Documentación
La adopción del nuevo perfil DCAT-AP-ES alinea a España con el perfil de aplicación en Europa (DCAT-AP), facilitando la federación automática entre catálogos de datos definidos en RDF (Resource Description Framework).
En este entorno de grafos RDF donde la flexibilidad es la norma, la ausencia de esquemas rígidos tradicionales puede derivar en una degradación silenciosa de la calidad de los datos, si no se sigue de forma rigurosa el estándar. Para mitigar este riesgo, existe el lenguaje de restricciones de formas SHACL (Shapes Constraint Language), recomendación del W3C. Estas pautas permiten definir «formas» que funcionan como verdaderos guardianes de la calidad y el cumplimiento de la interoperabilidad.
Las etapas del proceso de validación SHACL son las siguientes:
- Se dispone de un grafo de datos RDF
- Se selecciona un subgrado del grafo anterior
- Se comprueban las restricciones SHACL que aplican al subgrafo anterior
- Se obtiene un informe de validación con los elementos conformes, con errores o con recomendaciones.
En la siguiente figura se muestran estas etapas:

Figura 1: Etapas principales del proceso de validación SHACL
Objetivos y audiencia destino
Esta guía técnica tiene como objetivo ayudar a que los publicadores y reutilizadores incorporen la validación SHACL como una práctica continua de mejora de calidad, mediante un enfoque didáctico y accesible, inspirado en recursos claros y herramientas de validación abiertas del ecosistema de datos.
Además, se profundiza de forma especial en su relación con DCAT-AP-ES, detallando un caso práctico y exhaustivo del flujo de trabajo completo de validación y gobernanza de un catálogo conforme a dicho perfil.
Estructura y contenidos
El documento sigue un enfoque progresivo, partiendo de fundamentos teóricos hasta llegar a la implementación técnica e integración automática, estructurándose en los siguientes bloques clave:
- Fundamentos de la validación semántica: RDF y el desafío del mundo abierto que supone así como SHACL como mecanismo de realizar validaciones, definiendo conceptos clave como Shape o Validation Report.
- DCAT-AP-ES y la adopción de SHACL para su validación: se explican las formas SHACL definidas en DCAT-AP-ES y el caso de aplicación de las mismas en el proceso de federación del Catálogo Nacional.
- Caso práctico: Validación de grafos RDF: un tutorial paso a paso sobre cómo validar un catálogo con las formas SHACL de DCAT-AP-ES, resolución de problemas comunes y herramientas disponibles.
- Conclusiones: reflexiones sobre las ventajas de integrar validación SHACL para mejorar la gobernanza de catálogos de datos.
La validación mediante SHACL representa un cambio de paradigma en la gestión de la calidad de metadatos en los catálogos de datos. Esta guía recorre el proceso completo desde los fundamentos teóricos hasta la aplicación práctica, demostrando que la adopción de SHACL no es simplemente un requisito técnico, sino una oportunidad para fortalecer y mejorar la gobernanza de datos.
Blog
Los datos abiertos son una pieza central de la innovación digital en torno a la inteligencia artificial ya que permiten, entre otras cosas, entrenar modelos o evaluar algoritmos de aprendizaje automático. Pero entre “descargar un CSV de un portal” y acceder a un conjunto de datos listo para aplicar técnicas de aprendizaje automático hay, todavía, un abismo.
Buena parte de ese abismo tiene que ver con los metadatos, es decir cómo se describen los conjuntos de datos (a qué nivel de detalle y con qué estándares). Si los metadatos se limitan a título, descripción y licencia, el trabajo de comprensión y preparación de datos se hace más complejo y tedioso para la persona que diseña el modelo de aprendizaje automático. Si, en cambio, se usan estándares que faciliten la interoperabilidad, como DCAT, los datos se vuelven más FAIR (Findable, Accessible, Interoperable, Reusable) y, por tanto, más fáciles de reutilizar. No obstante, es necesario metadatos adicionales para que los datos sean más fáciles de integrar en flujos de aprendizaje automático.
Este artículo realiza un itinerario por las diversas iniciativas y estándares necesarios para dotar a los datos abiertos de metadatos útiles para la aplicación de técnicas de aprendizaje automático.
DCAT como columna vertebral de los portales de datos abiertos
El vocabulario DCAT (Data Catalog Vocabulary) fue diseñado por la W3C para facilitar la interoperabilidad entre catálogos de datos publicados en la Web. Describe catálogos, conjuntos de datos y distribuciones, siendo la base sobre la que se construyen muchos portales de datos abiertos.
En Europa, DCAT se concreta en el perfil de aplicación DCAT-AP, recomendado por la Comisión Europea y ampliamente adoptado para describir conjuntos de datos en el sector público, por ejemplo, en España con DCAT-AP-ES. Con DCAT-AP se responde a preguntas como:
- ¿Qué conjuntos de datos existen sobre un tema concreto?
- ¿Quién los publica, bajo qué licencia y en qué formatos?
- ¿Dónde están las URL de descarga o las API de acceso?
El uso de un estándar como DCAT es imprescindible para descubrir conjuntos de datos, pero es necesario ir un paso más allá con el fin de saber cómo se utilizan en modelos de aprendizaje automático o qué calidad tienen desde la perspectiva de estos modelos.
MLDCAT-AP: aprendizaje automático en el catálogo de un portal de datos abiertos
MLDCAT-AP (Machine Learning DCAT-AP) es un perfil de aplicación de DCAT desarrollado por SEMIC y la comunidad Interoperable Europe, en colaboración con OpenML, que extiende DCAT-AP al dominio del aprendizaje automático.
MLDCAT-AP incorpora clases y propiedades para describir:
- Modelos de aprendizaje automático y sus características.
- Conjuntos de datos utilizados en el entrenamiento y la evaluación.
- Métricas de calidad obtenidas sobre los conjuntos de datos.
- Publicaciones y documentación asociadas a los modelos de aprendizaje automático.
- Conceptos relacionados con riesgo, transparencia y cumplimiento del contexto regulatorio europeo del AI Act.
Con ello, un catálogo basado en MLDCAT-AP ya no solo responde a “qué datos hay”, sino también a:
- ¿Qué modelos se han entrenado con este conjunto de datos?
- ¿Cuál ha sido el rendimiento de ese modelo según determinadas métricas?
- ¿Dónde se describe este trabajo (artículos científicos, documentación, etc.)?
MLDCAT-AP representa un gran avance en trazabilidad y gobernanza, pero se mantiene la definición de metadatos a un nivel que todavía no considera la estructura interna de los conjuntos de datos ni qué significan exactamente sus campos. Para eso, se necesita bajar a nivel de la propia estructura de la distribución de conjunto de datos.
Metadatos a nivel de estructura interna del conjunto de datos
Cuando se quiere describir qué hay dentro de las distribuciones de los conjuntos de datos (campos, tipos, restricciones), una iniciativa interesante es Data Package, parte del ecosistema de Frictionless Data.
Un Data Package se define por un archivo JSON que describe un conjunto de datos. En este archivo se incluyen no sólo metadatos generales (como el nombre, título, descripción o licencia) y recursos (es decir, los ficheros de datos con su ruta o una URL de acceso a su correspondiente servicio), sino también se define un esquema con:
- Nombres de campos.
- Tipos de datos (integer, number, string, date, etc.).
- Restricciones, como rangos de valores válidos, claves primarias y ajenas, etc.
Desde la óptica del aprendizaje automático, esto se traduce en la posibilidad de realizar una validación estructural automática antes de usar los datos. Además, también permite una documentación precisa de la estructura interna de cada conjunto de datos y mayor facilidad para compartir y versionar conjuntos de datos.
En resumen, mientras que MLDCAT-AP indica qué conjuntos de datos existen y cómo encajan en el ámbito de modelos de aprendizaje automático, Data Package especifica exactamente “qué hay” dentro de los conjuntos de datos.
Croissant: metadatos que preparan datos abiertos para aprendizaje automático
Aun con el concurso de MLDCAT-AP y de Data Package, faltaría conectar los conceptos subyacentes en ambas iniciativas. Por una parte, el ámbito del aprendizaje automático (MLDCAT-AP) y por otro el de las estructuras internas de los propios datos (Data Package). Es decir, se puede estar usando los metadatos de MLDCAT-AP y de Data Package pero para solventar algunas limitaciones que adolecen ambos, es necesario complementarlo. Aquí entra en juego Croissant, un formato de metadatos para preparar los conjuntos de datos para la aplicación de aprendizaje automático. Croissant está desarrollado en el marco de MLCommons, con participación de industria y academia.
Específicamente, Croissant se implementa en JSON-LD y se construye sobre schema.org/Dataset, un vocabulario para describir conjuntos de datos en la Web. Croissant combina los siguientes metadatos:
- Metadatos generales del conjunto de datos.
- Descripción de recursos (archivos, tablas, etc.).
- Estructura de los datos.
- Capa semántica sobre aprendizaje automático (separación de datos de entrenamiento/validación/test, campos objetivo, etc.)
Cabe destacar que Croissant está diseñado para que distintos repositorios (como Kaggle, HuggingFace, etc.) puedan publicar conjuntos de datos en un formato que las librerías de aprendizaje automático (TensorFlow, PyTorch, etc.) puedan cargar de forma homogénea. También existe una extensión de CKAN para usar Croissant en portales de datos abiertos.
Otras iniciativas complementarias
Merece la pena mencionar brevemente otras iniciativas interesantes relacionadas con la posibilidad de disponer de metadatos que permitan preparar a los conjuntos de datos para la aplicación de aprendizaje automático (“ML-ready datasets”):
- schema.org/Dataset: usado en páginas web y repositorios para describir conjuntos de datos. Es la base sobre la que se apoya Croissant y está integrado, por ejemplo, en las directrices de datos estructurados de Google para mejorar la localización de conjuntos de datos en buscadores.
- CSV on the Web (CSVW): conjunto de recomendaciones del W3C para acompañar ficheros CSV con metadatos en JSON (incluyendo diccionarios de datos), muy alineado con las necesidades de documentación de datos tabulares que luego se usan en aprendizaje automático.
- Datasheets for Datasets y Dataset Cards: iniciativas que permiten desarrollar una documentación narrativa y estructurada para describir el contexto, la procedencia y las limitaciones de los conjuntos de datos. Estas iniciativas son ampliamente adoptadas en plataformas como Hugging Face.
Conclusiones
Existen diversas iniciativas que ayudan a realizar una definición de metadatos adecuada para el uso de aprendizaje automático con datos abiertos:
- DCAT-AP y MLDCAT-AP articulan el nivel de catálogo, modelos de aprendizaje automático y métricas.
- Data Package describe y valida la estructura y restricciones de los datos a nivel de recurso y campo.
- Croissant conecta estos metadatos con el flujo de aprendizaje automático, describiendo cómo los conjuntos de datos son ejemplos concretos para cada modelo.
- Iniciativas como CSVW o Dataset Cards complementan las anteriores y son ampliamente utilizadas en plataformas como HuggingFace.
Estas iniciativas pueden usarse de manera combinada. De hecho, si se adoptan de forma conjunta, se permite que los datos abiertos dejen de ser simplemente “ficheros descargables” y se conviertan en una materia prima preparada para el aprendizaje automático, reduciendo fricción, mejorando la calidad y aumentando la confianza en los sistemas de IA construidos sobre ellos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En todo entorno de gestión de datos (empresas, Administración pública, consorcios, proyectos de investigación), disponer de datos no basta: si no sabes qué datos tienes, dónde están, qué significan, quién los mantiene, con qué calidad, cuándo cambiaron o cómo se relacionan con otros datos, entonces el valor es muy limitado. Los metadatos —datos sobre los datos— son esenciales para:
-
Visibilidad y acceso: permitir que usuarios encuentren qué datos existen y puedan acceder.
-
Contextualización: saber qué significan los datos (definiciones, unidades, semántica).
-
Trazabilidad / linaje: entender de dónde vienen los datos y cómo han sido transformados.
-
Gobierno y control: conocer quién es responsable, qué políticas aplican, permisos, versiones, obsolescencia.
-
Calidad, integridad y consistencia: asegurar la fiabilidad de los datos mediante reglas, métricas y monitoreo.
-
Interoperabilidad: garantizar que diferentes sistemas o dominios puedan compartir datos, utilizando un vocabulario común, definiciones compartidas y relaciones explícitas.
En resumen, los metadatos son la palanca que convierte los datos “aislados” en un ecosistema de información gobernada. A medida que los datos crecen en volumen, diversidad y velocidad, su función va más allá de la simple descripción: los metadatos añaden contexto, permiten interpretar los datos y facilitan que puedan ser encontrados, accesibles, interoperables y reutilizables (FAIR).
En el nuevo contexto impulsado por la inteligencia artificial, esta capa de metadatos adquiere una relevancia aún mayor, ya que proporciona la información de procedencia (provenance) necesaria para garantizar la trazabilidad, la fiabilidad y la reproducibilidad de los resultados. Por ello, algunos marcos recientes amplían estos principios hacia FAIR-R, donde la “R” adicional resalta la importancia de que los datos estén listos para la IA (AI-ready), es decir, que cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial.
Así, hablamos de metadatos enriquecidos, capaces de conectar información técnica, semántica y contextual para potenciar el aprendizaje automático, la interoperabilidad entre dominios y la generación de conocimiento verificable.
De los metadatos tradicionales a los “metadatos enriquecidos”
Metadatos tradicionales
En el contexto de este artículo, cuando hablamos de metadatos con un uso tradicional, pensamos en catálogos, diccionarios, glosarios, modelos de datos de base de datos, y estructuras rígidas (tablas y columnas). Los tipos de metadatos más comunes son:
-
Metadatos técnicos: tipo de columna, longitud, formato, claves foráneas, índices, ubicaciones físicas.
-
Metadatos de negocio / semánticos: nombre de campo, descripción, dominio de valores, reglas de negocio, términos del glosario empresarial.
-
Metadatos operativos / de ejecución: frecuencia de actualización, última carga, tiempos de procesamiento, estadísticas de uso.
-
Metadatos de calidad: porcentaje de valores nulos, duplicados, validaciones.
-
Metadatos de seguridad / acceso: políticas de acceso, permisos, clasificación de sensibilidad.
-
Metadatos de linaje: rastreo de transformación en los pipelines de datos.
Estos metadatos se almacenan usualmente en repositorios o herramientas de catalogación, muchas veces con estructuras tabulares o en bases relacionales, con vínculos predefinidos.
¿Por qué metadatos enriquecidos?
Los metadatos enriquecidos son aquella capa que no solo describe atributos, sino que:
- Descubren e infieren relaciones implícitas, identificando vínculos que no están expresamente definidos en los esquemas de datos. Esto permite, por ejemplo, reconocer que dos variables con nombres diferentes en sistemas distintos representan en realidad el mismo concepto (“altitud” y “elevación”), o que ciertos atributos mantienen una relación jerárquica (“municipio” pertenece a “provincia”).
- Facilitan consultas semánticas y razonamiento automatizado, permitiendo que los usuarios y las máquinas exploren relaciones y patrones que no están explícitamente definidos en las bases de datos. En lugar de limitarse a buscar coincidencias exactas de nombres o estructuras, los metadatos enriquecidos permiten formular preguntas basadas en significado y contexto. Por ejemplo, identificar automáticamente todos los conjuntos de datos relacionados con “ciudades costeras” aunque el término no aparezca literalmente en los metadatos.
- Se adaptan y evolucionan de manera flexible, ya que pueden ampliarse con nuevos tipos de entidades, relaciones o dominios sin necesidad de rediseñar toda la estructura del catálogo. Esto permite incorporar fácilmente nuevas fuentes de datos, modelos o estándares, garantizando la sostenibilidad del sistema a largo plazo.
- Incorporan automatización en tareas que antes eran manuales o repetitivas, como la detección de duplicidades, el emparejamiento automático de conceptos equivalentes o el enriquecimiento semántico mediante aprendizaje automático. También pueden identificar incoherencias o anomalías, mejorando la calidad y la coherencia de los metadatos.
- Integran de forma explícita el contexto de negocio, enlazando cada activo de datos con su significado operativo y su rol dentro de los procesos organizativos. Para ello utilizan vocabularios controlados, ontologías o taxonomías que facilitan un entendimiento común entre equipos técnicos, analistas y responsables de negocio.
- Favorecen una interoperabilidad más profunda entre dominios heterogéneos, que va más allá del intercambio sintáctico facilitado por los metadatos tradicionales. Los metadatos enriquecidos añaden una capa semántica que permite comprender y relacionar los datos en función de su significado, no solo de su formato. Así, datos procedentes de diferentes fuentes o sectores —por ejemplo, Sistemas de información Geográfica (GIS en inglés), Building Information Modeling (BIM) o Internet de las Cosas (IoT)— pueden vincularse de manera coherente dentro de un marco conceptual compartido. Esta interoperabilidad semántica es la que posibilita integrar conocimiento y reutilizar información entre contextos técnicos y organizativos diversos.
Esto convierte los metadatos en un activo vivo, enriquecido y conectado con el conocimiento del dominio, no solo un “registro” pasivo.

La evolución de los metadatos: ontologías y grafos de conocimiento
La incorporación de ontologías y grafos de conocimiento representa una evolución conceptual en la manera de describir, relacionar y aprovechar los metadatos, de ahí que hablemos de metadatos enriquecidos. Estas herramientas no solo documentan los datos, sino que los conectan dentro de una red de significado, permitiendo que las relaciones entre entidades, conceptos y contextos sean explícitas y computables.
En el contexto actual, marcado por el auge de la inteligencia artificial, esta estructura semántica adquiere un papel fundamental: proporciona a los algoritmos el conocimiento contextual necesario para interpretar, aprender y razonar sobre los datos de forma más precisa y transparente. Ontologías y grafos permiten que los sistemas de IA no solo procesen información, sino que entiendan las relaciones entre los elementos y puedan generar inferencias fundamentadas, abriendo el camino hacia modelos más explicativos y confiables.
Este cambio de paradigma transforma los metadatos en una estructura dinámica, capaz de reflejar la complejidad del conocimiento y de facilitar la interoperabilidad semántica entre distintos dominios y fuentes de información. Para comprender esta evolución conviene definir y relacionar algunos conceptos:
Ontologías
En el mundo de los datos, una ontología es un mapa conceptual muy organizado que define claramente:
- Qué entidades existen (ej. ciudad, río, carretera).
- Qué propiedades tienen (ej. una ciudad tiene nombre, población, código postal).
- Cómo se relacionan entre sí (ej. un río atraviesa una ciudad, una carretera conecta dos municipios).
El objetivo es que personas y máquinas compartan un mismo vocabulario y entiendan los datos de la misma manera. Las ontologías permiten:
- Definir conceptos y relaciones: por ejemplo, “una parcela pertenece a un municipio”, “un edificio tiene coordenadas geográficas”.
- Poner reglas y restricciones: como “cada edificio debe estar exactamente en una parcela catastral”.
- Unificar vocabularios: si en un sistema se dice “parcela” y en otro “unidad catastral”, la ontología ayuda a reconocer que son análogos.
- Hacer inferencias: a partir de datos simples, descubrir nuevo conocimiento (si un edificio está en una parcela y la parcela en Sevilla, se puede inferir que el edificio está en Sevilla).
- Establecer un lenguaje común: funcionan como un diccionario compartido entre distintos sistemas o dominios (GIS, BIM, IoT, catastro, urbanismo).
En resumen: una ontología es el diccionario y las reglas del juego que permiten que diferentes sistemas geoespaciales (mapas, catastro, sensores, BIM, etc.) se entiendan entre sí y puedan trabajar de manera integrada.
Grafos de conocimiento (Knowledge Graphs)
Un grafo de conocimiento es una forma de organizar información como si fuera una red de conceptos conectados entre sí.
-
Los nodos representan cosas o entidades, como una ciudad, un río o un edificio.
-
Las aristas (líneas) muestran las relaciones entre ellas, por ejemplo: “está en”, “atraviesa” o “pertenece a”.
-
A diferencia de un simple dibujo de conexiones, un grafo de conocimiento también explica el significado de esas relaciones: añade semántica.
Un grafo de conocimiento combina tres elementos principales:
-
Datos: los casos concretos o instancias, como “Sevilla”, “Río Guadalquivir” o “Edificio Ayuntamiento de Sevilla”.
-
Semántica (u ontología): las reglas y vocabularios que definen qué tipos de cosas existen (ciudades, ríos, edificios) y cómo pueden relacionarse entre sí.
-
Razonamiento: la capacidad de descubrir nuevas conexiones a partir de las existentes (por ejemplo, si un río atraviesa una ciudad y esa ciudad está en España, el sistema puede deducir que el río está en España).
Además, los grafos de conocimiento permiten conectar información de distintos ámbitos (por ejemplo, datos sobre personas, lugares y empresas) bajo un mismo lenguaje común, facilitando el análisis y la interoperabilidad entre disciplinas.
En otras palabras, un knowledge graph es el resultado de aplicar una ontología (el modelo de datos) a varios conjuntos de datos individuales (elementos espaciales, otros datos del territorio, registros de pacientes o productos de catálogo, etc.). Los grafos de conocimiento son ideales para integrar datos heterogéneos, porque no requieren un esquema rígido previamente completo: se pueden ir creciendo de forma flexible. Además, permiten consultas semánticas y navegación con relaciones complejas. A continuación, se pone un ejemplo para datos espaciales con los que entender las diferencias:
|
Ontología de datos espaciales (modelo conceptual) |
Grafo de conocimiento (ejemplos concretos con instancias) |
|---|---|
|
|
|
|
Casos de uso
Para entender mejor el valor de los metadatos inteligentes y los catálogos semánticos, nada mejor que mirar ejemplos donde ya se están aplicando. Estos casos muestran cómo la combinación de ontologías y grafos de conocimiento permite conectar información dispersa, mejorar la interoperabilidad y generar conocimiento accionable en distintos contextos.
Desde la gestión de emergencias hasta la planificación urbana o la protección del medio ambiente, diferentes proyectos internacionales han demostrado que la semántica no es solo teoría, sino una herramienta práctica que transforma datos en decisiones.
Algunos ejemplos relevantes incluyen:
- LinkedGeoData que convirtió datos de OpenStreetMap en Linked Data, enlazándolos con otras fuentes abiertas.
- Virtual Singapore un gemelo digital 3D que integra datos geoespaciales, urbanos y en tiempo real para simulación y planificación.
- JedAI-spatial una herramienta para interconectar datos espaciales en 3D mediante relaciones semánticas.
- SOSA Ontology, estándar ampliamente usado en proyectos de sensores e IoT para observaciones ambientales con componente geoespacial.
- Proyectos europeos de permisos digitales de construcción (ej. ACCORD), que combinan catálogos semánticos, modelos BIM y datos GIS para validar automáticamente normativas de construcción.
Conclusiones
La evolución hacia metadatos enriquecidos, apoyados en ontologías, grafos de conocimiento y principios FAIR-R, representa un cambio sustancial en la manera de gestionar, conectar y comprender los datos. Este nuevo enfoque convierte los metadatos en un componente activo de la infraestructura digital, capaz de aportar contexto, trazabilidad y significado, y no solo de describir información.
Los metadatos enriquecidos permiten aprender de los datos, mejorar la interoperabilidad semántica entre dominios y facilitar consultas más expresivas, donde las relaciones y dependencias pueden descubrirse de forma automatizada. De este modo, favorecen la integración de información dispersa y apoyan tanto la toma de decisiones informadas como el desarrollo de modelos de inteligencia artificial más explicativos y confiables.
En el ámbito de los datos abiertos, estos avances impulsan la transición desde repositorios descriptivos hacia ecosistemas de conocimiento interconectado, donde los datos pueden combinarse y reutilizarse de manera flexible y verificable. La incorporación de contexto semántico y procedencia (provenance) refuerza la transparencia, la calidad y la reutilización responsable.
Esta transformación requiere, sin embargo, un enfoque progresivo y bien gobernado: es fundamental planificar la migración de sistemas, garantizar la calidad semántica, y promover la participación de comunidades multidisciplinares.
En definitiva, los metadatos enriquecidos son la base para pasar de datos aislados a conocimiento conectado y trazable, elemento clave para la interoperabilidad, la sostenibilidad y la confianza en la economía de los datos.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Documentación
A continuación, se recoge la definición de diversos términos relacionados con los datos y tecnologías relacionadas.
1. Glosario de términos relacionados con datos abiertos.
Blog
Los datos abiertos tienen un rol relevante en el desarrollo tecnológico por muchos motivos. A modo de ejemplo, son un componente fundamental en la toma de decisiones informadas, en la evaluación de procesos o incluso en el impulso de la innovación tecnológica. Siempre y cuando, cuenten con la calidad óptima, estén actualizados y respeten los aspectos éticos, los datos pueden ser el ingrediente clave para el alcanzar el éxito de un proyecto.
A fin de aprovechar plenamente las ventajas de los datos abiertos en la sociedad, la Unión Europea cuenta con diversas iniciativas para impulsar la economía del dato, un modelo digital único que fomenta el intercambio de datos, destacando la soberanía y el gobierno de los mismos, el marco ideal y necesario para los datos abiertos.
En la economía del dato, tal y como recoge la regulación vigente, se garantiza la privacidad de las personas y la interoperabilidad de los datos. El marco regulatorio se encarga de velar por el cumplimiento de esta premisa. Ejemplo de ello puede ser la modificación de la Ley 37/2007 para la reutilización de información del sector público en cumplimiento de la Directiva Europea 2019/1024. Esta regulación se alinea con la Estrategia de datos de la Unión Europea que define un horizonte con un mercado único de datos en el que se facilite un intercambio mutuo, libre y seguro entre el sector público y el privado.
Para lograr este objetivo, se deben abordar cuestiones clave, como preservar ciertas garantías jurídicas o acordar unas características comunes de descripción de metadatos que deben cumplir los dataset para facilitar el acceso y uso de los datos entre sectores, es decir, utilizar un lenguaje común que permita la interoperabilidad entre catálogos de conjuntos de datos.
¿Qué son los estándares de metadatos?
Un primer paso hacia la interoperabilidad y reutilización de los datos es desarrollar mecanismos que habiliten una descripción homogénea de los mismos y que, además, dicha descripción sea fácilmente interpretable y procesable tanto por humanos como por máquinas. En este sentido, se han ido creando diferentes vocabularios que, con el tiempo, se han ido consensuando hasta convertirse en estándares.
Los vocabularios estandarizados ofrecen una semántica que sirve como base para la publicación de conjuntos de datos que actúa como "leyenda" para facilitar la comprensión del contenido de los datos. Al fin y al cabo, se puede decir que estos vocabularios proporcionan una colección de metadatos para describir los datos que se publican; y como todos los usuarios de esos datos tienen acceso a los metadatos y entienden su significado, es más fácil interoperar y reutilizar los datos.
W3C: Estándares DCAT y DCAT-AP
A nivel internacional, se pueden destacar varias organizaciones que crean y mantienen estándares:
-
World Wide Web Consortium (W3C): desarrolla el Vocabulario de Catálogos de Datos (DCAT): un estándar de descripción diseñado con el objetivo de facilitar la interoperabilidad entre catálogos de conjuntos de datos publicados en la web.
-
Posteriormente, tomando como base DCAT, se desarrolló DCAT-AP, una especificación para el intercambio de descripciones de datos publicados en los portales de datos en Europa que cuenta con extensiones de DCAT-AP más específicas como:
- GeoDCAT-AP que extiende DCAT-AP para la publicación de datos espaciales.
- StatDCAT-AP que igualmente, extiende DCAT-AP para describir datasets de contenidos estadísticos.
-
ISO: Organización de Estandarización Internacional
Además de World Wide Web Consortium, existen otras organizaciones que se dedican a la estandarización, por ejemplo, la Organización de Estandarización Internacional (ISO, por sus siglas en inglés Internacional Standarization Organisation).
- Entre otros muchos tipos de estándares, ISO también ha definido normas de estandarización de metadatos de catálogos de datos:
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
- ISO 19115-2 para datos ráster e imágenes.
- ISO 19139 proporciona una implementación en XML del vocabulario.
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
El horizonte en los estándares de metadatos: retos y oportunidades
Tanto W3C como ISO trabajan en el desarrollo y mantenimiento de vocabularios estandarizados y adaptados a las necesidades de los usuarios. Su trabajo contribuye a lograr un ecosistema de datos abiertos interoperables que facilite la reutilización. Sin embargo, la interoperabilidad a menudo se encuentra con obstáculos derivados de debilidades de calidad, como pueden ser datos obsoletos, dificultades para acceder e interoperar con ellos o metadatos incompletos.
A pesar de ello, como se ha demostrado, la compartición de datos es un mecanismo fundamental en la economía del dato. Así que garantizar la interoperabilidad y reutilización de estos es una acción clave para abordar el desarrollo de la economía de los datos en línea con las expectativas de las organizaciones en lo que se refiere a innovación.
Entre las múltiples ventajas que ofrece la reutilización de conjuntos de datos y su interoperabilidad se puede destacar la creación de aplicaciones y servicios que aportan un valor a la sociedad o ayudan en la evaluación de políticas, por ejemplo.
Además, la reutilización e interoperabilidad de los conjuntos de datos favorece el desarrollo económico en general, y la economía del dato, en particular. Se estima que esta industria alcanzará un valor de 829.000 millones de euros en 2025, según previsiones de la Unión Europea. Para poder aprovechar los beneficios que ofrece compartir datos, primero, se deben acordar y respetar unas normas de descripción comunes: los estándares para describir metadatos de catálogos de conjuntos de datos.
Blog
El pasado diciembre el Congreso de los Diputados aprobó el Real Decreto-ley 24/2021, que incluía la transposición de la Directiva (UE) 2019/1024, relativa a los datos abiertos y la reutilización de la información del sector público. Con este Real Decreto se modifica la Ley 37/2007 sobre reutilización de la información del sector público, incluyendo nuevos requisitos para los organismos públicos, entre los que se encuentra el facilitar el acceso a los datos de alto valor.
Los datos de alto valor son aquellos cuya reutilización está asociada a considerables beneficios para la sociedad, el medio ambiente y la economía. Inicialmente, la Comisión Europea destacó como datos de alto valor aquellos pertenecientes a las categorías de datos geoespaciales, ambientales, meteorológicos, estadísticos, relativos a sociedades y de movilidad, aunque estas clases pueden ser ampliadas tanto por, la Comisión como por el Ministerio de Asuntos Económicos y Transformación Digital a través de la Oficina del Dato. De acuerdo con la Directiva, este tipo de datos “se pondrán a disposición para su reutilización en un formato legible por máquina, a través de interfaces de programación de aplicaciones adecuadas y, cuando proceda, en forma de descarga masiva”. Es decir, entre otras cuestiones, se hace necesario el contar con una API.
¿Qué es una API?
Una interfaz de programación de aplicaciones o API (la abreviatura en inglés de Application Programming Interfaces) es un conjunto de definiciones y protocolos que permite el intercambio de información entre sistemas. Cabe destacar que existen distintos tipos de APIs en base a su arquitectura, protocolos de comunicación y sistemas operativos.
Las APIs suponen una serie de ventajas para los desarrolladores, ya que permiten automatizar el consumo de datos y metadatos, facilitan la descarga masiva y optimizan la recuperación de información al admitir funcionalidades de filtrado, ordenación y paginación. Todo ello repercute en un ahorro tanto económico como de tiempo.
En este sentido, muchos portales de datos abiertos de nuestro país ya cuentan con sus propias APIs para facilitar el acceso a datos y metadatos. En la siguiente infografía puedes ver algunos ejemplos a nivel nacional, autonómico y local, incluyendo información sobre la API de datos.gob.es. La infografía también incluye información breve sobre qué es una API y qué se necesita para poder utilizarlas.

Haz clic aquí para ver la infografía en tamaño completo y en su versión accesible
Estos ejemplos ponen de manifiesto el esfuerzo que los organismos públicos de nuestro país están haciendo para facilitar el acceso a la información que custodian de forma más eficiente y automatizada, con el fin de impulsar la reutilización de sus datos abiertos.
En datos.gob.es contamos con una Guía práctica para la publicación de datos abiertos usando APIs donde se detallan una serie de pautas y buenas prácticas para definir e implementar este mecanismo en un portal open data.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Diariamente en el mundo, se generan grandes cantidades de datos que constituyen un potencial increíble para la creación de conocimiento. Muchos de estos datos son generados por organizaciones que los ponen a disposición de los ciudadanos.
Es recomendable que la publicación de estos datos en portales de datos abiertos, como el de datos.gob.es, siga los principios que caracterizan el Open Goverment Data desde sus orígenes, es decir, que los datos sean completos, primarios, en tiempo, accesibles, legibles por máquinas, no discriminatorios, en formatos libres y con licencias abiertas.
Para cumplir con estos principios y garantizar la trazabilidad de los datos, es muy importante su catalogación y para ello hay que conocer su ciclo de vida.
Ciclo de vida de los datos
Cuando hablamos de “ciclo de vida del dato” nos referimos a las diferentes etapas por las que pasa un dato desde su nacimiento hasta el fin. El dato no es un activo estático durante su ciclo de vida, sino que pasa por distintas fases, como recoge la siguiente imagen.

Fuente:El ciclo de Vida del Dato, @FUOC, Marcos Pérez. PID_00246836.
Dentro de las administraciones, se crean nuevas fuentes de datos continuamente, y es necesario mantener un registro que permita documentar los flujos de información a través de los distintos sistemas dentro de las organizaciones. Para ello, necesitamos establecer lo que se conoce como trazabilidad del dato.
La trazabilidad del dato es la capacidad de conocer todo el ciclo de vida del dato: la fecha y hora exacta de extracción, cuándo se produjo su transformación, y cuándo se cargó desde un entorno fuente a otro destino. A este proceso se le conoce como Data Linage.
Y para conocer cómo se ha comportado el dato durante su ciclo de vida, necesitamos una serie de metadatos.
Hablemos de los metadatos
La definición más concreta sobre los metadatos es que son los datos acerca de los datos y sirven para suministrar información sobre los datos que queremos usar. Los metadatos consisten en información que caracteriza datos, describe su contenido y estructura, las condiciones de uso, su origen y transformación, entre otra información relevante. Por ello son un elemento fundamental para conocer la calidad de los mismos.
La etimología del término metadatos también nos pone sobre la pista de su significado. Del griego meta, "después de" y de "data" plural del latín datum "datos”, literalmente significa "más allá de los datos", aludiendo a datos que describen otros datos.
Según el framework de trabajo DMBOK2 de la organización DAMA Internacional, existen tres tipos de metadatos:
- Metadatos técnicos: como su nombre indica, proporcionan información sobre detalles técnicos de los datos, los sistemas que los almacenan y los procesos que los mueven entre sistemas.
- Metadatos operacionales: describen detalles del procesamiento y acceso a los datos.
- Metadatos de negocio: se enfocan principalmente en el contenido y la condición de los datos e incluyen detalles relacionados con la gobernabilidad de los datos.
Como ejemplo, los conjuntos de metadatos que necesitamos para la catalogación y descripción de datos están recogidos en la Norma Técnica de Interoperabilidad (NTI) de Reutilización de recursos de la información y, entre otros, contienen:
- Título o denominación del conjunto de datos.
- Descripción que detalla aspectos relevantes del contenido de los datos.
- Organismo que publica los datos. Por ejemplo, Ayuntamiento de Madrid.
- Temática, que debemos seleccionar de la taxonomía de sectores primarios.
- Formato del set de datos.
- Conjunto de etiquetas que mejor describa el dataset para facilitar su descubrimiento.
- Periodicidad de actualización de la información.
Además, si la norma de referencia para describir metadatos permite incluir propiedades para ello, se puede agregar la siguiente información, aunque no los recoja la NTI:
- Si existen datos que han sufrido transformaciones, se deben comentar que métrica se ha utilizado.
- Indicador sobre la calidad de los datos. Se puede definir utilizando el vocabulario diseñado para tal fin, Data Quality Vocabulary (DQV)
- Trazo del linaje de los datos, es decir, como un árbol genealógico de los datos donde se explica de dónde viene cada fuente.
El beneficio de catalogar
Como hemos visto, gracias a la catalogación por medio de metadatos se proporciona información al usuario de los datos sobre dónde se han creado, cuándo se han creado, quién los ha creado, y cómo se han transformado cuando son objeto de flujos de información entre sistemas estando sujetos a operaciones extracción, transformación y carga.
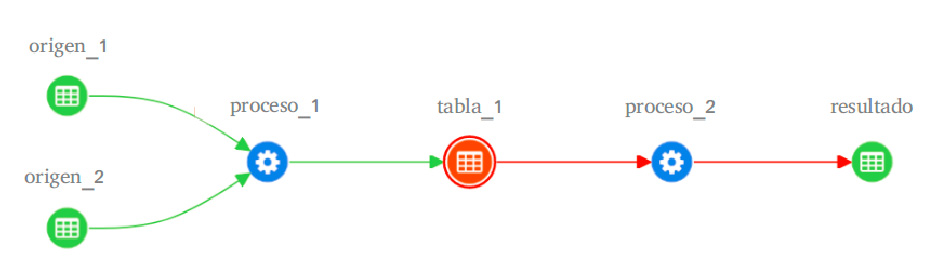
De esta manera, estamos proporcionando una información muy valiosa para el usuario sobre cómo se ha obtenido el resultado final y así garantizar que se tiene la traza completa del dato objeto de reutilización.
En concreto, una correcta catalogación nos ayuda a:
- Aumentar la confianza en los datos, proporcionando un contexto de los mismos permitiendo además medir su calidad.
- Aumentar el valor de los datos estratégicos, como por ejemplo a través de los datos maestros que caracterizan a los datos transaccionales.
- Evitar el uso de datos desactualizados o que ya han llegado a la fase final de su ciclo de vida.
- Reducir el tiempo que invierte el usuario en investigar si los datos que necesita cumplen con sus requisitos.
El éxito de un portal de datos abiertos se encuentra en poseer unos datos bien descritos y fiables, ya que éstos constituyen un activo informacional muy importante para la generación de conocimiento. El buen gobierno de los datos debe garantizar que los datos empleados para tomar decisiones sean verdaderamente fiables y para ello, una adecuada catalogación es esencial. La catalogación de los datos proporciona respuestas y ofrece una mayor interpretabilidad de los datos, de modo que se pueda entender qué datos son los mejores para incorporar a mi análisis informacional.
Contenido elaborado por David Puig, Graduado en Información y Documentación y responsable del grupo de trabajo de Datos Maestros y de Referencia en DAMA ESPAÑA.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos de investigación son muy valiosos, y su acceso permanente es uno de los mayores retos para todos agentes involucrados en el mundo científico: personal investigador, organismos de financiación, editores e instituciones académicas. La conservación a largo plazo de los datos y la cultura del acceso abierto son fuente de nuevas oportunidades para la comunidad científica. Son cada vez más las universidades y centros de investigación que ofrecen repositorios con los datos de sus investigaciones, permitiendo el acceso permanente a los mismos. Así, debido a los requisitos de cada disciplina académica, los repositorios existentes son muy variados.
El personal investigador se enfrenta día a día a este universo de múltiples repositorios, herramientas, formatos… en los que consultar los datos deseados sin una guía o pauta supone muchos recursos de tiempo y esfuerzo. Re3data.org es un registro internacional de repositorios de datos de investigación (Registry of Research Data Repositories) donde se recopilan metadatos de los repositorios especializados en almacenar datos procedentes de investigación. Gracias a este trabajo de compilación, el personal investigador, las organizaciones financiadoras, bibliotecas y editores pueden buscar y visualizar los principales repositorios de datos de investigación, siendo posible realizar búsquedas y vistas facetadas por disciplina, materia, país, contenidos, formatos, licencias, idioma, etc.
El registro re3data.org nació como un proyecto conjunto de varias organizaciones alemanas, financiado por la Fundación Alemana de Investigación (DFG). El lanzamiento oficial se produjo en mayo del 2013 y posteriormente se integró el catálogo DataBib para evitar la duplicación y confusión por la existencia de dos registros similares paralelos. El proyecto de unificación estuvo auspiciado por DataCite, una organización internacional sin ánimo de lucro cuyo objetivo es mejorar la calidad de las citas de datos. Además, re3data.org colabora con otros proyectos de Ciencia Abierta como BioSharing u OpenAIRE.
Múltiples editores, instituciones de investigación y organizaciones financiadoras hacen referencia al registro re3data.org en sus políticas editoriales o directrices, como la herramienta idónea para la identificación de repositorios de datos. Uno de los ejemplos más destacables es la Comisión Europea (junto con Nature y Springer), ya que la menciona en el documento “Directrices para las reglas sobre acceso abierto de publicaciones científicas y acceso abierto de los datos de investigación en el programa Horizon 2020” (Guidelines to the Rules on Open Access to Scientific Publications and Open Access to Research Data in Horizon 2020).
Actualmente, los metadatos de los repositorios que se almacenan son aquellos que se encuentran enumerados en la versión 3 del “Esquema de metadatos para la descripción de repositorios de datos de investigación” (Metadata Schema for the Description of Research Data Repositories).
El registro identifica y enumera cerca de 2.000 repositorios de datos de investigación, lo que hace al re3data.org el más grande y completo de los registros de repositorios de datos disponibles en la web. Su crecimiento ha sido constante desde su lanzamiento, cubriendo una amplia gama de disciplinas.
En lo referente a España, y a fecha de 1 de diciembre de 2017, se catalogan 23 repositorios de datos de investigación en los que participa España.
La promoción de la ciencia abierta, la cultura del intercambio, la reutilización de información y el acceso abierto se encuentra en los cimientos del proyecto re3data.org. Y sobre esos cimientos sólidos la herramienta sigue y sigue aumentando los metadatos recopilados, y por ende la visibilidad de los datos de investigación. Seguir trabajando en incrementar esta visibilidad y potenciar la ciencia abierta no sólo es fundamental para garantizar el trabajo investigador basado en los hitos anteriores, sino que permite expandir exponencialmente los horizontes de la labor científica.
Evento
El próximo 7 de octubre, bajo el marco del Proyecto HOMER, tendrá lugar en Bruselas la Conferencia “El Futuro del Open Data en la Agenda Digital europea” donde se debatirá los retos a los que se enfrentará el sector de datos abiertos en el futuro así como los resultados obtenidos hasta la fecha.
El encuentro contará con cuatro charlas de especialistas europeos en materia de apertura de la información, quienes hablarán de las expectativas de la Comisión Europea sobre el sector open data en la estrategia TIC para impulsar el mercado digital y utilizar las tecnologías de la información para el beneficio de la ciudadanía. A su vez, se mostrará el papel que juegan los datos abiertos en las Smart Cities y se presentarán herramientas que ayuden en la armonización de los datos en Europa.
En paralelo, se celebrarán mesas redondas donde diferentes expertos discutirán aquellos aspectos relacionados con la homogeneización del open data: identificación de futuros retos y soluciones adoptadas para casos reales del proyecto HOMER. Como resultado, se creará un documento donde se recojan los siguientes asuntos:
- Armonización de metadatos: experimentos con DCAT, CKAN, HOMER y el portal data.gouv.fr.
- Armonización de prácticas legales: comparativa de licencias y licencias para datos reutilizados.
- Previsiones del sector open data en Europa.