
Description
In recent years, artificial intelligence has gone from being an emerging technology to becoming an everyday reality in public administrations, companies and organizations of all kinds. There is talk of systems that predict health demand, optimize transport routes or detect anomalies in public spending. But behind each of these use cases is a question that rarely comes to the forefront of the debate: what does this artificial intelligence really rely on?
The answer is not only in algorithms. It's in the data. And, more specifically, in how organizations are structured, and structured, to manage them.
In this post we will address:
-
Why data is the real foundation of any AI system and what risks are involved in ignoring it
-
What organizational structures allow them to be effectively governed
-
The strategic role of open data in this ecosystem
-
The differences and synergies between data governance and AI governance
-
The standards and frameworks available in Spain and internationally
Data as the basis of artificial intelligence
Machine learning has transformed the paradigm of technological development. Where systems used to follow fixed and explicit rules, today they learn from patterns that emerge from data. This is a hugely important change: the behavior of an AI model does not depend so much on the logic with which it was programmed as on the quality, representativeness, and coherence of the data with which it was trained.
Herein lies one of the most underestimated risks of AI: the mirage of neutral data. Data are not objective truths; They are representations of reality captured in a specific context (business processes), with their own limitations and biases. A system trained on incomplete or biased data will not only replicate those biases, but amplify them. The examples are numerous: from facial recognition models with worse performance in certain population groups to prioritization systems that reproduce historical inequalities.
In addition, data is aging. What is a representative training set today may cease to be so tomorrow if reality changes and the model is not updated. This phenomenon, known as data drift, is one of the main reasons why initially successful AI systems end up degrading their performance over time if proper maintenance is not followed. An illustrative case was that of several predictive models deployed during the COVID-19 pandemic: trained with previous behavioral patterns, their accuracy deteriorated when reality changed drastically and suddenly, evidencing that a model is only as valid as the data that supports it.
For all these reasons, the quality of the data cannot be left to chance. It requires active, systematic management with clearly assigned responsibilities.
Organizational Structures to Govern Data
Recognizing that data is a strategic asset is the first step. The second, and more difficult, is to organize yourself to manage them as such.
Governing data means establishing who decides on data, how it is managed, and under what rules it is used. It is not a purely technical issue; it is, above all, organizational. It involves:
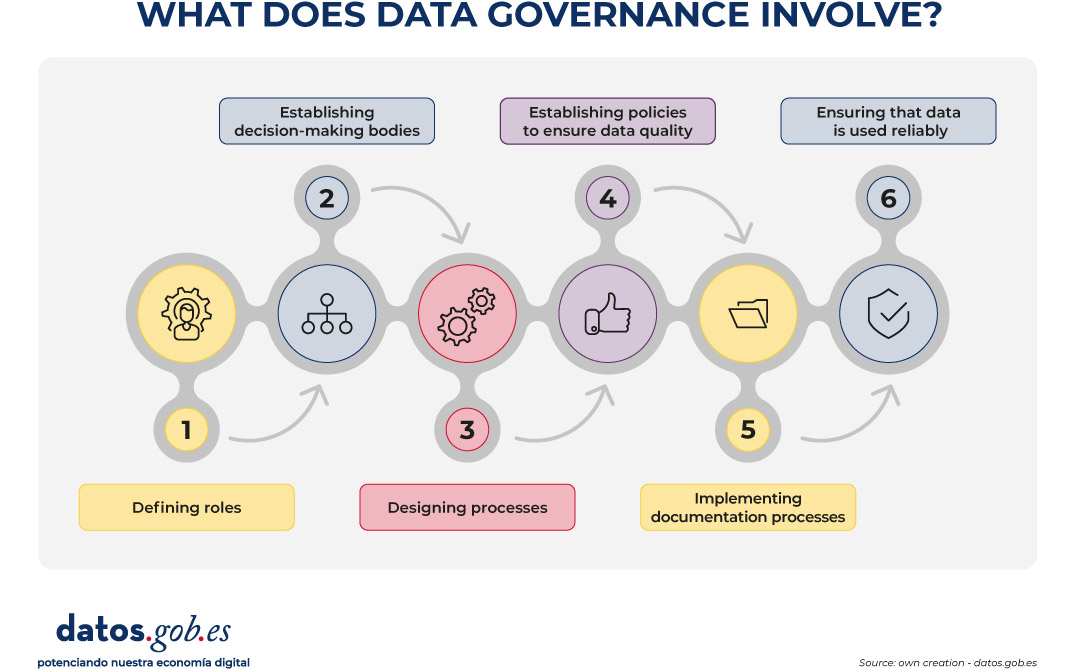
Figure 1. Visual representation of the implications of data governance. Source: created by the author - datos.gob.es
The most mature organizations in this field tend to articulate their governance around three levels:
-
At the strategic level, there are figures such as the Chief Data Officer (CDO) and collegiate oversight bodies, whose role is to define the role that data plays in the organization's strategy and ensure that high-level decisions are aligned with that vision.
-
At the operational level, a Data Governance Office translates that strategy into concrete policies: quality standards, metadata catalogs, data lifecycle management procedures, security and privacy standards.
-
At the domain level, data owners and data stewards are responsible for ensuring that data is managed correctly on a day-to-day basis: the former with formal responsibility for certain data sets; the latter ensuring their quality, consistency and correct documentation.
When AI enters the picture, this structure does not change in essence, but it does expand. New profiles are emerging, such as data scientists or model engineers, those responsible for algorithmic compliance, and new needs: documenting training sets, ensuring the traceability of model decisions, managing the risk of bias. All of this should be integrated into the existing governance framework, not added as a separate layer, and taking into account regulations such as the EU Artificial Intelligence Regulation (AI Act).
The open data within the data government
In the context of the Spanish public sector, data governance cannot be dissociated from open data policy. Both dimensions are mutually reinforcing.
Open data provides value far beyond transparency. In the context of artificial intelligence, its contributions are multiple.
First, as raw material for innovation: many AI projects, especially in their initial phases, rely on open datasets to train and validate models. Portals such as datos.gob.es make thousands of reusable datasets on mobility, demography, the environment or public spending, among other sectors, available to researchers, companies and administrations . A concrete example is the use of open traffic and public transport data to train demand prediction or route optimisation models: without this layer of public, structured and quality information, many of these initiatives simply do not take off.
Second, as an auditing and trust mechanism: when the data that feeds an AI system is accessible, the community can analyze it, identify potential biases, and question the results. This is especially relevant in high-impact decisions, where explainability and accountability are unavoidable demands.
And third, as a catalyst for data ecosystems: open data is one of the pillars of shared data spaces, where multiple organizations exchange information under common rules. Initiatives such as the National Health Data Space (ENDS) or the European sectoral spaces are based on this logic. To make them work, they need strong governance that ensures interoperability, access control, and trust between participants.
Data governance and AI governance: differences and complementarity
It is common for both concepts to be confused or used interchangeably, but they have different scopes, although deeply related.
-
The governance of data has as its object the asset itself. He asks: is the data quality? Are they well defined? Are they managed securely? Who is responsible for them? Its horizon is the integrity, availability and appropriate use of information.
-
The governance of AI, on the other hand, is aimed at the algorithmic system. He asks: is the model explainable? Does it introduce bias? Does it meet ethical and legal requirements? How is its operation monitored over time? Its horizon is responsibility, transparency and risk mitigation.
The relationship between the two is not one of substitution but of dependence: there can be no effective governance of AI without a prior and solid governance of data. If we don't know where the data that feeds a model comes from, if we can't guarantee its quality or representativeness, any AI management system is built on sand. Data governance is, in this sense, the invisible infrastructure on which trust in artificial intelligence rests.
Standards and frameworks
In order for these organizational structures not to remain a declaration of intent, it is essential to rely on regulatory frameworks and standards that offer practical guidance and allow the level of maturity achieved to be compared, evaluated and even certified.
In Spain, the UNE family of specifications promoted by the Data Directorate offers a complete and cohesive guide. UNE 0077 deals with data governance; UNE 0078, its management; UNE 0079, quality; UNE 0080, maturity assessment; and UNE 0085, the progressive implementation of these capabilities. In addition to these, UNE 0081 establishes specific criteria for the evaluation of the quality of datasets, a critical piece when we talk about training and validating AI models.
This approach is fully aligned with the recommendations published in datos.gob.es on data governance, which insist on the need to define clear roles, establish policies and ensure quality as structural elements to generate trust and value from data. In this sense, governance is not only an organizational layer, but an enabler of the entire data lifecycle, where the need to define clear roles, establish policies and ensure quality as structural elements to generate trust and value from data is insisted on. In this sense, governance is not just an organizational layer, but an enabler of the entire data lifecycle.
At the international level, this framework is expanded and directly connected to artificial intelligence. ISO/IEC 38507 provides guidelines for AI governance, while ISO/IEC 42001 defines the first AI-specific management system, setting out organizational, control, and continuous improvement requirements. These rules make it clear that there can be no effective management of AI without a solid foundation of governance and data management.
In turn, the quality of AI is articulated on three fundamental pillars: data, models and software, each supported by specific standards. Data quality is supported by standards such as ISO/IEC 5259, while safety and security are linked to standards such as ISO/IEC 27090 or ISO/IEC 27563. In the field of software and AI products, references such as ISO/IEC 25059 stand out, and in processes, standards such as ISO/IEC 5338, along with specific security standards such as ISO/IEC 5469 or ISO/IEC 22440.
All of these frameworks point in the same direction: data governance is not a bureaucratic requirement, but the foundation on which quality, security, and ultimately trust in AI systems are built. Without it, neither AI management nor quality can be sustained in a reliable or scalable way.
Conclusion: governing data is governing the future
Artificial intelligence has highlighted something that existed but wasn't always visible: the quality of any data-driven decision ultimately depends on how that data is managed.
In this sense, the organizations that will best take advantage of the opportunities offered by AI will be those that have built organizational structures capable of guaranteeing that their data is of quality, well documented, has clear managers and is managed under coherent policies.
And, in short, governing data rigorously is the condition that makes sustainable, responsible and trustworthy innovation possible. Because, in an environment where AI learns from what we give it, the most important question is not what model we use, but what data feeds it and how we have taken care of it.
Content produced by Dr Fernando Gualo, Lecturer at the University of Castilla-La Mancha (UCLM) and Consultant on Governance and Data Quality. The content and views expressed in this publication are the sole responsibility of the author.



Comments