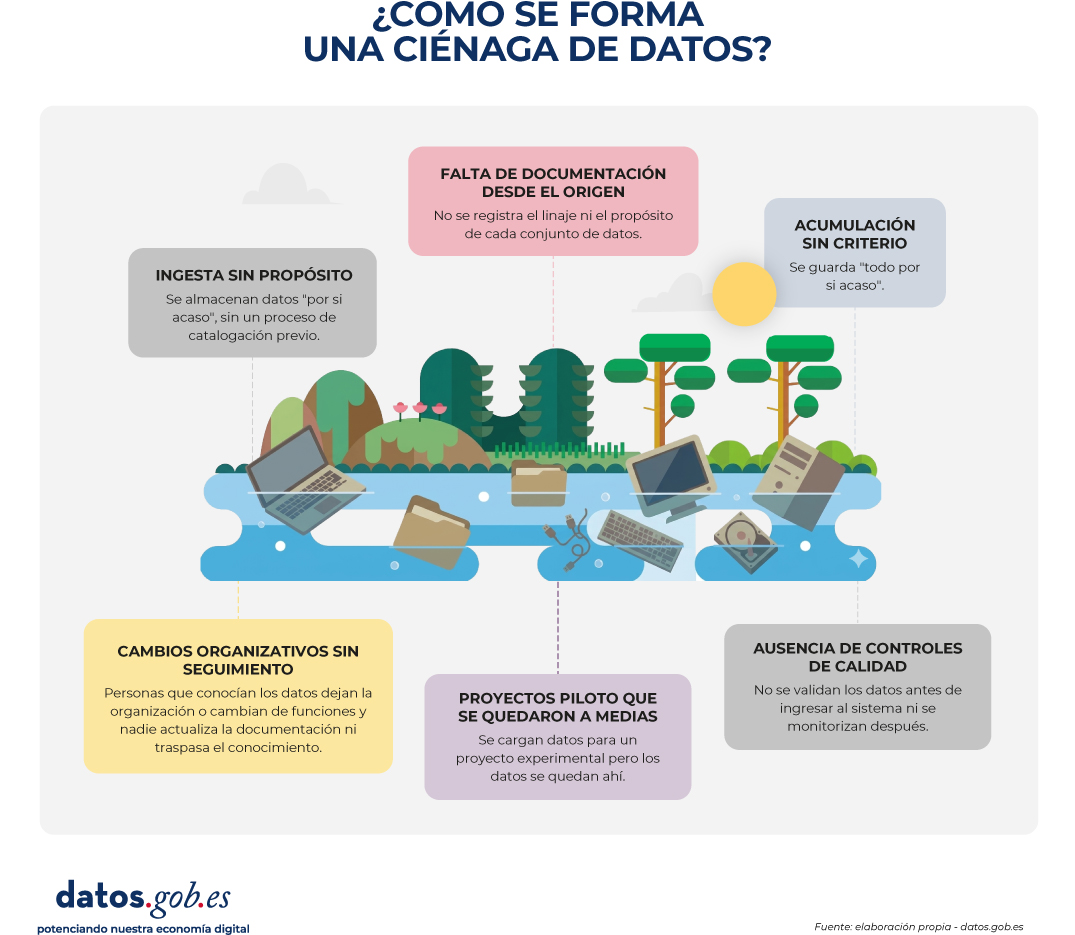
Figura 1. Visual explicativo sobre el proceso de formación de una ciénaga de datos. Fuente: elaboración propia - datos.gob.es
Data drift: cuando los datos envejecen sin que te des cuenta
Relacionado con los pantanos, el data drift (deriva de datos) es un fenómeno especialmente relevante en proyectos de inteligencia artificial, aunque afecta a cualquier análisis basado en datos históricos. Ocurre cuando los datos dejan de representar la realidad actual, bien porque el contexto ha cambiado, bien porque las fuentes se han modificado sin que nadie lo haya documentado.
Podemos identificar varios tipos de deriva:
-
Drift en las fuentes: un sistema de origen cambia su estructura, añade campos, elimina otros o modifica la lógica de cálculo de un indicador, pero nadie actualiza la documentación ni avisa a los usuarios de esos datos.
-
Drift en los patrones: la realidad que los datos describen cambia. Por ejemplo, los patrones de movilidad urbana antes y después de una pandemia son radicalmente distintos. Un modelo entrenado con datos previos dejará de funcionar bien si no se recalibra.
-
Drift en las definiciones: el significado de un campo cambia con el tiempo. Imaginemos que "vivienda vacía" se redefinió en 2022 para incluir segundas residencias, pero nadie actualizó la documentación. Quien compare datos de 2020 y 2024 estará mezclando conceptos distintos sin saberlo.
Como vimos en el post sobre estructuras organizativas de gobierno del dato para IA, un sistema de IA es tan bueno como los datos que lo alimentan. Si esos datos envejecen, el sistema empieza a fallar. Y si no hay mecanismos de monitorización activa, el problema puede pasar desapercibido durante meses. Un ejemplo claro es lo ocurrido durante la COVID-19, donde varios modelos predictivos vieron cómo su precisión caía drásticamente porque habían sido entrenados con patrones de comportamiento que dejaron de aplicarse de un día para otro. Es un caso extremo, pero ilustra bien el riesgo: un modelo es tan vigente como los datos que lo sustentan. Cuanto peor gobernados estén esos datos, más difícil será detectar estos cambios a tiempo.
Cómo evitar la ciénaga
Los pantanos de datos se pueden evitar. La clave está en adoptar un enfoque proactivo, basado en el mantenimiento continuo y en responsabilidades claras.
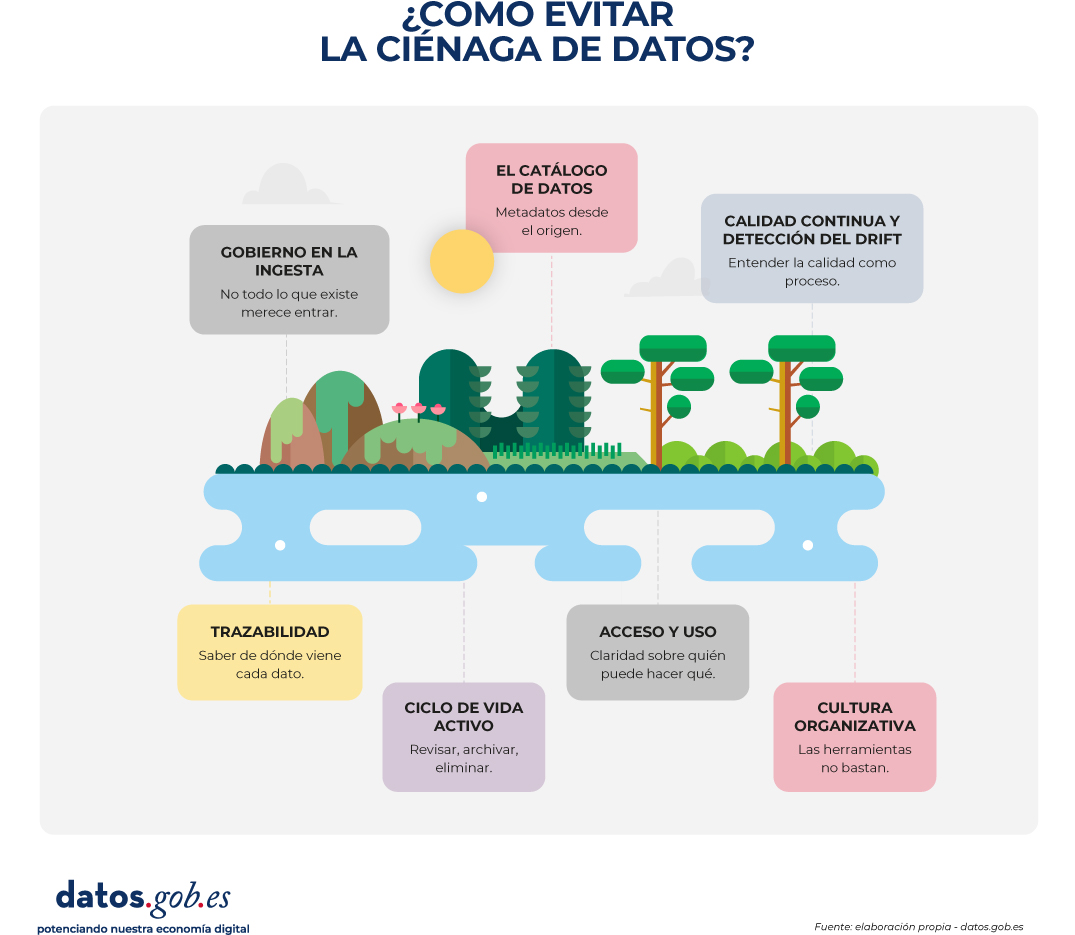
Figura 2. Visual explicativo sobre cómo evitar que un pantano de datos se convierte en una ciénaga. Fuente: elaboración propia - datos.gob.es
-
Gobierno en la ingesta: no todo lo que existe merece entrar: el primer error que lleva a la ciénaga es la ausencia de filtros en la entrada. Establecer una zona de aterrizaje (landing zone) donde se verifiquen unos mínimos antes de mover los datos a las zonas de consumo es fundamental. Eso requiere definir quién es responsable de cada conjunto de datos (data owner), quién garantiza su calidad y documentación en el día a día (data steward), y bajo qué criterios se puede cargar algo al sistema. Sin este marco básico, cada dato que entra es una semilla potencial de desorden.
-
El catálogo de datos: metadatos desde el origen: los metadatos son la capa de información que permite entender, encontrar y confiar en los datos. Sin ellos, un repositorio es una caja negra. Un buen catálogo responde a preguntas básicas: ¿qué contiene este conjunto de datos?, ¿de dónde viene?, ¿quién lo mantiene?, ¿cuándo se actualizó por última vez?, ¿qué significa cada campo? La catalogación no es una tarea que se hace una vez y se olvida. Es un proceso continuo: cada modificación actualiza la descripción, cada error detectado se documenta y corrige, cada reutilización genera información que mejora la documentación. Las herramientas de catalogación automatizada pueden ayudar a escanear repositorios y detectar cambios, pero la responsabilidad de validar esa información sigue siendo humana. En el ámbito de los datos abiertos, el perfil de metadatos DCAT-AP-ES ofrece un estándar común para describir conjuntos de datos de forma homogénea; el mismo enfoque puede aplicarse a cualquier repositorio interno.
-
Calidad continua y detección del drift: la calidad de los datos no es un estado, es un proceso. Un conjunto de datos puede ser excelente hoy y volverse inservible mañana sin monitorización activa. Las prácticas útiles incluyen validar los datos antes de cargarlos al sistema, establecer métricas de calidad revisadas periódicamente, configurar alertas que detecten desviaciones respecto a patrones históricos y hacer auditorías manuales para capturar errores que las métricas automáticas no ven. En España, la especificación UNE 0081 establece criterios para evaluar dimensiones como exactitud, completitud, consistencia o actualidad, lo que permite medir la calidad de forma objetiva y establecer compromisos concretos con los usuarios. En contextos donde los datos alimentan modelos de IA, las técnicas estadísticas de detección de drift permiten comparar la distribución actual de los datos con la de entrenamiento y lanzar alertas cuando la diferencia supera un umbral. Detectar el problema a tiempo permite reentrenar modelos antes de que su rendimiento se degrade.
-
Trazabilidad: saber de dónde viene cada dato: en entornos complejos es necesario conocer el origen de cada dato, las transformaciones que ha sufrido, los procesos que lo han generado y los productos que dependen de él. El linaje de datos permite detectar el impacto de un cambio en origen, depurar errores o cumplir con obligaciones legales. Sin él, cualquier problema se convierte en una búsqueda en el laberinto.
-
Ciclo de vida activo: revisar, archivar, eliminar: mantener datos obsoletos o irrelevantes aumenta el ruido, dificulta las búsquedas y consume recursos. Una política de ciclo de vida del dato define cuánto tiempo debe conservarse cada tipo de dato, cómo moverse a sistemas de almacenamiento más económicos cuando ya no se usan activamente, y cuándo pueden eliminarse —siempre respetando las obligaciones legales en materia de protección de datos—. Revisiones periódicas permiten identificar conjuntos que nadie ha consultado en meses, documentación desactualizada o datos que ya no tienen valor operativo. Esta "limpieza activa" evita que el repositorio crezca indefinidamente.
-
Acceso y uso: claridad sobre quién puede hacer qué: un pantano también aparece cuando no está claro quién puede acceder a qué datos y para qué. Las políticas de acceso deben clasificar los datos según su sensibilidad, definir permisos, documentar restricciones legales o éticas y asegurar que los usuarios conocen las condiciones de uso. En el ámbito de los datos abiertos, la apertura debe ir acompañada de información clara sobre licencias, formatos, periodicidad y contexto.
-
Cultura organizativa: las herramientas no bastan: las herramientas y los procesos son importantes, pero sin una cultura que valore la calidad del dato cualquier sistema acaba degradándose. Fomentar esa cultura requiere formación continua para que quienes generan o mantienen datos entiendan por qué importa la documentación, visibilidad directiva que sitúe la calidad del dato como prioridad estratégica, reconocimiento a los equipos que mantienen datos bien gestionados, y canales que permitan a quienes reutilizan datos reportar errores y sugerir mejoras.
Mantener datos limpios no puede depender del esfuerzo heroico de una persona. Tiene que ser parte del modo de trabajo habitual. La gobernanza bien diseñada es una ayuda para trabajar mejor, no un freno burocrático.
Marcos de referencia en España
Para abordar estos retos de forma estructurada existen marcos concretos. La familia de especificaciones UNE —impulsada desde la Dirección del Dato— cubre gobierno (UNE 0077), gestión (UNE 0078), gestión de calidad (UNE 0079), madurez de procesos de datos (UNE 0080), evaluación de datasets (UNE 0081), e implantación progresiva (UNE 0085). Para datos abiertos, DCAT-AP-ES establece requisitos sobre identificación, descripción, formatos y condiciones de uso. Estos marcos están pensados para aplicarse de forma incremental: se empieza por lo más crítico, se consolida y se avanza.
Conclusión: del pantano al valor, la gobernanza como sistema de depuración
Los pantanos de datos son prevenibles y, si ya existen, reversibles. Los datos solo generan valor cuando pueden encontrarse, entenderse y utilizarse con confianza. Almacenar información es necesario, pero sin gobierno, calidad, metadatos, trazabilidad y responsabilidades claras, incluso la plataforma más avanzada puede convertirse en un entorno confuso e inaprovechable.
Los beneficios de hacerlo bien son tangibles: equipos que dedican menos tiempo a buscar y limpiar datos, modelos de IA que se mantienen precisos porque el drift se detecta a tiempo, usuarios externos que confían en los datos porque saben que están actualizados. En un contexto donde los datos abiertos, los espacios de datos y la , , artificial adquieren cada vez más protagonismo, cuidar la base sobre la que se construyen estos ecosistemas es una decisión estratégica. El reto no es tener más datos, sino disponer de mejores datos: comprensibles, gobernados y listos para reutilizarse con confianza.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Imagina que tienes que cruzar datos de calidad del aire con padrón municipal, imágenes de satélite y un mapa de zonas inundables. Cada fuente llega en su propio sistema de referencia, su propia rejilla, su propio formato y su propia escala. Antes de poder analizar nada, dedicas horas —a veces semanas— a reproyectar, alinear, simplificar y reconciliar geometrías. Es un trabajo invisible que consume buena parte de los recursos de cualquier proyecto con dato espacial. Ahora imagina que todas esas fuentes hablan el mismo idioma desde el principio: el de un sistema de celdas globales, jerárquicas e interoperables que cubre toda la Tierra. Eso es, en esencia, lo que propone un DGGS.
DGGS son las siglas de Discrete Global Grid System (Sistema de Rejilla Global Discreta). En los últimos años han pasado de ser un concepto académico a convertirse en una infraestructura operativa, gracias al impulso de estándares como ISO 19170-1 (2021) y la reciente OGC API — DGGS, aprobada como estándar oficial en 2025. Para quienes nos dedicamos al gobierno del dato, esto no es una curiosidad técnica: es una nueva palanca para garantizar interoperabilidad, calidad y trazabilidad sobre la información geoespacial. En este artículo explicamos qué es exactamente un DGGS, por qué sus propiedades son relevantes para el dato, y cómo iniciativas como el piloto AI-DGGS de OGC están demostrando su valor.
Qué es exactamente un DGGS
La forma más sencilla de imaginar un DGGS es pensar en una pelota cubierta por un mosaico de celdas que encajan perfectamente entre sí, sin huecos ni solapes. La diferencia con la rejilla de latitud-longitud que conocemos está en cómo se construyen esas celdas: en lugar de simplemente cortar el globo en “cuadrículas” sobre el mapa, un DGGS parte de una figura geométrica regular —normalmente un icosaedro, un poliedro de 20 caras triangulares— que se ajusta sobre la esfera terrestre. Cada cara se subdivide después en celdas hexagonales, triangulares o cuadrangulares, y el resultado es una teselación homogénea que evita la deformación clásica de los mapas planos.
De este planteamiento se derivan las cuatro propiedades que caracterizan a cualquier DGGS conforme al estándar:
- Cobertura global y exhaustiva. Las celdas cubren toda la superficie terrestre. Cualquier punto del planeta cae en una y solo una celda.
- Área aproximadamente igual. Todas las celdas del mismo nivel tienen áreas equivalentes, sin la distorsión de las cuadrículas geográficas tradicionales (donde una celda cerca del ecuador puede ocupar varias veces más superficie que una celda en latitudes altas).
- Identificadores únicos. Cada celda lleva asociado un código único (Cell ID) que la identifica de forma inequívoca en todo el sistema. En lugar de decir “lat 40,4168, lon -3,7038” para localizar la Puerta del Sol, un DGGS diría algo como “celda 8a3969a05a07fff”.
- Jerarquía anidada. Cada celda se subdivide en un número fijo de celdas hijas (4, 7 o 9, dependiendo del DGGS) que cubren exactamente la celda original. Eso permite navegar entre niveles de resolución sin recalcular nada.
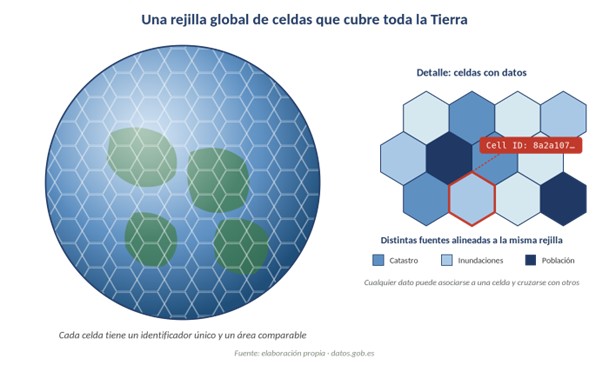
Figura 1. Una rejilla DGGS divide la Tierra en celdas comparables y con identificador propio. Cualquier dato —catastro, inundaciones, población— puede asociarse a una celda y cruzarse con el resto. Fuente: elaboración propia · datos.gob.es
La diferencia conceptual respecto a un sistema clásico de coordenadas es importante. Las coordenadas son continuas: existe un infinito de pares (lat, lon) entre dos puntos cualesquiera. Un DGGS, en cambio, es discreto: el conjunto de celdas a un nivel dado es finito y enumerable. Eso lo hace especialmente eficiente para almacenar, indexar y consultar grandes volúmenes de datos en bases de datos y procesos masivos. También simplifica muchas operaciones comunes que dejan de ser cálculos geométricos para convertirse en búsquedas sobre identificadores “¿qué hay alrededor de este punto?”, “¿qué zonas se solapan?” o “¿qué valor agregado tiene esta región?”, que pasan a ser búsquedas y operaciones sobre identificadores.
Las implementaciones más conocidas son H3 (de Uber, basada en hexágonos), S2 (de Google, basada en cuadrados sobre un cubo), rHEALPix (de origen astronómico) y la librería abierta DGGAL que utiliza el propio piloto AI-DGGS de OGC. Cada una toma decisiones distintas sobre forma de celda, factor de subdivisión y proyección, pero todas comparten la idea esencial de “tesela hierarquizada del planeta”.
Tres propiedades que cambian las reglas del juego
De las propiedades anteriores se derivan tres características que tienen consecuencias muy prácticas para quien trabaja con datos geoespaciales:
1. Jerarquía multiescala
Cada celda tiene un padre en el nivel superior, un número fijo de hijas en el nivel inferior y vecinos bien definidos en su mismo nivel. Esa estructura piramidal permite subir o bajar de resolución simplemente recorriendo la jerarquía, sin recalcular ninguna geometría. Agregar barrios para obtener una cifra municipal, o desagregar un indicador provincial al detalle de manzana, es seguir la jerarquía hacia arriba o hacia abajo.
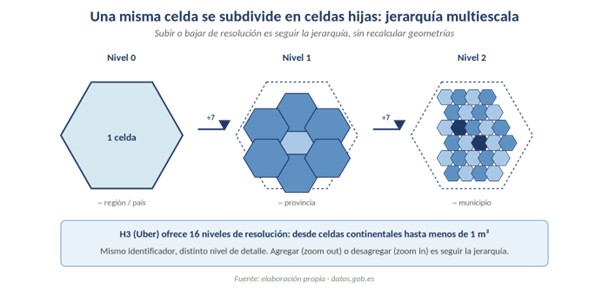
Figura 2. Una celda se subdivide en celdas hijas que, a su vez, vuelven a subdividirse. Mismo identificador estable, distinto nivel de detalle. Fuente: elaboración propia · datos.gob.es
La consecuencia práctica es directa: con un DGGS se puede pasar de celdas de varios kilómetros a celdas de menos de un metro cuadrado simplemente cambiando el nivel de resolución, manteniendo el mismo sistema de referencia. H3, por ejemplo, ofrece 16 niveles distintos. Y, más importante todavía, los datos no se duplican: el mismo dataset puede consumirse a la resolución adecuada para cada caso de uso —operativo, de gestión o estratégico— sin mantener réplicas separadas.
2. Área (aproximadamente) igual
Esta propiedad parece técnica, pero es decisiva. En las rejillas tradicionales en lat-long, una celda en el ecuador puede tener varias veces más superficie que una celda en Escandinavia. Cuando se calcula una densidad de población, una concentración de contaminantes o una intensidad de tráfico, esa diferencia de área distorsiona los resultados y obliga a aplicar correcciones. Con celdas de área equivalente, los cómputos son comparables entre regiones del planeta sin ajustes ad hoc.
3. Identificadores como sistema de referencia
Aquí está la idea más potente del estándar OGC, el identificador de cada celda funciona como una dirección. Pensemos en algo cotidiano: cuando enviamos un paquete, no escribimos las coordenadas GPS de la puerta del destinatario; escribimos un código postal y una calle. Todo el mundo —el remitente, la empresa de mensajería, el cartero— entiende esa dirección y la usa sin necesidad de hacer cálculos. Con un DGGS pasa algo parecido: en lugar de manejar coordenadas para localizar las cosas, usamos el código de la celda. Y, lo más importante, ese mismo código vale para localizar el dato, para preguntar por él y para combinarlo con datos de otras fuentes. Si dos organizaciones distintas dicen que algo está en la celda 8a3969a05a07fff, están hablando del mismo trozo de territorio sin posibilidad de confusión. Eso ahorra muchísimo trabajo previo de "poner los datos en la misma página" antes de poder analizarlos.
¿Por qué importa esto en el gobierno del dato?
El gobierno del dato persigue tres grandes objetivos: que los datos sean encontrables, fiables y reutilizables. Para conseguirlo, las organizaciones invierten en catálogos, en políticas de calidad, en marcos de linaje, en glosarios de negocio y en mecanismos de control de acceso. Cuando los datos llevan dimensión geoespacial, todo eso se complica: cada dataset puede haber sido capturado en una proyección distinta, con un detalle distinto y bajo un modelo de actualización distinto. Los DGGS no resuelven todos esos problemas, pero atacan varios de los más costosos.
- Interoperabilidad real entre dominios. Catastro, medio ambiente, movilidad, salud, energía y emergencias trabajan tradicionalmente con sus propios formatos, escalas y proyecciones. Cuando una organización tiene que cruzar, por ejemplo, datos de calidad del aire de una red de sensores con padrón municipal y con la red de transporte público, dedica una parte sustancial del esfuerzo a homogeneizar geometrías. Codificar la información sobre un mismo DGGS convierte ese cruce en un join sobre identificadores, que es la operación más básica y eficiente que existe en cualquier base de datos.
- Calidad y consistencia espacial. Los problemas clásicos de la información geográfica —solapes mínimos, huecos imperceptibles, geometrías inválidas, pequeñas diferencias entre versiones del mismo límite administrativo— desaparecen o se reducen mucho cuando la geometría se fija a celdas estables y conocidas. El identificador de celda actúa como una clave canónica: dos sistemas que asignen un dato a la misma celda están hablando, sin ambigüedad, del mismo trozo de territorio.
- Linaje y trazabilidad. Saber cómo se ha calculado un indicador es esencial en cualquier proceso de gobierno del dato. Con un DGGS, el linaje de un dato espacial se puede expresar de forma muy compacta: “este indicador se calculó al nivel 9 de H3, sobre estas celdas concretas, agregando estas fuentes”. Esa información cabe en metadatos estándar de un catálogo y es trivial de auditar a lo largo del tiempo.
- Análisis multiescala sin duplicar datos. Las administraciones suelen mantener la misma información a varias resoluciones —una versión para la web ciudadana, otra para gestión municipal, otra para el catálogo de datos abiertos— con el coste de mantenimiento que eso implica. Con DGGS, el mismo dataset puede consumirse al nivel adecuado en cada caso, agregando o desagregando sobre la marcha.
- Privacidad y agregación por diseño. Subir de resolución es un mecanismo natural de anonimización por agregación. En datos de salud, movilidad o consumo, agregar a una celda mayor reduce el riesgo de reidentificación manteniendo la utilidad analítica. Y, a diferencia de otros enfoques, esa agregación es reproducible: cualquier analista que parta del mismo nivel de celda obtendrá los mismos números.
- Mejor encaje con la analítica moderna y la IA. Las arquitecturas de datos actuales —data lakes, almacenes columnares, motores como BigQuery o Snowflake— funcionan especialmente bien con identificadores cortos como claves de partición. Y, como veremos más adelante, los modelos de IA también se benefician de poder razonar sobre celdas en lugar de sobre geometrías complejas.
DGGS en la práctica: quién los está usando
Aunque los DGGS pueden parecer un estándar reciente, varias organizaciones llevan años usando estos sistemas en producción con resultados muy concretos. Algunos ejemplos ilustrativos:
- Uber con H3. H3 nació dentro de Uber para resolver un problema muy concreto: calcular precios dinámicos y casar oferta y demanda en cada ciudad. La compañía agrupa los millones de eventos diarios (viajes, peticiones, posiciones de conductores) en celdas hexagonales y, sobre esa rejilla, calcula tarifas, predice demanda y optimiza despachos. La librería es de código abierto desde 2018 y se ha convertido en estándar de facto en muchos sectores.
- Foursquare y los “Hex Tiles”. El servicio de inteligencia de localización de Foursquare almacena y sirve sus datos sobre puntos de interés, visitas y movilidad usando Hex Tiles, un sistema de teselas basado en H3. Esto les permite ofrecer enriquecimiento de datos a sus clientes —cadenas de retail, plataformas de publicidad, urbanistas— con una sola clave de unión entre datasets que originalmente eran heterogéneos.
- Geoscience Australia y AusPIX. El gobierno australiano ha desarrollado AusPIX, una implementación de rHEALPix orientada a referenciar datos estadísticos, ambientales y de infraestructura sobre una misma rejilla. La iniciativa forma parte de su estrategia Loc-I (Location Index) y permite vincular información del censo, indicadores ambientales y datos sectoriales como capas alineadas sobre celdas comparables —un caso paradigmático de gobierno del dato espacial a escala nacional.
- Investigación en agricultura digital. Equipos de investigación españoles, como el Advanced Information Systems Laboratory de la Universidad de Zaragoza, están explorando DGGS como infraestructura de soporte a la transformación digital del sector agrario, donde conviven datos de muy distinta resolución: parcelas catastrales, imágenes Sentinel, mediciones de sensores y modelos climáticos.
- Inventarios de emisiones de metano. Trabajos recientes proponen rejillas DGGS como base para inventariar emisiones de metano del sector de petróleo y gas, donde la trazabilidad espacial y la comparabilidad entre regiones son críticas para la regulación internacional.
El patrón común en todos los casos es el mismo: cuando varias fuentes de datos heterogéneas tienen que combinarse a escala (continental, nacional o global) y el coste de mantener todo “en formato propio” se vuelve prohibitivo, los DGGS aparecen como la pieza que simplifica la integración.
El piloto AI-DGGS de OGC: cuando la IA necesita un “cerebro espacial”
Uno de los desarrollos más ilustrativos para entender el alcance práctico de los DGGS es el OGC AI-DGGS for Disaster Management Pilot, desarrollado entre 2025 y 2026 con el patrocinio de Natural Resources Canada y el USGS estadounidense, entre otros. El piloto se centró en la gestión de inundaciones en la cuenca del Río Rojo, en Manitoba (Canadá), un corredor de alto riesgo entre Winnipeg y la frontera con Estados Unidos.
La pregunta de partida no era trivial: en una emergencia, los responsables tienen demasiados datos, pero muy poca información accionable. Imágenes de satélite, modelos hidráulicos, capas de infraestructuras críticas y censos de población hablan formatos distintos. ¿Es posible que un usuario formule preguntas en lenguaje natural —del tipo “¿qué carreteras de Winnipeg pueden quedar cortadas?”— y obtenga respuestas trazables y precisas?
El planteamiento del piloto se apoya en dos piezas. La primera es un tejido digital (digital fabric) construido sobre DGGS: distintos servidores publican sus datos —hidrología, modelos de inundación, edificación, redes viarias— alineados sobre la misma rejilla global, accesible vía la OGC API — DGGS. La segunda es una capa de IA con arquitectura RAG (Retrieval-Augmented Generation): el modelo de lenguaje construye la respuesta recuperando contenidos autoritativos del propio DGGS.
La clave está en que la IA no calcula “dónde está el agua”: simplemente busca los Cell ID etiquetados como inundados y los cruza con los Cell ID de carreteras o de población. El razonamiento espacial se reduce a operaciones sobre identificadores, lo que hace las respuestas más rápidas, más explicables y, sobre todo, más auditables.
El resultado documentado por OGC fue una demostración con cuatro clientes de IA independientes y seis servidores DGGS funcionando como un único motor interoperable. Más allá del caso concreto de inundaciones, lo relevante para el gobierno del dato es el patrón: los DGGS proporcionan a los sistemas de IA una representación estable, multiescala y trazable del territorio, que es precisamente lo que evita las llamadas “alucinaciones espaciales” y permite explicar de dónde viene cada respuesta. Toda la documentación del piloto, los protocolos y los demostradores siguen disponibles en su página oficial.
A pesar de todo, los DGGS no sustituyen ni a las coordenadas ni a los SIG tradicionales. Conviven con ellos y, en muchos casos, se construyen encima. Lo que aportan es un eje común sobre el que apoyar la integración, especialmente cuando el volumen de datos crece y los casos de uso se diversifican.
Para una oficina de gobierno del dato, la conversación interesante no es “¿migramos todo a DGGS?”, sino más bien: ¿en qué dominios de nuestra organización tiene sentido empezar a usar identificadores DGGS como clave de integración? ¿Qué catálogos, indicadores o productos derivados ganarían en consistencia si se publicaran también referenciados sobre rejilla? ¿Qué políticas de calidad y de linaje queremos aplicar sobre esa rejilla común?
La buena noticia es que el ecosistema está madurando rápido: el estándar abstracto está consolidado, hay una API oficial, existen implementaciones abiertas —H3, S2, DGGAL, rHEALPix— y los pilotos como AI-DGGS demuestran que la pieza encaja con las arquitecturas modernas de datos e IA. La conversación, simplemente, ha empezado, y a las oficinas de gobierno del dato les corresponde liderarla en sus organizaciones.
Para saber más
Estándares y especificaciones
- OGC Abstract Specification Topic 21 — Discrete Global Grid Systems: https://docs.ogc.org/as/20-040r3/20-040r3.html
- ISO 19170-1:2021 — Geographic information — Discrete Global Grid Systems: https://www.iso.org/standard/82327.html
- OGC API — Discrete Global Grid Systems — Part 1: Core (2025): https://docs.ogc.org/is/21-038r1/21-038r1.html
Piloto AI-DGGS de OGC
- Página del piloto en OGC: https://www.ogc.org/initiatives/ai-dggs-pilot/
- Resultados técnicos y demostradores: https://aidggs-pilot.hartis.org/
Implementaciones de referencia
- H3 (Uber, hexagonal): https://h3geo.org/
- S2 (Google, cuadrangular): https://s2geometry.io/
- AusPIX (Geoscience Australia, rHEALPix): https://github.com/GeoscienceAustralia/AusPIX_DGGS
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
Durante años, el debate sobre la reutilización de datos se ha centrado principalmente en los procesos de publicación, es decir, en cómo exponer más y mejores conjuntos de datos desde las entidades proveedoras. En cambio, ha quedado con frecuencia en un segundo plano el apoyo a quienes deben localizarlos, comprenderlos, combinarlos y convertirlos en productos o servicios de valor añadido.
Con la irrupción de la inteligencia artificial (IA), esta mirada empezó a cambiar. La cuestión ya no era solo cuántos datos existen, sino cómo transformar datos dispersos, heterogéneos y sujetos a reglas distintas en materia prima útil para innovar (usando, entre otras, técnicas de analítica avanzada e IA). En ese contexto, la Unión Europea ha empezado a perfilar los data labs como una pieza clave de su Estrategia para una Unión de Datos: una iniciativa orientada a aumentar la disponibilidad de datos de calidad para la IA, simplificar las reglas aplicables y conectar mejor las fuentes de datos existentes (espacios de datos, portales de datos abiertos, portales estadísticos, etc.) con los ecosistemas de innovación.
Data labs, el nuevo concepto que aglutina servicios para la reutilización de datos
¿Y qué son exactamente los data labs? La Unión Europea los describe como centros operativos especializados que darán a empresas e investigadores acceso a conjuntos de datos diversos y ofrecerán servicios relacionados con la aplicación de técnicas de IA sobre esos datos.
Esto supone un cambio de enfoque relevante porque el foco, además de ayudar al proveedor para que publique los datos, está en acompañar al consumidor para que pueda encontrar, preparar y reutilizar los datos con mayor facilidad. En este sentido, uno de los aportes más interesantes de los data labs es que desplazan el foco desde la simple acumulación de datos hacia su calidad, preparación y reutilización efectiva.
En los proyectos de ciencia de datos e IA, desde hace años se repite una versión de la regla de Pareto que establece que alrededor del 80% del tiempo se dedica a localizar, limpiar, integrar, documentar y preparar los datos, mientras que solo el 20% restante se reserva para analizarlos o entrenar modelos. No es una ley matemática, pero sí una realidad que estudios recientes siguen situando en ese mismo orden de magnitud.
Y, precisamente, ahí es donde los data labs pueden marcar la diferencia, dándole la vuelta a estos porcentajes, ya que ayudan a descubrir fuentes relevantes, mejorar metadatos, armonizar formatos, resolver problemas de acceso y avanzar en tareas de curación que convierten el dato bruto en un activo realmente utilizable. En otras palabras, no se trata solo de tener más datos, sino de tener mejores datos.
Alcance y valor añadido de los data labs
La UE sitúa a los data labs en un contexto muy concreto: aumentar el acceso a datos de calidad para IA, simplificar el marco regulatorio y reforzar la posición europea en la economía global del dato. Visto desde la perspectiva de la reutilización, esto se traduce en tres necesidades muy reconocibles: encontrar y acceder al dato adecuado, operar con seguridad jurídica y confianza, y preparar los datos con la calidad suficiente para que generen impacto. Específicamente, el alcance de los data labs abarca seis ámbitos:
- Infraestructura y herramientas técnicas: aportan entornos seguros y herramientas para gestionar datos (desde anonimización hasta generación de datos sintéticos).
- Data pooling: ponen en común datos heterogéneos de diversas fuentes, combinándolos conforme a las reglas aplicables.
- Curación y etiquetado: ayudan a enriquecer conjuntos de datos para que sean más representativos y útiles para la IA.
- Guía regulatoria y formación: proporcionan orientación práctica sobre cómo cumplir la normativa europea aplicable a los datos y la IA.
- Conexión entre espacios de datos y ecosistemas de IA: actúan como puente entre los espacios europeos de datos y quienes desarrollan soluciones de IA.
- Facilitación del acceso a datos: ayudan a localizar conjuntos de datos relevantes y a superar barreras técnicas, legales o administrativas para utilizarlos.
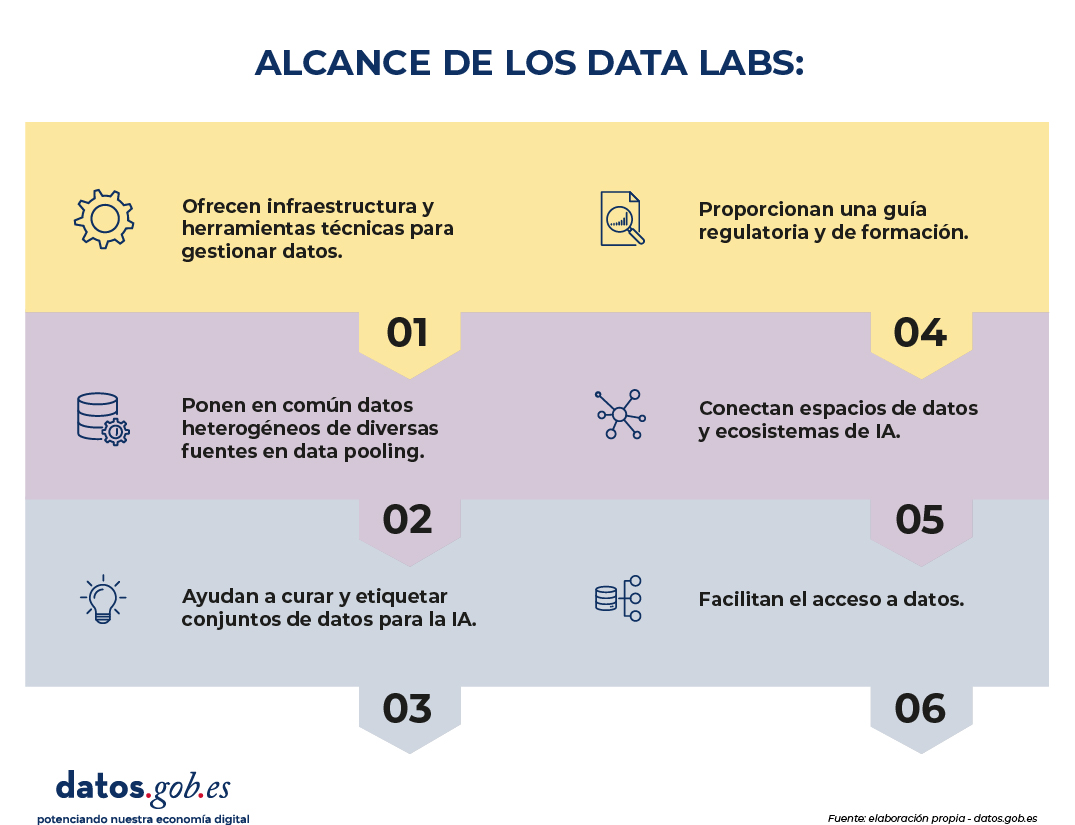
Figura 1. Alcance de los datalabs. Fuente: elaboración propia - datos.gob.es
Por todo ello, el valor de los data labs no está en “dar acceso” a los datos (de hecho, esto ya lo hacen los espacios de datos o los portales de datos abiertos), sino en hacer operativo el dato. Los data labs podrán ofrecer servicios como limpieza y enriquecimiento de conjuntos de datos, normalización, anonimización, generación de datos sintéticos y servicios de data pooling compatibles con la normativa de competencia. Por lo tanto, ofrecen menos fricción para pasar del dato bruto al dato listo para entrenar, probar o desplegar soluciones de IA.
Relación de data labs con datos abiertos y con espacios de datos
En el marco europeo, los datos abiertos siguen siendo la capa más accesible del ecosistema, especialmente cuando proceden del sector público. Destaca el concepto de datos de alto valor (high-value datasets o HVD) porque la propia normativa europea subraya que estos conjuntos son fuentes clave para el desarrollo de la IA. De hecho, la Estrategia para una Unión de Datos prevé ampliar durante 2026 la lista de datos de alto valor a ámbitos como los datos legales, judiciales y administrativos, así como, hacer disponibles 30 millones de objetos culturales digitalizados para entrenamiento de IA a través de Europeana. Por ello, los data labs añaden una capa adicional a los portales de datos abiertos, encargada de la búsqueda y combinación de datos (entre conjuntos de datos abiertos de diferentes fuentes, pero también entre conjuntos de datos abiertos y datos procedentes de otras fuentes), así como de su preparación.
Los data labs no sustituyen a las iniciativas de datos abiertos ni a las de espacios de datos, sino que las complementan.
Por otra parte, la UE define explícitamente que los data labs deben actuar como el puente entre los espacios de datos y el ecosistema de IA. Podría decirse, de manera simplificada, que los espacios de datos ponen orden en la disponibilidad del dato mientras que los data labs convierten esa disponibilidad en un recurso utilizable para innovar mediante el uso de IA. Es decir, los espacios de datos disponen de infraestructura y una gobernanza adecuada para compartir y reutilizar datos y los data labs convierten esa disponibilidad de datos en uso efectivo, ayudando a localizar, reunir, organizar, curar, etiquetar y preparar esos datos para casos de uso de IA y analítica avanzada.
Uniendo ambos escenarios (datos abiertos y espacios de datos), los data labs podrían servir para detectar qué nuevos conjuntos de datos del sector público merecería abrir o reforzar a partir de los conjuntos de datos disponibles en un espacio de datos.
Data labs y factorías de IA: el binomio perfecto
Las factorías de IA se conciben como ecosistemas que reúnen capacidad de cómputo, datos y talento para desarrollar modelos de IA y aplicaciones avanzadas. Los data labs se desplegarán precisamente en ese entorno, como una especie de capa de servicios de datos para esas factorías. La complementariedad es clara: una factoría de IA sin datos de calidad corre el riesgo de quedarse en capacidad de cómputo infrautilizada, mientras que un data lab sin acceso a infraestructuras de IA tiene más difícil cerrar el ciclo desde el dato hasta el modelo.
¿Qué no es un data lab?
Conviene aclarar, además, una posible confusión en cuanto al término data lab. No estamos hablando aquí de las “salas seguras” o entornos controlados para acceso a datos protegidos con fines de investigación, como ES_Datalab, que incluye datos del INE o del Banco de España. Esos entornos están pensados para el acceso controlado a microdatos y otra información sensible con fines de investigación, preservando confidencialidad y privacidad.
Los data labs europeos tienen un alcance distinto y más amplio, ya que son un instrumento para conectar datos públicos y privados (incluyendo espacios de datos) e innovación en IA mediante servicios de acceso, preparación, curación y apoyo regulatorio. Pueden incorporar técnicas de protección, pero no equivalen a una sala segura.
En conclusión, la apuesta europea de los data labs consiste en pasar de hablar solo de publicación de datos a hablar de activación del dato para la innovación a partir de su reutilización. Esto es muy útil para diferentes perfiles:
- Para los perfiles técnicos, los data labs prometen más datos preparados y mejor documentados.
- Para las empresas del sector infomediario, abren oportunidades en servicios de descubrimiento, calidad, metadatos, etiquetado, integración o cumplimiento de normativa.
- Para la administración pública, pueden convertirse en un mecanismo muy útil para orientar qué publicar en abierto, con qué calidad y para qué usos.
- Para la comunidad investigadora, ofrecen la posibilidad de acercar mejor el acceso al dato, la gobernanza y la infraestructura de computación.
Por lo tanto, los data labs no compiten con los datos abiertos ni con los espacios de datos, sencillamente ayudan a que ambos generen más valor en la práctica.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En los últimos años, la inteligencia artificial ha pasado de ser una tecnología emergente a convertirse en una realidad cotidiana en administraciones públicas, empresas y organizaciones de todo tipo. Se habla de sistemas que predicen la demanda sanitaria, optimizan rutas de transporte o detectan anomalías en el gasto público. Pero detrás de cada uno de estos casos de uso existe una pregunta que rara vez ocupa el primer plano del debate: ¿en qué se apoya realmente esa inteligencia artificial?
La respuesta no está solo en los algoritmos. Está en los datos. Y, más concretamente, en cómo las organizaciones se estructuran, y los estructuran, para gestionarlos.
En este post abordaremos:
-
Por qué los datos son la base real de cualquier sistema de IA y qué riesgos implica ignorarlos
-
Qué estructuras organizativas permiten gobernarlos de forma efectiva
-
El papel estratégico del dato abierto en este ecosistema
-
Las diferencias y sinergias entre gobierno del dato y gobierno de la IA
-
Los estándares y marcos de referencia disponibles en España y a nivel internacional
Los datos como base de la inteligencia artificial
El aprendizaje automático ha transformado el paradigma del desarrollo tecnológico. Donde antes los sistemas seguían reglas fijas y explícitas, hoy aprenden de patrones que emergen de los datos. Esto supone un cambio de enorme relevancia: el comportamiento de un modelo de IA no depende tanto de la lógica con la que fue programado como de la calidad, representatividad y coherencia de los datos con los que fue entrenado.
Aquí reside uno de los riesgos más subestimados de la IA: el espejismo del dato neutral. Los datos no son verdades objetivas; son representaciones de la realidad capturadas en un contexto concreto (procesos de negocio), con sus propias limitaciones y sesgos. Un sistema entrenado con datos incompletos o sesgados no solo replicará esos sesgos, sino que los amplificará. Los ejemplos son numerosos: desde modelos de reconocimiento facial con peor rendimiento en determinados grupos poblacionales hasta sistemas de priorización que reproducen desigualdades históricas.
Además, los datos envejecen. Lo que hoy es un conjunto de entrenamiento representativo puede dejar de serlo mañana si la realidad cambia y el modelo no se actualiza. Este fenómeno, conocido como data drift, es uno de los principales motivos por los que sistemas de IA inicialmente exitosos acaban degradando su rendimiento a lo largo del tiempo si no se sigue un adecuado mantenimiento. Un caso ilustrativo fue el de varios modelos predictivos desplegados durante la pandemia de COVID-19: entrenados con patrones de comportamiento previos, su precisión se deterioró cuando la realidad cambió de forma drástica y repentina, evidenciando que un modelo es tan vigente como los datos que lo sustentan.
Por todo ello, la calidad de los datos no puede dejarse al azar. Requiere una gestión activa, sistemática y con responsabilidades claramente asignadas.
Estructuras organizativas para gobernar el dato
Reconocer que los datos son un activo estratégico es el primer paso. El segundo, y más difícil, es organizarse para gestionarlos como tal.
Gobernar el dato significa establecer quién decide sobre los datos, cómo se gestionan y bajo qué reglas se utilizan. No es una cuestión puramente técnica; es, sobre todo, organizativa. Implica:
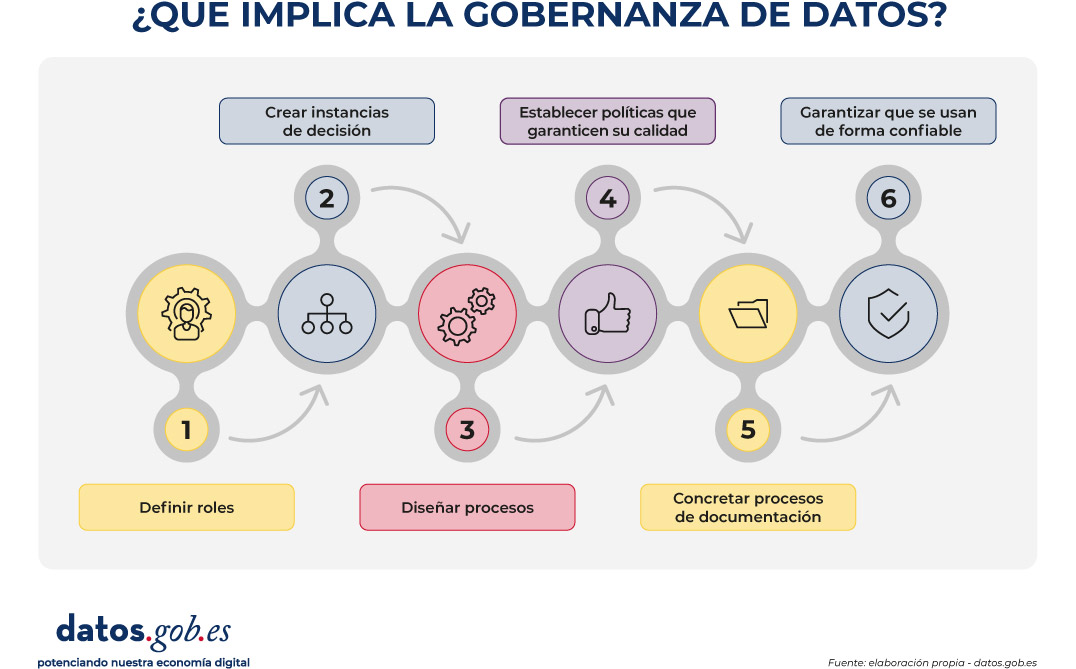
Figura 1. Visual sobre las implicaciones de la gobernanza de datos. Fuente: elaboración propia - datos.gob.es
Las organizaciones más maduras en este ámbito suelen articular su gobernanza en torno a tres niveles:
-
En el nivel estratégico, se sitúan figuras como el Chief Data Officer (CDO) y órganos colegiados de supervisión, cuya función es definir el papel que juegan los datos en la estrategia de la organización y asegurar que las decisiones de alto nivel estén alineadas con esa visión.
-
En el nivel operativo, una Oficina de Gobierno del Dato traduce esa estrategia en políticas concretas: estándares de calidad, catálogos de metadatos, procedimientos de gestión del ciclo de vida del dato, normas de seguridad y privacidad.
-
En el nivel de dominio, los data owners (responsable del dato) y data stewards (gestor del dato) son los responsables de que los datos se gestionen correctamente en el día a día: los primeros con responsabilidad formal sobre determinados conjuntos de datos; los segundos garantizando su calidad, consistencia y correcta documentación.
Cuando la IA entra en escena, esta estructura no cambia en esencia, pero sí se amplía. Aparecen nuevos perfiles como los científicos de datos o ingenieros de modelos, responsables de cumplimiento algorítmico, y nuevas necesidades: documentar los conjuntos de entrenamiento, garantizar la trazabilidad de las decisiones del modelo, gestionar el riesgo de sesgos. Todo ello debe integrarse en el marco de gobernanza existente, no añadirse como una capa separada, y teniendo en cuenta regulaciones como el Reglamento de Inteligencia Artificial de la UE (AI Act).
El dato abierto dentro del gobierno del dato
En el contexto del sector público español, el gobierno del dato no puede disociarse de la política de datos abiertos. Ambas dimensiones se refuerzan mutuamente.
El dato abierto aporta valor mucho más allá de la transparencia. En el contexto de la inteligencia artificial, sus aportaciones son múltiples.
Primero, como materia prima para la innovación: muchos proyectos de IA, especialmente en sus fases iniciales, se apoyan en datasets abiertos para entrenar y validar modelos. Portales como datos.gob.es ponen a disposición de investigadores, empresas y administraciones miles de conjuntos de datos reutilizables sobre movilidad, demografía, medio ambiente o gasto público, entre otros sectores. Un ejemplo concreto es el uso de datos abiertos de tráfico y transporte público para entrenar modelos de predicción de demanda o de optimización de rutas: sin esa capa de información pública, estructurada y de calidad, muchas de estas iniciativas simplemente no despegan.
En segundo lugar, como mecanismo de auditoría y confianza: cuando los datos que alimentan un sistema de IA son accesibles, la comunidad puede analizarlos, identificar posibles sesgos y cuestionar los resultados. Esto es especialmente relevante en decisiones de alto impacto, donde la explicabilidad y la rendición de cuentas son exigencias ineludibles.
Y, tercero, como catalizador de ecosistemas de datos: el dato abierto es uno de los pilares de los espacios de datos compartidos, donde múltiples organizaciones intercambian información bajo reglas comunes. Iniciativas como el Espacio Nacional de Datos de Salud (ENDS) o los espacios europeos sectoriales se apoyan en esta lógica. Para que funcionen, necesitan una gobernanza sólida que garantice la interoperabilidad, el control de acceso y la confianza entre los participantes.
Gobierno del dato y gobierno de la IA: diferencias y complementariedad
Es frecuente que ambos conceptos se confundan o se usen de forma intercambiable, pero tienen alcances distintos, aunque profundamente relacionados.
-
El gobierno del dato tiene como objeto el activo en sí mismo. Se pregunta: ¿son los datos de calidad? ¿Están bien definidos? ¿Se gestionan con seguridad? ¿Quién es responsable de ellos? Su horizonte es la integridad, la disponibilidad y el uso apropiado de la información.
-
El gobierno de la IA, en cambio, tiene como objeto el sistema algorítmico. Se pregunta: ¿es el modelo explicable? ¿Introduce sesgos? ¿Cumple con los requisitos éticos y legales? ¿Cómo se supervisa su funcionamiento a lo largo del tiempo? Su horizonte es la responsabilidad, la transparencia y la mitigación de riesgos.
La relación entre ambos no es de sustitución sino de dependencia: no puede haber un gobierno efectivo de la IA sin un gobierno previo y sólido del dato. Si no sabemos de dónde viene el dato que alimenta un modelo, si no podemos garantizar su calidad o su representatividad, cualquier sistema de gestión de IA se construye sobre arena. El gobierno del dato es, en este sentido, la infraestructura invisible sobre la que descansa la confianza en la inteligencia artificial.
Estándares y marcos de referencia
Para que estas estructuras organizativas no queden en una declaración de intenciones, es fundamental apoyarse en marcos normativos y estándares que ofrezcan orientación práctica y permitan comparar, evaluar e incluso certificar el nivel de madurez alcanzado.
En España, la familia de especificaciones UNE impulsadas desde la Dirección del Dato ofrece una guía completa y cohesionada. La UNE 0077 aborda el gobierno del dato; la UNE 0078, su gestión; la UNE 0079, la calidad; la UNE 0080, la evaluación de madurez; y la UNE 0085, la implantación progresiva de estas capacidades. A estas se suma la UNE 0081, que establece criterios específicos para la evaluación de la calidad de datasets, pieza crítica cuando hablamos de entrenamiento y validación de modelos de IA.
Este enfoque está plenamente alineado con las recomendaciones publicadas en datos.gob.es sobre gobernanza del datos, donde se insiste en la necesidad de definir roles claros, establecer políticas y asegurar la calidad como elementos estructurales para generar confianza y valor a partir de los datos. En este sentido, la gobernanza no es solo una capa organizativa, sino un habilitador de todo el ciclo de vida del dato., donde se insiste en la necesidad de definir roles claros, establecer políticas y asegurar la calidad como elementos estructurales para generar confianza y valor a partir de los datos. En este sentido, la gobernanza no es solo una capa organizativa, sino un habilitador de todo el ciclo de vida del dato.
En el plano internacional, este marco se amplía y se conecta directamente con la inteligencia artificial. La ISO/IEC 38507 proporciona directrices para el gobierno de la IA, mientras que la ISO/IEC 42001 define el primer sistema de gestión específico para IA, estableciendo requisitos organizativos, de control y mejora continua. Estas normas dejan claro que no puede existir una gestión efectiva de la IA sin una base sólida de gobernanza y gestión del dato.
A su vez, la calidad de la IA se articula sobre tres pilares fundamentales: datos, modelos y software, cada uno respaldado por estándares específicos. La calidad del dato se apoya en normas como la ISO/IEC 5259, mientras que la seguridad y la protección se vinculan a estándares como ISO/IEC 27090 o ISO/IEC 27563. En el ámbito del software y los productos de IA, destacan referencias como ISO/IEC 25059, y en procesos, estándares como ISO/IEC 5338, junto con normas de seguridad específicas como ISO/IEC 5469 o ISO/IEC 22440.
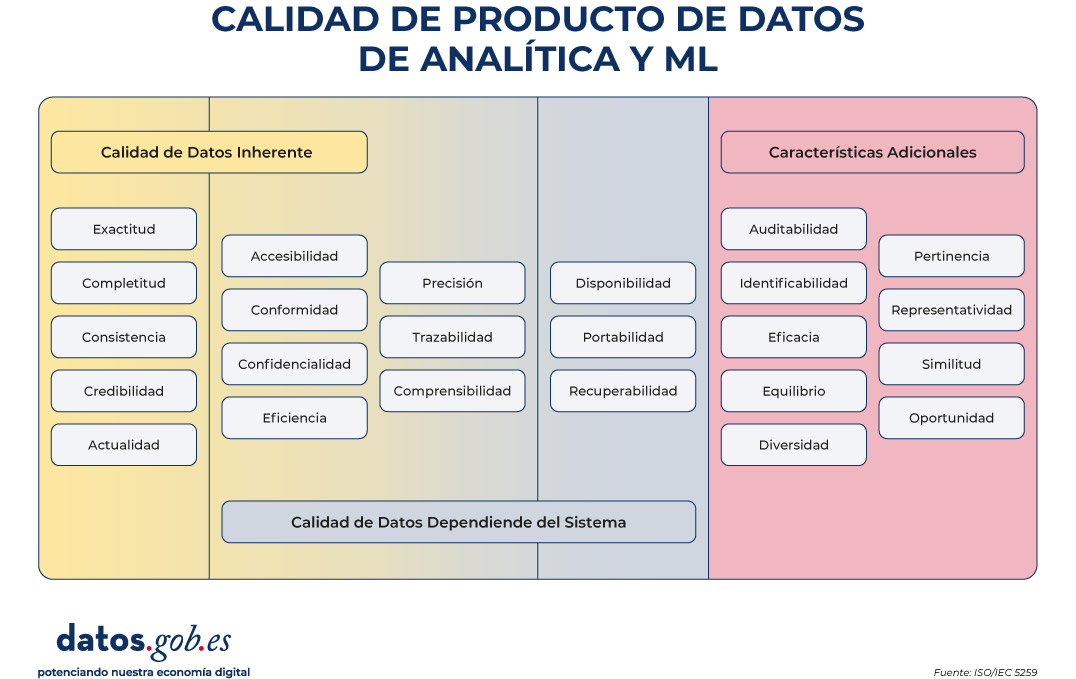
Figura 2. Visual sobre la calidad de producto de datos de analítica y machine learning (ML)
Todos estos marcos apuntan en la misma dirección: la gobernanza del dato no es un requisito burocrático, sino la base sobre la que se construye la calidad, la seguridad y, en última instancia, la confianza en los sistemas de inteligencia artificial. Sin ella, ni la gestión ni la calidad de la IA pueden sostenerse de forma fiable ni escalable.
Conclusión: gobernar el dato es gobernar el futuro
La inteligencia artificial ha puesto de relieve algo que existía pero que no siempre resultaba visible: la calidad de cualquier decisión basada en datos depende, en última instancia, de cómo esos datos se gestionan.
En este sentido, las organizaciones que mejor aprovecharán las oportunidades que ofrece la IA serán las que hayan construido estructuras organizativas capaces de garantizar que sus datos son de calidad, están bien documentados, cuentan con responsables claros y se gestionan bajo políticas coherentes.
Y, en definitiva, gobernar el dato con rigor es la condición que hace posible una innovación sostenible, responsable y digna de confianza. Porque, en un entorno donde la IA aprende de aquello que le damos, la pregunta más importante no es qué modelo usamos, sino qué datos lo alimentan y cómo los hemos cuidado.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
La gobernanza de datos es un elemento central de cualquier estrategia digital. Gobiernos, empresas, organizaciones sociales e instituciones internacionales coinciden en que, sin reglas claras sobre cómo se recopilan, gestionan, comparten y utilizan los datos, es imposible aprovechar todo su valor.
Este artículo busca aclarar este concepto, aportando información sobre sus principios básicos. Para ello, nos hemos basado en dos informes: Data Governance Toolkit: Navigating Data in the digital era de la Broadband Commission, cofundada por la UNESCO y la Unión Internacional de Telecomunicaciones (ITU en sus siglas en inglés), y What is Data Governance: 30 Questions and Answers, elaborado por The Govlab. El segundo informe profundiza en las definiciones y conceptos incluidos en el primero. Ambos documentos coinciden en que la gobernanza de datos no es solo un conjunto de normas, sino un marco integral que orientan todo el ciclo de vida de los datos.
A continuación, se recoge un resumen de lo que dicen ambos informes.
¿Qué es la gobernanza de datos?
La gobernanza de datos puede definirse como el conjunto de procesos, personas, políticas, prácticas y tecnologías que guían cómo se generan, gestionan y reutilizan los datos a lo largo de todo su ciclo de vida. Su objetivo es aumentar la confianza, el valor y la equidad, al tiempo que se minimizan los riesgos y los perjuicios, de conformidad con un conjunto de principios fundamentales.
Las 4P del Data Governance Toolkit
La Broadband Commission subraya cuatro elementos esenciales de la gobernanza de datos:
Por qué: definir la visión y el propósito de los datos y de su gobernanza.
- Cómo: establecer los principios que guiarán las decisiones y prácticas.
- Quién: identificar los roles, responsabilidades y procesos institucionales.
- Qué: concretar las políticas, mecanismos y tecnologías que se aplicarán en cada fase del ciclo de vida del dato.
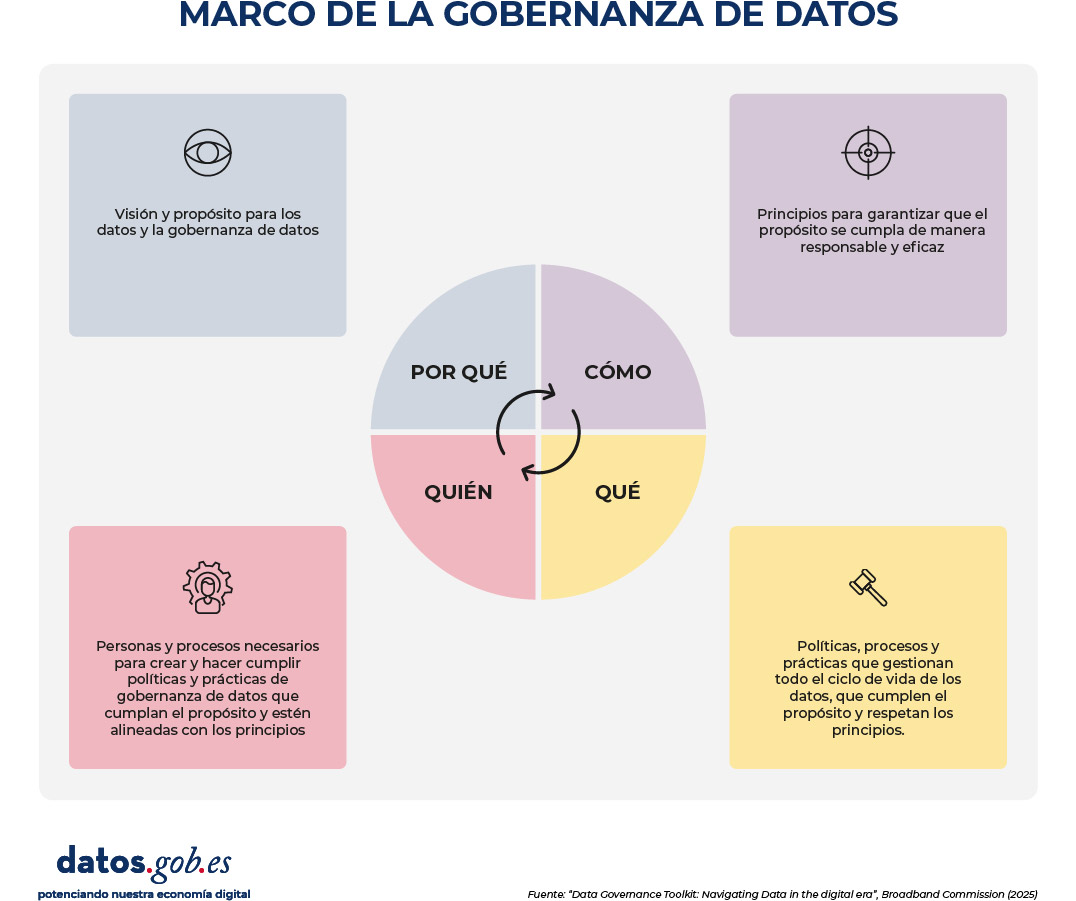
Figura 1. Marco de la gobernanza de datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Esta estructura -conocida como los 4P del Toolkit por sus nombres en inglés (Purpose, Principles, People, and Practices)- permite que la gobernanza no sea un ejercicio abstracto, sino una práctica operativa y medible. Funciona como bloques (building blocks) que pueden aprovecharse y adaptarse para orientar el desarrollo de nuevas estrategias de gobernanza de datos.
A continuación, se detallan cada uno de ellos:
1. ¿Por qué? (Purpose)
- El propósito y la visión son esenciales para orientar la gobernanza de los datos, dar coherencia a las iniciativas y garantizar una gestión responsable a lo largo de todo el ciclo de vida del dato.
- Un buen propósito de gobernanza debe reflejar valores y prioridades sociales, ser accionable y equilibrar oportunidades (como innovación o reutilización de datos) con riesgos (como sesgos, exclusión o daños).
- Los propósitos más habituales incluyen maximizar el valor de los datos, fomentar la innovación y el desarrollo sostenible, promover la equidad, apoyar objetivos de política pública y reforzar la participación y la agencia de las personas.
Un propósito bien formulado actúa como marco de referencia para asegurar alineación, coherencia y rendición de cuentas. Además, ayuda a evitar usos indebidos, duplicidades o esfuerzos desconectados. Para que sea eficaz, este propósito debe:
- Reflejar los valores fundamentales de la organización y las prioridades sociales (por ejemplo, la equidad, la innovación y los derechos humanos).
- Ser aplicables y estar en consonancia con los objetivos de la empresa.
- Abordar tanto las oportunidades (por ejemplo, la reutilización de datos o la implementación de la inteligencia artificial) como los riesgos (por ejemplo, los perjuicios, la exclusión o los sesgos).
- Servir de referencia para las decisiones de gobernanza, los indicadores de éxito y la mejora continua.
En la práctica, las organizaciones suelen orientar su gobernanza hacia metas como maximizar el valor económico y social del dato, fomentar la innovación y el desarrollo sostenible, promover la equidad, apoyar objetivos de política pública (como resultados en salud o protección ambiental) o fortalecer la participación y la autodeterminación digital. Estas finalidades no son excluyentes. Al combinarse permiten construir ecosistemas de datos más responsables, útiles y legítimos.
2. ¿Cómo? (Principles)
Es necesario desarrollar principios de gobernanza de datos mediante un proceso estructurado que parta de definir objetivos y alcance. Estos principios deben:
- Incorporar marcos de derechos humanos y principios básicos como transparencia, responsabilidad, proporcionalidad, equidad, participación, legalidad, seguridad, privacidad, calidad, etc.
- Anclarse en estándares internacionales ligados a la interoperabilidad, la ética de la IA o la protección de datos.
- Tener en cuenta el contexto cultural y los valores sociales locales mediante la participación de actores diversos y pruebas basadas en escenarios concretos.
- Revisarse y actualizarse de forma continua para mantener su relevancia ante cambios legales y tecnológicos.
3. ¿Quién? (People)
La creación de marcos eficaces de gobernanza de datos requiere involucrar a múltiples actores mediante procesos colaborativos que garanticen inclusión, transparencia y coherencia con estándares legales y éticos. Este bloque conlleva identificar a las principales partes interesadas, sus roles y responsabilidades, y establecer mecanismos eficaces de coordinación y rendición de cuentas. Para ello, se recomienda:
- Desarrollar talleres, consultas y mecanismos de retroalimentación para que gobiernos, empresas, sociedad civil y expertos técnicos contribuyan a definir principios y responsabilidades.
- Implementar herramientas como el mapeo de actores, la revisión de políticas y la comparación con marcos globales, incluidos derechos humanos, estándares de procedencia de datos o guías de IA ética.
- Realizar pruebas basadas en escenarios concretos para identificar brechas y fortalecer la resiliencia de los marcos de gobernanza.
- Desarrollar capacidades en gobernanza de datos combinando formación continua, estructuras claras y herramientas de gestión.
- Diseñar estructuras de responsabilidad y mecanismos de supervisión transparentes para garantizar el cumplimiento.
- Implementar acuerdos contractuales, políticas institucionales, enfoques de gobernanza por diseño y medidas de seguridad, como cifrado o controles de acceso.
Es importante tener en cuenta modelos como RACI. Así mismo, las evaluaciones de madurez y las auditorías ayudan a revisar y mejorar las prácticas.
4. ¿Qué? (Practices)
Antes de abordar este apartado, es necesario comprender en qué consiste el ciclo de vida del dato. El ciclo de vida del dato describe las distintas etapas por las que atraviesa la información, desde que se concibe su necesidad hasta que se utiliza para generar conocimiento o apoyar decisiones. Aunque existen múltiples marcos y cada uno puede emplear terminologías ligeramente distintas, la mayoría coincide en seis fases fundamentales: planificación, recogida, procesamiento, compartición, análisis y uso.
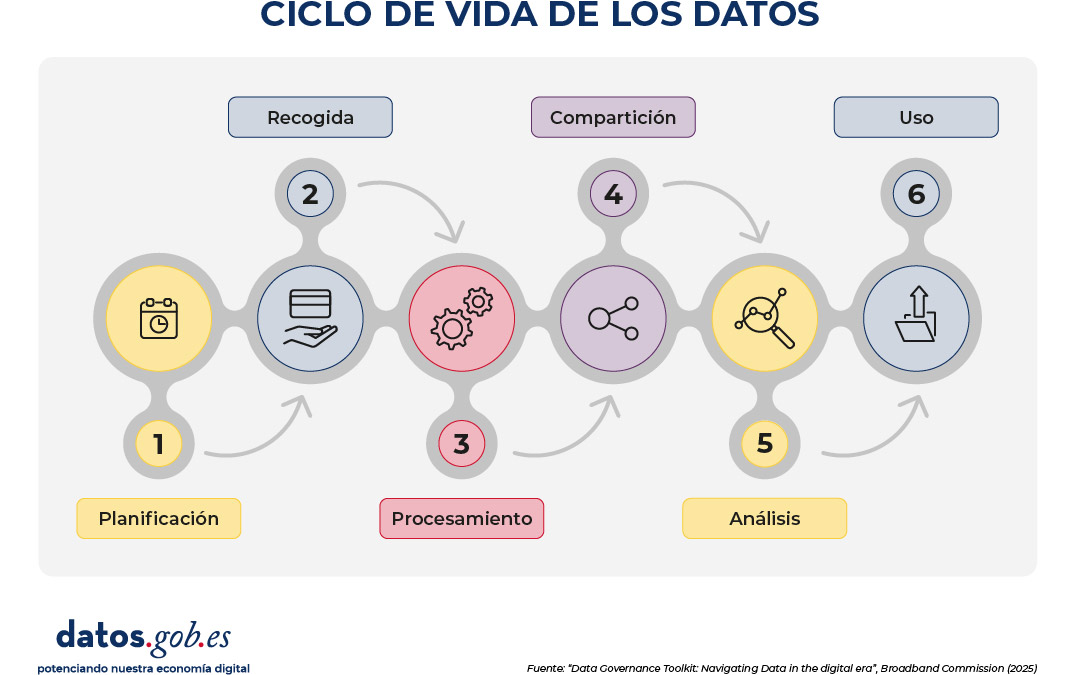
Figura 2. Ciclo de vida de los datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Estas fases consisten en:
1. Planificación. En esta fase se definen las necesidades de datos, los usos previstos y los requisitos de gobernanza que se aplicarán posteriormente. Es el momento de aclarar el propósito, alcance, viabilidad, identificar riesgos, establecer criterios de calidad y determinar quién será responsable de cada decisión. Una planificación deficiente -por ejemplo, un propósito ambiguo- puede comprometer todo el ciclo posterior.
2. Recogida. Consiste en obtener los datos mediante encuestas, sensores, transacciones, registros administrativos u otros mecanismos. Aquí se decide qué datos son realmente necesarios, cómo se obtienen de forma equitativa y ética, y cómo se garantiza que su captura respete principios como la privacidad o la minimización. Una fase de recogida desordenada o excesiva puede generar riesgos y costes innecesarios.
3. Procesamiento. Incluye todas las tareas de limpieza, validación, organización, almacenamiento y preservación de los datos. También abarca la eliminación cuando ya no son necesarios. La fase de procesamiento es crítica para asegurar la calidad, la trazabilidad y el manejo adecuado de la información. Un procesamiento deficiente puede introducir sesgos, errores o pérdidas de integridad que afectarán al análisis posterior.
4. Compartición. En esta etapa los datos se ponen a disposición de terceros para su reutilización, ya sea a través de plataformas, API, acuerdos de intercambio o espacios colaborativos. La gobernanza determina quién puede acceder, bajo qué condiciones, con qué salvaguardas y con qué mecanismos de control. Una compartición bien diseñada multiplica el valor del dato; una mal gestionada puede generar riesgos de seguridad o uso indebido.
5. Análisis. Aquí los datos se interpretan para generar conocimiento, mediante estadísticas, visualizaciones, modelos o técnicas avanzadas como la inteligencia artificial. La gobernanza influye en cómo se documentan los métodos, cómo se gestionan los sesgos y cómo se garantiza la reproducibilidad. Un análisis sin controles puede conducir a conclusiones erróneas o discriminatorias.
6. Uso. Finalmente, los resultados del análisis se aplican para informar decisiones, diseñar políticas, mejorar servicios o crear productos. Esta fase debe estar alineada con el propósito definido al inicio y con los principios éticos y legales establecidos. Un uso inadecuado puede generar impactos negativos, incluso si las fases anteriores se realizaron correctamente.
En cada una de estas etapas se toman decisiones clave: quién accede a los datos, cómo se garantiza su calidad, qué salvaguardas se aplican, cómo se documentan los procesos o qué mecanismos de supervisión existen. Estas decisiones no son independientes: se acumulan y condicionan lo que es posible en las fases posteriores.
Aplicar los principios y decisiones de gobernanza de datos a lo largo de todo el ciclo de vida del dato requiere integrarlos en procesos, herramientas y marcos de cumplimiento alineados con requisitos normativos. Además, es necesario adaptarse a las necesidades de cada sector, apoyándose en estándares globales o jurisdiccionales. Algunos aspectos a consideran son:
- Definir roles y requisitos legales desde la planificación.
- Usar marcos como DAMA‑DMBOK o acuerdos de intercambio, apoyándose en metadatos, trazabilidad y estándares de interoperabilidad para garantizar la transparencia y el uso responsable.
- Apoyarse en acuerdos legales, cooperación regulatoria y tecnologías de mejora de la privacidad para garantizar flujos correctos de datos.
- Garantizar un uso seguro y responsable de la inteligencia artificial mediante datos fiables, bien documentados y gestionados con transparencia y supervisión.
- Medir el éxito de la iniciativa evaluando el cumplimiento, la calidad, la seguridad y la madurez.
La guía de la Broadband Commission incluye un mecanismo de autoevaluación con diversas listas de validación (checklist). El objetivo es que gobiernos, instituciones públicas y organizaciones puedan conocer el estado actual de sus sistemas de gobernanza de datos e identificar oportunidades de mejora. Estas listas abarcan tanto las actividades del resto de bloques como los procesos recomendados en cada fase del ciclo de vida de los datos.
Otros marcos a considerar
La Broadband Commission no es la única organización que ha elaborado un marco de referencia. La siguiente tabla recoge otras iniciativas que también pueden ser de interés.
| Toolkit | Autor | Audiencia |
|---|---|---|
| Data Governance Toolkit | Gobierno del estado de Nueva Gales del Sur (Australia) | Sector público |
| Data Innovation Toolkit | Laboratorio de Innovación Digital de la Comisión Europea | Sector público |
| OECD Data Governance | Organización para la Cooperación y el Desarrollo Económicos (OECD, en inglés) | Sector público |
| Data to Policy Navigator | Iniciativa Data4Policy de la GIZ y la Oficina Digital del Programa de las Naciones Unidas para Desarrollo (PNUD, en inglés) | Sector público |
| Data policy Framework | Unión Africana (AU, en inglés) | Sector público |
| Data Management Framework | Asociación de Naciones de Asia Sudoriental (ASEAN, en inglés) | Sector público |
| Navigating Data Governance | Unión Internacional de Telecomunicaciones (ITU, en inglés) | Reguladores |
| The Data Playbook | Federación Internacional de Sociedades de la Cruz Roja y de la Media Luna Roja (IFRC, en inglés) y Solferimo Academy | Sector humanitario |
| Data Responsability Journey | The GovLab | Sector público y privado |
| Data Governance and Management Toolkit | Miembros del Comité de Dirección de Datos de los Gobiernos Indígenas Autónomos (SGIG DSC Members, en inglés) | Gobiernos indígenas |
Figura 2. Mapeo de conjuntos de herramientas para la gobernanza de datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Todos los marcos coinciden en un aspecto: la clave de la gobernanza de datos está en combinar un propósito claro, principios sólidos, mecanismos de participación y legitimidad y procesos aplicables a todo el ciclo de vida del dato.
En España contamos con la familia de normas UNE de gobierno, gestión y calidad del dato 0077, 0078, 0079 0080 y 0085, concebidas para aplicarse de manera conjunta y ofrecer un marco de referencia sólido que impulse la adopción de prácticas sostenibles y efectivas en torno al dato.
En un momento en que los datos impulsan desde la IA hasta los servicios públicos digitales, avanzar hacia una gobernanza responsable es una oportunidad para reforzar la confianza, potenciar la innovación y garantizar que los beneficios del dato se distribuyan de forma equitativa. Por ello es importante que todas las organizaciones apliquen un marco claro que garantice una gobernanza sólida de los datos.
Blog
Vivimos en una era en la que la ciencia depende cada vez más de datos. Desde la planificación urbana hasta la transición climática, el gobierno del dato se ha convertido en un pilar estructural de la toma de decisiones basada en evidencia. Sin embargo, existe un ámbito donde los principios tradicionales de gestión, validación y control del dato se ven sometidos a tensiones extremas: el universo.
Los datos espaciales —producidos por satélites científicos, telescopios, sondas interplanetarias y misiones de exploración— no describen realidades accesibles ni repetibles. Observan fenómenos que ocurrieron hace millones de años, a distancias imposibles de recorrer y bajo condiciones que nunca podrán replicarse en laboratorio. No existe una medición “in situ” que confirme directamente estos fenómenos.
En este contexto, el gobierno del dato deja de ser una cuestión organizativa y pasa a ser un elemento estructural de la confianza científica. La calidad, la trazabilidad y la reproducibilidad no pueden apoyarse en referencias físicas directas, sino en la transparencia metodológica, la documentación exhaustiva y la solidez de los marcos instrumentales y teóricos.
Gobernar datos del universo implica, por tanto, enfrentarse a retos únicos: gestionar incertidumbre estructural, documentar escalas extremas y garantizar la confianza en información que nunca podremos tocar.
A continuación, exploramos los principales desafíos que plantea el gobierno del dato cuando el objeto de estudio está más allá de la Tierra.
I. Retos específicos del dato del universo
1. Más allá de la Tierra: nuevas fuentes, nuevas reglas
Cuando hablamos de datos espaciales, nos referimos a mucho más que a imágenes de satélite de la superficie terrestre. Nos adentramos en un ecosistema complejo que incluye telescopios espaciales y terrestres, sondas interplanetarias, misiones de exploración planetaria y observatorios diseñados para detectar radiación, partículas o fenómenos físicos extremos.
Estos sistemas generan datos con retos claramente diferentes respecto a otros dominios científicos:
|
Desafío |
Impacto en el gobierno del dato |
|---|---|
| Acceso físico inexistente | No hay validación directa; la confianza reside en la integridad del canal. |
| Dependencia instrumental | El dato es "hijo" directo del diseño del sensor; si el sensor falla o se descalibra, la realidad se distorsiona. |
| Singularidad | Muchos eventos astronómicos son únicos. No hay una "segunda oportunidad" para capturarlos. |
| Coste extremo | El valor de cada byte es altísimo debido a la inversión necesaria para poner el sensor en órbita. |
Figura 1. Desafíos en el gobiernos de datos del universo. Fuente: elaboración propia - datos.gob.es.
A diferencia de los datos de observación de la Tierra —que en muchos casos pueden contrastarse mediante campañas de campo o sensores redundantes— los datos del universo dependen fundamentalmente de la arquitectura de la misión, la calibración del instrumento y los modelos físicos utilizados para interpretar la señal capturada.
En numerosos casos, lo que se registra no es el fenómeno en sí, sino una señal indirecta: variaciones espectrales, emisiones electromagnéticas, alteraciones gravitacionales o partículas detectadas tras recorrer millones de kilómetros. El dato es, en esencia, una traducción instrumental de un fenómeno inaccesible.
Por todo ello, en el espacio el dato no puede entenderse sin el contexto técnico que lo genera.
2. Incertidumbre estructural y escalas extremas
La incertidumbre se refiere al grado de margen de error o indeterminación asociado a una medición, interpretación o resultado científico debido a los límites de los instrumentos, las condiciones de observación y los modelos utilizados para analizar los datos. Si en otros ámbitos la incertidumbre es un factor que se intenta reducir mediante mediciones directas, repetibles y contrastables, en la observación del universo la incertidumbre forma parte del propio proceso de conocimiento. No se trata simplemente de “no saber lo suficiente”, sino de enfrentarse a límites físicos y metodológicos que no pueden eliminarse por completo.
Por tanto, en la observación del universo la incertidumbre es estructural. No se trata de una anomalía puntual, sino de una condición inherente al objeto de estudio.
Existen varias dimensiones críticas:
- Escalas espaciales y temporales extremas: las distancias cósmicas impiden cualquier validación directa. Las escalas temporales implican que, con frecuencia, el dato captura un “instante” del pasado remoto y no una realidad presente verificable.
- Señales débiles y ruido inevitable: los instrumentos capturan emisiones sumamente sutiles. La señal útil convive con interferencias, limitaciones tecnológicas y ruido de fondo. La interpretación depende de tratamientos estadísticos avanzados y de modelos físicos complejos.
- Fenómenos de observación limitada: algunos fenómenos astrofísicos —como determinadas supernovas, estallidos de rayos gamma o configuraciones gravitacionales singulares— no pueden recrearse experimentalmente y solo pueden observarse cuando ocurren. En estos casos, el registro disponible puede ser único o profundamente limitado, lo que incrementa la responsabilidad en su documentación y preservación.
No todos los fenómenos son irrepetibles, pero en muchos casos las oportunidades de observación son escasas o dependen de condiciones excepcionales.
II. Construir confianza cuando no podemos tocar el objeto observado
Ante estos retos, el gobierno del dato adquiere un papel estructural. No se limita a garantizar almacenamiento o disponibilidad, sino que define las reglas mediante las cuales los procesos científicos quedan documentados, trazables y auditables.
En este contexto, gobernar no significa producir conocimiento, sino garantizar que su producción sea transparente, verificable y reutilizable.
1. Calidad sin validación física directa
Cuando no puede verificarse directamente el fenómeno observado, la calidad del dato se apoya en:
- Protocolos rigurosos de calibración: los instrumentos deben someterse a procesos sistemáticos de calibración antes, durante y después de su operación. Esto implica ajustar sus mediciones frente a referencias conocidas, caracterizar sus márgenes de error, documentar desviaciones y registrar cualquier modificación en su configuración. La calibración no es un evento puntual, sino un proceso continuo que garantiza que la señal registrada refleje, con la mayor precisión posible, el fenómeno observado dentro de los límites físicos del sistema.
- Validación cruzada entre instrumentos independientes: cuando distintos instrumentos —ya sea en la misma misión o en misiones diferentes— observan un fenómeno similar, la comparación de resultados permite reforzar la fiabilidad del dato. La convergencia entre observaciones obtenidas con tecnologías distintas reduce la probabilidad de sesgos instrumentales o errores sistemáticos. Esta coherencia inter-instrumental actúa como un mecanismo de verificación indirecta.
- Repetición observacional cuando es posible: aunque no todos los fenómenos pueden repetirse, muchas observaciones sí pueden realizarse en diferentes momentos o bajo distintas condiciones. La repetición permite evaluar la estabilidad de la señal, identificar anomalías y estimar variabilidad natural frente a error de medición. La consistencia en el tiempo fortalece la robustez del resultado.
- Revisión por pares y consenso científico progresivo: los datos y sus interpretaciones son sometidos a evaluación por parte de la comunidad científica. Este proceso implica escrutinio metodológico, análisis crítico de supuestos y verificación de coherencia con el conocimiento existente. El consenso no surge de forma inmediata, sino a través de acumulación de evidencia y debate científico. La calidad, en este sentido, es también una construcción colectiva.
La calidad no es solo una propiedad técnica; es el resultado de un proceso documentado y auditable.
2. Trazabilidad científica completa
En el contexto espacial, el dato es inseparable del proceso técnico y científico que lo genera. No puede entenderse como un resultado aislado, sino como la culminación de una cadena de decisiones instrumentales, metodológicas y analíticas.
Por ello, la trazabilidad debe cubrir de forma explícita y documentada:
- Diseño y configuración del instrumento: es necesario conservar información sobre las características técnicas del instrumento que capturó la señal, por ejemplo, su arquitectura, capacidades de detección, límites de resolución y configuraciones operativas. Estas condiciones determinan qué tipo de señal puede registrarse y con qué precisión.
- Parámetros de calibración: deben registrarse los ajustes aplicados para asegurar que el instrumento opere dentro de los márgenes previstos, así como las modificaciones realizadas a lo largo del tiempo. Los parámetros de calibración influyen directamente en la interpretación de la señal obtenida.
- Versiones del software de procesamiento: el tratamiento del dato bruto depende de herramientas informáticas específicas. Conservar las versiones utilizadas permite comprender cómo se generaron los resultados y evitar ambigüedades si el software evoluciona.
- Algoritmos aplicados en la reducción de ruido: dado que las señales suelen estar acompañadas de interferencias o ruido de fondo, es esencial documentar los métodos empleados para filtrar, limpiar o transformar la información antes de su análisis. Estos algoritmos influyen en el resultado final.
- Supuestos científicos utilizados en la interpretación: la lectura del dato no es neutra: se apoya en marcos teóricos y modelos físicos aceptados en el momento del análisis. Registrar estos supuestos permite contextualizar las conclusiones y comprender posibles revisiones futuras.
- Transformaciones sucesivas del dato bruto al dato publicado: desde la señal original hasta el producto científico final, el dato atraviesa distintas fases de procesamiento, agregación y análisis. Cada transformación debe poder reconstruirse para entender cómo se llegó al resultado comunicado.
Sin trazabilidad exhaustiva, la reproducibilidad se debilita y la interpretabilidad futura se compromete. Cuando no es posible reconstruir el proceso completo que dio lugar a un resultado, su evaluación independiente se vuelve limitada y su reutilización científica pierde solidez.
3. Reproducibilidad a largo plazo
Las misiones espaciales pueden extenderse durante décadas, y sus datos pueden seguir siendo relevantes mucho después de que la misión haya finalizado. Además, la interpretación científica evoluciona con el tiempo: nuevos modelos, nuevas herramientas y nuevas preguntas pueden requerir volver a analizar información generada años atrás.
Por ello, los datos deben mantenerse interpretables incluso cuando los equipos originales ya no existen, los sistemas tecnológicos han cambiado o el contexto científico ha evolucionado.
Esto exige:
- Metadatos ricos y estructurados: la información contextual que acompaña al dato —sobre su origen, condiciones de adquisición, procesamiento y limitaciones— debe estar organizada de forma clara y normalizada. Sin metadatos suficientes, el dato pierde significado y se vuelve difícil de reinterpretar en el futuro.
- Identificadores persistentes: cada conjunto de datos debe poder localizarse y citarse de manera estable en el tiempo. Los identificadores persistentes permiten mantener la referencia incluso si cambian los sistemas de almacenamiento o las infraestructuras tecnológicas.
- Políticas de preservación digital robustas: la conservación a largo plazo requiere estrategias que contemplen la obsolescencia de formatos, la migración tecnológica y la integridad de los archivos. No basta con almacenar; es necesario asegurar que los datos sigan siendo accesibles y legibles con el paso del tiempo.
- Documentación accesible de los pipelines de procesamiento: el proceso que transforma el dato bruto en producto científico debe estar descrito de forma comprensible. Esto permite que investigadores futuros puedan reconstruir el análisis, verificar los resultados o aplicar nuevos métodos sobre los mismos datos originales.
La reproducibilidad, en este contexto, no significa repetir físicamente el fenómeno observado, sino poder reconstruir el proceso analítico que condujo a un resultado determinado. La gobernanza no solo gestiona el presente; garantiza la reutilización futura del conocimiento y preserva la capacidad de reinterpretar la información a la luz de nuevos avances científicos.
El siguiente visual resumen los tres desafíos:
Figura 2. Reglas para capturar datos espaciales documentados, trazables y auditables. Fuente: elaboración propia - datos.gob.es.
Conclusión: gobernar lo que no podemos tocar
Los datos del universo nos obligan a repensar cómo entendemos y gestionamos la información. Estamos trabajando con realidades que no podemos visitar, tocar ni comprobar directamente. Observamos fenómenos que ocurren a distancias inmensas y en tiempos que superan la escala humana, a través de instrumentos altamente especializados que traducen señales complejas en datos interpretables.
En este contexto, la incertidumbre no es un error ni una debilidad, sino una característica natural del estudio del cosmos. La interpretación de los datos depende de modelos científicos que evolucionan con el tiempo, y la calidad no se basa en una verificación directa, sino en procesos rigurosos, bien documentados y revisados por la comunidad científica. La confianza, por tanto, no surge de la experiencia directa, sino de la transparencia, la trazabilidad y la claridad con la que se explican los métodos utilizados.
Gobernar datos espaciales no significa únicamente almacenarlos o ponerlos a disposición del público. Significa conservar toda la información que permite entender cómo se obtuvieron, cómo se procesaron y bajo qué supuestos fueron interpretados. Solo así pueden ser evaluados, reinterpretados y reutilizados en el futuro.
Más allá de la Tierra, el gobierno del dato no es un detalle técnico ni una tarea administrativa. Es el fundamento que sostiene la credibilidad del conocimiento humano sobre el universo y la base que permite que nuevas generaciones continúen explorando lo que aún no podemos alcanzar físicamente.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
En la encrucijada del siglo XXI, las ciudades se enfrentan a desafíos de enorme magnitud. El crecimiento explosivo de la población, la urbanización acelerada y la presión sobre los recursos naturales están generando una demanda sin precedentes para encontrar soluciones innovadoras que permitan construir y gestionar entornos urbanos más eficientes, sostenibles y habitables.
A estos retos se suma el impacto del cambio climático en las ciudades. A medida que el mundo experimenta alteraciones en los patrones climáticos, las ciudades deben adaptarse y transformarse para garantizar la sostenibilidad y la resiliencia a largo plazo.
Una de las manifestaciones más directas del cambio climático en el entorno urbano es el aumento de las temperaturas. El efecto isla de calor urbana, agravado por la concentración de edificaciones y superficies asfaltadas que absorben y retienen el calor, se ve intensificado por el incremento global de la temperatura. Esto no solo afecta a la calidad de vida al aumentar los costes de refrigeración y la demanda energética, sino que también puede provocar graves problemas de salud pública, como golpes de calor y la agravación de enfermedades respiratorias y cardiovasculares.
El cambio en los patrones de precipitación es otro de los efectos críticos del cambio climático que afectan a las ciudades. Los episodios de lluvias intensas y las tormentas más frecuentes y severas pueden dar lugar a inundaciones urbanas, especialmente en zonas con infraestructuras de drenaje insuficientes u obsoletas. Esta situación ocasiona importantes daños estructurales, y también interrumpe la vida cotidiana, afecta a la economía local y aumenta los riesgos para la salud pública debido a la propagación de enfermedades transmitidas por el agua.
Ante estos desafíos, la planificación y el diseño urbano deben evolucionar. Las ciudades están adoptando estrategias de urbanismo sostenible que incluyen la creación de infraestructuras verdes, como parques y cubiertas vegetales, capaces de mitigar el efecto isla de calor y mejorar la absorción del agua durante episodios de lluvias intensas. Asimismo, la integración de sistemas de transporte público eficientes y la promoción de la movilidad no motorizada resultan esenciales para reducir las emisiones de carbono.
Los retos descritos también influyen en la normativa edificatoria y en los códigos de construcción. Los nuevos edificios deben cumplir estándares más exigentes de eficiencia energética, resistencia a condiciones meteorológicas extremas y reducción del impacto ambiental. Esto implica el uso de materiales sostenibles y técnicas constructivas que no solo disminuyan las emisiones de gases de efecto invernadero, sino que también ofrezcan seguridad y durabilidad frente a eventos climáticos extremos.
En este contexto, los gemelos digitales urbanos se han consolidado como una de las herramientas clave para apoyar la planificación, la gestión y la toma de decisiones en las ciudades. Su potencial es amplio y transversal: desde la simulación de escenarios de crecimiento urbano hasta el análisis de riesgos climáticos, la evaluación de impactos normativos o la optimización de servicios públicos. Sin embargo, más allá del discurso tecnológico y de las visualizaciones en 3D, la viabilidad real de un gemelo digital urbano depende de una cuestión fundamental de gobierno de datos: la disponibilidad, calidad y uso coherente de datos abiertos estandarizados.
¿Qué entendemos por gemelo digital urbano?
Un gemelo digital urbano no es simplemente un modelo tridimensional de la ciudad ni una plataforma de visualización avanzada. Se trata de una representación digital estructurada y dinámica del entorno urbano, que integra:
-
La geometría y semántica de la ciudad (edificios, infraestructuras, parcelas, espacios públicos).
-
Datos geoespaciales de referencia (catastro, planeamiento, redes, medio ambiente).
-
Información temporal y contextual, que permite analizar la evolución del territorio y simular escenarios.
-
En determinados casos, flujos de datos actualizables procedentes de sensores, sistemas de información municipales u otras fuentes operacionales.
Desde una perspectiva de estándares, un gemelo digital urbano puede entenderse como un ecosistema de datos y servicios interoperables, donde distintos modelos, escalas y dominios (urbanismo, edificación, movilidad, medio ambiente, energía) se conectan de forma coherente. Su valor no reside tanto en la tecnología concreta empleada como en su capacidad para alinear datos heterogéneos bajo modelos comunes, reutilizables y gobernables.
Además, la integración de datos en tiempo real en los gemelos digitales permite una gestión más eficiente de la ciudad en situaciones de emergencia. Desde la gestión de desastres naturales hasta la coordinación de eventos masivos, los gemelos digitales proporcionan a los responsables de la toma de decisiones una visión en tiempo real de la situación urbana, lo que facilita una respuesta rápida y coordinada.
Con el fin de contextualizar el papel de los estándares y facilitar la comprensión del funcionamiento interno de un gemelo digital urbano, la Figura 1 presenta un diagrama conceptual de la red de interfaces, modelos de datos y procesos que lo sustentan. El esquema ilustra cómo diferentes fuentes de información urbana —datos geoespaciales de referencia, modelos 3D de ciudad, información normativa y, en determinados casos, flujos dinámicos— se integran mediante estructuras de datos estandarizadas y servicios interoperables.
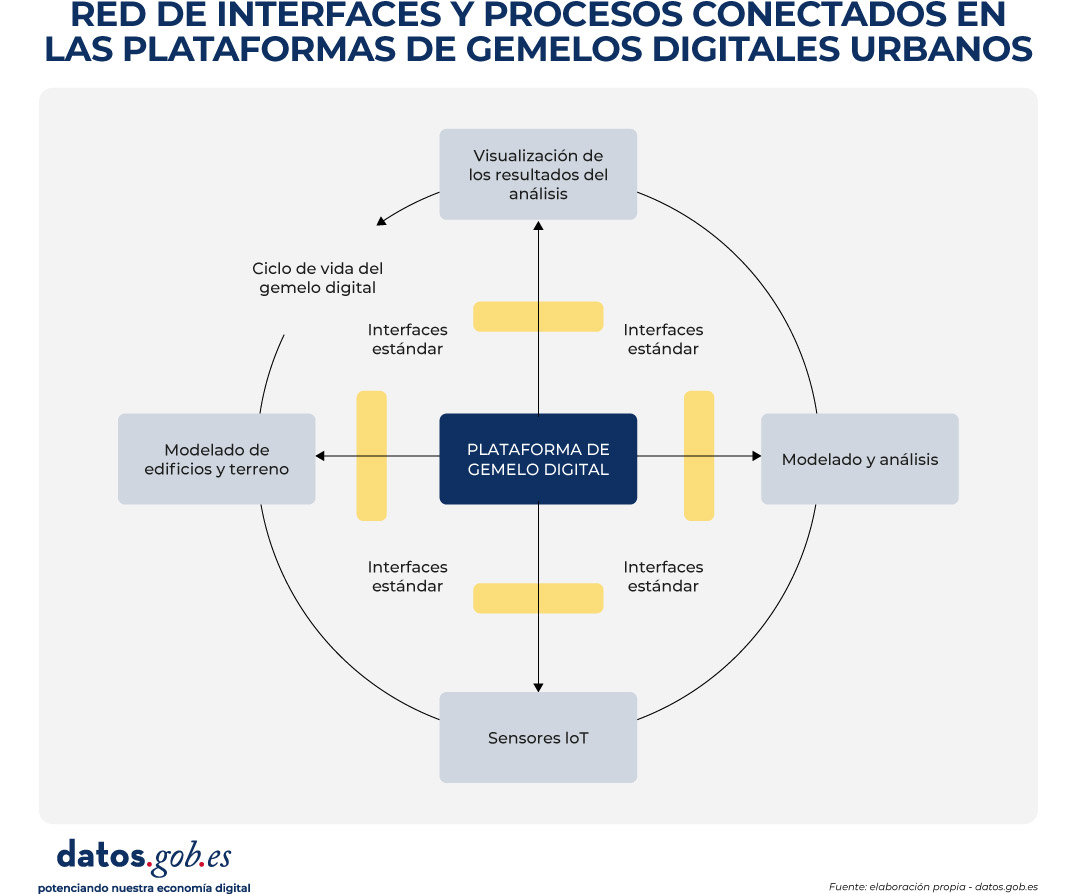
Figura 1. Diagrama conceptual de la red de interfaces y procesos conectados en las plataformas de gemelos digitales urbanos. Fuente: elaboración propia – datos.gob.es.
En estos entornos, CityGML y CityJSON actúan como modelos de información urbana que permiten describir digitalmente la ciudad de forma estructurada y comprensible. En la práctica, funcionan como “lenguajes comunes” para representar edificios, infraestructuras y espacios públicos, no solo desde el punto de vista de su forma (geometría), sino también de su significado (por ejemplo, si un objeto es un edificio residencial, una vía pública o una zona verde). Gracias a ello, estos modelos constituyen la base sobre la que se apoyan los análisis urbanos y la simulación de distintos escenarios.
Para que estos modelos tridimensionales puedan visualizarse de manera ágil en navegadores web y aplicaciones digitales, especialmente cuando se trata de grandes volúmenes de información, se puede incorporar 3D Tiles. Este estándar permite dividir los modelos urbanos en fragmentos manejables, facilitando su carga progresiva y su exploración interactiva, incluso en dispositivos con capacidades limitadas.
El acceso, intercambio y reutilización de toda esta información habitualmente se articula a través de OGC APIs, que pueden entenderse como interfaces normalizadas que permiten a distintas aplicaciones consultar y combinar datos urbanos de forma consistente. Estas interfaces hacen posible, por ejemplo, que una plataforma de planificación urbana, una herramienta de análisis climático o un visor ciudadano accedan a los mismos datos sin necesidad de duplicarlos ni transformarlos de manera específica.
De este modo, el diagrama refleja el flujo de datos desde las fuentes originales hasta las aplicaciones finales, mostrando cómo el uso de estándares abiertos permite separar claramente los datos, los servicios y los casos de uso. Esta separación resulta clave para garantizar la interoperabilidad entre sistemas, la escalabilidad de las soluciones digitales y la sostenibilidad del gemelo digital urbano a lo largo del tiempo, aspectos que se abordan de forma transversal en el resto del documento.

Figura 2. Vista General. Imagen de la UTE Fuses Viader + Perea + Mansilla + Desvigne.
Un ejemplo del impacto de los gemelos digitales urbanos en la construcción y gestión urbana puede encontrarse en el proyecto de regeneración urbana de la Plaza de las Glòries Catalanes, en Barcelona (España). Este proyecto tenía como objetivo transformar una de las zonas urbanas más emblemáticas de la ciudad en un espacio público más accesible, verde y sostenible.
Mediante el uso de gemelos digitales desde las fases iniciales del proyecto, los equipos de diseño y planificación pudieron crear modelos digitales detallados que representaban no solo la geometría de los edificios e infraestructuras existentes, sino también las complejas interacciones entre los distintos elementos urbanos, como el tráfico, el transporte público y las áreas peatonales.
Estos modelos no solo facilitaron la visualización y la comunicación del diseño propuesto entre todas las partes interesadas, sino que también permitieron simular distintos escenarios y evaluar su impacto en la movilidad, la calidad del aire y la accesibilidad peatonal. Como resultado, se pudieron tomar decisiones más informadas, contribuyendo de manera decisiva al éxito global de la iniciativa de regeneración urbana.
El papel crítico de los datos abiertos en los gemelos digitales urbanos
En el contexto de los gemelos digitales urbanos, los datos abiertos no deben entenderse como un complemento opcional ni como una acción puntual de transparencia, sino como la base estructural sobre la que se construyen sistemas urbanos digitales sostenibles, interoperables y reutilizables en el tiempo. Un gemelo digital urbano solo puede cumplir su función como herramienta de planificación, análisis y apoyo a la toma de decisiones si los datos que lo alimentan están disponibles, bien definidos y gobernados conforme a principios comunes.
Cuando un gemelo digital se desarrolla sin una estrategia clara de datos abiertos, tiende a convertirse en un sistema cerrado y dependiente de soluciones tecnológicas o proveedores concretos. En estos escenarios, la actualización de la información resulta costosa y compleja, la reutilización en nuevos contextos es limitada y el gemelo pierde rápidamente su valor estratégico, quedando obsoleto frente a la evolución real de la ciudad que pretende representar. Esta falta de apertura dificulta además la integración con otros sistemas y reduce la capacidad de adaptación a nuevas necesidades normativas, sociales o ambientales.
Uno de los principales aportes de los gemelos digitales urbanos es su capacidad para fundamentar las decisiones públicas en datos trazables y verificables. Cuando se apoyan en datos abiertos accesibles y comprensibles, estos sistemas permiten entender no solo el resultado de una decisión, sino también los datos, modelos y supuestos que la sustentan, integrando información geoespacial, modelos urbanos, normativa y, en determinados casos, datos dinámicos. Esta trazabilidad resulta clave para la rendición de cuentas, la evaluación de políticas públicas y la generación de confianza tanto a nivel institucional como ciudadano. Por el contrario, en ausencia de datos abiertos, los análisis y simulaciones que respaldan las decisiones urbanas se vuelven opacos, dificultando explicar cómo y por qué se ha llegado a una determinada conclusión y debilitando la confianza en el uso de tecnologías avanzadas para la gestión urbana.
Los gemelos digitales urbanos requieren, además, la colaboración de múltiples actores —administraciones, empresas, universidades y ciudadanía— y la integración de datos procedentes de distintos niveles administrativos y dominios sectoriales. Sin un enfoque basado en datos abiertos estandarizados, esta colaboración se ve obstaculizada por barreras técnicas y organizativas: cada actor tiende a utilizar formatos, modelos e interfaces diferentes, lo que incrementa los costes de integración y frena la creación de ecosistemas de reutilización en torno al gemelo digital.
Otro riesgo significativo asociado a la ausencia de datos abiertos es el incremento de la dependencia tecnológica y la consolidación de silos de información. Los gemelos digitales construidos sobre datos no estandarizados o de acceso restringido suelen quedar ligados a soluciones propietarias, dificultando su evolución, migración o integración con otros sistemas. Desde la perspectiva del gobierno del dato, esta situación compromete la soberanía de la información urbana y limita la capacidad de las administraciones para mantener el control sobre activos digitales estratégicos.
Por el contrario, cuando los datos urbanos se publican como datos abiertos estandarizados, el gemelo digital puede evolucionar como una infraestructura pública de datos, compartida, reutilizable y extensible en el tiempo. Esto implica no solo que los datos estén disponibles para su consulta o visualización, sino que sigan modelos de información comunes, con semántica explícita, geometría coherente y mecanismos de acceso bien definidos que faciliten su integración en distintos sistemas y aplicaciones.
Este enfoque permite que el gemelo digital urbano actúe como una base de datos común sobre la que puedan construirse múltiples casos de uso —planificación urbana, gestión de licencias, evaluación ambiental, análisis de riesgos climáticos, movilidad o participación ciudadana— sin duplicar esfuerzos ni generar inconsistencias. La reutilización sistemática de la información no solo optimiza recursos, sino que garantiza coherencia entre las distintas políticas públicas que inciden sobre el territorio.
Desde una perspectiva estratégica, los gemelos digitales urbanos basados en datos abiertos estandarizados permiten además alinear las políticas locales con los principios europeos de interoperabilidad, reutilización y soberanía del dato. El uso de estándares abiertos y modelos de información comunes facilita la integración de los gemelos digitales en iniciativas más amplias, como los espacios de datos sectoriales o las estrategias de digitalización y sostenibilidad promovidas a nivel europeo. De este modo, las ciudades no desarrollan soluciones aisladas, sino infraestructuras digitales coherentes con marcos normativos y estratégicos superiores, reforzando el papel del gemelo digital como herramienta transversal, transparente y sostenible para la gestión urbana.
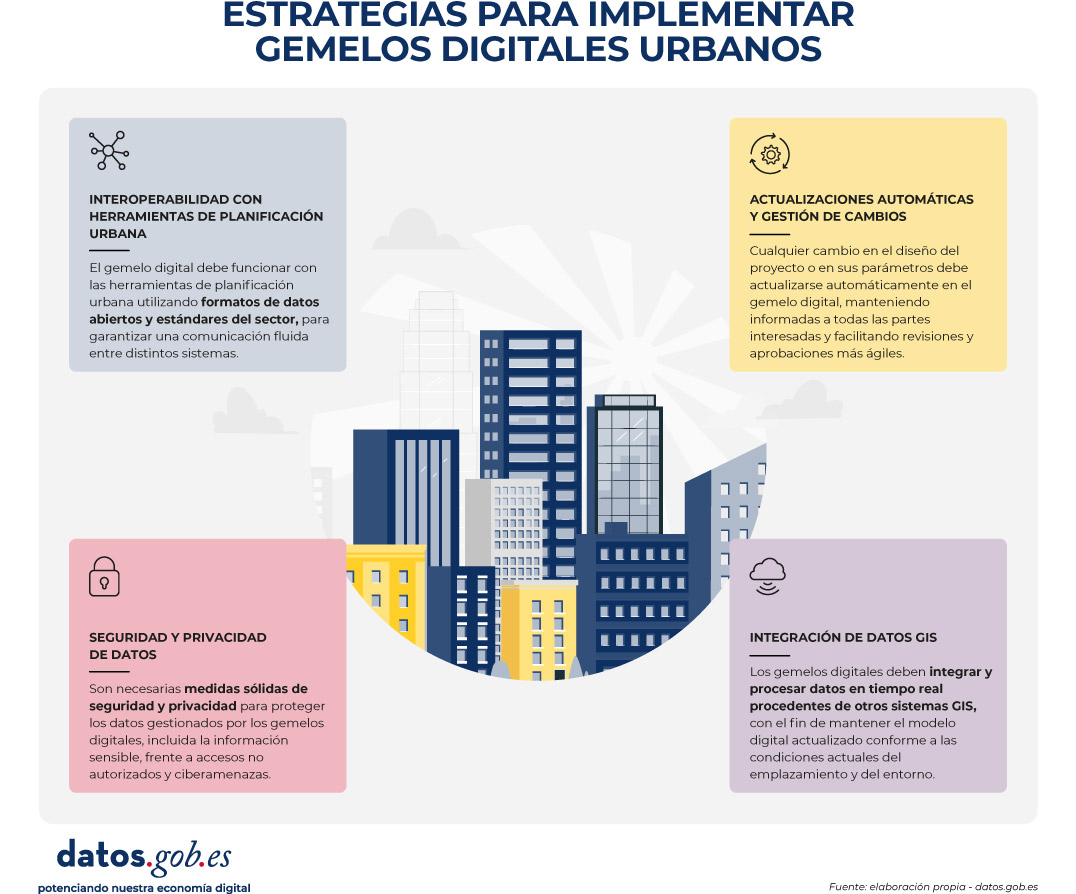
Figura 3. Estrategias para implementar gemelos digitales urbanos. Fuente: elaboración propia– datos.gob.es.
Conclusión
Los gemelos digitales urbanos representan una oportunidad estratégica para transformar la forma en que las ciudades planifican, gestionan y toman decisiones sobre su territorio. Sin embargo, su verdadero valor no reside en la sofisticación tecnológica de las plataformas ni en la calidad de las visualizaciones, sino en la solidez del enfoque de datos sobre el que se construyen.
Los gemelos digitales urbanos solo pueden consolidarse como herramientas útiles y sostenibles cuando se apoyan en datos abiertos estandarizados, bien gobernados y concebidos desde su origen para la interoperabilidad y la reutilización. En ausencia de estos principios, los gemelos digitales corren el riesgo de convertirse en soluciones cerradas, difíciles de mantener, escasamente reutilizables y desconectadas de los procesos reales de gobernanza urbana.
El uso de modelos de información comunes, estándares abiertos y mecanismos de acceso interoperables permite que el gemelo digital evolucione como una infraestructura pública de datos, capaz de servir a múltiples políticas públicas y de adaptarse a los cambios sociales, ambientales y normativos que afectan a la ciudad. Esta aproximación refuerza la transparencia, mejora la coordinación institucional y facilita la toma de decisiones basadas en evidencias verificables.
En definitiva, apostar por gemelos digitales urbanos basados en datos abiertos estandarizados no es únicamente una decisión técnica, sino una decisión de política pública en materia de gobierno del dato. Es esta visión la que permitirá que los gemelos digitales contribuyan de forma efectiva a afrontar los grandes retos urbanos y a generar un valor público duradero para la ciudadanía.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
En la era de la Inteligencia Artificial (IA), los datos han dejado de ser simples registros para convertirse en el combustible esencial de la innovación. Sin embargo, para que ese combustible impulse realmente nuevos servicios, políticas públicas más eficaces o modelos de IA avanzados, no basta con disponer de grandes volúmenes de información: los datos deben ser variados, de calidad y, sobre todo, accesibles.
En este contexto cobra protagonismo el data pooling o agrupación de datos, una práctica que consiste en poner datos en común para generar mayor valor a partir de su uso conjunto. Lejos de ser una idea abstracta, el data pooling se perfila como uno de los mecanismos clave para transformar la economía del dato en Europa y acaba de recibir un nuevo impulso con la propuesta del Digital Omnibus, orientada a simplificar y reforzar el marco europeo de compartición de datos.
Como ya analizamos en nuestro reciente post sobre la Estrategia de la Unión de Datos, la Unión Europea aspira a construir un mercado único de datos en el que la información pueda fluir de forma segura y con garantías. El data pooling es, precisamente, la herramienta operativa que permite hacer tangible esa visión, conectando datos hoy dispersos entre administraciones, empresas y sectores.
Pero ¿qué significa exactamente “data pooling”? ¿Por qué se habla cada vez más de este concepto en el contexto de la estrategia europea de datos y del nuevo Digital Omnibus? Y, sobre todo, ¿qué oportunidades abre para las administraciones públicas, las empresas y los reutilizadores de datos? en este artículo tratamos de responder estas preguntas.
¿Qué es el data pooling, cómo funciona y para qué sirve?
Para entender qué es el data pooling, puede resultar útil pensar en una cooperativa agrícola tradicional. En ella, pequeños productores que, de forma individual, tienen recursos limitados deciden poner en común su producción y sus medios. Al hacerlo, ganan escala, acceden a mejores herramientas y pueden competir en mercados a los que no llegarían por separado.
En el ámbito digital, el data pooling funciona de manera muy similar. Consiste en combinar o agrupar conjuntos de datos procedentes de distintas organizaciones o fuentes para analizarlos o reutilizarlos con un objetivo compartido. Al crear este “depósito común” de información —físico o lógico— se habilitan análisis más complejos y valiosos que difícilmente podrían realizarse desde una única fuente aislada.
Este “poner datos en común” puede adoptar distintas formas, en función de las necesidades técnicas y organizativas de cada iniciativa:
- Repositorios compartidos, en los que varias organizaciones aportan datos a una misma plataforma.
- Accesos conjuntos o federados, donde los datos permanecen en sus sistemas de origen, pero pueden analizarse de forma coordinada.
- Acuerdos de gobernanza, que establecen reglas claras sobre quién puede acceder a los datos, con qué finalidad y bajo qué condiciones.
En todos los casos, la idea central es la misma: cada participante contribuye con sus datos y, a cambio, todos se benefician de un mayor volumen, diversidad y riqueza de información, siempre bajo normas previamente acordadas.
¿Para qué sirve poner los datos en común?
El creciente interés por el data pooling no es casual. Compartir datos de forma estructurada permite, entre otras cosas:
- Detectar patrones que no son visibles con datos aislados, especialmente en ámbitos complejos como la movilidad, la salud, la energía o el medio ambiente.
- Mejorar el desarrollo de la inteligencia artificial, que necesita datos diversos, de calidad y a escala para generar resultados fiables.
- Evitar duplicidades, reduciendo costes y esfuerzos tanto en el sector público como en el privado.
- Impulsar la innovación, facilitando nuevos servicios, estudios comparativos o análisis predictivos.
- Reforzar la toma de decisiones basada en evidencias, un aspecto especialmente relevante en el diseño de políticas públicas.
En otras palabras, el data pooling multiplica el valor de los datos existentes sin necesidad de generar siempre nuevos conjuntos de información.
Distintos tipos de data pooling y su valor
No todos los data pools son iguales. Dependiendo del contexto y del objetivo perseguido, pueden identificarse distintos modelos de agrupación de datos:
- Data pooling M2M (Machine-to-Machine), muy habitual en el Internet de las Cosas (IoT). Por ejemplo, cuando fabricantes de sensores industriales agrupan datos de miles de máquinas para anticipar fallos o mejorar el mantenimiento.
- Data pooling transversal o intersectorial, que combina datos de sectores distintos —como transporte y energía— para optimizar servicios, por ejemplo, la gestión de la recarga de vehículos eléctricos en ciudades inteligentes.
- Data pooling para investigación, especialmente relevante en el ámbito de la salud, donde hospitales o centros de investigación comparten datos anonimizados para entrenar algoritmos capaces de detectar enfermedades poco frecuentes o mejorar diagnósticos.
Estos ejemplos muestran que el data pooling no es una solución única, sino un conjunto de prácticas adaptables, capaces de generar valor económico, social y científico cuando se aplican con las garantías adecuadas.
Del potencial a la práctica: garantías, reglas claras y nuevas oportunidades para el data pooling
Hablar de poner datos en común no significa hacerlo sin límites. Para que el data pooling genere confianza y valor sostenible, es imprescindible abordar cómo compartir datos de forma responsable. Este ha sido, de hecho, uno de los grandes retos que han condicionado su adopción en los últimos años.
Entre las principales preocupaciones destacan la protección de los datos personales, garantizando el cumplimiento del Reglamento General de Protección de Datos (RGPD) y minimizando riesgos de reidentificación; la confidencialidad y la protección de los secretos comerciales, especialmente cuando participan empresas; así como la calidad e interoperabilidad de los datos, ya que combinar información inconsistente puede conducir a conclusiones erróneas. A todo ello se suma un elemento transversal: la confianza entre las partes, sin la cual ningún mecanismo de compartición puede funcionar.
Por este motivo, el data pooling no es solo una cuestión técnica. Requiere marcos legales claros, modelos de gobernanza sólidos y mecanismos de confianza, que den seguridad tanto a quienes comparten los datos como a quienes los reutilizan.
El papel de Europa: de compartir datos a crear ecosistemas
Consciente de estos retos, la Unión Europea lleva años trabajando para construir un mercado único de datos, en el que compartir información sea más sencillo, seguro y beneficioso para todos los actores implicados. En este contexto han surgido iniciativas clave como los espacios europeos de datos, organizados por sectores estratégicos (salud, movilidad, industria, energía, agricultura), el impulso a estándares e interoperabilidad, y la aparición de intermediarios de datos como terceros de confianza que facilitan la compartición.
El data pooling encaja plenamente en esta visión: es uno de los mecanismos prácticos que permiten que estos espacios de datos funcionen y generen valor real. Al facilitar la agregación y el uso conjunto de datos, el pooling actúa como el “motor” que hace operativos muchos de estos ecosistemas.
Todo ello se enmarca en la Estrategia de la Unión de Datos, que busca conectar políticas, infraestructuras y normas para que los datos puedan circular de forma segura y eficiente en toda Europa.
El gran freno: la fragmentación normativa
Hasta hace poco, este potencial se encontraba con un obstáculo importante: la complejidad del marco legal europeo en materia de datos. Una organización que quisiera participar en un data pool transfronterizo debía navegar entre múltiples normas —RGPD, Data Governance Act, Data Act, Directiva de Datos Abiertos y regulaciones sectoriales o nacionales— con definiciones, obligaciones y autoridades competentes no siempre alineadas. Esta fragmentación generaba inseguridad jurídica: dudas sobre responsabilidades, miedo a sanciones, o incertidumbre sobre la protección real de los secretos comerciales. En la práctica, este “laberinto normativo” ha frenado durante años el desarrollo de muchos espacios comunes de datos y ha limitado la adopción del data pooling, especialmente entre pymes y empresas medianas con menos capacidad jurídica y técnica.
El Digital Omnibus: simplificar para que el data pooling escale
Es en este punto donde entra en juego el Digital Omnibus, la propuesta de la Comisión Europea para simplificar y armonizar el marco jurídico digital. Lejos de añadir nuevas capas regulatorias, el objetivo del Omnibus es ordenar, consolidar y reducir cargas administrativas, facilitando que compartir datos sea viable en la práctica.
Desde la perspectiva del data pooling, el mensaje es claro: menos fragmentación, más claridad y mayor confianza. El Omnibus busca concentrar las reglas en un marco más coherente, evitar duplicidades y eliminar barreras innecesarias que hasta ahora desincentivaban la colaboración basada en datos, especialmente en proyectos transfronterizos.
Además, se refuerza el papel de los servicios de intermediación de datos, actores clave para organizar el pooling de forma neutral y confiable. Al clarificar su rol y reducir determinadas cargas, se favorece la aparición de nuevos modelos —incluidas startups tecnológicas— capaces de actuar como “árbitros” del intercambio de datos entre múltiples participantes.
Otro elemento especialmente relevante es el refuerzo de la protección de los secretos comerciales, permitiendo a los poseedores de datos limitar o denegar el acceso cuando exista un riesgo real de uso indebido o transferencia a entornos sin garantías adecuadas. Este punto resulta clave para sectores industriales y estratégicos, donde la confianza es condición indispensable para compartir datos.
Nuevas oportunidades del data pooling: sector público, empresas y reutilización de datos
La simplificación normativa y el refuerzo de la confianza que introduce el Digital Omnibus no son un fin en sí mismos. Su verdadero valor reside en las oportunidades concretas que abre el data pooling para distintos actores del ecosistema del dato, especialmente para el sector público, las empresas y los reutilizadores de información.
En el caso de las administraciones públicas, el data pooling ofrece un potencial especialmente relevante. Permite combinar datos procedentes de distintas fuentes y niveles administrativos para mejorar el diseño y la evaluación de las políticas públicas, avanzar hacia una toma de decisiones basada en evidencias y ofrecer servicios más eficaces y personalizados a la ciudadanía. Al mismo tiempo, facilita la ruptura de silos de información, la reutilización de datos ya disponibles y la reducción de duplicidades, con el consiguiente ahorro de costes y esfuerzos.
Además, el data pooling refuerza la colaboración entre el sector público, el ámbito investigador y el sector privado, siempre bajo marcos seguros y transparentes. En este contexto, no compite con los datos abiertos, sino que los complementa, permitiendo conectar conjuntos de datos que hoy se publican de forma fragmentada y habilitando análisis más avanzados que amplían su valor social y económico.
Desde el punto de vista empresarial, el Digital Omnibus introduce una novedad significativa al ampliar el foco más allá de las pymes tradicionales. Las denominadas small mid-caps, empresas de mediana capitalización que también sufren el impacto de la burocracia, pasan a beneficiarse de la simplificación normativa. Esto incrementa de forma notable la base de organizaciones capaces de participar en esquemas de data pooling y amplía el volumen y la diversidad de datos disponibles en sectores estratégicos como la industria, la automoción o la química.
El impacto económico de este nuevo escenario es también relevante. La Comisión Europea estima importantes ahorros de costes administrativos y operativos, tanto para empresas como para administraciones públicas. Pero más allá de las cifras, estos ahorros representan capacidad liberada para innovar, invertir en nuevos servicios digitales y desarrollar modelos de inteligencia artificial más avanzados, alimentados por datos que ahora pueden compartirse con mayor seguridad.
En definitiva, el data pooling se consolida como una palanca clave para pasar de la compartición puntual de datos a la generación sistemática de valor, sentando las bases de una economía del dato más colaborativa, eficiente y competitiva en Europa.
Conclusión: cooperar para competir
La propuesta del data pooling en el Digital Omnibus marca un antes y un después en la forma en que entendemos la propiedad de la información. Europa ha entendido que, en la economía global del dato, la soberanía no se defiende cerrando fronteras, sino creando entornos seguros donde la colaboración sea la opción más sencilla y rentable.
El data pooling es el corazón de esta transformación. Al reducir la burocracia, simplificar las notificaciones y proteger los secretos comerciales, el Omnibus está quitando las piedras del camino para que empresas y ciudadanos puedan disfrutar de los beneficios de una verdadera Unión de Datos.
En definitiva, se trata de pasar de una economía de silos aislados a una de redes conectadas. Porque, en el mundo de los datos, compartir no es perder el control, es ganar escala.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Cada vez gana más terreno la idea de concebir la inteligencia artificial (IA) como un servicio de consumo inmediato o utility, bajo la premisa de que basta con “comprar una aplicación y empezar a utilizarla”. Sin embargo, subirse a la IA no es como comprar software convencional y ponerlo en marcha al instante. A diferencia de otras tecnologías de la información, la IA difícilmente se podrá utilizar con la filosofía del plug and play. Existe un conjunto de tareas imprescindibles que los usuarios de estos sistemas deberían emprender, no solo por razones de seguridad y cumplimiento legal, sino sobre todo para obtener resultados eficientes y confiables.
El Reglamento de inteligencia artificial (RIA)[1]
El RIA define marcos de referencia que deberían ser tenidos en cuenta por los proveedores[2] y responsables de desplegar[3] la IA. Esta es una norma muy compleja cuya orientación es doble. En primer lugar, en una aproximación que podríamos definir como de alto nivel, la norma establece un conjunto de líneas rojas que nunca podrán ser traspasadas. La Unión Europea aborda la IA desde un enfoque centrado en el ser humano y al servicio de las personas. Por ello, cualquier desarrollo deberá garantizar ante todo que no se vulneren derechos fundamentales ni se cause ningún daño a la seguridad e integridad de las personas. Adicionalmente, no se admitirá ninguna IA que pudiera generar riesgos sistémicos para la democracia y el estado de derecho. Para que estos objetivos se materialicen, el RIA despliega un conjunto de procesos mediante un enfoque orientado a producto. Esto permite clasificar los sistemas de IA en función de su nivel de riesgo, -bajo, medio, alto- así como los modelos de IA de uso general[4]. Y también, establecer, a partir de esta categorización, las obligaciones que cada sujeto participante deberá cumplir para garantizar los objetivos de la norma.
Habida cuenta de la extraordinaria complejidad del reglamento europeo, queremos compartir en este artículo algunos principios comunes que se deducen de su lectura y podrían inspirar buenas prácticas por parte de las organizaciones públicas y privadas. Nuestro enfoque no se centra tanto en definir una hoja de ruta para un determinado sistema de información como en destacar algunos elementos que, a nuestro juicio, pueden resultar de utilidad para garantizar que el despliegue y utilización de esta tecnología resulten seguros y eficientes, con independencia del nivel de riesgo de cada sistema de información basado en IA.
Definir un propósito claro
El despliegue de un sistema de IA es altamente dependiente de la finalidad que persigue la organización. No se trata de subirse al carro de una moda. Es cierto que la información pública disponible parece evidenciar que la integración de este tipo de tecnología forma parte importante de los procesos de transformación digital de las empresas y de la Administración, proporcionando mayor eficiencia y capacidades. Sin embargo, no puede convertirse en una moda instalar cualquiera de los Large Language Models (LLM). Se necesita una reflexión previa que tenga en cuenta cuáles son las necesidades de la organización y defina que tipo de IA va a contribuir a la mejora de nuestras capacidades. No adoptar esta estrategia podría poner en riesgo a nuestra entidad, no solo desde el punto de vista de su funcionamiento y resultados, sino incluso desde una perspectiva jurídica. Por ejemplo, introducir un LLM o un chatbot en un entorno de alto riesgo decisional podría suponer padecer impactos reputacionales o incurrir en responsabilidad civil. Insertar este LLM en un entorno médico, o utilizar un chatbot en un contexto sensible con población no preparada o en procesos de asistencia críticos, podría acabar generando situaciones de riesgo de consecuencias imprevisibles para las personas.
No hacer el mal
El principio de no maleficiencia es un elemento clave y debe inspirar de modo determinante nuestra práctica en el mundo de la IA. Por ello el RIA establece una serie de prácticas expresamente prohibidas para proteger los derechos fundamentales y la seguridad de las personas. Estas prohibiciones se centran en evitar manipulaciones, discriminaciones y usos indebidos de sistemas de IA que puedan causar daños significativos.
Categorías de prácticas prohibidas
1. Manipulación y control del comportamiento. Mediante el uso de técnicas subliminales o manipuladoras que alteren el comportamiento de personas o colectivos, impidiendo la toma de decisiones informadas y provocando daños considerables.
2. Explotación de vulnerabilidades. Derivadas de la edad, discapacidad o situación social/económica para modificar sustancialmente el comportamiento y causar perjuicio.
3. Puntuación social (Social Scoring). IA que evalúe a personas en función de su comportamiento social o características personales, generando calificaciones con efectos para los ciudadanos que resulten en tratos injustificados o desproporcionados.
4. Evaluación de riesgos penales basada en perfiles. IA utilizada para predecir la probabilidad de comisión de delitos únicamente mediante elaboración de perfiles o características personales. Aunque se admite su uso para la investigación penal cuando el delito se ha cometido efectivamente y existen hechos que analizar.
5. Reconocimiento facial y bases de datos biométricas. Sistemas para la ampliación de bases de datos de reconocimiento facial mediante la extracción no selectiva de imágenes faciales de Internet o de circuitos cerrados de televisión.
6. Inferencia de emociones en entornos sensibles. Diseñar o usar la IA para inferir emociones en el trabajo o en centros educativos, salvo por motivos médicos o de seguridad.
7. Categorización biométrica sensible. Desarrollar o utilizar una IA que clasifique a individuos según datos biométricos para deducir raza, opiniones políticas, religión, orientación sexual, etc.
8. Identificación biométrica remota en espacios públicos. Uso de sistemas de identificación biométrica remota «en tiempo real» en espacios públicos con fines policiales, salvo excepciones muy limitadas (búsqueda de víctimas, prevención de amenazas graves, localización de sospechosos de delitos graves).
Al margen de las conductas expresamente prohibidas es importante tener en cuenta que el principio de no maleficencia implica que no podemos utilizar un sistema de IA con la clara intención de causar un daño, con la conciencia de que esto podría ocurrir o, en cualquier caso, cuando la finalidad que perseguimos sea contraria a derecho.
Garantizar una adecuada gobernanza de datos
El concepto de gobernanza de datos se encuentra en el artículo 10 del RIA y aplica a los sistemas de alto riesgo. No obstante, contiene un conjunto de principios de alta rentabilidad a la hora de desplegar un sistema de cualquier nivel. Los sistemas de IA de alto riesgo que usan datos deben desarrollarse con conjuntos de entrenamiento, validación y prueba que cumplan criterios de calidad. Para ello se definen ciertas prácticas de gobernanza para asegurar:
- Diseño adecuado.
- Que la recogida y origen de los datos, y en el caso de los datos personales la finalidad perseguida, sean adecuadas y legítimas.
- Que se adopten procesos de preparación como la anotación, el etiquetado, la depuración, la actualización, el enriquecimiento y la agregación.
- Que el sistema se diseñe con casos de uso cuya información sea coherente con lo que se supone que miden y representan los datos.
- Asegurar la calidad de los datos garantizando la disponibilidad, la cantidad y la adecuación de los conjuntos de datos necesarios.
- Detectar y revisar de sesgos que puedan afectar a la salud y la seguridad de las personas, a los derechos o generar discriminación, especialmente cuando las salidas de datos influyan en las informaciones de entrada de futuras operaciones. Deben adoptarse medidas para prevenir y corregir estos sesgos.
- Identificar y resolver lagunas o deficiencias en los datos que impidan el cumplimiento del RIA, y añadiríamos que la legislación.
- Los conjuntos de datos empleados deben ser relevantes, representativos, completos y con propiedades estadísticas adecuadas para su uso previsto y deben considerar las características geográficas, contextuales o funcionales necesarias para el sistema, así como garantizar su diversidad. Además, carecerán de errores y estarán completos en vista de su finalidad prevista.
La IA es una tecnología altamente dependiente de los datos que la alimentan. Desde este punto de vista, no disponer de gobernanza de datos no solo puede afectar al funcionamiento de estas herramientas, sino que podría generar responsabilidad para el usuario.
En un futuro no lejano, la obligación de que los sistemas de alto riesgo obtengan un marcado CE emitido por un organismo notificado (es decir, designado por un Estado miembro de la Unión Europea) ofrecerá condiciones de confiabilidad al mercado. Sin embargo, para el resto de los sistemas de menor riesgo aplica la obligación de transparencia. Esto no implica en absoluto que el diseño de esta IA no deba tener en cuenta estos principios en la medida de lo posible. Por tanto, antes de realizar una contratación sería razonable verificar la información precontractual disponible tanto en relación con las características del sistema y su confiabilidad como respecto de las condiciones y recomendaciones de despliegue y uso.
Otra cuestión atañe a nuestra propia organización. Si no disponemos de las adecuadas medidas de cumplimiento normativo, organizativas, técnicas y de calidad que aseguren la confiabilidad de nuestros propios datos, difícilmente podremos utilizar herramientas de IA que se alimenten de ellos. En el contexto del RIA el usuario de un sistema también puede incurrir en responsabilidad. Es perfectamente posible que un producto de esta naturaleza haya sido desarrollado de modo adecuado por el proveedor y que en términos de reproducibilidad éste pueda garantizar que bajo las condiciones adecuadas el sistema funciona correctamente. Lo que desarrolladores y proveedores no pueden resolver son las inconsistencias en los conjuntos de datos que integre en la plataforma el usuario-cliente. No es su responsabilidad si el cliente no desplegó adecuadamente un marco de cumplimiento del Reglamento General de Protección de Datos o está utilizando el sistema para una finalidad ilícita. Tampoco será su responsabilidad que el cliente mantenga conjuntos de datos no actualizados o no confiables que al ser introducidos en la herramienta generen riesgos o contribuyan a la toma de decisiones inadecuadas o discriminatorias.
En consecuencia, la recomendación es clara: antes de implementar un sistema basado en inteligencia artificial debemos asegurarnos de que la gobernanza de datos y el cumplimiento de la legislación vigente se garanticen adecuadamente.
Garantizar la seguridad
La IA es una tecnología particularmente sensible que presenta riesgos de seguridad específicos, -los llamados efectos adversarios-, como por ejemplo la corrupción de los conjuntos de datos. No es necesario buscar ejemplos sofisticados. Como cualquier sistema de información la IA exige que las organizaciones los desplieguen y utilicen de modo seguro. En consecuencia, el despliegue de la IA en cualquier entorno exige el desarrollo previo de un análisis de riesgos que permita identificar cuáles son las medidas organizativas y técnicas que garantizan un uso seguro que la herramienta.
Formar a su personal
A diferencia del RGPD, en el que esta cuestión es implícita, el RIA expresamente establece como obligación el deber de formar. El artículo 4 del RIA es tan preciso que merece la pena su reproducción íntegra:
Los proveedores y responsables del despliegue de sistemas de IA adoptarán medidas para garantizar que, en la mayor medida posible, su personal y demás personas que se encarguen en su nombre del funcionamiento y la utilización de sistemas de IA tengan un nivel suficiente de alfabetización en materia de IA, teniendo en cuenta sus conocimientos técnicos, su experiencia, su educación y su formación, así como el contexto previsto de uso de los sistemas de IA y las personas o los colectivos de personas en que se van a utilizar dichos sistemas.
Este sin duda es un factor crítico. Las personas que utilizan la inteligencia artificial deben haber recibido una formación adecuada que les permita entender la naturaleza del sistema y ser capaces de tomar decisiones informadas. Uno de los principios nucleares de la legislación y del enfoque europeo es el de supervisión humana. Por tanto, con independencia de las garantías que ofrezca un determinado producto de mercado, la organización que lo utiliza siempre será responsable de las consecuencias. Y ello ocurrirá tanto en el caso en el que la última decisión se atribuya a una persona, como cuando en procesos altamente automatizados los responsables de su gestión no sean capaces de identificar una incidencia tomando decisiones adecuadas con supervisión humana.
La culpa in vigilando
La introducción masiva de los LLM plantea el riesgo de incurrir en la llamada culpa in vigilando: un principio jurídico que hace referencia a la responsabilidad que asume una persona por no haber ejercido la debida vigilancia sobre otra, cuando de esa falta de control se deriva un daño o un perjuicio. Si su organización ha introducido cualquiera de estos productos de mercado que integran funciones como realizar informes, evaluar información alfanumérica e incluso asistirle en la gestión del correo electrónico, será fundamental que asegure el cumplimiento de las recomendaciones que anteriormente hemos señalado. Resultará particularmente aconsejable que defina de modo muy preciso los fines para los que se implementa la herramienta, los roles y responsabilidades de cada usuario y proceda a documentar sus decisiones y a formar adecuadamente al personal.
Desgraciadamente el modelo de introducción en el mercado de los LLM ha generado por sí mismo un riesgo sistémico y grave para las organizaciones. La mayor parte de herramientas han optado por una estrategia de comercialización que no difiere en nada de la que en su día emplearon las redes sociales. Esto es, permiten el acceso en abierto y gratuito a cualquier persona. Es obvio que con ello consiguen dos resultados: reutilizar la información que se les facilita monetizando el producto y generar una cultura de uso que facilite la adopción y comercialización de la herramienta.
Imaginemos una hipótesis, por supuesto, descabellada. Un médico interno residente (MIR) ha descubierto que varias de estas herramientas han sido desarrolladas y, de hecho, se utilizan en otro país para el diagnóstico diferencial. Nuestro MIR está muy preocupado por tener que despertar al jefe de guardia médica en el hospital cada 15 minutos. Así que, diligentemente, contrata una herramienta, que no se ha previsto para ese uso en España, y toma decisiones basadas en la propuesta de diagnóstico diferencial de un LLM sin tener todavía las capacidades que lo habilitan para una supervisión humana. Evidentemente existe un riesgo significativo de acabar causando un daño a un paciente.
Situaciones como la descrita obligan a considerar cómo deben actuar las organizaciones que no utilizan IA pero que son conscientes del riesgo de que sus empleados las usen sin su conocimiento o consentimiento. En este sentido, se debería adoptar una estrategia preventiva basada en la emisión de circulares e instrucciones muy precisas respecto de la prohibición de su uso. Por otra parte, existe una situación de riesgo híbrida. El LLM se ha contratado por la organización y es utilizada por la persona empleada para fines distintos de los previstos. En tal caso la dupla seguridad-formación adquiere un valor estratégico.
Probablemente la formación y la adquisición de cultura sobre la inteligencia artificial sea un requisito esencial para el conjunto de la sociedad. De lo contrario, los problemas y riesgos sistémicos que en el pasado afectaron al despliegue de Internet volverán a suceder y quién sabe si con una intensidad difícil de gobernar.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
NOTAS
[1] Reglamento (UE) 2024/1689 del Parlamento Europeo y del Consejo, de 13 de junio de 2024, por el que se establecen normas armonizadas en materia de inteligencia artificial y por el que se modifican los Reglamentos (CE) n.° 300/2008, (UE) n.° 167/2013, (UE) n.° 168/2013, (UE) 2018/858, (UE) 2018/1139 y (UE) 2019/2144 y las Directivas 2014/90/UE, (UE) 2016/797 y (UE) 2020/1828 disponible en https://eur-lex.europa.eu/legal-content/ES/TXT/?uri=OJ%3AL_202401689
[2] El RIA define como «proveedor»: una persona física o jurídica, autoridad pública, órgano u organismo que desarrolle un sistema de IA o un modelo de IA de uso general o para el que se desarrolle un sistema de IA o un modelo de IA de uso general y lo introduzca en el mercado o ponga en servicio el sistema de IA con su propio nombre o marca, previo pago o gratuitamente.
[3] EL RIA define como «responsable del despliegue»: una persona física o jurídica, o autoridad pública, órgano u organismo que utilice un sistema de IA bajo su propia autoridad, salvo cuando su uso se enmarque en una actividad personal de carácter no profesional.
[4] El RIA define como «modelo de IA de uso general»: un modelo de IA, también uno entrenado con un gran volumen de datos utilizando autosupervisión a gran escala, que presenta un grado considerable de generalidad y es capaz de realizar de manera competente una gran variedad de tareas distintas, independientemente de la manera en que el modelo se introduzca en el mercado, y que puede integrarse en diversos sistemas o aplicaciones posteriores, excepto los modelos de IA que se utilizan para actividades de investigación, desarrollo o creación de prototipos antes de su introducción en el mercado.