Documentación
The adoption of the new DCAT-AP-ES profile aligns Spain with the application profile in Europe (DCAT-AP), facilitating automatic federation between data catalogs defined in RDF (Resource Description Framework).
In this RDF graph environment where flexibility is the norm, the absence of traditional rigid schemas can lead to a silent degradation of data quality, if the standard is not rigorously followed. To mitigate this risk, there is SHACL (Shapes Constraint Language), a recommendation of the W3C. These guidelines make it possible to define "shapes" that function as true guardians of quality and compliance with interoperability.
The stages of the SHACL validation process are as follows:
- An RDF data graph is available
- A subset from the previous graph is selected
- The SHACL constraints that apply to the previous subgraph are checked
- A validation report is obtained with the compliant elements, with errors or with recommendations.
The following figure shows these stages:

Figure 1: Main stages of the SHACL validation process
Objectives and target audience
This technical guide aims to help publishers and reusers incorporate SHACL validation as a continuous quality improvement practice, through a didactic and accessible approach, inspired by clear resources and open validation tools from the data ecosystem.
In addition, its relationship with DCAT-AP-ES is deepened in a special way, detailing a practical and exhaustive case of the complete workflow of validation and governance of a catalog according to this profile.
Structure and contents
The document follows a progressive approach, starting from theoretical foundations to technical implementation and automatic integration, structured in the following key blocks:
- Fundamentals of semantic validation: RDF and the challenge of the “open world, as well as SHACL as a mechanism to perform validations, defining key concepts such as Shape or Validation Report.
- DCAT-AP-ES and the adoption of SHACL for validation: the SHACL forms defined in DCAT-AP-ES and the case of their application in the federation process of the National Catalogue are explained.
- Case Study: RDF Graph Validation: A step-by-step tutorial on how to validate a catalog with DCAT-AP-ES SHACL forms, troubleshooting common issues, and available tools.
- Conclusions: Reflections on the advantages of integrating SHACL validation to improve data catalog governance.
SHACL validation represents a paradigm shift in metadata quality management in data catalogs. This guide walks through the entire process from theoretical foundations to practical application, demonstrating that the adoption of SHACL is not simply a technical requirement, but an opportunity to strengthen and improve data governance.
Blog
Open data is a central piece of digital innovation around artificial intelligence as it allows, among other things, to train models or evaluate machine learning algorithms. But between "downloading a CSV from a portal" and accessing a dataset ready to apply machine learning techniques , there is still an abyss.
Much of that chasm has to do with metadata, i.e. how datasets are described (at what level of detail and by what standards). If metadata is limited to title, description, and license, the work of understanding and preparing data becomes more complex and tedious for the person designing the machine learning model. If, on the other hand, standards that facilitate interoperability are used, such as DCAT, the data becomes more FAIR (Findable, Accessible, Interoperable, Reusable) and, therefore, easier to reuse. However, additional metadata is needed to make the data easier to integrate into machine learning flows.
This article provides an overview of the various initiatives and standards needed to provide open data with metadata that is useful for the application of machine learning techniques.
DCAT as the backbone of open data portals
The DCAT (Data Catalog Vocabulary) vocabulary was designed by the W3C to facilitate interoperability between data catalogs published on the Web. It describes catalogs, datasets, and distributions, being the foundation on which many open data portals are built.
In Europe, DCAT is embodied in the DCAT-AP application profile, recommended by the European Commission and widely adopted to describe datasets in the public sector, for example, in Spain with DCAT-AP-ES. DCAT-AP answers questions such as:
- What datasets exist on a particular topic?
- Who publishes them, under what license and in what formats?
- Where are the download URLs or access APIs?
Using a standard like DCAT is imperative for discovering datasets, but you need to go a step further in order to understand how they are used in machine learning models or what quality they are from the perspective of these models.
MLDCAT-AP: Machine Learning in an Open Data Portal Catalog
MLDCAT-AP (Machine Learning DCAT-AP) is a DCAT application profile developed by SEMIC and the Interoperable Europe community, in collaboration with OpenML, that extends DCAT-AP to the machine learning domain.
MLDCAT-AP incorporates classes and properties to describe:
- Machine learning models and their characteristics.
- Datasets used in training and assessment.
- Quality metrics obtained on datasets.
- Publications and documentation associated with machine learning models.
- Concepts related to risk, transparency and compliance with the European regulatory context of the AI Act.
With this, a catalogue based on MLDCAT-AP no longer only responds to "what data is there", but also to:
- Which models have been trained on this dataset?
- How has that model performed by certain metrics?
- Where is this work described (scientific articles, documentation, etc.)?
MLDCAT-AP represents a breakthrough in traceability and governance, but the definition of metadata is maintained at a level that does not yet consider the internal structure of the datasets or what exactly their fields mean. To do this, it is necessary to go down to the level of the structure of the dataset distribution itself.
Metadata at the internal structure level of the dataset
When you want to describe what's inside the distributions of datasets (fields, types, constraints), an interesting initiative is Data Package, part of the Frictionless Data ecosystem.
A Data Package is defined by a JSON file that describes a set of data. This file includes not only general metadata (such as name, title, description or license) and resources (i.e. data files with their path or a URL to access their corresponding service), but also defines a schema with:
- Field names.
- Data types (integer, number, string, date, etc.).
- Constraints, such as ranges of valid values, primary and foreign keys, and so on.
From a machine learning perspective, this translates into the possibility of performing automatic structural validation before using the data. In addition, it also allows for accurate documentation of the internal structure of each dataset and easier sharing and versioning of datasets.
In short, while MLDCAT-AP indicates which datasets exist and how they fit into the realm of machine learning models, Data Package specifies exactly "what's there" within datasets.
Croissant: Metadata that prepares open data for machine learning
Even with the support of MLDCAT-AP and Data Package, it would be necessary to connect the underlying concepts in both initiatives. On the one hand, the field of machine learning (MLDCAT-AP) and on the other hand, that of the internal structures of the data itself (Data Package). In other words, the metadata of MLDCAT-AP and Data Package may be used, but in order to overcome some limitations that both suffer, it is necessary to complement it. This is where Croissant comes into play, a metadata format for preparing datasets for machine learning application. Croissant is developed within the framework of MLCommons, with the participation of industry and academia.
Specifically, Croissant is implemented in JSON-LD and built on top of schema.org/Dataset, a vocabulary for describing datasets on the Web. Croissant combines the following metadata:
- General metadata of the dataset.
- Description of resources (files, tables, etc.).
- Data structure.
- Semantic layer on machine learning (separation of training/validation/test data, target fields, etc.)
It should be noted that Croissant is designed so that different repositories (such as Kaggle, HuggingFace, etc.) can publish datasets in a format that machine learning libraries (TensorFlow, PyTorch, etc.) can load homogeneously. There is also a CKAN extension to use Croissant in open data portals.
Other complementary initiatives
It is worth briefly mentioning other interesting initiatives related to the possibility of having metadata to prepare datasets for the application of machine learning ("ML-ready datasets"):
- schema.org/Dataset: Used in web pages and repositories to describe datasets. It is the foundation on which Croissant rests and is integrated, for example, into Google's structured data guidelines to improve the localization of datasets in search engines.
- CSV on the Web (CSVW): W3C set of recommendations to accompany CSV files with JSON metadata (including data dictionaries), very aligned with the needs of tabular data documentation that is then used in machine learning.
- Datasheets for Datasets and Dataset Cards: Initiatives that enable the development of narrative and structured documentation to describe the context, provenance, and limitations of datasets. These initiatives are widely adopted on platforms such as Hugging Face.
Conclusions
There are several initiatives that help to make a suitable metadata definition for the use of machine learning with open data:
- DCAT-AP and MLDCAT-AP articulate catalog-level, machine learning models, and metrics.
- Data Package describes and validates the structure and constraints of data at the resource and field level.
- Croissant connects this metadata to the machine learning flow, describing how the datasets are concrete examples for each model.
- Initiatives such as CSVW or Dataset Cards complement the previous ones and are widely used on platforms such as HuggingFace.
These initiatives can be used in combination. In fact, if adopted together, open data is transformed from simply "downloadable files" to machine learning-ready raw material, reducing friction, improving quality, and increasing trust in AI systems built on top of it.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
In any data management environment (companies, public administration, consortia, research projects), having data is not enough: if you don't know what data you have, where it is, what it means, who maintains it, with what quality, when it changed or how it relates to other data, then the value is very limited. Metadata —data about data—is essential for:
-
Visibility and access: Allow users to find what data exists and can be accessed.
-
Contextualization: knowing what the data means (definitions, units, semantics).
-
Traceability/lineage: Understanding where data comes from and how it has been transformed.
-
Governance and control: knowing who is responsible, what policies apply, permissions, versions, obsolescence.
-
Quality, integrity, and consistency: Ensuring data reliability through rules, metrics, and monitoring.
-
Interoperability: ensuring that different systems or domains can share data, using a common vocabulary, shared definitions, and explicit relationships.
In short, metadata is the lever that turns "siloed" data into a governed information ecosystem. As data grows in volume, diversity, and velocity, its function goes beyond simple description: metadata adds context, allows data to be interpreted, and makes it findable, accessible, interoperable, and reusable (FAIR).
In the new context driven by artificial intelligence, this metadata layer becomes even more relevant, as it provides the provenance information needed to ensure traceability, reliability, and reproducibility of results. For this reason, some recent frameworks extend these principles to FAIR-R, where the additional "R" highlights the importance of data being AI-ready, i.e. that it meets a series of technical, structural and quality requirements that optimize its use by artificial intelligence algorithms.
Thus, we are talking about enriched metadata, capable of connecting technical, semantic and contextual information to enhance machine learning, interoperability between domains and the generation of verifiable knowledge.
From traditional metadata to "rich metadata"
Traditional metadata
In the context of this article, when we talk about metadata with a traditional use, we think of catalogs, dictionaries, glossaries, database data models, and rigid structures (tables and columns). The most common types of metadata are:
-
Technical metadata: column type, length, format, foreign keys, indexes, physical locations.
-
Business/Semantic Metadata: Field Name, Description, Value Domain, Business Rules, Business Glossary Terms.
-
Operational/execution metadata: refresh rate, last load, processing times, usage statistics.
-
Quality metadata: percentage of null values, duplicates, validations.
-
Security/access metadata: access policies, permissions, sensitivity rating.
-
Lineage metadata: Transformation tracing in data pipelines .
This metadata is usually stored in repositories or cataloguing tools, often with tabular structures or relational bases, with predefined links.
Why "rich metadata"?
Rich metadata is a layer that not only describes attributes, but also:
- They discover and infer implicit relationships, identifying links that are not expressly defined in data schemas. This allows, for example, to recognize that two variables with different names in different systems actually represent the same concept ("altitude" and "elevation"), or that certain attributes maintain a hierarchical relationship ("municipality" belongs to "province").
- They facilitate semantic queries and automated reasoning, allowing users and machines to explore relationships and patterns that are not explicitly defined in databases. Rather than simply looking for exact matches of names or structures, rich metadata allows you to ask questions based on meaning and context. For example, automatically identifying all datasets related to "coastal cities" even if the term does not appear verbatim in the metadata.
- They adapt and evolve flexibly, as they can be extended with new entity types, relationships, or domains without the need to redesign the entire catalog structure. This allows new data sources, models or standards to be easily incorporated, ensuring the long-term sustainability of the system.
- They incorporate automation into tasks that were previously manual or repetitive, such as duplication detection, automatic matching of equivalent concepts, or semantic enrichment using machine learning. They can also identify inconsistencies or anomalies, improving the quality and consistency of metadata.
- They explicitly integrate the business context, linking each data asset to its operational meaning and its role within organizational processes. To do this, they use controlled vocabularies, ontologies or taxonomies that facilitate a common understanding between technical teams, analysts and business managers.
- They promote deeper interoperability between heterogeneous domains, which goes beyond the syntactic exchange facilitated by traditional metadata. Rich metadata adds a semantic layer that allows you to understand and relate data based on its meaning, not just its format. Thus, data from different sources or sectors – for example, Geographic Information Systems (GIS), Building Information Modeling (BIM) or the Internet of Things (IoT) – can be linked in a coherent way within a shared conceptual framework. This semantic interoperability is what makes it possible to integrate knowledge and reuse information between different technical and organizational contexts.
This turns metadata into a living asset, enriched and connected to domain knowledge, not just a passive "record".
The Evolution of Metadata: Ontologies and Knowledge Graphs
The incorporation of ontologies and knowledge graphs represents a conceptual evolution in the way metadata is described, related and used, hence we speak of enriched metadata. These tools not only document the data, but connect them within a network of meaning, allowing the relationships between entities, concepts, and contexts to be explicit and computable.
In the current context, marked by the rise of artificial intelligence, this semantic structure takes on a fundamental role: it provides algorithms with the contextual knowledge necessary to interpret, learn and reason about data in a more accurate and transparent way. Ontologies and graphs allow AI systems not only to process information, but also to understand the relationships between elements and to generate grounded inferences, opening the way to more explanatory and reliable models.
This paradigm shift transforms metadata into a dynamic structure, capable of reflecting the complexity of knowledge and facilitating semantic interoperability between different domains and sources of information. To understand this evolution, it is necessary to define and relate some concepts:

Ontologies
In the world of data, an ontology is a highly organized conceptual map that clearly defines:
- What entities exist (e.g., city, river, road).
- What properties they have (e.g. a city has a name, town, zip code).
- How they relate to each other (e.g. a river runs through a city, a road connects two municipalities).
The goal is for people and machines to share the same vocabulary and understand data in the same way. Ontologies allow:
- Define concepts and relationships: for example, "a plot belongs to a municipality", "a building has geographical coordinates".
- Set rules and restrictions: such as "each building must be exactly on a cadastral plot".
- Unify vocabularies: if in one system you say "plot" and in another "cadastral unit", ontology helps to recognize that they are analogous.
- Make inferences: from simple data, discover new knowledge (if a building is on a plot and the plot in Seville, it can be inferred that the building is in Seville).
- Establish a common language: they work as a dictionary shared between different systems or domains (GIS, BIM, IoT, cadastre, urban planning).
In short: an ontology is the dictionary and the rules of the game that allow different geospatial systems (maps, cadastre, sensors, BIM, etc.) to understand each other and work in an integrated way.
Knowledge Graphs
A knowledge graph is a way of organizing information as if it were a network of concepts connected to each other.
-
Nodes represent things or entities, such as a city, a river, or a building.
-
The edges (lines) show the relationships between them, for example: "is in", "crosses" or "belongs to".
-
Unlike a simple drawing of connections, a knowledge graph also explains the meaning of those relationships: it adds semantics.
A knowledge graph combines three main elements:
-
Data: specific cases or instances, such as "Seville", "Guadalquivir River" or "Seville City Hall Building".
-
Semantics (or ontology): the rules and vocabularies that define what kinds of things exist (cities, rivers, buildings) and how they can relate to each other.
-
Reasoning: the ability to discover new connections from existing ones (for example, if a river crosses a city and that city is in Spain, the system can deduce that the river is in Spain).
In addition, knowledge graphs make it possible to connect information from different fields (e.g. data on people, places and companies) under the same common language, facilitating analysis and interoperability between disciplines.
In other words, a knowledge graph is the result of applying an ontology (the data model) to several individual datasets (spatial elements, other territory data, patient records or catalog products, etc.). Knowledge graphs are ideal for integrating heterogeneous data, because they do not require a previously complete rigid schema: they can be grown flexibly. In addition, they allow semantic queries and navigation with complex relationships. Here's an example for spatial data to understand the differences:
|
Spatial data ontology (conceptual model) |
Knowledge graph (specific examples with instances) |
|---|---|
|
|
|
|
Use Cases
To better understand the value of smart metadata and semantic catalogs, there is nothing better than looking at examples where they are already being applied. These cases show how the combination of ontologies and knowledge graphs makes it possible to connect dispersed information, improve interoperability and generate actionable knowledge in different contexts.
From emergency management to urban planning or environmental protection, different international projects have shown that semantics is not just theory, but a practical tool that transforms data into decisions.
Some relevant examples include:
- LinkedGeoData that converted OpenStreetMap data into Linked Data, linking it to other open sources.
- Virtual Singapore is a 3D digital twin that integrates geospatial, urban and real-time data for simulation and planning.
- JedAI-spatial is a tool for interconnecting 3D spatial data using semantic relationships.
- SOSA Ontology, a standard widely used in sensor and IoT projects for environmental observations with a geospatial component.
- European projects on digital building permits (e.g. ACCORD), which combine semantic catalogs, BIM models, and GIS data to automatically validate building regulations.
Conclusions
The evolution towards rich metadata, supported by ontologies, knowledge graphs and FAIR-R principles, represents a substantial change in the way data is managed, connected and understood. This new approach makes metadata an active component of the digital infrastructure, capable of providing context, traceability and meaning, and not just describing information.
Rich metadata allows you to learn from data, improve semantic interoperability between domains, and facilitate more expressive queries, where relationships and dependencies can be discovered in an automated way. In this way, they favor the integration of dispersed information and support both informed decision-making and the development of more explanatory and reliable artificial intelligence models.
In the field of open data, these advances drive the transition from descriptive repositories to ecosystems of interconnected knowledge, where data can be combined and reused in a flexible and verifiable way. The incorporation of semantic context and provenance reinforces transparency, quality and responsible reuse.
This transformation requires, however, a progressive and well-governed approach: it is essential to plan for systems migration, ensure semantic quality, and promote the participation of multidisciplinary communities.
In short, rich metadata is the basis for moving from isolated data to connected and traceable knowledge, a key element for interoperability, sustainability and trust in the data economy.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
Blog
Open data plays a relevant role in technological development for many reasons. For example, it is a fundamental component in informed decision making, in process evaluation or even in driving technological innovation. Provided they are of the highest quality, up-to-date and ethically sound, data can be the key ingredient for the success of a project.
In order to fully exploit the benefits of open data in society, the European Union has several initiatives to promote the data economy, a single digital model that encourages data sharing, emphasizing data sovereignty and data governance, the ideal and necessary framework for open data.
In the data economy, as stated in current regulations, the privacy of individuals and the interoperability of data are guaranteed. The regulatory framework is responsible for ensuring compliance with this premise. An example of this can be the modification of Law 37/2007 for the reuse of public sector information in compliance with European Directive 2019/1024. This regulation is aligned with the European Union's Data Strategy, which defines a horizon with a single data market in which a mutual, free and secure exchange between the public and private sectors is facilitated.
To achieve this goal, key issues must be addressed, such as preserving certain legal safeguards or agreeing on common metadata description characteristics that datasets must meet to facilitate cross-industry data access and use, i.e. using a common language to enable interoperability between dataset catalogs.
What are metadata standards?
A first step towards data interoperability and reuse is to develop mechanisms that enable a homogeneous description of the data and that, in addition, this description is easily interpretable and processable by both humans and machines. In this sense, different vocabularies have been created that, over time, have been agreed upon until they have become standards.
Standardized vocabularies offer semantics that serve as a basis for the publication of data sets and act as a "legend" to facilitate understanding of the data content. In the end, it can be said that these vocabularies provide a collection of metadata to describe the data being published; and since all users of that data have access to the metadata and understand its meaning, it is easier to interoperate and reuse the data.
W3C: DCAT and DCAT-AP Standards
At the international level, several organizations that create and maintain standards can be highlighted:
- World Wide Web Consortium (W3C): developed the Data Catalog Vocabulary (DCAT): a description standard designed with the aim of facilitating interoperability between catalogs of datasets published on the web.
- Subsequently, taking DCAT as a basis, DCAT-AP was developed, a specification for the exchange of data descriptions published in data portals in Europe that has more specific DCAT-AP extensions such as:
- GeoDCAT-AP which extends DCAT-AP for the publication of spatial data.
- StatDCAT-AP which also extends DCAT-AP to describe statistical content datasets.
- Subsequently, taking DCAT as a basis, DCAT-AP was developed, a specification for the exchange of data descriptions published in data portals in Europe that has more specific DCAT-AP extensions such as:
ISO: Organización de Estandarización Internacional
Además de World Wide Web Consortium, existen otras organizaciones que se dedican a la estandarización, por ejemplo, la Organización de Estandarización Internacional (ISO, por sus siglas en inglés Internacional Standarization Organisation).
- Entre otros muchos tipos de estándares, ISO también ha definido normas de estandarización de metadatos de catálogos de datos:
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
- ISO 19115-2 para datos ráster e imágenes.
- ISO 19139 proporciona una implementación en XML del vocabulario.
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
The horizon in metadata standards: challenges and opportunities
Both W3C and ISO are working on the development and maintenance of standardized vocabularies adapted to the needs of users. Their work contributes to achieving an interoperable open data ecosystem that facilitates reuse. However, interoperability often encounters obstacles arising from quality weaknesses, such as outdated data, difficulties in accessing and interoperating with it, or incomplete metadata.
However, as has been demonstrated, data sharing is a fundamental mechanism in the data economy. So ensuring the interoperability and reuse of data is a key action to address the development of the data economy in line with the expectations of organizations in terms of innovation.
Among the multiple advantages offered by the reuse of datasets and their interoperability, we can highlight the creation of applications and services that bring value to society or help in the evaluation of policies, for example.
In addition, the reuse and interoperability of datasets favors economic development in general, and the data economy in particular. It is estimated that this industry will reach a value of 829 billion euros by 2025, according to European Union forecasts. In order to reap the benefits of data sharing, common description standards must first be agreed upon and adhered to: the standards for describing dataset catalog metadata.
Blog
Last December, the Congress of Deputies approved Royal Decree-Law 24/2021, which included the transposition of Directive (EU) 2019/1024 on open data and the reuse of public sector information. This Royal Decree amends Law 37/2007 on the reuse of public sector information, including new requirements for public bodies, including facilitating access to high-value data.
High-value data are data whose reuse is associated with considerable benefits to society, the environment and the economy. Initially, the European Commission highlighted as high-value data those belonging to the categories of geospatial, environmental, meteorological, statistical, societal and mobility data, although these classes can be extended both by the Commission and by the Ministry of Economic Affairs and Digital Transformation through the Data Office. According to the Directive, this type of data "shall be made available for reuse in a machine-readable format, through appropriate application programming interfaces and, where appropriate, in the form of bulk download". In other words, among other things, an API is required.
What is an API?
An application programming interface or API is a set of definitions and protocols that enable the exchange of information between systems. It should be noted that there are different types of APIs based on their architecture, communication protocols and operating systems.
APIs offer a number of advantages for developers, since they automate data and metadata consumption, facilitate mass downloading and optimize information retrieval by supporting filtering, sorting and paging functionalities. All of this results in both economic and time savings.
In this sense, many open data portals in our country already have their own APIs to facilitate access to data and metadata. In the following infographic you can see some examples at national, regional and local level, including information about the API of datos.gob.es. The infographic also includes brief information on what an API is and what is needed to use it.

Click here to see the infographic in full size and in its accessible version
These examples show the effort that public agencies in our country are making to facilitate access to the information they keep in a more efficient and automated way, in order to promote the reuse of their open data.
In datos.gob.es we have a Practical Guide for the publication of open data using APIs where a series of guidelines and good practices are detailed to define and implement this mechanism in an open data portal.
Content prepared by the datos.gob.es team.
Blog
Every day in the world, large amounts of data are generated that constitute an incredible potential for knowledge creation. Much of this data are generated by organisations that make them available to citizens.
It is recommended that the publication of these data in open data portals, such as datos.gob.es, follow the principles that have characterised Open Goverment Data since its origins, that is, that the data be complete, primary, on time, accessible, machine-readable, non-discriminatory, in free formats and with open licenses.
In order to comply with these principles and guarantee the traceability of the data, it is very important to catalogue it and to do so it is necessary to know its life cycle.
Data life cycle
When we speak of "data life cycle" we refer to the different stages through which a data passes from its birth to its end. The data is not a static asset during its life cycle, but passes through different phases, as the following image shows.
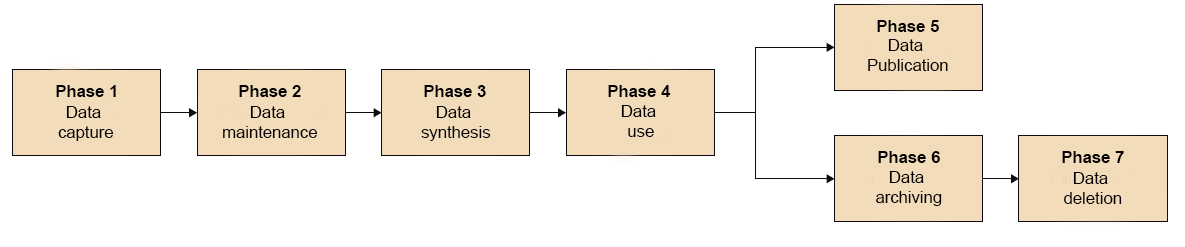
Source:El ciclo de Vida del Dato, @FUOC, Marcos Pérez. PID_00246836.
Within administrations, new sources of data are continually being created, and it is necessary to maintain a record that makes it possible to document the flows of information through the various systems within the organizations. To do this, we need to establish what is known as data traceability.
Data traceability is the ability to know the entire life cycle of the data: the exact date and time of extraction, when it was transformed, and when it was loaded from one source environment to another destination. This process is known as Data Linage.
And to know how the data has behaved during its life cycle, we need a series of metadata.
Let's talk about metadata
The most concrete definition of metadata is that they are data about data and serves to provide information about the data we want to use. Metadata consists of information that characterises data, describes its content and structure, the conditions of use, its origin and transformation, among other relevant information. Therefore, they are a fundamental element for knowing the quality of the data.
The etymology of the term metadata also puts us on the track of its meaning. From the Greek meta, "after" and from the plural "data" of the Latin datum "datos", it literally means "beyond data", alluding to data that describes other data.
According to the DMBOK2 framework of DAMA International, there are three types of metadata:
- Technical metadata: as the name suggests, they provide information about technical details of the data, the systems that store it and the processes that move it between systems.
- Operational metadata: describes details of data processing and access.
- Business metadata: focuses primarily on the content and condition of the data and includes details relating to data governance.
As an example, the sets of metadata we need for cataloguing and describing data are contained in the Information Resources Reuse Technical Standard (NTI, in its Spanish acronym) and, among others, contain:
- Title or name of the data set.
- Description detailing relevant aspects of the data content.
- Organism that publishes the data. For example, Madrid City Council, .
- Subject, which we must select from the taxonomy of primary sectors.
- Format of the dataset.
- Set of labels that best describe the dataset to facilitate its discovery.
- Periodicity of updating the information.
In addition, if the reference standard for describing metadata allows the inclusion of properties for this purpose, the following information can be added, even if they are not included in the NTI:
- If there are data that have undergone transformations, it should be commented on which metric has been used.
- Indicator on the quality of the data. It can be defined using the vocabulary designed for this purpose, Data Quality Vocabulary (DQV)
- Lineage trace of the data set, i.e. as a family tree of the data where it is explained where each source comes from.
The benefit of cataloguing
As we have seen, thanks to cataloguing by means of metadata, the user is provided with information about where the data has been created, when it has been created, who has created it, and how it has been transformed when it is the object of information flowing between systems being subject to extraction, transformation and loading operations.
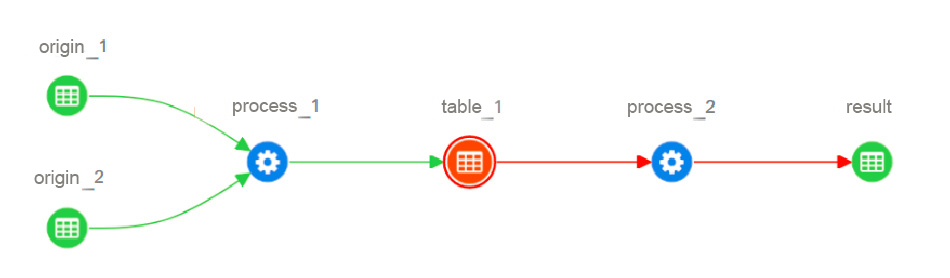
In this way, we are providing very valuable information to the user on how the final result has been obtained and thus ensuring that the full traceability of the data to be reused is available.
In particular, correct cataloguing helps us to:
- Increase confidence in the data, providing a context for it and allowing its quality to be measured.
- Increase the value of strategic data, such as through the master data that characterises transactional data.
- Avoid the use of outdated data or data that has reached the end of its life cycle.
- Reduce the time spent by the user in investigating whether the data they need meets their requirements.
The success of an open data portal lies in having well-described and reliable data, as this is a very important information asset for the generation of knowledge. Good data governance must ensure that the data used to make decisions is truly reliable and for this, proper cataloguing is essential. Cataloguing the data provides answers and offers greater interpretability of the data so that I can understand which data is best to incorporate into my informational analysis.
Content elaborated by David Puig, Graduate in Information and Documentation and responsible for the Master Data and Reference Group at DAMA ESPAÑA
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
The research data is very valuable, and its permanent access is one of the greatest challenges for all agents involved in the scientific world: research staff, funding agencies, publishers and academic institutions. The long-term conservation of data and the culture of open access are sources of new opportunities for the scientific community. More and more universities and research centers offer repositories with their research data, allowing permanent access to them. Thus, due to the requirements of each academic discipline, the existing repositories are very varied.
The research staff faces every day this universe of multiple repositories, tools, formats ... in which consulting the desired data without a guide requires many resources of time and effort. Re3data.orgis an international registry of research data repositories (Registry of Research Data Repositories) where metadata is collected from repositories specialized in storing research data. Thanks to this compilation work, the research staff, funding organizations, libraries and editors can search and visualize the main repositories of research data, being able to search and faceted views by discipline, subject, country, contents, formats, licenses, language, etc.
The re3data.org registry was born as a joint project of several German organizations, funded by the German Research Foundation (DFG). The official launch took place in May 2013 and the DataBib catalog was subsequently integrated to avoid duplication and confusion due to the existence of two similar parallel registers. The unification project was sponsored by DataCite, an international non-profit organization whose goal is to improve the quality of data citations. In addition, re3data.org collaborates with other Open Science projects such as BioSharing or OpenAIRE.
Multiple publishers, research institutions and funding organizations refer to the re3data.org registry in their editorial policies or guidelines, as the ideal tool for the identification of data repositories. One of the most notable examples is the European Commission (together with Nature and Springer), since it mentions it in the document "Guidelines for Guidelines to the Rules on Open Access to Scientific Publications and Open Access to Research Data in Horizon 2020
Currently, the metadata of the repositories stored are those listed in version 3 of the Metadata Schema for the Description of Research Data Repositories.
The registry identifies and lists nearly 2,000 repositories of research data, which makes re3data.org the largest and most complete repository of data repositories available on the web. Its growth has been constant since its launch, covering a wide range of disciplines.
As regards Spain, and as of December 1, 2017, 23 repositories of research data are cataloged in which Spain participates.
The promotion of open science, the culture of exchange, the reuse of information and open access is found in the foundations of the re3data.org project. And on these solid foundations the tool continues increasing the collected metadata, and therefore the visibility of the research data. Continuing to work on increasing this visibility and enhancing open science is not only essential to guarantee research work based on previous milestones, but it also allows us to exponentially expand the horizons of scientific work.