Blog
The Spanish Data Protection Agency (AEPD), through its own Innovation and Technology section, carries out an essential didactic task by providing a documentary corpus that translates the legal obligations of the General Data Protection Regulation (GDPR) into specific technological realities. Its value lies in its ability to offer legal certainty and technical guidelines in areas where regulations are still finding their practical fit, such as artificial intelligence or biometrics.
These are reference guides, articles and other teaching materials aimed especially at SMEs and entrepreneurs. In this post we present some of the most recent, ordered by sector and subject.
The new trends in artificial intelligence and its secure deployment
The evolution of artificial intelligence towards increasingly autonomous systems poses new challenges in terms of data protection. For this reason, the Spanish Data Protection Agency has developed various guides and documents aimed at facilitating a secure and responsible deployment of this technology. In general, AI is one of the areas of greatest document activity of the AEPD due to its transversal impact. The Agency's resources range from internal management to state-of-the-art technologies.
- Guide to agentric artificial intelligence from the perspective of data protection: theso-called agentric AI is one capable of making decisions and acting with a certain degree of independence. Unlike purely reactive models, an agent AI can carry out multiple tasks autonomously and make intermediate decisions during complex processes. This guide discusses the risks of loss of human control and sets out criteria to ensure that decision traceability is not lost in automation.
- General policy for the use of generative AI in AEPD administrative processes: generative artificial intelligence (IAG or GenAI) is a type of AI capable of producing new content, such as text, images, audio or code from learned patterns. This document establishes an internal policy for its responsible use in administrative processes.
- Implementation annex of the AEPD's general IAG policy: this annex to the above document includes the permitted use cases, the type of systems recommended (external, internal or ad hoc), the level of risk associated with each application and the specific obligations of review, human control, security and data protection.
- Basic summary of obligations and recommendations for the management of generative AI: this is a synthesized outline on aspects of governance, design and development of use cases, processing of personal data and sensitive information, transparency and explainability, and responsible use of tools, among others.
- Federated Learning Report: Federated learning is an AI approach that allows models to be trained collaboratively without centralizing data, improving privacy, and aligning with GDPR. This guide explains what it consists of, where personal data can be processed and what are the benefits and challenges in data protection.
To complement this information, users can also visit the AEPD's blog, which serves as a trend observatory where the visible and invisible risks of consumer technologies are analyzed. Some of the topics covered are:
- Image and voice processing: Analyses have been published on AI voice transcription and the use of services that convert photos to other formats (such as animations). These articles warn about the processing of biometric data and the ownership of data in the cloud.
- Algorithmic literacy: resources such as "Addressing AI Misconceptions" seek to raise the level of critical judgment of users and managers in the face of the opacity of algorithms.
- Balance of rights: the analysis of the protection of minors in the digital environment and the design of public contracts that integrate privacy by design stands out.
European Digital Identity Wallet
The evolution towards an interconnected Europe requires robust identity standards and security measures accessible to all levels of business.
Building a secure, interoperable and trustworthy digital identity is one of the pillars of digital transformation in Europe. The future European Digital Identity Portfolio is a project that aims to allow citizens to identify themselves electronically and share personal attributes in a controlled way across multiple services, both public and private.
To analyse its implications from the point of view of privacy, the Spanish Data Protection Agency has published a series of four monographic articles throughout 2025. In them, the Agency breaks down the relationship between the new digital identity wallet and the GDPR.
These contents address key issues such as:
- Data minimisation and the principle of proportionality in information exchange: explains how the eIDAS2 Regulation boosts the European digital identity portfolio. This regulation establishes a framework for secure, interoperable and user-centric electronic identification, aligned with the GDPR to ensure the control and protection of personal data across the EU.
- The risks associated with interoperability between systems: delves into how to prevent the use of the European Digital Identity Wallet from tracking citizens when they present credentials in different public or private services, highlighting the need for advanced cryptographic solutions.
- The need to ensure user control over their credentials: examines identification threats in digital identity wallets under eIDAS2, highlighting that, without strong safeguards such as pseudonymization and non-bonding, even selective disclosure of data can allow for the improper identification and profiling of users.
- The security measures needed to prevent misuse or data breaches: Raises the threats of inaccuracy in digital identity wallets under eIDAS2, highlighting how outdated data or linkable cryptographic mechanisms can lead to erroneous decisions and compromise privacy. To solve this, it stresses the need for solutions that guarantee both reliability and plausible deniability (that there is no technical evidence to prove that a person has carried out a specific action with their wallet or digital credential).
This series provides a progressive overview that helps to understand both the potential of European digital identity and the challenges posed by its implementation from a data protection perspective.
Personal Data Protection Encryption in SMBs
For many small and medium-sized businesses, ensuring the security of personal data remains a challenge, especially due to a lack of technical resources or specialized knowledge. In this context, encryption is presented as a fundamental tool to protect the confidentiality and integrity of information.
With the aim of bringing this concept closer to a non-expert audience, the Spanish Data Protection Agency has published the Encryption Guide for the self-employed and SMEs, accompanied by an explanatory infographic.
These resources explain in a clear and practical way:
- What is encryption and why is it important in data protection?
- What types of encryption exist and in which cases they are applied.
- How to implement encryption measures in common situations, such as sending emails or storing information.
- Which tools can be used without the need for advanced knowledge.
Scientific research and the European legal framework
For profiles that require a more in-depth and academic analysis, the Agency has promoted the publication of scientific articles in various international media, which connect technology with ethics and law. Some examples are:
- Addictive patterns: analysis of how interface design affects human behavior.
- Neurotechnology: study on the risks of brain-computer interfaces.
- Algorithmic governance: A comprehensive analysis that aligns the GDPR with the European Artificial Intelligence Regulation (AI Act), the Digital Services Act (DSA), and the Cyber Resilience Act.
The didactic value of these materials lies in their ability to offer a 360-degree view of the data. From cutting-edge academic research to encryption infographics for a small business, the AEPD provides the building blocks for innovation that doesn't sacrifice privacy.
Together, these materials shared by the Spanish Data Protection Agency help to incorporate effective security measures and comply with the requirements of the General Data Protection Regulation in a proportionate and accessible way. All of them, and some others, are compiled and ordered by theme in its website, available here.
Entrevista
In recent years, artificial intelligence (AI) has gone from being a futuristic promise to becoming an everyday tool: today we live with language models, generative systems and algorithms capable of learning more and more tasks. But as their popularity grows, so does an essential question: how do we ensure that these technologies are truly reliable and trustworthy? Today we are going to explore that challenge with two invited experts in the field:
- David Escudero, director of the Artificial Intelligence Center of the University of Valladolid.
- José Luis Marín, senior consultant in strategy, innovation and digitalisation.
Listen to the podcast (availible in spanish) completo
Summary / Transcript of the interview
1. Why is it necessary to know how artificial intelligences work and evaluate this behavior?
Jose Luis Marín: It is necessary for a very simple reason: when a system influences important decisions, it is not enough that it seems to work well in an eye-catching demo, but we have to know when it gets it right, when it can fail and why. Right now we are already in a phase in which AI is beginning to be applied in such delicate issues as medical diagnoses, the granting of public aid or citizen care itself in many scenarios. For example, if we ask ourselves whether we would trust a system that operates like a black box and decides whether to grant us a grant, whether we are selected for an interview or whether we pass an exam without being able to explain to us how that decision was made, surely the answer would be that we would not trust it; And not because the technology is better or worse, but simply because we need to understand what is behind these decisions that affect us.
David Escudero: Indeed, it is not so much to understand how algorithms work internally, how the logic or mathematics behind all these systems works, but to understand or make users see that this type of system has degrees of reliability that have their limits, just like people. People can also make mistakes, they can fail at a certain time, but you have to give guarantees for users to use them with a certain level of security. Providing metrics on the performance of these algorithms and making them appear reliable to some degree is critical.
2. A concept that arises when we talk about these issues is that of explainable artificial intelligence . How would you define this idea and why is it so relevant now?
David Escudero: Explainable AI is a technicality that arises from the need for the system not only to offer decisions, not only to say whether a certain file has to be classified in a certain way or another, but to give the reasons that lead the system to make that decision. It's opening that black box. We talk about a black box because the user does not see how the algorithm works. It doesn't need it either, but it does at least give you some clues as to why the algorithm has made a certain decision or another, which is extremely important. Imagine an algorithm that classifies files to refer them to one administration or another. If the end user feels harmed, he needs to have a reason why this has been so, and he will ask for it; He can ask for it and he can demand it. And if from a technological point of view we are not able to provide that solution, artificial intelligence has a problem. In this sense, there are techniques that advance in providing not only solutions, but also in saying what are the reasons that lead an algorithm to make certain decisions.
Jose Luis Marín: I can't explain it much better than David has explained it. What we are really looking for with explainable artificial intelligence is to understand the reason for those answers or those decisions made by artificial intelligence algorithms. To simplify it a lot, I think that we are not really talking about anything other than applying the same standards as when those decisions are made by people, whom we also make responsible for the decisions. We need to be able to explain why a decision has been made or what rules have been followed, so that we can trust those decisions.
3. How is this need for explainability and rigorous evaluation being addressed? Which methodologies or frameworks are gaining the most weight? And what is the role of open data in them?
Jose Luis Marín: This question has many dimensions. I would say that several layers are converging here. On the one hand, specific explainability techniques such as LIME (Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations) or many others. I usually follow, for example, the catalog of reliable AI tools and metrics of the OECD's Observatory of Public Policies on Artificial Intelligence, because there progress in the domain is recorded quite well. But, on the other hand, we have broader evaluation frameworks, which do not only look at purely technical issues, but also issues such as biases, robustness, stability over time and regulatory compliance. There are different frameworks such as the NIST (National Institute of Standards and Technology) risk management framework, the impact assessment of the algorithms of the Government of Canada or our own AI Regulations. We are in a phase in which a lot of public and private initiatives are emerging that will help us to have better and better tools.
David Escudero: For research, it is still a fairly open field. There are methodologies, indeed, but new models based on neural networks have opened up a huge challenge. The artificial intelligence that had been developed in the years prior to the generative AI boom, to a large extent, was based on expert systems that accumulated a lot of knowledge rules about the domain. In this type of technology, explainability was given because, since what was done was to trigger a series of rules to make decisions, following backwards the order in which the rules had been applied, you had an explanation; But now with neural systems, especially with large models, where we are talking about billions and billions of parameters, these types of approximations have become impossible, unapproachable, and other types of methodologies are applied that are mainly based on knowing, when you train a machine learning model, what are the properties or attributes in the training that lead you to make one decision or another. Let's say, what are the weights of each of the properties they are using.
For example, if you're using a machine learning system to decide whether to advertise a certain car to a bunch of potential customers, the machine learning system is trained based on an experience. In the end, you are left with a neural model where it is very difficult to enter, but you can do it by analyzing the weight of each of the input variables that you have used to make that decision. For example, the person's income will be one of the most important attributes, but there may be other issues that lead you to very important considerations, such as biases. Imagine that one of the most important variables is the gender of the person. There you enter into a series of considerations that are delicate. In other types of algorithms, for example, that are based on images, an explainable AI algorithm can tell you which part of the image was most relevant. For example, if you are using an algorithm to, based on the image of a person's face - I am talking about a hypothetical, a future, which would also be an extreme case - decide whether that person is trustworthy or not. Then you could look at what traits of that person artificial intelligence is paying more attention to, for example, in the eyes or expression. This type of consideration is what AI would make explainable today: to know which are the variables or which are the input data of the algorithm that take on greater value when making decisions.
This brings me to another part of your question about the importance of data. The quality of the training data is absolutely important. This data, these explainable algorithms, can even lead you to derive conclusions that indicate that you need data of more or less quality, because it may be giving you some surprising result, which may indicate that some training or input data is deriving outputs and should not. Then you have to check your own input data. Have quality reference data like you can find in datos.gob.es. It is absolutely essential to be able to contrast the information that this type of system gives you.
José Luis Marín: I think open data is key in two dimensions. First, because they allow evaluations to be contrasted and replicated with greater independence. For example, when there are validation datasets that are public, it not only assesses who builds the system, but also that third parties can evaluate (universities, administrations or civil society itself). That openness of evaluation data is very important for AI to be verifiable and much less opaque. But I also believe that open data for training and evaluation also provides diversity and context. In any minority context in which we think, surely large systems have not paid the same attention to these aspects, especially commercial systems. Surely they have not been tested at the same level in majority contexts as in minority contexts and hence many biases or poor performances appear. So, open datasets can go a long way toward filling those gaps and correcting those problems.
I think that open data in explainable artificial intelligence fits very well, because deep down they share a very similar objective, related to transparency.
4. Another challenge we face is the rapid evolution in the artificial intelligence ecosystem. We started talking about the popularity of chatbots and LLMs, but we find that we are still moving towards agentic AI, systems capable of acting more autonomously. What do these systems consist of and what specific challenges do they pose from an ethical point of view?
David Escudero: Agent AI seems to be the big topic of 2026. It is not such a new term, but if last year we were talking about AI agents, now we are talking about agent AI as a new technology that coordinates different agents to solve more complex tasks. To simplify, if an agent serves you to carry out a specific activity, for example, to book a plane ticket, what the agent AI would do is: plan the trip, contrast different offers, book the plane, plan the outward trip, the stay, again the return and, finally, evaluate the entire activity. What the system based on agent AI does is coordinate different agents. In addition, with a nuance. When we talk about the word agéntica – which we don't have a very direct translation in Spanish – we think of a system that takes the initiative. In the end, it is no longer just you who, as a user, ask artificial intelligence for things, but AI is already capable of knowing how it can solve things. It will ask you for information when it needs it and will try to adapt to give you a final solution as a user, but more or less autonomously, making decisions in intermediate processes.
Here precision and explainability are fundamental because a very important challenge is opened again. If at any given moment one of these agents used by the agentic AI fails, the effect of summing errors can be created and in the end it ends up like the phone smashed. From one system to another, from one agent to another, information is passed and if that information is not as accurate as it should be, in the end the solution can be catastrophic. Then new elements are introduced that make the problem even more exciting from a technological point of view. But we also have to understand that it is absolutely necessary, because in the end we have to move from systems that provide a very specific solution for a very particular case to systems that combine the output of different systems to be a little more ambitious in the response given to possible users.
Jose Luis Marín: Indeed. The moment we go from a type of system that, in principle, we give the "ability to think" about the actions that should be done and tell us about them, to other systems that it is as if they have hands to interact with the digital world - and we begin to see systems that even interact with the physical world and can execute those actions, that do not stop at telling you or recommending them to you – very interesting opportunities open up. But the complexity of the evaluation is also multiplied. The problem is no longer just whether the answer is right or wrong, but it is beginning to be who controls what the system does, what margin of decision it has, who supervises it and, above all, who responds if something goes wrong, because we are not only talking about recommendations, we are talking about actions that sometimes may not be so easy to undo. This leads to new or at least more intense risks: if traceability is lost in the execution of actions that were not foreseen or that should not have occurred at a certain time; or there may be misuses of information, or many other risks. I believe that agentic AI requires even more governance and a much more careful design aligned with people's rights.
5. Let's talk about real applications, where do you see the most potential and need for evaluation and explainability in the public sector?
Jose Luis Marín: I would say that the need for evaluation and explainability is greater where AI can influence decisions that affect people. The greater the impact on rights or opportunities or, even on trust in institutions, the greater this demand must be. If we think, for example, of areas such as health, social services, employment, education... In all of them, logically, the need for evaluation in the public sector is unavoidable.
In all cases, AI can be very useful in supporting decisions to achieve efficiencies in multiple scenarios. But we need to know very well how it behaves and what criteria are being used. This doesn't just affect the most complex systems. I think we have to look at the systems that at first may seem more or less sensitive at first glance, such as virtual assistants that we are already starting to see in many administrations or automatic translation systems... There is no final decision made by the AI, but a bad recommendation or a wrong answer can also have consequences for people. In other words, I think it does not depend so much on technological complexity as on the context of use. In the public sector, even a seemingly simple system can have a lot of impact.
David Escudero: I'll throw the rag at you to make another podcast about the concept that is also very fashionable, which is Human in the loop or Human on the loop. In the public sector we have a body of public officials who know their work very well and who can help. Human in the loop would be the role that the civil servant can play when it comes to generating data that can be useful for training systems, checking that the data with which systems can be trained is reliable, etc.; and Human on the loop would be the supervision of the decisions that artificial intelligence can make. The one who can review, who can know if that decision made by an automatic system is good or bad, is a public official.
In this sense, and also related to agentic AI, we have a project with the Spanish Foundation for Science and Technology to advise the Provincial Council of Valladolid on artificial intelligence tasks in the administration. And we see that many of the tasks that the civil servants themselves ask us do not have so much to do with AI, but with the interoperability of the services they already offer and that are automatic. Maybe in an administration they have a service developed by an automatic system, next to another service that offers them a form with results, but then they have to type in the data communicated by both services by hand. There we would also be talking about possibilities for the agency AI to intercommunicate. The challenge is to involve in this entire process the role of the civil servant as a watchdog that public functions are carried out rigorously.
Jose Luis Marín: The concept of Human in the loop is key in many of the projects we work on. In the end, it is the combination not only of technology, but of people who really know the processes and can supervise them and complement those actions that the Agent AI can perform. In any system of simple care, such supervision is already necessary in many cases, because a bad recommendation can also have many consequences, not only in the action of a complex system.
6. In closing, I'd like each of you to share a key idea about what we need to move towards a more trustworthy, assessable, and explainable AI.
David Escudero: I would point out, taking advantage of the fact that we are on the datos.gob.es podcast, the importance of data governance: to make sure that institutions, both public and private, are very concerned about the quality of the data, about having well-shared data that is representative, well documented and, of course, accessible. Data from public institutions is essential for citizens to have these guarantees and for companies and institutions to prepare algorithms that can use this information to improve services or provide guarantees to citizens. Data governance is critical.
Jose Luis Marín: If I had to summarise everything in a single idea, I would say that we are still a long way from assessment being a common practice. In AI systems we will have to make it mandatory within the development and deployment processes. Evaluating is not trying once and taking it for granted, it is necessary to continuously check how and where they can fail, what risks they introduce and if they are still appropriate when the context in which a certain system was designed has changed. I think we are still far from this.
Indeed, open data is key to contributing to this process. An AI is going to be more reliable the more we can observe it and improve it with shared criteria, not only with those of the organization that designs them. That is why open data provides transparency, can help us facilitate verification and build a more solid basis so that services are really aligned with the general interest.
David Escudero Mancebo: In that sense, I would also like to thank spaces like this that undoubtedly serve to promote that culture of data, quality and evaluation that is so necessary in our society. I think a lot of progress has been made, but that, without a doubt, there is still a long way to go and opening spaces for dissemination is very important.
Noticia
At the epicentre of global innovation that defines Mobile World Congress (MWC), a space has emerged where human talent takes centre stage: the Talent Arena.
The 2026 edition, promoted by Mobile World Capital Barcelona, brought together professionals, technology companies, training centres and emerging talent between 2 and 4 March with a common goal: to learn, connect and explore new opportunities in the digital field. At this event, Red.es actively participated with several sessions focused on one of the great current challenges: how to promote digital transformation through talent, training and innovation. Among them was the workshop "Open Data in Spain. From theory to practice with datos.gob.es", a session that focused on the strategic role of open data and its connection with emerging technologies such as artificial intelligence.
In this post we review the contents of the presentation that combined:
- A didactic look at the evolution, current state and future of open data in Spain
- A hands-on workshop on creating a conversational agent with MCP
What is open data? Evolution and milestones
The session began by establishing a fundamental pillar: the importance of open data in today's ecosystem. Beyond their technical definition – data that can be freely used, reused and shared by anyone, for any purpose – the talk underscored that their true power lies in the transformative impact they generate.
As addressed in the workshop, this data comes from multiple sources (public administrations, universities, companies and even citizens) and its openness allows:
- Promote institutional transparency, by facilitating access to public information.
- Encourage innovation, by enabling developers and businesses to create new services.
- Generate economic and social value, from the reuse of information in multiple sectors, such as health, education or the environment.
One of the key aspects of the workshop was to contextualize the historical evolution of open data. Although the first antecedents date back to the 50s and 60s, the modern concept of "open data" began to consolidate in the 90s. Subsequently, milestones such as the Memorandum on Transparency and Open Government (2007-2009) or the creation of the Open Government Partnership in 2011 marked a turning point at the international level.
In Spain, this development has been supported by a solid regulatory framework, such as Law 37/2007, which establishes key principles:
- Default opening of public data, especially high-value data.
- Creation of interoperable catalogs.
- Promotion of the reuse of information.
- Establishment of units responsible for data management.
The role of datos.gob.es: the national open data portal
At the heart of this ecosystem is datos.gob.es, the national open data portal, which acts as a unified access point to the public information available in Spain.
During the workshop, it was explained how this platform has evolved over time: from a few hundred datasets to hosting more than 100,000 today. It has also been incorporating new functionalities and adapting to international standards such as DCAT-AP and its national adaptation DCAT-AP-ES. These standards allow metadata to be structured in an interoperable way, facilitating integration between different catalogs.
Check here the Practical Guide to Implementing DCAT-AP-ES step by step
In addition, the data federation process in datos.gob.es was detailed , which ensures that data from different sources can be integrated in a consistent and accessible way.
Despite the progress, the presentation also addressed the remaining challenges:
- Data quality and updating.
- Standardization and interoperability.
- Security and access control, especially in AI-connected environments.
- Training of users, both technical and non-technical.

Figure 1. Photo taken during the Talent Arena presentation at the Mobile World Congress. The photo shows the slide from the presentation explaining the concept of open data. Source: own elaboration - datos.gob.es.
From data to intelligence: the leap to AI
One of the most innovative elements of the workshop was its practical approach, focused on the application of artificial intelligence to open data. This is where the Model Context Protocol (MCP) came into play, an open standard that allows you to connect language models (Large Language Model or LLM) with external data sources in real time.
The initial problem that the workshop had to answer is how AI models, on their own, do not have up-to-date access to information or external systems. This limits their usefulness in real contexts. One solution may be to develop an MCP that acts as a "bridge" between the model and data sources, enabling:
- Access up-to-date information.
- Execute actions on external systems.
- Integrate multiple data sources securely.
In simple words, it is about connecting the "brain" (the AI model) with the "tools" (databases, APIs, internal systems).
The exercise, which took place live in the Talent Arena, began with a simple example: creating a database of film preferences and developing an MCP that would allow it to be consulted using natural language.
From there, key concepts were introduced:
- Identification of the intention of the model.
- Function calling.
- Generation of natural language responses from structured data.
This approach allows us to abstract the technical complexity and bring the use of data closer to non-specialized profiles.
The next step was to apply this same approach to the datos.gob.es catalog. Through its API, it's possible. First, it allows you to search for datasets by title and filter by topic; then through the API you can obtain detailed information about a dataset and access catalog statistics.
The MCP developed in the workshop acted as an intermediary between the AI model and this API, allowing complex queries to be made using natural language.
This exercise combined a local database (SQLite) and the consumption of external data through an API, all integrated through an MCP server that allowed these functionalities to be exposed as accessible tools. The goal was to understand how to structure data, query it, and make it available to other AI systems or models in an organized way.
The full code is available as an attachment to this post in Python Notebook format.
This exercise is a sign of the enormous opportunities before us. The combination of open data and artificial intelligence can:
- Democratize access to information.
- Accelerate innovation.
- Improve decision-making in the public and private sectors.
In summary, the workshop "Open Data in Spain. From theory to practice with datos.gob.es" highlighted a fundamental idea: data, by itself, does not generate value. It is their use, interpretation and combination with other technologies that allows them to be transformed into knowledge and real solutions.
The evolution of open data in Spain shows that much progress has been made in recent years. However, the real potential is yet to be exploited, especially in its integration with technologies such as artificial intelligence. Events like Talent Arena 2026 serve precisely that: connecting ideas, sharing knowledge, and exploring new ways of doing things.
Evento
On May 8, 2026, a new edition of the National Open Data Meeting (ENDA) will take place, this time in Pamplona organized by the Government of Navarra. A key event for those working in public innovation, data reuse and digital entrepreneurship to exchange knowledge, experiences and good practices.
Under the slogan "Learn and undertake", this year's edition focuses on the role of data in education and in the promotion of new business projects, highlighting the importance of data literacy and the potential of open data as a driver of innovation, learning and the creation of job opportunities.
An open approach focused on practical experiences
This edition's agenda has been designed to address the main challenges and opportunities posed by the use of open data in this specific area. Throughout the day, issues such as the reuse of data in the field of education, the possibilities they offer at the workplace or the role of public administrations as drivers of this data ecosystem will be explored.
The session will begin at 9:00 a.m. with the inauguration by Javier Remírez Apesteguía, First Vice-President, Minister of the Presidency and Equality and spokesman for the Government of Navarre. It will be followed by the keynote speech "AI and open data: new ways of exploiting, understanding and creating value" by Mikel Galar Idoiate, professor in the area of Computer Science and Artificial Intelligence at the Public University of Navarra.
The event will then take place over various round tables that will allow for a deeper understanding of various topics from a practical perspective, with real examples and experiences shared by professionals who work with data on a daily basis.
- Table 1: Relationship between education, entrepreneurship and employment
- Table 2: The role of Public Administrations in the reuse of data
- Table 3: Entrepreneurship and open data: vision and future
- Table 4: The power of data in education
- Table 5: Evolution of Open Data Policies
Datos.gob.es will participate in this last table by contributing its experience as a reference platform at the national level in terms of opening and reusing public sector information. For its part, the General Directorate of Data will share its vision at table 2. In both cases, trends and the lines of work that are being developed to promote the culture of data throughout the country will be shared.
A new challenge to face
Since its first edition, ENDA has been a meeting place for those who work with open data from very diverse perspectives. Each year, the event has been consolidating a broader and more mature community, capable of generating projects, methodologies and alliances that transcend the meeting itself. In this sense, within the framework of each meeting, a central space is dedicated to the identification of a challenge that must be addressed in order to consolidate a more solid, useful and sustainable data ecosystem. These challenges, defined collaboratively, allow public policies and reuse initiatives to be oriented towards a more mature and impact-oriented model. The challenges addressed in previous editions have been:
- CHALLENGE 1. Generate data exchanges and facilitate their openness, where participants reached a series of conclusions to promote inter-administrative collaboration.
- CHALLENGE 2. Increase capacities for open data, where work was done on a competency framework so that public employees acquire the knowledge and skills necessary to promote open data.
- CHALLENGE 3. How to measure the impact of open data, where a methodological proposal was made for the development of a systematic mapping of initiatives that try to measure the impact of open data.
- CHALLENGE 4. Prioritization in the opening of public data, where the datasets to be published by public administrations (local, regional or national) were identified. To this end, a methodological proposal and a tool were developed to determine the level of organizational maturity in data openness policies.
We will have to wait for the celebration of the V ENDA to know what this year's challenge is.
Registration now open
The conference is open to both those who work with data in their day-to-day work and those who want to discover new opportunities in the educational, professional or entrepreneurial field. Whatever your case, in order to attend it is necessary to register through the event's website. The form will remain available until April 30, 2026.
After four editions held in different territories, ENDA continues to grow as an itinerant meeting that promotes collaboration between administrations, universities, companies and citizen organizations, consolidating a diverse community committed to open data. An opportunity to grow and continue learning.
If you want more information, on the official website you can consult the contents, materials and learnings from the four previous editions, which have contributed to strengthening the state open data ecosystem.
Blog
There's an idea that is repeated in almost any data initiative: "if we connect different sources, we'll get more value". And it is usually true. The nuance is that value appears when we can combine data without friction, without misunderstandings and without surprises. The Public Sector Data reuser´s decalogue sums it up nicely: interoperability is especially critical just when we're trying to mix data from a variety of sources, which is where open data tends to bring the most in.
In practice, interoperability is not just "that there is an API" or "that the file is downloadable". It is a broader concept, with several layers: if we only take care of one, the others end up breaking the reuse. We connect... But we don't understand what each field means. We understand... but there is no stability or versioning. There is stability... but there is no common process for resolving incidents. And, even with all of the above, clear rules of use may be lacking. For this reason, it is also a mistake to think that interoperability is a purely computer problem that can be fixed by "buying the right software": technology is only the tip of the iceberg. If we want data to truly flow between public administration, business and research centres, we need a holistic vision.
And here is the good news: it can be tackled incrementally, step by step. To do it well, the first thing is to clarify what type of interoperability we are looking for in each case, because not all barriers are technical or solved in the same way.
In this post we are going to break down the different types of interoperability, to identify what each one brings and what fails when we leave it out.
The different types of interoperability
Following the European Interoperability Framework (EIF), it is convenient to think of interoperability as a building with four main layers: technical, semantic, organisational and legal. If one fails, the whole suffers.
We then unify the four layers with a data-centric approach, including examples applied to different industries.
1. Technical interoperability: systems can exchange data
It is the "visible" layer: infrastructures, protocols and mechanisms to reliably send/receive data.
But what does it mean in practice?
-
Machine-readable formats: such as CSV, JSON, XML, RDF, avoiding human-readable documents only (such as PDF).
-
Stable APIs and endpoints: with documentation, authentication when applicable, and versioning.
-
Non-functional requirements: availability, performance, security and technical traceability.
What are the typical errors or failures that generate problems?
In the specific case of technical interoperability, these issues mainly arise from ‘silent’ changes, for example, columns and/or structure being altered and breaking integrations, or the presence of non‑persistent URLs, APIs without versioning, or lacking documentation.
Example: let's land it in a specific case for the mobility domain
Let's imagine that a city council publishes in real time the occupancy of parking lots. If the API changes the name of a field or the endpoint without warning, the navigation apps stop showing available spaces, even if "the data exists". The problem is technical: there is a lack of stability, versioning, and interface contract.
2. Semantic interoperability: they also understand each other
If technical interoperability is "the pipes", semantics is the language. We can have perfectly connected systems and still get disastrous results if each part interprets the data differently.
But what does it mean in practice?
-
Glossaries of clear terms: definition of each field, unit, format, range, business rules, granularity, and examples.
-
Controlled vocabularies , taxonomies, and ontologies for unambiguous classification and encoding of values.
-
Unique identifiers and standardised references through reference data with official codes, common catalogues, etc.
What are the typical errors or failures that generate problems?
These issues usually arise when there is ambiguity (for example, if it only says ‘date’, we don’t know whether it refers to the registration date, publication date, or effective date), different units (for example, the unit of measurement of the data is not known: kWh vs MWh, euros vs thousands of euros), incompatible codes (M/F vs 1/2 vs male/female) or even changes in meaning in historical series without explaining it.
Example: let's land it on a specific case in the energy sector
An administration publishes data on electricity consumption by building. A reuser crosses this data with another regional dataset, but one is in kWh and the other in MWh, or one measures "final" consumption and the other "gross". The crossing "fits" technically, but the conclusions go wrong because there is a lack of semantics: definitions and shared units.
3. Organisational interoperability: processes must maintain consistency
Here we talk less about systems and more about people, responsibilities and processes. Data doesn't stand on its own: it's published, updated, corrected, and explained because there's an organization behind it that makes it possible.
But what does it mean in practice?
-
Clear roles and responsibilities: who defines, who validates, who publishes, who maintains and who responds to incidents.
-
Change management: what is a major/minor change, how it is versioned, how it is communicated, and whether the history is preserved.
-
Incident management: single channel, response times, prioritization, traceability and closure.
-
Operational commitments (such as service level agreements or SLAs): update frequency, maintenance windows, quality criteria and periodic reviews.
Here, for example, the UNE specifications on data governance and management can help us, where the keys to establishing organisational models, roles, management processes and continuous improvement are given. Therefore, they fit precisely into this layer: they help to ensure that publishing and sharing data does not depend on the "heroic effort" of a team, but on a stable way of working in which the team matures.
What are the typical errors or failures that generate problems?
The classics: "each unit publishes in its own way", there is no clear responsible, there is no circuit to correct errors, it is updated without warning, it is not preserved historical or the feedback of the reuser is lost in a generic mailbox without tracking.
Example: let's land it in a specific case in the environment
A confederation publishes water quality data and several units provide measurements. Without a common validation process, a coordinated schedule, and an incident channel, the dataset begins to have inconsistent values, gaps, and late corrections. The problem is not the API or the format: it is organizational, because maintenance is not governed.
4. Legal interoperability: that the exchange is viable and compliant
This is the layer that makes the exchange secure and scalable. You can have perfect data at a technical, semantic and organizational level... and even so, not being able to reuse them if there is no legal clarity.
But what does it mean in practice?
-
Clear license and terms of use: attribution, redistribution, commercial use, obligations, etc.
-
Compatibility between licenses when mixing sources: avoiding unfeasible combinations.
-
Data protection compliance: such as the General Data Protection Regulation (GDPR), intellectual property, trade secrets or industry boundaries.
-
Explicit rules on what can and cannot be done: also indicating with what requirements).
What are the typical errors or failures that generate problems?
The classic "jungle": absent or ambiguous licenses, contradictory conditions between datasets, doubts about whether there is personal data or risk of re-identification, or restrictions that are discovered when the project is already advanced.
Example: let's land it in a specific case in culture and heritage
A public archive publishes images and metadata from a collection. Technically everything is fine, and the metadata is rich, but the license is confusing or incompatible with other data that you want to cross (for example, a private repository with restrictions). Result: a company or a university decides not to reuse due to legal uncertainty. The blockade is not technical: it is legal.
In short, interoperability works as a "pack" of four layers: connect (technical), understand the same (semantics), maintain it in a sustained way (organizational) and be able to reuse without risk (legal).
For a quick overview with real-world examples, the following infographic summarizes how each layer is implemented across different sectors (standards, models, practices, and regulatory frameworks) and which components are typically used as references in each case.

Figure 1. Infographic: “Interoperability: the key to working with data from diverse sources”. An accessible version is available here. Source: own elaboration - datos.gob.es.
The infographic above makes a clear idea: interoperability does not depend on a single decision, but on combining standards, agreements and rules that change according to the sector. From here, it makes sense to go down one level and see what references and tools are used in Spain and in Europe so that these four layers (technical, semantic, organisational and legal) do not remain in theory.
A practical reference in Spain: NTI-RISP (and why it makes sense to cite it)
In the Spanish context, the NTI‑RISP is a very useful guide because it clearly lays out what needs to be taken care of when publishing information so that others can reuse it: identification, description (metadata), formats, and terms of use, among other aspects.
Metadata as glue: DCAT-AP and DCAT-AP-ES
In open data, the place where interoperability is most noticeable in everyday practice is in catalogs: if datasets are not described consistently, they become harder to find, understand, and federate.
-
DCAT-AP provides a common metadata model for data catalogues in Europe, based on widely reused vocabularies.
-
In Spain, DCAT-AP-ES is promoted precisely to reinforce the interoperability of catalogues with a common profile that facilitates exchange and federation between portals.
How to approach interoperability without dying of ambition
Rather than "fixing it all at once," it often works better to treat interoperability as continuous improvement because it breaks down with changes in technology, organization, or regulation. A simple and realistic approach:
-
Start with the "why": Do you want to integrate into a service, cross for analysis, build comparable indicators, enrich entities...? The objective determines the level of rigor required.
-
It ensures the minimum level of stability: machine-readable access and formats, persistent identifiers, minimal documentation, and some versioning (even if it is basic). This prevents "useful today" datasets that break tomorrow.
-
Apply semantics where it hurts (Pareto principle: 80/20 - states that 80% of the results come from 20% of the causes or actions-): define very well the critical fields (those that intersect/filter), units, code tables and the exact meaning of dates/states. You don't need to "model it all" to reduce most errors.
-
Put minimum operating agreements: who maintains, when it is updated, how incidents are reported, how changes are announced, and if the history is preserved. This is where a data governance approach (and guidelines like NTI-RISP) makes the difference between "published dataset" and "sustainable dataset".
-
Pilot with a real crossover: a small pilot quickly detects whether the problem was technical, semantic, organizational or legal, and gives you a specific list of frictions to eliminate.
In conclusion, interoperability is not simply "having an API": it is the result of aligning four layers – technical, semantic, organizational and legal – to be able to combine data without friction, without misunderstandings and with security. Each layer solves a different problem: the technical one avoids integration breaks, the semantic one avoids misinterpretations, the organizational one makes publication and maintenance sustainable over time, and the legal one eliminates the uncertainty about what can be done with the data.
In this context, sectoral frameworks and standards act as practical shortcuts to accelerate agreements and reduce ambiguity, and that is why it is useful to see examples by sector. In addition, interoperable metadata and catalogs are a real multiplier: When a dataset is well described, it is found more quickly, better understood, and can be federated at lower cost. Finally, an incremental and measurable approach is usually most effective: start with the "why", ensure technical stability, reinforce critical semantics (80/20), formalize minimum operational agreements and validate with a real crossover, instead of trying to "solve interoperability" as a single closed project.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Noticia
On the occasion of Open Data Day 2026, the Open Knowledge Foundation (OKFN) held an online conference entitled "The Future of Open Data", an open-access event that brought together a diverse community of data professionals from governments, civil society organizations, universities, newsrooms and activist collectives. From datos.gob.es we follow the day live and share here a summary of the main ideas that marked the day.
Three approaches to understanding the role of open data in the age of AI
The conference was structured around three main thematic blocks:
- Navigating open data regulation in the public interest: interventions by representatives of academia, public policy makers and researchers from different countries who discussed the regulatory framework of open data in the current context of AI.
- Community Voices, Open Data, and AI: Short presentations of concrete projects from around the world exploring the intersection between open data and artificial intelligence, from tools for judicial analysis to citizen science dashboards.
- 20 years of CKAN: The future in the age of AI: reflections on the two decades of history of open data and CKAN, on the past, present and challenges to come.
Overall, the day combined political reflection, technical innovation and community vision, with voices from Spain, France, India, Ukraine, Kenya, the United States and Australia, among other countries. And the common thread of the event was the question that today runs through digital policy forums around the world: what is the role of open data in an ecosystem increasingly dominated by artificial intelligence?
Thematic block 1. A movement that was born out of activism
In its origins, the open data movement began in conversations between activists committed to transparency, accountability and access to public information to citizens.
This episode of the datos.gob.es podcast also discusses the origin of open data and its evolution
Today, however, the movement is more diversified because there are now more agents that influence, such as artificial intelligence. There is also a regulatory context that functions as a framework in the development of the open data movement.
The topic of regulation and governance was the backbone of the first session of the event, moderated by Renata Ávila, CEO of OKFN. The following participated in it:
- Jonathan Gray, author of the book Public Data Cultures (Polity, 2025) and professor at King's College London, presented his work as a reference source for reflecting on data as an open asset: how this openness is built and how it can help us respond to great collective challenges. His proposal is that public data is not simply technical information, but the result of cultural and political decisions about what we tell, how we tell it, and for whom.
- Renato Berrino Malaccorto, research manager of the Open Data Charter, stressed that the openness of data is fundamental for the ethical development of AI. Without open, auditable and quality data, it is not possible to build artificial intelligence systems that are accountable to citizens. At the same time, he pointed out that there is a real capacity gap: many organizations and governments lack the technical and human resources necessary to harness the potential of open data in this new context.
- Ruth del Campo, general director of data at the Ministry for Digital Transformation and Public Function of the Government of Spain, offered a very relevant institutional perspective for our context. He recalled that "The data economy is part of the economy", and underlined the boost that the Government is giving to initiatives such as datos.gob.es and Impulsa Data (aimed at modernizing internal management and feeding the Sectoral Data Spaces). He also stressed the importance of the data strategy incorporating AI ready principles, guaranteeing adequate resources – such as linguistic corpora – to train AI models efficiently and without generating new inequalities. Finally, he pointed out the need to simplify and harmonize data regulations, a process in which progress is already being made at the European level.
The panel's underlying message was clear: open data needs to be placed at the heart of the digital agenda, adequately resourced and explicitly connected to public AI strategies. AI of social interest cannot be built without open data; and open data without a vision of AI risks being relegated to irrelevance.
Thematic block 2. Lightning Talks: Projects That Demonstrate the Potential of Open Data
The second session of the day brought together short presentations of concrete projects that illustrated how open data and artificial intelligence can work together in the public interest. Some examples are:
- Ihor Samokhodskyi from the Ukrainian initiative Policy Genome presented an open data-based analysis tool for judicial practice that demonstrates how public information, combined with AI techniques, can contribute to transparency and the improvement of justice systems.
- Javier Conde, from the Polytechnic University of Madrid, presented the proposal he has developed together with his colleagues Andrés Muñoz-Arcentales and Álvaro Alonso to improve the integration of European open data in data spaces. This project facilitates the automatic generation of high-quality metadata, thus ensuring the interoperability and reuse of datasets. A directly relevant initiative for the improvement of portals such as datos.gob.es and its connection with data.europa.eu.
- Renu Kumari, from #semanticClimate and Frictionless Data (India), presented a project that works at the intersection between open climate data and semantic tools to make scientific literature and data on climate change more accessible, structured and reusable.
- Richard Muraya, from The Demography Project (Kenya), presented Uhai/Life, a citizen science dashboard that aggregates open data on natural resource use to provide insight into human and environmental well-being at the local scale. An example of how open data can empower communities to tell their own story, without relying on external narratives or institutions.
Figure 1. Presentation slide of one of the presentations of the event. Source: conference "The Future of Open Data" organized by OKFN.
- Finally, Sayantika Banik from DataJourney (India) showed an autonomous analytics assistant capable of transforming open datasets into easily understandable information.
Thematic block 3. Round table: 20 years of CKAN and the challenges of the future
The longest session of the day was also the most reflective: a round table to celebrate two decades of CKAN, the open data portal management tool born within OKFN and which today feeds hundreds of data portals around the world, including datos.gob.es. The panel was moderated by Jamaica Jones, CKAN/POSE community manager at the University of Pittsburgh. The following participated in this table:
- Rufus Pollock, founder of OKFN and Datopian, and co-founder of Life Itself, stressed the importance of keeping power in the hands of citizens and of betting on open source as a driver of economic development and shared knowledge. For Pollock, AI must be understandable and accessible to most, not just large corporations.
- Joel Natividad is Co-CEO and co-founder of datHere, a company specializing in open data solutions and analytics tools for the public sector. As a CKAN user for more than 15 years, he insisted on one idea: "We have always tried to learn how machines think, and now it is machines that are learning how humans think."
- Patricio Del Boca is Tech Lead and Open Activist at OKFN, where he leads the technical development of initiatives related to CKAN and open data infrastructures. He shared OKFN's next steps for 2026: building more community and developing use cases that demonstrate the practical value of open data in the current context.
- Andrea Borruso is an expert in Geographic Information Systems (GIS) and open data. As president of onData, an Italian non-profit association that promotes access to and reuse of public data, he highlighted data activism and citizen science as drivers of technological development that involve the community.
- Antonin Garrone of data.gouv.fr, France's national open data portal, brought to the table the perspective of an established portal that has spent years exploring how to integrate new technologies without losing sight of its public service mission.
- Steven De Costa is CEO of Link Digital, an Australian company specializing in the implementation and development of CKAN-based solutions, and Co-Steward of the CKAN project. His perspective combined technical vision with a concern to maintain an open and participatory governance model.
- Finally, Public AI research engineer Mohsin Yousufi insisted on the intersection between artificial intelligence, public data infrastructures, and technology policies, exploring how AI systems can be designed and governed to serve the public interest.
Final Thought: Open Data as Democratic Infrastructure
If there is one conclusion that ran through all the sessions of Open Data Day 2026, it is that open data is not in crisis, but at a decisive moment. The opportunities offered by artificial intelligence are real, but so are the risks. It is important to know them in order to know how to address them. Some of those that were mentioned are:
- Prevent public data from becoming the raw material of private systems without transparency or accountability.
- Preserve the political will to keep open data portals functional and updated.
- Bridging the digital skills and training gap to facilitate the participation of all countries and communities in the new AI ecosystem.
In the face of this, the message of the event was one of mobilization: it is necessary to vindicate open data as a democratic infrastructure, explicitly connect data policies with public AI strategies, and ensure that the benefits of artificial intelligence reach all citizens, and not only those who already have access to technological resources.
From datos.gob.es we will continue to work in that direction, and we celebrate the existence of spaces such as Open Data Day to remind us why we started and where we want to go.
You can watch the event video again here
Evento
Just a few months after the success of its first award, the Madrid City Council has opened the call for the second edition of the Open Data Reuse Awards. It is an initiative that seeks to recognize and promote innovative projects that use the datasets published on the datos.madrid.es portal. With a total endowment of 15,000 euros, these awards consolidate the municipal commitment to data culture, transparency and the creation of social and economic value from public information.
In this article we tell you some of the keys you must take into account to participate.
Two award categories to consider
The call establishes two categories, each with several prizes:
1) Web services, applications and visualizations: rewards projects that generate services, visualizations or web or mobile applications.
- First prize: €4,000
- Second prize: €3,000
- Third prize: €1,500
- Student prize: €1,500
2) Studies, research and ideas: focuses on research projects, analysis or description of ideas to create services, studies, visualizations, web or mobile applications. This category is also open to university end-of-degree and end-of-master's projects (TFG-TFM).
- First prize: €2,500
- Second prize: €1,500
- Third prize: €1,000
- Projects already awarded, subsidized or contracted by the Madrid City Council.
- Projects that do not use any datasets from the municipal portal.
In both categories, it is necessary that at least one set of data from the municipal portal is used, and can be combined with public or private sources from any territorial area. Projects can be recent or have been completed in the two years prior to the closing of the call.
Awards may be declared void if the minimum quality is not reached. In this case, the remaining amounts will be redistributed proportionally among the rest of the winners.
Requirements to participate
The call is open to natural and legal persons who are the authors of the projects or initiatives. The aim is for any person or entity with an interest in the reuse of data to be able to submit their proposal, regardless of their technical level. Therefore, both professionals and companies, researchers, journalists and developers, as well as amateurs and amateurs interested in data analysis and visualization can participate.
In the case of the student prize, only those individuals enrolled in official courses 2023/24, 2024/25 or 2025/26 may participate.
On the other hand, the following are excluded from all categories:
Process Phases
The municipal portal details the phases of the call, which include:
- Publication of the call. On March 3, the regulatory bases were published in the Official Gazette of the Madrid City Council.
- Submission of nominations. The deadline for submitting applications is from March 4 to May 4 (both included). They can be submitted online or in person, as explained below.
-
Analysis and correction. Until June 3, the review of the documentation submitted will be carried out. If necessary, applicants will be contacted to correct errors.
-
Assessment and deliberation. A jury will evaluate all the admitted projects, according to the criteria established in the rules of the call. Their usefulness, economic value, social value and contribution to transparency will be taken into account; their degree of innovation and creativity; the variety of datasets used from the Madrid Open Data Portal; and its technical quality. This phase will run until September 15.
-
Resolution. In the months of September and October , the proposal for the granting and official publication of the resolution will be carried out.
-
Awards ceremony. The awards will be presented at a public event, estimated for the month of November.
The official website will update dates and documentation as the process progresses.
How applications are submitted
As mentioned above, applications can be submitted electronically or in person:
- Online, through the electronic headquarters of the Madrid City Council. Identification and electronic signature are required for this.
- In person, at the registration assistance offices of the Madrid City Council, as well as at the registries of other public administrations.
Individuals may submit the application in both ways, while legal persons may only submit the application electronically.
In both cases, nominations must include:
- Official application form, to be downloaded from the Madrid City Council's electronic headquarters.
- Project report, based on a model to be downloaded from the aforementioned electronic office. This document will include the title, authorship and a detailed description, as well as the list of datasets used, the objectives, the target audience, the expected impact, the degree of innovation and the technology used.
- Responsible declaration.
- Collaboration agreement, in the case of presenting itself as a group.
Get inspired by the winning projects of the first edition
The second edition of the Open Data Reuse Awards comes on the heels of the success of the previous edition. In 2025, the Madrid City Council held the first edition of these awards, which brought together 65 nominations of great quality and diversity. Among them, proposals promoted by university students, startups, multidisciplinary teams and citizens committed to the intelligent use of public data stood out.
The award-winning projects demonstrated that open data can become real tools to improve urban life, boost transparency and generate useful knowledge for the city. In this article we summarize what these projects consisted of.
In summary, the II Open Data Reuse Awards 2026 are an opportunity to demonstrate how public data can be turned into real innovation. An invitation to develop projects that promote a smarter, more transparent and participatory Madrid.
Blog
The European High-Value Datasets (HVD) regulation, established by Implementing Regulation (EU) 2023/138, consolidates the role of APIs as an essential infrastructure for the reuse of public information, making their availability a legal obligation and not just a good technological practice.
Since 9 June 2024, public bodies in all Member States are required to publish datasets classified as HVDs free of charge, in machine-readable formats and accessible via APIs. The six categories regulated are: geospatial data, Earth observation, environment, statistics, business information and mobility.
This framework is not merely declarative. Member States must report to the European Commission compliance status every two years, including persistent links to APIs that give access to such data. The situation in Spain in terms of transparency, open data and Systematic API Provisioning can be consulted in the indicators published by the Open Data Maturity Report.
In practice, this means that APIs are the bridge between the norm and reality. The regulation not only says what data must be opened, but also requires it to be done in such a way that it can be automatically integrated into applications, studies or digital services. Therefore, reviewing the public APIs available in Spain is a concrete way to understand how this framework is being applied on a day-to-day basis.
Inventory of public APIs in Spain
INE — API JSON (Tempus3)
The National Institute of Statistics offers a API REST that Exposes the entire database Tempus3 broadcast format JSON, which includes official statistical series on demography, economy, labour market, industry, services, prices, living conditions and other socio-economic indicators.
To make calls, the structure must follow the pattern https://servicios.ine.es/wstempus/js/{language}/{function}/{input}. The tip=AM parameter allows you to get metadata along with the data, and tv filters by specific variables. For example, to obtain the population figures by province, simply consult the corresponding operation (IOE 30243) and filter by the desired geographical variable.
No authentication or API key required: any well-formed GET request returns data directly.
Example in Python — get the resident population series with metadata:
import requests
url = ("https://servicios.ine.es/wstempus/js/ES/"
"DATOS_TABLA/t20/e245/p08/l0/01002.px?tip=AM")
response = requests.get(url)
data = response.json()
for serie in data[:3]: # primeras 3 series
name = series["Name"]
last = series["Date"][-1]
print(f"{name}: {last['Value']:,.0f} ({last['PeriodName']})")
TOTAL AGES, TOTAL, Both sexes: 39,852,651 (1998)
TOTAL AGES, TOTAL, Males: 19,488,465 (1998)
TOTAL EDADES, TOTAL, Mujeres: 20,364,186 (1998)AEMET — OpenData API REST
The State Meteorological Agency exposes its data through a REST API, documented with Swagger UI (an open-source tool that generates interactive documentation), observed meteorological data and official predictions, including temperature, precipitation, wind, alerts and adverse phenomena.
Unlike the INE, AEMET requires a Free API key, which is obtained by providing an email address in the portal opendata.aemet.es. A API key works as A type of "password" or identifier: it is used to allow the agency to know who is using the service, control the volume of requests and ensure proper use of the infrastructure.
A relevant technical aspect is that AEMET implements a two-call model: the first request returns a JSON with a temporary URL in the data field, and a second request to that URL retrieves the actual dataset. The rate limit is 50 requests per minute.
Example in Python — daily weather data (double call):
import requests
API_KEY = "tu_api_key_aqui"
headers = {"api_key": API_KEY}
#1st call: Get temporary data URLs
url = ("https://opendata.aemet.es/opendata/api/"
"Values/Climatological/Daily/Data/"
"fechaini/2025-01-01T00:00:00UTC/"
"fechafin/2025-01-10T23:59:59UTC/"
"allseasons")
resp1 = requests.get(url, headers=headers).json()
#2nd call: Download the actual dataset
datos = requests.get(resp1["datos"], headers=headers).json()
for estacion in datos[:3]:
print(f"{station['name']}: "
f"Tmax={station.get('tmax','N/A')}°C, "
f"Prec={estacion.get('prec','N/A')}mm")
CITFAGRO_88_GAITERO: Tmax=8.8°C, Prev=0.0mm
ABANILLA: Tmax=14,8°C, Prec=0,0mm
LA RODA DE ANDALUCÍA: Tmax=15.7°C, Prec=0.2mmCNIG / IDEE — Servicios OGC y OGC API Features
The National Center for Geographic Information It publishes official geospatial data – base mapping, digital terrain models, river networks, administrative boundaries and other topographic elements – through interoperable services. These have evolved from WMS/WFS to the OGC API (Features, Maps and Processes), implemented with open software such as pygeoapi.
The main advantage of OGC API Features over WFS is the response format: instead of GML (heavy and complex), the data is served in GeoJSON and HTML, native formats of the web ecosystem. This allows them to be consumed directly from libraries such as Leaflet, OpenLayers or GDAL. Available datasets include Cartociudad addresses, hydrography, transport networks and geographical gazetteer.
Example in Python — query geographic features via OGC API:
import requests
# OGC API Features - Basic Geographical Gazetteer of Spain
base = "https://api-features.idee.es/collections"
collection = "falls" # Waterfalls
url = f"{base}/{collection}/items?limit=5&f=json"
resp = requests.get(url).json()
for feat in resp["features"]:
props = feat["properties"]
coords = feat["geometry"]["coordinates"]
print(f"{props['number']}: ({coords[0]:.4f}, {coords[1]:.4f})")
None: (-6.2132, 42.8982)
Cascada del Cervienzo: (-6.2572, 42.9763)
El Xaral Waterfall: (-6.3815, 42.9881)
Rexiu Waterfall: (-7.2256, 42.5743)
Santalla Waterfall: (-7.2543, 42.6510)MITECO — Open Data Portal (CKAN)
The Ministry for the Ecological Transition maintains a CKAN-based portal that exposes three access layers: the CKAN Action API for metadata and dataset search, the Datastore API (OpenAPI) for live queries on tabular resources, and RDF/JSON-LD endpoints compliant with DCAT-AP and GeoDCAT-AP. In its catalogue you can find data on air quality, emissions and climate change, water (state of masses and hydrological planning), biodiversity and protected areas, waste, energy and environmental assessment.
Featured datasets include Natura 2000 Network protected areas, bodies of water, and greenhouse gas emissions projections.
Example in Python — search for datasets:
import requests
BASE = "https://catalogo.datosabiertos.miteco.gob.es/ catalog"
# Search for datasets containing 'natura 2000'
busqueda = requests.get(
f"{BASE}/api/3/action/package_search",
params={"q": "natura 2000", "rows": 3},
).json()
for ds in busqueda["result"]["results"]:
print(f"{ds['title']} ({ds['num_resources']} resources)")
Protected Areas of the Natura 2000 Network (13 resources)
Database of Natura 2000 Network Protected Areas of Spain (CNTRYES) (1 resources)
Protected Areas of the Natura 2000 Network - API - High Value Data (1 resources)Technical comparison
| Organisim | Protocol | Format | Authentication | Rate limit | HVD |
|---|---|---|---|---|---|
| INE | REST | JSON | None | Undeclared | Yes (statistic) |
| AEMET | REST | JSON | API key (free) | 50 reg/min | Yes (environment) |
| CNIG/IDEA | OGC API/WFS | GeoJSON/GML | None | Undeclared | Yes (geoespatial) |
| MITECO | CKAN/REST | JSON/RDF | None | Undeclared | Yes (environment) |
Figure 1. Comparative table of the APIs from various public agencies discussed in this post. Source: Compiled by the author – datos.gob.es.
The availability of public APIs isn't just a matter of technical convenience. From a data perspective, these interfaces enable three critical capabilities:
- Pipeline automation: the periodic ingestion of public data can be orchestrated with standard tools (Airflow, Prefect, cron) without manual intervention or file downloads.
- Reproducibility: API URLs act as static references to authoritative sources, facilitating auditing and traceability in analytics projects.
- Interoperability: the use of open standards (REST, OGC API, DCAT-AP) allows heterogeneous sources to be crossed without depending on proprietary formats.
The public API ecosystem in Spain has different levels of development depending on the body and the sectoral scope. While entities such as the INE and AEMET have consolidated and well-documented interfaces, in other cases access is articulated through CKAN portals or traditional OGC services. The regulation regarding High Value Datasets (HVDs) is driving the progressive adoption of REST standards, although the degree of implementation evolves at different rates. For data professionals, these APIs are already a fully operational source that is increasingly common to integrate into data architectures in engineering and analytical environments.ás habitual en entornos analíticos y de ingeniería.
Content produced by Juan Benavente, a senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Noticia
On Wednesday, March 4, the Cajasiete Big Data, Open Data and Blockchain Chair of the University of La Laguna held a webinar to present the winning ideas of the Cabildo de Tenerife Open Data Contest: Reuse Ideas. An event to highlight the potential of public information when it is put at the service of citizens. The recording of the presentation is available here.
In this post we will review what each of the winning projects consists of – which are still pending ideas for development in apps – and what challenges they would answer.
Cultiva+ Tenerife: precision agriculture for the Tenerife countryside
The first prize-winning project was born from a very specific need that every farmer on the island knows well: to make the right decisions at the right time. Which crop is most profitable this season? What are the weather conditions forecast for the coming weeks? Is there a fair or event in the sector that should not be missed?
Cultiva+ Tenerife is an application designed specifically for the agricultural sector that integrates open data from the Cabildo to answer these questions in a simple and intuitive way.
Specifically, it is aimed at both workers already established in the sector and new farmers. In the first case, the app would facilitate daily work through irrigation recommendations and other issues that improve production; while for new farmers the application would help to select the best plot to start an agricultural activity according to soil type, weather conditions, etc.
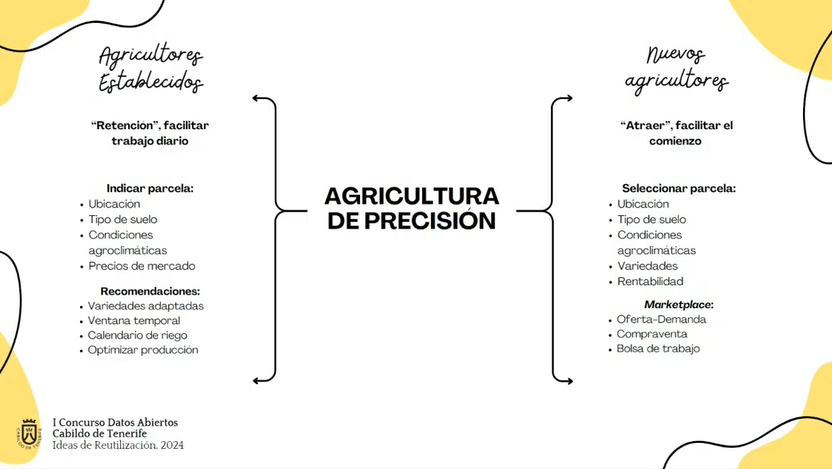
Figure 1. Possible uses of the Cultiva+ Tenerife application according to the type of user. Source: presentation by Cultiva+Tenerife in the Webinar "From data to innovation: Reuse ideas awarded in the I Open Data Contest of the Cabildo de Tenerife, Universidad de la Laguna".
The application would intuitively and clearly collect information such as:
- Price information: the farmer can consult the evolution of market prices of different products, which allows him to plan what to grow based on the expected profitability.
- Weather conditions: the app crosses weather data with the specific needs of each type of crop, helping to anticipate irrigation, protection or harvests.
-
Agenda of activities of interest: agricultural fairs, technical conferences, calls for grants... All relevant information for the sector, centralized in one place.
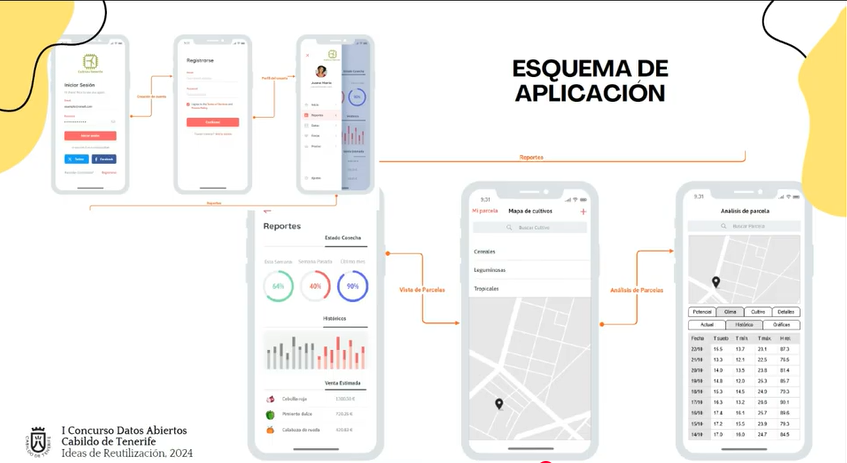
Figure 2. Visual structure of the Cultiva+Tenerife application. Source: presentation by Cultiva+Tenerife in the Webinar "From data to innovation: Reuse ideas awarded in the I Open Data Contest of the Cabildo de Tenerife, Universidad de la Laguna".
Something that was highlighted as valuable about this project in the webinar is its focus on a group that has historically had less access to digital tools: farmers in Tenerife. The proposal does not seek to complicate their day-to-day life with unnecessary technology, but to simplify decisions that today are often made by eye or with incomplete information. Precision agriculture is no longer just a matter for large farms: with open data and a good application, it can be within the reach of any local producer.
Analysis of trends and models on tourism in Tenerife: when the data reveal a crisis
The second winning project addresses one of the most complex and urgent issues in the reality of Tenerife: the relationship between tourism, housing and the labour market. An equation with multiple variables that directly affects the quality of life of residents and that, until now, was difficult to analyse rigorously without access to reliable data.
The starting point of the project is revealing: in June 2024, 35% of the new employment contracts signed in Tenerife corresponded to the hospitality sector. A figure that perfectly illustrates the structural dependence of the island's economy on tourism, but which also opens up uncomfortable questions: to what extent is tourism growth transforming the housing market? Are you displacing habitual residents from certain areas? How will tourist arrivals evolve in the coming years?
This project proposes to answer these questions through an analysis and prediction model built with data science tools. Its developer proposes to use data such as the number of tourists staying in Tenerife according to category and area of establishment, available in datos.tenerife.es, to build models with Python and NumPy that allow identifying trends and projecting future scenarios.
The objectives of the project are ambitious but concrete:
- Analyse the relationship between tourist demand and accommodation supply, identifying which areas of the island suffer the greatest pressure and at what times of the year.
- To develop a predictive model capable of estimating the future arrival of tourists and their impact on the tourist housing sector.
- Contribute to mitigating the housing crisis by providing data and analysis that allow us to understand how tourism is affecting the availability of housing for residents.
- To support business and urban planning, offering companies, investors and administrations an analysis tool that facilitates strategic decision-making.
In short, it is a matter of putting the intelligence of data at the service of one of the most current debates that Tenerife has on the table.
The university as a bridge between data and society
The choice of the Cajasiete Big Data, Open Data and Blockchain Chair of the University of La Laguna as a space to give visibility to the winners is in itself a message: the University has a key role in the construction of the open data ecosystem in Tenerife.
This chair has been working for years on the border between academic research and the practical application of technologies such as big data analysis, blockchain or the reuse of public information. Their involvement in this competition and in the dissemination of its results reinforces the idea that open data is also a valuable resource for training, research and local economic development.
The success of this first call has confirmed that there was a real demand for this type of initiative. So much so that the Cabildo has already launched the II Open Data Contest: APP Development, which gives continuity to the process by taking ideas to the next level: the development of functional applications.
If in the first edition ideas and conceptual proposals were awarded, in this second edition the challenge is to build real solutions, with code, user interface and proven functionalities. The economic endowment is 6,000 euros divided into three prizes.
Projects such as Cultiva+ Tenerife or the Analysis of the impact of tourism on housing show that there are ideas with the potential to become useful and sustainable tools. This second phase is the opportunity to materialize them.
Evento
Every year, the international open knowledge advocacy organization Open Knowledge Foundation (OKFN) organizes Open Data Day (ODD), a framework initiative that will bring together activities around the world to demonstrate the value of open data. It is a meeting point for public administrations, civil society, universities, technology companies and citizens interested in the reuse of public information. It is, above all, an invitation to move from theory to practice: to open data, reuse it and turn it into concrete solutions.
From datos.gob.es, national open data portal, we join this celebration by also compiling other activities that put data and related technologies at the center. In this post we review some events that will be held during this month of March. Take note and write down the agenda!
Data against misinformation: celebrate Open Data Day with Open Data Barcelona Initiative
This meeting is part of the activities organized in Spain on the occasion of Open Data Day 2026, and is focused on the role of open data as a tool to strengthen the quality of public information and combat disinformation. The event will give visibility to projects that use open data to promote a more transparent democracy, encourage informed citizen participation and contribute to the development of responsible artificial intelligence based on reliable data.
- When? On Tuesday, March 10 at 5:30 p.m.
- Where? Ca l'Alier C/ de Pere IV, 362 in Barcelona
- Learn more
The future of Open Data: OKFN's anniversary
On the occasion of Open Data Day 2026, the Open Knowledge Foundation (OKFN) is organizing an online conference to bring together the open data community and celebrate two decades of CKAN, the tool that emerged from OKFN's work that today powers data portals around the world. The meeting will provide an opportunity to discuss the current role of open data and data infrastructures in the face of contemporary technical and political challenges. It is aimed at professionals from governments, civil society, the media, activist groups and all those interested in reflecting on the future of open data in a rapidly changing technological context, marked especially by the emergence of artificial intelligence tools.
- When? On Wednesday, March 11 from 11 a.m. to 4 p.m.
- Where? Online
- Learn more
Data as a public good: European webinar
Organized by the data.europa.eu academy in the framework of Open Data Day, this webinar addresses how open data can act as a public good to improve decision-making in all territories, especially in rural areas. Through case studies from the United Kingdom and Ireland, the session will show how open information can identify local needs, reduce territorial inequalities and design evidence-based public policies that ensure more equitable access to essential services.
- When? Friday, March 13 from 10 a.m. to 11.30 a.m.
- Where? Online event
- Learn more
Solid World: innovation in the sharing and reuse of scientific data
This event will explore how to model, analyze, and share research data using technologies from the Solid* ecosystem. The session will feature representatives from W3C and Open Data Institute to present the SpOTy project, a web application for organizing and analyzing linguistic data that has migrated from RDF to Solid to give researchers greater control over the sharing of their data, also addressing challenges of interoperability and responsible reuse of scientific information.
*The Solid Ecosystem is a set of technologies, standards, and tools that enable individuals and organizations to control their own data on the web and decide how, when, and with whom it is shared.
- When? Monday, March 23 from 5 p.m. to 6 p.m.
- Where? Online event
- Learn more
How to prepare public portals for the AI era
The thirteenth edition of the Data Centric AI cycle, organized by the Open Data Institute (ODI), will explore how public data portals must evolve to adapt to new ways of interacting with datasets. It will address the transformation of infrastructures such as data.gov.uk, plans for the National Data Library and the role of academic research in the design of new public data architectures, combining preparation for artificial intelligence with a user-centric approach and reflecting on the social context surrounding data and AI.
- When? Thursday, March 26 from 5 pm to 6 pm
- Where? Online event
- Learn more
Online events on open data in different sectors with Open Data Week
Open Data Week is an annual festival of events held every March in New York City and organized by the NYC Open Data team in conjunction with BetaNYC and Data Through Design. The week commemorates the anniversary of the city's first open data law, signed on March 7, 2012, and also coincides with Open Data Day, reinforcing its connection with the international open data movement. Some of the scheduled activities will be in virtual format.
- When? From 22 to 29 March
- Where? Some events can be followed in streaming
- Learn more
Data ethics keys for organizations
This session of the Data Ethics Professionals cycle organized by ODI will focus on the main lessons learned by organizations that have initiated processes of integrating data ethics into their structures and workflows. The seminar will address common challenges such as obtaining management support, the practical incorporation of ethical tools and frameworks, and the management of workloads in organizational transformation processes.
- When? On Monday, March 30 from 2 p.m. to 3 p.m.
- Where? Online
- Learn more
In short, the calendar for the coming weeks offers multiple opportunities to delve into the strategic value of open data and associated technologies. From local initiatives against disinformation to sectoral data spaces and European seminars on data as a public good, the ecosystem continues to grow and diversify. We encourage you to participate, share these calls and transfer the learnings to your organization. Because Open Data Day is just the starting point: true transformation is built throughout the year, connecting community, knowledge and action through open data.
These are some of the events that are scheduled for this month of March. In any case, don't forget to follow us on social networks so you don't miss any news about innovation and open data. We are on X and LinkedIn you can write to us if you need extra information.