Publication date
14/01/2021
Update date
20/06/2024

Description
Every day in the world, large amounts of data are generated that constitute an incredible potential for knowledge creation. Much of this data are generated by organisations that make them available to citizens.
It is recommended that the publication of these data in open data portals, such as datos.gob.es, follow the principles that have characterised Open Goverment Data since its origins, that is, that the data be complete, primary, on time, accessible, machine-readable, non-discriminatory, in free formats and with open licenses.
In order to comply with these principles and guarantee the traceability of the data, it is very important to catalogue it and to do so it is necessary to know its life cycle.
Data life cycle
When we speak of "data life cycle" we refer to the different stages through which a data passes from its birth to its end. The data is not a static asset during its life cycle, but passes through different phases, as the following image shows.
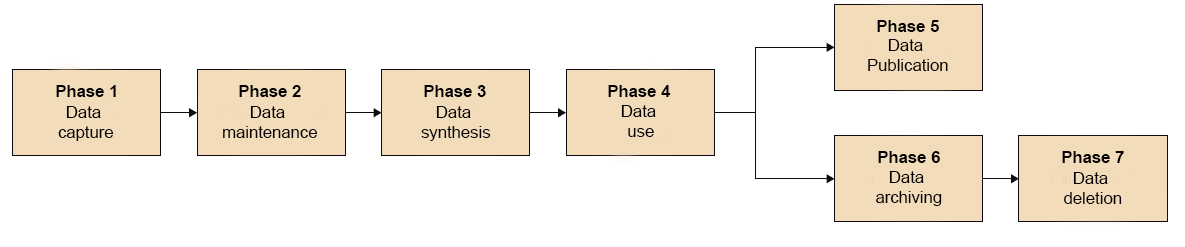
Source:El ciclo de Vida del Dato, @FUOC, Marcos Pérez. PID_00246836.
Within administrations, new sources of data are continually being created, and it is necessary to maintain a record that makes it possible to document the flows of information through the various systems within the organizations. To do this, we need to establish what is known as data traceability.
Data traceability is the ability to know the entire life cycle of the data: the exact date and time of extraction, when it was transformed, and when it was loaded from one source environment to another destination. This process is known as Data Linage.
And to know how the data has behaved during its life cycle, we need a series of metadata.
Let's talk about metadata
The most concrete definition of metadata is that they are data about data and serves to provide information about the data we want to use. Metadata consists of information that characterises data, describes its content and structure, the conditions of use, its origin and transformation, among other relevant information. Therefore, they are a fundamental element for knowing the quality of the data.
The etymology of the term metadata also puts us on the track of its meaning. From the Greek meta, "after" and from the plural "data" of the Latin datum "datos", it literally means "beyond data", alluding to data that describes other data.
According to the DMBOK2 framework of DAMA International, there are three types of metadata:
- Technical metadata: as the name suggests, they provide information about technical details of the data, the systems that store it and the processes that move it between systems.
- Operational metadata: describes details of data processing and access.
- Business metadata: focuses primarily on the content and condition of the data and includes details relating to data governance.
As an example, the sets of metadata we need for cataloguing and describing data are contained in the Information Resources Reuse Technical Standard (NTI, in its Spanish acronym) and, among others, contain:
- Title or name of the data set.
- Description detailing relevant aspects of the data content.
- Organism that publishes the data. For example, Madrid City Council, .
- Subject, which we must select from the taxonomy of primary sectors.
- Format of the dataset.
- Set of labels that best describe the dataset to facilitate its discovery.
- Periodicity of updating the information.
In addition, if the reference standard for describing metadata allows the inclusion of properties for this purpose, the following information can be added, even if they are not included in the NTI:
- If there are data that have undergone transformations, it should be commented on which metric has been used.
- Indicator on the quality of the data. It can be defined using the vocabulary designed for this purpose, Data Quality Vocabulary (DQV)
- Lineage trace of the data set, i.e. as a family tree of the data where it is explained where each source comes from.
The benefit of cataloguing
As we have seen, thanks to cataloguing by means of metadata, the user is provided with information about where the data has been created, when it has been created, who has created it, and how it has been transformed when it is the object of information flowing between systems being subject to extraction, transformation and loading operations.
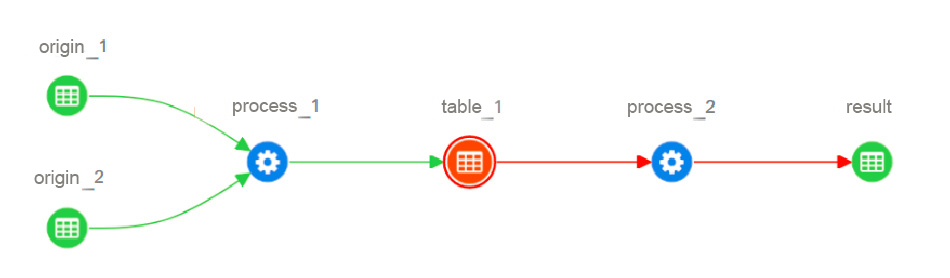
In this way, we are providing very valuable information to the user on how the final result has been obtained and thus ensuring that the full traceability of the data to be reused is available.
In particular, correct cataloguing helps us to:
- Increase confidence in the data, providing a context for it and allowing its quality to be measured.
- Increase the value of strategic data, such as through the master data that characterises transactional data.
- Avoid the use of outdated data or data that has reached the end of its life cycle.
- Reduce the time spent by the user in investigating whether the data they need meets their requirements.
The success of an open data portal lies in having well-described and reliable data, as this is a very important information asset for the generation of knowledge. Good data governance must ensure that the data used to make decisions is truly reliable and for this, proper cataloguing is essential. Cataloguing the data provides answers and offers greater interpretability of the data so that I can understand which data is best to incorporate into my informational analysis.
Content elaborated by David Puig, Graduate in Information and Documentation and responsible for the Master Data and Reference Group at DAMA ESPAÑA
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Comments