
Description
Imagine a building with no maintenance. At first it works perfectly: the doors open, the plumbing flows, everything is in order. Time passes and no one takes care of the little things: a leaky pipe, a window that doesn't close properly, papers that accumulate in the corridors. Five years later, the building still stands, but using it has become an odyssey. Nobody knows where anything is, there are rooms that no one enters anymore, and every time you try to fix something three more problems appear.
The same thing happens with data. An organization can start with the best intentions: well-designed systems, tidy data, everything documented. But without active maintenance, that data that, at first, was a valuable asset ends up becoming a swamp: a space where information exists, but it is impossible to find, understand or trust it.
From data lake to data swamp: a key difference
The concept of the data lake was presented as the ultimate solution: a centralized repository where data can be stored in its native format so that analysts and scientists could freely explore it. Many of these lakes, however, have ended up becoming what the industry calls data swamp: a repository of data that, although it contains a lot of information, has become useless in practice.
The difference between a lake and a swamp is not in the technology. Two organizations can use similar architectures and get very different results. What makes the difference is how the data is managed: if the data is known, if they are described, if their quality can be assessed, if they are kept up to date and if there are clear rules for incorporating, transforming or retiring them. A data lake brings value when it's governed; the swamp appears when storage grows faster than the ability to understand and reuse what's stored.
How is a data swamp formed?
The transition from a healthy environment to a degraded one is usually silent. Swamps are rarely the result of a great punctual error; They are the cumulative effect of small everyday decisions: data that is uploaded without documentation, systems that change without warning, managers that leave and no one replaces. Over time, the repository goes from being a strategic asset to an operational liability. And the worst part is that this deterioration is usually invisible until someone tries to do something with the data and discovers that they can't.
-
Purposeless ingestion: Data is stored "just in case", without a prior cataloguing process. An organization begins to capture data from new sources (sensors, forms, external APIs) without establishing who validates it, how it is documented, or where it is stored in an orderly manner.
-
Lack of documentation from the source: Data is entered without explaining what it means, where it comes from, how often it is updated, or under what rules it is captured. The lineage and purpose of each dataset are not recorded.
-
Accumulation without criteria: "everything just in case" is saved, without a clear policy of what data is relevant, how long it should be kept, or when it can be archived or deleted.
-
Organizational changes without follow-up: people who knew the data leave the organization, departments are reorganized, systems are migrated... and no one updates documentation or transfers knowledge.
-
Pilot projects that were left half-finished: data is uploaded for an experimental project, the project ends (or never starts), but the data stays there, without context or responsibility.
-
Absence of quality controls: Data is not validated before entering the system or monitored afterwards, so errors and inconsistencies accumulate silently.
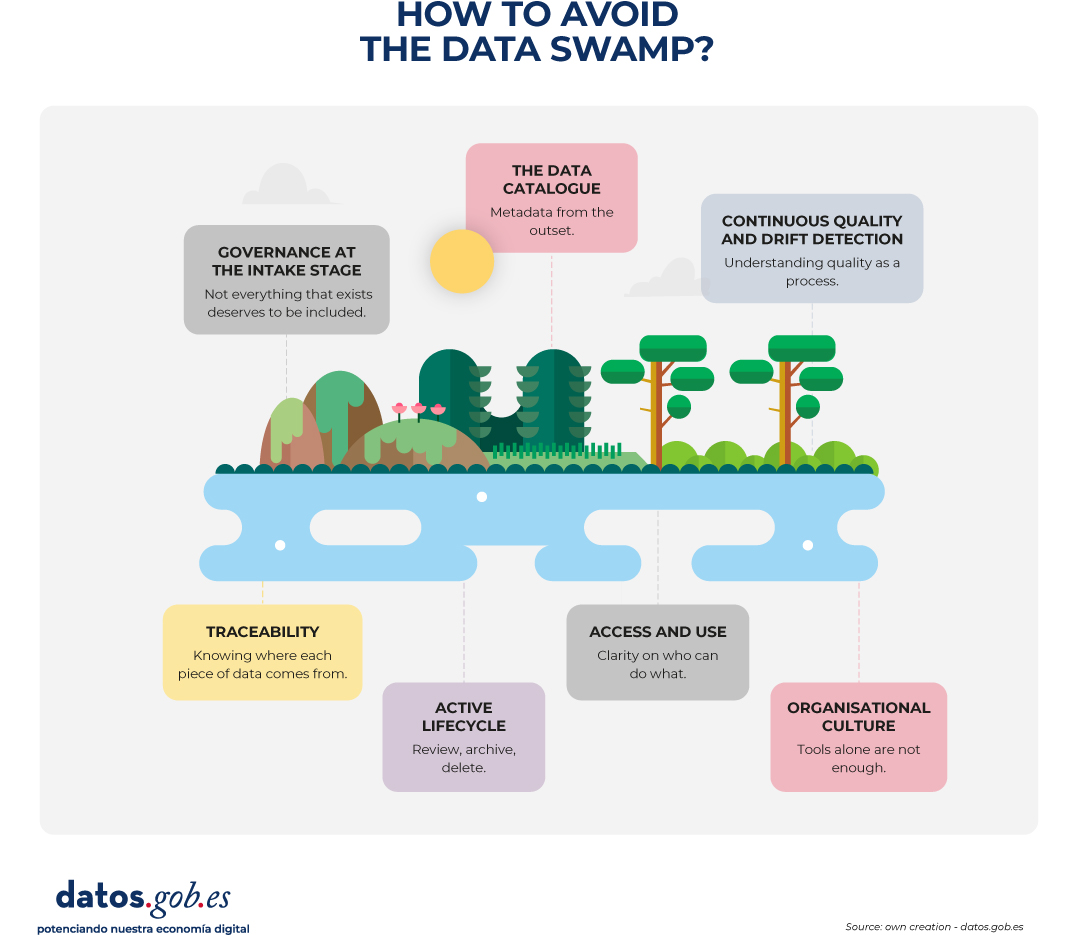
Figure 1. Illustration explaining how to avoid a data swamp. Source: own creation – datos.gob.es
Data drift: when data gets old without you noticing
Related to swamps, data drift is a particularly relevant phenomenon in artificial intelligence projects, although it affects any analysis based on historical data. It occurs when the data no longer represent the current reality, either because the context has changed, or because the sources have been modified without anyone having documented it.
We can identify several types of drift:
-
Drift in sources: a source system changes its structure, adds fields, deletes others or modifies the calculation logic of an indicator, but no one updates the documentation or notifies users of that data.
-
Drift in patterns: the reality that the data describes changes. For example, urban mobility patterns before and after a pandemic are radically different. A model trained on previous data will stop working well if it is not recalibrated.
-
Drift in definitions: the meaning of a field changes over time. Let's imagine that "empty housing" was redefined in 2022 to include second homes, but no one updated the documentation. Anyone who compares data from 2020 and 2024 will be mixing different concepts without knowing it.
As we saw in the post on data governance organizational structures for AI, an AI system is only as good as the data that feeds it. If that data gets old, the system starts to fail. And if there are no active monitoring mechanisms, the problem can go unnoticed for months. A clear example is what happened during COVID-19, where several predictive models saw their accuracy drop drastically because they had been trained with patterns of behavior that stopped being applied from one day to the next. It's an extreme case, but it illustrates the risk well: a model is only as relevant as the data that underpins it. The worse governed that data is, the harder it will be to detect these changes in time.
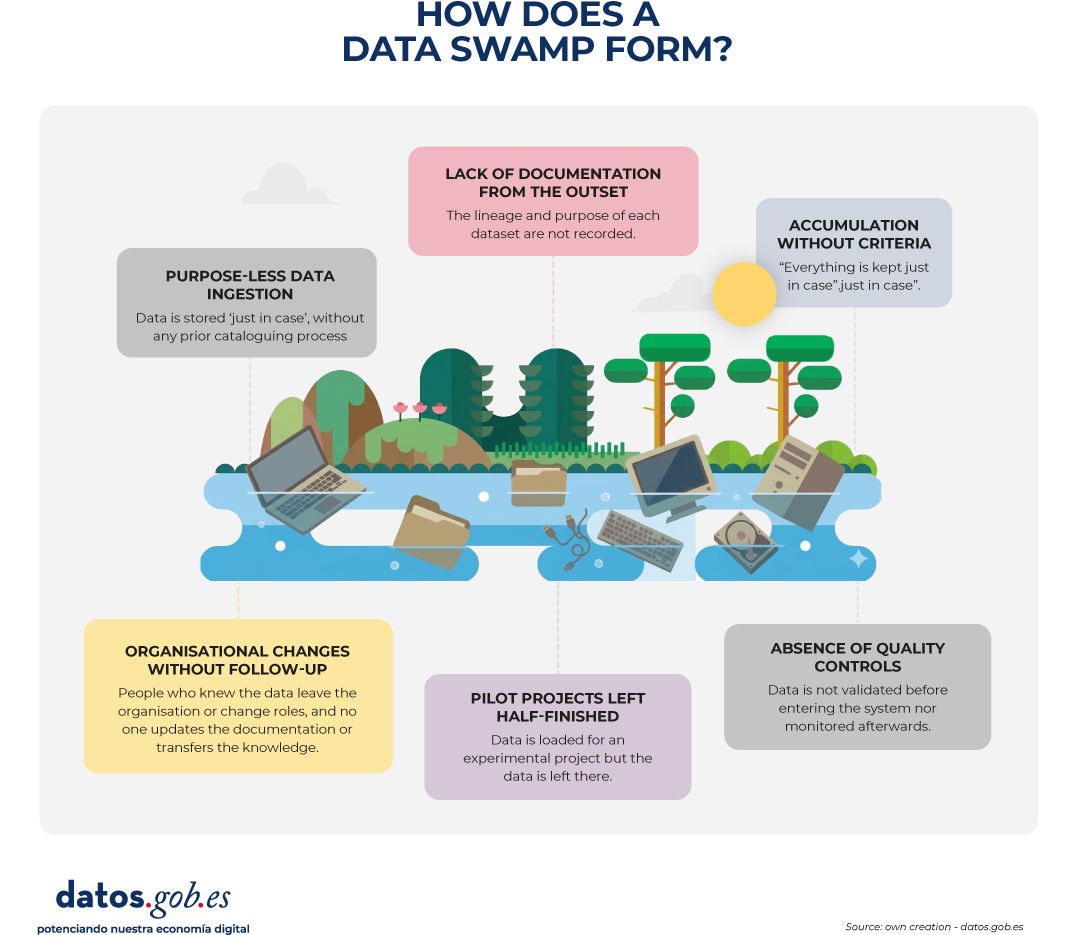
Figure 2. Illustration explaining how a data swamp forms. Source: own creation – datos.gob.es
How to Avoid the Swamp
Data swamps can be avoided. The key is to take a proactive approach, based on ongoing maintenance and clear responsibilities.
Government in intake: not everything that exists deserves to enter
The first mistake that leads to the swamp is the absence of filters at the entrance. Establishing a landing zone where minimums are checked before moving data to consumption zones is critical. This requires defining who is responsible for each data set (data owner), who guarantees its quality and documentation on a day-to-day basis (data steward), and under what criteria something can be uploaded to the system. Without this basic framework, every piece of data that comes in is a potential seed of disorder.
The Data Catalog: Metadata from the Source
Metadata is the layer of information that allows you to understand, find, and trust data. Without them, a repository is a black box. A good catalog answers basic questions: what does this dataset contain?, where does it come from?, who maintains it?, when was it last updated?, what does each field mean?
Cataloguing is not a once-and-forget-it-all task. It's an ongoing process: each modification updates the description, each detected error is documented and corrected, each reuse generates information that improves the documentation. Automated cataloging tools can help scan repositories and detect changes, but the responsibility for validating that information remains human. In the open data space, the DCAT-AP-ES metadata profile provides a common standard for describing datasets in a homogeneous way; the same approach can be applied to any internal repository.
Continuous quality and drift detection
Data quality is not a state, it is a process. A dataset can be great today and become useless tomorrow without active monitoring. Useful practices include validating data before uploading it to the system, establishing regularly reviewed quality metrics, setting up alerts that detect deviations from historical patterns, and performing manual audits to catch errors that automatic metrics do not see. In Spain, the UNE 0081 specification It establishes criteria to evaluate dimensions such as accuracy, completeness, consistency or timeliness, which allows quality to be measured objectively and to establish concrete commitments with users.
In contexts where data feeds AI models, statistical drift detection techniques make it possible to compare the current distribution of data with that of training and to launch alerts when the difference exceeds a threshold. Catching the problem early allows you to retrain models before their performance degrades.
Traceability: Knowing where each piece of data comes from
In complex environments, it is necessary to know the origin of each piece of data, the transformations it has undergone, the processes that have generated it and the products that depend on it. Data lineage allows you to detect the impact of a change at source, debug errors, or comply with legal obligations. Without it, any problem becomes a search in the labyrinth.
Active lifecycle: review, archive, delete
Keeping outdated or irrelevant data adds to the noise, makes searches difficult, and consumes resources. A data lifecycle policy defines how long each type of data should be retained, how to move to cheaper storage systems when they are no longer actively used, and when they can be deleted – always in compliance with legal obligations in terms of data protection. Periodic reviews make it possible to identify sets that no one has consulted in months, outdated documentation or data that no longer has operational value. This "active cleanup" prevents the repository from growing indefinitely.
Access and use: clarity on who can do what
A swamp also appears when it is unclear who can access what data and for what. Access policies should classify data according to its sensitivity, define permissions, document legal or ethical restrictions, and ensure that users are aware of the terms of use. In the field of open data, openness must be accompanied by clear information on licenses, formats, periodicity and context.
Organisational culture: tools are not enough
Tools and processes are important, but without a culture that values data quality, any system ends up degrading. Fostering that culture requires ongoing training so that those who generate or maintain data understand why documentation matters, managerial visibility that places data quality as a strategic priority, recognition of teams that maintain well-managed data, and channels that allow those who reuse data to report errors and suggest improvements.
Keeping data clean can't depend on one person's heroic effort. It has to be part of the usual way of working. Well-designed governance is an aid to work better, not a bureaucratic brake.
Frames of reference in Spain
To address these challenges in a structured way, concrete frameworks are in place. The UNE family of specifications – promoted by the Data Directorate – covers governance (UNE 0077), management (UNE 0078), quality management (UNE 0079), data process maturity (UNE 0080), dataset evaluation (UNE 0081), and progressive implementation (UNE 0085). For open data, DCAT-AP-ES establishes requirements on identification, description, formats and conditions of use. These frameworks are designed to be applied incrementally: you start with the most critical, consolidate and work your way up.
Conclusion: From swamp to value, governance as a purification system
Data swamps are preventable and, if they already exist, reversible. Data only creates value when it can be found, understood, and used with confidence. Storing information is necessary, but without clear governance, quality, metadata, traceability, and responsibilities, even the most advanced platform can become a confusing and unusable environment.
The benefits of getting it right are tangible: teams that spend less time searching for and cleaning data, AI models that stay accurate because drift is caught early, external users who trust the data because they know it's up to date. In a context where open data, data spaces and artificial , , are becoming more and more important, taking care of the foundation on which these ecosystems are built is a strategic decision. The challenge is not to have more data, but to have better data: understandable, governed, and ready to be reused with confidence.
Content produced by Dr Fernando Gualo, Lecturer at the University of Castilla-La Mancha (UCLM) and Consultant on Governance and Data Quality. The content and views expressed in this publication are the sole responsibility of the author.



Comments