Fecha publicación
12/06/2026
Fecha actualización
16/06/2026
Comparte este contenido

Descripción
Imagina un edificio sin mantenimiento. Al principio funciona perfectamente: las puertas abren, la fontanería fluye, todo está en orden. Pasa el tiempo y nadie se ocupa de las pequeñas cosas: una tubería que gotea, una ventana que no cierra bien, papeles que se acumulan en los pasillos. Cinco años después, el edificio sigue en pie, pero usarlo se ha convertido en una odisea. Nadie sabe dónde está nada, hay habitaciones a las que ya nadie entra, y cada vez que intentas arreglar algo aparecen tres problemas más.
Con los datos pasa lo mismo. Una organización puede empezar con las mejores intenciones: sistemas bien diseñados, datos ordenados, todo documentado. Pero sin mantenimiento activo, esos datos que, al principio, eran un activo valioso acaban convirtiéndose en una ciénaga: un espacio donde la información existe, pero es imposible encontrarla, entenderla o confiar en ella.
Del data lake al data swamp: una diferencia clave
El concepto de data lake se presentó como la solución definitiva: un repositorio centralizado donde almacenar datos en su formato nativo para que analistas y científicos pudieran explorarlos libremente. Muchos de estos lagos, sin embargo, han terminado convirtiéndose en lo que la industria llama data swamp, o pantano de datos: un repositorio de datos que, aunque contiene mucha información, se ha vuelto inútil en la práctica.
La diferencia entre un lago y una ciénaga no está en la tecnología. Dos organizaciones pueden usar arquitecturas similares y obtener resultados muy distintos. Lo que marca la diferencia es cómo se gestionan los datos: si se conocen sus responsables, si están descritos, si se puede evaluar su calidad, si se mantienen actualizados y si existen reglas claras para incorporarlos, transformarlos o retirarlos. Un data lake aporta valor cuando está gobernado; el pantano aparece cuando el almacenamiento crece más rápido que la capacidad de entender y reutilizar lo que se guarda.
¿Cómo se forma una ciénaga de datos?
El paso de un entorno saludable a uno degradado suele ser silencioso. Los pantanos, rara vez, son el resultado de un gran error puntual; son el efecto acumulado de pequeñas decisiones cotidianas: datos que se cargan sin documentar, sistemas que cambian sin avisar, responsables que se van y nadie sustituye. Con el tiempo, el repositorio pasa de ser un activo estratégico a un lastre operativo. Y, lo peor, es que este deterioro suele ser invisible hasta que alguien intenta hacer algo con los datos y descubre que no puede.
-
Ingesta sin propósito: se almacenan datos "por si acaso", sin un proceso de catalogación previo. Una organización empieza a capturar datos de nuevas fuentes (sensores, formularios, APIs externas) sin establecer quién los valida, cómo se documentan o dónde se almacenan de forma ordenada.
-
Falta de documentación desde el origen: los datos se ingresan sin explicar qué significan, de dónde vienen, con qué frecuencia se actualizan o bajo qué reglas se capturan. No se registra el linaje ni el propósito de cada conjunto de datos.
-
Acumulación sin criterio: se guarda "todo por si acaso", sin una política clara de qué datos son relevantes, cuánto tiempo deben conservarse o cuándo pueden archivarse o eliminarse.
-
Cambios organizativos sin seguimiento: personas que conocían los datos dejan la organización, se reorganizan departamentos, se migran sistemas… y nadie actualiza la documentación ni traspasa el conocimiento.
-
Proyectos piloto que se quedaron a medias: se cargan datos para un proyecto experimental, el proyecto termina (o nunca arranca), pero los datos se quedan ahí, sin contexto ni responsable.
-
Ausencia de controles de calidad: no se validan los datos antes de ingresar al sistema ni se monitorizan después, por lo que los errores y las inconsistencias se acumulan silenciosamente.
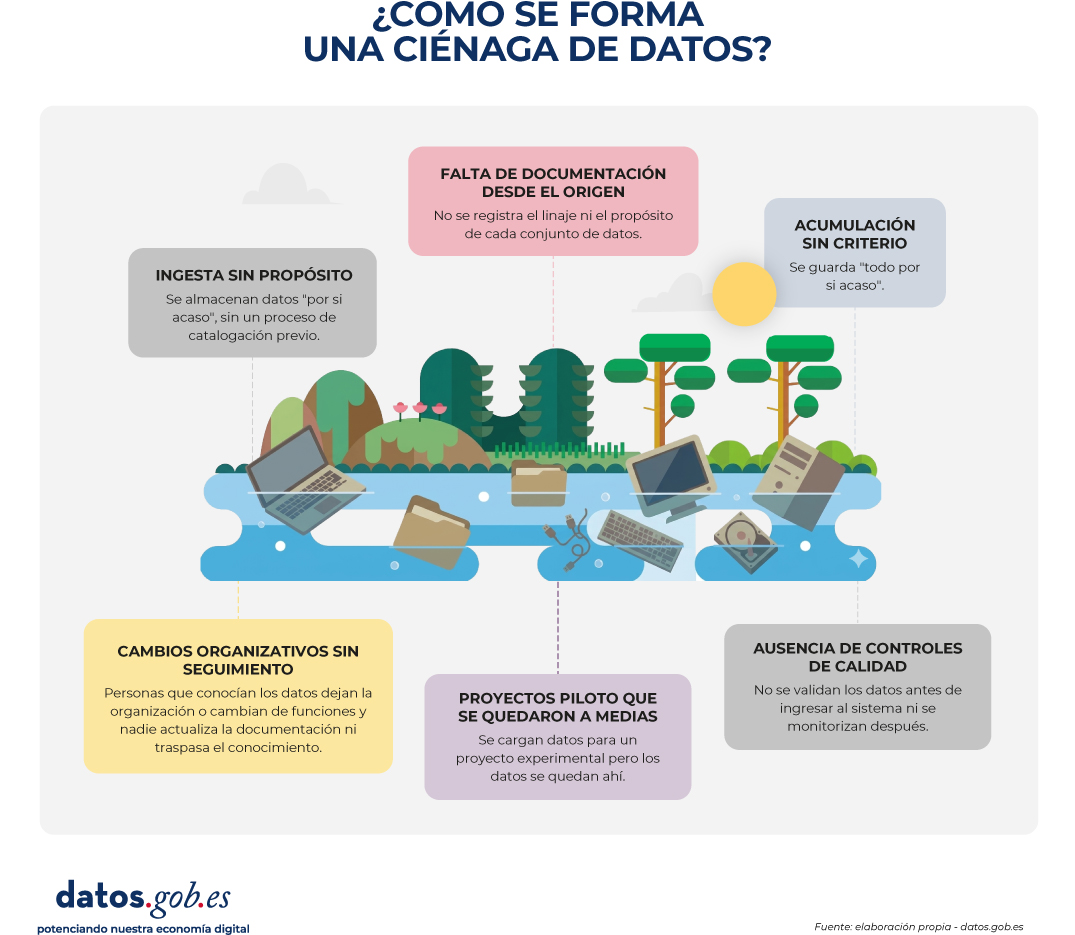
Figura 1. Visual explicativo sobre el proceso de formación de una ciénaga de datos. Fuente: elaboración propia - datos.gob.es
Data drift: cuando los datos envejecen sin que te des cuenta
Relacionado con los pantanos, el data drift (deriva de datos) es un fenómeno especialmente relevante en proyectos de inteligencia artificial, aunque afecta a cualquier análisis basado en datos históricos. Ocurre cuando los datos dejan de representar la realidad actual, bien porque el contexto ha cambiado, bien porque las fuentes se han modificado sin que nadie lo haya documentado.
Podemos identificar varios tipos de deriva:
-
Drift en las fuentes: un sistema de origen cambia su estructura, añade campos, elimina otros o modifica la lógica de cálculo de un indicador, pero nadie actualiza la documentación ni avisa a los usuarios de esos datos.
-
Drift en los patrones: la realidad que los datos describen cambia. Por ejemplo, los patrones de movilidad urbana antes y después de una pandemia son radicalmente distintos. Un modelo entrenado con datos previos dejará de funcionar bien si no se recalibra.
-
Drift en las definiciones: el significado de un campo cambia con el tiempo. Imaginemos que "vivienda vacía" se redefinió en 2022 para incluir segundas residencias, pero nadie actualizó la documentación. Quien compare datos de 2020 y 2024 estará mezclando conceptos distintos sin saberlo.
Como vimos en el post sobre estructuras organizativas de gobierno del dato para IA, un sistema de IA es tan bueno como los datos que lo alimentan. Si esos datos envejecen, el sistema empieza a fallar. Y si no hay mecanismos de monitorización activa, el problema puede pasar desapercibido durante meses. Un ejemplo claro es lo ocurrido durante la COVID-19, donde varios modelos predictivos vieron cómo su precisión caía drásticamente porque habían sido entrenados con patrones de comportamiento que dejaron de aplicarse de un día para otro. Es un caso extremo, pero ilustra bien el riesgo: un modelo es tan vigente como los datos que lo sustentan. Cuanto peor gobernados estén esos datos, más difícil será detectar estos cambios a tiempo.
Cómo evitar la ciénaga
Los pantanos de datos se pueden evitar. La clave está en adoptar un enfoque proactivo, basado en el mantenimiento continuo y en responsabilidades claras.
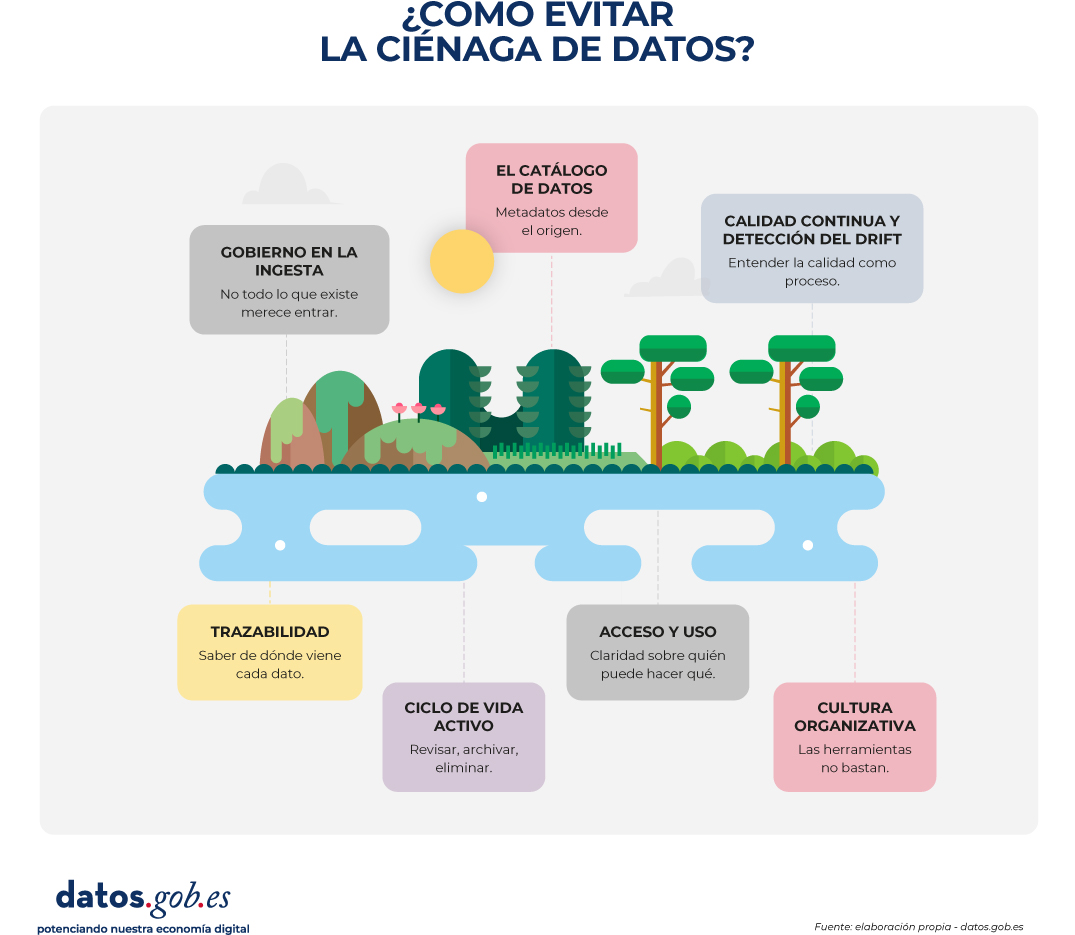
Figura 2. Visual explicativo sobre cómo evitar que un pantano de datos se convierte en una ciénaga. Fuente: elaboración propia - datos.gob.es
-
Gobierno en la ingesta: no todo lo que existe merece entrar: el primer error que lleva a la ciénaga es la ausencia de filtros en la entrada. Establecer una zona de aterrizaje (landing zone) donde se verifiquen unos mínimos antes de mover los datos a las zonas de consumo es fundamental. Eso requiere definir quién es responsable de cada conjunto de datos (data owner), quién garantiza su calidad y documentación en el día a día (data steward), y bajo qué criterios se puede cargar algo al sistema. Sin este marco básico, cada dato que entra es una semilla potencial de desorden.
-
El catálogo de datos: metadatos desde el origen: los metadatos son la capa de información que permite entender, encontrar y confiar en los datos. Sin ellos, un repositorio es una caja negra. Un buen catálogo responde a preguntas básicas: ¿qué contiene este conjunto de datos?, ¿de dónde viene?, ¿quién lo mantiene?, ¿cuándo se actualizó por última vez?, ¿qué significa cada campo? La catalogación no es una tarea que se hace una vez y se olvida. Es un proceso continuo: cada modificación actualiza la descripción, cada error detectado se documenta y corrige, cada reutilización genera información que mejora la documentación. Las herramientas de catalogación automatizada pueden ayudar a escanear repositorios y detectar cambios, pero la responsabilidad de validar esa información sigue siendo humana. En el ámbito de los datos abiertos, el perfil de metadatos DCAT-AP-ES ofrece un estándar común para describir conjuntos de datos de forma homogénea; el mismo enfoque puede aplicarse a cualquier repositorio interno.
-
Calidad continua y detección del drift: la calidad de los datos no es un estado, es un proceso. Un conjunto de datos puede ser excelente hoy y volverse inservible mañana sin monitorización activa. Las prácticas útiles incluyen validar los datos antes de cargarlos al sistema, establecer métricas de calidad revisadas periódicamente, configurar alertas que detecten desviaciones respecto a patrones históricos y hacer auditorías manuales para capturar errores que las métricas automáticas no ven. En España, la especificación UNE 0081 establece criterios para evaluar dimensiones como exactitud, completitud, consistencia o actualidad, lo que permite medir la calidad de forma objetiva y establecer compromisos concretos con los usuarios. En contextos donde los datos alimentan modelos de IA, las técnicas estadísticas de detección de drift permiten comparar la distribución actual de los datos con la de entrenamiento y lanzar alertas cuando la diferencia supera un umbral. Detectar el problema a tiempo permite reentrenar modelos antes de que su rendimiento se degrade.
-
Trazabilidad: saber de dónde viene cada dato: en entornos complejos es necesario conocer el origen de cada dato, las transformaciones que ha sufrido, los procesos que lo han generado y los productos que dependen de él. El linaje de datos permite detectar el impacto de un cambio en origen, depurar errores o cumplir con obligaciones legales. Sin él, cualquier problema se convierte en una búsqueda en el laberinto.
-
Ciclo de vida activo: revisar, archivar, eliminar: mantener datos obsoletos o irrelevantes aumenta el ruido, dificulta las búsquedas y consume recursos. Una política de ciclo de vida del dato define cuánto tiempo debe conservarse cada tipo de dato, cómo moverse a sistemas de almacenamiento más económicos cuando ya no se usan activamente, y cuándo pueden eliminarse —siempre respetando las obligaciones legales en materia de protección de datos—. Revisiones periódicas permiten identificar conjuntos que nadie ha consultado en meses, documentación desactualizada o datos que ya no tienen valor operativo. Esta "limpieza activa" evita que el repositorio crezca indefinidamente.
-
Acceso y uso: claridad sobre quién puede hacer qué: un pantano también aparece cuando no está claro quién puede acceder a qué datos y para qué. Las políticas de acceso deben clasificar los datos según su sensibilidad, definir permisos, documentar restricciones legales o éticas y asegurar que los usuarios conocen las condiciones de uso. En el ámbito de los datos abiertos, la apertura debe ir acompañada de información clara sobre licencias, formatos, periodicidad y contexto.
-
Cultura organizativa: las herramientas no bastan: las herramientas y los procesos son importantes, pero sin una cultura que valore la calidad del dato cualquier sistema acaba degradándose. Fomentar esa cultura requiere formación continua para que quienes generan o mantienen datos entiendan por qué importa la documentación, visibilidad directiva que sitúe la calidad del dato como prioridad estratégica, reconocimiento a los equipos que mantienen datos bien gestionados, y canales que permitan a quienes reutilizan datos reportar errores y sugerir mejoras.
Mantener datos limpios no puede depender del esfuerzo heroico de una persona. Tiene que ser parte del modo de trabajo habitual. La gobernanza bien diseñada es una ayuda para trabajar mejor, no un freno burocrático.
Marcos de referencia en España
Para abordar estos retos de forma estructurada existen marcos concretos. La familia de especificaciones UNE —impulsada desde la Dirección del Dato— cubre gobierno (UNE 0077), gestión (UNE 0078), gestión de calidad (UNE 0079), madurez de procesos de datos (UNE 0080), evaluación de datasets (UNE 0081), e implantación progresiva (UNE 0085). Para datos abiertos, DCAT-AP-ES establece requisitos sobre identificación, descripción, formatos y condiciones de uso. Estos marcos están pensados para aplicarse de forma incremental: se empieza por lo más crítico, se consolida y se avanza.
Conclusión: del pantano al valor, la gobernanza como sistema de depuración
Los pantanos de datos son prevenibles y, si ya existen, reversibles. Los datos solo generan valor cuando pueden encontrarse, entenderse y utilizarse con confianza. Almacenar información es necesario, pero sin gobierno, calidad, metadatos, trazabilidad y responsabilidades claras, incluso la plataforma más avanzada puede convertirse en un entorno confuso e inaprovechable.
Los beneficios de hacerlo bien son tangibles: equipos que dedican menos tiempo a buscar y limpiar datos, modelos de IA que se mantienen precisos porque el drift se detecta a tiempo, usuarios externos que confían en los datos porque saben que están actualizados. En un contexto donde los datos abiertos, los espacios de datos y la , , artificial adquieren cada vez más protagonismo, cuidar la base sobre la que se construyen estos ecosistemas es una decisión estratégica. El reto no es tener más datos, sino disponer de mejores datos: comprensibles, gobernados y listos para reutilizarse con confianza.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.



Comentarios